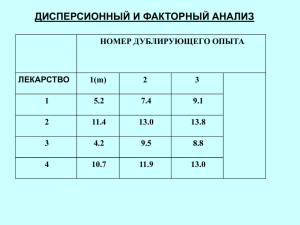
Дисперсионный анализ 1.1 Однофакторный дисперсионный анализ 1.1.1 Параметрический однофакторный дисперсионный анализ Пусть требуется проверить наличие влияния на результативный признак одного контролируемого фактора А, имеющего m уровней A j , j 1,2,...m . Наблюдаемые значения результативного признака Y на каждом из фиксированных уровней A j обозначим yij , i 1, n j , где n j - число объектов наблюдения. Можно также рассмотреть эту задачу как задачу проверки однородности нескольких генеральных совокупностей, а именно случайных величин 𝜉1 , 𝜉2 , … , 𝜉𝑚 , 𝐹𝜉1 (𝑥1 − 𝛼1 ), 𝐹𝜉2 (𝑥2 − 𝛼2 ), … , 𝐹𝜉𝑚 (𝑥𝑚 − 𝛼𝑚 ), где 𝛼1 . . 𝛼𝑚 −параметры сдвига. Для изучения случайных величин 𝜉1 , 𝜉2 , … , 𝜉𝑚 рассматриваем априорные выборки 𝜉1,𝑛1 , 𝜉2, 𝑛2 , … , 𝜉𝑚,𝑛𝑚 , где 𝜉𝑗,𝑛𝑗 , 𝑗 = 1. . 𝑚 Реализации априорных выборок представлены матрице: 𝑦11 𝑦21 y=( … 𝑦𝑛1 𝑦12 𝑦22 … 𝑦𝑛2 … 𝑦1𝑛 … 𝑦2𝑛 ) … … 𝑦𝑛𝑛 Где yij -Наблюдаемые значения результативного признака Y на каждом из фиксированных уровней A j . Любое наблюдение yij можно представить в виде: Апостериорная модель однофакторного дисперсионного анализа: 𝑦𝑖𝑗 = 𝑎 + 𝛼𝑗 + 𝑧𝑖𝑗 , 𝑗 = ̅̅̅̅̅̅ 1, 𝑚, 𝑖 = ̅̅̅̅̅̅ 1, 𝑛𝑗 где 𝑎 – некоторое общее среднее, 𝛼𝑗 – отклонение от среднего, вызванное влиянием фактора на j уровень, 𝑧𝑖𝑗 – величина отклонения 𝑦𝑖𝑗 от 𝑎 + 𝛼𝑗 Априорная модель: 𝑀1 – уровни фактора А фиксированы 𝑚 𝜉𝑖𝑗 = 𝑎 + 𝛼𝑗 + 𝜀𝑖𝑗 , где ∑ 𝛼𝑗 = 0 − отклонение 𝑗=1 𝑀2 – уровни фактора А случайны 𝜉𝑖𝑗 = 𝑎 + 𝛿𝑗 + 𝜀𝑖𝑗 Требования к 𝛿: 𝑀𝛿𝑗 = 0 𝑐𝑜𝑣(𝛿𝑗 , 𝛿𝑠 ) = 𝑀 ((𝛿𝑗 − 𝑀𝛿𝑗 )(𝛿𝑠 − 𝑀𝛿𝑠 )) = 𝑀𝛿𝑗 ∙ 𝛿𝑠 = 0, ∀ 𝑗 ≠ 𝑠 𝐷𝛿𝑗 = 𝑀𝛿𝑗2 = 𝜎 2 (один для всех уровней) 𝑐𝑜𝑣(𝛿𝑠 , 𝜀𝑖𝑗 ) = 𝑀𝛿𝑠 ∙ 𝜀𝑖𝑗 = 0 𝐷𝜉𝑖𝑗 = 𝜎𝜀2 𝐷𝛿𝑗 = 𝜎𝛿2 Требования на остаточную компоненту: Относительно ij будем предполагать, что они распределены нормально и удовлетворяют следующим условиям: M ij 0 ; M ij i ' j ' 0 i i' или j j ' ; M ij2 2 - остаточная дисперсия. В зависимости от изучаемой модели относительно j предполагаем: модель М1 – j - фиксированные величины, такие что j n j 0 и основная гипотеза H0: j 0 j 1, m , то есть нет влияния фактора А на результативный признак; модель М2 – j - случайные величины, удовлетворяющие условиям M j 0 ; M j j ' 0 j j ' ; M j ij 0 i, j ; M 2j 2 - факторная дисперсия и основная гипотеза H0: 2 0 , то есть нет влияния фактора А на результативный признак. Для проверки основной гипотезы дисперсионного анализа, утверждающей, что нет влияние фактора А (уровней фактора А) на изменение результативного признака, вычислим следующие средние: 1 𝑛𝑗 𝑦̅∗𝑗 (𝑦𝑗,𝑛𝑗 ) = 𝑛 ∑𝑖=1 𝑦𝑖𝑗 - групповые средние (средние уровней A j ); 𝑗 𝑛 1 1 𝑗 𝑚 𝑦̅∗∗ (𝑦1,𝑛1 , 𝑦2,𝑛2 , … , 𝑦𝑚,𝑛𝑚 ) = 𝑦̅∗∗ = 𝑛 ∑𝑚 ̅∗𝑗 - общая средняя 𝑗=1 ∑𝑖=1 𝑦𝑖𝑗 = 𝑛 ∑𝑗=1 𝑛𝑗 ∗ 𝑦 m результативного признака, где N n j . j 1 Определим две