Министерство образования и науки Российской Федерации
Федеральное государственное автономное образовательное учреждение высшего образования
«САНКТ-ПЕТЕРБУРГСКИЙ ПОЛИТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ ПЕТРА ВЕЛИКОГО»
Институт компьютерных наук и технологий
Кафедра Компьютерные интеллектуальные технологии
«Допустить к защите»
Зав. каф. КИТ, к.т.н.
______________ А.В. Речинский
«____» ____________ 20___ г.
МАГИСТЕРСКАЯ ДИССЕРТАЦИЯ
РАЗРАБОТКА И ИССЛЕДОВАНИЕ ОТКАЗОУСТОЙЧИВОГО СЕРВЕРА
СУБД НА ОСНОВЕ ТЕХНОЛОГИИ ORACLE DATA GUARD
направление: 02.04.03 «Математическое обеспечение и администрирование
информационных систем»
Выполнил:
Байдукалов Евгений Венерович
Подпись______________
Руководитель:
доцент КИТ ИКНТ, к.т.н.,
Сабинин Олег Юрьевич
Подпись______________
Рецензент:
доцент ИСЭМ ИПМЭиТ, к.п.н.,
Ильяшенко Оксана Юрьевна
Подпись______________
Санкт-Петербург
2016
РЕФЕРАТ
«Разработка и исследование отказоустойчивого сервера СУБД на основе технологии
Oracle Data Guard»
Работа содержит: стр. 74, ил. 10, табл. 8, библ.: 18 названий.
Ключевые слова: СУБД, резервная база данных, репликации, Standby, Data
Guard, ASM, RAC, Oracle.
Тема магистерской диссертации относится к области применения Maximum
Availability Architecture компании Oracle в построении отказоустойчивых решений .
В работе рассмотрен способ использования Oracle Active Data Guard для повышение
надежности сохранности данных компании, обеспечения высокой доступности и
автоматического преодоления последствий
системных сбоев. Изменения в
производственной базе данных могут быть переданы в резервные базы данных с
гарантией отсутствия потерь данных в процессе репликации. В работе представлены
результаты тестирования смоделированной системы. Приведены общие выводы по
проделанной работе.
"Development and research of the failover database server based on Oracle Data Guard
technology"
The work contains: p. 74, ill. 10, tab. 8, bibl .: 18 names.
Keywords: database, standby database, replication, Standby, Data Guard, ASM,
RAC, Oracle.
Master's thesis relates to the field of application Maximum Availability
Architecture of Oracle company in building fault-tolerant solutions. The paper considers
the way of using Oracle Active Data Guard to improve the reliability of the data security
of a company to provide a high availability and automatic overcome of system failure
consequences . Database production has changes which could be transferred to the standby
database with guarantee of absences data of the process replication. The paper contains the
results of testing the modeled system. The paper has general conclusions of the finish
work.
СОДЕРЖАНИЕ
ОПРЕДЕЛЕНИЯ………………………………………………………………………… 5
ВВЕДЕНИЕ……………………………………………………………………………… 7
1. АНАЛИЗ ОБЪЕКТА ИССЛЕДОВАНИЯ…………………………………………... 11
1.1 Постановка задач и методов решения……………..…………………………...13
1.2 Выбор показателей уровня отказоустойчивости системы…………………. 15
1.3 Анализ существующих решений для Oracle Grid Infrastructure по
повышению отказоустойчивости системы…………………………................ 18
1.3.1 Системы хранения………………………………………………………… 18
1.3.2 Процесс репликации, анализ инженерных решений …………………… 21
1.4 Вывод по главе…………………………………………………..……….………25
2. ИССЛЕДОВАНИЕ ИСПОЛЬЗОВАНИЯ ТЕХНОЛОГИЙ ORACLE ПРИ
ПОСТРОЕНИИ DATABASE HIGH AVAILABILITY………………….................. 27
2.1 Исследование архитектуры процессов экземпляра ASM …………………... 31
2.2 Исследование архитектуры процессов Oracle Data Guard ………………….. 37
2.3 Разработка дидактической модели настройки Data Guard
технологии в Grid Infrastructure 12c …………………………………………… 42
2.4 Вывод по главе………………………………………………………..…............. 43
3. РЕЗУЛЬТАТЫ ИССЛЕДОВАНИЯ И АПРОБАЦИЯ …………………………… 44
3.1 Создание виртуальных дисков ASM и установка программного
обеспечения Oracle……………….........................................................................45
3.2 Настройка потоковой репликации в конфигурации Data Guard …………….. 46
3.3 Тестирование и мониторинг работы системы…………………........................ 50
3.3.1 Результаты функционального тестирования ……………………………. 50
3.3.2 Результаты нагрузочного тестирования …………………………………. 53
3.4 Вывод по главе………………………………………………………..…………..54
ЗАКЛЮЧЕНИЕ…………………………………………………………………………. 56
3
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ………………………..................... 58
ПРИЛОЖЕНИЕ 1………………………………………………………………………..60
ПРИЛОЖЕНИЕ 2 ……………………………………………………………………… 63
ПРИЛОЖЕНИЕ 3 ……………………………………………………………………… 69
ПРИЛОЖЕНИЕ 4 ……………………………………………………………………... 73
4
ОПРЕДЕЛЕНИЯ
База данных (БД) — совокупность данных, хранимых в соответствии со
схемой данных, манипулирование которыми выполняют в соответствии с правилами
средств моделирования данных.
Система управления базами данных (СУБД) — совокупность программных и
лингвистических средств общего или специального назначения, обеспечивающих
управление созданием и использованием баз данных.
Отказоустойчивость - это такое свойство вычислительной системы, которое
обеспечивает ей, как логической машине, возможность продолжения действий,
заданных программой, после возникновения неисправностей.
Сбой
- кратковременная самоустраняющаяся утрата работоспособности
технического устройства.
Отказ - событие, заключающееся в нарушении работоспособного состояния
объекта.
Репликация - процесс, под которым понимается копирование данных из
одного источника на другой (или на множество других) и наоборот.
Service Level Agreement (SLA) -
это формальный договор между
пользователями и IT-службой о том в какие сроки, и на каких условиях
пользователи получают IT-сервисы. В том числе в SLA прописываются сроки
ликвидации инцидентов связанных с прерыванием различных сервисов, а также
штрафы за невыполнение этих сроков IT-службой.
Recovery point objective (RPO) - этот показатель определяет, какой объем
данных
вы
можете
себе
позволить
потерять
в
случае
наступления
катастрофического события.
этот показатель определяет допустимое
Recovery time objective (RTO) -
время простоя в случае наступления катастрофического события.
5
Automatic Storage Management (ASM) – это по сути средство управления
томами и файловая система, специально заточенное под хранение файлов СУБД
Oracle. Для других целей его применять не следует.
Active Data Guard (ADG) - программное решение, которое обеспечивает
хранение актуальной копии производственной базы данных для перенаправления
интенсивных запросов, отчетов и резервных копий с производственной базы данных
на резервную.
Первичная база данных (Primary DB) - роль в конфигурации Data Guard,
указывающая на основную производственную базу данных.
Резервная база данных (Standby DB) - роль в конфигурации Data Guard,
указывающая на резервную по отношению к основной базу данных.
6
ВВЕДЕНИЕ
Одной из основных проблем построения вычислительных систем остается
задача обеспечения их продолжительного функционирования. Эта задача имеет три
составляющих: надежность, готовность и удобство обслуживания. Все эти три
составляющих предполагают, в первую очередь, борьбу с неисправностями
системы, порождаемыми отказами и сбоями в ее работе. Эта борьба ведется по всем
трем направлениям, которые взаимосвязаны и применяются совместно.
В последние годы в литературе по вычислительной технике все чаще
употребляется термин "системы высокой готовности", "системы высокой степени
готовности", "системы с высоким коэффициентом готовности". Все эти термины по
существу являются синонимами, которые характеризуют тип системы с
цель
минимизации времени простоя. Имеется два типа времени простоя компьютера:
плановое и неплановое. Минимизация каждого из них требует различной стратегии
и технологии. Плановое время простоя обычно включает время, принятое
руководством, для проведения работ по модернизации системы и для ее
обслуживания. Неплановое время простоя является результатом отказа системы или
компонента. Хотя системы высокой готовности возможно больше ассоциируются с
минимизацией неплановых простоев, они оказываются также полезными для
уменьшения планового времени простоя. К этому следует добавить, что по SLA
соглашениям для некоторых вычислительных комплексов недопустимо время
простоя больше минуты, что определяет не только значительную потребность в
использовании такого типа систем, но и необходимость снижения стоимости
проактивного
исследования.
Повышение
уровня
катастрофоустойчивости
применяется также для гарантированной сохранности данных информационной
системы с целью обеспечения устойчивого состояния ведения бизнеса в
конкурентной среде.
Систематические исследования вопросов отказоустойчивости и надежности
сложных систем и программного обеспечения начались в середине 90-х годов. Но, в
7
плоть до настоящего времени, научное сообщество не располагает достаточно
полным представлением о причинах, которые приводят к возникновению сбоев в
работе элементов объектов информационной системы организации. Высокая
надежность систем, как показано в работах Беленкова В.Г., Будзко В.И.[1],
достигается в результате введения избыточности путем резервирования.
А на
основании исследований Аткиной В.С.[2] можно сделать вывод, что эффективность
отказоустойчивых решений зависит от параметров и особенностей информационной
системы и на основании требований к производительности можно подобрать
наиболее эффективные решения для каждой системы. При этом можно выделить два
класса направлений исследований:
-
эффективные системы хранения данных;
-
надежные процессы репликаций и резервирования данных.
В то время, используемые сегодня методы резервирования имеют недостатки
в плане надежности и стабильности. Кроме этого, применяемые сегодня стратегии
резервного
копирования
создают
дополнительную
нагрузку
на
весь
вычислительный комплекс. Это в свою очередь делает невозможным полноценное
использование
ресурсов системы и создает препятствие эффективной работе
пользователей.
Выбор темы магистерской диссертации
был обусловлен возникшей
проблемной ситуацией с подключением к базе данных "orcl" студентов различных
потоков обучения в недалеком прошлом. Поиск решения проблемы занял довольно
длительное время, во время которого многим студентам пришлось изрядно
понервничать из-за отсутствия доступа.
Актуальность диссертационной работы заключается в том, что до настоящего
времени фактически отсутствуют четкие пошаговые инженерные методики
построения отказоустойчивой СУБД на базе ASM в конфигурации Oracle Active
Date
Guard
показателями.
обладающей
высокими
качественными
и
эксплуатационными
В результате анализа работ российских и зарубежных авторов из
области исследования надежности программных систем был выявлен широкий ряд
8
проблем, основной причиной которого является отсутствие единого стандарта в
области обеспечения отказоустойчивости информационных систем.
Целью диссертационной работы - исследование подходов к разработке
отказоустойчивого сервера СУБД с различными структурными и алгоритмическими
решениями используемыми компанией Oracle в рамках концепции Maximum
Availability Architecture ( MAA, концепции повышенной надежности).
Формулировка цели предпринимаемого исследования определяет ряд задач,
которые предстоит решать по ходу работы:
-
анализ решений по обеспечению отказоустойчивости и исследование способов
применения технологии Data Guard
к обеспечению катастрофоустойчивости
промышленного сервера;
-
разработка метода построения отказоустойчивого сервера СУБД;
-
проектирование тестового стенда и установка программных средств обеспечения
отказоустойчивости;
-
анализ архитектуры процессов для выбранных структур;
-
исследование эффективности процесса репликации после сбоя.
Диссертационная работа направлена на повышение уровня уверенности
архитекторов информационных систем в надежности функционирования процесса
репликации,
обеспечение
точности
достижения
синхронизации
состояния
производственной базы данных и резервных баз данных, за счет использования
наиболее
эффективных
выступают
решение
программных
Oracle
Database
продуктов.
High
Объектом
Availability
по
исследования
нивелированию
последствия сбоя, порождающего потерю данных управляемых сервером СУБД.
Предметом исследования является комплекс методических и практических задач,
решение которых определяет возможность создания отказоустойчивого сервера
СУБД.
Исходя из изложенного, научная проблема диссертационного исследования
формулируется следующим образом:
-
требуется
систематизация
(анализируемые
сервера
совокупности
рассматриваются
9
накопленных
как
научных
определенное
знаний
множество
элементов, взаимосвязь которых обусловливает целостные свойства этого
множества);
-
выявление профессиональных проблем и поиск методов и приемов их решения
при
моделировании
программных
решений
в
области
обеспечения
отказоустойчивости и катастрофоустойчивости сервера СУБД Oracle 12c.
Для решения поставленных задач в работе использовались общенаучные
методы применяемые как при эмпирических, так и теоретических исследованиях
[5,7]. Среди них: 1) наблюдение, 2) сравнение, 3) измерение, 4) эксперимент; 5)
метод восхождения от общего к частному. Основой методологии по анализу
требований
в
управлении
доступности
данных
является
классификация
существующих приложений по двум основным показателям: RTO и RPO. Методы
построения
отказоустойчивого
сервера
СУБД
основаны
на
поддержании
информационной и программной избыточности в информационной системе с
применением репликации.
Научная
новизна
результатов
исследования,
выполненных
автором,
заключается в следующем:
-
разработаны и обоснованы для практического применения методические
положения по управлению процессом репликации на резервный сервер СУБД,
повышающем надежность и отказоустойчивость всей информационной системы
в целом;
-
предложен и обоснован методический материал для проведения апробации и
внедрения технологии Data Guard на Oracle Database 12c.
На защиту выносятся:
-
технологический метод построения отказоустойчивого сервера СУБД Oracle,
позволяющий существенно поднять скорость и эффективность внедрения
технологии Data Guard;
-
результаты экспериментальных исследований по отработке технологии Redo
Apply в процессе репликации.
