Минобрнауки России
Федеральное государственное бюджетное образовательное учреждение
высшего образования
«Сыктывкарский государственный университет имени Питирима Сорокина»
(ФГБОУ ВО «СГУ им. Питирима Сорокина»)
Институт точных наук и информационных технологий
Н. К. Попова
Алгоритмы и алгоритмические языки
Курс лекций
Текстовое учебное электронное издание на компакт-диске
Сыктывкар
Издательство СГУ им. Питирима Сорокина
2017
ISBN 978-5-906810-44-1
Титул
Об издании
©
©
©
Попова Н. К., 2017
ФГБОУ ВО «СГУ им. Питирима Сорокина», 2017
Оформление. Издательство СГУ им. Питирима
Сорокина, 2017
Производственно-технические сведения
Содержание
УДК
ББК
004.021
22.12
П58
Все права на размножение и распространение в любой форме остаются
за организацией-разработчиком.
Нелегальное копирование и использование данного продукта запрещено.
Издается по постановлению научно-методического совета
ФГБОУ ВО «СГУ им. Питирима Сорокина»
Рецензент
В. Н. Тарасов, к. ф.-м. н., старший научный сотрудник
физико-математического института Коми научного центра УрО РАН.
П58
Попова, Н. К.
Алгоритмы и алгоритмические языки [Электронный ресурс] : курс
лекций: текстовое учебное электронное издание на компакт-диске /
Н. К. Попова ; Федер. гос. бюдж. образоват. учреждение высш.
образования «Сыктыв. гос. ун-т им. Питирима Сорокина». – Электрон.
текстовые дан. (2,0 Мб). – Сыктывкар: Изд-во СГУ им. Питирима
Сорокина, 2017. – 1 опт. компакт-диск (CD-ROM). – Систем. требования:
ПК не ниже класса Pentium III ; 256 Мб RAM ; не менее 1,5 Гб на
винчестере ; Windows XP с пакетом обновления 2 (SP2) ; Microsoft Office
2003 и выше ; видеокарта с памятью не менее 32 Мб ; экран
с разрешением не менее 1024 × 768 точек ; 4-скоростной дисковод (CDROM) и выше ; мышь. – Загл. с титул. экрана. ISBN 978-5-906810-44-1.
Учебное пособие предназначено для изучения теоретического материала дисциплины
«Алгоритмы и алгоритмические языки». Рекомендовано студентам, обучающимся по
направлению 01.03.02 «Прикладная математика и информатика» по профилю
«Вычислительная математика и информационные технологии».
Учебное пособие будет полезно студентам бакалавриата, а также преподавателям в
качестве материала для организации аудиторной и внеаудиторной самостоятельной
работы по дисциплине.
УДК 004.021
ББК 22.12
Титул
Об издании
Производственно-технические сведения
Содержание
Алгоритмы и алгоритмические языки
Содержание
Введение ................................................................................................................................................ 4
Лекция 1. Понятие алгоритма .............................................................................................................. 1
Лекция 2. Компьютер — универсальный исполнитель ................................................................... 12
Лекция 3. Алгоритмические языки .................................................................................................... 22
Лекция 4. Структурирование программы ......................................................................................... 33
Лекция 5. Рекурсия.............................................................................................................................. 44
Лекция 6. Итерация. Проектирование цикла ................................................................................... 52
Лекция 7. Поиск в последовательных таблицах ............................................................................... 59
Лекция 8. Операции над таблицами. Сортировка ........................................................................... 70
Титул
Об издании
Производственно-технические сведения
Содержание
3
Алгоритмы и алгоритмические языки
Введение
Дисциплина «Алгоритмы и алгоритмические языки» является составной частью общего
курса по информатике. Данное учебное пособие предназначено для изучения
теоретического материала студентами, обучающимися по направлению 01.03.02
«Прикладная математика и информатика» по профилю «Вычислительная математика и
информационные технологии», и составлено в соответствии с требованиями ФГОС ВО.
Материал пособия разбит на 8 отдельных лекций. В первой лекции рассматривается
интуитивное определение алгоритма, способы записи алгоритмов, исполнители
алгоритма и их моделирование на компьютере.
Вторая лекция познакомит студентов с основами фоннеймановской архитектуры
компьютера, с устройством памяти и представлением данных в памяти компьютера.
Содержанием третьей лекции является краткий обзор алгоритмических языков,
представление об этапах трансляции и НФБ-грамматика как способ описания
алгоритмических языков (на примере Паскаля). Рассмотрение типов данных и
управляющих структур сопровождается графическими схемами и диаграммами,
способствующими лучшему пониманию изучаемого материала. В следующих лекциях
рассматривается использование процедур и функций для структурирования программ,
применение рекурсии и итерации как базисных схем обработки информации.
Завершают пособие две лекции по алгоритмам поиска и сортировки. Рассматривается
организация таблиц, последовательный и бинарный поиск в таблице, хэш-таблицы, а
также простейшие алгоритмы сортировки и быстрая сортировка.
Вопросы и задания к каждой лекции могут использоваться для организации
практических и самостоятельных работ. Для каждой лекции приводится список
рекомендуемых литературных источников.
4
Алгоритмы и алгоритмические языки
Лекция 1. Понятие алгоритма
Слово алгоритм (англ. algorithm) сравнительно новое. Оно произошло от «algorism», которое
использовалось для обозначения выполнения арифметических операций в позиционной
десятичной системе счисления. Слово Algorism происходит от имени арабского ученого АльХорезми, автора знаменитого математического труда «Книга о восполнении и
противопоставлении». Другая его книга «Об индийском счёте» в XII веке была переведена на
латинский язык и сыграла большую роль в развитии европейской арифметики и внедрении
десятичной системы счисления.
К 1950 году слово «алгоритм» чаще ассоциировалось не с арифметическими вычислениями, а
с алгоритмом Евклида (Euclid) — описанием процесса нахождения наибольшего общего
делителя двух натуральных чисел. Приведем это описание, следуя книге [1, с. 28].
Алгоритм Евклида (Алгоритм Е)
Даны два целых положительных числа m и n.
Требуется найти их наибольший общий делитель, то есть наибольшее целое положительное
число, которое нацело делит оба числа m и n.
E1. [Нахождение остатка.] Разделим m на n, и пусть остаток от деления будет равен
r, 0≤r<n.
E2. [Сравнение с нулем.] Если r=0, то выполнение алгоритма прекращается; n —
искомое значение.
E3. [Замещение.] Присвоить m ← n, n ← r и вернуться к шагу E1.
Формулируемому алгоритму1 дается имя (здесь — алгоритм Е). Каждый шаг алгоритма
(действие, которое рассматривается как целое, без разложения на составные части)
нумеруется и в квадратных скобках записывается содержание этого шага — комментарий.
Шаги алгоритма выполняются от меньших номеров к большим номерам, если нет явных
указаний об изменении порядка.
Если уже имеется алгоритм решения некоторой задачи, то для ее решения совершенно
необязательно понимать, как этот алгоритм был получен2. Для выполнения алгоритма
требуется понимать его в том только смысле, что требуется уметь выполнять указанные в нем
действия (шаги алгоритма). Например, вычислять остаток от деления m на n (r = m — n * q, где
q — частное).
1
Евклид формулировал способ нахождения НОД иначе. В частности, для нахождения остатка он
использовал последовательные вычитания.
2
Создание алгоритма — акт творческий, исполнение — рутинный, механический.
1
Алгоритмы и алгоритмические языки
Стрелка ←, используемая в алгоритме на шаге E3, обозначает операцию замещения, или
присваивания. Действие m ← n означает, что значение переменной m замещается текущим
значением переменной n. Или переменной m присваивается значение переменной n. В языках
программирования присваивание часто обозначается знаком =, или знаком :=. Стрелка
используется здесь, чтобы не путать присваивание и отношение равенства (на шаге E2).
Вообще запись «переменная ← формула» означает, что формула справа от стрелки будет
вычислена при текущих значениях всех входящих в нее переменных, а результат будет
присвоен переменной, стоящей слева от стрелки.
Словесная формулировка алгоритма часто сопровождается блок-схемой, чтобы было проще
представить себе описанный алгоритм. Например,
Рис. 1. Блок-схема алгоритма Евклида
Вычислим, используя алгоритм E, наибольший общий делитель чисел m = 16 и n = 18 (НОД(16,
18)).
E1. Остаток от деления 16 на 18 равен 16. Положим r= 16.
E2. r ≠ 0
E3. Положим m = 18, n = 16.
E1. Остаток от деления 18 на 16 равен 2. Положим r= 2.
E2. r ≠ 0
E3. Положим m = 16, n = 2.
E1. Остаток от деления 16 на 2 равен 0. Положим r= 0.
E2. r = 0. Закончить вычисления. Наибольший общий делитель равен 2.
Очевидно, что если m < n, то частное на шаге E2 всегда оказывается равным нулю и происходит
обмен значениями. Поэтому к алгоритму можно добавить еще один шаг:
E0. [Гарантировать m ≥ n.] Если m < n, то выполнить взаимный обмен m и n.
2
Алгоритмы и алгоритмические языки
Свойства алгоритмов
Понятие «алгоритм» часто ассоциируют с такими понятиями, как способ, метод вычислений,
рецепт, процесс, процедура, программа. Отметим следующие важные особенности (свойства)
алгоритма — набора конечного числа правил, задающих последовательность выполнения
операций для решения задачи определенного типа.
Конечность. Алгоритм всегда должен заканчиваться после выполнения конечного числа
шагов. В алгоритме E остаток r на каждом шаге уменьшается, так как уменьшается n.
Поэтому шаг E1 может быть выполнен только конечное (но, может быть, очень большое)
число раз.
Определенность. Действия, которые нужно выполнить на каждом шаге, должны быть строго и
недвусмысленно определены для каждого возможного случая. Поэтому для описания
алгоритмов обычно используют специально разработанные алгоритмические языки. В случае
алгоритма E требование определенности означает, что исполнитель понимает (умеет)
выполнять операцию вычисления остатка от деления двух целых положительных чисел,
операцию замещения (присваивания) ←.
Ввод. Алгоритм имеет некоторое количество (возможно, равное нулю) входных данных. Эти
данные берутся из определенного набора объектов. Например, алгоритм E не будет
корректно работать для любых целых чисел. Входные числа должны быть натуральными.
Вывод. Выходные данные (результат) имеют вполне определенную связь с входными
данными.
Эффективность. Д. Кнут предлагает считать алгоритм эффективным, если все его операции
достаточно просты, чтобы их можно было точно выполнить за конечное время с помощью
карандаша и бумаги. Например, операция вычисления остатка шага E1 — эффективна (для
натуральных конечных чисел).
Метод вычислений обладает всеми свойствами алгоритма за исключением, возможно,
свойства конечности. Например, методом вычислений является предложенное Евклидом
геометрическое построение «наибольшей общей меры» длин двух отрезков прямой:
вычисления не заканчиваются, если отрезки несоизмеримы.
Программа — это метод вычислений, выраженный на языке программирования
(алгоритмическом языке).
На практике нужны не просто алгоритмы, а хорошие алгоритмы в широком смысле этого
слова. Например, недостаточно требования конечности, желательно, чтобы алгоритм имел
достаточно ограниченное, разумное число шагов. Часто решить одну и ту же задачу можно
несколькими алгоритмами. Требования к ресурсам вычислительной системы (время и память)
могут сильно влиять на выбор алгоритма решения задачи. Другими критериями качества могут
быть простота реализации, изящество, приспособляемость к различным компьютерам.
3
Алгоритмы и алгоритмические языки
Исполнители. Моделирование исполнителей на ПК
Алгоритмы составляют в расчёте на некоторого исполнителя. Исполнителем может быть
человек, организация, механическое или электронное устройство, робот и т.п., умеющий
выполнять некоторый вполне определённый набор действий. Алгоритм составляют в терминах
допустимых данным исполнителем действий. Примеры исполнителей и простейших программ
можно найти в [2, с. 9].
Исполнитель «Счётчик»
Счётчик имеет табло, на котором отображается состояние единственной ячейки его памяти,
которая может хранить одно число.
Система команд:
1) начать работу (состояние ячейки памяти неопределенно);
2) установить в нуль;
3) увеличить на единицу;
4) показать значение;
5) закончить работу.
Программа Тройка
Дано:
Требуется: отобразить на табло счётчика число три.
Т1. начать работу
Т2. установить в нуль
Т3. увеличить на единицу
Т4. увеличить на единицу
Т5. увеличить на единицу
Т6. показать значение
Т7. закончить работу
Конец программы
Моделирование исполнителей на ПК
Поскольку ПК — универсальный исполнитель, то на нём можно смоделировать любого
исполнителя. Например, для всех команд Счётчика имеются прямые соответствия в языке
программирования Паскаль:
4
Алгоритмы и алгоритмические языки
program troika;
var m: integer;
begin
m:=0;
inc(m);
inc(m);
inc(m);
writeln(m)
end.
Алгоритмические конструкции: следование, ветвление, цикл
Любой алгоритм может быть представлен комбинацией трех базовых структур: следование,
ветвление, цикл. Характерной особенностью базовых структур является наличие в них одного
входа и одного выхода.
1. Базовая структура — следование
Образуется из последовательности действий, следующих одно за другим:
действие 1
действие 2
…
действие n
2. Базовая структура — ветвление
Обеспечивает в зависимости от результата проверки условия (да или нет, истина или ложь, 1
или 0) выбор одного из альтернативных путей работы алгоритма. Каждый из путей ведет к
общему выходу, так что работа алгоритма будет продолжаться независимо от того, какой путь
будет выбран.
Рассмотрим два основных варианта структуры ветвления:
5
Алгоритмы и алгоритмические языки
1) краткая форма если—то
если условие
то действия
конец если
2) полная форма если — то — иначе
если условие
то действия 1
иначе действия 2
конец если
3. Базовая структура — цикл
Базовой считается структура цикла с предусловием
цикл пока условие делать
тело цикла (последовательность
действий)
конец цикла
Пример. Блок-схема алгоритма Евклида
6
Алгоритмы и алгоритмические языки
Кроме рассмотренных базовых схем в ней используется овал для обозначения начала и конца
алгоритма и параллелограмм для операций ввода-вывода.
Материалы для самостоятельной работы
Деление. Частное и остаток
Деление целых чисел — это такая операция, в результате которой получается число (частное),
которое при умножении на делитель даёт делимое: 123 : 3 = 41. Здесь 123 — делимое, 3 —
делитель, 41 — частное. Очевидно, что 41 × 3 = 123.
Не каждое число делится нацело на другое число. Например, 357 не делится нацело на 23:
7
Алгоритмы и алгоритмические языки
Деление с остатком (деление по модулю, нахождение остатка от деления, остаток от
деления) — вид операции деления, результатом которой являются два целых числа:
(неполное) частное и остаток. Очевидно, что 23 × 15 + 12 = 357.
Остаток от деления образуется, если результат деления не может быть выражен целым
числом, при этом остаток от деления должен быть по абсолютной величине меньше делителя.
В случае если числа делятся друг на друга без остатка или нацело, то считают, что остаток
равен нулю.
Вопросы и упражнения
1. Каким будет результат вычислений НОД для m = 17, n = 9?
2. Если результатом работы алгоритма должно стать сообщение, являются или нет два
натуральных числа взаимно простыми, то какой базовой структурой надо дополнить
алгоритм Евклида? Составьте блок-схему проверки взаимной простоты двух
натуральных чисел.
3. Можно ли выполнить алгоритм Евклида для m = -4, n = 2? Что произойдет при попытке
выполнения алгоритма с этими числами?
4. Какие базовые структуры использованы в блок-схеме алгоритма Евклида?
5. Реализуйте действие шага Е0 (гарантировать m ≥ n) с помощью базовых структур.
6. Напишите программу для отображения на табло Счётчика всех нечётных чисел в
пределах первой десятки.
7. Напишите программу для отображения на табло Счётчика всех простых чисел в
пределах первой десятки.
Библиографический список:
1. Кнут Д. Искусство программирования. Т 1. Основные алгоритмы : учеб. пособие: пер. с
англ. 3-е изд. М.: Мир, 2000. 720 с.
2. Кушниренко А.Г., Лебедев Г.В. Программирование для математиков : учеб. пособие для
вузов. М.: Наука, 1988. 384 с.
8
Алгоритмы и алгоритмические языки
Персоналии
Дейкстра
Эдсгер Вибе Дейкстра
Дата
рождения:
11 мая 1930
Место
рождения:
Роттердам (Нидерланды)
Дата смерти:
6 августа 2002 (72 года)
Место
смерти:
Неунен (Нидерланды)
Известен как:
создатель алгоритма Дейкстры и
семафоров, один из основателей
структурного программирования,
один из создателей
операционной системы THE
Дейкстра был активным писателем, его перу (он предпочитал авторучку клавиатуре)
принадлежит множество книг и статей, самыми известными из которых являются книги
«Дисциплина программирования» и «Заметки по структурному программированию», а также
статья «О вреде оператора GOTO» (GOTO considered harmful) — классические книги по теории
структурного программирования.
По мнению Дейкстры, господствующий в компьютерной индустрии подход к
программированию как к процессу достижения результата методом проб и ошибок («написать
код — протестировать — найти ошибки — исправить — протестировать — …») порочен. Такой
подход стимулирует программистов не думать над задачей, а писать код и при этом
совершенно не гарантирует корректность программ, которая не может быть доказана
тестированием в принципе.
В работе «Заметки по структурному программированию» Дейкстра доказывал, что
большинство программ сложны и неуправляемы из-за отсутствия в них четкой математической
структуры. Интуитивному и бессознательному («хаотическому») программированию он
последовательно противопоставлял логически строгую методологию, предполагающую ко
всему прочему личную дисциплинированность и ответственность программиста. Одним из его
кардинальных предложений было признание оператора перехода goto недопустимым в
программировании. Это предложение смутило и удивило почти всех программистов, но
позднее была доказана теорема Бёма — Якопини о том, что любую программу можно
написать без goto. В 1974 году на защиту оператора goto выступил американец Дональд Кнут и
показал, что в некоторых случаях использование этого оператора желательно.
9
Алгоритмы и алгоритмические языки
Евклид
Дата рождения:
ок. 325 года до н. э.
Место рождения:
или Афины, или Тир
Дата смерти:
до 265 года до н. э.
Место смерти:
Александрия
Эллинистический
Египет
Известен как:
«Отец геометрии»
Евклид
О его жизни мы не имеем никаких достоверных сведений, может быть, даже он не был
реальной исторической личностью, а являлся коллективным псевдонимом некоей группы
Александрийских математиков. Если он жил, то жил во времена Птолемея Первого, которому,
согласно преданию, он надерзил: «К геометрии нет царской дороги».
Наиболее знаменитое и выдающееся произведение Евклида — тринадцать книг его «Начал».
Это первые математические труды, которые дошли до нас от древних греков полностью.
