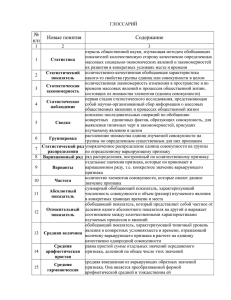
Введение
advertisement

Введение Слово статистика происходит от латинского “status” в переводе – состояние, положение вещей. В зависимости от отрасли статистического исследования различают: статистику населения, промышленности, с/х и т.д. - прикладная статистика. Общая теория статистики – совокупность методов и приемов по сбору, обработке, представлению и анализу числовых данных. Термин статистика в наши дни употребляется в 3х значениях: как синоним слова «данные»; отрасль значений объединяющая принципы и методы работы с числовыми данными характеризующими массовые явления; отрасль практической деятельности направленной на обработку и анализ числовых данных. Статистика позволяет выявить и измерить закономерность развития социально-экономических процессов и явлений, а также взаимосвязи между ними в конкретных условиях места и времени. Под закономерностью понимается повторяемость, последовательность и порядок изменений в явлениях. Статистическая закономерность – закономерность в которой необходимость неразрывно связанном в каждом отдельном явлении со случайностью и лишь во множестве явлений проявляет себя как закон. Понятию статистической закономерности противостоит понятие динамической закономерности проявляющейся в каждом явлении. Объектом статистического исследования является статистическая совокупность – множество единиц обладающих массовостью, однородностью, определяемой целостностью и наличием вариации. Каждый отдельно взятый элемент называется – единицей статистической совокупности. Таким образом, статистика – общественных это планомерный явлений, который и систематический осуществляется учет массовых государственными статистическими органами и дает числовое выражение проявляющимся закономерностям. 3 Тема 1. Понятие статистики и ее роль в современном обществе. 1.1.Сущность понятия "Статистика". Для раскрытия сущности современной статистики как отрасли общественных наук и практической деятельности по сбору, обработке и анализу информации сформулируем основные положения, характеризующие ее. Статистика – инструментальная, функциональная наука эффективное средство познания социально-экономических – т.е. процессов, закономерностей и тенденций, действующих при протекании массовых явлений. Статистика – одна из форм практической деятельности людей, цель которой - сбор, отработка и анализ массовых данных о социальноэкономических явлениях. Статистика – разновидность практической управленческой деятельности – т.е. совокупность цифровых данных, характеризующая различные стороны жизни общества, государства, региона. Статистика – числовая характеристика процессов, происходящих в обществе, – т.е. специфическая методология, совокупность статистических методов, применяемых при сборе, обобщении и интерпретации социально экономической информации. Статистика – это совокупность статистических методов для получения и обработки данных, т.е. сбор, обработка и анализ статистической информации. 1.2. Предмет изучения статистики, его особенности и задачи. Предмет статистики – исследование массовых явлений социальноэкономической жизни; изучение количественной стороны этих явлений в неразрывной связи с их качественным содержанием в конкретных условиях места и времени. 4 Особенности предмета статистической науки состоят в том, что: a) Статистика исследует не отдельные факты, а массовые социально-экономические явления и процессы, выступающие в виде множества фактов, которые обладают как индивидуальными, так и общими признаками. b) Объект статистического изучения – статистическая совокупность, то есть множество элементов, обладающих массовостью, однородностью, взаимозависимостью определенной состояний целостностью, отдельных элементов и наличием вариации (изменчивости, колеблемости) признаков. c) Статистика изучает количественную сторону общественных явлений и процессов в конкретных условиях места и времени, т.е. предмет статистики соотношения это социально детерминирующие Количественную – размеры - и экономических закономерности характеристику количественные их явлений, развития. общественных явлений и процессов статистика выражает через систему статистических показателей, отражающих результат определенных измерений по единицам совокупности и по совокупности в целом (три обязательных атрибута у показателя: количественная определенность, место и время). d) Статистика характеризует структуру общественных явлений, то есть внутреннее строение статистической совокупности. При этом используется метод группировок. e) Статистика исследует не только уровни и статистическую структуру явления, но и изменения уровня и структурные сдвиги в статистической совокупности, происходящие во времени, то есть динамику процесса. f) Статистика выявляет и изучает также причинно-следственные связи (взаимосвязи) в протекающих процессах. 5 Главные задачи статистики как науки заключаются в изучении: уровня и структуры, массовых социально-экономических явлений; динамики социально-экономических явлений и процессов; взаимосвязей массовых социально-экономических явлений. 1.3. Стадии статистического исследования. Статистическая методология - система приемов, способов и методов, направленных на изучение количественных закономерностей, которые проявляются в структуре, динамике и взаимосвязях социально- экономических явлений. Она - основа статистического исследования., которое проводится поэтапно. Стадии статистического исследования: статистическое наблюдение, или сбор информации; сводка и группировка результатов статистического наблюдения; анализ полученной информации. Статистическое наблюдение - научно организованный сбор сведений об изучаемых социально-экономических явлениях с помощью метода массовых наблюдений. Сводка - комплекс последовательных операций по обобщению данных статистического наблюдения для характеристики статистической совокупности в целом и отдельных ее частей (подсчет промежуточных и общих итогов). Группировка - разграничение общей статистической совокупности на группы качественно однородных единиц. Анализ сущности изучаемых явлений, включает в себя констатацию фактов и их оценку; установление характерных черт и причин каждого явления; сопоставление одного явления с другими; формулирование гипотез, выводов и предложений. 6 Тема 2. Статистическое наблюдение. 2.1. Понятие статистического наблюдения и требования к нему. Статистическое наблюдение - массовое, планомерное, научноорганизованное наблюдение за явлениями общественной жизни, заключающееся в регистрации отобранных признаков у каждой единицы статистической совокупности. Три этапа процесса статистического наблюдения: подготовка статистического наблюдения (решение методологических и организационных вопросов); проведение массового сбора данных и фиксирование его результатов; подготовка данных к автоматизированной обработке, их арифметический и логический контроль, кодирование. Требования к статистическим наблюдениям (собранным данным): достоверность данных, то есть соответствие реальной действительности и техническая (измерительная) точность; полнота данных (полнота охвата пространственного, временного и наиболее существенных сторон явления); сопоставимость (единообразие) данных; своевременность сбора данных; экономичность сбора данных. 2.2. Формы и виды статистического наблюдения. Существует две формы статистического наблюдения: государственная статистическая отчетность; специально-организованное статистическое наблюдение. Установленная государством обязательная, документально обоснованная отчетность - годовая и периодическая, телеграфная и почтовая, внешняя и внутренняя. 7 Специально-организованное статистическое наблюдение – переписка, единовременные учеты, переоценки, обследования сплошного и несплошного характера. Виды статистического наблюдения по охвату единиц наблюдения: сплошное; несплошное. Сплошное статистическое наблюдение охватывает все единицы статистической совокупности. Несплошное статистическое наблюдение охватывает лишь часть единиц, которое включает в себя: обследование основного массива – это статистическое наблюдение за частью самых крупных единиц; выборочное статистическое наблюдение предусматривает специальные методы отбора и формирования изучаемой части статистической совокупности (выборочной совокупности); монографическое обследование – подробное описание отдельных типичных единиц в статистической совокупности. Виды статистического наблюдения по времени проведения: непрерывное (текущее) наблюдение – статистическая регистрация фактов по мере их возникновения; единовременное наблюдение – регистрация фактов по мере возникновения потребности в их сборе; периодическое наблюдение – статистическое наблюдение, проводимое через определенные промежутки (периоды) времени. Виды статистического наблюдения по источникам сведений: непосредственное статистическое наблюдение проводится путем подсчета, обмера, взвешивания и регистрации признаков у единиц статистической совокупности; документальное статистическое наблюдение проводится на основе первичных документов; опрос, или анкетный способ (социологический метод). 8 Тема 3. Статистическая сводка и группировка. 3.1. Цель сводки, ее виды. Цель сводки – систематизация первичных данных и получение на этой основе сводной характеристики всего объекта статистического наблюдения при помощи обобщающих статистических показателей. Способы сводки по глубине обработки материала: простая сводка – это операция по подсчету общих и промежуточных итогов по совокупности единиц статистического наблюдения; сложная сводка – это комплекс операций, включающих элементарную группировку единиц статистического наблюдения, подсчет итогов по каждой группе, по всему объекту и представление результатов сводки в виде статистических таблиц. Способы сводки по форме обработки материала делятся на виды: децентрализованная сводка, при которой разработка данных статистического рассредоточена наблюдения по территориям, производственным подразделениям и т.д.; централизованная сводка, при которой весь первичный материал поступает в единый центр, где и подвергается обработке от начала до конца. Способы сводки по технике выполнения делятся на виды: механизированная сводка, при которой все операций выполняются на основе применения ЭВМ; ручная сводка, когда все основные операции (подсчет групповых и общих итогов) осуществляются вручную. 3.2. Метод группировок, виды группировок. Цель группировки – дать научную основу для правильного исчисления статистических показателей. Это важнейший статистический метод обобщения данных статистического наблюдения. 9 Задачи метода статистических группировок: выделения социально-экономических типов явлений; изучение структуры явления и структурных сдвигов; выявление связи и зависимости между явлениями. Исходя из характера решаемых задач, выделяют виды группировок: типологические группировки, при которых исследуемая качественно разнородная совокупность разделяется на классы, социально-экономические типы, однородные группы единиц в соответствии с правилами научной группировки; при структурной статистически группировке однородной происходит совокупности разделение на группы, характеризующие ее структуру по какому-либо варьирующему признаку; аналитической группировкой называется группировка, выявляющая взаимосвязи между изучаемыми явлениями и их факторными и результативными признаками (преимущество метода аналитических группировок перед другими методами анализа связей: он не требует соблюдения каких-либо условий для его применения, кроме одного - качественной однородности исследуемой совокупности). В зависимости от числа признаков, положенных в основу группировки, различают: простую группировку, в которой группы образованны по одному признаку; сложную группировку, в которой совокупность разделяется на группы и подгруппы по двум или более признакам, взятым в сочетании (комбинации). В зависимости от характера группировочного признака различают: количественные группировки (по количественным признакам); качественные группировки (по качественным признакам). 10 Классификация - это систематизированное распределение объектов и явлений на группы, классы, разряды на основании их сходства и различия. 3.3. Техника выполнения группировок. 3.3.1. Определение количества групп. Количество групп определяется для качественных группировок - по числу социально-экономических типов, а для количественных группировок с дискретно изменяющимся значением признака: по числу вариантов значений признака (если оно невелико); три – десять групп (если число вариантов значительно, они объединяются в группы). Для количественных группировок с непрерывно изменяющимся значением признака - по формуле Стерджесса: n = 1 + 3,322*lg N где, n – число групп; N – число единиц совокупности. 3.3.2. Определение величины интервала, его виды. При построении интервальной группировки вводятся понятия: интервал – это границы значения варьирующего признака. нижняя и верхняя границы интервала – соответственно минимальное и максимальное значения признака в интервале. величина интервала – разность между верхней и нижней границами. Виды и разновидности интервалов: равные (если значения признака варьируют равномерно); неравные (если значения признака варьируются неравномерно): прогрессивно возрастающие, прогрессивно убывающие, произвольные, специализированные. 