1 Виды и этапы научных исследований
1.1 Виды научно-исследовательских работ в текстильной промышленности
Научно-исследовательские работы подразделяются на теоретические, экспериментальные и теоретико-экспериментальные. В теоретических работах на основе аналитических исследований физической сущности изучаемого процесса (явления) с использованием известных законов физики устанавливаются его закономерности и прогнозируются оптимальные
условия осуществления действующего или вновь создаваемого процесса. В экспериментальных работах все перечисленные выше задачи решаются экспериментальным путем. Сочетание теоретических и экспериментальных методов научно-исследовательской работы способствует более глубокому решению исследовательской задачи.
Научно-исследовательские работы в текстильной промышленности подразделяются на
следующие виды:
1) Теоретико-экспериментальные работы, раскрывающие закономерности технологических процессов и определяющие оптимальный режим работы машин и механизмов с целью
повышения эффективности процессов, улучшения качества продукции, совершенствования
конструкций машин и автоматизации производства.
2) Экспериментальные работы по испытанию вновь созданных текстильных машин с
целью определения надежности и долговечности работы их устройств и механизмов, удобства обслуживания, повышения производительности и качества вырабатываемого продукта.
3) Поисковые исследовательские работы, направленные на разработку новых технологических процессов на основе более эффективного использования известных и широко применяемых в промышленности видов энергии - механической, аэродинамической, тепловой, а
также на основе новых принципов использования этих и других видов энергии и применения
достижений современной физики.
4) Поисковые работы, направленные на создание новых текстильных материалов и нового ассортимента нитей, пряжи, ткани, трикотажа и других изделий, работы по рациональному использованию натуральных и химических волокон, пряжи и нитей.
5) Исследовательские работы по изучению факторов, определяющих качество и эксплуатационные свойства изделий, а также работы по улучшению методов испытания материалов
и разработке новых методов и приборов.
6) Работы, направленные на создание новых методов исследования технологических
процессов и средств для измерения параметров, характеризующих процесс.
В зависимости от условий проведения и принятого объема экспериментальные исследовательские работы делятся на лабораторные и производственные. Первые отличаются малым объемом используемого сырья и малым фронтом наблюдения, т.е. меньшим числом используемых устройств (например, веретен, прядильных камер, мотальных головок и т.п.) и
машин.
В поисковых экспериментальных работах лабораторные исследования могут быть модельные и стендовые. В результате лабораторных исследований из большого числа возможных вариантов стендов отбирают один или несколько наиболее приемлемых и создают экспериментальный образец машины, который подвергают исследованию в лабораторных условиях. Затем проектируют и изготовляют производственный образец машины для испытания
в промышленности.
1.2 Основные особенности механико-технологических процессов и методов их исследования
Технологические процессы текстильной промышленности представляют собой сложный комплекс физических и химических явлений, изучение которого возможно только с
применением современных достижений науки и техники.
1
Использование в прядильном, ткацком и трикотажном производстве большой массы
неравномерных и неоднородных по свойствам текстильных материалов (волокон, нитей, полотен, тканей) и изменение с течением времени свойств сырья осложняют исследование технологических процессов и обусловливают проведение массовых испытаний сырья, полуфабрикатов и готовой продукции, а также увеличение числа замеров параметров, характеризующих технологический процесс. Кроме того, необходимость количественной оценки
массовых испытаний требует широкого применения методов математической статистики.
Многие процессы механической технологии текстильных материалов по своей физической сущности базируются на вероятностных схемах и имеют закономерности, присущие
случайным событиям массового характера, которые выявляются с помощью методов теории
вероятности.
В настоящее время наиболее массовые производства текстильной промышленности являются в основном дискретными, так как на каждом переходе производства получаемый
продукт формируется в паковку определенного вида. И только производство нетканых материалов и отдельные этапы прядильного и ткацкого производств являются непрерывнопоточными.
Непрерывность технологических и производственных процессов, а также получаемых
продуктов служит основанием для применения в исследованиях методов теории случайных
функций и статистической динамики.
Нестационарность некоторых технологических процессов и наличие дрейфа главнейших их параметров, релаксационные явления в текстильных материалах и изменчивость атмосферных условий в производстве осложняют исследование технологических процессов и
обусловливают применение специальных статистических и других методов исследования.
Быстрое протекание многих технологических процессов текстильной промышленности
затрудняет визуальное наблюдение и регистрацию основных параметров процесса и требует
высокоскоростной техники регистрации.
Закрытые зоны машин и малые размеры рабочих органов также затрудняют непосредственное наблюдение за протеканием технологического процесса и обусловливают использование специфичных для данных процессов технических средств и методов исследований.
Для исследования структуры продуктов текстильной промышленности, т.е. расположения в них волокон и элементов (участков) нитей и регистрации их перемещения, применяются различные виды индикаторов (радиоактивные, флуоресцентные и др.). Отсутствие измерительных элементов, датчиков и приборов, а также методик для определения многих важных характеристик текстильных продуктов затрудняет проведение экспериментальных исследовательских работ.
Все указанные выше особенности механико-технологических процессов требуют широких знаний методов и средств исследований в области не только текстильного производства, но и других отраслей промышленности и науки.
1.3 Этапы научно-исследовательских работ (НИР)
Любая научно-исследовательская работа состоит из ряда этапов, протекающих последовательно во времени. Каждый
этап имеет самостоятельное значение и является объектом планирования и финансирования. В некоторых случаях, когда НИР выполняют по договору, отдельные этапы работы
сдаются заказчику. Деление работы на этапы имеет важное значение для организации и планирования НИР.
Теоретико-экспериментальные работы в текстильной промышленности обычно включают следующие типовые этапы:
1) выбор и обоснование темы;
2) подготовительный этап;
2
3) теоретический анализ технологического процесса;
4) подготовка и проведение предварительного эксперимента;
5) проведение систематического основного эксперимента;
6) анализ результатов теоретических и экспериментальных исследований, выводы и
предложения по работе с экономическим обоснованием.
Экспериментальные работы по испытанию текстильных машин содержат все перечисленные выше этапы, кроме первого.
Поисковые исследовательские работы могут включать следующие типовые этапы:
1) подготовительный этап;
2) разработка теоретической части темы;
3) испытание моделей и внесение корректив в конструкцию и технологию;
4) проектирование и изготовление стендов (макетов);
5) подготовка и проведение предварительного эксперимента;
6) проведение систематического эксперимента;
7) анализ результатов испытаний, теоретических и экспериментальных исследований,
выводы и предложения;
8) разработка технического задания на проектирование экспериментального образца
машины.
Необходимо отметить, что поисковые исследовательские работы имеют ряд особенностей, которые следует учитывать при составлении тематических планов НИР. Они обычно сопряжены с творческим риском, использованием метода «проб и ошибок», корректировкой гипотез, а иногда выдвижением новых гипотез и моделей процесса с соответствующим
конструктивным оформлением.
Приведенная выше последовательность этапов поисковых исследовательских работ
предполагает успешное решение проблемы. Однако часто возникающие при проведении
трудности могут привести не только к изменению первоначально принятого плана и исключению некоторых типовых этапов, но и к включению нетрадиционных этапов и особых исследований. Поэтому для поисковых НИР рекомендуется составлять план, включающий
укрупненные этапы, которые определяются спецификой намечаемого исследования.
Научно-исследовательские работы, посвященные разработке технологических условий
для рационального использования сырья (натурального и химического) и нового ассортимента текстильных материалов, обычно имеют следующие типовые этапы:
1) подготовительный этап;
2) разработка теоретической части темы;
3) подготовка и проведение предварительного эксперимента;
4) проведение систематического эксперимента;
5) анализ результатов, разработка оптимального технологического режима работы машин в производстве, выбор оптимального сырья и структуры материалов.
Научно-исследовательские работы, включающие цикл материаловедческих исследований, содержат следующие типовые этапы:
1) подготовительный этап;
2) теоретическое исследование;
3) подготовка и проведение предварительного эксперимента;
4) проведение систематического эксперимента;
5) анализ результатов, разработка технического задания на проектирование экспериментального образца прибора.
Научно-исследовательские работы, направленные на разработку методов и средств для
исследования технологических процессов, содержат те же этапы, что и поисковые исследовательские работы.
Необходимо отметить, что часто по каждому законченному этапу научной работы исполнитель составляет и оформляет отчет. Поэтому увеличение числа этапов и чрезмерная их
3
детализация нецелесообразны, так как это не только искусственно удлиняет сроки выполнения работ, но и усложняет отчетность.
Очевидно, что все этапы НИР взаимосвязаны. Последний этап лабораторных исследований является первым этапом производственных исследований, потому что выводы и предложения первых формулируют задачи и методику вторых. Производственные исследования,
по существу, представляют собой производственную проверку и внедрение результатов лабораторных исследований. Последний этап является переходным к нормальной фабричной
эксплуатации и может быть оформлен в виде соответствующего акта сдачи работы заказчику.
1.4 Выбор темы для исследовательской работы
Для начинающего исследователя выбор темы научной работы представляет довольно
сложную задачу. Однако он значительно облегчается, если исследователь знаком с состоянием и путями развития техники и технологии текстильной промышленности, участвует
в работах различных научных конференций и совещаний, обращает внимание на вопросы,
требующие разрешения, знакомится со списками, которые предлагаются различными хозяйственными организациями для выполнения работ по конкурсу.
При выборе темы научной работы необходимо учитывать ряд следующих аспектов, в
большой степени определяющих успех работы:
1) склонности, подготовку и знания исследователя. Имеющим большую склонность к
теоретическим исследованиям целесообразнее выбирать тему теоретической работы. Если
же исследователь проявляет больший интерес и склонность к конструированию и изобретению, то лучше выбирать тему поисковой работы;
2) материальные возможности (наличие оборудования, приборов, сырья, подготовленных кадров и объем финансирования) для проведения исследовательской работы и сроки ее
выполнения;
3) актуальность темы, т.е. ее соответствие направлению развития науки, техники и технологии текстильной промышленности, а также современным запросам промышленности;
4) необходимость поручения больших по объему и сложных тем научной работы более
опытным исследователям. Следует подчеркнуть, что даже самая маленькая научная работа и
узкая тема, при условии их глубокой и всесторонней разработки, способствуют прогрессу
науки и техники и, несомненно, заслуживают внимания исследователя.
1.5 Подготовительный этап НИР
Подготовительный этап научно-исследовательской работы включает следующие действия:
1) составление библиографии по теме, изучение литературы и других материалов, относящихся к теме;
2) предварительное знакомство с объектом исследования, его структурой и особенностями;
3) изучение физической основы технологического процесса;
4) определение круга вопросов, подлежащих изучению, формулирование задач исследования и обоснование необходимости постановки работы на выбранную тему;
5) составление методической и рабочей программ НИР.
1.5.1
Изучение библиографии
Чтобы было легче найти необходимую литературу и составить библиографию по теме,
рекомендуется ознакомиться со следующими информационными изданиями: Реферативным
журналом по текстильной технологии и оборудованию, библиографическими справочниками
4
и др., а также библиографическими отделами в таких иностранных журналах, как The Journal
of the textile Institute, Melliand Textilberichte, Textil praxis, Textile Institute Parise. Необходимо
ознакомиться и со списками работ, которые приводятся в соответствующих диссертациях и
статьях. Кроме того, список необходимой литературы исследователь может составить сам,
используя метод «цепочки». Сущность этого метода заключается в том, что, изучая первую
статью, книгу, диссертацию или отчет по НИР, можно обнаружить ссылки на литературу по
теме, а в последующих статьях - на другие источники и т.д.
При изучении литературы и других источников исследователь должен:
1) установить, какие стороны выбранной темы к настоящему времени остались неясными и требуют проверки, что установлено и не требует дополнительной проверки, что необходимо вновь изучить для решения поставленной в работе цели, какие методы и средства использовались в исследованиях и какие методы обработки результатов исследования применялись;
2) обратить особое внимание на оригинальные взгляды и интересные идеи, которые исследователями высказаны, но экспериментально не проверены;
3) изучить теоретические представления и модели исследуемых процессов в родственных или смежных отраслях техники. Например, при изучении процесса смешивания в хлопкопрядильном производстве целесообразно познакомиться с теоретическими и экспериментальными методами исследования этого процесса в шерстопрядильном производстве, а также в химической, пищевой и других отраслях промышленности. При изучении литературных
источников исследователь обдумывает и намечает направления своей работы; определяет,
какие вопросы необходимо исследовать и какие экспериментальные методы использовать,
чтобы получить новые или уточнить ранее установленные закономерности.
1.5.2
Методическая программа НИР и ее содержание
Методическая программа является основным документом НИР, который составляется
на основе изучения литературы и предварительного знакомства с объектом исследования в
лаборатории или на производстве, а также после предварительного изучения физической
сущности технологических процессов, осуществляемых в этом объекте. От тщательности
проработки содержания этого важного документа в большой мере зависят успех и своевременность выполнения НИР.
Методическая программа должна содержать:
1) четкую и исчерпывающую формулировку темы работы;
2) определение цели работы, а также предполагаемых результатов;
3) причины, вызвавшие постановку данной работы, и обоснование целесообразности ее
проведения, как с научно-технических, так и с экономических позиций;
4) краткое изложение и критический анализ материалов научных работ и литературных
источников, имеющихся как в России, так и за границей, по выполняемой исследователем
теме с целью определения состояния данного вопроса в отечественной и мировой технике во избежание повторения и для учета уже накопленных опыта и знаний по изучаемому вопросу;
5) построение рабочей модели объекта или процесса (явления) и ее обоснование;
6) схему разработки данной темы по этапам (перечень этапов);
7) условия, матрицу планирования и методику проведения эксперимента, а также методику испытания материалов;
8) метод обработки результатов, наблюдений и испытаний, метод обобщения этих результатов и построения выводов;
9) методику подсчета экономической эффективности работы (если необходимо).
Теоретические положения по изучаемому вопросу должны служить основанием для
построения рабочей модели объекта или процессов. В зависимости от характера исследования в его программу необходимо включать разделы или этапы теоретического характера,
5
позволяющие обосновать практические выводы и рекомендации по усовершенствованию
или созданию новых технологических процессов, приборов, машин и т.п. Теоретической
разработке может предшествовать экспериментальная составляющая, и наоборот.
В научно-исследовательских работах теоретического характера разработка вопроса
должна иметь ярко выраженную направленность на приложение полученных данных к решению практических задач в настоящее время или в будущем. В поисковых работах вследствие новизны разрабатываемого вопроса и недостаточности отправных данных рекомендуется проведение разведочных экспериментов, которые могут помочь в построении рабочей
модели объекта или процесса и разработке методики проведения работы.
Исследование свойств сырья и получаемых продуктов необходимо проводить одновременно с экспериментальным исследованием процесса или работы машины, так как их результаты могут указать на необходимость пересмотра плана и условий исследования, их изменений или дополнений.
Этапы исследовательской работы должны быть различны. При большом объеме, если
позволяет характер исследования, возможны параллельные этапы или их разделы. Первыми
следует выполнять наиболее важные этапы, имеющие самостоятельный интерес. Результаты,
полученные на этих этапах, могут повлиять на ход всей последующей работы, резко сократить ее объем или изменить направление.
В методической программе должны быть точно определены условия проведения эксперимента. Если в нем используется известное оборудование, то этот выбор необходимо обосновать. Также следует обосновать используемые сырье, материалы, измерительные приспособления и приборы. Если нет требуемого оборудования, приборов и приспособлений для
проведения экспериментального исследования, то в методическую программу следует включать этап работы по созданию приборов или специальной экспериментальной установки, по
возможности монтируемых из стандартных узлов и деталей. Это, конечно, усложняет выполнение исследовательской работы, но во многих случаях является необходимым ее этапом.
Содержание экспериментов и их объем должны быть полностью обоснованы и вытекать из задач исследования. Программа проведения эксперимента должна не только включать матрицу планирования опытов для каждого этапа исследования и обоснование объема
опытов, но и обеспечивать наиболее простое решение поставленной задачи при минимальном количестве вариантов, опытов и испытаний. Объем эксперимента по каждому варианту
должен быть таким, чтобы полученные выводы были достаточно точными и достоверными.
При выполнении НИР по производствам, для которых разработаны условия достоверности экспериментов и испытаний, не следует отступать от этих условий без необходимости,
особо оговоренной в программе. Если такие условия не разработаны, рекомендуется включать в программу специальные разделы методического характера или проводить эксперименты в начальной стадии работы так, чтобы выявить точность получаемых результатов
и, исходя из них, обосновать объем последующих экспериментов. Если необходимы контрольные варианты или контрольные исследования в целом, то это должно быть предусмотрено методической программой.
Намечая методику экспериментального исследования, следует избегать простого шаблонного повторения опытов предшественников и предпочитать наиболее современные методы и аппаратуру, отвечающие поставленным задачам и обеспечивающие необходимую точность результатов и требуемую чувствительность.
При составлении методической программы исследователь должен выбирать не только
методы получения информации о свойствах сырья и получаемого продукта, о значениях параметров технологического процесса или объекта, но и методы обработки этой информации,
в том числе определения числовых характеристик случайных величин и функциональных
характеристик случайных функций, а также методы выделения скрытых периодичностей и
обнаружения нестационарности процесса, если они будут выявлены.
При разработке методики проведения предварительного эксперимента необходимо указать методы, которые будут использованы для количественной оценки степени влияния каж6
дого фактора на параметр процесса и свойства получаемого продукта с целью их ранжировки, а при разработке методики проведения систематического, т.е. основного, эксперимента методы получения статической и динамической модели процесса, а также методы ее оптимизации. В зависимости от принятого метода получения математической модели процесса
устанавливается план, т.е. матрица планирования эксперимента.
Таким образом, каждому из указанных этапов исследования соответствуют определенные методы. Выбор их определяется постановкой задачи исследования, свойствами объекта
и характеристиками самих методов (при рассмотрении последующих этапов НИР будут указаны применяемые методы и раскрыта их сущность).
Всякий новый эксперимент должен быть шагом вперед по сравнению с предшествующими, даже если исследование носит поверочный характер. Не следует увлекаться применением приборов высокой чувствительности и излишней точностью результатов в тех случаях, когда в этом нет необходимости и высокая точность не реализуется практически. При использовании выбранного метода исследования необходимо проверить, не влияет ли он на
ход технологического процесса или на природу изучаемого явления и не вызывает ли он каких-либо дополнительных процессов и изменения свойств продукта.
Исследователь должен убедиться, что изучаемая характеристика процесса или свойство
продукта является единственным действующим фактором (переменной) в данном методе исследования или, по крайней мере, что другие действующие факторы исключены или учтены
при проведении классического (однофакторного) эксперимента.
В том случае, когда имеются несколько средств исследования, необходимо выбирать
то, которое позволяет фиксировать изменения характеристик процесса или свойств продукта
и, являясь более чувствительным, дает показания, которые легко могут быть зарегистрированы даже при малой чувствительности. Если при исследовании требуется изучение ряда характеристик или свойств продукта, применение нескольких средств или методов исследования становится обязательным.
В некоторых случаях полезно применять для исследования не один, а два метода параллельно. Это позволяет осуществить взаимный контроль получаемых результатов, выявить
и устранить возможные ошибки отдельных методов. При выполнении комплексных работ
различными исполнителями и на нескольких объектах (как оборудования, так и приборов)
весьма важно обеспечить примерно одинаковую точность результатов.
Методическая программа составляется ответственным исполнителем, затем, после
утверждения научным руководителем лаборатории или отдела, рассматривается на техническом совещании сотрудников лаборатории и представителей промышленности, окончательно утверждается научным руководителем института. При оценке методических программ исследовательских работ особое значение придается оригинальному подходу авторов
к исследуемым вопросам, позволяющему сократить сроки работ или повысить их качество, и
использованию опыта других отраслей науки и техники.
Перед составлением методической программы НИР рекомендуется разработать общую
схему проведения работы - «скелет» методической программы. Последняя крайне необходима при выполнении переходных тем, т.е. проводимых в течение нескольких лет, и
больших комплексных тем. Для любой работы методическая программа составляется на
один год.
1.5.3
Рабочая программа НИР и ее содержание
Рабочая программа - это план проведения научно-исследовательской работы. Она составляется в полном соответствии с методической программой с целью установления календарного плана выполнения НИР, определения полной ее стоимости, а также для контроля
выполнения НИР по объему и стоимости.
Рабочая программа составляется после утверждения методической программы по форме, представленной в Таблица 1.