В истории Западного мира «Начала», после Библии, — наибольшее число раз изданная и
более всего изучавшаяся книга. Большая часть нашей школьной геометрии заимствована
буквально из первых шести книг «Начал». Их логическое дедуктивное построение повлияло на
сам способ научного мышления больше, чем какое бы то ни было другое произведение.
10
Алгоритмы и алгоритмические языки
Кнут
Дата
рождения:
10 января 1938
Место
рождения:
Милуоки (Висконсин, США)
Известен
как:
Дональд Эрвин Кнут
автор классических трудов
«Искусство программирования»,
«Конкретная математика» и мн.
др., создатель ΤΕΧ, METAFONT
Сайт: http://www-csfaculty.stanford.edu/~knuth
Большее влияние на юного Дональда Кнута оказали работы Андрея Петровича Ершова,
впоследствии его друга: «Это началось, ещё когда я был студентом последнего курса. Тогда
только появилась книга Андрея «Программирование для БЭСМ», и мы, группа студентов,
смогли убедить преподавателя русского языка включить её в курс в качестве одного из двух
сборников текстов для изучения научной лексики».
Кнут всегда считал монографию «Искусство программирования» основным проектом своей
жизни. В 1990 году он вышел на пенсию с намерением полностью сконцентрироваться на
написании недостающих частей и приведении в порядок существующих.
11
Алгоритмы и алгоритмические языки
Лекция 2. Компьютер — универсальный исполнитель
Принстонская (фоннеймановская) архитектура
В 1945 году группе инженеров-изобретателей, создавших компьютер ENIAC, был придан в
качестве математика-консультанта известный учёный фон Нейман. Работая в составе
группы над новой версией компьютера, фон Нейман подготовил и опубликовал
«Предварительный доклад о машине EDVAC», в котором впервые ясно и чётко была
обрисована логическая организация компьютера.
Фон Нейман выделил и детально описал пять ключевых компонентов вычислительной
системы (ВС):
1. Центральное арифметико-логическое устройство (АЛУ).
2. Центральное устройство управления (УУ).
3. Запоминающее устройство (ЗУ, память).
4. Устройство ввода данных.
5. Устройство вывода данных.
В современных компьютерах АЛУ
вместе с УУ называют процессором
(processor).
Кроме того, фон Нейман зафиксировал следующие положения:
1. ВС должна быть электронным устройством.
2. ВС должна работать с двоичными числами.
3. ВС должна выполнять операции последовательно.
4. Программа выполнения этих операций должна храниться в памяти ВС совместно с данными.
Вышеперечисленные положения стали называть принципами фон Неймана. Следует
понимать, что фон Нейман не придумал их, а систематизировал и обобщил то, что было
создано и придумано инженерами и учёными до него. Поскольку первые ВС в основном
использовались для вычислений, их стали называть компьютерами (computer — вычислитель,
тот, кто считает), в СССР использовался термин ЭВМ.
Ещё раз обратим внимание на два важных свойства компьютеров.
1. Программа и данные хранятся в памяти компьютера, и нет никаких отличий команды
от данных для её выполнения (принцип линейности и однородности памяти).
2. Команды выполняются последовательно, то есть только после завершения одной
команды процессор приступает к выполнению следующей (принцип
последовательного выполнения команд).
Закончив выполнение текущей команды, машина «забывает» о том, что это была за команда,
где она располагалась в памяти, с какими операндами работала и т. д. Это важное свойство
позволяет, например, надолго прерывать выполнение программы, запомнив относительно
небольшой объём информации (текущее состояние регистров компьютера, сведения об
12
Алгоритмы и алгоритмические языки
открытых файлах и т. д.). В дальнейшем в любой момент возможно возобновление счёта этой
программы с прерванного места (разумеется, сама программа и её данные в памяти
компьютера должны сохраниться, или же должны быть восстановлены в прежнем виде). Это
свойство является основой для так называемого мультипрограммного режима работы
компьютера.
Устройство памяти
Память компьютера (memory) — устройство для запоминания данных. В зависимости от
характера использования различают внутреннюю или внешнюю память.
Внутренняя память — память, взаимодействующая с процессором. Фактически различают три
вида внутренней памяти:
•
•
•
только читаемая память ROM[1], в которой помещаются программы, необходимые
для запуска компьютера;
память с произвольным доступом RAM[2] для хранения программ и обновляемых
данных[3];
кэш-память, увеличивающая производительность процессора.
На логическом уровне память представляет собой последовательность ячеек памяти, каждая
из которых имеет порядковый номер — адрес. Минимальный размер адресуемой ячейки
памяти — байт. Размер ячеек кратен байту. Ячейка в два байта называется слово, в четыре
байта — двойное слово. На физическом уровне в состав памяти помимо электрической цепи,
фиксирующей значения битов (шина данных), входит цепь, позволяющая выбирать нужную
ячейку памяти (адресная шина).
Взаимодействие процессора и памяти
Процессор может запросить память, чтобы
записать (сохранить, запомнить) определенные данные в определенной ячейке памяти
(содержимое памяти меняется);
прочитать (выбрать) данные из определенной ячейки памяти (содержимое памяти не
меняется).
Прочитать (записать) можно данные из любой ячейки памяти, именно поэтому оперативную
память называют random access memory (RAM) — память с произвольной выборкой.
Машинное представление данных
Регистровое представление числовых данных
Регистром называют совокупность устройств, используемых для хранения информации и
быстрого доступа к ней. В вычислительных машинах регистры состоят из строго
определенного числа запоминающих элементов. Состояние каждого запоминающего
элемента интерпретируется как нуль или единица. Каждый элемент называют разрядом.
13
Алгоритмы и алгоритмические языки
Разряды нумеруются справа налево начиная с нуля. Количество разрядов накладывает
ограничения на величину представляемого числа.
Рассмотрим для примера регистр из восьми разрядов. В восьми разрядах можно представить
28 = 256 двоичных комбинаций
00000000
00000001
00000010
00000011
00000100
…
11111111
Так как в счете участвуют только неотрицательные целые числа
(в десятичной системе счисления от 0 до 255), то такая
интерпретация регистра называется беззнаковой (unsigned).
Состояние байтового регистра чаще передают с помощью
шестнадцатеричных цифр: от 00 до FF. Попытка использовать в
счете число, большее FF, приведет к обращению содержимого
регистра в нуль и далее отсчету от нуля.
Итак, регистровая[4] операция FF + 1 даст в результате 0. Произошедшая ошибка называется
ошибкой переполнения числа без знака. Поскольку FF + 1 = 0, то можно считать регистровое
состояние FF записью отрицательного числа -1. Так мы приходим к обратному
дополнительному коду.
Обратный дополнительный код
Если рассматриваемое число неотрицательное, то обратный дополнительный код совпадает с
прямым кодом, рассмотренным ранее. Если число отрицательное, то оно кодируется
следующим способом: записывается регистровое представление модуля этого числа и каждый
его бит инвертируется, к полученному значению прибавляется единица. То, что получится,
называется обратным дополнительным кодом отрицательного числа. Получим обратный
дополнительный код числа -1. Модуль |-1| имеет регистровое (восьмиразрядное)
представление 000000012. Инверсия дает 111111102. Прибавляем единицу, получаем
111111112 = FF16. Это и есть обратный дополнительный код числа -1.
Заметим, что у отрицательного числа старший бит равен единице. Поэтому разряд, в котором
он содержится, называется знаковым разрядом. Числовое значение формируется
оставшимися (семью, в нашем примере) разрядами. Такая интерпретация регистра называется
знаковой (signed). Числа со знаком находятся в диапазоне от -128 до 127 для
восьмиразрядного регистра (всего 256 целых чисел). Регистровое представление числа 127
равно 011111112, если мы прибавим к нему единицу, то получим 100000002. Но это уже
отрицательное число. Оно равно — 128.
Использование обратного дополнительного кода позволяет выполнять
операцию вычитания как сложение, где второе слагаемое —
отрицательное число.
14
Алгоритмы и алгоритмические языки
Типы целых чисел
В зависимости от разрядности регистра и знаковой или беззнаковой интерпретации его
содержимого определяется диапазон целых чисел. В Паскале целые числа представлены
следующими типами:
Таблица 1
Целые типы
Тип
Диапазон
Разрядность
Shortint
–128..127
8
Integer
–32768..32767
16
Longint
–2147483648..2147483647
32
Byte
0..255
8
Word
0..65535
16
Для определения наибольших значений типов Integer и Longint можно использовать
встроенные константы MaxInt = 32767 и MaxLongint = 2147483647. Среды Delphi и Lazarus
позволяют работать с 64-битными знаковыми числами. Это тип int64.
Представление чисел с плавающей точкой
Для компьютеров естественными являются целые числа, а действительные числа
моделируются с использованием целых. Множество действительных чисел не только
бесконечно, но и непрерывно, поэтому, сколько бы мы ни взяли бит, мы неизбежно
столкнемся с числами, которые не имеют точного представления. Числа с плавающей запятой
(точкой) — один из возможных способов представления действительных чисел, который
является компромиссом между точностью и диапазоном принимаемых значений.
Нормальная и нормализованная форма записи числа
Действительные числа представляют в нормальной форме ±m10p, где мантисса 0 <= m <1 —
десятичная дробь, а порядок р — целое число. Такая форма записи имеет недостаток: одно и
то же число можно записать разными способами (числа записываются неоднозначно).
Например, 0,0001 можно записать в четырех формах — 0,0001·100, 0,001·10−1, 0,01·10−2,
0,1·10−3. Поэтому распространена (особенно в информатике) также другая форма записи —
нормализованная, в которой мантисса десятичного числа принимает значения от 0.1
(включительно) до 1 (не включительно). В такой форме любое число (кроме нуля)
записывается единственным образом. Например, число 0.0001 записывают как 0.110-3, а число
1000 ‒ как 0.1104. Недостаток заключается в том, что в таком виде невозможно представить
нуль, поэтому нуль кодируется специально и о нем говорят — выделенный элемент.
15
Алгоритмы и алгоритмические языки
Выводы
Во-первых, на самом деле действительные числа — это конечное подмножество
рациональных дробей (количество цифр мантиссы конечно и невелико, порядок ограничен).
Это делает вопрос о точности вычислений практически очень важным.
Во-вторых, вопрос о представлении нуля делает его (нуль) выделенным элементом.
В-третьих, упаковка и распаковка чисел для вычислений делают вычисления очень
медленными по сравнению с целочисленными вычислениями.
Типы действительных чисел
Более правильное название действительных чисел — числа с плавающей точкой. Числа этого
типа — дробные (подмножество рациональных дробей).
Для представления дробных чисел используются десятичные цифры. Дробная часть числа
отделяется от целой части десятичной точкой: 0.0, 1.0, 3.14, 0.001 и тому подобное.
Отрицательные числа начинаются со знака минус: –1.0, –2.5 и тому подобное. Очень большие и
очень маленькие числа обычно записывают с использованием степеней десятки. Например,
число 0.001 можно представить как 10 -3, что запишется в Паскале как 1.0E-3, или 1E-3. Буква E
заменяет основание системы счисления 10. Допустимо использовать строчную букву e. Перед
буквой E обязательно должно стоять число (мантисса). Например, 0.314E1 ‒ это 0.314*10 = 3.14.
А число 0.1E-6 потребует записи шести нулей после десятичной точки 0.0000001.
Таблица 2
Действительные типы
Тип
Диапазон значений
Количество цифр
мантиссы
Требуемая память
(байт)
Real
2.9e-39 .. 1.7e+38
11
6
Single
1.5e-45 .. 3.4e+38
7
4
Double
5.0e-324 .. 1.7e+308
15
8
Extended
3.4e-4932 .. 1.1e+4932
19
10
Comp
-9.2e+18 .. 9.2e+18
19
8
Здесь приведены данные для Турбо Паскаля. Для используемой вами системы
программирования размеры данных в байтах уточните с помощью функции sizeof(<тип>).
Диапазон значений и количество цифр мантиссы зависят от размера типа.
16
Алгоритмы и алгоритмические языки
Материалы для самостоятельной работы
Взаимодействие УУ и АЛУ
Революционность идей Джона фон Неймана заключалась в строгой специализации: каждое
устройство компьютера отвечает за выполнение только своих функций. Например, раньше
память ЭВМ часто не только хранила данные, но и могла производить операции над ними.
Теперь же было предложено, чтобы память только хранила данные, АЛУ производило
арифметико-логические операции над данными в своих регистрах, устройство ввода вводило
данные из «внешнего мира» в память и т. д. Таким образом, Джон фон Нейман предложил
жёстко распределить выполняемые ЭВМ функции между различными устройствами, что
существенно упростило схему машины и сделало более понятной её работу.
Устройство управления тоже имеет свои регистры, оно может считывать команды из памяти на
специальный регистр команд РK (IR — instruction register), на котором всегда хранится текущая
выполняемая команда. Регистр УУ с именем РA называется регистром или счётчиком адреса
(в англоязычной литературе его часто обозначают IP — instruction pointer), при выполнении
текущей команды в него по определённым правилам записывается адрес следующей
выполняемой команды (первую букву в сокращении слова регистр мы будем в дальнейшем
изложении часто записывать латинской буквой R).
Рассмотрим, например, схему выполнения команды, реализующей оператор присваивания с
операцией сложения двух чисел z:=x+y. ВАЖНО! Здесь x, y и z — адреса ячеек памяти, в
которых хранятся операнды и будет помещен результат операции сложения (предположим,
что такая команда есть в языке машины). После получения из памяти этой команды на регистр
команд РK, УУ последовательно посылает управляющие сигналы в АЛУ, предписывая ему
сначала считать операнды x и y из памяти и поместить их на регистры R1 и R2. Затем по
следующему управляющему сигналу устройства управления АЛУ производит операцию
сложения чисел, находящихся на регистрах R1 и R2, и записывает результат на регистр
сумматора S. По следующему управляющему сигналу АЛУ пересылает копию регистра S в
ячейку памяти с адресом z.
Приведем иллюстрацию описанного примера на языке Паскаль, где R1, R2 и S — переменные,
обозначающие регистры АЛУ, MEM — массив ячеек, условно обозначающий память ЭВМ, а
⊗ — бинарная операция (в нашем случае это сложение, т.е. ⊗ = +).
R1 := MEM[x]; R2 := MEM[y]; S: = R1⊗R2; MEM[z] := S;
В научной литературе по архитектуре ЭВМ принято конструкцию MEM[А] обозначать как <А>,
тогда наш пример выполнения команды перепишется так:
R1: = <x>; R2: = <y>; S: = R1⊗R2; <z> := S;
Опишем теперь более формально шаги выполнения одной команды в машине Фон Неймана:
17
Алгоритмы и алгоритмические языки
1) РK := <РA>; считать из ячейки памяти с адресом РA команду на регистр команд РK;
2) РA := РA+1; увеличить счётчик адреса на единицу;
3) выполнить очередную команду, хранящуюся в регистре РK.
Затем по такой же схеме из трёх шагов выполняется следующая команда и т.д. Заметим, что
после выполнения очередной команды ЭВМ «не помнит», какую именно команду она только
что выполнила. По такому же принципу выполняют свои «команды» (шаги алгоритма) и такие
известные абстрактные исполнители алгоритмов, как машина Тьюринга и Нормальные
алгоритмы Маркова.
Итак, если машинное слово попадает на регистр команд, то оно интерпретируется УУ как
команда, а если слово попадает в АЛУ, то оно по определению считается числом. Это
позволяет, например, складывать команды программы как числа либо выполнить некоторое
число как команду. Разумеется, обычно такая ситуация является семантической ошибкой, если
только специально не предусмотрена программистом для каких-то целей.
Современные ЭВМ в той или иной степени нарушают практически все принципы фон Неймана.
Исключение, пожалуй, составляют только принцип автоматической работы, он лежит в самой
основе определения ЭВМ как устройства для автоматической обработки данных, и принцип
хранимой программы.
Существуют компьютеры, которые различают команды и данные. В них каждая ячейка
основной памяти, кроме собственно машинного слова, хранит ещё специальный признак,
называемый тэгом (tag), который и определяет, чем является это машинное слово. Для
экономии памяти современные компьютеры могут приписывать такой тэг не каждой ячейке в
отдельности, а сразу целой последовательности ячеек, называемой сегментом. Таким
образом, различают, например, сегменты команд и данных, при этом выполнение данных в
виде команды может трактоваться как ошибка. Так нарушается принцип неразличимости
команд и чисел. В такой архитектуре при попытке выполнить число как команду либо
складывать команды как числа центральным процессором будет зафиксирована ошибка.
Очевидно, что это позволяет повысить надёжность программирования на языке машины, не
допуская, как часто говорят, случайного «выхода программы на константы».
Практически все современные ЭВМ нарушают принцип однородности и линейности памяти.
Память может, например, состоять из двух частей со своей независимой нумерацией ячеек в
каждой такой части; или быть двумерной, когда адрес ячейки задаётся не одним, а двумя
числами; либо ячейки памяти могут вообще не иметь адресов, такая память называется
ассоциативной и т.д.
Все современные достаточно мощные компьютеры нарушают и принцип последовательного
выполнения команд: они могут одновременно выполнять несколько команд как из одной
программы, так иногда и из разных программ (такие компьютеры имеют несколько
центральных процессоров), а также быть так называемыми конвейерными ЭВМ.
18
Алгоритмы и алгоритмические языки
Вообще говоря, следует отметить, что в архитектуре машины фон Неймана зафиксированы и
другие принципы, которые из работы самого фон Неймана явно не вытекали, так как,
безусловно, считались самоочевидными. Так, например, предполагается, что во время
выполнения программы не меняется число узлов компьютера и взаимосвязи между ними, не
меняется число ячеек в оперативной памяти. Далее, например, считалось, что машинный язык
при выполнении программы не изменяется (например, «вдруг» не появляются новые
машинные команды) и т.д. В то же время сейчас существуют ЭВМ, которые нарушают и этот
принцип. Во время работы одни устройства могут, как говорят, отбраковываться (например,
отключаться для ремонта), другие — автоматически подключаться. Кроме того, во время
работы программы могут как изменяться, так и появляться новые связи между элементами
ЭВМ (например, в так называемых транспьютерах). Существуют и компьютеры, которые
могут менять набор своих команд, они называются ЭВМ с микропрограммным управлением.
На этом закончим краткое описание машины фон Неймана и принципов её работы. Первая
ЭВМ, построенная на основе принципов фон Неймана, называлась EDVAC (Electronic Delay
Storage Automatic Calculator — автоматический вычислитель с электронной памятью на линиях
задержки). Компьютер EDVAC был построен в 1949 году в Англии М. Уилксом (при участии
А. Тьюринга). EDVAC работала в двоичной системе счисления со скоростью примерно 100
операций в секунду. Заметим, что именно от этой машины принято отсчитывать первое
поколение ЭВМ (все предшествующие «не совсем настоящие» компьютеры можно условно
отнести к нулевому поколению).
