Конспект лекций по Теории информ∀ции
реклама

Конспект лекций
по
Теории информ∀ции
В.Н. Горбачев∗†
∗ Лаборатория квантовой информации, СПб университет аэрокосмического приборостроения, С-Пб, 190000, Большая Морская, 67. тел: (+7 812) 110-6234, факс: (+7 812) 315-7778.
† Северо-Западный институт СПб университета технологии и дизайна, С-Пб, 191180, Джамбула, 13, тел: (+7 812) 764-6556,
факс: (+7 812) 764-6556
1
Содержание
1 Случайные величины.
1.1 Вероятность. Частотное определение
1.2 Сложение и умножение событий . .
1.3 Условные вероятности . . . . . . . .
1.4 Закон больших чисел . . . . . . . . .
1.5 Вероятностное пространство . . . . .
1.6 Случайная величина . . . . . . . . .
1.7 Вероятностная мера . . . . . . . . . .
1.8 Функция распределения . . . . . . .
1.9 Представление случайной величины
1.10 Моменты случайной величины . . .
1.11 Совместные случайные величины . .
1.12 Условные вероятности . . . . . . . .
1.13 Случайные процессы . . . . . . . . .
2 Энтропия и информация
2.1 Представление информации . . .
2.2 Энтропия . . . . . . . . . . . . . .
2.3 Функция энтропии . . . . . . . .
2.4 Взаимная и условная энтропия .
2.5 Иерархическая аддитивность . .
2.6 Энтропийные свойства секретных
2.7 Энтропия и термодинамика . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
. . . . .
. . . . .
. . . . .
. . . . .
. . . . .
систем
. . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
5
5
5
6
7
8
9
9
10
11
11
12
13
13
.
.
.
.
.
.
.
13
13
14
15
15
17
17
18
3 Источник дискретных сообщений
19
3.1 Статистическая модель ИДС . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2 Свойства энтропии ИДС . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Асимптотические свойства стационарного ИДС . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4 Кодирование дискретного источника
4.1 Кодирование и дихотомия . . . . . . . . . . . .
4.2 Коды с фиксированной длиной . . . . . . . . .
4.3 Неравномерное кодирование. Префиксный код
4.4 Неравенство Крафта . . . . . . . . . . . . . . .
4.5 Построение префиксного кода . . . . . . . . . .
4.6 Полнота префиксного кода и обезьяна . . . . .
4.7 Код Фано . . . . . . . . . . . . . . . . . . . . . .
4.8 Код Хаффмана . . . . . . . . . . . . . . . . . .
4.9 Оптимальный код . . . . . . . . . . . . . . . . .
4.10 Сжатие текстов . . . . . . . . . . . . . . . . . .
4.11 Предельное сжатие . . . . . . . . . . . . . . . .
4.12 Предельное сжатие текстов. Теорема Шеннона
.
.
.
.
.
.
.
.
.
.
.
.
5 Дискретные каналы
5.1 Пропускная способность дискретного канала без
5.2 Скорость передачи информации . . . . . . . . . .
5.3 Вычисление пропускной способности . . . . . . .
5.4 Симметричные каналы . . . . . . . . . . . . . . .
5.5 Бинарный симметричный канал . . . . . . . . . .
5.6 Двоичный стирающий канал . . . . . . . . . . . .
5.7 Еще канал со стиранием . . . . . . . . . . . . . .
2
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
22
22
22
23
24
25
25
26
26
27
28
28
29
памяти
. . . . .
. . . . .
. . . . .
. . . . .
. . . . .
. . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
30
30
32
32
33
34
35
36
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
6 Защита от случайных помех
6.1 Корректирующие коды . . . . . . . . .
6.2 Коды с повторением . . . . . . . . . . .
6.3 Арифметика по модулю 2 . . . . . . .
6.4 Коды с общей проверкой на четность .
6.5 Код Хемминга . . . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
37
37
37
37
38
38
Введение
Информация играет важную роль в нашей жизни. Однако, наряду с осознанием ее роли, полезно иметь
элементарные представления о том, что такое информация. Такие представления могут быть почерпнуты
из многочисленной литературы, которую можно разделить на два класса. Первый, написанный профессионалами, как правило, сильно математизирован из-за погони к общности, поэтому материал оказывается
доступным лишь для самих авторов и узкого круга специалистов. Напротив, в текстах второго класса,
широко представленных в Сети интернет, из-за стремления к популярности страдает точность обсуждаемых понятий. Среди всей литературы непревзойденной остается книга К. Шеннона, основоположника
теории информации, "Работы по теории информации и кибернетике".
Настоящий конспект лекций представляют собой спецкурс, который читается с 2001 г. студентам специальности 220200 ("Автоматические системы переработки информации и управления") в Северо-Западном
институте печати С-Петербургского государственного университета технологии и дизайна. Основное внимание уделено разъяснению сути дела наряду со строгим изложением, однако строгость не является
самоцелью. В шести представленных разделах рассмотрены основные фундаментальные понятия и методы классической теории информации такие, как: энтропия и мера информации, энтропия источника
дискретных сообщений, кодирование и сжатие информации, пропускная способность дискретных каналов
и корректирующие коды. Изложение начинается с обсуждения случайной величины, она составляет основу теории вероятностей, которая необходима для понимания методов теории информации. Знакомство со
специальным разделам математики и теории вероятностей не требуется, поскольку все нужные сведения
вводятся по мере изложения, хотя знание курса высшей математики в объеме вуза необходимы.
Работа выполнена при поддержке Delzell Foundation, Inc.
4
1
Случайные величины.
1.1
Вероятность. Частотное определение
Будет использоваться следующая терминология: опыт, исходы опыта и события. Опыт имеет исходы,
которые являются элементарными событиями. Из исходов строятся более сложные события. Исход опыта
достоверно предсказать нельзя.
Событие может произойти или нет. Если изучать фиксированные исходы одного и того же опыта или
события, то частота их повторения p будет примерно одинакова, ее называют вероятностью.
Исходам можно сопоставить числа x = x1 , . . . , xN , каждое из которых случается с вероятностью p(x) =
p(x1 ), . . . , p(xN ), тогда возникает случайная величина X:
X = {x; p(x); |X|},
(1)
где |X| = N – число исходов. Аналогично события 1 A = A1 . . . AM представляются своей вероятностью
p(A) = p(A1 ), . . . , p(AM ): A = {A; p(A)}.
Вероятность исхода опыта или вероятность события можно измерить, повторяя многократно один и тот
же опыт. Однако сама вероятность не зависит от того производился опыт или нет. Существуют методы,
которые позволяют определять вероятности событий без повторения опыта. В ряде случаев эти методы
интуитивно очевидны.
N Пример. Пусть в урне находятся 10 шаров красных, зеленых и голубых R,G и B . Из них 5 шаров R,
3 шара G и 2 шара B. Их вытаскивают не глядя. Какова вероятность того, что вынутый шар будет того
или иного цвета?
Решение. Опыт имеет 10 исходов. Ясно, что есть 5 шансов из 10 вынуть шар R и т. п. Поэтому вероятность
вынуть R, G и B шары соответственно равны 5/10 = 1/2, 3/10, 2/10 = 1/5. ¤
В данном случае рассматривается вероятность события AR,G,B : "Вынули шар R,G,B ". Если много раз
повторять этот опыт: вытащили шар, положили обратно, все тщательно перемешали, чтобы воспроизвести
исходные условия, то можно убедиться в справедливости найденных вероятностей.
N Пример. Какова вероятность того, что брошенная монетка выпадает "орлом"?
Решение. Задача эквивалентна предыдущей, где в урне лежат только два шара R и G. Вероятность равна
1/2. ¤
N Пример. Какова вероятность того, что при бросании кубика выпадет номер грани, который делится на
3?
Решение. Пусть в урне лежат шары с номерами 1, 2, 3, 4, 5, 6. Пусть два шара 3 и 6 закрашены красной
краской, а остальные нет. Тогда вероятность равна 2/6 = 1/3. ¤
В этом случае опыт имеет 6 исходов, а событие AR состоит в том, что вытащили либо шар с номером 3,
либо 6, какой неважно, важно, что есть 2 шанса из 6.
В рассмотренных примерах опыт имеет N исходов, которые равновероятны, поэтому вероятность каждого
исхода равна 1/N . Если интересующий исход или событие происходит m раз, то его вероятность, а точнее
частота, равна p = m/N . Для кубика с 6 гранями возникает случайная величина X, которая принимает
6 значений x = 1, . . . 6, с вероятностью p = 1/6. Среднее значение случайной величины определяется
соотношением
X
hxi = E{X} =
xk p(xk ).
(2)
k
1.2
Сложение и умножение событий
События представляют собой множество исходов, поэтому над ними, как над множествами, можно совершать операции объединение и пересечение, что соответствует сложению и умножению событий. События
бывают достоверные и невозможные, взаимоисключающие или дополнительные, совместные и несовместные. Вероятность события есть неотрицательное число: 0 ≤ p(A) ≤ 1.
Если p(A) = 1, то событие A называют достоверным. Оно возникает при любом исходе опыта. Так, если
в урне лежат только шары R, то вероятность вынуть R шар равна единице. Если p(A) = 0, то событие A
невозможное.
Два события A и B взаимоисключающие, если
p(A) + p(B) = 1.
1 Ниже
будут даны строгие определения на основе вероятностного пространства.
5
(3)
Если событие A реализуется в m из N исходах, то взаимоисключающее событие B = A возникает в N − m
исходах. Говорят, что B является дополнением множества A.
N Пример. Пусть в урне всего 5 шаров, из них 2 шара R и 3 шара G. События A: "извлечен R шар"и
событие B = A "извлечен G шар"являются взаимоисключающими, p(A) = 2/5, p(B) = 3/5 = 1 − p(A). ¤
События совместные, если могут произойти одновременно. Это означает, что пересечение множеств A и
B не пустое. Если A и B не могут произойти вместе, то они несовместные. Соответственно множества A
и B не пересекаются.
Суммой двух событий A и B называют событие A + B, которое состоит в том, что случилось событие
A или B или случились оба сразу. Сумме событий A + B соответствует операция объединения двух
множеств. Для нахождения вероятности суммы событий нужно различать два случая: 1) события A и B
несовместные, 2) события A и B совместные. Для несовместных событий
p(A + B) = p(A) + p(B).
(4)
Если A и B события совместные, это означает, что иногда они происходят вместе. Тогда
p(A + B) = p(A) + p(B) − p(AB),
(5)
где произведение событий AB означает событие, в котором A и B возникают вместе. Формулу можно
пояснить, используя частотное представление вероятности. Пусть q раз из N происходят оба события
AB, пусть A случилось в mA − q случаев из N , аB в mB − q случаях из N. Тогда A + B случается в
(mA − q) + (MB − q) + q раз из N , или mA + mB − q раз.
N Пример. В урне находится 6 шаров, из них 2 шара R, 3 шара G и 1 шар B. Рассмотрим событие
AX "извлекли X = R, G, B шар". События AR , AG , AB неcовместные и взаимоисключающие, поэтому
p(AR ) + p(AG ) + p(AB ) = 2/6 + 3/6 + 1/6 = 1. Попарные события типа AR , AG несовместные, но не
являются взаимоисключающими, поэтому p(AR ) + p(AG ) = 2/6 + 3/6. ¤
Если события A и B независимы, то
p(AB) = p(A)p(B).
(6)
Независимость событий означает, что исходы одного не влияют на исходы другого.
N Пример. В колоде 52 карты. Одна из четырех мастей козырная, пусть "крести". Какова вероятность
того, что взятая наугад карта будет: 1) тузом, 2) козырем, 3) козырным тузом?
Решение. Пусть событие A "выбранная карта – туз". Тогда p(A) = 4/52 = 1/13. Пусть событие B "выбранная карта – козырь". Тогда p(B) = 1/4. В этом случае произведение AB означает, что выбранная карта козырной туз, сумма A + B означает, что выбранная карта либо туз, либо козырь. Поэтому
p(AB) = p(A)p(B) = 1/52, p(A + B) = p(A) + p(B) − p(AB) = 4/13. ¤
Если X и Y две случайные величины, то всегда hx + yi = hxi + hyi, если они независимы, то hxyi = hxihyi.
1.3
Условные вероятности
Если события A и B независимы, то исходы опыта, в которых случается A, не влияют на исходы, в
которых случается B. Однако это может быть не так.
Например, пусть в урне находится M шаров, из них m шаров R и M − m шаров G. Пусть событие A
заключается в том, что извлечен R шар. Пусть событие B заключается в том, что извлечен R шар из той
же урны после того, как из нее вынут один любой шар. В данном случае вероятность B будет зависеть
от A.
Если первый вынутый шар был R, случилось A, то R шаров стало m − 1. Тогда вероятность события B
равна (m − 1)/(M − 1). Если первый вынули шар G, то произошло событие A, и вероятность B равна
m/(M −1). Непосредственно видно, что вероятность события B меняется в зависимости от того, случилось
A или нет.
Вероятность события B при условии, что произошло A, называется условной вероятностью и обозначается
p(B|A). В рассмотренном примере p(B|A) = (m−1)/(M −1) < m/M = p(B), p(B|A) = m/(M −1) > m/M =
p(B).
Для условных вероятностей справедливо выражение
p(A, B) = p(B|A)p(A) = p(A|B)p(B).
(7)
Эту формулу можно пояснить, используя частотное определение вероятности. Так, можно считать, что
p(B|A) = ν/µ,
6
(8)
где событие B случается ν раз из µ, а µ число исходов, в которых случается событие A и может случиться
или нет событие B. В рассмотренном опыте по извлечению двух шаров из урны, где общее число шаров
M , полное число исходов равно K = M (M − 1): сначала можно вынуть любой из M шаров, потом один
из M − 1 оставшихся. Число исходов, в которых случается A и может произойти B, равно µ = m(M − 1):
вынули один из m шаров R и любой оставшийся. Однако событие B могло не случиться. Число исходов, в
которых происходит еще и событие B, равно ν = m(m−1): вынули сначала один шар R из m шаров, затем
один шар R из оставшихся m − 1 шаров. Условная вероятность будет p(B|A) = ν/µ = (m − 1)/(M − 1).
Справедливо следующее тождество
ν
ν K
=
,
(9)
µ
K µ
где ν/K = m(m − 1)/M (M − 1) = p(A, B) число исходов, в которых происходят оба события A и B,
µ/K = m/(M − 1) = p(A) число исходов, в которых происходит событие A. В результате выражение (9)
принимает вид (7).