дисперсии: межгрупповую (дисперсию групповых средних) или факторную, обусловленную влиянием изучаемого фактора и внутригрупповую (остаточную), величина которой рассматривается как случайная. Необходимые суммы квадратов отклонений обозначим: Апостериорные суммы квадратов отклонений: 𝑛𝑗 𝑄факт (𝑦1,𝑛1 , 𝑦2,𝑛2 , … , 𝑦𝑚,𝑛𝑚 ) = ∑𝑚 ̅∗𝑗 − 𝑦̅∗∗ )2 = ∑𝑚 ̅∗𝑗 − 𝑦̅∗∗ )2𝑗=1 ∑𝑖=1(𝑦 𝑗=1 𝑛𝑗 ∗ (𝑦 факторная сумма квадратов отклонений; 𝑛𝑗 𝑄ост (𝑦1,𝑛1 , 𝑦2,𝑛2 , … , 𝑦𝑚,𝑛𝑚 ) = ∑𝑚 ̅∗𝑗 )2- остаточная сумма квадратов 𝑗=1 ∑𝑖=1(𝑦𝑖𝑗 − 𝑦 отклонений; 𝑛𝑗 𝑄общ (𝑦1,𝑛1 , 𝑦2,𝑛2 , … , 𝑦𝑚,𝑛𝑚 ) = ∑𝑚 ̅∗∗ )2 - общая сумма квадратов 𝑗=1 ∑𝑖=1(𝑦𝑖𝑗 − 𝑦 отклонений. Априорные суммы квадратов отклонений: 𝑛 𝑗 𝑄факт (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) = ∑𝑚 ̅∗𝑗(𝜉1,𝑛 𝑗=1 ∑𝑖=1(𝑦 1 ,𝜉2,𝑛2 , …,𝜉𝑚,𝑛𝑚 ) − 𝑦̅∗∗ (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ))2 = ∑𝑚 ̅∗𝑗 (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) − 𝑗=1 𝑛𝑗 ∗ (𝑦 2 𝑦̅∗∗ (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 )) - факторная сумма квадратов отклонений; 𝑛𝑗 𝑄ост (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) = ∑𝑚 ̅∗𝑗 (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ))2- остаточная 𝑗=1 ∑𝑖=1(𝜉𝑖𝑗 − 𝑦 сумма квадратов отклонений; 𝑛 𝑗 𝑄общ (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) = ∑𝑚 ̅∗∗ (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ))2𝑗=1 ∑𝑖=1(𝜉𝑖𝑗 − 𝑦 общая сумма квадратов отклонений. Легко проверить Qобщ Qфакт Qост Несмещенные оценки общей, факторной и остаточной дисперсий: 𝑄 𝑆 ^2 общ(𝜉 1,𝑛1 ,𝜉2,𝑛2 , …,𝜉𝑚,𝑛𝑚 ) 𝑆 ^2 факт(𝜉1,𝑛 ,𝜉2,𝑛 , …,𝜉𝑚,𝑛𝑚 ) 1 = общ(𝜉1,𝑛 ,𝜉2,𝑛 , …,𝜉𝑚,𝑛 ) 1 2 𝑚 𝑁−1 𝑄 = факт(𝜉1,𝑛 ,𝜉2,𝑛 , …,𝜉𝑚,𝑛 ) 1 2 𝑚 𝑚−1 2 𝑆 ^2 ост(𝜉 1,𝑛1 ,𝜉2,𝑛2 , …,𝜉𝑚,𝑛𝑚 ) = ; 𝑄ост (𝜉1,𝑛 ,𝜉2,𝑛 , …,𝜉𝑚,𝑛 ) Если влияние фактора отсутствует, то 1 2 𝑁−𝑚 2 S факт 2 𝑚 ; . и 2 S ост можно рассматривать как независимые оценки дисперсии всей совокупности. Наоборот, если фактор оказывает существенное влияние на результативный 2 2 признак, то отношение S факт : S ост будет расти и превзойдет некоторый критический предел. Таким образом, первоначальную гипотезу Н0 можно 2 2 заменить такой Н0: факт = ост . Для проверки нулевой гипотезы рассмотрим статистику: 1 𝑄факт (𝜉1,𝑛1 , … , 𝜉𝑚,𝑛𝑚 ) 𝑚 𝐹(𝜉1,𝑛1 , … , 𝜉𝑚,𝑛𝑚 ) = − 1 = 1 𝑄 (𝜉 , … , 𝜉 ) 𝑚,𝑛𝑚 𝑛 − 𝑚 ост 1,𝑛1 = 𝑆^2 факт(𝜉1,𝑛1 ,𝜉2,𝑛2,…,𝜉𝑚,𝑛𝑚 ) ~𝐹(𝑚 − 1; 𝑛 − 𝑚) 𝑆^2 ост(𝜉1,𝑛1 ,𝜉2,𝑛2,…,𝜉𝑚,𝑛𝑚 ) распределенную, очевидно, по закону Фишера-Снедекора со 1 m 1 и 2 N m степенями свободы. 