10
1 Анализ предмета исследования
В
настоящее
время
информационная
инфраструктура
современных
предприятий и организаций, к которым можно отнести и высшие учебные
заведения, работает в режиме высокой нагрузки. Эффективность ведения бизнеса,
качественное обслуживание заказчиков, круглосуточная поддержка порталов
дистанционного образования — все это требует максимально возможного уровня
защищенности данных и готовности системы. Поэтому одной из основных задач
инженеров становится создание таких условий функционирования информационной
системы и ее компонентов, которые бы обеспечили:
-
устойчивость системы к программным и аппаратным сбоям. Позволяли получать
доступ к данным на чтению и запись независимо от обстоятельств, будь то сбой
аппаратной платформы или какого-то компонента СУБД;
-
продолжение работы в обычном для пользователей режиме при условии
последовательных сбоев;
-
масштабируемость.
Объекты
вычислительного
комплекса
должны
быть
организованны таким образом, что для обработки увеличившейся нагрузки
необходимо было бы только добавить еще одну машину, причем чтобы это не
требовало перенастройки всей системы;
-
должную производительность вычислительного комплекса
с возможностью
смешанной загрузки разными типами задач. Оптимизацию структуры доступа к
данным в период отчетов.
Под устойчивостью понимается то, что СУБД должна быть в состоянии
восстановить последнее согласованное состояние БД после любого аппаратного или
программного сбоя. Обычно рассматриваются два возможных вида аппаратных
сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную
остановку работы компьютера (например, аварийное выключение питания),
и жесткие сбои, характеризуемые потерей информации на носителях внешней
памяти.
11
Сбои можно разделить на следующий группы :
-
аварийное завершение работы СУБД (по причине ошибки в программе или в
результате некоторого аппаратного сбоя);
-
аварийное завершение пользовательской программы, в результате чего некоторая
транзакция остается незавершенной;
-
сетевая потеря связи с СУБД;
-
ошибка пользователя;
-
сбой носителей информации в дисковой группе;
-
повреждение блока при проверки контрольных сумм;
-
повреждение словаря базы данных.
В зависимости от чего целесообразнее защищаться, используются различные
средства отказоустойчивости и восстановления СУБД Oracle 12c, но если
организации
нужен
больший
уровень
защиты,
то
разумно
использовать
дополнительные резервные базы данных в конфигурации Active Data Guard 12c.
Технология отработки отказов в этом случае требует учета способности
системы реагировать на каждый вариант последовательности развития событий, так
называемый, сценарий катастрофы с целью обеспечения максимально возможной
работоспособности и сохранности защищаемой информации. Тем самым, выбрав
надежную систему хранения и настроив надежный процесс репликаций при
проектировании
отказоустойчивого
сервера
СУБД
можно
минимизировать
неожиданные катастрофические ситуации в будущем.
Конечно, из-за существования резервной копии (библиотеки резервных
копий)
базы данных и аварийного восстановления технологией RMAN,
данных дает
база
нам как бы больше уверенности, когда мы храним важную
информацию в ней и делает систему наиболее надежной при постоянной
модификацией.
Но в
рамках анализа отказоустойчивости рассматривается и
понятие катастрофоустойчивости [3,4], в котором речь идет о полном или
частичном физическом разрушении технологической площадки сервера и полной
потери данных. Очевидно, потеря данных в результате разрушения серверной
комнаты в стенах университета является событием маловероятным, но, в тоже
12
время, для большинства коммерческих компаний решающим для существования
бизнеса. Основным способом защиты от подобного рода рисков является
построение территориально разнесенных вычислительных площадок с функцией
резервирования, к примеру расположенных в разных корпусах университета.
Целью диссертационной работы - исследование подходов к разработке
отказоустойчивого сервера СУБД с различными структурными и алгоритмическими
решениями используемыми компанией Oracle в рамках концепции Maximum
Availability Architecture ( MAA, концепции повышенной надежности).
Объектом исследования выступают решение Oracle Database High Availability
по нивелированию последствия сбоя, порождающего потерю данных управляемых
сервером
СУБД.
необходимостью
Выбор
внедрения
данного
объекта
резервного
сервера
исследования
СУБД
в
продиктован
информационно-
аналитическую систему ООО "ЗеФинанс".
Предметом исследования является комплекс методических и практических
задач, решение которых определяет возможность создания отказоустойчивого
сервера СУБД.
1.1 Постановка задач и методов решения
Формулировка цели предпринимаемого исследования определяет ряд задач,
которые предстоит решать по ходу работы:
-
анализ требований к отказоустойчивости сервера СУБД;
-
анализ решений по обеспечению отказоустойчивости и исследование способов
применения технологии Data Guard
к обеспечению катастрофоустойчивости
промышленного сервера;
-
разработка методов построения отказоустойчивого сервера СУБД;
-
проектирование тестового стенда и установка программных средств обеспечения
отказоустойчивости;
13
-
согласование
и
установка
программных
средств
обеспечения
отказоустойчивости;
-
анализ архитектуры процессов для выбранных структур;
-
выбор критериев и системы показателей для оценки эффективности процесса
репликации;
-
исследование эффективности процесса репликации после обнаружения сбоя.
Методологические подходы можно разделить на:
-
общенаучные методы;
-
схемы "active-passive" резервирования.
Метод - это система предписаний, рекомендаций, указывающих, как сделать
что-то. В диссертационном исследовании я использовал две группы общенаучных
методов и один специальный метод:
-
методы эмпирического исследования
(наблюдение, сравнение,
измерение,
эксперимент);
-
методы теоретического исследования (синтез, восхождение);
-
схемы метода "active-passive"
резервирования данных представляют собой
такую организацию репликаций, когда один сервер принимает транзакции и
осуществляет работу с базами данных, при этом «пассивный» резервный сервер
переходит в состояние «активного» при неисправности первого, или по запросу
администратора.
В
настоящее
время
существует
множество
причин
использования
виртуализации, как метода научного познания в информационных технологиях.
Возможно, что самой важной причиной является, так называемая, серверная
консолидация. Проще говоря, возможность виртуализации множества систем на
отдельном
сервере.
Это
дает
возможность
предприятию
(лаборатории,
исследователю) сэкономить на мощности, месте, охлаждении и администрировании
из-за наличия меньшего количества серверов. При этом немаловажным фактором
является абстрагирование от оборудования. Например, сервера иногда выходят из
строя. При этом есть возможность перераспределить нагрузку на оборудование.
Отсутствие привязки, к какому либо «железу» существенно облегчает жизнь
14
современного исследователя, что неизменно снижает риск простоя предприятия в
случае фатальной ошибки.
Основой методологии по анализу требований в управлении доступности
данных является классификация существующих приложений по
основным
показателям надежности, которые определены в SLA соглашении. Методов
идентификации сбойных ситуаций нет. Средства борьбы с последствиями отказов и
сбоях в сервере СУБД основаны на поддержании информационной и программной
избыточности в вычислительном комплексе [4].
1.2 Выбор показателей уровня отказоустойчивости системы
Для обеспечения оценки уровня отказоустойчивости информационных
систем предложено множество подходов, включая организационные методы
разработки, различные технологии и технологические программные средства, что
требует, очевидно, привлечения значительных ресурсов. Однако отсутствие
общепризнанных критериев не позволяет ответить на вопрос, насколько надежнее
становится система при соблюдении предлагаемых процедур и технологий и в какой
степени оправданы затраты на дальнейшее повышения ее уровня. Таким образом,
приоритет задачи оценки и целесообразности плана развития отказоустойчивой
структуры системы обработки информации должен быть выше приоритета задачи ее
обеспечения.
Главной целью повышения отказоустойчивости систем является целостность
хранимых в них данных. При возникновении сбоя или отказа в работе СУБД,
приложения находящееся в активной фазе исполнения, должны быть перенесены за
минимально возможный период времени на резервную СУБД без потери данных.
Под катастрофоустойчивостью обычно понимают способность к восстановлению
работы приложений и данных за минимально короткий период времени после
катастрофы. Причем под катастрофами подразумеваются не только пожар,
15
наводнение или землетрясение, но и возможные непредвиденные сбои в работе
служб, разрушение данных или повреждение всего центра обработки в результате
разных причин, например, разрыв телекоммуникационных линий в результате
проведения ремонтных работ, умышленной диверсии или саботажа. Проведенное
исследование при решении выше указанных проблем демонстрируют, как
структурная избыточность в сочетании с различными моделями
влияют на
эффективность восстановления системы, а также для какого набора прикладных
задач целесообразен выбор той или иной модели архитектурного решения с тем,
чтобы затраты на аппаратную и программную избыточность были оправданы.
Избыточность - это наличие в структуре устройства возможностей сверх тех,
которые могли бы обеспечить его нормальное функционирование. Избыточность
вводится для повышения надёжности работы и для исключения влияния на
достоверность передаваемой информации помех и сбоев.
При разработке и последующей эксплуатации систем с повышенным
значением надежности необходимо наличие решений, повышающих вероятность
того, что система в момент времени t будет находиться в работоспособном
состоянии. Такая вероятность называется доступностью системы. Основой
методологии
управления
доступностью
данных
является
классификация
существующих технологий и приложений по основным показателям (табл.1.1):
Таблица 1.1 - Параметры доступности и восстановления
Виды приложений Требование
к
простоя
Критичные
Недопустим
БизнесМинимальный
критичные
Уровня
Бизнес-час
предприятия
Не критичные
Час
-
времени RTO
RPO
Секунды
Минуты
Недопустимо
Недопустимо
Часы
Минимальная потеря
Дни
Не имеет значения
RPO (recovery point objective) - этот показатель определяет, какой объем данных
вы можете себе позволить потерять в случае наступления катастрофического
события. Обычно это значение выражается в количестве часов или рабочих дней,
в течение которых шли накопление и обработка данных. Например, если вы
16
сочтете, что можете позволить себе потерять данные, наработанные в течение 24
часов, вам необходимо будет убедиться в том, что резервные копии, которые вы
будете использовать при реализации вашего плана аварийного восстановления,
не "старше" 24 часов;
-
RTO (recovery time objective) - этот показатель определяет допустимое время
простоя в случае наступления катастрофического события. Если показатель RTO
составляет 24 часа, это означает, что промежуток между выходом вашей системы
из
строя
и
моментом,
когда
система
должна
будет
возвращена
в
полнофункциональное состояние, должен составлять не более 24 часов;
COST - стоимость внедрения и эксплуатации архитектуры модели. Сложные
-
системы, как правило имеют множество приложений с разной степенью
критичности данных. В подавляющем большинстве случаев не удается всю
защиту данных реализовать на базе одного решения;
MTTR (mean time to recover) - среднее время восстановления экземпляра Oracle.
-
Задается
в
файле
инициализации
путем
настройки
параметра
FAST_START_MTTR_TARGET. Если значение слишком низкое, сервер будет
производить запись на диск очень часто, и это может привести к снижению
скорости работы системы. Поэтому данный параметр необходимо настраивать
так, чтобы сервер не выполнял чрезмерное количество контрольных точек;
-
MTTF (mean time to failure) - среднее время появления сбоя. Измеряет время
между двумя последовательными сбоями;
коэффициент готовности системы - S - определяется как отношение разности
-
MTTR и MTTR к MTTF (табл. 1.2).
Таблица 1.2 - Классификация систем по уровню надежности
0.99
Максимальное время Тип системы
простоя в год
Conventional (Обычная)
3,5 суток
0.999
8,5 часов
0.9999
1 час
High
availability
(Высокой
надежности)
Fault resilient (Отказоустойчивая)
0.99999
5 мин.
Fault tolerant (Безотказная)
Коэффициент готовности
17
C
версии
Oracle9i
в
словарь
представление V$MTTR_TARGET_ADVICE,
базы
данных
которое
добавлено
позволяет
оценить
(спрогнозировать) зависимость количества операций записи из буферного кэша на
диск
от
различных
значений
параметра
инициализации
FAST_START_MTTR_TARGET. Выполнять мониторинг действующего в системе
механизма поддержания необходимого времени восстановления экземпляра в
случае сбоя можно с помощью V$Instance_Recovery.
1.3 Анализ существующих решений для Oracle Grid Infrastructure по
повышению отказоустойчивости системы
1.3.1 Системы хранения
Компания Oracle достаточно давно начала разработки файловой системы
хранением данных на уровне операционной системы сравнимую по эффективности
с RAW-партициями, работающую в кластерном режиме, единую для разных ОС.
Среди имеющихся продуктов выделим: 1) ZFS;
2) ASM - ACFS.
ZFS ( Zettabyte File System ) - это свободный менеджер логических томов с
открытым исходным кодом, разработанный в компании Sun Microsystems для
операционной системы Solaris. Предполагается, что мы всегда объединяем все
доступные серверу хранилища и диски в единый массив ZFS, а внутри него строим
столько файловых систем, сколько нужно. Такой массив носит название пул (pool).
Новизна подхода в том, что верхний слой – файловая система – знает, на каком
массиве она работает. Например, зная размер файлов, которые она туда пишет, ZFS
может создавать полоски (stripes) переменной длины на массивах RAID-0 и RAID-5,
обеспечивая
таким
образом
высокую
скорость
работы
и
повышенную
отказоустойчивость. ZFS высчитывает контрольные суммы для файлов, а не блоков
данных, избавляясь от возможной ошибки обычных RAID-массивов, когда блок с
18
правильной суммой бывает записан не туда, куда надо. Алгоритм RAID-Z –
виртуальное устройство на нескольких устройств физических, предназначенное для
хранения данных и их контрольных сумм с однократным или двойным контролем
чётности. В первом случае теоретически требуется не менее двух, во втором – не
менее трёх физических устройств. Форматируются диски с секторами по 520 байт.
Затем они группируются в блоки по 8 секторов: 4Кб данных (размер блока файловой
системы WAFL) и 64 байта контрольной суммы. Когда система WAFL читает блок,
данные сравниваются с контрольной суммой, как и в случае с массивом из
предыдущего примера, но с ключевым отличием: сравнение происходит после того,
как данные прошли весь путь ввода-вывода, что позволяет удостовериться в том,
что блок прошел путь от пластины диска до памяти без повреждения.
