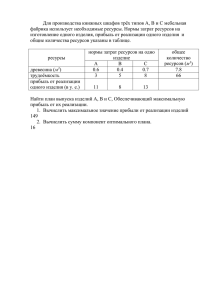
1. Введение, основные понятия - Институт Математического
реклама

Московский государственный университет им. М.В.Ломоносова
Параллельные мето
ды
и алгоритмы
Введение
Якобовский Михаил Владимирович
д.ф.-м.н.
Институт математического моделирования
РАН, Москва
Что происходит?
Вычислительная мощность суперкомпьютеров
быстро растет
Примеров успешного полноценного
использования суперкомпьютеров немного
В среднем вычислительная мощность
суперкомпьютеров используется не более чем на
несколько процентов
2
Кто виноват?
Вычислительная мощность суперкомпьютера не
более чем прямая сумма мощностей большого
числа входящих в его состав процессоров или
процессорных ядер
Современные алгоритмы не могут
автоматически использовать такую
«распределенную» мощность
3
Что делать?
Изучать известные методы анализа и создания
параллельных алгоритмов
Создавать новые методы использования
многопроцессорных систем для решения
актуальных значимых задач
4
Кризис эффективности
Вычислительная мощность суперкомпьютеров
велика, но:
– Она образована суммой мощностей множества
исполнительных устройств
На протяжении ряда лет увеличение
производительность компьютера автоматически
означало снижение времени работы
существующих программ. Теперь это не так:
– Последовательные программы не могут
работать на суперкомпьютерах быстрее
5
Кризис эффективности
Время вычислительных систем, обладающих
существенной производительностью и имеющих
в своем составе только один процессор прошло,
и, по всей видимости, безвозвратно
Автоматическое преобразование
последовательных программ в параллельные
невозможно
Необходимо знать существующие и развивать
новые методы решения задач на
многопроцессорных системах
6
Уточнение круга рассматриваемых систем
Системы на основе объединенных сетью
типовых вычислительных узлов – системы с
распределенной оперативной памятью
Системы с доступом всех процессоров к общей
оперативной памяти
Графические ускорители
ПЛИС
Нейрокомпьютеры
Другие …
7
Многопроцессорные системы с распределенной
памятью
Процессор 1
Процессор 2
Процессор 3
Локальная
Память 1
Локальная
Память 2
Локальная
Память 3
IO-Nodes
Router1
концентраторы
Network
Router2
P-Nodes
Процессорные узлы
8
Многопроцессорные системы с общей памятью
Процессор 1
Процессор 2
Процессор 3
Общая оперативная память
9
Уточнение круга рассматриваемых алгоритмов
Слабо взаимодействующие последовательные
процессы
10
Модель программы на распределенной памяти
При запуске указываем число требуемых процессоров Np и название
программы
На выделенных для расчета узлах запускается Np копий указанной
программы
– Например, на двух узлах запущены три копии программы. Копия программы с
номером 1 не имеет непосредственного доступа к оперативной памяти копий 0 и 2:
0
1
2
Каждая копия программы получает два значения:
– Np
– rank из диапазона [0 … Np-1]
Любые две копии программы могут непосредственно обмениваться
данными с помощью функций передачи сообщений
11
Модель программы на общей памяти
Работа начинается с запуска одной программы
При необходимости программа порождает новые
процессы, эти процессы:
– Обладают собственными локальными переменными
– Имеют доступ к общим глобальным переменным
int a_global;
main()
{
int b1_local;
}
fun()
{
int b2_local;
}
main
нить1
нить2
запуск нити1
запуск нити2
ожидание
окончания работы
12
Свойства канала передачи данных
T(n)=n*Tбайта+ Tлатентности
Gbit Ethernet
Infiniband
13
Свойства канала передачи данных
T(n)=n*Tбайта+ Tлатентности
Gbit Ethernet
Число передаваемых байт
14
Свойства канала передачи данных
T(n)=n*Tбайта+ Tлатентности
Infiniband
Число передаваемых байт
15
Методы передачи данных
Синхронный метод
Send(адрес данных, размер, номер процессора)
Recv(адрес данных, размер, номер процессора)
Асинхронные методы
– Небуферизованный
ASend(адрес данных, размер, номер процессора)
ARecv(адрес данных, размер, номер процессора)
ASync
– Буферизованный
ABSend(адрес данных, размер, номер процессора)
16
Синхронный
A=3
Send(&A)
A=5
A=3
B=4
Recv(&B)
Print(B)
B=4
Send
Recv
Результат
3
Print(B)
A=5
17
Асинхронные
A=3
АSend(&A)
A=5
B=4
АRecv(&B)
Print(B)
A=3
B=4
ARecv
Send
ASend
A=5
Recv
Print(B)
Результат
3?4?5
18
Асинхронные
A=3
АSend(&A)
Async()
A=5
B=4
АRecv(&B)
Print(B)
B=4
A=3
ARecv
Send
ASend
Recv
A=5
Print(B)
Результат
3?4
ASync
19
Асинхронные
A=3
АSend(&A)
Async()
A=5
B=4
АRecv(&B)
Async()
Print(B)
A=3
ASend
ARecv
Send
B=4
Результат
Recv
A=5
ASync
ASync
3
Print(B)
20
Асинхронные буферизованные
A=3
АBSend(&A)
A=5
B=4
АRecv(&B)
Async()
Print(B)
A=3
ABSend
buf=A
ARecv
B=4
Send(&buf)
A=5
Recv
ASync
Результат
3
Print(B)
21
Семафор
Целочисленная неотрицательная переменная
Две атомарные операции, не считая инициализации
V(S)
– Увеличивает значение S на 1
P(S)
– Если S положительно, уменьшает S на 1
– Иначе ждет, пока S не станет больше 0
Языки програмирования. Редактор Ф.Женюи. Перевод с англ
В.П.Кузнецова. Под ред. В.М.Курочкина. М:."Мир", 1972 Э. Дейкстра.