Вопросы и упражнения
1. Дайте краткое определение следующим понятиям,
а) регистр;
б) кэш-память;
в) основная память;
г) массовая память.
2. Предположим, что в машинной памяти записаны три числа (x, y и z). Опишите
последовательность действий (загрузка значений из памяти в регистры, сохранение
результатов в памяти и т. д.), необходимых для вычисления суммы х + у + z. А какая
последовательность действий потребуется для вычисления значения выражения (2х) + у?
3. Предположим, что в некотором машинном языке поле кода операции имеет длину четыре
бита. Сколько различных типов команд может существовать в этом языке? Что можно сказать
по этому поводу, если длина поля кода операции будет увеличена до 8 бит?
19
Алгоритмы и алгоритмические языки
Библиографический список
1. Баула В.Г. Введение в архитектуру ЭВМ и системы программирования. М. : Изд-во МГУ,
2003. 133 с.
2. Брукшир Дж. Гленн. Введение в компьютерные науки. Общий обзор. 6-е изд.: пер. с
англ. М.: Издательский дом «Вильямс», 2001. 688 с.
3. Одинец В. П. Зарисовки по истории компьютерных наук : учебное пособие : в 3 ч.
Сыктывкар: Коми пединститут, 2011.Ч. 1. 200 с.
4. Что нужно знать про арифметику с плавающей запятой.
URL: http://habrahabr.ru/post/112953/
Персоналии
Фон Нейман
Дата рождения:
Место рождения:
Дата смерти:
Место смерти:
Джон фон Не́йман (англ. John
von Neumann; или Иоганн фон
Нейман, нем. Johann von
Neumann; при рождении Я́нош
Ла́йош Не́йман, венг. Neumann
János Lajos)
28 декабря 1903 г.
Будапешт
8 февраля 1957 г.
Вашингтон
Известен как праотец современной архитектуры
компьютеров (так называемая архитектура фон
Неймана), применением теории операторов к
квантовой механике (алгебра фон Неймана), а также
как участник Манхэттенского проекта и как создатель
теории игр и концепции клеточных автоматов.
Джон фон Нейман — американский математик и физик, известен трудами по
функциональному анализу, квантовой механике, логике, метеорологии. Его теория игр сыграла
важную роль в экономике. Интерес фон Неймана к компьютерам связан с его участием в
Манхэттенском проекте. Так назывался проект по созданию атомной бомбы в США. Фон
Нейман математически доказал осуществимость взрывного способа детонации атомной
бомбы. Создание бомбы требовало очень сложных расчетов. В то время вообще вычисления
были очень востребованы: война и бизнес.
Фон Нейман был прикомандирован к группе инженеров, занимавшихся созданием одного из
первых в США компьютеров — ENIAC. Он осознал, что необходимо воспользоваться идеей
машины Тьюринга, для чего уравнять в правах программы и данные и перенести
гипотетическую тьюринговскую бесконечную ленту с записанными на ней командами в
оперативную память компьютера. В таком случае программирование сводится к записи
последовательности команд в память. Эта процедура заметно проще ручной коммутации
сотен или тысяч проводов; кроме того, в текст программ можно вставлять команды
управления, а значит, выполнять переходы и циклы. Созданием машины с хранимой в памяти
20
Алгоритмы и алгоритмические языки
программой было положено начало тому, что мы сегодня называем программированием.
В июле 1944 г., меньше чем через год после того, как он присоединился к группе Моучли и
Эккерта, фон Нейман подготовил отчет, озаглавленный «Предварительный доклад о машине
EDVAC». В нем он высказал несколько теоретических положений, не самых существенных в его
научной биографии, но именно они обеспечили его имени широкую известность. Военный
представитель Гольдштейн размножил доклад и разослал ученым как США, так и
Великобритании.
Фон Нейман умер в феврале 1957 года, успев дожить до времени, когда уже были созданы
языки Ассемблера, появлялись Кобол и Фортран. Тогда проблема языков программирования
активно обсуждалась, однако он считал это занятие бессмысленным, будучи уверенным в том,
что ни к чему тратить дорогостоящее машинное время на работу с текстами программ.
21
Алгоритмы и алгоритмические языки
Лекция 3. Алгоритмические языки
Машинный язык
Машинная программа — это последовательность машинных команд. Множество всех команд
называется языком машины.
Базовыми командами являются, как правило, следующие команды:
арифметические, например «сложения» и «вычитания»;
битовые, например «логическое и», «логическое или» и «логическое не»;
присваивание данных, например «переместить», «загрузить», «выгрузить»;
ввода-вывода для обмена данными с внешними устройствами;
управляющие инструкции, например «переход», «условный переход», «вызов
подпрограммы», «возврат из подпрограммы».
Для построения конкретной ЭВМ необходимо строго определить, как будет устроена память
этой машины, задать набор машинных команд, описать устройство центрального процессора,
определить возможности ввода / вывода и так далее. Поэтому машинный язык полностью
определяется архитектурой ЭВМ, и программа, написанная для одной ЭВМ, непригодна для
другой.
При программировании на машинном языке программист может держать под своим
контролем каждую команду и каждую ячейку памяти, использовать все возможности
имеющихся машинных операций. Результатом деятельности программиста может быть очень
эффективная программа, в максимальной степени учитывающая специфику конкретного
компьютера.
Программы на машинном языке состоят из сотен команд, потому что в них скрупулёзно
определяются все мельчайшие действия вычислительной системы. Процесс написания
программы на машинном языке очень трудоемкий и утомительный. Программа получается
громоздкой, трудно обозримой, ее трудно отлаживать, изменять и развивать. И ее
практически невозможно перенести на другую ЭВМ.
Поэтому в случае, когда нужно иметь эффективную программу, в максимальной степени
учитывающую специфику конкретного компьютера, вместо машинных языков используют
близкие к ним машинно ориентированные языки (ассемблеры).
Ассемблеры
Конечно, программисты быстро осознали, что инструкции можно писать, используя
мнемонические обозначения для команд и буквенные обозначения для ячеек памяти.
Например, add — команда добавить, а mov — переместить (присвоить). Рутинную работу по
переводу текста, содержащего мнемонические обозначения для команд и буквенные
обозначения для операндов, на машинный язык (в машинные коды) стала выполнять
специальная программа-транслятор, которую называют ассемблером (assemble — собирать).
Сам текст стали называть программой на ассемблере.
22
Алгоритмы и алгоритмические языки
Для записи текста на ассемблере используется уже «естественный» язык — латиница и
десятичная система счисления, но по сути — это запись машинной программы в более
удобном для человека виде.
Приведем пример ассемблерной вставки в Паскале. Задача состоит в вычислении sum := a + b.
Переменные описываются в программе, операции ввода / вывода также выполняются
средствами Паскаля.
var a, b, sum: word;
begin
a := 26;
b := 38;
asm
mov Ax, a
;значение переменной a помещается в регистр Ax —
;регистр общего назначения, так как операции
;выполняются в процессоре, а не в оперативной памяти
add Ax, b
;значение переменной b добавляется к регистру Ax
mov sum, Ax ;значение регистра Ax помещается в переменную sum
end;
writeln(sum)
end.
Программист, решая задачу на компьютере, по-прежнему выражает её решение не в терминах
задачи, а в терминах машинных команд. Машинных команд многие сотни. Поскольку
машинные языки зависят от набора команд вычислительной машины, от её архитектуры, то и
ассемблеры для разных машин разные. Вместе с тем существуют мультиплатформенные или
вовсе универсальные (точнее, ограниченно-универсальные, потому что на языке низкого
уровня нельзя написать аппаратно-независимые программы) ассемблеры, которые могут
работать на разных платформах и операционных системах. Среди последних можно также
выделить группу кросс-ассемблеров, способных собирать машинный код и исполняемые
модули (файлы) для других архитектур и операционных систем.
Ассемблеры были большим шагом вперёд в технологии программирования. Они до сих пор
востребованы, особенно в случаях, когда требуется оптимизировать вычисления,
непосредственно используя возможности вычислительной системы.
Алгоритмические языки высокого уровня
К концу шестидесятых годов прошлого века уже были разработаны первые языки
программирования высокого уровня COBOL, FORTRAN, Algol. Их главное отличие от
23
Алгоритмы и алгоритмические языки
ассемблеров в том, что они не связаны с конкретным машинным языком и моделью ЭВМ.
Такие языки используют не машинные команды, а алгоритмические конструкции, такие как
присваивание, выбор, повторение. В машинные команды их переводит специальная
программа-транслятор языка. Трансляторы разные для разных моделей ЭВМ, а язык один.
Отпала необходимость писать программы заново для разных компьютеров в связи с
изменившейся архитектурой. Программы, написанные на языке высокого уровня, можно
переносить с одного типа компьютеров на другой практически без изменений. Появилась
возможность писать программы на языке, ориентированном на человека, а не на машину.
Этапы трансляции
Логически процесс трансляции можно разбить на две основные части: этап анализа исходной
программы и синтез выполняемой объектной программы. Обычно эти этапы взаимосвязаны.
Если важна скорость компиляции (как, например, для учебных программ), то строится
однопроходный компилятор, просматривающий исходный текст программы один раз. Этот
подход реализован в Паскале. Но если скорость выполнения программы имеет большое
значение, то разрабатывают компилятор, делающий несколько проходов по исходному тексту.
Например, двухпроходный компилятор на первом проходе на основе анализа программы
осуществляет ее декомпозицию на составляющие и получает всю необходимую для второго
этапа информацию, а во время второго прохода генерирует объектную программу. Цель —
создать наиболее эффективно выполняемую программу на машинном языке.
Лексический анализ (сканирование). Для транслятора исходная программа представляет
собой длинную цепочку символов. Программист выделяет в своей программе раздел
описаний, раздел типов и переменных, процедур и функций, раздел операторов, но для
транслятора это просто последовательность многих тысяч символов. Транслятор проводит
анализ структуры программы, разбирая ее текст последовательно, символ за символом.
Сначала в исходной программе выделяются элементарные составляющие: идентификаторы,
разделители, символы операций, числа, ключевые (зарезервированные) слова и так далее.
Этот этап называется лексическим анализом, а элементарные составляющие — лексемами.
Соответствующая часть транслятора называется лексическим анализатором. Формальной
моделью для создания лексического анализатора являются конечные автоматы. Это
довольно затратный по времени этап, хотя бы потому, что исходная программа читается и
анализируется последовательно, символ за символом.
Синтаксический анализ (разбор). На этом этапе лексемы используются для выделения более
крупных программных структур: операторов, объявлений, выражений и т.п. Здесь
используется теория формальных грамматик.
Семантический анализ. На этом этапе обрабатываются структуры, распознанные
синтаксическим анализатором, и начинает формироваться структура исполняемого объектного
кода. Семантический анализатор обычно чередуется с синтаксическим. Сначала
синтаксический анализатор идентифицирует последовательность лексем, формирующих
синтаксическую единицу (объявление, выражение, оператор, вызов подпрограммы). Затем
вызывается семантический анализатор.
24
Алгоритмы и алгоритмические языки
Синтез объектной программы. На заключительном этапе трансляции происходит создание
выполняемой программы на основе того, что было сделано семантическим анализатором.
Этот этап обязательно включает генерацию кода и может включать оптимизацию
получившейся программы.
Формальные модели трансляции
Часть теории компиляции, относящаяся к распознаванию синтаксических структур,
основывается, как правило, на теории контекстно-свободных языков. Формальное
определение синтаксиса языка программирования называется грамматикой по аналогии с
общепринятой терминологией для естественных языков. Грамматика состоит из набора
правил, определяющих последовательности символов (лексем), которые допустимы для
определяемого языка. Формальная грамматика — это грамматика, в которой используется
строго определенная система обозначений. С основами формальных грамматик можно
познакомиться в [1].
НФВ-грамматика
НФБ — это сокращенная запись для «нормальная форма Бэкуса», или «форма Бэкуса-Наура».
Язык (программирования) с точки зрения синтаксиса представляет собой множество
синтаксически правильных программ, каждая из которых есть просто последовательность
символов. В отношении семантики синтаксически правильная программа может не иметь
никакого смысла, то есть при выполнении она может производить бессмысленные
вычисления, неправильные вычисления или вообще не производить никаких вычислений.
Определим язык как множество цепочек символов конечной длины, причем символы
выбираются из определенного конечного алфавита.
При таком определении языком можно назвать:
1) множество всех разделителей языка Паскаль (begin, end, if, then и т. д.). Этот язык
состоит из конечного множества цепочек;
2) множество всех программ на Паскале;
3) множество последовательностей из элементов 0 и 1, таких, что все элементы 0
предшествуют элементам 1, например 01, 001, 0111.
Важно, что цепочки символов конечны, а сами символы берутся из конечного алфавита.
Словесного описания языка недостаточно для полного описания. Например, для языка из
примера 3 неясно, принадлежит ли цепочка из одного символа 0 этому языку. Описать, что
является синтаксически правильным в языке, а что нет, можно с помощью множества
формальных математических правил, точно определяющих, какие цепочки допустимы в языке.
НФБ-грамматика состоит из конечного набора правил, позволяющих определить язык.
В простейшем случае грамматическое правило может быть задано простым перечислением
элементов конечного языка, например
25
Алгоритмы и алгоритмические языки
<цифра> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Это грамматическое правило читается так: «Цифра — это есть либо 0, либо 1, либо 2,…».
В левой части правила стоит нетерминальный символ. Символы, из которых образуются
цепочки в языке, называются терминальными символами (в нашем случае это 0, 1, 2,…).
Определив основной набор терминальных символов, можно использовать их для
конструирования более сложных цепочек. Например, правило
<целое без знака> ::= <цифра> | <целое без знака><цифра>
определяет <целое без знака> как последовательность элементов <цифра>.
Приведем пример более сложной грамматики, определяющей синтаксис арифметического
выражения.
<арифметическое выражение> ::= <терм>|<терм><знак+‑><арифметическое
выражение>
<знак + ‑> ::= + | ‑
<терм> ::= <множитель> | <множитель> * <терм>
<множитель> ::= <число> | (<арифметическое выражение>)
<число>
::= <целое без знака>
<целое без знака> ::= <цифра> | <целое без знака><цифра>
<цифра> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Расширения НФБ-нотации
НФБ-грамматики не являются идеальным средством для сообщения правил конкретного языка
программирования. Часто простые правила НФБ-грамматики приводят к неестественному
представлению общих синтаксических конструкций для необязательных, альтернативных и
повторяющихся элементов какого-либо синтаксического правила. Например, чтобы выразить
простую синтаксическую идею «целое со знаком есть последовательность цифр,
начинающаяся с необязательного символа плюс или минус», в НФБ-грамматике придется
написать довольно сложный ряд рекурсивных правил, а именно:
<целое со знаком> ::= <целое> | +<целое>| ‑<целое>
<целое> ::= <цифра> | <целое><цифра>
Расширенная НФБ-нотация позволяет избежать подобных неестественных способов
определения простых синтаксических свойств некоторых грамматик. Для расширения НФБнотации применяются следующие дополнительные обозначения, которые не ограничивают
возможности НФБ-грамматики, но упрощают описания языков:
необязательный элемент может быть обозначен заключением его в квадратные
скобки — [...];
26
Алгоритмы и алгоритмические языки
альтернативные варианты вводятся при помощи вертикальной черты | и в случае
необходимости могут быть заключены в квадратные скобки;
произвольная последовательность экземпляров одного и того же элемента может быть
обозначена заключением его в фигурные скобки, за которыми следует символ
«звездочка» — {...}*.
Например,
<целое со знаком> ::= [+ | ‑]<целое> {<целое>}*
<идентификатор> ::= <буква> {<буква>|<цифра>}*
Синтаксические схемы
Синтаксические схемы — это графический способ выражения правил грамматики с помощью
расширенной НФБ-нотации. Каждое правило представляется в виде некоторой траектории от
расположенной слева точки входа до расположенной справа точки выхода. Любая траектория
от входа к выходу представляет цепочку, генерируемую этим правилом. Другие правила
представляют в виде прямоугольников, а терминальные символы изображают кружочками.
Например, чтобы получить синтаксическую категорию <терм>, следует двигаться от точки
входа либо по траектории, проходящей через <первичное выражение> и выходящей справа
через точку выхода, либо по траектории, также проходящей через <первичное выражение> и
затем совершающей один или более циклов, через кружки с операциями умножения или
деления. Этому соответствует следующее правило, записанное с использованием
расширенной НФБ-нотации:
<терм> ::= <первичное выражение> {[* | /] <первичное выражение>}*
Материалы для самостоятельной работы
Предыстория появления языков программирования
Компьютер потому является универсальным инструментом, что он работает под управлением
программ. Для решения разных задач используются разные программы.
27
Алгоритмы и алгоритмические языки
Идея программируемого механизма принадлежит инженеру Мари Жаккарду, работавшему в
ткацкой промышленности. В 1804 году он создал полностью автоматизированный станок,
воспроизводящий узор на ткани по программе, записанной на перфокартах. Замена
перфокарт — и станок без всякой переналадки исполняет другой узор. Эта идея программного
управления нашла воплощение в аналитической машине Чарльза Бэббиджа — основателя
Королевского астрономического общества Англии. В состав его аналитической машины
входили «мельница» (АЛУ) и «склад» (ОЗУ). Машина должна была работать в соответствии с
инструкциями, которые вводились с помощью перфокарт. Программированием
аналитической машины занималась графиня Лавлейс, урождённая Огаста Ада Байрон,
единственный законный ребёнок поэта лорда Байрона. Графиня по праву считается первым
программистом, и в её честь один из современных языков программирования назван Ада.
Первые алгоритмические языки высокого уровня
К концу шестидесятых годов прошлого века уже были разработаны первые языки
программирования высокого уровня. Их главное отличие от ассемблеров в том, что они не
связаны с конкретным машинным языком и моделью ЭВМ. Такие языки используют не
машинные команды, а алгоритмические конструкции, такие как присваивание, выбор,
повторение. В машинные команды их переводит специальная программа-транслятор языка.
Трансляторы разные для разных моделей ЭВМ, а язык один. Отпала необходимость писать
программы заново для разных компьютеров, сообразуясь с изменившейся архитектурой.
Программы, написанные на языке высокого уровня, можно переносить с одного типа
компьютеров на другой практически без изменений. Появилась возможность писать
программы на языке, ориентированном на человека, а не на машину. Перечислим несколько
первых языков:
COBOL (первая версия в 1959) — для решения экономических, бухгалтерских задач
(министерство обороны США). Руководителем проекта по созданию Кобола была Грейс
Хоппер, известная как бабушка Кобола. Общая стоимость используемого в настоящее время
кода на коболе оценивается в 2 триллиона долларов США.
FORTRAN (создан в период с 1954 по 1957 год группой программистов под руководством
Джона Бэкуса в корпорацииIBM) — для решения инженерно-технических задач.