Технология ASM подробно будет рассмотрена в следующей главе, а
продолжение линейки этого продукта здесь. ACFS (Oracle Cloud File System ) - Это
комплект из двух уже известных продуктов – ASM Dynamic Volume Manager и ASM
Cluster File System. Кластерную файловую систему ASM Cluster File System можно
использовать в качестве самостоятельной файловой системы, а также в виде
надстройки поверх другой, более традиционной файловой системы – например,
поверх EXT3, NTFS (Network File System) или ZFS (Zetabyte File System), при этом
теряется возможность кластеризации данных по серверам, зато эффективно
используются
преимущества
локальных
файловых
на
уровне
физических
накопителей.
ASM распределяет данные по дискам, чтобы сбалансировать использование
их емкостей. Так же обеспечивается автоматическое зеркалирование данных. ASM
Dynamic Volume Manager позволяет добавлять новые накопители в систему без
ручного перераспределения данных по всем доступным ресурсам. С помощью ASM
Dynamic Volume Manager можно наращивать и сокращать суммарную емкость
хранилищ, переносить хранилище на новую аппаратную платформу без остановки
систем, а еще эта технология позволяет создавать контрольные снимки хранилища с
доступом только на чтение. ASM – это по сути средство управления томами и
файловая система, специально заточенное под хранение файлов СУБД Oracle. Для
19
других целей его применять не следует. Вот выдержка из документации по СУБД
Oracle 11.2, поясняющая для чего нужна ACFS [17]:
-
Oracle ASM – предпочтительный способ хранения файлов базы данных (это не
касается ORACLE_HOME);
-
Oracle ACFS – предпочтительный способ хранения файлов, не принадлежащих
СУБД. Он оптимизирована для самых широких целей;
-
компания Oracle не рекомендует (и не оказывает поддержку) хранить в ACFS
файлы, которые можно хранить в ASM;
-
Oracle ACFS не поддерживает инсталляцию файлов Oracle Grid Infrastructure
home;
-
Oracle ACFS не поддерживает хранение Oracle Cluster Registry (OCR) and voting
files;
-
ACFS разумно применять в организациям, которые создают внутренние
«облака», а также при тестировании «облачных» приложений перед их
переносом на внешний хостинг;
-
ACFS рекомендована для хранения файлов GoldenGate.
Преимущества в производительности использования ASM перед другими
файловыми системами таково, что файловая система не позволяет записать
несколько байт в любое место диска. Записать в файловую систему можно только
блок файловой системы. А не блок Oracle. У Oracle блок датафайла обычно 8К,
но могут быть 4К, 16К, 32К. Блок REDO равен 512 байт на всех платформах, за
исключением НPUX где он 1К. Блок ZFS равен по умолчанию равен 4K. Таким
образом, операцию записи, полученную от Oracle надо предварительно оформить в
виде блока файловой системы, т.е. операционная система должна транслировать
команду Oracle в свои команды. Сделать это может только процессор в оперативной
памяти, потому что диск сам по себе не способен превратить блок Оракла в один
или несколько блоков файловой системы. А чтобы блок файловой системы
изменить, его вначале надо прочитать с диска. В результате на одну операцию
записи со стороны Oracle, в операционной системе возникают две дисковых
операции:
20
-
чтения одного или нескольких блоков ZFS с диска в оперативную память;
-
изменение блоков файловой системы;
-
запись блоков ZFS обратно на диск.
При работе с сырыми томами
ASM Oracle посылает в операционную
систему команду записать несколько что-то куда-то, а она тупо выполняет эту
операцию записывая эти данные в соответствующий сектор диска (головка,
дорожка, сектор). Операции чтения в такой конфигурации не возникает. Это одна
из преимуществ организации сервера Oracle на ASM для увеличения одновременно
отказоустойчивости и производительности. Oracle Cloud File System (по сути более
усовершенствованная ASM) имеет единый интерфейс для управление, единые
инструменты для инсталляции и конфигурации, единую clusterware. Поддержка и
решение проблем предоставляется одним вендором. Таким, образом Вам не нужны
сторонние файловые системы и инструменты для управления томами.
1.3.2 Процесс репликации, анализ инженерных решений
В настоящее время при построении многих автоматизированных систем
возникает
проблема
синхронизации
данных
по
нескольким
источникам
информации. Один из способов решения этой проблемы - репликации. C точки
зрения катастрофоустойчивости эта технология путем создания избыточности
гарантирует сохранность данных. Для подтверждения актуальности исследований и
разработок эффективного процесса репликации, приведу пример из истории. "В
результате террористического акта 11 сентября более 800 международных компаний
потеряли важные данные, но глобальный отдел продаж Morgan Stanley работал в
обычном режиме уже на следующий день, т.к. защита важных данных
осуществлялась тиражированием на другие территориально разнесенные сервера" .
В СУБД Oracle репликация реализована несколькими технологиями:
-
репликации, основанные на материализованных представлениях. Производятся в
одну или две стороны в зависимости от лицензирования сервера. В базе, в
21
которую реплицируют, находятся не таблицы, а доступные только на чтение
Snapshots (Read Only Materialized Views). Работает на основе триггеров. Начиная
с
Enterprise
Edition
11g,
позволяет
передавать
изменение
структуры
реплицируемых объектов в автоматическом режиме без остановки БД;
-
Oracle Streams. Универсальный гибкий механизм обмена информацией между
серверами
во
много
серверной
архитектуре.
Позволяет
одновременно
реализовать репликацию, обмен сообщениями, загрузку хранилищ данных,
работу с событиями, поддержку резервной БД. Данные находятся в памяти:
Streams pool. Есть возможность фильтрации данных на основе правил.
Поддерживает
репликацию.
синхронную
(начиная
с
версии
11g)
или
асинхронную
Этот инструмент хотя и остался в функционале Oracle, но на
данный момент больше не развивается. Компания Oracle выбрала в качестве
основной технологии для интеграции и репликации данных Golden Gate [15];
-
Golden Gate. В Golden Gate 12.1.2.1 в добавок ко всем предыдущим наработкам
появилась возможность реплицировать данные, подключившись к Active Data
Guard (ADG) экземпляру. Этот режим обеспечивает Real - Time репликацию.
Плюс ADG дает возможность вообще не создавать подключение к источнику —
достаточно подключения к экземпляру ADG;
-
Data Guard. Обеспечивает поддержу функционирования Standby баз данных не
зависимо от территориальной удаленности серверов. Используется только схема
"active-passive", что и обеспечивает актуальность баз данных в момент времени и
возможность принять на себя нагрузку в случае сбоя основного сервера.
Так как технология Data Guard позиционируется, как Standby RAC ( в
кластере), то не всегда из-за стоимости дополнительного лицензирования опции
компанию целесообразно его использовать. Почти аналогичных функции можно
добиться от Oracle Golden Gate. Продукт может быть сконфигурирован, чтобы
использоваться в следующих сценариях:
-
создать и поддерживать резервную систему с задержкой менее минуты, чтобы
минимизировать время восстановления для бизнес- критичных систем. Golden
Gate может работать как в среде баз данных Oracle, так и в случае СУБД
22
сторонних производителей; Не останавливать бизнес во время обновления
систем, миграции и плановых работ;
-
гарантировать высокую производительность промышленных систем за счет
выноса нагрузки «на чтение» на отдельную систему (возможно на другой
платформе или СУБД). Oracle Golden Gate в режиме реального времени собирает
измененные данные и доставляет их в Хранилище Данных, отчетные системы и
другие
транзакционные
системы
с
минимальным
воздействием
на
производительность систем-источников. Доступ к информации в реальном
времени дает лучшее понимание происходящих в компании бизнес-процессов;
-
Golden Gate обеспечивает постоянный захват измененных данных и их
перемещение
из
OLTP-источников
в
единое
хранилище
данных.
При
необходимости Oracle Golden Gate интегрируется с ETL-инструментами
(например, Oracle Data Integrator).
Другой альтернативой выше описанным продуктам является Dbvisit
Replicate, поддерживающая репликации уже из различные базы данных. Dbvisit
Replicate использует собственную технологию отслеживания изменения данных для
репликации и распространения обновленной информации в режиме реального
времени по базам данных Oracle и других вендоров. Так же есть возможность
реплицировать данные в Oracle Cloud, однако развитие облачных технологий на
российском рынке имеют свою специфику, связанную не только с проблемами в
законодательстве, но и с несовершенными технологиями доступа в Интернет,
аппаратно программными средствами, ограничениями в финансовых возможностях.
Но способ дублирования данных, хранения резервных копий довольно приемлем в
контексте решения исследуемой проблемы.
Следующая
модель
обеспечения
отказоустойчивости
системы
это
разнесенный между технологическими площадками комплекс Oracle RAC. Это такая
модель архитектуры, в которой узлы кластера находятся в разных Центрах
Обработки Данных и обеспечивают быстрое восстановление, в случае сбоя на
какой-либо
площадке.
К
недостатку
этой
технологии
следует
отнести
относительную близость (не далее 100 км.) и существенно дорогие прямые каналы
23
связи между центрами; блокировки, несмотря на все желание, осуществляются не
на уровне строк (как в single- instance БД), а на уровне блоков, т.е. экземпляр может
заблокировать целый блок (содержаний и другие кому-то нужные данные).
Преимуществом кластерной среды, как мне представляется, является то, что с базой
данных одновременно могут работать множество экземпляров СУБД Oracle,
запущенных на различных узлах кластера. В некластерной конфигурации к базе
данных эксклюзивно имеет доступ один экземпляр программного обеспечения
СУБД.
Разнесение частей кластера на удаленные площадки является хорошей
защитой от многих катастрофоподобных обстоятельств (локальное отключение
электропитания, пожар, затопление помещения сервера), но такие стихийные
бедствия, как ураганы, землятресения могут охватывать очень большие территории.
Идеальным дополнением к решению RAC является Data Guard - механизм
способный поддерживать резервную базу данных в актуальном состоянии с
помощью выполнения транзакций, сохраненных в оперативных или архивных
журналах основной базы данных. В таком модели может одновременно
поддерживаться до 30 актуальных резервных баз данных, причем все они могут
быть использованы в бизнесе для разгрузки основной. Так же первичная
функциональность базы Oracle была расширена, чтобы основная база данных могла
использоваться и в резервном режиме. Место установки такой модели не имеет
значения, до тех пор, пока базы данных могут взаимодействовать друг с другом
через сеть. Например, можно разместить основную и резервную базу данных в той
же системе, а так же и на разных хостах. При этом достигается гарантированное
обеспечение нулевой потери данных, но, чем больше расстояние при синхронной
репликации, тем больше влияние на производительность. В Oracle 12c этот
недостаток был устранен новой опцией - возможностью добавить в модель
архитектуры построения Standby еще о экземпляр Far Sync, где хранятся только
standby control file, standby redo logs, archived redo logs. Теперь промежуточный
экземпляр получает redo поток с основной базы в синхронном режиме, а пересылает
его на резервные в асинхронном. При сбое standby получает последние
24
зафиксированные изменения в журнале с Far Sync и применяет их, тем самым
выполняя требования по обработке сбоя с нулевой потерей данных. Второй
экземпляр Far Sync может быть подготовлен на случай передачи журналов в
обратном направлении после смены роле баз данных.
1.4 Вывод по главе
Если в конце прошлого века информация была просто важна для бизнеса, то
сейчас, в начале нового века, многие полагают, что информация и есть бизнес.
Сегодня все больше предприятий начинают предъявлять повышенные требования к
своей информационной структуре. Все более или менее серьезное оборудование
подразумевает некоторую степень избыточности. Все эти усилия направлены на
устранение
единой
точки
отказа
внутри
оборудования.
Для
построения
отказоустойчивой системы это необходимо, но для катастрофоустойчивой - еще
недостаточно.
Если
отказоустойчивая
система
способна
сохранять
работоспособность в случае выхода из строя отдельных компонентов, то
катастрофоустойчивая остается работоспособной и в случае одновременного
множественного выхода из строя ее составных частей или узлов в результате
действий непредвиденного характера.
Шаги по определению требований к отказоустойчивости могут быть
следующими:
-
для каждой подсистемы определить возможные отказы и проанализировать их
последствия;
-
отнести отказы к соответствующей группе;
-
определить показатели RTO и RPO;
-
сформулировать алгоритмы решения и предотвращения критических сбоев для
уменьшения их вероятности.
25
Реализация таких решений - непростой процесс, требующий скрупулезного
подхода на всех этапах, начиная с определения требований по каждому сервису
и заканчивая процедурой внедрения и тестирования.
Maximum Availability
Architecture (MAA) Oracle Database 12c снижает до нуля внеплановые простои, не
снижая производительность системы.
26
2
Исследование технологий Oracle при построении Database High
Availability
Для повышения уровня отказоустойчивости сервера мною была выбрана
наиболее подходящая, на мой взгляд, модель, сочетающая в себе технологии из
набора решений Oracle Database High Availability (HA - высокая готовность Oracle
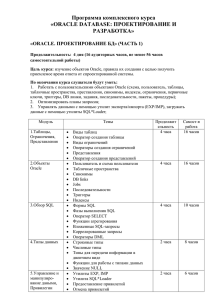
Database)(рисунок 2.1). Центральное место
в проектируемой модели занимает
программное обеспечение Data Guard. Так же в ходе внедрения будут использованы
технологии из пакета Grid Infrastructure 12c.
Рисунок 2.1 - Отказоустойчивые решения Oracle
C версии
11gR2 в линейки продуктов Oracle появилось понятие Grid
Infrastructure. Это несколько технологий объединенных в одном дистрибутиве:
ASM (Automatic Storage Management ), Clusterware ( Cluster Resource Management) ,
Oracle Restart. Последний это набор скриптов, который умеет следить за database,
listener, умеет их перестартовать и поднимать сервисы.
В версии 12с Oracle рекомендует использовать ASM и Flex ASM, так как по
заявленным возможностям она является очень мощной системой, позволяющей
серьезно сократить временные затраты при работе с данными. Но на данный момент
27
практически отсутствуют какие-либо статистические сведения о преимуществах
данной
технологии,
поэтому
основной
целью
явилось
исследование
предоставляемых ASM возможностей, сравнение ее с другими технологиями,
представляющими сервисы работы с дисками напрямую. База данных Oracle 12с
имеет два типа экземпляров: СУБД – система управления реляционными базами
данных (Relation DataBase
Management System) и автоматическое управление
хранением файлов (Automatic Storage Management) [10]. Экземпляр ASM монтирует
и управляет дисковыми группами, а экземпляр СУБД - базами данных. Экземпляр
ASM обеспечивает наиболее простое управление в отличие от экземпляра СУБД за
счет очень малого количества параметров, требуемых для его запуска. Он запускает
небольшой кусок кода в ядре Oracle, за счет чего он менее подвержен ошибкам.
