исследовать
реклама

Автоматический
морфологический анализ
Алгоритмические
методы (без обучения)
Часть 2
План
Задачи, этапы (лекция Морфология1)
Обзор технологий
Организация данных
Первичный анализ. Базовые формализмы
анализа словоформы
Разрешение омонимии
Предсказание незнакомых слов
План
Задачи,
этапы (лекция Морфология1)
Обзор технологий
Организация данных
Первичный анализ. Базовые формализмы
анализа словоформы
Разрешение омонимии
Предсказание незнакомых слов
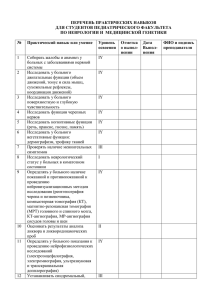
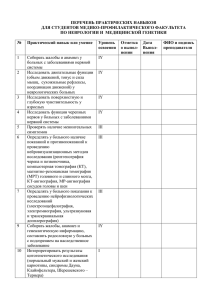
Задачи морфологического анализа
Графематический анализ (токенизация): текстоформы,
«неслова» («шаблоны», числа и т.п.), токены из списка (предлоги,
союзы и т.п.)
нормализация словоформ (лемматизация), т.е. сведение
различных словоформ к некоторому единому представлению - к
исходной форме, или лемме);
стемминг - другой вид нормализации, когда разные словоформы
приводятся к одной основе, точнее "псевдооснове" (для некоторых
задач, включая поиск в интернете, достаточно приведения к одной
основе различных дериватов; например, прилагательное
фотографический и существительное фотография могут быть
приведены к одной основе, так как пользовательскому запросу
будут удовлетворять и документы, содержащие словосочетание
фотографический портрет, и документы, содержащие словосочетание
портретная фотография)
Задачи морфологического анализа
частеречная аннотация (pos-tagging), т.е. указание части речи для
каждой словоформы в тексте)
полный морфологический анализ - приписывание грамматических
характеристик словоформе (например, в цепочке словоформ по берегу
реки словоформе берегу будут приписаны следующие грамматические
характеристики: сущ., неодушевленное, мужского р., единственного
числа, дательного падежа)
дизамбигуация - разрешение морфологической омонимии
(например, )
Основные проблемы, связанные с любым типом морфологического
анализа - это морфологическая омонимия (ср. предложение Эти
типы стали есть в цехе, где стали может быть формой глагола стать и
формой существительного сталь), а также существование новых,
редких слов или окказионализмов.
Основные этапы
морфологической разметки в BNC
A.
B.
C.
D.
E.
F.
Tokenization
Initial tag assignment
Tag selection (disambiguation)
Idiomtagging
Template Tagger
Postprocessing: including Ambiguity tagging
План
Задачи, этапы (лекция Морфология1)
Обзор
технологий
Организация данных
Первичный анализ. Базовые формализмы
анализа словоформы
Разрешение омонимии
Предсказание незнакомых слов
Краткий обзор основных методов
разметки
SUPERVISED
UNSUPERVISED
selection of tagset/tagged corpus
induction of tagset using untagged
training data
creation of dictionaries using tagged
corpus
induction of dictionary using training
data
calculation of disambiguation tools.
may include:
induction of disambiguation tools.
may include:
word frequencies
word frequencies
affix frequencies
affix frequencies
tag sequence probabilities
tag sequence probabilities
"formulaic" expressions
tagging of test data using dictionary
information
tagging of test data using induced
dictionaries
disambiguation using statistical,
hybrid or rule based approaches
disambiguation using statistical,
hybrid or rule based approaches
calculation of tagger accuracy
calculation of tagger accuracy
Морфологическая разметка:
Технологии морфологической разметки
Теория vs. практика
В 60-70 гг. все экспериментальные исследования в области
машинной морфологии начинались с создания машинного словаря.
Не было единого общепринятого формата и структуры такого
словаря.
Эти обстоятельства имели два последствия:
во-первых, все алгоритмы автоматически становились
словарнозависимыми,
во-вторых, каждый алгоритм разрабатывался под
определенный формат словаря.
Работы, посвященные морфологии, можно условно разделить на две
категории:
1. теоретические, в некоторых представлены описания
морфологических законов и формальные модели русской
морфологии;
2. прикладные, описание програмно-реализованных систем с
морфологическим модулем.
Морфологическая разметка:
Технологии морфологического анализа
Теоретический vs. Инженерный подход
В теоретических работах строятся многоуровневые
формальные модели морфологии, в большинстве своем,
предназначенные
для
синтеза.
Такие
модели
морфологического синтеза подразумевают наличие больших
словарей со сложной структурой. Они описывают широкий
круг морфологических явлений. Многие компоненты этих
моделей избыточны для задач машинного анализа
(фонетическая реализация слова, акцентная парадигма,
большое число словообразовательных аффиксов).
Морфологическая разметка:
Технологии морфологической разметки. Вопросы
архитектуры.
.
