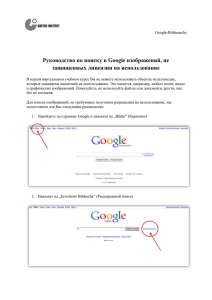
Machine Translated by Google Командир R и введение Наташа А. Карп [email protected] май 2010 г. Предисловие Этот материал задуман как вводное руководство по анализу данных с помощью R commander. Он был подготовлен как часть курса прикладной статистики, прочитанного в Wellcome Trust Sanger Institute летом 2010 года. Основная цель состоит в том, чтобы предоставить пошаговое руководство по использованию R commander для проведения исследовательского анализа данных и последующее применение статистического анализа для ответа на вопросы, широко задаваемые в науках о жизни. Эти заметки (версия 1.1) были написаны с помощью R Commander версии 1.4-10 под операционной системой Windows. Этот документ доступен для загрузки из сети комплексных архивов R (http://cran.r-project.org/) . и предоставляется бесплатно без каких-либо гарантий на его использование. Эта форма не может быть изменена без явного разрешения автора. Наташа А. Карп Биостатистик Группа генетики мышей Wellcome Trust Институт Сангера Кампус Wellcome Trust Genome Хинкстон Кембридж КБ10 1СА [email protected] 1 Machine Translated by Google Содержание 1. Запуск R Commander и импорт данных 1.1 Что такое R Commander? 1.2 Ссылки и дополнительные материалы для чтения 1.3 Установка R Commander 1.4 Запуск R Commander 1.5 Ввод данных 1.5.1 Ввод вручную 1.5.2 Импорт из текстового файла 1.5.3 Импорт из Excel 2. Использование R Commander для получения описаний 2.1 Проверка категориальных переменных 2.2 Проверка непрерывности переменные 3. Изменение набора данных 3.1 Вычисление новой переменной 3.2 Преобразование числовых переменных в категориальные переменные 3.3 Разделение данных 4. Использование R Commander для изучения данных 4.1 Графически 4.1.1 Гистограммы 4.1.2 Графики Norm QQ 4.1.3 Диаграммы рассеяния 4.1.4 Блочные диаграммы 4.2 Критерий Шапиро-Уилка на нормальность 5. Использование R commander для применения статистических тестов 5.1 Сравнение среднего 5.1.1 Критерий Стьюдента 5.1.2 Парный критерий Стьюдента 5.1.3 Стьюдентный критерий для одной выборки 5.1.4 Однофакторный дисперсионный анализ 5.2 Сравнение дисперсии 5.2.1 Тест Бартлетта 5.2.2 Тест Левена 5.2.3 Двухвариантный F-критерий 5.3 Непараметрические критерии 5.3.1 Двухвыборочный критерий Уилкоксона 2 Machine Translated by Google 5.3.2 Критерий Уилкоксона для парных выборок 5.3.3 Тест Краскела-Уоллиса 6. Изменение графического вывода 6.1 Изменение меток осей 6.2 Добавление основного заголовка 6.3 Добавление линии 6.4 Изменение внешнего вида линии 6.5 Изменение символа графика 6.6 Добавление текстовой метки 6.7 Изменение цветов графика 6.7.1 На блочной диаграмме 6.7.2 На точечной диаграмме 7 Rcommander Odds and Ends 7.1 Выход и произнесение скрипта 7.2 Сохранение и печать вывода 7.2.1 Копирование текста 7.2.2 Копирование графиков 7.3 Ввод команд непосредственно в окно скрипта 7.4 Текущее «дерево» меню R Commander (версия 1.4-10) 3 Machine Translated by Google 1. Запуск R commander и импорт данных 1.1 Что такое R Commander? R Commander — бесплатная статистическая программа. R Commander был разработан как простой в использовании графический пользовательский интерфейс (GUI) для R (бесплатный язык статистического программирования) и был разработан профессором Джоном Фоксом, чтобы позволить преподавать курсы статистики и устранить препятствия, связанные со сложностью программного обеспечения, в процессе изучения статистики. Это означает, что у него есть раскрывающиеся меню, которые могут управлять статистическим анализом данных. Он считается наиболее жизнеспособной альтернативой R коммерческим статистическим пакетам, таким как SPSS (Википедия). Пакет очень полезен для новичков в R, поскольку для каждого запуска анализа он отображает базовый код R. Домашняя страница: http://socserv.mcmaster.ca/jfox/Misc/Rcmdr/ Он также имеет серию плагинов, которые расширяют диапазон применения. RcmdrPlugin.Export — Графически экспортировать объекты в LaTeX или HTML RcmdrPlugin.FactoMineR — Графический пользовательский интерфейс для FactoMineR RcmdrPlugin.HH — Поддержка Rcmdr для пакета HH RcmdrPlugin.IPSUR. - Введение в вероятность и статистику с использованием R RcmdrPlugin.SurvivalT — Плагин Rcmdr Survival RcmdrPlugin.TeachingDemos — Подключаемый модуль демонстраций Rcmdr RcmdrPlugin.epack — Плагин Rcmdr для временных рядов RcmdrPlugin.orloca — Плагин orloca Rcmdr 1.2 Ссылки и дополнительные материалы для чтения • «R Commander: графический пользовательский интерфейс базовой статистики для R» Джон Фокс Журнал статистического программного обеспечения 2005 г., том 14, выпуск 9. • http://sociology.osu.edu/computing/helpDocs/rcmdr.pdf • http://socserv.mcmaster.ca/jfox/Misc/Rcmdr/Getting-Started-with-the-Rcmdr.pdf • http://courses.statistics.com/software/RCommander/RC00.htm • http://www.eau.ee/~ktanel/DK_0007/DK_prax4_2009.pdf 4 Machine Translated by Google 1.3 Установка R Commander Вам нужно сначала установить R, а затем R Commander. Следующая ссылка содержит хорошие инструкции по установке R: http://jekyll.math.byuh.edu/other/howto/R/R.shtml По следующей ссылке вы найдете хорошие инструкции по установке R Commander: http://jekyll.math.byuh.edu/other/howto/R/Rcmdr.shtml 1.4 Запуск R Commander я. Откройте программу R, например, дважды щелкните значок R или Пуск/все программы/R II. Чтобы открыть программу R Commander, введите в командной строке библиотеку («Rcmdr») и нажмите возвращаться. Откроется окно R Commander, показанное ниже. Панель инструментов Выпадающие меню Окно сценария: команды R, созданные графическим интерфейсом Вы можете вводить команды прямо здесь. Затем выберите, выделив, а затем отправьте код, нажав кнопку «Отправить» (справа под окном скрипта). Окно вывода ТЕМНО-СИНИЙ: распечатка КРАСНЫЙ: команда, которая использовалась Окно сообщения: КРАСНЫЙ: сообщения об ошибках ЗЕЛЕНЫЙ: Предупреждения СИНИЙ: Другая информация Примечание. Графики отображаются в отдельном окне графического устройства. Появится только самый последний график. Вы можете использовать клавиши page up и page down для вызова предыдущих графиков. 