11 Величина равного интервала определяется по формуле: где h - величина (шаг) интервала; (Xmax - Xmin) - размах вариации. Величины неравных интервалов исчисляются по формулам: для возрастающих (убывающих) в арифметической прогрессии: hj+1 = hj + a, где а - constanta; для возрастающих (убывающих) в геометрической прогрессии: hj+1 = hj * q, где q - constanta. Интервалы бывают также открытыми и закрытыми. Открытые – это те интервалы, у которых указана только одна граница: верхняя у первого (максимальное значение признака) и нижняя у последнего (минимальное значение признака). Закрытые – это те интервалы, у которых обозначены обе границы. Величина (ширина) открытого интервала применяется равной ширине смежного с ним закрытого интервала. Тема 4. Статистические таблицы. Элементы статистических таблиц, их виды. Статистическая таблица – форма реального и наглядного изложения цифровых характеристик исследуемых явлений и их составных частей. Основные элементы статистических таблиц - подлежащее и сказуемое. Подлежащее – это характеризуемый цифрами объект. Сказуемое – система показателей, которыми характеризуется объект изучения, то есть подлежащее. Виды статистических таблиц в зависимости от строения подлежащего: 12 простые (перечневые) статистические таблицы, в подлежащем которых дается простой перечень каких-либо объектов или территориальных единиц; групповыми называются подлежащее которых такие статистические содержит таблицы, группировку единиц совокупности по одному количественному или качественному признаку; комбинационными называются такие статистические таблицы, подлежащее которых содержит группировку единиц совокупности одновременно по двум и более признакам. Виды статистических таблиц в зависимости от строения сказуемого: статистическая таблица с простой разработкой сказуемого (показатель, его определяющий, не подразделяется на подгруппы); статистические таблицы со сложной разработкой сказуемого (предполагающий деление признака, формирующего сказуемое, на подгруппы). Основные правила построения статистических таблиц. статистическая таблица должна быть компактной и отражать только те исходные данные, которые прямо отражают исследуемое социально-экономическое явление в статике и динамике; заголовок статистической таблицы и название граф и строк должны быть четкими, краткими, лаконичными. В заголовке должны быть отражены объект, признак, время и место совершения события; графы и строки следует нумеровать; графы и строки должны содержать единицы измерения (их общепринятые сокращения – чел., руб., квт-ч); 13 лучше всего располагать сопоставляемую в ходе анализа информацию в соседних графах (либо одну под другой). Это облегчает процесс ее сравнения; для удобства чтения и работы числа в статистической таблице следует проставлять в середине граф, строго одно под другим: единицы под единицами, запятая под запятой; числа целесообразно округлять с одинаковой степенью точности (до целого знака, до десятой доли); отсутствие данных в разных случаях обозначается по-разному: если данная позиция не подлежит заполнению, то знак * (умножить); отсутствие сведений обозначается таким образом: ..., либо н.д., либо н.св.; при отсутствии явления ставится знак - (прочерк); для отображения очень малых чисел используют обозначение 0.0 или 0.00, предполагая наличие числа; в случае необходимости дополнительной информации - разъяснений к статистической таблице даются специальные примечания (о сущности специфического показателя, примененной методологии и т. д.). При соблюдении этих правил, статистическая таблица становятся основным средством представления, обработки и обобщения статистической информации о состоянии и развитии изучаемых социально-экономических явлений. Тема 5. Статистические графики. Статистические графики – важное средство выражения и анализа данных статистического наблюдения, позволяющее мгновенно охватить и осмыслить совокупность показателей: выявить типичные соотношения и 14 связи, определить тенденции развития, охарактеризовать структуру, оценить географическое размещение объектов. Статистические графики имеют достоинства – выразительность, доходчивость, лаконичность, универсальность, обозримость. Виды графических изображений: статистические графики классифицируются по трем признакам: по способу построения графического образа и по задачам, решаемым с помощью графического изображения; по геометрическим знакам, изображающим статистические показатели и отношения; (см. рис. 1 и 2). Рис.1. Классификация статистических графиков по форме графического образа Рис.2. Классификация статистических графиков по способу построения и задачам изображения. Тема 6. Статистические величины и показатели. Абсолютные и относительные величины в статистике. Статистическая величина – это количественная характеристика общественных явлений, одинаковая в качественном отношении для всех 15 единиц совокупности, но разная в количественном Виды статистических величин представлены на рис.3. СТАТИСТИЧЕСКИЕ ВЕЛИЧИНЫ АБСОЛЮТНЫЕ По степени агрегирова -ния явления сводные Индивидуальные ОТНОСИТЕЛЬНЫЕ СРЕДНИЕ ОВ динамики В зависимости от единиц измерения Выраженные в натуральных единицах измерения Выраженные в стоимостных единицах измерения ОВ планового задания ОВ выполнения планового задания ОВ структуры ОВ координации ОВ сравнения Выраженные в трудовых единицах измерения измерения ОВ интенсивности ОВ уровня экономического развития Рис.3. Виды статистических величин. Статистические показатели – это количественная характеристика общественных явлений в условиях качественной определенности. Система статистических показателей – это совокупность взаимосвязанных статистических показателей, используемых для получения целостной характеристики изучаемых социально-экономических процессов. По охвату единиц совокупности различают индивидуальные и сводные статистические показатели (объемные и расчетные). Индивидуальные статистические показатели характеризуют единицу статистической совокупности. Объемные статистические показатели получают путем суммирования индивидуальных статистических показателей, то есть они характеризуют общий объем признака. Расчетные статистические показатели исчисляются по различным формулам и служат для решения различных аналитических задач. По временному фактору четко отделяют друг от друга моментные и 16 интервальные показатели статистические – это показатели. статистические Моментные показатели, статистические зафиксированные на определенную дату. Интервальные статистические показатели – это статистические показатели за определенный период времени. Рассмотрим подробнее виды статистических величин, отраженные на схеме. Абсолютная величина явления. Все измеряются абсолютные в отражает уровень развития изучаемого величины конкретных являются единицах. именованными, Различают т.е. индивидуальные абсолютные величины (характеризующие размеры признака у отдельной единицы совокупности) и суммарные (характеризующие итоговое значение признака по статистическим определенной совокупности наблюдением). Абсолютные объектов, величины охваченных характеризуют изучаемое явление, но не показывают его структуру развития во времени, соотношение между другими абсолютными показателями. Эти функции выполняют определенные на основе абсолютных величин, относительные величины. Относительная величина (ОВ) – это обобщающий показатель, представляющий собой частное от деления одного абсолютного показателя на другой, сопоставимый с ним, и дающий числовую меру соотношения между ними. Основными видами ОВ являются: i - ОВ динамики i пл.з - ОВ планового задания i в. пл.з - ОВ выполнения планового задания d - ОВ структуры ОВС - ОВ сравнения ОВИ - ОВ интенсивности ОВ у.э.р. - ОВ уровня экономического развития Рассмотрим перечисленные выше относительные величины. 17 ОВ динамики признака во (i, Кр) – характеризует изменение какого-либо времени и называется коэффициент роста, определяется также темп роста (Тр) и темп прироста ( Тпр). I= Yi / Yi - 1, где: Yi – значение признака в наблюдаемый период времени Yi-1 - значение признака в предыдущий момент времени Тр = i * 100% Тпр = Тр – 100% Пример 6.1.: В 1-ом квартале 2006 года общий объем розничного товарооборота составил 173.7 млн руб. В 1-ом квартале 2003 года - 200.7 млн.руб. Рассчитаем: I =200.7 млн.руб / 173.7 млн руб. = 1.15 - коэффициент роста Тр =1.15 * 100% = 115% - темп роста Тпр = 15% - 100% =15 % - темп прироста Вывод. На 15% объем розничного товарооборота в 1 квартале 2007 года превысил объем розничного товарооборота в 1 квартале 2006 года. ОВ планового задания – (i пл.з. ) - это отношение уровня, запланированного на предстоящий период к уровню фактически сложившемуся в заданном периоде. Она также может быть представлена как коэффициент планового роста, плановый темп роста, плановый темп прироста. I пл.з. = Y пл.з./ Yф. Где Yпл.з., Y ф. – уровень, запланированный на предстоящий период и уровень, сложившийся в данном периоде. Тр пл.з. = i * 100% Тпр пл.з. = Тр пл.з. – 100% . ОВ выполнения планового задания ( i вып.пл.з. ) – характеризует отношение фактически достигнутого уровня к 18 запланированному. Также может быть представлена коэффициентом, темпом роста и темпом прироста. I вып.пл.з. = Y пл./ Y ф., где: Y пл., Y ф. – уровень, запланированный на предстоящий период, и уровень, фактически достигнутый в данном периоде. ОВ планового задания и ОВ выполнения планового задания связаны между собой следующим соотношением: i = i пл.з.* i вып.пл.з. Пример 6.2. Металлоемкость электромотора составила в базисном, 2005году 25 кг /кВт, было намечено сократить ее в плановом, 2006 году до 20 кг/ кВт, но сокращение в 2006 году произошло только до 22 кг/ кВт. i пл.з. =20:25=0.8 Т р пл.з. =0.8*100%=80% Т пр. пл.з.=80%-100%=-20% – на 20% было запланировано уменьшить металлоемкость электромотора i в.пл.з.=22:20=1.1 Т р в.пл.з.=1.1*100%=110% Тпр.в.пл.з.=110%-100%=10% – на 10% фактическая металлоемкость мотора превысила плановое задание i=0.8*1.1=0.88–коэффициент снижения фактической металлоемкости, рассчитанный по формуле взаимосвязи i пл.з. и i в.пл.з. i=22:25=0.88 – коэффициент убывания фактической металлоемкости, рассчитанный по формуле ОВ динамики. ОВ структуры, удельный вес (d) – характеризует состав изучаемой совокупности. Исчисляется как отношение абсолютной величины каждого из элементов совокупности к абсолютной величине всей совокупности ОВ координации (ОВК)- характеризует отношение частей данной совокупности к одной из них, принятой за базу сравнения. 19 ОВК = Уi / Уб., Где Уб. – уровень части совокупности, принятая за базу. Пример 3.(цифры условные): По нижеприведенным данным о заключении договоров страхования в 2006г. в регионе (цифры условные) рассчитаем d и ОВК, приняв для расчета ОВК за базу число договоров по жизни и здоровью. Таблица 6.1. Сумма, Удельный вес в ОВК тыс.руб. общем объеме,% Заключено договоров страхования 34300.9 100 -жизни и здоровья 5856.4 17.1 1 -имущества 2928.3 8.5 0.50 -предпринимательских рисков 59.2 0.2 0.01 -ответственности 14648.3 42.7 2.5 -прочих рисков 10792.0 31.5 1.84 ОВ сравнения (ОВС) - характеризует отношение одноименных статистических величин, относящихся к разным объектам в один временной период. Пример 6.4. Численность работников страховой компании «Надежда» составила на 01.01.2005 г. 25 человек; численность работников страховой компании «Лазурит» на ту же дату – 38 человек. Примем за базу сравнения численность работников страховой компании «Лазурит»», тогда ОВС=(25 : 38) * 100%= 66% , Вывод. Численность работников страховой компании «Надежда» составляет 66% от численности работников ТОО «Лазурит». ОВ интенсивности (ОВИ) – характеризует соотношение разноименных, но связанных между собой абсолютных величин. 20 Пример 6.5. На начало 2007 года в регионе работало 294 СК, в которых работало 1098 работников. ОВИ=1098 : 29.4=37.3 – т.е. на одну СК приходилось 37.3 работника, или на каждые 10 СК садов приходилось 373 работника. Разновидностью ОВИ является ОВ уровня экономического развития, которые оценивают развитие экономики страны (в основном это показатели «на душу населения»). Пример 6.6. В 2003 году численность региона составила 2284 тыс. чел, численность страховых работников на этот же период в регионе – 10.2 тыс. чел. ОВ уровня экономического развития = 10.2 / 2284, т.е. в регионе на каждые 2 тысячи человек населения приходилось 9 работников страхового дела. Тема 7. Степенные средние величины, виды и способы их расчета. Большое распространение в статистике имеют средние величины. В общем виде средняя величина - это один из распространенных приемов обобщений. Правильное понимание сущности средней определяет ее особую значимость в условиях рыночной экономики, когда средняя через единичное и случайное позволяет выявить общее и необходимое, выявить тенденцию закономерностей экономического и общественного развития. Средняя величина - это обобщающие показатели, в которых находят выражение действия общих условий, закономерностей изучаемого явления. 