Данные:
контекст vs.
???
информация о внутренней структуре словоформы
словарь
и о словоизменительных парадигмах
словарные методы vs. методы без словаря
Словарь:
что в словаре?
структура словаря?
Методы анализа
формализм
правила vs. статистика
Работа с незнакомыми словами:
правила предсказания
План
Задачи, этапы (лекция Морфология1)
Обзор технологий
Организация
данных
Первичный анализ. Базовые формализмы
анализа словоформы
Разрешение омонимии
Предсказание незнакомых слов
Данные
Контекст. Пример
Контекст:
The
Det
flights
N
can
fly
V(mod) V(inf)
Что нужно знать?
• набор тегов (частеречный (N,V…) vs. простой (Nsg) vs.
полный – Ncmsnn: Noun Type=common
Gender=masculine Number=singular Case=nominative
Animate=no)
• набор словоформ (ручкой – ручка, N; ручке – ручка, N …)
• возможные порядки тегов (NVN, NVV vs. *DV…
из + Gen / * из + Case≠Gen)
• частоту порядков
…. подробности позже
Словарь может состоять из списка
всех возможных словоформ
Данные
Внутренний состав словоформы. Пример
Такие
типы
стали есть
Таки-е:
тип-ы
стал-и
в
помеще
нии
ест-ь
цех-е
N,Sg,n,Nom; N,pl,Nom N,Pl,Nom,
N,Sg,Loc;
N,pl,Acc
N,Pl,Acc,
N,Sg,Dat
Adj,Brev,Sg N,Sg,Gen
…
Так-ие
Ти-пы
Ста-ли
N,sg,f,m,nom; Prep; N
N,sg,f,acc
N,Sg,n,Nom;
N,Sg,Loc;
N,Sg,Dat
Ес-ть
Це-хе
A,Pl,Nom
A,Pl,Acc
V,Inf
*
*
V,Pst,Pl
НЕОПТИМИЗИРОВАННАЯ
ФУНКЦИОНАЛЬНАЯ СХЕМА
обработки словоформы при машинном переводе
исследовать
research, explore,
investigate, examine, …
Inf-ve
исследую
research, explore,
investigate, examine, …
Simple Pres. (~3sg), Pres.
Cont., Simple Fut.,
Fut.Cont.,Fut.Perf.
исследуешь
research, explore,
investigate, examine, …
Simple Pres. (~3sg), Pres.
Cont., Simple Fut.,
Fut.Cont.,Fut.Perf.
исследует
research, explore,
investigate, examine, …
Simple Pres. 3sg, Pres.
Cont., Simple Fut.,
Fut.Cont.,Fut.Perf.
исследовал
research, explore,
investigate, examine, …
Simple Past, Pres.Perf.,
Past Cont., Past Perf.
исследовала
research, explore,
investigate, examine, …
Simple Past, Pres.Perf.,
Past Cont., Past Perf.
…
…
ОПТИМИЗИРОВАННАЯ
ФУНКЦИОНАЛЬНАЯ СХЕМА
обработки словоформы при машинном переводе
исследовать
{исследовать} +
+Неопр.ф.
…
{исследовать}
research, explore,
investigate,
examine, analyse,
test, inquire into…
исследую
{исследовать} +
+ Наст., Буд. вр. + Ед.ч.
+ 1 л.
исследуешь
{исследовать} +
+ Наст., Буд. вр. + Ед.ч.
+ 2 л.
…
исследует
{исследовать} +
+ Наст., Буд. вр. + Ед.ч.
+ 3 л.
Неопр.ф.
Inf-ve
Наст.+Ед.+1
S.Pres.(~3sg), Pres. Cont.
Наст.+Ед.+2
S.Pres.(~3sg), Pres. Cont.
Наст.+Ед.+3
S.Pres. 3sg, Pres. Cont.
Буд.+Ед.+1
S. Fut., Fut.Cont.,Fut.Perf.
Буд.+Ед.+1
S. Fut., Fut.Cont.,Fut.Perf.
Буд.+Ед.+1
S. Fut., Fut.Cont.,Fut.Perf.
Прош.+Ед.
S. Past, Pres.Perf., Past
Cont., Past Perf.
…
исследовал
исследовала
…
{исследовать} +
+ Прош. вр. + Ед.ч. + М
р.
{исследовать} +
+ Прош. вр. + Ед.ч. + Ж
р.
ОБРАБОТКА СЛОВОФОРМЫ:
морфологический анализ
исследовать
{исследовать} +
+Неопр.ф.
…
{исследовать}
research, explore,
investigate,
examine, analyse,
test, inquire into…
исследую
{исследовать} +
+ Наст., Буд. вр. + Ед.ч.
+ 1 л.
исследуешь
{исследовать} +
+ Наст., Буд. вр. + Ед.ч.
+ 2 л.
…
исследует
{исследовать} +
+ Наст., Буд. вр. + Ед.ч.
+ 3 л.
Неопр.ф.