ALGOL3 разработан комитетом по языку высокого уровня IFIP в 1958—1960 годы для решения
научных задач. Оказал заметное влияние на все разработанные позднее императивные языки
программирования, в частности на язык Pascal.
BASIC разработан в1963 году профессорами Дартмутского колледжа Томасом Куртом (Thomas
E. Kurtz) и Джоном Кемени (John G. Kemeny) для решения задач в интерактивном режиме, для
системного программирования.
Pascal был создан Никлаусом Виртом в 1968—69 гг. после его участия в работе комитета
разработки стандарта языкаАлгол-68 — язык для обучения программированию.
3
Кажется удивительным, что на Коболе и Фортране программируют уже более полувека, пусть языки и
сильно изменились. Алгол повлиял на развитие многих языковпрограммирования, хотя сам он давно
уже не используется. Универсальные языки программирования Паскаль и Си развили идеи Алгола.
28
Алгоритмы и алгоритмические языки
Язык Си разработан в начале 1970-х годов сотрудниками Bell LabsКеном Томпсоном и Денисом
Ритчи — язык для системного программирования.
Lisp (1958 год) — создатель Лиспа Джон Маккарти занимался исследованиями в области
искусственного интеллекта, и созданный им язык по сию пору является одним из основных
средств моделирования различных аспектов ИИ.
Ada — язык программирования, созданный в1979—1980 годы в результате проекта,
предпринятого Министерством обороны США с целью разработать единый язык
программирования для встраиваемых систем (т. е. систем управления автоматизированными
комплексами, работающими в реальном времени). Имелись в виду, прежде всего, бортовые
системы управления военными объектами. Перед разработчиками не стояло задачи создать
универсальный язык (хоть он и используется как таковой), поэтому решения, принятые
авторами Ады, нужно воспринимать в контексте особенностей выбранной предметной
области. Язык назван в честь Ады Лавлэйс.
Добавим Java,Python,PHP,Ruby,Perl — получился короткий (если не сказать — куцый) список
самых известных современных языков программирования. Трудно сказать, сколько всего
имеется языков программирования4. Хотя все современные языки программирования
универсальны, каждый из них для определённого круга задач может оказаться удобнее
другого. Современные языки программирования имеют в своем составе библиотеки
подпрограмм (функций) для решения часто встречающихся, рутинных задач. Например, для
операций ввода и вывода, для вычисления математических функций, для работы с
графическими возможностями компьютера.
Вопросы и упражнения
1. Что означает высказывание «язык программирования является машинно
независимым»?
2. В каком смысле программа, написанная на первых языках программирования
высокого уровня, является машинно независимой? В каком смысле она остается
машинно зависимой?
3. В чем разница между ассемблером и компилятором?
4. Опишите основные этапы процесса трансляции.
5. Напишите несколько строк, формат которых будет соответствовать структуре Ча-ча-ча,
определенной с помощью следующих синтаксических диаграмм:
4
Около 2500 языков согласно списку http://people.ku.edu/~nkinners/LangList/Extras/langlist.htm
29
Алгоритмы и алгоритмические языки
Библиографический список
1. Ахо А. В., Ульман Дж. Теория синтаксического анализа, перевода и компиляции : в 2 т.
М.: Мир, 1978.
2. Брукшир Дж., Гленн. Введение в компьютерные науки. Общий обзор. 6-е изд. : пер. с
англ. М. : Издательский дом Вильямс, 2001. 688 с.
3. Пратт Т., Зелковиц М. Языки программирования: разработка и реализация. 4-е изд.
СПб.: Питер, 2002. 688 с.
30
Алгоритмы и алгоритмические языки
Персоналии
Хоппер, Грейс
Дата рождения: 9 декабря 1906
Место
рождения:
Нью-Йорк
Дата смерти:
1 января 1992 (85 лет)
Место смерти:
Арлингтон
Грейс Хоппер
Grace Hopper
Известна как разработчик первого в истории
компилятора для языка программирования. В 1952 г. у
неё был готовый к работе компилятор.
«В это не могли поверить», — говорила она. — «У меня
был работающий компилятор, и никто им не
пользовался. Мне говорили, что компьютер может
выполнять только арифметические операции».
Для облегчения работы программистов Хоппер предложила составлять программы из так
называемых подпрограмм, представляющих собой часто повторяющиеся последовательности
команд. Она написала первую подпрограмму для вычисления sin(x).
Весной 1959 года на двухдневной Конференции по языкам систем обработки данных
(CODASYL) собрались компьютерные специалисты, работающие в бизнесе и состоящие на
службе у государства. Хоппер была техническим консультантом комитета, и многие её бывшие
подчинённые состояли во временном комитете, который стандартизировал новый язык
COBOL. В этом новом языке была заключена идея Хоппер о том, что программы лучше писать
на языке, который ближе к английскому, нежели на языке, который ближе к машинному коду
(как, напр., ассемблер). COBOL стал наиболее распространённым языком для бизнесприложений и остаётся таковым до сих пор.
Благодаря Грейс Хоппер стал популярным термин «дебаггинг» для обозначения процесса
удаления ошибок из компьютерной программы. В американском английском слово debugging
буквально означает «удаление насекомых». Во время разработки компьютера Mark II в
Университете Гарварда в 1947 её коллеги нашли и удалили мотылька, застрявшего в реле
и блокирующего передачу сигнала. Этот случай Хоппер отметила как «дебаггинг» системы.
31
Алгоритмы и алгоритмические языки
После выхода в отставку Хоппер читала различные лекции о заре компьютерной эры, о своей
карьере и об усилиях, которые разработчики компьютеров могут предпринять, чтобы
упростить жизнь своим пользователям.
В ее честь назван эскадренный миноносец USS Hopper.
Лавлейс, Ада
Августа Ада Кинг Лавлейс
Augusta Ada King Byron, Countess of Lovelace
Дата
рождения:
10 декабря 1815
Место
рождения:
Лондон, Великобритания
Дата смерти:
27 ноября 1852 (36 лет)
Место смерти:
Лондон, Великобритания
Автор единственной научной работы об аналитической
машине Беббиджа — Ада Лавлейс навсегда вписала
своё имя в историю науки. Составленные 28-летней
графиней Августой Адой Лавлейс примечания к статье
итальянского инженера Л. Ф. Менабреа дают основания
считать её первым программистом. По существу, она
заложила научные основы программирования на
вычислительных машинах за столетие до того, как стала
развиваться эта научная дисциплина.
Бэкус, Джон
Джон Бэкус
John Warner Backus
Дата
рождения:
3 декабря 1924
Место
рождения:
Филадельфия, Пенсильвания,
США
Дата смерти:
17 марта 2007 (82 года)
Место смерти:
Ашленд, Орегон, США
Известен как руководитель команды, разработавшей
ФОРТРАН — первый высокоуровневый язык
программирования, а также как изобретатель формы
Бэкуса — Наура, одной из самых универсальных нотаций,
используемых для определения синтаксиса формальных
языков.
32
Алгоритмы и алгоритмические языки
Лекция 4. Структурирование программы
Мы понимаем алгоритм как описание порядка действий исполнителя для достижения
результата (решения задачи) за конечное число действий. Вспомогательный алгоритм —
алгоритм, ранее разработанный и целиком используемый при составлении алгоритма для
решения конкретной задачи. В программировании алгоритму соответствует понятие
программы, а вспомогательному алгоритму — подпрограмма.
Процедуры и функции
В языках программирования подпрограммы реализуются как подпрограммы-функции (служат
для вычисления значений) и подпрограммы-процедуры (служат для выполнения действий, не
обязательно связанных с вычислениями значений).
Процедурой называется часть программы, имеющая имя и предназначенная для решения
определенной задачи.
Функцией называется часть программы, имеющая имя и предназначенная для вычисления
значения. Поэтому функция имеет тип.
Подпрограмму перед использованием в программе необходимо объявить и определить
действия, которые она должна исполнять. Определение действий выполняется в теле
подпрограммы (между begin и end). Каждая процедура и функция определяется только
однажды, но может использоваться многократно. Объявления процедур и функций
33
Алгоритмы и алгоритмические языки
осуществляются перед первым словом BEGIN программы. Определение текстуально может
находиться как в программе, так и в отдельном модуле. Объявленные параметры
подпрограммы называются формальными параметрами.
Место вызова подпрограммы называют точкой входа. В точке входа управление передается
операторам, составляющим тело подпрограммы. На месте формальных параметров
записывают их фактические значения, или просто — фактические параметры. После
выполнения подпрограммы управление возвращается программе.
Вызов процедуры является инструкцией (оператором) и выполняется в теле программы
(подпрограммы). Вызов функции является вычислением значения и выполняется в некотором
выражении5. Поэтому обязательно в теле функции должен быть оператор, присваивающий
значение имени функции.
Пример процедуры
С помощью последовательности печати «пустых» строк выполнить вертикальную табуляцию
(пропускаем несколько строк, чтобы «очистить» экран).
procedure VertTab;
совмещено}
{Объявление и определение процедуры текстуально
const v = 25;
{Объявления локальных констант и переменных.}
var i : integer;
begin
{Тело процедуры: раздел операторов}
for i := 1 to v do writeln;
end;
begin
{Тело программы}
VertTab;
{Вызов процедуры (точка входа)}
writeln('Hello, Word!')
end.
Процедура VertTab без параметра всегда будет пропускать ровно 25 строк. Чтобы изменить
количество пропусков, надо изменять текст процедуры (строку const v = 25). Приведем пример
процедуры с параметром:
procedure VertTab(v: integer);
число}
{Объявлен формальный параметр — целое
begin
while
5
v > 0 do begin
Расширенный синтаксис Паскаля позволяет вызывать функцию так же, как и процедуру.
34
Алгоритмы и алгоритмические языки
writeln;
dec(v)
end
end;
begin
VertTab(10);
{подставлено фактическое значение
10, то есть пропуск 10 строк}
writeln('Hello, Word!');
end.
Программа определяет количество пропущенных строк. Процедура VertTab текстуально может
быть описана отдельно от программы — в модуле. Программа не может (не должна)
управлять выполнением процедуры иначе, кроме как через значения параметров6.
Глобальные переменные
Рассмотрим еще один вариант определения процедуры VertTab:
var i: integer;
procedure VertTab(v: integer);
begin
for i := 1 to
v do
writeln;
end;
Переменная i — глобальная. Она определена в программе и используется подпрограммой.
Часто использование глобальных описаний приводит к трудно обнаруживаемым ошибкам.
Например, таким:
begin
for i := 1 to 5 dobegin
VertTab(2);
writeln('Hello, Word!');
end;
end.
Ошибка в том, что внутри счетного цикла нельзя изменять значения параметров цикла.
Результат выполнения этой программы непредсказуем. Иногда без глобальных переменных
не обойтись. Но программист должен жестко контролировать их использование.
6
И через глобальные переменные.
35
Алгоритмы и алгоритмические языки
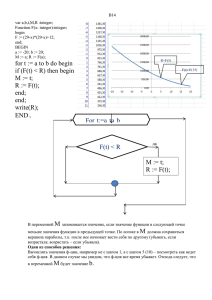
Пример структурирования с использованием функции gcd
Пусть для заданных натуральных чисел b и d надо вычислить наименьшее общее кратное. В
курсе математики доказывается, что
.
Для нахождения наибольшего общего делителя (greatest common divisor) воспользуемся
алгоритмом Евклида:
function gcd(m, n: integer):integer; {m и n — формальные параметры}
var r: integer;
{r — локальная переменная}
begin
r := m mod n;
while r<> 0 do begin
m := n; n := r;
r := m mod n
end;
gcd:=n
end;
var
b, d: integer;
lcm: integer;
{least common multiple}
begin
readln(b, d);
lcm := b * d div gcd(b, d) {вызов gcd, b и d — фактическиепараметры};
writeln(lcm);
end.
Формальные и фактические параметры
Вызов подпрограммы. Подпрограмма вызывается в соответствии с правилами синтаксиса.
Значение функции используется в выражении. Процедура не имеет значения и не может быть
использована в выражении. При вызове подпрограммы на место формальных параметров
подставляются фактические значения. Это могут быть переменные и выражения, в том числе
константные выражения. Важно соблюдать правило:
Каждому формальному параметру соответствует фактическое значение
при вызове подпрограммы.
36
Алгоритмы и алгоритмические языки
Это значит, что количество фактических параметров, порядок перечисления и тип совпадают с
количеством формальных параметров, их порядком перечисления и их типом.
Параметры-значения и параметры-переменные
Передача фактических значений формальным параметрам может осуществляться двумя
способами.
Первый способ — копирование. Фактические значения переменных остаются неизменными, в
подпрограмму передаются их копии. Все операции проводятся с копиями. Такие параметры
называются параметрами-значениями. Фактические значения таких параметров могут быть
выражениями (константами, переменными, формулами). Во всех вышеприведённых примерах
использовались параметры-значения.
Второй способ — передача значения по ссылке. Формальные параметры вместо значения
получают адрес фактических параметров. Все операции проводятся с самими фактическими
параметрами. Такие параметры называются параметрами-переменными. Фактическими
значениями таких параметров могут быть только переменные.
Пример. Процедура обмена значениями двух переменных
Подпрограмма Обмен
Дано: две переменные x и y (целые, действительные, символьные или строковые)
Требуется обменять значения данных переменных
1. [Введём дополнительную переменную r — буфер] r ← x
2. x ← y
3. y ← r
конец подпрограммы
Обмен должен осуществляться над фактическими параметрами, т. е. необходима передача
адресов фактических параметров.
procedure change(var x, y: integer);
var r: integer;
begin
r := x;
x := y;
y:=r
end;
Вызов процедуры может осуществляться только с параметрами переменными. Приведём
пример программы, использующей процедуру change для обмена значениями трёх
переменных.
37
Алгоритмы и алгоритмические языки
var a, b, c: integer;
begin
readln(a, b, c);
change(a, b);
change(b, c);
writeln(a, b, c);
end.
Материалы для самостоятельной работы
Структурирование программы
При создании (больших) программ полезно разбить исходную задачу на подзадачи и записать
программу, считая, что подзадачи решены. Повторить процесс для подзадач. Продолжать,
пока подзадачи не станут достаточно просты (метод постепенной детализации). Программы
для подзадач называют подпрограммами. Такая технология создания программ часто
называется технологией программирования «сверху — вниз».
Каждую подпрограмму надо оформить, указав её имя, входные данные (что дано) и результат
(что надо получить), т. е. параметры подпрограммы. Написать программу, считая, что
подзадачи решены, означает, что в программе записываются вызовы подпрограмм и для
каждого вызова указываются фактические значения параметров. Сами подпрограммы
текстуально могут быть оформлены или отдельно, или вместе с вызывающей программой.
Системы подпрограмм
Пусть требуется вычислить значение
(a*2 + b)*c + (b*2 + a)*d.
(1)
Ясно, что формулу (1) можно представить в виде
h(a, b, c) + h(b, a, d),
(2)
где
function h(a,b,c: real):real;
begin
h := (a * 2 + b) * c
end;
Итак, вычисление (1) можно описать в виде подпрограммы-функции
function s(a, b, c, d: real):real;
begin
38
Алгоритмы и алгоритмические языки
s := h(a, b, c) + h(b, a, d)
end;
Мы получили иерархическую систему подпрограмм (s, h), в которой s непосредственно
опирается на h.
Возможна дальнейшая структуризация7. Переопределим функцию
function h(a,b,c: real):real;
begin
h := g(a, b) * c
end;
где
function g(u,v: real):real;
begin
g := (u * 2 + v)
end;
Теперь имеем иерархическую систему подпрограмм (s, h, g), в которой s косвенно опирается
на g.
В Паскале систему подпрограмм (s, h, g) можно оформить как независимую, так и
подчинённую.
Независимые (одноуровневые) описания следуют в порядке, обратном выстроенной
иерархии. Выполняется правило «всё, что используется, должно быть описано ранее».
function g(u,v: real):real;
begin
g := (u * 2 + v)
end;
function h(a,b,c: real):real;
begin
h := g(a, b) * c
end;
function s(a, b, c, d: real):real;
begin
7
Структурировать — разлагать на составные части посредством введения вспомогательных
подпрограмм.
39
Алгоритмы и алгоритмические языки
s := h(a, b, c) + h(b, a, d)
end;
begin
writeln( s(1, 2, 3, 4));
{вычисляется h(1, 2, 3) + h(2, 1, 4) = g(1, 2) * 3 + g(2, 1) *
4 = (1*2 + 2)*3 + (2*2 + 1)*4 = 12 + 20 = 32}
{Здесь функции s, h, g равноправны и могут быть использованы
независимо друг от друга}
writeln( h(1, 2, 3));
writeln(g(5, 4));
end.
Подчинённые описания явно реализуют зависимость подпрограмм:
function s(a, b, c, d: real):real;
function h(a,b,c: real):real;
function g(u,v: real):real;
begin
g := (u * 2 + v)
end;
begin
h := g(a, b) * c
end;
begin
s := h(a, b, c) + h(b, a, d)
end;
begin
writeln( s(1, 2, 3, 4));
{Здесь функции s, h, g последовательно подчинены, нет доступа к
функциям h, g}
end.
Описание функции h известно функции s, а описание функции g известно функции h и
экранировано от функции s. Функция s «ничего не знает про существование функции g».
Способ, которым вычисляется значение функции h, — частное дело самой функции h. Вообще,
40
Алгоритмы и алгоритмические языки
за пределами функции h ничего неизвестно о функции g. Функция g локально описана в
функции h. Аналогично функция h локально описана в функции s и за пределами функции s, о
функции h ничего неизвестно.
С другой стороны, «изнутри» функции g можно было бы «увидеть» значения параметров a, b,
c, d, которые являются глобальными для функции g. Изменение значений глобальных
параметров внутри локальной подпрограммы правилами языка допускается, это называется
«побочным эффектом» и обычно крайне нежелательно.
Программирование сверху вниз и снизу вверх
Программирование сверху вниз представляет собой способ реализации и тестирования в
иерархической последовательности, начиная с модулей, требования к которым вытекают из
требований к программе в целом.
Программирование снизу вверх — это способ реализации и тестирования в обратной
иерархической последовательности, начиная с модулей нижнего уровня, которые по
предъявляемым к ним требованиям дальше всего отстоят от программы в целом.
Сторонники метода сверху вниз считают, что их подход более естественный, дает возможность
лучше оценивать состояние работ и зачастую исключает болезненный процесс объединения
модулей, необходимый при разработке снизу вверх.
Сторонники же метода снизу вверх утверждают, что их подход ведет к более основательной
отладке модулей и лучшему выделению и использованию стандартных модулей.
