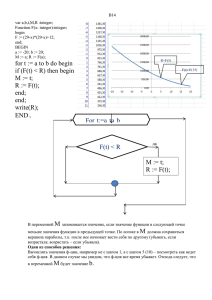
Поиск и сортировка
реклама

LOGO
Поиск и сортировка
10 класс, углублённый уровень
по учебнику Калинина И.А. и Самылкиной Н.Н.
Задача поиска
Крупная задача = алгоритм 1+
алгоритм 2+ … + алгоритм n
Каждый алгоритм решает
определённую подзадачу.
Задача поиска: в наборе элементов a1,
a2, …, an требуется найти элементы,
соответствующие некоторому условию
(например, ai=b), или выяснить, что
таких элементов нет.
Прямой поиск
Перебираются все элементы
последовательно.
Если элемент удовлетворяет условию,
то элемент искомый найден.
Если дошли до конца, но
переобозначений не делали, такого
элемента нет.
Сложность алгоритма: О(n) – в
плохом случае, в лучшем – О(1),
средний случай – О(n/2).
Минусы прямого поиска:
За один проход ищется один элемент.
Для поиска m элементов в n сложность
алгоритма О(nm).
Постоянно занята оперативная память
или неудобно постоянно обращаться к
внешнему устройству.
Задача: в массиве из десяти случайных
целых чисел найдите:
А) 5
Б) 5, 7, -3
Метод половинного деления
Когда последовательность
отсортирована, то поиск производится
быстрей.
Общая идея метода: отрезок делится
на две половины. Искомый элемент
сравнивают с «серединой» и выбирают
часть, в которой продолжается поиск.
Метод половинного деления
Найдём число b и определим его место в массиве
(индекс k):
left = 1
right = n
While (left < right)
k = left + (right – left) div 2
if (a[k] > b)
left = k + 1
else
if (b <> a[k])
right = k – 1
else
break
Задание: постройте блок-схему
алгоритма.
Важно! Мы делаем середину либо левой, либо правой границей следующего
отрезка.
Сложность алгоритма: каждый шаг отбрасывает половину имеющихся
вариантов, поэтому для a циклов сложность составит n=2a, т.е. a=log2n.
Следовательно, О (log2n).
Хэширование
Рассмотрим хэшированные таблицы (от англ. hash –
мешанина, мелкая нарезка).
Основная идея этой группы алгоритмов состоит в вычислении
некоторого характеристического значения, которое будет
удовлетворять следующим требованиям:
1. легко вычисляться,
2. иметь существенно меньшее количество значений, чем ключи
поиска,
3. большинство встречающихся в задаче ключей поиска будут
иметь примерно равно распределённые значения хэшфункции.
Коллизия – ситуация, когда разные ключи имеют одно и то же
значение функции.
Хэширование
Допустим, функция есть, тогда:
1. Строится таблица (чаще - массив) соответствий
значений функции и ключа поиска. Можно строить
постепенно (дополнять).
2. При получении значения для поиска, вычисляется
хэш и проверяется соответствующая строка
таблицы. Если искомый элемент есть, то строка
обязательно присутствует.
3. Если хэш ранее не встречался, его заносят в
таблицу (процесс достраивания).
Хэш-функции
Выбор зависит от входных данных.
Для символьных данных лучше, когда выполняется накопление
к хэшу символов как однобайтовых натуральных чисел, с
домножением предыдущего результата на число 31 или 37.
Количество значений будет зависеть от длины массива. Обычно
длину выбирают как простое число.
Для символьных данных хэш-функция даёт 256 значений.
Пример:
function hashBKDR(S)
h=0
for i = 1 to length(s)
h = h*31 + s[i]
return h div NumHashArray
Хэш-функции
Хэш-функции
Работа с
элементом
Возможны коллизии.
Поиск адреса
элемента
Позволяет
коллизий.
избежать
Во втором случае таблица может быть больше, чем количество
элементов в наборе данных. Однако, использование подобной
функции позволяет находить значение за О(1) шагов.
Сортировка
Сортировка (англ. sorting — классификация,
упорядочение) – последовательное расположение
элементов (по убыванию или по невозрастанию и
т.п.). Будем рассматривать по неубыванию.
На общий вид алгоритма конкретный вид сортировки
не влияет.
Замена знака сравнения = инверсия прохода
массива.
Выбор вида зависит от ряда критериев, включая
возможность выполнения тех или иных операций на
магнитной ленте (вспомните машину Тьюринга).
Виды сортировок: пузырьковым методом, методом вставок,
сортировка выбором, сортировка Quicksort, Heapsort, сортировка
перечислением.
«Алгоритм пузырька»
Он же – сортировка простыми обменами.
Все элементы находятся в оперативной памяти (внутренняя
сортировка), не потребуется постоянно растущий объём памяти.