5 Machine Translated by Google Пункт раскрывающегося меню Файл Пункты меню для загрузки и сохранения файлов скриптов; для сохранения вывода и рабочего пространства R; и для выхода. Редактировать Пункты меню (Вырезать, Копировать, Вставить и т.д.) для редактирования содержимого окна скрипта и вывода. Щелчок правой кнопкой мыши в окне сценария или вывода также вызывает контекстное меню редактирования. Данные Подменю, содержащие пункты меню для чтения и управления данными. Статистика Подменю, содержащие пункты меню для различных основных статистических анализов. Графики Пункты меню для создания простых статистических графиков. Модели Пункты меню и подменю для получения числовых сводок, доверительных интервалов, проверки гипотез, диагностики и графиков для статистической модели, а также для добавления диагностических величин, таких как остатки, в набор данных. Распределения Вероятности, квантили и графики стандартных статистических распределений (для использования, например, вместо статистических таблиц). Инструменты Элементы меню для загрузки пакетов R, не связанных с пакетом Rcmdr (например, для доступа к данным, сохраненным в другом пакете), и для настройки некоторых параметров. Помощь Пункты меню для получения информации о R Commander (включая вводное руководство, взятое из этого документа). Кроме того, в каждом диалоговом окне R Commander есть кнопка «Справка». Кнопки панели инструментов Набор данных Показывает имя активного набора данных Кнопка: позволяет выбрать из набора данных, находящихся в настоящее время в памяти, какой из них будет активным. Изменить набор данных Позволяет открыть активный набор данных Просмотр набора данных Позволяет просматривать активный набор данных Модель Показывает название активной статистической модели, например, линейная модель. Кнопка: позволяет выбрать среди текущих моделей в памяти Элементы меню неактивны (т. е. выделены серым цветом), если они не применимы к текущему контексту. 6 Machine Translated by Google 1.5 Ввод данных 1.5.1 Ручной ввод я. Запустите новый набор данных через Данные -> Новый набор данных ii. Введите новое имя для набора данных -> OK Примечание: в имени не может быть пробелов . Примечание. R чувствителен к регистру, поэтому mydata MyData III. Окно редактора данных, в котором вы можете ввести свои данные, используя обычный формат электронной таблицы. Каждая строка соответствует независимому объекту, например, субъекту, на котором было выполнено измерение. IV. Определите переменные (столбец), щелкнув метку столбца, а затем в появившемся диалоговом окне введите имя и тип. Где тип может быть числовым (количественным) или символьным (качественным). Нажмите на x в правом углу, чтобы закрыть это диалоговое окно. v. Этот фрейм данных становится активным набором данных для R-командира. 7 Machine Translated by Google 1.5.2 Импорт из текстового файла Примечание: файл данных должен быть организован как классический фрейм данных. Каждый столбец представляет одну переменную, например, уровень глюкозы. Каждая строка представляет человека. Информация заголовка должна содержаться в одной строке. я. Данные -> Импорт данных -> из текстового файла II. Выберите имя для нового набора данных (обратите внимание, что пробелов быть не может). III. Укажите характеристики файлов данных (например, запятые для файлов csv) -> OK IV. Найдите и выберите файл/Открыть После того, как данные будут импортированы, вы должны еще раз проверить правильность считывания файла: в. Окно сообщения: есть ли ошибки? ви. Соответствует ли количество строк и столбцов ожидаемому? vii. Просмотрите данные с помощью кнопки View data set 1.5.3 Импорт из Excel Файлы данных можно считывать из Excel, однако с ними часто возникают проблемы. Вместо этого рекомендуется преобразовать файл в текстовый файл, а затем импортировать, как описано в 1.5.2. Как? 1. В Excel: Office -> Сохранить как и выберите формат файла с разделителями-запятыми (.csv). 8 Machine Translated by Google 2. Использование R Commander для получения описаний Роль описательных? 1. Проверка на ошибки Поиск значений, выходящих за пределы возможных значений переменной Поиск избыточного количества пропущенных значений 2. Как описательные Чтобы описать образец в своем отчете Для решения конкретных вопросов исследования 2.1 Проверка категориальных переменных я. Статистика -> Сводки -> Частотное распределение -> Выберите переменные-> ОК II. Вывод: для каждой выбранной вами переменной будет отображаться частота для каждого уровня. Красный текст III.после подсказки: Красный текст после #: IV. Код R, используемый для генерации вывода Объяснение того, что делает код Результат анализа показано синим цветом в. ви. Проверьте наличие неожиданных уровней, например, норма, а не норма. Проверьте количество пропущенных значений, кажется ли это уместным? 9 Machine Translated by Google 2.2 Проверка непрерывных переменных я. Статистика -> Сводки -> Числовая сводка II. Если у вас есть несколько групп (например, контроль и лечение), нажмите «Суммировать по группам» и выберите соответствующую переменную -> «ОК». Выход: Понимание вывода: параметр Что это? иметь в виду Мера центральной тенденции сд Стандартное отклонение - мера изменчивости данных. Н Количество показаний нет данных Количество пропущенных значений 0% Минимальное значение 25% Значение, ниже которого можно найти 25 процентов наблюдений. 50% Значение, ниже которого можно найти 50 процентов наблюдений. 75% Значение, ниже которого можно найти 75 процентов наблюдений. 100% Максимальное значение III. Проверьте свои минимальные и максимальные значения – имеют ли они смысл? IV. Проверьте количество пропущенных значений — если пропущенных значений много, вам нужно спросить, почему? 10 Machine Translated by Google v. Имеют ли смысл средние баллы? Это то, что вы ожидаете от предыдущего опыта? ви. Определение выброса Графики -> Индексный график vii. Выберите интересующую переменную VIII. Отметьте идентифицировать наблюдения с помощью мыши икс. Посмотрите на графический вывод и щелкните мышью по наблюдению, которое является выбросом. для него порядковый номер. 