Слайд 1 - Интелтек Плюс
advertisement

1
Тема доклада
Технология сбора, извлечения и
систематизации ядерных знаний,
представленных в виде текстовых
документов
2
МГТУ им. Н.Э. Баумана. Факультет ИУ
Факультет «Информатика и системы
управления» (ИУ) МГТУ им. Н.Э. Баумана
готовит высококвалифицированные
инженерные и научные кадры,
специализирующиеся в тех областях научнотехнических знаний, которые связаны с
созданием и внедрением новейших
информационных технологий, программноаппаратных средств вычислительной техники,
средств автоматизации приборов и систем
управления, ориентации, стабилизации и
навигации.
3
НПЦ «ИНТЕЛТЕК ПЛЮС»
Работает в области информационных
технологий с 1992.
Ядро коллектива составляют выпускники МГТУ
им. Н.Э. Баумана, среди них – 4 кандидата
технических наук.
Тесное сотрудничество с кафедрой
«Компьютерные системы и сети» МГТУ им. Н.Э.
Баумана (ИУ-6). В результате были
подготовлены и успешно защищены 8
кандидатских диссертаций по тематике НПЦ.
4
Основные направления деятельности
Объектные СУБД
Технологии полнотекстового поиска и семантического
анализа документов
Технологии извлечения и классификации информации
Технологии Data mining, Text Mining, Web Mining и Process
Mining
Создание и использование онтологических моделей
данных
Решение задач интеграции справочных данных и данных
о жизненном цикле сложных изделий с использованием
стандарта ISO 15926
Разработка специализированных ИС и Web-сервисов
5
Технология извлечения и систематизации
ядерных знаний. Основные принципы
ядерные знания содержатся в электронных
документах, имеющих разные форматы и
наборы метаданных в виде текстов либо в
форме табличного представления;
• документы распределены по различным
разнородным источникам (открытым –
Интернет-ресурсы и ограниченного доступа);
• имеются эксперты, которые могут определить
интересующие источники информации,
сформулировать темы, подлежащие
мониторингу и определить принципы
систематизации знаний.
•
6
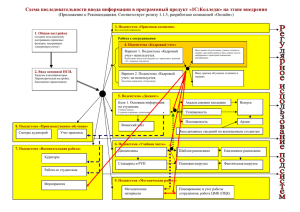
7
Основные технологические блоки
Система
онтологического
моделирования
знаний
предметной
области
Интернетисточники
Система сбора
материалов из
разнородных
источников
Внешние
Внешние ИС
ИС
Система
интеграции
знаний
Внешние
Внешние системы
системы
управления
управления знаниями
знаниями
Подсистема
хранения
текстовых
материалов
ПользовательПользовательаналитик
аналитик
ИПС
Подсистема
хранения
табличных
данных
Система
Система
накопления
накопления ии
хранения
хранения данных
данных
Система анализа
данных и прогноза
ПользовательПользовательаналитик
аналитик
8
Структура ИС
Интернетисточники
Сбор текстовых
материалов с
веб-сайтов
Устранение
дублей
Интеграция с
внешними
документальными ИС
Документы из
внешней ИС
Внешние
Внешние ИС
ИС
ПользовательПользовательаналитик
аналитик
Система
Система сбора
сбора материалов
материалов из
из
разнородных
разнородных источников
источников
Материалы
SQL
СУБД
Классификация
текстовых
материалов
Хранилище
Хранилище
Извлечение
табличных
данных
Сервер
хранилищ
Табличные
данные
Внешние
Внешние
аналитические
аналитические
системы
системы
Пользователь
Пользователь ИС
ИС
Web-сервер
Веб-клиент
АРМ Редактор
Документ
для проверки
Сервис
онтологического
мэппинга
Интегрируемые
Интегрируемые
онтологии
онтологии
ODB-Jupiter
Распределенная
Распределенная
система
система
хранилищ
хранилищ
Хранилище
Сервер
хранилищ
Java-сервис
интеграции
Хранилище
Аналитические
Аналитические
приложения
приложения
Внешняя
Внешняя
аналитическая
аналитическая
система
система
Документ
описания
Сервис
аннотирования и
кластеризации
Веб-клиент
ПользовательПользовательаналитик
аналитик
Сервис
построения
прогноза
Веб-клиент
Сервис геопривязки
Извлечение
характеристик из
документа
Управление
онтологиями
посредством
Jena и SPARQL
Проверка по
онтологии
Подготовка
каталожных
описаний
SQL
СУБД
OWL
RDF БД
Подготовка
инженерных
онтологий и
онтологий ИСО
15926
Редактор
онтологий
Protégé
ГИС
Редактор
Редактор кталожных
кталожных
описаний
описаний
Система
Система онтологического
онтологического
моделирования
моделирования знаний
знаний
предметной
предметной области
области
Подсистема хранения текстовых материалов.