Взаимодействие последовательных процессов.
http://khpi-iip.mipk.kharkiv.edu/library/extent/dijkstra/ewd123/index.html
22
Ускорение и эффективность параллельных
алгоритмов
ускорение
параллельного
алгоритма
эффективность
использования
процессорной мощности
E(p)=S(p)/p
S(p)=T(1)/T(p)
Ускорение параллельного
алгоритма относительно
наилучшего последовательного
S*(p)=T * /T(p)
E *(p)=S *(p)/p
23
Может ли быть S(p)>p ?
Да:
– Плохой последовательный алгоритма
– Влияние аппаратных особенностей вычислительной
системы
24
Может ли неэффективный алгоритм работать
быстрее эффективного?
Да
– Если первый алгоритм позволяет использовать больше
процессоров, чем второй.
Самый эффективный алгоритм – использующий
один (1) процессор.
– Его эффективность по определению равна 100%, но он
не всегда самый быстрый.
25
Определить сумму конечного ряда
Все элементарные операции (+ - * / )
выполняются за время с
Все операции выполняются точно, результат не
зависит от порядка их выполнения
26
Последовательный алгоритм
S=1;
a=1;
for(i=1;i<= n;i++)
{
a=a*x/i;
S=S+a;
}
T1= 3nс
27
Параллельный алгоритм
Вычислить для всех
i =1,…,n :
xi
Вычислить для всех
i =1,…,n :
i!
Вычислить для всех
i =1,…,n : ai =
Вычислить сумму всех членов
ai
28
xi
Для вычисления xi воспользуемся методом
бинарного умножения
x
x2
1
2
3
x3
x5
4 x9 x10
x6
x11 x12
x4
x7
x8
x13 x14 x15 x16
29
i!
Для вычисления i! воспользуемся
аналогичным методом
4 12 34 56 78910 1112 1314 1516=16!
3 1 2 3 4 5 6 7 8
910 1112 1314 1516
2 12 34 56 78 910 1112 1314 1516
1 1 2 3 4 5 6 7 8
910 1112 1314 1516
30
12!
Для вычисления i! воспользуемся
аналогичным методом
4 12 34 56 78910 1112 =12!
3 1 2 3 4 5 6 7 8
910 1112 1314 1516
2 12 34 56 78 910 1112 1314 1516
1
12 34 56 78 910 1112 1314 1516
31
14!
Для вычисления i! воспользуемся
аналогичным методом
4 12 34 56 78910 1112 1314=14!
3 1 2 3 4 5 6 7 8
910 1112 1314
2 12 34 56 78 910 1112
1 1 2 3 4 5 6 7 8
910 1112 1314 1516
32
Параллельный алгоритм
xi
i!
ai
Вычислить все
Вычислить все
Вычислить все
Вычислить сумму всех ai :
a1
a2
a1+a2
a3
a4
a3+a4
a1+a2+a3+a4
a5
a6
a5+a6
:
:
:
a7
- надо n процессоров
a8
a7+a8
a5+a6+a7+a8
2
a1+a2+a3+a4+a5+a6+a7+a8
33
Ускорение и эффективность при p=n
p=n
1.5
2
700
600
500
400
300
200
100
0
0
2000
4000
6000
8000
10000
100%
90%
80%
70%
60%
50%
40%
30%
20%
10%
0%
1.5
0
2000
4000
6000
8000
10000
34
Заключение
Определены понятия ускорения и эффективности
параллельных алгоритмов
Представлен ряд способов организации
взаимодействия последовательных процессов
Представлен алгоритм, обладающий низкой
эффективностью, но высоким быстродействием
35
Литература…
Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. - СПб.: БХВПетербург, 2002.
Грегори Р. Эндрюс - Основы многопоточного, параллельного и
распределенного программирования. "Вильямс ", 2003
Роберт Седжвик - Фундаментальные алгоритмы на C. Части 1 - 5. Анализ.
Структуры данных. Сортировка. Поиск. Алгоритмы на графах
Языки программирования. Редактор Ф.Женюи. Перевод с англ.
В.П.Кузнецова. Под ред. В.М.Курочкина. М:."Мир", 1972 Э. Дейкстра.
Взаимодействие последовательных процессов.
http://khpi-iip.mipk.kharkiv.edu/library/extent/dijkstra/ewd123/index.html
Дональд Э. Кнут Искусство программирования
36
Литература…
Учебные курсы Интернет Университета Информационных технологий
Гергель В.П. Теория и практика параллельных вычислений. —
http://www.intuit.ru/department/calculate/paralltp/
Лекции в форме видео-конференций
Гергель В.П. Основы параллельных вычислений. —
http://www.hpcu.ru/courses/15/
Немнюгин С.А. Основы параллельного программирования с использованием
MPI . — http://www.hpcu.ru/courses/14/
Крюков В.А., Бахтин В.А. Параллельное программирование с OpenMP . —
http://www.hpcu.ru/courses/16/
Дополнительные учебные курсы:
Воеводин В.В. Вычислительная математика и структура алгоритмов. —
http://www.intuit.ru/department/calculate/calcalgo/
37
Литература
Ресурсы Internet
http://parallel.ru
http://top500.org
http://supercomputers.ru
38