𝑃(𝐹(𝜉) > 𝐹крит ) = 𝛼 𝑃(𝐹(𝜉) < 𝐹крит ) = 1 − 𝛼 𝐹крит представляет собой квантиль уровня 1 − 𝛼 Если Fнабл Fкр ( , m 1, N m) , то гипотеза не отвергается, то есть влияние фактора А на результативный признак не доказано. Если Fнабл Fкр , то Н0 отвергается и с вероятностью ошибки можно утверждать: влияние фактора А на результативный признак существенно. Если влияние фактора доказано, то можно проверить гипотезы: 1) Н0: j j ' - о равенстве двух средних выбранных уровней с помощью статистики 𝐹(𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) = (𝑦∗𝑗(𝜉1,𝑛 ,𝜉2,𝑛 − 𝑦∗𝑗′(𝜉1,𝑛 ,𝜉2,𝑛 , …,𝜉𝑚,𝑛 ) )2 𝑚 1 2 1 𝑄ост (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) 𝑛−𝑚 ~ 𝐹(1; 𝑛 − 𝑚) 1 = ∗ 2) 𝑛𝑗 𝑛𝑗′ 𝑛𝑗 + 𝑛𝑗′ 2 , …,𝜉𝑚,𝑛𝑚 ) , распределенной по закону Фишера-Снедекора с 1 1 и 2 N m При проверке гипотезы Н0: а=а0 не пользуется: в случае модели М1 статистика 𝐹(𝜉1,𝑛 1 ,𝜉2,𝑛2 , …,𝜉𝑚,𝑛𝑚 ) = 𝑛(𝑦∗∗ (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) − 𝑎0 )2 𝑄факт (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) 𝑛−𝑚 ~ 𝐹(1; 𝑛 − 𝑚) имеющая F – распределение с 1 1 и 2 N m ; в случае модели М2 и nj n 𝐹(𝜉1,𝑛 1 ,𝜉2,𝑛2 , …,𝜉𝑚,𝑛𝑚 ) = 𝑁(𝑦∗∗ (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) − 𝑎0 )2 𝑄факт (𝜉1,𝑛1 , 𝜉2,𝑛2 , … , 𝜉𝑚,𝑛𝑚 ) 𝑚−1 статистика ~ 𝐹(1; 𝑚 − 1) имеющая F – распределение с 1 1 и 2 m 1 . Несмещенную точечную оценку для факторной дисперсии, в случае отклонения нулевой гипотезы, можно уточнить N (m 1) 2 2 2 . Sˆфакт ( Sˆфакт Sˆост ) 2 N n 2j уточ Интервальная оценка для D( ij ) 2 с надежностью Qост Qост . 2 2 1 2 1 x ( , N m) x ( , N m) 2 2 Практическая реализация Предполагая, что фактор имеет случайные уровни, а значения результативного признака распределены нормально, требуется: А) проверить при α=0,05 существенность влияния фактора на результативный признак; Б) проверить при α=0,05 существенность влияния фактора на втором и третьем уровнях на результативный признак; В) проверить при α=0,05 гипотезу относительно равенства общей средней заданному номиналу. Исследовалась зависимость объема выручки (млн. руб.) от расходов на рекламу (тыс. руб.). Были получены следующие данные: Таблица 1 - Исходные данные Номер исследования 1 150-200 6,6 2 3 4 5,9 6,4 7,1 Расходы на рекламу 200-250 250-300 6,0 8,4 6,8 7,4 8,1 5 7,5 6,9 7,3 300-400 8,7 7,8 7,1 7,6 7,7 Для проверки существенности влияния расходов на рекламу на объем выручки выдвинем гипотезу 𝐻0 и альтернативную 𝐻1 : 2 2 (нет влияния расходов на рекламу на объем выручки); H 0 : факт ост В основе проверки гипотезы лежит сравнение факторной и остаточной дисперсий. Для проверки нулевой гипотезы воспользуемся статистикой Qфакт (1n1 , 2 n2 ,..., m ,nm ) 2 Sˆфакт (1n1 , 2 n2 ,..., m,nm ) m 1 F (1n1 , 2 n2 ,..., m,nm ) 2 , где m 4, N 17 , Q ( S ост (1n1 , 2 n2 ,..., m,nm ) ост 1n1 , 2 n2 ,..., m , nm ) N m которая при справедливости гипотезы 𝐻0 имеет распределение Фишера-Снедекора со 𝜈1 = 3 𝜈2 = 13 степенями свободы. Если Fнабл Fкр (m 1, N m) , то гипотеза не отвергается, то есть влияние расходов на рекламу на объем выручки не доказано. Если Fнабл Fкр , то Н0 отвергается