11 Machine Translated by Google 3. Изменение набора данных 3.1 Вычислите новую переменную i. Данные -> Управление переменными в активном наборе данных -> вычисление новых переменных II. Введите новое имя переменной III. Записывается выражение (уравнение), отражающее требуемый расчет. В таблице ниже указаны доступные операторы и примеры их использования. Примечание. Двойной щелчок по переменной в поле текущих переменных отправит переменную в выражение. Операторы Функция Пример 1 х+у Добавление Переменная 1 + Переменная 2 Переменная 1 + 25 х-у вычитание Переменная 1 – Переменная 2 35 - Переменная 1 Несколько Переменная 1*Переменная 2 100*переменная 1 Разделение Переменная 1/Переменная 2 Переменная 1 / 63 Икс * ух / у Икс ^ у X в степени Y Переменная 1 ^ Переменная2 лог10(х) Log10 (переменная 1) Преобразование Log10 журнал (х, база) Преобразование журнала Журнал (переменная 1, 2) на указанную базу 12 Пример 2 Переменная1^10 Machine Translated by Google 3.2 Преобразование числовых переменных в категориальные переменные Категориальные переменные — это меры на номинальной шкале, т. е. там, где вы используете метки. Например, горные породы обычно можно разделить на магматические, осадочные и метаморфические. Значения, которые можно взять, называются уровнями. Категориальные переменные не имеют числового значения, но часто кодируются для облегчения ввода и обработки данных в электронных таблицах. Например, пол часто кодируется таким образом, что мужской = 1, а женский = 2. Таким образом, данные можно вводить в виде символов (например, «нормальный») или цифр (например, 0, 1, 2). Важно убедиться, что программа различает категориальные переменные, введенные в числовом виде, и те переменные, значения которых имеют прямое числовое значение. Оценка того, введена ли переменная как категориальная: я. Статистика -> Сводки -> Частотное распределение Будут перечислены только категориальные переменные ИЛИ ЖЕ II. Изменить набор данных -> щелкните заголовок каждой строки, и он сообщит вам, что он числовой/категориальный. Преобразование числовых переменных в коэффициенты: я. Данные -> Управление переменными в активном наборе данных -> Преобразование числовых переменных в коэффициенты… II. Выберите переменные III. Вы можете сгенерировать новую переменную, введя имя в поле «имя новой переменной…». или же перезапишите исходное имя. 1. Уровни можно отформатировать как уровни, выбрав «использовать числа». 2. Перекодировано в имя, выбрав «имена уровня предложения». Если выбран этот параметр, появится другое диалоговое окно для ввода имени для каждого числового значения. IV. ХОРОШО 13 Machine Translated by Google 3.3 Разделение данных 3.3.1 по столбцам (переменным) i. данные -> активный набор данных -> подмножество активного набора данных II. Удерживайте клавишу CTRL, чтобы выбрать переменные, которые вы хотите сохранить. III. Дайте новому набору данных имя -> OK 3.3.2 по строкам (и переменным, если хотите) i. Данные -> активный набор данных -> подмножество активного набора данных II. Выберите переменные, которые вы хотите включить в новый набор данных. III. Напишите «выражение подмножества», которое является правилом для выбора строк. 14 Machine Translated by Google Символ/код == знак равно & Имя Использовать равенство используется для указания того, что переменная должна быть Неравенство равна используется для указания, что переменная не должна быть равна А также используется для объединения нескольких выражений Или же используется для объединения нескольких выражений is.na(имя_переменной) ! Включить пропущенные значения переменной is.na(имя_переменной) Исключить пропущенные значения переменной > Лучше чем < Меньше, чем >= Больше или равно <= Меньше или равно Примечание 1: Если вы используете имя в выражении, его необходимо заключить в двойные кавычки, например, «имя». Примечание 2: имя переменной чувствительно к регистру (т. е. оно должно точно совпадать с именем, используемым в качестве заголовка столбца). Пример: ПОЛ == «Женщина» Пример 2: ПОЛ == «Женщина» и ВОЗРАСТ <= 25 лет. IV. Дайте набору данных новое имя -> OK. 15 Machine Translated by Google 4. Использование R Commander для изучения данных 4.1 Графически Командир R может генерировать различные базовые статистические графики. Графический вывод в R commander ограничен выбором, предлагаемым в меню. Слишком много вариантов, чтобы их можно было разумно включить. В то время как в R, используя командную строку, варианты бесконечны. Если это станет проблемой, я бы порекомендовал поговорить с пользователем R или использовать книги и веб-ресурсы. Узнать больше. Некоторые ссылки для создания графиков в R R Graphics (информатика и анализ данных) Пола Мюррелла http://www.harding.edu/ fmccown/R/ http://www.statmethods.net/graphs/index.html http://freshmeat.net/articles/creating-charts-and-graphs-with-gnu-r http://www.ats.ucla.edu/stat/R/library/lecture_graphing_r.htm 4.1.1 Гистограммы В статистике гистограмма представляет собой графическое отображение табличных частот в виде полос. Он показывает, какая доля случаев попадает в каждую из нескольких категорий. я. График -> Гистограмма II. Выберите интересующую переменную III. Выберите масштаб оси IV. ХОРОШО 16 Machine Translated by Google 4.1.2 Графики нормы QQ В статистике график QQ («Q» означает квантиль) представляет собой график вероятностей, который представляет собой графический метод сравнения двух распределений вероятностей путем построения их квантилей относительно друг друга. Если два сравниваемых распределения подобны, точки на графике QQ будут приблизительно лежать на линии y = x. График нормы QQ сравнивает выборочное распределение с нормальным распределением. Дополнительная информация: http://www.cms.murdoch.edu.au/areas/maths/statsnotes/samplestats/qqplot.html. http://webhelp.esri.com/arcgisdesktop/9.2/index.cfm?TopicName=Normal_QQ_plot_and_gen eral_QQ_plot