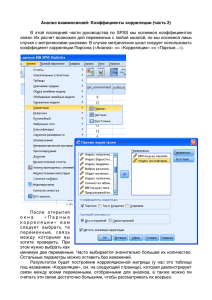
Статистические переменные
реклама

«Информационные технологии обработки статистических данных» Москва 2012 ОСНОВНЫЕ ПОЛОЖЕНИЯ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ Статистические переменные Переменными называются величины, которые можно измерять, контролировать или изменять. В статистике различают зависимые и независимые переменные. Независимыми переменными называются переменные, которые изменяются исследователем. Зависимые переменные - это переменные, которые измеряются или регистрируются. Например, если изучается реакция на новый товар отдельно мужчин и женщин, то при статистической обработке результатов переменная ПОЛ может считаться независимой, а переменная РЕАКЦИЯ НА ТОВАР (выраженная, например, в баллах оценочной шкалы) - зависимой. Шкалы измерений • Номинальная шкала. Номинальные переменные используются только для качественной классификации. • Например, можно сказать, что респонденты принадлежат к разным национальностям. Типичные примеры номинальных переменных - пол, национальность, цвет, город и т.д. • Часто номинальные переменные называют категориальными. Шкалы измерений • Порядковая шкала. Порядковые переменные позволяют ранжировать (упорядочить) объекты, указав какие из них в большей или меньшей степени обладают качеством, выраженным данной переменной. Однако они не позволяют сказать "на сколько больше" или "на сколько меньше". • Типичный пример порядковой переменной уровень дохода респондента при предложенных вариантах ответа: низкий, ниже среднего, средний, выше среднего, высокий, очень высокий. Шкалы измерений • Интервальная шкала. Интервальные переменные позволяют не только упорядочивать объекты измерения, но и численно выразить и сравнить различия между ними. Нулевая точка отсчета не фиксирована и масштаб измерения может изменяться. Шкалы измерений • Относительная шкала. Относительные переменные похожи на интервальные переменные, но дополнительно ко всем свойствам интервальных переменных, их характерной чертой является наличие определенной точки абсолютного нуля. Типичными примерами шкал отношений являются измерения времени или пространства. Известно, что в большинстве статистических процедур не делается различия между свойствами интервальных шкал и шкал отношения. Различие интервальных шкал и шкал отношений для исследований мало существенны, поэтому эти 2 типа шкал часто объединяют в один, который называют метрическими шкалами. Особенностью метрических шкал является наличие единиц измерения и допустимость операции сложения. Связи и зависимости между переменными Основной целью статистического исследования является нахождение зависимостей между переменными: В математической статистике выделяют две основные черты каждой зависимости: 1. Величина зависимости Например, если по результатам опроса оказалось, что большинство мужчин имеет доход выше среднего, а большинство женщин - ниже среднего, исследователь может сделать вывод, что зависимость между двумя переменными (ПОЛ и УРОВЕНЬ ДОХОДА) высокая. Связи и зависимости между переменными 2. Надежность зависимости показывает, насколько вероятно, что зависимость, подобная найденной, подтвердится на данных другой выборки, извлеченной из той же самой генеральной совокупности. Надежность найденных зависимостей между переменными выборки можно количественно оценить и представить с помощью стандартной статистической меры (называемой p-уровень или статистический уровень значимости). В математической статистике p-уровень - это показатель, находящийся в убывающей зависимости от надежности результата: более высокий p-уровень соответствует более низкому уровню доверия к найденной в выборке зависимости между переменными. Именно, p-уровень представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на всю генеральную совокупность. Например, p - уровень, равный 0,05 показывает, что имеется 5%-ная вероятность, что найденная в выборке связь между переменными является лишь случайной особенностью данной выборки. В исследованиях принято p-уровень 0,05 рассматривать как "приемлемую границу" уровня ошибки. Результаты с уровнем значимости 0,01 рассматриваются как статистически значимые, а результаты с уровнем 0,005 или 0,001 как высоко значимые. Величина выборки Размеры выборки зависят от величины зависимости между переменными: если связь между переменными слабая, то для проверки существования зависимости необходимо исследовать выборку достаточно большого объема. Если зависимость в генеральной совокупности очень сильная, тогда она может быть обнаружена с высокой степенью значимости даже на маленькой выборке. На практике при проведении, например, опросов потребителей, ограничиваются размерами выборки в 1000 - 1500 чел., считая такую выборку достаточно значимой. Меры взаимосвязи между переменными В математической статистике существует много различных мер взаимосвязи между переменными. Выбор определенной меры в конкретном исследовании зависит от – – – числа переменных, используемых шкал измерения, природы зависимостей и т.