Устройство обмена с оперативной памятью системы на кристалле "Эльбрус-S"
реклама

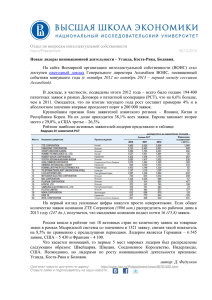
Устройство обмена с оперативной памятью системы на кристалле "Эльбрус-S" “Эльбрус” 0.13 um 300 MHz Core Core L2 L2 MAU 100 MHz Chipset 1.6/3.2 GB/s Memory MAU “Эльбрус-S” Memory 8 GB/s Memory Core Core L2 L2 MAU Chipset 2 GB/s 0.09 um 500 MHz Memory MAU Chipset Chipset MAU Chipset MAU L2 L2 Core Core Memory Задача: • Разработка MAU для новой системы с обеспечением максимально возможной эффективности доступа к памяти Требования: • Поддержка когерентности • Максимальная пропускная способность • Минимальное время доступа Структурная схема i/o Link A Link B Link C MC#1 Chipset MC#2 MAU KM LD Data LD Buff CPU ST Buff ST Data Операция Load Memory Memory Core Core L2 L2 MAU Chipset MAU Chipset Chipset MAU Chipset MAU L2 L2 Core Core Memory Memory Буфер приёма данных и сбора когерентных ответов Для завершения LD необходимо: • Собрать когерентные ответы • Принять данные • Взять из LDB сопровождающую информацию и отдать с ней данные в процессор Требования к буферу: • Параллельный асинхронный приём данных и когерентных ответов со всех направлений • Приоритет данных из кэшей над данными из памяти • Максимально быстрая выдача данных в процессор на основе собранной информации Буфер приёма данных и сбора когерентных ответов (принятая схема) 69 69 69 code ready release 69 24 48 in_regs mc0 wait ack mem coh rq 4xDW приоритет mc1 link0 когерентные ответы ответ о завершении link1 link2 num c p tag 6 1 4x 1 4 data[63:0] 64 Пропускная способность Запросы по чтению – 32 или 64 байт за такт (16 или 32 ГБ/с) Приём данных процессором – 32 байт за такт (16 ГБ/с) Приём данных MAU: • из памяти – 8 ГБ/с • из линков – по 2 ГБ/с • из ввода-вывода – 1 ГБ/с на практике - в сумме не более ~12 ГБ/с Лишние запросы нехватка ПСП + доп. задержки в линках Необходима оптимизация работы LDB LDB CPU MRQ Addr LD Data dst03 dst47 LDB 24 Chipset Оптимизация работы LDB «Эльбрус»: Возможность подклеивания заявок: • не требующих нового обращения в память (за 4xDW) • не требующих тех же DW LDB + = Задача – добавить возможность подклеивания заявок, запрашивающих пересекающиеся группы DW Решение – буфер виртуальных заявок Типы входящих в LDB заявок: • обычная – заведение новой строки, запрос в память за 4xDW или 8xDW • подклеиваемая – добавление значимостей DW и соотв. DST в имеющуюся строку • вторичная – новый тип, заведение новой строки без запроса в память Аппаратная реализация: • введение в LDB битов вторичности запросов (для блокирования ухода таких заявок в память) и сигналов заведения вторичных строк • буфер вторичных заявок - ссылок на исходные строки LDB для вторичных строк LDB • поддержка буфером приёма данных удержания данных на своём выходе по сигналу из буфера вторичных заявок Схема взаимодействия LDB, буфера приёма данных и буфера вторичных заявок destination data_out номер текущей вторичной строки LDB информация о заведении Буфер вторичных заявок hold номер первичной строки Буфер данных Задержки в LDB, STB – примерно 3 такта (физические) + ожидание в очереди Буфер приема данных (до оптимизаций): • задержка данных на входных регистрах -1-2 для MC, 1-7 для линков, 1-8 для I/O • задержка на принятие решения – 1 такт (физическая) • ожидание выдачи из-за одновременного возникновения готовности нескольких строк - 0-? Задержка на входных регистрах in_regs mc0 приоритет mc1 link0 link1 link2 I/O Приоритетная схема необходима для избежания переполнения, либо требуется более сложный механизм увеличение задержки и площади Однако не учитывает ни время ожидания, ни готовность по когерентным ответам доп. задержка при интенсивном приходе данных (0-7 тактов) Решение • Байпас значимостей готовностей по данным • Внеочередная запись в массив данных • Запись «приоритетных» данных на регистр «внеочередного» источника Результат: + Динамика заполнения регистров не меняется + Задержка на регистрах на итоговую задержку не влияет - Данные из массива можно получить только через 3 такта после принятия решения Временная диаграмма работы буфера приёма данных и сбора когерентных ответов р е г и с т р ы и в х о д ы нельзя! готовность по данным Внеочередная запись в массив номер адреса готовность строки назначения для по ответам из LDB выдачи hold и hold и вторичные вторичные строки строки Чтение из массива чёт Данные в ЦП Адреса назначения в ЦП такты ЦП Потребовался ещё 1 такт задержки данных на выходе буфера. Но ЦП всё равно принимает данные только через 2 такта после адресов. Общая задержка не увеличилась Проблема выбора строки из множества готовых Готовность по данным – до 6 строк одновременно Готовность по ответам – до 6 строк одновременно Итого 12 + накопленные ранее. Неадекватный выбор разброс времени доступа Приоритет по номеру: + простота, минимальные задержки и площадь - возможность «зависания» некоторых строк Решение #1 – приоритет по номеру, смещающийся по счётчику (простое). Решение #2 – приоритет по очерёдности поступления запроса (сложное). Оба оказались реализуемыми, тема для отдельного исследования. Результаты • Разработано verilog-описание MAU, удовлетворяющее поставленным требованиям и решающее поставленные задачи • Начата отладка и физдизайн