- susu-psychometrics
реклама

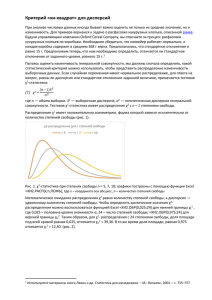
Статистические методы в психологии Методологические основы тестирования статистических гипотез Критерий верификации Проблемы: 1. сколько свидетельств надо? 2. проблема неполной индукции (Карл Поппер – Постпозитивизм) – критерий фальсификации Прохазка и Норкросс (2007) Системы психотерапии Методологические основы тестирования статистических гипотез Ошибка 1 и 2 рода Выборка и популяция Основное свойство репрезентативность Полезные ссылки и адреса Скачать пробную версию СПСС http://www14.software.ibm.com/webapp/downl oad/search.jsp?pn=SPSS+Statistics Электронный учебник по статистике www.statsoft.ru Страница с заданиями и презентацией http://susu-psychometrics.wikispaces.com/ Электронная почта [email protected] Понятие распределения Распределение – это набор данных, упорядоченный по частоте встречаемости признака Пример распределения Нормальное распределение Математические характеристики распределений Меры центральной тенденции Меры разброса Меры центральной тенденции Среднее арифметическое (mean) Мода (mode) Медиана (median) Мода Мода – числовое значение, которое встречается в выборке наиболее часто 5 5 6 6 7 7: моды нет (амодальное распределение) 1 2 2 2 5 5 5 6: мода=3,5 1 2 2 2 3 4 5 5 5 6: моды две (2 и 5). Бимодальное распределение Медиана Значение, которое делит упорядоченное множество данных пополам 3 4 5 8 9 11 13: Me=8 1 4 9 11 13 20: Me=10 Меры разброса Размах Дисперсия Стандартное отклонение (standard deviation, std.dev.) Стандартное отклонение Дисперсия и размах Размах: R = Xmax – Xmin (range) Дисперсия (s2, D, v) = стандартное отклонение в квадрате. (variance) Основные характеристики нормального распределения Среднее = медиана = мода Зоны нормы * Зоны нормы Среднее плюс/минус 1 сигма = 68.3 процента людей («норма») Среднее плюс/минус 2 сигма = 95.4 процента людей («границы нормы») Среднее плюс/минус 3 сигма = 99.9 процента людей Среднее плюс/минус 0.5 сигмы = «абсолютная норма» Зоны нормы Стандартизованные шкалы Z-оценки Т-баллы = 50 + 10*z IQ = 100 + 15*z Стены = 5.5 + 2*z Стенайны = 5 + 2*z Процентили= процент людей в выборке, которые выполнили тест так же или хуже (от 0 до 100) В z-оценках среднее=0, стандартное отклонение = 1 Три граничные значения z Z = +/- 1.96 (95.4 процента людей, плюс-минус две сигмы) Z = +/- 2.58 (99 процентов людей) Z = +/- 3.29 (99.9 процентов людей) p<0.05 p<0.01 p<0.001 Интервалы доверия Интервал доверия – диапазон данных, в которых с вероятностью 95, 99 или 99.9 процента находится «реальное» среднее арифметическое в генеральной совокупности (популяции) Выборочное распределение и стандартная ошибка Выборочное распределение средних – распределение средних арифметических из большого количества возможных выборок, которые набираются из популяции (мысленный эксперимент) Стандартная ошибка среднего (Standard error of the mean) – стандартное отклонение в выборочном распределении Стандартная ошибка среднего Формулы интервалов доверия (95, 99, 99.9) Проверка распределения на нормальность Сравнение асимметрии (skewness) и эксцесса (kurtosis) со стандартными ошибками асимметрии и эксцесса Критерий Колмогорова-Смирнова (тест должен быть статистически незначимым, т.е. P (sig.) должен быть > 0.05. «На глазок»: визуальное сопоставление эмпирического распределения с теоретически ожидаемым нормальным Проверка распределения на нормальность Проверка распределения на нормальность Важно помнить о том, что критерий Колмогорова-Смирнова зависит от N. С большим количеством человек (больше 100-150) критерий слишком чувствителен, т.е. отвергает нормальность слишком часто. Параметрика и непараметрика Все статистические процедуры делятся на 2 вида: Параметрическая статистика (предполагает нормальность распределения) Непараметрическая статистика (такого допущения не имеет) Предпочитают параметрическую, потому что непараметрическая статистика: 1) неустойчивее, 2) чувствительнее к отдельным индивидуальным результатам, 3) непараметрика существует не для всех задач, напр., нету такой штуки, как непараметрический факторный анализ Одномерная и многомерная статистика Все статистические процедуры делятся еще на одномерные и многомерные В одномерных либо сравниваются две группы, либо исследуется связь двух переменных В многомерной статистике – больше двух групп либо больше двух переменных (одновременно). Мы изучаем одномерную Одномерная статистика включает в себя: меры различий и меры связи Одномерная статистика: Меры различий Параметрические (например, Ткритерий Стьюдента) Непараметрические (например, Uкритерий Манна-Уитни) Цель – исследовать разницу в двух средних арифметических Т-критерий Стьюдента Для независимых групп (следует ожидать высокой несистематической вариативности) Для зависимых групп (несистематическая вариативность низкая) На практике это обычно означает следующее: Для независимых групп = 2 группы, один замер Для зависимых = 1 группа, 2 замера Вариативность ( дисперсия) Систематическая (часть вариативности = дисперсии, которая объясняется экспериментальным воздействием) Несистематическая (часть вариативности, которая объясняется побочными факторами, например, индивидуальными различиями испытуемых) Пример с обезьянами и стихотворчеством Одну группу обезьян кормим бананами, другую – капустой. Ждем миллион лет и оцениваем среднее количество стихотворений, которые они настучали, сидя у клавиатуры. Чем обусловлена разница в 2 балла? Т-критерий Стьюдента для независимых групп Образное представление в виде «облачков» U-критерий Манна-Уитни Человек Результат Ранг 1 4 5 1 2 7 1 1 12 8 1 2 2 1 8 2 6 3 2 2 3 5 6 4 Сумма рангов 15 21 U-критерий Манна-Уитни Логика вычисления: Проставляются ранги Вычисляется сумма рангов внутри двух групп Возможные аргументы: Если суммы рангов очень разные, разница между группами большая Таким образом, не применяем «параметры» - среднее и стандартное отклонение. Поэтому критерий называется непараметрическим. Одномерная статистика: Меры связи Параметрические (например, коэффициент корреляции Пирсона) Непараметрические (например, ранговый коэффициент корреляции Спирмена) Цель – исследовать взаимосвязь двух переменных Коэффициент корреляции Пирсона Корреляция – мера линейной связи между двумя переменными Располагается от -1 до 1 Проблемы интерпретации корреляционной связи Причинность. Корреляцию нельзя интерпретировать в терминах причинно-следственной взаимосвязи Криволинейность. Проблема третьей переменной Проблема выбросов Ранговый коэффициент корреляции Спирмена Непараметрический аналог Пирсона Коэффициент детерминации При возведении корреляции в квадрат получается коэффициент детерминации = доля объяснимой дисперсии Интерпретация величины эффекта Cohen (1988): 0.1 – 0.3 – слабая взаимосвязь 0.3 – 0.5 – умеренная взаимосвязь 0.5 - 0.7 - сильная взаимосвязь Больше 0.7 – очень сильная взаимосвязь