21 Средняя величина Степенная В зависимости от степени средней Средняя гармоническая Средняя геометрическая Структурная В зависимости от вида исходных данных В зависимости от способа определения Простая средняя Мода Взвешенная средняя Медиана В зависимости от вида исходных данных Средняя арифметическая Структурная средняя в дискретном ряду Структурная средняя в интервальном ряду и т. д... 7.1. Степенные средние величины. Существуют различные степенные средние: * средняя арифметическая; * средняя геометрическая; * средняя гармоническая; * средняя квадратическая; * средняя хронологическая. Рассмотрим виды степенных средних величин, которые используются наиболее часто. Средняя арифметическая Средняя арифметическая простая используется для несгруппированных данных. Отдельные значения признака называют вариантами и обозначают через х ( x1, x2 , x3 ,..., xn ); число единиц совокупности обозначают через n, среднее значение признака - через х . Простая средняя арифметическая простая равна: 22 x x x ... xn x x 1 2 3 n n Пример 7.1. Имеются следующие данные о производстве рабочими продукции А за смену: Таблица 7.1. № раб. 1 Выпущено изделий за смену 16 17 18 17 16 17 18 20 21 18 2 3 4 5 6 7 8 9 10 В данном примере варьирующий признак - выпуск продукции за смену. Численные значения признака (16, 17 и т. д.) называют вариантами. Определим среднюю выработку продукции рабочими данной группы: x 16 17 18...18 178 17,8 10 10 Если данные представлены в виде рядов распределения или группировок, то средняя исчисляется иначе. Пример 7.2. Имеются следующие данные о заработной плате рабочих - сдельщиков: Таблица 7.2. Месячная з/п (варианта - х), руб. Число рабочих, n xn х = 110 n=2 220 х = 130 n=6 780 х = 160 n = 16 2560 х = 190 n = 12 2280 х = 220 n = 14 3080 ИТОГО 50 8920 По данным дискретного ряда распределения видно, что одни и те же значения признака (варианты) повторяются несколько раз. Так, варианта х встречается в совокупности 2 раза, а варианта х-16 раз и т.д. Число одинаковых значений признака в рядах распределения называется частотой или весом и обозначается символом n. 23 Вычислим среднюю заработную плату одного рабочего x в руб.: x 110 * 2 130 * 6 160 * 16 190 * 12 220 * 14 8920 178,4 50 50 В соответствии с этим, расчеты можно представить в общем виде: x x1n1 x2 n2 x3 n3 ... xn nn n1 n2 n3 ...nn x x n n i i i Полученная формула называется средней арифметической взвешенной. Из нее видно, что средняя зависит не только от значений признака, но и от их частот, т.е. от состава совокупности, от ее структуры. Изменим в условии задачи состав рабочих и исчислим среднюю в измененной структуре. Статистический материал в результате обработки может быть представлен не только в виде дискретных рядов распределения, но и в виде интервальных вариационных рядов с закрытыми или открытыми интервалами. Пример 7.2. Таблица 7.2. Группы рабочих по количеству Число Середина хn произведенной продукции за смену, шт. рабочих, n интервала, х 3—5 10 4 40 5—7 30 6 180 7—9 40 8 320 9 — 11 15 10 150 11 — 13 5 12 60 ИТОГО 100 750 Исчислим среднюю выработку продукции одним рабочим за смену. В данном ряду варианты осредняемого признака (продукция за смену) представлены не одним числом, а в виде интервала. Таким образом, каждая группа ряда распределения имеет нижнее и верхнее значения вариант, или 24 закрытые интервалы. Исчисление средней по сгруппированным данным производится по формуле средней арифметической взвешенной: x x n n i i i Чтобы применить эту формулу, необходимо варианты признака выразить одним числом (дискретным). За такое дискретное число принимается средняя арифметическая простая из верхнего и нижнего значения интервала. Так, для первой группы дискретная величина х будет равна: (3 + 5) / 2 = 4 Дальнейший расчет производится обычным методом определения средней арифметической взвешенной: x 750 / 100 7,5 Итак, все рабочие произвели 750 шт. изделий за смену, а каждый в среднем произвел 7,5 шт. Преобразуем рассмотренный выше ряд распределения в ряд с открытыми интервалами. Пример 7.3. Имеются следующие данные о производстве продукции за смену: Таблица 7.3. Группы рабочих по количеству Число Середина хn произведенной продукции за смену, шт. рабочих, n интервала, х до 5 10 4 40 5—7 30 6 180 7—9 40 8 320 9 — 11 15 10 150 свыше 11 5 12 60 ИТОГО 100 В таких принимается рядах равной условно величине величина 750 интервала первой интервала последующей, а группы величина 25 интервала последней группы - величине интервала предыдущей. Дальнейший расчет аналогичен изложенному выше. В практике экономической статистики иногда приходится исчислять среднюю по групповым средним или по средним отдельных частей совокупности (частным средним). В таких случаях за варианты (х) принимаются групповые или частные средние. Пример 7.4. Определим средний процент выполнения плана по выпуску продукции по группе заводов на основании следующих данных: Таблица 7.4. Номер завода Выпуск продукции по плану, млн.руб. Выполнение плана, % 1 18 100 2 22 105 3 25 90 4 20 106 5 40 108 ИТОГО 125 — В этой задаче варианты (процент выполнения плана) являются не индивидуальными, а средними по заводу. Весами являются выпуск продукции по плану. При вычислении среднего процента выполнения плана следует использовать формулу средней арифметической взвешенной: x x n n i i x n , где i i — фактически выпущенная продукция, получаемая i путём умножения вариант (процент выполнения плана) на веса (выпуск продукции по плану). Производя вычисления, варианты (х) лучше брать в коэффициентах. x x n n i i i 128 1,024 125 1,00 * 18 1,05 * 22 0,9 * 25 1,06 * 20 1,08 * 40 125 или 102,4% 26 Средняя арифметическая величина обладает рядом свойств: 1. От уменьшения или увеличения частот каждого значения признака х в п раз величина средней арифметической не изменится. 2. Общий множитель индивидуальных значений признака может быть вынесен за знак средней: Kx Kx 3. Средняя суммы (разности) двух или нескольких величин равна сумме (разности) их средних: xy xy 4. Если х = с, где с - постоянная величина, то x c c . 5. Сумма отклонений значений признака Х от средней арифметической х равна нулю: 0 Наряду со средней арифметической, в статистике применяется средняя гармоническая величина, обратная средней арифметической из обратных значений признака. Как и средняя арифметическая, она может быть простой и взвешенной. Пример 7.5. Бригада токарей была занята обточкой одинаковых деталей в течение 8-часового рабочего дня. Первый токарь затратил на одну деталь 12 мин, второй - 15 мин., третий - 11, четвертый - 16 и пятый - 14 мин. Определите среднее время, необходимое на изготовление одной детали. На первый взгляд кажется, что задача легко решается по формуле средней арифметической простой: x x 12 15 11 16 14 13,6 n 5 Полученная средняя была бы правильной, если бы каждый рабочий сделал только по одной детали. Но в течение дня отдельными рабочими 27 было изготовлено различное число деталей. Для определения числа деталей, изготовленных каждым рабочим, воспользуемся следующим соотношением: все затраченное время Среднее время, затраченное = -------------------------------------на одну деталь Число число деталей деталей, изготовленных каждым рабочим, определяется отношением всего времени работы к среднему времени, затраченному на одну деталь. Тогда среднее время, необходимое для изготовления одной детали, равно: 8 * 60 8 * 60 8 * 60 8 * 60 8 * 60 8 * 60 8 * 60 8 * 60 8 * 60 8 * 60 12 15 11 16 14 2400 13,3 40 32 43,6 30 34,2 x Это же решение можно представить иначе: x 8 * 60 * 5 5 13,3 1 1 1 1 0,3747 1 * 8 * 60 12 15 11 16 14 Таким образом, формула для расчета средней гармонической простой будет иметь вид: x n 1 1 1 1 ... x1 x2 x3 xn n 1 x Пример 7.6. Издержки производства и себестоимость единицы продукции А по трем заводам характеризуются следующими данными: Таблица 7.6. Номер Издержки производства, тыс.руб. завода Себестоимость единицы продукции, руб. 1 200 20 2 460 23 3 110 22 Исчислим среднюю себестоимость изделия по трем заводам. 28 Издержки производства Средняя себестоимость = -------------------------------единицы продукции ( х ) x Количество продукции 200 460 110 22,0 руб. 200 460 110 20 23 22 Таким образом, формулу для расчета средней гармонической взвешенной можно представить в общем виде: x n1 n2 n3 ...nn n 1 1 1 1 1 n1 n2 n3 ... nn n x1 x2 x3 xn x 7.2. Структурные средние Характеристиками вариационных рядов, наряду со средними, являются структурные средние – мода и медиана. Мода - это повторяющаяся в величина изучаемой признака (варианта), совокупности. Для наиболее часто дискретных рядов распределения модой будет значение варианта с наибольшей частотой. Пример 7.7. Распределение проданной обуви по размерам характеризуется следующими показателями: Таблица 7.7. Размер обуви 36 37 38 39 40 41 42 43 44 45 Число пар, в % к итогу — 1 8 20 11 1 1 6 22 30 В этом ряду распределения мода равна 41. Именно этот размер обуви пользовался наибольшим спросом покупателей. Для интервальных рядов распределения с равными интервалами мода определяется по формуле: M o x M o iM o * f f M o f M o1 Mo f M o1 f M o f M o1 . где x Mo - начальное значение интервала, содержащего моду; 29 i Mo - величина модального интервала; f Mo - частота модального интервала; f Mo1 - частота интервала, предшествующего модальному; f Mo1 - частота интервала, следующего за модальным. Пример 7.8. Распределение предприятий по численности промышленно - производственного персонала характеризуется следующими данными: Таблица 7.8. Группы предприятий по числу работающих, чел Число предприятий 100 — 200 1 200 — 300 3 300 — 400 7 400 — 500 30 500 — 600 19 600 — 700 15 700 — 800 5 ИТОГО 80 В этой задаче наибольшее число предприятий (30) имеет численность работающих от 400 до 500 человек. Следовательно, этот интервал является модальным интервалом ряда распределения. Введем следующие обозначения: x Mo =400, i Mo =100, f Mo =30, f Mo1 =7, f Mo1 =19 Подставим эти значения в формулу моды и произведем вычисления: Mo x Mo i Mo * 400 100 * fMo fMo fMo 1 fMo 1 fMo fMo 1 30 7 467,6 30 7 30 19 чел. 30 Медиана - это варианта, расположенная в середине вариационного ряда. Если ряд распределения дискретный и имеет нечетное число членов, то медианой будет варианта, находящаяся в середине упорядоченного ряда (упорядоченный ряд - это расположение единиц совокупности в возрастающем или убывающем порядке). Например, стаж пяти рабочих составил 2, 4, 7, 8, 10 лет. В таком упорядоченном ряду медиана - 7 лет. По обе стороны от нее находится одинаковое число рабочих. Если упорядоченный ряд состоит из четного числа членов, то медианой будет средняя арифметическая из двух вариант, расположенных в середине ряда. Пусть теперь будет не пять человек в бригаде, а шесть, имеющих стаж работы 2, 4, 6, 7, 8 и 10 лет. В этом ряду имеются две варианты, стоящие в центре ряда. Это варианты 6 и 7. Средняя арифметическая из этих значений и будет медианой ряда: Ме = (6 + 7) / 2 = 6,5 лет. Рассмотрим пример расчета медианы в дискретном ряду. Пример 7.9. Определим медиану заработной платы рабочих. Таблица 7.9. Месячная з/п , руб. Число рабочих Сумма накопительных частот 110 2 2 130 6 8 (2+6) 160 16 24 (8+16) 190 12 — 220 4 — 40 В нашем примере полусумма частот составила - 20. Варианта, соответствующая этой сумме, т.е. 160 руб., и есть медиана. Если же сумма накопленных частот против одной из вариант равна точно половине сумме частот, то медиана определяется как средняя этой варианты и последующей. 31 Пример 7.10. Таблица 7.10. Месячная з/п, руб. Число рабочих Сумма накопительных частот 110 2 2 130 6 8 (2+6) 160 12 20 (8+12) 190 16 — 220 4 — 40 Медиана будет равна: Ме = (150 + 170) / 2 = 160 руб. Медиана интервального вариационного определяется по формуле Me x Me i Me ряда распределения 0,5 f S Me1 f Me где x Me — начальное значение интервала, содержащего медиану; i Me — величина медианного интервала; f — сумма частот ряда; S Me1 — сумма накопленных частот, предшествующих медианному; f Me — частота медианного интервала. Пример 7.11. Таблица 7.11. Группы предприятий по числу рабочих Число предприятий Накопленные частоты 100 — 200 1 1 200 — 300 3 4 (1+3) 300 — 400 7 11 (4+7) 400 — 500 30 41 (11+30) 500 — 600 19 — 600 — 700 15 — 700 — 800 5 — ИТОГО 80 32 Определим прежде всего медианный интервал. В данной задаче сумма накопленных частот, превышающая соответствует интервалу 400 - 500. половину всех значений (41), Это и есть медианный интервал, в котором находится медиана. Определим ее значение по приведенной выше формуле. Известно, что: x Me 400, i Me 100, f 80, S Me1 11, f Me 30. Следовательно, Me 400 100 0,5 * 80 11 400 96,66 496,66 . 30 Тема 8: Изучение вариации с помощью абсолютных и относительных показателей. Различие индивидуальных значений признака внутри изучаемой совокупности в статистике называется вариацией признака. Она возникает в результате того, что его индивидуальные значения складываются под совокупным влиянием разнообразных факторов, которые по-разному сочетаются в каждом отдельном случае. Средняя величина абстрактная, обобщающая характеристика признака — это изучаемой совокупности, но она не показывает строения совокупности, которое весьма существенно для ее познания. Средняя величина не дает представления о том, как отдельные значения изучаемого признака группируются вокруг средней, сосредоточены ли они вблизи или значительно отклоняются от нее. В некоторых случаях отдельные значения признака близко примыкают к средней арифметической и мало от нее отличаются. В таких случаях средняя хорошо представляет всю совокупность. В других, наоборот, отдельные значения совокупности далеко отстают от средней, и средняя плохо представляет всю совокупность. Колеблемость отдельных значений характеризуют показатели вариации. Термин "вариация" произошел от латинского variatio –“изменение, колеблемость, различие”. Однако не всякие различия принято называть 33 вариацией. Под вариацией в статистике понимают такие количественные изменения величины совокупности, которые исследуемого признака в пределах однородной обусловлены перекрещивающимся влиянием действия различных факторов. Различают вариацию признака: случайную и систематическую. Анализ систематической вариации позволяет оценить степень зависимости изменений в изучаемом признаке от определяющих ее факторов. Например, изучая силу и характер вариации в выделяемой совокупности, можно оценить, насколько однородной является данная совокупность в количественном, а иногда и качественном отношении, следовательно, а насколько характерной является исчисленная средняя величина. Степень близости данных отдельных единиц хi к средней измеряется рядом абсолютных, средних и относительных показателей. 