и с вероятностью ошибки можно утверждать, что влияние расходов на рекламу на объем выручки существенно. Для проверки гипотезы рассчитаем оценки факторной, остаточной и общей дисперсий. Qфакт 4,06 Qост 5,69 Qобщ 9,75 2 Sˆфакт 2 Sˆост Fнабл 1 1 Qфакт 4,06 1,35 m 1 4 1 1 1 Qост 5,69 0,43 N m 17 4 1,35 3,09 0,43 Fкр 3,41(0,05;3;17) Так как Fнабл. Fкр . , следовательно, нулевая гипотеза принимается, то есть, нет влияния расходов на рекламу на объем выручки. Проверим результаты в пакете STATISTICA. Для реализации однофакторного непараметрического дипсперионного анализа в пакете STATISTICA воспользуемся функцией One-way ANOVA – Quick specs dialog.Результаты представлены в таблице 2 а так же в приложении 1. Таблица 2-Результаты проверки нулевой гипотезы об отсутствии влияния расходов на рекламу от объема выручки. Effect SS a 4,063 Degr. Of MS freedom 3 1,354 F p 3,089 0,064 Здесь приведены факторная сумма квадратов 4,063, несмещенная оценка факторной дисперсии 1,354, выборочное значение статистики 3,089 и достигаемый уровень значимости 0,064. Поскольку 0,064 > 0,05, то нулевая гипотеза об отсутствии влияния фактора на результат принимается (Приложение А, рисунок 1, таблица 2) На рисунке 2 показан график оценок средних на каждом уровне факторе вместе с доверительными интервалами для них Таблица 3-Результаты дисперсионного анализа представленные на рисунке 3. 𝑅̂ y 0,645 ̂2 𝑅 2 𝑅̂несм 0,416 0,281 SS Df 4,063 3 MS SS Df MS F Model Residual Residual Residual 1,354 5,7 13 0,44 3,089 p 0,065 Такая форма дает возможность вывести факторную и остаточную суммы квадратов (𝑄факт = SS Model = 4,063 и 𝑄ост =SS Residual = 5,7 соответственно), несмещенные оценки факторной и остаточной дисперсий 2 2 (𝑆̂факт =MS Model =1,354 и 𝑆̂ост =MS Residual =0,44), значение статистики F = 3,089 и достигаемый уровень значимости p=0,064. Таблица 4-Наиболее полный результат дисперсионного анализа представленный в приложении 4 . Degr. Of y SS y MS yF yP Intercept a Error Total Freedom 1 3 13 16 881,3 4,06 5,7 9,76 881,3 1,354 0,44 2010,16 3,09 0,000 0,064 Для реализации однофакторного дисперсионного анализа в пакете STATA воспользуемся функцией Statistics – Linear models and related – ANOVA/MANOVA – One –way ANOVA. Таблица 5-Результаты выполнения однофакторного дисперсионного анализа представленные на рисунке 5 Var2 1 2 3 4 Total Mean 6,5 7,075 7,559 7,8 7,253 Std. Dev. 0,4966 0,892 0,555 0,668 0,78 Freq. 4 4 5 4 17 В столбце Mean приведены средние на каждом уровне фактора y*1=6,5, y*2=7,075, y*3=7,56, y*4=7,8; Std. Dev. – оценки среднеквадратических отклонений; Freq. – количество наблюдений на каждом уровне фактора n1=4, n2=4, n3=5, n4=4. В строке Total приведены оценки среднего y**=7,253, оценка среднеквадратического отклонения 