Чтобы понять процессы программирования сверху вниз и снизу вверх, программу следует
рассматривать как структуру из модулей в виде дерева или сети с верхним уровнем,
содержащим управляющие элементы, в соответствии с заданными требованиями. Обычно
структура расширяется книзу по мере того, как управляющий модуль вызывает подчиненные
функции, которые в свою очередь вызывают следующие функции.
Программирование сверху вниз начинается с самого высокого уровня, затем разрабатывается
следующий уровень и объединяется в единую программу путем тестирования и т. д. до тех
пор, пока не будет достигнут низ структуры. Каждый незапрограммированный модуль
заменяется при сборке «заглушкой», которая удовлетворяет требованиям интерфейса, но не
выполняет его функций или выполняет их частично. Заглушки заменяются или дорабатываются
до настоящих модулей в соответствии с планом программирования. На каждой стадии
процесса реализации уже созданная программа должна правильно функционировать по
отношению к более низкому уровню.
Программирование снизу вверх начинается с модулей самого низкого уровня. Отладка обычно
ведется с помощью специальных отладочных программ — от отдельных блоков самого
низкого уровня до полного набора блоков.
Возможность исключения из процесса разработки программы фазы объединения компонент
делает программирование сверху вниз привлекательным с точки зрения надежности.
Поскольку каждая часть программы тестируется по мере ее включения в целое, то полностью
41
Алгоритмы и алгоритмические языки
реализованная программа является уже и полностью тестированной. Такой способ
объединения позволяет на каждом шаге иметь обозримую программу. Ошибки и
несоответствия ее отдельных частей выявляются и устраняются на ранних стадиях
программирования.
Отладка и тестирование программ
Отладка программы — это деятельность, направленная на обнаружение и исправление
ошибок в программе. Обнаружить ошибки, связанные с нарушением правил записи
программы на языке программирования (синтаксические и семантические ошибки),
помогает используемая система программирования. Пользователь получает сообщение об
ошибке, исправляет ее и снова повторяет попытку исполнить программу.
Тестирование программы — это процесс выполнения программы с целью обнаружения
ошибки в программе на некотором наборе данных, для которого заранее известен результат
применения или известны правила поведения этих программ. Указанный набор данных
называется тестовым или просто тестом. Прохождение теста — необходимое условие
правильности программы. На тестах проверяется правильность реализации программой
запланированного алгоритма. Таким образом, отладку можно представить в виде
многократного повторения трех процессов: тестирования, в результате которого может быть
констатировано наличие в программе ошибки, поиска места ошибки в программах и
документации и редактирования программ и документации с целью устранения
обнаруженной ошибки.
Успех отладки в значительной степени предопределяет рациональная организация
тестирования. При отладке отыскиваются и устраняются в основном те ошибки, наличие
которых в программе устанавливается при тестировании. Тестирование не может доказать
правильность программы, в лучшем случае оно может продемонстрировать наличие в нем
ошибки. Другими словами, нельзя гарантировать, что тестированием программы на
соответствующих наборах тестов можно установить наличие каждой имеющейся в программе
ошибки. Поэтому возникают две задачи. Первая: подготовить такой набор тестов и применить
к ним программу, чтобы обнаружить в нем по возможности большее число ошибок. Однако
чем дольше продолжается процесс тестирования (и отладки в целом), тем большей становится
стоимость программы. Отсюда вторая задача: определить момент окончания отладки
программы (или отдельной ее компоненты). Признаком возможности окончания отладки
является полнота охвата тестами, к которым применена программа, множества различных
ситуаций, возникающих при выполнении программы, и относительно редкое проявление
ошибок в программе на последнем отрезке процесса тестирования. Последнее определяется в
соответствии с требуемой степенью надежности программы, указанной в спецификации ее
качества.
Для оптимизации набора тестов, т.е. для подготовки такого набора тестов, который позволял
бы при заданном их числе (или при заданном интервале времени, отведенном на
тестирование) обнаруживать большее число ошибок, необходимо, во-первых, заранее
планировать этот набор и, во-вторых, использовать рациональную стратегию планирования
тестов.
42
Алгоритмы и алгоритмические языки
Таким образом, тестирование и отладка включают в себя синтаксическую отладку; отладку
семантики и логической структуры программы; тестовые расчеты и анализ результатов
тестирования. Затем идет совершенствование программы.
Вопросы и упражнения
1. Чем отличается процедура от функции?
2. Чем отличаются формальные параметры от фактических?
3. Предположим, что функция f получает два числа в качестве параметров и возвращает
меньшее из них в качестве результата. Если переменные w, х, у и z представляют собой
числа, то какой результат будет возвращен этой функцией при вычислении выражения
f(f(w, х), f(y, z))?
4. Реализуйте вычисление наименьшего общего кратного в примере структурирования с
использованием функции gcd с помощью функции, создав иерархическую систему
подпрограмм.
5. В чем состоит процесс отладки программы?
6. Что такое тестирование программы? Для чего она служит? Приведите примеры тестов
для тестирования функции из упражнения 3.
Библиографический список
1. Бауэр Ф.Л., Гооз Г. Информатика. Вводный курс : в 2 ч. М.: Мир, 1990. С. 125—169.
2. Кнут Д. Искусство программирования для ЭВМ. Основные алгоритмы. М.: Мир, 2000.
Т. 1. С. 221—236.
3. Павловская Т.А. Паскаль. Программирование на языке высокого уровня : учебник для
вузов. 2-е изд. СПб.: Питер, 2010. 464 с.
4. Майерс Г. Надежность программного обеспечения. М.: Мир, 1980.
43
Алгоритмы и алгоритмические языки
Лекция 5. Рекурсия
Рекурсия — это одна из базисных схем обработки информации. Под рекурсией понимается
такой способ решения, при котором подпрограмма вызывает сама себя либо
непосредственно, либо косвенно, через другие подпрограммы. Получается, что таким
способом решение задачи сводится к решению точно такой же задачи, но с другими
исходными данными. Такой приём называют рекурсией, подпрограмму называют
рекурсивной подпрограммой.
Рекурсия используется, когда можно выделить самоподобие задачи.
Рекурсия в лингвистике проявляется в способности языка порождать вложенные
предложения и конструкции. Базовое предложение «кошка съела мышь» может быть за счет
рекурсии расширено как «Ваня видел, что кошка съела мышь», далее как «Катя знает, что Ваня
видел, что кошка съела мышь», «Петя догадался, что Катя знает, что Ваня видел, что кошка
съела мышь» и так далее. Широко известен стих «У попа была собака…» и «Дом, который
построил Джек».
Юмор. Большая часть всех шуток о рекурсии касается бесконечной рекурсии, в которой нет
условия выхода. Известное высказывание: Чтобы понять рекурсию, нужно сначала понять
рекурсию. Весьма популярна шутка о рекурсии, напоминающая
словарную статью:
рекурсия
см. рекурсия
Google, например, в поиске по слову рекурсия дает ссылку
«Возможно, вы имели в виду: рекурсия».
Архитектура. Один из важнейших элементов убранства в период
поздней готики — ажурная резьба по камню на оконных переплетах.
Для техники использования тонких, искусно вытесанных планок,
разделяющие окно на много маленьких фрагментов, рекурсия —
базовый принцип.
Фракталы — одно из самых красивых математических изобретений
прошлого века — тоже строятся с помощью рекурсии http://fxart.ru/blog/fractal/.
Рекурсивный алгоритм Евклида
Решать задачу нахождения наибольшего общего делителя двух натуральных чисел можно
так: если числа равны, то любое из них — наибольший общий делитель. В противном случае
надо из большего вычесть меньшее число и решать задачу нахождения наибольшего общего
делителя двух получившихся натуральных чисел. Это и есть рекурсия. В основе лежит тот
математический факт, что НОД(a, b) = НОД(a — b, b) при условии a>b. В Паскале это
оформляется так:
44
Алгоритмы и алгоритмические языки
function gcd(a, b:integer): integer;
begin
if a = b then gcd := a
else
if a>b then gcd := gcd(a — b, b)
else gcd := gcd(a, b — a)
end;
begin
writeln(gcd(32, 48));
end.
Работу исполнителя этой программы можно представить, как если бы при каждом вызове
рекурсивной функции он получал новый лист с инструкциями:
Вызов
gcd(32, 48)
gcd(32, 16)
gcd(16, 16)
Инструкции
if a = b then gcd := a
else
if a>b
then gcd := gcd(a —
else gcd := gcd(a,
if a = b then gcd := a
else
if a>b
then gcd := gcd(a —
else gcd := gcd(a,
if a = b then gcd := a
else
if a>b
then gcd := gcd(a —
else gcd := gcd(a,
Обратный ход
gcd(32, 48) = 16
b, b)
b — a)
gcd(32, 16) = 16
b, b)
b — a)
gcd(16, 16) = 16
b, b)
b — a)
Конечно, реально нет никакой необходимости создавать и хранить тексты инструкций,
достаточно запоминать точки входа и результаты вычислений. Первый вызов gcd(32, 48) = ?
⇒ второй вызов gcd(32, 16) = ? третий вызов gcd(16, 16) = 16и теперь обратный ход 16 = gcd(16,
16) ⇒ gcd(32, 16) ⇒ gcd(32, 48). Здесь рекурсия очень простая, она линейная (на каждом шаге
порождается только один вызов) и гладкая, т. е. полученное значение просто передаётся
«наверх».
Косвенную рекурсию покажем на чисто формальном примере. Пусть процедура A опирается
на процедуру B, а B опирается на A. Тогда имеем косвенную рекурсию: «За что же, не боясь
греха, кукушка хвалит петуха? Зато, что хвалит он кукушку»:
procedure B; forward;
procedure A;
begin
…
45
Алгоритмы и алгоритмические языки
B;
end;
procedure B;
begin
…
A;
end;
Конечно, надо тщательно проверять конечность рекурсивных вызовов. Количество вложенных
вызовов функции или процедуры называется глубиной рекурсии.
Имеется сходство понятий рекурсии и математической индукции. У рекурсии, как и у
математической индукции, есть база — аргументы, для которых значения функции
определены (элементарные задачи), и шаг рекурсии — способ сведения задачи к более
простым.
Ханойская башня
Эту известную игру придумал французский математик Эдуард Люка в 1883 году.
В одном из буддийских монастырей монахи уже тысячу лет занимаются перекладыванием
колец. Они располагают тремя пирамидами, на которые надеты кольца разных размеров.
В начальном состоянии 64 кольца были надеты на первую пирамиду и упорядочены по
размеру. Монахи должны переложить все кольца с первой пирамиды на вторую, выполняя
единственное условие — кольцо нельзя положить на кольцо меньшего размера. При
перекладывании можно использовать все три пирамиды. Монахи перекладывают одно кольцо
за одну секунду. Как только они закончат свою работу, наступит конец света.
Ход решения головоломки с тремя дисками
Начнем с самого маленького кольца и переложим его с первой пирамиды на третью. Второе
кольцо переложим на вторую пирамиду и на него положим самое маленькое кольцо. Третье,
самое большое кольцо, положим на освободившуюся третью пирамиду. Затем произведем
единственно возможное перемещение оставшихся колец.
Ход решения головоломки с четырьмя дисками
С тремя дисками задачу решать умеем. Перенесем пирамиду из трех дисков на второй штырь.
Оставшийся четвертый диск перенесем на третий штырь. И опять имеем задачу с тремя
дисками. И так далее.
Количество перекладываний в зависимости от количества колец вычисляется по формуле 2 n −
1. Для 64-х колец это 18 446 744 073 709 551 615 перекладываний, и, если учесть скорость одно
перекладывание в секунду, получится около 584 942 417 355 лет, т. е. апокалипсис наступит
нескоро.
46
Алгоритмы и алгоритмические языки
Procedure Hanoi(first, // номер начального стержня
second, // номер промежуточного стержня
third, // номер конечного стержня
N // количество дисков, которые надо перенести
: byte);
Begin
If N=1 then writeln(first,' --> ',third,'; ')
{тривиальный перенос одного диска — вместо вывода на экран можно
вызвать процедуру, отображающую перенос графически}
else begin
{перенос N-1 дисков на промежуточный стержень}
Hanoi(first, third, second, N-1);
{перенос 1 диска на конечный стержень}
Hanoi(first, second, third, 1);
{перенос N-1 дисков с промежуточного на конечный стержень}
Hanoi(second, first, third, N-1);
end;
End;
Var N : byte;
Begin
{ввод N — количество дисков}
read(N);
if N>0 then
{переносим N дисков со стержня №1 на стержень №3}
Hanoi(1,2,3,N);
End.
Реализация рекурсивных вызовов функций в практически применяемых языках и средах
программирования, как правило, требует дополнительной памяти для размещения
параметров и локальных переменных подпрограммы при каждом рекурсивном вызове,
благодаря чему каждый следующий рекурсивный вызов этой функции пользуется своим
набором локальных переменных и за этот счёт работает корректно. Оборотной стороной этого
довольно простого по структуре механизма является то, что при чрезмерно большой глубине
рекурсии может просто не хватить памяти. Вследствие этого обычно рекомендуется избегать
рекурсивных программ, которые приводят (или в некоторых условиях могут приводить) к
слишком большой глубине рекурсии.
Числа Фибоначчи
Вычислить N чисел в последовательности Фибоначчи, — 1, 1, 2, 3, 5, 8, … — в которой первые
два члена равны единице, а все остальные представляют собой сумму двух предыдущих.
F0 = 1;
47
Алгоритмы и алгоритмические языки
F1 = 1;
Fn = Fn-1 + Fn-2 для n > 1.
Самый очевидный способ решения задачи состоит в написании рекурсивной функции
примерно следующего вида:
Function F(X:integer):longint;
Begin
if (X=1) or (X=2) then F:=1 else F := F(X-1) + F(X-2)
end;
Для небольших значений n такая программа может быть пригодна, но уже для вычисления
F(40) = F(39) + F(38) она начинает заметно «тормозить».
37
24157817
6.000 мкс
38
39088169
9.000 мкс
39
63245986
14.000 мкс
Действительно, F(38) мы считаем заново, «забывая», что уже вычислили его, когда считали
F(39). При этом на шестом-седьмом десятке программа заметно затормозит самый быстрый
компьютер.
То есть основная ошибка применения рекурсии к вычислению чисел Фибоначчи в том, что
значение функции при одном и том же значении аргумента считается много (слишком много!)
раз. Если исключить повторный счет, то функция станет заметно эффективней.
Материалы для самостоятельной работы
Примеры рекурсивных процедур и функций
Рекурсия не должна восприниматься как некий программистский трюк. Это скорее некий
принцип, метод. Если в программе нужно выполнить что-то повторно, можно действовать
двумя способами:
−
с помощью последовательного присоединения (итерации в форме цикла);
−
с помощью вложения одной операции в другую (рекурсии).
Приведем несколько примеров рекурсивных программ.
Пример 1. Бесконечная рекурсия, с помощью которой можно установить, насколько велик
стек. При использовании директивы (*$S+*) при переполнении стека получим сообщение об
ошибке; а при использовании директивы (*$S-*) — нет, а значит, мы, скорее всего, столкнемся
с зависанием системы. Установкой по умолчанию является (*$S+*). Программа будет
прервана с выдачей сообщения об ошибке «Error 202: stack overflow error» (Ошибка 202:
переполнение стека).
(*$S+*)
48
Алгоритмы и алгоритмические языки
procedure proc(i:integer);
begin
if i mod 1024 = 0 then writeln(i:6);
proc(i+1);
end;
begin
proc(1);
end.
Пример 2. Один раз счет от 1 до n ведется с помощью цикла, а второй — с помощью рекурсии.
При этом хорошо видно, как заполняется, а затем освобождается стек. Показывает
принципиальное различие между итерацией и рекурсией: итерации необходим цикл и
локальная переменная k как переменная цикла. Рекурсии ничего этого не требуется!
procedure rekursion (i:integer);
begin
writeln(i:30);
if i > 1 then rekursion(i-1);
writeln(i:3);
end; (* Рекурсия *)
procedure schleife(i:integer);
var k:integer;
bagin
k :=1;
while k <= i do begin
write(k:3);
k :=k+1;
end;
end; (* Цикл *)
var n:integer;
begin
write(‘Введите n:’); readln(n);
writeln(‘Пока:’);
scheife(n);
writeln;
writeln(‘Рекурсия’);
rekursion(n);
end.
49
Алгоритмы и алгоритмические языки
Пример 3. Рекурсивная процедура convert переводит десятичное число z в восьмеричную
систему путем деления его на 8 и выдачи остатка в обратной последовательности.
procedure convert(z:integer);
begin
if z > 7 then convert(z div 8);
(* Это рекурсивный вызов *)
write(z mod 8:1);
end;
var z:integer;
begin
writeln(‘Введите некоторое положительное число:’);
readln(z);
writeln(‘Десятичное число:’,z:6);
write(‘Восьмеричное число:
’);
convert(z);
end.
Одно из важных достоинств рекурсивных алгоритмов заключается в том, что они просты и
наглядны. Но рекурсия не всегда является эффективным (самым быстрым) решением.
Вопросы и упражнения
1. Чем рекурсия отличается от циклических вычислений?
2. Напишите рекурсивную функцию для вычисления натуральной степени
действительного числа.
3. Напишите рекурсивную процедуру для перевода десятичного числа в двоичную
систему счисления.
4. Другой подход к решению головоломки «Ханойская башня» состоит в следующем.
Представьте себе, что стержни расставлены по кругу в положениях, соответствующих
отметкам 4, 8 и 12 часов на циферблате. Кольца,
находящиеся исходно на одном из стержней,
нумеруются числами 1, 2, 3 и т.д., начиная с верхнего.
Кольца с нечетными номерами, находящиеся сверху
набора, разрешается перемещать только на стержень,
следующий по часовой стрелке, кольца с четными
номерами можно перемещать только против часовой
стрелки (при условии, что такое перемещение не
приведет к помещению большего кольца над
меньшим). Учитывая вышеизложенные требования, вы всегда должны выбирать
кольцо с наибольшим номером из числа тех, которые доступны для перемещения.
Используя такой подход, разработайте нерекурсивный алгоритм решения головоломки
«Ханойская башня».
50
Алгоритмы и алгоритмические языки
Библиографический список
1. Бауэр Ф. Л., Гооз Г. Информатика. Вводный курс : в 2 ч. М.: Мир, 1990. С. 125—169.
2. Вирт Н. Алгоритмы и структуры данных. М.: Мир, 1989. С. 171—210.
3. Персональная страничка Диканева Т.В. «Рекурсия и рекурсивные алгоритмы».
URL :http://www.tvd-home.ru/recursion 16.10.2014
51
Алгоритмы и алгоритмические языки
Лекция 6. Итерация. Проектирование цикла
Ситуация, в которой некоторые действия должны быть выполнены несколько раз, возможно,
ни разу, встречается очень часто. Такие циклические вычисления программируются с
использованием базовых схем обработки информации: рекурсии и итерации.