8.1. Абсолютные показатели вариации. Для характеристики совокупностей и исчисленных величин важно знать, какая вариация изучаемого признака скрывается за средним. Для характеристики колеблемости признака используется ряд показателей. Размах вариации - это разность между наибольшим ( xmak ) и наименьшим ( xmin ) значениями вариантов. R x mak x min Пример 8.1. Таблица 8.1. Группы предприятий по объему товарооборота, млн.руб. Число предприятий 90 — 100 28 100 — 110 48 110 — 120 20 120 — 130 4 ИТОГО 100 Определяем показатель размаха вариации: R = 130 - 90 = 40 млн. руб. 34 Этот показатель улавливает только крайние отклонения и не отражает отклонений всех вариант в ряду. Чтобы дать обобщающую характеристику распределению отклонений, исчисляют среднее линейное отклонение d, которое учитывает различие всех единиц изучаемой совокупности. Среднее линейное отклонение определяется как средняя отклонений индивидуальных значений от средней, арифметическая из без учета знака этих отклонений: d / x x / / x 1 n x / / x2 x / ... / xn x / n . Порядок расчета среднего линейного отклонения следующий: 1) по значениям признака исчисляется средняя арифметическая: x x n ; 2) определяются отклонения каждой варианты xi от средней xi x ; / x 3) рассчитывается сумма абсолютных величин отклонений: i x/ ; 4) сумма абсолютных величин отклонений делится на число значений: / x i x/ n . Пример 8.2. Таблица 8.2 Табельный номер рабочего xi xi x / xi x / 1 2 -8 8 2 3 -7 7 3 12 2 2 4 15 5 5 5 18 8 8 Итого 50 0 30 / x d= i n x/ 30 6,0 = 5 35 Если данные наблюдения представлены в виде дискретного ряда распределения с частотами, среднее линейное отклонение исчисляется по формуле средней арифметической взвешенной: d /x x / n n i i i Порядок / x1 x / n1 / x 2 x / n2 ... / x n x / nn n1 n2 ... nn расчета среднего линейного отклонения взвешенного следующий: 1) вычисляется средняя арифметическая взвешенная: xn n ; 2) определяются абсолютные отклонения вариант от средней / xi x /; 3) полученные отклонения умножаются на частоты / xi x / ni ; 4) находится сумма взвешенных отклонений без учета знака: 5) сумма взвешенных отклонений делится на сумму частот: / xi x / ni ; / x i x / ni n . Основными обобщающими показателями вариации в статистике являются дисперсии и среднее квадратическое отклонение. Дисперсия - это средняя арифметическая квадратов отклонений каждого значения признака от общей средней. В зависимости от исходных данных дисперсия может вычисляться по средней арифметической простой или взвешенной: S2 S 2 (x x ) n 2 i (x i — дисперсия невзвешенная (простая); x ) 2 ni ni — дисперсия взвешенная. Среднее квадратическое отклонение представляет собой корень квадратный из дисперсии и обозначается S: S (x x )2 n i — среднее квадратическое отклонение невзвешенное; 36 S (x x ) n i i 2 ni — среднее квадратическое отклонение взвешенное. Среднее квадратическое отклонение - это обобщающая характеристика абсолютных размеров вариации признака в совокупности. Чем меньше среднее квадратическое отклонение, тем лучше средняя арифметическая отражает собой всю представляемую совокупность. Порядок расчета дисперсии взвешенной: xn n ; 1) определяют среднюю арифметическую взвешенную 2) определяются отклонения вариант от средней x i x ; 3) возводят в квадрат отклонение каждой варианты от средней x 4) умножают квадраты отклонений на веса (частоты) x 5) суммируют полученные произведения x i x ; 2 2 x ni ; 2 x ni x x n ; 2 i 6) Полученную сумму делят на сумму весов i i i ni . Пример 8.3. Таблица 8.3. Произведено продукции одним Число xi ni x i x x i x 2 x рабочим, шт. ( xi варианта) рабочих, ni 8 7 56 -2 4 28 9 10 90 -1 1 10 10 15 150 0 0 0 11 12 132 1 1 12 12 6 72 4 24 ИТОГО 50 500 2 x ni 2 i 74 Исчислим среднюю арифметическую взвешенную: 37 xn 500 10 n 50 x шт. Определим дисперсию: S 2 (x x ) n 2 i ni i 74 50 =1,48 Среднее квадратическое отклонение будет равно: (x x ) n 2 i S ni 148 , 1216 , шт. i Если исходные данные представлены в виде интервального ряда распределения, то сначала надо определить дискретное значение признака, а далее применить тот же метод, что изложен выше. Пример 8.4. Покажем расчет дисперсии для интервального ряда на данных о распределении посевной площади колхоза по урожайности пшеницы: Таблица 8.4 xi xi ni x i x x i x 2 x 100 15 1500 -3,4 11,56 1156 16 - 18 300 17 5100 -1,4 1,96 588 18 - 20 400 19 7600 0,6 0,36 144 20 - 22 200 21 4200 2,6 6,76 1352 ИТОГО 1000 Урожайность Посевная пшеницы, ц/га площадь, га 14 - 16 18400 x ni 2 i 3240 Средняя арифметическая равна: x xn 18400 18,4 n 1000 ц с 1га. Исчислим дисперсию: S 2 (x x ) n i i 2 ni 3240 3,24 1000 38 Техника вычисления дисперсии сложна, а при больших значениях вариант и частот может быть громоздкой. Расчеты можно упростить, используя свойства дисперсии. Свойства дисперсии: Уменьшение или увеличение весов (частот) варьирующего признака в определенное число раз дисперсии не изменяет. Уменьшение или увеличение каждого значения признака на одну и ту же постоянную величину А дисперсии не изменяет. Уменьшение или увеличение каждого значения признака в какоето число раз к соответственно уменьшает или увеличивает дисперсию в k 2 раз, а среднее квадратическое отклонение - в к раз. Дисперсия признака относительно произвольной величины всегда больше дисперсии относительно средней арифметической на квадрат разности между средней и произвольной величиной: S 2 S A2 ( x A) 2 . Если А равна нулю, то приходим к следующему 2 2 2 равенству: S x x , т.е. дисперсия признака равна разности между средним квадратом значений признака и квадратом средней. Каждое свойство при расчете дисперсии может быть применено самостоятельно или в сочетании с другими. Порядок расчета дисперсии простой: 1) определяют среднюю арифметическую x x n ; x x n 2 2 2) возводят в квадрат среднюю арифметическую ; 2 3) возводят в квадрат каждую варианту ряда xi ; 4) находим сумму квадратов вариант x 2 i ; 39 5) делят сумму квадратов вариант на их число, средний квадрат x2 x n т.е. определяют 2 i ; 6) определяют разность между средним квадратом признака и 2 2 квадратом средней x x . Пример 8.5. Таблица 8.5 Табельный номер рабочего Произведено продукции, шт. xi2 1 8 64 2 9 81 3 10 100 4 11111 121 5 12 144 ИТОГО 50 510 Произведем следующие расчеты: S x x 2 2 2 x n 2 x 50 10 5 шт. 2 x 510 50 5 5 102 100 2,0 n 2 Пример 8.6. Определить дисперсию в дискретном ряду распределения. Таблица 8.6. Произведено продукции 1 рабочим, шт. (х) Число рабочих, n xi ni xi2 xi2 ni 8 7 56 64 448 9 10 90 81 810 10 15 150 100 1500 11 12 132 121 1452 12 6 72 144 864 ИТОГО 50 500 510 5074 40 x n xn n n 2 S x x 2 2 2 2 2 5074 500 1,48 50 50 Рассмотрим расчет дисперсии в интервальном ряду распределения. 2 2 2 Порядок расчета дисперсии взвешенной (по формуле S x x ): x 1. определяют среднюю арифметическую xn n ; 2 x 2. возводят в квадрат полученную среднюю ; 2 3. возводят в квадрат каждую варианту ряда xi ; 2 4. умножают квадраты вариант на частоты xi ni ; 5. x n суммируют полученные произведения 2 i i ; 6. делят полученную сумму на сумму весов и получают средний x квадрат признака 2 x n n 2 i i i ; 7. определяют разность между средним значением квадратов и 2 2 2 квадратом средней арифметической, т.е. дисперсию S x x . Пример 7. Имеются следующие данные о распределении посевной площади колхоза по урожайности пшеницы: Таблица 6.6 Урожайность пшеницы, Посевная площадь, га xi xi ni xi2 xi2 ni ц/га 14 - 16 100 15 1500 225 22500 16 - 18 300 17 5100 289 36700 18 - 20 400 19 7600 361 144400 20 - 22 200 21 4200 441 88200 ИТОГО 1000 18400 341200 41 В подобных примерах прежде всего определяется дискретное значение признака в каждом интервале, а затем применяется метод расчета, указанный выше: x n xn n n 2 S x x 2 2 2 2 Средняя величина отражает главных причин. Среднее 2 341800 18400 3,24 1000 1000 тенденцию развития, т.е. действие квадратическое отклонение измеряет силу воздействия прочих факторов. 8.2. Относительные показатели вариации. Для характеристики меры колеблемости изучаемого признака исчисляются показатели колеблемости в относительных величинах. Они позволяют сравнивать характер рассеивания в различных распределениях (различные единицы наблюдения одного и того же признака в двух совокупностях, при различных значениях средних, при сравнении разноименных совокупностей). Расчет показателей меры относительного рассеивания осуществляют как отношение абсолютного показателя рассеивания к средней арифметической, умножаемое на 100%. 1. Коэффициент осцилляции отражает относительную колеблемость крайних значений признака вокруг средней. Ko R *100% x (1) 2. Относительное линейное отклонение характеризует долю усредненного значения абсолютных отклонений от средней величины. Ko d *100% x (2) 3. Коэффициент вариации. V S *100% x (3) Учитывая, что среднеквадратическое отклонение дает обобщающую характеристику колеблемости всех вариантов совокупности, коэффициент 42 вариации является наиболее распространенным показателем колеблемости, используемым для оценки типичности средних величин. При этом исходят из того, что если V больше 40 %, то это говорит о большой колеблемости признака в изучаемой совокупности. 8.3. Виды дисперсий. Правило сложения дисперсий. Для того чтобы оценить влияние различных факторов на вариацию признака в совокупности, расчлененной на группы по одному фактору, изучение вариации достигается посредством исчисления и анализа трех видов дисперсий: общей, межгрупповой и внутригрупповой. 1.Общая дисперсия измеряет вариацию признака во всей совокупности под влиянием всех факторов, обусловивших эту вариацию. 2.Межгрупповая дисперсия характеризует систематическую вариацию результативного порядка, обусловленную влиянием признака – фактора, положенного в основание группировки 3. Внутригрупповая дисперсия отражает часть вариации, обусловленную влиянием неучтенных факторов и независящую от признакафактора, положенного в основание группировки. На основании внутригрупповой дисперсии по каждой группе, т.. на основании.. можно определить общую среднюю из внутригрупповых дисперсий. Согласно правилу сложения дисперсий, общая дисперсия равна сумме средней из внутригрупповых дисперсий и межгрупповой дисперсии, т.е. общая дисперсия, возникающая под воздействием всех факторов, должна быть равна сумме дисперсий, возникающих под влиянием всех прочих факторов, и дисперсии, возникающей за счет факторов группировки. Три направления использования правила сложения дисперсий: зная любые два вида дисперсий, всегда можно найти или проверить правильность расчета третьего вида; можно оценить удельное значение фактора, лежащего в основе группировки, во всей совокупности факторов, воздействующих 43 на группировочный признак. Для этого исчисляется коэффициент детерминации, который показывает долю общей вариации изучаемого признака, обусловленную вариацией группировочного признака; можно определить показатель тесноты связи результативного и группировочного исчисления (факторного) эмпирического признаков корреляционного посредством отношения: Если этот показатель равен нулю, то группировочный признак не влияет на результативный (связь между ними отсутствует). Если же этот показатель равен единице, то результативный признак изменяется только в зависимости от группировочного признака (между ними существует функциональная связь). Закон сложения трех видов дисперсий используется в дисперсионном анализе. 8.4.Вариация альтернативного признака. Альтернативным называются признаки, которыми обладают одни единицы совокупности и не обладают другие. Их вариация проявляется в значении "0" у единиц, которые этим признаком не обладают, или "1" у тех, которые данный признак имеют. р - доля единиц, обладающих данным признаком; q - доля единиц, не обладающих данным признаком. 44 где m - число единиц совокупности, обладающих данным признаком; Тема 9. Статистическое изучение взаимосвязей между явлениями. Важнейшей познавательной задачей статистики является изучение статистических закономерностей. При этом необходимо считаться с взаимосвязью процессов и явлений. Формы проявления взаимосвязей весьма разнообразны. В качестве двух самых общих их видов выделяют функциональную и корреляционную связь. При функциональной связи определенной величине факторного признака строго соответствует одно или несколько значений результативного признака. У = f (х) Где : х – значения факторного признака, У – значения результативного признака под воздействием факторного. Например, связь между оплатой труда и количеством выпущенных деталей при простой сдельной оплате труда. Корреляционная связь (статистическая) проявляется в среднем, для массовых наблюдений, когда заданным значениям факторного признака соответствует некоторый ряд вероятностных значений результативного признака. 