0,78 и общее число наблюдений N = 17. В строке Between groups приведены факторная сумма квадратов (обозначена SS) и несмещенная оценка факторной дисперсии (обозначена MS). В строке Within groups приведены остаточная сумма квадратов (обозначена SS) и несмещенная оценка остаточной дисперсии (обозначена MS). В строке Total приведены общая сумма квадратов (обозначена SS) и несмещенная оценка общей дисперсии (обозначена MS). Значение статистики Фишера-Снедекора составило 3,09, достигаемый уровень значимости 0,0645. Поскольку 0,0645> 0,05, то на уровне значимости 5% нулевая гипотеза об отсутствии влияния фактора на результат принимается. Таблица 6-Результаты выполнения команды anova представленные на рисунке 6 source Partial ss df ms f Prob>f Model 3,988 3 1,33 2,83 0,0836 Var2 3,988 3 1,33 2,83 0,836 Residual Total 5,646 9,63 13 15 0,47 0,64 1.2 Двухфакторный дисперсионный анализ 1.2.1 Параметрический двухфакторный дисперсионный анализ (без повторений) Будем исследовать влияние двух факторов А и В на результативный нормально распределенный признак Y; Ai , i 1, m ; B j , j 1, l - уровни факторов. Рассмотрим два случая. Пусть каждой паре уровней факторов Ai и B j соответствует одно наблюдаемое значение результативного признака yij , то есть наблюденные значение можно представить в виде матрицы с двумя входами. 𝐵1 𝑦11 𝑦 y=( 21 … 𝑦𝑛1 𝐵2 𝐵3 𝑦12 … 𝑦1𝑛 𝐴 1 𝑦22 … 𝑦2𝑛 ) 𝐴2 … … 𝑦𝑛2 … 𝑦𝑛𝑛 𝐴3 Где yij наблюдаемое значение результативного признака для каждой пары уровней факторов Ai и B j . В этом случае апостериорная модель дисперсионного анализа будем рассматривать в виде: 𝑦𝑖𝑗 = 𝜇 + 𝛼𝑖 + 𝛽𝑗 + 𝑧𝑖𝑗 𝑖 = ̅̅̅̅̅̅ 1, 𝑚, 𝑗 = ̅̅̅̅ 1, 𝑙 Априорная модель: 𝜂𝑖𝑗 = 𝜇 + 𝛼𝑖 + 𝛽𝑗 + 𝜀𝑖𝑗 , где а – общая генеральная средняя; ij - независимые нормально распределенные остатки, с M ij 0 и D ij 2 , i 1, m ; j 1, l ; i , j - отклонения от а, обусловленные влиянием соответствующих уровней факторов А и В. Если уровни факторов Ai и B j фиксированные (модель М1), то i и j есть неслучайные величины, удовлетворяющие очевидным условиям m i 0 ; i 1 l j 0. j 1 Ненулевые гипотезы формулируются в виде: Н0: i 0 , i 1, m ; Н0: j 0 , j 1, l ; Если уровни факторов Ai и B j случайные, то i и j будем считать независимыми между собой и с ij случайными величинами распределенными нормально. M j M j 0 и D i 2 ; D j 2 . Отсутствие влияния уровней факторов на изменения результативного признака – нулевые гипотезы – формально записывается в виде: Н0: 2 0 ; Н0: 2 0 . Если уровни фактора А – случайные, а В – фиксированные (смешанная модель), то i независимые между собой и с ij случайные величины с M j 0 , D i 2 ; j - неслучайные величины, удовлетворяющие условию j 0. Нулевые гипотезы об отсутствии влияния уровней факторов на изменения результативного признака