Занятие 3. Линейная регрессия. Метод наименьших квадратов
реклама

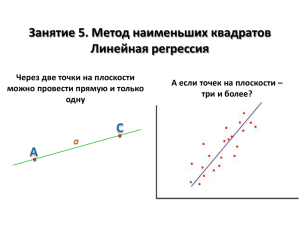
Занятие 3. Метод наименьших квадратов Линейная регрессия Через две точки на плоскости можно провести прямую и только одну А если точек на плоскости – три и более? Часть 1. Одномерная линейная регрессия Метод наименьших квадратов Дано: 1. Набор экспериментальных точек (𝒚𝟏 , 𝒙𝟏 ), (𝒚𝟐 , 𝒙𝟐 ), …, (𝒚𝒏 , 𝒙𝒏 ) 2. Линейная модель 𝒚 = 𝒂 + 𝒃𝒙 Найти коэффициенты 𝒂 и 𝒃 Переопределённая система уравнений 𝑎 + 𝑏𝑥1 = 𝑦1 𝑎 + 𝑏𝑥2 = 𝑦2 … 𝑎 + 𝑏𝑥𝑛 = 𝑦𝑛 В общем случае решения не имеет (т.к. экспериментальные точки обычно не ложатся в точности на одну прямую) Необходимость в приближенных методах Метод наименьших квадратов (МНК) Минимизация суммы квадратов отклонений RSS (Resudiual Sum of Squares) 𝑅𝑆𝑆 = 𝑦𝑖 − (𝑎 + 𝑏𝑥𝑖 ) 𝑖 2 Линейная регрессия: коэффициенты Минимизируемая функция 𝑅𝑆𝑆 = 𝑦𝑖 − (𝑎 + 𝑏𝑥𝑖 ) Результат расчёта 2 𝑎 = 𝑦 − 𝑏𝑥 𝑥𝑦 − 𝑥 𝑦 𝑏= 2 𝑥 − 𝑥 2 𝑖 Поиск стационарных точек для RSS 𝜕𝑅𝑆𝑆 = 𝜕𝑎 𝜕𝑅𝑆𝑆 = 𝜕𝑏 𝑦𝑖 − 𝑛𝑎 − 𝑏 2 𝑦𝑖 − 𝑎 − 𝑏𝑥𝑖 = 0 𝑖 𝑖 𝑖 𝑦 − 𝑎 − 𝑏𝑥 = 0 𝑥𝑦 − 𝑎𝑥 − 𝑏𝑥 2 = 0 𝑖 𝑥𝑖 𝑦𝑖 − 𝑎 2 𝑦𝑖 − 𝑎 − 𝑏𝑥𝑖 𝑥𝑖 = 0 𝑖 𝑥𝑖 = 0 𝑥𝑖2 = 0 𝑥𝑖 − 𝑏 𝑖 𝑖 𝑎 = 𝑦 − 𝑏𝑥 𝑎 = 𝑦 − 𝑏𝑥 2 𝑥𝑦 − (𝑦 − 𝑏𝑥)𝑥 − 𝑏𝑥 2 = 0 𝑥𝑦 − 𝑥 𝑦 + 𝑏 𝑥 − 𝑥 2 = 0 Линейная регрессия: коэффициенты r и R2 𝑅𝑆𝑆 = Коэффициент детерминации R2 𝑅2 = 1 − 𝑖 𝑖 𝑦𝑖 − 𝑦𝑖 𝑦𝑖 − 𝑦 2 2 =1− 2 𝑦𝑖 − 𝑦𝑖 𝑖 𝑅𝑆𝑆 𝐸𝑆𝑆 = 𝑇𝑆𝑆 𝑇𝑆𝑆 residual sum of squares (сумма квадратов отклонений) 𝑅𝑆𝑆 + 𝐸𝑆𝑆 = 𝑇𝑆𝑆 𝑇𝑆𝑆 = 𝑦𝑖 − 𝑦 2 𝑖 total sum of squares (общая сумма квадратов) Коэффициент корреляции Пирсона 𝒓𝒚,𝒚 𝑟𝑦,𝑦 = 𝑖 (𝑦𝑖 − 𝑦)(𝑦 − 𝑦) 𝑖 (𝑦𝑖 −𝑦)2 𝑖 (𝑦𝑖 − 𝑦)2 = 𝑇𝑆𝑆 ⋅ 𝐸𝑆𝑆 𝑦𝑖 = 𝑎 + 𝑏𝑥𝑖 Связь между R2 и 𝒓𝒚,𝒚 𝑟𝑦,𝑦 = 𝑖 (𝑦𝑖 − 𝑦𝑖 + 𝑦𝑖 − 𝑦)(𝑦𝑖 − 𝑦) 𝑇𝑆𝑆 ⋅ 𝐸𝑆𝑆 𝐸𝑆𝑆 = 𝑖 (𝑦𝑖 − 𝑦)(𝑦𝑖 − 𝑦) 𝑦𝑖 − 𝑦 2 𝑖 explained sum of squares (объяснённая сумма квадратов) 0 (т.