Рекуррентные вычисления
Если вычисления задаются равенствами, определяющими зависимость общего члена от
предыдущих членов при некоторых начальных значениях, то говорят о рекуррентности
(повторяемости), или о возвратном соотношении, или о рекурсивной зависимости. Примеры
рекуррентных соотношений:
1. Вычисление факториала числа n: 0! = 1, n! = (n-1)! * n при n > 0;
f:=1;
For i:= n downto 1 do
f:=f * n;
2. Вычисление натуральной степени действительного числа:
x0 = 1, xn = xn — 1* x при n > 0;
p:=1;
For i:= 1 to n
do
p:=p * x;
3. Количество перекладываний дисков в задаче о ханойской башне
T0 = 0, Tn = 2 Tn — 1 + 1 при n > 0.
В последнем случае методом математической индукции можно показать, что Tn = 2n — 1. Во
всех приведённых примерах следующий член зависит только от предыдущего. Поэтому
говорят о рекуррентности первого порядка. Бывают рекуррентности более высоких порядков.
Например, числа Фибоначчи вычисляются по правилу
f0 = 1, f1 = 1, fn = fn-1 + fn-2 при n > 1.
Это рекуррентность второго порядка. Вычислим несколько чисел Фибоначчи:
f2 = f1 + f0 = 1 + 1 = 2,
f3 = f2 + f1 = 2 + 1 = 3,
f4 = f3 + f2 = 3 + 2 = 5,
f5 = f4 + f3 = 5 + 3 = 8 и так далее. Для n > 1 задачу вычисления n-го числа Фибоначчи решает
следующая программа:
var n, f, f0, f1, i: integer;
52
Алгоритмы и алгоритмические языки
begin
readln(n);
f0 := 1;
f1 := 1;
f := 1;
for i := 2 to n do begin
f := f1 + f0;
f0 := f1;
f1 :=f
end;
writeln(f);
end.
Суммирование ряда
Вычисление сумм тоже может рассматриваться как рекуррентные вычисления.
Пример 1. Вычислить для заданного числа x с точностью ε > 0 значение
Обозначим Sn конечную сумму.
Очевидно, что
для любого n = 1, 2, …, причём s0 = 0. Обозначим
.
Тогда Sn = Sn-1 + an. По определению сумма сходящегося бесконечного ряда y вычислена с
точностью ε > 0, если |Sn – Sn-1| <ε для некоторого n. Поскольку |Sn – Sn-1| = |an|, то сумма
сходящегося бесконечного ряда y будет вычислена с точностью ε > 0, когда найдется такое n,
что |an|<ε . Это и будет условие окончания цикла.
В теле цикла на каждом шаге вычисляется конечная сумма добавлением к предыдущему
значению n-го члена ряда. Вычислять на каждом шаге an заново нерационально. Заметим, что
, откуда имеем
.
Оформим алгоритм в виде функции:
function y(x, eps:real):real;
53
Алгоритмы и алгоритмические языки
var a, s:real;
n:integer;
begin
n := 0;
a := 1;
s := 0;
while abs(a) >= eps do begin
s := s + a;
inc(n);
a := a * x / n;
end;
y := s
end;
Замечание. Не каждый ряд сходится. Например, ряд
расходится. Конечная сумма этого ряда
встречается так часто, что заслуживает специального упоминания. Буква H происходит от слова
«harmonic», так что Hn — это гармоническое число. Входящие в состав этой суммы величины
1/k , k = 1, 2, …, n связаны с основными тонами в музыке. И хотя ряд расходится, ничто не
мешает вычислять гармонические числа.
Инвариант цикла. Быстрый алгоритм возведения в степень
Если программа содержит только линейные фрагменты, конструкции ветвления и цикл с
параметром (счётный цикл), то её исполнение заведомо заканчивается за конечное число
шагов. Но если используются цикл с предусловием (или с постусловием) или рекурсия, то
нельзя заранее сказать, сколько раз выполнится тело цикла. Например, в алгоритме Евклида,
конечность которого очевидна (на каждом шаге один из параметров уменьшается, а так как
каждый параметр — натуральное число, то количество уменьшений конечно), нельзя заранее
предсказать, сколько раз выполнится цикл для каждой пары чисел.
Рассмотрим программу.
var n, k: integer;
a, b, c: real;
54
Алгоритмы и алгоритмические языки
begin
readln(a, k);
b:=1;
n := k;
c := a;
while n> 0 do
if odd(n) then
begin
b := b * c;
dec(n) end
else begin
c := c * c;
n := n div 2 end;
writeln(b);
end.
Что она делает? Конечно, можно исполнить программу для нескольких пар чисел, высказать
гипотезу (например, что вычисляется k-я степень числа a), но как доказать, что программа
делает именно это?
Для доказательства используют инвариант цикла, т. е. такое свойство обрабатываемого
программой объекта, которое не меняется в цикле. Итак, высказана гипотеза, что результатом
работы программы будет b = ak. Проверим, не является ли инвариантом цикла величина bcn.
Составим протокол исполнения программы. До начала цикла имеем bcn = 1* ak = ak.
bcn
Действие
Проверка чётности odd(n)
Не меняется
Проверка ветви после then
b' := bc, n’ = n – 1, b’cn’ = bc * c n — 1 = bcn
Поскольку b не менялось, то не изменилась и величина bcn
Проверка ветви после else
c' := c2, n’ = n / 2, (c')n’ = (c2)n / 2 = cn.
Поскольку b не менялось, то не изменилась и величина bcn
Итак, bcn ‒ инвариант цикла, причём bcn = ak, а поскольку условием окончания цикла является n
= 0, то bc0 = b = ak. Высказанная гипотеза доказана.
Итерация
Рассмотрим математическую модель метода итераций. Пусть M — некоторое множество,
природа его элементов нас сейчас не интересует. Пусть P: M → {true, false} — отображение M в
множество из двух элементов: истина и ложь, т.е предикат (логическое выражение) на M.
Обозначим M\P = {x M : P(x) = false} — множество тех элементов x из M, для которых P(x)
ложно. Требуется найти такой элемент x из M, для которого P(x) = true.
55
Алгоритмы и алгоритмические языки
Метод итераций (дословно — повторений) состоит в том, что строится некоторое
преобразование T: M \ P → M, и это преобразование последовательно применяется, начиная с
какого-то x0 M:
до тех пор, пока мы впервые не получим xk такое, что P(xk) = true. Естественно, должна быть
уверенность, что такое xk имеется.
Метод половинного деления
Рассмотрим в качестве примера метод половинного деления для решения уравнения f(x) = 0.
Будем предполагать, что функция f(x) непрерывна. Пусть имеется отрезок [a0, b0], на котором
функция меняет знак ровно один раз, так что f(a0)×f(b0) < 0.
Найдем точку
и вычислим значение f(c0). Определим, на каком из отрезков [a0,
c0] или [c0, b0] функция меняет знак, и обозначим этот интервал [a1, b1]. Его середину назовем с1
и далее продолжаем аналогично. Нам требуется найти решение уравнения, т. е. x*, такое, что
f(x*) тождественно равно нулю. Однако нет никакой гарантии, что для какого-нибудь ck, k=0, 1,
2,…выполнится f(ck ) = 0. Значит, надо придумать какой-то другой предикат, который прервет
итеративные вычисления троек ak, bk, ck. Можно, например, проводить вычисления до тех пор,
пока на k-ом шаге длина отрезка не станет меньше заданной величины, называемой
точностью нахождения решения. Пусть, например, нам задано ε > 0. Тогда если для некоторого
k выполнится bk — ak< 2ε, то его середина ckотличается от решения x* не более чем на ε.
Рассмотрим отдельно способ построения отрезка [an, bn], если известны an-1, bn-1, cn-1, n = 1,
2,…Так как на отрезке [an-1, bn-1] функция меняет знак, то f(an-1)×f(bn-1) < 0. Остается выяснить,
верно ли, что f(an-1) × f(сn-1) < 0. Если это так, то функция меняет знак на отрезке [an-1, cn-1] и надо
положить an = an-1, bn = cn-1. В противном случае an = cn-1 и bn = bn-1.
На практике может случиться, что для некоторого ck выполнится f (ck ) = 0. Тогда ck = x* и
решение найдено. Значит, искомый предикат P запишется так:
(bk — ak< 2ε) ИЛИ (f(ck-1) = 0).
Соответственно отрицание НЕ P с учетом законов де Моргана приобретет вид
56
Алгоритмы и алгоритмические языки
(bk — ak ≥ 2ε) И (f(ck-1) ≠ 0).
Оформим построенный итеративный процесс в виде функции bisect. Для хранения значений ak,
bk, ck будем использовать переменные a, b, c. Будем также считать, что вычисление значений
f(x) также оформлено в виде функции.
function bisect(a, b, eps: real):real;
var c: real;
begin
c := (a + b) / 2;
while (b — a >= 2 * eps) and (f(c) <> 0) do begin
if f(a) * f(c) < 0 then b := c
else a :=c;
c := (a + b) / 2
end;
bisect:=c
end;
Замечание. Частным случаем задачи является вычисление
. В самом деле, положив x =
, т.е. x2 = 2, получим уравнение x2 — 2 = 0, решение которого надо найти на отрезке [1; 2]
(приближение к решению с недостатком и избытком).
Вопросы и упражнения. Материалы для самостоятельной работы
1. Напишите программу для вычисления значений многочлена по схеме Горнера:
i) у =x10+2x9+3x8+…+10x+11.
ii) у =11x10+10x9+9x8+…+2x+1.
2. Числа Фибоначчи fn определяются формулами f0 = f1 = 1; fn = fn-1 + fn-2 при n = 2, 3, ... .
Составьте программу, которая печатала бы ряд чисел Фибоначчи в виде звездочек.
Начало ряда
*
*
**
***
*****
********
Строки печатаются до тех пор, пока число звездочек умещается в строке.
3. Не используя стандартные функции (за исключением, возможно, abs), вычислить с
точностью eps>0:
57
Алгоритмы и алгоритмические языки
Считать, что требуемая точность достигнута, если очередное слагаемое по модулю меньше
eps. Все последующие слагаемые можно уже не учитывать.
Библиографический список
1. Бауэр Ф.Л., Гооз Г. Информатика. Вводный курс : в 2 ч. М.: Мир, 1990. С. 188—227.
2. Кнут Д. Искусство программирования для ЭВМ. Основные алгоритмы: М.: Мир, 2000.
Т. 1. С. 37—138.
3. Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы. Построение и анализ. М.: МЦНМО, 2002.
С. 59—68.
58
Алгоритмы и алгоритмические языки
Лекция 7. Поиск в последовательных таблицах
Таблица
Таблицу можно рассматривать как одномерный массив (вектор), элементами которого
являются записи. Характерной логической особенностью доступа к элементу таблицы, является
то, что доступ осуществляется не по номеру (индексу), а по ключу — по значению одного из
свойств объекта, описываемого элементом таблицы.
Пусть, например, имеются следующие записи:
Индекс
1
2
3
4
Табельный
номер
212007
571994
132006
211999
Фамилия
Год рождения
Образование
Иванов
Петров
Сидоров
Яковлев
1951
1949
1975
1964
высшее
среднее
среднее
высшее
Эту таблицу можно описать как массив:
type
var
education = (начальное, среднее, спец, высшее);
person = record
Num: word;
Name: string[20];
Year: integer;
ed: education
end;
Table = array[1 .. 4] of person;
t: Table;
Доступ по индексу очевиден, например t[2]. Но, как правило, доступ к записи нужен по
некоторой содержательной информации, например по табельному номеру, т. е. по ключу.
Ключ — это свойство, идентифицирующее данную запись во множестве однотипных записей.
Как правило, к ключу предъявляется требование уникальности в данной таблице. Ключ может
включаться в состав записи и быть одним из ее полей (как в примере), но может и не
включаться в запись, а вычисляться по положению записи. Таблица может иметь один или
несколько ключей.
Основной операцией при работе с таблицами является операция доступа к записи по ключу.
Она реализуется процедурой поиска. Поскольку поиск может быть значительно более
эффективным в таблицах, упорядоченных по значениям ключей, довольно часто над
таблицами необходимо выполнять операции сортировки.
59
Алгоритмы и алгоритмические языки
Алгоритмы поиска
Последовательный или линейный поиск
Простейшим методом поиска элемента, находящегося в неупорядоченном наборе данных, по
значению его ключа является последовательный просмотр каждого элемента набора, который
продолжается до тех пор, пока не будет найден желаемый элемент. Если просмотрен весь
набор, но элемент не найден — значит, искомый ключ отсутствует в наборе.
Словесно алгоритм последовательного поиска можно описать фразой: «Пока есть где искать, и
не найдено, взять следующий (элемент для проверки)».
Используем алгоритмическую конструкцию цикла с предусловием для формализации
сказанного:
while (есть где искать) and (не найдено)
do<брать следующий>
Остается ответить на вопрос, чем закончился поиск. Очевидно, есть два варианта. Либо
искомое найдено, либо область поиска пуста. Для проверки используем ветвление:
if (множество поиска не пусто) then<найдено>else<не найдено>
Эти две конструкции и реализуют алгоритм последовательного поиска. В последующем
изложении все описания алгоритмов даны для работы с таблицей, состоящей из записей R[1],
R[2], ..., R[N] с ключами A[1], A[2], ..., A[N]. Во всех случаях N — количество элементов таблицы.
Для последовательного поиска в среднем требуется (N+1)/2 сравнений. Таким образом,
порядок алгоритма — линейный — O(N).
Задача поиска элемента в неупорядоченном массиве
Во всех примерах, относящихся к поиску в одномерном массиве, будем использовать
переменную A (ключ):
A: array[1..N] of integer;
Конкретный тип элемента (integer) в большинстве описываемых алгоритмов не важен, он
может быть как любым числовым, так и символьным или даже строковым. Лишь бы для него
была определена операция сравнения.
Задача. Найти среди элементов массива A элемент, значение которого равно K. Результатом
поиска должен быть индекс элемента в массиве или 0, если такого элемента нет.
Пусть, например, в массиве из 5 чисел (3, 7, –2, 7, 0) надо найти элемент, равный 7. Ответом
будет 2 — номер (индекс) первого встреченного ключа. Если же надо найти элемент, равный 5,
то ответом будет 0 — такого элемента нет.
Алгоритм поиска в массиве элемента, значение которого равно K, может выглядеть так:
60
Алгоритмы и алгоритмические языки
i:=1;
while (i <= n) and (A[i] <> K) do i:=i+1;
if i <= n then write(i) else write(0)
Поиск в упорядоченных массивах
Под упорядоченными массивами в дальнейшем будут пониматься неубывающие массивы,
если не оговорено иное. То есть a[1] ≤ a[2] ≤ … ≤ a[N].
Приведем пример реализации широко известного алгоритма двоичного (бинарного,
дихотомического) поиска элемента, равного K, в уже упорядоченном массиве.
const n=8;
type
item = integer;
vector = array [1 .. n] of item;
const a: vector = (2, 4, 6, 7, 23, 56, 78, 132);
var x:item;
L, R, m: integer;
found: boolean;
begin
x := 23;
L := 1;
R := n;
found := false;
while (L <= R) andnot found do begin
m := (L + R) shr 1;
if a[m] = x then found := true
else if a[m] < x then L := m + 1 else R := m — 1;
end;
writeln (found);
end.
Для того чтобы найти нужную запись в таблице, в худшем случае требуется log2(N) сравнений.
Прямой доступ и хеширование
В рассмотренных выше методах поиска число проб при поиске в лучшем случае было
пропорционально log2(N). Естественно, возникает желание найти такой метод поиска, при
61
Алгоритмы и алгоритмические языки
котором число проб не зависело бы от размера таблицы, а в идеальном случае поиск сводился
бы к одной пробе.
Таблицы прямого доступа
Простейшей организацией таблицы, обеспечивающей идеально быстрый поиск, является
таблица прямого доступа. В такой таблице ключ является адресом записи в таблице или
может быть преобразован в адрес, причем таким образом, что никакие два разных ключа не
преобразуются в один и тот же адрес. При создании таблицы выделяется память для хранения
всей таблицы и заполняется пустыми записями. Затем записи вносятся в таблицу — каждая на
свое место, определяемое ее ключом. При поиске ключ используется как адрес и по этому
адресу выбирается запись, если выбранная запись пустая, то записи с таким ключом вообще
нет в таблице.
Таблицы прямого доступа применимы только для таких задач, в которых размер пространства
записей может быть равен размеру пространства ключей. В большинстве реальных задач,
однако, размер пространства записей много меньше, чем пространства ключей. Так, если в
качестве ключа используется строка из 10 символов (буквы от A до Z), мы получаем 2610
возможных значений ключей. Ни в какой вычислительной системе не может быть выделено
пространство записей такого размера. Но даже если ресурсы вычислительной системы и
позволят это, то значительная часть этого пространства будет заполнена пустыми записями,
так как в каждом конкретном заполнении таблицы фактическое множество ключей не будет
полностью покрывать пространство ключей.
Таблицы со справочниками
Основная таблица содержит записи в произвольном порядке. В дополнение к основной
строится справочная или индексная таблица, записи которой состоят всего из двух
полей: ключа и адреса в основной таблице. Поиск по ключу производится в справочной
таблице. Если справочная таблица является таблицей прямого доступа, то потери памяти на
пустые записи уменьшаются. Обычно справочные таблицы содержат только фактические
ключи, их сортируют и применяют, например, двоичный поиск.
Два важных свойства таблиц со справочниками делают их очень полезными:
1. Если основная таблица расположена на внешней памяти, то справочная таблица (или
значительная часть ее) может быть размещена в оперативной памяти и поиск ключа,
таким образом, будет выполняться в оперативной памяти, что гораздо быстрее.
2. Для одной основной таблицы могут быть построены несколько справочников,
обеспечивающих использование в качестве ключа разных полей записи основной
таблицы.
Для таблиц прямого доступа и для таблиц со справочниками нет необходимости хранить ключ
в составе записи основной таблицы, так как ключ может быть восстановлен по адресу записи
либо по справочнику.
62
Алгоритмы и алгоритмические языки
Хешированные таблицы
Поскольку память является одним из самых дорогостоящих ресурсов вычислительной
системы, из соображений ее экономии целесообразно назначать размер пространства записей
равным размеру фактического множества записей или превосходящим его незначительно.
В этом случае мы должны иметь некоторую функцию, обеспечивающую отображение точки из
пространства ключей в точку в пространстве записей, т. е. преобразование ключа в адрес
записи: r = H(k), где — r адрес записи, k — ключ. Такая функция называется функцией
хеширования (функция перемешивания, функция рандомизации).
Хеширование (или хэширование, англ. hashing ) — это преобразование входного массива
данных определенного типа и произвольной длины в выходную битовую строку
фиксированной длины. Такие преобразования также называются хеш-функциями или
функциями свертки, а их результаты называют хешем, хеш-кодом, хеш-таблицей или
дайджестом сообщения (англ. message digest ). Лет 20 тому назад слово это считалось
сленговым, и, например у Н. Вирта в «Алгоритмах и структурах данных», этот же метод
называется методом преобразования ключей, или расстановкой ключей.