45 У = f (х) + E Где: У – значения результативного признака, f (х) - часть значения результативного признака, сформировавшаяся под действием факторного признака х. E - часть значения результативного признака, возникшая под действием каких-либо неучтенных случайных явлений. Например, связь между количеством внесенных удобрений и урожайностью. Корреляционная связь может возникнуть разными путями: причинная зависимость вариации результативного признака от вариации факторного признака; причинная зависимость между 2 следствиями одной причины (пожары, кол-во пожарников, размер пожара); причинная зависимость признаков каждый из которых и причина и следствие одновременно (производительность труда и з/плата) В статистике принято различать следующие виды зависимости: парная корреляция – связь между признаками результативным и факторным, либо между двумя факторными; частная корреляция – зависимость между результативным и одним факторным признаком при фиксированном значении другого факторного признака; множественная корреляция – зависимость результативного признака от двух и более факторных признаков. Корреляционно-регрессионный анализ как общее понятие включает в себя изменение тесноты связи и установления аналитического выражения связи. Условия применения и ограничения КРА: наличие массовых данных, т.к. корреляционная связь является статистической необходима качественная однородность совокупности. 46 подчинение распределения совокупности по результативному и факторному признаку, нормальному закону распределения, что связано с применением метода наименьших квадратов. Регрессионный анализ заключается в определении аналитического выражения связи. По форме различают линейную регрессию, которая выражается уравнением прямой y a bx cx 2 или y a y a bx , и не линейную регрессию b x. По направлению связи различают на прямую т.е. с увеличением признака х увеличивается признак у. обратная прямая y y 2 min Разница между фактическим значением и значением рассчитанным по уравнению связи возведенное в квадрат должна стремиться к минимуму. Для линейной зависимости: na b xi y i a xi b x xi y i а,b 2 i для параболы na b xi c xi2 y i a xi b xi2 c xi3 xi y i a, b, c a xi2 b xi3 c xi4 xi2 y i Для гиперболы 1 y x a, b 1 1 y a b 2 x x x na b 47 параметры a,b,c записываются в уравнение, затем подставляем полученное уравнение эмпирическое значение xi и находим теоретическое значение yi. Затем сравниваем yi теоретическое и yi эмпирическое. Сумма квадратов разности между ними должна быть минимальна. Выбираем тот вид зависимости при котором выполняется данная зависимость. В уравнении парной линейной регрессии: b – коэффициент парной линейной регрессии, он измеряет силу связи, т.е. характеризует среднее по совокупности отклонение у от его средней величины на принятую единицу измерения. Положительный знак при коэффициенте регрессии говорит о прямой связи между признаками, знак «-» говорит об обратной связи между признаками. Основное применение парного линейного уравнения регрессии– прогнозирование по уравнению регрессии. Ограничением при прогнозировании служат условия стабильности других факторов и условий процесса. Если резко измениться в нем среда протекающего процесса, то данное уравнение регрессии не будет иметь места. Точечный прогноз получается подстановкой в уравнение регрессии ожидаемого значения фактора. Вероятность точной реализации такого прогноза крайне мала. Если точечный прогноз сопровождается значением средней ошибки прогноза, то такой прогноз называется интервальным. Средняя ошибка прогноза образуется из двух видов ошибок: ошибок 1 рода – ошибка линии регрессии ошибка 2 рода – ошибка связанная с ошибкой вариации. Средняя ошибка прогноза. 48 my xk m~y k S y2ост m~y k S у ост ( y y )2 n2 S у ост m y xk ( xk x ) 2 ( xi x )2 1 n i - ошибка положения линии регрессии в генеральной совокупности n - объем выборки xk – ошибочное значение фактора S у о ст - СКО результативного признака от линии регрессии в генеральной совокупности Корреляционный анализ предполагает оценку тесноты связи. Показатели: линейные коэффициент корреляции – характеризует тесноту и направление связи между двумя признаками в случае наличия между ними линейной зависимости rxy ( x x )( y y ) (x x) ( y y) i 2 i rxy b i x y 1 rxy 1 rxy 2 i при rxy =-1 связь функциональная обратная, =1 связь функциональная прямая, при rxy =0 связь отсутствует. Корреляционно-регрессионная модель (КРМ) – такое уравнение регрессии, которое включает основные факторы, влияющие на вариацию результативного признака. Построение модели множественной регрессии включает этапы: выбор формы связи; отбор факторных признаков; обеспечение достаточного объема совокупности для получения верных оценок. 49 Все множество связей между переменными, встречающиеся на практике достаточно полно описывается функциями 5-ти видов: линейная: у а b1 х1 b2 х2 ... bn xn b b b степенная: у ax1 x2 ... x k 1 k 2 а b х b х ... b x показательная: у e 1 1 2 2 n n 2 2 2 парабола: y а b1 х1 b2 х2 ... bn xn гипербола: y а b1 x1 b2 х2 ... bn xn Отбор факторов для включения в уравнение множественной регрессии: между результативным и фактическим признаками должна быть причинно-следственная зависимость; результативный и фактический признаки должны быть тесно связаны между собой иначе возникает явление мультиколлинеарности (>06), т.е. включенные в уравнение факторные признаки влияют не только на результативный, но друг на друга, что влечет к неверной интерпретации числовых данных. Методы отбора факторов для включения в уравнение множественной регрессии: экспертный метод – основан на интуитивно логическом анализе который выполняется высококвалифицированными экспертами; использование матриц парных коэффициентов корреляции осуществляется параллельно с первым методом, матрица симметрична относительно единичной диагонали; пошаговый регрессионный анализ – последовательное включение факторных признаков в уравнение регрессии и проверки значимости проводится на основании значений двух показателей на каждом шаге. 50 Тема 10. Виды и показатели анализа статистических рядов. 10.1. Понятие динамического ряда и задачи его изучения Основная цель статистического изучения динамики коммерческой деятельности состоит в выявлении и измерении закономерностей их развития во времени. Это достигается посредством построения и анализа статистических рядов динамики. Рядами динамики называются статистические данные, отображающие развитие изучаемого явления во времени. В каждом ряду динамики имеются два основных элемента: показатель времени t; соответствующие им уровни развития изучаемого явления у. В качестве показаний времени в рядах динамики выступают либо определенные даты (моменты) времени, либо отдельные периоды (годы, кварталы, месяцы, сутки). Уровни рядов динамики отображают количественную оценку (меру) развития во времени изучаемого явления. Они могут выражаться абсолютными, относительными или средними величинами. В зависимости от характера изучаемого явления уровни рядов динамики могут относиться или к определенным датам (моментам) времени, или к отдельным периодам. В соответствии с этим, ряды динамики подразделяются на моментные и интервальные. Моментные ряды динамики отображают состояние изучаемых явлений на определенные даты (моменты) времени. Примером моментного ряда динамики является следующая информация о списочной численности работников страховой фирмы N в 2006 г.: Дата 1.01 1.04 1.07 1.10 1.01 Год 2006 г 2006 г 2006 г 2006 г 2007 г 190 195 198 200 Число работников, чел. 192 51 Особенностью моментного ряда динамики является то, что в его уровни могут входить одни и те же единицы изучаемой совокупности. Так, основная часть персонала фирмы N, составляющая списочную численность на 1.01.2006 г., продолжающая работать в течение данного года, отображена в уровнях последующих периодов. Поэтому при суммировании уровней моментного ряда динамики может возникнуть повторный счет. Интервальные ряды динамики отображают итоги развития (функционирования) изучаемых явлений за отдельные периоды (интервалы) времени. Примером интервального ряда динамики могут служить данные о объеме выплат по страховым случаям компанией в 2000-2003 гг.: Год 2000 2001 2002 Объем выплат по страховым случаям, тыс. руб. 885,7 932,6 980,1 928,7 2003 Особенностью интервального ряда динамики является то, что каждый его уровень складывается из данных за более короткие интервалы времени. Например, суммируя объем выплат по страховым случаям за первые три месяца года, получают его объем за I квартал, а сумма объема выплат по страховым случаям четырех кварталов дает объем выплат по страховым случаям четырех кварталов за год и т.д. Ряды динамики могут быть полными и неполными. Полный ряд - ряд динамики, в котором одноименные моменты времени или периоды времени строго следуют один за другим в календарном порядке или равноотстоят друг от друга. Неполный ряд динамики - ряд, в котором уровни зафиксированы в неравноотстоящие моменты или периоды времени. Ряды динамики, изучающие изменение статистического показателя, могут охватывать значительный период времени, протяжении происходить которого могут события, на нарушающие сопоставимость отдельных уровней ряда динамики (изменение методологии учета, изменение цен и т.д.). 52 Для того, чтобы анализ ряда был объективен, необходимо учитывать события, приводящие к несопоставимости уровней ряда и использовать приемы обработки рядов для приведения их в сопоставимый вид. Наиболее характерные случаи несопоставимости уровней ряда динамики: территориальные изменения объекта исследования, к которому относится изучаемый показатель (изменение границ городского района, пересмотр административного деления области и т.д.); разновеликие интервалы времени, к которым относится показатель. Так, например, в феврале - 28 дней, в марте - 31 день, анализируя изменения показателя по месяцам, необходимо учитывать разницу в количестве дней; изменение даты учета. Например, численность поголовья скота в разные годы могла определяться по состоянию на 1 января или на 1 октября, что в данном случае приводит к несопоставимости; изменение методологии учета или расчета показателя; изменение цен; изменение единиц измерения. Пример 10.1. Динамика изменения численности населения района области по состоянию на 1 января (в тыс. человек) представлена рядом динамики: 1982 1983 1984 22,0 22,3 22,8 - в старых границах района. В 1984 году произошло изменение административного деления области, и площадь района увеличилась, соответственно увеличилась и численность населения района: 1985 1986 1987 34,2 34,3 34,4 - в новых границах района. 53 Для приведения ряда в сопоставимый вид необходимо для 1984 года знать численность населения в старых и новых границах района для определения коэффициента пересчета: K 34,2 1,5 22,8 Все уровни ряда, предшествующие 1984 году, умножаются на коэффициент К и ряд принимает вид: 1982 1983 1984 1985 1986 1987 33,0 33,3 34,2 34,2 34,3 34,4 После этого преобразования ряда динамики возможен дальнейший анализ ряда (определение темпов роста и др.). 10.2. Определение среднего уровня ряда динамики. В качестве обобщенной характеристики уровней ряда динамики служит средний уровень ряда динамики y . В зависимости от типа ряда динамики используются различные расчетные формулы. Интервальный ряд абсолютных величин с равными (интервалами времени): y y периодами i n Моментный ряд с равными интервалами между датами: 1 1 y 1 y 2 ... y n 1 y n 2 y 2 n 1 y Моментный ряд с неравными интервалами между датами: y t t i i i где yi - уровни ряда, сохраняющиеся без изменения на протяжении интервала времени t i . 10.3. Система показателей анализа рядов динамики Одним из важнейших направлений анализа рядов динамики является изучение особенностей развития явления за отдельные периоды времени. С этой целью для динамических рядов рассчитывают ряд показателей: 54 К - темпы роста; y - абсолютные приросты; K - темпы прироста. Темп роста - относительный показатель, получающийся в результате деления двух уровней одного ряда друг на друга. Темпы роста могут рассчитываться как цепные, когда каждый уровень ряда сопоставляется с предшествующим ему уровнем: Kö yi y i 1 , либо как базисные, когда все уровни ряда сопоставляются с одним и тем же уровнем y 0 , выбранным за базу сравнения: Ká yi y 0 . Темпы роста могут быть представлены в виде коэффициентов либо в виде процентов. Абсолютный прирост - разность между двумя уровнями ряда динамики, имеет ту же размерность, что и уровни самого ряда динамики. Абсолютные приросты могут быть цепными и базисными, в зависимости от способа выбора базы для сравнения: цепной абсолютный прирост - yö yi yi 1 ; базисный абсолютный прирост - yá yi y0 . Для относительной оценки абсолютных приростов рассчитываются показатели темпов прироста. Темп прироста - относительный показатель, показывающий на сколько процентов один уровень ряда динамики больше (или меньше) другого, принимаемого за базу для сравнения. Базисные темпы прироста: Цепные темпы прироста: yá и yö Ká Kö yá y0 . yö yi 1 . - абсолютный базисный или цепной прирост; 55 y 0 - уровень ряда динамики, выбранный за базу для определения базисных абсолютных приростов; yi1 - уровень ряда динамики, выбранный за базу для определения i-го цепного абсолютного прироста. Существует связь между темпами роста и прироста: К = К - 1 или К = К - 100 % (если темпы роста определены в процентах). Если разделить абсолютный прирост (цепной) на темп прироста (цепной) за соответствующий период, получим показатель, называемый A абсолютное значение одного процента прироста: yö K ö . Пример 10.2. Выпуск продукции предприятия за 2000-2005 гг. характеризуются следующими данными (в сопоставимых ценах), млн. руб.: 1985 1986 1987 1988 1989 1990 23,3 24,9 26,6 27,6 29,0 32,2 Требуется произвести анализ динамики выпуска продукции предприятием за пять лет. 1. Определяем цепные и базисные темпы роста (К). Цепные: Базисные: K 1986 24,9 1,069 23,3 K 1986 24,9 1,069 23,3 K 1987 26,6 1,068 24,9 K 1987 26,6 1142 , 23,3 K 1988 27,6 1,038 26,6 K 1988 27,6 1185 , 23,3 K 1989 29,0 1,051 27,6 K 1989 29,0 1,245 23,3 K 1990 32,2 111 , 29,0 K 1990 32,2 1,386 23,3 56 2. Определяем цепной и базисный абсолютный прирост ( y ). Цепные: Базисные: y1986 24,9 23,3 16 , y1986 24,9 23,3 16 , y1987 26,6 24,9 17 , y1987 26,6 23,3 3,3 y1988 27,6 26,6 10 , y1988 27,6 23,3 4,3 y1989 29,0 27,6 14 , y1989 29,0 23,3 5,7 y1990 32,3 29,0 3,3 y1990 32,3 23,3 9,0 3. Определяем цепные и базисные темпы прироста ( K ). Цепные: Базисные: K 1986 1,6 0,069 23,3 K 1986 1,6 0,069 23,3 K 1987 1,7 0,068 24,9 K 1987 3,3 0,142 23,3 K 1988 1,0 0,038 26,6 K 1987 4,3 0,185 23,3 K 1989 1,4 0,051 27,6 K 1989 5,7 0,245 23,3 K 1990 3,3 0,114 29,0 K 1990 9,0 0,386 23,3 Проверим связь между темпами роста и прироста. Цепные темпы прироста: K K 1 K 1986 K 1986 1 K 1986 1069 , 1 0,069 K 1987 1068 , 1 0,068 и т.