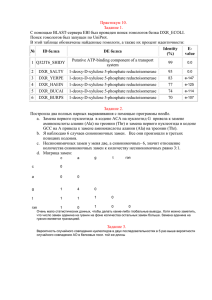
Правдоподобие и баейсов подход – как это работает? Тагир Самигуллин 2 октября 2014
реклама

Правдоподобие и баейсов подход –
как это работает?
Тагир Самигуллин
2 октября 2014
Модели эволюции нуклеотидных последовательностей
JC
Процесс
замещения
одного
основания
другим…
K2P
GTR
Модели семейства GTR
JC K2P K3P SYM F81 HKY85 TN93 GTR
Частоты оснований равны
+
+
+
+
Частоты оснований не равны
Одна скорость замен
2 скорости замен
(транзиции и трансверсии)
3 скорости замен
(трансверсии и 2 типа транзиций)
6 скоростей замен
+
+
+
+
+
+
+
+
+
+
+
+
Подразумевается, что:
•Эволюция последовательностей – случайный процесс
•Частоты оснований – постоянные
•Замены происходят независимо друг от друга
•Вероятности замен не меняются со временем (гомогенный эволюционный
процесс)
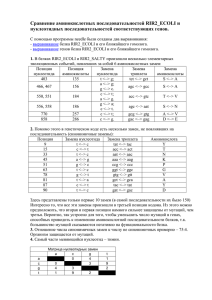
Модели для аминокислотных последовательностей
Матрица 20х20? => слишком много параметров для оптимизации, обычно
недостаточно информации. К примеру, матрица скоростей модели GTR будет
выглядеть так:
Можно использовать математические модели (z.B. модель Пуассона, что
эквивалентно модели JC для белков). Можно использовать модели эволюции
кодонов (матрица 61х61 !!!)
Чаще всего используются эмпирические матрицы
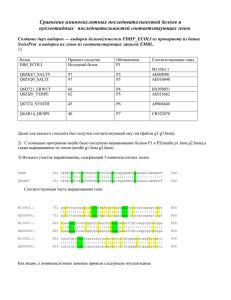
Эмпирические матрицы : Дейхов (Dayhoff)
Dayhoff et al. 1978:
Использованы последовательности ядерных водорастворимых белков, 72
белковых семейства, 1300 последовательности, 1572 замены. Поскольку
сходство высоко (> 85%), сразу построено МР-дерево, реконструированы
предковые последовательности, посчитаны замены:
Таксон
Предковая
последовательность
затем матрица посчитанных замен
преобразована в матрицу вероятностей замен:
значения умножены на 10 000
Значения в этой матрице справедливы для близкородственных белков
(диагональ >> вне-диагональ) PAM1, что соответствует одной замене на
100 сайтов. Для отдаленных белков матрица преобразуется (возводится
в степень): PAM10… PAM100 (D≈1) … PAM250…
Эмпирические матрицы : другие и BLOSUM
На сегодняшний день предложены и другие матрицы, получены они
•либо с использованием похожего подхода (дистанционное дерево) на
бОльшем количестве данных (JTT-модель)
•либо с использованием похожего подхода (ML-дерево) на еще
бОльшем количестве данных (WAG-модель, mtREV-модель)
•либо непосредственно из парных выравниваний (BLOSUM)
BLOSUM: 2000 блоков из выравнивания 500 семейств родственных
белков разного уровня сходства, от 45 до 90% (серия BLOSUM45…90)
block 1
WWYIR
WFYVR
WYYVR
WYFIR
…
block 2
block 3
CASILRKIYIYGPV
CASILRHLYHRSPA
AAAVARHIYLRKTV
AASICRHLYIRSPA
GVSRLRTAYGGRKNRG
GVGSITKIYGGRKRNG
GVGRLRKVHGSTKNRG
GIGSFEKIYGGRRRRG
…
Правдоподобие – вероятность данных для выбранной модели
Модель = дерево и модель эволюции признаков
Модель эволюции признаков = состав …
Одна последовательность, один нуклеотид
Правдоподобие = ?
А
Одна последовательность, два нуклеотида
АC
Для модели “100% А” = 1
Для модели “100% С” = 0
Для модели “ 30% А” = 0.3
Правдоподобие = ?