Inf-ve
Наст.+Ед.+1
S.Pres.(~3sg), Pres. Cont.
Наст.+Ед.+2
S.Pres.(~3sg), Pres. Cont.
Наст.+Ед.+3
S.Pres. 3sg, Pres. Cont.
Буд.+Ед.+1
S. Fut., Fut.Cont.,Fut.Perf.
Буд.+Ед.+1
S. Fut., Fut.Cont.,Fut.Perf.
Буд.+Ед.+1
S. Fut., Fut.Cont.,Fut.Perf.
Прош.+Ед.
S. Past, Pres.Perf., Past
Cont., Past Perf.
…
исследовал
исследовала
…
{исследовать} +
+ Прош. вр. + Ед.ч. + М
р.
{исследовать} +
+ Прош. вр. + Ед.ч. + Ж
р.
ПОРОЖДЕНИЕ СЛОВОФОРМЫ:
морфологический синтез
{исследовать} + Неопр.ф.
исследовать
{исследовать} + Наст. вр. + Ед.ч. + 1 л.
исследую
{исследовать} + Наст. вр. + Ед.ч. + 2 л.
исследуешь
{исследовать} + Наст. вр. + Ед.ч. + 3 л.
исследует
…
{исследовать} + Буд. вр. + Ед.ч. + 1 л.
исследую, буду исследовать
{исследовать} + Буд. вр. + Ед.ч. + 2 л.
исследуешь , будешь исследовать
{исследовать} + Буд. вр. + Ед.ч. + 3 л.
исследует, будет исследовать
…
{исследовать} + Прош. вр. + Ед.ч. + М р.
исследовал
{исследовать} + Прош. вр. + Ед.ч. + Ж р.
исследовала
…
ПОРОЖДЕНИЕ СЛОВОФОРМЫ:
морфологический синтез
{исследовать} + Неопр.ф.
исследовать
{исследовать} + Наст. вр. + Ед.ч. + 1 л.
исследую
{исследовать} + Наст. вр. + Ед.ч. + 2 л.
исследуешь
{исследовать} + Наст. вр. + Ед.ч. + 3 л.
исследует
…
{исследовать} + Буд. вр. + Ед.ч. + 1 л.
исследую, буду исследовать
{исследовать} + Буд. вр. + Ед.ч. + 2 л.
исследуешь , будешь исследовать
{исследовать} + Буд. вр. + Ед.ч. + 3 л.
исследует, будет исследовать
…
{исследовать} + Прош. вр. + Ед.ч. + М р.
исследовал
{исследовать} + Прош. вр. + Ед.ч. + Ж р.
исследовала
…
ПОРОЖДЕНИЕ СЛОВОФОРМЫ:
морфологический синтез
{исследовать} + Неопр.ф.
исследовать
{исследовать} + Наст. вр. + Ед.ч. + 1 л.
исследую
{исследовать} + Наст. вр. + Ед.ч. + 2 л.
исследуешь
{исследовать} + Наст. вр. + Ед.ч. + 3 л.
исследует
…
{исследовать} + Буд. вр. + Ед.ч. + 1 л.
исследую, буду исследовать
{исследовать} + Буд. вр. + Ед.ч. + 2 л.
исследуешь , будешь исследовать
{исследовать} + Буд. вр. + Ед.ч. + 3 л.
исследует, будет исследовать
…
{исследовать} + Прош. вр. + Ед.ч. + М р.
исследовал
{исследовать} + Прош. вр. + Ед.ч. + Ж р.
исследовала
…
МОРФОЛОГИЧЕСКИЙ АНАЛИЗ и ЛЕММАТИЗАЦИЯ
исследовать
{исследовать} +
+Неопр.ф.
исследовать
{исследовать}
исследую
{исследовать} +
+ Наст., Буд. вр. + Ед.ч.
+ 1 л.
исследую
{исследовать}
исследуешь
{исследовать} +
+ Наст., Буд. вр. + Ед.ч.
+ 2 л.
исследуешь
{исследовать}
исследует
{исследовать} +
+ Наст., Буд. вр. + Ед.ч.
+ 3 л.
исследует
{исследовать}
…
…
исследовал
{исследовать} +
+ Прош. вр. + Ед.ч. + М
р.
исследовала
{исследовать} +
+ Прош. вр. + Ед.ч. + Ж
р.
…
исследовал
{исследовать}
исследовала
{исследовать}
…
МОРФОЛОГИЧЕСКИЙ СИНТЕЗ и
ПОРОЖДЕНИЕ ПАРАДИГМЫ
{исследовать} +
Неопр.ф.
исследовать
{исследовать} + Наст.
вр. + Ед.ч. + 1 л.
исследую
{исследовать} + Наст.
вр. + Ед.ч. + 2 л.
исследуешь
{исследовать} + Наст.
вр. + Ед.ч. + 3 л.
исследует
…
{исследовать} + Буд.
вр. + Ед.ч. + 1 л.
исследую,
буду исследовать
{исследовать} + Буд.