Для условных вероятностей справедливы следующие свойства
P (B|A) ∈ [0, 1],
p(B|A) = 1 − p(B|A),
p(B) = p(A)p(B|A) + p(A)p(B|A).
Если A и B несовместны, то
p(B|A) = p(B).
Если B и C несовместны, то
p(B + C|A) = p(B|A) + p(C|A).
1.4
Закон больших чисел
Рассмотрим случайную величину X = {x1 . . . xN , p(x1 ) . . . p(xN )} со средним значением E{X} = m. Ее
дисперсия, которая характеризует среднее отклонение от среднего, определяется соотношением
X
σ 2 = E{(X − m)2 } =
p(xk )(hxi − xk )2 .
(10)
k
Справедливо следующее наблюдение. Рассмотрим n независимых случайных величин X1 . . . Xn c одинаковыми средними значениями m и дисперсиями σ 2 : E{Xk } = m, σ 2 = E{(Xk − m)2 }. Пусть новая случайная
величина Z определяется как их среднее арифметическое
Z=
1
(X1 + . . . Xn ).
n
(11)
Тогда E{Z} = m, а дисперсия Z будет в n раз меньше E{(Z − m)2 } = σ 2 /n.
Поскольку дисперсия уменьшается, то вероятность больших отклонений для Z будет мала. Эту особенность используют при проведения измерений.
N Пример. Пусть требуется измерить расстояние. Результат одного измерения является случайным. Пусть
проведено n независимых серий X1 . . . Xn , в каждой из которых расстояние измерялось несколько раз.
Пусть измеряется расстояние порядка 100 м. При n = 1 ошибка может быть, скажем, σ ≈ 1 м. Поскольку
дисперсия уменьшается с ростом n, то при n = 9 ошибка будет σ/3 ≈ 33 см. ¤
Указанное свойство обязано неравенству Чебышева
P (|x − E{X}| > ²) <
σ2
,
²2
(12)
где ² > 0. Оно означает, что вероятность отклонения ² случайной величины X от своего среднего значения
m зависит от дисперсии и величины самого отклонения. Если в качестве случайной величины X в (13)
взять Z, определенную (12), то неравенство Чебышева принимает вид
P (|Z − m| > ²) <
7
σ2
.
n²2
(13)
Отсюда следует, что для любого ² > 0 всегда можно выбрать число n настолько большим, чтобы гарантировать маленькое отклонение от среднего. Это утверждение известно, как закон больших чисел, который
устанавливает общий характер поведение случайной величины. Так, сумма большого числа случайных
величин в отличие от одной случайной величины с большой вероятностью принимает значения близкие
к своему среднему значению, а большие отклонения от среднего. Одно из практических применений закона больших чисел на практике состоит в том, что по сравнительно небольшой пробе судят о качестве
однородного материала, например, как при дегустации.
Еще вариант неравенства Чебышева. Пусть случайная величина X принимает только положительные
значения x > 0, тогда
P (x > ²) ≤
hxi
.
²
(14)
Доказательство. Используя определение
P (x > ²) =
X
p(x),
x>²
найдем
P (x > ²) =
X
p(x) ≤
x>²
1.5
X
p(x) ≤
x
X
x
x/² p(x) = hxi/².
|{z}
≥1
Вероятностное пространство
Для описания случайной величины служит вероятностное пространство (Ω, A, P ), которое состоит из
пространства элементарных исходов или элементарных событий Ω, поля событий или алгебры A и вероятностной меры P .
Рассмотрим эксперимент, исходы которого нельзя предсказать достоверно. Пусть ω любой из исходов.
Пространство элементарных событий Ω есть множество всех элементарных исходов Ω = {ω}. Число элементарных исходов может быть конечным, счетным или бесконечным. Если в урне имеется M шаров, то
эксперимент по вытаскиванию шаров имеет M исходов.
Элемент вероятностного пространства A называется σ полем, или σ алгеброй событий. Алгебра A состоит
из множества событий A, которые в свою очередь составлены из элементарных исходов ω. Говорят, что
событие происходит, если элементарный исход ω ∈ A. Алгебра A = {A : A ⊂ Ω} обладает следующими
свойствами.
1. Достоверное событие принадлежит A. Действительно, если выполнен эксперимент, то он завершиться одним из исходов
Ω ∈ A.
(15)
2. Невозможное событие или пустое множество ∅ содержится в A. Действительно, если выполнен
эксперимент, то он может не завершиться ни одним из интересующих исходов
∅ ∈ A.
(16)
3. Дополнение A = Ω − A к событию A есть событие
A ∈ A → A ∈ A.
4. Если A и B события, то их объединение и пересечение также событие
[
\
A, B ∈ A → A B ∈ A, A B ∈ A.
(17)
(18)
Любое множество A подмножеств пространства Ω, удовлетворяющее (15) - (18), называется σ алгеброй
или полем.
Множество всех событий A меньше или равно множеству всех подмножеств пространства элементарных
событий Ω, которое называют булиан P(Ω). Если пространство Ω конечно и содержит, например, M элементов, то |P(Ω)| = 2M и число элементов A не больше 2M .
8
N Пример. Пусть пространство исходов содержит M = 3 элемента Ω = {a, b, c}. Тогда множество всех возможных подмножеств Ω будет состоять из четырех множеств, которые содержат 0 элементов, 1 элемент, 2
элемента и 3 соответственно: 0 = {∅}, 1 = {a, b, c}, 2 = {ab, ac, bc, } и 3 = {abc}. В итоге 1+3+3+1 = 23 = 8.
¤
Результат, согласно которому число всех подмножеств, составленных из M элементов, равно 2M , легко
понять из следующих соображений. Пусть каждому исходу ω1 , ω2 . . . ωM сопоставлено число, которое принимает два значения 0 и 1: bk = 0, 1, k = 1, . . . M . Тогда все исходы можно представить строкой b1 b2 . . . bM
длины M , составленной из 0 и 1. Так будет строка 11 . . . 0, где первые две цифры 1, а остальные 0. Эта
строка описывает множество, состоящее из двух элементов {ω1 , ω2 }. Всего будет 2M различных строк или
различных множеств, составленных из элементов ω. Число множеств n(K), состоящих из K элементов,
N
. В частности
будет равно числу различных строк, содержащих K единиц: n(K) = M !/K!(M − K)! = CK
при M = 3, найдем, что для K = 2 число n(2) = 3, для K = 3 число n(3) = 1.
1.6
Случайная величина
Случайная величина X представляет собой функцию, которая отображает пространство элементарных
исходов Ω в пространство состояний, в качестве которого выбирают множество вещественных чисел X :
Ω → R.
Функция X будет случайной величиной, если она обладает следующим свойством
A = {ω : X(ω) ≤ x} ∈ A
∀x ∈ R.
(19)
Это условие означает, что X будет случайной величиной только в том случае, если множество A, состоящее из элементарных исходов ω, для которых функция X(ω) ограничена, будет событием. Из условия
ограниченности функции X(ω) ∈ (−∞; x] следует, что элементарному исходу ω ставится в соответствие
интервал (−∞, x] на вещественной оси. Если ввести обратную функцию X −1 , то
A = X −1 ((−∞, x]) ∈ A
∀x ∈ R.
(20)
Функция X преобразует исходы из пространства элементарных событий ω ∈ Ω в пространство состояний
(−∞, x] ∈ R. Ее можно интерпретировать, как некоторую процедуру измерения, которая позволяет получить информацию об основном пространстве элементарных исходов с помощью прибора, осуществляющего преобразование X : Ω → R. Тогда пространство R можно принять за новое пространство элементарных
событий величины X. События в R определяются интервалами (−∞, x]. 2 Разумно потребовать, чтобы
любое событие X в пространстве R соответствовало событию в основном пространстве Ω. В противном
случае измерительный прибор будет давать ложную информацию. Но в самом общем случае не всякое
событие A ∈ A представимо в виде A = X −1 (−∞, x]. Поэтому σ поле, порожденное всеми множествами
вида A(X) = {X −1 ((−∞, x]), x ∈ R}, является лишь подполем поля событий A.
Является ли X случайной величиной, определяется выбором поля событий. Рассмотрим пример. Пусть в
сосуде находится M газовых молекул. Пусть пространство Ω составлено из этих молекул и, следовательно,
содержит M элементарных исходов. Пусть в качестве функции X выбрана скорость: X = V . Это означает,
что молекуле сопоставляется скорость. Является ли скорость случайной величиной? Иными словами, будет ли A = {ω : V (ω) ≤ v} событием: A ∈ A, ∀x ∈ R? Рассмотрим два случая выбора A: 1) A = P(Ω), где
P(Ω) множество всевозможных подмножеств молекул, 2) A = {Ω, ∅, A+ , A− }, где A± количество молекул,
скорость которых направлена по или против некоторой оси. Число молекул A, скорость которых меньше
заданного значения A = {ω : V (ω) ≤ u}, не совпадает ни с одним из элементов ∅, Ω, A+ , A− . Поэтому во
втором случае скорость не является случайной величиной.
1.7
Вероятностная мера
В вероятностном пространстве {Ω, A, P } элемент P представляет собой вероятностную меру. Функция P
осуществляет отображение P : A → [0, 1], которое сопоставляет событию A ∈ A число на интервале [0, 1],
называемое вероятностью. Можно заметить, что функция P определена на поле A, а не на пространстве
исходов Ω. Поэтому вероятность определена для событий, а не только для элементарных исходов ω. Эта
особенность будет существенной для бесконечного множества исходов, когда вероятность элементарного
2 В общем случае можно взять интервалы B = [x, y]. Если над ними производить теоретико - множественные операции
пересечения, объединения и дополнения, то они порождают σ поле B, известное как борелевское поле. Чтобы породить
борелевское σ поле, достаточно использовать интервалы (−∞, x].
9
события ω часто строго равна нулю.
По определению любая функция P является вероятностной мерой, если обладает следующими свойствами
P (∅) = 0,
P (Ω) = 1,
An , Am ∈ A,
An
\
Am = ∅ → P (An
[
Am ) = P (An ) + P (Am ).
(21)
n6=m
Эти свойства отражают наши интуитивные представления о вероятности. Так, невозможное событие ∅
имеет нулевую вероятность, вероятность достоверного события равна единице, а вероятности двух взаимно исключающих события (непересекающихся) складываются. Последнее условие сохраняется для счетного числа взаимно исключающих событий.
В приложениях вероятность может выводиться из длинной серии испытаний, где определяется относительная частота события. Но в таком подходе есть математические тонкости. Задача теории вероятностей
состоит не в определении вероятностной меры, а в вычислении новых вероятностей по заданным.
Вероятность событий в пространстве состояний R случайной величины X можно выразить через P . Действительно, случайная величина X : Ω → R осуществляет перенос вероятностной меры P из пространства элементарных событий Ω в R, где элементарным событием является интервал (−∞; x]. Поскольку
P (ω) = p ∈ [0, 1] то событию X(ω) ≤ x можно приписать вероятность p. Иными словами, можно ввести вероятность P (X ≤ x), c которой случайная величина X попадает в интервал (−∞; x]. В результате
вероятностная мера будет определена уже на пространстве состояний.
1.8
Функция распределения
Функцией распределения случайной величины X называют вероятностную меру на пространстве состояний
F (x) = P (X ≤ x),
x ∈ R.
(22)
Функция F (x) равна вероятности, с которой случайная величина попадает в интервал (−∞; 1], и обладает
следующими свойствами
F (−∞) = 0,
F (+∞) = 1,
lim F (x + ²) = F (x).
²→0+
(23)
Последнее свойство означает, что F (x) – возрастающая непрерывная справа функция. Всякая функция,
удовлетворяющая приведенным условиям, будет функцией распределения.
Случайные величины могут быть двух типов: дискретные и непрерывные. Для непрерывной величины
Z x
F (x) =
dx0 p(x0 ),
(24)
−∞
где p(x) – плотность вероятности, а p(x)dx – вероятность найти значение X в интервале x ± dx. Условие
F (∞) = 1 означает, что площадь под кривой p(x) равна 1.
Для случая дискретной величины
X
F (x) =
p(x0 ),
(25)
x0 ≤x
P
где p(x) – вероятность случиться значению X, а условие F (∞) = 1 принимает вид x p(x) = 1.
Для примера рассмотрим вероятность, с которой непрерывная случайная величина X принимает определенное значение X = x0 . Вероятность, что X ∈ [x0 ± ²] равна
Z x0 +²
P (X ∈ [x0 ± ²]) =
p(x)dx ≈ p(x0 )2².
(26)
x0 −²
Откуда видно, что P (X = x0 ) = 0. Иными словами, случайная величина не может принимать какое-либо
определенное значение.
10
1.9
Представление случайной величины
В пространстве состояний R случайная величина X полностью описывается своей функцией распределения F (x) = P (X ≤ x). Поэтому вероятностное пространство {Ω, A, P } можно опустить, считая что X
задана функцией распределения, для кототой существует плотность вероятности. Далее будем представлять X в виде
X = {x; p(x); |X|},
(27)
где X – название случайной величины, x – значения, которые она принимает. Для дискретных величин
p(x) – вероятность, с которой случается значение x, для непрерывных величин p(x) – плотность вероятности. Через |X| обозначена мощность множества X.
1.10
Моменты случайной величины
Полная информация о случайной величине содержится в ее функции распределения, которая может быть
получена, например, путем измерения. Результаты измерения можно описать с помощью средних значений или моментов.
Первый момент известен, как среднее значение или математическое ожидание
R
xp(x)dx,
E{X} = hxi =
(28)
P
p(x).
x
Если случайная величина X преобразуется по закону Y = f (X), где функция f не является случайной,
тогда
R
f (x)p(x)dx,
(29)
E{f (X)} = hf (x)i =
P
f
(x)p(x).
x
Моментами случайной величины X называются средние вида E{X q }. В то время как нулевой момент
существует всегда 1 = P (Ω), высшие моменты могут обращаться в бесконечность.
Мерой флуктуаций служит дисперсия, которая описывает среднее отклонение случайной величины от
среднего значения. Она определяется соотношением
σ 2 = E{(X − E{X})2 } = hx2 i − hxi2 .
(30)
Дисперсия является вторым центральным моментом, в общем случае центральные моменты определены
соотношением
Mq = E{(X − E{X})q }.
(31)
Если дисперсия характеризует ширину плотности вероятности, то третий центральный момент описывает асимметрию или "перекос". Для симметричной относительно среднего значения функции E{(X −
E{X})2q+1 } = 0, q = 1, 2 . . .
Три примера.
