NSHipster
An imprint of Read Evaluate Press, LLC
Portland, Oregon
https://readeval.press
Copyright © 2019 Mattt Zmuda
All rights reserved
ISBN
978-1-949080-24-7
Printed in Minion, by Carol Twombly and Robert Slimbach, and Avenir, by Adrian Frutiger.
Code excerpts set in Menlo, by Jim Lyles.
Twemoji graphics made by Twitter and other contributors.
Cover type set in Trajan, by Carol Twombly and Robert Slimbach,
in an homage to The C Programming Language by Brian Kernighan and Dennis Ritchie.
Table of Contents
Objective-C
#pragma ..................................................................................................................................................3
@ ..............................................................................................................................................................7
nil / Nil / NULL / NSNull ...................................................................................................................17
BOOL / bool / Boolean / NSCFBoolean ...........................................................................................21
NS_ENUM & NS_OPTIONS .............................................................................................................25
Associated Objects ..............................................................................................................................29
Method Swizzling ................................................................................................................................35
Objective-C Direct Methods ..............................................................................................................41
Swift
Equatable and Comparable ................................................................................................................51
Hashable / Hasher ...............................................................................................................................59
Identifiable ...........................................................................................................................................65
Void .......................................................................................................................................................77
Never ....................................................................................................................................................87
OptionSet .............................................................................................................................................95
numericCast(_:) .................................................................................................................................101
guard & defer .....................................................................................................................................107
Mirror / CustomReflectable / CustomLeafReflectable ..................................................................117
KeyValuePairs ....................................................................................................................................129
Swift Property Wrappers ..................................................................................................................137
Swift API Availability ........................................................................................................................155
Swift Import Declarations ................................................................................................................167
API Pollution in Swift Modules .......................................................................................................175
Swift Operators ..................................................................................................................................183
Swift Literals ......................................................................................................................................193
ExpressibleByStringInterpolation ....................................................................................................203
TextOutputStream .............................................................................................................................211
Regular Expressions in Swift ............................................................................................................219
Swift GYB ...........................................................................................................................................229
SwiftSyntax .........................................................................................................................................235
Swift Documentation ........................................................................................................................245
Swift Property Observers .................................................................................................................257
Cocoa
TimeInterval, Date, and DateInterval .............................................................................................265
CharacterSet .......................................................................................................................................271
NLLanguageRecognizer ...................................................................................................................279
Locale ..................................................................................................................................................285
Formatter ............................................................................................................................................293
FileManager .......................................................................................................................................315
Temporary Files .................................................................................................................................325
CoreGraphics Geometry Primitives ................................................................................................333
Bundles and Packages .......................................................................................................................345
Miscellaneous
Empathy .............................................................................................................................................355
Objective-C
#pragma
#pragma
declarations are a mark of craftsmanship in Objective-C. Although originally used to make
source code compatible across different compilers, Xcode-savvy programmers use #pragma declarations
to very different ends.
Whereas other preprocessor directives allow you to define behavior when code is executed, #pragma is
unique in that it gives you control at the time code is being written — specifically, by organizing code
under named headings and inhibiting warnings.
As we’ll see in this week’s article, Good developer habits start with #pragma mark.
Organizing Your Code
Code organization is a matter of hygiene. How you structure your code is a reflection of you and your
work. A lack of convention and internal consistency indicates either carelessness or incompetence —
and worse, it makes a project more challenging to maintain and collaborate on.
We here at NSHipster believe that code should be clean enough to eat off of. That’s why se use #pragma
mark to divide code into logical sections.
If your class overrides any inherited methods, organize them under common headings according to
their superclass. This has the added benefit of describing the responsibilities for each ancestor in the
class hierarchies; for example, an NSInputStream subclass might have a group marked NSInputStream,
followed by NSStream, and then finally NSObject.
If your class adopts any protocols, it makes sense to group each of their respective methods with a
#pragma mark header with the name of that protocol (bonus points for following the same order as the
original declarations).
Additional concerns that naturally align under their own headings include initializers, @dynamic
properties, helper methods, Interface Builder outlets or actions, and handlers for notification or KeyValue Observing (KVO) selectors.
For example, the @implementation for a ViewController class that inherits from UITableView
Controller might organize Interface Builder actions together at the top, followed by overridden view
controller life-cycle methods, and then methods for each adopted protocol, each under their respective
heading.
@implementation ViewController
- (instancetype)init { … }
#pragma mark - IBAction
- (IBAction)confirm:(id)sender { … }
- (IBAction)cancel:(id)sender { … }
#pragma mark - UIViewController
- (void)viewDidLoad { … }
- (void)viewDidAppear:(BOOL)animated { … }
#pragma mark - UITableViewDataSource
- (NSInteger)tableView:(UITableView *)tableView
numberOfRowsInSection:(NSInteger)section { … }
#pragma mark - UITableViewDelegate
- (void)tableView:(UITableView *)tableView
didSelectRowAtIndexPath:(NSIndexPath *)indexPath { … }
@end
Not only do these sections make for easier reading in the code itself, but they also create visual cues to
the Xcode source navigator and minimap.
#pragma mark declarations beginning with a dash (-) are preceded with a horizontal divider
in Xcode.
Inhibiting Warnings
Do you know what’s even more annoying than poorly-formatted code? Code that generates warnings —
especially 3rd-party code. Is there anything more irksome than a vendor SDK that generates dozens
of warnings each time you hit ⌘ R ? Heck, even a single warning is one too many for many
developers.
Warnings are almost always warranted, but sometimes they’re unavoidable. Under those rare
circumstances where you are absolutely certain that a particular warning from the compiler or static
analyzer should be inhibited, #pragma comes to the rescue.
Let’s say you’ve deprecated a class:
@interface DeprecatedClass __attribute__ ((deprecated))
…
@end
Now, deprecation is something to be celebrated. It’s a way to responsibly communicate future intent to
API consumers that provides a transition period to migrate to an alternative solution. But you might
not feel so appreciated if you have CLANG_WARN_DEPRECATED_OBJC_IMPLEMENTATIONS enabled in your
project. Rather than being praised for your consideration, you’d be admonished for ““implementing a
deprecated class””.
One
way
to
silence
the
compiler would be to disable the warnings by setting
-Wno-deprecated-implementations. However, doing this for the entire project is too coarse, and
doing this for this file only is too much work. A better option would be to use #pragma to ignore the
unhelpful warning around the problematic code.
Using #pragma clang diagnostic push/pop, you can tell the compiler to ignore certain warnings for
a particular section of code:
#pragma clang diagnostic push
#pragma clang diagnostic ignored "-Wdeprecated-implementations"
@implementation DeprecatedClass
…
@end
#pragma clang diagnostic pop
Before you start copy-pasting this across your project in a rush to zero out your warnings, remember
that, in the overwhelming majority of cases, Clang is going to be right. Actually fixing an analyzer
warning is strongly preferred to ignoring it, so you should use #pragma clang diagnostic ignored
as a method of last resort.
Finding app development to be too easy for you? Enable all diagnostics with the -Weverything
flag and enable “Treat Warnings as Errors”. This turns on “Hard Mode” in Xcode.
Though it skirts the line between comment and code, #pragma remains a vital tool in the modern app
developer’s toolbox. Whether it’s for grouping methods or suppressing spurious warnings, judicious use
of #pragma can go a long way to make projects easier to understand and maintain.
Like the thrift store 8-track player you turned into that lamp in the foyer, #pragma remains a curious
vestige of the past: Once the secret language of compilers, now re-purposed to better-communicate
intent to other programmers. How delightfully vintage!
@
Birdwatchers refer to it as (and I swear I’m not making this up) “Jizz”: Those indefinable characteristics
unique to a particular kind of thing.
This term can be appropriated to describe how seasoned developers might distinguish Rust from Go,
or Ruby from Elixir at a glance.
Some just stick out like sore thumbs:
Perl, with all of its short variable names with special characters, reads like Q*bert swearing.
Lisp, whose profusion of parentheses is best captured by that old joke about Russians in the 1980s
proving that they had stolen the source code of some SDI missile interceptor by showing the last page:
)))
) )
))) ) ))
)))))
)))
)
))
)))) ))
)))) ))
)))
So if we were to go code-watching for the elusive Objective-C species, what would we look for?
That’s right:
• Square brackets
• Ridiculously-long method names
• @’s
@,
or “at” sign compiler directives, are as central to understanding Objective-C’s gestalt as its ancestry
and underlying mechanisms. It’s the sugary glue that allows Objective-C to be such an expressive
language, and yet still compile all the way down to C.
Its uses are varied and disparate, to the point that the only accurate way to describe what @ means by
itself is “shorthand for something to do with Objective-C”. They cover a broad range in usefulness and
obscurity, from staples like @interface and @implementation to ones you could go your whole career
without running into, like @defs and @compatibility_alias.
But to anyone aspiring to be an NSHipster, intimate familiarity with @ directives is tantamount
to a music lover’s ability to enumerate the entire Beatles catalog in chronological order (and most
importantly, having unreasonably strong opinions about each of them).
Interface & Implementation
@interface
and @implementation are the first things you encounter when you start learning
Objective-C:
// MyObject.h
@interface MyObject
…
@end
// MyObject.m
@implementation MyObject
…
@end
What you don’t learn about until later on are categories and class extensions.
Categories allow you to extend the behavior of existing classes by adding new class or instance methods.
As a convention, categories are defined in their own .{h,m} files:
// MyObject+CategoryName.h
@interface MyObject (CategoryName)
- (void)foo;
- (BOOL)barWithBaz:(NSInteger)baz;
@end
// MyObject+CategoryName.m
@implementation MyObject (CategoryName)
- (void)foo {
…
}
- (BOOL)barWithBaz:(NSInteger)baz {
return YES;
}
@end
Categories are particularly useful for convenience methods on standard framework classes (just don’t go
overboard with your utility functions).
Extensions look like categories, but omit the category name. These’re typically declared before an
@implementation to specify a private interface or override properties declared in the public interface:
// MyObject.m
@interface MyObject ()
@property (readwrite, nonatomic, strong) NSString *name;
- (void)somePrivateMethod;
@end
@implementation MyObject
…
@end
Properties
Property directives are likewise concepts learned early on:
• @property
• @synthesize
• @dynamic
Though, since Xcode introduced automatic property synthesis in version 4.4, @synthesize has
become less relevant to Objective-C code bases.
Forward Class Declarations
Occasionally, @interface declarations will reference an external type in a property or as a parameter.
Rather than adding an #import statement in the interface, you can use a forward class declaration in
the header and import the necessary in the implementation.
• @class
Shorter compile times, less chance of cyclical references; you should definitely get in the habit of doing
this if you aren’t already.
Instance Variable Visibility
It’s a matter of general convention that classes provide state and mutating interfaces through properties
and methods, rather than directly exposing ivars.
Although ARC makes working with ivars much safer by taking care of memory management, the
aforementioned automatic property synthesis removes the one place where ivars would otherwise be
declared.
Nonetheless, in cases where ivars are directly manipulated, there are the following visibility directives:
• @public: instance variable can be read and written to directly, using the notation person>age = 32"
• @package: instance variable is public, except outside of the framework in which it is specified
(64-bit architectures only)
• @protected: instance variable is only accessible to its class and derived classes
• @private: instance variable is only accessible to its class
@interface Person : NSObject {
@public
NSString *name;
int age;
@private
int salary;
}
@end
Protocols
There’s a distinct point early in an Objective-C programmer’s evolution when they realize that they can
define their own protocols.
The beauty of protocols is that they let you design contracts that can be adopted outside of a class
hierarchy. It’s the egalitarian mantra at the heart of the American Dream: It doesn’t matter who you are
or where you come from; anyone can achieve anything if they work hard enough.
@protocol…@end
defines a set of methods to be implemented by any conforming class, as if they were
added to the interface of that class directly.
Architectural stability and expressiveness without the burden of coupling? Protocols are awesome.
Requirement Options
You can further tailor a protocol by specifying methods as required or optional. Optional methods are
stubbed in the interface, so as to be auto-completed in Xcode, but do not generate a warning if the
method is not implemented. Protocol methods are required by default.
The syntax for @required and @optional follows that of the visibility macros:
@protocol CustomControlDelegate
- (void)control:(CustomControl *)control didSucceedWithResult:(id)result;
@optional
- (void)control:(CustomControl *)control didFailWithError:(NSError *)error;
@end
Exception Handling
Objective-C communicates unexpected state primarily through NSError. Whereas other languages
would use exception handling for this, Objective-C relegates exceptions to truly exceptional behavior.
@ directives are used for the traditional convention of try/catch/finally blocks:
@try{
// attempt to execute the following statements
[self getValue:&value error:&error];
// if an exception is raised, or explicitly thrown...
if (error) {
@throw exception;
}
} @catch(NSException *e) {
…
} @finally {
// always executed after @try or @catch
[self cleanup];
}
Literals
Literals are shorthand notation for specifying fixed values. Literals are more -or-less directly correlated
with programmer happiness. By this measure, Objective-C has long been a language of programmer
misery.
Object Literals
Until recently, Objective-C only had literals for NSString. But with the release of the Apple LLVM 4.0
compiler, literals for NSNumber, NSArray and NSDictionary were added, with much rejoicing.
• @"": Returns an NSString object initialized with the Unicode content inside the quotation
marks.
• @42, @3.14, @YES, @'Z': Returns an NSNumber object initialized with pertinent class
constructor, such that @42 → [NSNumber
numberWithInteger:42], or @YES →
[NSNumber numberWithBool:YES]. Supports the use of suffixes to further specify type, like
@42U → [NSNumber numberWithUnsignedInt:42U].
• @[]: Returns an NSArray object initialized with the comma-delimited list of objects as its contents.
It uses +arrayWithObjects:count: class constructor method, which is a more precise alternative
to the more familiar +arrayWithObjects:. For example, @[@"A", @NO, @2.718] → id
objects[] = {@"A", @NO, @2.718}; [NSArray arrayWithObjects:objects
count:3].
• @{}: Returns an NSDictionary object initialized with the specified key-value pairs as its
contents, in the format: @{@"someKey" : @"theValue"}.
• @(): Dynamically evaluates the boxed expression and returns the appropriate object literal based
on its value (i.e. NSString for const char*, NSNumber for int, etc.). This is also the
designated way to use number literals with enum values.
Objective-C Literals
Selectors and protocols can be passed as method parameters. @selector() and @protocol() serve as
pseudo-literal directives that return a pointer to a particular selector (SEL) or protocol (Protocol *).
• @selector(): Returns an SEL pointer to a selector with the specified name. Used in methods
like -performSelector:withObject:.
• @protocol(): Returns a Protocol * pointer to the protocol with the specified name. Used
in methods like -conformsToProtocol:.
C Literals
Literals can also work the other way around, transforming Objective-C objects into C values. These
directives in particular allow us to peek underneath the Objective-C veil, to begin to understand what’s
really going on.
Did you know that all Objective-C classes and objects are just glorified structs? Or that the entire
identity of an object hinges on a single isa field in that struct?
For most of us, at least most of the time, coming into this knowledge is but an academic exercise. But
for anyone venturing into low-level optimizations, this is simply the jumping-off point.
• @encode(): Returns the type encoding of a type. This type value can be used as the first argument
encode in NSCoder -encodeValueOfObjCType:at:.
• @defs(): Returns the layout of an Objective-C class. For example, to declare a struct with the
same fields as an NSObject, you would simply do:
struct {
@defs(NSObject)
}
@defs is unavailable in the modern Objective-C runtime.
Optimizations
There are some @ compiler directives specifically purposed for providing shortcuts for common
optimizations.
• @autoreleasepool{}: If your code contains a tight loop that creates lots of temporary objects,
you can use the @autoreleasepool directive to optimize for these short-lived, locally-scoped
objects by being more aggressive about how they’re deallocated. @autoreleasepool replaces
and improves upon the old NSAutoreleasePool, which is significantly slower, and unavailable
with ARC.
• @synchronized(){}: This directive offers a convenient way to guarantee the safe execution
of a particular block within a specified context (usually self). Locking in this way is expensive,
however, so for classes aiming for a particular level of thread safety, a dedicated NSLock
property or the use of low-level locking functions like OSAtomicCompareAndSwap32(3) are
recommended.
Compatibility
In case all of the previous directives were old hat for you, there’s a strong likelihood that you didn’t
know about this one:
• @compatibility_alias: Allows existing classes to be aliased by a different name.
For example PSTCollectionView uses @compatibility_alias to significantly improve the experience
of using the backwards-compatible, drop-in replacement for UICollectionView:
// Allows code to just use UICollectionView as if it would be available on iOS
SDK 5.
// http://developer.apple.
com/legacy/mac/library/#documentation/
DeveloperTools/gcc-3.
3/gcc/compatibility_005falias.html
#if __IPHONE_OS_VERSION_MAX_ALLOWED < 60000
@compatibility_alias UICollectionViewController PSTCollectionViewController;
@compatibility_alias UICollectionView PSTCollectionView;
@compatibility_alias UICollectionReusableView PSTCollectionReusableView;
@compatibility_alias UICollectionViewCell PSTCollectionViewCell;
@compatibility_alias UICollectionViewLayout PSTCollectionViewLayout;
@compatibility_alias UICollectionViewFlowLayout PSTCollectionViewFlowLayout;
@compatibility_alias UICollectionViewLayoutAttributes
PSTCollectionViewLayoutAttributes;
@protocol UICollectionViewDataSource <PSTCollectionViewDataSource> @end
@protocol UICollectionViewDelegate <PSTCollectionViewDelegate> @end
#endif
Using this clever combination of macros, a developer can develop with UICollectionView by including
PSTCollectionView–without worrying about the deployment target of the final project. As a drop-in
replacement, the same code works more-or-less identically on iOS 6 as it does on iOS 4.3.
Thus concludes this exhaustive rundown of the many faces of @. It’s a versatile, power-packed character
that embodies the underlying design and mechanisms of the language.
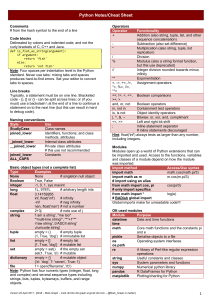
nil /
Nil /
NULL /
NSNull
Understanding the concept of nothingness is as much a philosophical issue as it is a pragmatic one. We
are inhabitants of a universe of somethings, yet reason in a logical universe of existential uncertainties.
As a physical manifestation of a logical system, computers are faced with the intractable problem of
how to represent nothing with something.
In Objective-C, there are several different varieties of nothing. The reason for this goes back to a
common NSHipster refrain, of how Objective-C bridges the procedural paradigm of C with Smalltalkinspired object-oriented paradigm.
C represents nothing as 0 for primitive values, and NULL for pointers (which is equivalent to 0 in a
pointer context).
Objective-C builds on C’s representation of nothing by adding nil. nil is an object pointer to nothing.
Although semantically distinct from NULL, they are technically equivalent to one another.
On the framework level, Foundation defines NSNull, which defines a class method, +null, which
returns the singleton NSNull object. NSNull is different from nil or NULL, in that it is an actual object,
rather than a zero value.
Additionally, in Foundation/NSObjCRuntime.h, Nil is defined as a class pointer to nothing. This lesserknown title-case cousin of nil doesn’t show up much very often, but it’s at least worth noting.
There’s Something About nil
Newly-alloc‘d NSObjects start life with their contents set to 0. This means that all pointers that object
has to other objects begin as nil, so it’s unnecessary to, for instance, set self.(association) = nil
in init methods.
Perhaps the most notable behavior of nil, though, is that it can have messages sent to it.
In other languages, like C++, this would crash your program, but in Objective-C, invoking a method
on nil returns a zero value. This greatly simplifies expressions, as it obviates the need to check for nil
before doing anything:
// For example, this expression...
if (name != nil && [name isEqualToString:@"Steve"]) { ... }
// ...can be simplified to:
if ([name isEqualToString:@"Steve"]) { ... }
Being aware of how nil works in Objective-C allows this convenience to be a feature, and not a lurking
bug in your application. Make sure to guard against cases where nil values are unwanted, either by
checking and returning early to fail silently, or adding a NSParameterAssert to throw an exception.
NSNull: Something for Nothing
NSNull
is used throughout Foundation and other frameworks to skirt around the limitations of
collections like NSArray and NSDictionary not being able to contain nil values. You can think of
NSNull as effectively boxing the NULL or nil value so that it can be used in collections:
NSMutableDictionary *mutableDictionary = [NSMutableDictionary dictionary];
mutableDictionary[@"someKey"] = [NSNull null]; // Sets value of NSNull
singleton for `someKey`
NSLog(@"Keys: %@", [mutableDictionary allKeys]); // @[@"someKey"]
So to recap, here are the four values representing nothing that every Objective-C programmer should
know about:
Symbol
Value
Meaning
NULL
(void *)0
literal null value for C pointers
nil
(id)0
literal null value for Objective-C objects
Nil
(Class)0
literal null value for Objective-C classes
NSNull
[NSNull null]
singleton object used to represent null
BOOL /
bool /
Boolean /
NSCFBoolean
We’ve talked before about the philosophical and technical concerns of nothingness in programming.
This week, our attention turns to another fundamental matter: Truth.
Truth. Vēritās. The entire charter of Philosophy is founded upon the pursuit of it, and yet its exact
meaning and implications still elude us. Does truth exist independently, or is it defined contingently
against falsity? Can a proposition be at once both true and false? Is there absolute truth in anything, or
is everything relative?
Once again, encoding our logical universe into the cold, calculating bytecode of computers forces us to
deal with these questions one way or another. And as you’ll see from our discussion of boolean types in
Objective-C and its kin, truth is indeed stranger than fiction.
Objective-C defines BOOL to encode truth value. It is a typedef of a signed char, with the macros YES
and NO to represent true and false, respectively.
Boolean values are used in conditionals, such as if or while statements, to conditionally perform logic
or repeat execution. When evaluating a conditional statement, the value 0 is considered “false”, while
any other value is considered “true”. Because NULL and nil are defined as 0, conditional statements on
these nonexistent values are also evaluated as “false”.
In Objective-C, use the BOOL type for parameters, properties, and instance variables dealing with truth
values. When assigning literal values, use the YES and NO macros.
The Wrong Answer to the Wrong Question
Novice programmers often include an equality operator when evaluating conditionals:
if ([a isEqual:b] == YES) {
...
}
Not only is this unnecessary, but depending on the left-hand value, it may also cause unexpected results,
as described in the Big Nerd Ranch blog post, “BOOL’s Sharp Edges”:
static BOOL different (int a, int b) {
return a - b;
}
An overly clever C programmer might take some satisfaction in the simplicity of this approach: indeed,
two integers are equal if and only if their difference is 0.
However, because of the reality of BOOL being typedef‘d as a signed char, this will not behave as
expected:
if (different(11, 10) == YES) {
printf ("11 != 10\n");
} else {
printf ("11 == 10\n");
}
if (different(10, 11) == YES) {
printf ("10 != 11\n");
} else {
printf ("10 == 11\n");
}
if (different(512, 256) == YES) {
printf ("512 != 256\n");
} else {
printf ("512 == 256\n");
}
This evaluates to:
11 != 10
10 == 11
512 == 256
Now, this might be acceptable for JavaScript, but Objective-C don’t suffer fools gladly.
Deriving truth value directly from an arithmetic operation is never a good idea. Like the sentence
“Colorless green ideas sleep furiously”, it may be grammatical (after all, BOOL is a signed char like any
other, so it could be treated as a number), but it doesn’t make sense semantically. Instead, use the result
of the == operator, or cast values into booleans with the ! (or !!) operator.
The Truth About NSNumber and BOOL
Pop quiz: what is the output of the following expression?
NSLog(@"%@", [@(YES) class]);
The answer:
__NSCFBoolean
Wait, what?
All this time, we’ve been led to believe that NSNumber boxes primitives into an object representation.
Any other integer- or float-derived NSNumber object shows its class to be __NSCFNumber. What gives?
NSCFBoolean
is a private class in the NSNumber class cluster. It is a bridge to the CFBooleanRef type,
which is used to wrap boolean values for Core Foundation property lists and collections. CFBoolean
defines the constants kCFBooleanTrue and kCFBooleanFalse. Because CFNumberRef and CFBoolean
Ref are different types in Core Foundation, it makes sense that they are represented by different
bridging classes in NSNumber.
For most people, boolean values and boxed objects “just work”, and don’t really care what goes into
making the sausage. But here at NSHipster, we’re all about sausages.
So, to recap, here is a table of all of the truth types and values in Objective-C:
Name
Typedef
Header
True Value
False Value
BOOL
signed char
objc.h
YES
NO
bool
_Bool (int)
stdbool.h
true
false
Boolean
unsigned char
MacTypes.h
TRUE
FALSE
NSNumber
__NSCFBoolean
Foundation.h
@(YES)
@(NO)
CFBooleanRef
struct
CoreFoundation.h
kCFBooleanTrue
kCFBooleanFalse
NS_ENUM & NS_OPTIONS
When everything is an object, nothing is.
So, there are a few ways you could parse that, but for the purposes of this article, this is all to say:
sometimes it’s nice to be able to drop down to the C layer of things.
Yes–that non-objective part of our favorite Smalltalk-inspired hybrid language, C can be a great asset.
It’s fast, it’s battle-tested, it’s the very foundation of modern computing. But more than that, C is the
escape hatch for when the Object-Oriented paradigm cracks under its own cognitive weight.
Static functions are nicer than shoe-horned class methods. Enums are nicer than string constants.
Bitmasks are nicer than arrays of string constants. Preprocessor directives are nicer than runtime hacks.
A skilled Objective-C developer is able to gracefully switch between Objective and Procedural
paradigms, and use each to their own advantage.
And on that note, this week’s topic has to do with two simple-but-handy macros: NS_ENUM and
NS_OPTIONS.
Introduced in Foundation with iOS 6 / OS X Mountain Lion, the NS_ENUM and NS_OPTIONS macros are
the new, preferred way to declare enum types.
enum,
or enumerated value types, are the C way to define constants for fixed values, like days of the
week, or available styles of table view cells. In an enum declaration, constants without explicit values will
automatically be assigned values sequentially, starting from 0.
There are several legal ways that enums can be defined. What’s confusing is that there are subtle
functional differences between each approach, and without knowing any better, someone is just as likely
to use them interchangeably.
For instance:
enum {
UITableViewCellStyleDefault,
UITableViewCellStyleValue1,
UITableViewCellStyleValue2,
UITableViewCellStyleSubtitle
};
…declares integer values, but no type.
Whereas:
typedef enum {
UITableViewCellStyleDefault,
UITableViewCellStyleValue1,
UITableViewCellStyleValue2,
UITableViewCellStyleSubtitle
} UITableViewCellStyle;
…defines the UITableViewCellStyle type, suitable for specifying the type of method parameters.
However, Apple had previously defined all of their enum types as:
typedef enum {
UITableViewCellStyleDefault,
UITableViewCellStyleValue1,
UITableViewCellStyleValue2,
UITableViewCellStyleSubtitle
};
typedef NSInteger UITableViewCellStyle;
…which ensures a fixed size for UITableViewCellStyle, but does nothing to hint the relation between
the aforementioned enum and the new type to the compiler.
Thankfully, Apple has decided on “One Macro To Rule Them All” with NS_ENUM.
NS_ENUM
Now, UITableViewCellStyle is declared with:
typedef NS_ENUM(NSInteger, UITableViewCellStyle) {
UITableViewCellStyleDefault,
UITableViewCellStyleValue1,
UITableViewCellStyleValue2,
UITableViewCellStyleSubtitle
};
The first argument for NS_ENUM is the type used to store the new type. In a 64-bit environment, UITable
ViewCellStyle will be 8 bytes long–same as NSInteger. Make sure that the specified size can fit all of
the defined values, or else an error will be generated. The second argument is the name of the new type
(as you probably guessed). Inside the block, the values are defined as usual.
This approach combines the best of all of the aforementioned approaches, and even provides hints to
the compiler for type-checking and switch statement completeness.
NS_OPTIONS
enum
can also be used to define a bitmask. Using a convenient property of binary math, a single
integer value can encode a combination of values all at once using the bitwise OR (|), and decoded with
bitwise AND (&). Each subsequent value, rather than automatically being incremented by 1 from 0, are
manually given a value with a bit offset: 1 << 0, 1 << 1, 1 << 2, and so on. If you imagine the binary
representation of a number, like 10110 for 22, each bit can be though to represent a single boolean. In
UIKit, for example, UIViewAutoresizing is a bitmask that can represent any combination of flexible
top, bottom, left, and right margins, or width and height.
Rather than NS_ENUM, bitmasks should now use the NS_OPTIONS macro.
The syntax is exactly the same as NS_ENUM, but this macro alerts the compiler to how values can be
combined with bitmask |. Again, you must be careful that all of the enumerated values fit within the
specified type.
NS_ENUM and NS_OPTIONS are handy additions to the Objective-C development experience, and reaffirm
the healthy dialectic between its objective and procedural nature. Keep this in mind as you move
forward in your own journey to understand the logical tensions that underpin everything around us.
Associated Objects
#import <objc/runtime.h>
Objective-C developers are conditioned to be wary of whatever follows this ominous incantation. And
for good reason: messing with the Objective-C runtime changes the very fabric of reality for all of the
code that runs on it.
In the right hands, the functions of <objc/runtime.h> have the potential to add powerful new behavior
to an application or framework, in ways that would otherwise not be possible. In the wrong hands,
it drains the proverbial sanity meter of the code, and everything it may interact with (with terrifying
side-effects).
Therefore, it is with great trepidation that we consider this Faustian bargain, and look at one of the
subjects most-often requested by NSHipster readers: associated objects.
Associated Objects—or Associative References, as they were originally known—are a feature of the
Objective-C 2.0 runtime, introduced in OS X Snow Leopard (available in iOS 4). The term refers to the
following three C functions declared in <objc/runtime.h>, which allow objects to associate arbitrary
values for keys at runtime:
• objc_setAssociatedObject
• objc_getAssociatedObject
• objc_removeAssociatedObjects
Why is this useful? It allows developers to add custom properties to existing classes in categories, which
is an otherwise notable shortcoming for Objective-C.
@interface NSObject (AssociatedObject)
@property (nonatomic, strong) id associatedObject;
@end
@implementation NSObject (AssociatedObject)
@dynamic associatedObject;
- (void)setAssociatedObject:(id)object {
objc_setAssociatedObject(self, @selector(associatedObject), object,
OBJC_ASSOCIATION_RETAIN_NONATOMIC);
}
- (id)associatedObject {
return objc_getAssociatedObject(self, @selector(associatedObject));
}
It is often recommended that they key be a static char—or better yet, the pointer to one. Basically, an
arbitrary value that is guaranteed to be constant, unique, and scoped for use within getters and setters:
static char kAssociatedObjectKey;
objc_getAssociatedObject(self, &kAssociatedObjectKey);
However, a much simpler solution exists: just use a selector.
Since SELs are guaranteed to be unique and constant, you can use _cmd as the key for objc_set
AssociatedObject(). #objective-c #snowleopard
— Bill Bumgarner (@bbum) August 28, 2009
Associative Object Behaviors
Values can be associated onto objects according to the behaviors defined by the enumerated type
objc_AssociationPolicy:
Behavior
@property
Equivalent
@property (assign)
OBJC_ASSOCIATION_ASSIGN
Description
or
@property
Specifies a weak reference to the associated object.
(unsafe_unretained)
@property (nonatomic,
OBJC_ASSOCIATION_RETAIN_NONATOMIC
strong)
Specifies a strong reference to the associated object, and
that the association is not made atomically.
OBJC_ASSOCIATION_COPY_NONATOMIC
@property (nonatomic, copy)
Specifies that the associated object is copied, and that
the association is not made atomically.
OBJC_ASSOCIATION_RETAIN
@property (atomic, strong)
Specifies a strong reference to the associated object, and
that the association is made atomically.
OBJC_ASSOCIATION_COPY
@property (atomic, copy)
Specifies that the associated object is copied, and that
the association is made atomically.
Weak associations to objects made with OBJC_ASSOCIATION_ASSIGN are not zero weak references, but
rather follow a behavior similar to unsafe_unretained, which means that one should be cautious
when accessing weakly associated objects within an implementation.
According to the deallocation timeline described in WWDC 2011, Session 322 (~36:00), associated
objects are erased surprisingly late in the object lifecycle — object_dispose(), which is invoked
by NSObject -dealloc.
Removing Values
One may be tempted to call objc_removeAssociatedObjects() at some point in their foray into
associated objects. However, as described in the documentation, it’s unlikely that you would have an
occasion to invoke it yourself:
The main purpose of this function is to make it easy to return an object to a “pristine state”.
You should not use this function for general removal of associations from objects, since it also
removes associations that other clients may have added to the object. Typically you should use
objc_setAssociatedObject with a nil value to clear an association.
Patterns
Adding private variables to facilitate implementation details
When extending the behavior of a built-in class, it may be necessary to keep track of additional state.
This is the textbook use case for associated objects.
Adding public properties to configure category behavior.
Sometimes, it makes more sense to make category behavior more flexible with a property, than in
a method parameter. In these situations, a public-facing property is an acceptable situation to use
associated objects.
Creating an associated observer for KVO
When using KVO in a category implementation, it is recommended that a custom associated-object be
used as an observer, rather than the object observing itself.
Anti-Patterns
Storing an associated object, when the value is not needed
A common pattern for views is to create a convenience method that populates fields and attributes based
on a model object or compound value. If that value does not need to be recalled later, it is acceptable,
and indeed preferable, not to associate with that object.
Storing an associated object, when the value can be inferred
For example, one might be tempted to store a reference to a custom accessory view’s containing
UITableViewCell, for use in tableView:accessoryButtonTappedForRowWithIndexPath:, when this
can retrieved by calling cellForRowAtIndexPath:.
Using associated objects instead of X
…where X is any one the following:
• Subclassing for when inheritance is a more reasonable fit than composition.
• Target-Action for adding interaction events to responders.
• Gesture Recognizers for any situations when target-action doesn’t suffice.
• Delegation when behavior can be delegated to another object.
• NSNotification & NSNotificationCenter for communicating events across a system in a looselycoupled way.
Associated objects should be seen as a method of last resort, rather than a solution in search of a problem
(and really, categories themselves really shouldn’t be at the top of the toolchain to begin with).
Like any clever trick, hack, or workaround, there is a natural tendency for one to actively seek out
occasions to use it—especially just after learning about it. Do your best to understand and appreciate
when it’s the right solution, and save yourself the embarrassment of being scornfully asked “why in the
name of $DEITY” you decided to go with that solution.
Method Swizzling
If you could blow up the world with the flick of a switch
Would you do it?
If you could make everybody poor just so you could be rich
Would you do it?
If you could watch everybody work while you just lay on your back
Would you do it?
If you could take all the love without giving any back
Would you do it?
And so we cannot know ourselves or what we’d really do…
With all your power … What would you do?
― The Flaming Lips, “The Yeah Yeah Yeah Song (With All Your Power)”
In last week’s article about associated objects, we began to explore the dark arts of the Objective-C
runtime. This week, we venture further, to discuss what is perhaps the most contentious of runtime
hackery techniques: method swizzling.
Method swizzling is the process of changing the implementation of an existing selector. It’s a technique
made possible by the fact that method invocations in Objective-C can be changed at runtime, by
changing how selectors are mapped to underlying functions in a class’s dispatch table.
For example, let’s say we wanted to track how many times each view controller is presented to a user in
an iOS app:
Each view controller could add tracking code to its own implementation of viewDidAppear:, but that
would make for a ton of duplicated boilerplate code. Subclassing would be another possibility, but it
would require subclassing UIViewController, UITableViewController, UINavigationController,
and every other view controller class—an approach that would also suffer from code duplication.
Fortunately, there is another way: method swizzling from a category. Here’s how to do it:
#import <objc/runtime.h>
@implementation UIViewController (Tracking)
+ (void)load {
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
Class class = [self class];
SEL originalSelector = @selector(viewWillAppear:);
SEL swizzledSelector = @selector(xxx_viewWillAppear:);
Method originalMethod = class_getInstanceMethod(class,
originalSelector);
Method swizzledMethod = class_getInstanceMethod(class,
swizzledSelector);
// When swizzling a class method, use the following:
// Class class = object_getClass((id)self);
…
// Method originalMethod = class_getClassMethod(class,
originalSelector);
// Method swizzledMethod = class_getClassMethod(class,
swizzledSelector);
BOOL didAddMethod =
class_addMethod(class,
originalSelector,
method_getImplementation(swizzledMethod),
method_getTypeEncoding(swizzledMethod));
}
});
if (didAddMethod) {
class_replaceMethod(class,
swizzledSelector,
method_getImplementation(originalMethod),
method_getTypeEncoding(originalMethod));
} else {
method_exchangeImplementations(originalMethod, swizzledMethod);
}
#pragma mark - Method Swizzling
- (void)xxx_viewWillAppear:(BOOL)animated {
[self xxx_viewWillAppear:animated];
NSLog(@"viewWillAppear: %@", self);
}
@end
Now, when any instance of UIViewController, or one of its subclasses invokes viewWillAppear:, a
log statement will print out.
Injecting behavior into the view controller lifecycle, responder events, view drawing, or the Foundation
networking stack are all good examples of how method swizzling can be used to great effect. There
are a number of other occasions when swizzling would be an appropriate technique, and they become
increasingly apparent the more seasoned an Objective-C developer becomes.
Regardless of why or where one chooses to use swizzling, the how remains absolute:
In computer science, pointer swizzling is the conversion of references based on name or position
to direct pointer references. While the origins of Objective-C’s usage of the term are not entirely
known, it’s understandable why it was co-opted, since method swizzling involves changing the
reference of a function pointer by its selector.