вр. + Ед.ч. + 2 л.
исследуешь ,
будешь
исследовать
{исследовать} + Буд.
вр. + Ед.ч. + 3 л.
исследует,
будет
исследовать
…
{исследовать}
исследовать
исследую
исследуешь
исследует
исследуем
исследуете
исследуют
буду исследовать
будешь исследовать
будет исследовать
…
исследовал
исследовала
…
ЕСТЬ ЛИ ДОСТАТОЧНАЯ ПРЕДСКАЗУЕМОСТЬ?
дневн(ой)
вечерн(ий)
ночн(ой)
утренн(ий)
дневник
вечерник
ночник
утренник
ЕСТЬ ЛИ ДОСТАТОЧНАЯ ПРЕДСКАЗУЕМОСТЬ?
АНАЛИЗ:
дневник
{дневной} + тетрадь для записей, заполняемая с
указанной периодичностью,
{дневной} + студент формы обучения,
предусматривающей занятия в указанное время суток
вечерник
{вечерний} + студент формы обучения,
предусматривающей занятия в указанное время суток
ночник
{ночной} + лампа, используемая в указанное время
суток
утренник
{утренний} + представление, происходящее в
указанное время суток
ЕСТЬ ЛИ ДОСТАТОЧНАЯ ПРЕДСКАЗУЕМОСТЬ?
СИНТЕЗ:
{дневной} + студент формы обучения,
предусматривающей занятия в указанное время
суток
дневник
{вечерний} + студент формы обучения,
предусматривающей занятия в указанное время
суток
вечерник
{утренний} + студент формы обучения,
предусматривающей занятия в указанное время
суток
??
{дневной} + лампа, используемая в указанное
время суток
??
{вечерний} + представление, происходящее в
указанное время суток
??
СЛОВОИЗМЕНЕНИЕ И СЛОВООБРАЗОВАНИЕ
Внутренний смысл противопоставления:
варианты одной лексической единицы или разные
лексические единицы
Подходы в теоретической морфологии:
28 «элементарных различий» словоизменения и
словообразования по Ф.Планку
15 критериев противопоставления лексического и
грамматического у Н.В.Перцова
вхождение/невхождение в категории противопоставленных
единиц и обязательные категории;
коррелятивность;
композиционность;
и т.д.
СЛОВОИЗМЕНЕНИЕ И СЛОВООБРАЗОВАНИЕ
Внутренний смысл противопоставления:
варианты одной лексической единицы или разные
лексические единицы
Технические критерии противопоставления:
при анализе
композиционность: словоформа без остатка разбивается на
формальные показатели (знаки), значение формы без остатка
раскладывается на значения этих показателей
при синтезе
регулярность (коррелятивность): лексические единицы
разбиты на (достаточно большие) классы, и для каждого
класса известен набор возможных словоформ, а также
правила, по которым их можно строить
СЛОВОИЗМЕНЕНИЕ И СЛОВООБРАЗОВАНИЕ
Технический критерий позволяет подключить к явлениям
словоизменения (для русского языка):
образование существительных от прилагательных
образование существительных (имен действия и имен
деятеля) от глаголов
образование уменьшительных существительных
Более осторожный термин С.А.Крылова и
С.А.Старостина для таких явлений – «номинационное
формообразование» (2003)
СЛОВОИЗМЕНЕНИЕ И СЛОВООБРАЗОВАНИЕ
Общий вывод для компьютерной морфологии:
Класс явлений словоизменения может быть расширен,
нужно только исчерпывающее и объективное описание
указать класс лексем, которые подвергаются такому
варьированию (образуют уменьшит./ аугментатив.
форму и т.п.)
указать правила варьирования для каждой лексемы из
класса достаточно экономным образом
Но следует учитывать
фактор практической целесообразности с учетом
функции конкретной компьютерной системы
ФОРМАЛЬНЫЙ РАЗРЯД В
КОМПЬЮТЕРНОЙ МОРФОЛОГИИ
учител-ь
учител-я
учител-я
учител-ей
учител-ю
учител-ям
учител-я
учител-ей
учител-ем
учител-ями
учител-е
учител-ях
учитель, соболь, егерь…
(типовая парадигма, морфологический тип)
ОДНА ПАРАДИГМА ИЛИ БОЛЬШЕ?
