таблица фактов F(dk1, dk2, dk3, m)
реклама
")
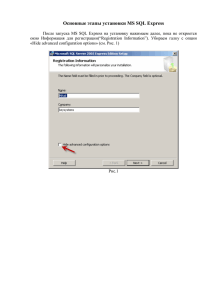
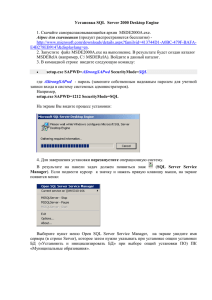
BI 303 Борис Барышников Senior Program Manager Microsoft Corp. Основные принципы хранилищ данных (Data Warehousing – DW) Логический и физический дизайн базы Некоторые элементы дизайна и конфигурации Загрузка данных Возможности SQL Server 2008 и 2008 R2 в области хранилищ данных для ускорения скорости выполнения запросов Анонс возможностей SQL Server “Denali” В Microsoft Corp. чуть более 6 лет Всё время в команде SQL Server Engine Работал с различными компонентами и технологиями движка SQL Server В 2008 версии руководил проектом создания регулятора ресурсов В настоящее время работаю над новыми возможностями сервера для улучшения предсказуемости времени выполнения запросов Функции хранилища данных Депозитарий данных для поддержки тщательного анализа данных и создания отчётов Источником данных в DW часто являются многочисленные базы обработки транзакций (OLTP) Например: Продажи Стадия подготовки Склад Системы обработки транзакций DW Отчёты и анализ Наиболее распространёнными являются схемы «звезда» и «снежинка» Customer Таблица измерений Sales Product Store Country Territory Date Таблица фактов Измерение по схеме «снежинка» Принципы моделирования подобных схем можно найти в The Data Warehouse Toolkit by Ralph Kimball, 2002. Используйте схему по типу «звезда» или «снежинка» Избегайте длинных строк, большого объема двоичных данных или колонок типа uniqueidentifier в таблице фактов Используйте целочисленные типы для ключевых колонок таблиц измерений Избегайте указания точности выше, чем необходимо в типах numeric (напр., (15,4) vs. (38,4)) Реализация физической структуры базы для оптимальной производительности Хороший физический дизайн – сложный и трудоёмкий процесс Главные шаги Выбор расположения файлов и файловых групп на диске для вашей системы I/O Выбор оптимального секционирования таблиц Использование PAGE compression для таблиц фактов Принципы: быстрый последовательный доступ I/O, простота создания и управления большими таблицами Каждый файл отдельный диск Все файлы одна группа Все таблицы в эту файловую группу File Group 1 File 1 File 2 … File 32 Избегайте использования более 32 файлов в одной группе Известная проблема производительности в настоящий момент Если у вас более 32 физических дисков, сгруппируйте их в логические, используя средства ОС или SAN Далее используйте логические устройства как описано выше Более подробно в SQL Server Fast Track guide Для больших объемов данных, см. также Parallel Data Warehouse Для таблиц фактов Используйте clustered index on DateKey column Если таблица > ~50GB, также секционируйте её по DateKey (напр., по месяцам) DateKey в формате YYYYMMDD, e.g. 20101117 Используйте PAGE compression Без дополнительных индексов (если не требуются point lookups) Как правило признак смешанного использования системы Для таблиц измерений Для маленьких таблиц – не используйте индексы кроме тех, что обеспечивают гарантии целостности данных (constraint enforcement) Для больших таблиц – индексы для ускорения наиболее типичных фильтров Инструменты в помощь: missing index DMV и DTA (database tuning advisor) Принципы/цели: Быстрая загрузка данных С минимальной фрагментацией Дополнительная информация в Fast Track 2.0 Guide Загрузка кластерного индекса 2 опции – загрузка напрямую, загрузка через дополнительную таблицу (staging) Загрузка кластерного индекса, вариант 1: BULK INSERT напрямую в таблицу Полный набор данных должен помещаться в память для сортировки – максимальная производительность Все данные загружаются в единственной транзакции с BATCHSIZE = 0. Это предотвращает дробление страниц и лишнюю фрагментацию Загрузка происходит последовательно (single threaded) Загрузка кластерного индекса, вариант 2: Загрузка BULK INSERT последовательно или параллельно в пустую промежуточную таблицу – кластерный индекс Ненулевой размер в BATCHSIZE (подбирается, чтобы не было сортировки в TempDB) Далее единственный INSERT…SELECT с MAXDOP = 1 для предотвращения фрагментации Позволяет достигать более высокой скорости загрузки на первоначальной стадии (если использовать несколько параллельных потоков) Предварительно разбиваем данные по файлам по дате Загружаем в несколько