я. График -> График сравнения квантилей II. Выберите интересующую переменную III. Выберите раздачу как обычно IV. ХОРОШО 17 Machine Translated by Google 4.1.3 Диаграммы рассеяния а. График -> Диаграмма рассеяния б. Выберите переменные для оси x и оси y в. Введите имя для метки оси X и метки оси Y. д. Если вы хотите, оси x или y могут быть зарегистрированы. е. Джиттер: это полезно, когда есть много точек данных, чтобы увидеть, не перекрываются ли они, как Функция используется для случайного смещения точек, но это не влияет на подгонку линии. ф. Линия наименьших квадратов может быть выбрана для наилучшего соответствия линии линейной регрессии. грамм. График по группам позволит выбрать категориальную переменную, так что точечная диаграмма будет использовать цвет, чтобы различать группы по категориальной переменной, и подгонять линии регрессии независимо для каждой группы. час Интерпретация вывода? 18 Machine Translated by Google Пунктирная линия: лучше всего подходит линейная регрессия Сплошная линия: лёссовая линия. Лёссовая линия представляет собой локально взвешенную линию и используется для оценки того, уместно ли предположение о линейности. Визуально вы смотрите, предлагает ли лессовая линия значительное отклонение от линейной. Ящичные диаграммы дают представление о разбросе каждой переменной независимо. 19 Machine Translated by Google 4.1.4 Блочные диаграммы Блочная диаграмма или диаграмма с ячейками и усами обеспечивает простую графическую сводку набора данных. Это удобный способ графического представления данных с помощью сводки из пяти чисел: наименьшее наблюдение (минимум), нижний квартиль (Q1), медиана (Q2), верхний квартиль (Q3) и наибольшее наблюдение (максимум). Квартиль — это любое из трех значений, которые делят отсортированный набор данных на четыре равные части, так что каждая часть представляет собой одну четвертую выборки. Выбросы, точки, которые находятся более чем в 1,5 межквартильного диапазона (Q3-Q1) от межквартильных границ, отмечаются индивидуально. а. Выберите интересующую переменную б. График по группам: позволяет располагать ящичные диаграммы рядом друг с другом, разделяя переменную на категориальная переменная. в. Идентифицировать выбросы с помощью мыши: этот параметр позволяет навести указатель мыши на точку данных выброса и определить его положение в наборе данных. д. ХОРОШО 4.2 Тест Шапиро-Уилка на нормальность Это проверка гипотезы с помощью нулевой гипотезы о том, что данные получены из нормального распределения. Следовательно, если p-значение ниже порога значимости (обычно 0,05), нулевая гипотеза отклоняется и принимается альтернативная гипотеза. Здесь альтернативная гипотеза состоит в том, что данные не поступают из нормального распределения. а. Резюме -> Тест нормальности Шаприо-Уилка б. Выберите интересующий параметр в. ХОРОШО д. Интерпретация: если p-значение ниже порога значимости, то принимается альтернативная гипотеза о том, что данные не поступают из нормального распределения. 20 Machine Translated by Google 5. Использование R commander для применения статистических тестов 5.1 Сравнение средних 5.1.1 Критерий Стьюдента Двухвыборочный t-критерий Стьюдента используется, чтобы определить, равны ли два средних значения совокупности. а. Статистика -> Средства -> Стьюдентный критерий независимых выборок . б. Выберите группирующую переменную, например, генотип в. Выберите переменную ответа (параметр, который вас интересует). д. Обычно вы выбираете двустороннюю гипотезу; это означает, что изменение среднего может быть либо увеличение или уменьшение. е. Обычно используется уровень достоверности 0,95. ф. Если вы не предполагаете равную дисперсию, этот тест эквивалентен t-критерию Велча и считается более надежным. Небольшие отклонения от равной дисперсии существенно влияют на надежность результатов. Критерий Левена (5.3.2) можно использовать для проверки равенства дисперсий. грамм. ХОРОШО. час Интерпретация? Если p-значение ниже порога значимости, то существует значительное разница в средних баллах для каждой из двух групп. 21 Machine Translated by Google 5.1.2 Парный критерий Стьюдента Парный тест используется для сравнения средних значений по одному и тому же или родственному предмету с течением времени или в различных обстоятельствах. В парном эксперименте существует однозначное соответствие между значениями в двух выборках (например, до и после лечения, парные испытуемые, например, близнецы). Парный подход считается более чувствительным, поскольку он ищет различия в лечении, исключая первоначальные биологические различия. Примечание. Формат файла данных Нужны две колонки; один столбец содержит первое число в каждой паре наборов данных (например, данные «до»), а другой столбец содержит второе число в каждой паре наборов данных. Пары чисел должны быть в одном ряду. а. Статистика -> Средства -> Парный t-критерий б. Выберите первую переменную в. Выберите вторую переменную д. Обычно вы выбираете двустороннюю гипотезу; это означает, что изменение среднего может быть либо увеличение или уменьшение. е. Обычно используется уровень достоверности 0,95. ф. ХОРОШО. грамм. Интерпретация? • Если p-значение ниже порога значимости, то разница в средних значениях не равна 0 • Среднее значение разницы указывает среднюю разницу (переменная 1 — переменная 2) • 95% доверительный интервал — это доверительный интервал вокруг средней разницы. 22 Machine Translated by Google 5.1.3 Стьюдентный критерий для одной выборки Стьюдентный критерий для одной выборки проверяет нулевую гипотезу о том, что среднее значение генеральной совокупности равно заданному значению. Если это значение равно нулю (или не введено), то дается доверительный интервал для выборочного среднего. а. Статистика -> Средства -> Одновыборочный t-критерий б. Выберите интересующую переменную в. Введите предполагаемое среднее значение (нулевая гипотеза: mu=) d. Обычно используется уровень достоверности 0,95. е. Возможны три альтернативные гипотезы: а. Среднее значение не равно указанному значению b. Среднее значение меньше указанного значения c. Среднее значение больше указанного значения ф. ХОРОШО. грамм. Интерпретация? Если p-значение ниже порога значимости, то разница в средних не равен 0. 