В обратную сторону этот вид иногда называют «методом камня».
Общая идея: элементы сравниваются попарно и меняются местами,
если они не удовлетворяют условиям сортировки. Наверх «всплывает»
первое наибольшее значение, далее выполняем для n-1 элемента и т.д.,
пока не закончится одна пара.
for i=1 to n–1
for j=1 to n–i
if (a[j] > a[j+1])
b = a[j]
a[j] = a[j+1]
a[j+1] = b
Дополнительно:
http://www.youtub
e.com/watch?v=N
s4TPTC8whw
Сложность алгоритма: пропорциональна квадрату количества
элементов, т.е. О(n2).
«Метод пузырька» с флагом
lim = n–1
do
k=0
for i = 1 to lim
if (a[i] > a[i+1])
b = a[i]
a[i] = a[i+1]
a[i+1] = b
k=i
lim = k–1
while (k <> 0)
Сложность алгоритма: один проход теперь имеет сложность О(n), однако
средний показатель и сложность всего алгоритма не изменятся.
Быстрая сортировка (Quick Sort)
Общий принцип: массив разбивается на две части, что позволяет
уменьшить количество повторов. Каждый раз массив разбивается
снова на две части (не обязательно равных) и выполняется обмен
(пока не упрёмся в границу), после которого все элементы в левой
части меньше элементов в правой. Потом сортируем внутри левой и
правой части.
Partion (A,len,r)
x = A[l+(r–len) div 2]
i = len–1
j = r+1
do
do
j = j–1
while (A[j] > x)
do
i=i+1
while (A[i] < x)
if (i < j)
b = a[i]
a[i] = a[j]
a[j] = b
while (i <= j)
return j
Вид процедуры:
QuickSort(A,l,r)
If (r < l)
q = Partion(A,l,r)
QuickSort(a,l,q)
QuickSort(a,q+1,r)
Первый вызов:
QuickSort(A,1,length(A))
Быстрая сортировка (Quick Sort)
Видео: https://youtu.be/ywWBy6J5gz8
Максимально возможная оценка
времени: О(n2). Но таких
последовательностей очень мало,
поэтому чаще имеет среднюю оценку –
O(n logn).
1. В таком виде алгоритм неприменим для больших массивов, т.к.
рекурсивный вызов функции требует выделения памяти в стеке вызовов
для большого количества переменных, а он (стек) конечен. На самом деле
алгоритм требует еще O(log n) памяти.
2. Разбиение массива выполнено простым, но не самым быстрым
способом.
3. Для некоторых массивов (коротких или уже отсортированных) этот
метод сортировки менее эффективен, чем другие.
Практическая часть
1. С клавиатуры вводят слова (не менее 3 и не более 15 букв).
Предложите способ сортировки, который сразу после окончания
ввода выдаст слова в алфавитном порядке.
2. Из файла читают слова, которых значительно больше, чем
есть в наличии памяти. Но многие слова повторяются.
Предложите метод, который позволит сформировать файл со
всеми словами в алфавитном порядке.
Свой выбор обоснуйте!
Практическая часть
3. В файле перечислены слова и названия документов, в
которых они встречаются (в формате – слово: название 1,
название 2 и т.д.). Напишите программу, которая будет
максимально быстро выдавать список документов по
введённому слову.
Примечания: текстовый файл назовите dictionary.txt и
заполните приведённым ниже контентом.
информатика: учебник.pdf
математика:учебник1.doc,учебник2.doc,задачник.doc
Код для задания 3
program hashedSearch;
const
NumHashLen = 577;
//Возьмём тот же список, который изучали на предудущем занятии:
type
pHashNode = ^HashNode;
HashNode = record
val: string[40];
docList: string;
next: ^HashNode;
end;
function hashBKDR(S: string): word;//Хэш-функция
var
i: byte;
h: uint64;
begin
h := 0;
for i := 1 to length(s) do
h := h * 61 + ord(s[i]);// где 61 - ближайшее простое
hashBKDR := h mod NumHashLen;
end;
//Добавление записи
function addNode(wrd: string; head: pHashNode; list: string ): pHashNode;
begin
new(result);
Result^.val := wrd;
Result^.docList := list;
Result^.next := head;
end;
function searchword(wrd: string; head: pHashNode): pHashNode;
begin
result := head;
while (result <> nil) and (result^.val <> wrd) do
result := result^.next;
end;
var
SearchArray: array[0..NumHashLen]
of pHashNode;
txt: PABCSystem.Text;
hs: word;
n: pHashNode;
s, wrd: string;
begin
for hs := 0 to NumHashLen do // Инициализация пустого массива
SearchArray[hs] := nil;
Assign(txt, 'dictionary.txt');
Reset(txt);
while not Eof(txt) do
begin
ReadLn(txt, s);// Читаем по одному слову
if length(s) > 1 then
begin
wrd := s.Split(':')[0];
hs := hashBKDR(wrd); // Вычисляем хэш
SearchArray[hs] := addNode(wrd,
SearchArray[hs], s.Split(':')[1] );
end;
end;
close(txt);
repeat
write('Введите слово для поиска: ');
readln(wrd);
if length(wrd) > 0 then
begin
hs := hashBKDR(wrd); // Вычисляем хэш
n := searchword(wrd, SearchArray[hs]);
if n <> nil then
writeln('Список документов: ', n^.docList)
else
if wrd<>'отмена' then
writeln('Такого слова в списке нет')
else
writeln('Поиск завершён.');
end;
until wrd = 'отмена';
end.