+load vs. +initialize
Swizzling should always be done in +load.
There are two methods that are automatically invoked by the Objective-C runtime for each class. +load
is sent when the class is initially loaded, while +initialize is called just before the application calls its
first method on that class or an instance of that class. Both are optional, and are executed only if the
method is implemented.
Because method swizzling affects global state, it is important to minimize the possibility of race
conditions. +load is guaranteed to be loaded during class initialization, which provides a modicum of
consistency for changing system-wide behavior. By contrast, +initialize provides no such guarantee
of when it will be executed—in fact, it may never be called, if that class is never messaged directly
by the app.
dispatch_once
Swizzling should always be done in a dispatch_once.
Again, because swizzling changes global state, we need to take every precaution available to us in
the runtime. Atomicity is one such precaution, as is a guarantee that code will be executed exactly
once, even across different threads. Grand Central Dispatch’s dispatch_once provides both of these
desirable behaviors, and should be considered as much a standard practice for swizzling as they are for
initializing singletons.
Selectors, Methods, & Implementations
In Objective-C, selectors, methods, and implementations refer to particular aspects of the runtime,
although in normal conversation, these terms are often used interchangeably to generally refer to the
process of message sending.
Here is how each is described in Apple’s Objective-C Runtime Reference:
• Selector (typedef struct objc_selector *SEL): Selectors are used to represent
the name of a method at runtime. A method selector is a C string that has been registered
(or “mapped”) with the Objective-C runtime. Selectors generated by the compiler are
automatically mapped by the runtime when the class is loaded .
• Method (typedef struct objc_method *Method ): An opaque type that
represents a method in a class definition.
• Implementation (typedef id (*IMP)(id, SEL, ...)): This data type is a pointer
to the start of the function that implements the method. This function uses standard C
calling conventions as implemented for the current CPU architecture. The first argument is
a pointer to self (that is, the memory for the particular instance of this class, or, for a class
method, a pointer to the metaclass). The second argument is the method selector. The method
arguments follow.
The best way to understand the relationship between these concepts is as follows: a class (Class)
maintains a dispatch table to resolve messages sent at runtime; each entry in the table is a method
(Method), which keys a particular name, the selector (SEL), to an implementation (IMP), which is a
pointer to an underlying C function.
To swizzle a method is to change a class’s dispatch table in order to resolve messages from an existing
selector to a different implementation, while aliasing the original method implementation to a new
selector.
Invoking _cmd
It may appear that the following code will result in an infinite loop:
- (void)xxx_viewWillAppear:(BOOL)animated {
[self xxx_viewWillAppear:animated];
NSLog(@"viewWillAppear: %@", NSStringFromClass([self class]));
}
Surprisingly, it won’t. In the process of swizzling, xxx_viewWillAppear: has been reassigned to the
original implementation of UIViewController -viewWillAppear:. It’s good programmer instinct for
calling a method on self in its own implementation to raise a red flag, but in this case, it makes sense
if we remember what’s really going on. However, if we were to call viewWillAppear: in this method, it
would cause an infinite loop, since the implementation of this method will be swizzled to the viewWill
Appear: selector at runtime.
Remember to prefix your swizzled method name as you would any other contentious category
method.
Considerations
Swizzling is widely considered a voodoo technique, prone to unpredictable behavior and unforeseen
consequences. While it is not the safest thing to do, method swizzling is reasonably safe, when the
following precautions are taken:
• Always invoke the original implementation of a method (unless you have a good reason not
to): APIs provide a contract for input and output, but the implementation in-between is a black
box. Swizzling a method and not calling the original implementation may cause underlying
assumptions about private state to break, along with the rest of your application.
• Avoid collisions: Prefix category methods, and make damn well sure that nothing else in your code
base (or any of your dependencies) are monkeying around with the same piece of functionality
as you are.
• Understand what’s going on: Simply copy-pasting swizzling code without understanding how it
works is not only dangerous, but is a wasted opportunity to learn a lot about the Objective-C
runtime. Read through the Objective-C Runtime Reference and browse <objc/runtime.h> to
get a good sense of how and why things happen. Always endeavor to replace magical thinking with
understanding.
• Proceed with caution: No matter how confident you are about swizzling Foundation, UIKit, or any
other built-in framework, know that everything could break in the next release. Be ready for that,
and go the extra mile to ensure that in playing with fire, you don’t get NSBurned.
Like associated objects, method swizzling is a powerful technique when you need it, but should be used
sparingly.
Objective-C Direct Methods
It’s hard to get excited when new features come to Objective-C. These days, any such improvements are
in service of Swift interoperability rather than an investment in the language itself (see nullability and
lightweight generics).
So it was surprising to learn about this recently merged patch to Clang, which adds a new direct
dispatch mechanism to Objective-C methods.
The genesis of this new language feature is unclear; the most we have to go on is an Apple-internal
Radar number (2684889), which doesn’t tell us much beyond its relative age (sometime in the early
’00s, by our estimation). Fortunately, the feature landed with enough documentation and test coverage
to get a good idea of how it works. (Kudos to implementor Pierre Habouzit, review manager John McCall,
and the other LLVM contributors).
This week on NSHipster, we’re taking this occasion to review Objective-C method dispatching and try
to understand the potential impact of this new language feature on future codebases.
(Direct methods could show up as early as Xcode 11.x, but most likely, it’ll be announced at WWDC 2020.)
To understand the significance of direct methods, you need to know a few things about the Objective-C
runtime. But let’s start our discussion one step before that, to the origin of OOP itself:
Object-Oriented Programming
Alan Kay coined the term “object-oriented programming in the late 1960s. With the help of Adele
Goldberg, Dan Ingalls, and his other colleagues at Xerox PARC, Kay put this idea into practice in the
’70s with the creation of the Smalltalk programming language.
(During this time, researches at Xerox PARC also developed the Xerox Alto, which would become the
inspiration for Apple’s Macintosh and all other GUI computers.)
In the 1980s, Brad Cox and Tom Love started work the first version of Objective-C, a language that
sought to take the object-oriented paradigm of Smalltalk and implement it on solid fundamentals of C.
Through a series of fortuitous events in the ’90s, the language would come to be the official language of
NeXT, and later, Apple.
For those of us who started learning Objective-C in the iPhone era, the language was often seen as
yet another proprietary Apple technology — one of a myriad, obscure byproducts of the company’s
“Not invented here” (NIH) culture. However, Objective-C isn’t just “an object-oriented C”, it’s one of
the original object-oriented languages, with as strong a claim to OOP credentials as any other.
Now, what does OOP mean? That’s a good question. ’90s era hype cycles have rendered the term almost
meaningless. However, for our purposes today, let’s focus on something Alan Kay wrote in 1998:
I’m sorry that I long ago coined the term “objects” for this topic because it gets many people to focus
on the lesser idea. The big idea is “messaging” […] >
― Alan Kay
Dynamic Dispatch and the Objective-C Runtime
In Objective-C, a program consists of a collection of objects that interact with each other by passing
messages that, in turn, invoke methods, or functions. This act of message passing is denoted by square
bracket syntax:
[someObject aMethod:withAnArgument];
When Objective-C code is compiled, message sends are transformed into calls to a function called
objc_msgSend (literally “send a message to some object with an argument”).
objc_msgSend(object, @selector(message), withAnArgument);
• The first argument is the receiver (self for instance methods)
• The second argument is _cmd: the selector, or name of the method
• Any method parameters are passed as additional function arguments
objc_msgSend
is responsible for determining which underlying implementation to call in response to
this message, a process known as method dispatch.
In Objective-C, each class (Class) maintains a dispatch table to resolve messages sent at runtime.
Each entry in the dispatch table is a method (Method) that keys a selector (SEL) to a corresponding
implementation (IMP), which is a pointer to a C function. When an object receives a message, it
consults the dispatch table of its class. If it can find an implementation for the selector, the associated
function is called. Otherwise, the object consults the dispatch table of its superclass. This continues
up the inheritance chain until a match is found or the root class (NSObject) deems the selector to be
unrecognized.
(And that’s to say nothing of how Objective-C lets you do things like replace method implementations and
create new classes dynamically at runtime. It’s absolutely wild what you can do.)
If you think all of this indirection sounds like a lot of work… in a way, you’d be right!
If you have a hot path in your code, an expensive method that’s called frequently, you could imagine
some benefit to avoiding all of this indirection. To that end, some developers have used C functions as
a way around dynamic dispatch.
Direct Dispatch with a C Function
As we saw with objc_msgSend, any method invocation can be represented by an equivalent function by
passing implicit self as the first argument.
For example, consider the following declaration of an Objective-C class with a conventional,
dynamically-dispatched method.
@interface MyClass: NSObject
- (void)dynamicMethod;
@end
If a developer wanted to implement some functionality on MyClass without going through the whole
message sending shebang, they could declare a static C function that took an instance of MyClass as an
argument.
static void directFunction(MyClass *__unsafe_unretained object);
Here’s how each of these approaches translates to the call site:
MyClass *object = [[[MyClass] alloc] init];
// Dynamic Dispatch
[object dynamicMethod];
// Direct Dispatch
directFunction(object);
Direct Methods
A direct method has the look and feel of a conventional method, but has the behavior of a C function.
When a direct method is called, it directly calls its underlying implementation rather than going
through objc_msgSend.
With this new LLVM patch, you now have a way to annotate Objective-C methods to avoid participation
in dynamic dispatch selectively.
objc_direct, @property(direct), and objc_direct_members
To make an instance or class method direct, you can mark it with the objc_direct Clang attribute.
Likewise, the methods for an Objective-C property can be made direct by declaring it with the direct
property attribute.
@interface MyClass: NSObject
@property(nonatomic) BOOL dynamicProperty;
@property(nonatomic, direct) BOOL directProperty;
- (void)dynamicMethod;
- (void)directMethod __attribute__((objc_direct));
@end
By our count, the addition of direct brings the total number of @property attributes to 16:
• getter and setter
• readwrite and readonly,
• atomic and nonatomic
• weak, strong, copy, retain, and unsafe_unretained
• nullable, nonnullable, and null_resettable
• class
When an @interface for a category or class extension is annotated with the objc_direct_members
attribute, all method and property declarations contained within it are considered to be direct, unless
previously declared by that class.
You can’t annotate the primary class interface with the objc_direct_members attribute.
__attribute__((objc_direct_members))
@interface MyClass ()
@property (nonatomic) BOOL directExtensionProperty;
- (void)directExtensionMethod;
@end
Annotating an @implementation with objc_direct_members has a similar effect, causing nonpreviously declared members to be deemed direct, including any implicit methods resulting from
property synthesis.
__attribute__((objc_direct_members))
@implementation MyClass
- (BOOL)directProperty { … }
- (void)dynamicMethod { … }
- (void)directMethod { … }
- (void)directExtensionMethod { … }
- (void)directImplementationMethod { … }
@end
A dynamic method can’t be overridden in a subclass by a direct method, and a direct method can’t
be overridden at all.
Protocols can’t declare direct method requirements, and a class can’t implement a protocol
requirement with a direct method.
Applying these annotations to our example from before, we can see how direct and dynamic methods
are indistinguishable at the call site:
MyClass *object = [[[MyClass] alloc] init];
// Dynamic Dispatch
[object dynamicMethod];
// Direct Dispatch
[object directMethod];
Direct methods seem like a slam dunk feature for the performance-minded developers among us. But
here’s the twist:
In most cases, making a method direct probably won’t have a noticeable performance advantage.
As it turns out, objc_msgSend is surprisingly fast. Thanks to aggressive caching, extensive low-level
optimization, and intrinsic performance characteristics of modern processors, objc_msgSend has an
extremely low overhead.
We’re long past the days when iPhone hardware could reasonably be described as a resource-constrained
environment. So unless Apple is preparing for a new embedded platform (AR glasses, anyone?), the most
reasonable explanation we have for Apple implementing Objective-C direct methods in 2019 stems
from something other than performance.
Mike Ash is the Internet’s foremost expert on objc_msgSend. Over the years, his posts have
provided the deepest and most complete understanding to the Objective-C runtime you’ll find
outside of Cupertino. For the curious, “Dissecting objc_msgSend on ARM64” is a great place
to start.
Hidden Motives
When an Objective-C method is marked as direct, its implementation has hidden visibility. That is,
direct methods can only be called within the same module (or to be pedantic, linkage unit). It won’t even
show up in the Objective-C runtime.
Hidden visibility has two direct advantages:
• Smaller binary size
• No external invocation
Without external visibility or a way to invoke them dynamically from the Objective-C runtime, direct
methods are effectively private methods.
If you want to participate in direct dispatch, but still want to make your API accessible externally,
you can wrap it in a C function.
static inline void performDirectMethod(MyClass *__unsafe_unretained
object) {
[object directMethod];
}
While hidden visibility can be used by Apple to prevent swizzling and private API use, that doesn’t
seem to be the primary motivation.
According to Pierre, who implemented this feature, the main benefit of this optimization is code size
reduction. Reportedly, the weight of unused Objective-C metadata can account for 5 – 10% of the
__text section in the compiled binary.
You could imagine that, from now until next year’s developer conference, a few engineers could
go through each of the SDK frameworks, annotating private methods with objc_direct and private
classes with objc_direct_members as a lightweight way to progressively tighten its SDK.
If that’s true, then perhaps it’s just as well that we’ve become skeptical of new Objective-C features.
When they’re not in service of Swift, they’re in service of Apple. Despite its important place in the
history of programming and Apple itself, it’s hard not to see Objective-C as just that — history.
Swift
Equatable and Comparable
Objective-C required us to wax philosophic about the nature of equality and identity. To the relief of
any developer less inclined towards discursive treatises, this is not as much the case for Swift.
In Swift, there’s the Equatable protocol, which explicitly defines the semantics of equality and
inequality in a manner entirely separate from the question of identity. There’s also the Comparable
protocol, which builds on Equatable to refine inequality semantics to creating an ordering of values.
Together, the Equatable and Comparable protocols form the central point of comparison throughout
the language.
Equatable
Values conforming to the Equatable protocol can be evaluated for equality and inequality. Conformance
to Equatable requires the implementation of the equality operator (==).
As an example, consider the following Binomen structure:
struct Binomen {
let genus: String
let species: String
}
let
let
= Binomen(genus: "Canis", species: "lupus")
= Binomen(genus: "Ursus", species: "arctos")
We can add Equatable conformance through an extension, implementing the required type method
for the == operator like so:
extension Binomen: Equatable {
static func == (lhs: Binomen, rhs: Binomen) -> Bool {
return lhs.genus == rhs.genus &&
lhs.species == rhs.species
}
}
==
==
// true
// false
Easy enough, right?
Well actually, it’s even easier than that — as of Swift 4.1, the compiler can automatically synthesize
conformance for structures whose stored properties all have types that are Equatable. We could replace
all of the code in the extension by simply adopting Equatable in the declaration of Binomen:
struct Binomen: Equatable {
let genus: String
let species: String
}
==
==
// true
// false
The Benefits of Being Equal
Equatability isn’t just about using the == operator — there’s also the != operator! it also lets a value,
among other things, be found in a collection and matched in a switch statement.
[
,
].contains(
) // true
func commonName(for binomen: Binomen) -> String? {
switch binomen {
case
: return "gray wolf"
case
: return "brown bear"
default: return nil
}
}
commonName(for:
) // "gray wolf"
Equatable is also a requirement for conformance to Hashable, another important type in Swift.
This is all to say that if a type has equality semantics — if two values of that type can be considered
equal or unequal – it should conform to Equatable.
The Limits of Automatic Synthesis
The Swift standard library and most of the frameworks in Apple SDKs do a great job adopting
Equatable for types that make sense to be. So, in practice, you’re unlikely to be in a situation where the
dereliction of a built-in type spoils automatic synthesis for your own type.
Instead, the most common obstacle to automatic synthesis involves tuples. Consider this poorlyconsidered Trinomen type:
struct Trinomen {
let genus: String
let species: (String, subspecies: String?) //
}
extension Trinomen: Equatable {}
//
Type 'Trinomen' does not conform to protocol 'Equatable'
As described in our article about Void, tuples aren’t nominal types, so they can’t conform to Equatable.
If you wanted to compare two trinomina for equality, you’d have to write the conformance code for
Equatable.
…like some kind of animal.
Conditional Conformance to Equality
In addition to automatic synthesis of Equatable, Swift 4.1 added another critical feature: conditional
conformance.
To illustrate this, consider the following generic type that represents a quantity of something:
struct Quantity<Thing> {
let count: Int
let thing: Thing
}
Can Quantity conform to Equatable? We know that integers are equatable, so it really depends on
what kind of Thing we’re talking about.
What conditional conformance Swift 4.1 allows us to do is create an extension on a type with a
conditional clause. We can use that here to programmatically express that _“a quantity of a thing is
equatable if the thing itself is equatable”:
extension Quantity: Equatable where Thing: Equatable {}
And with that declaration alone, Swift has everything it needs to synthesize conditional Equatable
conformance, allowing us to do the following:
let oneHen = Quantity<Character>(count: 1, thing: " ")
let twoDucks = Quantity<Character>(count: 2, thing: " ")
oneHen == twoDucks // false
Conditional conformance is the same mechanism that provides for an Array whose Element is
Equatable to itself conform to Equatable:
[
,
] == [
,
] // true
Equality by Reference
For reference types, the notion of equality becomes conflated with identity. It makes sense that two
Name structures with the same values would be equal, but two Person objects can have the same name
and still be different people.
For Objective-C-compatible object types, the == operator is already provided from the isEqual:
method:
import Foundation
class ObjCObject: NSObject {}
ObjCObject() == ObjCObject() // false
For Swift reference types (that is, classes), equality can be evaluated using the identity equality operator
(===):
class Object: Equatable {
static func == (lhs: Object, rhs: Object) -> Bool {
return lhs === rhs
}
}
Object() == Object() // false
That said, Equatable semantics for reference types are often not as straightforward as a straight identity
check, so before you add conformance to all of your classes, ask yourself whether it actually makes
sense to do so.
Comparable
Building on Equatable, the Comparable protocol allows for values to be considered less than or greater
than other values.
Comparable requires implementations for the following operators:
Operator
Name
<
Less than
<=
Less than or equal to
>=
Greater than or equal to
>
Greater than
…so it’s surprising that you can get away with only implementing one of them: the < operator.
Going back to our binomial nomenclature example, let’s extend Binomen to conform to Comparable
such that values are ordered alphabetically first by their genus name and then by their species name:
extension Binomen: Comparable {
static func < (lhs: Binomen, rhs: Binomen) -> Bool {
if lhs.genus != rhs.genus {
return lhs.genus < rhs.genus
} else {
return lhs.species < rhs.species
}
}
}
>
// true ("Ursus" lexicographically follows "Canis")
Implementing the < operator for types that consider more than one property is deceptively hard to
get right the first time. Be sure to write test cases to validate correct behavior.
This is quite clever. Since the implementations of each comparison operator can be derived from just <
and ==, all of that functionality is made available automatically through type inference.
Contrast this with how Ruby and other languages derive equality and comparison operators from a
single operator, <=> (a.k.a the “UFO operator”). A few pitches to bring formalized ordering to Swift
have floated around over the years, such as this one, but we haven’t seen any real movement in this
direction lately.
Incomparable Limitations with No Equal
Unlike Equatable, the Swift compiler can’t automatically synthesize conformance to Comparable. But
that’s not for lack of trying — it’s just not possible.
There are no implicit semantics for comparability that could be derived from the types of stored
properties. If a type has more than one stored property, there’s no way to determine how they’re
compared relative to one another. And even if a type had only a single property whose type was
Comparable, there’s no guarantee how the ordering of that property would relate to the ordering of the
value as a whole
Comparable Benefits
Conforming to Comparable confers a multitude of benefits.
One such benefit is that arrays containing values of comparable types can call methods like sorted(),
min(), and max():
let
let
let
let
=
=
=
=
Binomen(genus:
Binomen(genus:
Binomen(genus:
Binomen(genus:
"Tursiops", species: "truncatus")
"Helianthus", species: "annuus")
"Amanita", species: "muscaria")
"Canis", species: "domesticus")
let menagerie = [ ,
,
,
,
,
]
menagerie.sorted() // [ ,
,
,
,
,
menagerie.min() //
menagerie.max() //
]
Having a defined ordering also lets you create ranges, like so:
let lessThan10 = ..<10
lessThan10.contains(1) // true
lessThan10.contains(11) // false
let oneToFive = 1...5
oneToFive.contains(3) // true
oneToFive.contains(7) // false
In the Swift standard library, Equatable is a type without an equal; Comparable a protocol without
compare. Take care to adopt them in your own types as appropriate and you’ll benefit greatly.
Hashable /
Hasher
When you make a Genius Bar reservation at an Apple Store, you’re instructed to show up at a particular
time of day and check in with the concierge. After directing you to pull up a stool, the concierge adds
you to the queue and makes a note about how to identify you.
According to anonymous reports from former retail employees, there are strict guidelines about how
customers can be described. Nothing about their physical appearance is used: age, gender, ethnicity,
height — not even hair color. Instead, all customers are described by their clothing, as in “Person with
black turtleneck, jeans, and glasses”.
This practice of describing customers has a lot in common with a hashing function in programming.
Like any good hashing function, it’s consistent and easy to compute, and can be used to quickly find
what (or who) you’re looking for. Much better than a queue, I think you’ll agree!
Our topic this week is Hashable and its new related type, Hasher. Together, they comprise the
functionality underlying two of Swift’s most beloved collection classes: Dictionary and Set.
Let’s say you have a list of objects that can be compared for equality with one another. To find a particular
object in that list, you iterate all the elements until you find a match. As you add more elements to the
array, the average amount of time necessary to find any one of them increases linearly (O(n)).
If you instead store those objects in a set, you can theoretically find any one of them in constant time
(O(1)) — that is, a lookup on a set with 10 elements takes the same amount of time as a lookup on a set
with 10,000*. How does this work? Instead of storing objects sequentially, a set computes a hash as an
index based on the contents of the object. When you perform a lookup of an object in a set, you use the
same function to compute a new hash and look for the object there.
*
Two objects produce a hash collision when they have the same hash value but aren’t equal. When a
collision occurs on insertion, they’re stored in a list at that address. The higher the rate of collision
between objects, the more linear the performance of a hash collection becomes.
Hashable
In Swift, Array provides the standard interface for lists and Set for sets. In order for an object to be
stored in a Set, its type must conform to Hashable (and by extension, Equatable). Swift’s standard
map interface, Dictionary has a similar constraint on its associated Key type.
In previous versions of the language, it took quite a bit of boilerplate code to satisfy the requirements
for storing a custom type in a Set or Dictionary.
Consider the following Color type, which represents a color using 8-bit values for red, green, and blue
intensity:
struct Color {
let red: UInt8
let green: UInt8
let blue: UInt8
}
To conform to Equatable, you had to provide an implementation for the == operator. To conform to
Hashable, you had to provide an implementation of the computed hashValue property:
// Swift < 4.1
extension Color: Equatable {
static func ==(lhs: Color, rhs: Color) -> Bool {
return lhs.red == rhs.red &&
lhs.green == rhs.green &&
lhs.blue == rhs.blue
}
}
extension Color: Hashable {
var hashValue: Int {
return self.red.hashValue ^
}
}
self.green.hashValue ^
self.blue.hashValue
For most developers, implementing Hashable was a speed bump on the way to getting real work done,
so they’d simply XOR over all the stored properties and call it a day.
One downside to this approach is its high rate of hash collisions. Because XOR is commutative, colors
as different as cyan and yellow produce a hash collision:
// Swift < 4.2
let cyan = Color(red: 0x00, green: 0xFF, blue: 0xFF)
let yellow = Color(red: 0xFF, green: 0xFF, blue: 0x00)
cyan.hashValue == yellow.hashValue // true, collision
Most of the time, this isn’t a problem; modern computers are so powerful that you have to get a lot of
implementation details wrong in order to notice any decrease in performance.
But that’s not to say that details don’t matter — they often matter immensely. More on that later.
Automatic Synthesis of Hashable Conformance
As of Swift 4.1, the compiler automatically synthesizes conformance to the Equatable and Hashable
protocols for types that adopt these protocols in their declaration if their members also conform to
those protocols.
In addition to being a huge boost to developer productivity, this can drastically reduce the size of a
codebase. For instance, our Color example from before — is now ⅓ of its original size:
// Swift >= 4.1
struct Color: Hashable {
let red: UInt8
let green: UInt8
let blue: UInt8
}
Despite these unambiguous improvements to the language, there was still a lingering question about
some of the implementation details.
In his Swift Evolution proposal SE-0185: Synthesizing Equatable and Hashable conformance, Tony
Allevato offered this note about hashing functions:
The choice of hash function is left as an implementation detail, not a fixed part of the design; as such,
users should not depend on specific characteristics of its behavior. The most likely implementation
would call the standard library’s _mixInt function on each member’s hash value and then combine
them with exclusive-or (^), which mirrors the way Collection types are hashed today.
Fortunately, it didn’t take long for Swift to settle on a hash function. We got our answer in the very
next release:
Hasher
Swift 4.2 refines Hashable even further by introducing the Hasher type and adopting a new universal
hashing function.
From the Swift Evolution proposal, SE-0206: Hashable Enhancements:
With a good hash function, simple lookups, insertions and removals take constant time on average.
However, when the hash function isn’t carefully chosen to suit the data, the expected time of such
operations can become proportional to the number of elements stored in the table.
As Karoy Lorentey and Vincent Esche note, the main draw of hash-based collections like Set and
Dictionary is their ability to look up values in constant time. If the hash function doesn’t produce an
even distribution of values, these collections effectively become linked lists.
Swift 4.2 implements hashing based on the SipHash family of pseudorandom functions, specifically
SipHash-1-3 and SipHash-2-4, with 1 or 2 rounds of hashing per message block and 3 or 4 rounds of
finalization, respectively.
Now if you want to customize how your type implements Hashable, you can override the hash(into:)
method instead of hashValue. The hash(into:) method passes a Hasher object by reference, which
you call combine(_:) on to add the essential state information of your type.
// Swift >= 4.2
struct Color: Hashable {
let red: UInt8
let green: UInt8
let blue: UInt8
// Synthesized by compiler
func hash(into hasher: inout Hasher) {
hasher.combine(self.red)
hasher.combine(self.green)
hasher.combine(self.blue)
}
}
// Default implementation from protocol extension
var hashValue: Int {
var hasher = Hasher()
self.hash(into: &hasher)
return hasher.finalize()
}
By abstracting away low-level bit manipulation details, developers automatically take advantage of
Swift’s built-in hashing function, which has the extra benefit of not reproducing the collisions we had
with our original XOR-based implementation:
// Swift >= 4.2
let cyan = Color(red: 0x00, green: 0xFF, blue: 0xFF)
let yellow = Color(red: 0xFF, green: 0xFF, blue: 0x00)
cyan.hashValue == yellow.hashValue // false, no collision
Customizing Hash Function
By default, Swift uses a universal hash function that reduces a sequence of bytes to a single integer.
However, you can improve on this by tailoring your hash function to your domain. For example, if you
were writing a program to play a board game like chess or go, you might implement Zobrist hashing to
quickly store the game state.
Guarding Against Hash-Flooding
Selecting a cryptographic algorithm like SipHash helps protect against hash-flooding DoS attacks, which
deliberately try to generate hash collisions in an attempt to enforce the worst case of hashing data
structures and cause a program to slow to a halt. This caused a bunch of problems for the web in the
early 2010’s.
To make things even safer, Hasher generates random seed values each time an app is launched, to make
hash values even less predictable.
You shouldn’t rely on specific hash values or save them across executions. On the rare occasion that
you would need deterministic behavior, you can set the flag SWIFT_DETERMINISTIC_HASHING to
disable random hash seeds.
The challenge of programming analogies is they normalize antisocial behavior by way of edge cases.
We excel as software engineers when we can think through all the ways that an attacker might leverage
a particular behavior to some sinister end — as in the case of hash-flooding DoS attacks. But by doing
so, we risk failing as humans when we apply that knowledge AFK.
That is to say… I’m not in any way encouraging you, dear reader, to coordinate outfits with your besties
the next time you visit your local Apple retailer in an attempt to sow confusion and discord among
Geniuses.
Please don’t.
Instead, please let your takeaway be this:
If you’re waiting at the Genius Bar, stay away from anyone wearing the same color shirt as you. It’ll
make things a lot easier for everyone.
Identifiable
What constitutes the identity of an object?
Philosophers have contemplated such matters throughout the ages. Whether it’s to do with reconstructed
seafaring vessels from antiquity or spacefaring vessels from science fiction, questions of Ontology reveal
our perception and judgment to be much less certain than we’d like to believe.
Our humble publication has frequented this topic with some regularity, whether it was attempting to
make sense of equality in Objective-C or appreciating the much clearer semantics of Swift vis-à-vis the
Equatable protocol.
Swift 5.1 gives us yet another occasion to ponder this old chestnut by virtue of the new Identifiable
protocol. We’ll discuss the noumenon of this phenomenal addition to the standard library, and help
you identify opportunities to realize its potential in your own projects.
But let’s dispense with the navel gazing and jump right into some substance:
Swift 5.1 adds the Identifiable protocol to the standard library, declared as follows:
protocol Identifiable {
associatedtype ID: Hashable
var id: ID { get }
}
Values of types adopting the Identifiable protocol provide a stable identifier for the entities they
represent.
For example, a Parcel object may use the id property requirement to track the package en route to its
final destination. No matter where the package goes, it can always be looked up by its id:
import CoreLocation
struct Parcel: Identifiable {
let id: String
var location: CLPlacemark?
}
Our first introduction to the Identifiable protocol actually came by way of SwiftUI; it’s thanks to
the community that the type was brought into the fold of the standard library.
Though as evidenced by GitHub search results, many of us were already working with Identifiable
protocols of similar design… which prompts the question: When was the Identifiable protocol
really introduced?
The Swift Evolution proposal for Identifiable, SE-0261, was kept small and focused in order to be
incorporated quickly. So, if you were to ask, “What do you actually get by conforming to Identifiable?”,
the answer right now is “Not much.” As mentioned in the future directions, conformance to Identifiable
has the potential to unlock simpler and/or more optimized versions of other functionality, such as the
new ordered collection diffing APIs.
But the question remains: “Why bother conforming to Identifiable?”
The functionality you get from adopting Identifiable is primarily semantic, and require some more
explanation. It’s sort of like asking, “Why bother conforming to Equatable?”
And actually, that’s not a bad place to start. Let’s talk first about Equatable and its relation to
Identifiable:
Identifiable vs. Equatable
Identifiable distinguishes the identity of an entity from its state.
A parcel from our previous example will change locations frequently as it travels to its recipient. Yet a
normal equality check (==) would fail the moment it leaves its sender:
extension Parcel: Equatable {}
var specialDelivery = Parcel(id: "123456789012")
specialDelivery.location = CLPlacemark(
location: CLLocation(latitude: 37.3327,
longitude: -122.0053),
name: "Cupertino, CA"
)
specialDelivery == Parcel(id: "123456789012") // false
specialDelivery.id == Parcel(id: "123456789012").id // true
While this is an expected outcome from a small, contrived example, the very same behavior can lead to
confusing results further down the stack, where you’re not as clear about how different parts work with
one another.
var trackedPackages: Set<Parcel> = …
trackedPackages.contains(Parcel(id: "123456789012")) // false (?)
On the subject of Set, let’s take a moment to talk about the Hashable protocol.
Identifiable vs. Hashable
In our article about Hashable, we described how Set and Dictionary use a calculated hash value to
provide constant-time (O(1)) access to elements in a collection. Although the hash value used to bucket
collection elements may bear a passing resemblance to identifiers, Hashable and Identifiable have
some important distinctions in their underlying semantics:
• Unlike identifiers, hash values are typically state-dependent, changing when an object is mutated.
• Identifiers are stable across launches, whereas hash values are calculated by randomly generated
hash seeds, making them unstable between launches.
• Identifiers are unique, whereas hash values may collide, requiring additional equality checks when
fetched from a collection.
• Identifiers can be meaningful, whereas hash values are chaotic by virtue of their hashing functions.
In short, hash values are similar to but no replacement for identifiers.
So what makes for a good identifier, anyway?
Choosing ID Types
Aside from conforming to Hashable, Identifiable doesn’t make any other demands of its associated
ID type requirement. So what are some good candidates?
If you’re limited to only what’s available in the Swift standard library, your best options are Int and
String. Include Foundation, and you expand your options with UUID and URL. Each has its own
strengths and weaknesses as identifiers, and can be more or less suited to a particular situation:
Int as ID
The great thing about using integers as identifiers is that (at least on 64-bit systems), you’re unlikely to
run out of them anytime soon.
Most systems that use integers to identify records assign them in an auto-incrementing manner, such
that each new ID is 1 more than the last one. Here’s a simple example of how you can do this in Swift:
struct Widget: Identifiable {
private static var idSequence = sequence(first: 1, next: {$0 + 1})
let id: Int
}
init?() {
guard let id = Widget.idSequence.next() else { return nil}
self.id = id
}
Widget()?.id // 1
Widget()?.id // 2
Widget()?.id // 3
If you wanted to guarantee uniqueness across launches, you might instead initialize the sequence with
a value read from a persistent store like UserDefaults. And if you found yourself using this pattern
extensively, you might consider factoring everything into a self-contained property wrapper.
Monotonically increasing sequences have a lot of benefits, and they’re easy to implement.
This kind of approach can provide unique identifiers for records, but only within the scope of the device
on which the program is being run (and even then, we’re glossing over a lot with respect to concurrency
and shared mutable state).
If you want to ensure that an identifier is unique across every device that’s running your app, then
congratulations —you’ve hit a fundamental problem in computer science. But before you start in on
vector clocks and consensus algorithms, you’ll be relieved to know that there’s a much simpler solution:
UUIDs.
Insofar as this is a concern for your app, don’t expose serial identifiers to end users. Not only do you
inadvertently disclose information about your system (“How many customers are there? Just sign
up and check the user ID!”), but you open the door for unauthorized parties to enumerate all of the
records in your system (“Just start at id = 1 and keep incrementing until a record doesn’t exist”).
Granted, this is more of a concern for web apps, which often use primary keys in URLs, but it’s
something to be aware of nonetheless.
UUID as ID
UUIDs, or universally unique identifiers, (mostly) sidestep the problem of consensus with probability.
Each UUID stores 128 bits — minus 6 or 7 format bits, depending on the version — which, when
randomly generated, make the chances of collision, or two UUIDs being generated with the same value,
astronomically small.
As discussed in a previous article, Foundation provides a built-in implementation of (version-4) UUIDs
by way of the UUID type. Thus making adoption to Identifiable with UUIDs trivial:
import Foundation
struct Gadget: Identifiable {
let id = UUID()
}
Gadget().id // 584FB4BA-0C1D-4107-9EE5-C555501F2077
Gadget().id // C9FECDCC-37B3-4AEE-A514-64F9F53E74BA
Beyond minor ergonomic and cosmetic issues, UUID serves as an excellent alternative to Int for
generated identifiers.
However, your model may already be uniquely identified by a value, thereby obviating the need to
generate a new one. Under such circumstances, that value is likely to be a String.
On macOS, you can generate a random UUID from Terminal with the built-in uuidgen command:
$ uuidgen
39C884B8-0A11-4B4F-9107-3AB909324DBA
String as ID
We use strings as identifiers all the time, whether it takes the form of a username or a checksum or a
translation key or something else entirely.
The main drawback to this approach is that, thanks to The Unicode® Standard, strings encode thousands
of years of written human communication. So you’ll need a strategy for handling identifiers like “⽜”,
“𐂌”, “”, and “ ” …and that’s to say nothing of the more pedestrian concerns, like leading and trailing
whitespace and case-sensitivity!
Normalization is the key to successfully using strings as identifiers. The easiest place to do this is in the
initializer, but, again, if you find yourself repeating this code over and over, property wrappers can help
you here, too.
import Foundation
fileprivate extension String {
var nonEmpty: String? { isEmpty ? nil : self }
}
struct Whosit: Identifiable {
let id: String
init?(id: String) {
guard let id = id.trimmingCharacters(in: CharacterSet.letters.inverted)
.lowercased()
.nonEmpty
else {
return nil
}
}
}
self.id = id
Whosit(id: "Cow")?.id // cow
Whosit(id: "--- cow ---")?.id // cow
Whosit(id: " ") // nil
URL as ID
URLs (or URIs if you want to be pedantic) are arguably the most ubiquitous kind of identifier among all
of the ones described in this article. Every day, billions of people around the world use URLs as a way
to point to a particular part of the internet. So URLs a natural choice for an id value if your models
already include them.
URLs look like strings, but they use syntax to encode multiple components, like scheme, authority,
path, query, and fragment. Although these formatting rules dispense with much of the invalid input
you might otherwise have to consider for strings, they still share many of their complexities — with a
few new ones, just for fun.
The essential problem is that equivalent URLs may not be equal. Intrinsic, syntactic details like case
sensitivity, the presence or absence of a trailing slash (/), and the order of query components all affect
equality comparison. So do extrinsic, semantic concerns like a server’s policy to upgrade http to https,
redirect from www to the apex domain, or replace an IP address with a which might cause different
URLs to resolve to the same webpage.
URL(string: "https://nshipster.com/?a=1&b=2")! ==
URL(string: "http://www.NSHipster.com?b=2&a=1")! // false
try! Data(contentsOf: URL(string: "https://nshipster.com?a=1&b=2")!) ==
Data(contentsOf: URL(string: "http://www.NSHipster.com?b=2&a=1")!) // true
Many of the same concerns apply to file URLs as well, which have the additional prevailing concern
of resolving relative paths.