Экземпляр ASM обеспечивает экстент карту (extent map) для экземпляра БД при
открытии или создании файла, а затем экземпляры СУБД читают и записывают
информацию непосредственно на диск, основываясь на ту самую extent map.
Экземпляр СУБД никогда не обновляет метаданные ASM, они записываются
исключительно экземпляром ASM [11]. Идея Flex ASM заключается в том, что
теперь экземпляры БД не зависят от одного ASM-экземпляра на текущем узле
кластера, а могут задействовать ASM-экземпляры на других узлах. В общем случае
на узле может работать только ASM-экземпляр, и может не быть экземпляра СУБД.
Для поддержки коммуникации с ASM-экземплярами и балансировки нагрузки
между ними, вводится новая подсеть - ASM Network (помимо public и interconnect
сетей). Все узлы с в кластере должны иметь прямой доступ к ASM дисков. Выбрать
модель развертывания Oracle ASM можно во время установки Oracle Grid
инфраструктуры или с помощью Oracle ASM Assistant Configuration (ASMCA). Эта
функция доступна только в конфигурации инфраструктуры Oracle Grid. Для того,
чтобы определить, был ли включен Flex ASM, используйте одну из следующих
команд (рисунок 2.2):
$ asmcmd showclustermode
$ Srvctl config ASM
28
Рисунок 2.2 - Получение информации о конфигурации ASM.
Преимуществом опции Flex ASM с точки зрения отказоустойчивости
является то, что пользователи будут автоматически переведены на другой
экземпляр, если экземпляр Oracle ASM перестает работать. При необходимости,
пользователи
могут быть перемещены вручную с помощью команды ALTER
SYSTEM RELOCATE CLIENT. Например:
SQL> ALTER SYSTEM RELOCATE CLIENT 'client-id';
ASM с помощью Clusterware
позволяет произвести консолидацию
дисковых ресурсов в группы, так что они могут использоваться совместно всеми
базами данных работающих в одном кластере. Для пользования совместным пулом
база данных не обязательно должна быть кластерной, поэтому эта технология тоже
используется мной в проектировании модели инфраструктуры. C версии 11g в ASM
введена опция запуска RESTRICTED для команды MOUNT. При запуске с этой
опцией экземпляр ASM исключительно монтирует все дисковые группы, указанные
в параметре ASM_DISKGROUPS. СУБД не имеет доступа к данному режиму, а в
случае с RAC ни один экземпляр ASM в кластере в дисковой группе не будет
доступен. Эта опция может быть полезной при выполнении технических работ,
таких как ребалансировка на дисковых групп [17]. Дисковая группа делится на
группы отказа (Failure Groups) в количестве минимум одной на диск. Группы отказа
нужны для того, чтобы, в случае отказа одного из дисков, не терялся доступ к
остальным дискам, и операции восстановления проводили только над отказавшей
группой дисков. ASM зеркалирует экстенты, что в случае отказа и обеспечивает
восстановление не всего диска, а только поврежденной части, поэтому ASM
гарантирует, что основной объем и его зеркальная копия никогда не находятся в той
же группе сбоя.
29
Oracle Clusterware необходимо для работы Oracle RAC, но даже для моей
конфигурации эта технология так же необходима и она вполне адекватно себя ведет
на некластерном экземпляре СУБД. Это является программное обеспечение, которое
позволяет узлам взаимодействовать друг с другом, что позволяет им формировать
кластер узлов, который ведет себя как один логический сервер. Oracle Clusterware
управляется CRS (Cluster Ready Services), состоящий из трех основных процессов:
CSSD (Cluster Synchronization Service Daemon) - Механизм синхронизации для
взаимодействия узлов в кластерной среде; CRSD (Cluster Ready Services Daemon) Основной «движок» для поддержки доступности ресурсов; EVMD (Event Monitor
Daemon) - Процесс оповещения о событиях, происходящих в кластере (рисунок 2.3).
Рисунок 2.3 - Процессы Clusterware
Так как я использую ASM без RAC, то CRS необходима, но ее функционал
будет задействован минимально и не будет отслеживать разрушение процессов
экземпляра. Однако с версии 11g и из на это неудобство появилось альтернативное
решение в качестве технологии Oracle Restart. Однако в этой версии Oracle есть
такая же возможность, что даже без применения RAC. Агент проверяет наличие
важных компонентов, таких как база данных, листенер, ASM и т.д., и автоматически
переводит
их
в
рабочее
состояние,
если
они
в
том
нуждаются.
Эта
функциональность доступна как встроенная и не требует дополнительного
программирования в базовой конфигурации Grid Infrastructure. Компонент, который
проверяет доступность и обеспечивает перезагрузку неисправных компонентов,
называется HAS (High Availability Service). Теперь становится более понятно ряд
команд утилиты crsctl. Вот так сервису можно установить автоматический запуск
(рисунок 2.4):
30
Рисунок 2.4 - Запуск crs.
Когда работают ресурсы, управляемые HAS, о них можно получить много
информации. Команда, которая это делает приведена ниже (опция "-v" означает
подробный ("verbose") вывод; следующая - удаляет конкретную базу данных из
сервисов HAS, сама база данных не удаляется).
$ CRSCTL status resource -v
$ SRVCTL remove database -d spbstu -v
2.1 Исследование архитектуры процессов экземпляра ASM
ASM – это по сути средство управления томами и файловая система,
специально заточенное под хранение файлов СУБД Oracle (рис 2.5). Для других
целей его применять не следует.
Для эффективного взаимодействия с базой данных ASM кроме файлов имеет
экземпляр ASM CУБД Oracle.
Файл ASM составляется набором экстентов ASM, составленных из единиц
выделения памяти (AU). У каждого файла ASM есть уникальное сгенерированное
системой имя. Полностью определенное имя файла ASM представляет иерархию,
начинающуюся со связи знака "плюс" с именем дисковой группы. За именем
дисковой группы следует имя базы данных и тип файла. Заключительный элемент
составляется из имени тега, номера файла и числа инкарнации.
Дополнительно может быть создан псевдоним, чтобы предоставить
администраторам более удобное для использования средство обращения к файлу
ASM.
31
Рисунок 2.5 - Сравнение Обычной файловой системы и ASM
Файлы равномерно распределяются по дискам ASM в дисковой группе,
используя политику чередования и зеркалирования. ASM исходно поддерживает
большинство связанных с базой данных типов файлов, таких как файлы данных,
файлы журнала, управляющие файлы, резервные копии RMAN и другие.
До релиза 2 Oracle Database 11g, ASM поддерживал только связанные с базой
данных Oracle файлы и не мог использоваться, чтобы хранить и управлять файлами
трассировки ASCII и журналами предупреждений, двоичными файлами Oracle,
Oracle Cluster Registry (OCR) и cluster-voting диск. Релиз 2 Базы данных Oracle 11g
устраняет это ограничение, обеспечивая средства реализации файловой системы
общего назначения поверх ASM.
ASM
отслеживает
расположение
файлов
посредством
метаданных,
называемых картой экстентов (рисунок 2.6). Карта экстентов является таблицей,
которая отображает экстенты данных в файле на единицы выделения памяти на
диске. Отношение между экстентами файла и единицами выделения памяти
следующие. Экстент содержит:
-
один AU для первых 20 000 экстентов (0–19999);
-
4 AU для следующих 20 000 экстентов (20000–39999);
-
16 AU для экстентов более 40 000.
32
Рисунок 2.6 - Карта экстентов ASM.
Содержимое файлов, которые хранятся в группе дисков, равномерно
распределяется или чередуется по дискам в дисковой группе, чтобы устранить
горячие точки и обеспечить одинаковую производительность по дискам. Каждый
файл ASM полностью содержится в пределах единственной группы дисков. Однако,
группа дисков может содержать файлы, принадлежащие нескольким базам данных,
и единственная база данных может использовать различные файлы из нескольких
дисковых групп.
Ключевой атрибут дисковой группы - установка избыточности. Есть три
возможных настройки избыточности дисковой группы:
-
нормальная избыточность, где ASM поддерживает двойное зеркалирование по
умолчанию, чтобы гарантировать целостность данных для менее надежного
хранения.
-
высокая избыточность, где ASM поддерживает тройное зеркалирование по
умолчанию для еще более надежного обеспечения целостности данных.
-
внешняя избыточность, где ASM не обеспечивает зеркального отражения, и
диски, как предполагается, высоконадежны (рисунок 2.7).
33
Рисунок 2.7 - Создание дисковой группы и выбор избыточности.
В пределах дисковой группы диски могут быть собраны в группы отказа.
Группы отказа являются способом, которым администратор хранения или базы
данных указывает аппаратные границы, через которые работает зеркалирование
ASM. Например, все диски, присоединенные к единственному дисковому
контроллеру, могли бы быть включены в общую группу отказа. Это привело бы к
тому, что экстенты файла, зеркалировались на дисках, соединенных с отдельными
контроллерами. Дополнительно, администратор может сконфигурировать ASM,
чтобы выбрать групповую политику отказа по умолчанию. Политика по умолчанию
состоит в том, что каждый отдельный диск находится в своей собственной группе
отказа. Группы отказа могут использоваться, чтобы защитить от отказа отдельных
дисков, дисковых контроллеров, компонентов сети ввода-вывода и даже всех систем
хранения.
Процесс создания файла предоставляет прекрасный пример взаимодействий,
которые имеют место между экземплярами базы данных и ASM. Процесс создания
файла происходит следующим образом (рисунок 2.8):
-
база данных запрашивает создание файла;
-
приоритетный процесс ASM создает запись Непрерывного Рабочего Каталога
(COD) и выделяет место для нового файла в дисковой группе.
-
процесс базы данных ASMB получает карту экстентов для нового файла;
34
-
файл
теперь
открыт,
и
процесс
базы
данных
инициализирует
файл
непосредственно;
-
после инициализации процесс базы данных запрашивает, чтобы создание файла
зафиксировалось;
-
подтверждение фиксации файла неявно закрывает файл, экземпляр базы данных
должен будет вновь открыть файл для будущего ввода-вывода.
Рисунок 2.8 - Взаимодействие экземпляров СУБД Oracle.
Экземпляр Базы данных должен взаимодействовать с ASM, чтобы
отобразить файлы базы данных на экстенты ASM. Экземпляр Базы данных также
получает постоянный поток сообщений, касающихся операций ASM (таких как
ребалансировка дисковой группы), которые может заблокировать или переместить
экстенты ASM. Ввод-вывод базы данных не направляется через экземпляр ASM.
Фактически, база данных проводит операции ввода-вывода непосредственно с
файлами ASM, как проиллюстрировано в шаге 4 на рисунке 2.8.
Основные процессы экземпляра ASM ответственны за действия, связанные с
ASM (таблица 2.1).
35
Таблица 2.1 - Процессы экземпляра ASM СУБД Oracle
Процесс
RBAL
MARK
GMON
ARBn
ASMB
Описание
Работает в обоих экземплярах базы данных и ASM. В экземпляре базы
данных, он предоставляет глобальный доступ к ASM дискам. На ASM, он
также координирует деятельность ребалансировки данных для дисковых
групп
MARK отмечает единицы распределения ASM, как несвежий после
пропущенной записи в автономный диск. Это по существу отслеживает
экстенты, которые должны пересинхронизироваться для автономных
дисков.
GMON поддерживает членство диска в группах дисков ASM.
ARBN выполняет фактические движения экстентов данных в
перебалансировки данных
ASMB работает в экземпляре базы данных, используя дисковую группу
ASM. ASMB связывается с экземпляром ASM, управление системой
хранения и представления статистических данных. ASMB также может
работать в экземпляре ASM. ASMB работает в тех случаях, когда ASM
выполнения команды ASMCMD Ср, или когда экземпляр базы данных
запускается впервые, если SPFILE хранится в ASM.
Экземпляр ASM использует выделенные фоновые процессы для большой
части своей функциональности.
RBAL координирует операцию ребанасировки для дисковых групп в
экземпляре Автоматического Управления Хранением. Он выполняет глобальное
открытие дисков Автоматического Управления Хранением. Процессы ARBn
выполняют фактические перемещения экстентов данных при ребанасировке в
экземпляре Автоматического Управления Хранением. Их может быть несколько и
они будут названы ARB0, ARB1 и так далее. Процесс GMON поддерживает
членство дисков в дисковых группах ASM. Процесс MARK маркирует единицы
выделения памяти ASM как устаревшие, после чего запись на оффлайн диск
пропускается. Процессы Onnn представляют серверную сторону клиент-серверного
соединения. Эти процессы появятся в момент запуска экземпляра и исчезнут после
этого. Они формируют пул соединений с экземпляром ASM для того, чтобы
обмениваться сообщениями, и появляются только при необходимости. Процессы
PZ9n представляют один или более параллельных второстепенных процессов,
которые используются в выборке данных, когда ASM работает в кластеризируемой
конфигурации более чем на одной машине одновременно.
36
2.2 Исследование архитектуры процессов Oracle Data Guard
Одним из самых важных условий эксплуатации любого программного
продукта является знание основ взаимодействия процессов отвечающих за нужную
нам функциональность . В этой главе я обозначу основные моменты архитектуры
процессов Data Guard, знание которых необходимо будет для дальнейшего
понимания сути внедрения и построения на его основе Standby.