Архитектура ODB-Jupiter
9
10
Архитектура системы сбора материалов из
разнородных источников
Веб-клиент ИПС
Результат сбора
текстовых данных
Открытые источники
текстовых материалов
АРМ
администратора
сбора
Текст
материала
Метаданные в
XML форме
Подсистема
обнаружения
сбоев
Подсистема
накопления (ИПС)
Подсистема
удаления
дубликатов
АРМ
администратора
ИПС
Подсистема контроля
качества
RSS, HTML, DOC,
XLS
АРМ редактора
ИПС
Текстовые
материалы
Сбор текстовых и
табличных
материалов
Результат сбора табличных
данных
Журнал работы
Табличные данные в
XML форме
Табличные данные
Внешние
аналитические
системы
11
Архитектура подсистемы сбора текстовых
материалов
АРМ
администратора
сбора
Подсистема сбора
текстовых материалов
Планировщик
RSS, HTML, DOC,
XLS
Загрузчик
Результат сбора
Парсер
Метаданные
Формирование
материала
Текст
Источники текстовых
материалов
Загрузчик текстов
Парсер текстов
Текст
материала
Журнал работы
Журнал работы
XML-документ с
метаданными
12
Веб-интерфейс системы сбора
13
Возможные области применения
Подсистема сбора текстовой и табличной
информации извлекает требуемые данные из
разнородных источников, в том числе вебсайтов. Например:
Новости атомной энергетики;
Статистические показатели;
Результаты мониторинга оборудования и
протекания технологических процессов;
Научные статьи;
Технические характеристики новых приборов.
14
Подсистема обнаружения сбоев
Возможные последствия изменения структуры веб-сайта:
Данные не извлекаются (проблема может быть обнаружена самой
системой сбора)
Данные извлекаются некорректно (требуется подсистема обнаружения
сбоев)
Веб-сайты
Система
сбора
Подсистема
обнаружения сбоев
Сбоя нет
База данных
Обнаружен сбой
Правила
Xpath
Параметры
Администратор
15
Архитектура подсистемы обнаружения сбоев
АРМ
администратора
системы сбора
Подсистема обнаружения сбоев
Веб-сайты
RSS, HTML, DOC,
XLS
Оперативный детектор
Параметры
детектора
Система сбора
Классификатор
Текст
XML-карточка с
метаданными
да
нет
Статистические
данные
Обнаружен сбой?
Журнал
Подсистема
накопления
Два этапа проверки:
• Оперативная проверка;
• Отложенная проверка.
Текстовые
материалы
Статистические
данные
Эталон
Анализатор
Преимущества такого подхода:
• Быстрая реакция на сбой;
• Высокое качество анализа.
да
нет
Обнаружен сбой?
Отложенный детектор
Администратор
Характеристики разработанного подхода к
обнаружению сбоев
Основные характеристики:
•
•
•
•
Двухступенчатый анализ.
Быстрая иерархическая кластеризация.