7
Таблица 1 - Форма рабочей программы НИР
Срок проведения
№ Этап работы и Удельный
п/п его содержание вес этапов Начало Окончание
Необходимые сотрудники
Специальность или Число месяквалификация
цев работы
Деление НИР на этапы следует проводить исходя из методической программы так, чтобы каждый представлял собой вполне законченную часть работы. Не допускаются общие неконкретные формулировки этапов. Наименование этапов и вариантов в рабочей программе
должно точно соответствовать их наименованиям в методической программе. Продолжительность этапа может быть различной в зависимости от объема работы, но учет его
выполнения должен осуществляться ежемесячно. В связи с этим необходимо указывать
часть этапа, завершаемую в течение каждого месяца. Продолжительность первого (подготовительного) этапа работы, включающего изучение вопроса и разработку методической и рабочей программ, не должна превышать 2-3 месяца.
Важное место в рабочей программе отводится определению расходов и общей стоимости научно-исследовательской работы, на основании чего ведется ее финансирование. Для
определения расходов по экспериментальной части ответственный исполнитель составляет
по каждому ее этапу подробную расшифровку затрат по разделам: сырье, вспомогательные
материалы, командировки, расходы на стороне и пр. При определении стоимости сырья и
вспомогательных материалов необходимо учитывать только невозвратные расходы. При
установлении расходов на командировки следует исходить из фактической потребности в
них с учетом лимита расходов на оперативные командировки, установленного для лаборатории (отдела). В расходы на стороне включается оплата работ, выполненных для института
предприятиями и учреждениями других ведомств. По статье «прочие расходы» учитывается
оплата консультаций специалистов, привлекаемых из других учреждений. Она производится
из установленного фонда зарплаты для лиц, не состоящих в штате института.
Так как разработка методической программы занимает значительное время, а система
финансирования заранее требует плана необходимых расходов на выполнение предстоящей
работы, то на основе «скелета» методической программы составляется предварительная рабочая программа с ориентировочной сметой расходов. Затем эта рабочая программа уточняется на основе разработанной методической программы и становится окончательным документом.
1.6 Математическое описание технологических процессов. Математические модели
Многие технологические процессы и объекты текстильной промышленности могут
быть отнесены к категории сложных. Такие процессы (объекты) обычно характеризуются
большим числом взаимосвязанных факторов, наличием существенных неконтролируемых
возмущений и ошибок измерения отдельных факторов и случайным изменением во времени
характеристик. Поэтому научные исследования технологических процессов текстильной
промышленности проводятся с целью:
1) раскрытия сущности и закономерностей процесса;
2) определения оптимального режима работы объекта (механизма, машины, агрегата)
для обеспечения заданного качества выпускаемой продукции и высокой производительности;
3) определения статических и динамических характеристик объекта и др.
8
Результаты исследований могут быть представлены в виде таблиц, графиков и уравнений, т.е. математического описания технологического процесса, чему в настоящее время, в
связи с широкой автоматизацией технологических процессов, уделяется особенно большое
внимание. Сущность математического описания объекта (системы) или процесса заключается в получении математической модели или соотношения, связывающего характеристики
входящего в объект материала, объекта (системы) или процесса и выходящего продукта, т.е.:
Y A{X } ,
где Y- совокупность выходных параметров процесса, которые определяют физические и
химические свойства выходящего продукта или технико-экономические показатели процесса
(объекта). Часто этот параметр называют критерием оптимизации, параметром оптимизации,
целевой функцией отклика, выходом «черного ящика» или, наконец, реакцией динамической
системы;
Х- совокупность входных параметров (факторов), определяющих характеристики
процесса (объекта) и свойства входящего материала (сырья, продукта). Часто входные факторы называют аргументами, входными параметрами, входами «черного ящика» или внешними воздействиями на систему; А { } - символ, называемый оператором, который характеризует математическую операцию преобразования входных функций X i (t ) в функции
выхода Yi (t ) , т.е. математическую модель объекта или системы.
Рисунок 1 - Обобщенная модель объекта
Математическую модель объекта (системы, процесса) удобно представлять в виде
блок-схемы (Рисунок 1), т.е. параметрической схемы, в которой прямоугольник соответствует объекту или системе, стрелки X1 , ..., X i обозначают входные параметры (факторы) или
воздействия на систему, а стрелки Y1 , ..., Yi - выходные параметры. На схеме внутри прямоугольника записывают оператор или динамическую характеристику.
Наличие математической модели процесса (объекта) и алгоритма управления им обеспечивает условия для более быстрого инженерного конструирования рациональной системы
автоматического регулирования технологического процесса, создания системы автоматического технического контроля процессов и управления агрегатами и поточными линиями.
Зная математическую модель процесса или объекта, можно спрогнозировать свойства
выходящего продукта, оценить степень влияния входных факторов с целью разработки схемы контроля и стабилизации наиболее сильно влияющих факторов, а также осуществить оптимизацию процесса.
Отсутствие математических моделей и недостаточное знание динамических свойств
объектов приводит к интуитивному управлению процессом, что соответственно отражается
на производительности машин и качестве выпускаемого продукта. Для большинства технологических процессов текстильной промышленности известны основные качественные зависимости, характеризующие протекание процесса, однако к настоящему времени математические модели получены только для некоторых процессов.
Было проведено и опубликовано много теоретических исследований таких важных технологических процессов прядильного производства, как кардочесание, гребнечесание, вытягивание, смешивание, наматывание, формирование ткани и др. Однако еще многие процессы прядильного, ткацкого и трикотажного производств теоретически изучены слабо и не
имеют математической модели. Несовершенные гипотезы о моделях процессов и отсутствие
полного учета факторов, определяющих входные воздействия и свойства объекта, приводят к
отклонению прогнозируемых характеристик продукта от получаемых в реальных условиях.
Математическая модель считается адекватной объекту, если с достаточной точностью
отражает его поведение, т.е. изменения одного или нескольких выходных параметров при
варьировании входных параметров (факторов) в заранее заданном диапазоне.
9
В основу классификации математических моделей положены следующие признаки:
1 Число аргументов, от которых зависят параметры процесса или оператор системы:
а) если входные параметры процесса X или оператор А { } не зависят от аргументов, то
математическая модель называется статической. Этот вид модели обычно описывается алгебраическим уравнением:
б) если входные параметры процесса или оператор зависят от аргументов, то такая модель называется динамической. Если параметр процесса или оператор зависят только от одного аргумента (например, времени X = X(t)), модель называется динамической моделью с
сосредоточенными параметрами, т.е.:
Эти модели описываются обыкновенными дифференциальными уравнениями;
в) если число независимых аргументов более одного (например, время и пространственные координаты), то такая модель называется математической моделью с распределенными параметрами, т.е.:
Эти модели описываются дифференциальными уравнениями в частных производных.
Здесь необходимо отметить, что входные параметры или оператор могут обладать
свойством однородности. Параметр X или оператор А { } называются однородными по аргументу a , если изменение a на произвольную величину a не меняет параметра или оператора, т.е.:
В случае, когда аргументом, по которому однороден параметр или оператор, является
время, параметр или оператор называется стационарным. Система, оператор которой стационарен, называется стационарной. Если условие однородности оператора процесса не
удовлетворяется, то система называется нестационарной.
2 Природа исследуемого процесса или объекта. По этому признаку модели делятся
на вероятностные и детерминированные.
В вероятностной модели учитывается случайная природа входных параметров или
оператора. Вероятностные модели могут быть нескольких видов:
а) если выходной параметр процесса представляет случайную величину, а факторы
(входные параметры) являются неслучайными (жесткими), то математическая модель называется регрессионной. Случайные значения выходного пара метра могут быть обусловлены,
например, воздействием части неучтенных факторов. Эта модель позволяет предполагать,
что
колеблемость
выходного
параметра
содержит
в
себе
две
части:
одна, неслучайная, является функцией факторов; другая, слу чайная, не связана с факторами.
При построении регрессионных моделей используются различного вида алгебраические уравнения. Например, формулы для расчета натяжения нити на различных машинах,
полученные при обработке экспериментальных данных, представляют собой регрессионные
модели;
б) если выходной параметр процесса и факторы представляют случайные величины с
определенным законом распределения, то взаимосвязь между ними, или математическая модель процесса, называется корреляционной. В этом случае к вопросам выяснения зависимости между случай ными величинами параметров процесса добавляются вопросы исследования степени связи между ними, и при построении этих моделей используется корреляционный анализ случайных величин. Формулы для расчета прочности пряжи, ткани и трикотажа,
полученные при обработке экспериментальных данных, представляют собой корреляционные модели, так как входные и выходные параметры - случайные величины.
В детерминированной модели не учитывается случайная природа входных параметров
процесса и оператора, а выходные параметры процесса однозначно определяются факторами
10
и оператором процесса. В этом случае не требуются математико-статистические методы анализа процесса.
При построении детерминированных моделей используют различные классические методы математики: дифференциальные и интегральные уравнения, алгебраические уравнения
и операторы.
3 Свойство линейности модели. Математическая модель называется линейной, если
линеен оператор системы. Оператор А { } называется линейным, если выполняется равенство:
где X - символ произвольного приращения входных параметров (факторов).
Это свойство линейного оператора называется также свойством суперпозиции или
наложения. Если это равенство не выполняется, то оператор и, соответственно, модель называются нелинейными.
1.7 Методы получения математических моделей
Методы получения математического описания технологических процессов и объектов
подразделяются на теоретические и экспериментальные.
Теоретический метод заключается в аналитическом исследовании физической сущности микропроцессов с использованием общих законов физики, справедливых для данного
технологического процесса, или макропроцессов с использованием уравнений материального и энергетического балансов. Второе направление теоретического метода обеспечивает получение более простого математического описания процесса.
Применение чисто теоретического метода получения математической модели объекта
представляет большую трудность вследствие сложности явлений, происходящих в процессах, и недостаточной степени их изученности. Однако при проектировании новых процессов
и в поисковых исследовательских работах теоретический метод построения математической
модели часто имеет доминирующее значение.
Экспериментальный метод математического описания технологического процесса или
объекта заключается в обработке экспериментальных данных, полученных непосредственно
на действующих объектах производства, или на полупромышленной лабораторной машине,
или на физической модели процесса - стенде. Часто экспериментальный метод используется
с целью получения информации для разработки алгоритма управления процессом и при отсутствии теоретического описания изучаемого процесса.
Наиболее эффективным решением задачи получения математической модели сложного
процесса является сочетание теоретического и экспериментального методов. При этом на
долю теоретического метода приходится анализ в основном структурных свойств объекта и
продуктов и получение общего вида уравнений, а на долю экспериментального - количественный анализ (определение численных значений коэффициентов уравнений для изучаемого объекта) и проверка теоретических выводов. Эксперимент играет решающую роль в
получении математической модели сложного реального процесса или объекта.
Так как изучаемые явления и информация, поступающая от объекта к исследователю во
время эксперимента, подвержены воздействию ряда неконтролируемых возмущений (изменение трудноконтролируемых факторов, ошибки измерения и т.д.), получаемая информация носит случайный характер.
Эффективным средством экспериментального изучения объектов являются статистические методы, основанные на проведении экспериментов и последующей статистической
обработке их результатов с целью извлечения объективной информации о свойствах объекта.
В этом случае объект рассматривают как кибернетическую систему, называемую «черным
ящиком» (Рисунок 1).
При экспериментальном исследовании промышленного объекта, находящегося в непрерывной эксплуатации, возникают трудности, обусловленные:
11
1) большим числом взаимосвязанных и часто неконтролируемых входных параметров
(факторов);
2) высоким уровнем помех, в том числе и от неконтролируемых воздействий, величина
и природа которых неизвестны и носят случайный характер. К этим воздействиям относятся:
изменение режима работы объекта, изменение характеристик технологического оборудования вследствие износа и нарушения нормального взаимного положения рабочих органов,
воздействие многочисленных внешних факторов (температуры и влажности воздуха и др.),
присутствие случайных примесей во входящих продуктах, неконтролируемые параметры
входящего сырья или продукта и т.п.;
3) значительной трудоемкостью обработки данных эксперимента;
4) отсутствием необходимых измерительных приборов и датчиков;
5) нарушением нормального режима объекта, особенно на длительное время, и, следовательно, большими издержками производства.
Все указанные выше трудности исследователь должен учитывать при выборе экспериментального метода получения математической модели.
12
2 Эксперимент как предмет исследования
2.1 Понятие эксперимента
Во многих областях научной и практической деятельности современного человека значительное место занимают теоретические методы изучения различных объектов и процессов
окружающего нас мира. Однако, несмотря на высокую эффективность теоретических методов, при рассмотрении конкретных технологических проблем, особенно в условиях действующего производства, инженеру зачастую приходится сталкиваться с задачами, решение
которых практически невозможно без организации и проведения того или иного экспериментального исследования.
С общефилософской точки зрения эксперимент (от латинского experimentium – проба,
опыт) – это чувственно-предметная деятельность в науке; в более узком смысле – опыт, воспроизведение объекта познания, проверка гипотез и т.д.
В технической литературе термину эксперимент устанавливается следующее определение – система операций, воздействий и (или) наблюдений, направленных на получение информации об объекте исследования.
Являясь источником познания и критерием истинности теорий и гипотез, эксперимент
играет очень важную роль как в науке, так и в инженерной практике. Эксперименты ставятся
в исследовательских лабораториях и на действующем производстве, в медицинских клиниках и на опытных сельскохозяйственных полях, в космосе и в глубинах океана.
Хотя объекты исследований очень разнообразны, методы экспериментальных исследований имеют много общего:
− каким бы простым ни был эксперимент, вначале выбирают план его проведения;
− стремятся сократить число рассматриваемых переменных, для того чтобы уменьшить
объем эксперимента;
− стараются контролировать ход эксперимента;
− пытаются исключить влияние случайных внешних воздействий;
− оценивают точность измерительных приборов и точность получения данных;
− и наконец, в процессе любого эксперимента анализируют полученные результаты и
стремятся дать их интерпретацию, поскольку без этого решающего этапа весь процесс экспериментального исследования не имеет смысла.
К сожалению, зачастую работа экспериментатора настолько хаотична и неорганизованна, а ее эффективность так мала, что полученные результаты не в состоянии оправдать даже
тех средств, которые были израсходованы на проведение опытов. Поэтому вопросы организации эксперимента, снижения затрат на его проведение и обработку полученных результатов являются весьма и весьма актуальными.
Современные методы планирования эксперимента и обработки его результатов, разработанные на основе теории вероятностей и математической статистики, позволяют существенно (зачастую в несколько раз) сократить число необходимых для проведения опытов.
Знание и использование этих методов делает работу экспериментатора более целенаправленной и организованной, существенно повышает как производительность его труда, так и
надежность получаемых им результатов.
Процесс организации и планирования эксперимента имеют свою строго определенную,
во многом регламентируемую стандартами (ГОСТ 15895-77, ГОСТ 16504-81, ГОСТ 2402680), терминологию.
2.2 Классификация видов экспериментальных исследований
Любой эксперимент предполагает проведение тех или иных опытов.
Опыт – воспроизведение исследуемого явления в определенных условиях проведения
эксперимента при возможности регистрации его результатов.
13
По цели проведения и форме представления полученных результатов эксперименты делят на качественный и количественный.
Качественный эксперимент устанавливает только сам факт существования какого-либо
явления, но при этом не дает никаких количественных характеристик объекта исследования.
Любой эксперимент, каким бы сложным он ни был, всегда заканчивается представлением его
результатов, формулировкой выводов, выдачей рекомендаций. Эта информация может быть
выражена в виде графиков, чертежей, таблиц, формул, статистических данных или словесных описаний. Качественный эксперимент как раз и предусматривает именно словесное описание его результатов.
Пример 2.1. Если взять два куска ткани, обработанных разными методами, и подвергнуть их тесту на прочность, то скорее всего один из них порвется при меньшем усилии. То
есть у двух кусков ткани прочность будет различна.
Однако словесное описание – не самый эффективный и информативный способ представления результатов эксперимента, поскольку он не позволяет дать количественных рекомендаций, проанализировать свойства объекта в иных условиях. Поэтому в инженерной
практике основное содержание эксперимента представляется числом и количественными зависимостями.
Количественный эксперимент не только фиксирует факт существования того или иного
явления, но, кроме того, позволяет установить соотношения между количественными характеристиками явления и количественными характеристиками способов внешнего воздействия
на объект исследования.
В условиях примера 2.1, для того чтобы перевести эксперимент из разряда "качественный" в "количественный", необходимо:
− определить и количественно описать те параметры процесса обработки и те свойства
материала, которые по предположению могут повлиять на прочность ткани;
− выбрать ту или иную количественную характеристику прочности ткани;
− в результате эксперимента необходимо установить количественную зависимость
между прочностью ткани и параметрами процесса обработки.
Итак, количественный эксперимент прежде всего предполагает количественное определение всех тех способов внешнего воздействия на объект исследования, от которых зависит его поведение – количественное описание всех факторов.
Фактор – переменная величина, по предположению влияющая на результаты эксперимента.
В отдельном конкретном опыте каждый фактор может принимать одно из возможных
своих значений – уровень фактора.
Уровень фактора – фиксированное значение фактора относительно начала отсчета.
Фиксированный набор уровней всех факторов в каждом конкретном опыте как раз и
определяет одно из возможных состояний объекта исследования.
При проведении опытов очень многое зависит от того, насколько активно экспериментатор может "вмешиваться" в исследуемое явление, имеет он или нет возможность устанавливать те уровни факторов, которые представляют для него интерес.
С этой точки зрения все факторы можно разбить на три группы:
− контролируемые и управляемые – это факторы, для которых можно не только зарегистрировать их уровень, но еще и задать в каждом конкретном опыте любое его возможное
значение;
− контролируемые, но неуправляемые факторы – это факторы, уровни которых можно
только регистрировать, а вот задать в каждом опыте их определенное значение практически
невозможно;
− неконтролируемые – это факторы, уровни которых не регистрируются экспериментатором и о существовании которых он даже может и не подозревать.
В количественном эксперименте необходимо не только регистрировать уровни всех
контролируемых факторов, но и иметь возможность устанавливать количественное описание
14
того свойства (отклика) исследуемого явления, которое изучает (наблюдает) экспериментатор. Причем поскольку на объект исследования в процессе эксперимента всегда влияет
огромное количество неконтролируемых факторов, что вносит в получаемые результаты некоторый элемент неопределенности, значение отклика, в каждом конкретном опыте, невозможно предсказать заранее. Поэтому воспроизведение исследуемого явления при одном и
том же фиксированном наборе уровней всех контролируемых факторов всегда будет приводить к различным значениям отклика, т.е. отклик – это всегда случайная величина.
Отклик – наблюдаемая случайная переменная, по предположению зависящая от факторов.
Откликом в условиях примера 2.1 является прочность ткани. Причем даже если взять
куски ткани от одного и того же рулона, то и при этом для каждого куска ткани мы получим
разные (хотя и очень близкие друг к другу) значения прочности ткани.
И наконец, в результате количественного эксперимента необходимо найти зависимость
между откликом и факторами – функцию отклика. Причем поскольку отклик – это случайная
величина, то, с точки зрения теории вероятностей, его можно задать одним из параметров
своего распределения, например математическим ожиданием.
Функция отклика – зависимость математического ожидания отклика от факторов.
В примере с тканью – это зависимость математического ожидания величины прочности
ткани от параметров обработки (температура, скорости охлаждения и химического состава
вещества которым проведена обработка и т.д.).
С учетом приведенного выше деления факторов на три группы, функцию отклика в самом общем случае можно записать в виде
M y f ( xi , hi ) (1.1)
Где M y – математическое ожидание отклика; xi – контролируемые и управляемые факторы; hi – контролируемые, но неуправляемые факторы; – ошибка эксперимента, учитывающая влияние неконтролируемых факторов.
По тому, какой группой факторов располагает исследователь, количественный эксперимент в свою очередь можно разделить еще на два вида. Если в распоряжении экспериментатора нет управляемых факторов, то такой эксперимент носит название пассивного.
Пассивный эксперимент – эксперимент, при котором уровни факторов в каждом опыте
регистрируются исследователем, но не задаются.
Поскольку при пассивном эксперименте исследователь не имеет возможность задать
уровень ни одного из факторов, то при проведении опытов ему остается лишь "пассивно"
наблюдать за явлением и регистрировать результаты. Планирование пассивного эксперимента сводится к определению числа опытов, которые необходимо провести исследователю для
решения поставленной перед ним задачи, а конечной целью пассивного эксперимента в
большинстве случаев является получение функции отклика в виде
M y f (hi ) (1.2)
Если же экспериментатор имеет возможность не только контролировать факторы, но и
управлять ими, то такой эксперимент носит название активного.