к. МНК) = 𝑖 (𝑦𝑖 − 𝑦𝑖 )(𝑦𝑖 − 𝑦) + 𝑇𝑆𝑆 ⋅ 𝐸𝑆𝑆 𝑖 𝑦𝑖 − 𝑦 2 = 𝐸𝑆𝑆 = 𝑇𝑆𝑆 𝑅2 Линейная регрессия: критерий Фишера (F-тест) Шаг 1. Найти Fэмп 𝐹𝑒𝑚𝑝 𝑅2 𝑓2 = ⋅ 1 − 𝑅2 𝑓1 𝑓2 - число степеней свободы для данных (N – 2 для 𝑦 = 𝑎 + 𝑏𝑥) 𝑓1 - число независимых коэффициентов (1 для 𝑦 = 𝑎 + 𝑏𝑥) Откуда взята формула? 𝐸𝑆𝑆/𝑓1 𝐸𝑆𝑆/𝑇𝑆𝑆 𝑓2 𝑅2 𝑓2 = ⋅ = ⋅ 𝑅𝑆𝑆/𝑓2 𝑅𝑆𝑆/𝑇𝑆𝑆 𝑓1 1 − 𝑅2 𝑓1 Шаг 2. Сравнить с табличным значением квантиля Если 𝐹𝑒𝑚𝑝 ~𝐹 𝑓1 ; 𝑓2 , то зависимость статистически незначима На практике: Если 𝐹𝑒𝑚𝑝 < 𝐹 𝛼; 𝑓1 ; 𝑓2 (т.е. сравнивают с табличным значением квантиля) Пример: R2=0.667, N=11, аппроксимация y = a + bx 𝐹𝑒𝑚𝑝 = 0.667 9 ⋅ = 18 0.333 1 𝐹 0.95,1,9 = 5.12 Регрессия значима Квартет Энскомба (Anscombe’s quartet) y=3.00+0.500x r=0.816 y=3.00+0.500x r=0.816 y=3.00+0.500x r=0.816 y=3.00+0.500x r=0.816 Линейная регрессия в MS Excel Способ 1. Линия тренда на графике 1. Построить точечный график по имеющимся данным вида (yi, xi) 2. Щелкнуть правой кнопкой мыши на серии точек и выбрать «добавить линию тренда» 3. Отметить флажками нужные опции (вид аппроксимирующей функции, показывать ли уравнение на диаграмме, показывать ли R2 и т.п.) Нагляден, но не проводятся F-тест и оценка доверительных интервалов коэффициентов регрессии Способ 2. Использование пакета анализа данных 1. Выбрать вкладку данные, щелкнуть по пункту меню «анализ данных» 2. Из предлагаемых опций выбрать регрессию 3. Указать входные данные и изучить результат Нагляден, содержит F-тест и оценку доверительных интервалов коэффициентов регрессии Способ 3. Вручную Использовать функции MS Excel вроде КОВАР, ДИСП, СРЗНАЧ, СУММ, КОРРЕЛ и т.