узел
узлы
узла
узлов
узлу
узлам
узел
узлы
узлом
узлами
узле
узлах
хребет
хребты
хребта
хребтов
хребту
хребтам
хребет
хребты
хребтом
хребтами
хребте
хребтах
бубен
бубны
бубна
бубнов
бубну
бубнам
бубен
бубны
бубном
бубнами
бубне
бубнах
СТРУКТУРА СЛОВАРНОЙ БАЗЫ ДАННЫХ
Идентификатор лексемы
Идентификатор парадигмы
порогов
пород
породнени
порожда
302
005
002
401
СТРУКТУРА СЛОВАРНОЙ БАЗЫ ДАННЫХ
Идентификатор
лексемы
Основа
Идентификатор
парадигмы
пороговый
порода
породнение
порождать
порогов
пород
породнени
порожда
302
005
002
401
ПЕРВИЧНЫЕ И ВТОРИЧНЫЕ ФУНКЦИИ
(ПРОЦЕДУРЫ) В КОМПЬЮТЕРНОЙ
МОРФОЛОГИИ
ПРОЦЕДУРА ОПРЕДЕЛЕНИЯ ТИПОВОЙ
ПАРАДИГМЫ
если слово оканчивается на щийся, то ТП 5;
если слово оканчивается на ин, ын, то ТП 20;
если слово оканчивается на ов, ёв, ев, то ТП 21;
если слово оканчивается на цый, то ТП 6;
если слово оканчивается на ый, то ТП 1;
если слово оканчивается на кий, гий, хий, то ТП 3;
если слово оканчивается на щий, то ТП 4;
если слово оканчивается на жий, ший, чий, то ТП 4 или ТП 24;
если слово оканчивается на ий, то ТП 2 или ТП 24;
если слово оканчивается на кой, гой, хой, жой, шой, чой, щой, то
ТП 8;
если слово оканчивается на ой, то ТП 7.
ТИПИЗАЦИЯ ВНУТРИ ПРЕДСКАЗАНИЯ
ВОЗМОЖНОСТИ ИСПОЛЬЗОВАНИЯ КОДОВ ГСРЯ В
МОРФОЛОГИЧЕСКИХ МОДУЛЯХ
Могут быть слишком дробными (для обработки
письменного текста)
дол м 1е//1а
порт м 1е
клён м 1а
имеют одинаковый набор окончаний
Могут быть недостаточно точными (для некоторых
процедур компьютерной морфологии)
восстановление начальной формы:
бугор м 1*b
котёл м 1*b
псалом м 1*b
сон м 1*b
хребет м 1*b
бугра: (- ра), (+ ор)
котла: (- ла), (+ ёл)
псалма: (- ма), (+ ом)
сна: (- на), (+ он)
хребта: (- та), (+ ет)
НЕДОСТАТКИ СЛОВАРЯ ЗАЛИЗНЯКА
сложная структура словоизменительной характеристики
формальная «вседозволенность» (свобода образования форм
множественного числа - вреды, зарезы, неонацизмы, кратких
форм - бегл, кредитово, соляны, сравнительной степени тяжелораненее, убитее, изюбревее)
неполнота словника
РЕКОМЕНДОВАННАЯ ЛИТЕРАТУРА
Леонтьева Н.Н. Автоматическое понимание
текстов: системы, модели, ресурсы. М., 2006
(глава 4, (3))
Коваль С.А. Лингвистические проблемы
компьютерной морфологии. СПб., 2005
Библиография, собранная С. Нагелем
(Sebastian Nagel):
http://www.cis.unimuenchen.de/~wastl/rmorph/rusmorphBib.pd
f
УПОМЯНУТАЯ ЛИТЕРАТУРА
Перцов Н.В. Инварианты в русском
словоизменении. М.: Языки русской
культуры, 2001 (глава 2)
Крылов С.А., Старостин С.А. Актуальные
задачи морфологического анализа и синтеза
в интегрированной информационной среде
STARLING // Тр. Междунар. конф.
Диалог’2003 (http://www.dialog21.ru/Archive/2003/Krylov.htm)
Данные
Внутренняя структура словоформы. Пример
Входные данные
городк”е
Результат морфологического анализа:
городк” - е
Данные
Внутренняя структура словоформы. Пример
Городок | городка |городк”е
Морфонологические правила:
(1) V -> Ø | __ □ CV (beglie)
(2) C тв -> C мягк | __ □ Vпередн ряд (Palatalization)
(3) C зв -> C гл | __ □ Сгл (Oglushenie)
Обратный пересчет:
Данные
Внутренняя структура словоформы. Пример
Данные
Полный список словоформ с их формами
Полная декомпозиция:
План
Задачи, этапы (лекция Морфология1)
Обзор технологий
Организация данных
Первичный
анализ. Базовые
формализмы анализа словоформы
Разрешение омонимии
Предсказание незнакомых слов
Формализмы
FST (конечные преобразователи – Finite State
Trasducers)
Порождающая грамматика
Язык регулярных выражений
Порождающие граммаики
упорядоченная четверка ,
где V и W - непересекающиеся конечные множества, наз.
соответственно основным и вспомогательным алфавитами,
или словарями (их элементы наз. соответственно
основными, пли терминальными, и вспомогательными, или
нетерминальными, символам и), - элемент , наз. начальным
символом, и - конечное множество правил, имеющих вид ,
где - цепочки ( слова).в алфавите и не принадлежит ; Rназ.
схемой грамматики.
