Практикум 6. Алгоритм выравнивания последовательностей. без потери баллов в рейтинг:
реклама

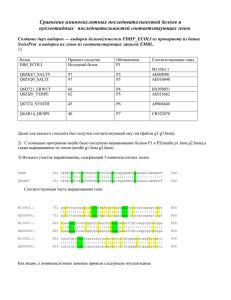
Практикум 6. Алгоритм выравнивания последовательностей. Deadline без потери баллов в рейтинг: день накануне следующего занятия ( 25 или 30 марта, в зависимости от группы) Результаты должны содержаться в файлах: XXXXXXX_aln.xls (или .xlsx) XXXXXXX_needle.msf XXXXXXX_water.msf XXXXXXX_senseless_needle.msf XXXXXXX_senseless_water.msf и в протоколе – продолжение протоколов практикумов 4 и 5. Все файлы для проверки должны быть скопированы в директорию Credit2 Словарь. Гэп – то, что ставится в одной последовательности, если в ней нет остатков, аналогичным остаткам второй. Динамическое программирование – подход, когда для решения большой задачи она разбивается на подзадачи, аналогичные полной. Diff, репозитории – спросите Петю… Глобальное выравнивание – установление соответствия между двумя версиями одного текста. Алгоритм Нидльмана – Вунша – базовый алгоритм глобального выравнивания. Локальное выравнивание – поиск схожих частей в двух текстах, которые не обязательно сходны целиком. Алгоритм Смита – Ватермана – алгоритм поиска локального выравнивания. Матрицы аминокислотных замен (BLOSUM, PAM) Аффинные штрафы за гэп – это когда есть 2 разных штрафа - за открытие и удлинение гэпа. Гомологичные последовательности – последовательности белков или ДНК, произошедшие от одной предковой последовательност Сходные последовательности - последовательности, имеющие сравнительно много одинаковых (или сходных) букв Задания. 1. Сделайте 2 замены, пропустите 2 буквы и вставьте лишнюю в своей фамилии (или своего однокурсника ) . Постройте глобальное выравнивание получившегося слова с фамилией в правильном написании. Сделайте это в Excel, с помощью таблички, как в лекции. За совпадение букв увеличивайте вес на 1, за вставку – уменьшайте на 1, за сопоставление гласной с гласной или согласной с согласной присуждайте 0; за сопоставление гласной с согласной вычитайте единицу. В табличке отметьте цветом путь, соответствующий выравниванию, а под табличкой напишите само выравнивание (один символ – в одной клетке). Сохраните результат в файле XXXXXX_aln.xls, где XXXXXX – строго ВАША фамилия. 2. Постройте локальное выравнивание слов “neuroectoderm” и “exotermic”. Параметры веса – те же. Результат – выравнивание и его вес – сохраните в том же файле XXXXXX_aln.xls на странице “local”. 3. Постройте выравнивания последовательностей двух белков из данных вам PDB файлов: (a) глобальное с помощью программы needle (b) локальное с помощью программы water Результаты сохраните в файлах XXXXXXX_needle.msf и XXXXXXX_water.msf. Откройте в GeneDoc, cравните, опишите сходство и отличие этих выравниваний в протоколе. 4. Возьмите две части своего белка и выровняйте их между собой программами needle и water. Комментарии об алгоритмическом выравнивании последовательностей, не имеющих биологически обоснованного выравнивания вообще, внесите в протокол. Создайте файл foo.fasta, где будет первая часть вашего белка и bar.fasta, где будет вторая часть. Файлы должны содержать: >foo MALFGHERT… - первые 60 остатков белка >bar NGHFAH… - следующие 60 остатков белка оследовательность1.fasta последовательность2.fasta Выровняйте эти последовательности. Посмотрите внутрь выходного файла – помимо всякой всячины увидите там выравнивание. Как вы понимаете, все это выравнивание – полный бред. Сходство последовательностей, скорее всего, случайно. Тем не менее, программа очень постарается что-нибудь общее все же подогнать, и это будет выглядеть весьма правдоподобно. Посмотрите, каков вес такого выравнивания и посчитайте, сколько консервативных позиций нашлось. Все это нужно, чтобы вы не обманывались, когда будете находить сходства такого качества в реальных выравниваниях – не верьте им – это программа постаралась! Притом, как вы понимаете, чем длиннее последовательности, тем большая свобода у программы для подгонки, и тем лучше будет выглядеть полученное выравнивание. Вообще, можно так поиграть – брать случайные последовательности и равнять друг с другом – что-то найдется, только верить этому не надо.