Хеш-таблица — это структура данных, позволяющая хранить пары вида «ключ- значение» и
выполнять три операции: операцию добавления новой пары, операцию поиска и операцию
удаления пары по ключу. Хеш-таблица является массивом, формируемым в определенном
порядке хеш-функцией.
Вот иллюстрация хеш-таблицы. Мы видим, что индексами ключей в хеш-таблице является
результат хеш-функции h, применённой к ключу.
Этот рисунок также иллюстрирует одну из основных проблем. При достаточно маленьком
значении m (размера хеш-таблицы) по отношению к n (количеству ключей) или при плохой
хеш-функции может случиться так, что два ключа будут хешированы в одну и ту же ячейку
массива H. Такая ситуация называется коллизией. Хорошие хеш-функции стремятся
минимизировать вероятность коллизий, однако, учитывая то, что пространство всех
63
Алгоритмы и алгоритмические языки
возможных ключей может быть больше размера нашей хеш-таблицы H, всё же избежать их
вряд ли удастся. На этот случай имеются несколько технологий для разрешения коллизий.
Основные из них мы и рассмотрим далее.
Хеш-функция. Принято считать, что хорошей, с точки зрения практического применения,
является такая хеш-функция, которая удовлетворяет следующим условиям:
●
функция должна быть простой с вычислительной точки зрения;
функция должна распределять ключи в хеш-таблице наиболее равномерно;
функция не должна отображать какую-либо связь между значениями ключей в связь
между значениями адресов;
функция должна минимизировать число коллизий — т. е. ситуаций, когда разным
ключам соответствует одно значение хеш-функции (ключи в этом случае называются
синонимами).
●
●
●
Приведем пример хеш-функции. В хэш-функцию, в общем, передается элемент данных,
который она преобразовывает в целое число. Полученное число используется как индекс в
таблице (адрес).
const
M = 32; // размер хеш-таблицы
var h: array[0..M — 1] of string;
function hash(str:string): integer;
var h, i: integer;
begin
h := 0;
for
i := 0 to length(str) do begin
h := ((h shl 1) xor ord(str[i]));
if (h < 0) then h := — h;
h := h mod M;
end;
hash := h;
end;
var s: string;
begin
assign(input, 'PrimeRec.pas); reset(input);
assign(output, 'output.txt'); rewrite(output);
while not eof do begin
64
Алгоритмы и алгоритмические языки
readln(s);
write(hash(s), ' ');
end;
end.
Для входного файла, состоящего из 14 разных строк:
1
function ispr(n, m: integer): boolean;
2
begin
3
if m = n then
4
else
5
if n mod m = 0 then
6
else ispr := ispr(n, m + 1)
7
end;
ispr := true
ispr := false
8
9
function isprime(n: integer): boolean;
10
begin
if n = 1 then
11
isprime := false
12
else isprime := ispr(n, 2) end;
13
var i: integer;
14
begin writeln(isprime(2)) end.
получилась последовательность индексов, в которой довольно много повторений, т. е. разные
строки формируют одинаковые индексы:
строка
индекс
1
11
2
8
3
7
4
27
5
27
6
19
7
3
8
0
9
11
10
4
11
27
12
3
13
3
14
22
Существуют библиотечные функции, например CRC32 или md5 (устаревший, для серьезного
применения не рекомендуемый), SHA-2 (англ.Secure Hash Algorithm Version 2 — безопасный
алгоритм хеширования, версия 2) с гораздо лучшими характеристиками, но ни одна не
гарантирует от коллизий. На случай коллизий имеется несколько технологий для их
разрешения. Основные из них рассматриваются в материалах для самостоятельной работы.
65
Алгоритмы и алгоритмические языки
Материалы для самостоятельной работы
Поиск с барьером
Рассмотренный алгоритм последовательного поиска имеет ряд недостатков. Во-первых, в нем
используется сложное логическое выражение. Во-вторых, в этом условии неявно используется
способность компилятора к неполному вычислению значения такого выражения. Т. е. если в
процессе вычисления логического выражения оказалось, что (i <= n) ложно, то второе условие
можно не проверять. Это важно, так как в противном случае пришлось бы проверять значение
a[n + 1], а оно не определено. Однако если положить его равным K, то алгоритм можно
существенно упростить, избавившись в условии окончания цикла от проверки на выход за
границу массива:
a[n + 1]:=K;
i:=1;
while (a[i]<>K) do i:=i+1;
if i <= n then write(i) else write(0);
Эта программа проще и эффективней. В ней практически невозможно сделать ошибку.
Сложность алгоритма есть величина O(n/2).
Улучшенный поиск в упорядоченных массивах
Оказывается, досрочный выход из цикла в случае нахождения элемента выигрыша по скорости
практически не дает, а лишние проверки делают программу более громоздкой. Поэтому
рекомендуется производить поиск, пока диапазон рассматриваемых элементов состоит более,
чем из одного элемента.
L:=1; R:=N+1;
while L<R do
begin
m:=(L+R)div 2;
if a[m]<K then L:=m+1
else R:=m
end;
if a[R]=K then write(R) else write(0)
Хеширование с цепочками
В случае открытого хеширования (другое название хеширования цепочками) мы объединяем
элементы, хешированные в одну и ту же ячейку, в связный список. Следующий рисунок
иллюстрирует это.
66
Алгоритмы и алгоритмические языки
Так, идея достаточно проста. Если при добавлении в хеш-таблицу в заданную ячейку мы
встречаем ссылку на элемент связного списка, то случается коллизия. Так, мы просто
вставляем наш элемент как узел в список. При поиске мы проходим по цепочкам
(последовательный поиск), сравнивая ключи между собой на эквивалентность, пока не
доберёмся до нужного ключа. При удалении ситуация такая же.
Процедура вставки выполняется даже в наихудшем случае за O(1), учитывая то, что мы
предполагаем отсутствие вставляемого элемента в таблице. Время поиска зависит от длины
списка, и в худшем случае равно O(n). Эта ситуация, когда все элементы хешируются в
единственную ячейку. Если функция распределяет n ключей по m ячейкам таблицы
равномерно, то в каждом списке будет содержаться порядка n/m ключей. Это число
называется коэффициентом заполнения хеш-таблицы. Математический анализ хеширования с
цепочками показывает, что в среднем случае все операции в такой хеш-таблице в среднем
выполняются за время O(1).
Хеширование с открытой адресацией
В случае метода открытой адресации (или по-другому: закрытого хеширования) все элементы
хранятся непосредственно в хеш-таблице, без использования связанных списков. В отличии от
хеширования с цепочками, при использовании метода открытой адресации может возникнуть
ситуация, когда хеш-таблица окажется полностью заполненной, так что будет невозможно
добавлять в неё новые элементы. Так что при возникновении такой ситуации решением может
быть динамическое увеличение размера хеш-таблицы, с одновременной её перестройкой.
Для разрешения же коллизий применяются несколько подходов. Самый простой из них — это
метод линейного исследования. В этом случае при возникновении коллизии следующие за
текущей ячейки проверяются одна за другой, пока не найдётся пустая ячейка, куда и
помещается наш элемент. Так, при достижении последнего индекса таблицы, мы
перескакиваем в начало, рассматривая её как «цикличный» массив. Иллюстрация этого
способа представлена на следующем рисунке:
67
Алгоритмы и алгоритмические языки
Линейное хеширование достаточно просто реализуется, однако с ним связана существенная
проблема — кластеризация. Это явление создания длинных последовательностей занятых
ячеек, которое увеличивает среднее время поиска в таблице. Для снижения эффекта
кластеризации используется другая стратегия разрешения коллизий — двойное хеширование.
Основная идея заключается в том, что для определения шага смещения исследований при
коллизии в ячейке используется другая хеш-функция, вместо линейного смещения на одну
позицию.
Один из сложных вопросов реализации хеширования с открытой адресацией — это операция
удаления элемента. Дело в том, что если мы просто удалим некий элемент из хеш-таблицы, то
сделаем невозможным поиск ключа, в процессе вставки которого текущая ячейка оказалась
заполненной. Чтобы этого избежать, мы можем помечать очищенные ячейки какой-то меткой,
чтобы впоследствии это учитывать.
Вопросы и упражнения
1. Элементы массивов A и B натуральные числа. Определить, верно ли, что каждый
элемент массива A содержится в массиве B.
2. Изобразить процесс поиска элементов 1) 39; 2) 57; 3) 9; 4) -14 методом бинарного
поиска (половинного деления) на примере возрастающего массива: (3, 7, 8, 10, 13, 15,
16, 18, 21, 23, 39, 40, 44, 53). Процесс представить в виде таблицы. Как изменится
последовательность действий (и программа) бинарного поиска, если массив будет
упорядочен по убыванию?
3. Дан массив целых чисел A, упорядоченный по убыванию. Написать программу,
реализующую метод бинарного поиска элемента в массиве A.
4. Часто бывает непросто увидеть метод двоичного поиска в хорошей задаче по
информатике. Вот один пример — задача «Провода» с полуфинала чемпионата мира
по программированию ACM, проходившему в Санкт-Петербурге в октябре 2002 года:
На складе имеется N проводов целочисленной длины. Необходимо из них получить
K кусков провода одинаковой и как можно большей длины. Провода нельзя спаивать.
68
Алгоритмы и алгоритмические языки
В первой строчке указаны числа N и K, (1 <= N, K <=104). Далее разделённые
пробельными символами перечислены N натуральных чисел — длины имеющихся
проводов. Они не превосходят 107. Выведите целое максимальное число L — такое,
что можно из имеющихся проводов получить K кусочков длины L.
Рассуждения о способах разрезания проводов, конечно, могут привести к решению, но
гораздо более простой путь— дихотомия по длине про́ вода. Функция общего числа
проводов от проверяемой длины L легко вычисляется, она, очевидно, является
монотонной, и искать решение можно, например, на интервале от L = 1 до L=107+1.
Задача сводится к классическому методу двоичного поиска, и её решение оказывается
на удивление простым. Решите эту задачу.
Библиографический список
1. Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. 2-е изд. М.:
МЦНМО, 2002.
2. Дональд Э. Кнут. Искусство программирования. Т. 3. Сортировка и поиск. 2-е изд. М.:
Издательский дом «Вильямс», 2000. Гл. 6.
3. Ахо А. В., Хопкрофт Д., Ульман Дж. Д. Структуры данных и алгоритмы. М.: Изд. дом
«Вильямс», 2000.
4. Левитин — Алгоритмы. Введение в разработку и анализ. М.: Изд. дом «Вильямс», 2006.
Гл. 7.3. С. 323.
5. Керниган Б., Пайк Р. Практика программирования. 4 изд. М.: Изд. дом «Вильямс», 2004.
Гл. 2.9. С. 72. (Пример реализации хеширования с цепочками).
69
Алгоритмы и алгоритмические языки
Лекция 8. Операции над таблицами. Сортировка
Задача сортировки
Для самого общего случая сформулируем задачу сортировки таким образом: имеется
некоторое неупорядоченное входное множество ключей, и мы должны получить выходное
множество тех же ключей, упорядоченных по возрастанию или убыванию в численном или
лексикографическом порядке. То есть под сортировкой понимается процесс перестановки
заданной последовательности данных в некотором определённом порядке, часто — в порядке
неубывания. Сортировку иногда называют упорядочиванием. Цель сортировки — облегчить
последующий поиск данных в отсортированной последовательности. Например, сортируются
данные в телефонных книгах, словарях, каталогах, складах — почти везде, где стоит задача
поиска.
Выбор алгоритма сортировки зависит от структуры обрабатываемых данных. Если данные
хранятся в виде массива в ОП компьютера (прямой доступ, время доступа достаточно мало,
сравнительно небольшой объём памяти), используют алгоритмы сортировки «на месте». Если
данные размещены на диске в виде файлов (последовательный доступ, время доступа велико,
объём памяти большой), используют алгоритмы слияния, сортируя отдельные части файла в
ОП.
Формализуем сказанное. Пусть имеются данные a1, a2,…, an. Осуществим перестановку этих
данных ak1, ak2,…, akn, где при некоторой упорядочивающей функции f выполняется
соотношение f(ak1)≤ f(ak2) ≤…≤ f(akn).
Обычно упорядочивающая функция не вычисляется по какому-либо правилу, а хранится как
явная компонента каждого элемента данных. Её значение называется ключом (key) элемента
данных. Поэтому для представления данных хорошо подходят такие структуры, как записи.
Пусть, например, имеются следующие записи:
Табельный номер
212007
571994
132006
211999
Фамилия
Иванов
Петров
Сидоров
Яковлев
Год рождения
1951
1949
1975
1964
Образование
высшее
среднее
среднее
высшее
Они упорядочены по полю «Фамилия». Это поле — ключ сортировки. Если провести
сортировку по ключу «Год рождения», записи расположатся в порядке
571994
212007
211999
132006
Петров
Иванов
Яковлев
Сидоров
1949
1951
1964
1975
среднее
высшее
высшее
среднее
Одним способом сортируются данные по ключу «Табельный номер». А результат сортировки
по ключу образование может быть разным. Нередко важным требованием к сортировке
70
Алгоритмы и алгоритмические языки
является сохранение относительного расположения элементов с равными ключами. Такие
сортировки называют устойчивыми. Если к первой таблице применить устойчивую
сортировку, результатом будет сохранение алфавитного порядка для записей с равными
ключами:
571994
132006
212007
211999
Петров
Сидоров
Иванов
Яковлев
1949
1975
1951
1964
среднее
среднее
высшее
высшее
Поскольку ключ всегда можно представить в виде числа, рассматривать алгоритмы сортировок
будем на массиве чисел.
Алгоритмы сортировки
Из всех задач программирования сортировка, возможно, имеет самый богатый выбор
алгоритмов решения. Разнообразие алгоритмов сортировки требует некоторой их
классификации. Классификацию будем основывать на логических характеристиках
применяемых алгоритмов. Согласно этому подходу любой алгоритм сортировки использует
одну из следующих четырех стратегий (или их комбинацию).
1. Стратегия выборки. Из входного множества выбирается следующий по критерию
упорядоченности элемент и включается в выходное множество на место, следующее
по номеру.
2. Стратегия включения. Из входного множества выбирается следующий по номеру
элемент и включается в выходное множество на то место, которое он должен занимать
в соответствии с критерием упорядоченности.
3. Стратегия распределения. Входное множество разбивается на ряд подмножеств
(возможно, меньшего объема) и сортировка ведется внутри каждого такого
подмножества.
4. Стратегия слияния. Выходное множество получается путем слияния маленьких
упорядоченных подмножеств.
Эффективность алгоритмов
Объективным критерием, позволяющим оценить эффективность того или иного алгоритма,
является порядок алгоритма. Порядком алгоритма называется функция O(N), позволяющая
оценить зависимость времени выполнения алгоритма от объема перерабатываемых данных
(N — количество элементов в массиве или таблице). Эффективность алгоритма тем выше, чем
меньше время его выполнения при одинаковом объеме данных. Большинство алгоритмов с
точки зрения порядка сводятся к трем основным типам (перечислены по ухудшению
эффективности):
●
●
логарифмические — O(loga(N));
линейные — O(N);
71
Алгоритмы и алгоритмические языки
● степенные — O(Na) .
На графике сравнивается поведение функций разного порядка.
Обменная сортировка простой выборкой
Входное и выходное множество располагаются в одной и той же области памяти; выходное —
в начале области, входное — в оставшейся ее части. В исходном состоянии входное множество
занимает всю область, а выходное множество — пустое. По мере выполнения сортировки
входное множество сужается, а выходное — расширяется.
На первом шаге метода находим наименьший ключ и переставляем соответствующий элемент
с первым элементом массива. Исключаем первый элемент из рассмотрения и повторяем
алгоритм на оставшейся части массива. Так поступаем до конца массива (пример взят из [8]) .
8
i
44
55
12
42
94
18
6
67
1
6
55
12
42
94
18
44
67
2
6
12
55
42
94
18
44
67
3
6
12
18
42
94
55
44
67
4
6
12
18
42
94
55
44
67
5
6
12
18
42
44
55
94
67
6
6
12
18
42
44
55
94
67
7
6
12
18
42
44
55
67
94
Вирт Н. Алгоритмы и структуры данных. М.: Мир, 1989.
72
Алгоритмы и алгоритмические языки
program selection;
const n=8;
type
key = integer;
vector=array[1..n] of key;
const a:vector =(44,55,12,42,94,18,6,67);
var
min: key;
i, j, k:integer;
begin
for i:=1 to n — 1 do begin
k := i;
min := a[i];
for j := i + 1 to n do
if a[j] < min then begin k := j; min := a[k] end;
a[k] := a[i]; a[i] := min
end;
for i:=1 to n do write(a[i]:3); writeln
end.
Главное достоинство этого алгоритма — простота реализации. Алгоритм не является
устойчивым. Количество сравнений
и не учитывает исходной упорядоченности.
Число перестановок зависит от упорядоченности исходного множества.
Анализ прямого выбора. Число сравнений ключей (С), очевидно, не зависит от начального
порядка ключей. Для С имеем
С = (n2 – n)/2.
Число перестановок минимально в случае изначально упорядоченных ключей
Mmin = 3*(n – 1)
и максимально, если первоначально ключи располагались в обратном порядке.
Mmax = п2/4 + 3 * (n – 1).
Для того чтобы определить Mavg, рассуждаем так. Алгоритм просматривает массив, сравнивая
каждый элемент с только что обнаруженной минимальной величиной; если он меньше
первого, то выполняется некоторое присваивание. Вероятность, что второй элемент окажется
меньше первого, равна 1/2, с этой же вероятностью происходят присваивания минимуму.
Вероятность, что третий элемент окажется меньше первых двух, равна 1/3, а вероятность для
73
Алгоритмы и алгоритмические языки
четвертого оказаться наименьшем — 1/4 и т. д. Поэтому полное ожидаемое число пересылок
равно Нn — 1, где Нn —n-е гармоническое число:
Нn = 1 + 1/2 + 1/3+ ... +1/n.
Нnможно выразить и так:
Hn = In n + g + 1/2n — 1/12n2 + ... ,
где g = 0.577216 ... — константа Эйлера. Для достаточно больших n мы можем игнорировать
дробные составляющие и поэтому аппроксимировать среднее число присваиваний на i-м
просмотре выражением Fi = ln i + g + 1.
Среднее число пересылок Mavg в сортировке с выбором имеет приблизительное значение
Mavg = п * (ln (п) + g).