23 Machine Translated by Google 5.1.4 Однофакторный дисперсионный анализ Этот тест используется, когда вы хотите сравнить средние баллы более чем двух групп. Дисперсионный анализ называется так потому, что он сравнивает дисперсию (изменчивость оценок) между различными группами (считается, что она обусловлена группирующей переменной) с изменчивостью внутри каждой из групп (считается, что она обусловлена случайностью). Отношение дисперсии преобразуется в p-значение, которое оценивает вероятность того, что эта разница в дисперсии возникает из-за влияния выборки. Значительное значение p указывает на то, что мы можем отклонить нулевую гипотезу, которая утверждает, что средние значения популяций равны. Однако это не говорит нам, какие из групп отличаются. Если в однофакторном дисперсионном анализе получена значительная оценка, то используется апостериорное тестирование, чтобы определить, где возникла разница. Программное обеспечение использует процедуру апостериорного сравнения Тьюки, которая необходима, как t-критерий Стьюдента, однако тест учитывает риск накопления ложноположительных результатов при проведении нескольких тестов. а. Статистика -> Средства -> Однофакторный дисперсионный анализ б. Введите название модели в. Выберите переменную ответа d. Выберите группирующую переменную е. ХОРОШО ф. Интерпретация? 24 Machine Translated by Google р-значение Резюме группы Если p-значение ниже порога значимости, то где-то имеется статистически значимая разница в средних значениях двух или более групп. грамм. Если p-значение является значимым, повторите анализ с отмеченной кнопкой попарных сравнений средних. Это повторяет анализ, когда группы сравниваются друг с другом с использованием контрастов Тьюки. час Интерпретация? Результатом является средняя разница и 95% доверительный интервал этой средней разницы для каждого возможного сравнения. Этот результат отображается математически и графически. Вы ищете сравнения, в которых доверительный интервал средней разницы не охватывает ноль, что указывает на статистически значимую разницу в этих группах. 25 Machine Translated by Google Это групповое сравнение имеет оценочную разницу в 0,6 и уверенность интервал по этой оценке не охватывает ноль. Таким образом, это статистически значительный. 26 Machine Translated by Google 5.2 Сравнение дисперсии Эти тесты проверяют, имеют ли разные выборки одинаковую дисперсию (однородность дисперсии). Нулевая гипотеза состоит в том, что дисперсия одинакова для всех групп. Когда вычисленное значение p падает ниже порога значимости (обычно 0,05), нулевая гипотеза отклоняется и принимается альтернативная гипотеза о том, что дисперсия неодинакова по группам. 5.2.1 Тест Бартлетта Тест Бартлетта чувствителен к отклонениям от нормы. То есть, если ваши выборки получены из ненормальных распределений, то тест Бартлетта может просто проверять на ненормальность. Тест Левена (5.3.2) является альтернативой тесту Бартлетта, который менее чувствителен к отклонениям от нормы. а. Статистика -> дисперсия -> критерий Бартлетта б. Выберите группирующую переменную в. Выберите переменную ответа д. ХОРОШО е. Интерпретация: если p-значение ниже порога значимости, то дисперсия в группы не равны. 5.2.2 Тест Левена Критерий Левена менее чувствителен к отклонениям от нормы, чем критерий Бартлетта (5.3.1). Если у вас есть веские доказательства того, что ваши данные действительно имеют нормальное или почти нормальное распределение, то тест Бартлетта работает лучше. а. Статистика -> дисперсия -> тест Левена 27 Machine Translated by Google б. Выберите группирующую переменную в. Выберите переменную ответа д. ХОРОШО е. Интерпретация: если p-значение ниже порога значимости, то дисперсия в группы не равны. 5.2.3 F-тест с двумя дисперсиями F-тест используется для проверки равенства стандартных отклонений двух популяций. Этот тест может быть двусторонним или односторонним. Двусторонняя версия проверяет альтернативу, в которой стандартные отклонения не равны. Односторонняя версия проверяет только в одном направлении, т. е. стандартное отклонение от первой совокупности либо больше, либо меньше (но не в обоих случаях) стандартного отклонения второй совокупности. Выбор определяется задачей. Например, если мы тестируем новый процесс, нас может интересовать только то, является ли новый процесс менее изменчивым, чем старый процесс. а. Статистика -> дисперсия -> F-тест с двумя дисперсиями б. Выберите группирующую переменную в. Выберите переменную ответа д. Выберите одно- или двухвостый е. ХОРОШО ф. Интерпретация: Когда p-значение падает ниже порога значимости, нулевая гипотеза принимается. отвергается, а альтернативная гипотеза принимается. 28 Machine Translated by Google 5.3 Непараметрические тесты Это статистические тесты, которые являются методами без распределения, поскольку они не полагаются на предположения о том, что данные взяты из заданного распределения вероятностей. 5.3.1 Двухвыборочный критерий Уилкоксона Непараметрический эквивалент критерия Стьюдента . Также можно назвать двухвыборочный U-критерий Манна-Уитни. Этот тест оценивает, различаются ли значения в двух выборках по размеру. а. Статистика -> Непараметрические тесты -> Критерий Уилкоксона для двух выборок б. Выберите группирующую переменную в. Выберите переменную ответа (переменная, представляющая интерес) д. Если n низкое (<50), то в качестве типа теста следует выбрать точный. е. Если разница в обработке может возникать в любом направлении (т. е. увеличиваться или уменьшаться), выберите двусторонний тест. ф. ХОРОШО грамм. Интерпретация: Когда p-значение падает ниже порога значимости, нулевая гипотеза принимается. отвергается, а альтернативная гипотеза принимается. 