д. Большинство этих мер подчиняются общему принципу: они оценивают наблюдаемую зависимость, сравнивая ее с "максимальной возможной зависимостью" между рассматриваемыми переменными. Обычный способ выполнить такие оценки заключается в том, чтобы посмотреть как варьируются значения переменных и затем подсчитать, какую часть всей имеющейся вариации можно объяснить наличием "общей" ("совместной") вариации двух (или более) переменных. Иначе говоря, сравнивается то "что есть общего в этих переменных", с тем "что потенциально было бы у них общего, если бы переменные были абсолютно зависимы". В терминах математической статистики, эти критерии представляют собой отношение изменчивости, общей для рассматриваемых переменных, к полной изменчивости. Это отношение обычно называется отношением объясненной вариации к полной вариации. Нормальное распределение • Распределение многих статистик является нормальным или может быть получено из нормального с помощью некоторых преобразований. Многие случайные величины в природе имеют нормальное распределение. • Точная форма нормального распределения (характерная "колоколообразная кривая") определяется только двумя параметрами: средним и стандартным отклонением. Характерное свойство нормального распределения состоит в том, что 68% всех его наблюдений лежат в диапазоне ±1 стандартное отклонение от среднего µ, а диапазон ±2 стандартных отклонения содержит 95% значений. Пример нормального распределения Описательные статистики и проверка статистических гипотез Самой простой описательной статистикой является среднее значение. Среднее - очень информативная мера "центрального положения" наблюдаемой переменной, особенно если сообщается ее доверительный интервал. Доверительный интервал для среднего представляет интервал значений вокруг оценки, где с данным уровнем доверия находится среднее генеральной совокупности. Например, если среднее переменной ВОЗРАСТ РЕСПОНДЕНТА равно 40 (лет), а нижняя и верхняя границы доверительного интервала с уровнем 0.95 равны 20 и 60 соответственно, то с вероятностью 95% интервал с границами 20 и 60 накрывает среднее генеральной совокупности (потребителей). Ширина доверительного интервала зависит от объема или размера выборки, а также от разброса (изменчивости) данных: увеличение размера выборки делает оценку среднего более надежной, а увеличение разброса наблюдаемых значений, напротив, уменьшает надежность оценки. Важно отметить, что вычисление доверительных интервалов основывается на предположении нормальности наблюдаемых величин. Если это предположение не выполнено, то оценка может оказаться плохой, особенно для малых выборок. Распределение переменной Важным способом описания переменной является форма ее распределения, которая показывает, с какой частотой значения переменной попадают в определенные интервалы, выбираемые исследователем. Обычно исследователя интересует, насколько точно распределение можно аппроксимировать нормальным. Простые описательные статистики дают об этом некоторую информацию. Если мода, медиана и среднее близки по своим значениям, значит распределение близко к нормальному. Кроме того существуют два важных показателя вида распределения переменной, позволяющие проверить гипотезу нормальности: асимметрия и эксцесс. Например, если асимметрия (показывающая отклонение распределения от симметричного) существенно отличается от нуля, то распределение несимметрично (нормальное распределение абсолютно симметрично). Асимметрия скошенного вправо распределения положительна, скошенного влево - отрицательна. Эксцесс показывает "остроту пика" распределения, и если он существенно отличен от нуля, то распределение имеет или более закругленный пик, чем нормальное, или, напротив, имеет более острый пик (возможно, имеется несколько пиков). Обычно, если эксцесс положителен, то пик заострен, если отрицательный, то пик закруглен. Эксцесс нормального распределения равен нулю. Пример гистограммы распределения переменной Гистограмма позволяет качественно оценить различные характеристики распределения. Пример гистограммы с наложенной кривой нормального распределения На гистограмме можно увидеть, что распределение бимодально, т.