п. На практике способ не удобен, но полезен для понимания сути происходящего Линейная регрессия: линеаризация Если данные описываются нелинейной зависимостью, то в некоторых случаях её можно линеаризовать 𝐸𝑎 (уравнение Аррениуса) 𝑅𝑇 𝐸𝑎 (т.е. вместо (k; T) – (ln k; 1/T) 𝑅𝑇 Пример 1: 𝑘1 = 𝑘0 𝑒𝑥𝑝 − Решение: ln 𝑘1 = ln 𝑘0 − ) Пример 2: Δ𝑚𝑖𝑥 𝐻 = 𝑥(1 − 𝑥)(𝐴 + 𝐵𝑥) (энтальпия смешения) Δ 𝐻 Решение: 𝑚𝑖𝑥 = 𝐴 + 𝐵𝑥 𝑥(1−𝑥) 𝑣𝑚 𝑆 (схема 𝑆+𝐾𝑚 1 𝐾 + 𝑚 𝑣𝑚 𝑣𝑚 𝑆 Пример 3: 𝑣 = 1 𝑣 Решение: = Михаэлиса-Ментен) Простая линейная регрессия в GNU Octave 𝑦1 𝑥1 1 𝑎𝑥1 + 𝑏 = 𝑦1 𝑎 … ⇔ … … = … ⇔ 𝑋𝛽 = 𝑦 𝑏 𝑦𝑛 𝑥𝑛 1 𝑎𝑥𝑛 + 𝑏 = 𝑦𝑛 Т.к. матрица X – не квадратная, то записать 𝛽 = 𝑋 −1 𝑦 нельзя Но Octave/MATLAB решит эту систему уравнений, если написать b=X\y >> x = (0:0.1:5)’; >> y = 2*x + 5 + randn(size(x)); >> X = [x ones(size(x))]; >> beta = X\y beta = 2.0653 4.7701 >> close all; >> plot(x,y,’bo’,’LineWidth’,2); >> hold on; >> yfunc = @(x)beta(1)*x+beta(2); >> plot(x,yfunc(x),’k-’,’LineWidth’,2); >> hold off; >> print(gcf,’graph’,’-dpng’,’-r75’); Часть 2. Многомерная линейная регрессия Постановка задачи Исходные данные Точки в (k+1) – мерном пространстве (𝑦𝑖 , 𝑥𝑖1 , … , 𝑥𝑖𝑘 ) Система уравнений (переопределённая): 𝛽1 𝑥11 + 𝛽2 𝑥12 + ⋯ + 𝛽𝑘 𝑥1𝑘 = 𝑦1 𝛽1 𝑥21 + 𝛽2 𝑥22 + ⋯ + 𝛽𝑘 𝑥2𝑘 = 𝑦2 … 𝛽1 𝑥𝑛1 + 𝛽2 𝑥𝑛2 + ⋯ + 𝛽𝑘 𝑥𝑛𝑘 = 𝑦𝑛 + Аппроксимирующая функция 𝑦 = 𝛽0 + 𝛽1 𝑥𝑖1 + ⋯ + 𝛽𝑘 𝑥𝑖𝑘 𝛽 – параметры модели Система в матричном виде: 𝑿𝜷 = 𝒚 𝑥11 𝑋= ⋮ 𝑥𝑛1 ⋯ 𝑥1𝑘 𝑦1 ⋱ ⋮ ;𝑦 = ⋮ ; ⋯ 𝑥𝑛𝑘 𝑦𝑛 𝛽1 𝛽= ⋮ 𝛽𝑛 Некоторые свойства матриц Умножение и транспонирование След матрицы След матрицы – сумма элементов её главной диагонали 1. 