д. Видим, что получаем такие же результаты. 10.3. Средние характеристики рядов динамики Средний уровень ряда для интервального ряда ( Y ): 57 где n - число уровней ряда. Средний уровень ряда для моментного ряда ( YХР ): Средний абсолютный прирост: Средний коэффициент роста: или Средний темп роста: 10.4. Ряды распределения. Рядом распределения называется упорядоченное распределение единиц совокупности, как по количественным, так и по атрибутивным признакам. Если говорят о распределении единиц совокупности только по атрибутивным признакам, говорят об атрибутивном ряде распределения. Если единицы совокупности упорядоченно распределяются в ряду по возрастающим, или по убывающим значениям количественного признака, такой ряд называют вариационным. Ряд называется ранжированным, если перечень отдельных единиц совокупности (или их групп) расположен в порядке возрастания или убывания. Вариационные ряды распределения делят на дискретные и интервальные. Дискретный ряд представляет собой таблицу, состоящую из двух граф, или строк 6 конкретных значений признака и числа единиц совокупности (частот). Пример 10.3. Распределение магазинов города по числу товарных секций. 58 Число товарных секций Число магазинов 1 3 2 10 3 15 4 12 5 7 6 3 Итого: 60 Графическим изображением дискретного ряда распределения является полигон распределения. При его построении по оси абсцисс в соответствии с принятым масштабом откладываются значения варьирующего признака, по оси ординат – соответствующие им частоты. Интервальный ряд представляет собой таблицу, состоящую из двух граф (строк) – интервалов признака, вариация которого изучается и числа единиц совокупности, попадающих в этот интервал (частот). Пример 10.4. Распределение населения региона по размеру ежемесячного среднедушевого денежного дохода (цифры условные). Ежемесячный среднедушевой доход, руб. Количество человек, млн. чел. До 300 28.4 300-500 32 500-1000 26.5 1000-2000 18 2000-5000 6.7 5000-10000 1.2 Графическим изображением интервального ряда распределения является гистограмма. При ее построении по оси абсцисс в соответствии с принятым масштабом откладываются границы интервалов, по оси ординат – соответствующие им частоты. Преобразованной формой вариационного ряда 59 является ряд накопленных частот (кумулятивный ряд). Графическим изображением таких рядов являются огивы и кумуляты. Тема 11 :Индексный метод в статистике. Статистический индекс - это относительная величина сравнения сложных совокупностей и отдельных единиц. В зависимости от степени охвата подвергнутых обобщению единиц, индексы делят на индивидуальные и общие. 11.1. Индивидуальные индексы Индивидуальные индексы характеризуют изменение отдельных единиц статистической совокупности. Индекс называется базисным, если сравнение осуществляется с базой, и цепным, если сравнение осуществляется с предыдущим периодом. Между цепными и базисными индексами существует взаимосвязь, позволяющая переходить от одних индексов к другим. Произведение последовательных цепных - индивидуальных индексов дает базисный индекс последнего периода. Отношение базисного индекса отчетного периода к базисному индексу предшествующего периода дает цепной индекс отчетного периода. отношения является индексируемая Основным элементом индексного величина. Под индексируемой величиной понимается значение признака статистической совокупности, изменение которой является объектом изучения. Так, при изучении изменения цен индексируемой величиной является цена единицы товара p. При изучении изменения физического объема товарной массы в качестве индексируемой величины выступают данные о количестве товаров в натуральных измерителях q. Стоимость продукции обозначается через s. Пример 11.1. В текущем, отчётном году предприятие произвело 120 тыс.т. продукции вместо 100 тыс.т. в прошлом базисном, году. Цены за каждую тонну этой продукции снизились с 20 до 18 рублей; а её общая стоимость возросла с 2 000 до 2 160 тыс. руб. 60 В данном примере можно вычислить три индекса: индекс объёма продукции: индекс цен: ip iq q1 120000 1,2 q0 100000 или 120%; p1 18 0,9 p0 20 или 90%; индекс стоимости продукции: is s1 2160000 1,08 s0 2000000 или 108% Полученные индексы показывают, что объём продукции и её стоимость возросла в отчётном году по сравнению с базисным в 1,2 и 1,08 раза, а цены, наоборот, снизились до 1,9 их базисного уровня. Все три индекса образуют систему показателей — сомножителей: iq * i p i s или 1,2 * 0,9 = 1,08. 11.2.Общие (агрегатные индексы). Агрегатный (общий) индекс применяется в том случае, когда изучаемое явление (совокупность) неоднородно, и сравнение уровней можно выполнить, только приведя их к общей мере. Основной формой общих индексов являются агрегатные индексы. Достижение в сложных статистических совокупностях сопоставимости разнородных единиц осуществляется введением в индексные отношения специальных сомножителей индексируемых величин. Такие сомножители называются соизмерителями. Они необходимы для перехода от натуральных измерителей разнородных единиц статистической совокупности к однородным показателям. При этом в числителе и знаменателе общего индекса изменяется лишь значение индексируемой величины, а их соизмерители являются постоянными величинами. В качестве соизмерителей индексируемых величин выступают тесно связанные с ними экономические показатели: цены, количество и др. 61 Произведение каждой индексируемой величины на соизмеритель образует в индексном отношении определённые экономические категории. Пример 11.2. Таблица 11.1. Товар Ед.изм. I период II период Индивидуальные индексы цена за кол- цена за кол- цен единицу во единицу во, ip товара, товара, руб. p0 q0 руб. p1 p0 физич-го объёма iq q1 q1 q0 p1 А т 20 7 500 25 9500 1,25 1,27 Б м 30 2 000 30 2500 1,0 1,25 В шт. 15 1 000 10 1500 0,67 1,5 При определении по данным таблицы статистических индексов первый период принимается за базисный, в котором цена единицы товара принимается p0 , а количество — q 0 . Второй период принимается за текущий (или отчетный), в котором цена единицы товара обозначается p1 , а количество — q1 . Индивидуальные индексы показывают, что в текущем периоде по сравнению с базисным цена на товар А повысилась на 25%, на товар Б осталась без изменения, а на товар В снизилась на 33%. Количество реализации товара А возросло на 27%, товара Б — на 25%, а товара В — на 50%. При определении общего индекса цен в агрегатной форме Ip в качестве соизмерителя индексируемых величин p1 и p0 могут приниматься данные о количестве реализации товаров в текущем периоде q1 . При умножении q1 на индексируемые величины в числителе индексного отношения образуется значение q p 1 1 , сумма стоимости продажи товаров в текущем периоде по ценам того же текущего периода. В знаменателе индексного отношения образуется 62 значение q p 1 0 , т.е. сумма стоимости продажи товаров в текущем периоде по ценам базисного периода. Агрегатная формула такого общего индекса цен имеет следующий вид: Ip q p q p = 1 1 1 0 Расчёт агрегатного индекса цен по данной формуле предложил немецкий экономист Г. Пааше, поэтому он называется индексом Пааше. Применяем формулу для расчёта агрегатного индекса цен по данным таблицы: числитель индексного отношения q p 1 1 =25 * 9 500 + 30 * 2 500 + 10 * 1 500 = 327 500 руб. знаменатель индексного отношения q p 1 0 = 20 * 9 500 + 30 * 2 500 + 15 * 1 500 = 287 500 руб. Полученные значения подставляем в формулу общего индекса: Ip 327500 1139 , = 287500 или 113,9% Применение формулы 1 показывает, что по данному ассортименту товаров в целом цены повысились в среднем на 13,9%. При другом способе определения агрегатного индекса цен в качестве соизмерителя индексируемых величин p1 и p0 могут применяться данные о количестве реализации товаров в базисном периоде q 0 . При этом умножение q 0 на индексируемые величины в числителе индексного отношения образует значение q p , т.е. сумму стоимости продажи товаров в базисном периоде 0 1 по ценам текущего периода. В знаменателе индексного отношения образуется значение q p , т.е. 0 0 сумма стоимости продажи товаров в базисном периоде по ценам того же базисного периода. Агрегатная формула такого общего индекса имеет вид: 63 q I p q = 0 p1 0 p0 Расчёт общего индекса цен по данной формуле предложил немецкий экономист Э. Ласпейрес, и получил название индекса Ласпейреса. Применяем формулу для расчёта агрегатного индекса цен: числитель индексного отношения q 0 p1 = 25 * 7 500 + 30 * 2 000 + 10 * 1000 = 257 500 руб. знаменатель индексного отношения q 0 p0 = 20 * 7 500 + 30 * 2 000 + 15 * 1 000 = 225 000 руб. Полученные значения подставляем в формулу 2: Ip 257500 1144 , = 225000 или 114,4% Применение формулы индекса цен показывает, что по данному ассортименту товаров в целом цены повысились в среднем на 14,4%. Таким образом, выполненные по формулам индекса цен расчёты имеют разные показания индексов цен. Это объясняется тем, что индексы Пааше и Ласпейреса характеризуют различные качественные особенности изменения цен. Индекс Пааше характеризует влияние изменения цен на стоимость товаров, реализованных в отчётном периоде. Индекс Ласпейреса показывает влияние изменения цен на стоимость количества товаров, реализованных в базисном периоде. Другим важным видом общих индексов, которые широко применяются в статистике, являются агрегатные индексы физического объёма товарной массы. При определении агрегатного индекса физического объёма товарной массы Iq в качестве соизмерителей индексируемых величин q1 и q 0 могут применяться неизменные цены базисного периода p0 . При умножении p0 на индексируемые величины в числителе индексного отношения образуются 64 q p значение 1 0 , т.е. сумма стоимости товарной массы текущего периода в базисных ценах. В знаменателе — q 0 p0 , т.е. сумма стоимости товарной массы базисного периода в ценах того же базисного периода. Агрегатная форма общего индекса имеет следующий вид: Iq q q = 1 p0 0 p0 Поскольку, в числителе формулы общего индекса содержится сумма стоимости реализации товаров в текущем периоде по неизменным (базисным) ценам, а в знаменателе — сумма фактической стоимости товаров, реализованных в базисном периоде в тех же неизменных (базисных) ценах, то данный индекс является агрегатным индексом товарооборота в сопоставимых (базисных) ценах. Используем формулу общего индекса для расчёта агрегатного индекса физического объёма реализации товаров по данным таблицы: числитель индексного отношения q p 1 0 = 9 500 * 20 + 2 500 * 30 + 1 500 * 15 = 287 500 руб. знаменатель индексного отношения q 0 p0 = 7 500 * 20 + 2 000 * 30 + 1 000 * 15 = 225 000 руб. Полученные значения подставляем в формулу 3: Iq 287500 1,278 = 225000 или 127,8% Применение формулы 3 показывает, что по данному ассортименту товаров в целом прирост физического объёма реализации в текущем периоде составил в среднем 27,8%. Агрегатный определяться индекс посредством физического объёма использования в товарооборота качестве может соизмерителя индексируемых величин q1 и q 0 цен текущего периода p1 . Агрегатная формула общего индекса будет иметь вид: Iq q p q p = 1 1 0 1 (4) 65 числитель индексного отношения q p = 9 500 * 25 + 2 500 * 30 + 1 500 * 10 = 327 500 руб. 1 1 знаменатель индексного отношения q 0 p1 = 7 500 * 25 + 2 000 * 30 + 1 000 * 10 = 257 500 руб. Полученные значения подставляем в формулу 4: Iq 327500 1,272 = 257500 или 127,2% Применение формулы 4 показывает, что по данному ассортименту товаров в целом прирост физического объёма реализации в текущем периоде составил в среднем 27,2%. Аналогичным образом производится расчёт индекса себестоимости, при этом сравниваются суммы затрат в производстве в отчётном периоде ( q1 z1 — числитель индекса) с суммой затрат в производстве на продукцию отчётного периода по себестоимости базисного периода ( q1 z0 — знаменатель). 11.3.Индексы с постоянными и переменными весами. При изучении динамики коммерческой деятельности приходится производить индексные сопоставления более чем за два периода. Поэтому индексные величины могут определяться как на постоянной, так и на переменной базах сравнения. При этом, если задача анализа состоит в получении характеристик изменения изучаемого явления во всех последующих периодах по сравнению с начальным, то вычисляются базисные индексы. Например, сопоставление объёма розничного товарооборота II, III и IV кварталов с I кварталом. Но если требуется охарактеризовать последовательно изменения изучаемого явления из периода в период, то вычисляются цепные индексы. Например, при изучении объёма розничного товарооборота по кварталам года сопоставляют товарооборот II квартала c I, III — cо II и IV — с III кварталом. 66 В зависимости от задачи исследования и характера исходной информации базисные и цепные индексы исчисляются как индивидуальные, так и общие. Способы расчёта индивидуальных базисных и цепных индексов аналогичны расчёту относительных величин динамики. Общие индексы в зависимости от их вида вычисляются с переменными и постоянными весами — соизмерителями. Используя индексный ряд за несколько периодов, можно получить динамику стоимости продукции и динамику товарооборота в неизменных ценах, т.