1) Гауссовское распределение. Плотность распределения имеет вид
p(x) = √
³ (x − m)2 ´
1
exp −
,
2σ 2
2πσ
(32)
где m – среднее значение, σ 2 – дисперсия. Распределение описывается полностью двумя первыми моментами m и σ 2 и симметрично относительно среднего значения. Для центральных моментов
E{(X − m)q } = 0,
E{(X − m)q } = (q − 1)!!σ q ,
q = 1, 3, 5 . . .
q = 2, 4, 6 . . .
(33)
Нормальное распределение играет важную роль в силу центральной предельной теоремы. Эта теорема
утверждает, что сумма из n независимых случайных величин Z = X1 + . . . Xn с любым распределением
11
стремится к нормальному распределению при n ≥ 1 3 . Это означает, что на практике большое число
случайных величин можно описывать с помощью распределения Гаусса.
2) Пуассоновское распределение. Говорят, что случайная величина X, принимающая только целые неотрицательные значения, имеет пуассоновское распределение, если
mν
exp(−m), ν = 0, 1, 2, . . .
ν!
Для пуассоновского распределения среднее значение и дисперсия соответственно равны
P (X = ν) = p(ν) =
E{X} = m =
σ2 =
X
(34)
∞
X
mν
ν
exp(−m),
ν!
ν=0
(35)
mν
exp(−m).
ν!
(36)
(ν − m)2
ν
Для высших моментов
E{(X − m)q } =
q
X
S(q, k)mk ,
(37)
k=0
где S(q, k) – числа Стирлинга второго рода.
3) Распределение Бернулли. Если производится серия из n независимых испытаний, где в каждой серии
событие A может произойти с вероятностью p, то число появления событий A, равное m, есть случайная
величина, распределенная по закону Бернулли или биномиальному закону
p(m; n) = Cnm pm (1 − p)n−m ,
(38)
где Cnm = n!/m!(n − m)!
N Пример. Кубик бросают 5 раз. Какова вероятность, что грань с номером 6 выпадет дважды? Здесь
n = 5, m = 2, p = 1/6. ¤
N Пример. Есть последовательность {0, 1}n длиной n, составленная из 0 и 1, которые появляются с вероятностями p(1) = p, p(0) = 1 − p. Вероятность всех последовательностей с фиксированным числом 1
или 0 определяется формулой Бернулли. Если одна последовательность содержит m единиц, то ее вероятность pm (1 − p)n−m , число таких последовательностей Cnm = n!/m!(n − m)!, поэтому вероятность всех
последовательностей равна p(m, n). ¤
1.11
Совместные случайные величины
Рассмотрим две случайные величины X и Y , для которых функция их совместного распределения F (x, y) =
P (X ≤ x, Y ≤ y) задается соотношением
Ry
Rx
−∞ dx0 −∞ dy 0 p(x0 y 0 )
(39)
F (x, y) =
P
0 0
x0 ≤x,y 0 ≤y p(x , y ).
Она равна вероятности, с которой величины X и Y могут попадать в интервалы (x, ∞] и (∞, y]. Частичные
функции распределения этих величин будут
F (x) = F (x, ∞)
F (y) = F (∞, y).
Отсюда в частности следуют соотношения
p(x) =
(40)
R
dyp(x, y)
P
y
(41)
p(x, y).
Величины X и Y могут быть независимыми, тогда p(x, y) = p(x)p(y) и E{XY } = E{X}E{Y }. В противном
случае это не так. Чтобы характеризовать связь X и Y вводится ковариация
σxy = E{(X − mX )(Y − mY )} = E{XY } − E{X}E{Y }.
Если σxy = 0, то говорят, что X и Y нескоррелированы.
3 Если
слагаемые вносят равномерно малый вклад в сумму.
12
1.12
Условные вероятности
Задача об определении вероятности события B, если произошло событие A, приводит к условной вероятности P (B|A). Если события A и B совместны, условная вероятность определяется соотношением
S
P (A B)
P (B|A) =
,
(42)
P (A)
где P (A) 6= 0.
В пространстве состояний справедливы равенства
p(x, y) = p(x|y)p(y) = p(y|x)p(x),
(43)
где p(x|y) и p(y|x) – условные вероятности, которые равны вероятности найти x либо y, если случилось
значение y либо x.
Для
P условной
P вероятности справедливы следующие свойства. Используя определения, найдем p(x) =
y p(x, y) =
y p(y|x)p(x). Отсюда
X
p(y|x) = 1.
(44)
y
Аналогично
1.13
P
x
p(x|y) = 1.
Случайные процессы
Если случайная величина X меняется со временем, то возникает случайный процесс. Чтобы отличать
его от детерминированной функции X(t), вводится обозначение Xt . В результате отображение Ω → R
будет разным для разных моментов времени t. Поэтому случайный процесс можно рассматривать как
функцию Xt (ω) двух аргументов параметра t и элементарного события ω. Если зафиксировать время t,
и разрешить ω принимать все свои значения, то будет случайная величина. Если фиксировать ω, выбрав
некоторое элементарное событие, и отпустить время, то будет реализация случайного процесса.
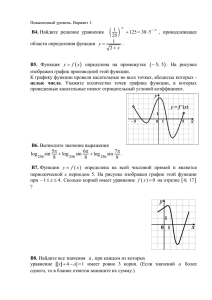
N Пример.
p
p1
p2
p3
2
2.1
ω
ω1
ω2
ω3
x
x1
x2
x3
Xt1
x1
x1
x3
Xt2
x2
x3
x1
Xt3
x3
x1
x3
Энтропия и информация
Представление информации
Информация – это сведения о каких-либо событиях.
С самой общей философской точки зрения информацию рассматривают как отражение, которое представляет собой связь взаимодействующих систем. Можно рассматривать связь реальности и наших ощущений, связь стрелки амперметра и силы электрического тока.
Информацию, фиксированную в определенной форме, называют сообщением. Сообщение может иметь
разное содержание. Однако, как правило, оно состоит из последовательности символов, которые рассматривают как буквы некоторого алфавита. Алфавит может содержать любое количество букв или символов, например, x1 , x2 . . . xN . В русском языке N = 32 (приравнивают ъ и ь, е и ё, тогда 33 − 2 + пробел
= 32 = 25 ), в алфавите с N = 2 есть две буквы, которые обозначают символами 0 и 1.
Сообщение связано с материальным носителем, объектом или физической системой, однако интерес может представлять только часть свойств этого объекта. Текст, написанный на бумаге, представляет собой
сообщение. С информационной точки зрения тексты отличаются различием символов. Такие полиграфические качества, как типы шрифтов, их цвет и др. не важны. Важно, что информация имеет физический
носитель и кодируется или представляется состояниями физической системы. Будучи физическим процессом, информация не может распространяться быстрее скорости света.
Наши интуитивные представления об информации отчасти связаны с двумя свойствами: различимость
и неопределенность. Если буквы хорошо различаются, то текст можно прочитать. Сколько информации
13
содержится в сообщении "дважды два четыре"? Ответ зависит от того, знаем ли мы таблицу умножения.
Поэтому говорят, что информация есть мера нашего незнания. Математически "незнание"можно описать
случайной величиной, значения которой можно только предсказать с некоторой вероятностью.
В стандартной схеме источник информации или отправитель A посылает сообщение в канал, на выходе
которого находится получатель B. В теории информации одним из главных является вопрос: сколько
информации A должен отправить в канал, чтобы B восстановил исходное сообщение. Реальный канал
обладает шумами, что является источником ошибок, поэтому задача усложняется. В действительности
возможен еще один персонаж E, злоумышленник, который прослушивает канал. Поэтому возникает задача, как защитить информацию или как обеспечить конфиденциальность передаваемых сведений. Чтобы
сохранить секрет, криптография рекомендует зашифровать сообщение. Однако существует ли надежный
шифр? Эти и другие задачи рассмотрены в классической теории информации Шеннона, где центральным
является вопрос измерения количества информации.
2.2
Энтропия
Энтропия служит мерой неопределенности или информации.
Неопределенность можно связать с вероятностью: чем вероятность события выше, тем меньше его неопределенность. Пусть событие A заключается в том, чтобы определить цвет первой попавшейся вороны. Поскольку все вороны в основном черные, энтропия A будет мала, равно как и количество информации.
Есть и белые вороны, но они встречаются редко.
Количество энтропии или информации, которая содержится в случайной величине
X = {x1 . . . xN , p(x1 ), . . . , p(xN )}
равно
H(X) = −
X
p(xk ) logb p(xk ).
(45)
k
Функция H(X) обладает следующими свойствами.
1. Неотрицательность. Поскольку p(xk ) ∈ [0, 1]
H(X) ≥ 0.
(46)
2. Если X – неслучайная величина, то она принимает лишь одно значение с вероятностью 1. Поэтому
для неслучайной величины
H(X) = 0.
(47)
3. При равномерном распределении p(xk ) = 1/N энтропия достигает своего максимума
max H(X) = logb N.
(48)
Если основание логарифма b = 2, то энтропия измеряется в битах, иногда используют натуральный логарифм. С помощью формулы logb Z = loga Z logb a можно перейти от одного основания к другому.
Наряду со случайной величиной X энтропию можно определить для элементарных исходов опыта или
отдельных значений hk = − log p(xk ). Тогда из определения (45) может показаться, что с точки зрения
случайных величин энтропия H(X) представляет собой среднее значение E{h(xk )}. Однако такая интерпретация небезопасна. С физической точки зрения это означает введение динамической переменной для
энтропии или наблюдаемой в классической или квантовой механике, например, H = − log ρ, где ρ – оператор плотности. Если эволюция описывается унитарным оператором U , то ρ → ρ(t) = U (t)ρU † (t) и среднее
значение рассматриваемого оператора энтропии H меняется: Sp{ρH(t)} = hH(t)i. Однако известно, что
при унитарной эволюции, описывающей обратимый процесс, энтропия сохраняется.
N Рассмотрим кубик. Если он идеальный, то при бросании вероятность того, что выпадет любая грань
равна 1/6. В данном случае имеет место случайная величина X, которая принимает N = 6 значений с вероятностью p(xk ) = 1/6. Количество информации, которое в ней содержится, будет H = log 6 ≈ 2.58 бита.
Пусть кубик неидеальный, и пусть вероятности p(xk ) = 1/10, k = 1, 2, 3, 4, 5, а вероятность p(x6 ) = 1/2.
Для такого неравномерного распределения H = 2, 15 бит, что меньше чем maxH = 2, 58 бит.
14
2.3
Функция энтропии
Случайная величина X называется бинарной, если она принимает два значения. Эти значения можно
обозначить 0 и 1. Пусть 0 и 1 случаются с вероятностью p(0) = q и p(1) = p, где q + p = 1. Для бинарной
величины энтропия, определенная согласно (45), будет зависеть только от p:
H(X) ≡ H(p) = −p log p − (1 − p) log(1 − p).
(49)
Функция H(p) определена лишь на промежутке [0, 1], где для значений p = 0 и p = 1 она обращается в
ноль. При p = 1/2, когда оба значения случайной переменной равновероятны, функция имеет максимум,
где H(1/2) = 1. Энтропия бинарной величины H(P ) имеет важное значение.
Бинарная переменная с равновероятными значениями называется бит. В такой величине содержится
H(1/2) = 1 бит информации, что и принимают за единицу ее измерения. Другими словами, с помощью бинарной переменной можно закодировать или сохранить 1 бит.
Носителем информации являются физические объекты, точнее их состояния, а не математические случайные величины. Поэтому бит – это любая физическая система с двумя хорошо различимыми состояниями,
которые должны быть ортогональны, но это дополнение следует уже из квантовой механики. Разумеется,
состояния должны быть устойчивыми или по крайней мере не распадаться за время вычислений. Можно
указать следующие примеры. Электрический импульс, где одно состояние – напряжение равное нулю,
другое – напряжение, скажем, +5В. Можно и наоборот. Монета, два состояния которой "орел"и "решетка". Электрическая лампочка, где горящая лампочка кодирует 1, а выключенная – 0. Фотон, квант света,
у которого есть две поляризации или направления, вдоль которых смотрит вектор электрического поля,
к примеру, это горизонтально и вертикально поляризованный фотон.
Следует иметь в виду, что в бинарной переменной количество информации может быть меньше одного
бита, если ее значения не равновероятны. Если распределение случайной величины неравномерное, то в
ней содержится меньше 1 бита информации. Это согласуется с интуитивным представлением об информации как мере нашего незнания. Вместе с тем неравномерность связана с избыточностью информации.
Последнее обстоятельство играет важную роль, и связано, в частности, с возможностью сжатия данных.
Для измерения информации помимо бита используется байт – величина в 8 раз большая, чем бит. Байт
обозначают заглавной буквой Б или B. Используются производные от этих единиц, образованные при
помощи приставок кило (К), мега (М), гига (Г или G), тера (Т) и др. Но для битов и байтов они означают
не степени 10, а степени 2. Так кило – 210 = 1024 ≈ 103 , мега – 220 ≈ 106 , гига – 230 ≈ 109 , тера –
240 ≈ 1012 . Например, 1 MБ = 1024 КБ = 1048576 Б = 8192 Кбит.
2.4
Взаимная и условная энтропия
Рассмотрим две случайные величины X = {x, p(x)}, Y = {y, p(y)}, где для краткости обозначено x =
x1 . . . , xN , p(x) = p(x1 ) . . . , p(xN ) и т. п. Для их описания служит совместная вероятность p(x, y), которую
можно представить в виде произведения условных и безусловных вероятностей
p(x, y) = p(x|y)p(y) = p(y|x)p(x),
(50)
где, например, p(x|y) вероятность случиться величине x, при условии, что случилось фиксированное значение y. Тогда можно ввести следующий набор функций энтропии
X
p(x, y) log p(x, y),
(51)
H(X, Y ) = −
x,y
H(X|Y ) = −
X
p(x.y) log p(x|y),
(52)
p(x, y)
.
p(x)p(y)
(53)
x,y
I(X : Y ) =
X
p(x, y) log
x,y
Величина H(X, Y ) описывает энтропию или информацию, которая содержится в X и Y , условная энтропия H(X|Y ) характеризует количество информации в X, если известно Y , взаимная энтропия I(X : Y )
показывает сколько информации X и Y содержат друг о друге.
Эти величины имеют простой "геометрический смысл который следует, непосредственно из определений.
S
Так, энтропия двух случайных величин H(X, Y ) соответствует объединению двух множеств X Y , где
15
каждый элемент из множества X и Y учитывают только один раз. H(X|Y ) отвечает дополнению Y множества Y до X и состоит из тех элементов x, которых нетTу Y . Наконец условная энтропия H(X|Y ) = H(Y |X)
аналогична операции пересечения двух множеств X Y .