формулируются в виде: Н0: 2 0 ; Н0: j 0 , j 1, l . Аналогично строиться смешанная модель, в которой фактор А имеет фиксированные уровни, а фактор В – случайные. Построим разложение для: m l m l Qобщ ( yij y** ) ( yij y* j yi * y* j yi * y** y** y** ) 2 2 i 1 j 1 m i 1 j 1 l (( y* j y** ) ( yi * y** ) ( yij y* j yi * y** )) 2 i 1 j 1 m l (( y* j y** ) 2 ( yi* y** ) 2 ( yij y* j yi* y** ) 2 i 1 j 1 2( y* j y** )( yi* y** ) 2( y* j y** )( yij y* j yi* y** ) l l i 1 j 1 2( yi * y** )( yij y* j yi * y** )) m ( y* j y** ) 2 l ( yi * y** ) 2 m l ( yij y* j yi * y** ) QB Q A Qост i 1 j 1 m где QA l ( yi * y** ) 2 ; i 1 l QB m ( y* j y** ) 2 ; j 1 m l Qост ( yij y* j yi * y** ) 2 i 1 j 1 В случае двухфакторного дисперсионного анализа с повторениями для каждого сочетания уровней А и В имеется ровно 𝑝 наблюдений матрица 11: 𝐵1 𝑦111 , 𝑦112 , … 𝑦11𝑝 … ( 𝑦𝑚11 , 𝑦𝑚12 , … 𝑦𝑚1𝑝 𝑦𝑖𝑗𝑘 𝐵2 𝑦121 , 𝑦122 , … 𝑦12𝑝 … 𝑦𝑚21 , 𝑦𝑚22 , … 𝑦𝑚2𝑝 𝐵3 … 𝑦1𝑙1 , 𝑦1𝑙2 , … 𝑦1𝑙𝑝 𝐴1 … ) 𝐴2 … 𝑦𝑚𝑙1 , 𝑦𝑚𝑙2 , … 𝑦𝑚𝑙𝑝 𝐴3 Апостериорная модель 𝑖 = ̅̅̅̅̅̅ 1, 𝑚 = 𝜇 + 𝛼𝑖 + 𝛽𝑗 + (𝛼𝛽)𝑖𝑗 + 𝑧𝑖𝑗𝑘 𝑗 = ̅̅̅̅ 1, 𝑙 𝑘 = ̅̅̅̅̅ 1, 𝑝 Априорная модель 𝜂𝑖𝑗 = 𝜇 + 𝛼𝑖 + 𝛽𝑗 + 𝜀𝑖𝑗 Для проверки нулевой гипотезы об отсутствии влияния одного из факторов D A; B рассматриваем статистику QD m, D A n 1 , где nD F D Qост l , D B N nD распределенную, очевидно, по закону Фишера-Снедекора с 1 nD 1 и 2 N n D степенями свободы. 1.2.2 Параметрический двухфакторный дисперсионный анализ (без повторений) В общем случае, когда для каждой пары уровней Ai и B j имеется n(n>1) наблюдений. 𝐵1 𝐵2 𝐵3 y111, y112, … , y11n y121, y122, … , y12n … y1𝑛1, y1n2, … , y1nn 𝐴 … y2l1, y2l2, … , y2ln 𝐴1 y211, y212, … , y21n y221, y222, … , y22n ( ) 2 … … 𝐴3 ym11, ym12, … , ym1n ym21, ym22, … , ym2n … yml1, yml2, … , ymln Где yijk - к-ое наблюдение результативного признака для i-го уровня фактора А и j-го уровня фактора В; Модель дисперсионного анализа представим в виде yijk a i j ( )ij ijk , i 1, m j 1, l , k 1, n , а – общая генеральная средняя; i , j - отклонения от а, обусловленные влиянием соответствующих уровней Аi и Вj; ( )ij - отклонения от а, обусловленные совместным влиянием уровней факторов А и В; ijk (0, ) и независимы между собой. Если уровни факторов Аi и Вj фиксированные (модель М1), то отклонения i , j и ( )ij - неслучайные величины, удовлетворяющие условиям: m l m l i 1 j 1 i 1 j 1 i 0 ; j 0 ; ( )ij 0 ; ( )ij 0 . Сформулируем гипотезы об отсутствии влияния: фактора А – Н0: i 0 ; i 1, m ; фактора В – Н0: j 0 ; j 1, l ; совместного влияния факторов А и В – Н0: ( ) ij 0 ; i 1, m ; j 1, l . В случае модели М2 i , j и ( )ij есть независимые между собой и с ijk случайные величины, распределенные нормально с нулевым 2 математическим ожиданием и с дисперсиями 2 , 2 и . Сформулируем нулевые гипотезы