АВТОМАТИЗАЦИЯ ОЦЕНКИ СТИЛЯ ТЕКСТОВ НА ОСНОВЕ
advertisement

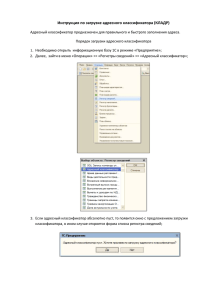
АВТОМАТИЗАЦИЯ ОЦЕНКИ СТИЛЯ ТЕКСТОВ НА ОСНОВЕ СТАТИСТИЧЕСКИХ ПАРАМЕТРОВ Л.С. Фазылова, Л.В. Устинова Карагандинский государственный университет им. Е.А. Букетова, Казахстан leyla.fazilova@mail.ru, ustinovakrg@mail.ru В XX веке появился ряд дисциплин прикладного характера на стыке лингвистики, математики и информатики. В частности, статистическая лингвистика – это дисциплина, изучающая количественные закономерности естественного языка, проявляющиеся в текстах. На данный момент существует ряд исследований, в которых представлены математические модели оценки сложности текста. Однако эти модели получены в основном для английских текстов и не подкреплены соответствующими системами автоматизированного анализа. Между тем, необходимость подобных систем и соответствующих методик анализа текстов возникает у экспертов-методистов, создателей учебников, а также учителей, разрабатывающих различные методические материалы. С развитием системы экспертизы и сертификации учебной и методической литературы появилась необходимость в объективных и быстро реализуемых оценках ряда параметров сложности учебных текстов [1]. Задачей нашего исследования является изучение количественной оценки сложности текста. В качестве основных критериев используются статистические параметры текста, такие, как длина слова, средняя длина предложения, процент многосложных слов и другие. Названные параметры требуют достаточно сложных методов и технологий определения. Полученные на основе этих параметров различные формулы оценивают так называемую удобочитаемость или сложность текста. Эти параметры легко поддаются количественному выражению и могут быть использованы для автоматизации оценки. Целью работы является разработка программы для автоматизации определения стиля текстов. Программа может применяться в учебном процессе для верификации курсовых и дипломных работ и определения соответствия публикаций стилю научной статьи. Автоматический классификатор функционального стиля текста создан на базе текстов, относящихся к четырём различным функциональным стилям [2]. Критерием классификации является спектр длин слов и энтропия проверяемого текста. В ходе создания программы«Классификатор текста» были проанализированы существующие программы поиска и анализа текстовой информации: продукт Кирсанова компании «Гарант-Парк-Интернет», инструмент удобочитаемости, «Худломер» [3], «Орфограммка». Для создания программы «Классификатор текста» синтезированы возможности языка программирования Delphi 7.0, языка гипертекстовой разметки HTML. Для обработки html документа был использованJavaScript. Версия написана на языке JavaScript и определяет функциональный стиль текста:разговорный стиль, стиль художественной литературы, газетно-информационный стиль, научно-деловой стиль.Принцип работы программы основывается на следующих оценках [3]: энтропия текста; спектр Манденхолла; закон Дж. Ципфа. Основным этапом при разработке программного обеспечения является определение интерфейсных частей программы. На рисунке 1 представлено главное окно программы Рисунок 1. Главное окно программы «Классификатор текста» Главная форма содержит компонент TWebBrowser для загрузки или ввода обрабатываемых документов. Компонент TOpenDialog реализует диалог открытия файла.При запуске этого диалога появляется окно (рис. 2), в котором можно выбрать имя открываемого файла. Рисунок 2. Диалоговое окно загрузки файлов В случае успешного закрытия диалогового окна (нажатием кнопки Open) в качестве результата возвращается выбранное имя файла. Файл загружается в окно WebBrowser. Ограничением загрузки данных являются файлы в формате RTF. При нажатии на кнопку «Проверить» выполняется скрипт, результатомкоторого является соответствие или несоответствие стиля уровню курсовой работы (научный текст), с выводом дополнительных характеристик проверяемого текста (рис. 3): Рисунок 3. Результат анализа текста При нажатии на кнопку «Назад» выполняется переход к главному окну загрузки или ввода обрабатываемых документов. Для выбора нескольких файлов в OpenDialogиспользуется клавиша-модификаторCtrl. Результат обработки содержит путь проверяемого документа, вывод о стиле проверяемого текста, процент соответствия (рис. 4): Рисунок 4. Результат обработки нескольких документов Для оптимизации программы используетсяASPack. Созданный классификатор текста требует дополнительного тестирования для статистической обработки больших массивов текстовых учебников и других методических материалов. В перспективе предлагаемый классификатор текста может применяться в учебном процессе для определения соответствия уровня курсовых, дипломных работ, а также для ускорения проверки на наличие и определения количества ошибок в тексте. Литература 1. Оборнева И. В. Автоматизация оценки качества восприятия текста // Вестник Московского городского педагогического университета. Серия "Информатика и информатизация образования", 2005, № 2 (5), С. 86-92. 2. Розенталь Д.Э. Практическая стилистика русского языка. Учебное пособие для вузов. М.: Высшая школа, 1987 — 352 с. 3. http://teneta.rinet.ru/2000/hudlomer/