𝐴 + 𝐵 2. 𝐴𝐵 3. 𝐴−1 ⊤ ⊤ ⊤ = = 𝐴⊤ + 𝐵⊤ tr 𝐴 = 𝑖 𝐵⊤ 𝐴⊤ = 𝐴⊤ −1 𝑎𝑖𝑖 1. tr 𝛼𝐴 + 𝛽𝐵 = 𝛼tr 𝐴 + 𝛽tr 𝐵 4. 𝐴𝐵 𝐶 = 𝐴(𝐵𝐶) 2. tr 𝐴𝐵 = tr 𝐵𝐴 5. 𝐴 𝐵 + 𝐶 = 𝐴𝐵 + 𝐴𝐶 3. tr 𝐴⊤ = tr 𝐴 6. 𝐴 + 𝐵 𝐶 = 𝐴𝐶 + 𝐵𝐶 4. tr 𝐴𝐵𝐶 = tr 𝐵𝐶𝐴 = tr(𝐶𝐴𝐵) Метод наименьших квадратов Поиск минимума Сумма квадратов отклонений 𝜕𝑅𝑆𝑆 𝜕(𝑦 ⊤ 𝑋𝛽) 𝜕(𝛽⊤ 𝑋 ⊤ 𝑋𝛽) = −2 + =0 𝜕𝛽 𝜕𝛽 𝜕𝛽 𝜕𝑅𝑆𝑆 = −2𝑋 ⊤ 𝑦 + 2𝑋 ⊤ 𝑋𝛽 = 0 𝜕𝛽 𝑋 ⊤ 𝑋𝛽 = 𝑋 ⊤ 𝑦 ⇔ 𝛽 = 𝑋 ⊤ 𝑋 −1 𝑋 ⊤ 𝑦 𝑒𝑖2 = 𝑒 ⊤ 𝑒 = 𝑅𝑆𝑆 = 𝑖 = 𝑦 − 𝑋𝛽 ⊤ 𝑦 − 𝑋𝛽 = = 𝑦 ⊤ 𝑦 − 2𝑦 ⊤ 𝑋𝛽 + 𝛽⊤ 𝑋 ⊤ 𝑋𝛽 Дифференцирование 𝜕(𝑦 ⊤ 𝑋𝛽) 𝜕𝛽𝑘 = 𝜕( 𝑖 𝑃𝑖 𝛽𝑖 ) 𝜕𝛽𝑘 = 𝑃𝑘 ⇒ 𝑛 𝛽 ⊤ 𝑋 ⊤ 𝑋𝛽 = 𝑋𝛽 ⊤ 𝜕(𝑦 ⊤ 𝑋𝛽) 𝜕𝛽 2 𝑥𝑖𝑗 𝛽𝑗 𝑖=1 𝑚 𝑥𝑖𝑘 𝑖=1 𝑗=1 = 𝑋 ⊤ 𝑦, где 𝑃𝑖 = 𝑦 ⊤ 𝑋 𝜕(𝛽 ⊤ 𝑋 ⊤ 𝑋𝛽) ⇒ =2 𝜕𝛽𝑘 𝑥𝑖𝑗 𝛽𝑗 = 2 𝑋𝛽 𝑗=1 ⊤ 2 𝑚 𝑋𝛽 = 𝑛 = 𝑦⊤𝑋 ⊤𝑋 ⊤ = 2𝑋 ⊤ 𝑋𝛽 𝑛 𝑚 𝑥𝑖𝑘 𝑖=1 𝑖 𝑥𝑖𝑗 𝛽𝑗 𝑗=1 Метод наименьших квадратов: одномерный случай 𝑦1 𝑥1 1 𝑎𝑥1 + 𝑏 = 𝑦1 𝑎 … ⇔ … … = … ⇔ 𝑋𝛽 = 𝑦 𝑏 𝑦𝑛 𝑥𝑛 1 𝑎𝑥𝑛 + 𝑏 = 𝑦𝑛 Т.к. матрица X – не квадратная, то записать 𝛽 = 𝑋 −1 𝑦 нельзя Но Octave/MATLAB решит эту систему уравнений, если написать b=X\y >> x = (0:0.1:5)’; >> y = 2*x + 5 + randn(size(x)); >> X = [x ones(size(x))]; >> beta = X\y beta = 2.0653 4.7701 >> close all; >> plot(x,y,’bo’,’LineWidth’,2); >> hold on; >> yfunc = @(x)beta(1)*x+beta(2); >> plot(x,yfunc(x),’k-’,’LineWidth’,2); >> hold off; >> print(gcf,’graph’,’-dpng’,’-r75’); Задача: нахождение коэффициентов регрессии Шаг 1. Создать выборку точек x = rand(500, 1); y = rand(500, 1); z = 3*x+4*y+5+randn(size(x)); plot3(x,y,z,’bo’); Шаг 2. Записать и решить систему уравнений X = [x y ones(size(x))]; b = (X'*X)\(X'*z); format long; disp(b); xv = 0:0.1:1; [Xm,Ym]=meshgrid(xv,xv); Zm = b(1)*Xm + b(2)*Ym + b(3); hold on; mesh(Xm,Ym,Zm); hold off; Теорема Гаусса-Маркова Пусть выполняются следующие условия: 1. Модель правильно специфицирована 2. 