от отсутствии влияния: фактора А – Н0: 2 0 ; фактора В – Н0: 2 0 ; совместного влияния 2 факторов А и В – Н0: 0. Для смешанной модели, когда, к примеру, уровни фактора А случайные, а фактора В – фиксированные, отклонения i и ( )ij независимые между собой и с ijk нормально распределены случайные величины с нулевыми математическими ожиданиями, с дисперсиями 2 и 2 , при этом m ( )ij 0 , а i 1 l ( )ij 0 ; j 1 l j 0. j 1 Нулевые гипотезы об отсутствии влиянием факторов имеют вид: Фактора А – Н0: 2 0 ; Фактора В – Н0: j 0 ; j 1, l ; 2 совместного влияния факторов А и В – Н0: 0 .` Аналогично строится другая смешанная модель. Разложив, как и при n=1, общую сумму квадратов на составляющие: Qобщ QA Q B QAB Qост , где m l n 2 Qобщ ( y ijk y***) ; i 1 j 1k 1 m QA l n ( y i 1 l 2 ; i** y***) 2 Q B m n ( y * j * y ***) ; m j 1 l Q AB n ( y i 1 j 1 m l n ij * y i** y* j* y***) 2 ; 2 Qост ( y ijk y* j *) ; i 1 j 1k 1 Практическая реализация Двухфакторный дисперсионный анализ без повторений По данным индивидуального задания при α=0,05: А) проверить нулевую гипотезу об отсутствии влияния первого фактора на результативный признак; Б) проверить нулевую гипотезу об отсутствии влияния второго фактора на результативный признак; В) проверить нулевую гипотезу об отсутствии совместного влияния факторов на результативный признак В двухфакторном комплексе приводится сменная выработка рабочего в зависимости от типа станка (А) и стажа его работы (В). При α=0,01 проверить влияние факторов А и В на сменную выработку рабочего: Таблица 12-Исходные данные. В1 В2 В3 А1 122 128 162 А2 128 118 160 А3 126 116 165 Для реализации двухфакторного дисперсионного анализа без повторений в пакете STATISTICA воспользуемя функцией Statistics – Nonparametrics-Comparing multiple dep. Samples (variables)-Variables (var1-var3)-Summary. Таблица 13-Проверка влияния фактора A (рисунок 7): Average rank Sum of ranks mean Std. Dev. Var1 3,0000 27,0000 136,1111 20,12737 Var2 1,5000 13,0000 2,00000 0,86603 Var3 1,5000 13,5000 2,00000 0,86603 Фактор А (тип станка) оказывает влияние на результативный признак, так как значимость (0,04979) меньше заданного уровня 0,05, то нулевая гипотеза об отсутствии влияния фактора на результат принимается Для реализации двухфакорного диспреснионного анализа в пакете STATA вопользуемся функцией Statistics – Lineat models and related – ANOVA/MANOVA – Analysis of variance and covariances (рисунок 8, таблица 14). Таблица 14-Реализация двухфакторного дисперсионного анализа в пакете STATA source Model Partial SS DF 3133,77778 4 MS 783,44444 f 29,26 Prob>f 0,0032 Var2 Var3 Residual Total 6,88889 3126,8889 107,1111 3240,88889 3,444444 0,13 1563,44444 58,39 26,777778 405,11111 0,8828 0,0011 2 2 4 8 В строке var2 приведены