промежуточных таблиц одновременно Загружаем каждую из таблиц как на предыдущем слайде Последовательно переключаем секций между промежуточными и основной таблицей Final table Staging tables Load files P1 P2 Pn … Добавлено в SQL Server 2008 Сжатие данных и файлов резервного копирования Обработка запросов типа «звезда» (Star join) Обработка запросов типа few outer rows Выровненные по секциям индексированные представления (partition aligned indexed views) Независимо от версии Использование сводных таблиц и индексированных представлений для запросов агрегирования данных Добавлено в SQL Server 2008 R2 Поддержка до 256 аппаратных потоков Реализация сжанитя Unicode 2 типа: PAGE and ROW (страница и запись) Используйте PAGE для хранилищ данных В среднем даёт 3X сжатие (диапазон 2-8X) Используйте для таблиц фактов и на огромных таблицах измерений Избегайте для небольших таблиц Увеличение скорости, снижение кол-ва дисковых обращений, экономия места В SQL Server 2008 R2 добавлена реализация сжатия Юникода Наибольший эффект для языков, не изменяющих старший байт Фактически делает тип однобайтовым в таком случае (менее эффективен для таких языков как китайский или японский) Например, использование для сжатия Unicode URLs (type nvarchar) Функционал доступен автоматически для новых таблиц SQL Server 2008 R2 Для миграции 2008 2008 R2 требуется обновить запись или перестроить индекс, чтобы «включить» такое сжатие Оптимизация обработки запросов типа «звезда» select t.SalesTerritoryCountry, COUNT(*) SalesCount, ... from FactResellerSalesPart f, DimSalesTerritory t where f.SalesTerritoryKey = t.SalesTerritoryKey and t.SalesTerritoryCountry <> 'United States‘ group by t.SalesTerritoryCountry; Ускоряет обработку таких запросов на 30% в среднем и в некоторых случаях до 7X Практические рекомендации Используйте схему типа «звезда» или «снежинка». Для нормализованных таблиц (3NF) преимущество минимально Используйте целочисленный тип данных для ключевых колонок таблиц измерений для максимального эффекта Доступно только в редакции Enterprise и выше SQL Server 2005 и ранее использует блочный алгоритм вложенных циклов (nested loop join) Каждая страница данных обрабатывается только одним потоком SQL Server 2008 использует отдельный поток для каждого «внешнего» ряда Возможно использование всех доступных процессоров Нет необходимости переписывать запрос для обхода этого ограничения, т.е. вместо SELECT ..., SUM(f.m) FROM f, ... WHERE f.date_key BETWEEN 20050101 AND 20050107 GROUP BY ... Можно использовать следующий вариант без потери производительности SELECT ..., SUM(f.m) FROM f, dim_date d WHERE f.date_key = d.date_key AND d.year = 2010 and d.week = 1 … GROUP BY ... Для максимальной возможности распараллелить запрос, первый вариант предпочтителен (MAXDOP = MAX CPUs) SELECT ..., SUM(f.m) FROM f, ... WHERE f.date_key BETWEEN 20050101 AND 20050107 GROUP BY ... А этот – будет ограничен 7 (количеством дней в неделе) SELECT ..., SUM(f.m) FROM f, dim_date d WHERE f.date_key = d.date_key AND d.year = 2010 and d.week = 1 … GROUP BY ... Секционированное индексированное представление (агрегат) Секционированная таблица фактов Агрегат(P1) Секция 1 Агрегат(P2) Секция 2 Агрегат(P3) Секция 3 Агрегат для новой секции Новая секция таблицы фактов Переключение секций создаёт агрегаты для секции Практика использования Выравнивание индексированного представления по секциям позволяет Переключать секции без перестройки всего представления (экономия времени) Такие представления могут быть использованы оптимизатором при создании плана запроса в SQL Server 2008 Полный пример использования можно увидеть здесь Добавлено в SQL Server 2008 SP2 Функционал с ограничениями По умолчанию недоступен, нужно включить Детали в статье здесь Примеры сценариев использования Миграция с Oracle без изменения схемы секционирования Секционирование по дням и необходимость иметь более 3 лет данных в одной таблице -- таблица фактов F(dk1, dk2, dk3, m) -- пример схемы для сводной -- таблицы или представления F_1_2(dk1, dk2, m) -- создаём представление CREATE VIEW F_1_2 WITH SCHEMABINDING AS SELECT dk1, dk2, SUM(m) as m, COUNT_BIG(*) as c FROM dbo.F GROUP BY dk1, dk2; -- Альтернатива – сводная таблица SELECT dk1, dk2, SUM(m) as m INTO F_1_2 FROM dbo.F GROUP BY dk1, dk2; -- пример переписывания