If your model gets identifier URLs for records from a trusted source, then you may take URL equality
as an article of faith; if you regard the server as the ultimate source of truth, it’s often best to follow
their lead.
But if you’re working with URLs in any other capacity, you’ll want to employ some combination of URL
normalizations before using them as an identifier.
Unfortunately, the Foundation framework doesn’t provide a single, suitable API for URL canonicalization,
but URL and URLComponents provide enough on their own to let you roll your own (though we’ll leave
that as an exercise for the reader):
import Foundation
fileprivate extension URL {
var normalizedString: String { … }
}
struct Whatsit: Identifiable {
let url: URL
var id: { url.normalizedString }
}
Whatsit(url: "https://example.com/123").id // example.com/123
Whatsit(id: "http://Example.com/123/").id // example.com/123
Creating Custom Identifier ID Types
UUID
and URL both look like strings, but they use syntax rules to encode information in a structured
way. And depending on your app’s particular domain, you may find other structured data types that
would make for a suitable identifier.
Thanks to the flexible design of the Identifiable protocol, there’s nothing to stop you from
implementing your own ID type.
For example, if you’re working in a retail space, you might create or repurpose an existing UPC type to
serve as an identifier:
struct UPC: Hashable {
var digits: String
…
}
struct Product: Identifiable {
let id: UPC
var name: String
var price: Decimal
}
Three Forms of ID Requirements
As Identifiable makes its way into codebases, you’re likely to see it used in one of three different ways:
The newer the code, the more likely it will be for id to be a stored property — most often this will be
declared as a constant (that is, with let):
import Foundation
// Style 1: id requirement fulfilled by stored property
struct Product: Identifiable {
let id: UUID
}
Older code that adopts Identifiable, by contrast, will most likely satisfy the id requirement with a
computed property that returns an existing value to serve as a stable identifier. In this way, conformance
to the new protocol is purely additive, and can be done in an extension:
import Foundation
struct Product {
var uuid: UUID
}
// Style 2: id requirement fulfilled by computed property
extension Product: Identifiable {
var id { uuid }
}
If by coincidence the existing class or structure already has an id property, it can add conformance by
simply declaring it in an extension (assuming that the property type conforms to Hashable).
import Foundation
struct Product {
var id: UUID
}
// Style 3: id requirement fulfilled by existing property
extension Product: Identifiable {}
No matter which way you choose, you should find adopting Identifiable in a new or existing
codebase to be straightforward and noninvasive.
As we’ve said time and again, often it’s the smallest additions to the language and standard library that
have the biggest impact on how we write code. (This speaks to the thoughtful, protocol-oriented design
of Swift’s standard library.)
Because what Identifiable does is kind of amazing: it extends reference semantics to value types.
When you think about it, reference types and value types differ not in what information they encode,
but rather how we treat them.
For reference types, the stable identifier is the address in memory in which the object resides. This fact
can be plainly observed by the default protocol implementation of id for AnyObject types:
extension Identifiable where Self: AnyObject {
var id: ObjectIdentifier {
return ObjectIdentifier(self)
}
}
Ever since Swift first came onto the scene, the popular fashion has been to eschew all reference types
for value types. And this neophilic tendency has only intensified with the announcement of SwiftUI.
But taking such a hard-line approach makes a value judgment of something better understood to be a
difference in outlook.
It’s no coincidence that much of the terminology of programming is shared by mathematics and
philosophy. As developers, our work is to construct logical universes, after all. And in doing so, we’re
regularly tasked with reconciling our own mental models against that of every other abstraction we
encounter down the stack — down to the very way that we understand electricity and magnetism
to work.
Void
Nothingness has been a regular topic of discussion on NSHipster, from our first article about nil in
Objective-C to our recent look at the Never type in Swift. But today’s article is perhaps the most fraught
with horror vacui of them all, as we gaze now into the Void of Swift.
What is Void? In Swift, it’s nothing but an empty tuple.
typealias Void = ()
We become aware of the Void as we fill it.
let void: Void = ()
void. // No Completions
Void
values have no members: no methods, no values, not even a name. It’s a something more nothing
than nil. For an empty vessel, Xcode gives us nothing more than empty advice.
Something for Nothing
Perhaps the most prominent and curious use of the Void type in the standard library is found in the
ExpressibleByNilLiteral protocol.
protocol ExpressibleByNilLiteral {
init(nilLiteral: ())
}
Types conforming to ExpressibleByNilLiteral can be initialized with the nil literal. Most types
don’t adopt this protocol, as it makes more sense to represent the absence of a specified value using an
Optional for that type. But you may encounter it occasionally.
The required initializer for ExpressibleByNilLiteral shouldn’t take any real argument. (If it did,
what would that even be?) However, the requirement can’t just be an empty initializer init() — that’s
already used as the default initializer for many types.
You could try to work around this by changing the requirement to a type method that returned a nil
instance, but some mandatory internal state may be inaccessible outside of an initializer. But a better
solution — and the one used here — is to add a nilLiteral label by way of a Void argument. It’s an
ingenious use of existing functionality to achieve unconventional results.
No Things Being Equal
Tuples, along with metatypes (like Int.Type, the result of calling Int.self), function types (like
(String) -> Bool) and existentials (like Encodable & Decodable), comprise non-nominal types. In
contrast to the nominal, or named, types that comprise most of Swift, non-nominal types are defined in
relation to other types.
Non-nominal types cannot be extended. Void is an empty tuple, and because tuples are non-nominal
types, you can’t add methods or properties or conformance to protocols.
extension Void {} // Non-nominal type 'Void' cannot be extended
Void
doesn’t conform to Equatable — it simply can’t. Yet when we invoke the “is equal to” operator
(==), it works as expected.
void == void // true
We reconcile this apparent contradiction with a global free-function, declared outside of any formal
protocol.
func == (lhs: (), rhs: ()) -> Bool {
return true
}
This same treatment is given to the “is less than” operator (<), which acts as a stand-in for the
Comparable protocol and its derived comparison operators.
func < (lhs: (), rhs: ()) -> Bool {
return false
}
The Swift standard library provides implementations of the comparison functions for tuples with
arity, or size, up to 6. This is, however, considered a hack. At various times, the Swift core team has
expressed interest in adding formal Equatable conformance for tuples, but at the time of writing,
no formal proposals are being discussed.
Ghost in the Shell
Void,
as a non-nominal type, can’t be extended. However, Void is still a type, and can, therefore, be
used as a generic constraint.
For example, consider this generic container for a single value:
struct Wrapper<Value> {
let value: Value
}
We can first take advantage of conditional conformance, arguably the killer feature in Swift 4.1, to
extend Wrapper to adopt Equatable when it wraps a value that is itself Equatable.
extension Wrapper: Equatable where Value: Equatable {
static func ==(lhs: Wrapper<Value>, rhs: Wrapper<Value>) -> Bool {
return lhs.value == rhs.value
}
}
Using the same trick from before, we can approximate Equatable behavior by implementing a top-level
== function that takes Wrapper<Void> arguments.
func ==(lhs: Wrapper<Void>, rhs: Wrapper<Void>) -> Bool {
return true
}
In doing so, we can now successfully compare two constructed wrappers around Void values.
Wrapper(value: void) == Wrapper(value: void) // true
However, if we attempt to assign such a wrapped value to a variable, the compiler generates a
mysterious error.
let wrapperOfVoid = Wrapper<Void>(value: void)
//
error: Couldn't apply expression side effects :
// Couldn't dematerialize wrapperOfVoid: corresponding symbol wasn't found
The horror of the Void becomes once again its own inverted retort.
The Phantom Type
Even when you dare not speak its non-nominal name, there is no escaping Void.
Any function declaration with no explicit return value implicitly returns Void
func doSomething() { ... }
// Is equivalent to
func doSomething() -> Void { ... }
This behavior is curious, but not particularly useful, and the compiler will generate a warning if you
attempt to assign a variable to the result of a function that returns Void.
doSomething() // no warning
let result = doSomething()
//
️ Constant 'result' inferred to have type 'Void', which may be unexpected
You can silence this warning by explicitly specifying the Void type.
let result: Void = doSomething() // ()
By contrast, functions that return non-Void values generate warnings if you don’t assign their
return value.
For more details, see SE-0047 “Defaulting non-Void functions so they warn on unused results”.
Trying to Return from the Void
If you squint at Void? long enough, you might start to mistake it for Bool. These types are isometric,
both having exactly two states: true / .some(()) and false / .none.
But isometry doesn’t imply equivalence. The most glaring difference between the two is that Bool is
ExpressibleByBooleanLiteral, whereas Void isn’t — and can’t be, for the same reasons that it’s not
Equatable. So you can’t do this:
(true as Void?) // error
Void may be the spookiest type in Swift, but Bool gives it a run for its money when typealias’d to
Booooooool
.
But hard-pressed, Void? can act in the same way as Bool. Consider the following function that
randomly throws an error:
struct Failure: Error {}
func failsRandomly() throws {
if Bool.random() {
throw Failure()
}
}
The correct way to use this method is to call it within a do / catch block using a try expression.
do {
try failsRandomly()
// executes on success
} catch {
// executes on failure
}
The incorrect-but-ostensibly-valid way to do this would be to exploit the fact that failsRandomly()
implicitly returns Void. The try? expression transforms the result of a statement that throws into an
optional value, which in the case of failsRandomly(), results in Void?. If Void? has .some value (that
is, != nil), that means the method returned without throwing an error. If success is nil, then we
know that the method produced an error.
let success: Void? = try? failsRandomly()
if success != nil {
// executes on success
} else {
// executes on failure
}
As much as you may dislike the ceremony of do / catch blocks, you have to admit that they’re a lot
prettier than what’s happening here.
It’s a stretch, but this approach might be valid in very particular and peculiar situations. For example,
you might use a static property on a class to lazily produce some kind of side effect exactly once using
a self-evaluating closure:
static var oneTimeSideEffect: Void? = {
return try? data.write(to: fileURL)
}()
Even still, an Error or Bool value would probably be more appropriate.
Things that go “Clang” in the Night
If, while reading this chilling account you start to shiver, you can channel the necrotic energy of the
Void type to conjure immense amounts of heat to warm your spirits.
…which is to say, the following code causes lldb-rpc-server to max out your CPU:
extension Optional: ExpressibleByBooleanLiteral where Wrapped == Void {
public typealias BooleanLiteralType = Bool
}
public init(booleanLiteral value: Bool) {
if value {
self.init(())!
} else {
self.init(nilLiteral: ())!
}
}
let pseudoBool: Void? = true // we never get to find out
Keeping in the Lovecraft-ian tradition, Void has a physical form that the computer is incapable of
processing; simply witnessing it renders the process incurably insane.
A Hollow Victory
Let’s conclude our hallowed study of Void with a familiar refrain.
enum Result<Value, Error> {
case success(Value)
case failure(Error)
}
If you recall our article about the Never type, a Result type with its Error type set to Never can be
used to represent operations that always succeed.
In a similar way, we might use Void as the Value type to represent operations that, when they succeed,
don’t produce any meaningful result.
For example, apps may implement tell-tale heartbeat by regularly “pinging” a server with a simple
network request.
func ping(_ url: URL, completion: (Result<Void, Error>) -> Void) {
…
}
According to HTTP semantics, the correct status code for a hypothetical /ping endpoint would be
204 No Content.
In the completion handler of the request, success would be indicated by the following call:
completion(.success(()))
Not enamored with effusive parentheticals (but why not?), you could make thing a bit nicer through a
strategic extension on Result.
extension Result where Value == Void {
static var success: Result {
return .success(())
}
}
Nothing lost; nothing gained.
completion(.success)
It may seem like a purely academic exercise — philosophical, even. But an investigation into the Void
yields deep insights into the very fabric of reality for the Swift programming language.
In ancient times, long before Swift had seen the light of day, tuples played a fundamental role in the
language. They represented argument lists and associated enumeration values, fluidly moving between
its different contexts. At some point that model broke down. And the language has yet to reconcile the
incongruities between these disparate constructs.
So according to Swift Mythos, Void would be the paragon of the elder gods: the true singleton, blind
nullary at the center of infinity unaware of its role or influence; the compiler unable to behold it.
But perhaps this is all just an invention at the periphery of our understanding — a manifestation of our
misgivings about the long-term viability of the language. After all, when you stare into the Void, the
Void stares back into you.
Never
“Never” is a proposition that an event doesn’t occur at any time in the past or future. It’s logical
impossibility with a time axis; nothingness stretching out in all directions, forever.
…which is why it’s especially worrisome to encounter this comment in code:
// this will never happen
Every compiler textbook will tell you that a comment like this one can’t and won’t affect the behavior of
compiled code. Murphy’s Law says otherwise.
How does Swift keep us safe in the unpredictable chaos that is programming? You’ll never believe the
answer: nothing and crashing.
Never
was proposed as a replacement for the @noreturn attribute in SE-0102: “Remove @noreturn
attribute and introduce an empty Never type”, by Joe Groff.
Prior to Swift 3, functions that stop execution, like fatalError(_:file:line:), abort(), and
exit(_:), were annotated with the @noreturn attribute, which told the compiler that there was no
return to the call site.
// Swift < 3.0
@noreturn func fatalError(_ message: () -> String = String(),
file: StaticString = #file,
line: UInt = #line)
After the change, fatalError and its trapping cohorts were declared to return the Never type:
// Swift >= 3.0
func fatalError(_ message: @autoclosure () -> String = String(),
file: StaticString = #file,
line: UInt = #line) -> Never
For a type to replace the functionality of an annotation, it must be pretty complex, right? Nope! Actually,
just the opposite — Never is arguably the simplest type in the entire Swift standard library:
enum Never {}
Uninhabited Types
Never
is an uninhabited type, which means that it has no values. Or to put it another way, uninhabited
types can’t be constructed.
Enumerations with no cases are the most common example of an uninhabited type in Swift. Unlike
structures or classes, enumerations don’t receive an initializer. And unlike protocols, enumerations are
concrete types that can have properties, methods, generic constraints, and nested types. Because of
this, uninhabited enumeration types are used throughout the Swift standard library to do things like
namespace functionality and reason about types.
But Never isn’t like that. It doesn’t have any fancy bells or whistles. It’s special by virtue of it being what
it is (or rather, isn’t).
Consider a function declared to return an uninhabited type: Because uninhabited types don’t have any
values, the function can’t return normally. (Because how could they?) Instead, the function must either
stop execution or run indefinitely.
Eliminating Impossible States in Generic Types
Sure, this is interesting from a theoretical perspective, but what practical use does Never have for us?
Not much — or at least not before the acceptance SE-0215: Conform Never to Equatable and Hashable.
In his proposal, Matt Diephouse explains the motivation behind conforming this obscure type to
Equatable and other protocols this way:
Never is very useful for representing impossible code. Most people are familiar with it as the return
type of functions like fatalError, but Never is also useful when working with generic classes. For
example, a Result type might use Never for its Value to represent something that always errors
or use Never for its Error to represent something that never errors.
Swift doesn’t have a standard Result type, but most of them look something like this:
enum Result<Value, Error> {
case success(Value)
case failure(Error)
}
Result
types are used to encapsulate values and errors produced by functions that execute
asynchronously (whereas synchronous functions can use throws to communicate errors).
For example, a function that makes an asynchronous HTTP request might use a Result type to wrap
either a response and data or an error:
func fetch(_ request: URLRequest,
completion: (Result<(URLResponse, Data), Error>) -> Void) {
…
}
When calling that method, you’d switch over result to handle .success and .failure separately:
fetch(request) { result in
switch result {
case let .success(response, _):
print("Success: \(response)")
case .failure(let error):
print("Failure: \(error)")
}
}
Now consider a function that’s guaranteed to always return a successful result in its completion handler:
func alwaysSucceeds(_ completion: (Result<String, Never>) -> Void) {
completion(.success("yes!"))
}
By specifying Never as the result’s Error type, we’re using the type system to signal that failure is not
an option. What’s really cool about this is that Swift is smart enough to know that you don’t need to
handle .failure for the switch statement to be exhaustive:
alwaysSucceeds { (result) in
switch result {
case .success(let string):
print(string)
}
}
You can see this effect played out to its logical extreme in the implementation conforming Never to
Comparable:
extension Never: Comparable {
public static func < (lhs: Never, rhs: Never) -> Bool {
switch (lhs, rhs) {}
}
}
Because Never is an uninhabited type, there aren’t any possible values of it. So when we switch over lhs
and rhs, Swift understands that there aren’t any missing cases. And since all cases — of which there
aren’t any — return Bool, the method compiles without a problem. Neat!
Never as a Bottom Type
As a corollary, the original Swift Evolution proposal for Never hints at the theoretical usefulness of the
type with further enhancement:
An uninhabited type can be seen as a subtype of any other type — if evaluating an expression never
produces a value, it doesn’t matter what the type of that expression is. If this were supported by the
compiler, it would enable some potentially useful things…
Unwrap or Die
The forced unwrap operator (!) is one of the most controversial parts of Swift. At best, it’s a necessary
evil. At worst, it’s a code smell that suggests sloppiness. And without additional information, it can be
really tough to tell the difference between the two.
For example, consider the following code that assumes array to not be empty:
let array: [Int]
let firstIem = array.first!
To avoid force-unwrapping, you could use a guard statement with conditional assignment instead:
let array: [Int]
guard let firstItem = array.first else {
fatalError("array cannot be empty")
}
In the future, if Never is implemented as a bottom type, it could be used in the right-hand side of
nil-coalescing operator expression.
// Future Swift?
let firstItem = array.first ?? fatalError("array cannot be empty")
If you’re really motivated to adopt this pattern today, you can manually overload the ?? operator thusly
(however…):
func ?? <T>(lhs: T?, rhs: @autoclosure () -> Never) -> T {
switch lhs {
case let value?:
return value
case nil:
rhs()
}
}
In the rationale for SE-0217: Introducing the !! “Unwrap or Die” operator to the Swift Standard
Library, Joe Groff notes that “[…] We found that overloading [?? for Never] had unacceptable
impact on type-checking performance…”. Therefore, it’s recommended that you don’t add this to
your codebase.
Expressive Throw
Similarly, if throw is changed from being a statement to an expression that returns Never, you could
use throw on the right-hand side of ??:
// Future Swift?
let firstItem = array.first ?? throw Error.empty
Typed Throws
Looking even further down the road: If the throws keyword in function declarations added support for
type constraints, then the Never type could be used to indicate that a function won’t throw (similar to
the Result example before):
// Future Swift?
func neverThrows() throws<Never> {
…
}
neverThrows() // `try` unnecessary because it's guaranteed to succeed (perhaps)
Making a claim that something will never be the case can feel like an invitation for the universe to prove
otherwise. Whereas modal or doxastic logics allow for face-saving compromise (“it was true at the time,
or so I believed!”), temporal logic seems to hold propositions to a higher standard.
Fortunately for us, Swift lives up to this higher standard thanks to the unlikeliest of types, Never.
OptionSet
Objective-C uses the NS_OPTIONS macro to define option types, or sets of values that may be combined
together. For example, values in the UIViewAutoresizing type in UIKit can be combined with the
bitwise OR operator (|) and passed to the autoresizingMask property of a UIView to specify which
margins and dimensions should automatically resize:
typedef NS_OPTIONS(NSUInteger, UIViewAutoresizing) {
UIViewAutoresizingNone
= 0,
UIViewAutoresizingFlexibleLeftMargin
= 1 << 0,
UIViewAutoresizingFlexibleWidth
= 1 << 1,
UIViewAutoresizingFlexibleRightMargin = 1 << 2,
UIViewAutoresizingFlexibleTopMargin
= 1 << 3,
UIViewAutoresizingFlexibleHeight
= 1 << 4,
UIViewAutoresizingFlexibleBottomMargin = 1 << 5
};
Swift imports this and other types defined using the NS_OPTIONS macro as a structure that conforms to
the OptionSet protocol.
extension UIView {
struct AutoresizingMask: OptionSet {
init(rawValue: UInt)
}
}
static
static
static
static
static
static
var
var
var
var
var
var
flexibleLeftMargin: UIView.AutoresizingMask
flexibleWidth: UIView.AutoresizingMask
flexibleRightMargin: UIView.AutoresizingMask
flexibleTopMargin: UIView.AutoresizingMask
flexibleHeight: UIView.AutoresizingMask
flexibleBottomMargin: UIView.AutoresizingMask
The renaming and nesting of imported types are the result of a separate mechanism.
At the time OptionSet was introduced (and RawOptionSetType before it), this was the best
encapsulation that the language could provide. Towards the end of this article, we’ll demonstrate how
to take advantage of language features added in Swift 4.2 to improve upon OptionSet.
…but that’s getting ahead of ourselves.
This week on NSHipster, let’s take a by-the-books look at using imported OptionSet types, and how
you can create your own. After that, we’ll offer a different option for setting options.
Working with Imported Option Set Types
According to the documentation, there are over 300 types in Apple SDKs that conform to OptionSet,
from ARHitTestResult.ResultType to XMLNode.Options.
No matter which one you’re working with, the way you use them is always the same:
To specify a single option, pass it directly (Swift can infer the type when setting a property so you can
omit everything up to the leading dot):
view.autoresizingMask = .flexibleHeight
OptionSet
conforms to the SetAlgebra protocol, so to you can specify multiple options with an array
literal — no bitwise operations required:
view.autoresizingMask = [.flexibleHeight, .flexibleWidth]
To specify no options, pass an empty array literal ([]):
view.autoresizingMask = [] // no options
Declaring Your Own Option Set Types
You might consider creating your own option set type if you have a property that stores combinations
from a closed set of values and you want that combination to be stored efficiently using a bitset.
To do this, declare a new structure that adopts the OptionSet protocol with a required rawValue
instance property and type properties for each of the values you wish to represent. The raw values of
these are initialized with increasing powers of 2, which can be constructed using the left bitshift (<<)
operation with incrementing right-hand side values. You can also specify named aliases for specific
combinations of values.
For example, here’s how you might represent topping options for a pizza:
struct Toppings: OptionSet {
let rawValue: Int
static
static
static
static
static
static
}
let
let
let
let
let
let
pepperoni
onions
bacon
extraCheese
greenPeppers
pineapple
=
=
=
=
=
=
Toppings(rawValue:
Toppings(rawValue:
Toppings(rawValue:
Toppings(rawValue:
Toppings(rawValue:
Toppings(rawValue:
1
1
1
1
1
1
<<
<<
<<
<<
<<
<<
0)
1)
2)
3)
4)
5)
static let meatLovers: Toppings = [.pepperoni, .bacon]
static let hawaiian: Toppings = [.pineapple, .bacon]
static let all: Toppings = [
.pepperoni, .onions, .bacon,
.extraCheese, .greenPeppers, .pineapple
]
Taken into a larger example for context:
struct Pizza {
enum Style {
case neapolitan, sicilian, newHaven, deepDish
}
struct Toppings: OptionSet { ... }
let diameter: Int
let style: Style
let toppings: Toppings
}
init(inchesInDiameter diameter: Int,
style: Style,
toppings: Toppings = [])
{
self.diameter = diameter
self.style = style
self.toppings = toppings
}
let dinner = Pizza(inchesInDiameter: 12,
style: .neapolitan,
toppings: [.greenPeppers, .pineapple])
Another advantage of OptionSet conforming to SetAlgebra is that you can perform set operations
like determining membership, inserting and removing elements, and forming unions and intersections.
This makes it easy to, for example, determine whether the pizza toppings are vegetarian-friendly:
extension Pizza {
var isVegetarian: Bool {
return toppings.isDisjoint(with: [.pepperoni, .bacon])
}
}
dinner.isVegetarian // true
A Fresh Take on an Old Classic
Alright, now that you know how to use OptionSet, let’s show you how not to use OptionSet.
As we mentioned before, new language features in Swift 4.2 make it possible to have our cake pizza pie
and eat it too.
First, declare a new Option protocol that inherits RawRepresentable, Hashable, and CaseIterable.
protocol Option: RawRepresentable, Hashable, CaseIterable {}
Next, declare an enumeration with String raw values that adopts the Option protocol:
enum Topping: String, Option {
case pepperoni, onions, bacon,
extraCheese, greenPeppers, pineapple
}
Compare the structure declaration from before to the following enumeration. Much nicer, right? Just
wait — it gets even better.
Automatic synthesis of Hashable provides effortless usage with Set, which gets us halfway to the
functionality of OptionSet. Using conditional conformance, we can create an extension for any Set
whose element is a Topping and define our named topping combos. As a bonus, CaseIterable makes
it easy to order a pizza with “the works”:
extension Set where Element == Topping {
static var meatLovers: Set<Topping> {
return [.pepperoni, .bacon]
}
static var hawaiian: Set<Topping> {
return [.pineapple, .bacon]
}
}
static var all: Set<Topping> {
return Set(Element.allCases)
}
typealias Toppings = Set<Topping>
And that’s not all CaseIterable has up its sleeves; by enumerating over the allCases type property,
we can automatically generate the bitset values for each case, which we can combine to produce the
equivalent rawValue for any Set containing Option types:
extension Set where Element: Option {
var rawValue: Int {
var rawValue = 0
for (index, element) in Element.allCases.enumerated() {
if self.contains(element) {
rawValue |= (1 << index)
}
}
}
}
return rawValue
Because OptionSet and Set both conform to SetAlgebra our new Topping implementation can be
swapped in for the original one without needing to change anything about the Pizza itself.
This approach assumes that the order of cases provided by CaseIterable is stable across
launches. If it isn’t, the generated raw value for combinations of options may be inconsistent.
So, to summarize: you’re likely to encounter OptionSet when working with Apple SDKs in Swift. And
although you could create your own structure that conforms to OptionSet, you probably don’t need
to. You could use the fancy approach outlined at the end of this article, or do with something more
straightforward.
Whichever option you choose, you should be all set.
numericCast(_:)
Everyone has their favorite analogy to describe programming.
It’s woodworking or it’s knitting or it’s gardening. Or maybe it’s problem solving and storytelling and
making art. That programming is like writing there is no doubt; the question is whether it’s poetry or
prose. And if programming is like music, it’s always jazz for whatever reason.
But perhaps the closest point of comparison for what we do all day comes from Middle Eastern folk
tales: Open any edition of The Thousand and One Nights ( )أَْلف لَْيَلة َولَْيَلةand you’ll find descriptions of
supernatural beings known as jinn, djinn, genies, or . No matter what you call them, you’re certainly
familiar with their habit of granting wishes, and the misfortune that inevitably causes.
In many ways, computers are the physical embodiment of metaphysical wish fulfillment. Like a genie, a
computer will happily go along with whatever you tell it to do, with no regard for what your actual intent
may have been. And by the time you’ve realized your error, it may be too late to do anything about it.
As a Swift developer, there’s a good chance that you’ve been hit by integer type conversion errors and
thought “I wish these warnings would go away and my code would finally compile.”
If that sounds familiar, you’ll happy to learn about numericCast(_:), a small utility function in the
Swift Standard Library that may be exactly what you were hoping for. But be careful what you wish for,
it might just come true.
Let’s start by dispelling any magical thinking about what numericCast(_:) does by looking at its
implementation:
func numericCast<T: BinaryInteger, U: BinaryInteger>(_ x: T) -> U {
return U(x)
}
(As we learned in our article about Never, even the smallest amount of Swift code can have a big
impact.)
The BinaryInteger protocol was introduced in Swift 4 as part of an overhaul to how numbers work in
the language. It provides a unified interface for working with integers, both signed and unsigned, and
of all shapes and sizes.
When you convert an integer value to another type, it’s possible that the value can’t be represented by
that type. This happens when you try to convert a signed integer to an unsigned integer (for example,
-42 as a UInt), or when a value exceeds the representable range of the destination type (for example,
UInt8 can only represent numbers between 0 and 255).
BinaryInteger
defines four strategies of conversion between integer types, each with different
behaviors for handling out-of-range values:
• Range-Checked Conversion - init(_:): Trigger a runtime error for out-of-range values
• Exact Conversion - init?(exactly:): Return nil for out-of-range values
• Clamping Conversion - init(clamping:): Use the closest representable value for out-ofrange values
• Bit Pattern Conversion - init(truncatingIfNeeded:): Truncate to the width of the target
integer type
The correct conversion strategy depends on the situation in which it’s being used. Sometimes it’s
desireable to clamp values to a representable range; other times, it’s better to get no value at all. In
the case of numericCast(_:), range-checked conversion is used for convenience. The downside is that
calling this function with out-of-range values causes a runtime error (specifically, it traps on overflow
in -O and -Onone).
For more information about the changes to how numbers work in Swift 4, see SE-0104: “Protocoloriented integers”.
This subject is also discussed at length in the Flight School Guide to Numbers.
Thinking Literally, Thinking Critically
Before we go any further, let’s take a moment to talk about integer literals.
As we’ve discussed in previous articles, Swift provides a convenient and extensible way to represent
values in source code. When used in combination with the language’s use of type inference, things often
“just work” …which is nice and all, but can be confusing when things “just don’t”.
Consider the following example in which arrays of signed and unsigned integers are initialized from
identical literal values:
let arrayOfInt: [Int] = [1, 2, 3]
let arrayOfUInt: [UInt] = [1, 2, 3]
Despite their seeming equivalence, we can’t, for example, do this:
arrayOfInt as [UInt] // Error: Cannot convert value of type '[Int]' to type
'[UInt]' in coercion
One way to reconcile this issue would be to pass the numericCast function as an argument to map(_:):
arrayOfInt.map(numericCast) as [UInt]
This is equivalent to passing the UInt range-checked initializer directly:
arrayOfInt.map(UInt.init)
But let’s take another look at that example, this time using slightly different values:
let arrayOfNegativeInt: [Int] = [-1, -2, -3]
arrayOfNegativeInt.map(numericCast) as [UInt] //
is not representable
Fatal error: Negative value
As a run-time approximation of compile-time type functionality numericCast(_:) is closer to as!
than as or as?.
Compare this to what happens if you instead pass the exact conversion initializer, init?(exactly:):
let arrayOfNegativeInt: [Int] = [-1, -2, -3]
arrayOfNegativeInt.map(UInt.init(exactly:)) // [nil, nil, nil]
numericCast(_:),
like its underlying range-checked conversion, is a blunt instrument, and it’s
important to understand what tradeoffs you’re making when you decide to use it.
The Cost of Being Right
In Swift, the general guidance is to use Int for integer values (and Double for floating-point values)
unless there’s a really good reason to use a more specific type. Even though the count of a Collection
is nonnegative by definition, we use Int instead of UInt because the cost of going back and forth
between types when interacting with other APIs outweighs the potential benefit of a more precise type.
For the same reason, it’s almost always better to represent even small numbers, like weekday numbers,
with an Int, despite the fact that any possible value would fit into an 8-bit integer with plenty of room
to spare.
The best argument for this practice is a 5-minute conversation with a C API from Swift.
Older and lower-level C APIs are rife with architecture-dependent type definitions and finely-tuned
value storage. On their own, they’re manageable. But on top of all the other inter-operability woes like
headers to pointers, they can be a breaking point for some (and I don’t mean the debugging kind).
numericCast(_:) is there for when you’re tired of seeing red and just want to get things to compile.
Random Acts of Compiling
The example in the official docs should be familiar to many of us:
Prior to SE-0202, the standard practice for generating numbers in Swift (on Apple platforms) involved
importing the Darwin framework and calling the arc4random_uniform(3) function:
uint32_t arc4random_uniform(uint32_t __upper_bound)
arc4random
requires not one but two separate type conversions in Swift: first for the upper bound
parameter (Int → UInt32) and second for the return value (UInt32 → Int):
import Darwin
func random(in range: Range<Int>) -> Int {
return Int(arc4random_uniform(UInt32(range.count))) + range.lowerBound
}
Gross.
By using numericCast(_:), we can make things a little more readable, albeit longer:
import Darwin
func random(in range: Range<Int>) -> Int {
return numericCast(arc4random_uniform(numericCast(range.count))) +
range.lowerBound
}
numericCast(_:)
isn’t doing anything here that couldn’t otherwise be accomplished with typeappropriate initializers. Instead, it serves as an indicator that the conversion is perfunctory — the
minimum of what’s necessary to get the code to compile.
But as we’ve learned from our run-ins with genies, we should be careful what we wish for.
Upon closer inspection, it’s apparent that the example usage of numericCast(_:) has a critical flaw: it
traps on values that exceed UInt32.max!
random(in: 0..<0x1_0000_0000) //
the passed value
Fatal error: Not enough bits to represent
If we look at the Standard Library implementation that now lets us do Int.random(in: 0...10),
we’ll see that it uses clamping, rather than range-checked, conversion. And instead of delegating to a
convenience function like arc4random_uniform, it populates values from a buffer of random bytes.
Getting code to compile is different than doing things correctly. But sometimes it takes the former to
ultimately get to the latter. When used judiciously, numericCast(_:) is a convenient tool to resolve
issues quickly. It also has the added benefit of signaling potential misbehavior more clearly than a
conventional type initializer.
Ultimately, programming is about describing exactly what we want — often with painstaking detail.
There’s no genie-equivalent CPU instruction for “Do the Right Thing” (and even if there was, would we
really trust it?) Fortunately for us, Swift allows us to do this in a way that’s safer and more concise than
many other languages. And honestly, who could wish for anything more?
guard & defer
“We should do (as wise programmers aware of our limitations) our utmost best to … make the
correspondence between the program (spread out in text space) and the process (spread out in
time) as trivial as possible.”
—Edsger W. Dijkstra, “Go To Considered Harmful”
It’s a shame that his essay is most remembered for popularizing the “____ Consider Harmful” meme
among programmers and their ill-considered online diatribes. Because (as usual) Dijkstra was making
an excellent point: the structure of code should reflect its behavior.
Swift 2.0 introduced two new control statements that aimed to simplify and streamline the programs
we write: guard and defer. While the former by its nature makes our code more linear, the latter does
the opposite by delaying execution of its contents.
How should we approach these new control statements? How can guard and defer help us clarify the
correspondence between the program and the process?
Let’s defer defer and first take on guard.
guard
guard is a conditional statement requires an expression to evaluate to true for execution to continue. If
the expression is false, the mandatory else clause is executed instead.
func sayHello(numberOfTimes: Int) {
guard numberOfTimes > 0 else {
return
}
}
for _ in 1...numberOfTimes {
print("Hello!")
}
The else clause in a guard statement must exit the current scope by using return to leave a function,
continue or break to get out of a loop, or a function that returns Never like fatalError(_:file
:line:).
guard
statements are most useful when combined with optional bindings. Any new optional bindings
created in a guard statement’s condition are available for the rest of the function or block.
Compare how optional binding works with a guard-let statement to an if-let statement:
var name: String?
if let name = name {
// name is nonoptional inside (name is String)
}
// name is optional outside (name is String?)
guard let name = name else {
return
}
// name is nonoptional from now on (name is String)
If the multiple optional bindings syntax introduced in Swift 1.2 heralded a renovation of the pyramid
of doom, guard statements tear it down altogether.
for imageName in imageNamesList {
guard let image = UIImage(named: imageName)
else { continue }
}
// do something with image
Guarding Against Excessive Indentation and Errors
Let’s take a before-and-after look at how guard can improve our code and help prevent errors.
As an example, we’ll implement a readBedtimeStory() function:
enum StoryError: Error {
case missing
case illegible
case tooScary
}
func readBedtimeStory() throws {
if let url = Bundle.main.url(forResource: "book",
withExtension: "txt")
{
if let data = try? Data(contentsOf: url),
let story = String(data: data, encoding: .utf8)
{
if story.contains(" ") {
throw StoryError.tooScary
} else {
print("Once upon a time... \(story)")
}
} else {
throw StoryError.illegible
}
} else {
throw StoryError.missing
}
}
To read a bedtime story, we need to be able to find the book, the storybook must be decipherable, and
the story can’t be too scary (no monsters at the end of this book, please and thank you!).
But note how far apart the throw statements are from the checks themselves. To find out what happens
when you can’t find book.txt, you need to read all the way to the bottom of the method.
Like a good book, code should tell a story: with an easy-to-follow plot, and clear a beginning, middle,
and end. (Just try not to write too much code in the “post-modern” genre).
Strategic use of guard statements allow us to organize our code to read more linearly.
func readBedtimeStory() throws {
guard let url = Bundle.main.url(forResource: "book",
withExtension: "txt")
else {
throw StoryError.missing
}
guard let data = try? Data(contentsOf: url),
let story = String(data: data, encoding: .utf8)
else {
throw StoryError.illegible
}
if story.contains(" ") {
throw StoryError.tooScary
}
}
print("Once upon a time... \(story)")
Much better! Each error case is handled as soon as it’s checked, so we can follow the flow of execution
straight down the left-hand side.
Don’t Not Guard Against Double Negatives
One habit to guard against as you embrace this new control flow mechanism is overuse — particularly
when the evaluated condition is already negated.
For example, if you want to return early if a string is empty, don’t write:
// Huh?
guard !string.isEmpty else {
return
}
Keep it simple. Go with the (control) flow. Avoid the double negative.
// Aha!
if string.isEmpty {
return
}
defer
Between guard and the new throw statement for error handling, Swift encourages a style of early return
(an NSHipster favorite) rather than nested if statements. Returning early poses a distinct challenge,
however, when resources that have been initialized (and may still be in use) must be cleaned up before
returning.
The defer keyword provides a safe and easy way to handle this challenge by declaring a block that will
be executed only when execution leaves the current scope.
Consider the following function that wraps a system call to gethostname(2) to return the current
hostname of the system:
import Darwin
func currentHostName() -> String {
let capacity = Int(NI_MAXHOST)
let buffer = UnsafeMutablePointer<Int8>.allocate(capacity: capacity)
guard gethostname(buffer, capacity) == 0 else {
buffer.deallocate()
return "localhost"
}
let hostname = String(cString: buffer)
buffer.deallocate()
}
return hostname
Here, we allocate an UnsafeMutablePointer<Int8> early on but we need to remember to deallocate it
both in the failure condition and once we’re finished with the buffer.