С помощью определений можно записать следующие соотношения
H(X, Y ) = H(X) + H(Y ) − H(X|Y ),
(54)
H(X|Y ) = H(X) − I(X : Y ),
H(X, Y ) = H(X) + H(Y |X),
H(X, Y ) = H(Y ) + H(X|Y ).
(55)
(56)
(57)
Взаимная энтропия H(X : Y ) характеризует корреляцию двух случайных величин, которая описывается
отношением p(x, y)/p(x)p(y). Если x и y независимы, то p(x, y) = p(x)p(y), поэтому взаимная энтропия
H(X : Y ) = 0 и H(X|Y ) = H(X), а общая энтропия равна сумме: H(X, Y ) = H(X) + H(Y ).
N Пример. Пусть в урне содержится m черных и n − m белых шаров. Пусть эксперимент A и B заключается в последовательном извлечении шаров: A – "вынули любой первый шар B – "вынули любой второй
шар". Вынутые шары обратно не возвращаются. Найти энтропию экспериментов A, B и условные энтропии.
Решение. Пусть исходы экспериментов A и B описываются случайными величинами X и Y , принимающие каждая два значения x = x1 , x2 и y = y1 , y2 . Пусть значения x = x1 и y = y1 описывают исходы
экспериментов A и B, в которых вытащен черный шар, а значения x = x2 и y = y2 – исходы, в которых
вытащен белый шар. Чтобы вычислить энтропии, нужно найти набор условных и безусловных вероятностей для X и Y . Безусловные вероятности p(x) и p(y) описывают два одинаковых события: "вынули
черный шар если x = x1 , y = y1 или "вынули белый шар если x = x2 , y = y2 . Поскольку всего шаров n, то
p(x1 ) = p(y1 ) = m/n, и p(x2 ) = p(y2 ) = (n − m)/n. Если в эксперименте A получен определенный исход,
или у величины X случилось значение x = x1 , то исходы эксперимента B или значения величины Y будут
описываться условной вероятностью p(y|x). Значения вероятностей приведены в следующей таблице:
p(y|x)
x1 , y1
x1 , y2
x2 , y1
x2 , y2
p(x)
(m − 1)/(n − 1)
(n − m)/(n − 1)
m/(n − 1)
(n − m − 1)/(n − 1)
p(y)
p
p
1−p
1−p
p
1−p
p
1−p
Отсюда следует, что обе случайные величины имеют одинаковую энтропию H(X) = H(Y ) = H(p), где
p = m/n, где функция энтропии H(p) определена согласно (49). Воспользовавшись соотношением p(x, y) =
p(y|x)p(x) можно найти безусловную вероятность p(x, y) и условную вероятность p(x|y) = p(x, y)/p(y), которые необходимы для вычисления энтропии H(X, Y ), H(X|Y ), I(X : Y ) и H(Y |X).¤
N Пример. Пусть эксперимент B заключается в определении положения точки Q, относительно которой
известно заранее, что она лежит на отрезке CD длиной L. Пусть эксперимент A заключается в измерении
длины отрезка CM с помощью линейки, дающей ошибку ∆. Чему равна информация I(A : B), содержащаяся в результате измерения положения точки Q.
Решение. В данном случае оба эксперимента могут иметь бесконечное число исходов, поскольку, например, положение точки Q может совпадать с любой точкой отрезка CD. Чтобы обойти эту трудность,
можно считать, что длины L и ∆ соизмеримы. Это означает, что можно выбрать маленький отрезок ²,
квант длины, такой что он целиком уложится на L и ∆, при этом оба отношения L/² и ∆/² будут целыми
числами. Тогда положение Q будет определяться с точностью ². Поскольку заранее известно, что точка Q
расположена где-то на отрезке CD, то эксперимент B имеет L/² равновероятных исходов с вероятностью
p = ²/L. Поэтому энтропия равна H(B) = log l/². После того, как проведен эксперимент A, где измеряют
длину CQ, установлено, что точка Q может находиться в окрестности CQ ± ∆. Эта окрестность имеет
размер 2∆, поэтому эксперимент A имеет 2∆/² исходов с вероятностью ²/2∆. Тогда условная энтропия
H(B|A) = log(²/2∆), а количество информации, полученной в результате измерения равно
I(A : B) = H(B) − H(B|A) = log
L
.
2∆
Отсюда следует, что количество информации не зависит от ², поэтому приведенный вывод будет справедлив в общем случае. Количество информации определяется отношением L/2∆, которое будет возрастать
с уменьшением ∆, т. е. с увеличение точности измерения. ¤
16
2.5
Иерархическая аддитивность
Свойство иерархической аддитивности. Пусть X1 , . . . Xn , случайные величины, тогда
H(X1 , X2 . . . Xn ) = H(X1 ) + H(X2 |X1 ) + . . . H(Xn |X1 , X2 , . . . Xn−1 ).
(58)
Здесь энтропия H(Xn |X1 , X2 , . . . Xn−1 ) определяется условной вероятностью p(xn |x1 , x2 . . . xn−1 ), которая
показывает вероятность значения xn , если случились значения x1 , x2 . . . xn−1 . Соотношение (58) вытекает
из свойства условной вероятности
p(x1 . . . xn ) = p(xk . . . xn |x1 . . . xk−1 )p(x1 . . . xk−1 ), k ≤ n,
p(x1 . . . xn ) = p(x1 )p(x2 |x1 ) p(x3 |x1 x2 ) . . . p(xn |x1 . . . xn−1 ).
|
{z
}
(59)
p(x1 ,x2 )
2.6
Энтропийные свойства секретных систем
Использование введенного понятия энтропии для анализа секретных систем позволяет установить свойства совершенной секретности.
Секретные системы с одним ключом можно описать тремя случайными величинами
M = {m, p(m); |M |},
D = {d, p(d); |D|},
K = {k, p(k); |K|},
(60)
где M – множество сообщений, D – множество криптограмм, K – множество ключей. Ключ k, который используется с вероятностью p(k), определяет процесс шифрования Ek : m → d и расшифрования
Dk : d → m, где Dk Ek = 1, чтобы прочитать сообщение. Поскольку для шифрования и расшифрования
используется один ключ, то секретная система называется симметричной 4 . Важным свойством секретной
системы является ее стойкость против атак противника.
При математической оценке стойкости считают, что противник имеет неограниченные вычислительные
ресурсы и неограничен во времени. В результате атаки противник может перехватить сообщение или
криптограмму, вычислить вероятности p(m|d), p(d|m) и определить H(M |D) и H(D|M ).
Справедливо следующее определение (Шеннон 1949). Система называется совершенно секретной, если
H(M |D) = H(M ).
(61)
Это условие означает, что неопределенность или информация о сообщении не изменяется, если известна
криптограмма. Другими словами, перехваченная криптограмма не добавляет никаких новых сведений о
сообщении. Из (61) следует, что M и D независимы, поэтому для совершенно секретных систем
H(D|M ) = H(D),
I(M : D) = 0.
(62)
Здесь первое равенство означает, что перехваченное сообщение не добавляет никаких новых сведений
относительно криптограммы.
Используя свойство иерархической аддитивности (58), можно получить связь между длиной ключа и
длиной сообщения. Для безусловной энтропии H(D, M, K) следует выражение
H(D, M, K) = H(D) + H(M |D) + H(K|M, D).
(63)
H(D, M, K) = H(D) + H(K|D) + H(M |M, K),
(64)
Заменив K ↔ M , найдем
4В
несимметричных системах, например RSA, ключи для шифрования и расшифрования разные.
17
где H(M |K, D) = 0, поскольку при фиксированном ключе и фиксированном сообщении само сообщение
m = Dk d не является случайной величиной. Тогда, вычитая (64) и (63), найдем
H(M |D) = H(K|D) − H(K|M, D).
(65)
Поскольку H(K|D) ≤ H(K), а для совершенно секретных систем H(M |D) = H(M ), то (65) принимает
вид
H(M ) ≤ H(K).
(66)
Выражения для энтропии H(M ) и H(K) можно записать как произведение числа букв на энтропию одной
буквы, тогда
nM log NM ≤ nK log NK ,
(67)
где nM , nK – длина сообщения и длина ключа, NM , NK – количество букв в алфавите сообщения и ключа.
Для бинарного алфавита NM = NK = 2, тогда
nM ≤ nK .
(68)
Это условие означает, что для совершенно секретной системы длина ключа должна быть не меньше длины
сообщения, а ключ должен представлять собой случайную последовательность из 0 и 1 и использоваться
только один раз (Шеннон, 1949).
Примером совершенно секретной симметричной системы является шифр Вернама, известный как одноразовый блокнот (one time pad). В этой системе сообщение и ключ, который представлен случайной
двоичной последовательностью, имеют одинаковые длины, а правило шифрования имеет вид d = m + k,
где сложение осуществляется по mod 2. Например, m = 0100111, k = 0010110, тогда d = 0110001.
Можно ли взломать совершенно секретную систему? Ответ положительный. Для этого нужно угадать
секретный ключ, который представляет собой двоичную строку пусть длиной n, взятую случайным образом из множества всевозможных последовательностей {0, 1}n . Общее число всех последовательностей
равно C = 2n , вероятность угадать нужную последовательность p = 1/2n . При n À 1 вероятность угадывания p → 0, однако можно заняться перебором всех вариантов, число которых C → ∞. Поскольку C
имеет экспоненциальную зависимость от n, то с точки зрения теории вычислений такая задача считается
трудной или NP задачей. Решение NP задач требует больших вычислительных ресурсов. Поэтому при
n À 1 для решения задачи может потребоваться слишком много времени или неоправданное количество
ресурсов.
2.7
Энтропия и термодинамика
Понятие энтропии в термодинамику было введено Больцманом для описания физических систем. Согласно одной из формулировок II Начала термодинамики замкнутая система может развиваться только по
пути увеличения энтропии. Это утверждение согласуется со свойством субаддитивности для энтропии
двух систем:
H(X, Y ) ≤ H(X) + H(Y ).
(69)
В общем случае есть два подхода для описания эволюции: 1) метод открытых систем, 2) метод замкнутых
систем. В первом есть две взаимодействующие системы A и E, где E - окружение, и рассматривается
эволюция A. Во втором случае есть одна большая замкнутая система. Чтобы описать ее часть вводят
грубый временной или пространственный масштаб, который позволяет записать замкнутые уравнения
известные в физике как кинетические.
Рассмотрим две системы A и E, которые вначале были независимые. Для них
H(A, E) = H(A) + H(E).
(70)
За счет взаимодействия, которое в самом общем случае описывается унитарным оператором U : U U † = 1,
состояние систем изменяется: A → A0 , E → E 0 . Из физики известно, что при унитарном преобразовании
энтропия не изменяется, поэтому H(A, E) = H(A0 , E 0 ). Кроме того из-за взаимодействия системы не будут
независимыми, тогда
H(A) + H(E) = H(A0 , E 0 ) ≤ H(A0 ) + H(E 0 ).
Это означает, что в результате эволюции энтропия всего мира может только увеличиваться.
18
(71)
3
3.1
Источник дискретных сообщений
Статистическая модель ИДС
В качестве источника сообщений может выступать текст. В основе статистического описания источника
сообщений лежит следующее свойство. Текст, составленный из букв, представляет собой случайный процесс, где буквы встречаются со своей вероятностью.
Пусть X = {x1 , . . . xN } алфавит источника. Если он содержит конечное число букв 2 ≤ N < ∞, то говорят
об источнике дискретных сообщений (ИДС). Помимо алфавита ИДС задается множеством сообщений
M = {m; p(m), |M |},
(72)
где каждое сообщение представляет последовательность из n символов
m = s1 . . . sn ∈ {x1 . . . xN }n ,
а каждый символ sk = x1 , . . . , xN , k = 1, . . . n.
Сообщение m описывается набором из n случайных величин s1 , . . . , sn и характеризуется своей вероятностью p(m), которая определяется n – мерной вероятностью p(s1 , . . . , sn ). Различают два типа ИДС: без
памяти и с памятью. Для ИДС без памяти все символы независимы, поэтому
p(s1 , . . . , sn ) = p(s1 )p(s2 ) . . . p(sn ).
(73)
Для ИДС с памятью это не так, поскольку в осмысленном языке между буквами есть связь. Так, сочетание
"ий"встречается часто, а "иы"никогда.
В общем случае для многомерных вероятностей следует правило самосогласования
X
p(s1 , . . . , sk ) =
p(s1 , . . . , sk , sk+1 , . . . , sn ).
(74)
k+1...n
Условные вероятности определяются соотношением
p(s1 , . . . , sk |sk+1 , . . . , sn ) =
p(s1 , . . . , sn )
.
p(sk+1 , . . . , sn )
(75)
Если в алфавите ИДС две буквы (N = 2), то сообщение представлено набором нулей и единиц
n
m = 00110
| {z. . . 0} ∈ {0, 1} .
(76)
n
Для фиксированного n будет 2n различных сообщений. Количество сообщений длиной n, в которых содержится b единиц, равно
Cbn =
n!
b!(n − b)!
(77)
Pn
Очевидно, что b=0 Cbn = 2n . Если символы независимы, что справедливо для ИДС без памяти, и p(1) =
p, p(0) = q = 1 − p, то вероятность сообщения длиной n с числом единиц b равна
p(m) = pb (1 − p)n−b .
(78)
Для источника с алфавитом из N букв число различных сообщений длиной n равно N n . Так, если N = 33,
то число слов длиной n равно 33n , однако, говорят, что при n À 1 из этого набора только 2n слов
оказываются осмысленными.
3.2
Свойства энтропии ИДС
Энтропия ИДС H(M ) определяется как энтропия, содержащаяся в сообщении m = s1 . . . sn , где каждый
символ представляется одной из букв алфавита sk = x1 . . . xN . Функция H(M ) описывает энтропию n
случайных величин
H(M ) = H(s1 , . . . , sn ).
Для H(M ) справедливы следующие свойства.
19
(79)
1. Неотрицательность. Энтропия H(M ) ≥ 0 и обращается в ноль для вырожденного распределения:
p(xq ) = 1, p(xk ) = 0, k 6= q.
2. Для алфавита ИДС с мощностью N максимальное значение
max H(s) = log N
(80)
достигается при равномерном распределении символов p(xk ) = 1/N, k = 1 . . . n. Для доказательства
можно воспользоваться неравенством Йенсена: E{f (w)} ≤ f (E{w}), которое справедливо для любой
случайной величины w и произвольной выпуклой вверх функции f (w). Полагая w = 1/p(x), f (w) =
00
log w, где f = −1/(x2 ln 2) < 0 выпуклая вверх функция, найдем, что E{f (w)} = H(p(x)), E{w} =
N , f (E{w}) = log N .