29 Machine Translated by Google 5.3.2 Критерий Уилкоксона для парной выборки Критерий Уилкоксона для парных выборок является непараметрическим эквивалентом парных выборок t тест. Примечание. Формат данных Нужны две колонки; один столбец содержит первое число в каждой паре наборов данных (например, данные «до»), а другой столбец содержит второе число в каждой паре наборов данных. Пары чисел должны быть в одном ряду. а. Статистика -> Непараметрические тесты -> Критерий Уилкоксона для парной выборки б. Выберите первую переменную в. Выберите вторую переменную д. Если изменение может быть как увеличением, так и уменьшением, выберите двусторонний тест. е. ХОРОШО ф. Интерпретация: Когда p-значение падает ниже порога значимости, нулевая гипотеза отвергается и принимается альтернативная гипотеза. 30 Machine Translated by Google 5.3.3 Тест Краскела-Уоллиса Этот тест представляет собой непараметрический метод проверки равенства медиан генеральной совокупности среди групп. Он идентичен дисперсионному анализу (5.1.4), в котором данные заменены их рангами. Это расширение двухвыборочного теста Уилкоксона на 3 или более групп. а. Статистика -> Непараметрические тесты -> Критерий Крускала-Уоллиса б. Выберите группирующую переменную в. Выберите переменную ответа (переменная, представляющая интерес) д. ХОРОШО 31 Machine Translated by Google 6. Изменение графического вывода Одна из основных причин, по которой аналитики данных обращаются к R , заключается в его сильных графических возможностях. Однако в R Commander возможности графиков ограничены, они выглядят не очень красиво и не подходят для отчетов или презентаций. Здесь я привожу несколько примеров того, что вы можете сделать, а затем это должно дать вам основу для дальнейших действий, если вам это нужно. Общая стратегия состоит в том, чтобы вызвать код для базового графа, а затем изменить код вручную, изменив графические параметры или вызвав вторую функцию для выполнения определенной работы (например, добавления метки). Для будущих советов и поддержки по R и графикам я рекомендую: 1. R Graphics от Пола Мюррелла 2. Анализ данных и графика с использованием R: подход, основанный на примерах, Джон Майндональд и Джон Браун. Внесение поправок в код - вещи для заметок 1. Если вы добавляете другой параметр (инструкцию) к функции, он должен быть частью списка, поэтому он помещается в скобки информации, передаваемой этой функции, и запятая ставится между каждой инструкцией. 2. Если вы используете слова для описания желаемого цвета или для добавления метки, то они должны быть заключены в кавычки (т. е. «»), чтобы программное обеспечение знало, что оно просматривает строковую (т. е. текстовую) информацию. 3. Письмо особенно важно, поэтому заглавные буквы и т. д. имеют значение. 32 Machine Translated by Google 6.1 Изменение меток осей а. Используйте выпадающие меню, чтобы запросить график, например, блочную диаграмму (9.1.4). б. Теперь вы можете изменить код. Чтобы изменить метку на оси x, вы либо изменяете текст в кавычках для xlab= «XX» и аналогично для ylab, либо добавляете текст, который хотите включить. Пример: изменение метки с CHOL на уровень холестерина (ммоль/л) Исходный код Измененный код кнопка отправки в. Выделите код и нажмите кнопку отправки, чтобы активировать скрипт. 33 Machine Translated by Google 6.2 Добавление основного заголовка а. Используйте выпадающие меню, чтобы запросить график. б. Параметр, управляющий заголовком, является основным. Вы можете либо изменить текст, если он существует или добавьте параметр в инструкции для функции графика. в. Пример: Исходный код: boxplot(CHOL~GENOTYPE, ylab="Уровень холестерина (ммоль/л)", xlab="GENOTYPE", data=ALL) Измененный код: boxplot(CHOL~GENOTYPE, ylab="Уровень холестерина (ммоль/л)", main="Гендерное сравнение уровней холестерина", xlab="GENOTYPE", data=ALL)Добавить в код д. Выделите код и нажмите кнопку «Отправить», чтобы активировать скрипт. 34 Machine Translated by Google 6.3 Добавление линии а. Используйте раскрывающиеся меню, чтобы запросить точечную диаграмму. б. Здесь нужна вторая функция (abline), чтобы добавить строку. Параметры в скобках используются для передачи информации функции. Они используются для управления размещением линий на графике. Если вы не укажете параметр, то параметр будут установлены настройки по умолчанию. Abline структура: abline (a = NULL, b = NULL, h = NULL, v = NULL, , ...) параметр По умолчанию а НУЛЕВОЙ б НУЛЕВОЙ час перехватите наклон значения y для НУЛЕВОЙ в горизонтальной линии (линий). НУЛЕВОЙ ... значение(я) x для вертикальной линии(й). графические параметры, такие как col, lty и lwd , а также характеристики линий lend , ljoin и lmitre. в. Добавление вертикальной линии в точке x я. Введите код abline(v=x) в окно скрипта II. Выделите код и отправьте. Пример: диаграмма рассеяния (Fat.Percentage.Estimate~Weight, reg.line=lm, smooth=FALSE, метки = ЛОЖЬ, диаграммы = ЛОЖЬ, диапазон = 0,5, данные = DEXA) Аблин (v = 22,5) 35 Machine Translated by Google д. Добавление горизонтальной линии в точке x я. Введите код abline(h=x) в окно скрипта II. Выделите код и отправьте.# е. Добавление строки известного уравнения я. Введите код abline(a=x, b=y) в окно скрипта II. Выделите код и отправьте. ф. Добавление строки эквивалентности я. Введите код abline(b=1) в окно скрипта II. Выделите код и отправьте. 