Для модели “4 равновероятных нуклеотида“ :
¼
Для модели “40% A, 10% C“ :
0.4 x 0.1 = 0.04
x ¼ = 1/16
Модель эволюции признаков = состав и процесс
Данные:
Две последовательности
по одному нуклеотиду
А
C
Модель:
Правдоподобие ветви
между последовательностями:
A(0.25) C(0.25)
0.25 x 0.4 = 0.1
A↔C = 0.4
A
C
G
T
состав
A
процесс
C
G
T
A
Данные:
Две последовательности
по 4 нуклеотида
ССАT
CCGT
Модель:
C
G
T
Правдоподобие ветви
между последовательностями :
Изменение длины ветви
Likelihood
И, наконец, правдоподобие простейшего дерева:
Данные
Первый столбец
данных:
Дерево
Модель
Второй столбец
данных:
Третий столбец
данных:
Четвертый столбец
данных:
Значение правдоподобия
Модели эволюции нуклеотидных последовательностей
еще раз…
JC
K2P
GTR
Процесс
замещения
одного
основания
другим…
…и
нуклеотидный состав
скорости
замен
вероятности
замен
Ключевое понятие –
апостериорная вероятность
априорная вероятность
дерева
Pr (T,D) = Pr (D,T)
Pr(T) Pr(D|T) = Pr(D) Pr(T|D)
правдоподобие
Pr(T) Pr(D|T)
Pr(T|D) =
Pr(D)
вероятность данных
(маргинальная)
апостериорная вероятность
длины ветвей
топологии
маргинальная вероятность
совместная вероятность
Марковская цепь Монте-Карло (МСМС)
Распределение плотности апостериорной вероятности :
Марковская цепь Монте-Карло (МСМС)
Начальная точка. Следущая точка выбирается случайно, переход
на нее определяется следующим правилом: Если плотность её РР
выше чем текущей позиции - шаг делается, если нет – делается с
ненулевой вероятностью, которая пропорциональна отношению
плотностей РРi+1 /РРi . Принципиально важна возможность
перехода на более низкую позицию, иначе не удастся
исследовать искомое распределение плотности РР!
Марковская цепь Монте-Карло (МСМС)
Пусть соотношение РРi+1 /РРi равно 0.8 и это число мы
сравниваем со случайным числом от 0 до 1. Если это
число меньше 0.8, шаг принимается. Интервал значений
меньше 0.8 шире, чем больше 0.8 !
Пусть соотношение РРi+1 /РРi равно 0.5. Интервалы
равны, шансы 50/50. Если РРi+1 /РРi станет меньше 0.5,
шаг будет чаще отвергаться, чем приниматься!
Марковская цепь Монте-Карло (МСМС)
Первый шаг : принимается с вероятностью 1
Марковская цепь Монте-Карло (МСМС)
Второй шаг : мог быть принят с вероятностью 0.144
Марковская цепь Монте-Карло (МСМС)
Третий шаг : принимается с вероятностью 0.123
Марковская цепь Монте-Карло (МСМС)
После 3 шагов имеем:
Марковская цепь Монте-Карло (МСМС)
После 10 000 шагов :
Марковская цепь Монте-Карло (МСМС)
Конечный результат :
Чем выше плотность РР в
некотором интервале, тем чаще
он посещается!
Марковская цепь Монте-Карло (МСМС)
MCRobot
Lewis, 2006
Короткие ветви и байесовская филогения
100 наборов, 1000 оснований, модель К2Р
Поддержка неверных узлов
Количество верных узлов
Alfaro et al., 2003
Байесовский метод может
присвоить коротким ветвям
очень высокие значения
апостериорной вероятности
(коротким – это от 1,3-1,4
ожидаемых замен). Для
парсимонии, например, для
поддержки 95% требуется
минимум 3 ожидаемых замены.
Количество верно разрешенных
узлов для байесовского метода
выше, чем для парсимонии, но и
очень короткие неверные ветви
получают поддержку выше, чем
дает метод максимальной
экономии. Эта поддержка в
некоторых случаях превышает
50%, то есть в 50% консенсусном
дереве могут появиться
неверные короткие ветви!
Конвергенция МСМС
…We then compare their [thirteen convergence diagnostics]
performance in two simple models and conclude that all the methods
can fail to detect the sorts of convergence failure they were designed
to identify.
Mary Kathryn Cowles and Bradley P. Carlin, 1996
How can we know that the chain we are sampling from has
converged and mixes well?
The disappointing answer is that it is impossible to know for certain.
JOHN P. HUELSENBECK et al., 2002
Конвергенция МСМС
Схождение (конвергенция) Марковских цепей очень важно для
получения корректного результата. Однако, даже отсутствие
видимых проблем с конвергенцией не гарантирует, что цепи
сошлись, и это главный недостаток метода. Главное преимущество
– в разумные сроки можно получить результат в виде топологии с
поддержкой ветвей!
Nylander et al., 2008
Интерпретация бутстрепа
Высокие значения бутстрепа (>85%) часто интерпретируют
как высокую достоверность узла, что не совсем верно
даже несмотря на статистическую природу бутстрепа.