Error prone? Yes. Frustratingly repetitive? Check.
By using a defer statement, we can remove the potential for programmer error and simplify our code:
func currentHostName() -> String {
let capacity = Int(NI_MAXHOST)
let buffer = UnsafeMutablePointer<Int8>.allocate(capacity: capacity)
defer { buffer.deallocate() }
guard gethostname(buffer, capacity) == 0 else {
return "localhost"
}
}
return String(cString: buffer)
Even though defer comes immediately after the call to allocate(capacity), its execution is delayed
until the end of the current scope. Thanks to defer, buffer will be properly deallocated regardless of
where the function returns.
Consider using defer whenever an API requires calls to be balanced, such as allocate(capacity:) /
deallocate(), wait() / signal(), or open() / close(). This way, you not only eliminate a potential
source of programmer error, but make Dijkstra proud. “Goed gedaan!” he’d say, in his native Dutch.
Deferring Frequently
If you use multiple defer statements in the same scope, they’re executed in reverse order of appearance
— like a stack. This reverse order is a vital detail, ensuring everything that was in scope when a deferred
block was created will still be in scope when the block is executed.
For example, running the following code prints the output below:
func procrastinate() {
defer { print("wash the dishes") }
defer { print("take out the recycling") }
defer { print("clean the refrigerator") }
}
print("play videogames")
play videogames
clean the refrigerator
take out the recycling
wash the dishes
What happens if you nest defer statements, like this?
defer { defer { print("clean the gutter") } }
Your first thought might be that it pushes the statement to the very bottom of the stack. But that’s
not what happens. Think it through, and then test your hypothesis in a Playground.
Deferring Judgement
If a variable is referenced in the body of a defer statement, its final value is evaluated. That is to say:
defer blocks don’t capture the current value of a variable.
If you run this next code sample, you’ll get the output that follows:
func flipFlop() {
var position = "It's pronounced /ɡɪf/"
defer { print(position) }
}
position = "It's pronounced /dʒɪf/"
defer { print(position) }
It's pronounced /dʒɪf/
It's pronounced /dʒɪf/
Deferring Demurely
Another thing to keep in mind is that defer blocks can’t break out of their scope. So if you try to call a
method that can throw, the error can’t be passed to the surrounding context.
func burnAfterReading(file url: URL) throws {
defer { try FileManager.default.removeItem(at: url) }
//
Errors not handled
}
let string = try String(contentsOf: url)
Instead, you can either ignore the error by using try? or simply move the statement out of the defer
block and at the end of the function to execute conventionally.
(Any Other) Defer Considered Harmful
As handy as the defer statement is, be aware of how its capabilities can lead to confusing, untraceable
code. It may be tempting to use defer in cases where a function needs to return a value that should
also be modified, as in this typical implementation of the postfix ++ operator:
postfix func ++(inout x: Int) -> Int {
let current = x
x += 1
return current
}
In this case, defer offers a clever alternative. Why create a temporary variable when we can just defer
the increment?
postfix func ++(inout x: Int) -> Int {
defer { x += 1 }
return x
}
Clever indeed, yet this inversion of the function’s flow harms readability. Using defer to explicitly
alter a program’s flow, rather than to clean up allocated resources, will lead to a twisted and tangled
execution process.
“As wise programmers aware of our limitations,” we must weigh the benefits of each language feature
against its costs.
A new statement like guard leads to a more linear, more readable program; apply it as widely as possible.
Likewise, defer solves a significant challenge but forces us to keep track of its declaration as it scrolls
out of sight; reserve it for its minimum intended purpose to prevent confusion and obscurity.
Mirror /
CustomReflectable /
CustomLeafReflectable
Reflection in Swift is a limited affair, providing read-only access to information about objects. In fact,
this functionality might be better described as introspection rather than reflection.
But can you really blame them for going with that terminology?
“Introspection” is such a bloviated and acoustically unpleasant word compared to “Reflection.” And
how could anyone pass on the nominal slam dunk of calling the type responsible for reflecting an
object’s value a Mirror? What equivalent analogy can we impart for the act of introspection? struct
LongDarkTeaTimeOfTheSoul? (As if we didn’t have better things to do than ask our Swift code about
the meaning of Self)
Without further ado, let’s take a peek inside the inner workings of how Swift exposes that of our own
code: Mirror, CustomReflectable, and CustomLeafReflectable.
Swift provides a default reflection, or structured view, for every object. This view is used by Playgrounds
(unless a custom description is provided), and also acts as a fallback when describing objects that don’t
conform to the CustomStringConvertible or CustomDebugStringConvertible protocols.
You can customize how instances of a type are reflected by adopting the CustomReflectable protocol
and implementing the required customMirror property.
The computed customMirror property returns a Mirror object, which is typically constructed by
reflecting self and passing the properties you wish to expose to the reflected interface. Properties may
be either keyed and passed in a dictionary or unkeyed and passed in an array. You can optionally
specify a display style to override the default for the kind of type (struct, class, tuple, etc.); if the
type is a class, you also have the ability to adjust how ancestors are represented.
Conforming to CustomReflectable
To get a better understanding of how this looks in practice, let’s look at an example involving an
implementation of a data model for the game of chess:
A chessboard comprises 64 squares, divided into 8 rows (called ranks) and 8 columns (called files). A
compact way to represent each location on a board is the 0x88 method, in which the rank and file are
encoded into 3 bits of each nibble of a byte (0b0rrr0fff).
For simplicity, Rank and File are typealias’d to UInt8 and use one-based indices; a more complete
implementation might use enumerations instead.
struct ChessBoard {
typealias Rank = UInt8
typealias File = UInt8
struct Coordinate: Equatable, Hashable {
private let value: UInt8
var rank: Rank {
return (value >> 3) + 1
}
var file: File {
return (value & 0b00000111) + 1
}
}
}
init(rank: Rank, file: File) {
precondition(1...8 ~= rank && 1...8 ~= file)
self.value = ((rank - 1) << 3) + (file - 1)
}
If we were to construct a coordinate for b8 (rank 8, file “b” or 2), its default reflection wouldn’t be
particularly helpful:
let b8 = ChessBoard.Coordinate(rank: 8, file: 2)
String(reflecting: b8) // ChessBoard.Coordinate(value: 57)
57
in decimal is equal to 0111001 in binary, or a value of 7 for rank and 1 for file, which adding the
index offset of 1 brings us to rank 8 and file 2.
The default mirror provided for a structure includes each of an object’s stored properties. However,
consumers of this API shouldn’t need to know or even care about the implementation details of how
this information is stored. It’s more important to reflect the programmatic surface area of the type, and
we can use CustomReflectable to do just that:
extension ChessBoard.Coordinate: CustomReflectable {
var customMirror: Mirror {
return Mirror(self,
children: ["rank": rank, "file": file])
}
}
Rather than exposing the private stored value property, our custom mirror provides the computed rank
and file properties. The result: a much more useful representation that reflects our understanding of
the type:
String(reflecting: b8) // ChessBoard.Coordinate(rank: 8, file: 2)
Introspecting the Custom Mirror
The String(reflecting:) initializer is one way that mirrors are used. But you can also get at
them directly through the customMirror property to access the type metatype and display style, and
enumerate each of the mirror’s children.
b8.customMirror.subjectType // ChessBoard.Coordinate.Type
b8.customMirror.displayStyle // struct
for child in b8.customMirror.children {
print("\(child.label ?? ""): \(child.value)")
}
Customizing the Display of a Custom Mirror
There are differently-shaped mirrors for each kind of Swift value, each with their own particular
characteristics.
For example, the most important information about a class is its identity, so its reflection contains only
its fully-qualified type name. Whereas a structure is all about substance and offers up its type name
and values.
If you find this to be less than flattering for your special type you can change up your look by specifying
an enumeration value to the displayStyle attribute in the Mirror initializer.
Here’s a sample of what you can expect for each of the available display styles when providing both
labeled and unlabeled children:
Labeled Children
extension ChessBoard.Coordinate: CustomReflectable {
var customMirror: Mirror {
return Mirror(self,
children: ["rank": rank, "file": file])
displayStyle: displayStyle )
}
}
Style
Output
class
ChessBoard.Coordinate
struct
Coordinate(rank: 8, file: 2)
enum
Coordinate(8)
optional
8
tuple
(rank: 8, file: 2)
collection
[8, 2]
set
{8, 2}
dictionary
[rank: 8, file: 2]
Unlabeled Children
extension ChessBoard.Coordinate: CustomReflectable {
var customMirror: Mirror {
return Mirror(self,
unlabeledChildren: [rank, file],
displayStyle: displayStyle )
}
}
Style
Output
class
ChessBoard.Coordinate
struct
Coordinate()
enum
Coordinate(8)
optional
8
tuple
(8, 2)
collection
[8, 2]
set
{8, 2}
dictionary
[ 8, 2]
You can’t change how tuples are reflected. As described in our article about Void, tuples aren’t
nominal types, so you can’t write extensions to add conformance to CustomReflectable
Reflection and Class Hierarchies
Continuing with our chess example, let’s introduce some class by defining an abstract Piece class
and subclasses for pawns, knights, bishops, rooks, queens, and kings. (For flavor, let’s add standard
valuations while we’re at it).
class Piece {
enum Color: String {
case black, white
}
let color: Color
let location: ChessBoard.Coordinate?
}
init(color: Color, location: ChessBoard.Coordinate? = nil) {
self.color = color
self.location = location
precondition(type(of: self) != Piece.self, "Piece is abstract")
}
class
class
class
class
class
class
Pawn:
Knight:
Bishop:
Rook:
Queen:
King:
Piece
Piece
Piece
Piece
Piece
Piece
{ static
{ static
{ static
{ static
{ static
{}
let
let
let
let
let
value
value
value
value
value
=
=
=
=
=
1
3
3
5
9
}
}
}
}
}
So far, so good. Now let’s use the same approach as before to define a custom mirror (setting the display
Style to struct so that we get more reflected information than we would otherwise for a class):
extension Piece: CustomReflectable {
var customMirror: Mirror {
return Mirror(self,
children: ["color": color,
"location": location ?? "N/A"],
displayStyle: .struct))
}
}
Let’s see what happens if we try to reflect a new Knight object:
let knight = Knight(color: .black, location: b8)
String(reflecting: knight) //
Piece(color: black, location: (rank: 8, file: 2))
Hmm… that’s no good. What if we try to override that in an extension to Knight?
extension Knight {
override var customMirror: Mirror {
return Mirror(self,
children: ["color": color,
"location": location ?? "N/A"])
}
} // ! error: overriding declarations in extensions is not supported
No dice (to mix metaphors).
Let’s look at three different options to get this working with classes.
Option 1: Conform to CustomLeafReflectable
Swift actually provides something for just such a situation — a protocol that inherits from Custom
Reflectable called CustomLeafReflectable.
If a class conforms to CustomLeafReflectable, its reflections of subclasses will be suppressed unless
they explicitly override customMirror and provide their own Mirror.
Let’s take another pass at our example from before, this time adopting CustomLeafReflectable in our
initial declaration:
class Piece: CustomLeafReflectable {
…
}
var customMirror: Mirror {
return Mirror(reflecting: self)
}
class Knight: Piece {
…
}
override var customMirror: Mirror {
return Mirror(self,
children: ["color": color,
"location": location ?? "N/A",
"value": Knight.value],
displayStyle: .struct)
}
Now when go to reflect our knight, we get the correct type — Knight instead of Piece.
String(reflecting: knight)
// Knight(color:Piece.Color.black, location: (rank: 8, file: 2), value: 3)
Unfortunately, this approach requires us to do the same for each of the subclasses. Before we suck it up
and copy-paste our way to victory, let’s consider our alternatives.
Types that wrap a single value like a string or number can improve their reflected representation
simply by conforming to the CustomStringConvertible protocol.
For example, the nested Color type can be unambiguously understood by its raw value alone:
extension Piece.Color: CustomStringConvertible {
var description: String {
return self.rawValue
}
}
With this in place, the raw string values will be used anytime Piece.Color is reflected or shows
up as a child in a mirror representation.
String(reflecting: Piece.Color.black) // black
String(reflecting: knight)
// Knight(color: black, location: (rank: 8, file: 2), value: 3)
Option 2: Encode Type in Superclass Mirror
A simpler alternative to going the CustomLeafReflectable route is to include the type information as
a child of the mirror declared in the base class.
extension Piece: CustomReflectable {
var customMirror: Mirror {
return Mirror(self,
children: ["type": type(of: self),
"color": color,
"location": location ?? "N/A"],
displayStyle: .struct)
}
}
String(reflecting: knight)
// Piece(type: Knight, color: black, location: (rank: 8, file: 2))
This approach is appealing because it allows reflection to be hidden as an implementation detail.
However, it can only work if subclasses are differentiated by behavior. If a subclass adds stored members
or significantly differs in other ways, it’ll need a specialized representation.
Which begs the question: why are we using classes in the first place?
Option 3: Avoid Classes Altogether
Truth be told, we only really introduced classes here as a contrived example of how to use CustomLeaf
Reflectable. And what we came up with is kind of a mess, right? Ad hoc additions of value type
members for only some of the pieces (kings don’t have a value in chess because they’re a win condition)?
An “abstract” base class that crashes if you try to instantiate it (for current lack of a first-class language
feature)? Yikes. These are the kinds of things that give OOP a bad name.
We can mitigate nearly all of these problems by adopting a protocol-oriented approach like the
following:
First, define a protocol for Piece and a new protocol to encapsulate pieces that have value, called
Valuable:
protocol Piece {
var color: Color { get }
var location: ChessBoard.Coordinate? { get }
}
protocol Valuable: Piece {
static var value: Int { get }
}
Next, define value types — an enum for Color and structures for each piece:
enum Color: String {
case black, white
}
…
struct Knight: Piece, Valuable {
static let value: Int = 3
let color: Color
let location: ChessBoard.Coordinate?
}
…
Although we can’t provide conformance by protocol through an extension, we can provide a default
implementation for the requirements and declare adoption in extensions to each concrete Piece type.
As a bonus, Valuable can provide a specialized variant that includes its value:
extension Piece {
var customMirror: Mirror {
return Mirror(self,
children: ["color": color,
"location": location ?? "N/A"],
displayStyle: .struct)
}
}
extension Valuable{
var customMirror: Mirror {
return Mirror(self,
children: ["color": color,
"location": location ?? "N/A",
"value": Self.value],
displayStyle: .struct)
}
}
…
extension Knight: CustomReflectable {}
…
Putting that all together, we get exactly the behavior we want with the advantage of value semantics.
let b8 = ChessBoard.Coordinate(rank: 8, file: 2)
let knight = Knight(color: .black, location: b8)
String(reflecting: knight)
// Knight(color: black, location: (rank: 8, file: 2))
Ultimately, CustomLeafReflectable is provided mostly for compatibility with the classical, hierarchical
types in Objective-C frameworks like UIKit. If you’re writing new code, you need not follow in their
footsteps.
When Swift first came out, longtime Objective-C developers missed the dynamism provided by that
runtime. And — truth be told — truth be told, things weren’t all super great. Programming in Swift
could, at times, feel unnecessarily finicky and constraining. “If only we could swizzle…” we’d grumble.
And perhaps this is still the case for some of us some of the time, but with Swift 4, many of the most
frustrating use cases have been solved.
Codable is a better solution to JSON serialization than was ever available using dynamic introspection.
Codable can also provide mechanisms for fuzzing and fixtures to sufficiently enterprising and clever
developers. The CaseIterable protocol fills another hole, allowing us a first-class mechanism for
getting an inventory of enumeration cases. In many ways, Swift has leap-frogged the promise of
dynamic programming, making APIs like Mirror largely unnecessary beyond logging and debugging.
That said, should you find the need for introspection, you’ll know just where to look.
KeyValuePairs
Cosmologies seek to create order by dividing existence into discrete, interdependent parts. Thinkers in
every society throughout history have posited various arrangements — though Natural numbers being
what they are, there are only so many ways to slice the ontological pie.
There are dichotomies like 陰陽 ( yīnyáng ) (
) : incontrovertible and self-evident (albeit reductive).
There are trinities, which position man in relation to heaven and earth. One might divide everything
into four, like the ancient Greeks with the elements of earth, water, air, and fire. Or you could carve
things into five, like the Chinese with Wood ( 木 mù ) , Fire ( 火 huǒ ) , Earth ( 土 tǔ ) , Metal ( 金 jīn )
, and Water ( 水 shuǐ ) . Still not satisfied? Perhaps the eight-part 八卦 (bāguà) will provide the answers
that you seek:
☰
☱
☲
☳
☴
☵
☶
☷
天
澤
火
雷
風
水
山
地
( Heaven )
( Lake / Marsh )
( Fire )
( Thunder )
( Wind )
( Water )
( Mountain )
( Ground )
Despite whatever galaxy brain opinion we may have about computer science, the pragmatic philosophy
of day-to-day programming more closely aligns with a mundane cosmology; less imago universi, more
じゃんけん jan-ken ( Rock-Paper-Scissors
️).
For a moment, ponder the mystical truths of fundamental Swift collection types:
Arrays are ordered collections of values.
Sets are unordered collections of unique values.
Dictionaries are unordered collections of key-value associations.
― The Book of Swift
Thus compared to the pantheon of java.util collections or std containers, Swift offers a coherent
coalition of three. Yet, just as we no longer explain everyday phenomena strictly in terms of humors or
æther, we must reject this formulation. Such a model is incomplete.
We could stretch our understanding of sets to incorporate OptionSet (as explained in a previous article),
but we’d be remiss to try and shoehorn Range and ClosedRange into the same bucket as Array — and
that’s to say nothing of the panoply of Swift Collection Protocols (an article in dire need of revision).
This week on NSHipster, we’ll take a look at KeyValuePairs, a small collection type that challenges
our fundamental distinctions between Array, Set, and Dictionary. In the process, we’ll gain a new
appreciation and a deeper understanding of the way things work in Swift.
KeyValuePairs
is a structure in the Swift standard library that — surprise, surprise — represents a
collection of key-value pairs.
struct KeyValuePairs<Key, Value>: ExpressibleByDictionaryLiteral,
RandomAccessCollection
{
typealias Element = (key: Key, value: Value)
typealias Index = Int
typealias Indices = Range<Int>
typealias SubSequence = Slice<KeyValuePairs>
}
…
This truncated declaration highlights the defining features of KeyValuePairs:
• Its ability to be expressed by a dictionary literal
• Its capabilities as a random-access collection
KeyValuePairs as Expressible by Dictionary Literal
Literals allow us to represent values directly in source code, and Swift is rather unique among other
languages by extending this functionality to our own custom types through protocols.
A dictionary literal represents a value as mapping of keys and values like so:
["key": "value"]
However, the term “dictionary literal” is a slight misnomer, since a sequence of key-value pairs — not a
Dictionary — are passed to the ExpressibleByDictionaryLiteral protocol’s required initializer:
protocol ExpressibleByDictionaryLiteral {
associatedtype Key
associatedtype Value
}
init(dictionaryLiteral elements: (Key, Value)...)
This confusion was amplified by the existence of a DictionaryLiteral type, which was only recently
renamed to KeyValuePairs in Swift 5. The name change served to both clarify its true nature and
bolster use as a public API (and not some internal language construct).
You can create a KeyValuesPairs object with a dictionary literal (in fact, this is the only way to
create one):
let pairs: KeyValuePairs<String, String> = [
"木": "wood",
"火": "fire",
"土": "ground",
"金": "metal",
"水": "water"
]
For more information about the history and rationale of this change, see SE-0214: “Renaming the
DictionaryLiteral type to KeyValuePairs”.
KeyValuePairs as Random-Access Collection
KeyValuePairs
conforms to RandomAccessCollection, which allows its contents to be retrieved by
(in this case, Int) indices. In contrast to Array, KeyValuePairs doesn’t conform to RangeReplaceable
Collection, so you can’t append elements or remove individual elements at indices or ranges.
This narrowly constrains KeyValuePairs, such that it’s effectively immutable once initialized from a
dictionary literal.
These functional limitations are the key to understanding its narrow application in the standard library.
KeyValuePairs in the Wild
Across the Swift standard library and Apple SDK, KeyValuePairs are found in just two places:
• A Mirror initializer (as discussed previously):
struct Mirror {
init<Subject>(_ subject: Subject,
children: KeyValuePairs<String, Any>,
displayStyle: DisplayStyle? = nil,
ancestorRepresentation: AncestorRepresentation = .generated)
}
typealias RGBA = UInt32
typealias RGBAComponents = (UInt8, UInt8, UInt8, UInt8)
let color: RGBA = 0xFFEFD5FF
let mirror = Mirror(color,
children: ["name": "Papaya Whip",
"components": (0xFF, 0xEF, 0xD5, 0xFF) as
RGBAComponents],
displayStyle: .struct)
mirror.children.first(where: { (label, _) in label == "name" })?.value
// "Papaya Whip"
• The @dynamicCallable method:
@dynamicCallable
struct KeywordCallable {
func dynamicallyCall(withKeywordArguments args: KeyValuePairs<String, Int>)
-> Int {
return args.count
}
}
let object = KeywordCallable()
object(a: 1, 2) // desugars to `object.dynamicallyCall(withKeywordArguments:
["a": 1, "": 2])`
On both occasions, KeyValuePairs is employed as an alternative to [(Key, Value)] to enforce
restraint by the caller. Without any other public initializers, KeyValuePairs can only be constructed
from dictionary literals, and can’t be constructed dynamically.
(Sort of like how one-way streets are used to prevent rat running on residential streets.)
Working with KeyValuePairs Values
If you want to do any kind of work with a KeyValuePairs, you’ll first want to convert it into a
conventional Collection type — either Array or Dictionary.
Converting to Arrays
KeyValuePairs
is a Sequence, by virtue of its conformance to RandomAccessCollection (and
therefore Collection). When we pass it to the corresponding Array initializer, it becomes an array of
its associated Element type ((Key, Value)).
let arrayOfPairs: [(Key, Value)] = Array(pairs)
Though, if you just want to iterate over each key-value pair, it’s conformance to Sequence means that
you can pass it directly to a for-in loop:
for (key, value) in pairs {
…
}
You can always create an Array from a KeyValuePairs object, but creating Dictionary is more
complicated.
Converting to Dictionaries
There are four built-in types that conform to ExpressibleByDictionaryLiteral:
• Dictionary
• NSDictionary
• NSMutableDictionary
• KeyValuePairs
Each of the three dictionary types constitutes a surjective mapping, such that every value element has
one or more corresponding keys. KeyValuePairs is the odd one out: it instead maintains an ordered
list of tuples that allows for duplicate key associations.
Dictionary
got a number of convenient initializers in Swift 4 thanks to SE-0165 (thanks, Nate!),
including init(uniqueKeysWithValues:), init(_:uniquingKeysWith:), and init(grouping:by)
Consider the following example that constructs a KeyValuePairs object with a duplicate key:
let pairsWithDuplicateKey: KeyValuePairs<String, String> = [
"天": "Heaven",
"澤": "Lake",
"澤": "Marsh",
…
]
Attempting to pass this to init(uniqueKeysWithValues:) results in a fatal error:
Dictionary<String, Int>(uniqueKeysWithValues: Array(pairsWithDuplicateKey))
// Fatal error: Duplicate values for key: '澤'
Instead, you must either specify which value to map or map
Dictionary(Array(pairsWithDuplicateKey),
uniquingKeysWith: { (first, _) in first })
// ["澤": "Lake", … ]
Dictionary(Array(pairsWithDuplicateKey),
uniquingKeysWith: { (_, last) in last })
// ["澤": "Marsh", … ]
Dictionary(grouping: Array(pairsWithDuplicateKey),
by: { (pair) in pair.value })
// ["澤": ["Lake", "Marsh"], … ]
(The resolution of KeyValuePairs into a Dictionary is reminiscent of a conflict-free replicated data type
(CRDT).)
Outside of its narrow application in the standard library, KeyValuePairs are unlikely to make an
appearance in your own codebase. You’re almost always better off going with a simple [(Key, Value)]
tuple array.
Much as today’s Standard Model more closely resembles the cacophony of a zoo than the musica
universalis of celestial spheres, KeyValuePairs challenges our tripartite view of Swift collection types.
But like all cosmological exceptions — though uncomfortable or even unwelcome at times — it serves
to expand our understanding.
That’s indeed its key value.
Swift Property Wrappers
Years ago, we remarked that the “at sign” (@) — along with square brackets and ridiculously-long method
names — was as characteristic of Objective-C as parentheses are to Lisp or punctuation is to Perl.
Then came Swift, and with it an end to these curious little
Or so we thought.
-shaped glyphs.
At first, the function of @ was limited to Objective-C interoperability: @IBAction, @NSCopying,
@UIApplicationMain, and so on. But in time, Swift has continued to incorporate an ever-increasing
number of @-prefixed attributes.
We got our first glimpse of Swift 5.1 at WWDC 2019 by way of the SwiftUI announcement. And
with each “mind-blowing” slide came a hitherto unknown attribute: @State, @Binding, @Environment
Object…
We saw the future of Swift, and it was full of @s.
We’ll dive into SwiftUI once it’s had a bit longer to bake.
But this week, we wanted to take a closer look at a key language feature for SwiftUI — something
that will have arguably the biggest impact on the «je ne sais quoi» of Swift in version 5.1 and beyond:
property wrappers
About Property Delegates Wrappers
Property wrappers were first pitched to the Swift forums back in March of 2019 — months before the
public announcement of SwiftUI.
In his original pitch, Swift Core Team member Douglas Gregor described the feature (then called
“property delegates”) as a user-accessible generalization of functionality currently provided by language
features like the lazy keyword.
Laziness is a virtue in programming, and this kind of broadly useful functionality is characteristic of
the thoughtful design decisions that make Swift such a nice language to work with. When a property
is declared as lazy, it defers initialization of its default value until first access. For example, you could
implement equivalent functionality yourself using a private property whose access is wrapped by a
computed property, but a single lazy keyword makes all of that unnecessary.
SE-0258: Property Wrappers is currently in its third review (scheduled to end yesterday, at the time of
publication), and it promises to open up functionality like lazy so that library authors can implement
similar functionality themselves.
The proposal does an excellent job outlining its design and implementation. So rather than attempt to
improve on this explanation, we thought it’d be interesting to look at some new patterns that property
wrappers make possible — and, in the process, get a better handle on how we might use this feature in
our projects.
So, for your consideration, here are four potential use cases for the new @propertyWrapper attribute:
• Constraining Values
• Transforming Values on Property Assignment
• Changing Synthesized Equality and Comparison Semantics
• Auditing Property Access
Constraining Values
SE-0258 offers plenty of practical examples, including @Lazy, @Atomic, @ThreadSpecific, and @Box.
But the one we were most excited about was that of the @Constrained property wrapper.
Swift’s standard library offer correct, performant, floating-point number types, and you can have it in
any size you want — so long as it’s 32 or 64 (or 80) bits long (to paraphrase Henry Ford).
If you wanted to implement a custom floating-point number type that enforced a valid range of values,
this has been possible since Swift 3. However, doing so would require conformance to a labyrinth of
protocol requirements.
Pulling this off is no small feat, and often far too much work to justify for most use cases.
Fortunately, property wrappers offer a way to parameterize standard number types with significantly
less effort.
Implementing a value clamping property wrapper
Consider the following Clamping structure. As a property wrapper (denoted by the @propertyWrapper
attribute), it automatically “clamps” out-of-bound values within the prescribed range.
@propertyWrapper
struct Clamping<Value: Comparable> {
var value: Value
let range: ClosedRange<Value>
init(initialValue value: Value, _ range: ClosedRange<Value>) {
precondition(range.contains(value))
self.value = value
self.range = range
}
}
var wrappedValue: Value {
get { value }
set { value = min(max(range.lowerBound, newValue), range.upperBound) }
}
You could use @Clamping to guarantee that a property modeling acidity in a chemical solution within
the conventional range of 0 – 14.
struct Solution {
@Clamping(0...14) var pH: Double = 7.0
}
let carbonicAcid = Solution(pH: 4.68) // at 1 mM under standard conditions
Attempting to set pH values outside that range results in the closest boundary value (minimum or
maximum) to be used instead.
let superDuperAcid = Solution(pH: -1)
superDuperAcid.pH // 0
You can use property wrappers in implementations of other property wrappers. For example, this
UnitInterval property wrapper delegates to @Clamping for constraining values between 0 and
1, inclusive.
@propertyWrapper
struct UnitInterval<Value: FloatingPoint> {
@Clamping(0...1)
var wrappedValue: Value = .zero
}
init(initialValue value: Value) {
self.wrappedValue = value
}
For example, you might use the @UnitInterval property wrapper to define an RGB type that
expresses red, green, blue intensities as percentages.
struct RGB {
@UnitInterval var red: Double
@UnitInterval var green: Double
@UnitInterval var blue: Double
}
let cornflowerBlue = RGB(red: 0.392, green: 0.584, blue: 0.929)
Related Ideas
• A @Positive / @NonNegative property wrapper that provides the unsigned guarantees to
signed integer types.
• A @NonZero property wrapper that ensures that a number value is either greater than or less
than 0.
• @Validated or @Whitelisted / @Blacklisted property wrappers that restrict which
values can be assigned.
Transforming Values on Property Assignment
Accepting text input from users is a perennial headache among app developers. There are just so many
things to keep track of, from the innocent banalities of string encoding to malicious attempts to inject
code through a text field. But among the most subtle and frustrating problems that developers face
when accepting user-generated content is dealing with leading and trailing whitespace.
A single leading space can invalidate URLs, confound date parsers, and sow chaos by way of off-byone errors:
import Foundation
URL(string: " https://nshipster.com") // nil (!)
ISO8601DateFormatter().date(from: " 2019-06-24") // nil (!)
let words = " Hello, world!".components(separatedBy: .whitespaces)
words.count // 3 (!)
When it comes to user input, clients most often plead ignorance and just send everything as-is to the
server. ¯\_(ツ)_/¯.
While I’m not advocating for client apps to take on more of this responsibility, the situation presents
another compelling use case for Swift property wrappers.
Foundation bridges the trimmingCharacters(in:) method to Swift strings, which provides, among
other things, a convenient way to lop off whitespace from both the front or back of a String value.
Calling this method each time you want to ensure data sanity is, however, less convenient. And if you’ve
ever had to do this yourself to any appreciable extent, you’ve certainly wondered if there might be a
better approach.
In your search for a less ad-hoc approach, you may have sought redemption through the willSet
property callback… only to be disappointed that you can’t use this to change events already in motion.
struct Post {
var title: String {
willSet {
title = newValue.trimmingCharacters(in: .whitespacesAndNewlines)
/*
️ Attempting to store to property 'title' within its own
willSet,
which is about to be overwritten by the new
value
*/
}
}
}
From there, you may have realized the potential of didSet as an avenue for greatness… only to realize
later that didSet isn’t called during initial property assignment.
struct Post {
var title: String {
//
Not called during initialization
didSet {
self.title = title.trimmingCharacters(in: .whitespacesAndNewlines)
}
}
}
Setting a property in its own didSet callback thankfully doesn’t cause the callback to fire again, so
you don’t have to worry about accidental infinite self-recursion.
Undeterred, you may have tried any number of other approaches… ultimately finding none to yield an
acceptable combination of ergonomics and performance characteristics.
If any of this rings true to your personal experience, you can rejoice in the knowledge that your search
is over: property wrappers are the solution you’ve long been waiting for.
Implementing a Property Wrapper that Trims Whitespace from String Values
Consider the following Trimmed struct that trims whitespaces and newlines from incoming string values.
import Foundation
@propertyWrapper
struct Trimmed {
private(set) var value: String = ""
var wrappedValue: String {
get { value }
set { value = newValue.trimmingCharacters(in: .whitespacesAndNewlines) }
}
}
init(initialValue: String) {
self.wrappedValue = initialValue
}
By marking each String property in the Post structure below with the @Trimmed annotation, any string
value assigned to title or body — whether during initialization or via property access afterward —
automatically has its leading or trailing whitespace removed.
struct Post {
@Trimmed var title: String
@Trimmed var body: String
}
let quine = Post(title: " Swift Property Wrappers ", body: " … ")
quine.title // "Swift Property Wrappers" (no leading or trailing spaces!)
quine.title = "
@propertyWrapper
"
quine.title // "@propertyWrapper" (still no leading or trailing spaces!)
Related Ideas
• A @Transformed property wrapper that applies ICU transforms to incoming string values.
• A @Normalized property wrapper that allows a String property to customize its normalization
form.
• A @Quantized / @Rounded / @Truncated property that quantizes values to a particular
degree (e.g. “round up to nearest ½”), but internally tracks precise intermediate values to prevent
cascading rounding errors.
Changing Synthesized Equality and Comparison Semantics
This behavior is contingent on an implementation detail of synthesized protocol conformance and
may change before this feature is finalized (though we hope this continues to work as described
below).
In Swift, two String values are considered equal if they are canonically equivalent. By adopting these
equality semantics, Swift strings behave more or less as you’d expect in most circumstances: if two
strings comprise the same characters, it doesn’t matter whether any individual character is composed or
precomposed — that is, “é” (U+00E9 LATIN SMALL LETTER E WITH ACUTE) is equal to “e” (U+0065 LATIN SMALL
LETTER E) + “◌́” (U+0301 COMBINING ACUTE ACCENT).
But what if your particular use case calls for different equality semantics? Say you wanted a case
insensitive notion of string equality?
There are plenty of ways you might go about implementing this today using existing language features:
• You could take the lowercased() result anytime you do == comparison, but as with any
manual process, this approach is error-prone.
• You could create a custom CaseInsensitive type that wraps a String value, but you’d
have to do a lot of additional work to make it as ergonomic and functional as the standard
String type.
• You could define a custom comparator function to wrap that comparison — heck, you could even
define your own custom operator for it — but nothing comes close to an unqualified == between
two operands.
None of these options are especially compelling, but thanks to property wrappers in Swift 5.1, we’ll
finally have a solution that gives us what we’re looking for.
As with numbers, Swift takes a protocol-oriented approach that delegates string responsibilities
across a constellation of narrowly-defined types.
While you could create your own String-equivalent type, the documentation carries a strong
directive to the contrary:
Do not declare new conformances to StringProtocol. Only the String and Substring
types in the standard library are valid conforming types.
Implementing a case-insensitive property wrapper
The CaseInsensitive type below implements a property wrapper around a String / SubString value.
The type conforms to Comparable (and by extension, Equatable) by way of the bridged NSString API
caseInsensitiveCompare(_:):
import Foundation
@propertyWrapper
struct CaseInsensitive<Value: StringProtocol> {
var wrappedValue: Value
}
extension CaseInsensitive: Comparable {
private func compare(_ other: CaseInsensitive) -> ComparisonResult {
wrappedValue.caseInsensitiveCompare(other.wrappedValue)
}
static func == (lhs: CaseInsensitive, rhs: CaseInsensitive) -> Bool {
lhs.compare(rhs) == .orderedSame
}
static func < (lhs: CaseInsensitive, rhs: CaseInsensitive) -> Bool {
lhs.compare(rhs) == .orderedAscending
}
}
static func > (lhs: CaseInsensitive, rhs: CaseInsensitive) -> Bool {
lhs.compare(rhs) == .orderedDescending
}
Although the greater-than operator (>) can be derived automatically, we implement it here as
a performance optimization to avoid unnecessary calls to the underlying caseInsensitive
Compare method.
Construct two string values that differ only by case, and they’ll return false for a standard equality
check, but true when wrapped in a CaseInsensitive object.
let hello: String = "hello"
let HELLO: String = "HELLO"
hello == HELLO // false
CaseInsensitive(wrappedValue: hello) == CaseInsensitive(wrappedValue: HELLO) //
true
So far, this approach is indistinguishable from the custom “wrapper type” approach described above.
And this is normally where we’d start the long slog of implementing conformance to Expressible
ByStringLiteral and all of the other protocols to make CaseInsensitive start to feel enough like
String to feel good about our approach.
Property wrappers allow us to forego all of this busywork entirely:
struct Account: Equatable {
@CaseInsensitive var name: String
}
init(name: String) {
$name = CaseInsensitive(wrappedValue: name)
}
var johnny = Account(name: "johnny")
let JOHNNY = Account(name: "JOHNNY")
let Jane = Account(name: "Jane")
johnny == JOHNNY // true
johnny == Jane // false
johnny.name == JOHNNY.name // false
johnny.name = "Johnny"
johnny.name // "Johnny"
Here, Account objects are checked for equality by a case-insensitive comparison on their name property
value. However, when we go to get or set the name property, it’s a bona fide String value.
That’s neat, but what’s actually going on here?
Since Swift 4, the compiler automatically synthesizes Equatable conformance to types that adopt it in
their declaration and whose stored properties are all themselves Equatable. Because of how compiler
synthesis is implemented (at least currently), wrapped properties are evaluated through their wrapper
rather than their underlying value:
// Synthesized by Swift Compiler
extension Account: Equatable {
static func == (lhs: Account, rhs: Account) -> Bool {
lhs.$name == rhs.$name
}
}
Related Ideas
• Defining @CompatibilityEquivalence such that wrapped String properties with the
values "①" and "1" are considered equal.
• A @Approximate property wrapper to refine equality semantics for floating-point types (See
also SE-0259)
• A @Ranked property wrapper that takes a function that defines strict ordering for, say, enumerated
values; this could allow, for example, the playing card rank .ace to be treated either low or high
in different contexts.