Активный эксперимент – эксперимент, в котором уровни факторов в каждом опыте задаются исследователем.
Поскольку в этом случае экспериментатор имеет возможность "активно" вмешиваться в
исследуемое явление, то естественно, что активный эксперимент всегда предполагает какойлибо план его проведения.
План эксперимента – совокупность данных, определяющих число, условия и порядок
реализации опытов.
Поэтому активный эксперимент всегда должен начинаться с планирования.
Планирование эксперимента – выбор плана эксперимента, удовлетворяющего поставленным требованиям.
15
К требованиям, предъявляемым при планировании активного эксперимента, можно отнести степень точности и надежности результатов, полученных после проведения эксперимента, сроки и средства, имеющиеся в распоряжении исследователя, и т.д.
Целью активного эксперимента может быть либо определение функции отклика в виде
M y f ( xi ) (1.3)
либо поиск такого сочетания уровней управляемых факторов xi , при котором достигается оптимальное (экстремальное – минимальное или максимальное) значение функции отклика. В этом последнем случае эксперимент носит еще название поискового (экстремального) эксперимента.
Например, если в случае с прочностью ткани мы бы поставили перед собой целью
найти такое сочетание температуры обработки и скорости охлаждения, при которых прочность ткани была бы максимальной, то наш эксперимент стал бы поисковым.
И наконец, по условиям проведения различают лабораторный и промышленный эксперименты.
Лабораторный эксперимент. В лаборатории меньше влияние случайных погрешностей,
обеспечивается большая "стерильность" условий проведения опытов, в большинстве случаев
осуществляется и более тщательная подготовка, одним словом, выше "культура эксперимента". Как правило, в лабораторных условиях экспериментатор может воспроизвести опыт
"одинаково" значительно лучше, чем в промышленности. Это означает, что при прочих равных условиях для установления некоторого факта на заводе потребуется выполнить значительно больше опытов, чем в лаборатории. Другое важное отличие – это большая возможность варьировать (изменять) уровни факторов.
Промышленный эксперимент. В промышленных условиях обеспечить условия лабораторного эксперимента значительно труднее. Усложняются измерения и сбор информации,
значительно большее влияние на объект исследования и измерительные приборы оказывают
различного рода помехи (резко возрастает число неконтролируемых факторов), поэтому в
промышленном эксперименте особенно необходимо использовать специальные статистические методы обработки результатов. Кроме того, на реальном действующем производстве
всегда желательно по возможно меньшему числу измерений получить наиболее достоверные
результаты.
16
3 Краткие сведения из теории вероятностей и математической статистики
3.1 Случайные величины и параметры их распределений
Поскольку из-за влияния неконтролируемых факторов отклик – это всегда случайная
величина, при обработке результатов эксперимента широко используется аппарат теории вероятностей и математической статистики, поэтому напомним некоторые основные понятия и
определения этого раздела математики.
Случайное событие – событие, реализацию которого при определенном комплексе
условий невозможно заранее предсказать.
Например, реализацию такого события, как пять остановок ткацкого станка в течение
месяца, невозможно предсказать заранее, поскольку остановок может быть и три, и семь, и
четыре, и т.д.
Случайная величина – величина, которая может принимать какое-либо значение из
установленного множества и с которой связано вероятностное распределение.
Случайная величина может быть дискретной или непрерывной.
Дискретная случайная величина – случайная величина, которая может принимать значения только из конечного или счетного множества действительных чисел.
Непрерывная случайная величина - случайная величина, которая может принимать любые значения из конечного или бесконечного интервала.
Если при фиксированном наборе уровней всех контролируемых факторов провести n
измерений отклика X, то в результате будет получен ряд хотя и близких, но отличающихся
друг от друга значений:
где xi – i -е измерение величины X;
x1, x2,..., xn – реализация случайной величины X.
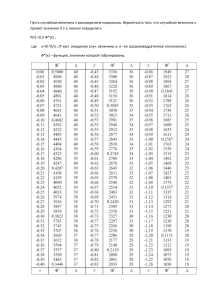
Пример 3.1. В результате изучения работы ткацкого станка на протяжении полутора
лет было зарегистрировано следующее количество его остановок в течение каждого месяца
(Таблица 2).
Таблица 2 - Число остановок ткацкого станка по месяцам
1
2
3
4
5
6
7
8
9
Месяц
10
11
12
13
14
15
16
17
18
Число
3
4
3
5
5
5
6
4
6
5
5
2
4
6
7
5
6
7
остановок
В данном примере число остановок ткацкого станка в течение месяца - это дискретная
случайная величина. В первом из n = 18 измерений этой величины было получено значение
x1 = 3, во втором – x2 = 4 и т.д., до x18 = 7. Приведенные в Таблица 2 значения – это реализация такой случайной величины, как число остановок ткацкого станка в течение месяца.
Каждому значению дискретной случайной величины X (любому из событий А, когда
случайная величина X принимает какое-либо строго определенное значение x), можно поставить в соответствие следующее отношение:
W m/ n
где m – число наблюдений, в которых дискретная случайная величина X оказалась равна x;
n – общее количество наблюдений.
Величину W называют частотой реализации события А.
В примере 2.1, в шести наблюдениях: i = 4, 5, 6, 10, 11 и 16, количество остановок ткацкого станка в течение месяца X оказалось равным пяти (X = 5), следовательно, частота реализации такого события, как пять остановок, равна 6/18 = 0,33. Частоты реализаций для других
событий (две, три, четыре и т.д. остановки) приведены в Таблица 3.
Таблица 3 - Частота остановок ткацкого станка
Число остановок, x
2
3
4
5
6
7
17
Количество наблюдений m, в
которых реализовалось событие X = x
Частота реализации, W = m / n
1
2
3
6
4
2
0,06
0,11
0,17
0,33
0,22
0,11
Если продолжить наблюдения за работой ткацкого станка в течение еще полутора лет,
то, конечно же, совершенно не обязательно, что на протяжении следующих восемнадцати
месяцев пять остановок будет снова зарегистрировано ровно в 6 случаях из 18 наблюдений, а
частота реализации этого события опять окажется равной 0,33. Однако при возрастании числа повторений одного и того же комплекса условий частота реализации такого события, как,
например, пять остановок станка в течение месяца, будет принимать все более и более
устойчивое значение. Так, если подсчитать частоту реализации данного события за 36 месяцев, то она уже практически не будет отличаться от того значения, которое затем можно будет получить за четыре с половиной года (при условии, что за все это время наблюдений в
работе ткацкого станка не произойдет никаких существенных изменений).
Предел, к которому стремится отношение m/n при неограниченном возрастании числа
опытов n, называется вероятностью случайного события.
Вероятность P(А) события А – число от нуля до единицы, которое представляет собой
предел частоты реализации события А при неограниченном числе повторений одного и того
же комплекса условий.
Для дискретной случайной величины можно указать вероятность, с которой она принимает каждое из своих возможных значений конечного или счетного множества действительных чисел. Для непрерывной случайной величины задают вероятность ее попадания в
один из заданных интервалов области ее определения (поскольку вероятность того, что она
примет какое-либо конкретное свое значение, стремится к нулю).
Полностью свойства случайной величины описываются законом ее распределения, под
которым понимают связь между возможными значениями случайной величины и соответствующими им вероятностями.
Распределение случайной величины – функция, которая однозначно определяет вероятность того, что случайная величина принимает заданное значение или принадлежит к некоторому заданному интервалу.
В математике используют два способа описания распределений случайных величин:
интегральный (функция распределения) и дифференциальный (плотность распределения).
Функция распределения F(x)– функция, определяющая для всех действительных х вероятность того, что случайная величина Х принимает значение не больше, чем х.
Рисунок 2 - Пример функции распределения
Функция распределения F(x) имеет следующие свойства (Рисунок 2):
1 Ее ордината, соответствующая произвольной точке х1, представляет собой вероятность того, что случайная величина X будет меньше, чем х1, т.е. F(x1) = P(Х ≤ x1).
2 Функция распределения принимает значение, заключенное между нулем и единицей:
3 Функция распределения стремится к нулю при неограниченном уменьшении х и
стремится к единице при неограниченном возрастании х, то есть
18
4 Функция распределения представляет собой монотонно возрастающую кривую, то
есть
F(x2)>F(x1), если х2>х1.
5 Ее приращение на произвольном отрезке (х1; х2) равно вероятности того, что случайная величина X попадет в данный интервал:
Плотность распределения f(x) – первая производная (если она существует) функции
распределения.
Плотность функции распределения f(x) имеет следующие свойства (Рисунок 3):
Рисунок 3 - Плотность функции распределения
1 Плотность распределения вероятностей является неотрицательной функцией, т.е.
Это свойство справедливо, так как F(x) есть неубывающая функция.
2 Функция распределения случайной величины Х равна определенному интегралу от
плотности распределения вероятностей в пределах (−∞, х):
3 Вероятность события, состоящая в том, что случайная величина Х примет значение,
заключенное в полуинтервале [x1 ,x2 ], равна определенному интегралу от плотности распределения вероятностей на этом полуинтервале:
4 Интеграл плотности распределения в бесконечно большом интервале (-∞, + ∞) равен
единице:
так как попадание случайной величины в интервал −∞ < Х< + ∞ есть достоверное событие.
В большинстве случаев при обработке экспериментальных данных, основываясь на тех
или иных предположениях (гипотезах) относительно свойств исследуемой случайной величины, удается записать функцию ее распределения (а следовательно, и плотность распределения как первую производную от функции распределения) с точностью до некоторых неизвестных параметров.
19
Например, для случайной величины, которая удовлетворяет так называемому нормальному закону распределения (закону распределения Гаусса), функцию распределения можно
записать в виде
В функциях константы Mx, σx2 являются параметрами распределений, причем это выражение относится к двухпараметрическому виду закона распределения.
Параметр распределения – постоянная, от которой зависит функция распределения.
Следовательно, если известен вид функции распределения (каким-либо образом установлено, что случайная величина не противоречит тому или иному закону распределения), то
для того, чтобы однозначно охарактеризовать случайную величину, достаточно задать только лишь параметры ее распределения.
Важнейшими параметрами распределения, задающими случайную величину Х, являются ее математическое ожидание Mx (характеризует центр рассеивания) и дисперсия σx2 (характеризует степень рассеивания).
Математическое ожидание Mx – среднее взвешенное по вероятностям значение случайной величины.
Для дискретной случайной величины математическое ожидание определяется выражением
где хi – значения дискретной случайной величины, а pi = P(X= хi).
Если в условиях примера 3.1 предположить, что pi ≈ Wi (см. Таблица 3), то для математического ожидания такой дискретной случайной величины, как число остановок ткацкого
станка в течение месяца, можно получить следующее значение:
Mx = 2·0,06 + 3·0,11 + 4·0,17 + 5·0,33 + 6·0,22 + 7·0,11 = 4,87.
Для непрерывной случайной величины математическое ожидание определяется интегралом
где f(x) – плотность распределения непрерывной случайной величины.
Кроме математического ожидания центр рассеивания случайной величины можно еще
охарактеризовать такими параметрами ее распределения, как мода и медиана.
Мода Мо – значение случайной величины, соответствующее локальному максимуму
плотности вероятностей для непрерывной случайной величины или локальному максимуму
вероятности для дискретной случайной величины.
Для примера 3.1 (см. Таблица 3), при условии, что pi ≈ Wi, мода Мо числа остановок
ткацкого станка равна 5, поскольку именно этому значению данной дискретной случайной
величины соответствует локальный максимум вероятности, равный 0,33.
Медиана Ме – значение случайной величины, для которого функция распределения
принимает значение 1/2, или имеет место «скачок» со значения, меньшего чем 1/2, до значения, большего чем 1/2.
Таким образом, для дифференциального закона распределения медиана есть такое значение непрерывной случайной величины Х, которое делит пополам площадь под кривой
плотности распределения f(x).
В примере 3.1, если предположить, что функция распределения от четырех остановок
F(4) (вероятность того, что число остановок ткацкого станка в течение месяца будет не более
четырех) равна 0,06 + 0,11 + 0,17 = 0,34 , а функция распределения F(5) = 0,34 + 0,33 = 0,67,
то медианой Ме такой дискретной случайной величины, как число остановок ткацкого станка в течение месяца, будет значение Ме = 5.
20
Дисперсия случайной величины σx2 – математическое ожидание случайной величины (Х
- Mx)2.
Для дискретной случайной величины дисперсия определяется следующим математическим выражением:
В примере 3.1 (опять же, если предположить, что pi ≈ Wi) значение дисперсии числа
остановок ткацкого станка равно:
σx2 = (2 – 4,87)2·0,06 + (3 – 4,87)2·0,11 + (4 – 4,87)2·0,17 +
+ (5 – 4,87)2·0,33 + (6 – 4,87)2·0,22 + (7 – 4,87)2·0,11 = 1,7931.
Для непрерывной случайной величины дисперсия определяется выражением
где х – значения непрерывной случайной величины Х;
f(х) – плотность распределения;
Mx – математическое ожидание.
Дисперсия имеет размерность квадрата единицы измерения случайной величины, а положительное значение квадратного корня из дисперсии называется средним квадратичным
отклонением.
Среднее квадратичное отклонение σx – неотрицательный квадратный корень из дисперсии.
Для примера 3.1 среднее квадратичное отклонение числа остановок ткацкого станка в
течение месяца равно
В заключение этого раздела дадим определение еще одного параметра распределения
случайной величины, который носит название квантиль.
Квантиль порядка P, x p – значение случайной величины, для которого функция распределения принимает значение P или имеет место «скачок» со значения, меньшего чем P, до
значения, большего чем P:
F(xp) = P.
Из этого определения квантиля следует, что медиана Ме – это квантиль порядка 1/2, т.е.
Ме = х0,5.
Вероятность попадания случайной величины Х в интервал [ хP1, хP2 ] равна
В примере 3.1 квантиль порядка 0,95 числа остановок ткацкого станка скорее всего равен семи х 0,95 = 7, поскольку F(6) ≈ 0,06 + 0,11 + 0,17 + 0,33 + 0,22 = 0,89, а F(7) ≈ 0,89 + 0,11
= 1,00.
3.2 Нормальный закон распределения
Функция распределения F(x) и соответствующая ей плотность распределения f(x) представляют собой некоторую математическую модель свойств исследуемой случайной величины (отклика), значения которой регистрируются в ходе эксперимента. Поэтому одной из основных задач статистической обработки опытных данных является нахождение таких функций распределения, которые, с одной стороны, достаточно хорошо описывали бы наблюдаемые значения случайной величины, а с другой – были бы удобны для дальнейшего статистического анализа. При этом вид функции распределения предпочтительно выбирать на основе
представлений о физической природе рассматриваемого явления, т.к. в этом случае исключаются возможные погрешности при распространении найденных закономерностей за пре-
21
делы изучаемого в эксперименте интервала варьирования (изменения) случайной величины
(отклика).
Из всех изученных к настоящему времени случайных величин при обработке экспериментальных данных исследователи чаще всего оперируют со случайными величинами, которые имеют так называемое нормальное (Гауссово) распределение (Рисунок 4). Cогласно
центральной предельной теореме математической статистики, «при определенных условиях
распределение нормированной суммы n независимых случайных величин, распределенных
по произвольному закону, стремится к нормальному, когда n стремится к бесконечности».
Необходимые условия, при которых эта теорема оказывается справедливой, состоят в том,
что различные случайные величины должны иметь конечные дисперсии и дисперсия любой
случайной величины не должна быть слишком большой по сравнению с дисперсиями других.
При обработке экспериментальных данных эта теорема имеет очень большое значение,
поскольку отклик становится случайной величиной в результате влияния неконтролируемых
факторов, число которых скорее всего стремится к бесконечности. Кроме того, если при проведении опытов все наиболее существенные факторы контролируются, то воздействие на отклик каждого из неконтролируемых факторов не должно быть слишком большим по сравнению с остальными неконтролируемыми факторами. Другими словами, та дисперсия (рассеивание) отклика, которую вызывает какой-либо из неконтролируемых факторов, не должна
сильно отличаться от дисперсий, связанных с влиянием остальных неконтролируемых факторов. В противном случае фактор, дисперсия от которого существенно отличается от других, обязательно должен быть переведен в разряд контролируемых.
Следовательно, если при планировании эксперимента учтены все наиболее существенные факторы и затем, при проведении опытов, они контролируются, то при обработке экспериментальных данных можно предполагать, что отклик не должен противоречить нормальному распределению.
Рисунок 4 - Плотность распределения (а,г) и функция распределения (при нормальном законе распределения случайных величин б,в)
Большинство других распределений, которые используются в математической статистике (Стьюдента, Фишера, Пирсона, Кохрена, а также распределения, по которым составлены различные критериальные таблицы), получены на основе нормального распределения.
22
Но не все случайные величины распределены по нормальному закону. Тем не менее на
практике, если явление подвержено действию многих случайных факторов, их суммарное
воздействие вполне оправданно можно описать с помощью нормального закона.
Для случайной величины, которая не противоречит нормальному закону, функция распределения и соответствующая ей плотность распределения
определяются двумя параметрами: Мx – математическим ожиданием и σx2 – дисперсией.
Отметим некоторые свойства нормального закона распределения.
1. Кривая плотности распределения симметрична относительно значения Мx, называемого иногда центром распределения.
2. При больших значениях σx2 кривая f(x) более пологая, т.е. σx2 является мерой величины рассеивания значения случайной величины около значений Мx. При уменьшении параметра σx2 кривая нормального распределения сжимается вдоль оси ОХ и вытягивается вдоль
f(x).
3. Максимум ординаты кривой плотности распределения определяется выражением
что при σx2=1 соответствует значению примерно 0,4.
4. Для нормального распределения математическое ожидание, мода и медиана совпадают:
В ряде случаев рассматривается не сама случайная величина Х, а ее отклонение от математического ожидания:
Такая случайная величина Y называется центрированной.
Отношение случайной величины Х к ее среднему квадратичному отклонению
называется нормированной случайной величиной.
Таким образом, центрированная случайная величина – разность между данной случайной величиной и ее математическим ожиданием, а нормированная случайная величина – отношение данной случайной величины к ее среднему квадратичному отклонению.
Очевидно, что математическое ожидание центрированной случайной величины равно
нулю, My = 0, а дисперсия нормированной случайной величины равна единице,
.
Приведенная случайная величина – центрированная и нормированная случайная величина
Математическое ожидание и дисперсия приведенной случайной величины Z равны соответственно нулю, Mz= 0, и единице, σz 2 = 1.
Нормальное распределение с параметрами Mz= 0 и σz 2 = 1 называется стандартным
(нормированным).
Для приведенной случайной величины нормальное стандартное распределение принимает вид
Графики этих функций показаны на Рисунок 4 в, г, причем
23
Значения нормированной функции нормального распределения (функции Лапласа) и
значения плотности нормированного нормального распределения табулированы и приведены
в различных учебниках и справочниках по математической статистике. В списке статистических функций электронных таблиц Microsoft Excel им соответствуют НОРМРАСП(x; 0; 1;
ИСТИНА) или НОРМСТРАСП(z) – для (2.27) и НОРМРАСП(x; 0; 1; ЛОЖЬ) – для (2.28).
Геометрически функция Лапласа представляет площадь под кривой f(z) в интервале от
−∞ до некоторой конкретной величины z.
Квантиль zр порядка р, нормированного нормального закона распределения - это такое
значение приведенной случайной величины Z, для которого функция распределения (2.27)
принимает значение Р:
Ф(zp) = P. (2.31)
При определении квантили zр необходимо решать задачу, обратную задаче определения
значений функции Лапласа, т.е. по известному значению Р этой функции (2.27) находить соответствующее ему значение аргумента zр. Для этого можно либо воспользоваться табулированными значениями функции Лапласа (например, поскольку Ф(1,64) = 0,94950, а Ф(1,65) =
0,9505, то z0,95 ≈ 1,645 ), либо воспользоваться таблицами для функции, обратной функции
Лапласа, т.е. табулированными значениями квантилей нормированного нормального закона
распределения. Определение квантили zp в электронных таблицах Microsoft Excel сводится к
вычислению статистической функции НОРМОБР(Р; 0; 1) или НОРМСТОБР(Р) (например,
НОРМОБР(0,95; 0; 1) = НОРМСТОБР(0,95) = 1,644853).
Для квантили стандартного нормального распределения справедливо следующее равенство:
z1 – p = - zp .
Рассмотрим график плотности стандартного нормального распределения (Рисунок 5).