3. Аддитивность. Если два символа s1 и s2 независимы, то совместная энтропия равна сумме энтропий
H(s1 , s2 ) = H(s1 ) + H(s2 ).
(81)
Для доказательства достаточно заметить, что p(s1 , s2 ) = p(s1 )p(s2 ).
4. Для ИДС без памяти
H(s1 , . . . sn ) = H(s1 ) + . . . H(sn ) = nH(s).
(82)
Отсюда следует, что количество информации в сообщении m длиной n будет
H(m) ≤ n log N.
3.3
(83)
Асимптотические свойства стационарного ИДС
Если буквы ИДС имеют неравномерное распределение, что характерно для осмысленного текста, то множество всех сообщений можно разделить на два подмножества, в одном из которых содержится высоковероятные сообщения, число которых определяется количеством информации, содержащимся в сообщении.
Это свойство является основой оптимального кодирования и сжатия информации.
Пусть алфавит ИДС без памяти состоит из двух букв 0 и 1. Пусть буквы случаются с вероятностями
p(0) = q, p(1) = p, p + q = 1. Положим q > p, это означает, что p < 1/2. Противоположный случай p > 1/2
получается простым переобозначением 0 ↔ 1. Пусть рассматриваемый источник генерирует сообщение
длиной n
m = s 1 . . . sn ,
(84)
где каждый символ принимает два значения sk = 0, 1, k = 1, . . . n.
Неравномерность появления символов, что свойственно для осмысленных текстов, означает, что есть сообщения, которые встречаются часто или редко. Если b – число единиц в сообщении m, то его вероятность
будет p(m) = pb q n−b . Максимальную вероятность pmax будет иметь последовательность, составленная из
одних нулей, а минимальную pmin – из одних 1. Их отношение
³ q ´n
pmax
rn =
=
(85)
pmin
p
быстро растет при n → ∞. Это означает сильное различие между высоко- и низковероятными сообщениями. С практической точки зрения этим свойством можно воспользоваться для задач кодирования информации, сопоставляя высоковероятным сообщениям короткие кодовые слова, а низковероятным длинные.
Тогда при передачи больших сообщений будет выигрыш. Указанное наблюдение является основой следующей теоремы.
Теорема. Все сообщения {0, 1}n ИДС без памяти можно представить в виде суммы двух неперсекающихся подмножеств
[
\
A B = {0, 1}n , A B = 0
(86)
так, что при n → ∞ выполняются два свойства
1) сообщения из A имеет исчезающе малую вероятность:
m ∈ A, p(m) → 0,
20
(87)
2)сообщения из множества B относительно равновероятны:
¯ log p(m) − log p(m0 ) ¯
¯
¯
m, m0 ∈ B ¯
¯ → 0.
log p(m)
(88)
Доказательство. Пусть b число единиц в сообщении m. Эту величину можно представить как сумму n
случайных величин:
b=
n
X
sk ,
(89)
k=1
где sk = 0, 1. Среднее значение b определяется выражением
X
hbi =
hsk i = n[0q + 1p] = np.
k
Дисперсию b можно вычислить следующим образом:
X
X
X
σb2 = hb2 i − hbi2 =
hsk sk0 i − n2 hsi2 =
hsk ihsk0 i +
hs2k i − n2 hsi2
kk0
2
k6=k0
2
2
2
2
k
2
= n(n − 1)hsi + nhs i − n hsi = n(hs i − hsi ) = n(p − p2 ) = npq,
где использовано, что ИДС не обладает памятью.
Используя неравенство Чебышева
P (|hbi − b| > ²) ≤
σb2
²2
(90)
и полагая ² = n3/4 , найдем, что вероятность с которой b отклоняется от своего среднего значения больше,
чем на величину n3/4 будет
pq
P (|hbi − b| > n3/4 ) ≤ √ .
n
(91)
Тогда можно построить два искомых множества
A = {m : b ∈ [hbi ± n3/4 ]},
B = {m : b ∈ [hbi ± n3/4 ]}.
(92)
√
Из неравенства Чебышева (91) следует, что для всех сообщений m ∈ A вероятность p(m) ≤ pq/ n → 0
при n → ∞, что доказывает свойство 87.
Определим сообщения из множества B, которые имеют максимальную и минимальную вероятность. В
них число число единиц будет b− и b+ соответственно, где b± = np ± n3/4 . Для произвольного m ∈ B
число единиц b можно взять виде b = hbi + u, где |u| ≤ n3/4 и hbi = np. Тогда
max p(m) = pb− q n−b− ,
min p(m) = pb+ q n−b+ ,
p(m) = phbi+u q n−hbi−u .
(93)
¯ log max p(m) − log min p(m) ¯ ¯
¯
2n3/4 log(p/q)
¯
¯ ¯
¯
¯
¯=¯
¯ → 0,
log p(m)
n log q + (np + u) log(p/q)
(94)
В результате найдем
при n → ∞, что и завершает доказательство. ¤
Поскольку все последовательности в B имеют сравнительно одинаковую вероятность, то можно оценить
их число как 1/p(m).
Теорема. При n → ∞ для мощности множества всех высоковероятных сообщений B справедлива оценка
log |B| = nH(p),
21
(95)
где H(p) = −p log p − q log q = − log pp q q – количество информации в одном символе алфавита ИДС.
Доказательство. Для любого сообщения из B число единиц b = np + u, где |u| ≤ n3/4 . Тогда
p(m) = pnp+u q n−np−u = pnp q n(1−p) (p/q)u = 2−n[H(p)−(u/n) log(p/q)] .
Поскольку в пределе u/n = (1/n1/4 ) → 0, то
p(m) → 2−nH(p) .
(96)
Тогда |B| = 1/p(m) = 2nH(p) . ¤
Отсюда следует, что доля всех заслуживающих внимание сообщений будет равна
fn = |B|/2n = 2n[H(p)−1] .
(97)
Поскольку H(p) ≤ 1, то fn будет маленькой величиной, если n À 1. Так, полагая p = 0.1 и n = 100,
найдем, что доля сообщений, заслуживающих внимание, составляет 10−16 .
4
4.1
Кодирование дискретного источника
Кодирование и дихотомия
Кодирование можно рассматривать как преобразование сообщений.
ИДС генерирует множество сообщений, представляющих текст, который затем преобразуется кодером.
Кодирование необходимо для: 1) хранения информации, при этом осуществляется сжатие данных, 2)
для передачи информации через канал связи, 3) для защиты информации путем шифрования. Интерес
представляют оптимальные коды, которые экономят место и время, например, ячейки памяти и время
передачи данных.
В общем случае преобразование кодирования имеет вид
m ∈ {x1 . . . xN }n → d ∈ {y1 . . . yL }l ,
(98)
где каждому сообщению ИДС длиной n сопоставляется кодовое слово d, составленное из l букв нового
алфавита y1 . . . yL . Таким образом возникает множество кодовых слов или код D = {d; p(d), |D|}.
Часто используется двоичное кодирование, связанное с принципом дихотомии, который применяется для
решения различных задач. Рассмотрим пример. Пусть нужно угадать некоторое число от 0 до N − 1, если
ответ на вопрос имеет только две формы "да"и "нет"Пусть N = 8. Согласно принципу дихотомии нужно
разбить интервал пополам и выяснить в какой из половинок, [0; 3] или [4; 7], лежит неизвестное число.
Для этого можно задать вопрос "находится ли задуманное число в интервале [0; 3]?"Если оно лежит в
[4; 7], то следует разделить интервал [4; 7] еще раз пополам и выяснить, лежит ли неизвестное число в
[4; 5] или [6; 7]. И так далее. Пусть ответы "да"кодируются символом 0, а "нет"символом 1. Пусть было
задумано число 5. Для него возникает последовательность 101, которая означает, что 5 ∈ [0; 3] – нет = 1,
5 ∈ [4; 7] – да = 0 и 5 6= 4 – нет = 1 Последовательность 101 является двоичным представлением числа
5, а общее количество вопросов в среднем будет равно log N = log 8 = 3. В данном случае каждое из
чисел кодируется своим двоичным представлением. Вместо чисел можно взять N различных сообщений
и поставить им в соответствие двоичную последовательность длиной log N . Другими словами, любую
последовательность из N символов можно закодировать с помощью log N бит.
4.2
Коды с фиксированной длиной
Пусть все кодовые слова имеют одинаковую длину. Два примера. ASCII (American Standard Code for
Information Interchange) – Американский стандартный код для обмена информацией) на каждый символ
отводится байт (8 бит), что позволяет закодировать 28 = 256 символов. Но чтобы построить однозначное
соответствие для всех букв из множества национальных алфавитов народов мира, требуется по крайней
мере 16 бит на символ, что обеспечивает стандарт Unicode, где возникает возможность закодировать
216 = 65536 букв.
Из требования однозначности кодирования можно установить основные свойства кодов с фиксированной
длиной. Для этого преобразование (98) запишем в виде
mn = s1 . . . sn → dl = q1 . . . ql .
22
(99)
Для однозначного соответствия число сообщений, равное N n , должно быть не меньше, чем число кодовых
слов Ll : N n ≤ Ll или
n log N ≤ l log L,
(100)
где n – длина сообщения, l длина кодового слова, N, L – число букв в алфавите ИДС и кодера. Из условия
однозначного соответствия возникают следующие свойства.
1. Длина кодового слова в расчете на один символ сообщения ограничена снизу
l
log N
≥
.
n
log L
2. Поскольку максимальное значение энтропии ИДС max H(m) = n log N и кодера max H(d) = l log L,
то количество информации в кодовом слове не меньше, чем в сообщении
H(m) ≤ H(d).
3. Полагая n = 1, L = 2, имеем двоичное кодирование букв алфавита ИДС
xk → {0, 1}l .
(101)
l ≥ log N.
(102)
Для него
Отсюда следует значение длины кодового слова на одну букву.
Неравенство (102) приводит к важному свойству: коды с фиксированной длиной оказываются расточительными.
Для примера рассмотрим кодирование алфавита, в котором число букв N = 34 = 33+ пробел. В этом
случае l ≥ log 34 > 5. Пусть l = 6, или 6 бит на букву. Тогда
0
1
...
33
...
63
a
б
...
пробел
...
...
000000
000001
...
100001
...
111111
Декодирование осуществляется простым разбиением последовательности двоичных символов на блоки из
6 символов. Из-за неэффективности такого кодирования вместо 34 букв можно закодировать 64 символа.
Компактное кодирование осуществляется, если выполняется равенство l = log N , при котором число
букв в алфавите равно целой степени двойки: N = 2l . Для этого можно, например, принять некоторые
соглашения, считая, скажем, буквы "е "ё"и знаки "ъ "ь"неразличимыми. Тогда N = 34 − 2 = 32 = 25 .
4.3
Неравномерное кодирование. Префиксный код
Пусть длина кодового слова будет разной для разных сообщений. Основу такого кодирования составляет неравномерность появления букв в ИДС. Поэтому часто повторяющиеся буквы можно кодировать
короткими последовательностями, а редко повторяющиеся – более длинными. В среднем при большом
количестве сообщений будет возникать экономия при равенстве информации в исходном тексте и коде.
При таком подходе методы кодирования оказываются неоднозначными, но среди них есть оптимальные.
Однако само понятие оптимальности требует уточнения.
Если рассматривать кодирование букв xk , k = 1, . . . N из алфавита ИДС, то при неравномерном кодировании длина кодового слова lk зависит от выбранной буквы:
xk → d = q1 q2 . . . qlk .
(103)
Средняя длина кодового слова будет определяться равенством
X
lcp =
p(xk )lk .
(104)
k
23
При таком преобразовании возникает проблема декодирования, поскольку нужно установить начало и
конец кодового слова. Для этого можно использовать специальный символ "пробел что, однако, приводит
к увеличению средней длины кодового слова. Другой метод заключается в использовании кодов "без запятой".
Коды, где однозначное декодирование осуществляется без помощи разделительных символов, называются
кодами без запятой. Частным случаем являются префиксные коды.
Префиксом называют любую последовательность, составленную из начальной части кодового слова. Так,
префиксом слова q1 . . . qr . . . ql является q1 . . . qr , где r ≤ l.
Код называется префикным, если каждое кодовое слово не является началом никакого другого кодового
слова. Префиксный код является однозначно декодируемым, он отличается от других однозначно декодируемых тем, что конец кодового слова всегда может быть опознан, поэтому декодирование осуществляется
сразу без, задержки.
Какой длины могут быть кодовые слова для однозначного декодирования? Например, префиксного двоичного кода из трех кодовых слов с длинами 1,1 и 2 не существует. Действительно, здесь кодовые слова
нужно взять из набора {0, 1, 00, 01, 10, 11}. Пусть, например, {0, 1, 00}. Тогда кодовое слово 000 при декодировании может быть воспринято неоднозначно: 0 − 0 − 0 или 0 − 00. Однако префиксный код в 100 слов
с длинами от 1 до 100 существует.
4.4
Неравенство Крафта
Длины кодовых слов не могут быть выбраны произвольно, они ограничены условием, которое называется
неравенством Крафта (1949).
Рассмотрим неравномерный код алфавита ИДС, содержащего N букв, с длинами кодовых слов l1 , . . . , lN .
Кодовые слова могут иметь одинаковую длину, например, l1 = l2 . Следующая теорема устанавливает
условия на длины кодовых слов.
Теорема. При двоичном кодировании длины кодовых слов l1 . . . lN удовлетворяют неравенству Крафта
N
X
2−lk ≤ 1.
(105)
k=1
Доказательство. Пусть Nk число кодовых слов с длиной lk = k и пусть C = max lk . Тогда весь код
разбивается на группы слов с одинаковой длиной
l1 . . . lr . . . ls . . . lN ,
| {z }
Nk
PC
и k Nk = N .
Для фиксированного значения k число различных кодовых слов Nk ограничено: Nk ≤ 2k . Однако для
префиксного кода это неравенство следует уточнить. Для заданных значений N1 , . . . Nk−1
Nk ≤ 2k − 2Nk−1 − 22 Nk−2 · · · − 2k−1 N1 .
(106)
Это неравенство можно представить в виде
k
X
2k−j Nj ≤ 2k .
(107)
j=1
Сокращая обе части на 2k и полагая k = C, найдем
C
X
2−lk Nk =
N
X
2−lk ≤ 1.
(108)
k=1
k=1
¤
Обобщение на алфавит кодера, содержащего L букв дает
N
X
L−lk ≤ 1.
k=1
24
(109)
Вывод неравенства Крафта приведен для префиксного кода, однако оно справедливо для любого кода без
запятой.