Сравнение законов распределения характеристик документов с
помощью расстояния Кульбака-Лейблера.
Использование пороговой функции при отложенном детектировании
сбоев.
Качество работы оперативного детектора:
•
•
99,54% правильно распознанных корректных документов;
100% правильно распознанных некорректных документов.
Качество работы отложенного детектора:
•
•
В 90,47% – 100% случаев правильно определено отсутствие сбоя;
В 72,22% – 100% случаев правильно определено наличие сбоя.
16
17
Подсистема обнаружения дубликатов
Документы, опубликованные одним из источников, могут дублироваться
другими. В результате в базу данных системы попадают одинаковые или
очень близкие по содержанию документы (дубликаты)
Процесс обнаружения дубликатов включает два этапа:
•
построение векторных моделей документов;
•
сравнение векторных моделей двух документов и определение, являются ли
они нечеткими дубликатами.
Устранение дублей
Построение
векторной модели
Векторная
модель
Текст документа
Сравнение
документов
Построение
векторной модели
Текст документа
Векторная
модель
Вердикт о
наличии
дубликата
18
Построение векторных моделей документа
Построение векторной модели документа включает 2 этапа:
• токенизация – разбиение текста документа на множество элементов;
• векторизация – присвоение этим элементам весов, характеризующих
их значимость.
Построение векторной модели
Векторизация
Токенизация
Выделение слов
Российская
академия
наук
планирует
предложить
Выделение N-грамм
рос
осс
сси
сий
ийс
Текст документа
Выделение
характеристик
Число параграфов: 4
Число слов: 214
Число букв: 1293
Средняя длина слова:
6.04
Расчёт весов слов
weight tf * idf
Расчёт весов N-грамм
tf
nti
k
n
j 1
tj
Расчёт весов
характеристик
zi*
zi Z
Z
Фортов
Минобрнауки
наука
кандидатура
Ливанов
0.023
0.014
0.012
0.009
0.008
нау
аук
орт
кан
уки
0.009
0.009
0.006
0.005
0.005
Число параграфов
Число слов
Число букв
0.15
0.28
0.25
Средняя длина слова
-0.24
19
Сравнение документов
При обнаружении дублей сравниваются векторные модели документов и
делается заключение о том, является ли один из них дубликатом другого.
Для этого выполняются следующие шаги:
1. Сравнение. Векторы, соответствующие одной категории токенов,
сравниваются с использованием косинусной меры близости. Полученные
результаты сравнения объединяются в результирующий вектор.
2. Принятие решения. Определяется наличие или отсутствие
дублирования путем бинарной классификации результирующего вектора
методом SVM.
слова:
Векторная модель документа A
слова =>
Сравнение
векторов
Сравнение векторных моделей
Δ слов
n-граммы =>
n-граммы:
характеристики =>
Δ n-граммов
Сравнение
векторов
Векторная модель документа B
слова =>
n-граммы =>
характеристики =>
характеристики:
Сравнение
векторов
Δ характеристик
Δ слов
Δ n-граммов
Δ характеристик
Бинарный
классификатор
Результат
Архитектура подсистемы прогноза
Сервис
построения
прогноза
Веб-клиент
Сервис
построения
прогноза
Сервер
хранилищ
Хранилище
Хранилище
Java-сервис
интеграции
Сервер СУБД
ODB-Jupiter
Сервер
хранилищ
ПользовательПользовательаналитик
аналитик
20
Внешний
Внешний сервис
сервис
построения
построения
прогноза
прогноза
Внешний
Внешний сервис
сервис
построения
построения
прогноза
прогноза
Хранилище
Хранилище
Распределенная
Распределенная
система
система
хранилищ
хранилищ
Пример поискового шаблона и результатов
поиска
ядерн*\5/безопасност*\500/фукусим*
21
22
Методы анализа и прогноза
Подсистема построения прогноза позволяет выполнить
прогнозирование ситуации, заданной поисковым шаблоном.