е. имеет 2 пика. Пример диаграммы box-and-whisker plot При проверке статистических гипотез для оценки вида распределения используются также "ящичковые диаграммы" (box-and whisker plot). Они дают общее представление о распределении переменной: высота ящика - разброс значений, черта внутри ящика - медиана или 50%-ный процентиль, нижняя грань 25%-ный процентиль, верхняя - 75%-ный процентиль. Экстремальные значения, не попавшие внутрь, изображаются вне ящика, и их можно исследовать отдельно. Пример графика на нормальной вероятностной бумаге Для исследования нормальности распределения используется построение графиков на нормальной вероятностной бумаге. На графике выводятся координаты фактических значений переменных (квадратики) и теоретические значения, вычисленные при условии нормальности распределения (прямая линия). Чем ближе фактические значения к этой прямой, тем более нормальным является распределение. Частотные таблицы • К методам описательной статистики относится также построение частотных таблиц. Таблицы частот представляют собой простейший метод анализа категориальных (номинальных) переменных. Часто их используют, чтобы просмотреть, каким образом различные группы данных распределены в выборке. • Например, если в опросном листе встречается вопрос о количестве детей у респондента, то из частотной таблицы исследователь может выяснить, что 419 опрошенных или 27,6% не имеют детей, 255 (16,8%) имеют одного ребенка и т.д. • Кроме того, в таблице приводятся такие показатели, как значимый процент (данные с учетом тех опросных листов, где на этот вопрос даны ошибочные ответы, которые исследователь не может интерпретировать и помечает при проведении расчетов как так называемые "пропущенные" значения), а также кумулятивный (накопленный) процент. Пример частотной таблицы Столбиковая диаграмма к таблице Описательные статистики К данным описательной статистики относятся • частоты, • проценты, • кумулятивный процент, • среднее значение, • мода (самое часто встречающееся значение), • медиана (значение, которое делит упорядоченное множество данных пополам), • сумма, • стандартное отклонение (наиболее распространенный показатель рассеивания значений относительно среднего значения), • минимальное и максимальное значения переменных, • • • вариация (различие значений признака у отдельных единиц совокупности), ранг (разница между максимальным и минимальным значениями) асимметрия (Skewness) и эксцесс (Kurtosis). Корреляция • • • Вычисление корреляции требуется при исследовании зависимости между переменными. Коэффициент корреляция и является мерой такой зависимости. Наиболее известной является корреляция Пирсона. При вычислении корреляции Пирсона предполагается, что переменные измерены, как минимум, в интервальной шкале. В случае, если используются менее информативные шкалы, применяют другие коэффициенты корреляции, как, например, коэффициент корреляции Спирмена. Коэффициенты корреляции изменяются в пределах от -1.00 до +1.00. Значение -1.00 означает, что переменные имеют строгую отрицательную корреляцию, значение +1.00 означает, соответственно, что переменные имеют строгую положительную корреляцию. Значение коэффициента, равное нулю, означает отсутствие корреляции (т.е. означает, что зависимость установить не удается, а вовсе не отсутствие зависимости!). Коэффициент корреляции Пирсона • Наиболее часто используемый коэффициент корреляции Пирсона r называется также линейной корреляцией, т.к. измеряет степень линейной зависимости между переменными. • Важно, что значение коэффициента корреляции не зависит от масштаба измерения. Например, корреляция между ростом и весом будет одной и той же, независимо от того, проводились измерения в дюймах и футах или в сантиметрах и килограммах. Вычисление коэффициента корреляции Пирсона для переменных Возраст респондента и Количество лет обучения (уровень образованности) Корреляция • Корреляция высокая, если на графике, называемом диаграммой рассеяния зависимость можно представить прямой линией с положительным или отрицательным углом наклона. Эта прямая называется прямой регрессии или прямой, построенной методом наименьших квадратов (сумма квадратов расстояний от наблюдаемых точек до прямой является минимальной). Пример диаграммы рассеяния с наложенной линией наименьших квадратов Корреляция • • • • На корреляцию оказывают влияние следующие факторы: 1. Выбросы, т.е. нетипичные, резко выделяющиеся наблюдения. Так как при построении прямой регрессии используется сумма квадратов расстояний наблюдаемых точек до прямой, то выбросы могут существенно повлиять на наклон прямой и, следовательно, на значение коэффициента корреляции. 