На основе неравенства Крафта можно сформулировать следующую теорему о существовании префиксного
кода.
Теорема. Если целые числа l1 . . . lN удовлетворяют неравенству
N
X
L−lk ≤ 1,
(110)
k=1
то существует префиксный код с алфавитом из L символов и длинами кодовых слов l1 . . . lN . При L = 2
возникает двоичный код.
Верно и обратное утверждение: длины кодовых слов любого префиксного кода удовлетворяют неравенству (110).
Нужно заметить, что приведенная теорема не утверждает, что любой код с длинами (110) является префиксным, она устанавливает существование префиксного кода, являясь лишь необходимым условием.
N Пример. Два двоичных кода, которые удовлетворяют неравенству Крафта: K1 = {0, 00, 11} и K2 =
{0, 10, 11}. Здесь l1 = 1, l2 = l3 = 2 и 2−1 + 2 · 2−2 = 1. Однако в отличие от K2 код K1 не является
префиксным. ¤
4.5
Построение префиксного кода
Для построения префиксного кода удобно использовать кодовое дерево.
Кодовое дерево имеет высоту, равную максимальной длине кодового слова C = max Ck . При двоичном
кодировании у дерева из корня, это нулевой этаж, идут две ветви, которым присваивают значения 0 и 1.
На первом этаже есть две концевые вершины, из каждой идут две ветви, этим ветвям также присваивают
значения 0 и 1. На этаже k, где k = 1, . . . C имеется 2k вершин, из каждой вершины идут две ветви.
Для построения префиксного кода нужно выбрать Nk слов с длиной lk . Это означает, что на первом
этаже фиксировано N1 концевых вершин, на втором этаже фиксировано N2 концевых вершин и т. д. Из
неравенства (106) следует
Nk ≤ 2k − 2k−1 N1 − 2k−2 N2 · · · − 2Nk−1 .
(111)
При k = 1 получим N1 ≤ 2, что не превосходит общего числа вершин на 1 этаже. Значит на этом этаже
можно выбрать число концевых вершин N1 = 0, 1, 2. Если это сделано, то их общего числа вершин на
2 этаже останется N2 ≤ 4 − 2N1 . Если фиксировать число N2 , то на 3 этаже число концевых вершин
будет N3 = 8 − 2N2 − 4N1 . Выбранные концевые вершины являются кодовыми словами, которым можно
поставить в соответствие последовательность двоичных символов.
N Пример. Пусть максимальная длина кодовых слов равна 2. Пусть фиксирована одна вершина на первом этаже N1 = 1 и две вершины на втором этаже N2 = 2. Тогда возникает набор из трех кодовых
слов, отвечающих одной вершине на первом этаже – слово "1 и двум вершинам на втором этаже по ветви "0.. которыми являются слова "00 "01". Кодовый набор 1, 00, 01 является префиксным, и им можно
закодировать какие-нибудь три символа исходного текста. ¤
4.6
Полнота префиксного кода и обезьяна
Префиксный код называется полным, если добавление к нему нового кодового слова нарушает префиксность. Пусть, к примеру, буквам A, B и C сопоставлены кодовые слова 1, 00, 01. Тогда любая попытка
закодировать еще одну букву приведет к нарушению свойства префиксности, поскольку кодирование будет осуществляться через ветвь 1, либо через 0, поэтому, например, слово 1 может стать началом нового
кодового слова 11. Это означает, что код 1, 00, 01 является полным. Напротив код 00, 01, 10 неполный, поскольку через ветвь 11 . . . можно закодировать новые буквы не нарушая свойство префиксности. Неполным также является код 1, 000, 001.
На практике наибольший интерес представляют полные коды, поскольку средняя длина их кодовых слов
оказывается меньше, чем у неполных кодов. Полноту префиксного кода устанавливает следующая теорема.
Теорема. Префиксный код является полным тогда и только тогда, когда неравенство Крафта становится равенством
d−l1 + d−l2 + · · · + d−lN = 1.
(112)
25
Доказательство. Пусть d = 2, что отвечает двоичному кодированию. Рассмотрим дерево, которое описывает полный префиксный код. Пусть на дерево взбирается обезьяна. Начав с корня, она выбирает любую
из d = 2 двух исходящих из него ветвей. Вероятность выбора равна 1/2. Добравшись до очередной развилки, она вновь выбирает одну из двух ветвей с вероятностью 1/2. Тогда с вероятностью (1/2)k обезьяна
окажется на этаже k и достигнет какой-нибудь концевой вершины. Если таких вершин Nk , то с вероятностью Nk 2−k обезьяна останется на высоте k. Обезьяна может остановиться на любом
этаже, поэтому
P
вероятность найти ее на дереве равна 1. С другой стороны, эта вероятность равна k Nk 2−k = 1, что и
завершает доказательство ¤.
Из приведенного доказательства легко увидеть, где использовано условие полноты префиксного кода.
Если код полный, то на любом этаже кодового дерева есть хотя бы одна концевая вершина, которая
отвечает кодовому слову. Поэтому обезьяна может остановиться на любом из этажей. В рассмотренных
выше примерах код 1, 00, 01 полный: одна концевая вершина на первом этаже и две – на втором. Код
00, 01, 10 неполный: на 1 этаже нет фиксированных концевых вершин. Код 1, 000, 001 также неполный, в
его кодовом дереве отсутствуют фиксированные вершины на 2 этаже.
4.7
Код Фано
Код Фано является префиксным полным кодом. Метод кодирования осуществляется по следующей схеме.
1. Расположить буквы алфавита исходного текста в порядке убывания их вероятностей.
2. Разделить все буквы на два множества так, чтобы сумма вероятностей всех букв в первом и сумма
вероятностей букв во втором множестве были бы приблизительно одинаковы.
3. Одному из множеству присвоить значение 0, другому 1.
4. Рассматривая каждое из двух множеств, как исходное, осуществить операции, указанные в пп. 2 и
3.
5. Процесс продолжается, пока в очередном подмножестве не останется одна буква.
6. Каждой букве приписывается двоичный код, состоящий из последовательностей нулей и единиц,
встречающихся на пути из исходного множества.
Пользуясь этим методом можно построить следующий код для 8 символов xk , k = 1 . . . 8 с вероятностями, указанными в таблице
xk p( xk )
lk lp
x1 0, 44 0 0
00 000
x2 0, 08 0 1
01 001
x3 0, 08 1 0 0 0 1000 010
x4 0, 08 1 0 0 1 1001 011
x5 0, 08 1 0 1
101 100
x6 0, 08 1 1 0 0 1100 101
x7 0, 08 1 1 0 1 1101 110
x8 0, 08 1 1 1
111 111
P
Средняя длина кодового слова l = k p(xk )lk = 2, 8 будет меньше на 7 %, чем при равномерном кодировании, где на букву требуется 3 двоичных символа.
4.8
Код Хаффмана
Метод Хаффмана (1952) обеспечивает наименьшую возможную при побуквенном кодировании длину кодового слова. В этом смысле он является оптимальным.
Кодирование осуществляется по следующей схеме.
1. Расположить буквы алфавита исходного текста списком в порядке убывания их вероятностей. Двум
буквам с самой низкой вероятностью присваиваются значения 0 и 1.
2. Процедура повторяется снова, но две буквы, которым на предыдущем шаге присвоены значения 0
и 1 участвуют как одна с вероятностью, равной сумме вероятностей.
26
3. Процедура продолжается до тех пор, пока в списке не остается одна буква с вероятностью, равной
1.
4. Кодовое слово определяется следующим образом. Начиная с последнего списка рассматривают только те буквы, которые занимают два последних места. Если в указанном месте очередного списка
встречается интересующая буква, которая может входить в состав сложной буквы, то в очередном
разряде кодового слова записывается присвоенный ей двоичный символ. Процесс продолжается до
тех пор, пока в очередном списке буква не встретится в сольном варианте.
Пусть требуется построить код для 8 символов xk ,
Первые два шага
x1 0, 44
x2 0, 08
x3 0, 08
x4 0, 08
x5 0, 08
x6 0, 08
x7 0, 08 0
x8 0, 08 1
k = 1 . . . 8 с заданным распределением вероятностей.
x1
(x7 x8 )
x2
x3
x4
x5
x6
0, 44
0, 16
0, 08
0, 08
0, 08
0, 08
0, 08
0
1
Следующие два шага
x1
(x7 x8 )
(x5 x6 )
x2
x3
x4
0, 44
0, 16
0, 16
0, 08
0, 08
0, 08
x1
(x7 x8 )
(x5 x6 )
(x3 x4 )
x2
0
1
0, 44
0, 16
0, 16
0, 16 0
0, 08 1
Еще пара шагов
x1
(x2 x3 x4 )
(x5 x6 )
(x7 x8 )
0, 44
0, 24
0, 16
0, 16
x1
0, 44
(x5 x6 x7 x8 ) 0, 32 0
(x2 x3 x4 )
0, 24 1
0
1
Последний шаг
(x2 x3 x4 x5 x6 x7 x8 ) 0, 56 0
x1
0, 44 1
Итогом является код
Средняя длина кодового слова составляет l =
l = 2, 8.
4.9
x1
x2
x3
x4
x5
x6
x7
x8
P
1
011
0100
0101
0000
0001
0010
0011
k
p(xk )lk = 2, 6 против средней длины в схеме Фано
Оптимальный код
Оптимальный код обладает наименьшей длиной кодового слова. Такой код может быть не единственным,
однако для него можно сформулировать некоторые общие свойства.
Пусть алфавит исходного текста x1 , x2 . . . xN имеет вероятности p1 ≥ p2 ≥ · · · ≥ pn , где pm = p(xm ), и
кодируются двоичными словами длиной l1 , l2 . . . lN . Оптимальный код имеет следующие свойства.
1. Менее вероятный символ не может кодироваться более коротким словом.
2. Всегда можно так переименовать символы и соответствующие им кодовые слова, что
p1 ≥ · · · ≥ pN при l1 ≤ · · · ≤ lN .
27
3. В оптимальном двоичном коде всегда найдется по крайней мере два слова наибольшей длины, равной
lN , которые отличаются друг от друга в последнем символе.
Приведем некоторые пояснения.
Относительно свойства 1 заметим. Пусть проведено кодирование xk , pk → lk , и xm , pm → lm . Оно оптимальное, если pk > pm , и lk < lm . Для выбранного оптимального кодирования средняя длина кодового
слова будет lcp = pk lk +pm lm . Заменим lk ↔ lm . Это означает, что часто встречающемуся символу xk будет
сопоставлено более длинное кодовое слово lm > lk . При таком кодировании средняя длина кодового слова
0
0
будет lcp
= pk lm + pm lk . Видно, что длина кодового слова lcp
− lcp = (lm − lk )(pm − pk ) > 0 увеличивается.
Что касается свойства 2, то нужную нумерацию можно получить путем переобозначения символов. Тогда
символ с наименьшей вероятностью xN будет кодироваться самым длинным словом lN . Если свойство
3 не выполняется, то оба слова с наибольшей длиной содержат одинаковые символы. Тогда можно откинуть последний символ кодового слова не нарушая префиксности. В результате длина кодового слова
уменьшилась бы, что противоречит оптимальности.
Код Хаффмена является оптимальным.
4.10
Сжатие текстов
Простым примером сжатия является сокращение слов при письме. Это оказывается возможным, поскольку в словах есть избыточная информация. Под сжатием понимают кодирование, при котором сжатый блок
содержит меньше битов, чем исходный, но возможно однозначное декодирование. В практике используются следующие термины: кодирование/декодирование, сжатие/разжатие, компрессия/декомпрессия,
упаковка/распаковка.
Различают следующие типы сжатия: 1) без потерь, 2) с потерями. Сжатие с потерями содержит два этапа. Вначале выделяется часть информации на основе некоторых критериев и модели источника, затем
выделенная информация сжимается без потерь. Далее будет рассматриваться сжатие без потерь.
Основой сжатия, которое является частным случаем кодирования, служит неравномерность появления
символов в осмысленном тексте, где в качестве текста может выступать графическое изображение. Тогда
часто встречающиеся элементы кодируются более короткими кодовыми словами. В результате для хранения и передачи информации потребуется меньше места и времени.
Исходя из условий декодируемости можно получить довольно общие свойства процесса сжатия. Так справедливо следующее свойство.
Свойство. Ни один компрессор не может сжать любой файл. После обработки компрессором часть
файлов уменьшается, а оставшаяся часть либо увеличивается, либо не изменяется.
Доказательство. Это утверждение можно доказать в самом общем случае, однако мы ограничимся простой иллюстрацией. Если n длина файла или сообщения, то всего будет 2n различных сообщений. Если
каждое сообщение уменьшилось на 1 бит, их длина стала n−1, а общее число 2n−1 , что в 2 раза меньше исходного числа сообщений. При таком сжатии 2n элементов преобразуется в 2n /2, поэтому двум исходным
сообщениям ставится в соответствие одно. Откуда следует невозможность однозначного декодирования.
¤
Благодаря указанному свойству не существует "вечного архиватора"который сжимает до бесконечности
свой архив. Наилучшим архиватором является копирование, поскольку объем данных при таком преобразовании не увеличивается.
Заметим, что в русском алфавите максимальное количество информации в букве log 32 = 5 бит, в кодировке ASCII на символ приходится 8 бит, а в Unicode – 16 бит. Однако эти значения справедливы,
если считать что все буквы появляются одинаково часто, что не так для осмысленного текста, который
обладает большой избыточностью.
4.11
Предельное сжатие
Условие однозначного декодирования означает, что исходная информация не должна уменьшиться. Это
согласуется с известным принципом физики о возрастания энтропии. Используя это условие можно пояснить наличие предела для сжатия информации.
При двоичном побуквенном кодировании xk → lk в кодовом слове должно содержаться
информации не
P
меньше, чем в букве исходного текста. Средняя длина кодового слова lcp = k lk pk показывает, сколько
бит требуется для его записи, или количество информации, которое в нем содержится. Средняя длина
кодового слова будет определяться как методом кодирования, так и количеством информации в исходном
28
символе H(X), при этом
lcp ≥ H(X).
(113)
N Пример. Рассмотрим алфавит из 3 символов, с вероятностями 0, 8; 0, 1; 0, 1. Побуквенное кодирование
по схеме Фано или Хаффмена дает одинаковый результат
x1
x2
x3
0, 8
0, 01
0, 01
0
10
11
Отсюда средняя длина кодового слова или количество бит в кодовом слове равно lcp = 0, 8 + 2 · 0, 1 = 1, 20,
а количество информации в одном символе H(X) = −(0, 8 log 0, 8 + 2 · 0, 1 log 0, 1) = 0, 92, что находится в
соответствии с (113). ¤
N Пример. Однако можно отказаться от побуквенного кодирования и рассмотреть всевозможные пары,
считая для простоты, что они независимы и вероятность каждой пары равна произведению вероятностей.