факторная сумма квадратов по фактору стаж работы (фактор B) 𝑄𝐵 = 6,88889 (обозначена Partial SS) и несмещенная оценка факторной дисперсии по фактору А 𝑆̂𝐵2 = 3,444444 (обозначена MS). В строке var3 приведены факторная сумма квадратов по фактору тип станка (фактор A) 𝑄А =3126,8889 и несмещенная оценка факторной дисперсии по фактору А 𝑆̂А2 = 1563,44444. В строке Residual приведены остаточная сумма квадратов 𝑄ост = 107,1111 (обозначена Partial SS) и несмещенная оценка остаточной 2 дисперсии 𝑆̂ост = 26,777778 (обозначена MS). В строке Total приведены общая сумма квадратов 𝑄общ = 3240,88889 2 (обозначена SS) и несмещенная оценка общей дисперсии 𝑆̂общ = 405,11111 (обозначена MS). Значение статистики Фишера-Снедекора для проверки гипотезы об отсутствии влияния фактора А приведено в строке Столбцы, столбец F – оно составило 58,39. В столбце Prob > F приведено соответствующее p-value (достигаемый уровень значимости) 0,0011< 0,05, нулевая гипотеза об отсутствии влияния отвергается, есть влияние фактора А. Значение статистики Фишера-Снедекора для проверки гипотезы об отсутствии влияния фактора В приведено в строке Строки, столбец F – оно составило 0,13. В столбце Prob > F приведено соответствующее p-value (достигаемый уровень значимости) 0,8828>0,05, нулевая гипотеза об отсутствии влияния принимается, нет влияния фактора В. Двухфакторный дисперсионный анализ с повторениями Изучается зависимость заработной платы выпускника вуза (тыс. руб.) на первом месте работы в зависимости от направления подготовки и способностей студента Таблица 15- Исходные данные Низкие На 50; 40;30;20;25;60 правлен ие 1 На 15;20;15;15;20;15;16;16; правлен 17;20;21;22 ие 2 На 15;15;15;16;17;19;9;8;10 правлен ;10;12 ие 3 На 20;25;25;25;25;24;22;24 правлен ие 4 Средние 45;60;50;50;50;50 Высокие 50;45;70;80;100;120; 120; 20;20;25;30;35;35 ;35; 30;35;35;30;20;12;15; 15;16;17;18 10;12;15;17;16;18 ;30;30;24 15;20;30;30;32;25;25 25;22;30;30;30 25;22;24;26;23;30;29; 30;35; 40;35;33;34;36;36;38 Для реализации двухфакторного дисперсионного анализа с повторениями в пакете STATA воспользуемся функцией anova var1 var2 var3#var3 (рисунок 9, таблица 16). Таблица 16-Реализация двухфакторного дисперсионного анализа с повторениями в пакете STATA source Model Var2 Var3 Partial ss 25194,2405 20369,5811 3845,94951 df 5 3 2 MS 5038,84809 6789,86036 1922,97476 F 34,42 46,38 13,14 Prob>F 0,000 0,000 0,000 Residual Total 14493,15 99 39687,3905 104 146,395455 381,609524 В столбце Prob > F приведено соответствующее p-value (достигаемый уровень значимости) 0,000 < 0,05. Значит, есть влияние стажа работы, влияние вида станка, а так же эффекта их взаимодействия. Приложение А Рисунок 1 Рисунок 2 Рисунок 3 Рисунок 4 Рисунок 5 Рисунок 6 Рисунок 7 Рисунок 8 Рисунок 9