36 Machine Translated by Google 6.4 Изменение параметров линии В функцию abline можно добавить ряд параметров, чтобы изменить вывод. колонка Самый простой способ указать цвет — использовать имя, например, «красный». R понимает 657 различных названий цветов. Введите colors(), чтобы увидеть полный список известных имен. лти Тип линии. Типы линий могут быть указаны как целое число (0=пустое, 1=сплошное (по умолчанию), 2=штриховое, 3=точечное, 4=точка-тире, 5=длинное тире, 6=двойное тире) или как одна из строк символов "пусто" . ", "сплошной", "пунктирный", "точечный", "точечный", "длинный" или "двойной", где "пусто" использует "невидимые линии" (т. е. не рисует их). лвд Ширина линии, положительное число, по умолчанию равное 1. Пример: диаграмма рассеяния (Fat.Percentage.Estimate~Weight, reg.line=lm, smooth=FALSE, метки = ЛОЖЬ, диаграммы = ЛОЖЬ, диапазон = 0,5, данные = DEXA) abline (v = 22,5, col = "фиолетовый", lty = "пунктир", lwd = 3) 37 Machine Translated by Google 6.5 Изменение графического символа R предоставляет фиксированный набор из 26 символов данных для построения графика, а символ управляется pch . параметр. Pch 21–25 позволяют использовать цвет заливки отдельно от цвета границы, при этом параметр bg управляет цветом заливки в этих случаях. Пример: диаграмма рассеивания (Жирность. Процент. Оценка ~ Вес, reg.line = lm, span = 0,5, данные = DEXA) диаграмма рассеивания (Fat.Percentage.Estimate ~ Weight, reg.line = lm, pch = 2, col = «red», span = 0,5, data = DEXA) 38 Machine Translated by Google 6.6 Добавление текстовой метки Здесь вторая функция (текст) используется для добавления текста. Параметры в квадратных скобках используются для передачи информации в функцию для управления текстом и местом его размещения. Если вы не укажете параметр, для него будут установлены значения по умолчанию. Текстовая функция: текст (x, y, метка, столбец) параметр По умолчанию Х, у Координаты, где должен быть написан текст «метки» этикетка Это указывает текст, который будет написан колонка Черный Цвет текста. Пример 1 точечная диаграмма (Fat.Percentage.Estimate ~ Weight, reg.line = lm, smooth = FALSE, labels = FALSE, boxplots = FALSE, span = 0,5, данные = DEXA) text(x=25, y=20, label = "пример метки") 39 Machine Translated by Google 6.7 Изменение цветов графика 6.7.1 Для коробчатой диаграммы а. Используйте выпадающие меню, чтобы запросить блочную диаграмму. б. Измените сценарий, добавив параметр col. я. Чтобы добавить один цвет ко всем диаграммам, добавьте col=("COLOUR OF YOUR CHOICE") к коду. II. Чтобы изменить каждую диаграмму по отдельности, вам нужно добавить список цветов с помощью длина, соответствующая количеству ящиков для кода. Например. col=c("красный", "черный", "зеленый") III. Выделите измененный код и отправьте. IV. Пример: ящичковая диаграмма (Жирность. Процент. Оценка ~ Генотип, lab="Fat.Percentage.Estimate", xlab="Генотип", col=c("серый", "желтый"), data=DEXA) 40 Machine Translated by Google 6.7.2 Для точечной диаграммы а. Использование выпадающих меню для запроса точечной диаграммы. б. Вы можете изменить цвет точечных диаграмм с помощью параметра col. а. Для графика с одной группой введите col=c("черный", "ЦВЕТ ПО ВАШЕМУ ВЫБОРУ") в список. Пример: диаграмма рассеяния (Вес ~ Жирность. Процент. Оценка, reg.line = lm, smooth = TRUE, labels = FALSE, boxplots = 'xy', span = 0,5, col = c ("черный", "синий"), данные =DEXA) б. Для графика с несколькими группами: Вы добавляете цвета в виде списка (например, col=c("черный", "зеленый", "розовый", "желтый")). Первый цвет в списке предназначен для чего-то, что я не могу понять, и я установил черный только в кейс. Следующие цвета предназначены для ваших групп. Порядок будет соответствовать уровням групп, если они выводятся в алфавитном порядке. Пример: диаграмма рассеяния (Вес ~ Жир. Процент. Оценка | Генотип, reg.line = lm, smooth = FALSE, labels = FALSE, boxplots = FALSE, span = 0,5, by.groups = TRUE, data = DEXA, col = c( "черный", "красный", "фиолетовый")) 41 Machine Translated by Google 42 Machine Translated by Google 7. Разногласия 7.1 Выход и сохранение скрипта я. Файл -> Выход -> Из R Commander и R -> ОК II. Есть два преимущества сохранения сценария а. Предоставляет отчет о проведенном анализе. б. Во время следующего сеанса пользователь может «вернуться туда, где остановился», открыв сохраненный сценарий и отправив синтаксис. III. При выходе из R спросит, сохранить ли образ рабочей области, лучше ответить НЕТ потому что программа R может запутаться переносимыми объектами (наборами данных/параметрами). Лучший способ — сохранить сценарий (кодирование). 7.2 Сохранение и печать вывода Рекомендуется собрать текстовый вывод и графики, которые вы хотите сохранить в документе текстового процессора. Таким образом, вы можете чередовать вывод R с типизированными примечаниями и пояснениями. 7.2.1 Копирование текста Выделите текст мышью -> ctrl-c и вставьте ctrl-v, как в любом оконном приложении. 7.2.2 Копирование графиков Щелкните правой кнопкой мыши график, выберите «Копировать как метафайл» и вставьте прямо в Word или PowerPoint. В качестве альтернативы можно также сохранить график как независимый файл: 43 Machine Translated by Google Графики -> Сохранить график в файл -> как растровое изображение/EPS/PDF ….. 7.3 Ввод команд непосредственно в окно сценария Команды, сгенерированные R Commander, отображаются в окне сценария, и в этом окне вы можете вводить и редактировать команды. Чтобы отправить этот скрипт, вы должны выделить соответствующий текст и нажать кнопку «Отправить». Заметки: 1. Все строки многострочной команды должны быть представлены на исполнение одновременно. 2. Команды, занимающие более одной строки, должны иметь вторую и последующие строки с отступом в один или несколько пробелов или табуляций. 7.4 Текущее «дерево» меню R Commander (версия 1.4-10) Файл Изменить рабочий каталог… Откройте файл сценария… Сохранить сценарий… Сохранить скрипт как… Сохранить вывод… Сохранить вывод как… Сохранить рабочую область R… Сохранить рабочую область R как… Выход От командира От Командира и Р Редактировать Резать Копировать Вставить Удалить Находить… Выбрать все Отменить Повторить Чистое окно Данные Новый набор данных… Загрузить набор данных… Импорт данных из текстового файла, буфера обмена или URL-адреса… из набора данных SPSS… из набора данных Minitab… 44 Machine Translated by Google из набора данных STATA... из набора данных Excel, Access или dbase... Данные в пакетах Список наборов данных в пакетах Чтение набора данных из прикрепленного пакета… Активный набор данных Выберите активный набор данных… Обновить активный набор данных Справка по активному набору данных (если применимо) Переменные в активном наборе данных Установить имена наблюдений… Подмножество активного набора данных Удалить строку(и) из активного набора данных… Переменные