Будет 9 пар, которые можно рассматривать как символы нового алфавита и построить код
x1 x1
x2 x1
x3 x1
x1 x2
x1 x3
x2 x2
x2 x3
x3 x2
x3 x3
0, 64
0, 08
0, 08
0, 08
0, 08
0, 01
0, 01
0, 01
0, 01
Cхемы Фано и Хаффмена приводят к одинаковой длине кодового слова lcp (2) = 1, 92, но это среднее
число бит на два символа исходного алфавита, поэтому на один символ lcp (2)/2 = 0, 96, что по-прежнему
находится в соответствии с неравенством (113). ¤
Приведенные соображения о предельном сжатии, которые носят качественный характер, можно сформулировать в виде теоремы (Шеннон 1948).
4.12
Предельное сжатие текстов. Теорема Шеннона
Предельное сжатие устанавливается теоремой Шеннона, которая имеет разные формулировки.
P
Теорема. Пусть букве ИДС сопоставляется кодовое слово xk → lk со средней длиной lcp = k lk p(xk ).
Пусть H(X) – энтропия одной буквы ИДС, а алфавит кодера содержит L букв. Тогда
lcp ≥ H(X)/ log L.
(114)
P
Доказательство. Основано на неравенстве Крафта k Llk ≤ 1, и свойстве функции log, согласно которому
log z ≤ (z − 1) loge при z ≥ 0. Пусть L = 2, тогда нужно доказать, что
lcp ≥ H(X).
Рассматривая разность lcp − H(X), найдем
lcp − H(X) =
Xh
i
pk lk + pk log pk
k
=
X
k
=
X
i
h
pk log 2lk + log pk
i
h
pk (−1) log 2−lk /pk
k
h
2−lk i
pk 1 −
log e
pk
k
i
h
X
2−lk log e ≥ 0.
=( 1−
≥
X
k
29
¤
Приведенная теорема (114) имеет довольно простой смысл: количество информации в кодовом слове
lcp log L (напомним, что log L – максимальное количество информации в одной букве алфавита кодера)
должно быть не меньше, чем количество информации H(X) в кодируемом символе ИДC.
Этот результат обобщается на случай любого кодирования, полагая снова, что количество информации в
кодовом слове должно быть не меньше, чем в кодируемом сообщении.
Теорема. При любом кодировании сообщения m = {x1 . . . xN }n средняя длина кодового слова в расчете
на один символ сообщения
lcp /n ≥ H(X)/ log L,
(115)
где H(X) – энтропия буквы алфавита источника.
Вариант этой теоремы был доказан при рассмотрении асимптотических свойств ИДС, где множество всех
сообщений фиксированной длины разделяется на высоковероятное и маловероятное подмножества.
Теорема Шеннона, однако, не дает никакого рецепта, как построить код, для которого lcp = H(X). Она
лишь гарантирует его существование, и устанавливает нижнюю границу, которая определяется энтропией
H(X). Эта граница находится в соответствии с интуитивно ясным требованием: в результате преобразования количество информации или энтропии не должно уменьшится. С другой стороны, это требование
находится в рамках Второго Начала термодинамики, согласно которому энтропия может только возрастать.
N Пример. Для этой теоремы рассмотрим иллюстрацию, которая использует асимптотические свойства
ИДС. Пусть L = N = 2 и двоичное сообщение имеет длину n : m = {0, 1}n . Пусть вероятности появления
символов p(1) = p и p(0) = q, p + q = 1. Тогда в m среднее число "1"будет pn, а среднее число "0"будет
qn. Число различных сообщений длиной n, которые содержат r = pn единиц, равно
K=
n!
.
r!(n − r)!
(116)
Если n велико: n À 1, то для оценки K можно воспользоваться формулой Стирлига log n! ≈ n log n − n,
где n À 1. Тогда из (116) следеут, что
log K ≈ nH(p),
(117)
P
где H(p) = − k pk log pk – энтропия в одной букве алфавита. Весь набор из K сообщений в среднем будет
иметь одинаковую вероятность, равную 1/K = 2−nH(p) , поскольку все сообщения содержат одинаковое
количество "1"и "0". Построенное множество K совпадает с высоковероятным множеством B из теоремы
об асимптотических свойствах ИДС.
Чтобы закодировать K ≈ 2nH(X) элементов с одинаковой вероятностью, потребуется кодовое слово длиной
l = log K ≈ nH(X). В итоге возникает сжатие, поскольку блок длиной n бит преобразуется в кодовое слово
длиной l = nH(p) ≤ n бит в соответствии с (115).
5
5.1
Дискретные каналы
Пропускная способность дискретного канала без памяти
Канал представляет собой физическую систему, которая служит для передачи информации от отправителя к получателю. Закодированные сообщения ИДС поступают в канал, на выходе которого находится
получатель. Каналы связи могут иметь разную природу. Далее будет рассматриваться дискретный канал
без памяти, где символ на выходе в данный момент времени зависит лишь от символа, поступившего на
вход. Если все входные символы воспроизводятся на выходе, то канал называют идеальным или нешумящим. Однако в реальной ситуации всегда существует шум.
Действие канала можно рассматривать как преобразование
T :
X → Y,
(118)
где X = {x1 . . . xN } – случайная величина на входе, а Y = {y1 . . . yM } – случайная величина на выходе.
Это преобразование описывается передаточными функциями p(y|x), которые представляют вероятность
принять значение y, если отправлено значение x. Безусловная вероятность появления символа на выходе
30
будет p(y) =
P
x
p(y|x)p(x). Передаточные функции образуют матрицу передаточную M × N
TM N
p(yM |x1 )
.
...
p(yM |xN )
p(y1 |x1 ) . . .
...
= ...
p(y1 |xN ) . . .
(119)
P
Поскольку p(x, y) = p(y|x)p(x), то отсюда следует, что сумма всех элементов в строке матрицы: y p(y|x) =
1.
Соответствие между посланным и принятым сообщением определяется взаимной информацией или энтропией
I(X : Y ) = H(X) − H(X|Y ) = H(Y ) − H(Y |X).
(120)
Отсюда видно, что условная энтропия H(X|Y ) приводит к уменьшению взаимной информации. Это связано с шумами канала, которые приводят к ошибке при приеме.
Взаимная информация I(X : Y ) зависит от свойств канала, которые описываются p(y|x), и свойств источника сообщений, который определяется вероятностью p(x):
I(X : Y ) =
X
p(x, y) log p(x, y)/p(x)p(y)
x,y
=
X
p(x)p(y|x) log p(y|x)/p(y)
x,y
=
X
p(y|x)
.
p(x)p(y|x)
x
p(x)p(y|x) log P
x,y
Используя это соотношение, взаимную энтропию можно представить как среднее
I(X : Y ) =
X
p(x)I(x : Y ),
x
I(x : Y ) =
X
p(y|x)
.
p(x)p(y|x)
x
p(y|x) log P
y
(121)
(122)
Чтобы описывать свойства только канала, вместо взаимной информации вводится пропускная способность канала.
Пропускная способность равна максимуму взаимной энтропии по всем возможным распределениям источника
C = max I(X : Y ).
p(x)
(123)
Величина C имеет размерность бит/символ и равна количеству полученных бит в расчете на один посланный символ. Если послали один символ, то получили C бит. В идеальном канале все символы на входе
воспроизводятся на выходе без искажения. Для него p(x|y) = δxy , H(X|Y ) = 0 и I(X : Y ) = H(X) = H(Y )
и пропускная
C = max H(X) = log N,
(124)
где N – число букв в алфавите исходного сообщения. Это означает, что будет получено log N бит на один
отправленный символ. Если величины X и Y оказываются полностью независимыми, то H(X|Y ) = H(X)
и взаимная информация равна нулю. В таком канале C = 0, это означает, что шумы настолько велики,
что передавать информацию нельзя.
В общем случае взаимная энтропия H(X|Y ), H(Y |X) ≥ 0, поэтому количество принятой информации
будет меньше, чем в H(X), и соответственно C ≤ H(X). Это означает, что появление символа на выходе
канала не дает получателю с уверенностью судить, какой символ был послан.
31
5.2
Скорость передачи информации
Обычно источник генерирует символы с некоторой скоростью. Пусть T время, которое требуется на передачу одного символа, пусть оно одинаково для всех символов. Если H(X) энтропия на один символ, то
производительность дискретного источника можно определить как энтропию в единицу времени
H 0 (X) =
1
H(X) = υH(X),
T
(125)
где введена скорость передачи символа υ.
Можно определить взаимную энтропию в единицу времени
I 0 (X : Y ) = υ[H(X) − H(X|Y )] = υ[H(Y ) − H(Y |X)],
(126)
которую называют скоростью передачи информации по каналу. Здесь υH(X) – производительность источника, а υH(Y ), называют "производительность"канала. Две условные энтропии υH(X|Y ) и υH(Y |X)
можно рассматривать как потерю информации или ненадежность канала в единицу времени, соотношение между ними зависит от свойств канала.
С помощью (126) можно определить пропускную способность канала в единицу времени или скорость
передачи информации по каналу
C 0 = max I 0 (X : Y ).
(127)
Эта величина имеет размерность бит на переданный символ в секунду: за секунду принимают C 0 бит на
переданный символ. Для C 0 можно указать нижнюю и верхнюю границы
0 ≤ C 0 ≤ υ log N,
(128)
где свое максимальное значение max C 0 = υ log N скорость передачи принимает для канала без шумов.
Заметим, что скорость передачи может зависеть от физических свойств канала. Тогда пропускная способность будет ограничена этой величиной. Так, говорят, что для следующих каналов связи справедливы
оценки для предельных частот. Телеграф – 140 Гц, телефон до 3,1 КГц, короткие волны (10 – 100 м) –
3–30 МГц, УКВ (1–10 м) – 30–300 МГц, спутник (сантиметровые волны) – до 30 ГГц, оптические (инфракрасный дипазон) – 0,15 – 400 ТГц (Тера = 1012 ), оптический (видимый диапазон) – 400–700 ТГц.
Скорость передачи информации измеряется в количестве бит, переданных за одну секунду или в бодах
(baud): 1 бод = 1 бит/с (bps). Производные единицы для бода такие-же как и для бита и байта, например,
10 Kbaud = 1024 baud.
5.3
Вычисление пропускной способности
Пропускная способность C определяется как максимум взаимной энтропии I(X : Y ) по распределению
источника, поэтому для вычисления C нужно найти такое распределение p(x), для которого функционал
I(X : Y ) принимает максимальное значение. С математической точки зрения это задача вариационного
исчисления. Однако при некоторых предположениях можно получить простые рецепты для вычисления
пропускной способности.
Для взаимной информации справедливо выражение (121)
X
I(X : Y ) =
p(x)X(x : Y ),
(129)
x
P
где X(x : Y ) =
y p(y|x) log p(y|x)/p(y). Пусть величина X(x : Y ) не зависит от x. Это означает, что
X(x1 : Y ) = X(x2 : Y ) = . . . Тогда по определению
X
p(x)X(x : Y )
C = max I(X : Y ) = max
p(x)
p(x)
= X(x : Y )
X
x
p(x) = X(x : Y ).
x
В итоге возникает следующее свойство. Если
X(x : Y ) = Const(x),
32
(130)
то пропускная способность определяется выражением
C = X(x : Y ).
(131)
Чтобы воспользоваться найденным рецептом, можно угадать вид распределения p(x), которое приводит
к (130). В ряде случаев удачным оказывается равномерное распределение p(x) = 1/N .
5.4
Симметричные каналы
Если канал обладает свойствами симметрии, то можно получить точные и простые выражения для его
пропускной способности. Так, пропускная способность симметричного канала
C = log M − H(Y |X),
(132)
где M число значений Y .
Симметрия канала определяется его передаточной матрицей
p(y1 |x1 ) . . . p(yM |x1 )
.
...
...
TM N = . . .
p(y1 |xN ) . . . p(yM |xN )
(133)
Далее введем определения канала симметричного по входу и выходу.
Определение. Канал называют симметричным по входу, если любая строка передаточной матрицы получается перестановкой любой другой строки.
Это свойство означает, что все строчки составлены из одного набора элементов: например, (a, b, c), (a, c, b),
(c, b, a). Тогда справедливо следующее.
Свойство. Сумма по всем выходам y от произвольной функции условной вероятности постоянна для
любой строчки
X
f (p(y|x)) = Const(x).
(134)
y
Доказательство. Достаточно заметить, например, что
X
f (p(y|x)) = f (a) + f (b) + f (c).
(135)
y
¤.
Из приведенного свойства следует, что условная энтропия H(Y |X) не зависит от входного распределения
p(x):
X
X
H(Y |X) =
p(x)p(y|x) log p(y|x) = −
f (p(y|x)).
(136)
x,y
y
Тогда для пропускной способности канала симметричного по входу следует выражение
C = max[H(Y ) − H(Y |X)] = max H(Y ) − H(Y |X).
p(x)
p(x)
(137)
Задача определения максимума энтропии H(Y ) на входном распределении p(x) упрощается, если канал
симметричный по входу обладает дополнительной симметрией.
Определение. Канал называют симметричным по выходу, если каждый столбец передаточной матрицы
является перестановкой любого другого столбца.
Это означает, что все столбцы составлены из одного набора элементов, поэтому аналогично (134) справедливо следующее.
Свойство. Для любого столбца сумма от произвольной функции условных вероятностей f (p(y|x)) постоянна и не зависит от y
X
f (p(y|x)) = Const(y).
(138)
x
Следствие. Если канал симметричен по выходу, то равномерное распределение источника X приводит
33
к равномерному распределению Y .
Доказательство. Непосредственно вычисление вероятности на выходе дает
X
X
1
Const(y)
1
p(y) =
p(y|x)p(x) =
p(y|x) =
=
.
N
N
M
x
x
(139)
¤
Определение. Канал называется симметричным, если он симметричен по входу и выходу.
Для симметричного канала пропускная способность определяется (132). Действительно, используя (137)
и (139), найдем
C = max I(X : Y ) = max[H(Y ) − H(Y |X)] = max H(Y ) − H(Y |X) = log M − H(Y |X).
p(x)
5.5
p(x)
p(x)
Бинарный симметричный канал
Канал называется бинарным, если по нему передается только два символа 0 и 1.