Пузырьковая сортировка (bubble sort)
Входное множество просматривается, при этом попарно сравниваются соседние элементы
множества. Если порядок их следования не соответствует заданному критерию
упорядоченности, то элементы меняются местами. В результате одного такого просмотра при
сортировке по возрастанию элемент с самым большим значением ключа переместится
(«всплывет») на последнее место в множестве. При следующем проходе на свое место
«всплывет» второй по величине ключа элемент и т. д. Для постановки на свои места N
элементов следует сделать N-1 проходов. Выходное множество, таким образом, формируется
в конце сортируемой последовательности, при каждом следующем проходе его объем
увеличивается на 1, а объем входного множества уменьшается на 1.
Пример.
1
2
3
4
5
6
7
44
6
6
6
6
6
6
6
55
44
12
12
12
12
12
12
12
55
44
18
18
18
18
18
42
12
55
44
42
42
42
43
94
42
18
55
44
44
44
44
18
94
42
42
55
55
55
55
6
18
94
67
67
67
67
67
67
67
67
94
94
94
94
94
Программа
program bubble_sort;
const n=8;
type
key = integer;
74
Алгоритмы и алгоритмические языки
vector=array[0..n] of key;
const a:vector =(0,44,55,12,42,94,18,6,67);
var
x:key;
i,j:integer;
begin
for i:=2 to n do
for j:=n downto i do
if a[j]<a[j-1] then begin
x:=a[j-1];
a[j-1]:=a[j];
a[j]:=x
end;
for i:=1 to n do write(a[i]:3); writeln
end.
Алгоритм устойчивый. Оценка эффективности равна
. Минимальное, среднее и
максимальное число перемещений (присваиваний) равно соответственно
Mmin = 0, Mavg = 3*(n2 – n)/2, Mmax = 3*(n2 – n)/4.
Программа легко реализуется. Существует много вариантов этого алгоритма. Известна,
например, «шейкерная» сортировка, в которой шаг пузырьковой сортировки «снизу вверх»
чередуется с шагом «сверху вниз». При современном быстродействии компьютеров варианты
методов порядка n2 не актуальны. Если требуется большая производительность сортировки,
рекомендуется использовать алгоритм быстрой сортировки (quick sort) или пирамидальной
сортировки, имеющих в среднем оценку O(n*log n).
Сортировка простыми вставками
Этот метод — «дословная» реализации стратегии включения. Порядок алгоритма сортировки
простыми вставками — O(n2), если учитывать только операции сравнения.
Идея: числа просматриваются слева направо. Как только нашли число «не на месте», его
передвигают влево, пока оно не встанет там, где оно должно стоять. Так продолжают, пока не
дойдут до конца последовательности чисел. Приведём пример:
i
44
55
12
42
94
18
6
67
2
44
55
12
42
94
18
6
67
75
Алгоритмы и алгоритмические языки
3
12
44
55
42
94
18
6
67
4
12
42
44
55
94
18
6
67
5
12
42
44
55
94
18
6
67
6
12
18
42
44
55
94
6
67
7
6
12
18
42
44
55
94
67
8
6
12
18
42
44
55
67
94
Программа
program sorting_by_insertion;
const n=8;
type
key = integer;
vector=array[0..n] of key;
const a:vector =(0,44,55,12,42,94,18,6,67);
var
x:key;
i,j:integer;
begin
for i:=2 to n do begin
x:=a[i];
a[0]:=x;
j:=i;
while x<a[j-1] do begin
a[j]:=a[j-1];
dec(j)
end;
a[j]:=x;
end;
for i:=1 to n do write(a[i]:3); writeln
end.
Общее число сравнений и число пересылок таковы:
Cmin = n – 1
Mmin = 3*(n – 1)
Cavg = (n2 + n – 2) /4
Mavg = (n2 + 9n – 10) /4
76
Алгоритмы и алгоритмические языки
Cmax = (n2 + n – 4) /4
Mmax = (n2 + 3n – 4) /2
Наилучшие оценки встречаются в случае уже упорядоченной исходной последовательности
элементов, наихудшие же оценки — когда они первоначально расположены в обратном
порядке. Ясно, что приведенный алгоритм описывает процесс устойчивой сортировки:
порядок элементов с равными ключами при нем остается неизменным.
Алгоритм с прямыми включениями можно легко улучшить, если обратить внимание на то, что
готовая последовательность, в которую надо вставить новый элемент, сама уже упорядочена.
Естественно остановиться на двоичном поиске, при котором делается попытка сравнения с
серединой готовой последовательности, а затем процесс деления пополам идет до тех пор,
пока не будет найдена точка включения. Такой модифицированный алгоритм сортировки
называется методом с двоичным включением (binary insertion).
Сортировка шелла. Сортировка Шелла является довольно интересной модификацией
алгоритма сортировки простыми вставками. Фактически для сортировки элементов
используются другие алгоритмы, такие как: пузырьком, вставками, выбором и т.д. Но только
эти алгоритмы применяются не ко всей исходной последовательности, а к ее частям.
Сначала в исходной последовательности сортируются между собой элементы, отстоящие друг
от друга на расстоянии n/2 элементов, затем на расстоянии n/4 и т.д. до тех пор, пока не
получим 2 последовательности, элементы которых отстоят друг от друга на расстоянии 1-го
элемента. После этого делаем сортировку этой полученной последовательности выбранным
методом и на выходе имеем уже полностью отсортированную последовательность.
Сортировка неустойчивая. Среднее время для сортировки Шелла равняется O(n1.25), для
худшего случая оценкой является O(n1.5).
Сортировка упорядоченным двоичным деревом. Алгоритм складывается из построения
упорядоченного двоичного дерева и последующего его обхода. Если нет необходимости в
построении всего линейного упорядоченного списка значений, то нет необходимости и в
обходе дерева, в этом случае применяется поиск в упорядоченном двоичном дереве.
Алгоритмы работы с упорядоченными двоичными деревьями рассмотрены в теме 6. Порядок
алгоритма — O(N*logN)), но в конкретных случаях все зависит от упорядоченности исходной
последовательности, который влияет на степень сбалансированности дерева.
Сортировка подсчетом
Пусть дана последовательность (файл) целых чисел, причем каждое число не слишком велико.
Положим, например, что каждое число находится в диапазоне от 0 до M, причем M таково, что
в ОП можно поместить массив из M + 1 чисел. Требуется сортировать последовательность по
неубыванию. Идея состоит в том, чтобы подсчитать, сколько раз каждое число содержится в
файле, а затем напечатать каждое число столько раз, сколько оно встретилось, от меньших к
большим.
Пример. Пусть имеется последовательность неотрицательных целых чисел, каждое из которых
не больше 10. Например, 9, 2, 5, 9, 3, 3, 5, 0, 1, 2, 3, 5. Запоминать, сколько раз встретилось
77
Алгоритмы и алгоритмические языки
каждое число будем в массиве s из M + 1 чисел. В s[0] — сколько раз встретился ноль, в s[1] —
сколько раз встретилась единица и так далее. То есть каждое число последовательности
используется как индекс массива. Для заданной последовательности чисел получим массив (1,
1, 2, 3, 0, 3, 0, 0, 0, 2, 0). Осталось напечатать каждый индекс столько раз, каково значение
счётчика: 0, 1, 2, 2, 3, 3, 3, 5, 5, 5, 9, 9.
const M=16;
var s: array[0..M] of integer;
var
i, j: integer;
begin
for i:=0 to M do s[i]:=0;
while not eof do begin
read(i);
if i in [0..M] then inc(s[i])
else begin writeln('Range check error');halt end;
end;
for i:=0 to M do
if s[i] > 0 then
for j:=1 to s[i] do writeln(i);
end.
Количество операций пропорционально количеству чисел в файле. Но алгоритм работает
только при ограничении на диапазон сортируемых чисел. Эту сортировку иногда называют
сортировкой вычерпыванием, а каждый s[i] — черпаком.
Обобщение. Сортировка в лексикографическом порядке
Как сортированы слова в словаре? В первом словаре английского языка даётся инструкция:
«Если слово, которое ты ищешь, начинается с "a”, то ищи его в начале, а если оно
начинается с “v”, то ищи его в конце. Опять же, если слово начинается с “ca”, то искать
его следует в начале буквы “c”, а если с “cv”, то смотреть надлежит в конце этой буквы. И
так поступай до конца слова».
Описанный здесь порядок называется лексикографическим порядком. У каждой буквы есть
номер (код), поэтому можно считать, что лексикографический порядок устанавливается над
числами. Пусть имеются слова s1, s2,…, sp и t1, t2,…, tq, где si и ti ‒ числа. Неравенство s1, s2,…, sp ≤
t1, t2,…, tq в лексикографическом смысле означает, что выполнено одно из двух условий:
1) существует такое целое число j, что si< ti, и для всех i< j справедливо si = ti;
2) p < q и si = ti при 1 ≤ j ≤ p.
Например, WINDOW ≤ WINDOWS, STUDENT ≤ STUDY.
78
Алгоритмы и алгоритмические языки
В базах данных строки символов (списки) в таблицах называются кортежами. Сортировку
кортежей естественно проводить вычерпыванием, последовательно выполняя проход за
проходом, упорядочивая кортежи справа налево.
Пример. Пусть имеется последовательность кортежей AABC, BACD, ABCA, BACA, BCAA, BBCA,
CABA. Требуется сортировать их в лексикографическом порядке.
1-й проход
2-й проход
3-й проход
4-й проход
ABCA
BACA
BCAA
BBCA
CABA
AABC
BACD
BCAA
CABA
AABC
ABCA
BACA
BBCA
BACD
CABA
AABC
BACA
BACD
ABCA
BBCA
BCAA
AABC
ABCA
BACA
BACD
BBCA
BCAA
CABA
Быстрая сортировка Хоара
Для достижения наилучшей эффективности сначала лучше производить перестановки на
большие расстояния. Например, если есть уверенность, что данные отсортированы по
убыванию, а их нужно отсортировать по возрастанию, эффективнее всего обменивать местами
крайние, двигаясь с двух сторон к центру массива. Это потребует всего n/2 обменов.
Эта идея и применяется в быстрой сортировке, только обмениваются местами элементы
относительно некоторого произвольно взятого элемента. Обычно берут средний элемент.
Пусть, например, имеется массив 18,6,12,42,94,55,44,67. Средний элемент равен x = 42.
Просматриваем левую часть слева направо, правую справа налево. Слева ищем элемент,
меньший x, справа больший x. Как только находим такие, меняем их местами:
1..8
18 6 12 42 94 55 44 67 //x = 42, слева все меньше, менять не с чем, 42 стоит на своём месте
1..3
6 18 12 42 94 55 44 67 //x = 6, местами поменялся 18 и 6
2..3
6 12 18 42 94 5544 67 //x = 18, местами поменялся 12 и 18
5..8
6 12 18 42 44 5594 67 //x = 55, местами поменялся 94 и 44
7..8
6 12 18 42 44 55 67 94 //x = 94, местами поменялся 94 и 67
Обмен закончен. Потребовалось 5 обменов.
const n= 8;
a: array [1..n] of integer =(18,6,12,42,94,55,44,67);
procedure sort(l, r: integer);
var i,j: integer; {индекс}
79
Алгоритмы и алгоритмические языки
w, x :integer;
{переменная с индексом}
begin
i := l; j := r;
x := a[(l + r) div 2];
repeat
while a[i] <x do inc(i);
while x<a[j] do dec(j);
if i <= j then begin
w := a[i]; a[i] := a[j]; a[j]:= w;
inc(i); dec(j);
end;
until i >j;
if l <j then sort(l, j);
if i <r then sort(i, r);
end;
var i: integer;
begin
sort(1, n);
for i:= 1 to n do writeln(a[i]);
end.
Анализ алгоритма в среднем даёт производительность O(n*log(n)) сравнений, что
представляется замечательным. Среднее число обменов равно (n – 1/n)/6. Однако в худшем
случае, когда для сравнения по несчастной случайности будет выбираться наибольший в
рассматриваемой части, потребуется n разделений и производительность будет порядка n*n.
Печально. В принципе всё равно, какой элемент брать для сравнения. Сам Хоар предлагал
выбирать x случайно. Это мало влияет на результат в хороших случаях и сильно улучшает
результат в плохих случаях. Кстати сортировка методом heapsort (пирамидальная) даёт
производительность O(n*log(n)) даже в наихудших случаях.
Рекурсивные процедуры и функции на современных компьютерах выполняются довольно
быстро, и «накладные расходы» на вызовы подпрограмм не так уж и разорительны. Тем не
менее, полезно иметь итеративную версию этой замечательной сортировки, тем более она
позволит понять, как реализуется рекурсия стеком.
80
Алгоритмы и алгоритмические языки
const
n= 8;
a: array [1..n] of integer =(18,6,12,42,94,55,44,67);
procedure sort;
const m = 12; {размер стека с большим запасом}
var i,j,l,r: integer;
w,x:integer;
stack: array[1..m] ofrecord l,r: integer end;
top: 0..m;
begin
top := 1; stack[top].l := 1; stack[top].r := n;
repeat {выбор из стека последнего запроса}
l := stack[top].l; r :=
stack[top].r; dec(top);
repeat {шагразделения}
i:=l; j:= r;
x := a[(l+r) div 2];
repeat {обмены}
while a[i] <x do inc(i);
while x<a[j] do dec(j);
if i<=j then begin
w := a[i]; a[i] := a[j]; a[j]:= w; inc(i); dec(j);
end;
until i>j;
if i<r then begin
inc(top); stack[top].l := i; stack[top].r := r;
end;
r := j;
until l>= r;
until top = 0;
end;
var i:integer;
begin
sort;
for i:= 1 to n do writeln(a[i]);
end.
81
Алгоритмы и алгоритмические языки
Размер стека m — это ожидаемое число обменов. Его определяют из вероятностных
соображений равным 1/6(n – 1/n). Но в худшем случае может потребоваться размер стека,
равный n. Кстати, с рекурсивной версией дело обстоит точно так же. Рекурсия тоже
организуется с использованием стека, только этот процесс автоматизирован.
Выход в том, чтобы в стек прятать сортировки более длинных частей, а короткие сортировать
сразу. Тогда размер стека можно ограничить числом log(n).
if j — l<r — I then begin
if i<r then begin {запись в стек запроса на сортировку правой части}
inc(top); stack[top].l := i; stack[top].r := r;
end;
r := j end {продолжаем сортировку левой части}
else begin
if l<j then begin{запись в стек запроса на сортировку левой части}
inc(top); stack[top].l := l; stack[top].r := j;
end;
l := i; {продолжаем сортировку правой части}
end;
Сложность операций на каждом шаге заставляет сомневаться в хорошей производительности
метода при сравнительно малых n. Советуют провести сравнительные испытания быстрой
сортировки и, например, метода пузырька, для небольших, средних по величине и очень
больших массивов.
Сортировки слиянием
Алгоритмы сортировки слиянием, как правило, имеют порядок O(N*log2(N)), но отличаются от
других алгоритмов большей сложностью и требуют большого числа пересылок. Алгоритмы
слияния применяются в основном, как составная часть внешней сортировки. Здесь же для
понимания принципа слияния приведен простейший алгоритм слияния в оперативной памяти.
Сортировка попарным слиянием. Входное множество рассматривается как
последовательность подмножеств, каждое из которых состоит из единственного элемента и,
следовательно, является уже упорядоченным. На первом проходе каждые два соседних
одноэлементных множества сливаются в одно двухэлементное упорядоченное множество. На
втором проходе двухэлементные множества сливаются в 4-элементные упорядоченные
множества и т.д. В конце концов, получается одно большое упорядоченное множество.
Вопросы и упражнения
1. Сколько сравнений выполняется при сортировке массива из n элементов по алгоритму
пузырька?
82
Алгоритмы и алгоритмические языки
2. При каком условии алгоритм пузырька может завершить сортировку массива за n – 2
прохода? За n – 3 прохода? На сколько операций сравнения меньше будет выполнено в
этих случаях?
3. Предположим, что в алгоритме вставок значение очередной перемещаемой
переменной сравнивается со значениями элементов массива не в обратном порядке
(ak, ak–1, ak–2,…, a1), а в прямом (a1, a2, a3, …, ak). Повлияет ли это на правильность и
эффективность алгоритма? Какой из двух вариантов больше подходит для сортировки
Шелла?
4. Объясните, почему в нерекурсивном варианте QuickSort при занесении в стек более
длинных отрезков глубина стека оказывается меньше, чем при занесении более
коротких.
5. Объясните, почему в рекурсивном варианте QuickSort глубина используемого стека
оказывается значительно больше, чем в нерекурсивном.
6. Запрограммируйте смешанный вариант QuickSort, в котором разделение массива и
сортировка меньшего из получившихся отрезков выполняется в цикле, а для
сортировки большего отрезка используется рекурсивный вызов (при этом нет
необходимости явно использовать переменную-стек).
7. Какая глубина стека может потребоваться для реализации QuickSort, описанной в
предыдущем упражнении?
8. Алгоритм сортировки называется устойчивым, если элементы массива, имеющие одно
и то же значение ключа, сохраняют после сортировки свое взаимное положение. Какие
из рассмотренных в разделе алгоритмов являются устойчивыми?
9. Дан массив чисел A = (20, 13, 5, 25, 16, 18, 40, 32, 21, 11, 1, 30). Выполнить сортировку
массива по алгоритму QuickSort. В качестве разделяющего выбирать первый элемент
отрезка. Показать состояние массива после каждой операции разделения.
Библиографический список
1. Ахо А. А., Хопкрофт Д. Э., Ульман Д. Д. Структуры данных и алгоритмы. М.: Вильямс,
2000.
2. Вирт Н. Алгоритмы и структуры данных. М.: Мир, 1989.
3. Кнут Д. Искусство программирования для ЭВМ. Сортировка и поиск. Т. 3. М.: Мир, 2000.
83
Учебное издание
Нина Константиновна Попова
Алгоритмы и алгоритмические языки
Курс лекций
Выполнено с использованием программы Microsoft Office Word
Системные требования:
ПК не ниже Pentium III; 256 Мб RAM; не менее 1,5 Гб на винчестере;
Windows XP с пакетом обновления 2 (SP2); Microsoft Office 2003 и выше;
видеокарта с памятью не менее 32 Мб; экран с разрешением не менее 1024 × 768
точек; 4-скоростной дисковод (CD-ROM) и выше; мышь.
Редактор С.Б. Свигзова
Корректор Е.М. Насирова
Верстка и компьютерный макет Т.В. Матвеевой
Техническое редактирование Н.Е. Чарковой
Выпускающий редактор Л.Н. Руденко
2,0 Мб. 1 компакт-диск, пластиковый бокс, вкладыш.
Подписано к использованию 27.03.2018 г. Тираж 100 экз. Заказ № 35.
Адрес типографии:
167023. Сыктывкар, ул. Морозова, 25
Издательский центр ФГБОУ ВО «СГУ им. Питирима Сорокина»
Тел. (8212)390-473, 390-472.
E-mail: [email protected]
http://www.syktsu.ru
Титул
Об издании
Производственно-технические сведения
Содержание