запроса -- запрос данного вида SELECT F.dk1, SUM(F.m) as m FROM F GROUP BY F.dk1 -- может быть переписан как SELECT F.dk1, SUM(F.m) as m FROM F_1_2 as F WITH(NOEXPAND) GROUP BY F.dk1 -- Если F_1_2 – сводная таблица вместо представления необходимо убрать NOEXPAND hint См. Mastering Data Warehouse Aggregates by C. Adamson про этот метод Добавлено в версии SQL Server 2008 R2 Enterprise или выше В основном для систем обработки транзакций (OLTP) Для хранилищ данных параллелизм (DOP)>32 как правило неэффективен Однако это позволяет поддерживать разнородную нагрузку на больших системах По умолчанию DOP всегда ≤64 даже на больших системах Override with OPTION(MAXDOP n) См. также SQL Server Parallel Data Warehouse Сначала используйте настройку по умолчанию (‘max degree of parallelism’ sp_configure option = 0) В случае большого кол-ва CXPACKET waits установите значение на ½ или ¼ от доступных процессоров sp_configure option Подсказка OPTION(MAXDOP n) Регулятор ресурсов - один из удобных внешних механизмов управления этим параметром Более низкие значения MAXDOP могут помочь повысить производительность путём Уменьшения время ожидания ресурсов (доступные потоки) Уменьшения размера ожидаемого гранта памяти Избегайте явного указания ‘max degree of parallelism’ >64 На практике DOP > 16 неэффективен Скачать здесь! CTP1 можно скачать по данной ссылке Проект Apollo (функционал не доступен в CTP1) Ускорение выполнения запросов хранилищ данных в несколько раз Плавная деградация для остальных запросов и интеграция с обычными запросами Достигается с помощью Column store (новый тип индекса) Новые алгоритмы обработки данных (блочная обработка) VertiPaq™ column store Необходимые элементы хорошо спроектированного хранилища данных Адекватный логический и физический дизайн базы Выбор и конфигурация аппаратного обеспечения для оптимальной производительности Используйте возможности SQL Server 2008 и 2008 R2 для ускорения скорости выполнения DW запросов Дополнительные решения Parallel Data Warehouse SQL Server “Denali” – проект Apollo Fast Track 2.0 Guide Parallel Data Warehouse Переключение секций при наличии индексированных представлений Поддержка 15000 секций Data loading performance guide MS Connect «Книга жалоб и предложений» Microsoft SQL Server “Denali” CTP1 Ваше мнение очень важно для нас. Пожалуйста, оцените доклад, заполните анкету и сдайте ее при выходе из зала Спасибо! Сессия: BI 303 Борис Барышников [email protected] Вы сможете задать вопросы докладчику в зоне «Спроси эксперта» в течение часа после завершения этого доклада Более 300 официальных курсов Microsoft доступно в России. Официальные курсы можно прослушать только в авторизованных учебных центрах Microsoft под руководством опытного сертифицированного инструктора Microsoft интенсивное обучение с акцентом на практику более 80-и учебных центров более чем в 20-и городах России (+ дистанционные и выездные курсы) Сертификат Microsoft - показатель квалификации ИТ-специалиста для работодателя . Microsoft предлагает гибкую систему сертификаций. • 40 % Доказательство № 75 сертифицированных специалистов считают, что сертификация помогла им получить работу или повышение • 57 % Доказательство № 119 рекрутеров считают сертификацию сотрудников одним из критериев для повышения в должности Все курсы, учебные центры и центры тестирования: www.microsoft.com/rus/learning Сертификационный пакет со вторым шансом Пакеты экзаменационных ваучеров со скидкой от 15 до 20% и бесплатной пересдачей («вторым шансом»). Все экзамены сдаются одним человеком. Сэкономьте 15% на сертификации вашей ИТ-команды Пакет из 10-и экзаменационных ваучеров со скидкой 15% для сотрудников ИТ-отдела. «Второй шанс» включен. Ваучеры можно произвольно распределять между сотрудниками. Microsoft Certified Career Conference Первая 24-часовая глобальная виртуальная конференция с 18 ноября с 15.00 (моск. время) по 19 ноября 2010 г. Сессии по технологиям и построению карьеры Скидка 50% для сертифицированных специалистов Microsoft и студентов Бесплатная подписка на TechNet для слушателей официальных курсов Некоторые курсы по SharePoint, Windows 7; Windows Server 2008; SQL Server 2008 Детали: www.microsoft.com/rus/learning С 22 ноября 2010 г. – подписка TechNet бесплатно для слушателей курсов. Количество ограничено!