стека в активном наборе данных… Удалить обращения с отсутствующими данными… Сохранить активный набор данных… Экспортировать активный набор данных… Управление переменными в активном наборе данных Перекодировать переменные… Вычислить новую переменную… Добавить номера наблюдений в набор данных Стандартизировать переменные… Преобразование числовых переменных в коэффициенты… Числовая переменная Bin… Переупорядочить уровни фактора… Определить контрасты для фактора… Переименовать переменные… Удалить переменные из набора данных… Статистика Сводки Активный набор данных Численные сводки… Распределение частот… Подсчет пропущенных наблюдений Таблица статистики Корреляционная матрица… Корреляционный тест… Тест Шапиро-Уилка на нормальность… Таблицы непредвиденных обстоятельств Двусторонняя таблица… Многосторонний стол… Введите и проанализируйте двустороннюю таблицу… 45 Machine Translated by Google Означает Одновыборочный t-критерий… Стьюдентный критерий независимых выборок… Парный t-тест… Однофакторный дисперсионный анализ… Многофакторный дисперсионный анализ… Пропорции Одновыборочный пропорциональный тест… Двухвыборочный тест пропорций… Отклонения Двухвариантный F-критерий… Тест Бартлетта… Тест Левена… Непараметрические критерии Двухвыборочный критерий Вилкоксона… Тест Уилкоксона для парных выборок… Тест Краскела-Уоллиса… Критерий суммы рангов Фридмана… Размерный анализ Надежность весов… Анализ главных компонент… Факторный анализ… Кластерный анализ Кластерный анализ k-средних… Иерархический кластерный анализ… Суммировать иерархические кластеризация… Добавить иерархическую кластеризацию в набор данных… Подходящие модели Линейная регрессия… Линейная модель… Обобщенная линейная модель… Полиномиальная логит-модель… Модель порядковой регрессии… Цветовая палитра графиков… Индексный график… Гистограмма… Выставка «стебель-листья»… Блочная диаграмма… График количественного сравнения… 46 Machine Translated by Google Диаграмма рассеяния… Матрица рассеяния… Линейный график… График кондиционирования XY… Сюжет средств… Гистограмма… Круговая диаграмма… 3D-график 3Dдиаграмма рассеяния… Идентифицировать наблюдения с помощью мыши Сохранить график в файл Сохранить график в файл как растровое изображение… как PDF/Postscript/EPS… 3D-график RGL… Модели Выберите активную модель Суммировать модель Добавить статистику наблюдения к данным Доверительные интервалы Информационный критерий Акаике (AIC) Байесовский информационный критерий (БИК) Гипотеза проверяет таблицу ANOVA… Сравните две модели… Линейная гипотеза… Численная диагностика Факторы дисперсии-инфляции Тест Бреуша-Пагана на гетероскедастичность Тест Дарбина-Ватсона на автокорреляцию СБРОС теста на нелинейность Тест Бонферрони на выбросы Графики Основные диагностические графики График сравнения остаточных квантилей Компонент + остаточные участки Графики с добавленными переменными График влияния Графики эффектов Распределения 47 Machine Translated by Google Непрерывные распределения Нормальное распределение Нормальные квантили… Нормальные вероятности… Постройте нормальное распределение… Образец из нормального распределения… т распределение t квантилей… t вероятностей… Распределение t… Образец из распределения t… Распределение хи-квадрат Квантиль хи-квадрат… Вероятность хи-квадрат… Постройте распределение хи-квадрат… Образец из распределения хи-квадрат… распределение F F-квантили… F вероятности… Распределение участка F… Образец из дистрибутива F… Экспоненциальное распределение Экспоненциальные квантили… Экспоненциальные вероятности… Постройте экспоненциальное распределение… Образец из экспоненциального распределения… Равномерное распределение Равномерные квантили… Равномерные вероятности… Участок Равномерное распределение… Образец из равномерного распределения… Бета-распределение Бета-квантили… Бета-вероятность… Бета-распределение сюжета… Образец из бета-версии… Распределение Коши Квантиль Коши… Коши вероятности … Постройте распределение Коши… Образец из распределения Коши… Логистическая дистрибуция Логистические квантили… 48 Machine Translated by Google Логистические вероятности… Участок Логистическое распределение… Образец из логистической дистрибуции… Логнормальное распределение Логнормальные квантили… Логнормальные вероятности… Постройте логнормальное распределение… Образец из логнормального распределения… Гамма-распределение Гамма-квантили… Гамма вероятности… Постройте гамма-распределение… Образец из гамма-распределения… Распределение Вейбулла Квантиль Вейбулла… Вероятность Вейбулла… Постройте распределение Вейбулла… Образец из дистрибутива Вейбулла… Распределение Гамбеля Квантиль Гамбеля… Вероятность Гамбеля… Постройте распределение Гамбеля… Образец из дистрибутива Гамбеля… Дискретные распределения Биномиальное распределение Биномиальные квантили… Биномиальные хвостовые вероятности… Биномиальные вероятности… Постройте биномиальное распределение… Образец из биномиального распределения… распределение Пуассона Квантиль Пуассона… Вероятность пуассоновского хвоста… Вероятности Пуассона… Постройте распределение Пуассона… Образец из распределения Пуассона… Геометрическое распределение Геометрические квантили… Вероятности геометрического хвоста… Геометрические вероятности… График Геометрическое распределение… Образец из геометрического распределения… Гипергеометрическое распределение 49 Machine Translated by Google Гипергеометрические квантили… Вероятности гипергеометрического хвоста… Гипергеометрические вероятности… Постройте гипергеометрическое распределение… Образец из гипергеометрического распределения… Отрицательное биномиальное распределение Отрицательные биномиальные квантили… Отрицательные биномиальные хвостовые вероятности… Отрицательные биномиальные вероятности… Постройте отрицательное биномиальное распределение… Образец из отрицательного биномиального распределения… Инструменты Загрузить пакет(ы)… Загрузить плагин(ы) Rcmdr… Опции… Помощь Помощь командира Знакомство с R Commander Справка по активному набору данных (если применимо) О Rcmdr 50