Строго говоря, бутстреп показывает, достаточно ли данных
для поддержки узла, нет ли конфликта в данных. Даже
полностью неверное дерево может иметь максимальную
поддержку узлов!
Значения бутстреп-поддержки некоторой группы зависят в
первую очередь от количества признаков,
поддерживающих группу, и уровня поддержки
альтернативной группировки.
Если трактовать бутстреп как показатель уровня достоверности, то BP
97% означает, что из неверных ветвей только 3% будут иметь такую
же высокую поддержку.
“Essentially,
all models are wrong,
but some are useful.” George Box
?
<=тенденция
или
y=ax+b
все-нюансность=>
y=ax6+bx5+cx4+dx3+ex2+fx+g
что более
сложные
модели
лучше
“Очевидно,
With four parameters
I can
fit an elephant,
and
вписывются
в данные
и более
правдоподобны.
Однако
with
five I can make
him wiggle
his trunk.
”
усложнение модели
быть оправдано
Johnдолжно
von Neumann
соответствующим повышением правдоподобия, в
противном случае выбирается более простая модель.
Критерии для выбора модели
AIC = Akaike Information criterion
AIC = -2 lnL +2k, где k = число параметров модели
преимущество при ΔAIC
> 10
>4
<2
сильное
слабое
никакое
AICс= AIC с поправкой на малые наборы данных (n/k<40)
n = длина выравнивания
BIC = Bayesian Information criterion
BIC = -2 lnL +kln(n)
Модель с меньшим BIC предпочтительнее
Bayes factor
DT (Decision Theory)
, преимущество:
3 - 20 = есть
20 - 150 = сильное
150+ = очень сильное
Сравнение топологий
Если топология дерева не совпадает с имеющейся
гипотезой, значит ли это, что данные отвергают гипотезу?
AU (Approximately Unbiased) test даст ответ
CONSEL, PAUP, …?
Принцип: В случае конфликта данных (наличие
гомоплазий) выбирается гипотеза, которая
поддерживается бОльшим количеством синапоморфий.
Следствие: Это приводит к уменьшению количества
гомоплазий.
Практический вывод: наилучшая реконструкция
А
seq 1
2 7
6
3
филогении
(филогенетическое
древо)
—
та,
которая
7
seq 2
А 3
seq
3
2
объясняет
наблюдаемые
состояния признаков
С
seq 4
6
Т
наименьшим
числом
замен.
Т
seq
5
С
А замен является наименьшим,
seq
6
С
Дерево,
для которого число
называют Т
seq
7
максимально
экономным (МР tree). Поиск такой топологии идет
эвристическим путем.
Словарик:
Синапоморфия – мутация, унаследованная потомками от предкового таксона
Аутапоморфия – мутация, характерная для таксона
Гомоплазия – независимое появление одной и той же мутации у разных таксонов
Симплезиоморфия – унаследованное потомками от предка «древнее» состояние признака
О признаках в методе МР
Признаки:
•постоянные (инвариабельные)
•изменчивые (вариабельные).
Последние делятся на
информативные и
неинформативные.
seq 1
seq 2
seq 3
seq 4
seq 5
seq 6
seq 7
постоянный
неинформативный
информативный
T A T
T
seq2 seq3seq4 seq1
G G A A
A G A G
seq2 seq3seq4 seq1 seq4seq2seq1 seq3
T Т А T
seq2 seq4seq3 seq1
дерево 2.1
дерево 1.1
дерево 1.2
дерево 2.1 и дерево 2.2
требует меньшего числа замен,
требуют одинакового
т. е. более экономно, чем дерево 1.2
дерево
2.2
числа замен
Информативные признаки позволяют
Оценка длины дерева
Алгоритм Санкова
Алгоритм Фитча
3
Позволяет придать разным
заменам разный вес:
Tv :Ts = 4 : 1
{GA} 1
{A} 1
1{С}
С
2
С G A
A
Топология оптимальна?
Для первой клетки: [1;12;2;12] + [8;4;9;6] = 5
Напоследок о максимальной экономии:
Метод максимальной экономии – реализация кладистического
подхода в филогенетике. Используя эвристический алгоритм
реконструкции, метод отбирает топологии, для которых
количество синапоморфий максимально, такие топологии
требуют минимального количества замен (принцип экономии).
Количество равнооптимальных топологий может быть
довольно большим.
Основные недостатки метода :
• часть информации не используется (как неинформативные
признаки)
• не может использовать различные модели эволюции
последовательностей
• не учитывает возможности повторных замен
• не учитывает гетерогенности скоростей накопления замен,
предполагает равномерность
Лучше всего использовать в случаях, когда дивергенция
последовательностей невелика.