𝑟𝑎𝑛𝑔 𝑋 = 𝑚, где m – число коэффициентов регрессии 3. 𝐸 𝜀𝑖 = 0 (нулевое матожидание ошибок регрессии) 4. 𝐸 𝜀𝑖 𝜀𝑗 = 𝐸 𝜀𝑖 𝐸 𝜀𝑗 = 0 (независимость ошибок друг от друга) 5. 𝑉𝑎𝑟 𝜀𝑖 = 𝐸 𝜀𝑖 𝜀𝑖 = 𝜎 2 (гомоскедастичность ошибок регрессии) Тогда оценки параметров регрессии методом наименьших квадратов являются наилучшими в классе линейных несмещённых оценок (англ. Best Linear Unbiased Estimator, BLUE). Ковариационная матрица Несмещённость оценок параметров регрессии 𝐸 𝛽 = 𝐸 𝑋 ⊤ 𝑋 −1 𝑋 ⊤ 𝑋𝐵 + 𝜀 = 𝐸 𝐵 + 𝑋 ⊤ 𝑋 −1 𝑋 ⊤ 𝐸 𝜀 = 𝐸[𝐵] B – истинное значение параметров регрессии, 𝜀 – вектор ошибок Ковариационная матрица ⊤ cov 𝛽, 𝛽 = 𝐸 𝛽 − 𝐵 𝛽 − 𝐵 = 𝐸 𝑋 ⊤ 𝑋 −1 𝑋 ⊤ 𝜀𝜀 ⊤ 𝑋 𝑋 ⊤ 𝑋 = 𝑋 ⊤ 𝑋 −1 𝑋 ⊤ 𝐸[𝜀𝜀 ⊤ ]𝑋 𝑋 ⊤ 𝑋 −1 = 𝜎 2 𝑋 ⊤ 𝑋 −1 −1 = B – истинное значение параметров регрессии, 𝜀 – вектор ошибок Вид ковариационной матрицы cov 𝛽, 𝛽 = Var[𝛽1 ] cov(𝛽1 , 𝛽2 ) ⋯ cov(𝛽1 , 𝛽2 ) Var[𝛽2 ] ⋯ ⋮ ⋮ ⋱ cov(𝛽𝑚 , 𝛽1 ) cov(𝛽𝑚 , 𝛽2 ) ⋯ cov(𝛽1 , 𝛽𝑚 ) cov(𝛽2 , 𝛽𝑚 ) ⋮ Var[𝛽𝑚 ] Доверительные интервалы 𝑠𝛽2𝑖 = Var[𝛽] Δ𝛽𝑖 = 𝑠𝛽𝑖 ⋅ 𝑡(𝛼, 𝑓) t – двухсторонний квантиль tраспределения; 𝛼 – вероятность, f = n – m – число степеней свободы Оценка ошибки регрессии Несмещённая оценка ошибки регрессии 𝜎2 1 = 𝑛−𝑚 𝑒𝑖2 𝑖 Проекционная матрица 𝑦 = 𝐻𝑦; 𝐻 = 𝑋 𝑋 ⊤ 𝑋 ⊤ 𝑒 𝑒 = 𝑛−𝑚 −1 𝑋 ⊤ Свойства 1. 𝐻 ⊤ = 𝐻 (симметричность) 2. 𝐻 2 = 𝐻 (идемпотентность) 3. 