Пусть канал обладает шумом, приводящий к ошибкам, которые бывают весьма разнообразные. Рассмотрим далее ошибку типа переворота 0 → 1 и 1 → 0. Пусть она возникает с одинаковой вероятностью ² для
всех битов, тогда канал описывается следующим набором условных вероятностей p(y|x)
p(0|0) = 1 − ²,
p(1|0) = ²,
p(0|1) = ε,
p(1|1) = 1 − ².
Передаточная матрица имеет
µ
¶
1−²
²
T22 =
(140)
²
1−²
Из вида матрицы следует, что ее строчки, равно как столбцы, составлены из одного набора элементов
1 − ²² и отличаются только их перестановкой. Это означает, что канал является симметричным по входу и
выходу или просто симметричным. Поэтому его пропускная способность определяется выражением (132)
C = 1 − H(Y |X).
(141)
С учетом (136) для условной энтропии H(Y |X) следует выражение
X
H(Y |X) = −
p(y|x) log p(y|x) = −² log ² − (1 − ²) log(1 − ²) = H(²).
y
Тогда
C = 1 − H(²).
(142)
Отсюда следует, что на один отправленный бит будет получено 1−H(²) ≤ 1 бит информации. Если ошибки
отсутствуют ² = 0, то H(² = 0) = 0 и пропускная способность C = 1. Если ² = 1, то канал становится
идеальным инвертором, поскольку всегда 0 → 1 и 1 → 0. Для идеального инвертора C = 1. Если ² = 1/2,
то ошибка и правильный прием возникают одинаково часто, поэтому C = 0. Это означает, что по каналу
информацию передавать невозможно.
P
Вычислим далее выходные вероятности p(y) = x p(y|x)p(x). Введем обозначение
p(x = 0) = a, p(x = 1) = b,
p(y = 0) = p(0),
тогда
µ
p(0)
p(1)
¶
=
¡
a,
p(y = 1) = p(1),
µ
¢ 1 − ²,
b
²,
¶
²
.
1−²
(143)
Отсюда найдем
p(0) = (1 − ²)a + ²b,
p(1) = ²a + (1 − ²)b.
Поскольку канал является симметричным по выходу, то равномерное распределение на входе, когда a =
b = 1/2, приводит к равномерному распределению вероятностей на выходе: p(0) = p(1) = 1/2.
34
5.6
Двоичный стирающий канал
В стирающем канале оба символа 0 и 1 преобразуются в один, который в общем случае может отличаться
от входных.
Пусть канал осуществляет преобразование {0, 1} → {0, 1, 2} и описывается следующим набором условных
вероятностей
p(y = 0|x = 0) = 1 − ²,
p(y = 1|x = 0) = ²,
p(y = 1|x = 1) = ²,
p(y = 2|x = 1) = 1 − ²,
где ² = 0 – вероятность ошибки. Если ошибка отсутствует, то 0 → 0, 1 → 2, и канал является идеальным.
В противоположном случае ² = 1, оба входных символа преобразуются в один: 0, 1 → 1. В этом смысле
происходит стирание. Передаточная матрица канала имеет вид
T32
µ
1−² ²
=
0
²
¶
0
.
1−²
(144)
Строки матрицы получаются друг из друга перестановкой, поэтому канал является симметричным по
входу и его пропускная способность определяется выражением (137)
C = max H(Y ) − H(Y |X),
(145)
p(x)
где условная энтропия в соответствии с (136) имеет вид
H(Y |X) = −
X
p(y|x) log p(y|x) = −² log ² − (1 − ²) log(1 − ²) = H(²).
y
Канал не является полностью симметричным, но максимум энтропии H(Y ) можно вычислить непосредственно.
Чтобы вычислить H(Y ), найдем вероятности на выходе канала p(y)
µ
p(0)
¡
¢ 1−² ²
p(1) = a, b
0
²
p(2)
¶
0
,
1−²
(146)
которые будут
p(0) = (1 − ²)a,
p(1) = ²,
p(2) = (1 − ²)b,
где по-прежнему p(x = 0) = a, p(x = 1) = b. Эти выражения позволяют вычислить энтропию на выходе
H(Y )
H(Y ) = −(1 − ²)a log(1 − ²)a − ²) log ² − (1 − ²)b log(1 − ²)b = (1 − ²)H(a) + H(²),
где H(a) = −a log a − b log b – энтропия источника. В результате
C = max(1 − ²)H(a) = (1 − ²).
p(x)
(147)
Если ² = 0, то канал всегда преобразует 0 → 0, 1 → 2, являясь идеальным, поэтому C = 1. Напротив, при
² = 1 возникает идеальное стирание 0, 1 → 1, и оба входных символа воспринимаются как один.
35
5.7
Еще канал со стиранием
Пусть в канале осуществляется преобразование {0, 1} → {0, 1, 2}, где вероятность ошибки x → 1 − x
для обоих символов x = 0, 1 одинакова и равна p, а вероятность стирания x → 2 равна q. Этот канал
описывается набором условных вероятностей
p(y = 0|x = 0) = 1 − p − q,
p(y = 1|x = 0) = p,
p(y = 2|x = 0) = q,
p(y = 0|x = 1) = p,
p(y = 1|x = 1) = 1 − p − q,
p(y = 2|x = 1) = q.
Передаточная матрица канала имеет вид
T32
µ
1−p−q
=
p
p
1−p−q
¶
q
.
q
(148)
Строки матрицы получаются друг из друга перестановкой, поэтому канал является симметричным по
входу. Для вычисления его пропускной способности будем использовать формулу (131)
I(x = 0 : Y ) = I(x = 1 : Y ) = C,
(149)
I(x = 0 : Y ) = I(x = 1 : Y )
(150)
полагая, что условие
справедливо для равномерного входного распределения.
Выражение для взаимной энтропии I(x : Y ) запишем в виде
I(x : Y ) =
X
y
где R(x) =
P
y
p(y|x) log
X
X
p(y|x) X
=
p(y|x) log p(y|x) −
p(y|x) log p(y) =
f (p(y|x)) − R(x),
p(y)
y
y
y
p(y|x) log p(y). Определим выходные вероятности p(y), для которых следует выражение
p(0) = (1 − p − q)a + pb,
p(1) = pa + (1 − p − q)b,
p(2) = q,
где вероятности на входе канала p(x = 0) = a, p(x = 1) = b.
Далее нужно убедиться, что пропускная способность реализуется на равномерном входном распределении
a = b = 1/2. Для этого следует проверить равенство R(x = 0) = R(x = 1), которое в соответствии с (149)
дает
X
C=
p(y|x) log p(y|x) − R(x = 1).
(151)
y
Для равномерного входного распределения a = b = 1/2 выходные вероятности принимают значение
p(0) = p(1) = (1 − q)/2, p(2) = q. При сделанных предположениях
R(x) = p(0|x) log p(0) + p(1|x) log p(1) + p(2|x) log p(2)
1
1
= [1 − p(2|x)] log (1 − q) + p(2|x) log p(2) = (1 − q) log (1 − q) + q log q,
2
2
P
где использовано равенство p(0) = p(1) и условие y p(y|x) = 1. Отсюда следует, что R(x) не зависит
от x при равномерном распределении на входе. Тогда для пропускной способности канала (151) следует
выражение
1
C = (1 − p − q) log(1 − p − q) + p log p − (1 − q) log (1 − q).
2
При q = 0 стирание отсутствует и в соответствии с (141) C = 1 − H(p).
36
6
6.1
Защита от случайных помех
Корректирующие коды
При хранении и передаче информации возникают ошибки. Их причиной являются шумы, устранить которые невозможно. Для исправления ошибок служат корректирующие коды.
Оптимальное кодирование позволяет экономить ресурсы при передаче и хранении информации. Однако сообщение оказывается беззащитным, поскольку любой символ содержит максимально возможную
информацию, которая теряется в случае ошибки. Чтобы обнаружить ошибки, вводятся дополнительные
исправляющие символы. Пусть алфавит ИДС содержит 2m букв xk , k = 1, . . . N = 2m , тогда при двоичном
побуквенном кодировании
xk → {0, 1}m + z,
(152)
где m – длина кодового слова, z – число исправляющих символов. Используя простые соображения, можно
получить оценку для числа исправляющих символов z. Пусть ошибка происходит только в одном символе,
и пусть все ошибки независимы. Тогда один символ может измениться или остаться неизменным в m+z+1
случаях, поэтому количество информации об ошибках будет равно log(m + z + 1) бит. Чтобы исправлять
ошибки, количество информации в исправляющих битах, равное z при двоичном кодировании, должно
быть
z ≥ log(m + z + 1).
6.2
(153)
Коды с повторением
Чтобы защитить сообщение от ошибок, его можно повторить несколько раз.
При кодировании с повторением каждый символ преобразуется в блок длиной z, например, 0 → {0}z , 1 →
{1}z . При декодировании блока решение принимается "большинством голосов": если в принятом блоке
нулей больше, чем единиц, то он декодируется как 0. Код позволяет восстанавливать посланные символы,
если ошибки произошли меньше, чем в 50% символов. Если выбрать большую длину блока z, то ошибок
практически не будет, однако возрастет длина кодового слова.
6.3
Арифметика по модулю 2
В арифметике по модулю 2 есть две цифры 0 и 1 и две операции: сложение и умножение. Умножение
определяется следующим образом
0·0=0
0·1=0
1·0=0
1 · 1 = 1.
Сложение по модулю 2 a + b mod 2 определяется как
0+0=0
0+1=1
1+0=1
1 + 1 = 0.
где z mod 2 = z, если z < 2 и z mod 2 = остаток от деления z/2, если z ≥ 2. В этой арифметике
справедливы все законы сложения и умножения. Кроме того
0+a=a
1+a=1−a
a + a = 0.
Нетрудно увидеть, что если a1 + . . . an = 0 mod 2, то в сумме содержится четное число единиц, если
a1 + . . . an = 1 mod 2, то в сумме нечетное число единиц.
37
6.4
Коды с общей проверкой на четность
Коды с проверкой на четность строятся путем добавления к сообщению одного символа, который зависит
от всех букв сообщения:
m = s1 s2 . . . sn → mZ,
(154)
Z = s1 + s2 + . . . sn .
(155)
где
Если Z = 1, то в m содержится нечетное число единиц, если Z = 0, то в m содержится четное число
единиц. Пример:
m = 1010 → 10100
m = 1110 → 11101.
Наблюдение. Добавлении проверочного символа Z всегда дает четное число единиц в кодовом слове:
s1 + s2 + . . . sn + Z = 0.
(156)
Коррекция осуществляется следующим образом. Если произошла ошибка в 1 символе, когда 0 → 1 или
1 → 0, то число единиц изменится на одну единицу и станет нечетным. Тогда проверочное соотношение
(156) нарушится. Ясно, что таким способом можно определить только нечетное число ошибок.
6.5
Код Хемминга
Коды Хемминга обнаруживают и исправляют одиночные ошибки, когда число исправляющих символов z
удовлетворяет точному равенству z = log(m + z + 1). Для этих кодов m = 4, z = 3, поэтому кодовое слово
состоит из 4 символов сообщения и 3 символов исправляющих
a1 a2 a3 a4 a5 a6 a7 .
| {z }
message
Все исправляющие символы определяются символами алфавита: ak = ak (a1 , a2 , a3 , a4 ), k = 5, 6, 7.
Позицию ошибочного символа дают три функции, которые зависят от всех символов кодового слова
e0 = e0 (a1 , a2 , a3 , a4 , a5 , a6 , a7 ),
e1 = e1 (a1 , a2 , a3 , a4 , a5 , a6 , a7 ),
e2 = e2 (a1 , a2 , a3 , a4 , a5 , a6 , a7 ).
Эти функции строятся так, что последовательность e2 e1 e0 представляет собой запись позиции ошибочного символа в двоичном представлении. При этом 0 означает отсутствие ошибки, а 1 – наличие ошибки.
Так, если e2 e1 e0 = 000, то ошибки не произошло.
Последовательностью e2 e1 e0 кодируется 8 чисел от 0 до 7
0
1
2
3
4
5
6
7
e2
0
0
0
0
1
1
1
1
e1
0
0
1
1
0
0
1
1
e0
0
1
0
1
0
1
0
1
a1
a2
a3
a4
a5
a6
a7
Отсюда следует, что функция e0 связана с символами a1 , a3 , a5 , a7 , на что указывают единицы в столбце
e0 , соответственно функция e1 связана с символами a2 , a3 , a6 , a7 , функция e2 связана с a4 , a5 , a6 , a7 :
e0 = a1 + a3 + a5 + a7 ,
e1 = a2 + a3 + a6 + a7 ,
e2 = a4 + a5 + a6 + a7 .
38
(157)
Полагая e0 = e1 = e2 = 0, выразим исправляющие символы через буквы сообщения
a5 + a7 = a1 + a3 ,
a6 + a7 = a2 + a3 ,
a5 + a6 + a7 = a4 .
Заметим, что здесь использована арифметика по модулю 2. Отсюда, например, с помощью
a + a = 0, найдем
a5 = a2 + a3 + a4 ,
a6 = a1 + a3 + a4 ,
a7 = a1 + a2 + a4 .
(158)
Полученные уравнения решают задачу. Так, с помощью (158) для заданного сообщения записываются
исправляющие символы, а место ошибочного символа определяется из (157).
Для примера рассмотрим сообщение a1 a2 a3 a4 = 1001. Для него согласно (158) исправляющие символы
будут a5 a6 a7 = 100. Кодовое слово имеет вид 1101100. Пусть в кодовом слове произошла ошибка, скажем
во втором символе, тогда будет новое кодовое слово 1001100. Для него согласно (157) e0 = 1 + 0 + 1 + 0 = 0,
e1 = 1 + 0 + 0 + 0 = 1, e2 = 1 + 1 + 0 + 0 = 0. Последовательность e2 e1 e0 = 010 = 2 указывает позицию
ошибочного символа.
Список литературы
[1] К. Шеннон. Работы по теории информации и кибернетике. М., ИЛ, 1963.
[2] Б.Д. Гнеденко. Курс теории вероятностей. М., ГИФМЛ, 1961.
[3] А.М. Яглом, И. М. Яглом. Вероятность и информация. М., ГИФМЛ, 1960.
[4] Р. Галлагер. Теория информации и надежная связь. М. Советское радио, 1974.
[5] М.Н. Аршинов, Л.Е. Садовский. Коды и математика. М., Наука, 1983.
[6] Ю.С. Харин, В.И. Берник, Г.В. Матвеев. Математические основы криптологии. Минск, БГУ, 1999
39