Auditing Property Access
Business requirements may stipulate certain controls for who can access which records when or
prescribe some form of accounting for changes over time.
Once again, this isn’t a task typically performed by, say, an iOS app; most business logic is defined on
the server, and most client developers would like to keep it that way. But this is yet another use case too
compelling to ignore as we start to look at the world through property-wrapped glasses.
Implementing a Property Value Versioning
The following Versioned structure functions as a property wrapper that intercepts incoming values
and creates a timestamped record when each value is set.
import Foundation
@propertyWrapper
struct Versioned<Value> {
private var value: Value
private(set) var timestampedValues: [(Date, Value)] = []
var wrappedValue: Value {
get { value }
}
}
set {
defer { timestampedValues.append((Date(), value)) }
value = newValue
}
init(initialValue value: Value) {
self.wrappedValue = value
}
A hypothetical ExpenseReport class could wrap its state property with the @Versioned annotation to
keep a paper trail for each action during processing.
class ExpenseReport {
enum State { case submitted, received, approved, denied }
}
@Versioned var state: State = .submitted
Related Ideas
• An @Audited property wrapper that logs each time a property is read or written to.
• A @Decaying property wrapper that divides a set number value each time the value is read.
However, this particular example highlights a major limitation in the current implementation of
property wrappers that stems from a longstanding deficiency of Swift generally: Properties can’t be
marked as throws.
Without the ability to participate in error handling, property wrappers don’t provide a reasonable way
to enforce and communicate policies. For example, if we wanted to extend the @Versioned property
wrapper from before to prevent state from being set to .approved after previously being .denied,
our best option is fatalError(), which isn’t really suitable for real applications:
class ExpenseReport {
@Versioned var state: State = .submitted {
willSet {
if newValue == .approved,
$state.timestampedValues.map { $0.1 }.contains(.denied)
{
fatalError("J'Accuse!")
}
}
}
}
var tripExpenses = ExpenseReport()
tripExpenses.state = .denied
tripExpenses.state = .approved // Fatal error: "J'Accuse!"
This is just one of several limitations that we’ve encountered so far with property wrappers. In the
interest of creating a balanced perspective on this new feature, we’ll use the remainder of this article to
enumerate them.
Limitations
Some of the shortcomings described below may be more a limitation of my current understanding
or imagination than that of the proposed language feature itself.
Please reach out with any corrections or suggestions you might have for reconciling them!
Properties Can’t Participate in Error Handling
Properties, unlike functions, can’t be marked as throws.
As it were, this is one of the few remaining distinctions between these two varieties of type members.
Because properties have both a getter and a setter, it’s not entirely clear what the right design would be
if we were to add error handling — especially when you consider how to play nice with syntax for other
concerns like access control, custom getters / setters, and callbacks.
As described in the previous section, property wrappers have but two methods of recourse to deal with
invalid values:
1. Ignoring them (silently)
2. Crashing with fatalError()
Neither of these options is particularly great, so we’d be very interested by any proposal that addresses
this issue.
Wrapped Properties Can’t Be Aliased
Another limitation of the current proposal is that you can’t use instances of property wrappers as
property wrappers.
Our UnitInterval example from before, which constrains wrapped values between 0 and 1 (inclusive),
could be succinctly expressed as:
typealias UnitInterval = Clamping(0...1) //
However, this isn’t possible. Nor can you use instances of property wrappers to wrap properties.
let UnitInterval = Clamping(0...1)
struct Solution { @UnitInterval var pH: Double } //
All this actually means in practice is more code replication than would be ideal. But given that this
problem arises out of a fundamental distinction between types and values in the language, we can
forgive a little duplication if it means avoiding the wrong abstraction.
Property Wrappers Are Difficult To Compose
Composition of property wrappers is not a commutative operation; the order in which you declare
them affects how they’ll behave.
Consider the interplay between an attribute that performs string inflection and other string transforms.
For example, a composition of property wrappers to automatically normalize the URL “slug” in a blog
post will yield different results if spaces are replaced with dashes before or after whitespace is trimmed.
struct Post {
…
@Dasherized @Trimmed var slug: String
}
But getting that to work in the first place is easier said than done! Attempting to compose two property
wrappers that act on String values fails, because the outermost wrapper is acting on a value of the
innermost wrapper type.
@propertyWrapper
struct Dasherized {
private(set) var value: String = ""
var wrappedValue: String {
get { value }
set { value = newValue.replacingOccurrences(of: " ", with: "-") }
}
}
init(initialValue: String) {
self.wrappedValue = initialValue
}
struct Post {
…
@Dasherized @Trimmed var slug: String //
}
️ An internal error occurred.
There’s a way to get this to work, but it’s not entirely obvious or pleasant. Whether this is something
that can be fixed in the implementation or merely redressed by documentation remains to be seen.
Property Wrappers Aren’t First-Class Dependent Types
A dependent type is a type defined by its value. For instance, “a pair of integers in which the latter is
greater than the former” and “an array with a prime number of elements” are both dependent types
because their type definition is contingent on its value.
Swift’s lack of support for dependent types in its type system means that any such guarantees must be
enforced at run time.
The good news is that property wrappers get closer than any other language feature proposed thus far
in filling this gap. However, they still aren’t a complete replacement for true value-dependent types.
You can’t use property wrappers to, for example, define a new type with a constraint on which values
are possible.
typealias pH = @Clamping(0...14) Double //
func acidity(of: Chemical) -> pH {}
Nor can you use property wrappers to annotate key or value types in collections.
enum HTTP {
struct Request {
var headers: [@CaseInsensitive String: String] //
}
}
These shortcomings are by no means deal-breakers; property wrappers are extremely useful and fill an
important gap in the language.
It’ll be interesting to see whether the addition of property wrappers will create a renewed interest in
bringing dependent types to Swift, or if they’ll be seen as “good enough”, obviating the need to formalize
the concept further.
Property Wrappers Are Difficult to Document
Pop Quiz: Which property wrappers are made available by the SwiftUI framework?
Go ahead and visit the official SwiftUI docs and try to answer.
In fairness, this failure isn’t unique to property wrappers.
If you were tasked with determining which protocol was responsible for a particular API in the standard
library or which operators were supported for a pair of types based only on what was documented on
developer.apple.com, you’re likely to start considering a mid-career pivot away from computers.
This lack of comprehensibility is made all the more dire by Swift’s increasing complexity.
Property Wrappers Further Complicate Swift
Swift is a much, much more complex language than Objective-C. That’s been true since Swift 1.0 and
has only become more so over time.
The profusion of @-prefixed features in Swift — whether it’s
@dynamicMemberLookup and @dynamicCallable from Swift 4, or @differentiable and @memberwise
from Swift for Tensorflow — makes it increasingly difficult to come away with a reasonable
understanding of Swift APIs based on documentation alone. In this respect, the introduction of
@propertyWrapper will be a force multiplier.
How will we make sense of it all? (That’s a genuine question, not a rhetorical one.)
Alright, let’s try to wrap this thing up —
Swift property wrappers allow library authors access to the kind of higher-level behavior previously
reserved for language features. Their potential for improving safety and reducing complexity of code is
immense, and we’ve only begun to scratch the surface of what’s possible.
Yet, for all of their promise, property wrappers and its cohort of language features debuted alongside
SwiftUI introduce tremendous upheaval to Swift.
Or, as Nataliya Patsovska put it in a tweet:
iOS API design, short history:
• Objective C - describe all semantics in the name, the types don’t mean much
• Swift 1 to 5 - name focuses on clarity and basic structs, enums, classes and protocols hold
semantics
• Swift 5.1 - @wrapped $path @yolo
― @nataliya_bg
Perhaps we’ll only know looking back whether Swift 5.1 marked a tipping point or a turning point for
our beloved language.
Swift API Availability
Code exists in a world of infinite abundance. Whatever you can imagine is willed into being — so long
as you know how to express your desires.
As developers, we know that code will eventually be compiled into software, and forced to compete in
the real-world for allocation of scarce hardware resources. Though up until that point, we can luxuriate
in the feeling of unbounded idealism… well, mostly. For software is not a pure science, and our job —
in reality — is little more than shuttling data through broken pipes between leaky abstractions.
This week on NSHipster, we’re exploring a quintessential aspect of our unglamorous job: API availability.
The good news is that Swift provides first-class constructs for dealing with these real-world constraints
by way of @available and #available. However, there are a few nuances to these language features,
of which many Swift developers are unaware. So be sure to read on to make sure that you’re clear on all
the options available to you.
@available
In Swift, you use the @available attribute to annotate APIs with availability information, such as “this
API is deprecated in macOS 10.15” or “this API requires Swift 5.1 or higher”. With this information,
the compiler can ensure that any such APIs used by your app are available to all platforms supported
by the current target.
The @available attribute can be applied to declarations, including top-level functions, constants, and
variables, types like structures, classes, enumerations, and protocols, and type members — initializers,
class deinitializers, methods, properties, and subscripts.
The @available attribute, however, can’t be applied to operator precedence group
(precedencegroup) or protocol associated type (associatedtype) declarations.
Platform Availability
When used to designate platform availability for an API, the @available attribute can take one or
two forms:
• A “shorthand specification” that lists minimum version requirements for multiple platforms
• An extended specification that can communicate additional details about availability for a single
platform
Shorthand Specification
@available( platform
version
, [platform version] ... , *)
• A platform ; iOS, macCatalyst, macOS / OSX, tvOS, or watchOS, or any of those with
ApplicationExtension appended (e.g. macOSApplicationExtension).
• A version number consisting of one, two, or three positive integers, separated by a period (.), to
denote the major, minor, and patch version.
• Zero or more versioned platforms in a comma-delimited (,) list.
• An asterisk (*), denoting that the API is unavailable for all other platforms. An asterisk is always
required for platform availability annotations to handle potential future platforms (such as the
long-rumored iDishwasherOS).
For example, new, cross-platform APIs introduced at WWDC 2019 might be annotated as:
@available(macOS 10.15, iOS 13, watchOS 6, tvOS 13, *)
The list of available platform names is specified by the Clang compiler front-end.
Look a few lines up, though, and you’ll find a curious mention of “android”(introduced by D7929).
Does anyone have more context about why that’s in there?
Shorthand specifications are a convenient way to annotate platform availability. But if you need to
communicate more information, such as when or why an API was deprecated or what should be used
as a replacement, you’ll want to opt for an extended specification instead.
Introduced, Deprecated, Obsoleted, and Unavailable
// With introduced, deprecated, and/or obsoleted
@available( platform | *
, introduced: version , deprecated: version
[, renamed: "..."]
[, message: "..."] )
, obsoleted: version
// With unavailable
@available( platform | * , unavailable [, renamed: "..."]
[, message: "..."] )
• A platform , same as before, or an asterisk (*) for all platforms.
• Either introduced, deprecated, and/or obsoleted…
◦ An introduced version , denoting the first version in which the API is available
◦ A deprecated version , denoting the first version when using the API generates a compiler
warning
◦ An obsoleted version , denoting the first version when using the API generates a
compiler error
• …or unavailable, which causes the API to generate a compiler error when used
• renamed with a keypath to another API; when provided, Xcode provides an automatic “fix-it”
• A message string to be included in the compiler warning or error
Unlike shorthand specifications, this form allows for only one platform to be specified. So if you want
to annotate availability for multiple platforms, you’ll need stack @available attributes. For example,
here’s how the previous shorthand example can be expressed in multiple attributes:
@available(macOS, introduced: 10.15)
@available(iOS, introduced: 13)
@available(watchOS, introduced: 6)
@available(tvOS, introduced: 13)
Once again, diving into the underlying Clang source code unearths some curious tidbits. In addition
to the @available arguments listed above, Clang includes strict and priority. Neither of
these works in Swift, but it’s interesting nonetheless.
Apple SDK frameworks make extensive use of availability annotations to designate new and deprecated
APIs with each release of iOS, macOS, and other platforms.
For example, iOS 13 introduces a new UICollectionViewCompositionalLayout class. If you jump to
its declaration by holding command ( ⌘ ) and clicking on that symbol in Xcode, you’ll see that it’s
annotated with @available:
@available(iOS 13.0, *)
open class UICollectionViewCompositionalLayout : UICollectionViewLayout { … }
(At the time of writing, the docs for UICollectionViewCompositionalLayout are “No overview
available.” — Which is a real shame because this is an insanely great addition to UIKit. If you haven’t already,
go watch WWDC Session 215: “Advances in Collection View Layout” for a great overview of this new API.)
This @available attribute tells the compiler that UICollectionViewCompositionalLayout can only
be called on devices running iOS, version 13.0 or later (with caveats; see note below).
If your app targets iOS 13 only, then you can use UICollectionViewCompositionalLayout without
any special consideration. If, however, your deployment target is set below iOS 13 in order to support
previous versions of iOS (as is the case for many existing apps), then any use of UICollectionView
CompositionalLayout must be conditionalized.
More on that in a moment.
When an API is marked as available in iOS, it’s implicitly marked available on tvOS and Mac Catalyst,
because both of those platforms are derivatives of iOS. That’s why, for example, the (missing)
documentation for UICollectionViewCompositionalLayout reports availability in iOS 13.0+,
Mac Catalyst 13.0+, and tvOS 13.0+ despite its declaration only mentions iOS 13.0.
If necessary, you can explicitly mark these derived platforms as being unavailable with additional
@available attributes:
@available(iOS 13, *)
@available(tvOS, unavailable)
@available(macCatalyst, unavailable)
func handleShakeGesture() { … }
Swift Language Availability
Your code may depend on a new language feature of Swift, such as property wrappers or default
enumeration case associated values — both new in Swift 5.1. If you want to support development of
your app with previous versions of Xcode or for your Swift package to work for multiple Swift compiler
toolchains, you can use the @available attribute to annotate declarations containing new language
features.
When used to designate Swift language availability for an API, the @available attribute takes the
following form:
@available(swift version )
Unlike platform availability, Swift language version annotations don’t require an asterisk (*); to the
compiler, there’s one Swift language, with multiple versions.
Historically, the @available attribute was first introduced for platform availability and later
expanded to include Swift language version availability with SE-0141. Although these use cases
share a syntax, we recommend that you keep any combined application in separate attributes for
greater clarity.
import Foundation
@available(swift 5.1)
@available(iOS 13.0, macOS 10.15, *)
@propertyWrapper
struct WebSocketed<Value: LosslessStringConvertible> {
private var value: Value
var wrappedValue: URLSessionWebSocketTask.Message {
get { .string(value) }
set {
if case let .string(description) = newValue {
value = Value(description)
}
}
}
}
#available
In Swift, you can predicate if, guard, and while statements with an availability condition, #available,
to determine the availability of APIs at runtime. Unlike the @available attribute, an #available
condition can’t be used for Swift language version checks.
The syntax of an #available expression resembles that of an @available attribute:
if | guard | while #available( platform
…
version
, [platform version] ... , *)
You can’t combine #available expressions with other conditions using logical operators like &&
and ||.
Now that we know how APIs are annotated for availability, let’s look at how to annotate and
conditionalize code based on our platform and/or Swift language version.
Working with Unavailable APIs
Similar to how, in Swift, thrown errors must be handled or propagated, use of potentially unavailable
APIs must be either annotated or conditionalized code.
When you attempt to call an API that is unavailable for at least one of your supported targets, Xcode
will recommend the following options:
• “Add if #available version check”
• “Add @available attribute to enclosing declaration ” (suggested at each enclosing scope; for
example, the current method as well as that method’s containing class)
Following our analogy to error handling, the first option is similar to prepending try to a function call,
and the second option is akin to wrapping a statement within do/catch.
For example, within an app supporting iOS 12 and iOS 13, a class that subclasses UICollectionView
CompositionalLayout must have its declaration annotated with @available, and any references to
that subclass would need to be conditionalized with #available:
@available(iOS 13.0, *)
final class CustomCompositionalLayout: UICollectionViewCompositionalLayout { …
}
func createLayout() -> UICollectionViewLayout {
if #available(iOS 13, *) {
return CustomCompositionalLayout()
} else {
return UICollectionViewFlowLayout()
}
}
Swift comprises many inter-dependent concepts, and crosscutting concerns like availability often result
in significant complexity as various parts of the language interact. For instance, what happens if you
create a subclass that overrides a property marked as unavailable by its superclass? Or what if you try
to call a function that’s renamed on one platform, but replaced by an operator on another?
While it’d be tedious to enumerate every specific behavior here, these questions can and often do arise
in the messy business of developing apps in the real world. If you find yourself wondering “what if ” and
tire of trial-and-error experimentation, you might instead try consulting the Swift language test suite to
determine what’s expected behavior.
A quick shout-out to Slava Pestov for this gem of a test case:
@available(OSX, introduced: 10.53)
class EsotericSmallBatchHipsterThing : WidelyAvailableBase {}
Alternatively, you can surmise how things work generally from Clang’s diagnostic text:
Annotating Availability in Your Own APIs
Although you’ll frequently interact with @available as a consumer of Apple APIs, you’re much less
likely to use them as an API producer.
Availability in Apps
Within the context of an app, it may be convenient to use @available deprecation warnings to
communicate across a team that use of a view controller, convenience method, or what have you is no
longer advisable.
@available(iOS, deprecated: 13, renamed: "NewAndImprovedViewController")
class OldViewController: UIViewController { … }
class NewAndImprovedViewController: UIViewController { … }
Use of unavailable or deprecated, however, are much less useful for apps; without any expectation to
vend an API outside that context, you can simply remove an API outright.
Availability in Third-Party Frameworks
If you maintain a framework that depends on the Apple SDK in some way, you may need to annotate
your APIs according to the availability of the underlying system calls. For example, a convenience
wrapper around Keychain APIs would likely annotate the availability of platform-specific biometric
features like Touch ID and Face ID.
However, if your APIs wrap the underlying system call in a way that doesn’t expose the implementation
details, you may be able For example, an NLP library that previously delegated functionality to
NSLinguisticTagger could instead use Natural Language framework when available (as determined
by #available), without any user-visible API changes.
Availability in Swift Packages
If you’re writing Swift qua Swift in a platform-agnostic way and distributing that code as a Swift
package, you may want to use @available to give a heads-up to consumers about APIs that are on
the way out.
Unfortunately, there’s currently no way to designate deprecation in terms of the library version (the
list of platforms are hard-coded by the compiler). While it’s a bit of a hack, you could communicate
deprecation by specifying an obsolete / non-existent Swift language version like so:
@available(swift, deprecated: 0.0.1, message: "Deprecated in 1.2.0")
func going(going: Gone...) {}
The closest we have to package versioning is the private _PackageDescription platform used
by the Swift Package Manager.
public enum SwiftVersion {
@available(_PackageDescription, introduced: 4, obsoleted: 5)
case v3
@available(_PackageDescription, introduced: 4)
case v4
}
…
If you’re interested in extending this functionality to third-party packages, consider starting a
discussion in Swift Evolution.
Working Around Deprecation Warnings
As some of us are keenly aware, it’s not currently possible to silence deprecation warnings in Swift.
Whereas in Objective-C, you could suppress warnings with #pragma clang diagnostic push /
ignored / pop, no such convenience is afforded to Swift.
If you’re among the l33t coders who have “hard mode” turned on (“Treat Warnings as Errors” a.k.a.
SWIFT_TREAT_WARNINGS_AS_ERRORS), but find yourself stymied by deprecation warnings, here’s a cheat
code you can use:
class CustomView {
@available(iOS, introduced: 10, deprecated: 13, message: "
func method() {}
}
CustomView().method() // "'method()' was deprecated in iOS 13:
")
"
protocol IgnoringMethodDeprecation {
func method()
}
extension CustomView: IgnoringMethodDeprecation {}
(CustomView() as IgnoringMethodDeprecation).method() // No warning!
As an occupation, programming epitomizes the post-scarcity ideal of a post-industrial world economy
in the information age. But even so far removed from physical limitations, we remain inherently
constrained by forces beyond our control. However, with careful and deliberate practice, we can learn
to make use of everything available to us.
Swift Import Declarations
One of the first lessons we learn as software developers is how to organize concepts and functionality
into discrete units. At the smallest level, this means thinking about types and methods and properties.
These pieces then form the basis of one or more modules, which may then be packaged into libraries or
frameworks.
In this way, import declarations are the glue that holds everything together.
Yet despite their importance, most Swift developers are familiar only with their most basic form:
import module
This week on NSHipster, we’ll explore the other shapes of this most prominent part of Swift.
An import declaration allows your code to access symbols that are declared in other files. However, if
more than one module declares a function or type with the same name, the compiler may not be able
to tell which one you want to call in code.
To demonstrate this, consider two modules representing the multisport competitions of Triathlon and
Pentathlon:
A triathlon consists of three events: swimming, cycling, and running.
// Triathlon Module
func swim() {
print(" Swim 1.5 km")
}
func bike() {
print("
Cycle 40 km")
}
func run() {
print(" Run 10 km")
}
The modern pentathlon comprises five events: fencing, swimming, equestrian, shooting, and running.
// Pentathlon Module
func fence() {
print("
Bout with épées")
}
func swim() {
print(" Swim 200 m")
}
func ride() {
print("
Complete a show jumping course")
}
func shoot() {
print("
Shoot 5 targets")
}
func run() {
print(" Run 3 km cross-country")
}
If we import either of the modules individually, we can reference each of their functions using their
unqualified names without a problem.
import Triathlon
swim() // OK, calls Triathlon.swim
bike() // OK, calls Triathlon.bike
run() // OK, calls Triathlon.run
But if we import both modules together, we can’t always use unqualified function names. Triathlon and
Pentathlon both include swimming and running, so a reference to swim() is ambiguous.
import Triathlon
import Pentathlon
bike() // OK, calls Triathlon.bike
fence() // OK, calls Pentathlon.fence
swim() // Error, ambiguous
How do we reconcile this? One strategy is to use fully-qualified names to work around any ambiguous
references. By including the module name, there’s no confusion about whether the program will swim
a few laps in a pool or a mile in open water.
import Triathlon
import Pentathlon
Triathlon.swim() // OK, fully-qualified reference to Triathlon.swim
Pentathlon.swim() // OK, fully-qualified reference to Pentathlon.swim
Another way to resolve API name collision is to change the import declaration to be more selective
about what’s included from each module.
Importing Individual Declarations
Import declarations have a form that can specify individual structures, classes, enumerations, protocols,
and type aliases as well as functions, constants, and variables declared at the top-level:
import kind
module.symbol
Here, kind can be any of the following keywords:
Kind
Description
struct
Structure
class
Class
enum
Enumeration
protocol
Protocol
typealias
Type Alias
func
Function
let
Constant
var
Variable
For example, the following import declaration adds only the swim() function from the Pentathlon
module:
import func Pentathlon.swim
swim() // OK, calls Pentathlon.swim
fence() // Error, unresolved identifier
Resolving Symbol Name Collisions
When multiple symbols are referenced by the same name in code, the Swift compiler resolves this
reference by consulting the following, in order:
1. Local Declarations
2. Imported Declarations
3. Imported Modules
If any of these have more than one candidate, Swift is unable to resolve the ambiguity and raises a
compilation error.
For example, importing the Triathlon module provides the swim(), bike(), and run() methods. The
imported swim() function declaration from the Pentathlon overrides that of the Triathlon module.
Likewise, the locally-declared run() function overrides the symbol by the same name from Triathlon,
and would also override any imported function declarations.
import Triathlon
import func Pentathlon.swim
// Local function shadows whole-module import of Triathlon
func run() {
print(" Run 42.195 km")
}
swim() // OK, calls Pentathlon.swim
bike() // OK, calls Triathlon.bike
run() // OK, calls local run
The result of calling this code? A bizarre multi-sport event involving a few laps in the pool, a modest
bike ride, and a marathon run. (@ us, IRONMAN)
If a local or imported declaration collides with a module name, the compiler first consults the
declaration and falls back to qualified lookup in the module.
import Triathlon
enum Triathlon {
case sprint, olympic, ironman
}
Triathlon.olympic // references local enumeration case
Triathlon.swim() // references module function
The Swift compiler doesn’t communicate and cannot reconcile naming collisions between modules
and local declarations, so you should be aware of this possibility when working with dependencies.
Clarifying and Minimizing Scope
Beyond resolving name collisions, importing declarations can also be a way to clarify your intent as a
programmer.
If you’re, for example, using only a single function from a mega-framework like AppKit, you might
single that out in your import declaration.
import func AppKit.NSUserName
NSUserName() // "jappleseed"
This technique can be especially helpful when importing top-level constants and variables, whose
provenance is often more difficult to discern than other imported symbols.
For example, the Darwin framework exports — among other things — a top-level stderr variable.
An explicit import declaration here can preempt any questions during code review about where that
variable is coming from.
import func Darwin.fputs
import var Darwin.stderr
struct StderrOutputStream: TextOutputStream {
mutating func write(_ string: String) {
fputs(string, stderr)
}
}
var standardError = StderrOutputStream()
print("Error!", to: &standardError)
Importing a Submodule
The final form of import declarations offers another way to limit API exposure:
import module.submodule
You’re most likely to encounter submodules in large system frameworks like AppKit and Accelerate.
These umbrella frameworks are no longer considered a best-practice, but they served an important role
during Apple’s transition to Cocoa in the early 00’s.
For example, you might import only the DictionaryServices submodule from the Core Services
framework to insulate your code from the myriad deprecated APIs like Carbon Core.
import Foundation
import CoreServices.DictionaryServices
func define(_ word: String) -> String? {
let nsstring = word as NSString
let cfrange = CFRange(location: 0, length: nsstring.length)
guard let definition = DCSCopyTextDefinition(nil, nsstring, cfrange) else {
return nil
}
}
return String(definition.takeUnretainedValue())
define("apple") // "apple | ˈapəl | noun 1 the round fruit of a tree..."
In practice, isolating imported declarations and submodules doesn’t confer any real benefit beyond
signaling programmer intent. Your code won’t compile any faster doing it this way. And since most
submodules seem to re-import their umbrella header, this approach won’t do anything to reduce noise
in autocomplete lists.
Like many obscure and advanced topics, the most likely reason you haven’t heard about these import
declaration forms before is that you don’t need to know about them. If you’ve gotten this far making
apps without them, you can be reasonably assured that you don’t need to start using them now.
Rather, the valuable takeaway here is understanding how the Swift compiler resolves name collisions.
And to that end, import declarations are a concept of great import.
API Pollution in Swift Modules
When you import a module into Swift code, you expect the result to be entirely additive. That is to say:
the potential for new functionality comes at no expense (other than, say, a modest increase in the size
of your app bundle).
Import the NaturalLanguage framework, and *boom* your app can determine the language of text;
import CoreMotion, and *whoosh* your app can respond to changes in device orientation. But it’d be
surprising if, say, the ability to distinguish between French and Japanese interfered with your app’s
ability to tell which way was magnetic north.
Although this particular example isn’t real (to the relief of Francophones in Hokkaido), there are
situations in which a Swift dependency can change how your app behaves — even if you don’t use
it directly.
In this week’s article, we’ll look at a few ways that imported modules can silently change the behavior
of existing code, and offer suggestions for how to prevent this from happening as an API provider and
mitigate the effects of this as an API consumer.
Module Pollution
It’s a story as old as <time.h>: two things are called Foo, and the compiler has to decide what to do.
Pretty much every language with a mechanism for code reuse has to deal with naming collisions one
way or another. In the case of Swift, you can use fully-qualified names to distinguish between the Foo
type declared in module A (A.Foo) from the Foo type in module B (B.Foo). However, Swift has some
unique characteristics that cause other ambiguities to go unnoticed by the compiler, which may result
in a change to existing behavior when modules are imported.
For the purposes of this article, we use the term pollution to describe such side-effects caused by
importing Swift modules that aren’t surfaced by the compiler. We’re not 100% on this terminology,
so please get in touch if you can think of any other suggestions.
Operator Overloading
In Swift, the + operator denotes concatenation when its operands are arrays. One array plus another
results in an array with the elements of the former array followed by those of the latter.
let oneTwoThree: [Int] = [1, 2, 3]
let fourFiveSix: [Int] = [4, 5, 6]
oneTwoThree + fourFiveSix // [1, 2, 3, 4, 5, 6]
If we look at the operator’s declaration in the standard library, we see that it’s provided in an unqualified
extension on Array:
extension Array {
@inlinable public static func + (lhs: Array, rhs: Array) -> Array {}
}
The Swift compiler is responsible for resolving API calls to their corresponding implementations. If an
invocation matches more than one declaration, the compiler selects the most specific one available.
To illustrate this point, consider the following conditional extension on Array, which defines the +
operator to perform member-wise addition for arrays whose elements conform to Numeric:
extension Array where Element: Numeric {
public static func + (lhs: Array, rhs: Array) -> Array {
return Array(zip(lhs, rhs).map {$0 + $1})
}
}
oneTwoThree + fourFiveSix // [5, 7, 9]
Because the requirement of Element: Numeric is more specific than the unqualified declaration in the
standard library, the Swift compiler resolves + to this function instead.
Now, these new semantics may be perfectly acceptable — indeed preferable. But only if you’re aware
of them. The problem is that if you so much as import a module containing such a declaration you can
change the behavior of your entire app without even knowing it.
This problem isn’t limited to matters of semantics; it can also come about as a result of ergonomic
affordances.
Function Shadowing
In Swift, function declarations can specify default arguments for trailing parameters, making them
optional (though not necessarily Optional) for callers. For example, the top-level function dump(_:name
:indent:maxDepth:maxItems:) has an intimidating number of parameters:
@discardableResult func dump<T>(_ value: T, name: String? = nil, indent: Int =
0, maxDepth: Int = .max, maxItems: Int = .max) -> T
But thanks to default arguments, you need only specify the first one to call it:
dump("
") // "
"
Alas, this source of convenience can become a point of confusion when method signatures overlap.
Imagine a hypothetical module that — not being familiar with the built-in dump function — defines a
dump(_:) that prints the UTF-8 code units of a string.
public func dump(_ string: String) {
print(string.utf8.map {$0})
}
The dump function declared in the Swift standard library takes an unqualified generic T argument in
its first parameter (which is effectively Any). Because String is a more specific type, the Swift compiler
will choose the imported dump(_:) method when it’s available.
dump("
") // [240, 159, 143, 173, 240, 159, 146, 168]
Unlike the previous example, it’s not entirely clear that there’s any ambiguity in the competing
declarations. After all, what reason would a developer have to think that their dump(_:) method could
in any way be confused for dump(_:name:indent:maxDepth:maxItems:)?
Which leads us to our final example, which is perhaps the most confusing of all…
String Interpolation Pollution
In Swift, you can combine two strings by interpolation in a string literal as an alternative to
concatenation.
let name = "Swift"
let greeting = "Hello, \(name)!" // "Hello, Swift!"
This has been true from the first release of Swift. However, with the new ExpressibleByString
Interpolation protocol in Swift 5, this behavior can no longer be taken for granted.
Consider the following extension on the default interpolation type for String:
extension DefaultStringInterpolation {
public mutating func appendInterpolation<T>(_ value: T) where T:
StringProtocol {
self.appendInterpolation(value.uppercased() as TextOutputStreamable)
}
}
StringProtocol
inherits, among other things the TextOutputStreamable and CustomString
Convertible protocols, making it more specific than the appendInterpolation method declared by
DefaultStringInterpolation that would otherwise be invoked when interpolating String values.
public struct DefaultStringInterpolation: StringInterpolationProtocol {
@inlinable public mutating func appendInterpolation<T>(_ value: T)
where T: TextOutputStreamable, T: CustomStringConvertible {}
}
Once again, the Swift compiler’s notion of specificity causes behavior to go from expected to unexpected.
If the previous declaration is made accessible by any module in your app, it would change the behavior
of all interpolated string values.
let greeting = "Hello, \(name)!" // "Hello, SWIFT!"
Admittedly, this last example’s a bit contrived; an implementor has to go out of their way to make
the implementation not recursive. But consider this a stand-in for a less-obvious example that’s
more likely to actually happen in real-life.
Given the rapid and upward trajectory of the language, it’s not unreasonable to expect that these
problems will be solved at some point in the future.
But what are we to do in the meantime? Here are some suggestions for managing this behavior both as
an API consumer and as an API provider.
Strategies for API Consumers
As an API consumer, you are — in many ways — beholden to the constraints imposed by imported
dependencies. It really shouldn’t be your problem to solve, but at least there are some remedies available
to you.
Add Hints to the Compiler
Often, the most effective way to get the compiler to do what you want is to explicitly cast an argument
down to a type that matches the method you want to call.
Take our example of the dump(_:) method from before: by downcasting to CustomStringConvertible
from String, we can get the compiler to resolve the call to use the standard library function instead.
dump("
dump("
") // [240, 159, 143, 173, 240, 159, 146, 168]
" as CustomStringConvertible) // "
"
Scoped Import Declarations
As discussed in a previous article you can use Swift import declarations to resolve naming collisions.
Unfortunately, scoping an import to certain APIs in a module doesn’t currently prevent extensions
from applying to existing types. That is to say, you can’t import an adding(_:) method without
also importing an overloaded + operator declared in that module.
Fork Dependencies
If all else fails, you can always solve the problem by taking it into your own hands.
If you don’t like something that a third-party dependency is doing, simply fork the source code, get
rid of the stuff you don’t want, and use that instead. (You could even try to get them to upstream the
change.)
Unfortunately, this strategy won’t work for closed-source modules, including the ones in Apple’s
SDKs. “Radar or GTFO”, I suppose.
Strategies for API Provider
As someone developing an API, it’s ultimately your responsibility to be deliberate and considerate in
your design decisions. As you think about the greater consequences of your actions, here are some
things to keep in mind:
Be More Discerning with Generic Constraints
Unqualified <T> generic constraints are the same as Any. If it makes sense to do so, consider making
your constraints more specific to reduce the chance of overlap with unrelated declarations.
Isolate Core Functionality from Convenience
As a general rule, code should be organized into modules such that module is responsible for a single
responsibility.
If it makes sense to do so, consider packaging functionality provided by types and methods in a module
that is separate from any extensions you provide to built-in types to improve their usability. Until it’s
possible to pick and choose which behavior we want from a module, the best option is to give consumers
the choice to opt-in to features if there’s a chance that they might cause problems downstream.
Avoid Collisions Altogether
Of course, it’d be great if you could knowingly avoid collisions to begin with… but that gets into the
whole “unknown unknowns” thing, and we don’t have time to get into epistemology now.
So for now, let’s just say that if you’re aware of something maybe being a conflict, a good option might
be to avoid it altogether.
For example, if you’re worried that someone might get huffy about changing the semantics of
fundamental arithmetic operators, you could choose a different one instead, like .+:
infix operator .+: AdditionPrecedence
extension Array where Element: Numeric {
static func .+ (lhs: Array, rhs: Array) -> Array {
return Array(zip(lhs, rhs).map {$0 + $1})
}
}
oneTwoThree + fourFiveSix // [1, 2, 3, 4, 5, 6]
oneTwoThree .+ fourFiveSix // [5, 7, 9]
As developers, we’re perhaps less accustomed to considering the wider impact of our decisions. Code is
invisible and weightless, so it’s easy to forget that it even exists after we ship it.
But in Swift, our decisions have impacts beyond what’s immediately understood so it’s important to be
considerate about how we exercise our responsibilities as stewards of our APIs.
Swift Operators
What would a program be without operators? A mishmash of classes, namespaces, conditionals, loops,
and namespaces signifying nothing.
Operators are what do the work of a program. They are the very execution of an executable; the
teleological driver of every process. Operators are a topic of great importance for developers and the
focus of this week’s NSHipster article.
Operator Precedence and Associativity
If we were to dissect an expression — say 1 + 2 — and decompose it into constituent parts, we would
find one operator and two operands:
1
+
2
left operand
operator
right operand
Expressions are expressed in a single, flat line of code, from which the compiler constructs an AST, or
abstract syntax tree:
+
1
2
For compound expressions, like 1 + 2 * 3 or 5 - 2 + 3, the compiler uses rules for operator precedence
and associativity to resolve the expression into a single value.
Operator precedence rules, similar to the ones you learned in primary school, determine the order in
which different kinds of operators are evaluated. In this case, multiplication has a higher precedence
than addition, so 2 * 3 evaluates first.
1
+
(2 * 3)
left operand
operator
right operand
+
1
*
2
3
Associativity determines the order in which operators with the same precedence are resolved. If an
operator is left-associative, then the operand on the left-hand side is evaluated first: ((5 - 2) + 3); if
right-associative, then the right-hand side operator is evaluated first: 5 - (2 + 3).
Arithmetic operators are left-associative, so 5 - 2 + 3 evaluates to 6.
(5 - 2)
+
3
left operand
operator
right operand
+
3
5
2
Swift Operators
The Swift Standard Library includes most of the operators that a programmer might expect coming
from another language in the C family, as well as a few convenient additions like the nil-coalescing
operator (??) and pattern match operator (~=), as well as operators for type checking (is), type casting
(as, as?, as!) and forming open or closed ranges (..., ..<).
Infix Operators
Swift uses infix notation for binary operators (as opposed to, say Reverse Polish Notation). The Infix
operators are grouped below according to their associativity and precedence level, in descending order:
BitwiseShiftPrecedence
<<
>>
Bitwise left shift
Bitwise right shift
MultiplicationPrecedence
*
&*
&
Multiply
Multiply, ignoring overflow
Bitwise AND
/
&/
Divide
Divide, ignoring overflow
%
&%
Remainder
Remainder, ignoring overflow
AdditionPrecedence
+
&+
|
Add
Add with overflow
Bitwise OR
-
&-
^
Subtract
Subtract with overflow
Bitwise XOR
RangeFormationPrecedence
..<
...