Площадь под графиком левее квантили zp по определению равна p. Значит, площадь правее
этой точки равна 1 – p. Такая же площадь расположена левее точки z1 –p. Итак, площади левее
z1 –p и правее zp равны. Поскольку график симметричен относительно оси ординат, из этого
следует, что эти точки расположены на одинаковом расстоянии от нуля.
Рисунок 5 - Квантиль стандартного нормального распределения
Зная квантиль zр порядка р нормированного нормального закона распределения (Mz = 0
и σz 2 = 1), всегда можно найти квантиль xр соответствующего порядка р для нормального
распределения с произвольными параметрами Mx и σx 2 .
Поскольку
то
и, следовательно,
24
В ряде случаев важно знать вероятность того, что случайная величина Х, подчиняющаяся нормальному закону распределения, не будет отличаться от своего математического
ожидания Мx больше чем на величину ±δ = ε·σx (Рисунок 4,г).
Так, при δ = σx (ε =1) получаем, что
а поскольку по
таблицам Ф(1) = 0,84135 (или в Microsoft Excel НОРМРАСП(1;0;1;ИСТИНА) = НОРМСТРАСП(1) = 0,84135), то для случайной величины с нормальным законом распределения
вероятность того, что она примет такое значение, которое не будет отличаться от ее математического ожидания более чем на одно среднее квадратичское отклонение, равна 2⋅0,84135–
1=0,68. Иными словами, при нормальном распределении примерно 2/3 всех значений случайной величины (отклика) лежит в интервале Mx ± σx.
Аналогично можно подсчитать, что интервалу Mx ± 1,96σx ≈ Mx ± 2σx соответствует вероятность 0,95 (Ф(1,96) = 0,975002), а интервалу Mx ± 3σx - 0,997 (Ф(3) = 0,99865). Отметим
дополнительно, что 90% значений случайной величины лежат в диапазоне Mx ± 1,64σx
(Ф(1,64) = 0,949497).
Следовательно, отличие какого-либо из значений случайной величины с нормальным
законом распределения от ее математического ожидания не превосходит утроенного среднего квадратичного отклонения с вероятностью 0,997. Это свойство в математической статистике носит название «правило трех сигм».
Чем больше величина интервала Mx ± δ, тем с большей вероятностью случайная величина X попадает в этот интервал.
25
4 Предварительная обработка экспериментальных данных
Предварительная обработка результатов измерений и наблюдений необходима для того, чтобы в дальнейшем, при построении эмпирических зависимостей (функций отклика), с
наибольшей эффективностью использовать статистические методы и корректно анализировать полученные результаты.
Содержание предварительной обработки состоит в отсеивании грубых погрешностей и
оценке достоверности результатов измерений. Другими важными моментами предварительной обработки данных являются проверка соответствия результатов измерения нормальному
закону и определение параметров этого распределения. Если гипотеза о том, что отклик не
противоречит нормальному распределению, окажется неприемлемой, то следует определить,
какому закону распределения подчиняются опытные данные или, если это возможно, преобразовать опытное распределение к нормальному виду.
4.1 Вычисление параметров эмпирических распределений. Точечное оценивание
Рассмотрение вопросов обработки экспериментальных данных начнем с простейшей
ситуации, когда отклик регистрируется при фиксированных уровнях всех контролируемых
факторов и при проведении опытов (в результате влияния неконтролируемых факторов) исследователь получает хотя и близкие, но отличные друг от друга результаты.
Пример 4.1. При испытании пряжи на разрыв были получены следующие значения ее
прочности: 199; 239; 214; 229; 224; 234; 219; 300; 224; 218.
Попытаемся найти ответ на вопрос – чему равна прочность пряжи на разрыв?
На первый взгляд решение поставленной задачи не вызывает никаких особых проблем,
большинство скорее всего ответят, что прочность на разрыв равна (П1 – первый вариант ответа)
П1 199 239 214 229 224 234 219 300 224 218 / 10 230
т.е. будет найдено среднее арифметическое (выборочное среднее арифметическое) из
десяти полученных значений отклика.
Однако опытные данные можно усреднять и другими способами. Например, можно
подсчитать среднее геометрическое (П2 – второй вариант ответа):
П2 10 199 239 214 229 224 234 219 300 224 218 228,73
или найти среднее, только между минимальным (199) и максимальным (300) значениями – так называемую середину размаха (П3 – третий вариант ответа):
П3 199 300 / 2 249,5
или, расположив все значения в возрастающей последовательности 199; 214; 218; 219;
224; 224; 229; 234; 239; 300, взять средний член полученного ряда – средний член вариационного ряда (П4 – четвертый вариант ответа):
П4 224 .
Можно придумать и какие-либо другие способы (например, очень «оригинальной» может быть идея еще раз усреднить все четыре полученных значения), однако остановимся пока только на этих четырех вариантах ответа на поставленный перед нами вопрос.
Таким образом, очевидно, что не привлекая никаких дополнительных соображений,
нам пока достаточно трудно обосновать тот или иной вариант, на котором было бы предпочтительно остановиться.
Так, если выбирать тот ответ, который потребует от нас меньшего количество вычислений, то тогда лучше всего отдать предпочтение значению П4=224,00 (вообще не требует
никаких расчетов). Однако подобное обоснование вряд ли можно считать достаточно надежным и убедительным.
Проанализируем, почему вообще мы столкнулись с подобной ситуацией.
26
Если бы, например, нам нужно было найти ответ на вопрос, какое количество операций
в технологическом процессе изготовления пряжи, и мы по ходу технологического процесса
проследили за тремя партиями пряжи, то в результате было бы получено три абсолютно одинаковых значения (допустим, пятнадцать). В подобной ситуации нет необходимости считать
ни выборочное среднее, ни среднее геометрическое, ни середину размаха, ни находить средний член вариационного ряда и т.д., поскольку можно сразу указать то количество операций,
которые происходят в процессе изготовления пряжи.
Следовательно, между такими величинами, как число операций технологического процесса и прочность пряжи на разрыв, есть принципиальная разница, которая заключается в
том, что первая из двух названых величин является детерминированной, а вторая – случайной. И если для того, чтобы описать детерминированную величину, достаточно указать одно
ее значение (например, число операций технологического процесса равное, например, 15), то
для описания случайной величины нужно знать ее распределение. Другими словами, для
случайной величины недостаточно указать только лишь какое-либо ее значение (или комбинацию ее значений, как, например, выборочное среднее арифметическое), а нужно записать
функцию, которая однозначно определяет вероятность того, что случайная величина принимает заданное значение или принадлежит к некоторому заданному интервалу.
4.2 Термины и определения в области обработки экспериментальных данных
Наблюдаемая единица – действительный или условный предмет, над которым проводят
серию наблюдений.
Результат наблюдения – характеристика свойств единицы, полученная опытным путем.
Генеральная совокупность – множество всех рассматриваемых единиц.
Другими словами, генеральная совокупность - это такое воображаемое, в пределе бесконечно большое число предметов, над которыми можно провести наблюдения при неограниченном числе повторений одного и того же комплекса условий.
В примере 4.1 под генеральной совокупностью можно понимать, допустим, все участки
пряжи, в которых в принципе можно было бы замерить прочность, либо вообще все мотки
пряжи, которые когда-либо изготавливались или еще будут производиться по соответствующему стандарту.
В распоряжении исследователя никогда нет генеральной совокупности, и он может
изучать только ее часть – выборку, причем всегда ограниченного объема.
Выборка – любое конечное подмножество генеральной совокупности, предназначенное
для непосредственных исследований.
Объем – количество единиц в выборке.
По выборке невозможно однозначно определить ни функцию распределения, ни плотность распределения, ни параметры распределения (например, математическое ожидание
или дисперсию) случайной величины, поскольку для этого потребуется неограниченное
(бесконечно большое) количество результатов наблюдений, т.е. необходимо исследовать всю
генеральную совокупность, поэтому проводится оценивание случайной величины.
Оценивание – определение приближенного значения неизвестного параметра генеральной совокупности по результатам наблюдений.
Идея оценивания должна быть вполне понятна из соображений ежедневной практики.
Ведь для того, чтобы, например, купить пару килограмм яблок, у нас никогда не возникает
желание съесть все имеющиеся у данного продавца фрукты (изучить всю генеральную совокупность), мы пробуем дольку только лишь одного яблока (исследуем выборку), определяем
ее вкус (оцениваем) и принимаем решение, стоит нам или нет покупать именно эти яблоки.
Исходными данными при оценивании, как и при проверке любых предположений (статистических гипотез), касающихся неизвестного распределения случайной величины могут
быть лишь только те результаты наблюдений, которые были получены в ходе проведения
опытов (на выборке ограниченного объема). Причем предварительная обработка экспери27
ментальных данных обычно начинается с подсчета тех или иных функций от результатов
наблюдений (статистик).
Статистика – функция результатов наблюдений, используемая для оценки параметров
распределения и (или) для проверки статистических гипотез.
По выборке невозможно найти параметры распределения случайной величины (поскольку для этого требуется бесконечное количество результатов наблюдений – изучение
всей генеральной совокупности), поэтому, имея в своем распоряжении всегда ограниченный
объем экспериментальных данных, исследователю остается довольствоваться только лишь
получением некоторых оценок.
Оценка – статистика, являющаяся основой для оценивания неизвестного параметра
распределения.
Для одного и того же параметра распределения может быть предложено несколько
оценок.
В примере 4.1 рассматривалось четыре различных оценки для такого параметра распределения прочности, как математическое ожидание данной случайной величины (выборочное среднее арифметическое, выборочное среднее геометрическое, середина размаха и
средний член вариационного ряда).
Поэтому при оценивании всегда возникает проблема выбора наилучшей оценки из всех
возможных оценок данного параметра.
Причем, когда формулируются те или иные требования, по которым оценку целесообразно считать наилучшей, прежде всего, учитывается тот факт, что любая оценка – это также
случайная величина.
Из тех соображений, что любая оценка Θ* какого-либо параметра распределения Θ
случайной величины тоже есть случайная величина, к оценкам предъявляются требования
состоятельности, несмещенности и эффективности.
Состоятельная оценка – оценка, сходящаяся по вероятности к значению оцениваемого
параметра при безграничном возрастании объема выборки.
где Θ - оцениваемый параметр; Θ* - оценка; n - объем выборки.
Иными словами, для состоятельной оценки Θ* отклонение ее от Θ на малую величину
ε и более становится маловероятным при большом объеме выборки.
Исследователей в первую очередь интересуют те оценки, которые хотя бы в пределе
(при проведении бесконечно большого количества наблюдений) давали им возможность
определить интересующий их параметр распределения, т.е. чтобы оценки прежде всего были
состоятельными. Однако следует отметить, что на практике приходится оценивать неизвестные параметры и при малых объемах выборки.
Естественным является требование, при выполнении которого оценка не дает систематической погрешности в сторону завышения (или занижения) истинного значения параметра
Θ.
Несмещенная оценка – оценка, математическое ожидание которой равно значению
оцениваемого параметра:
M(Θ*)=Θ.
Удовлетворение требованию несмещенности позволяет устранить систематическую погрешность оценки параметра, которая зависит от объема выборки n и в случае состоятельности оценки стремится к нулю при n→∞.
Эффективная оценка – несмещенная оценка, имеющая наименьшую дисперсию из всех
возможных несмещенных оценок данного параметра.
или
где Θi* – любая другая оценка.
28
Иными словами, дисперсия эффективной оценки параметра в некотором классе является минимальной среди дисперсий всех оценок из рассматриваемого класса несмещенных
оценок.
Из всех состоятельных и несмещенных оценок следует предпочесть такую, которая
оказывается наиболее близкой к оцениваемому параметру (эффективной), однако используемые в математической статистике оценки не всегда одновременно удовлетворяют всем трем
перечисленным выше требованиям.
После того как исследователь выбрал и подсчитал состоятельную, несмещенную и эффективную оценки интересующего его параметра распределения исследуемой случайной величины, первое и наиболее простое, что он может сделать, так это принять значение оценки
за неизвестное значение параметра распределения, т.е. выполнить точечное оценивание.
Точечное оценивание – способ оценивания, заключающийся в том, что значение оценки принимают как неизвестное значение параметра распределения.
Рассмотрим некоторые точечные оценки основных параметров распределения для непрерывной случайной величины, не противоречащей нормальному закону распределения.
Выборочное среднее арифметическое – сумма значений рассматриваемой величины,
полученных по результатам испытания выборки, деленная на ее объем.
где n – объем выборки; хi– результат измерения i-й единицы.
В математической статистике доказано, что выборочное среднее арифметическое является наилучшей (состоятельной, несмещенной и эффективной) оценкой математического
ожидания случайной величины, подчиняющейся нормальному закону распределения.
В примере 4.1, даже если предположить, что прочность пряжи не противоречит нормальному закону распределения, из четырех полученных оценок предпочтение следует отдать значению П1 199 239 214 229 224 234 219 300 224 218 / 10 230 (выборочному среднему арифметическому) как наилучшей оценке для математического ожидания
данной случайной величины. Три другие рассмотренные в этом примере оценки также являются состоятельными для математического ожидания. Однако среднее геометрическое
П2 10 199 239 214 229 224 234 219 300 224 218 228,73 – это смещенная оценка (она
будет наилучшей только тогда, когда случайная величина подчиняется так называемому логарифмически нормальному распределению, т.е. когда закону Гаусса подчиняется не сама
случайная величина, а ее логарифм). Середина размаха Ï 3 199 300 / 2 249,5 и средний
член вариационного ряда Ï 4 224 – это хотя и несмещенные оценки для математического
ожидания, но их эффективность, как показано в математической статистике, меньше, чем у
выборочного среднего арифметического.
Выборочная дисперсия или - сумма квадратов отклонений выборочных результатов
наблюдений от их выборочного среднего арифметического в выборке, деленная на n-1 или на
n.
или
2
Оценки S , S x и являются состоятельными, несмещенными и, в случае нормального
распределения, асимптотически эффективными оценками дисперсии σ2.
Для практических расчетов первое выражение можно преобразовать к виду
2
x
В условиях примера 4.1 выборочная дисперсия прочность пряжи равна S x2 728 .
29
Выборочное среднее квадратичное отклонение S x или S x – положительный квадратный
корень из выборочной дисперсии:
S S 2 или S S 2
x
x
x
x
В примере 4.1 . S x 728 26,98
Зная выборочное среднее арифметическое x и выборочное среднее квадратичное отклонение S x , можно подсчитать меру относительной изменчивости случайной величины –
выборочный коэффициента вариации ν - по формуле
или, в процентах,
Для примера 4.1 выборочный коэффициент вариации прочности равен ν=26,98/230=
=0,117, или 11,7%.
Через выборочное среднее арифметическое x и выборочное среднее квадратическое
отклонение S x могут быть сделаны точечные оценки для любых значений функции распределения, а также для вероятности попадания случайной величины в любой из заданных интервалов.
Так, для какого-либо значения функции нормального распределения, поскольку
в качестве точечной оценки F(x) можно использовать
Точечную оценку вероятности попадания случайной величины Х с нормальным законом распределения в любой из заданных интервалов (х1, х2) можно найти по формуле
Точечная оценка квантили xр порядка р для нормального распределения равна
4.3 Оценивание с помощью доверительного интервала
В отличие от точечной оценки, интервальная оценка позволяет получить вероятностную характеристику точности оценивания неизвестного параметра.
Идея оценивания с помощью доверительного интервала заключается в том, чтобы в
окрестности точечной оценки попытаться построить такой интервал (доверительный интервал), который с некоторой, отличной от нуля, вероятностью (доверительной вероятностью)
накрыл бы оцениваемый параметр распределения.
Доверительный интервал – интервал, который с заданной вероятностью накроет неизвестное значение оцениваемого параметра распределения.
Доверительная вероятность – вероятность того, что доверительный интервал накроет
действительное значение параметра, оцениваемого по выборочным данным.
Оценивание с помощью доверительного интервала – способ оценки, при котором с заданной доверительной вероятностью устанавливают границы доверительного интервала.
Предположим, что для оценки параметра Θ удалось найти две функции Θ1*(x1, x2, ...,
xn) и Θ2*(x1, x2, ..., xn), такие, что при всех (x1, x2, ..., xn) и при любых значениях Θ выполняется условие
30
Это означает, что действительное значение параметра Θ находится в интервале значений (Θ1*;Θ2*) с вероятностью P.
Интервал (Θ1*;Θ2*) как раз и называют доверительным интервалом для неизвестного
параметра Θ, а соответствующую ему вероятность P{Θ1*≤Θ≤Θ2*} - доверительной вероятностью (или надежностью) P=1-α, где α - уровень значимости. Если, к примеру, α=0,05, то
строится доверительный интервал с доверительной вероятностью 0,95 (или 95-процентный
доверительный интервал).
Вероятностное утверждение P{Θ1*≤Θ≤Θ2*} не следует понимать таким образом, что
параметр Θ есть случайная величина, которая с вероятностью P попадет в интервал между
Θ1* и Θ2*.
Любой параметр распределения Θ (в отличие от его оценок) – это детерминированная
величина, неизвестная нам, но имеющая строго определенное, фиксированное значение (которое, по крайней мере, теоретически, может быть найдено при исследовании всей генеральной совокупности). Границы Θ1* и Θ2* (как некоторые функции от результатов наблюдений)
есть случайные величины. Поэтому утверждение P{Θ1*≤Θ≤Θ2*} = P означает, что для данного доверительного интервала (Θ1*;Θ2*) вероятность содержать значение Θ равна P.
4.3.1
Построение доверительного интервала для математического ожидания
Как уже было отмечено, наилучшей (состоятельной, несмещенной и эффективной) точечной оценкой математического ожидания случайной величины Х с нормальным законом
распределения является ее выборочное среднее арифметическое x . Поэтому за основу построения доверительного интервала для математического ожидания обычно выбирается
именно эта точечная оценка данного параметра. Задача получения интервальной оценки в
этом случае заключается в поиске границ x ; x такого интервала, который с заданной
доверительной вероятностью PMx накроет действительное значение математического ожидания Mx (Рисунок 6).
Рисунок 6 - Построение доверительного интервала для математического ожидания
При построении любой интервальной оценки, в том числе и для математического ожидания, необходимо знать распределение той точечной оценки (случайной величины), которая
берется за основу для построения доверительного интервала.
В математической статистике доказано, что выборочное среднее арифметическое x из
n независимых результатов наблюдений случайной величины, распределенной нормально с
параметрами Mx и σx2, также подчиняется нормальному закону распределения с параметрами:
Подтвердить справедливость первого равенства можно тем, что выборочное среднее
арифметическое - это несмещенная оценка математического ожидания, следовательно, по
определению, математическое ожидание этой оценки (выборочного среднего арифметического) равно значению оцениваемого параметра (математическому ожиданию).
31
Логика возникновения второго соотношения: если подсчитать выборочное среднее
арифметическое по нескольким выборкам одного и того же объема, а затем найти дисперсию
полученных значений, то вероятнее всего предположить, что разброс (дисперсия) выборочных средних арифметических будет меньше, чем разброс (дисперсия) самих опытных данных.
Если заранее известна дисперсия σx2, то доверительный интервал для математического
ожидания Mx рассчитывается достаточно просто. Его границы можно найти, например, следующим образом.
Поскольку случайная величина X подчиняется нормальному закону распределения с
параметрами M(x) = Mx и σ2(x) = σx2/n , то соответствующая ей приведенная случайная величина
.
имеет нормированный стандартный нормальный закон распределения.
Квантиль x p порядка P такой случайной величины, как x , определяется как:
Далее
Если в последнем соотношении неравенство, стоящее под знаком вероятности, разрешить относительно Mx, то получим
Если
, то
и, следовательно,
но, если
то
и, следовательно,
Таким образом, вероятность того, что выполняется неравенство
, и, аналогич.
будет P = P2 – P1 = 1- α.
Если для примера принять P1= 0,025 и P2 = 0,975 (P=0,975–0,025 =0,95; α=0,05), то, поскольку z0,025 = z1-0,975 = - z0,975 ,а z0,975 = 1,96 (Таблица 4 или используя НОРМСТОБР(0,975)
= 1,959961), получим
т.е. при многократном извлечении выборок (объемом n каждая) из нормально распределенной генеральной совокупности (с параметрами Mx и σx2) можно построить последовательность соответствующих данным выборкам интервалов, причем примерно 95% этих интервалов будут включать в себя (накрывать) истинное значение математического ожидания
Mx.