ФОРМАЛЬНАЯ (ПОРОЖДАЮЩАЯ)
ГРАММАТИКА - пример
Четверка (V, W, I, R):
V = {а, е, й, к, л, о, у, ы}
W = {Слово, Основа, Окончание}
I = {Слово}
R – множество правил грамматики
Правила R :
1. Слово Основа Окончание
2. Основа к у к л
3. Окончание а
4. Окончание ы
5. Окончание у
6. Окончание е
7. Окончание о й
ВЫВОД В ФОРМАЛЬНОЙ ГРАММАТИКЕ
Правила R :
1.
Слово Основа Окончание
2.
Основа к у к л
3.
Окончание а
4.
Окончание ы
5.
Окончание у
6.
Окончание е
ВЫВОД:
Слово
Основа Окончание
к у к л Окончание
куклой
(1)
(2)
(6)
Основные формализмы
FST
Один из наиболее распространенных Finite
State Transducer (Конечные преобразователи)
Конечный автомат — абстрактный автомат без выходного
потока, число возможных состояний которого конечно.
Результат работы автомата определяется по его конечному
состоянию.
Конечный автомат
Существуют различные варианты задания конечного
автомата. Например, конечный автомат может быть задан с
помощью пяти параметров: , где:
Q — конечное множество состояний автомата;
q0 — начальное состояние автомата ();
F — множество заключительных (или допускающих) состояний, таких
что ;
Σ — допустимый входной алфавит (конечное множество допустимых
входных символов), из которого формируются строки, считываемые
автоматом;
δ — заданное отображение множества во множество подмножеств
Q: (иногда δ называют функцией переходов автомата).
Конечные автоматы
Автомат начинает работу в состоянии q0, считывая по
одному символу входной строки. Считанный символ
переводит автомат в новое состояние из Q в соответствии с
функцией переходов. Если по завершении считывания
входного слова (цепочки символов) автомат оказывается в
одном из допускающих состояний, то слово «принимается»
автоматом. В этом случае говорят, что оно принадлежит
языку данного автомата. В противном случае слово
«отвергается».
Конечный преобразователь: анализирует цепочку символов
на входной ленте и записывает другую цепочку на выходной
ленте.
Недетерминированные
конечные автмоматы
•Недетерминированный конечный автомат (НКА) является обобщением
•детерминированного. Недетерминированность автоматов достигается двумя способами:
Существуют переходы, помеченные
пустой цепочкой ε
Из одного состояния выходит несколько
переходов, помеченных одним и тем же
символом
КОНЕЧНЫЙ ПРЕОБРАЗОВАТЕЛЬ
a1
читающая
головка
устройства
b1
aу 2
к
qi
о
л
#
#
#
направление движения
обеих лент
b2
Правила вида qi ai bi qj
Распознавание (порождение) цепочек пар символов
Перекодирование (переход от записи на языке верхней ленты к
записи на языке нижней ленты и наоборот)
КОНЕЧНЫЙ ПРЕОБРАЗОВАТЕЛЬ В
ВИДЕ ДИАГРАММЫ
К
У
К
Записать в виде таблицы?
Л
А:Ø
Им.:А
Ед.: Ø
ФРАГМЕНТ АНГЛИЙСКОЙ ГЛАГОЛЬНОЙ
СИСТЕМЫ: КОНЕЧНЫЙ
ПРЕОБРАЗОВАТЕЛЬ
n
Inf: Ø
g
3PSg: s
i
Ø
s
p
i:a
r
i:u
n
n
g
g
Past:Ø
PP: Ø
ЛЕКСИКОН В ФОРМАТЕ Xerox Tools
Multichar_Symbols +Inf
LEXICON Root
sing+Inf:sing # ;
sing+3pSg:sings
sing+Past:sang # ;
sing+PP:sung # ;
spring+Inf:spring
spring+3pSg:springs
spring+Past:sprang
spring+PP:sprung
#;
#;
#;
#;
#;
+3pSg +Past +PP
Язык регулярных выражений
Регулярные выражения состоят из констант и операторов, которые
определяют множества строк и множества операций на них
соответственно. На данном конечном алфавите Σ определены
следующие константы:
(пустое множество) ∅.
(пустая строка) ε обозначает строку, не содержащую ни одного символа.
Эквивалентно «».
(символьный литерал) «a», где a — символ алфавита Σ.
Язык регулярных выражений
и следующие операции:
(сцепление, конкатенация) RS обозначает множество {αβ | α ∈ R & β ∈ S}.
Например, {"boy", "girl"}{"friend", "cott"} = {"boyfriend", "girlfriend",
"boycott", "girlcott"}.
(дизъюнкция, чередование) R|S обозначает объединение R и S. Например,
{"ab", "c"}|{"ab", "d", "ef"} = {"ab", "c", "d", "ef"}.[4]
(замыкание Клини, звезда Клини) R* обозначает минимальное надмножество
множества R, которое содержит ε и замкнуто относительно
конкатенации. Это есть множество всех строк, полученных
конкатенацией нуля или более строк из R. Например, {"Go", "Russia"}*
= {ε, "Go", "Russia", "GoGo", "GoRussia", "RussiaGo", "RussiaRussia",
"GoGoGo", "GoGoRussia", "GoRussiaGo", …}.