е. в ценах какого - то одного прошлого периода. Такие индексные ряды называются индексами с постоянными весами. Для них действует правило: произведение цепных индексов даёт индекс базисный. Пример 11.3. По заводу имеются данные об объёме производства и стоимости продукции. Требуется рассчитать индексы физического объёма продукции. Таблица 11.2. Вид. Ед. Произведено Цена 1985г., Стоимость прод. изм. продукции тыс.руб. 1988 1989 1990 продукции ценах 1985г., тыс.руб. 1988 1989 1990 А тыс.т. 60 64 69 5 000 300 320 345 Б млн.шт 5,5 6,2 7,0 2 000 11000 12400 14000 всего - - - 11300 12720 14345 - в Индексы с постоянной базой (базисные): I 1989 1988 14350 12720 I 1990 1,27 1126 , 11300 11300 1988 Индексы с переменной базой (цепные): I 1989 1988 12720 14350 1126 , I 1990 1128 , 11300 12720 1989 Убедимся, что произведение цепных индексов равно базисному: 67 1,126 * 1,128 = 1,27 Если индексы цен, себестоимости и производительности труда имеют в качестве весов количество продукции отчётного периода, то эти индексы образуют индексные ряды с переменными весами, поскольку в каждом отдельном индексе отчётный период изменяется. Индексы с переменными весами не подчиняются правилу, согласно которому произведение цепных индексов равно базисному. Пример11.4. Имеются данные об объёме производства и себестоимости продукции: Таблица 11.3. Выработано продукции Себестоимость единицы Вид Единица за квартал продукции, руб. Продукции измерения I II III I II III А шт. 100 120 150 10 9,9 9,6 Б шт. 300 310 320 35 35 34 В кг. 7 800 8 200 8 500 0,5 0,48 0,45 Рассчитать индексы себестоимости с переменными весами. I IIKB IKB I IIIKB IIKB 9,9 *120 35 * 310 0,48 * 8200 0,989 10 *120 35 * 310 0,5 * 8200 9,6 *150 34 * 320 0,45 * 8500 0,963 9,9 *150 35 * 320 0,48 * 8500 Перемножив цепные индексы, получим: 0,989 * 0, 963 = 0, 9524 Рассчитаем базисный индекс III квартала: I IIIKB IKB 9,6 * 150 34 * 320 0,45 * 8500 0,9525 10 * 150 35 * 320 0,5 * 8500 Как видим, расхождение есть, но оно проявляется только в четвёртом знаке после запятой. Величина расхождения не многим более 0,01%. 11.4. Средние индексы. 68 Всякий агрегатный индекс может быть преобразован в средний арифметический из индивидуальных индексов. Для этого индексируемая величина заменяется произведением индивидуального индекса на индексируемую величину базисного периода. i Так, индивидуальный индекс цен равен p1 p0 , откуда p i * p . 1 0 Следовательно, преобразование агрегатного индекса цен в средний q p q p i I p q p q p = = арифметический имеет вид: 1 1 1 0 1 0 1 0 i Аналогично индекс себестоимости равен z1 z0 , откуда z1 iz0 , q z q z i Iz = q z = q z , следовательно, 1 1 1 0 1 0 1 0 Аналогично индекс физического объёма продукции (товарооборота) равен q i 1 q0 , откуда q1 iq0 , следовательно, q p q p i I p q p q p = = 1 0 0 0 0 0 0 0 Пример 13.5. Определить арифметический индекс физического объёма продукции. Таблица 11.4. Отрасль произв. Стоимость прод. в Индексы физич. объёма прод. в базисном году, млн. руб. отчёт. году (базис. год = 1) Сахарная 20 1,47 Мукомольная 30 1,55 Мясная 25 1,71 Рыбная 15 2,1 ИТОГО 90 - 69 q p i 1,47 * 20 1,55 * 30 1,71 * 25 2,1 * 15 1,667 I p q p 20 30 25 15 = = 0 0 0 0 или 166,7%, т.е. физический объём продукции этих отраслей увеличился на 66,7%. 11.5. Расчеты недостающих индексов с помощью индексных систем. Многие экономические индексы тесно связаны между собой и образуют индексные системы. Так, индекс цен связан с индексом физического объема товарооборота или физического объема продукции, образуя следующую индексную систему: p q p q 1 1 0 1 q p q p 1 0 0 0 Произведение товарооборота p q p q 1 1 0 0 индекса или , или цен продукции I p I q I pq на индекс физического объема дает индекс физического объема товарооборота в фактических ценах, или индекс стоимости продукции. Индекс себестоимости промышленной продукции связан с индексом физического объема продукции по себестоимости, образуя следующую индексную систему: z q z q 1 1 0 1 q z q z Произведение 1 0 0 0 z q z q индекса 1 1 0 0 , или I z I q I zq себестоимости продукции на индекс физического объема дает индекс затрат в производстве. Используя индексы системы, можно по двум известным индексам найти третий, неизвестный. Пример 11.6. Имеются следующие данные о продаже товаров в магазинах А: Таблица 11.5. 70 Товар Продано, кг Цена 1 кг, руб. Год 2005 2006 2005 2006 Яблоки 5000 6000 12 10 Бананы 2000 2500 25 24 Апельсины 4000 3800 16 14 Необходимо исчислить индексы цен, физического объема товарооборота в фактических ценах по трем товарам вместе. Рассчитаем индекс цен: Ip p q p q 1 1 0 1 10 6000 24 2500 14 3800 173200 0,8867 12 6000 25 2500 16 3800 195300 Цены снизились на 11,33%, и покупатель имел экономию, равную 22100 руб. (19530 — 173200). Определим индекс физического объема товарооборота: Iq q q 1 p0 0 p0 6000 12 2500 25 3800 16 195300 11223 , 5000 12 2000 25 4000 16 174000 Товарооборот в неизменных ценах вырос на 12,23%, прирост товарооборота в неизменных ценах составил 21300 руб. (195300 — 174000). Рассчитаем индекс товарооборота в фактических ценах: I pq p q p q 1 1 0 0 173200 0,995 174000 Товарооборот в фактических ценах снизился на 0,5%, что в абсолютном выражении составляет 800 руб. (174000 — 173200). Произведение первых двух индексов дает третий индекс I p I q I pq ; 0,8867 11223 , 0,995. В определенной связи находятся и разности между знаменателем и числителем индексов: населению по ценам базисного периода было продано товаров на 21300 руб. больше, но в силу того, что население имело экономию от снижения цен на товары в сумме 22100 руб., оно за эти товары в отчетном периоде по фактическим ценам уплатило на 800 руб. меньше. 71 Тема 12. Применение выборочных методов наблюдения в статистических исследованиях. Статистическое исследование может осуществляться по данным несплошного наблюдения, основная цель которого состоит в получении характеристик изучаемой совокупности по обследованной ее части. Одним из наиболее распространенных в статистике методов, применяющих несплошное наблюдение, является выборочный метод. 12.1. Понятие и виды выборочных наблюдений. Под выборочным понимается метод статистического исследования, при котором обобщающие показатели изучаемой совокупности устанавливаются по некоторой ее части на основе положений случайного отбора. При этом подлежащая изучению статистическая совокупность, из которой производится отбор части единиц, называется генеральной совокупностью. Отобранная из генеральной совокупности некоторая часть единиц, подвергающаяся обследованию, называется выборочной совокупностью или просто выборкой. Цель (задача) выборочного наблюдения: по обследуемой части дать характеристику всей совокупности единиц при условии соблюдения всех правил и принципов статистического наблюдения. Причины применения выборочного наблюдения: 1. экономия материальных, трудовых затрат и времени; 2. возможность более детально и подробно изучит отдельные единицы статистической совокупности и их группы. 3. некоторые специфические задачи можно решить только с применением выборочного наблюдения. 4. грамотное и хорошо организованное выборочное наблюдение дает высокую точность результатов. 72 Виды выборочного наблюдения подразделяют: 1. По методу отбора: повторное - попавшая в выборку единица после регистрации наблюдаемых признаков возвращаются в генеральную совокупность для участия в дальнейшей процедуре отбора, объем генеральной совокупности остается неизменным, что обуславливает постоянное попадание в выборку какой-либо единицы; бесповторное - попавшая в выборку единица не возвращается в совокупность, из которой происходит отбор. 2.По способу отбора: 73 собственно-случайная заключается в отношении единиц из генеральной совокупности наугад или наудачу без каких-либо элементов системности, технически сложившейся отбор осуществляется методом жеребьевки или с помощью таблицы случайных чисел; механическая выборка которая - устанавливается пропорция отбора, устанавливается соотношением генеральной совокупности и выборочной совокупности; районированная выборка используется когда все единицы генеральной совокупности можно разбить на группы (районы, страны) по какому-либо признаку; комбинированная выборка - отбор единиц может быть произведен: либо пропорционально объему группы, либо пропорционально внутригрупповой дифференциации признака; серийный отбор - используется когда ЕСС объединены в небольшие группы (серии), серии отбираются собственно случайным, либо механическим способом, а затем осуществляется сплошное обследование внутри отобранной серии; комбинированный отбор - комбинация рассмотренных выше способов отбора чаще применяется комбинация типичных и серийных серии, т.е. отбор серий из нескольких типических групп. Отбор может быть еще многоступенчатым и одноступенчатым, многофразным и однофразным. Многоступенчатый отбор: из генеральной совокупности сначала извлекаются укрупненные группы, затем более мелкие, и так до тех пор, пока не будут отобраны те единицы, которые подвергаются обследованию. Многофразная выборка: предполагает сохранение одной и той же единицы отбора на всех этапах его проведения. При этом отобранные на 74 каждой последующей стадии единицы отбора подвергаются обследованию, программа которого расширяется (Пример: студенты всего института, затем студенты каких-то факультетов). Значение выборочного метода состоит в том, что при минимальной численности обследуемых единиц проведение исследования осуществляется в более короткие сроки и с минимальными затратами труда и средств. Это повышает оперативность статистической информации, уменьшает ошибки регистрации. В проведении ряда исследований выборочный метод является единственно возможным, например, при контроле качества продукции (товара), если проверка сопровождается уничтожением или разложением на составные части обследуемых образцов (определение сахаристости фруктов, клейковины печеного хлеба, установление носкости обуви, прочности тканей на разрыв и т.д.). Проведение исследования социально — экономических явлений выборочным методом складывается из ряда последовательных этапов: 1) обоснование (в соответствии с задачами исследования) целесообразности применения выборочного метода; 2) составление программы проведения статистического исследования выборочным методом; 3) решение организационных вопросов сбора и обработки исходной информации; 4) установление доли выборки, т.е. части подлежащих обследованию единиц генеральной совокупности; 5) обоснование способов формирования выборочной совокупности; 6) осуществление отбора единиц из генеральной совокупности для их обследования; 7) фиксация в отобранных единицах (пробах) изучаемых признаков; 8) статистическая обработка полученной в выборке информации с определением обобщающих характеристик изучаемых признаков; 75 9) определение количественной оценки ошибки выборки; 10) распространение обобщающих выборочных характеристик на генеральную совокупность. В генеральной совокупности доля единиц, обладающих изучаемым признаком, называется генеральной долей (обозначается р), а средняя величина изучаемого варьирующего признака — генеральной средней (обозначается x ). В выборочной совокупности долю изучаемого признака называют выборочной долей, или частостью (обозначается ), а среднюю величину в выборке — выборочной средней (обозначается ~х ). 12.2. Понятие ошибки выборки. Ошибка выборки — это объективно возникающее расхождение между характеристиками выборки и генеральной совокупности. Она зависит от ряда факторов: степени вариации изучаемого признака, численности выборки, методом отбора единиц в выборочную совокупность, принятого уровня достоверности результата исследования. При случайном повторном отборе средняя ошибка выборочной средней рассчитывается по формуле: s2 , n где — средняя ошибка выборочной средней; s 2 — дисперсия выборочной совокупности; n — численность выборки. При бесповторном отборе она рассчитывается по формуле: s2 n 1 , n N где N — численность генеральной совокупности. При повторном отборе средняя ошибка выборочной доли рассчитывается по формуле: 76 1 n где , m — выборочная n доля единиц, обладающих изучаемым признаком; m — число единиц, обладающих изучаемым признаком; n — численность выборки. При бесповторном способе отбора средняя ошибка выборочной доли определяется по формулам: 1 n 1 N n Предельная ошибка выборки связана со средней ошибкой выборки отношением: t * . При этом t как коэффициент кратности средней ошибки выборки зависит от значения вероятности Р, с которой гарантируется величина предельной ошибки выборки. Предельная ошибка выборки при бесповторном отборе определяется по следующим формулам: t x t 1 n sx2 n n 1 , N n 1 . N Предельная ошибка выборки при повторном отборе определяется по формуле: t 1 n , s x2 x t . n 77 При контроле качества товаров в экономических исследованиях эксперимент может проводиться на основе малой выборки. Под малой выборкой понимается несплошное статистическое обследование, при котором выборочная совокупность образуется из сравнительно небольшого числа единиц генеральной совокупности. Объем малой выборки обычно не превышает 30 единиц и может доходить до 4 — 5 единиц. Средняя ошибка малой выборки вычисляется по формуле: sM2 .B , n M .B где M .B s2M .B — дисперсия малой выборки. При определении дисперсии s 2 число степеней свободы равно n-1: s 2 M .B (x i n 1 Предельная формуле M .B ~ x )2 . ошибка малой выборки M .B определяется по t M .B При этом значение коэффициента доверия t зависит не только от заданной доверительной вероятности, но и от численности единиц выборки n. Для отдельных значений t и n доверительная вероятность малой выборки определяется по специальным таблицам Стьюдента (Табл. 14.1.), в которых даны распределения стандартизированных отклонений: ~ xx t . s M .B Таблица 12.1. n t 0,5 1,0 1,5 2,0 3,0 4 0,347 0,609 0,769 0,861 0,942 6 0,362 0,637 0,806 0,898 0,970 78 8 0,368 0,649 0,823 0,914 0,980 10 0,371 0,657 0,832 0,923 0,985 15 0,376 0,666 0,846 0,936 0,992 20 0,377 0,670 0,850 0,940 0,993 Поскольку при проведении малой выборки в качестве доверительной вероятности практически принимается значение 0,59 или 0,99, то для определения предельной ошибки малой выборки M .B используются следующие показания распределения Стьюдента (Табл. 14.2.) Таблица 12.2. n St 0,95 0,99 4 3,183 5,841 5 2,777 4,604 6 2,571 4,032 7 2,447 3,707 8 2,364 3,500 9 2,307 3,356 10 2,263 3,250 15 2,119 2,921 20 2,078 2,832 Пример 14.2. При контрольной проверке качества поставленной в торговлю колбасы получены данные о содержании поваренной соли в пробах. По данным выборочного обследования нужно установить с вероятностью 0,95 предел, в котором находится средний процент содержания поваренной соли в данной партии товара. Составляем расчётную таблицу и по её итогам определяем среднюю пробу малой выборки. Таблица 12.3. 