2. Отсутствие однородности в выборке также является фактором, смещающим выборочную корреляцию. Высокая корреляция может быть следствием, например, разбиения данных на две группы, а вовсе не отражать зависимость между двумя переменными (зависимость может вообще практически отсутствовать). Корреляция Пирсона хорошо подходит для описания линейной зависимости. Отклонения от линейности увеличивают общую сумму квадратов расстояний от регрессионной прямой, даже если она представляет "истинные" и очень тесные связи между переменными. Пример корреляционной зависимости между переменными которую можно описать с помощью кубической функции Корреляция • Чтобы оценить зависимость между переменными, нужно знать как величину коэффициента корреляции, так и его значимость. Уровень значимости, вычисленный для каждой корреляции, представляет собой главный источник информации о надежности полученных результатов (как правило, используется 5%-ный уровень значимости). • Значимость определенного коэффициента корреляции зависит от объема выборки. Критерий значимости основывается на предположении, что распределение отклонений наблюдений от регрессионной прямой для зависимой переменной является нормальным. Таблицы сопряженности • Построение таблиц сопряженности (Crosstabs) позволяет оценить взаимосвязи данных в двумерных или многомерных таблицах. Каждая ячейка таблицы сопряженности содержит информацию о количестве объектов, попадающих в группу, определенную комбинацией двух значений. • Например, таблица сопряженности для переменных ПОЛ (sex), ОТНОШЕНИЕ К ЖИЗНИ (life) (значения – восторженное, обыденное, унылое) и РАСА (race of respondent) (значения – белая, черная, другая). Пример таблицы сопряженности Таблица сопряженности САМООЦЕНКА х ПОЛ Например, насколько важна самооценка для мужчин и для женщин? Из таблицы сопряженности можно узнать, что очень важна самооценка для 193 (19,7%) опрошенных мужчин и для 317 (32,3%) опрошенных женщин или для 510 (51,9%) опрошенных респондентов. Регрессионный анализ • • • • Линейный регрессионный анализ позволяет оценить коэффициенты линейного уравнения, содержащего одну или несколько (множественная регрессия) независимых переменных, значения которых используются для прогнозирования значения зависимой переменной. Вычислив коэффициенты такого уравнения, исследователь может получать прогноз значений зависимой переменной. Регрессионный анализ является достаточно сложной статистической процедурой, поэтому ограничимся рассмотрением случая одной зависимой и одной независимой переменной и, соответственно, использования простой линейной регрессии. Например, исследователь хочет предсказать, как будет изменяться уровень образования у респондентов при повышении уровня образования их родителей (предположим, предпринимателя интересует прогноз сбыта товаров для высокообразованных интеллектуалов). При проведении исследования прежде всего необходимо, используя результаты опроса, получить двумерные диаграммы рассеяния для изучаемых данных. Диаграммы рассеяния помогают визуально изучить данные и предположить наличие (отсутствие) линейной взаимосвязи. Диаграмма рассеяния для двух переменных КОЛИЧЕСТВО ЛЕТ ОБУЧЕНИЯ РЕСПОНДЕНТА КОЛИЧЕСТВО ЛЕТ ОБУЧЕНИЯ ОТЦА РЕСПОНДЕНТА Проверка нормальности распределения С использованием гистограммы Проверка нормальности распределения с использованием графика на нормальной вероятностной бумаге Результаты построения регрессионной модели в таблице Model Summary приводится расчетная информация, показывающая насколько хорошо значение зависимой переменной может быть представлено на основе независимой: R - коэффициент корреляции между переменными, R-square - квадрат коэффициента корреляции, показывающий, какая часть изменчивости зависимой переменной может быть объяснена независимой переменной; Результаты построения регрессионной модели Важным показателем является уровень значимости коэффициентов Sig. в таблице ANOVA. Линейная модель зависимости может считаться надежной, если уровень значимости не превышает 0,05 (5%); Результаты построения модели линейной регрессии В таблице Coefficients приведены рассчитанные коэффициенты регрессионной модели. Регрессионная модель • Поскольку модель является линейной, ее графическим выражением будет являться прямая • y = k * x + B, где • x - независимая переменная (в приведенном примере это уровень образования отца); y - зависимая переменная (уровень образования респондента); k - тангенс угла наклона (регрессионный коэффициент); B - постоянная прямой. • Из таблицы Coefficients получаем: • значение в первой строке (постоянная В) - 9,926; значение коэффициента (k) - 0, 322, и, таким образом, имеем линейную регрессионную модель • y = 0,322 *x + 9,926. • Полученная модель может быть использована для предсказания уровня образования респондентов при изменении уровня образования их родителей (в приведенном примере отцов).