Oracle Date Guard - программное обеспечение, которое автоматизирует
создание, поддержку и контроль за одной или несколькими резервными базами
данных для защиты корпоративных данных от сбоев, катастроф, ошибок
пользователей. Технология поддерживает синхронизацию первичной (Primary) и
резервных (Standby) баз данных, используя для этого журнальные данные. Процесс
записи в журнал транзакций LGWR (LogWriter) решает одну критически важную
для производительности базы данных задачу: копирует содержимое буфера журнала
из памяти на диск. Однако объем работы и задач, окружающей этот процесс с
возникновением технологий синхронных репликаций в резервные базы данных
начал существенно увеличиваться. Добавленный в основную архитектуру новый
процесс LNS (LogWriter Network Server – сетевой сервер записи в журнал) избавляет
процесс LogWriter от заботы, связанной с передачей журнальных данных в
удаленную
резервную
базу
данных
посредством
режимов
NSS/NSA
(синхронный/асинхронный транспорт журналов ) в 11g [12]. Синхронный режим
также иногда упоминается как метод "без потери данных", потому что процесс
LGWR не фиксирует транзакцию пока LNS не подтвердит, что аналогичная запись
есть на Standby.
При совершении транзакции создается redo log в области SGA, LGWR
читает эту запись из relo log buffer и записывает ее в online redo log file - и ждет
подтверждения от LNS. LNS читает ту же запись из буфера и передает ее в
резервную базу данных с помощью Oracle Net Services, процесс Remote File Server
(RFS) получает запись и записывает ее в Standby Redo Logs (SRL). Когда запись
37
записана, RFS передает подтверждение обратно в LNS, который в свою очередь
уведомляет LGWR, что передача завершена, LGWR отправляет отчет об успешной
фиксации транзакции пользователю. Как видно из описанной схемы, большую роль
в производительности системы будет оказывать пропускная способность сети. Она
должна быть адекватной чтобы получить минимально возможную задержку и
сократить время вынужденного ожидания на primary database. Посмотреть значение
можно из динамического представления v$system_event.
Асинхронный транспорт (ASYNC) отличается от SYNC, тем что у него
отсутствует требование для LGWR ждать немедленного подтверждения от LNS .
Если LNS не успевает забирать запись из буфера , то он автоматически переходит к
чтению и отправке записи из файла журнала транзакций вместо redo log buffer.
После того, как LNS сможет догнать LGWR, он опять возвращается к чтению прямо
из буфера в SGA. Соотношение redo log buffer отслеживается с помощью
представления X$LOGBUF_READHIST: низкий коэффициент указывает, что LNS
читает из журнального файла вместо буфера (на заметку, если это происходит
регулярно, попробуйте увеличить размер буфера журнала). Недостатком ASYNC
является повышенный риск потери данных. Если произойдет сбой на primary
database, то данные о транзакциях, на которые было отставание будут потеряны в
Standby. Но преимущество этого алгоритма в том, что ASYNC очень эффективно
направляет redo log потоки в резервную базу данных, устраняя любые накладные
расходы, вызванные необходимостью передачи по сети подтверждений, которые
иначе привели бы к сокращению её пропускной способности. Если вследствие
отказа сети или отказов резервных серверов разрывается соединение первичной и
резервных баз данных, то первичная база данных продолжает обрабатывать
транзакции и накапливать журнальные данные, которые не могут быть отправлены в
резервные базы данных до тех пор, пока не будет установлено новое сетевое
подключение [8]. В таком случае будет выполнятся следующий сценарий:
-
имеющийся процесс ARCH в Primary постоянно будет опрашивать Standby,
чтобы определить ее состояние;
38
-
когда связь восстанавливается, то ARCH опрашивает Standby Control File (с
помощью процесса RFS), чтобы определить последнюю версию журнального
файла полученных от Primary;
-
Data Guard узнает какие журнальные файлы нужны для синхронизации с и сразу
начинает их передавать с помощью дополнительных ARCH процессов;
-
после синхронизации LNS уже работает в обычном режиме (рисунок 2.9).
Рисунок 2.9 - Архитектура процессов в асинхронном режиме
Далее следует рассмотреть такое понятие как Apply Services и его процессы
в Standby Database. Итак, Redo поток передаваемый из Primary Database
записывается в Standby Redo Log, а Apply Services автоматически применяет их на
Standby Database. В организации резервной базы данных выделяют два вида,
основное отличие которых в организации работы apply services по отношению к
Archived Redo Data: Redo Apply (Physical Standby); Sql Apply (Logical Standby). Redo
Apply блок за блоком копирует Primary Database используя для этого специальный
процесс, который называется Managed Recovery Process (MRP – процесс
управляемого восстановления). По мере того как процесс RFS записывает
журнальные данные в SRL, MRP читает данные из SRL и применяет изменения
непосредственно к Standby Database (таблица 2.2). Процесс MRP может также
прозрачно переключиться на чтение из архивного журнала резервной базы данных,
если SRL архивирован прежде, чем MRP может закончить чтение SRL (ситуация,
которая может произойти, когда первичная база данных имеет очень высокую
скорость генерации журнальных данных, см. рисунок 2.3). Также, если активирован
Data Guard Broker, Data Guard использует процесс Data Guard Broker Monitor
39
(DMON) для управления и ведения мониторинга Primary и Standby Database, как
единой объединенной конфигурации.
Таблица 2.2. - Отслеживание процессов
View
Primary
Standby
V$ARCHIVED_LOG
Какие логи отправляются
Полученные логи
V$ARCHIVED_DEST_STATUS Состояние arch процессов, В каком режиме применяются
куда они отправляют файлы, логи
последний
отправленный
файл
V$DATAGUARD_STATUS
V$MANAGED_STANDBY
Информация из alert log файла
Запущен ли процесс MRP
-
Опция Active Data Guard позволяет получить доступ read-only к Physical
Standby для
выполнения различных бизнес- задач (запросов, сортировка,
отчетности, веб-доступа и т.д.), в то время как процесс MRP продолжает применять
данные из redo потока к Standby в фоновом режиме (таблица 2.3).
Таблица 2.3 - Сравнение функциональности
DataGuard 11g
Остановка применения журнальных файлов
для перехода в режим read-only в 8.00
Может быть открыта для выполнения
запросов
На 16.00 пользователи работают с базой
данных на состояние 8.00, получая
устаревшие данные
При сбое primary в 17.00 нужно тратить
время на recovery до уровня 17.00,что
лишает нас standby database.
Active DataGuard 11g
Синхронизация проводится постоянно в процессе
реального времени
Всегда открыта в режиме read-only
Пользователи всегда видят последние актуальные
данные
Переключение на standby происходит немедленно
при возникновении проблем в primary database, т к
данные всегда синхронизированы.
В Logical Standby содержится та же самая логическая информация, что и в
Primary Database, хотя ее физическая организация и структура данных могут
отличаться. Технология SQL Apply обеспечивает синхронизацию Logical Standby с
Primary Database путем преобразования в SQL-операторы журнальных данных,
полученных от Primary. Далее эти SQL-операторы выполняются в резервной базе
данных.
40
Sql Apply требует больше процессов, ресурсов CPU, памяти и I/O,чем Redo
Apply. Ниже следует краткое перечисление функциональных возможностей каждого
из процессов:
-
reader читает входящие записи журнала из оперативных журналов резервной
базы данных;
-
preparer - конвертирует изменения блоков в изменения таблицы, или логические
записи файла изменений (Logical Change Records – LCR);
-
Builder собирает из индивидуальных LCR законченные транзакции;
-
analyzer исследует завершенные транзакции, определяя зависимости между
различными транзакциями;
-
logical standby process (LSP) - координатор, который назначает транзакции
процессам применения, ведет мониторинг зависимостей между транзакциями и
авторизует фиксацию изменений в логической резервной базе данных;
-
applier - процессы применяют к базе данных LCR для назначенной транзакции и
фиксируют транзакции, когда это разрешается координатором.
Logical standby не решает проблему должной отказоустойчивости основной
базы
данных,
имеет
определенные
ограничения
и
намного
сложнее
в
сопровождении, чем физическая. Синхронизация основной базы данных с
резервными осуществляется путем передачи журнальных данных через SQL операторы, выполняемые над резервной базой данных. Но использовать их для
обеспечения копии исходной базы - не лучшее решение, так как копия будет не
соврем точная
(не все типы данных поддерживаются), а повторный разбор логов и
применение SQL - затратная операция по ресурсам.
Основное преимущество такой архитектуры состоит лишь в том, что
пользователь может создавать свои схемы, объекты, логические структуры,
дополнительные индексы на «реплицируемые» таблички для ускорения выборки из
каких-либо отчетов и т.п.
41
2.3 Дидактическая модель настройки Data Guard технологии в Grid
Infrastructure 12c
Представленный выше материал позволяет сформировать дидактическую
модель внедрения и настройки механизмов, повышающих
отказоустойчивость
системы [6]. Нынешняя ее концепция основывается на системном подходе к
пониманию процесса настройки технологии Data Guard в среде Oracle Linux 6.7. Для
создания резервной базы данных должны быть выполнены следующие основные
этапы:
1. Предварительный. В него входит:
-
установка и настройка GI, создание и запуск ASM;
-
настройка listener;
-
установка программного обеспечения Oracle RDBMS 12c;
-
создание и запуск экземпляра.
По завершению этого этапа мы имеем два экземпляра ASM, которые
расположены на разных хостах ( ol67-Primary, ol68-Standby)
СУБД.
2. Cоздание физической резервной базы данных. В него входит:
-
перевод базы данных в режим логирования;
-
настройка сетевых файлов;
-
настройка параметров init.ora;
-
копируем файл паролей и init.ora на резервную базе данных;
-
запустить резервный экземпляр;
-
настраиваем базу данных под Data Guard;
-
из Standby хоста клонируем базу данных;
-
добавляем online redo logs файлы в резервную базу данных;
-
запускаем MRP процесс;
-
конфигурируем Data Guard Broker.
42
и один экземпляр
2.4 Вывод по главе
В главе описаны компоненты проектируемой отказоустойчивой модели, их
свойство отказоустойчивости и роль в модели. Разобраны процессы, которые
непосредственно участвуют в поддержании работоспособности инфраструктуры.
Составлена логическая последовательность настройки Data Guard в инфраструктуре
Grid.
43
3 Результаты исследования и апробация
Проект конфигурирования и настройки системы на основе Data Guard был
разбит на несколько этапов:
1. Развернуть тестовый стенд на базе виртуальных машин Oracle Virtual box c
программным обеспечением
Oracle Linux 6.7, Oracle Grid Infrastructure 12c,
Oracle Database 12c.
2. Провести все регламентированные действия по настройке сервера СУБД до
клонирования БД на резервный хост. Цель – БД должны работать, как одна
логическая машина.
3. С помощью технологии RMAN клонировать БД на резервный хост. Цель –
создание такой же структуры и содержания БД.
4. Провести настройку сервера для запуска процесса Redo Apply в режиме
реального времени. Цель – запуск процесса репликации.
5. Конфигурирование Data Guard Broker.
Цель
-
получение
дополнительного
инструмента
для
мониторинга
и
последующего тиражирования резервных БД.
6. Тестирование эффективности процесса репликации. Цель - проверить качество
данных на резервной БД после применения процесса репликации.
7.
Апробация и внедрение отказоустойчивого сервера СУБД в архитектуру
информационно - аналитической системы компании OOO "ЗеФинанс".
Последний этап подразумевает под собой возможность параллельной
эксплуатации старой и новой архитектуры, когда можно «переключиться» с одной
на другую в случае полного отказа последней. Такой способ эксплуатации позволяет
тестировать и настраивать систему в условиях, максимально приближенным к
реальным. Более того, он позволяет до
продуктивного старта выявить все
существующие проблемы в системе и найти к ним решения.
44
3.1 Создание виртуальных дисков для имитации дисков ASM и
установка программного обеспечения Oracle
Для функционирования ASM на любой версии Linux кроме Oracle Linux
необходимо установить три пакета ASMlib – oracleasmlib, oracleasm, oracleasmsupport. Пакеты oracleasm-support и oracleasmlib не зависят от версии ядра, а только
от платформы. Для Oracle Linux драйвера ASM интегрированы прямо в ядро UEK и
не требуют отдельной установки. Далее создание группы пользователей: asmadmin,
asmdba, asmoper. После проверки установки пакетов надо сконфигурировать
Automatic Storage Management Library Driver.
Установим инфраструктуру Grid и СУБД Oracle с помощью Oracle Universal
Installer (приложение 1). Далее с помощью утилит DBCA или ASMCA настроим
дисковые группы (таблица 3.1). Технология ASM предоставляет на выбор несколько
алгоритмов реализации избыточности хранения данных. High – зеркалирование по
трём путям, Normal – по двум. External – ASM не делает зеркалирования. Вариант
External подходит, если избыточность обеспечивается другими средствами,
например RAID. Следует учесть, что избыточность требует дискового места,
например, если выбрать Normal, то половина дискового пространства группы уйдет
на избыточность и нужно будет как минимум два диска ASM для создания группы,
поэтому если дисковая группа создаётся на RAID массиве – можно установить
External и не тратить дисковое место на обеспечение избыточности, которая итак
обеспечивается RAID массивом.
Создать ASM диски можно с помощью консольной утилиты oracleasm:
# oracleasm createdisk CRS01 /dev/sbd1
Создать дисковую группу можно с помощью графической утилиты asmca, а
также через консоль:
SQL> SELECT NAME, PATH FROM V$ASM_DISK;
SQL>CREATE DISKGROUP DATA EXTERNAL REDUNDANCY DISK 'путь…','путь…'
45
Таблица 3.1 - Описание дисковой подсистемы
Диск
Дисковая группа
Предназначение
CRS01
CRS
ASM - CRS ассемблерная дисковая группа, куда Cluster
Ready Services (CRS) размещает свои файлы при
инсталляции
DATA01
DATA
FRA01
FRA
REDO01
REDO
+DATA ASM группа дисков . Здесь база данных будет
хранить все файлы данных, управляющие файлы
ASM - FRA ассемблерная дисковая группа, для быстрое
восстановление
базы данных на момент времени.
Например, там хранятся резервные копии, копии файлов
управления базой данных.
+REDO ASM группа дисков . Здесь база данных будет
хранить файлы журналов
3.2 Настройка потоковой репликации в конфигурации Data Guard
Существует несколько способов установки физической резервной базы
данных. Я использую метод клонирования базы данных с помощью технологии
RMAN из активной базы данных. Преимущества этого метода в том, что во-первых,
он не требует остановки базы данных, это очень полезно для системы работающей
в режиме 24/7, а во-вторых не нужно загружать файлы резервного копирования
базы данных на резервный сервер.