Half-open range
Closed range
CastingPrecedence
is
as
Type check
Type cast
NilCoalescingPrecedence
??
nil Coalescing
ComparisonPrecedence
<
>=
===
Less than
Greater than or equal
Identical
<=
==
!==
Less than or equal
Equal
Not identical
>
!=
~=
Greater than
Not equal
Pattern match
LogicalConjunctionPrecedence
&&
Logical AND
LogicalDisjunctionPrecedence
||
Logical OR
DefaultPrecedence
(None)
AssignmentPrecedence
=
+=
&=
Assign
Add and assign
Bitwise AND and assign
*=
-=
^=
Multiply and assign
Subtract and assign
Bitwise XOR and assign
/=
<<=
|=
Divide and assign
Left bit shift and assign
Bitwise OR and assign
%=
>>=
Remainder and assign
Right bit shift and assign
Operator precedence groups were originally defined with numerical precedence. For example,
multiplicative operators defined a precedence value of 150, so they were evaluated before additive
operators, which defined a precedence value of 140.
In Swift 3, operators changed to define precedence by partial ordering to form a DAG or directed
acyclic graph. For detailed information about this change, read Swift Evolution proposal SE-0077
“Improved operator declarations”.
Unary Operators
In addition to binary operators that take two operands, there are also unary operators, which take a
single operand.
Prefix Operators
Prefix operators come before the expression they operate on. Swift defines a handful of these by default:
• +: Unary plus
• -: Unary minus
• !: Logical NOT
• ~: Bitwise NOT
• ...: Open-ended partial range
• ..<: Closed partial range
For example, the ! prefix operator negates a logical value of its operand and the - prefix operator
negates the numeric value of its operand.
!true // false
-(1.0 + 2.0) // -3.0
The increment/decrement (++ / --) operators were removed in Swift 3. This was one of the first
changes to be made as part of the Swift Evolution process after the language was released as open
source. In the proposal, Chris Lattner describes how these operators can be confusing, and argues
for why they aren’t needed in the language.
Postfix Operators
Unary operators can also come after their operand, as is the case for the postfix variety. These are less
common; the Swift Standard Library declares only the open-ended range postfix operator, ....
let fruits = [" ", " ", " ", "
fruits[3...] // [" ", " "]
", "
"]
Ternary Operators
The ternary ?: operator is special. It takes three operands and functions like a single-line if-else
statement: evaluate the logical condition on the left side of the ? and produces the expression on the left
or right-hand side of the : depending on the result:
true ? "Yes" : "No" // "Yes"
In Swift, TernaryPrecedence is defined lower than DefaultPrecedence and higher than Assignment
Precedence. But, in general, it’s better to keep ternary operator usage simple (or avoid them altogether).
Operator Overloading
Once an operator is declared, it can be associated with a type method or top-level function. When
an operator can resolve different functions depending on the types of operands, then we say that the
operator is overloaded.
The most prominent examples of overloading can be found with the + operator. In many languages,
+ can be used to perform arithmetic addition (1 + 2 => 3) or concatenation for arrays and other
collections ([1] + [2] => [1, 2] ).
Developers have the ability to overload standard operators by declaring a new function for the operator
symbol with the appropriate number and type of arguments.
For example, to overload the * operator to repeat a String a specified number of times, you’d declare
the following top-level function:
func * (lhs: String, rhs: Int) -> String {
guard rhs > 0 else {
return ""
}
}
return String(repeating: lhs, count: rhs)
"hello" * 3 // hellohellohello
This kind of language use is, however, controversial. (Any C++ developer would be all too eager to
regale you with horror stories of the non-deterministic havoc this can wreak)
Consider the following statement:
[1, 2] + [3, 4] // [1, 2, 3, 4]
By default, the + operator concatenates the elements of both arrays, and is implemented using a generic
function definition.
If you were to declare a specialized function that overloads the + for arrays of Double values to perform
member-wise addition, it would override the previous concatenating behavior:
//
func + (lhs: [Double], rhs: [Double]) -> [Double] {
return zip(lhs, rhs).map(+)
}
[1.0, 3.0, 5.0] + [2.0, 4.0, 6.0] // [3.0, 7.0, 11.0]
Herein lies the original sin of operator overloading: ambiguous semantics.
It makes sense that + would work on numbers — that’s maths. But if you really think about it, why
should adding two strings together concatenate them? 1 + 2 isn’t 12 (except in Javascript). Is this really
intuitive? …or is it just familiar.
Something to keep in mind when deciding whether to overload an existing operator.
By comparison, PHP uses . for string concatenation, whereas SQL uses ||; Objective-C doesn’t
have an operator, per se, but will append consecutive string literals with whitespace.
Defining Custom Operators
One of the most exciting features of Swift (though also controversial) is the ability to define custom
operators.
Consider the exponentiation operator, **, found in many programming languages, but missing from
Swift. It raises the left-hand number to the power of the right-hand number. (The ^ symbol, commonly
used for superscripts, is already used by the bitwise XOR operator).
Exponentiation has a higher operator precedence than multiplication, and since Swift doesn’t have a
built-in precedence group that we can use, we first need to declare one ourselves:
precedencegroup ExponentiationPrecedence {
associativity: right
higherThan: MultiplicationPrecedence
}
Now we can declare the operator itself:
infix operator ** : ExponentiationPrecedence
Finally, we implement a top-level function using our new operator:
import Darwin
func ** (lhs: Double, rhs: Double) -> Double {
return pow(lhs, rhs)
}
2 ** 3 // 8
We need to import the Darwin module to access the standard math function, pow(_:_:).
(Alternatively, we could import Foundation instead to the same effect.)
When you create a custom operator, consider providing a mutating variant as well:
infix operator **= : AssignmentPrecedence
func **= (lhs: inout Double, rhs: Double) {
lhs = pow(lhs, rhs)
}
var n: Double = 10
n **= 1 + 2 // n = 1000
Use of Mathematical Symbols
A custom operator can use combinations of the characters /, =, -, +, !, *, %, <, >, &, |, ^, or ~, and any
characters found in the Mathematical Operators Unicode block, among others.
This makes it possible to take the square root of a number with a single √ prefix operator:
import Darwin
prefix operator √
prefix func √ (_ value: Double) -> Double {
return sqrt(value)
}
√4 // 2
Or consider the ± operator, which can be used either as an infix or prefix operator to return a tuple with
the sum and difference:
infix operator ± : AdditionPrecedence
func ± <T: Numeric>(lhs: T, rhs: T) -> (T, T) {
return (lhs + rhs, lhs - rhs)
}
prefix operator ±
prefix func ± <T: Numeric>(_ value: T) -> (T, T) {
return 0 ± value
}
2 ± 3 // (5, -1)
±4 // (4, -4)
For more examples of functions using mathematical notation in Swift, check out Euler.
Custom operators are hard to type, and therefore hard to use, so exercise restraint with exotic symbols.
Code should be typed, not be copy-pasted.
When overriding or defining new operators in your own code, make sure to follow these guidelines:
1. Don’t create an operator unless its meaning is obvious and undisputed. Seek out any potential
conflicts to ensure semantic consistency.
2. Pay attention to the precedence and associativity of custom operators, and only define new
operator groups as necessary.
3. If it makes sense, consider implementing assigning variants for your custom operator (e.g. +=
for +).
Swift Literals
In 1911, linguist Franz Boas observed that speakers of Eskimo–Aleut languages used different words
to distinguish falling snowflakes from snow on the ground. By comparison, English speakers typically
refer to both as “snow,” but create a similar distinction between raindrops and puddles.
Over time, this simple empirical observation has warped into an awful cliché that “Eskimos [sic] have
50 different words for snow” — which is unfortunate, because Boas’ original observation was empirical,
and the resulting weak claim of linguistic relativity is uncontroversial: languages divide semantic
concepts into separate words in ways that may (and often do) differ from one another. Whether that’s
more an accident of history or reflective of some deeper truth about a culture is unclear, and subject for
further debate.
It’s in this framing that you’re invited to consider how the different kinds of literals in Swift shape the
way we reason about code.
Standard Literals
A literal is a representation of a value in source code, such as a number or a string.
Swift provides the following kinds of literals:
Name
Default Inferred Type
Examples
Integer
Int
123, 0b1010, 0o644, 0xFF,
Floating-Point
Double
3.14, 6.02e23, 0xAp-2
String
String
"Hello", """ . . . """
Extended Grapheme Cluster
Character
Unicode Scalar
Unicode.Scalar
"A", "´", "\u{1F1FA}"
Boolean
Bool
true, false
Nil
Optional
nil
Array
Array
[1, 2, 3]
Dictionary
Dictionary
["a": 1, "b": 2]
"A", "é", "
"
The most important thing to understand about literals in Swift is that they specify a value, but not a
definite type.
When the compiler encounters a literal, it attempts to infer the type automatically. It does this by
looking for each type that could be initialized by that kind of literal, and narrowing it down based on
any other constraints.
If no type can be inferred, Swift initializes the default type for that kind of literal — Int for an integer
literal, String for a string literal, and so on.
57 // Integer literal
"Hello" // String literal
In the case of nil literals, the type can never be inferred automatically and therefore must be declared.
nil // ! cannot infer type
nil as String? // Optional<String>.none
For array and dictionary literals, the associated types for the collection are inferred based on its
contents. However, inferring types for large or nested collections is a complex operation and may
significantly increase the amount of time it takes to compile your code. You can keep things snappy by
adding an explicit type in your declaration.
// Explicit type in the declaration
// prevents expensive type inference during compilation
let dictionary: [String: [Int]] = [
"a": [1, 2],
"b": [3, 4],
"c": [5, 6],
…
]
Playground Literals
In addition to the standard literals listed above, there are a few additional literal types for code in
Playgrounds:
Name
Default Inferred Type
Examples
Color
NSColor
/ UIColor
#colorLiteral(red: 1, green: 0, blue: 1, alpha: 1)
Image
NSImage
/ UIImage
#imageLiteral(resourceName: "icon")
File
URL
#fileLiteral(resourceName: "articles.json")
In Xcode or Swift Playgrounds on the iPad, these octothorpe-prefixed literal expressions are
automatically replaced by an interactive control that provides a visual representation of the referenced
color, image, or file.
// Code
#colorLiteral(red: 0.7477839589, green: 0.5598286986, blue: 0.4095913172,
alpha: 1)
// Rendering
This control also makes it easy for new values to be chosen: instead of entering RGBA values or file
paths, you’re presented with a color picker or file selector.
Most programming languages have literals for Boolean values, numbers, and strings, and many have
literals for arrays, dictionaries, and regular expressions.
Literals are so ingrained in a developer’s mental model of programming that most of us don’t actively
consider what the compiler is actually doing.
Having a shorthand for these essential building blocks makes code easier to both read and write.
How Literals Work
Literals are like words: their meaning can change depending on the surrounding context.
["h", "e", "l", "l", "o"] // Array<String>
["h" as Character, "e", "l", "l", "o"] // Array<Character>
["h", "e", "l", "l", "o"] as Set<Character>
In the example above, we see that an array literal containing string literals is initialized to an
array of strings by default. However, if we explicitly cast the first array element as Character, the
literal is initialized as an array of characters. Alternatively, we could cast the entire expression as
Set<Character> to initialize a set of characters.
How does this work?
In Swift, the compiler decides how to initialize literals by looking at all the visible types that implement
the corresponding literal expression protocol.
Literal
Protocol
Integer
ExpressibleByIntegerLiteral
Floating-Point
ExpressibleByFloatLiteral
String
ExpressibleByStringLiteral
Extended Grapheme Cluster
ExpressibleByExtendedGraphemeClusterLiteral
Unicode Scalar
ExpressibleByUnicodeScalarLiteral
Boolean
ExpressibleByBooleanLiteral
Nil
ExpressibleByNilLiteral
Array
ExpressibleByArrayLiteral
Dictionary
ExpressibleByDictionaryLiteral
To conform to a protocol, a type must implement its required initializer. For example, the Expressible
ByIntegerLiteral protocol requires init(integerLiteral:).
What’s really great about this approach is that it lets you add literal initialization for your own
custom types.
Supporting Literal Initialization for Custom Types
Supporting initialization by literals when appropriate can significantly improve the ergonomics of
custom types, making them feel like they’re built-in.
For example, if you wanted to support fuzzy logic, in addition to standard Boolean fare, you might
implement a Fuzzy type like the following:
struct Fuzzy: Equatable {
var value: Double
}
init(_ value: Double) {
precondition(value >= 0.0 && value <= 1.0)
self.value = value
}
A Fuzzy value represents a truth value that ranges between completely true and completely false over
the numeric range 0 to 1 (inclusive). That is, a value of 1 means completely true, 0.8 means mostly true,
and 0.1 means mostly false.
In order to work more conveniently with standard Boolean logic, we can extend Fuzzy to adopt the
ExpressibleByBooleanLiteral protocol.
extension Fuzzy: ExpressibleByBooleanLiteral {
init(booleanLiteral value: Bool) {
self.init(value ? 1.0 : 0.0)
}
}
In practice, there aren’t many situations in which it’d be appropriate for a type to be initialized using
Boolean literals. Support for string, integer, and floating-point literals are much more common.
Doing so doesn’t change the default meaning of true or false. We don’t have to worry about existing
code breaking just because we introduced the concept of half-truths to our code base (“view did appear
animated… maybe?”). The only situations in which true or false initialize a Fuzzy value would be
when the compiler could infer the type to be Fuzzy:
true is Bool // true
true is Fuzzy // false
(true as Fuzzy) is Fuzzy // true
(false as Fuzzy).value // 0.0
Because Fuzzy is initialized with a single Double value, it’s reasonable to allow values to be initialized
with floating-point literals as well. It’s hard to think of any situations in which a type would support
floating-point literals but not integer literals, so we should do that too (however, the converse isn’t true;
there are plenty of types that work with integer but not floating point numbers).
extension Fuzzy: ExpressibleByIntegerLiteral {
init(integerLiteral value: Int) {
self.init(Double(value))
}
}
extension Fuzzy: ExpressibleByFloatLiteral {
init(floatLiteral value: Double) {
self.init(value)
}
}
With these protocols adopted, the Fuzzy type now looks and feels like a bona fide member of Swift
standard library.
let completelyTrue: Fuzzy = true
let mostlyTrue: Fuzzy = 0.8
let mostlyFalse: Fuzzy = 0.1
(Now the only thing left to do is implement the standard logical operators!)
If convenience and developer productivity is something you want to optimize for, you should consider
implementing whichever literal protocols are appropriate for your custom types.
Future Developments
Literals are an active topic of discussion for the future of the language. Looking forward to Swift 5, there
are a number of current proposals that could have terrific implications for how we write code.
Raw String Literals
At the time of writing, Swift Evolution proposal 0200 is in active review. If it’s accepted, future versions
of Swift will support “raw” strings, or string literals that ignores escape sequences.
From the proposal:
Our design adds customizable string delimiters. You may pad a string literal with one or more
# (pound, Number Sign, U+0023) characters […] The number of pound signs at the start of the
string (in these examples, zero, one, and four) must match the number of pound signs at the end of
the string.
"This is a Swift string literal"
#"This is also a Swift string literal"#
####"So is this"####
This proposal comes as a natural extension of the new multi-line string literals added in Swift 4
(SE-0165), and would make it even easier to do work with data formats like JSON and XML.
If nothing else, adoption of this proposal could remove the largest obstacle to using Swift on Windows:
dealing with file paths like C:\Windows\All Users\Application Data.
Literal Initialization Via Coercion
Another recent proposal, SE-0213: Literal initialization via coercion is already implemented for Swift 5.
From the proposal:
T(literal) should construct T using the appropriate literal protocol if possible.
Currently types conforming to literal protocols are type-checked using regular initializer rules,
which means that for expressions like UInt32(42) the type-checker is going to look up a set of
available initializer choices and attempt them one-by-one trying to deduce the best solution.
In Swift 4.2, initializing a UInt64 with its maximum value results in a compile-time overflow because
the compiler first tries to initialize an Int with the literal value.
UInt64(0xffff_ffff_ffff_ffff) // overflows in Swift 4.2
Starting in Swift 5, not only will this expression compile successfully, but it’ll do so a little bit faster, too.
The words available to a language speaker influence not only what they say, but how they think as well.
In the same way, the individual parts of a programming language hold considerable influence over how
a developer works.
The way Swift carves up the semantic space of values makes it different from languages that don’t,
for example, distinguish between integers and floating points or have separate concepts for strings,
characters, and Unicode scalars. So it’s no coincidence that when we write Swift code, we often think
about numbers and strings at a lower level than if we were hacking away in, say, JavaScript.
Along the same lines, Swift’s current lack of distinction between string literals and regular expressions
contributes to the relative lack of regex usage compared to other scripting languages.
That’s not to say that having or lacking certain words makes it impossible to express certain ideas — just
a bit fuzzier. We can understand “untranslatable” words like “Saudade” in Portuguese, “Han” in Korean,
or “Weltschmerz” in German.
We’re all human. We all understand pain.
By allowing any type to support literal initialization, Swift invites us to be part of the greater conversation.
Take advantage of this and make your own code feel like a natural extension of the standard library.
ExpressibleByString
Interpolation
Swift is designed — first and foremost — to be a safe language. Numbers and collections are checked for
overflow, variables are always initialized before first use, optionals ensure that non-values are handled
correctly, and any potentially unsafe operations are named accordingly.
These language features go a long way to eliminate some of the most common programming errors, but
we’d be remiss to let our guard down.
Today, I want to talk about one of the most exciting new features in Swift 5: an overhaul to how values
in string literals are interpolated by way of the ExpressibleByStringInterpolation protocol. A lot
of folks are excited about the cool things you can do with it. (And rightfully so! We’ll get to all of that
in just a moment) But I think it’s important to take a broader view of this feature to understand the full
scope of its impact.
Format strings are awful.
After incorrect NULL handling, buffer overflows, and uninitialized variables, printf / scanf-style
format strings are arguably the most problematic holdovers from C-style programming language.
In the past 20 years, security professionals have documented hundreds of vulnerabilities related to
format string vulnerabilities. It’s so commonplace that it’s assigned its very own Common Weakness
Enumeration (CWE) category.
Not only are they insecure, but they’re hard to use. Yes, hard to use.
Consider the dateFormat property on DateFormatter, which takes an strftime format string. If we
wanted to create a string representation of a date that included its year, we’d use "Y", as in "Y" for
year …right?
import Foundation
let formatter = DateFormatter()
formatter.dateFormat = "M/d/Y"
formatter.string(from: Date()) // "2/4/2019"
It sure looks that way, at least for the first 360-ish days of the year. But what happens when we jump to
the last day of the year?
let dateComponents = DateComponents(year: 2019,
month: 12,
day: 31)
let date = Calendar.current.date(from: dateComponents)!
formatter.string(from: date) // "12/31/2020" ( )
Huh what? Turns out "Y" is the format for the ISO week-numbering year, which returns 2020 for
December 31st, 2019 because the following day is a Wednesday in the first week of the new year.
What we actually want is "y".
formatter.dateFormat = "M/d/y"
formatter.string(from: date) // 12/31/2019 (
)
Format strings are the worst kind of hard to use, because they’re so easy to use incorrectly. And date
format strings are the worst of the worst, because it may not be clear that you’re doing it wrong until it’s
too late. They’re literal time bombs in your codebase.
Take a moment now, if you haven’t already, to audit your code base for use of "Y" in date format
strings when you actually meant to use "y".
The problem up until now has been that APIs have had to choose between dangerous-but-expressive
domain-specific languages (DSLs), such as format strings, and the correct-but-less-flexible method calls.
New in Swift 5, the ExpressibleByStringInterpolation protocol allows for these kinds of APIs to be
both correct and expressive. And in doing so, it overturns decades’ worth of problematic behavior.
So without further ado, let’s look at what ExpressibleByStringInterpolation is and how it works:
ExpressibleByStringInterpolation
Types that conform to the ExpressibleByStringInterpolation protocol can customize how
interpolated values (that is, values escaped by \( … )) in string literals.
You can take advantage of this new protocol either by extending the default String interpolation type
(DefaultStringInterpolation) or by creating a new type that conforms to ExpressibleByString
Interpolation.
For more information, see Swift Evolution proposal SE-0228: “Fix ExpressibleByStringInterpolation”.
Extending Default String Interpolation
By default, and prior to Swift 5, all interpolated values in a string literal were sent to directly to a String
initializer. Now with ExpressibleByStringInterpolation, you can specify additional parameters as
if you were calling a method (indeed, that’s what you’re doing under the hood).
As an example, let’s revisit the previous mixup of "Y" and "y" and see how this confusion could be
avoided with ExpressibleByStringInterpolation.
By extending String’s default interpolation type (aptly-named DefaultStringInterpolation), we
can define a new method called appendingInterpolation. The type of the first, unnamed parameter
determines which interpolation methods are available for the value to be interpolated. In our case, we’ll
define an appendInterpolation method that takes a Date argument and an additional component
parameter of type Calendar.Component that we’ll use to specify which
import Foundation
extension DefaultStringInterpolation {
mutating func appendInterpolation(_ value: Date,
component: Calendar.Component)
{
let dateComponents =
Calendar.current.dateComponents([component],
from: value)
}
}
self.appendInterpolation(
dateComponents.value(for: component)!
)
Now we can interpolate the date for each of the individual components:
"\(date, component: .month)/\(date, component: .day)/\(date, component: .year)"
// "12/31/2019" ( )
It’s verbose, yes. But you’d never mistake .yearForWeekOfYear, the calendar component equivalent of
"Y", for what you actually want: .year.
But really, we shouldn’t be formatting dates by hand like this anyway. We should be delegating that
responsibility to a DateFormatter:
You can overload interpolations just like any other Swift method, and having multiple with the same
name but different type signatures. For example, we can define interpolators for dates and numbers that
take a formatter of the corresponding type.
import Foundation
extension DefaultStringInterpolation {
mutating func appendInterpolation(_ value: Date,
formatter: DateFormatter)
{
self.appendInterpolation(
formatter.string(from: value)
)
}
}
mutating func appendInterpolation<T>(_ value: T,
formatter: NumberFormatter)
where T : Numeric
{
self.appendInterpolation(
formatter.string(from: value as! NSNumber)!
)
}
This allows for a consistent interface to equivalent functionality, such as formatting interpolated dates
and numbers.
let dateFormatter = DateFormatter()
dateFormatter.dateStyle = .full
dateFormatter.timeStyle = .none
"Today is \(Date(), formatter: dateFormatter)"
// "Today is Monday, February 4, 2019"
let numberformatter = NumberFormatter()
numberformatter.numberStyle = .spellOut
"one plus one is \(1 + 1, formatter: numberformatter)"
// "one plus one is two"
Implementing a Custom String Interpolation Type
In addition to extending DefaultStringInterpolation, you can define custom string interpolation
behavior on a custom type that conforms to ExpressibleByStringInterpolation. You might do that
if any of the following is true:
• You want to differentiate between literal and interpolated segments
• You want to restrict which types can be interpolated
• You want to support different interpolation behavior than provided by default
• You want to avoid burdening the built-in string interpolation type with excessive API surface area
For a simple example of this, consider a custom type that escapes values in XML, similar to one of the
loggers that we described last week. Our goal: to provide a nice templating API that allows us to write
XML / HTML and interpolate values in a way that automatically escapes characters like < and >.
We’ll start simply with a wrapper around a single String value.
struct XMLEscapedString: LosslessStringConvertible {
var value: String
init?(_ value: String) {
self.value = value
}
}
var description: String {
return self.value
}
We add conformance to ExpressibleByStringInterpolation in an extension, just like any other
protocol. It inherits from ExpressibleByStringLiteral, which requires an init(stringLiteral:)
initializer. ExpressibleByStringInterpolation itself requires an init(stringInterpolation:)
initializer that takes an instance of the required, associated StringInterpolation type.
This associated StringInterpolation type is responsible for collecting all of the literal segments and
interpolated values from the string literal. All literal segments are passed to the appendLiteral(_:)
method. For interpolated values, the compiler finds the appendInterpolation method that matches
the specified parameters. In this case, both literal and interpolated values are collected into a mutable
string.
The
StringInterpolationProtocol,
requires
an
initializer,
init(literalCapacity
:interpolationCount:); as an optional optimization, the capacity and interpolation counts can
be used to, for example, allocate enough space to hold the resulting string.
import Foundation
extension XMLEscapedString: ExpressibleByStringInterpolation {
init(stringLiteral value: String) {
self.init(value)!
}
init(stringInterpolation: StringInterpolation) {
self.init(stringInterpolation.value)!
}
struct StringInterpolation: StringInterpolationProtocol {
var value: String = ""
init(literalCapacity: Int, interpolationCount: Int) {
self.value.reserveCapacity(literalCapacity)
}
mutating func appendLiteral(_ literal: String) {
self.value.append(literal)
}
mutating func appendInterpolation<T>(_ value: T)
where T: CustomStringConvertible
{
let escaped = CFXMLCreateStringByEscapingEntities(
nil, value.description as NSString, nil
)! as NSString
}
}
}
self.value.append(escaped as String)
With all of this in place, we can now initialize XMLEscapedString with a string literal that automatically
escapes interpolated values. (No XSS exploits for us, thank you!)
let name = "<bobby>"
let markup: XMLEscapedString = """
<p>Hello, \(name)!</p>
"""
print(markup)
// <p>Hello, &lt;bobby&gt;!</p>
One of the best parts of this functionality is how transparent its implementation is. For behavior that
feels quite magical, you’ll never have to wonder how it works.
Compare the string literal above to the equivalent API calls below:
var interpolation =
XMLEscapedString.StringInterpolation(literalCapacity: 15,
interpolationCount: 1)
interpolation.appendLiteral("<p>Hello, ")
interpolation.appendInterpolation(name)
interpolation.appendLiteral("!</p>")
let markup = XMLEscapedString(stringInterpolation: interpolation)
// <p>Hello, &lt;bobby&gt;!</p>
Reads just like poetry, doesn’t it?
For a more advanced example of ExpressibleByStringInterpolation, check out the Unicode
Styling playground included in the sample code for the Flight School Guide to Swift Strings
Seeing how ExpressibleByStringInterpolation works, it’s hard not to look around and find
countless opportunities for where it could be used:
• Formatting String interpolation offers a safer and easier-to-understand alternative to date and
number format strings.
• Escaping Whether its escaping entities in URLs, XML documents, shell command arguments,
or values in SQL queries, extensible string interpolation makes correct behavior seamless and
automatic.
• Decorating Use string interpolation to create a type-safe DSL for creating attributed strings for
apps and terminal output with ANSI control sequences for color and effects, or pad unadorned
text to match the desired alignment.
• Localizing Rather than relying on a a script that scans source code looking for matches on
“NSLocalizedString”, string interpolation allows us to build tools that leverage the compiler to find
all instances of localized strings.
If you take all of these and factor in possible future support for compile-time constant expression, what
you find is that Swift 5 may have just stumbled onto the new best way to deal with formatting.
TextOutputStream
print
is among the most-used functions in the Swift standard library. Indeed, it’s the first function a
programmer learns when writing “Hello, world!”. So it’s surprising how few of us are familiar with its
other forms.
For instance, did you know that the actual signature of print is print(_:separator:terminator:)?
Or that it had a variant named print(_:separator:terminator:to:)?
Shocking, I know.
It’s like learning that your best friend “Chaz” goes by his middle name and that his full legal name
is actually “R. Buckminster Charles Lagrand Jr.” — oh, and also, they’ve had an identical twin the
whole time.
Once you’ve taken a moment to collect yourself, read on to find out the whole truth about a function
that you may have previously thought to need no further introduction.
Let’s start by taking a closer look at that function declaration from before:
func print<Target>(_ items: Any...,
separator: String = default,
terminator: String = default,
to output: inout Target)
where Target : TextOutputStream
This overload of print takes a variable-length list of arguments, followed by separator and terminator
parameters — both of which have default values.
• separator is the string used to join the representation of each element in items into a single
string. By default, this is a space (" ").
• terminator is the string appended to the end of the printed representation. By default, this is a
newline ("\n").
The last parameter, output takes a mutable instance of a generic Target type that conforms to the Text
OutputStream protocol.
An instance of a type conforming to TextOutputStream can be passed to the print(_:to:) function
to capture and redirect strings from standard output.
Implementing a Custom Text Output Stream Type
Due to the mercurial nature of Unicode, you can’t know what characters lurk within a string just
by looking at it. Between combining marks, format characters, unsupported characters, variation
sequences, ligatures, digraphs, and other presentational forms, a single extended grapheme cluster can
contain much more than meets the eye.
So as an example, let’s create a custom type that conforms to TextOutputStream. Instead of writing a
string to standard output verbatim, we’ll have it inspect each constituent code point.
Conforming to the TextOutputStream protocol is simply a matter of fulfilling the write(_:) method
requirement.
protocol TextOutputStream {
mutating func write(_ string: String)
}
In our implementation, we iterate over each Unicode.Scalar value in the passed string; the
enumerated() collection method provides the current offset on each loop. At the top of the method, a
guard statement bails out early if the string is empty or a newline (this reduces the amount of noise in
the console).
struct UnicodeLogger: TextOutputStream {
mutating func write(_ string: String) {
guard !string.isEmpty && string != "\n" else {
return
}
}
}
for (index, unicodeScalar) in
string.unicodeScalars.lazy.enumerated()
{
let name = unicodeScalar.name ?? ""
let codePoint = String(format: "U+%04X", unicodeScalar.value)
print("\(index): \(unicodeScalar) \(codePoint)\t\(name)")
}
To use our new UnicodeLogger type, initialize it and assign it to a variable (with var) so that it can be
passed as an inout argument. Anytime we want to get an X-ray of a string instead of merely printing
its surface representation, we can tack on an additional parameter to our print statement.
Doing so allows us to reveal a secret about the emoji character
: it’s actually a sequence of four
individual emoji joined by ZWJ characters — seven code points in total!
print(" ")
// Prints: "
"
var logger = UnicodeLogger()
print(" ", to: &logger)
// Prints:
// 0:
U+1F468
MAN
// 1:
U+200D
ZERO WIDTH JOINER
// 2:
U+1F469
WOMAN
// 3:
U+200D
ZERO WIDTH JOINER
// 4:
U+1F467
GIRL
// 5:
U+200D
ZERO WIDTH JOINER
// 6:
U+1F467
GIRL
In Swift 5.0, you can access the name of a scalar value by through its Unicode properties
property. In the meantime, we can use a string transform to pull the name for us (we just need to
strip some cruft at either end).
import Foundation
extension Unicode.Scalar {
var name: String? {
guard var escapedName =
"\(self)".applyingTransform(.toUnicodeName,
reverse: false)
else {
return nil
}
escapedName.removeFirst(3) // remove "\\N{"
escapedName.removeLast(1) // remove "}"
}
}
return escapedName
For more information, see SE-0211: “Add Unicode Properties to Unicode.Scalar”.
Ideas for Using Custom Text Output Streams
Now that we know about an obscure part of the Swift standard library, what can we do with it?
As it turns out, there are plenty of potential use cases for TextOutputStream. To get a better sense of
what they are, consider the following examples:
Logging to Standard Error
By default, Swift print statements are directed to standard output (stdout). If you wanted to instead
direct to standard error (stderr), you could create a new text output stream type and use it in the
following way:
import func Darwin.fputs
import var Darwin.stderr
struct StderrOutputStream: TextOutputStream {
mutating func write(_ string: String) {
fputs(string, stderr)
}
}
var standardError = StderrOutputStream()
print("Error!", to: &standardError)
Writing Output to a File
The previous example of writing to stderr can be generalized to write to any stream or file by instead
creating an output stream to a FileHandle (for which standard error is accessible through a type
property).
import Foundation
struct FileHandlerOutputStream: TextOutputStream {
private let fileHandle: FileHandle
let encoding: String.Encoding
init(_ fileHandle: FileHandle, encoding: String.Encoding = .utf8) {
self.fileHandle = fileHandle
self.encoding = encoding
}
mutating func write(_ string: String) {
if let data = string.data(using: encoding) {
}
}
}
fileHandle.write(data)
Following this approach, you can customize print to write to a file instead of a stream.
let url = URL(fileURLWithPath: " /path/to/file.txt ")
let fileHandle = try FileHandle(forWritingTo: url)
var output = FileHandlerOutputStream(fileHandle)
print("\(Date())", to: &output)
Escaping Streamed Output
As a final example, let’s imagine a situation in which you find yourself frequently copy-pasting console
output into a form on some website. Unfortunately, the website has the unhelpful behavior of trying to
parse < and > as if they were HTML.
Rather than taking an extra step to escape the text each time you post to the site, you could create a
TextOutputStream that takes care of that for you automatically (in this case, we use an XML-escaping
function that we found buried deep in Core Foundation).
import Foundation
struct XMLEscapingLogger: TextOutputStream {
mutating func write(_ string: String) {
guard !string.isEmpty && string != "\n",
let xmlEscaped = CFXMLCreateStringByEscapingEntities(nil, string as
NSString, nil)
else {
return
}
}
}
print(xmlEscaped)
var logger = XMLEscapingLogger()
print("<3", to: &logger)
// Prints "&lt;3"
Printing is a familiar and convenient way for developers to understand the behavior of their code. It
complements more comprehensive techniques like logging frameworks and debuggers, and — in the
case of Swift — proves to be quite capable in its own right.
Have any other cool ideas for using TextOutputStream that you’d like to share? Let us know on Twitter!
Regular Expressions in Swift
Like everyone else in the Pacific Northwest, we got snowed-in over the weekend. To pass the time, we
decided to break out our stash of board games: Carcassonne, Machi Koro, Power Grid, Pandemic; we
had plenty of excellent choices available. But cooped up in our home for the afternoon, we decided on
a classic: Cluedo.
Me, I’m an avid fan of Cluedo — and yes, that’s what I’m going to call it. Because despite being born
and raised in the United States, where the game is sold and marketed exclusively under the name
“Clue”, I insist on referring to it by its proper name. (Otherwise, how would we refer to the 1985 film
adaptation?)
Alas, my relentless pedantry often causes me to miss out on invitations to play. If someone were to ask:
var invitation = "Hey, would you like to play Clue?"
invitation.contains("Cluedo") // false
…I’d have no idea what they were talking about. If only they’d bothered to phrase it properly, there’d be
no question about their intention:
invitation = "Fancy a game of Cluedo™?"
invitation.contains("Cluedo") // true
Of course, a regular expression would allow me to relax my exacting standards. I could listen for
/Clue(do)?™?/ and never miss another invitation.
But who can be bothered to figure out regexes in Swift, anyway?
Well, sharpen your pencils, gather your detective notes, and warm up your 6-sided dice, because this
week on NSHipster, we crack the case of the cumbersome class known as NSRegularExpression.
Who killed regular expressions in Swift?
I have a suggestion:
It was NSRegularExpression, in the API, with the cumbersome usability.
In any other language, regular expressions are something you can sling around in one-liners.
• Need to substitute one word for another?
Boom: regular expression.
• Need to extract a value from a templated string?
Boom: regular expression.
• Need to parse XML?
Boom: regular expression actually, you should really use an XML parser in this case
But in Swift, you have to go through the trouble of initializing an NSRegularExpression object and
converting back and forth from String ranges to NSRange values. It’s a total drag.
Here’s the good news:
1. You don’t need NSRegularExpression to use regular expressions in Swift.
2. Recent additions in Swift 4 and 5 make it much, much nicer to use NSRegularExpression
when you need to.
Let’s interrogate each of these points, in order:
Regular Expressions without NSRegularExpression
You may be surprised to learn that you can, in fact, use regular expressions in a Swift one-liner — you
just have to bypass NSRegularExpression entirely.
Matching Strings Against Patterns
When you import the Foundation framework, the Swift String type automatically gets access to
NSString instance methods and initializers. Among these is range(of:options:range:locale:),
which finds and returns the first range of the specified string.
Normally, this performs a by-the-books substring search operation. Meh.
But, if you pass the .regularExpression option, the string argument is matched as a pattern. Eureka!
Let’s take advantage of this lesser-known feature to dial our Cluedo sense to the “American” setting.
import Foundation
let invitation = "Fancy a game of Cluedo™?"
invitation.range(of: #"\bClue(do)?™?\b"#,
options: .regularExpression) != nil // true
If the pattern matches the specified string, the method returns a Range<String.Index> object.
Therefore, checking for a non-nil value tells us whether or not a match occurred.
The method itself provides default arguments to the options, range, and locale parameters; by
default, it performs a localized, unqualified search over the entire string in the current locale.
Within a regular expression, the ? operator matches the preceding character or group zero or one times.
We use it in our pattern to make the “-do” in “Cluedo” optional (accommodating both the American
and correct spelling), and allow a trademark symbol (™) for anyone wishing to be prim and proper
about it.
The \b metacharacters match if the current position is a word boundary, which occurs between word
(\w) and non-word (\W) characters. Anchoring our pattern to match on word boundaries prevents false
positives like “Pseudo-Cluedo”.
The raw string literals introduced in Swift 5 are a perfect fit for declaring regular expression patterns,
which frequently contain backslashes (such as for the \b metacharacter) that would otherwise need
to be escaped.
That solves our problem of missing out on invitations. The next question is how to respond in kind.
Searching and Retrieving Matches
Rather than merely checking for a non-nil value, we can actually use the return value to see the string
that got matched.
import Foundation
func respond(to invitation: String) {
if let range = invitation.range(of: #"\bClue(do)?™?\b"#,
options: .regularExpression) {
switch invitation[range] {
case "Cluedo":
print("I'd be delighted to play!")
case "Clue":
print("Did you mean Cluedo? If so, then yes!")
default:
fatalError("(Wait... did I mess up my regular expression?)")
}
} else {
print("Still waiting for an invitation to play Cluedo.")