Практическая часть
4*. Усовершенствуйте программу так, чтобы она могла выдать
список документов, в которых встречается несколько слов.
//Ошибка стека, из-за переполнения. Добавляет в список пустые значения (судя по выводу ассемблера).
program hashedSearchWords;
const
NumHashLen = 577;
type
pHashNode = ^HashNode;
HashNode = record
val: string;
docList: string[40];
next: ^HashNode;
end;
pWordNode = ^WordNode;
WordNode = record
vl: string;
next: ^WordNode;
mark: boolean;
end;
iterate = function(item: pWordNode): pWordNode;
function hashBKDR(S: string): word;// Хэш-функция
var
i: byte;
h: uint64;
begin
h := 0;
for i := 1 to length(s) do
h := h * 61 + ord(s[i]);
hashBKDR := h mod NumHashLen;
end;
function addNode(wrd: string; head: pHashNode; list: string ): pHashNode;
begin
new(result);
Result^.val := wrd;
Result^.docList := list;
Result^.next := head;
end;
function searchword(wrd: string; head: pHashNode): pHashNode;
begin
result := head;
while (result <> nil) and (result^.val <> wrd) do
result := result^.next;
end;
function iterateWordList(start: pWordNode; iter: iterate): pWordNode;
var
current: pWordNode;
begin
current := start;
while current <> nil do
current := iter(current);
end;
function doPrint(nod: pWordNode): pWordNode;
begin
writeln(nod^.vl );
result := nod^.next;
end;
function doMarcFalse(nod: pWordNode): pWordNode;
begin
nod^.mark := false;
result := nod^.next;
end;
function Intersection(head: pWordNode;docs: string ): pWordNode; //Пересечение списков документов
var
current, prev: pWordNode;
wrd: string;
begin
iterateWordList(head, doMarcFalse);
foreach wrd in docs.Split(',') do //Помечаем все документы, которые есть в списке
begin
current := head;
while current <> nil do
begin
if current^.vl = wrd then
current^.mark := true;
current := current^.next;
end;
end;
current := head;
prev := nil;
while current <> nil do
begin
if not current^.mark then //Удаляем документы, которых не оказалось в новом списке
begin
if prev <> nil then
begin
prev^.next := current^.next;
Dispose(current);
current := prev^.next;
end
else
begin
prev := current^.next;
Dispose(current);
current := prev;
result := current;
prev := nil;
end;
end
else
begin
prev := current;
current := current^.next;
end;
end;
end;
function SplitList(docs: string): pWordNode;
var
wrd: string;
current: pWordNode;
begin
foreach wrd in docs.Split(',') do
begin
if result = nil then
begin
new(current);
result := current
end
else
begin
new(current^.next);
current := current^.next;
end;
current^.next := nil;
current^.vl := wrd;
end;
end;
var
SearchArray: array[0..NumHashLen]
of pHashNode;
txt: PABCSystem.Text;
hs: word;
n: pHashNode;
s, wrd: string;
resSearch: pWordNode;
begin
for hs := 0 to NumHashLen do //Инициализация пустого массива
SearchArray[hs] := nil;
Assign(txt, 'dictionary.txt');
Reset(txt);
while not Eof(txt) do
begin
ReadLn(txt, s);// Читаем по одному слову
if length(s) > 1 then
begin
wrd := s.Split(':')[0];
hs := hashBKDR(wrd); // Вычисляем хэш
SearchArray[hs] := addNode(wrd,
SearchArray[hs], s.Split(':')[1]);
end;
end;
close(txt);
repeat
writeln('Введите слова для поиска:');readln(s);
if length(s) > 0 then
begin
foreach wrd in s.Split(' ') do
begin
hs := hashBKDR(wrd); // Вычисляем хэш
n := searchword(wrd, SearchArray[hs]);
if n <> nil then
begin
if resSearch <> nil then resSearch := Intersection(resSearch, n^.docList)
else
resSearch := SplitList(n^.docList);
end
else
break;
end;
if resSearch <> nil then
iterateWordList(resSearch, doPrint)
else
WriteLn('Извините, таких документов в списке нет.');
end;
until wrd = 'отмена';
end.