79 Пробы X i xi ~ x ( xi ~ x )2 4,3 0,2 0,04 4,2 0,1 0,01 3,8 0,3 0,09 4,3 0,2 0,04 3,7 - 0,4 0,16 3,9 - 0,2 0,04 4,5 0,4 0,16 4,4 0,3 0,09 4,0 - 0,1 0,01 3,9 - 0,2 0,04 — 0,68 41,0 ~ x x n i 41 4,1% 10 Определяем дисперсию малой выборки: s 2 M .B (x i ~ x )2 n 1 0,68 0,075% 10 1 Определяем среднюю ошибку малой выборки: M .B s 2M .B n 0,075 0,087% 10 Исходя из численности выборки (n=10) и заданной вероятности St =0,95, устанавливается по распределению Стьюдента (см. Табл. 9.2.) значение коэффициента доверия t=2,263. Предельная ошибка малой выборки составит: M .B t M .B 2,263(0,087) 0,02% Следовательно, с вероятностью 0,95 можно утверждать, что во всей партии колбасы содержание поваренной соли находится в пределах: x~ x M .B 4,1% 0,2% , т.е. от 4,1% - 0,2%=3,9% до 4,1%+0,2%=4,3%. 80 12.3. Способы распространения характеристик выборки на генеральную совокупность. Выборочный метод чаще всего применяется для получения характеристик генеральной совокупности по соответствующим показателям выборки. В зависимости от целей исследований это осуществляется или прямым пересчётом показателей выборки для генеральной совокупности, или посредством расчёта поправочных коэффициентов. Способ прямого пересчёта. Он состоит в том, что показатели выборочной доли или средней ~x распространяется на генеральную совокупность с учётом ошибки выборки. Так, в торговле определяется количество поступивших в партии товара нестандартных изделий. Для этого (с учётом принятой степени вероятности) показатели доли нестандартных изделий в выборке умножаются на численность изделий во всей партии товара. Пример 14.3. При выборочном обследовании партии нарезных батонов 2 000 ед. доля нестандартных изделий в выборке составляет: 0,1 (10 : 100) при установленной с вероятностью St =0,954 предельной ошибке выборки 0,06 . На основе этих данных доля нестандартных изделий во всей партии составит: p 0,1 0,06 или от 0,04 до 0,16. Способом прямого пересчёта можно определить пределы абсолютной численности нестандартных изделий во всей партии: минимальная численность — 2 000 : 0,04 = 80 шт.; максимальная численность — 2 000 : 0,16 = 320 шт. Способ поправочных коэффициентов. Применяется в случаях, когда целью выборочного метода является уточнение результатов сплошного учета. 81 В статистической практике этот способ используется при уточнении данных ежегодных переписей скота, находящегося у населения. Для этого после обобщения данных сплошного учета практикуется 10%-ное выборочное обследование с определением так называемого “процента недоучета”. Так, например, если в хозяйствах населения поселка по данным 10%ной выборки было зарегистрировано 52 головы скота, а по данным сплошного учета в этом массиве значится 50 голов, то коэффициент недоучета составляет 4% [(2*50):100]. С учетом полученного коэффициента вносится поправка в общую численность скота, находящегося у населения данного поселка. 12.4.Способы отбора единиц в выборочную совокупность из генеральной совокупности. В статистике применяются различные способы формирования выборочных совокупностей, что обусловливается задачами исследования и зависит от специфики объекта изучения. Основным условием проведения выборочного обследования является предупреждение возникновения систематических ошибок, возникающих вследствие нарушения принципа равных возможностей попадания в выборку каждой единицы генеральной совокупности. Предупреждение систематических ошибок достигается в результате применения научно обоснованных способов формирования выборочной совокупности. Существуют следующие способы отбора единиц из генеральной совокупности: 1) индивидуальный отбор — в выборку отбираются отдельные единицы; 2) групповой отбор — в выборку попадают качественно однородные группы или серии изучаемых единиц; 82 3) комбинированный отбор — это комбинация индивидуального и группового отбора. Способы отбора определяются правилами формирования выборочной совокупности. Собственно-случайная выборка состоит в том, что выборочная совокупность образуется в результате случайного (непреднамеренного) отбора отдельных единиц из генеральной совокупности. При этом количество отобранных в выборочную совокупность единиц обычно определяется исходя из принятой доли выборки. Так, при 5%-ной выборке из партии товара в 2 000 ед. численность выборки n составляет 100 ед. (5*2000:100), а при 20%-ной выборке она составит 400 ед. (20*2000:100) и т.д. Механическая выборка состоит в том, что отбор единиц в выборочную совокупность производится из генеральной совокупности, разбитой на равные интервалы (группы). При этом размер интервала в генеральной совокупности равен обратной величине доли выборки. Так, при 2%-ной выборке отбирается каждая 50-я единица (1:0,02), при 5%-ной выборке — каждая 20-я единица (1:0,05) и т.д. Таким образом, в соответствии с принятой долей отбора, генеральная совокупность как бы механически разбивается на равновеликие группы. Из каждой группы в выборку отбирается лишь одна единица. Важной особенностью механической выборки является то, что формирование выборочной совокупности можно осуществить, не прибегая к составлению списков. На практике часто используют тот порядок, в котором фактически размещаются единицы генеральной совокупности. Например, последовательность выхода готовых изделий с конвейера или поточной линии, порядок размещения единиц партии товара при хранении, транспортировке, реализации и т.д. Типическая выборка. При типической выборке генеральная совокупность вначале расчленяется на однородные типические группы. Затем из каждой типической группы собственно-случайной или механической выборкой производится индивидуальный отбор единиц в 83 выборочную совокупность. Типическая выборка обычно применяется при изучении сложных статистических совокупностей. Например, при выборочном обследовании производительности труда работников торговли, состоящих из отдельных групп по квалификации. Важной особенностью типической выборки является то, что она дает более точные результаты по сравнению с другими способами отбора единиц в выборочную совокупность. Для определения средней ошибки типической выборки используются формулы: повторный отбор бесповторный отбор (1 ) n , (1 ) n n 1 , N sx 2 n sx 2 n 1 n N Дисперсия определяется по следующим формулам: s 2 1 n n i i i , s 2 i si2 ni ni Пример 12.4. Для выявления доли простоев из-за несвоевременного поступления полуфабрикатов была проведена фотография рабочего дня 10% рабочих четырех различных цехов. Отбор рабочих внутри цехов производится методом механического отбора. В результате выборки были получены следующие данные: Таблица 14.5 Цех Число рабочих в Удельный вес простоев из-за несвоевременного выборке поступления полуфабрикатов, % №1 20 5 №2 36 10 №3 14 15 №4 30 2 84 С вероятностью 0,954 требуется определить пределы, в которых находится доля простоев на заводе из-за несвоевременного поступления полуфабрикатов. Рассчитаем долю простоев из-за несвоевременного поступления полуфабрикатов в выборке: n n i i 5 * 20 10 * 36 15 * 14 30 * 2 7,3% 100 Рассчитаем дисперсии типических групп: sI2 1 1 1 5 * 95 475; I 2 II sII 2 1 2 10 * 90 900; для группы III s2 1 15 * 85 1275; III 3 3 IV s2 1 2 * 98 196. VI 4 4 Средняя из внутригрупповых дисперсий определяется по формуле: 1 1 n n i i i i 475 * 20 900 * 36 1275 * 4 196 * 30 656,3 100 Определяем среднюю ошибку в выборочной доле: 656,3 100 1 2,42% 100 1000 Рассчитаем предельную ошибку выборки для доли с вероятностью 0,954: 2 * 2,42 4,8% С вероятностью 0,954 можно утверждать, что доля простоев рабочих из-за несвоевременного поступления полуфабрикатов находится в пределах 2,5% p 12,1% . Серийная выборка. При серийной выборке генеральную совокупность делят на одинаковые по объему группы — серии. В выборочную 85 совокупность отбираются серии. Внутри серий производится сплошное наблюдение единиц, попавших в серию. При бесповторном отборе серий средняя ошибка выборочной серии определяется по формуле: d2 r 1 , r R где d 2 — межсерийная дисперсия средних; R — число серий в генеральной совокупности; r — число отобранных серий. Пример 14.5. В механическом цехе завода в десяти бригадах работает 100 рабочих. В целях изучения квалификации рабочих была произведена 20%-ная серийная бесповторная выборка, в которую вошли 2 бригады. Получено следующее распределение обследованных рабочих по разрядам: Таблица 12.6. Рабочие Разряды рабочих в бригаде 1 Разряды рабочих в бригаде 2 1 2 3 2 4 6 3 5 1 4 2 5 5 5 3 6 6 4 7 5 2 8 8 1 9 4 3 10 5 2 Необходимо определить с вероятностью 0,997 пределы, в которых находится средний разряд рабочих механического цеха. Определим выборочные средние по бригадам и общую среднюю: 86 2 4 5 2 5 658 4 5 ~ xI 4,6 10 3 6 1 5 3 4 2 1 3 2 ~ x II 3,0 10 30 46 ~ xc 3,8. 20 Определим межсерийную дисперсию: d2 4,6 3,82 3,0 3,82 2 0,64 Рассчитаем среднюю ошибку выборки: ~x 0,64 2 1 0,5 2 10 Вычислим предельную ошибку выборки с вероятностью 0,997. ~ 0,5 * 3 1,5 С вероятностью 0,997 можно утверждать, что средний разряд рабочих механического цеха находится в пределах 2,0 x 5,0 . При бесповторном серийном отборе средняя ошибка выборки для доли определятся по формуле: d2 r r 2 1 , где d — межсерийная дисперсия R доли. Пример 12.6. 200 ящиков деталей упакованы по 40 шт. в каждом. Для проверки качества деталей был проведён сплошной контроль деталей в 20 ящиках (выборка бесповторная). В результате контроля установлено, что доля бракованных деталей составляет 15%. Межсерийная дисперсия равна 49. С вероятностью 0,997 определим пределы, в которых находится доля бракованной продукции в партии ящиков. Определим среднюю ошибку выборки для доли: 49 20 1 1,48% . 20 200 87 Предельная ошибка выборки для доли с вероятностью 0,997 равна: 1,48 * 3 4,44% . С вероятностью 0,997 можно утверждать, что доля бракованных деталей в партии будет находиться в пределах от 10,59% до 19,41%. В статистике различают одноступенчатые и многоступенчатые способы отбора единиц в выборочную совокупность. При одноступенчатой выборке каждая отобранная единица сразу же подвергается изучению по заданному признаку. Так обстоит дело при собственно-случайной и серийной выборке. При многоступенчатой выборке производят подбор из генеральной совокупности отдельных групп, а из групп выбираются отдельные единицы. Так производится типическая выборка с механическим способом отбора единиц в выборочную совокупность. Комбинированная выборка может быть двухступенчатой. При этом генеральная совокупность сначала разбивается на группы. Затем производят отбор групп, а внутри последних осуществляется отбор отдельных единиц. Заключение Статистика имеет многовековую историю. Её возникновение и развитие обусловлены общественными потребностями: подсчет населения, скота, учета земельных угодий, имущества и т.д. Наиболее ранние сведения о таких работах в Китае относятся к 13 в. до нашей эры. В Древнем Риме проводились учеты свободных граждан и их имущества. В развитии статистики видное место принадлежит представителям отечественной науки и практики. В эпоху Петра I статистика трактовалась преимущественно как описательная наука. Но уже со второй половины XIX в. выдвигается познавательное значение статистики. Профессор петербургского университета Ю.Э. Янсон (1835-93) назвал статистику общественной наукой. Видный экономист А.И. Чупров (1842-1908) отмечал необходимость массового статистического исследования при помощи метода количественного наблюдения большого числа факторов для того, чтобы 88 описать общественные явления, подметить законы и определить причины, их вызвавшие. Развитие статистики в России тесным образом связано с созданной после отмены крепостного права земской статистикой, которая пользовалась заслуженным авторитетом за объективность и профессионализм. История развития статистики показывает, что статистическая наука сложилась в результате теоретического обобщения человечеством передового опыта - учетно накопленного статистических работ, обусловленных, прежде всего, потребностями управления жизни общества. В настоящее время статистика - это планомерный и систематический учет массовых общественных явлений, который осуществляется государственными статистическими органами и дает числовое выражение проявляющимся закономерностям. 89