}
}
Conveniently, the range returned by the range(of:...) method can be plugged into a subscript to get
a Substring for the matching range.
Finding and Replacing Matches
Once we’ve established that the game is on, the next step is to read the instructions. (Despite its relative
simplicity, players often forget important rules in Cluedo, such as needing to be in a room in order to
suggest it.)
Naturally, we play the original, British edition. But as a favor to the American players, I’ll go to the
trouble of localizing the rules on-the-fly. For example, the victim’s name in the original version is “Dr.
Black”, but in America, it’s “Mr. Boddy”.
We automate this process using the replacingOccurrences(of:with:options:) method — again
passing the .regularExpression option.
import Foundation
let instructions = """
The object is to solve by means of elimination and deduction
the problem of the mysterious murder of Dr. Black.
"""
instructions.replacingOccurrences(
of: #"(Dr\.|Doctor) Black"#,
with: "Mr. Boddy",
options: .regularExpression
)
Regular Expressions with NSRegularExpression
There are limits to what we can accomplish with the range(of:options:range:locale:) and
replacingOccurrences(of:with:options:) methods.
Specifically, you’ll need to use NSRegularExpression if you want to match a pattern more than once in
a string or extract values from capture groups.
Enumerating Matches with Positional Capture Groups
A regular expression can match its pattern one or more times on a string. Within each match, there may
be one or more capture groups, which are designated by enclosing by parentheses in the regex pattern.
For example, let’s say you wanted to use regular expressions to determine how many players you need
to play Cluedo:
import Foundation
let description = """
Cluedo is a game of skill for 2-6 players.
"""
let pattern = #"(\d+)[ \p{Pd}](\d+) players"#
let regex = try NSRegularExpression(pattern: pattern, options: [])
This pattern includes two capture groups for one or more digits, as denoted by the + operator and \d
metacharacter, respectively.
Between them, we match on a set containing a space and any character in the Unicode General Category
Pd (Punctuation, dash). This allows us to match on hyphen / minus (-), en dash (–), em dash (—), or
whatever other exotic typographical marks we might encounter.
The en dash is the correct punctuation for denoting a span or range of numbers.
We can use the enumerateMatches(in:options:range) method to try each match until we find one
that has three ranges (the entire match and the two capture groups), whose captured values can be
used to initialize a valid range. In the midst of all of this, we use the new(-ish) NSRange(_: in:) and
Range(_:in:) initializers to convert between String and NSString index ranges. Once we find such
a match, we set the third closure parameter (a pointer to a Boolean value) to true as a way to tell the
enumeration to stop.
var playerRange: ClosedRange<Int>?
let nsrange = NSRange(description.startIndex..<description.endIndex,
in: description)
regex.enumerateMatches(in: description,
options: [],
range: nsrange) { (match, _, stop) in
guard let match = match else { return }
if match.numberOfRanges == 3,
let firstCaptureRange = Range(match.range(at: 1),
in: description),
let secondCaptureRange = Range(match.range(at: 2),
in: description),
{
}
}
let lowerBound = Int(description[firstCaptureRange]),
let upperBound = Int(description[secondCaptureRange]),
lowerBound > 0 && lowerBound < upperBound
playerRange = lowerBound...upperBound
stop.pointee = true
print(playerRange!)
// Prints "2...6"
Each capture group can be accessed by position by calling the range(at:) method on the match object.
*Sigh*. What? No, we like the solution we came up with — longwinded as it may be. It’s just… gosh,
wouldn’t it be nice if we could play Cluedo solo?
Matching Multi-Line Patterns with Named Capture Groups
The only thing making Cluedo a strictly multiplayer affair is that you need some way to test a theory
without revealing the answer to yourself.
If we wanted to write a program to check that without spoiling anything for us, one of the first steps
would be to parse a suggestion into its component parts: suspect, location, and weapon.
let suggestion = """
I suspect it was Professor Plum, \
in the Dining Room, \
with the Candlestick.
"""
When writing a complex regular expression, it helps to know exactly which features your platform
supports. In the case of Swift, NSRegularExpression is a wrapper around the ICU regular expression
engine, which lets us do some really nice things:
let pattern = #"""
(?xi)
(?<suspect>
((Miss|Ms\.) \h Scarlett?) |
((Colonel | Col\.) \h Mustard) |
((Reverend | Mr\.) \h Green) |
(Mrs\. \h Peacock) |
((Professor | Prof\.) \h Plum) |
((Mrs\. \h White) | ((Doctor | Dr\.) \h Orchid))
),?(?-x: in the )
(?<location>
Kitchen
| Ballroom | Conservatory |
Dining \h Room
|
Library
|
Lounge
| Hall
| Study
),?(?-x: with the )
(?<weapon>
Candlestick
| Knife
| (Lead(en)?\h)? Pipe
| Revolver
| Rope
| Wrench
)
"""#
let regex = try NSRegularExpression(pattern: pattern, options: [])
First off, declaring the pattern with a multi-line raw string literal is a huge win in terms of readability.
That, in combination with the x and i flags within those groups, allows us to use whitespace to organize
our expression into something more understandable.
Another nicety is how this pattern uses named capture groups (designated by (?<name>)) instead of the
standard, positional capture groups from the previous example. Doing so allows us to access groups by
name by calling the range(withName:) method on the match object.
Beyond the more outlandish maneuvers, we have affordances for regional variations, including the
spelling of “Miss Scarlet(t)”, the title of “Mr. / Rev. Green”, and the replacement of Mrs. White with Dr.
Orchid in standard editions after 2016.
let nsrange = NSRange(suggestion.startIndex..<suggestion.endIndex,
in: suggestion)
if let match = regex.firstMatch(in: suggestion,
options: [],
range: nsrange)
{
for component in ["suspect", "location", "weapon"] {
let nsrange = match.range(withName: component)
if nsrange.location != NSNotFound,
let range = Range(nsrange, in: suggestion)
{
print("\(component): \(suggestion[range])")
}
}
//
//
//
//
}
Prints:
"suspect: Professor Plum"
"location: Dining Room"
"weapon: Candlestick"
Regular expressions are a powerful tool for working with text, but it’s often a mystery how to use them
in Swift. We hope this article has helped clue you into finding a solution.
Swift GYB
The term “boilerplate” goes back to the early days of print media. Small regional newspapers had column
inches to fill, but typically lacked the writing staff to make this happen, so many of them turned to large
print syndicates for a steady flow of content that could be added verbatim into the back pages of their
dailies. These stories would often be provided on pre-set plates, which resembled the rolled sheets of
steel used to make boilers, hence the name.
Through a process of metonymy, the content itself came to be known as “boilerplate”, and the concept
was appropriated to encompass standardized, formulaic text in contracts, form letters, and, most
relevant to this week’s article on NSHipster, code.
Not all code can be glamorous. In fact, a lot of the low-level infrastructure that makes everything work
is a slog of boilerplate.
This is true of the Swift standard library, which includes families of types like signed integers (Int8,
Int16, Int32, Int64) whose implementation varies only in the size of the respective type.
Copy-pasting code may work as a one-off solution (assuming you manage to get it right the first time),
but it’s not sustainable. Each time you want to make changes to these derived implementations, you risk
introducing slight inconsistencies that cause the implementations to diverge over time — not unlike
the random mutations responsible for the variation of life on Earth.
Languages have various techniques to cope with this, from C++ templates and Lisp macros to eval and
C preprocessor statements.
Swift doesn’t have a macro system, and because the standard library is itself written in Swift, it can’t take
advantage of C++ metaprogramming capabilities. Instead, the Swift maintainers use a Python script
called gyb.py to generate source code using a small set of template tags.
GYB is an acronym for “Generate Your Boilerplate”, a reference to another Python tool, GYP
(“Generate Your Projects”) the Haskell package SYB (“Scrap Your Boilerplate”) .
How GYB Works
GYB is a lightweight templating system that allows you to use Python code for variable substitution and
flow control:
• The sequence %{ code } evaluates a block of Python code
• The sequence % code : ... % end manages control flow
• The sequence ${ code } substitutes the result of an expression
All other text is passed through unchanged.
A good example of GYB can be found in Codable.swift.gyb. At the top of the file, the base Codable
types are assigned to an instance variable:
%{
codable_types = ['Bool', 'String', 'Double', 'Float',
'Int', 'Int8', 'Int16', 'Int32', 'Int64',
'UInt', 'UInt8', 'UInt16', 'UInt32', 'UInt64']
}%
Later on, in the implementation of SingleValueEncodingContainer, these types are iterated over to
generate the methods declarations for the protocol’s requirements:
% for type in codable_types:
mutating func encode(_ value: ${type}) throws
% end
Evaluating the GYB template results in the following declarations:
mutating
mutating
mutating
mutating
mutating
mutating
mutating
mutating
mutating
mutating
mutating
mutating
mutating
mutating
func
func
func
func
func
func
func
func
func
func
func
func
func
func
encode(_
encode(_
encode(_
encode(_
encode(_
encode(_
encode(_
encode(_
encode(_
encode(_
encode(_
encode(_
encode(_
encode(_
value:
value:
value:
value:
value:
value:
value:
value:
value:
value:
value:
value:
value:
value:
Bool) throws
String) throws
Double) throws
Float) throws
Int) throws
Int8) throws
Int16) throws
Int32) throws
Int64) throws
UInt) throws
UInt8) throws
UInt16) throws
UInt32) throws
UInt64) throws
This pattern is used throughout the file to generate similarly formulaic declarations for methods like
encode(_:forKey:), decode(_:forKey:), and decodeIfPresent(_:forKey:). In total, GYB reduces
the amount of boilerplate code by a few thousand LOC:
$ wc
2183
$ wc
5790
-l Codable.swift.gyb
Codable.swift.gyb
-l Codable.swift
Codable.swift
A valid GYB template may not generate valid Swift code. If compilation errors occur in derived files,
it may be difficult to determine the underlying cause.
Installing GYB
GYB isn’t part of the standard Xcode toolchain, so you won’t find it with xcrun. Instead, you can
download it using Homebrew:
$ brew install nshipster/formulae/gyb
Alternatively, you can download the source code and use the chmod command to make gyb executable
(the default installation of Python on macOS should be able to run gyb):
$ wget https://github.com/apple/swift/raw/master/utils/gyb
$ wget https://github.com/apple/swift/raw/master/utils/gyb.py
$ chmod +x gyb
If you go this route, be sure to move these somewhere that can be accessed from your Xcode project,
but keep them separate from your source files (for example, a Vendor directory at your project root).
Using GYB in Xcode
In Xcode, click on the blue project file icon in the navigator, select the active target in your project, and
navigate to the “Build Phases” panel. At the top, you’ll see a + symbol that you can click to add a new
build phase. Select “Add New Run Script Phase”, and enter the following into the source editor:
find . -name '*.gyb' |
\
while read file; do
\
./path/to/gyb --line-directive '' -o "${file%.gyb}" "$file"; \
done
Make sure to order the GYB build phase before Compile Sources.
Now when you build your project any file with the .swift.gyb file extension is evaluated by GYB,
which outputs a .swift file that’s compiled along with the rest of the code in the project.
When to Use GYB
As with any tool, knowing when to use it is just as important as knowing how. Here are some examples
of when you might open your toolbox and reach for GYB.
Generating Formulaic Code
Are you copy-pasting the same code for elements in a set or items in a sequence? A for-in loop with
variable substitution might be the solution.
As seen in the example with Codable from before, you can declare a collection at the top of your GYB
template file and then iterate over that collection for type, property, or method declarations:
%{
abilities = ['strength', 'dexterity', 'constitution',
'intelligence', 'wisdom', 'charisma']
}%
class Character {
var name: String
% for ability in abilities:
var ${ability}: Int
% end
}
Evaluating this with GYB produces the following Swift code:
class Character {
var name: String
}
var
var
var
var
var
var
strength: Int
dexterity: Int
constitution: Int
intelligence: Int
wisdom: Int
charisma: Int
A lot of repetition in code is a smell and may indicate that there’s a better way to accomplish your task.
Built-in language feature like protocol extensions and generics can eliminate a lot of code duplication,
so be on the lookout to use these instead of brute-forcing with GYB.
Generating Code Derived from Data
Are you writing code based on a data source? Try incorporating GYB into your development!
GYB files can import Python packages like json, xml, and csv, so you can parse pretty much any kind
of file you might encounter:
%{ import csv }
% with open('path/to/file.csv') as file:
% for row in csv.DictReader(file):
If you want to see this in action, check out Currencies.swift.gyb which generates Swift enumerations for
each of the currencies defined by the ISO 4217 specification.
Keep compilation fast and deterministic by downloading data to files that can be checked into
source control rather than making HTTP requests or database queries in GYB files.
Code generation makes it trivial to keep your code in sync with the relevant standards. Simply update
the data file and re-run GYB.
Swift has done a lot to cut down on boilerplate recently with the addition of compiler synthesis of
Encodable and Decodable in 4.0, Equatable and Hashable in 4.1, and CaseIterable in 4.2. We hope
that this momentum is carried in future updates to the language.
In the meantime, for everything else, GYB is a useful tool for code generation.
Another great tool from the community for this is Sourcery, which allows you to write templates in
Swift (via Stencil) rather than Python.
“Don’t Repeat Yourself ” may be a virtue in programming, but sometimes you have to say things a few
times to make things work. When you do, you’ll be thankful to have a tool like GYB to say it for you.
SwiftSyntax
SwiftSyntax is a Swift library that lets you parse, analyze, generate, and transform Swift source code.
It’s based on the libSyntax library, and was spun out from the main Swift language repository in
August 2017.
Together, the goal of these projects is to provide safe, correct, and intuitive facilities for structured
editing, which is described thusly:
What is structured editing? It’s an editing strategy that is keenly aware of the structure of source
code, not necessarily its representation (i.e. characters or bytes). This can be achieved at different
granularities: replacing an identifier, changing a call to global function to a method call, or
indenting and formatting an entire source file based on declarative rules.
At the time of writing, SwiftSyntax is still in development and subject to API changes. But you can start
using it today to work with Swift source code in a programmatic way.
It’s currently used by the Swift Migrator, and there are ongoing efforts to adopt the tool, both internally
and externally.
How Does It Work?
To understand how SwiftSyntax works, let’s take a step back and look at the Swift compiler architecture:
The Swift compiler is primarily responsible for turning Swift code into executable machine code. The
process is divided up into several discrete steps, starting with the parser, which generates an abstract
syntax tree, (AST). From there, semantic analysis is performed on the syntax to produce a type-checked
AST, which lowered into Swift Intermediate Language; the SIL is transformed and optimized and itself
lowered into LLVM IR, which is ultimately compiled into machine code.
The most important takeaway for our discussion is that SwiftSyntax operates on the AST generated at
the first step of the compilation process. As such, it can’t tell you any semantic or type information
about code.
Contrast this with something like SourceKit, which operates with a much more complete understanding
of Swift code. This additional information can be helpful for implementing editor features like codecompletion or navigating across files. But there are plenty of important use cases that can be satisfied
on a purely syntactic level, such as code formatting and syntax highlighting.
Demystifying the AST
Abstract syntax trees can be difficult to understand in the abstract. So let’s generate one and see what it
looks like.
Consider the following single-line Swift file, which declares a function named one() that returns the
value 1:
func one() -> Int { return 1 }
Run the swiftc command on this file passing the -frontend -emit-syntax arguments:
$ xcrun swiftc -frontend -emit-syntax ./One.swift
The result is a chunk of JSON representing the AST. Its structure becomes much clearer once you
reformat the JSON:
{
"kind": "SourceFile",
"layout": [{
"kind": "CodeBlockItemList",
"layout": [{
"kind": "CodeBlockItem",
"layout": [{
"kind": "FunctionDecl",
"layout": [null, null, {
"tokenKind": {
"kind": "kw_func"
},
"leadingTrivia": [],
"trailingTrivia": [{
"kind": "Space",
"value": 1
}],
"presence": "Present"
}, {
"tokenKind": {
"kind": "identifier",
"text": "one"
},
"leadingTrivia": [],
"trailingTrivia": [],
"presence": "Present"
}, ...
The Python json.tool module offers a convenient way to format JSON. It comes standard in
macOS releases going back as far as anyone can recall. For example, here’s how you could use it
with the redirected compiler output:
$ xcrun swiftc -frontend -emit-syntax ./One.swift | python -m json.tool
At the top-level, we have a SourceFile consisting of CodeBlockItemList elements and their constituent
CodeBlockItem parts. This example has a single CodeBlockItem for the function declaration (Function
Decl), which itself comprises subcomponents including a function signature, parameter clause, and
return clause.
The term trivia is used to describe anything that isn’t syntactically meaningful, like whitespace. Each
token can have one or more pieces of leading and trailing trivia. For example, the space after the Int in
the return clause (-> Int) is represented by the following piece of trailing trivia.
{
}
"kind": "Space",
"value": 1
Working Around File System Constraints
SwiftSyntax generates abstract syntax trees by delegating system calls to swiftc. However, this requires
code to be associated with a file in order to be processed, and it’s often useful to work with code as
a string.
One way to work around this constraint is to write code to a temporary file and pass that to the compiler.
We’ve written about temporary files in the past, but nowadays, there’s a much nicer API for working
with them that’s provided by the Swift Package Manager itself. In your Package.swift file, add the
following package dependency, and add the "Utility" dependency to the appropriate target:
.package(url: "https://github.com/apple/swift-package-manager.git", from:
"0.3.0"),
Now, you can import the Basic module and use its TemporaryFile API like so:
import Basic
import Foundation
let code: String
let tempfile = try TemporaryFile(deleteOnClose: true)
defer { tempfile.fileHandle.closeFile() }
tempfile.fileHandle.write(code.data(using: .utf8)!)
let url = URL(fileURLWithPath: tempfile.path.asString)
let sourceFile = try SyntaxTreeParser.parse(url)
What Can You Do With It?
Now that we have a reasonable idea of how SwiftSyntax works, let’s talk about some of the ways that
you can use it!
Writing Swift Code: The Hard Way
The first and least compelling use case for SwiftSyntax is to make writing Swift code an order of
magnitude more difficult.
SwiftSyntax, by way of its SyntaxFactory APIs, allows you to generate entirely new Swift code from
scratch. Unfortunately, doing this programmatically isn’t exactly a walk in the park.
For example, consider the following code:
import SwiftSyntax
let structKeyword = SyntaxFactory.makeStructKeyword(trailingTrivia: .spaces(1))
let identifier = SyntaxFactory.makeIdentifier("Example", trailingTrivia:
.spaces(1))
let leftBrace = SyntaxFactory.makeLeftBraceToken()
let rightBrace = SyntaxFactory.makeRightBraceToken(leadingTrivia: .newlines(1))
let members = MemberDeclBlockSyntax { builder in
builder.useLeftBrace(leftBrace)
builder.useRightBrace(rightBrace)
}
let structureDeclaration = StructDeclSyntax { builder in
builder.useStructKeyword(structKeyword)
builder.useIdentifier(identifier)
builder.useMembers(members)
}
print(structureDeclaration)
Whew. So what did all of that effort get us?
struct Example {
}
Oofa doofa.
This certainly isn’t going to replace GYB for everyday code generation purposes. (In fact, libSyntax and
SwiftSyntax both make extensive use of gyb to generate its interfaces.)
But this interface can be quite useful when precision matters. For instance, you might use SwiftSyntax
to implement a fuzzer for the Swift compiler, using it to randomly generate arbitrarily-complex-butostensibly-valid programs to stress test its internals.
Rewriting Swift Code
The example provided in the SwiftSyntax README shows how to write a program to take each integer
literal in a source file and increment its value by one.
Looking at that, you can already extrapolate out to how this might be used to create a canonical
swift-format tool.
But for the moment, let’s consider a considerably less productive — and more seasonally appropriate (
) — use of source rewriting:
import SwiftSyntax
public class ZalgoRewriter: SyntaxRewriter {
public override func visit(_ token: TokenSyntax) -> Syntax {
guard case let .stringLiteral(text) = token.tokenKind else {
return token
}
}
}
return token.withKind(.stringLiteral(zalgo(text)))
What’s that zalgo function all about? You’re probably better off not knowing…
Anyway, running this rewriter on your source code transforms all string literals in the following manner:
// Before
print("Hello, world!")
// After
print("H͞͏̟̂ͩel̵ͬ͆͜ĺ͎̪̣͠ơ̡̼͓̋͝, w͎̽̇ͪ͢ǒ̩͔̲̕͝r̷̡̠͓̉͂l̘̳̆ͯ̊d!")
Spooky, right?
Highlighting Swift Code
Let’s conclude our look at SwiftSyntax with something that’s actually useful: a Swift syntax highlighter.
A syntax highlighter, in this sense, describes any tool that takes source code and formats it in a way that’s
more suitable for display in HTML.
NSHipster is built on top of Jekyll, and uses the Ruby library Rouge to colorize the example code you
see in every article. However, due to Swift’s relatively complex syntax and rapid evolution, the generated
HTML isn’t always 100% correct.
Instead of messing with a pile of regular expressions, we could instead build a syntax highlighter that
leverages SwiftSyntax’s superior understanding of the language.
At its core, the implementation is rather straightforward: implement a subclass of SyntaxRewriter
and override the visit(_:) method that’s called for each token as a source file is traversed. By
switching over each of the different kinds of tokens, you can map them to the HTML markup for their
corresponding highlighter tokens.
For example, numeric literals are represented with <span> elements whose class name begins with
the letter m (mf for floating-point, mi for integer, etc.). Here’s the corresponding code in our Syntax
Rewriter subclass:
import SwiftSyntax
class SwiftSyntaxHighlighter: SyntaxRewriter {
var html: String = ""
override func visit(_ token: TokenSyntax) -> Syntax {
switch token.tokenKind {
…
case .floatingLiteral(let string):
html += "<span class=\"mf\">\(string)</span>"
case .integerLiteral(let string):
if string.hasPrefix("0b") {
html += "<span class=\"mb\">\(string)</span>"
} else if string.hasPrefix("0o") {
html += "<span class=\"mo\">\(string)</span>"
} else if string.hasPrefix("0x") {
html += "<span class=\"mh\">\(string)</span>"
} else {
html += "<span class=\"mi\">\(string)</span>"
}
…
default:
break
}
}
}
return token
Although SyntaxRewriter has specialized visit(_:) methods for each of the different kinds of syntax
elements, I found it easier to handle everything in a single switch statement. (Printing unhandled
tokens in the default branch was a really helpful way to find any cases that I wasn’t already handling).
It’s not the most elegant of implementations, but it was a convenient place to start given my limited
understanding of the library.
Anyway, after a few hours of development, I was able to generate reasonable colorized output for a wide
range of Swift syntactic features:
The project comes with a library and a command line tool. Go ahead and try it out and let me know
what you think!
Swift Documentation
Code structure and organization is a matter of pride for developers. Clear and consistent code signifies
clear and consistent thought. Even though the compiler lacks a discerning palate when it comes to
naming, whitespace, or documentation, it makes all the difference for human collaborators.
This week, we’ll be documenting the here and now of documentation in Swift.
Since the early ’00s, Headerdoc has been Apple’s preferred documentation standard. Starting off as little
more than a Perl script that parsed trumped-up Javadoc comments, Headerdoc would eventually be the
engine behind Apple’s developer documentation online and in Xcode.
But like so much of the Apple developer ecosystem, Swift changed everything. In the spirit of “Out
with the old, in with the new”, Xcode 7 traded Headerdoc for fan favorite Markdown — specifically,
Swift-flavored Markdown.
Documentation Comments & Swift-Flavored Markdown
Even if you’ve never written a line of Markdown before, you can get up to speed in just a few minutes.
Here’s pretty much everything you need to know:
Basic Markup
Documentation comments look like normal comments, but with a little something extra. Single-line
documentation comments have three slashes (///). Multi-line documentation comments have an extra
star in their opening delimiter (/** ... */).
Standard Markdown rules apply inside documentation comments:
• Paragraphs are separated by blank lines.
• Unordered lists are marked by bullet characters (-, +, *, or •).
• Ordered lists use numerals (1, 2, 3, …) followed by either a period (1.) or a right parenthesis (1)).
• Headers are preceded by # signs or underlined with = or -.
• Both links and images work, with web-based images pulled down and displayed directly in Xcode.
/**
# Lists
You can apply *italic*, **bold**, or `code` inline styles.
## Unordered Lists
- Lists are great,
- but perhaps don't nest;
- Sub-list formatting...
- ...isn't the best.
## Ordered Lists
*/
1.
2.
3.
4.
Ordered lists, too,
for things that are sorted;
Arabic numerals
are the only kind supported.
Summary & Description
The leading paragraph of a documentation comment becomes the documentation Summary. Any
additional content is grouped together into the Discussion section.
If a documentation comment starts with anything other than a paragraph, all of its content is put
into the Discussion.
Parameters & Return Values
Xcode recognizes a few special fields and makes them separate from a symbol’s description. The
parameters, return value, and throws sections are broken out in the Quick Help popover and inspector
when styled as a bulleted item followed by a colon (:).
• Parameters: Start the line with Parameter <param name>: and the description of the
parameter.
• Return values: Start the line with Returns: and information about the return value.
• Thrown errors: Start the line with Throws: and a description of the errors that can be thrown.
Since Swift doesn’t type-check thrown errors beyond Error conformance, it’s especially important
to document errors properly.
/**
Creates a personalized greeting for a recipient.
- Parameter recipient: The person being greeted.
- Throws: `MyError.invalidRecipient`
if `recipient` is "Derek"
(he knows what he did).
- Returns: A new string saying hello to `recipient`.
*/
func greeting(to recipient: String) throws -> String {
guard recipient != "Derek" else {
throw MyError.invalidRecipient
}
}
return "Greetings, \(recipient)!"
Are you documenting a function whose method signature has more arguments than a Hacker News
thread about tabs vs. spaces? Break out your parameters into a bulleted list underneath a Parameters:
callout:
/// Returns the magnitude of a vector in three dimensions
/// from the given components.
///
/// - Parameters:
///
- x: The *x* component of the vector.
///
- y: The *y* component of the vector.
///
- z: The *z* component of the vector.
func magnitude3D(x: Double, y: Double, z: Double) -> Double {
return sqrt(pow(x, 2) + pow(y, 2) + pow(z, 2))
}
Additional Fields
In addition to Parameters, Throws and Returns, Swift-flavored Markdown defines a handful of other
fields, which can be loosely organized in the following way:
Algorithm/Safety Information
Metadata
General Notes & Exhortations
• Precondition
• Author
• Attention
• Postcondition
• Authors
• Bug
• Requires
• Copyright
• Experiment
• Invariant
• Date
• Note
• Complexity
• SeeAlso
• Remark
• Important
• Since
• ToDo
• Warning
• Version
Each of these fields is rendered in Quick Help as a bold header followed by a block of text:
Field Header:
The text of the subfield is displayed starting on the next line.
Code blocks
Demonstrate the proper usage or implementation details of a function by embedding code blocks. Inset
code blocks by at least four spaces:
/**
The area of the `Shape` instance.
Computation depends on the shape of the instance.
For a triangle, `area` is equivalent to:
let height = triangle.calculateHeight()
let area = triangle.base * height / 2
*/
var area: CGFloat { get }
Fenced code blocks are also recognized, delimited by either three backticks (`) or tildes (~):
/**
The perimeter of the `Shape` instance.
Computation depends on the shape of the instance, and is
equivalent to:
~~~
// Circles:
let perimeter = circle.radius * 2 * Float.pi
// Other shapes:
let perimeter = shape.sides.map { $0.length }
.reduce(0, +)
~~~
*/
var perimeter: CGFloat { get }
Documentation Is My New Bicycle
How does this look when applied to an entire class? Quite nice, actually!
///
A two-wheeled, human-powered mode of transportation.
class Bicycle {
/// Frame and construction style.
enum Style {
/// A style for streets or trails.
case road
/// A style for long journeys.
case touring
/// A style for casual trips around town.
case cruiser
}
/// A style for general-purpose transportation.
case hybrid
/// Mechanism for converting pedal power into motion.
enum Gearing {
/// A single, fixed gear.
case fixed
}
/// A variable-speed, disengageable gear.
case freewheel(speeds: Int)
/// Hardware used for steering.
enum Handlebar {
/// A casual handlebar.
case riser
/// An upright handlebar.
case café
/// A classic handlebar.
case drop
}
/// A powerful handlebar.
case bullhorn
/// The style of the bicycle.
let style: Style
/// The gearing of the bicycle.
let gearing: Gearing
/// The handlebar of the bicycle.
let handlebar: Handlebar
/// The size of the frame, in centimeters.
let frameSize: Int
/// The number of trips traveled by the bicycle.
private(set) var numberOfTrips: Int
/// The total distance traveled by the bicycle, in meters.
private(set) var distanceTraveled: Double
/**
Initializes a new bicycle with the provided parts and specifications.
- Parameters:
- style: The style of the bicycle
- gearing: The gearing of the bicycle
- handlebar: The handlebar of the bicycle
- frameSize: The frame size of the bicycle, in centimeters
- Returns: A beautiful, brand-new bicycle,
custom-built just for you.
*/
init(style: Style,
gearing: Gearing,
handlebar: Handlebar,
frameSize centimeters: Int)
{
self.style = style
self.gearing = gearing
self.handlebar = handlebar
self.frameSize = centimeters
}
self.numberOfTrips = 0
self.distanceTraveled = 0
/**
Take a bike out for a spin.
Calling this method increments the `numberOfTrips`
and increases `distanceTraveled` by the value of `meters`.
- Parameter meters: The distance to travel in meters.
- Precondition: `meters` must be greater than 0.
*/
func travel(distance meters: Double) {
precondition(meters > 0)
}
}
distanceTraveled += meters
numberOfTrips += 1
Option-click on the initializer declaration, and the description renders beautifully with a bulleted list:
Open Quick Documentation for the method travel, and the parameter is parsed out into a separate
field, as expected:
MARK / TODO / FIXME
In Objective-C, the preprocessor directive #pragma mark is used to divide functionality into meaningful,
easy-to-navigate sections. In Swift, the same can be accomplished with the comment // MARK:.
The following comments are surfaced in the Xcode source navigator:
• // MARK:
• // TODO:
• // FIXME:
Other conventional comment tags, such as NOTE and XXX aren’t recognized by Xcode.
As with #pragma, marks followed by a single dash (-) are preceded with a horizontal divider
To show these new tags in action, here’s how the Bicycle class could be extended to adopt the Custom
StringConvertible protocol, and implement the description property.
// MARK: - CustomStringConvertible
extension Bicycle: CustomStringConvertible {
public var description: String {
var descriptors: [String] = []
switch self.style {
case .road:
descriptors.append("A
case .touring:
descriptors.append("A
case .cruiser:
descriptors.append("A
case .hybrid:
descriptors.append("A
transportation")
}
road bike for streets or trails")
touring bike for long journeys")
cruiser bike for casual trips around town")
hybrid bike for general-purpose
switch self.gearing {
case .fixed:
descriptors.append("with a single, fixed gear")
case .freewheel(let n):
descriptors.append("with a \(n)-speed freewheel gear")
}
switch self.handlebar {
case .riser:
descriptors.append("and
case .café:
descriptors.append("and
case .drop:
descriptors.append("and
case .bullhorn:
descriptors.append("and
}
casual, riser handlebars")
upright, café handlebars")
classic, drop handlebars")
powerful bullhorn handlebars")
descriptors.append("on a \(frameSize)\" frame")
// FIXME: Use a distance formatter
descriptors.append("with a total of \(distanceTraveled) meters traveled
over \(numberOfTrips) trips.")
// TODO: Allow bikes to be named?
}
}
return descriptors.joined(separator: ", ")
Bringing everything together in code:
var bike = Bicycle(style: .road,
gearing: .freewheel(speeds: 8),
handlebar: .drop,
frameSize: 53)
bike.travel(distance: 1_500) // Trip around the town
bike.travel(distance: 200) // Trip to the store
print(bike)
// "A road bike for streets or trails, with a 8-speed freewheel gear, and
classic, drop handlebars, on a 53" frame, with a total of 1700.0 meters
traveled over 2 trips."
At the time of writing, there’s no official tool for transforming documentation comments into something
more tangible than Quick Help panels in Xcode,
Fortunately, where necessity arises, open source (often) delivers.
Jazzy
Jazzy is a terrific open-source command-line utility that transforms your project’s documentation
comments into a set of Apple-like HTML documentation (but that nice vintage style, before that
whole redesign). Jazzy uses Xcode’s SourceKitService to read your beautifully written type and method
descriptions.
Install Jazzy as a gem, then run from the root of your project folder to generate documentation.
$ gem install jazzy
$ jazzy
Running xcodebuild
Parsing ...
building site
jam out ♪♫ to your fresh new docs in `docs`
Take a peek at a Jazzy-generated documentation for the Bicycle class.
Although the tooling and documentation around Swift is still developing, one would be wise to
adopt good habits early, by using the new Markdown capabilities for documentation, as well as MARK:
comments in Swift code going forward.
Go ahead and add it to your TODO: list.
Swift Property Observers
By the 1930’s, Rube Goldberg had become a household name, synonymous with the fantastically
complicated and whimsical inventions depicted in comic strips like “Self-Operating Napkin.” Around
the same time, Albert Einstein popularized the phrase “spooky action at a distance” in his critique of
the prevailing interpretation of quantum mechanics by Niels Bohr.
Nearly a century later, modern software development has become what might be seen as the
quintessence of a Goldbergian contraption — sprawling ever closer into that spooky realm by way of
quantum computers.
As software developers, we’re encouraged to reduce action-at-a-distance in our code whenever possible.
This is codified in impressive-sounding guidelines like the Single Responsibility Principle, Principle of
Least Astonishment, and Law of Demeter. Yet despite their misgivings about code that produces side
effects, there are sometimes occasions where such techniques may clarify rather than confound.
Such is the focus of this week’s article about property observers in Swift, which offer a built-in,
lightweight alternative to more formalized solutions like model-view-viewmodel (MVVM) functional
reactive programming (FRP).
There are two kinds of properties in Swift: stored properties, which associate state with an object, and
computed properties, which perform a calculation based on that state. For example,
struct S {
// Stored Property
var stored: String = "stored"
}
// Computed Property
var computed: String {
return "computed"
}
When you declare a stored property, you have the option to define property observers with blocks of
code to be executed when a property is set. The willSet observer runs before the new value is stored
and the didSet observer runs after. And they run regardless of whether the old value is equal to the
new value.
struct S {
var stored: String {
willSet {
print("willSet was called")
print("stored is now equal to \(self.stored)")
print("stored will be set to \(newValue)")
}
}
}
didSet {
print("didSet was called")
print("stored is now equal to \(self.stored)")
print("stored was previously set to \(oldValue)")
}
For example, running the following code prints the resulting text to the console:
var s = S(stored: "first")
s.stored = "second"
• willSet was called
• stored is now equal to first
• stored will be set to second
• didSet was called
• stored is now equal to second
• stored was previously set to first
An important caveat is that observers don’t run when you set a property in an initializer. As of Swift
4.2, you can work around that by wrapping the setter call in a defer block, but that’s a bug that
will soon be fixed, so you shouldn’t depend on this behavior.
Swift property observers have been part of the language from the very beginning. To better understand
why, let’s take a quick look at how things work in Objective-C:
Properties in Objective-C
In Objective-C, all properties are, in a sense, computed. Each time a property is accessed through dot
notation, the call is translated into an equivalent getter or setter method invocation. This, in turn, is
compiled into a message send that executes a function that reads or writes an instance variable.
// Dot accessor
person.name = @"Johnny";
// ...is equivalent to
[person setName:@"Johnny"];
// ...which gets compiled to
objc_msgSend(person, @selector(setName:), @"Johnny");
// ...whose synthesized implementation yields
person->_name = @"Johnny";
Side effects are something you generally want to avoid in programming because they make it difficult
to reason about program behavior. But many Objective-C developers had come to rely on the ability to
inject additional behavior into getter or setter methods as needed.
Swift’s design for properties formalized these patterns and created a distinction between side effects
that decorate state access (stored properties) and those that redirect state access (computed properties).
For stored properties, the willSet and didSet observers replace the code that you’d otherwise include
alongside ivar access. For computed properties, the get and set accessors replace code that you might
implement for @dynamic properties in Objective-C.
As a result, we get more consistent semantics and better guarantees about mechanisms like Key-Value
Observing (KVO) and Key-Value Coding (KVC) that interact with properties.
So what can you do with property observers in Swift? Here are a couple ideas for your consideration:
Validating / Normalizing Values
Sometimes you want to impose additional constraints on what values are acceptable for a type.
For example, if you were developing an app that interfaced with a government bureaucracy, you’d need
to ensure that the user wouldn’t be able to submit a form if it was missing a required field, or contained
an invalid value.
If, say, a form required that names use capital letters without accents, you could use the didSet property
observer to automatically strip diacritics and uppercase the new value:
var name: String? {
didSet {
self.name = self.name?
.applyingTransform(.stripDiacritics,
reverse: false)?
.uppercased()
}
}
Setting a property in the body of an observer (fortunately) doesn’t trigger additional callbacks, so we
don’t create an infinite loop here. This is the same reason why this won’t work as a willSet observer;
any value set in the callback is immediately overwritten when the property is set to its newValue.
While this approach can work for one-off problems, repeat use like this is a strong indicator of business
logic that could be formalized in a type.
A better design would be to create a NormalizedText type that encapsulates the requirements of text
to be entered in such a form:
struct NormalizedText {
enum Error: Swift.Error {
case empty
case excessiveLength
case unsupportedCharacters
}
static let maximumLength = 32
private(set) var value: String
init(_ string: String) throws {
if string.isEmpty {
throw Error.empty
}
guard let value = string.applyingTransform(.stripDiacritics,
reverse: false)?