Так как процесс развертывания резервной базы данных занял продолжительное
время. Интуитивным путем я определил три контрольных точки при работе над
проектом. Сформулировать эти вехи можно следующим образом:
1. До клонирования. Цель – БД должны работать, как одна логическая машина.
2. Клонирование. Цель – создание такой же структуры и содержания БД.
3. После клонирования. Цель – запуск процесса репликации. Настройка Data Guard
Broker.
Перед тем как выполнить клонирование первичной базы данных, она должна
быть правильно настроена:
46
1. Должна работать в режиме archivelog и force logging. Режим force logging нужен
для принудительной записи транзакций в redo logs даже для операций,
выполняемых с опцией NOLOGGING. Отсутствие этого режима может привести
к тому, что на standby базе будут повреждены некоторые файлы данных, т.к. при
«накатке» архивных журналов из них нельзя будет получить данные о
транзакциях, выполненных с опцией NOLOGGING.
2. Параметр инициализации "db_name" должен быть одинаковым и на первичной и
резервной базы данных, а параметр
"db_unique_name" должен отличаться.
Проверим это значение, а затем используем его и уникальное имя резервной
базы
данных,
чтобы
установить
dg_config
настройку
параметра
log_archive_config для идентификации баз данных в конфигурации в Data Guard.
SQL> SHOW PARAMETER db_unique_name ;
SQL> ALTER SYSTEM SET log_archive_config = 'DG_CONFIG=(spbstu, spbstu_stb)'
scope=
both;
3.
Для установки подходящего локального и удаленного пути архивирования
журнала использую параметр log_archive_dest_n. Число резервных баз данных,
которые позволяет создать сервер Oracle в разных версиях различно. Это зависит
от ограничений количества параметров log_archive_dest_n.
SQL> SHOW PARAMETER db_recovery_file_dest;
SQL> ALTER SYSTEM SET log_archive_dest_1= 'LOCATION= use_db_recovery_file_dest'
scope=both;
SQL> ALTER SYSTEM SET log_archive_dest_state_1=ENABLE scope=both;
SQL> ALTER SYSTEM SET log_archive_dest_2= 'SERVICE=spbstu_stb ASYNC|SYNC
VALID_FOR=
(ONLINE_LOGFILE,PRIMARY_ROLE)
COMPRESSION=ENABLE
db_unique_name=spbstu_stb' scope=both;
SQL> ALTER SYSTEM SET log_archive_dest_state_2=defer|enable scope=both;
4. Чтобы при создании на основном сервере нового файла (или удалении) на
резервном создавался автоматически, надо установить standby_file_managent в
AUTO. Так же Oracle рекомендует установить параметры fal_client и fal_server,
когда база данных запущена в режиме Stanbdy. Fal_client='spbstu'
– этот
параметр определяет, что когда экземпляр перейдет в режим standby, он будет
47
являться клиентом для приема архивных журналов (fetch archive log).
Fal_server='spbstu_stb' – определяет FAL (fetch archive log) сервер, с которого
будет осуществляться передача архивных журналов.
5. Создаю файл паролей и копируем его на Standby.
$ORAPWD file=orapwspbstu password=oracle entries=5
$scp
$ORACLE_HOME/dbs/orapwspbstu.ora
oracle@ol68:
$ORACLE_HOME/dbs/
orapwspbstu_stb.ora
6. Делаю копию файла параметров инициализации (pfile) и редактирую его для
Standby (Приложение 2 ). Сразу следует создать директории, которые указаны в
init файле.
SQL>CREATE pfile = '/u02/initspbstu_stb.ora' FROM spfile ;
7. Задаем формат для архивных файлов.
SQL>ALTER SYSTEM SET log_archive_format='arch_%t_%s_%r.arc' SCOPE=spfile;
8. Настройка сетевой среды Oracle (Приложение 2).
9. Помимо физического и логического подключения к сети (например, по TCP/IP)
на двух серверах должны быть настроены Oracle Net Services, чтобы основная
база
могла
передавать Redo поток в резервную. Дескрипторы соединения
задаются в файле tnsnames.ora и идентичны на обоих серверах (Приложение 2). В
файле listener.ora надо прописать ORACLE_HOME на Standby. Это имеет
значение для утилиты RMAN при клонировании.
10. Создание Standby Redo Log на Primary. Команда RMAN DUPLICATE будет
автоматически создавать Standby redo logs на резервном сервере. Тем не менее,
рекомендуется вручную создать резервный журнал повтора
на первичном
сервере, чтобы обеспечить основной базе возможность переключение в Standby
режим. Они не будут использоваться в режиме Primary. Следует обратить
внимание так же на следующее:
- для простоты администрирования, Oracle рекомендует, чтобы все redo;
logs в журнале повтора в исходной базе данных и standby redo logs
были одного размера;
- standby redo log file должен иметь по крайней мере на одну redo
48
log группу больше, чем журнал повтора в основной базе данных.
11. Запуск
Auxiliary
Instance.
Команда
RMAN
DUPLICATE
использует
вспомогательный экземпляр для копирования основной базы данных
в
резервную :
SQL> STARTUP NOMOUNT pfile='/u02/initspbstu_stb.ora'
SQL>CREATE spfile FROM pfile='/u02/initspbstu_stb.ora'
После того, как удалось выполнить все подготовительные действия, то
можно переходить на следующую фазу, а именном к операции клонирования базы
данных (приложение 3):
$RMAN CHECKSYNTAX @rmanscript1.rman
$RMAN target sys/oracle@spbstu auxiliary sys/oracle@spbstu_stb
@rmanscript1.rman
Хотя RMAN автоматически создаст online redo log , и standby redo log и
переведет базу данных в режиме архивирования журналов, проверка не помешает.
Что касается online redo log, то они останутся неиспользованными до тех пор, пока
роль не изменится.
SQL> SELECT GROUP#, STATUS, BYTES FROM V$LOG UNION
SELECT GROUP#,
STATUS,
BYTES
FROM
V$STANDBY_LOG;
SQL>SELECT MEMBER FROM V$LOGFILE;
Заключительная фаза в реализации проекта - запуск процесса Redo Apply. В
режиме реального времени применяется накат
redo потока
на Standby. Это
приводит к более быстрому переключению при аварийной ситуации и позволяет
сразу же пользоваться базой данных в актуальном состоянии.
SQL> ALTER DATABASE RECOVER MANAGED STANDBY USING
CURRENT
LOGFILE DISCONNECT FROM SESSION;
Если мы не хотим использовать режим Real-time apply redo, а хотим
дожидаться когда будет закончено формирование очередного архивного журнала на
основном сервере и он будет передан на standby для применения сохраненных в нем
транзакций, то нам необходимо переводить нашу Standby базу в режим redo apply
командой:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE
49
DISCONECT;
Если что-то пошло не так, то для решения проблемы в первую очередь
необходимо остановить применение логов:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE
CANCEL;
3.3 Тестирование и мониторинг работы системы
3.3.1 Результаты функционального тестирования
После настройки всех элементов системы необходимо убедиться, что все
процессы
качественно выполняют свою работу, и при этом
дополнительная
нагрузка на сервер, связанная с передачей redo потока на резервную базу не
мешает нормальной работе с основной базой данных. Для этого выполним ряд
тестов, чтобы проследить за изменениями на стороне Standby. Для начала проверим
статус и состояние основных процессов Data Guard:
SQL> SELECT status, instance_name, database_role, open_mode
FROM V$DATABASE, V$INSTANCE;
SQL> SELECT process, status, sequence# FROM V$MANAGED_STANDBY;
SQL> SELECT RECOVERY_MODE FROM V$ARCHIVE_DEST_STATUS;
Далее выполняю на primary и standby, запрос который нам покажет
количество архивных логов и на primary принудительно переключаю текущею
группу online redo log file - alter system switch logfile и проверяем совпадают ли
значения на двух базах.
SQL> ALTER SESSION NLS_DATA_FORMAT='DD-MON-YYYY HH24:MI:SS';
SQL> SELECT sequence#, first_time, next_time, applied
FROM V$ARCHIVED_LOG ORDER BY sequence#;
Сейчас резервная база работает в режиме mount и доступ для чтения к ней
запрещен. Так было в ранних версиях Data Guard. Большинство компаний
50
предполагали, что никогда не получат пользы от инвестиций в обеспечение
катастрофоустойчивости своих информационных систем и, организовав надежную
стратегию резервного копирования- восстановления продолжали жить спокойно.
Основная же проблема таких резервных систем - простой ресурсов. С версии 10g
Oracle добавил опцию Active Data Guard, которая позволяет перевести резервную
базу данных в режим read only with apply и задействовать в процессе эксплуатации, а
процесс MRP продолжает применять поступающий новый redo поток:
SQL> ALTER DATABASE RECOVER MANAGER STANDBY DATABASE CANCEL;
SQL> ALTER DATABASE OPEN READE ONLY;
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE
USING CURRENT LOGFILE DISCONNECT FROM SESSION;
Чтобы протестировать возможность переключения ролей между базами
данных я решил сконфигурировать дополнительную утилиту для более удобной
работы со Standby - DataGuard Broker.
Преимущества его использования
следующие:
-
централизованный инструмент управления, который может быть использован
для управления всей конфигурацией с помощью графического интерфейса. Это
обеспечивает обширный мониторинг
основной базы данных, резервных баз
данных и вспомогательных служб в конфигурации;
-
снижается сложность управления. Переключение и отказоустойчивых операции
могут быть выполнены с помощью централизованной консоли;
-
может быть использован для сбора полезной статистики для тонкой настройки
транспортировки redo потока.
Oracle Data Guard Broker
является фреймворком, который
позволяет
автоматизировать и централизовать создание, обслуживание и мониторинг
конфигурации
Data Guard . Модель управления брокера представляет собой
иерархическую структуру, состоящую из конфигурации, сайта и ресурса базы
данных. Вы можете создать резервную базу данных с помощью Data Guard брокера,
или добавить существующую резервную базу данных в конфигурацию. При
создании резервной базы данных с помощью брокера, он берет на себя заботу о
51
создании набора вспомогательных файлов, например, SPFILE, Oracle Net файлы
конфигурации и так далее.
Сама технология состоит из компонентов на стороне сервера и на стороне
клиента, реализующих распределенную вычислительную архитектуру.
Серверный компонент Data Guard Broker включает в себя процесс Data Guard
Monitor (DMON) и конфигурационный файл. DMON представляет собой фоновый
процесс, который выполняется на каждом из объектов, управляемых Data Guard
Broker. Файл конфигурации представляет собой бинарный файл, который содержит
свойства и состояния всех узлов в конфигурации. Процесс DMON отвечает за
управление последовательной копии файла конфигурации по всей конфигурации,
взаимодействуя через Oracle Net для управления ролями. Кроме того, процесс
DMON собирает статистические данные о состоянии системы, которые могут быть
использованы для мониторинга и тонкой настройки.
Клиентские компоненты брокера - это
утилита командной строки
(DGMGRL). DGMGRL удобна для написания пользовательских сценариев для
автоматизации задач по администрированию Data Guard.
DGMGRL> CONNECT SYS/ORACLE@SPBSTU
DGMGRL> SWITCHOVER TO SPBSTU_STB
DGMGRL> SHOW CONFIGURATION
Теперь инициирую ситуацию, когда на основной базе данных запланированы
плановые административные работы. Для этого выполним следующие команды
(приложение 4):
SQL> alter database commit to switchover to physical standby with session shutdown wait;
SQL> shutdown immediate;
SQL> startup nomount;
SQL> alter database mount standby database;
SQL> alter database recover managed standby database disconnect;
SQL> select database_role from v$database;
Переключаем обратно.
SQL> alter database commit to switchover to primary with session shutdown wait;
SQL> shutdown
52
SQL> startup
SQL> alter system archive log start;
SQL> alter system switch logfile;
Ситуация же сбоя на основной базе данных в данной конфигурации
продуктов Oracle не привела к автоматическому переключению ролей, так как
концепция повышенной надежности при которой происходит автоматическое
переключение реализована только в кластерной архитектуре. Это объясняет
использование именно Standby RAC с технологией Data Guard в критичных
информационных бизнес- системах.
3.3.2 Результаты нагрузочного тестирования
Настройка реплики на резервную базу данных может негативно сказаться на
производительности сервера. Для исследования факта влияния технологии Data
Guard я
написал специальный скрипт, содержащий PL/SQL блок с циклами
(приложение 4).
Выполнение скрипта для генерации большого потока данных журнала
передаваемых на резервный сервер выполнялось одновременно из нескольких
активных сессий (таблица 3.2).
По результатам можно сказать, что, если между SQL-командами нет пауз, это
создает высокую нагрузку на процессор, ОЗУ и на дисковые накопители. Такая
ситуация была инициирована специально, так как экономически технология Data
Guard подходит преимущественно для больших высоконагруженных систем.
Таблица 3.2 - Результаты тестирования под высокой нагрузкой
Количество сессий (в одной
сессии создается объект)
3
6
9
Время
выполнения
скрипта в Data Guard, с
237
341
478
53
Проверка соответствия максимального
номера архивных логов на обоих базах
199
298
397
Из тестирования прототипа видно, что при наличии хорошей пропускной
способности сети и незначительной территориальной удаленности, данные
реплицируются на резервную базу данных моментально и не противоречат
производственной базе данных (таблица 3.2).
Мерой качества функциональной пригодности системы может быть степень
покрытия целей, назначения и функций резервных баз данных
пользователям
актуальной
информации.
На
по доступной
содержательном
уровне
функциональную пригодность резервной базы данных отражает таблица 3.3 [14].:
Таблица 3.3 - Тестирование функциональной пригодности
Функциональная пригодность
Primary
Standby
Полнота созданных объектов
Создан объект
Создан объект
Идентичность данных
Заполнена таблица
Актуальность данных
Получена выборка из
таблицы
Данные переданы в полном
объеме
После репликации данными
можно воспользоваться на
чтение
1. Полнота созданных объектов - синхронизация измененной структуры основной
базы данных с резервными.