При построении доверительного интервала для математического ожидания обычно
принимают P1= α/2 и P2 = 1 – α/2, т.е. рассматривают симметричные границы относительно
выборочного среднего арифметического. В инженерных приложениях для значений α обычно выбирают α = 0,1 или α = 0,05, реже α = 0,01, т.е. строят такие доверительные интервалы,
которые в 90 или 95% (реже 99%) случаев накрывают математическое ожидание.
32
Таблица 4 - Квантили стандартного нормального распределения
Так как z α/2= - z1- α/2, то получаем, что вероятность выполнения неравенства
равна P = 1 – α/2 - α/2 = 1- α.
Следовательно, интервал является доверительным интервалом для математического
ожидания Mx случайной величины с нормальным законом распределения, построенным с доверительной вероятностью P = 1- α. Границы этого интервала равны
и
, а половина его ширины (Рисунок 6)
.
Пример 4.2. Было проведено исследование длины мотков пряжи. В процессе исследования рассмотрены n = 49 мотков и получены следующие данные: средняя длина мотка
x 203 , σ(x) =26. Необходимо определить доверительный интервал M x с надежностью
Р=0,95, объем выборки n, который необходимо выполнить, чтобы точность статистических
выводов δ ≤ 2.
Рассчитаем доверительный интервал:
26
26
.
203 1,96
M x 203 1,96
49
49
195,72≤ Mx≤ 210,28.
Необходимый объем выборки для δ = 2 составит
2
26
n 1,96 649
2
На практике, как правило, число измерений конечно и не превышает 10…30. При таком
малом числе наблюдений фактическая дисперсия σx2 неизвестна, поэтому при построении
доверительного интервала для математического ожидания Mx используют выборочную дисперсию Sx2.
Рассматриваемая величина может и не подчиняться нормальному распределению, а,
например, распределению Стьюдента или гамма распределению, в этом случае формула
определения доверительного интервала остается прежней за исключением того, что уже используется квантиль соответствующего распределения, а не нормального.
4.3.2
Построение доверительного интервала для дисперсии
При построении доверительного интервала для дисперсии используется случайная величина χ2 ,
которая имеет так называемое распределение Пирсона (по имени английского математика и биолога К.Пирсона), или χ2–распределение.
Плотность распределения случайной величины χ2 описывается уравнением
33
где Г(m/2) – гамма – функция; m – число степеней свободы (при построении доверительного интервала m = n-1).
Функция распределения описывается уравнением:
m 2
,
2 2
,
F 2
m
Ã
2
где - неполная гамма-функция.
Число степеней свободы m – это понятие, которое учитывает в статистических ситуациях связи, ограничивающие свободу изменения случайных величин. Поэтому число степеней свободы вычисляется как разность между числом экспериментальных точек n и числом
связей f, ограничивающих свободу изменения случайной величины. Свободу изменения случайной величины в данном случае ограничивает лишь один параметр, оценка дисперсии, поэтому m = n-1.
На Рисунок 7 приведены кривые f(χ2) для различных значений m. Эти кривые асимметричны, причем асимметрия особенно резко выражена при малых значениях параметра m.
Так, при m =1 и χ2=0 кривая уходит в бесконечность, а при m = 2 и χ2=0 она достигает максимального значения, равного 0,5. При m>2 кривые имеют максимум при χ2max = m - 2. При
больших значениях m (m>30) χ2-распределение переходит в нормальное со средним значени-
ем
и дисперсией σ2=1.
Для построения доверительного интервала для дисперсии рассмотрим соотношение
и с учетом того, что
сительно σx2 :
решим стоящее в скобках неравенство отно-
,
где
тельной вероятностью
есть доверительный интервал для дисперсии 2x с довери-
P= P2- P1=1-α.
Как и при построении доверительного интервала для математического ожидания в технических приложениях обычно принимают P1=α/2 и P2=1-α/2, а α выбирают равным 0,1 или
0,05, реже 0,01.
Квантили распределения Пирсона находят по таблицам (Таблица 5), а в Microsoft Excel
для этого используется функция ХИ2ОБР.
Границы доверительного интервала для среднего квадратичного отклонения σx находятся путем извлечения квадратного корня из значений доверительных границ для дисперсии.
В примере 4.1 по десяти выборочным значениям 199; 239; 214; 229; 224; 234; 219; 300;
224; 218 S 2 728 , при α=0,05 (P1=0,05/2=0,025 и P2=1-0,05/2=0,975; ХИ2ОБР(0,025;9) =
19,0228 и ХИ2ОБР(0,975;0) = 2,7004) доверительный интервал для прочности на разрыв составит
34
10 1
10 1
или после вычислений 344,23 x2 2426,31 , а довери x2 728
19,0228
2,7004
тельный интервал для среднего квадратичного отклонения будет равен 18,55 x 49,26
728
Таблица 5 - Хи-квадрат распределение. Критические области для хи-квадрат распределения
df\area
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
.995
0.00004
0.01003
0.07172
0.20699
0.41174
0.67573
0.98926
1.34441
1.73493
2.15586
2.60322
3.07382
3.56503
4.07467
4.60092
5.14221
5.69722
6.26480
6.84397
7.43384
8.03365
8.64272
9.26042
9.88623
10.51965
11.16024
11.80759
12.46134
13.12115
13.78672
.990
.975
.950
0.00016 0.00098 0.00393
0.02010 0.05064 0.10259
0.11483 0.21580 0.35185
0.29711 0.48442 0.71072
0.55430 0.83121 1.14548
0.87209 1.23734 1.63538
1.23904 1.68987 2.16735
1.64650 2.17973 2.73264
2.08790 2.70039 3.32511
2.55821 3.24697 3.94030
3.05348 3.81575 4.57481
3.57057 4.40379 5.22603
4.10692 5.00875 5.89186
4.66043 5.62873 6.57063
5.22935 6.26214 7.26094
5.81221 5.90766 7.96165
6.40776 7.56419 8.67176
7.01491 8.23075 9.39046
7.63276 8.90652 10.11701
8.26040 9.59078 10.85081
8.89720 10.28290 11.59131
9.54249 10.98232 12.33801
10.19572 11.68855 13.09051
10.85636 12.40115 13.84843
11.52398 13.11972 14.61141
12.19815 13.84390 15.37916
12.87850 14.57338 16.15140
13.56471 15.30786 16.92788
14.25645 16.04707 17.70837
14.95346 16.79077 18.49266
.900
0.01579
0.21072
0.57437
1.06362
1.61031
2.20413
2.83311
3.48954
4.16816
4.46518
5.57778
6.30380
7.04150
7.78953
8.54676
9.31224
10.08519
10.86494
11.65091
12.44261
13.23960
14.04149
14.84796
15.65868
16.47341
17.29188
18.11390
18.93924
19.76774
20.59923
.750
0.10153
0.57536
1.21253
1.92256
2.67460
3.45460
4.25485
5.07064
5.89883
6.73720
7.58414
8.43842
9.29907
10.16531
11.03654
11.91222
12.79193
13.67529
14.56200
15.45177
16.34438
17.23962
18.13730
19.03725
19.93934
20.84343
21.74940
22.65716
23.56659
24.47761
.500
0.45494
1.38629
2.36597
3.35669
4.35146
5.34812
6.34581
7.34412
8.34283
9.34182
10.34100
11.34032
12.33976
13.33927
14.33886
15.33850
16.33818
17.33790
18.33765
19.33743
20.33723
21.33704
22.33688
23.33673
24.33659
25.33646
26.33634
27.33623
28.33613
29.33603
.250
1.32330
2.77259
4.10834
5.38527
6.62568
7.84080
9.03715
10.21885
11.38875
12.54886
13.70069
14.84540
15.98391
17.11693
18.24509
19.36886
20.48868
21.60489
22.71781
23.82769
24.93478
26.03927
27.14134
28.24115
29.33885
30.43457
31.52841
32.62049
33.71091
34.79974
.100
2.70554
4.60517
6.25139
7.77944
9.23636
10.64464
12.01704
13.36157
14.68366
15.98718
17.27501
18.54935
19.81193
21.06414
22.30713
23.54183
24.76904
25.98942
27.20357
28.41198
29.61509
30.81328
32.00690
33.19624
34.38159
35.56317
36.74122
37.91592
39.08747
40.25602
.050
3.84146
5.99146
7.81473
9.48773
11.07050
12.59159
14.06714
15.50731
16.91898
18.30704
19.67514
21.02607
22.36203
23.68479
24.99579
26.29623
27.58711
28.86930
30.14353
31.41043
32.67057
33.92444
35.17246
36.41503
37.65248
38.88514
40.11327
41.33714
42.55697
43.77297
.025
.010
.005
5.02389 6.63490 7.87944
7.37776 9.21034 10.59663
9.34840 11.34487 12.83816
11.14329 13.27670 14.86026
12.83250 15.08627 16.74960
14.44938 16.81189 18.54758
16.01276 18.47531 20.27774
17.53455 20.09024 21.95495
19.02277 21.66599 23.28935
20.48318 23.20925 25.18818
21.92005 24.72497 26.75685
23.33666 26.21697 28.29952
24.73560 27.68825 29.81947
26.11895 29.14124 31.31935
27.48839 30.57791 32.80132
28.84535 31.99993 34.26719
30.19101 33.40866 35.71847
31.52638 34.80531 37.15645
32.85233 36.19087 38.58226
34.16961 37.56623 39.99685
35.47888 38.93217 41.40106
36.78081 40.28936 42.79565
38.07563 41.63840 44.18128
39.36408 42.97982 45.55851
40.64647 44.31410 46.92789
41.92317 45.64168 48.28988
43.19451 46.96294 49.64492
44.46079 48.27824 50.99338
45.72229 49.58788 52.33562
46.97924 50.89218 53.67196
Рисунок 7 - Плотность распределения (а) и функция распределения (б)
2
35
4.3.3
Отсев грубых погрешностей
Часто даже тщательно поставленные эксперименты могут давать неоднородные данные, поскольку в процессе эксперимента могут измениться условия проведения опытов. Если
экспериментатор по каким-либо причинам не уловил этих изменений, наблюдения, соответствующие разным уровням факторов, будут принадлежать к разным генеральным совокупностям. Данные, соответствующие изменившимся условиям, называют грубыми погрешностями (ошибками) или резко выделяющимися (аномальными) значениями. Грубые погрешности появляются также при неправильной записи показаний приборов.
В литературе приводятся сведения о том, что экспериментальные данные могут содержать ~ 10% аномальных значений. Однако эти 10% могут дать сильное смещение при оценке
параметров распределения, особенно для дисперсии, так как ошибки заметно отклоняются от
основной группы значений, а на дисперсию особенно сильно влияют крайние члены вариационного ряда (вариационный ряд – результаты наблюдений, расположенные в возрастающей последовательности x1≤ x2≤ x3 ... ≤ xi …≤xn).
В случае отсева грубых погрешностей (ошибок) нулевая гипотеза формулируется следующим образом:
Н0 :"Среди результатов наблюдений (выборочных, опытных данных) нет резко выделяющихся (аномальных) значений ".
Альтернативной гипотезой может быть:
1) либо Н1(1): "Среди результатов наблюдений есть только одна грубая ошибка",
2) либо Н1(2): "Среди результатов наблюдений есть две или более грубых ошибки".
В литературе можно встретить большое количество различных критериев для отсева
грубых погрешностей наблюдений. Обычно экспериментаторы имеют дело с выборками небольшого объема (т.е. когда генеральная дисперсия σx2 неизвестна и оценивается по опытным данным через выборочную дисперсию Sx2), причем именно в этом случае аномальные
данные имеют большой вес. Наиболее распространенным и теоретически обоснованным в
этом случае является критерий Н.В. Смирнова.
Если известно, что есть только одно аномальное значение (альтернативная гипотеза
(1)
Н1 ), то оно будет крайним членом вариационного ряда. Поэтому проверять выборку на
наличие одной грубой ошибки естественно при помощи статистики:
,
если сомнение вызывает первый член вариационного ряда, x1 min xi , или
если сомнителен максимальный член вариационного ряда xn max xi .
При этом, среднее значение параметра вычисляется по формуле:
1 n
x xi ,
n i 1
где n - число наблюдений.
Среднеквадратическое отклонение вычисляется по формуле:
2
1 n 2 1 n
1 n
2
xi xi
Sx
xi x или S x n 1
n i 1
n 1 i 1
i 1
При выбранном уровне значимости α критическая область для критерия Н.В. Смирнова
строится следующим образом:
u1 > uα,n или un > uα,n .
36
где uα,n – это табличные значения (таблица 6).
В случае если выполняется последнее условие (статистика попадает в критическую область), то нулевая гипотеза отклоняется, т.е. выброс x1 или xn не случаен и не характерен для
рассматриваемой совокупности данных, а определяется изменившимися условиями или грубыми ошибками при проведении опытов. В этом случае значение x1 или xn исключают из рассмотрения, а найденные ранее оценки подвергаются корректировке с учетом отброшенного
результата.
Пример. Пирометром измеряется температура поверхности нагретого тела. Было проведено шесть измерений температуры T °С, и получены следующие значения: 925, 930, 950,
975, 990, 1080 (n = 6, причем, как видно, все значения приведены в возрастающей последовательности, т.е. в виде вариационного ряда T1=925 ≤ T2=930 ≤ T3 =950... ≤T6=1080). Можно ли
значение T6=1080 считать грубой погрешностью, полученной, допустим, в результате неправильной регистрации показаний пирометра?
Таблица 6 - Критические значения критерия Н.В. Смирнова un в зависимости от объема выборки n и
уровня значимости α
n
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
un
a=0.10
1.15
1,42
1,60
1,73
1,83
1,91
1,98
2,03
2,09
2,13
2,17
2,21
2,25
2,28
2,31
2,34
2,36
2,38
2,41
2,43
2,45
2,47
2,49
a=0,05
1,15
1,46
1-67
1,82
1,94
2,03
2,11
2,18
2,23
2,29
2,33
2,37
2,41
2,44
2,48
2,50
2,53
2,53
2,58
2,60
2,62
2,64
2,66
a=0,01
1,15
1,49
1.75
1,94
2,10
2,22
2,32
2,41
2,48
2,55
2,61
2,66
2,70
2,75
2,78
2,82
2,85
2,88
2,91
2,94
2,96
2,99
3,01
Для ответа на поставленный в этом примере вопрос предварительно вычислим оценки
параметров распределения исследуемой случайной величины T (предполагая, что она не
противоречит нормальному закону распределения): выборочное среднее арифметическое T
и выборочное среднее квадратичное отклонение ST:
37
Теперь воспользуемся предложенным выше алгоритмом проверки статистических гипотез.
1. Формулируем нулевую гипотезу Н0: "Среди значений 925; 930: 950; 975; 990: 1080
нет грубых погрешностей".
2. Исходя из условий примера выбираем следующую альтернативную гипотезу Н1(1):
"Значение 1080 является (одной) грубой погрешностью".
3. Сформулированная нулевая гипотеза Н0 может быть проверена по критерию Н.В.
Смирнова.
4. Значение статистики критерия Н.В. Смирнова равно:
5. Уровень значимости α примем равным 0,05.
6. По таблица 6 при α = 0,05 и n = 6 находим u0,05;6 = 1,82, и строим критическую область ω: u6 > u0,05;6, т.е. u6 > 1,82.
7. Принимаем решение: поскольку значение статистики (1,83 > 1,82) попало в критическую область – нулевая гипотеза отвергается, и в качестве рабочей принимается альтернативная гипотеза, т.е. значение 1080 с вероятностью 0,95 (уровень значимости, не превышает
0,05) по критерию Н.В. Смирнова можно считать грубой погрешностью. Интересно отметить, что если бы на этапе 5 мы приняли α = 0,01, по таблицам критерия Н.В. Смирнова u0,01;6
= 1,94 и подсчитанное значение статистики при этом уровне значимости, то оно не попало
бы в критическую область (1,83<1,94). Следовательно, при α = 0,01 мы не можем отвергнуть
нулевую гипотезу, т.е. по критерию Н.В. Смирнова с вероятностью 0,99 (надежностью, достоверностью) мы не можем сказать, что значение 1080 является грубой погрешностью.
38
5 Сравнение числовых характеристик по выборочным данным
5.1 Понятие о статистических гипотезах и критериях оценки
При обработке экспериментальных данных (измерений) часто возникает задача определения значимости различия между числовыми характеристиками 1 и 2 , т.е. между генеральными средними 1 и 2 , дисперсиями 12 и 22 , коэффициентами вариации 1 , и 2 и
др. Это бывает в следующих случаях:
1) при оценке влияния изменения уровня фактора (в каком-либо процессе) на выходной
параметр. Например, будет ли значимая разница в прочности пряжи при изменении коэффициента крутки на 10 единиц (130 вместо 120) или в плотности ткани по утку при увеличении заправочного натяжения основы на 10 %, или в плотности трикотажа (по вертикали)
при увеличении глубины кулирования на 0,5 мм;
2) при сравнении свойств двух партий сырья или готовой продукции, полученной из
этого сырья, Например, будет ли значимая разница между двумя марками хлопка одного
сорта, полученного фабрикой в разное время года;
3) при сравнении двух систем прядения, технологических процессов или объектов.
Например, будет ли значимая разница по чистоте и степени разъединенности волокон в ватке-прочесе, полученной на двух различного типа кардочесальных машинах;
4) при сравнении разного состава или структуры продуктов производства;
5) при определении воспроизводимости и стационарности процесса;
6) при сравнении двух методов исследования свойств продукта или работы машины.
Такие задачи могут быть решены только на основе анализа статистических данных и
проверки статистических гипотез.
Различают два вида статистических гипотез: предположение о числовых характеристиках (параметрах) генеральной совокупности (в том случае, если известен тип распределения
генеральной совокупности) и предположение о типе распределения (в том случае, если об
изучаемой переменной ничего неизвестно).
На практике чаще встречается первый вид статистических гипотез, т.е. так называемая
нулевая гипотеза - H 0 , например, «О равенстве числовых характеристик 1 и 2 » для рассматриваемых двух выборок вместо конкурирующей (альтернативной) гипотезы H1 «О неравенстве числовых характеристик 1 и 2 ». Поскольку при проверке гипотез речь идет об
оценках генеральных совокупностей на основании случайных выборок, то выводы будут носить вероятностный характер.
Из математической статистики известны две группы критериев проверки нулевой гипотезы H 0 - параметрические и непараметрические.
Первая группа критериев в качестве необходимого условия их применимости требует, в
частности, независимости рядов измерений выходного параметра и распределения этих рядов по нормальному закону. При выполнении этих условий мощность параметрических критериев достаточно высока; по мере отступления от них она снижается. Другими словами, невыполнение необходимых условий влечет за собой увеличение вероятности принятия нулевой гипотезы H 0 в качестве истинной, хотя в действительности она является ложной.
Вторая группа критериев, обладая меньшей мощностью по сравнению с первой, не
налагает на ряды измерений никаких необходимых условий, их вычисления проще. Это объясняет предпочтительность практического применения критериев второй группы, а в некоторых случаях делает его единственно возможным.
Искомый параметрический критерий проще всего получить, если предположить, что
проверяемая гипотеза H 0 верна, т.е. рассматриваемая случайная величина ξ действительно
распределена по закону, задаваемому функцией f , и рассмотреть область, в которой оказалось значение величины ξ. Пусть ξ попало в область, расположенную вблизи правого
39
(Рисунок 8, а) или левого (Рисунок 8, б) хвоста функции f , и, следовательно, вероятность
попадания случайной величины в эту область, вычисленная при помощи функции f ,
практически равна или достаточно близка к нулю. В этой ситуации целесообразно признать
ошибочность гипотезы H 0 . Если значение ξ оказалось в интервале, достаточно удаленном от
обоих хвостов функции f , то целесообразно считать, что гипотеза H 0 может быть принята.
Рисунок 8 - Критические области дифференциального закона распределения для одностороннего и двустороннего критерия принятия гипотезы
Искомый критерий оценки соответствия анализируемой гипотезы H 0 опыту можно получить, если этим качественным рассуждениям придать количественный характер. Вероятность попадания случайной величины ξ в критическую область (заштрихованная часть на
Рисунок 8, а) называют уровнем значимости . Он равен:
Если ξ > ξκρ для выбранного уровня значимости , то ξ попадает в критическую область функции распределения f и гипотеза H 0 должна быть отброшена. Если ξ < ξκρ, то ξ
лежит вне критической области и гипотеза H 0 может быть принята. Однако утверждать правильность гипотезы нельзя, можно лишь сказать, что на основе проведенных измерений она
не является неправильной (может оказаться, что после оценки какой-то большой выборки
гипотеза окажется неправильной). Область допустимых значений с уменьшением уровня
значимости увеличивается.