Язык регулярных выражений
Представление символов
Обычные символы (литералы) и специальные символы
(метасимволы)
Большинство символов в регулярном выражении представляют сами
себя за исключением специальных символов [ ] \ / ^ $ . | ? * + ( ) { },
которые могут быть предварены символом \ (обратная косая черта)
(«экранированы», «защищены») для представления их самих в качестве
символов текста.
Городо?[кк”]([еауи]/ом/ами/ах)?
План
Задачи, этапы (лекция Морфология1)
Обзор технологий
Организация данных
Первичный анализ. Базовые формализмы
анализа словоформы
Методы,
основанные на словарях
Разрешение омонимии
Предсказание незнакомых слов
.
Методы, основанные
на словаре
Основные вопросы:
Как разделять исходную словоформу
на
сколько частей и какие?
Что хранить в словаре:
словоформу,
основу
+ правила преобразования + словоизменительные
парадигмы,
квазиосновы + квазиокончания
Морфологическая разметка
Методы, основанные на словаре
Существует три базовых подхода к проектированию морфологических
машинных словарей (лексиконов) для флективных языков.
1) копируется академическая лингвистическая модель описания, где
выделяются основные парадигматические классы, соответствующие
типу склонения и спряжения, и правила регулярных альтернаций
(фонетических чередований), а нерегулярные формы (например,
сильные глаголы в немецком и английском языках) задаются
перечислением.
(на базе модели грамматического словаря А.Зализняка, разрабатывая 8 классов именного
склонения и 16 глагольного спряжения, а чередования в основе и глагольной темы
выносятся в отдельное множество пост-морфологических правил альтернаций)
2) рассматривается любого вида регулярное и нерегулярное чередование
как часть расширенной псевдо-флексии (в таком случае, основа
словоформы ‘день’ – ‘д’, а флексия – ‘-ень’; для словоформы ‘песок’: ‘пес’ и
‘-ок’). В подобной модели описания число парадигматических классов для
русского языка возрастает до 3000
3) В лексиконе для каждой лексемы приводится полный список словоформ
.
Методы, основанные
на словаре
LEXICON Verbs;
вписывать+Verb+Perf:впи(с/ш) V1;
LEXICON V1;
+Inf+Active:^Hать #;
+Imperf+Inf+Passive:^Hаться #;
+Ind+NotPast+P1+Sg+Active:^Sьу #;
+Ind+NotPast+P2+Sg+Active:^Sьэшь #;
+Ind+NotPast+P3+Sg+Active:^Sьэт #;
+Ind+NotPast+P1+Pl+Active:^Sьэм #;
+Ind+Past+Sg+Masc+Active:^Hал #;
+Ind+Past+Sg+Fem+Active:^Hала #;
+Ind+Past+Sg+Neut+Active:^Hало #;
лексическая форма
‘вписывать+Verb+Perf+Ind+NotPast+P3+Sg+Active’ соответствует
поверхностной форме ‘впи(с/ш) ^Sьэт’.
Морфологическая разметка:
Методы, основанные
на словаре
.
Фрагмент описания парадигмы для лексемы ‘рукоплескать’:
1740
%СКАТЬ*ка%СКАВШАЯ*мз%ЩУ*кб%ЩУТ*кж%ЩУЩЕГО*
лблглп%….
…………………
РУКОПЛЕ 1740
‘Рукопле’ – основа слова в лексиконе; ‘1740’ – уникальный
идентификатор парадигматического класса; ‘%’ маркирует
начало псевдо-флексии; ‘*’ маркирует начало аношкинского
кода; ‘ка’, ‘кб’, ‘лб’, ‘лг’, etc. – код. В таблице приведена
расшифровка аношкинских кодов, использованных в примере:
Морфологическая разметка:
Методы, основанные
на словаре
.
%СКАТЬ*ка%СКАВШАЯ*мз%ЩУ*кб%ЩУТ
*кж%ЩУЩЕГО*лблглп%….
Аношкинский код:
Морфологическая разметка:
Технологии морфологической разметки
1. Традиционные алгоритмические методы:
Словарь со всеми словоизменительными моделями без снятия
омонимии
Словарь + все словоизменительные модели + предсказание +
эвристики (ad hoc правила)
Словарь с моделями + алгоритмические контекстные правила
снятия омонимии
Словарь с моделями + частичный синтаксический анализ
Хороший словарь + исчерпывающее описание
словоизменительных моделей
Для русского языка:
А. А. Зализняк
«Русское именное словоизменение» М.: Языки славянской культуры, 2002. І—VІІІ, 752 с.
(Studia philologica)
«Грамматический словарь русского языка» АСТ-Пресс Книга, 2009 г., 720 с.