2. Идентичность данных - оценка совпадения данных на обеих базах.
3. Актуальность данных - время, через которое данные станут идентичными (если
данные выборки не совпадают на обеих данных).
3.3 Вывод по главе
Опираясь в своей работе на последовательное выполнение задач данного
исследования, в виртуальной среде на двух хостах под операционной системой
Linux 6.7 установлена система управления объемами данных и файловой системой
Oracle Automatic Storage Management, интегрированная в Oracle Database 12с. Тесткейсы показали, что она обеспечивает возможность
54
добавлять, удалять и
балансировать объемы данных на дисковых группах
без необходимости
прерывания сетевых процессов функционирования базы данных, что важно для
обеспечения отказоустойчивости всей информационной системы.
Апробация данного метода проходила в OOO "ЗеФинанс" (рисунок П4.1).
Работы по плану апробации и внедрения отказоустойчивого сервера СУБД в
информационную систему компании проведены в полном объеме.
55
ЗАКЛЮЧЕНИЕ
В работе широкое применение нашли публикаций отечественных и
зарубежных
авторов
отказоустойчивости
в
и
области
исследования
катастрофоустойчивости
повышения
сложных
надежности,
вычислительных
комплексов. Выполнен системный анализ наиболее популярных решений по
обеспечению сохранности данных и работоспособности системы, а также путей
повышения их надежности и функциональности на основе практики известных
исследователей и проведенных автором тестовых испытаний.
Созданные в ходе работы конструкции позволяют существенно улучшить
производительность, отказоустойчивость и надежность сервера СУБД в контексте
архитектуры сложных систем.
Выполнены
опытно-исследовательские
работы
по
конфигурированию
технологии Data Guard 12c с резервным сервером СУБД , отработке ситуаций
программных сбоев и чрезвычайных ситуаций.
Для решения задач исследования автором создана и представлена
классификация типов существующих программных решений в области резервного
копирования, реплицирования и восстановления базы данных, позволяющая
наглядно и обозримо провести систематизацию средств повышения надежности
сервера СУБД в концепции Maximum Availability Architecture компании Oracle.
Автором представлены
теоретические положения
по
ASM и
Grid
Infrastructure 12c. Разработана методика построения отказоустойчивого сервера
СУБД на основе технологии Automatic Storage Management, CRS и Oracle Active
Data Guard 12c. Системно проанализированы и представлены экономические
требования по отказоустойчивости приложений информационной системы, где
сервер СУБД - компонента этой системы.
Разработка теоретических положений по структуре процессов в Grid
Infrastructure 12c, настройки сервера СУБД для процесса потоковой репликации
56
стало возможным благодаря комплексному использованию теоретических и
экспериментальных методов исследования. Созданная методика настройки процесса
репликации на резервную базу данных согласуется с опытом
проектирования
отказоустойчивого сервера СУБД. Разработанные положения и
решения
опробованы экспериментально. Экспериментальные исследования проводились в
виртуальной среде на стандартной базе данных Oracle. Результаты эксперимента и
испытаний анализировались и сопоставлялись с известными экспериментальными
данными СУБД других вендеров. По итогу найдены отличия в самом алгоритме
репликаций данных на резервный сервер.
Разработанные в диссертационной работе дидактические положения теории
конфигурирования Data Guard в резервных базах данных позволяют упростить
механизм
построения
отказоустойчивого
сервера
и
повысить
уверенность
инженеров при работе с данной технологией. Сформулированные алгоритмы
позволяют полностью исключить экспериментальные исследования на тестовых
средах
компаний
использующих
резервные
сервера
в
работе
своих
информационных систем, что дает возможность значительно снизить затраты
времени сотрудников на отработку регламентирующих действий.
Результаты исследования технологии построения отказоустойчивого сервера
СУБД с помощью резервной базы данных представляют практический интерес не
только для специалистов Oracle, а так же для разработчиков аналогичных продуктов
в других СУБД, к примеру в PostgreSQL.
Основные положения и результаты работы докладывались и обсуждались на
семинарах
и
научной
конференции
ComCon-2016
Политехнического Университета Петра Великого.
57
Санкт-Петербургского
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1. В.
Г.
Беленков,
В.И.
Будзко.
Катастрофоустойчивость
корпоративных
информационных систем. - М.: ИПИ РАН, 2002. 162с.
2. В. С. Аткина. Анализ методик оценки катастрофоустойчивости информационной
системы// Проблемы обеспечения информационной безопасности в регионе. –
Влг. : ВолГУ, 2010. c. 52–56.
3. А. С. Кузнецов, С.В. Ченцов, Р.Ю. Царев. Многоэтапный анализ архитектурной
надежности и синтез отказоустойчивого программного обеспечения сложных
систем. - М.: Изд-во "Проспект", 2015. 144 с.
4. Ю. М. Морозов. Надежность аппаратно-программных комплексов. - Спб.:
СпбПУ, 2011. 136 с.
5. В. И. Загвязинский. Методология и методика дидактического исследования. - М.:
Педагогика, 2003. - 212 с.
6. А. М. Новиков, Д. А. Новиков. Методология научного исследования. – М.:
Либроком, 2009. – 280 с.
7. Г. И. Андреев, С. А. Смирнов, В. А. Тихомиров. Основы научной работы и
оформление результатов научной деятельности. - М.: "Финансы и Статистика",
2003. 272 с.
8. E. Baransel, N. Basha. Oracle Data Guard 11gR2 Administration Beginner's Guide. Birmingham, UK.: PACKT Publishing, 2013. 404c.
9. Van Vugt S. Red Hat Enterprise Linux 6 Administration: Real World Skills for Red
Hat Administrators. – John Wiley & Sons, 2013.
10. S. Shaw, M. Bach Automatic Storage Management //Pro Oracle Database 11g RAC on
Linux. – New York, NY.: Apress, 2010. – 830c.
11. L. Carpenter. Data Guard 11g Handbook. - New York, NY.: McGraw-Hill Companies,
2009. 545c.
12. T. Kyte, Expert Oracle Database Architecture: Oracle Database 9i, 10g, and 11g
Programming Techniques and Solutions. – New York, NY.: Apress, 2010. 832 с.
58
13. J. Lewis. Oracle Core: Essential Internals for DBAs and Developers. - New York,
NY.: Apress, 2011. 280c.
14. Липаев В.В. Выбор и оценивание характеристик качества программных средств.
М.: «Синтег», 2001
15. Zakharchuk O.G. A Basis for constructive theory of General systems. The crucial
field, as a functional model of the subsystem optimizing the adaptation of the
noosphere. [Electronic resource]: http://zakharchuk.dialog21.]
16. А. Рындин, Использование Oracle Streams для репликации: [Электронный
документ]. (http://www.oraclegis.com/blog/?p=301). Проверено: 11.04.2016.
17. Л. Корольков, Как обеспечить максимальную отказоустойчивость системы :
[Электронный
документ].
(http://efsol.ru/articles/system-fault-tolerance.html).
Проверено: 11.04.2016.
18. В.
В.
Соколов,
Подход
к
оценке
сложности
систем:
[Электронный
документ].(http://www.ait.org.ua/p/pub_podhod.html).Проверено:11.04.2016
59
ПРИЛОЖЕНИЕ 1
Подготовка операционной системы к установке Oracle Grid
1. Проверка требований к аппаратному обеспечению:
-
Доступная память и своп:
[root@ol67 ~]# free
-
Разделяемая память:
[root@ol67 ~]# df -h /dev/shm/
-
Дисковое пространство:
[root@ol67 ~]# df -h
Утилита df (disk free) — показывает список всех файловых систем по именам устройств,
сообщает их размер, занятое и свободное пространство и точки монтирования. Я собираюсь
создавать папку для установки в корневой файловой системе (/), поэтому смотрю на
наличие свободного места в ней. Файлы установки Oracle Grid займут на диске минимум
5,5Гб.
2. Проверка требований к операционной системе:
-
Версия ядра:
[root@ol67 ~]# uname -r
-
Проверка установленных пакетов:
[root@localhost Server]# rpm -q
-
Установка oracle-rdbms-server-11gR2-preinstall:
[root@ol67 ~]# cd /etc/yum.repos.d
[root@ol67 yum.repos.d]# wget http://public-yum.oracle.com/public-yum-ol6.repo
в файле public-yum-ol6.repo устанавливаем enabled=1 в секции [ol6_u6_base]
[root@ol67 yum.repos.d]# yum install oracle-rdbms-server-11gR2-preinstall
-
Установка пакета kernel-uek-devel
Установка Automatic Storage Management Library Driver (ASMLib):
[root@ol67 ~]# yum install oracleasm oracleasm-support
[root@ol67 ~]# rpm -qa | grep oracleasm
-
-
Следующие пакеты нужны для старта графической консоли:
[root@ol67 ~]# yum install -y \ xorg-x11-apps \ xorg-x11-xauth \ xorg-x11-fonts-* \ xorg-x11font-utils\ xdpyinfo
[root@ol67 ~]# yum provides * /xclock
Дополнительные пакеты:
60
[root@ol67 ~]# yum install -y \ vim \ wget \screen \unzip \ readline-delev.x86_64
[root@ol67 ~]# cd /tmp
[root@ol67 ~]# wget http://utopia.knoware.nl/~hlub/uck/rlwrap/rlwrap-0.37.tar.gz
[root@ol67 ~]# tar zxvf rlwrap-0.37.tar.gz
[root@ol67 ~]# cd rlwrap-0.37
[root@ol67 ~]# ./configure
[root@ol67 ~]# make && make check && make install
3. Создание пользователей и групп:
-
Группы:
/usr/sbin/groupadd -g 501 oinstall
/usr/sbin/groupadd -g 502 dba
/usr/sbin/groupadd -g 504 asmadmin
/usr/sbin/groupadd -g 506 asmdba
/usr/sbin/groupadd -g 507 asmoper
-
Пользователи:
/usr/sbin/useradd -u 501 -g oinstall -G asmadmin,asmdba,asmoper,dba grid
/usr/sbin/useradd -u 502 -g oinstall -G dba,asmdba oracle
-
Вновь созданным пользователям нужно задать пароли:
[root@ol67 ~]# passwd grid
[root@ol67 ~]# passwd oracle
4. Создание папок:
-
-
-
-
Oracle Inventory
mkdir -p /u01/app/oraInventory
chown -R grid:oinstall /u01/app/oraInventory
chmod -R 775 /u01/app/oraInventory
Grid Infrastructure Home
mkdir -p /u01/11.2.0/grid
chown -R grid:oinstall /u01/11.2.0/grid
chmod -R 775 /u01/11.2.0/grid
Oracle Base Directory
mkdir -p /u01/app/oracle
mkdir /u01/app/oracle/cfgtoollogs
chown -R oracle:oinstall /u01/app/oracle
chmod -R 775 /u01/app/oracle
Oracle RDBMS Home
mkdir -p /u01/app/oracle/product/11.2.0/db_1
chown -R oracle:oinstall /u01/app/oracle/product/11.2.0/db_1
chmod -R 775 /u01/app/oracle/product/11.2.0/db_1
5. Конфигурирование ASM:
61
-
Проверки установленных пакетов:
[root@ol67 ~]# rpm -qa | grep oracleasm
Будет выведен список из установленных пакетов. На OL с ядром UEK это будут 2 пакета.
На других версиях Linix в списке должно быть 3 пакета.
-
Конфигурируем Oracle ASM Library driver ( рисунок П1):
[root@ol67 ~]# /etc/init.d/oracleasm configure -i
[root@ol67 ~]# /usr/sbin/oracleasm init
7. Создание дисков для ASM:
-
Утилита fdisk используется для работы с диском. Просмотреть список дисков:
/sbin/fdisk -l
-
Создать раздел:
/sbin/fdisk /dev/sdb ; Так же создаю разделы на оставшихся дисках.
-
Утилита oracleasm используется для работы с кластерной файловой системой Oracle ASM.
Создать диски ASM:
/usr/sbin/oracleasm createdisk CRS01 /dev/sdb1
/usr/sbin/oracleasm
createdisk
DATA01
/dev/sdb1
/usr/sbin/oracleasm
createdisk
FRA01
/dev/sdc1
/usr/sbin/oracleasm createdisk REDO01 /dev/sdd1
-
-
Проверка :
/usr/sbin/oracleasm listdisks
ls -ltr /dev/oracleasm/disks
/usr/sbin/oracleasm-discover ORCL:*
Для удаления диска ASM (если ошиблись) используйте:
/usr/sbin/oracleasm deletedisk XXX
Рисунок П1 - Конфигурирование ASM library driver.
62
ПРИЛОЖЕНИЕ 2
Подготовка Database к клонированию на Standby-хост
1. Установить программное обеспечение Oracle Grid на резервный хост:
-
Установить программное обеспечение Oracle Grid;
Проверка работоспособности crs (выполнять под grid). Вполне возможно, что при
работающем экземпляре ASM утилита crsctl Clusterware не запускается ( рис.П2.1, П2.2):
[grid@ol67 ~]$ crsctl check has
[grid@ol67 ~]$ crsctl check css
[grid@ol67 ~]$ crs_stat -t
[grid@ol67 ~]$ crsctl enable crs -h
Рисунок П2.1 - Проверка работоспособности процессов CRS
Рисунок П2.2 - Проверка работоспособности процессов CRS
Утилита CRSCTL (Oracle Clusterware Control) - обеспечивает команды, с которыми можно
выполнить проверку, запуск и остановку операций на кластере.