Если критическая область целиком расположена в правой (или левой) части графика
f , то критерий называется односторонним. Он используется, когда заранее имеются веские основания для утверждения, что попадание случайной величины в противоположную
область функции распределения или невозможно, или не имеет практического значения.
Если у исследователя заранее нет оснований для подобного предположения, критическую область необходимо рассматривать состоящей из двух частей.
В этом случае уровень значимости критерия а численно равен сумме заштрихованных
на Рисунок 8,в площадей, а соответствующий критерий называется двусторонним.
Следовательно, осуществляя проверку гипотезы, можно допустить две взаимосвязанные ошибки: отвергнуть правильную гипотезу (ошибка первого рода); принять неправильную гипотезу (ошибка второго рода). Вероятность допустить ошибку первого рода рав40
на уровню значимости . Вероятность ошибки второго рода обозначается β, а величина 1 - β
называется мощностью критерия. Последняя определяет вероятность того, что отвергнута
нулевая гипотеза, если верна конкурирующая (альтернативная) гипотеза. С уменьшением
увеличивается значение β и наоборот.
Одновременное уменьшение вероятностей ошибок первого и второго рода возможно
только при увеличении объема выборок. Для выбранного уровня значимости критическую
область целесообразно выбирать так, чтобы мощность критерия была максимальной и тем
самым достигалась максимальная ошибка второго рода.
Последовательность проверки гипотезы следующая:
1) формулировка проверяемой, т.е. нуль-гипотезы H 0 , и конкурирующей (альтернативной) H1 гипотез;
2) выбор критерия или статистической характеристики для проверки гипотезы H 0 и
определение выборочного распределения критерия, когда допускается гипотеза H 0 ;
3) выбор уровня значимости ;
4) определение критической области для проверки гипотезы H 0 ;
5) расчет критерия по данным выборки;
6) сравнение расчетного критерия с табличным, который определяется критической областью.
При выборе параметрического критерия для проверки гипотезы H 0 необходимо, прежде всего, сопоставить оба ряда измерений с целью определения соизмеримости их числовых
статистических характеристик. При этом возможны два случая: ряды равноточны 12 22 , и
ряды неравноточны 12 22 .
5.2 Сравнение дисперсии свойств нового продукта со стандартной дисперсией
При введении нового метода исследования процесса или продукта, а также при получении продукта новой структуры или по новой технологии исследователь должен установить
соответствие генеральной дисперсии 2 ряда полученных измерений и стандартной дисперсии 02 , которая известна по теоретическим или предшествующим экспериментальным исследованиям.
Проверка нулевой гипотезы H 0 : σ2 = M{S2} = 02 при конкурирующей гипотезе H1 : σ2 = M{S2}
> 02 состоит в том, что рассчитывают случайную величину:
m 1S 2 .
R2
2
0
Последняя имеет распределение с m-1 степенями свободы. Расчетное значение критерия R2 сопоставляют с односторонним табличным (критическим) значением критерия T2
2
для заданного уровня значимости . Если
, то считается, что полученный результат не противоречит гипотезе H 0 (дисперсия какого-либо свойства продукта,
полученного по новой технологии, значимо не отличается от стандартной дисперсии); в противном случае нулевая гипотеза отвергается.
Проверка нулевой гипотезы H 0 : σ2 = M{S2} = 02 при конкурирующей гипотезе H1 : σ2
= M{S2} 02 также осуществляется с помощью критерия 2 , расчетное значение которого
определяется по той же формуле. В этом случае критическая область будет двусторонней,
т.е. вероятность выхода за верхнюю и нижнюю критические границы одинакова. Нулевая
41
гипотеза не отвергается, если удовлетворяется одно из неравенств: R2 T2 1 ; f m 1 ,
2
R2 T2 ; f m 1 . В противном случае нулевая гипотеза отвергается.
2
5.3 Сравнение двух дисперсий нормальных генеральных совокупностей
Сравнение дисперсий исследователь проводит при сопоставлении различных технологических объектов по устойчивости (воспроизводимости) их работы, при выборе метода измерения параметров процесса или свойств продукта, обладающего меньшей ошибкой. Сравнение дисперсий проводится также при определении значимости разности средних двух рядов измерений.
Пусть S12 и S 22 являются оценкой одной и той же нормальной генеральной дисперсии.
Требуется проверить гипотезу H 0 : 12 22 по отношению к трем конкурирующим гипотезам: H1 : 12 22 ; H 2 : 12 22 ; H 3 : 12 22 . Чаще всего встречается конкурирующая гипотеза H 2 .
Так как случайные величины X 1 и X 2 распределены по нормальному закону, то в качестве критерия сравнения двух дисперсий принимается частное оценок дисперсии генеральной совокупности:
где в числителе - большая из двух оценок рассеяния (для того чтобы значение F всегда
было больше единицы).
Доказано, что отношение дисперсий как статистическая характеристика при верной гипотезе H 0 имеет распределение Фишера с m1 1 и m2 1 степенями свободы. Критическая
область для проверяемой гипотезы при уровне значимости а является односторонней.
Расчетное значение критерия Фишера, определяемое по формуле:
1 m1
xi1 x1 2
2
S
m 1 i 1
FR 12 1
1 m2
S2
xi 2 x2 2
m2 1 i 1
сравнивается с табличным критерием Фишера - FT , определяемым при известных значениях а, f ( S12 ) , f ( S 22 ) . Если FR FT 1 ; f S12 m1 1; f S 22 m2 1 , то гипотеза о равенстве дисперсий не отвергается, т.е. два ряда измерений являются равнозначными.
Если FR FT то гипотеза H 0 отвергается и с доверительной вероятностью pD 1
можно утверждать, что 12 22 т.е. два полученных ряда измерений являются неравнозначными.
В случае, когда альтернативной гипотезой по отношению к нулевой является H1 :
12 22 проверяемая гипотеза H 0 : 12 22 не отвергается, если выполняется неравенство
2
2
FR FT ; f S1 m1 1; f S 2 m2 1 , т.е. принимается двусторонняя критическая область
2
при условии, что нулевая гипотеза справедлива и вероятность попадания критерия FR в каждый из двух интервалов критической области равна / 2 (вдвое меньше заданного).
Пример 1.
Пусть выходной параметр объекта при одном уровне фактора характеризуется дисперсией S12 X 2,8 с числом степеней свободы f1 2 (число измерений 3); для второго уровня
42
соответственно S 22 X 1,6
f 2 12 . Оцениваем возможность принятия гипотезы H 0 :
.
2
1
2
2
При альтернативной гипотезе H1 : 12 22 и уровню значимости 0 0,05 по Таблица 8
находим FT p 0,05; f1 2; f 2 12 3,89 .
Так как FR 2,8 /1,6 1,75 FT 3,89 , то выдвинутую гипотезу об однородности (воспроизводимости) дисперсии или равноточности двух рядов измерений X 1 и X 2 , безусловно,
надо принять.
Пример 2.
Пусть для двух рядов измерений выборочные дисперсии равны S12 X 20,2 и
S 22 X 1,8 с числом степеней свободы f1 f 2 5 (число измерений 6). Требуется дать
оценку гипотезе H 0 : 12 22 , при конкурирующей гипотезе, H1 : 12 22 приняв уровень
значимости 0 0,05 .
Табличное
значение
критерия
Фишера
находим
из
Таблица
8:
FT p 0,05; f1 5; f 2 5 5,05
Так как FR 20,2 /1,8 11,5 FT 5,05 , то с 5 %-ным уровнем значимости проверяемая
гипотеза принята быть не может.
Оценим теперь возможность отбрасывания гипотезы. Для этого налагаем уровень значимости 0,01 и по Таблица 10 находим табличное значение критерия Фишера:
FT p 0,01; f1 5; f 2 5 10,97 .
Так как FR 20,2 /1,8 11,5 FT 10,97 , то оцениваемая гипотеза H 0 должна быть отброшена с 1 %-ным уровнем значимости.
Таким образом, статистическая оценка гипотезы 12 22 по экспериментальным значениям выборочных дисперсий S12 и S 22 показывает, что в рассматриваемом случае проверяемая гипотеза уверенно может быть отвергнута, т.е. дисперсии S12 и S 22 следует признать неоднородными.
Пример 3.
Пусть для двух рядов измерений выходного параметра при двух уровнях фактора получены следующие выборочные дисперсии: S12 X 10 с числом степеней свободы f1 10 и
S 22 X 2 f 2 5 . Требуется дать оценку гипотезе H 0 : 12 22 при конкурирующей гипотезе H1 : 12 22 .
Оцениваем вначале возможность принятия гипотезы. Для этого принимаем уровень
значимости 0 0,05 и по Таблица 8 находим: FT p 0,05; f1 10; f 2 5 4,74 .
Так как FR 10 / 2 5 FT 4,74 , то с 5 %-ным уровнем значимости проверяемая гипотеза принята быть не может.
Оценим теперь возможность отбрасывания гипотезы. Для этого находим по Таблица 10
при 0,01 табличное значение критерия Фишера: FT p 0,01; f1 10; f 2 5 10,05 .
Так как FR 10 / 2 5 FT 10,05 FR = 5 < FT = 10,05, то 1 %-ный уровень значимости не
позволяет отбросить оцениваемую гипотезу, т.е., следовательно, проверяемая гипотеза с уверенностью не может быть ни принята, ни отброшена.
При 0,025 имеем: FR 10 / 2 5 FT p 0,025; f1 10; f 2 5 6,62 и, следовательно, оцениваемая гипотеза может быть принята с 2,5 %-ным уровнем значимости.
В данной ситуации можно пойти на риск принятия гипотезы. Однако наиболее целесообразным следует считать проведение повторного эксперимента для более уверенного заключения относительно проверяемой гипотезы.
43
Таблица 7 - Таблица критерия Фишера при P=0,10
df2/df1
1
2
3
4
5
1
39.8634
8.52632
5.53832
4.54477
4.06042
2
49.5000
9.00000
5.46238
4.32456
3.77972
3
53.5932
9.16179
5.39077
4.19086
3.61948
4
55.8329
9.24342
5.34264
4.10725
3.52020
5
57.2400
9.29263
5.30916
4.05058
3.45298
6
58.2044
9.32553
5.28473
4.00975
3.40451
7
58.9059
9.34908
5.26619
3.97897
3.36790
8
59.4389
9.36677
5.25167
3.95494
3.33928
9
59.8575
9.38054
5.24000
3.93567
3.31628
10
60.1949
9.39157
5.23041
3.91988
3.29740
12
60.7052
9.40813
5.21562
3.89553
3.26824
15
61.2203
9.42471
5.20031
3.87036
3.23801
20
61.7402
9.44131
5.18448
3.84434
3.20665
24
62.0020
9.44962
5.17636
3.83099
3.19052
30
62.2649
9.45793
5.16811
3.81742
3.17408
40
62.5290
9.46624
5.15972
3.80361
3.15732
60
62.7942
9.47456
5.15119
3.78957
3.14023
120
63.0606
9.48289
5.14251
3.77527
3.12279
INF
63.32812
9.49122
5.13370
3.76073
3.10500
6
7
8
9
10
3.77595
3.58943
3.45792
3.36030
3.28502
3.46330
3.25744
3.11312
3.00645
2.92447
3.28876
3.07407
2.92380
2.81286
2.72767
3.18076
2.96053
2.80643
2.69268
2.60534
3.10751
2.88334
2.72645
2.61061
2.52164
3.05455
2.82739
2.66833
2.55086
2.46058
3.01446
2.78493
2.62413
2.50531
2.41397
2.98304
2.75158
2.58935
2.46941
2.37715
2.95774
2.72468
2.56124
2.44034
2.34731
2.93693
2.70251
2.53804
2.41632
2.32260
2.90472
2.66811
2.50196
2.37888
2.28405
2.87122
2.63223
2.46422
2.33962
2.24351
2.83634
2.59473
2.42464
2.29832
2.20074
2.81834
2.57533
2.40410
2.27683
2.17843
2.79996
2.55546
2.38302
2.25472
2.15543
2.78117
2.53510
2.36136
2.23196
2.13169
2.76195
2.51422
2.33910
2.20849
2.10716
2.74229
2.49279
2.31618
2.18427
2.08176
2.72216
2.47079
2.29257
2.15923
2.05542
11
12
13
14
15
3.22520
3.17655
3.13621
3.10221
3.07319
2.85951
2.80680
2.76317
2.72647
2.69517
2.66023
2.60552
2.56027
2.52222
2.48979
2.53619
2.48010
2.43371
2.39469
2.36143
2.45118
2.39402
2.34672
2.30694
2.27302
2.38907
2.33102
2.28298
2.24256
2.20808
2.34157
2.28278
2.23410
2.19313
2.15818
2.30400
2.24457
2.19535
2.15390
2.11853
2.27350
2.21352
2.16382
2.12195
2.08621
2.24823
2.18776
2.13763
2.09540
2.05932
2.20873
2.14744
2.09659
2.05371
2.01707
2.16709
2.10485
2.05316
2.00953
1.97222
2.12305
2.05968
2.00698
1.96245
1.92431
2.10001
2.03599
1.98272
1.93766
1.89904
2.07621
2.01149
1.95757
1.91193
1.87277
2.05161
1.98610
1.93147
1.88516
1.84539
2.02612
1.95973
1.90429
1.85723
1.81676
1.99965
1.93228
1.87591
1.82800
1.78672
1.97211
1.90361
1.84620
1.79728
1.75505
16
17
18
19
20
3.04811
3.02623
3.00698
2.98990
2.97465
2.66817
2.64464
2.62395
2.60561
2.58925
2.46181
2.43743
2.41601
2.39702
2.38009
2.33274
2.30775
2.28577
2.26630
2.24893
2.24376
2.21825
2.19583
2.17596
2.15823
2.17833
2.15239
2.12958
2.10936
2.09132
2.12800
2.10169
2.07854
2.05802
2.03970
2.08798
2.06134
2.03789
2.01710
1.99853
2.05533
2.02839
2.00467
1.98364
1.96485
2.02815
2.00094
1.97698
1.95573
1.93674
1.98539
1.95772
1.93334
1.91170
1.89236
1.93992
1.91169
1.88681
1.86471
1.84494
1.89127
1.86236
1.83685
1.81416
1.79384
1.86556
1.83624
1.81035
1.78731
1.76667
1.83879
1.80901
1.78269
1.75924
1.73822
1.81084
1.78053
1.75371
1.72979
1.70833
1.78156
1.75063
1.72322
1.69876
1.67678
1.75075
1.71909
1.69099
1.66587
1.64326
1.71817
1.68564
1.65671
1.63077
1.60738
21
22
23
24
25
2.96096
2.94858
2.93736
2.92712
2.91774
2.57457
2.56131
2.54929
2.53833
2.52831
2.36489
2.35117
2.33873
2.32739
2.31702
2.23334
2.21927
2.20651
2.19488
2.18424
2.14231
2.12794
2.11491
2.10303
2.09216
2.07512
2.06050
2.04723
2.03513
2.02406
2.02325
2.00840
1.99492
1.98263
1.97138
1.98186
1.96680
1.95312
1.94066
1.92925
1.94797
1.93273
1.91888
1.90625
1.89469
1.91967
1.90425
1.89025
1.87748
1.86578
1.87497
1.85925
1.84497
1.83194
1.82000
1.82715
1.81106
1.79643
1.78308
1.77083
1.77555
1.75899
1.74392
1.73015
1.71752
1.74807
1.73122
1.71588
1.70185
1.68898
1.71927
1.70208
1.68643
1.67210
1.65895
1.68896
1.67138
1.65535
1.64067
1.62718
1.65691
1.63885
1.62237
1.60726
1.59335
1.62278
1.60415
1.58711
1.57146
1.55703
1.58615
1.56678
1.54903
1.53270
1.51760
26
27
28
29
30
2.90913
2.90119
2.89385
2.88703
2.88069
2.51910
2.51061
2.50276
2.49548
2.48872
2.30749
2.29871
2.29060
2.28307
2.27607
2.17447
2.16546
2.15714
2.14941
2.14223
2.08218
2.07298
2.06447
2.05658
2.04925
2.01389
2.00452
1.99585
1.98781
1.98033
1.96104
1.95151
1.94270
1.93452
1.92692
1.91876
1.90909
1.90014
1.89184
1.88412
1.88407
1.87427
1.86520
1.85679
1.84896
1.85503
1.84511
1.83593
1.82741
1.81949
1.80902
1.79889
1.78951
1.78081
1.77270
1.75957
1.74917
1.73954
1.73060
1.72227
1.70589
1.69514
1.68519
1.67593
1.66731
1.67712
1.66616
1.65600
1.64655
1.63774
1.64682
1.63560
1.62519
1.61551
1.60648
1.61472
1.60320
1.59250
1.58253
1.57323
1.58050
1.56859
1.55753
1.54721
1.53757
1.54368
1.53129
1.51976
1.50899
1.49891
1.50360
1.49057
1.47841
1.46704
1.45636
40
60
120
inf
2.83535
2.79107
2.74781
2.70554
2.44037
2.39325
2.34734
2.30259
2.22609
2.17741
2.12999
2.08380
2.09095
2.04099
1.99230
1.94486
1.99682
1.94571
1.89587
1.84727
1.92688
1.87472
1.82381
1.77411
1.87252
1.81939
1.76748
1.71672
1.82886
1.77483
1.72196
1.67020
1.79290
1.73802
1.68425
1.63152
1.76269
1.70701
1.65238
1.59872
1.71456
1.65743
1.60120
1.54578
1.66241
1.60337
1.54500
1.48714
1.60515
1.54349
1.48207
1.42060
1.57411
1.51072
1.44723
1.38318
1.54108
1.47554
1.40938
1.34187
1.50562
1.43734
1.36760
1.29513
1.46716
1.39520
1.32034
1.23995
1.42476
1.34757
1.26457
1.16860
1.37691
1.29146
1.19256
1.00000
44
Таблица 8 - Таблица критерия Фишера при P=0,05
45
Таблица 9 - Таблица критерия Фишера при P=0,025