Основные характеристики:
• Анализ развития ситуации на основе частоты встречаемости
документов, удовлетворяющих соответствующему поисковому
шаблону.
• Возможность использования различных моделей прогноза, таких
как:
o Авторегрессионные модели;
o Регрессионные модели;
o Искусственные нейронные сети;
o Модели на основе нечетких временных рядов.
• Возможность использования для построения прогноза внешних
аналитических систем.
Представление результатов
Аналитический отчет
Графики реального и прогнозируемого развития
ситуации
Пример отчета
23
24
Результаты прогноза
Прогноз ситуации средствами внешней
аналитической системы
25
26
Гео-привязка
Извлечение информации о географии новостей
Построение распределения новостей по географическому
принципу
Визуализация результатов извлечения
Извлечение информации
Особенности нашего подхода:
Метод основан на использовании шаблонов;
Правила извлечения хранятся в формате XML отдельно от
системного кода;
Изменение правил извлечения отделено от изменения системы
извлечения;
Метод учитывает неоднозначность естественного языка;
Выразительная сила языка правил извлечения может быть с
легкостью расширена путем добавления предметноориентированных семантических признаков;
Правила извлечения имеют простую структуру и просты как для
человеческого понимания, так и для автоматического построения.
27
28
Пример правила извлечения
<rule name=“company_1" size="5">
<ct len="[1;1]" set="{ЕД},{И|ЕД}"/>
<ex len="[1;1]" set="{eng}"/>
<ct len="[0;1]" set="{нрч}"/>
<ct len="[1;1]" set="{сов|пхд|нвз|глг|ЕД|3}"/>
<ct len="[1;1]" set="{В}"/>
</rule>
Компания nVidia официально
отложила
день
выпуска
видеокарты ...
Фирма Apple опровергла слухи о
том...
Построение правил извлечения с
использованием машинного обучения
Подход, основанный на машинном обучении:
Может быть использован для построения правил извлечения на
основе подготовленных обучающих примеров;
Может существенно снизить стоимость разработки системы
извлечения информации;
Использует индуктивный подход машинного обучения;
Демонстрирует высокое качество работы несмотря на ошибки,
которые могут присутствовать в обучающих примерах;
Демонстрирует высокую производительность;
Обучение производится для оптимизации точности и полноты
целевой системы извлечения информации.
29
30
Распознавание словосочетаний
Подсистема интеграции ядерных знаний
в соответствии с ISO 15926
Цели использования стандарта:
обмен информацией между различными
компаниями без необходимости предъявления
требований к организации хранилищ этой
информации;
организация непосредственного
взаимодействия ИС предприятий без
необходимости непосредственного участия
человека в процессе этого взаимодействия;
повышение точности передаваемой
информации, исключению ошибок человекаоператора при передаче данных, организации
автоматического контроля при обмене
данными.
31
32
Схема подсистемы интеграции
Сторонние
приложения
Мэппинг
Модуль
работы с
онтологией
OWL
Модуль
генерации
интерфейса
Запросы
Браузер
Информация для
отображения
SPARQL
RDL
RDF Store (Jena)
Поисковые
запросы
Адаптер
Ссылки на
документы
Адаптер
Словарная служба
НСИ
(ТЗ, ТУ,
ГОСТ)
НСИ
(ТЗ, ТУ,
ГОСТ)
Документы
ODB Text
33
Этапы интеграции
Включение в федеральную
систему каталогизации
Средство маркетинга продукции
ТУ, НСИ
Стандарт Консорциума W3C
Semantic WEB
Широкое использование
WEB-технологий
КО
OWL
ISO
15926
Интеграция
приложений,
САПР и т.д.
34
Краткий обзор результатов этапов интеграции
ТУ, НСИ
КО
OWL
ISO
15926
Интеграция
35
Вопросы?
Березкин Дмитрий
e-mail: dmitryb2007@yandex.ru