-
Создание дисковых групп:
[grid@ol67 ~]$ create diskgroup DATA external redundancy disk '/dev/sda1','/dev/sda2'
63
[grid@ol67 ~]$ create diskgroup FRA external redundancy disk '/dev/sdb1','/dev/sdb2'
[grid@ol67 ~]$ create diskgroup ARCH external redundancy disk '/dev/sdc1','/dev/sdc2'
В приведенном выше примере, использовалась опция external redundancy ( внешняя
избыточность). Это означает, что ASM не обеспечат дополнительную поддержку
избыточности и, следовательно, не может помочь в случае сбоя диска. Этот вариант
используется, если мы используем ASM в комбинации с RAID1. Тем не менее,
избыточность может быть установлена следующим способом:
[grid@ol67 ~]$ create diskgroup DATA normal redundancy disk '/dev/sda1','/dev/sda2'
-
Установка программного обеспечения Oracle Database;
Проверяем чтоб Database распознавал ASM:
[oracle@ol67 ~]$ sqlplus sys/oracle@spbstu_stb as sysdba
SQL> select name from V$asm_diskgroup;
Но, если на хосте не создавалась база данных, то используем утилиту DBCA, просто чтоб
при клонировании базы данных утилита RMAN не выдавала неожиданных результатов и
ошибок (рис.П2.3)
Рисунок П2.3 - Database не распознает дисковые группы ASM
-
Настраиваем сеть и задаем ip адреса:
$ ifconfig eth0 192.168.0.2 netmask 255.255.255.0
-
Копируем файл паролей:
SQL> show parameter remote_login_passwordfile;
$> cd $Oracle_home/dbs
$> ls –lrt
$> rm –f orapwspbstu
$> orapwd file=orapwspbstu password=oracle entries=7
$>ls –lrt
$ scp $ORACLE_HOME/dbs/orapwspbstu oracle@ol68:$ORACLE_HOME/dbs/
standby
$ chmod 4640 $ORACLE_HOME/dbs/orapwspbstu
64
-
Создаем директории как на Primary:
Primary
SQL> show parameter audit
audit_file_dest
/u01/oracle/admin/spbstu/adump
Standby
$ mkdir -p /u01/oracle/admin/spbstu/adump
2. Изменение настроек в работе Primary Database
-
перевод базы данных в режим логирования:
SQL> archive log list;
SQL> shutdown immediate;
SQL> startup mount;
SQL> alter database archivelog;
SQL> alter database open;
SQL> archive log list;
Database log mode
Archive Mode
Automatic archival
Enabled
SQL> alter database force logging;
SQL> select force_logging from v$database;
FORCE_LOGGING
--------------------------------------YES
-
настройка параметров init.ora:
SQL> show parameter db_unique_name;
SQL> alter system set log_archive_config='dg_config=(spbstu,spbstu_stb)’ scope=both;
SQL> alter system set log_archive_dest_2='SERVICE=spbstu_stb LGWR ASYNC
VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) db_unique_name=spbstu_stb’
scope=both;
SQL> alter system set log_archive_dest_state_2=ENABLE scope=both;
SQL> alter system set FAL_SERVER=spbstu_stb scope=both;
SQL> alter system set FAL_CLIENT=spbstu scope=both;
SQL> alter system set standby_file_management='AUTO’ scope=both;
SQL> show parameter arch
SQL> show parameter log_archive_dest_state_1
SQL> show parameter log_archive_dest_state_2
SQL> show parameter fal;.
65
-
fal_client=’spbstu’ – этот параметр определяет, что когда экземпляр перейдет в режим
standby, он будет являться клиентом для приема архивных журналов (fetch archive log);
fal_server=’spbstu_stb’ – определяет FAL (fetch archive log) сервер, с которого будет
осуществляться передача архивных журналов. Параметры fal_client и fal_server работают
только когда база запущена в standby режиме;
-
cоздание файла инициализации для Primary и Standby:
-
SQL> create pfile from spfile;
SQL> create pfile= '/u01/app/oracle/pfilespbstu_stb.ora' from spfile;
-
изменяем и передаем на резервный хост:
*.db_unique_name='spbstu_stb'
*.fal_server='spbstu_stb'
*.fal_client='spbstu'
*.log_archive_config='DG_CONFIG=(spbstu, spbstu_stb)'
*.log_archive_dest_1='LOCATION=+ARCH VALID_FOR=(all_logfiles,all_roles)
db_unique_name=spbstu_spb'
*.log_archive_dest_2='SERVICE=spbstu LGWR ASYNC VALID_FOR=(
ONLINE_LOGFILES, PRIMARY_ROLE) DB_UNIQUE_NAME=spbstu‘
$ scp '/u01/app/oracle/pfilespbstu_stb.ora‘
oracle@ol68: '/u01/app/oracle/pfilespbstu_stb.ora'
-
настройка сетевых файлов:
Primary
LISTENER2 =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(
HOST = 192.168.10.102)(PORT = 1522))
)
)
SID_LIST_LISTENER2 =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = spbstu)
(SID_NAME = spbstu)
(ORACLE_HOME = /u01/app/oracle/product/12.1.0/db_1)
)
)
66
Standby
LISTENER2 =
(DESCRIPTION_LIST =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(
HOST = 192.168.10.103)(PORT = 1522))
)
)
SID_LIST_LISTENER2 =
(SID_LIST =
(SID_DESC =
(GLOBAL_DBNAME = spbstu)
(SID_NAME = spbstu_stb)
(ORACLE_HOME = /u01/app/oracle/product/12.1.0/db_1)
)
)
Primary, Standby
#
tnsnames.ora
Network
Configuration
/u01/app/oracle/product/12.1.0/db_1/network/admin/tnsnames.ora
# Generated by Oracle configuration tools.
SPBSTU =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.10.102)(PORT = 1522))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = spbstu)
)
)
SPBSTU_STB =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.10.103)(PORT = 1522))
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.10.103)(PORT = 1523))
(CONNECT_DATA =
(SERVER = DEDICATED)
67
File:
(SERVICE_NAME = spbstu)
#(SID_NAME = spbstu)
(UR = A)
)
)
-
добавление standby_redo_log файлов:
ALTER SYSTEM SET STANDBY_FILE_MANAGEMENT=MANUAL SCOPE=BOTH;
ALTER DATABASE ADD STANDBY LOGFILE
thread 1 GROUP
'+DATA/SPBSTU_STB/STANDBYLOG/stby_4.log' size 52428800 reuse ;
ALTER DATABASE ADD STANDBY LOGFILE thread 1 GROUP 5
'+DATA/SPBSTU_STB/STANDBYLOG/stby_5.log' size 52428800 reuse ;
ALTER DATABASE ADD STANDBY LOGFILE thread 1 GROUP 6
'+DATA/SPBSTU_STB/STANDBYLOG/stby_6.log' size 52428800 reuse ;
ALTER DATABASE ADD STANDBY LOGFILE thread 1 GROUP 7
'+DATA/SPBSTU_STB/STANDBYLOG/stby_7.log' size 52428800 reuse ;
ALTER SYSTEM SET STANDBY_FILE_MANAGEMENT=AUTO SCOPE=BOTH
-
Удаление (если потребовалось ) standby_redo_log файлов
SQL> alter database drop logfile group 7;
3. Проверяем Oracle Net и RMAN:
[oracle@ol67 ~]$ rman target sys/oracle@spbstu auxiliary sys/oracle@spbstu_stb
68
4
ПРИЛОЖЕНИЕ 3
Клонирование и настройка Redo Apply
1. Установка параметра local_listener:
Primary
SQL> alter system set local_listener='(DESCRIPTION =(ADDRESS = (PROTOCOL =
TCP)(HOST = )(PORT = 1522)))' scope=both;
Standby
SQL> alter system set local_listener='(DESCRIPTION =(ADDRESS = (PROTOCOL =
TCP)(HOST = )(PORT = 1522)))' scope=both;
2. Запускаем скрипт:
run{
allocate channel chan1 type disk;
allocate channel chan2 type disk;
allocate auxiliary channel aux1 device type disk;
allocate auxiliary channel aux2 device type disk;
duplicate target database for standby from active database
dorecover nofilenamecheck; }
Параметр nofilenamecheck нужен, чтобы rman не ругался на повторяющиеся
имена файлов (если мы используем одинаковую структуру каталогов на primary
и standby).
2. Проверяем наличие файлов на Standby:
SQL> select * from v$standby_log;
3. Проверяем режим базы данных:
Standby
SQL> select name, db_unique_name, database_role, protection_mode from v$database;
SQL> select name, controlfile_type, open_mode, log_mode
from v$database;
NAME
CONTROL OPEN_MODE
LOG_MODE
--------- -------------------- -----------SPBSTU
STANDBY MOUNTED
ARCHIVELOG
69
Если нужно, то выполняем следующие команды
SQL> SHUTDOWN IMMEDIATE;
SQL>STARTUP NOMOUNT;
SQL>ALTER DATABASE MOUNT STANDBY DATABASE;
4. Узнаем максимальный номер redo log:
-
выполняем на primary и standby, запрос который нам покажет количество
архивлогов:
SQL> select max(sequence#) from v$archived_log;
-
Потом на primary, выполняем несколько раз команду:
SQL> ALTER SYSTEM SWITCH LOGFILE
5. Запускаем Redo Apply:
-
Переводим нашу standby базу в режим Real-time apply redo:
SQL> alter database recover managed standby database using current logfile disconnect;
Или
SQL> alter database recover managed standby database using current logfile disconnect
from session;
-
если мы не хотим использовать режим Real-time apply redo, а хотим
дожидаться когда будет закончено формирование очередного архивного
журнала на основном сервере и он будет передан на standby для применения
сохраненных в нем транзакций, то нам необходимо переводить нашу standby
базу в режим redo apply командой:
SQL> alter database recover managed standby database disconnect;
-
если что-то пошло не так, то для решения проблемы в первую очередь
необходимо остановить «накатку» логов:
SQL> alter database recover managed standby database cancel;
6. Перевод базы данных в режим read only:
SQL> shutdown immediate;
SQL> startup mount;
SQL> alter database open read only;
SQL> select name, open_mode, database_role from v$database;
NAME
OPEN_MODE
DATABASE_ROLE
--------- -------------------- ------------ ---------------SPBSTU
READ ONLY WITH APPLY
PHYSICAL STANDBY
7. Конфигурирование Oracle Data Guard Broker:
-
primary и standby:
70
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_2=" ";
SQL> ALTER SYSTEM set dg_broker_config_file1='+DATA/db_brocker1.dat' SCOPE=both;
SQL> ALTER SYSTEM set dg_broker_config_file2='+ARCH/db_brocker2.dat' SCOPE=both;
SQL> ALTER SYSTEM SET dg_broker_start=TRUE SCOPE=both;
-
primary
$ dgmgrl
DGMGRL> CONNECT sys@spbstu
DGMGRL> CREATE CONFIGURATION ‘spbstu' AS PRIMARY DATABASE IS
‘spbstu' CONNECT IDENTIFIER IS primary;
-
standby
DGMGRL> ADD DATABASE 'spbstu_stb' AS CONNECT IDENTIFIER IS standby
maintained as physical;
DGMGRL> ENABLE CONFIGURATION;
DGMGRL> show configuration
DGMGRL> show database spbstu
DGMGRL> show database spbstu_stb
-
остановить bkoker
SQL> ALTER SYSTEM SET dg_broker_start=FALSE SCOPE=both;
-
выключить конфигурацию:
DGMGRL> disable configuration;
-
удалить конфигурацию:
DGMGRL> REMOVE CONFIGURATION;
-
получить подробную информации по базе:
DGMGRL> show database verbose spbstu_stb
-
получить подробную информации по экземпляру:
DGMGRL> show instance verbose spbstu on database spbstu_stb
8. Планового переключения Primary:
-
например, требуется увеличить размер SGA. Вариант 1
SQL> alter database commit to switchover to physical standby with session shutdown
wait;
SQL> shutdown immediate;
SQL> startup nomount;
SQL> alter database mount standby database;
SQL> alter database recover managed standby database disconnect;
SQL> select database_role from v$database;
71
переключаем обратно
SQL> alter database commit to switchover to primary with session shutdown wait;
SQL> shutdown
SQL> startup
SQL> alter system archive log start;
SQL> alter system switch logfile;
-
вариант 2.
DGMGRL> switchover to 'SPBSTU_STB';
DGMGRL> switchover to 'SPBSTU';
72
ПРИЛОЖЕНИЕ 4
Тестирование
1. Изменение структуры Primary и генерация redo потока:
SQL> CREATE TABLE pow(vremya DATE, dbuser VARCHAR2(20), nomer NUMBER(8));
SQL> BEGIN
FOR i IN 1..500 LOOP
FOR i IN 1..1000 LOOP
INSERT INTO pow VALUES (sysdate, user, i);
END LOOP;
UPDATE pow set vremya = sysdate +1;
DELETE FROM pow;
END LOOP; END;
/
2. Мониторинг:
SQL> select instance_name, status from v$instance;
INSTANCE_NAME STATUS
---------------- -----------spbstu_stb
MOUNTED
SQL> SELECT process, status, sequence# FROM V$MANAGED_STANDBY;
PROCESS STATUS
SEQUENCE#
--------- ------------ ---------ARCH CONNECTED
0
ARCH CONNECTED
0
ARCH CONNECTED
0
ARCH CONNECTED
0
SQL> alter database recover managed standby database using current logfile disconnect;
Database altered.
73
SQL> SELECT process, status, sequence# FROM V$MANAGED_STANDBY;
PROCESS STATUS
SEQUENCE#
--------- ------------ ---------ARCH CONNECTED
0
ARCH CONNECTED
0
ARCH CONNECTED
0
ARCH CONNECTED
0
MRP0 WAIT_FOR_LOG
52
SQL> select max(sequence#) from v$log_history;
MAX(SEQUENCE#)
-------------51
SQL> select group#,thread#,status,bytes/1024/1024 mb from v$standby_log;
GROUP# THREAD# STATUS
---------- ---------- ---------- ---------4
1 UNASSIGNED
5
1 UNASSIGNED
6
1 UNASSIGNED
7
1 UNASSIGNED
MB
50
50
50
50
Рисунок П4.1 - Мониторинг Redo Apply
74
ЗАКЛЮЧИТЕЛЬНЫЙ ЛИСТ РАБОТЫ
Магистерская
диссертация
выполнена
мною
самостоятельно.
Использованные в работе материалы и концепции из опубликованной научной
литературы и других источников имеют ссылки на них.
Список использованных источников: 18 наименований.
Работа выполнена на 74 листах,
включая приложения на 15 листах.
Один экземпляр сдан на кафедру.
Подпись______________/_________________/
(фамилия, инициалы)
Дата «______» _______________ 20______г.