𝐻𝑋 = 𝑋 𝑒 =𝑦−𝑦 n – число точек, m – число коэффициентов регрессии Связь погрешности с проекционной матрицей 𝑒 = 𝑦 − 𝑦 = 𝐼 − 𝐻 𝑦 = 𝑀 𝑋𝐵 + 𝜀 = 𝑀𝜀; 𝑅𝑆𝑆 = 𝑒 ⊤ 𝑒 = 𝑀𝜀 ⊤ 𝑀𝜀 = 𝜀 ⊤ 𝑀𝜀 𝑒 ⊤ 𝑒 = tr 𝑒 ⊤ 𝑒 = tr 𝜀 ⊤ 𝑀𝜀 = tr 𝑀𝜀𝜀 ⊤ ⇒ 𝐸 𝑅𝑆𝑆 = 𝑡𝑟 𝑀𝐸 𝜀𝜀 ⊤ = 𝜎 2 tr(𝑀) Вычисление следа проекционной матрицы 𝑡𝑟 𝑀 = 𝑡𝑟 𝐼𝑛 − 𝑡𝑟 𝑋 𝑋 ⊤ 𝑋 −1 𝑋 ⊤ = 𝑛 − 𝑡𝑟 𝑋 ⊤ 𝑋 𝑋 ⊤ 𝑋 −1 =𝑛−𝑚 Задача: доверительные интервалы значений 𝜷 Шаг 1. Ошибка регрессии >> res = z–(b(1)*x+b(2)*y+b(3)); >> f = numel(res) - numel(b); >> sigma2 = res'*res/f sigma2 = 0.808416630656864 Шаг 2. Ковариационная матрица >> format short; >> C = sigma2 * inv(X'*X) C = 0.0204893 -0.0013650 -0.0096530 -0.0013650 0.0188808 -0.0085331 -0.0096530 -0.0085331 0.0106459 Шаг 3. Ошибки и доверительные интервалы коэффициентов >> sb = sqrt(diag(C));disp(sb'); 0.14314 0.13741 0.10318 >> db = sb * tinv(1-0.05/2,f); >> disp(db'); 0.28124 0.26997 0.20272 Шаг 4. Корреляционная матрица >> sbm = [sb sb sb]; >> r = C./(sbm.*sbm') r = 1.000000 -0.069400 -0.653593 -0.069400 1.000000 -0.601874 -0.653593 -0.601874 1.000000 Внимание! 𝒓 𝜷𝒊 , 𝜷𝒋 ≠ 𝟎 Оставляйте «запасные» знаки при округлении 𝜷! Шаг 4. R2 и F-критерий >> TSS = sum((z-mean(z)).^2) TSS = 1497.7 >> RSS = res'*res; RSS = 401.78 >> R2 = 1 - RSS/TSS; R2 = 0.73173 >> F = R2/(1-R2)*f/2 F = 677.80 >> finv(0.95,2,f) ans = 3.0139 Линеаризация многомерной нелинейной регрессии 1. Нелинейная зависимость 𝑐 𝑐𝑝 𝑇 = 𝑎 + 𝑏𝑇 + 𝑇 3. Система уравнений 𝑋𝛽 = 𝑦 1 𝑋= ⋮ 1 𝑇1 ⋱ 𝑇𝑛 𝑎 1/𝑇1 ⋮ ;𝛽 = 𝑏 𝑐 1/𝑇𝑛 2. Линеаризация 𝑐𝑝 𝑇 = 𝑎𝑥1 + 𝑏𝑥2 + 𝑐𝑥3 ; 𝑥1 = 1; 𝑥2 = 𝑇; 𝑥3 = 𝑇 −1 Доверительный интервал и интервал предсказания Доверительный интервал 𝒚 (confidence interval) 𝑦 ± 𝜎𝑡𝛼,𝑛−𝑚 𝑥 ⊤ 𝑋 ⊤ 𝑋 −1 𝑥 Исходная функция с вероятностью 95% проходит через этот интервал n=20 Интервал предсказания (prediction interval) 𝑦 ± 𝜎𝑡𝛼,𝑛−𝑚 1 + 𝑥 ⊤ 𝑋 ⊤ 𝑋 −1 𝑥 Новая точка попадёт в этот интервал с вероятностью 95% n=200