(http://starling.rinet.ru/cgi-bin/main.cgi?flags=eygtmnl)
Морфологическая разметка
Методы, основанные на словаре
Первый подход к проектированию лексиконов для построения
морфологических анализаторов европейских и восточных языков
был применен в научно-исследовательском центре Xerox
(Гренобль) в середине 90-ых, а позже усовершенствован и доведен
до промышленного использования в исследовательских отделах
Inxight Software (Санта-Клара, США и Антверпен, Бельгия) в 20002002 гг. Конечный продукт Inxight LinguistX Platform 3.5 включает
в себя морфологии 26 языков: 5 восточных (арабский, корейский,
японский, etc.) и 21 европейский (английский, голландский,
испанский, русский, etc.).
Морфологическая разметка
Методы, основанные на словаре
Наиболее разработанные языковые модули, такие как
английский, немецкий и русский, имеют четыре уровня текстового
анализа: tokenizer – графематика, осуществляющая деление
исходного текста на предложения и словоформы;
stemmer – лемматизация входных словоформ;
tagger – снятие морфологической омонимии и унификация
значений грамматических характеристик;
np-grouper – синтаксическое выделение именных и
составляющих NP из текстов.
План
Задачи, этапы (лекция Морфология1)
Обзор технологий
Организация данных
Первичный анализ. Базовые формализмы
анализа словоформы
Разрешение омонимии
Предсказание незнакомых слов
Разрешение омонимии
Морфологический анализ с использованием
«ручных правил»
… и предложили систему диагностических ситуаций,
помогающих разрешить некоторые типы омонимии:
Морфологическая разметка
Методы «борьбы» с незнакомыми
словами: предсказания в АОТ
1)
2)
предсказание префиксального образования
предсказание по концовке, взятой из
известных словоформ
План
Задачи, этапы (лекция Морфология1)
Обзор технологий
Организация данных
Первичный анализ. Базовые формализмы
анализа словоформы
Разрешение омонимии
Предсказание
незнакомых слов
Морфологическая разметка
Методы «борьбы» с незнакомыми словами:
предсказания в АОТ
попытка найти существующую словоформу языка,
которая максимально совпадала бы справа со
входным словом. Если левая часть (потенциальный
префикс) не длиннее M символов (пяти), а правая
часть (совпавшая с известной словоформой) не
короче N символов (четырех), то слово разбирается
по образцу известной словоформы.
[евро]технологию, [супер]коньками
ПРЕДСКАЗАНИЕ В АОТ: ПРЕДСКАЗАНИЕ
ПО КОНЦОВКЕ ИЗ ИЗВЕСТНОЙ
СЛОВОФОРМЫ
создается конечный автомат, построенный на строках вида:
ReverseSuffix(X)|Annot(X),
где ReverseSuffix(Х) – инвертированная концовка известной
словоформы длины K (пять букв), Annot(X) – аннотация
словоформы X (анкод), например:
меина|ед
где аннотация «ед» интерпретируется как «ср. род, ед. ч., тв. пад.»
Такая строка заносится в исходный лексикон, если она встречается:
не менее L раз (трех) и
чаще конкурентов (строк с таким же ReverseSuffix(X), но другим
Annot(X) ) в пределах одной части речи
ВСЕГДА предусматривается разбор именем существительным, хотя
бы неизменяемым.
ПРЕДСКАЗАНИЕ В АОТ: ОЦЕНКА
КАЧЕСТВА
В новостных текстах наугад выбраны 150 неповторяющихся
предсказанных слов. Исключались слова, у которых все
буквы в верхнем регистре (аббревиатуры).
Все слова оказались либо существительными, либо
прилагательными.
Для 131 слова в результатах предсказания был хотя бы один
правильный результат (одновременно лемма, часть речи,
род, число и падеж). Т.е. точность предсказания – 87%.
Результат вполне сравним с известными результатами для
английского языка - 85 % или для французского – 88%.
http://www.aot.ru/demo/morph.html
План
Морфологический
анализ без словаря
Стемминг
Сте́мматизация (сте́мминг) — это процесс нахождения
основы слова для заданного исходного слова. Основа слова
необязательно совпадает с морфологическим корнем слова.
Алгоритм стемматизации представляет собой давнюю
проблему в области компьютерных наук. Первый документ
по этому вопросу был опубликован в 1968 году. Данный
процесс применяется в поиcковых системах для обобщения
поискового запроса пользователя.
Конкретные реализации стемматизации называются
алгоритм стемматизации или просто стеммер
Стеммер Портера — алгоритм стемминга, опубликованный
Мартином Портером в 1980 году. Оригинальная версия
стеммера была предназначена для английского языка и была
написана на языке BCPL. Впоследствии Мартин создал проект
«Snowball» и, используя основную идею алгоритма, написал
стеммеры для распространённых индоевропейских языков, в
том числе для русского.
Алгоритм не использует баз основ слов, а лишь, применяя
последовательно ряд правил, отсекает окончания и суффиксы,
основываясь на особенностях языка, в связи с чем работает
быстро, но не всегда безошибочно.