df2/df1
1
2
3
4
5
1
647.789
38.5063
17.4434
12.2179
10.0070
2
799.500
39.0000
16.0441
10.6491
8.4336
3
864.163
39.1655
15.4392
9.9792
7.7636
4
899.583
39.2484
15.1010
9.6045
7.3879
5
921.847
39.2982
14.8848
9.3645
7.1464
6
937.111
39.3315
14.7347
9.1973
6.9777
7
948.216
39.3552
14.6244
9.0741
6.8531
8
956.656
39.3730
14.5399
8.9796
6.7572
9
963.284
39.3869
14.4731
8.9047
6.6811
10
968.627
39.3980
14.4189
8.8439
6.6192
12
976.707
39.4146
14.3366
8.7512
6.5245
15
984.866
39.4313
14.2527
8.6565
6.4277
20
993.102
39.4479
14.1674
8.5599
6.3286
24
997.249
39.4562
14.1241
8.5109
6.2780
30
1001.41
39.465
14.081
8.461
6.227
40
1005.59
39.473
14.037
8.411
6.175
60
1009.80
39.481
13.992
8.360
6.123
120
1014.02
39.490
13.947
8.309
6.069
INF
1018.25
39.498
13.902
8.257
6.015
6
7
8
9
10
8.8131
8.0727
7.5709
7.2093
6.9367
7.2599
6.5415
6.0595
5.7147
5.4564
6.5988
5.8898
5.4160
5.0781
4.8256
6.2272
5.5226
5.0526
4.7181
4.4683
5.9876
5.2852
4.8173
4.4844
4.2361
5.8198
5.1186
4.6517
4.3197
4.0721
5.6955
4.9949
4.5286
4.1970
3.9498
5.5996
4.8993
4.4333
4.1020
3.8549
5.5234
4.8232
4.3572
4.0260
3.7790
5.4613
4.7611
4.2951
3.9639
3.7168
5.3662
4.6658
4.1997
3.8682
3.6209
5.2687
4.5678
4.1012
3.7694
3.5217
5.1684
4.4667
3.9995
3.6669
3.4185
5.1172
4.4150
3.9472
3.6142
3.3654
5.065
4.362
3.894
3.560
3.311
5.012
4.309
3.840
3.505
3.255
4.959
4.254
3.784
3.449
3.198
4.904
4.199
3.728
3.392
3.140
4.849
4.142
3.670
3.333
3.080
11
12
13
14
15
6.7241
6.5538
6.4143
6.2979
6.1995
5.2559
5.0959
4.9653
4.8567
4.7650
4.6300
4.4742
4.3472
4.2417
4.1528
4.2751
4.1212
3.9959
3.8919
3.8043
4.0440
3.8911
3.7667
3.6634
3.5764
3.8807
3.7283
3.6043
3.5014
3.4147
3.7586
3.6065
3.4827
3.3799
3.2934
3.6638
3.5118
3.3880
3.2853
3.1987
3.5879
3.4358
3.3120
3.2093
3.1227
3.5257
3.3736
3.2497
3.1469
3.0602
3.4296
3.2773
3.1532
3.0502
2.9633
3.3299
3.1772
3.0527
2.9493
2.8621
3.2261
3.0728
2.9477
2.8437
2.7559
3.1725
3.0187
2.8932
2.7888
2.7006
3.118
2.963
2.837
2.732
2.644
3.061
2.906
2.780
2.674
2.585
3.004
2.848
2.720
2.614
2.524
2.944
2.787
2.659
2.552
2.461
2.883
2.725
2.595
2.487
2.395
16
17
18
19
20
6.1151
6.0420
5.9781
5.9216
5.8715
4.6867
4.6189
4.5597
4.5075
4.4613
4.0768
4.0112
3.9539
3.9034
3.8587
3.7294
3.6648
3.6083
3.5587
3.5147
3.5021
3.4379
3.3820
3.3327
3.2891
3.3406
3.2767
3.2209
3.1718
3.1283
3.2194
3.1556
3.0999
3.0509
3.0074
3.1248
3.0610
3.0053
2.9563
2.9128
3.0488
2.9849
2.9291
2.8801
2.8365
2.9862
2.9222
2.8664
2.8172
2.7737
2.8890
2.8249
2.7689
2.7196
2.6758
2.7875
2.7230
2.6667
2.6171
2.5731
2.6808
2.6158
2.5590
2.5089
2.4645
2.6252
2.5598
2.5027
2.4523
2.4076
2.568
2.502
2.445
2.394
2.349
2.509
2.442
2.384
2.333
2.287
2.447
2.380
2.321
2.270
2.223
2.383
2.315
2.256
2.203
2.156
2.316
2.247
2.187
2.133
2.085
21
22
23
24
25
5.8266
5.7863
5.7498
5.7166
5.6864
4.4199
4.3828
4.3492
4.3187
4.2909
3.8188
3.7829
3.7505
3.7211
3.6943
3.4754
3.4401
3.4083
3.3794
3.3530
3.2501
3.2151
3.1835
3.1548
3.1287
3.0895
3.0546
3.0232
2.9946
2.9685
2.9686
2.9338
2.9023
2.8738
2.8478
2.8740
2.8392
2.8077
2.7791
2.7531
2.7977
2.7628
2.7313
2.7027
2.6766
2.7348
2.6998
2.6682
2.6396
2.6135
2.6368
2.6017
2.5699
2.5411
2.5149
2.5338
2.4984
2.4665
2.4374
2.4110
2.4247
2.3890
2.3567
2.3273
2.3005
2.3675
2.3315
2.2989
2.2693
2.2422
2.308
2.272
2.239
2.209
2.182
2.246
2.210
2.176
2.146
2.118
2.182
2.145
2.111
2.080
2.052
2.114
2.076
2.041
2.010
1.981
2.042
2.003
1.968
1.935
1.906
26
27
28
29
30
5.6586
5.6331
5.6096
5.5878
5.5675
4.2655
4.2421
4.2205
4.2006
4.1821
3.6697
3.6472
3.6264
3.6072
3.5894
3.3289
3.3067
3.2863
3.2674
3.2499
3.1048
3.0828
3.0626
3.0438
3.0265
2.9447
2.9228
2.9027
2.8840
2.8667
2.8240
2.8021
2.7820
2.7633
2.7460
2.7293
2.7074
2.6872
2.6686
2.6513
2.6528
2.6309
2.6106
2.5919
2.5746
2.5896
2.5676
2.5473
2.5286
2.5112
2.4908
2.4688
2.4484
2.4295
2.4120
2.3867
2.3644
2.3438
2.3248
2.3072
2.2759
2.2533
2.2324
2.2131
2.1952
2.2174
2.1946
2.1735
2.1540
2.1359
2.157
2.133
2.112
2.092
2.074
2.093
2.069
2.048
2.028
2.009
2.026
2.002
1.980
1.959
1.940
1.954
1.930
1.907
1.886
1.866
1.878
1.853
1.829
1.807
1.787
40
60
120
inf
5.4239
5.2856
5.1523
5.0239
4.0510
3.9253
3.8046
3.6889
3.4633
3.3425
3.2269
3.1161
3.1261
3.0077
2.8943
2.7858
2.9037
2.7863
2.6740
2.5665
2.7444
2.6274
2.5154
2.4082
2.6238
2.5068
2.3948
2.2875
2.5289
2.4117
2.2994
2.1918
2.4519
2.3344
2.2217
2.1136
2.3882
2.2702
2.1570
2.0483
2.2882
2.1692
2.0548
1.9447
2.1819
2.0613
1.9450
1.8326
2.0677
1.9445
1.8249
1.7085
2.0069
1.8817
1.7597
1.6402
1.943
1.815
1.690
1.566
1.875
1.744
1.614
1.484
1.803
1.667
1.530
1.388
1.724
1.581
1.433
1.268
1.637
1.482
1.310
1.000
46
Таблица 10 - Таблица критерия Фишера при P=0,01
df2/df1
1
2
3
4
5
1
4052.18
98.503
34.116
21.198
16.258
2
4999.50
99.000
30.817
18.000
13.274
3
5403.35
99.166
29.457
16.694
12.060
4
5624.58
99.249
28.710
15.977
11.392
5
5763.65
99.299
28.237
15.522
10.967
6
5858.98
99.333
27.911
15.207
10.672
7
5928.35
99.356
27.672
14.976
10.456
8
5981.07
99.374
27.489
14.799
10.289
9
6022.47
99.388
27.345
14.659
10.158
10
6055.84
99.399
27.229
14.546
10.051
12
6106.32
99.416
27.052
14.374
9.888
15
6157.28
99.433
26.872
14.198
9.722
20
6208.73
99.449
26.690
14.020
9.553
24
6234.63
99.458
26.598
13.929
9.466
30
6260.64
99.466
26.505
13.838
9.379
40
6286.78
99.474
26.411
13.745
9.291
60
6313.03
99.482
26.316
13.652
9.202
120
6339.39
99.491
26.221
13.558
9.112
INF
6365.86
99.499
26.125
13.463
9.020
6
7
8
9
10
13.745
12.246
11.259
10.561
10.044
10.925
9.547
8.649
8.022
7.559
9.780
8.451
7.591
6.992
6.552
9.148
7.847
7.006
6.422
5.994
8.746
7.460
6.632
6.057
5.636
8.466
7.191
6.371
5.802
5.386
8.260
6.993
6.178
5.613
5.200
8.102
6.840
6.029
5.467
5.057
7.976
6.719
5.911
5.351
4.942
7.874
6.620
5.814
5.257
4.849
7.718
6.469
5.667
5.111
4.706
7.559
6.314
5.515
4.962
4.558
7.396
6.155
5.359
4.808
4.405
7.313
6.074
5.279
4.729
4.327
7.229
5.992
5.198
4.649
4.247
7.143
5.908
5.116
4.567
4.165
7.057
5.824
5.032
4.483
4.082
6.969
5.737
4.946
4.398
3.996
6.880
5.650
4.859
4.311
3.909
11
12
13
14
15
9.646
9.330
9.074
8.862
8.683
7.206
6.927
6.701
6.515
6.359
6.217
5.953
5.739
5.564
5.417
5.668
5.412
5.205
5.035
4.893
5.316
5.064
4.862
4.695
4.556
5.069
4.821
4.620
4.456
4.318
4.886
4.640
4.441
4.278
4.142
4.744
4.499
4.302
4.140
4.004
4.632
4.388
4.191
4.030
3.895
4.539
4.296
4.100
3.939
3.805
4.397
4.155
3.960
3.800
3.666
4.251
4.010
3.815
3.656
3.522
4.099
3.858
3.665
3.505
3.372
4.021
3.780
3.587
3.427
3.294
3.941
3.701
3.507
3.348
3.214
3.860
3.619
3.425
3.266
3.132
3.776
3.535
3.341
3.181
3.047
3.690
3.449
3.255
3.094
2.959
3.602
3.361
3.165
3.004
2.868
16
17
18
19
20
8.531
8.400
8.285
8.185
8.096
6.226
6.112
6.013
5.926
5.849
5.292
5.185
5.092
5.010
4.938
4.773
4.669
4.579
4.500
4.431
4.437
4.336
4.248
4.171
4.103
4.202
4.102
4.015
3.939
3.871
4.026
3.927
3.841
3.765
3.699
3.890
3.791
3.705
3.631
3.564
3.780
3.682
3.597
3.523
3.457
3.691
3.593
3.508
3.434
3.368
3.553
3.455
3.371
3.297
3.231
3.409
3.312
3.227
3.153
3.088
3.259
3.162
3.077
3.003
2.938
3.181
3.084
2.999
2.925
2.859
3.101
3.003
2.919
2.844
2.778
3.018
2.920
2.835
2.761
2.695
2.933
2.835
2.749
2.674
2.608
2.845
2.746
2.660
2.584
2.517
2.753
2.653
2.566
2.489
2.421
21
22
23
24
25
8.017
7.945
7.881
7.823
7.770
5.780
5.719
5.664
5.614
5.568
4.874
4.817
4.765
4.718
4.675
4.369
4.313
4.264
4.218
4.177
4.042
3.988
3.939
3.895
3.855
3.812
3.758
3.710
3.667
3.627
3.640
3.587
3.539
3.496
3.457
3.506
3.453
3.406
3.363
3.324
3.398
3.346
3.299
3.256
3.217
3.310
3.258
3.211
3.168
3.129
3.173
3.121
3.074
3.032
2.993
3.030
2.978
2.931
2.889
2.850
2.880
2.827
2.781
2.738
2.699
2.801
2.749
2.702
2.659
2.620
2.720
2.667
2.620
2.577
2.538
2.636
2.583
2.535
2.492
2.453
2.548
2.495
2.447
2.403
2.364
2.457
2.403
2.354
2.310
2.270
2.360
2.305
2.256
2.211
2.169
26
27
28
29
30
7.721
7.677
7.677
7.598
7.562
5.526
5.488
5.453
5.420
5.390
4.637
4.601
4.568
4.538
4.510
4.140
4.106
4.074
4.045
4.018
3.818
3.785
3.754
3.725
3.699
3.591
3.558
3.528
3.499
3.473
3.421
3.388
3.358
3.330
3.304
3.288
3.256
3.226
3.198
3.173
3.182
3.149
3.120
3.092
3.067
3.094
3.062
3.032
3.005
2.979
2.958
2.926
2.896
2.868
2.843
2.815
2.783
2.753
2.726
2.700
2.664
2.632
2.602
2.574
2.549
2.585
2.552
2.522
2.495
2.469
2.503
2.470
2.440
2.412
2.386
2.417
2.384
2.354
2.325
2.299
2.327
2.294
2.263
2.234
2.208
2.233
2.198
2.167
2.138
2.111
2.131
2.097
2.064
2.034
2.006
40
60
120
inf
7.314
7.077
6.851
6.635
5.179
4.977
4.787
4.605
4.313
4.126
3.949
3.782
3.828
3.649
3.480
3.319
3.514
3.339
3.174
3.017
3.291
3.119
2.956
2.802
3.124
2.953
2.792
2.639
2.993
2.823
2.663
2.511
2.888
2.718
2.559
2.407
2.801
2.632
2.472
2.321
2.665
2.496
2.336
2.185
2.522
2.352
2.192
2.039
2.369
2.198
2.035
1.878
2.288
2.115
1.950
1.791
2.203
2.028
1.860
1.696
2.114
1.936
1.763
1.592
2.019
1.836
1.656
1.473
1.917
1.726
1.533
1.325
1.805
1.601
1.381
1.000
47
5.4 Сравнение выборочной средней с теоретически предполагаемым средним или
стандартным значением
Пусть проведен ряд измерений технологического параметра или свойства продукта и
получено N значений, среднее выборочное значение которых равно Υ.
Первый случай (выборка большого объема). Чтобы проверить нулевую гипотезу H 0 :
M X X 0 о равенстве генеральной средней M X нормальной совокупности с известной
дисперсией (которая найдена теоретически или вычислена по выборке большого объема)
2 X S 2 X предполагаемому (гипотетическому) генеральному среднему или стандартному значению X 0 , пользуются критерием:
uR
X X0 m
X
X X0 m
S X
Случайная величина u R распределена нормально, причем если нулевая гипотеза справедлива, то M u R 0 и u R 1.
Критическая область строится в зависимости от вида конкурирующей гипотезы. При
конкурирующей гипотезе H1 : M X X 0 используется двусторонний табличный критерий,
который определяется по равенству:
1
ФuT 2
2
где ФuT 2 = Фz - функция Лапласа (Таблица 11).
При конкурирующей гипотезе H1 : M X X 0 используется односторонний табличный
критерий, который определяется по равенству:
1 2
ФuT 1 Ф z
.
2
Если u R uT 1 или uR uT 2 , то при заданном уровне значимости нет оснований отвергать нулевую гипотезу. Если u R uT 1 или uR uT 2 , то нулевую гипотезу отвергают.
Таблица 11 - Нормированная функция Лапласа
x
Ф(х)
x
Ф(х)
x
Ф(х)
x
Ф(х)
x
Ф(х)
x
Ф(х)
0,00 0,0000 0,50 0,1915 1,00 0,3413 1,50 0,4332 2,00 0,4772 3,00 0,49865
0,01 0,0040 0,51 0,1950 1,01 0,3438 1,51 0,4345 2,02 0,4783 3,20 0,49931
0,02 0,0080 0,52 0,1985 1,02 0,3461 1,52 0,4357 2,04 0,4793 3,40 0,49966
0,03 0,0120 0,53 0,2019 1,03 0,3485 1,53 0,4370 2,06 0,4803 3,60 0,499841
0,04 0,0160 0,54 0,2054 1,04 0,3508 1,54 0,4382 2,08 0,4812 3,80 0,499928
0,05 0,0199 0,55 0,2088 1,05 0,3531 1,55 0,4394 2,10 0,4821 4,00 0,499968
0,06 0,0239 0,56 0,2123 1,06 0,3554 1,56 0,4406 2,12 0,4830 4,50 0,499997
0,07 0,0279 0,57 0,2157 1,07 0,3577 1,57 0,4418 2,14 0,4838 5,00 0,499997
0,08 0,0319 0,58 0,2190 1,08 0,3599 1,58 0,4429 2,16 0,4846
0,09 0,0359 0,59 0,2224 1,09 0,3621 1,59 0,4441 2,18 0,4854
0,10 0,0398 0,60 0,2257 1,10 0,3643 1,60 0,4452 2,20 0,4861
0,11 0,0438 0,61 0,2291 1,11 0,3665 1,61 0,4463 2,22 0,4868
0,12 0,0478 0,62 0,2324 1,12 0,3686 1,62 0,4474 2,24 0,4875
48
0,13 0,0517 0,63 0,2357 1,13 0,3708 1,63 0,4484 2,26 0,4881
0,14 0,0557 0,64 0,2389 1,14 0,3729 1,64 0,4495 2,28 0,4887
0,15 0,0596 0,65 0,2422 1,15 0,3749 1,65 0,4505 2,30 0,4893
0,16 0,0636 0,66 0,2454 1,16 0,3770 1,66 0,4515 2,32 0,4898
0,17 0,0675 0,67 0,2486 1,17 0,3790 1,67 0,4525 2,34 0,4904
0,18 0,0714 0,68 0,2517 1,18 0,3810 1,68 0,4535 2,36 0,4909
0,19 0,0753 0,69 0,2549 1,19 0,3830 1,69 0,4545 2,38 0,4913
0,20 0,0793 0,70 0,2580 1,20 0,3849 1,70 0,4554 2,40 0,4918
0,21 0,0832 0,71 0,2611 1,21 0,3869 1,71 0,4564 2,42 0,4922
0,22 0,0871 0,72 0,2642 1,22 0,3883 1,72 0,4573 2,44 0,4927
0,23 0,0910 0,73 0,2673 1,23 0,3907 1,73 0,4582 2,46 0,4931
0,24 0,0948 0,74 0,2703 1,24 0,3925 1,74 0,4591 2,48 0,4934
0,25 0,0987 0,75 0,2734 1,25 0,3944 1,75 0,4599 2,50 0,4938
0,26 0,1026 0,76 0,2764 1,26 0,3962 1,76 0,4608 2,52 0,4941
0,27 0,1064 0,77 0,2794 1,27 0,3980 1,77 0,4616 2,54 0,4945
0,28 0,1103 0,78 0,2823 1,28 0,3997 1,78 0,4625 2,56 0,4948
0,29 0,1141 0,79 0,2852 1,29 0,4015 1,79 0,4633 2,58 0,4951
0,30 0,1179 0,80 0,2881 1,30 0,4032 1,80 0,4641 2,60 0,4953
0,31 0,1217 0,81 0,2910 1,31 0,4049 1,81 0,4649 2,62 0,4956
0,32 0,1255 0,82 0,2939 1,32 0,4066 1,82 0,4656 2,64 0,4959
0,33 0,1293 0,83 0,2967 1,33 0,4082 1,83 0,4664 2,66 0,4961
0,34 0,1331 0,84 0,2995 1,34 0,4099 1,84 0,4671 2,68 0,4963
0,35 0,1368 0,85 0,3023 1,35 0,4115 1,85 0,4678 2,70 0,4965
0,36 0,1406 0,86 0,3051 1,36 0,4131 1,86 0,4686 2,72 0,4967
0,37 0,1443 0,87 0,3078 1,37 0,4147 1,87 0,4693 2,74 0,4969
0,38 0,1480 0,88 0,3106 1,38 0,4162 1,88 0,4699 2,76 0,4971
0,39 0,1517 0,89 0,3133 1,39 0,4177 1,89 0,4706 2,78 0,4973
0,40 0,1554 0,90 0,3159 1,40 0,4192 1,90 0,4713 2,80 0,4974
0,41 0,1591 0,91 0,3186 1,41 0,4207 1,91 0,4719 2,82 0,4976
0,42 0,1628 0,92 0,3212 1,42 0,4222 1,92 0,4726 2,84 0,4977
0,43 0,1664 0,93 0,3238 1,43 0,4236 1,93 0,4732 2,86 0,4979
0,44 0,1700 0,94 0,3264 1,44 0,4251 1,94 0,4738 2,88 0,4980
0,45 0,1736 0,95 0,3289 1,45 0,4265 1,95 0,4744 2,90 0,4981
0,46 0,1772 0,96 0,3315 1,46 0,4279 1,96 0,4750 2,92 0,4982
0,47 0,1808 0,97 0,3340 1,47 0,4292 1,97 0,4756 2,94 0,4984
0,48 0,1844 0,98 0,3365 1,48 0,4306 1,98 0,4761 2,96 0,4985
49
0,49 0,1879 0,99 0,3389 1,49 0,4319 1,99 0,4767 2,98 0,4986
Второй случай (выборка малого объема). Если дисперсия σ2 генеральной совокупности
неизвестна (например, в случае малых выборок), то для проверки гипотезы H 0 : M X X 0
используется критерий:
X X0 m
tR
S X
Случайная величина tR имеет распределение Стьюдента с f m 1 степенями свободы.
Критическая область строится в зависимости от вида конкурирующей гипотезы.
При конкурирующей гипотезе H1 : M X X 0 используется двусторонний табличный
критерий tT 2 , который определяется по Таблица 12 по заданному уровню значимости и
при f m 1 . При конкурирующей гипотезе H1 : M X X 0 используется односторонний
табличный критерий tT 1 , который определяется по заданному уровню значимости α
и f m 1.
Если t R tT 1 или t R tT 2 то нет оснований отвергать нулевую гипотезу, и выборочная
средняя незначимо отличается от предполагаемой средней или постоянной стандартной величины.
В тех случаях, когда по данным проведенного эксперимента разница X X 0 оказалась
при pD 0,95 незначимой, рекомендуется проверить это при большем объеме выборки.
50
Таблица 12 - Табличные значения коэффициента Стьюдента для односторонних (α) и двусторонних (α/2)
гипотез при заданном числе степеней свободы df (n-1)
51
В случае определения наименьшего объема т, при котором с заданной вероятностью
разность X X 0 оказалась бы значимой, используют приведенную выше формулу критерия
Стьюдента. При этом приравнивают t R tT 2 pD ; f m 1 и получают:
tT 2 pD ; f m 1
X X0 m
K1
S X
m
Определив значение K1 правой части формулы, находят искомый объем т по Таблица
13 для полученного K1 и заданной доверительной вероятности. Двусторонний критерий tT 2
используется при H 0 : M X X 0 и односторонний – при H 0 : M X X 0 или M X X 0 .
t
Таблица 13 - Достаточная численность выборки m в зависимости от величины T K1
m
52
Пример.
Проведено 200 измерений прочности пряжи, и получены средние значения X 303 и
S (X) 30 . Необходимо проверить, значимо ли различие выборочной средней от стандартной
прочности X 0 300 при двух конкурирующих гипотезах H1 : M X X 0 и H 2 : M X X 0
на уровне значимости 5%.
Пользуясь формулой, получаем:
X X 0 m 303 300 200
uR
1,41
S X
30
По формулам находим:
1 1 0,05
0,475 и по Таблица 11 находим соответствующую
- при H1 : ФuT 2
2
2
величину uT 2 1,96
1 2 1 2 0,05
0,45 и по Таблица 11 находим соответствую- при H 2 : ФuT 1
2
2
щую величину uT1 1,65
Следовательно, при двух конкурирующих гипотезах нет оснований отвергнуть нулевую гипотезу, т.е. нельзя доказать значимого различия выборочной средней и стандартной
прочности пряжи.
5.5 Сравнение двух средних больших независимых выборок
Если выборки имеют большой объем (т > 30) и независимы, то выборочные средние
распределены приближенно нормально, а выборочные дисперсии являются достаточно хорошими оценками генеральных дисперсий, и поэтому их можно считать известными приближенно. При этих условиях случайная величина:
X1 X 2
u
S 2 X1 S 2 X 2
m1
m2
распределена приближенно нормально с параметрами M u 0 (при условии справедливости нулевой гипотезы) и 2 u 1 (если выборки независимы).
Для проверки нулевой гипотезы H 0 : X 1 X 2 принимается приближенный критерий,
расчетное значение которого равно:
X1 X 2
uR
S 2 X1 S 2 X 2
m1
m2
Критическая область строится в зависимости от вида конкурирующей гипотезы.
Первый случай. Если конкурирующая гипотеза H1 : X 1 X 2 то при заданном уровне
значимости а по таблице функции Лапласа (Таблица 11) находят табличное значение двустороннего критерия по равенству:
1
Ô uT 2 Ô z
2
Если uR uT 2 то нет оснований отвергнуть нулевую гипотезу о равенстве X 1 и X 2 , т.е.
X1 X 2 .
Если uR uT 2 , то нулевую гипотезу отвергают.
Пример.
53
Проведено измерение прочности двух образцов пряжи, и получены следующие данные:
X 1 210 ; S X 1 20 ; m1 100 ; X 2 190 ; S X 2 18 ; m2 100 . При уровне значимости α =
0,05 требуется проверить нулевую гипотезу H 0 : X 1 X 2 при конкурирующей гипотезе H1 :
X1 X 2 .
Находим расчетное значение критерия по формуле (2.66):
X1 X 2
210 190
uR
7,4
S 2 X1 S 2 X 2
20 2 182
m1
m2
100 100
Используя равенство Ô uT 2 Ô z
1 1 0,05
0,475
2
2
по таблице Лапласа
(Таблица 11) находим uT 2 1,96 .
Так как uR uT 2 то нулевую гипотезу отвергаем, т.е. разница между средними значениями прочности двух образцов пряжи существенна.
Второй случай. Если конкурирующая гипотеза H1 : X 1 X 2 то при заданном уровне
значимости а, используя таблицу функции Лапласа (Таблица 11), находят табличное значение одностороннего критерия по равенству:
1 2
.
2
Если u R uT 1 то нулевая гипотеза не отвергается.
В противном случае гипотеза отвергается.
Пример.
Исследователь после введения конструктивных изменений в прядильное пневмомеханическое устройство ожидает повышения прочности пряжи, т.е. принимает по отношению к
гипотезе H 0 : X 1 X 2 конкурирующую гипотезу H1 : X 1 X 2 . Числовые статистические характеристики двух образцов пряжи приведены в предыдущем примере, поэтому
X1 X 2
210 190
uR
7,4
2
2
S X1 S X 2
20 2 182
m1
m2
100 100
Ô uT 1 Ô z
1 2 1 2 0,05
0,45 по таблице функции Лапласа
2
2
(Таблица 11) находим uT1 1,65 . Так как u R uT 1 , нулевую гипотезу отвергают, т.е. конструктивное изменение в прядильном устройстве обусловило значимое изменение прочности
пряжи.
Используя равенство Ô uT 1
5.6 Сравнение двух средних из нормально распределенных генеральных совокупностей
Если проверяется гипотеза о равенстве двух средних из нормально распределенных генеральных совокупностей, дисперсии которых неизвестны, то, прежде всего, следует проверить с помощью F-критерия гипотезу о равенстве дисперсий в генеральных совокупностях.
При этом возможны два случая.
Первый случай - равноточность двух рядов измерений 12 22 доказана. Для проверки
гипотезы о равенстве средних, найденных по независимым малым выборкам, используется
критерий t, расчетное значение которого определяется по формуле:
54
tR
X1 X 2
S X 1 X 2
X1 X 2
S X
2
m1m2
m1 m2
где S X 1 X 2 - среднее квадратическое отклонение разности X 1 X 2 , или ошибка
разницы;
m 1S12 m2 1S22
S 2 X 1
m1 m2 2
Доказано, что величина t при справедливости нулевой гипотезы H 0 : X 1 X 2 имеет tраспределение Стьюдента с f m1 m2 2 степенями свободы. Критическая область строится в зависимости от вида конкурирующей гипотезы.
Если проверяется гипотеза H 0 : X 1 X 2 при конкурирующей гипотезе H 2 : X 1 X 2 , то
в этом случае используется двусторонний критерий tT 2 , табличное значение которого определяют по Таблица 12 при заданном уровне значимости α и числе степеней свободы
f m1 m2 2 . Если t R tT 2 , f нулевую гипотезу отвергают, т.е. исследователь устанавливает, например, что применение уровня фактора или конструктивные изменения в машине
обусловили значимое различие между выходными параметрами. Если t R tT 2 , f , то нет
оснований отвергать гипотезу H 0 о равенстве средних, т.е. оба ряда измерений относятся к
одной и той же совокупности, для которой среднее значение определяется по формуле:
m X m2 X 2
X 1 1
m1 m2
а дисперсия - по формуле указанной выше S 2 X .
Если разность между средними двух выборок значима только при доверительной вероятности в пределах pD 0,95...0,99 , то прежде чем идти на риск по принятию нулевой гипотезы H 0 : X 1 X 2 , следует увеличить объем выборки, т.е. провести дополнительный эксперимент.
m
Оптимальным соотношением объемов сравниваемых выборок является m1 m2
2
где m m1 m2 так как при этом ошибка разности X 1 X 2 оказывается наименьшей.
Считая дисперсии сравниваемых совокупностей одинаковыми и равными 12 22 2
m
при m1 m2
из формулы получаем:
2
m m2 2S Y
S X 1 X 2 S X 1
m1m2
m
В этом случае расчетное значение критерия Стьюдента:
X1 X 2
X1 X 2
tR
m
S X 1 X 2
2S Y
Чтобы разность X 1 X 2 можно было бы считать значимой, t R должна быть если не
больше, то, по крайней мере, равна tT 2 для заданной доверительной вероятности и заданного
числа степеней свободы f m 2 .
После замены t R на tT 2 , сосредоточивая в левой части предыдущей формулы члены,
зависящие от m, и возводя обе части в квадрат, получим:
tT2 2 pD ; f
K2
m
55
X2
4S 2 X
Зная К2 при заданной p D , по Таблица 14 определяют искомое значение т.
t
Таблица 14 - Достаточная численность выборок m в зависимости от величины T K 2
m
где K 2
X
2
1
56
Для случая, когда К2< 0,13, искомое т находят по формуле:
t2 p , f
m T 2 D2
Ê2
(что также нашло отражение в Таблица 14). Величина S 2 X , входящая в формулу для
К2, определяется по данным проведенного эксперимента или по данным других исследований. Величину разности X 1 X 2 принимают равной или наименьшему различию между
средними, которое может представлять практический интерес, или разности, которая оказалась незначимой в предварительном эксперименте. При использовании формул для К2 предполагается, что увеличение объема выборки не вызовет значительного изменения X 1 X 2 и
2 X .
Пример.
При испытании прочности полосок двух вариантов ткани, выработанной при различной
плотности по утку, получены следующие числовые статистические характеристики двух рядов измерений: X 1 80 ; S 2 X 1 10 ; т1 = 12; X 2 70 ; S 2 X 2 8 ; т2 = 10. Проверяем гипотезу о равенстве дисперсий H 0 : 12 22 при конкурирующей гипотезе H1 : 12 22 .
S12 10
1,25 . Табличное значение критеS 22 8
рия определяем по Таблица 8 при уровне значимости а = 0,05 и числе степеней свободы ft =
12 - 1 = 11 и f2 = 10-1=9, т.е. FT pD 0,95; f1 11; f 2 9 3,1 . Так как FR < FT, гипотеза о равенстве дисперсий не отвергается, т.е. нельзя было доказать значимого различия по дисперсии прочности полосок ткани.
Проверим гипотезу о равенстве средних H 0 : X 1 X 2 при конкурирующей гипотезе
Расчетное значение критерия Фишера FR
H1 : X 1 X 2 . По формуле определяем дисперсию:
S 2 X
m1 1S12 X m2 1S 22 X 12 110 10 18 9,1
m1 m2 2
10 12 2
Затем находим расчетное значение критерия Стьюдента:
X1 X 2
m1m2
80 70 12 10
tR
24,6
9,1 12 10
S 2 X m1 m2
и его табличное значение (Таблица 12): tT 2 0,05; f 10 12 2 20 2,09 . Так как
t R tT 2 гипотеза о равенстве средних значений прочности полоски ткани отвергается, т.е.
увеличение плотности ткани по утку обусловило значимое различие в их прочности.
Если проверяется гипотеза средних H 0 : X 1 X 2 при конкурирующей гипотезе H1 :
X 1 X 2 , то используется односторонний критерий, табличное значение которого определяют по Таблица 12 при заданном уровне значимости а и числе степеней свободы
f m1 m2 2 т.е. tT 1 , f . Если t R tT 1 то нет оснований отвергать нулевую гипотезу. Если tR> (л, то нулевую гипотезу отвергают.
Для предыдущего примера при конкурирующей гипотезе H1 : X 1 X 2 ,табличное значение критерия Стьюдента находится по Таблица 12: tT 1 0,05; f 10 12 2 20 1,72 .
Так как t R 24,6 tT1 1,72 , то гипотеза X 1 X 2 должна быть отброшена, т.е. и при второй
конкурирующей гипотезе статистическое исследование показало, что проведенное изменение плотности ткани по утку обусловило значимое изменение ее прочности.
Второй случай - равноточность двух рядов измерений 12 22 не доказана. Для проверки нулевой гипотезы о равенстве средних X 1 X 2 используется также критерий t (Стьюдента), расчетное значение которого определяется по приближенной формуле:
57
tR
X1 X 2
S 2 X1 S 2 X 2
m1
m2
Табличное значение двустороннего критерия определяется при заданном уровне значимости а и числе степеней свободы:
f1 f 2
f
2
f1 1 C C 2 f 2
S 2 X1
m1
где C 2
; f1 m1 1; f 2 m2 1 .
S X1 S 2 X 2
m1
m2
Если t R tT 2 , f то разница X 1 X 2 незначима, а если t R tT 2 , f , то разница между
средними значима.
Пример.
Статистическая обработка трех рядов измерений выходного параметра, полученных
при трех типах конструктивных рабочих органов машины, дала следующие числовые характеристики: 1-й ряд - X 1 4,57 ; S X1 4,17 ; т1 = 10.
2-й ряд - X 2 2,17 ; S X 2 1,55 ; т2 = 10.
3-й ряд - X 3 7,33 ; S X 3 3,06 ; т3 = 10.
Следует установить, имеется ли значимая разница между средними трех этих рядов измерений.
1 Сопоставим 1-й и 2-й ряды. Вначале определим значимость различия дисперсий, используя критерий Фишера. Проверяем гипотезу H 0 : 12 22 при конкурирующей гипотезе
H1 : 12 22 . Для этого находим расчетное значение критерия F по формуле (2.57):
S12 4,17 2
7,2
S 22 1,552
По Таблица 8 определяем: FT pD 0,95; f1 9; f 2 9 3,18 . Так как FR > FT, то гипотеза H 0 отвергается и принимается конкурирующая гипотеза, т.е. 12 22 .
FR
При этих условиях для проверки гипотезы H 0 : X 1 X 2 определим расчетное значение
критерия Стьюдента по формуле:
X1 X 2
4,57 2,17
tR
1,7
2
2
S X1 S X 2
4,17 2 1,552
m1
m2
10
10
Вычислим число степеней свободы:
S 2 X1
m1
4,17 2 / 10
C 2
0,879 ,
S X 1 S 2 X 2 4,17 2 / 10 1,552 / 10
m1
m2
f1 f 2
99
f
11 .
2
2
f1 1 C C 2 f 2 91 0,879 0,8792 9
Табличное значение двустороннего критерия находим по Таблица 12:
tT 2 0,05; f 11 2,2 . Так как tR < tT, нулевая гипотеза не подтвердилась, т.е. разница
между средними 1-го и 2-го рядов незначима.
58
2 Сопоставим 2-й и 3-й ряды. Проверяем гипотезу H 0 : 12 22 при конкурирующей
гипотезе H1 : 12 22 .
S32 3,06 2
3,9 . FT pD 0,95; f1 9; f 2 9 3,18 , следовательно, FR>FT,
S 22 1,552
гипотеза H 0 с уровнем значимости а = 0,05 не может быть принята.
Оценим теперь возможность отбрасывания гипотезы H 0 . Для этого определяем FT, при
уровне значимости а = 0,01 по Таблица 10: FT 0,01; f1 9; f 2 9 5,35 . Так как FR < FT,
при а = 0,01 оцениваемую гипотезу H 0 отбросить нельзя. То же самое нельзя сделать и при
а = 0,025, так как FR = 3,9 < FT = 4,03. В данной ситуации рекомендуется сравнить средние
при условии 32 22 и 32 22 .
Так как FR
а) если 32 22 , то для проверки гипотезы H 0 : X 3 X 2 по формулам находим:
X3 X2
tR
S X 3 S X 2
m1
m2
2
2
7,33 2,17
3,06 2 1,552
10
10
4,73
S 2 X1
m1
3,06 2 / 10
C 2
0,8
S X 1 S 2 X 2 3,06 2 / 10 1,552 / 10
m1
m2
f 2 f3
99
f
13
2
2
2
f 3 1 C C f 2 91 0,8 0,82 9
Табличное
значение
двустороннего
критерия
tT 2 0,05; f 13 2,16 ,
tT 2 0,01; f 11 3,11 . Так как при уровнях значимости 0,05 и 0,01 имеем tR > tT, то это
дает основание заключить, что средние 2-го и 3-го рядов значимо отличаются;
б) если 32 22 , то для проверки гипотезы H 0 : X 3 X 2 при конкурирующей гипотезе
H1 : X 3 X 2 по формулам находим:
S
2
2
2
m2 1S 22 X m3 1S 32 X 10 1 1,55 10 1 3,06
X
m2 m3 2
tR
X3 X2
10 10 2
5,883
m3m2
7,33 2,17 10 10
4,757
m3 m2
10 10
5,883
S 2 X
Так
как
табличное
значение
двустороннего
критерия
tT 2 0,05; f 10 10 2 2,101, нулевая гипотеза отвергается, т.е. средние 2-го и 3-го рядов значимо отличаются.
3 Сопоставим 1-й и 3-й ряды. Проверяем гипотезу H 0 : 12 32 при конкурирующей
гипотезе H1 : 12 32 .
S12 4,17 2
1,85 . FT 0,05; f1 9; f 2 9 3,18 , следовательно, FR<FT,
S32 3,06 2
гипотеза H 0 с уровнем значимости а = 0,05 о равенстве дисперсий принимается.
При уровне значимости а = 0,05 FT 0,01; f1 9; f 2 9 5,35 и FR<FT. Поэтому гипотеза о равенстве дисперсий безусловно не отвергается.
Если 12 32 , то для проверки гипотезы H 0 : X 3 X 1 при конкурирующей гипотезе
Так как FR
H1 : X 3 X 1 по формулам находим:
59
S 2 X
m3 1S32 X m1 1S12 X 10 1 3,06 2 10 1 4,17 2
m3 m1 2
tR
X 3 X1
10 10 2
13,376
m3m1
7,33 4,57 10 10
1,69
m3 m1
13,376 10 10
S X
Односторонний критерий при уровне значимости α = 0,05 и числе степеней свободы
0,05
; f 18 2,101 . Так как tR < tT, то нулевая гипотеза не отf=10+10-2 =18 равен: tT 1
2
вергается, т.е. средние 1-го и 3-го рядов отличаются не значимо.
2
В тех случаях, когда разница средних оказалась при pD = 0,95 незначимой, рекомендуется увеличить объем двух выборок. Ниже приводится метод определения этого объема с оптимальным соотношением m1 и m2 .
Если предполагается, что дисперсии двух выборок не равны ( 12 22 ), то при данном
m m1 m2 наилучшим соотношением величин m1 и m2 является такое, при котором среднее квадратическое отклонение разности средних
S 2 X 1 S 2 X 2
.
m1
m2
получается по возможности наименьшим, а число степеней свободы для критерия Стьюдента
- наибольшим.
Оптимальным соотношением является такое, когда
m2 S X 1
a
m1 S X 2
и объемы выборок
m
m1
1 a
m2 m m1 .
S X 1 X 2
При этих условиях формула для критерия Стьюдента принимает вид:
tR
X1 X 2 m
S 2 X 1 1 a
2
.
и tR имеет распределение Стьюдента с f m1 m2 2 m 2 степенями свободы в
очень широкой области значений a и т. Это позволяет определять объем необходимой выборки при сравнении средних двух выборок, если известно, что их дисперсии не равны. Для
этого принимается t R tT 2 ; f1 , и предыдущая формула после возведения в квадрат принимает вид:
X X 2 K .
tT2 2 , f
2 1
2
2
m
S X 1 1 a
2
Определив по данным предварительного эксперимента S 2 X j и задаваясь желаемой
разностью средних, находят по Таблица 14 при выбранном значении p D искомый объем выборки т. Затем по формулам определяют т1 и т2.
Пример.
При анализе данных предыдущего примера установлено, что разница X 1 X 2 незначима. Найдем необходимый объем выборки, чтобы различия между средними, если они превышают 2,4, были значимы c pD = 0,95.
По данным предыдущего примера, используя формулы, находим:
60
X X 2
S X 2 1,55
2,4 2
0,372 K 2 2 1
0,176
2
2
S X 1 4,17
S X 1 1 a
4,17 2 1 0,372
а по Таблица 14 - искомый объем: т = 25. Затем по формулам определяем оптимальное
соотношение объемов:
m
25
m1
18 ; m2 m m1 25 18 7 .
1 a 1 0,372
Определим значимость разницы X 1 X 2 24 при вновь найденных объемах выборок.
Прежде
проверим
значимость
различия
дисперсий,
используя
формулу
2
2
S
4,17
FR 12
7,2 . По Таблица 8 находим: FT 0,05; f1 18 1 17; f 2 7 1 6 3,9 .
S 2 1,552
Так как FR = 7,2 > FT= 3,9, то различие дисперсий значимо. При этой ситуации для решения
поставленной задачи необходимо использовать критерий Стьюдента. По формулам и рассчитываем:
S 2 X1
m1
4,17 2 / 18
C 2
0,738 ,
S X 1 S 2 X 2 4,17 2 / 18 1,552 / 7
m1
m2
f1 f 2
17 6
f
23 ,
2
2
2
f1 1 C C f 2 171 0,738 0,7382 6
2
a
tR
X1 X 2
S 2 X1 S 2 X 2
m1
m2
2,4
4,17 2 1,552
18
7
2,1 .
По Таблица 12 находим: tT 2 pD 0,95; f 23 2,07 . Так как tR =2,1 > tT2 = 2,07, при pD
= 0,95 разница X 1 X 2 значима. Следовательно, разница X 1 X 2 2,4 будет тем более значима.
61