.uppercased(),
value.canBeConverted(to: .ascii)
else {
throw Error.unsupportedCharacters
}
guard value.count < NormalizedText.maximumLength else {
throw Error.excessiveLength
}
}
}
self.value = value
A failable or throwing initializer can surface errors to the caller in a way that a didSet observer can’t.
Now, when a troublemaker like Jøhnny from Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch
comes a’knocking, we can give him what’s for! (Which is to say, communicate errors to him in a
reasonable manner rather than failing silently or allowing invalid data)
Propagating Dependent State
Another potential use case for property observers is propagating state to dependent components in a
view controller.
Consider the following example of a Track model and a TrackViewController that presents it:
struct Track {
var title: String
var audioURL: URL
}
class TrackViewController: UIViewController {
var player: AVPlayer?
var track: Track? {
willSet {
}
self.player?.pause()
didSet {
guard let track = self.track else {
return
}
self.title = track.title
}
}
}
let item = AVPlayerItem(url: track.audioURL)
self.player = AVPlayer(playerItem: item)
self.player?.play()
When the track property of the view controller is set, the following happens automatically:
1. Any previous track’s audio is paused
2. The title of the view controller is set to the new track title
3. The new track’s audio is loaded and played
Pretty cool, right?
You could even cascade this behavior across multiple observed properties a la that one scene from
Mousehunt.
As a general rule, side effects are something to avoid when programming, because they make it difficult
to reason about complex behavior. Keep that in mind the next time you reach for this new tool.
And yet, from the tippy top of this teetering tower of abstraction, it can be tempting — and perhaps
sometimes rewarding — to embrace the chaos of the system. Always following the rules is such a Bohr.
Cocoa
TimeInterval, Date, and Date
Interval
Nestled between Madrid’s Centro and Salamanca districts, just a short walk from the sprawling Buen
Retiro Park, The Prado Museum boasts an extensive collection of works from Europe’s most celebrated
painters. But if, during your visit, you begin to tire of portraiture commissioned by 17th-century
Spanish monarchs, consider visiting the northernmost room of the 1st floor — Sala 002. There you’ll
find this Baroque era painting by the French artist Simon Vouet.
You’d be forgiven for wondering why this pair of young women, brandishing a hook and spear, stand
menacingly over a cowering old man while a mob of cherubim tears at his back. It is, of course,
allegorical: reading the adjacent placard, you’ll learn that this piece is entitled Time defeated by Hope
and Beauty. The old man? That’s Time. See the hourglass in his hand and scythe at his feet?
Take a moment, standing in front of this painting, to reflect on the enigmatic nature of time. Think
now about how our limited understanding of time is reflected in — or perhaps exacerbated by — the
naming of the Foundation date and time APIs.
It’s about time we got them straight.
Seconds are the fundamental unit of time. They’re also the only unit that has a fixed duration.
Months vary in length (“30 days hath September”), as do years (“53 weeks hath 71 years every cycle of
400”). Certain years pick up an extra day (leap years are misnamed if you think about it), and days gain
and lose an hour from daylight saving time (thanks, Benjamin Franklin). And that’s to say nothing of
leap seconds, which are responsible for such oddities as the 61 second minute, the 3601 second hour,
and, of course, the 1209601 second fortnight.
TimeInterval
(née NSTimeInterval) is a typealias for Double that represents duration as a number
of seconds. You’ll see it as a parameter or return type for APIs that deal with a duration of time. Being
a double-precision floating-point number, TimeInterval can represent submultiples in its fraction,
(though for anything beyond millisecond precision, you’ll want to use something else).
Date and Time
It’s unfortunate that the Foundation type representing time is named Date. Colloquially, one typically
distinguishes “dates” from “times” by saying that the former has to do with calendar days and the latter
has more to do with the time of day. But Date is entirely orthogonal from calendars, and contrary to its
name represents an absolute point in time.
Why NSDate and not NSTime? Our guess is that the originators of this API wanted to match its
counterpart in java.util.date when EOF targeted both Java and Objective-C.
Another source of confusion for Date is that, despite representing an absolute point in time, it’s defined
by a time interval since a reference date:
public struct Date : ReferenceConvertible, Comparable, Equatable {
public typealias ReferenceType = NSDate
fileprivate var _time: TimeInterval
}
…
The reference date, in this case, is the first instant of January 1, 2001, Greenwich Mean Time (GMT).
While we’re on the subject of conjectural sidebars, does anyone know why Apple created a new
standard instead of using, say, the Unix Epoch (January 1, 1970)? 2001 was the year that Mac OS
X was first released, but NSDate pre-NSDates that from its NeXT days. Was it perhaps a hedge
against Y2K?
Date Intervals and Time Intervals
DateInterval
is a recent addition to Foundation. Introduced in iOS 10 and macOS Sierra, this type
represents a closed interval between two absolute points in time (again, in contrast to TimeInterval,
which represents a duration in seconds).
So what is this good for? Consider the following use cases:
Getting the Date Interval of a Calendar Unit
In order to know the time of day for a point in time — or what day it is in the first place — you need
to consult a calendar. From there, you can determine the range of a particular calendar unit, like a day,
month, or year. The Calendar method dateInterval(of:for:) makes this really easy to do:
let calendar = Calendar.current
let date = Date()
let dateInterval = calendar.dateInterval(of: .month, for: date)
Because we’re invoking Calendar, we can be confident in the result that we get back. Look how it
handles daylight saving transition without breaking a sweat:
let dstComponents = DateComponents(year: 2018,
month: 11,
day: 4)
calendar.dateInterval(of: .day,
for: calendar.date(from: dstComponents)!)?.duration
// 90000 seconds
It’s 2018. Don’t you think that it’s time you stopped hard-coding secondsInDay = 86400?
Calculating Intersections of Date Intervals
For this example, let’s return to The Prado Museum and admire its extensive collection of paintings by
Rubens — particularly this apparent depiction of the god of Swift programming.
Rubens, like Vouet, painted in the Baroque tradition. The two were contemporaries, and we can
determine the full extent of how they overlap in the history of art with the help of DateInterval:
import Foundation
let calendar = Calendar.current
// Simon Vouet
// 9 January 1590 – 30 June 1649
let vouet =
DateInterval(start: calendar.date(from:
DateComponents(year: 1590, month: 1, day: 9))!,
end: calendar.date(from:
DateComponents(year: 1649, month: 6, day: 30))!)
// Peter Paul Rubens
// 28 June 1577 – 30 May 1640
let rubens =
DateInterval(start: calendar.date(from:
DateComponents(year: 1577, month: 6, day: 28))!,
end: calendar.date(from:
DateComponents(year: 1640, month: 5, day: 30))!)
let overlap = rubens.intersection(with: vouet)!
calendar.dateComponents([.year],
from: overlap.start,
to: overlap.end) // 50 years
According to our calculations, there was a period of 50 years where both painters were living.
We can even take things a step further and use DateIntervalFormatter to provide a nice representation
of that time period:
let formatter = DateIntervalFormatter()
formatter.timeStyle = .none
formatter.dateTemplate = "%Y"
formatter.string(from: overlap)
// "1590 – 1640"
Beautiful. You might as well print this code out, frame it, and hang it next to The Judgement of Paris.
The fact is, we still don’t really know what time is (or if it even actually exists). But I’m hopeful that we,
as developers, will find the beauty in Foundation’s Date APIs, and in time, learn how to overcome our
lack of understanding.
That does it for this week’s article. See you all next time.
CharacterSet
In Japan, there’s a comedy tradition known as Manzai (漫才). It’s kind of a cross between stand up
and vaudeville, with a straight man and a funny man delivering rapid-fire jokes that revolve around
miscommunication and wordplay.
As it were, we’ve been working on a new routine as a way to introduce the subject for this week’s article,
CharacterSet, and wanted to see what you thought:
Is CharacterSet a Set<Character>?
キャラクターセットではないキャラクターセット?
Of course not!
もちろん違います!
What about NSCharacterSet?
何エンエスキャラクタセットは?
That's an old reference.
それは古いリファレンスです。
Then what do you call a collection of characters?
何と呼ばれる文字の集合ですか?
That would be a String!
それは文字列でしょ!
(╯° 益 °)╯ 彡 ┻━┻
無駄無駄無駄無駄無駄無駄無駄
(Yeah, we might need to workshop this one a bit more.)
All kidding aside, CharacterSet is indeed ripe for miscommunication and wordplay (so to speak): it
doesn’t store Character values, and it’s not a Set in the literal sense.
So what is CharacterSet and how can we use it? Let’s find out! (行きましょう!)
CharacterSet (and its reference type counterpart, NSCharacterSet) is a Foundation type used to trim,
filter, and search for characters in text.
In Swift, a Character is an extended grapheme cluster (really just a String with a length of 1) that
comprises one or more scalar values. CharacterSet stores those underlying Unicode.Scalar values,
rather than Character values, as the name might imply.
The “set” part of CharacterSet refers not to Set from the Swift standard library, but instead to the
SetAlgebra protocol, which bestows the type with the same interface: contains(_:), insert(_:),
union(_:), intersection(_:), and so on.
Predefined Character Sets
CharacterSet
defines constants for sets of characters that you’re likely to work with, such as letters,
numbers, punctuation, and whitespace. Most of them are self-explanatory and, with only a few
exceptions, correspond to one or more Unicode General Categories.
Type Property
Unicode General Categories & Code Points
alphanumerics
L*, M*, N*
letters
L*, M*
*
capitalizedLetters
Lt
lowercaseLetters
Ll
uppercaseLetters
Lu, Lt
nonBaseCharacters
M*
decimalDigits
Nd
punctuationCharacters
P*
symbols
S*
whitespaces
Zs, U+0009
newlines
U+000A – U+000D, U+0085, U+2028, U+2029
whitespacesAndNewlines
Z*, U+000A – U+000D, U+0085
controlCharacters
Cc, Cf
illegalCharacters
Cn
A common mistake is to use capitalizedLetters when what you actually want is uppercase
Letters. Unicode actually defines three cases: lowercase, uppercase, and titlecase. You can see
this in the Latin script used for Czech as well as Serbo-Croatian and other South Slavic languages,
in which digraphs like “dž” are considered single letters, and have separate forms for lowercase
(dž), uppercase (DŽ), and titlecase (Dž). The capitalizedLetters character set contains only a
few dozen of those titlecase digraphs.
The remaining predefined character set, decomposables, is derived from the decomposition type and
mapping of characters.
Trimming Leading and Trailing Whitespace
Perhaps the most common use for CharacterSet is to remove leading and trailing whitespace from text.
"""
""".trimmingCharacters(in: .whitespacesAndNewlines) // "
"
You can use this, for example, when sanitizing user input or preprocessing text.
Predefined URL Component Character Sets
In addition to the aforementioned constants, CharacterSet provides predefined values that correspond
to the characters allowed in various components of a URL:
• urlUserAllowed
• urlPasswordAllowed
• urlHostAllowed
• urlPathAllowed
• urlQueryAllowed
• urlFragmentAllowed
Escaping Special Characters in URLs
Only certain characters are allowed in certain parts of a URL without first being escaped. For
example, spaces must be percent-encoded as %20 (or +) when part of a query string like https
://nshipster.com/search/?q=character%20set.
URLComponents
takes care of percent-encoding components automatically, but you can replicate this
functionality yourself using the addingPercentEncoding(withAllowedCharacters:) method and
passing the appropriate character set:
let query = "character set"
query.addingPercentEncoding(withAllowedCharacters: .urlQueryAllowed)
// "character%20set"
Internationalized domain names encode non-ASCII characters using Punycode instead of percentencoding (for example, NSHipster.中国 would be NSHipster.xn–fiqy6j) Punycode encoding /
decoding isn’t currently provided by Apple SDKs.
Building Your Own
In addition to these predefined character sets, you can create your own. Build them up character by
character, inserting multiple characters at a time by passing a string, or by mixing and matching any of
the predefined sets.
Validating User Input
You might create a CharacterSet to validate some user input to, for example, allow only lowercase and
uppercase letters, digits, and certain punctuation.
var allowed = CharacterSet()
allowed.formUnion(.lowercaseLetters)
allowed.formUnion(.uppercaseLetters)
allowed.formUnion(.decimalDigits)
allowed.insert(charactersIn: "!@#$%&")
func validate(_ input: String) -> Bool {
return input.unicodeScalars.allSatisfy { allowed.contains($0) }
}
Depending on your use case, you might find it easier to think in terms of what shouldn’t be allowed, in
which case you can compute the inverse character set using the inverted property:
let disallowed = allowed.inverted
func validate(_ input: String) -> Bool {
return input.rangeOfCharacter(from: disallowed) == nil
}
Caching Character Sets
If a CharacterSet is created as the result of an expensive operation, you may consider caching its
bitmapRepresentation for later reuse.
For example, if you wanted to create CharacterSet for Emoji, you might do so by enumerating over the
Unicode code space (U+0000 – U+1F0000) and inserting the scalar values for any characters with Emoji
properties using the properties property added in Swift 5 by SE-0221 “Character Properties”:
import Foundation
var emoji = CharacterSet()
for codePoint in 0x0000...0x1F0000 {
guard let scalarValue = Unicode.Scalar(codePoint) else {
continue
}
// Implemented in Swift 5 (SE-0221)
// https://github.com/apple/swift-evolution/blob/master/proposals/
0221-character-properties.md
if scalarValue.properties.isEmoji {
emoji.insert(scalarValue)
}
}
The resulting bitmapRepresentation is a 16KB Data object.
emoji.bitmapRepresentation // 16385 bytes
You could store that in a file somewhere in your app bundle, or embed its Base64 encoding as a string
literal directly in the source code itself.
extension CharacterSet {
static var emoji: CharacterSet {
let base64Encoded = """
AAAAAAgE/wMAAAAAAAAAAAAAAAAA...
"""
let data = Data(base64Encoded: base64Encoded)!
}
}
return CharacterSet(bitmapRepresentation: data)
CharacterSet.emoji.contains("
") // true
Because the Unicode code space is a closed range, CharacterSet can express the membership of
a given scalar value using a single bit in a bit map, rather than using a universal hashing function like
a conventional Set. On top of that, CharacterSet does some clever optimizations, like allocating
on a per-plane basis and representing sets of contiguous scalar values as ranges, if possible.
Much like our attempt at a Manzai routine at the top of the article, some of the meaning behind
CharacterSet is lost in translation.
NSCharacterSet was designed for NSString at a time when characters were equivalent to 16-bit UCS-2
code units and text rarely had occasion to leave the Basic Multilingual Plane. But with Swift’s modern,
Unicode-compliant implementations of String and Character, the definition of terms has drifted
slightly; along with its NS prefix, CharacterSet lost some essential understanding along the way.
Nevertheless, CharacterSet remains a performant, specialized container type for working with
collections of scalar values.
FIN おしまい。
NLLanguageRecognizer
One of my favorite activities, when I travel, is to listen to people as they pass and try to guess what
language they’re speaking. I’d like to think that I’ve gotten pretty good at it over the years (though I
rarely get to know if I guessed right).
If I’m lucky, I’ll recognize a word or phrase as a cognate of a language I’m familiar with, and narrow
things down from there. Otherwise, I try to build up a phonetic inventory, listening for what kinds
of sounds are present. For instance, is the speaker mostly using voiced alveolar trills ⟨r⟩, flaps ⟨ɾ⟩, or
postalveolar approximants ⟨ɹ⟩? Are the vowels mostly open / close; front / back? Any unusual sounds,
like ⟨ʇ⟩?
…or at least that’s what I think I do. To be honest, all of this happens unconsciously and automatically –
for all of us, and for all manner of language recognition tasks. And have only the faintest idea of how
we get from input to output.
Computers operate in a similar manner. After many hours of training, machine learning models can
predict the language of text with accuracy far exceeding previous attempts from a formalized top-down
approach.
Machine learning has been at the heart of natural language processing in Apple platforms for many
years, but it’s only recently that external developers have been able to harness it directly.
New in iOS 12 and macOS 10.14, the Natural Language framework refines existing linguistic APIs and
exposes new functionality to developers.
NLTagger
is NSLinguisticTagger with a new attitude. NLTokenizer is a replacement for enumerate
Substrings(in:options:using:) (neé CFStringTokenizer). NLLanguageRecognizer offers an
extension of the functionality previously exposted through the dominantLanguage in NSLinguistic
Tagger, with the ability to provide hints and get additional predictions.
Recognizing the Language of Natural Language Text
Here’s how to use NLLanguageRecognizer to guess the dominant language of natural language text:
import NaturalLanguage
let string = """
私はガラスを食べられます。それは私を傷つけません。
"""
let recognizer = NLLanguageRecognizer()
recognizer.processString(string)
recognizer.dominantLanguage // ja
First, create an instance of NLLanguageRecognizer and call the method processString(_:) passing
a string. From there, the dominantLanguage property returns an NLLanguage object containing the
BCP-47 language tag of the predicted language (for example "ja" for 日本語 / Japanese).
Getting Multiple Language Hypotheses
If you studied linguistics in college or joined the Latin club in high school, you may be familiar with
some fun examples of polylingual homonymy between dialectic Latin and modern Italian.
For example, consider the readings of the following sentence:
CANE NERO MAGNA BELLA PERSICA!
Language
Translation
Latin
Sing, o Nero, the great Persian wars!
Italian
The black dog eats a nice peach!
To the chagrin of Max Fisher, Latin isn’t one of the languages supported by NLLanguageRecognizer, so
any examples of confusable languages won’t be nearly as entertaining.
With some experimentation, you’ll find that it’s quite difficult to get NLLanguageRecognizer to guess
incorrectly, or even with low precision. Beyond giving it a single cognate shared across members of a
language family, it’s often able to get past 2σ to 95% certainty with a handful of words.
After some trial and error, we were finally able to get NLLanguageRecognizer to guess incorrectly for
a string of non-trivial length by passing the Article I of the Universal Declaration of Human Rights in
Norsk, Bokmål:
let string = """
Alle mennesker er født frie og med samme menneskeverd og menneskerettigheter.
De er utstyrt med fornuft og samvittighet og bør handle mot hverandre i
brorskapets ånd.
"""
let languageRecognizer = NLLanguageRecognizer()
languageRecognizer.processString(string)
recognizer.dominantLanguage // da (!)
The Universal Declaration of Human Rights, is the among the most widely-translated documents
in the world, with translations in over 500 different languages. For this reason, it’s often used for
natural language tasks.
Danish and Norwegian Bokmål are very similar languages to begin with, so it’s unsurprising that
NLLanguageRecognizer guessed incorrectly. (For comparison, here’s the equivalent text in Danish)
We can use the languageHypotheses(withMaximum:) method to get a sense of how confident the
dominantLanguage guess was:
languageRecognizer.languageHypotheses(withMaximum: 2)
Language
Confidence
Danish (da)
56%
Norwegian Bokmål (nb)
43%
At the time of writing, the languageHints property is undocumented, so it’s unclear how exactly it
should be used. However, passing a weighted dictionary of probabilities seems to have the desired effect
of bolstering the hypotheses with known priors:
languageRecognizer.languageHints = [.danish: 0.25, .norwegian: 0.75]
Language
Confidence (with Hints)
Danish (da)
30%
Norwegian Bokmål (nb)
70%
So what can you do once you know the language of a string?
Here are a couple of use cases for your consideration:
Checking Misspelled Words
Combine NLLanguageRecognizer with UITextChecker to check the spelling of words in any string:
Start by creating an NLLanguageRecognizer and initializing it with a string by calling the process
String(_:) method:
let string = """
Wenn ist das Nunstück git und Slotermeyer?
Ja! Beiherhund das Oder die Flipperwaldt gersput!
"""
let languageRecognizer = NLLanguageRecognizer()
languageRecognizer.processString(string)
let dominantLanguage = languageRecognizer.dominantLanguage! // de
Then, pass the rawValue of the NLLanguage object returned by the dominantLanguage property to the
language parameter of rangeOfMisspelledWord(in:range:startingAt:wrap:language:):
let textChecker = UITextChecker()
let nsString = NSString(string: string)
let stringRange = NSRange(location: 0, length: nsString.length)
var offset = 0
repeat {
let wordRange =
textChecker.rangeOfMisspelledWord(in: string,
range: stringRange,
startingAt: offset,
wrap: false,
language: dominantLanguage.rawValue)
guard wordRange.location != NSNotFound else {
break
}
print(nsString.substring(with: wordRange))
offset = wordRange.upperBound
} while true
When passed the The Funniest Joke in the World, the following words are called out for being
misspelled:
• Nunstück
• Slotermeyer
• Beiherhund
• Flipperwaldt
• gersput
Synthesizing Speech
You can use NLLanguageRecognizer in concert with AVSpeechSynthesizer to hear any natural
language text read aloud:
let string = """
Je m'baladais sur l'avenue le cœur ouvert à l'inconnu
J'avais envie de dire bonjour à n'importe qui.
N'importe qui et ce fut toi, je t'ai dit n'importe quoi
Il suffisait de te parler, pour t'apprivoiser.
"""
let languageRecognizer = NLLanguageRecognizer()
languageRecognizer.processString(string)
let language = languageRecognizer.dominantLanguage!.rawValue // fr
let speechSynthesizer = AVSpeechSynthesizer()
let utterance = AVSpeechUtterance(string: string)
utterance.voice = AVSpeechSynthesisVoice(language: language)
speechSynthesizer.speak(utterance)
It doesn’t have the lyrical finesse of Joe Dassin, but ainsi va la vie.
In order to be understood, we first must seek to understand. And the first step to understanding natural
language is to determine its language.
NLLanguageRecognizer
offers a powerful new interface to functionality that’s been responsible for
intelligent features throughout iOS and macOS. See how you might take advantage of it in your app to
gain new understanding of your users.
Locale
“You take delight not in a city’s seven or seventy wonders, but in the answer it gives to a question
of yours.”
― Italo Calvino, Invisible Cities
Localization (l10n) is the process of adapting your application for a specific market, or locale.
Internationalization (i18n) is the process of preparing your app to be localized. Internationalization is a
necessary, but not sufficient condition for localization. And whether or not you decide to localize your
app for other markets, it’s always a good idea to do everything with internationalization in mind.
The hardest thing about internationalization (aside from saying the word itself) is learning how to think
outside of your cultural context. Unless you’ve had the privilege to travel or to meet people from other
places, you may not even be aware that things could be any other way. But when you venture out into
the world, everything from the price of bread to the letters in the alphabet to the numbers of hours in a
day — all of that is up in the air.
It can be absolutely overwhelming without a guide. Fortunately for us, we have Locale to show us the
ways of the world.
Foundation’s Locale type encapsulates the linguistic and cultural conventions of a user, which include:
• Language and Orthography
• Text Direction and Layout
• Keyboards and Input Methods
• Collation Ordering
• Personal Name Formatting
• Calendar and Date Formatting
• Currency and Number Formatting
• Units and Measurement Formatting
• Use of Symbols, Colors, and Iconography
Locale objects are often used as parameters for methods that perform localized operations like sorting
a list of strings or formatting a date. Most of the time, you’ll access the Locale.current type property
to use the user’s current locale.
import Foundation
let units = ["meter", "smoot", "agate", "ångström"]
units.sorted { (lhs, rhs) in
lhs.compare(rhs, locale: .current) == .orderedAscending
}
// => ["agate", "ångström", "meter", "smoot"]
You can also construct a Locale that corresponds to a particular locale identifier. A locale identifier
typically comprises an ISO 639-1 language code (such as en for English) and an ISO 3166-2 region code
(such as US for the United States).
let
= Locale(identifier: "sv_SE")
units.sorted { (lhs, rhs) in
lhs.compare(rhs, locale:
) == .orderedAscending
}
// => ["agate", "meter", "smoot", "ångström"]
Most methods and properties that take a Locale do so optionally or with a default value such
that — if left unspecified — the current locale is used.
Locale identifiers may also specify an explicit character encoding or other preferences like currency,
calendar system, or number format with the following syntax:
language[_region][.character-encoding][@modifier=value[, ...]]
For example, the locale identifier de_DE.UTF8@collation=phonebook,currency=DDM specifies a
German language locale in Germany that uses UTF-8 text encoding, phonebook collation, and the
pre-Euro Deutsche Mark currency.
Support for identifiers specifying other than language or region is inconsistent across system APIs
and different platforms, so you shouldn’t rely on specific behavior.
Users can change their locale settings in the “Language & Text” system preference on macOS and in
“General > International” in the iOS Settings app.
Terra Cognita
Locale often takes a passive role, being passed into a property here and a method there. But if you give
it a chance, it can tell you more about a place than you ever knew there was to know:
• Language and Script (languageCode, scriptCode, exemplarCharacterSet)
• Region (regionCode)
• Collation (collationIdentifier, collatorIdentifier)
• Calendar (calendar)
• Currency (currencyCode, currencySymbol)
• Numbers and Units (decimalSeparator, usesMetricSystem)
• Quotation
Delimiters
(quotationBeginDelimiter
/
quotationEndDelimiter,
alternateQuotationBeginDelimiter / alternateQuotationEndDelimiter)
While this all may seem like fairly esoteric stuff, you’d be surprised by how many opportunities this
kind of information unlocks for making a world-class app.
It’s the small things, like knowing that quotation marks vary between locales:
English
“I can eat glass, it doesn’t harm me.”
German
„Ich kann Glas essen, das tut mir nicht weh.“
Japanese
「私はガラスを食べられます。それは私を傷つけません。」
So if you were building a component that added quotations around arbitrary text, you should use these
properties rather than hard-coding English quotation marks.
Si Fueris Romae…
As if it weren’t enough to know, among other things, the preferred currency for every region on the
planet, Locale can also tell you how you’d refer to it in a particular locale. For example, here in the
USA, we call our country the United States. But that’s just an endonym; elsewhere, American has other
names — exonyms. Like in France, it’s…
import Foundation
let
let
= Locale(identifier: "en_US")
= Locale(identifier: "fr_FR")
.localizedString(forIdentifier:
// => "English (United States)"
.identifier)
.localizedString(forIdentifier:
// => "anglais (États-Unis)"
.identifier)
Use this technique whenever you’re displaying locale, like in this screen from the Settings app, which
shows language endonyms alongside exonyms:
Behind the scenes, all of this locale information is provided by the Common Locale Data Repository
CLDR, a companion project to the Unicode standard.
Vox Populi
The last stop in our tour of Locale is the preferredLanguages property. Contrary to what you might
expect for a type (rather than an instance) property, the returned value depends on the current language
preferences of the user. Each of the array elements is IETF BCP 47 language identifier and is returned
in order of user preference.
If your app communicates with a web app over HTTP, you might use this property to set the
Accept-Language header field to give the server an opportunity to return localized resources:
import Foundation
let url = URL(string: "https://nshipster.com")!
var request = URLRequest(url: url)
let acceptLanguage = Locale.preferredLanguages.joined(separator: ", ")
request.setValue(acceptLanguage, forHTTPHeaderField: "Accept-Language")
Even if your server doesn’t yet localize its resources, putting this in place now allows you to flip the
switch when the time comes — without having to push an update to the client. Neat!
HTTP content negotiation is a complex topic, and apps interacting with localized, remote resources
should use Locale.preferredLanguages as a starting point for generating a more precise
Accept-Language field value. For example, you might specify an associated quality value like in
en-SG, en;q=0.9 to tell the server “I prefer Singaporean English, but will accept other types of
English”.
For more information, see RFC 7231.
Travel is like internationalization: it’s something that isn’t exactly fun at the time, but we do it because it
makes us better people. Both activities expand our cultural horizons and allow us to better know people
we’ll never actually meet.
With Locale you can travel the world without going AFK.
Formatter
Conversion is a tireless errand in software development. Most programs boil down to some variation of
transforming data into something more useful.
In the case of user-facing software, making data human-readable is an essential task — and a complex
one at that. A user’s preferred language, calendar, and currency can all factor into how information
should be displayed, as can other constraints, such as a label’s dimensions.
All of this is to say: calling description on an object just doesn’t cut it under most circumstances.
Indeed, the real tool for this job is Formatter: an ancient, abstract class deep in the heart of the
Foundation framework that’s responsible for transforming data into textual representations.
Formatter’s origins trace back to NSCell, which is used to display information and accept user input in
tables, form fields, and other views in AppKit. Much of the API design of (NS)Formatter reflects this.
Back then, formatters came in two flavors: dates and numbers. But these days, there are formatters for
everything from physical quantities and time intervals to personal names and postal addresses. And as
if that weren’t enough to keep straight, a good portion of these have been soft-deprecated, or otherwise
superseded by more capable APIs (that are also formatters).
There are so many formatters in Apple SDKs that it’s impossible to keep them all in working memory.
Apparently, this is as true of computers as it is for humans; at the time of writing, searching for
“formatter” on developer.apple.com fails with a timeout!
To make sense of everything, this week’s article groups each of the built-in formatters into one of four
categories:
Numbers and Quantities
NumberFormatter
MeasurementFormatter
Dates, Times, and Durations
DateFormatter
ISO8601DateFormatter
DateComponentsFormatter
DateIntervalFormatter
RelativeDateTimeFormatter
People and Places
PersonNameComponentsFormatter
CNPostalAddressFormatter
Lists and Items
ListFormatter
Formatting Numbers and Quantities
Class
Example Output
Availability
NumberFormatter
“1,234.56”
iOS 2.0
macOS 10.0+
MeasurementFormatter
“-9.80665 m/s²”
iOS 10.0+
macOS 10.12+
ByteCountFormatter
“756 KB”
iOS 6.0+
macOS 10.8+
EnergyFormatter
“80 kcal”
iOS 8.0+
macOS 10.10+
MassFormatter
“175 lb”
iOS 8.0+
macOS 10.10+
LengthFormatter
“5 ft, 11 in”
iOS 8.0+
macOS 10.10+
MKDistanceFormatter
“500 miles”
iOS 7.0+
macOS 10.9+
ByteCountFormatter,
EnergyFormatter,
MassFormatter,
LengthFormatter,
and
MKDistanceFormatter are superseded by MeasurementFormatter.
Legacy Formatter
Measurement Formatter Unit
ByteCountFormatter
UnitInformationStorage
EnergyFormatter
UnitEnergy
MassFormatter
UnitMass
LengthFormatter
UnitLength
MKDistanceFormatter
UnitLength
The only occasions in which you might still use EnergyFormatter, MassFormatter, or Length
Formatter are when working with the HealthKit framework; these formatters provide conversion
and interoperability with HKUnit quantities.
NumberFormatter
NumberFormatter covers every aspect of number formatting imaginable. For better or for worse (mostly
for better), this all-in-one API handles ordinals and cardinals, mathematical and scientific notation,
percentages, and monetary amounts in various flavors. It can even write out numbers in a few different
languages!
So whenever you reach for NumberFormatter, the first order of business is to establish what kind of
number you’re working with and set the numberStyle property accordingly.
Number Styles
Number Style
Example Output
none
123
decimal
123.456
percent
12%
scientific
1.23456789E4
spellOut
one hundred twenty-three
ordinal
3rd
currency
$1234.57
currencyAccounting
($1234.57)
currencyISOCode
USD1,234.57
currencyPlural
1,234.57 US dollars
NumberFormatter also has a format property that takes a familiar SPRINTF(3)-style format
string. As we’ve argued in a previous article, format strings are something to be avoided unless
absolutely necessary.
Rounding & Significant Digits
To prevent numbers from getting annoyingly pedantic (“thirty-two point three three — repeating, of
course…”), you’ll want to get a handle on NumberFormatter’s rounding behavior. Here, you have two
options:
• Set usesSignificantDigits to true to format according to the rules of significant figures
var formatter = NumberFormatter()
formatter.usesSignificantDigits = true
formatter.minimumSignificantDigits = 1 // default
formatter.maximumSignificantDigits = 6 // default
formatter.string(from:
formatter.string(from:
formatter.string(from:
formatter.string(from:
formatter.string(from:
1234567) // 1234570
1234.567) // 1234.57
100.234567) // 100.235
1.23000) // 1.23
0.0000123) // 0.0000123
• Set usesSignificantDigits to false (or keep as-is, since that’s the default) to format
according to specific limits on how many decimal and fraction digits to show (the number of digits
leading or trailing the decimal point, respectively).
var formatter = NumberFormatter()
formatter.usesSignificantDigits = false
formatter.minimumIntegerDigits = 0 // default
formatter.maximumIntegerDigits = 42 // default (seriously)
formatter.minimumFractionDigits = 0 // default
formatter.maximumFractionDigits = 0 // default
formatter.string(from:
formatter.string(from:
formatter.string(from:
formatter.string(from:
formatter.string(from:
1234567) // 1234567
1234.567) // 1235
100.234567) // 100
1.23000) // 1
0.0000123) // 0
If you need specific rounding behavior, such as “round to the nearest integer” or “round towards zero”,
check out the roundingMode, roundingIncrement, and roundingBehavior properties.
Locale Awareness
Nearly everything about the formatter can be customized, including the grouping separator, decimal
separator, negative symbol, percent symbol, infinity symbol, and how to represent zero values.
Although these settings can be overridden on an individual basis, it’s typically best to defer to the
defaults provided by the user’s locale.
The advice to defer to user locale defaults has a critical exception: money
Consider the following code that uses the default NumberFormatter settings for American and
Japanese locales to format the same number:
let number = 1234.5678 //
let formatter = NumberFormatter()
formatter.numberStyle = .currency
let
= Locale(identifier: "en_US")
formatter.locale =
formatter.string(for: number) // $1,234.57
let
= Locale(identifier: "ja_JP")
formatter.locale =
formatter.string(for: number) // ¥ 1,235
NSNumberFormatter *numberFormatter = [[NSNumberFormatter alloc] init];
[numberFormatter setNumberStyle:NSNumberFormatterCurrencyStyle];
for (NSString *identifier in @[@"en_US", @"ja_JP"]) {
numberFormatter.locale = [NSLocale
localeWithLocaleIdentifier:identifier];
NSLog(@"%@: %@", identifier, [numberFormatter
stringFromNumber:@(1234.5678)]);
}
// Prints "$1,234.57" and "¥ 1,235"
At the time of writing, the difference between $1,234.57 and ¥ 1,235 is roughly equivalent to the
price difference between a new MacBook Air and a Lightning - 3.5 mm Adapter. Make a mistake
like that in your app, and someone — developer or user — is going to be pretty upset.
Working with money in code is a deep topic, but the basic guidance is this: Use Decimal values
(rather than Float or Double) and specify an explicit currency. For more information, check out
the Flight School Guide to Swift Numbers and its companion Swift library, Money.
MeasurementFormatter
MeasurementFormatter
was introduced in iOS 10 and macOS 10.12 as part of the full complement of
APIs for performing type-safe dimensional calculations:
• Unit subclasses represent units of measure, such as count and ratio
• Dimension subclasses represent dimensional units of measure, such as mass and length, (which
is the case for the overwhelming majority of the concrete subclasses provided, on account of them
being dimensional in nature)
• A Measurement is a quantity of a particular Unit
• A UnitConverter converts quantities of one unit to a different, compatible unit
MeasurementFormatter
and its associated APIs are a intuitive — just a delight to work with, honestly.
The only potential snag for newcomers to Swift (or Objective-C old-timers, perhaps) are the use of
generics to constrain Measurement values to a particular Unit type.
import Foundation
// "The swift (Apus apus) can power itself to a speed of 111.6km/h"
let speed = Measurement<UnitSpeed>(value: 111.6,
unit: .kilometersPerHour)
let formatter = MeasurementFormatter()
formatter.string(from: speed) // 69.345 mph
Configuring the Underlying Number Formatter
By delegating much of its formatting responsibility to an underlying NumberFormatter property,
MeasurementFormatter maintains a high degree of configurability while keeping a small API footprint.
Readers with an engineering background may have noticed that the localized speed in the previous
example gained an extra significant figure along the way. As discussed previously, we can enable uses
SignificantDigits and set maximumSignificantDigits to prevent incidental changes in precision.
formatter.numberFormatter.usesSignificantDigits = true
formatter.numberFormatter.maximumSignificantDigits = 4
formatter.string(from: speed) // 69.35 mph
Changing Which Unit is Displayed
A MeasurementFormatter, by default, will use the preferred unit for the user’s current locale (if one
exists) instead of the one provided by a Measurement value.
Readers with a non-American background certainly noticed that the localized speed in the original
example converted to a bizarre, archaic unit of measure known as “miles per hour”. You can override
this default unit localization behavior by passing the providedUnit option.
formatter.unitOptions = [.providedUnit]
formatter.string(from: speed) // 111.6 km/h
formatter.string(from: speed.converted(to: .milesPerHour)) // 69.35 mph
Formatting Dates, Times, and Durations
Class
Example Output
Availability
DateFormatter
“July 15, 2019”
iOS 2.0
macOS 10.0+
ISO8601DateFormatter
“2019-07-15”
iOS 10.0+
macOS 10.12+
DateComponentsFormatter
“10 minutes”
iOS 8.0
macOS 10.10+
DateIntervalFormatter
“6/3/19 - 6/7/19”
iOS 8.0
macOS 10.10+
RelativeDateTimeFormatter
“3 weeks ago”
iOS 13.0+
macOS 10.15
DateFormatter
DateFormatter
is the OG class for representing dates and times. And it remains your best, first choice
for the majority of date formatting tasks.
For a while, there was a concern that it would become overburdened with responsibilities like its sibling
NumberFormatter. But fortunately, recent SDK releases spawned new formatters for new functionality.
We’ll talk about those in a little bit.
Date and Time Styles
The most important properties for a DateFormatter object are its dateStyle and timeStyle. As with
NumberFormatter and its numberStyle, these date and time styles provide preset configurations for
common formats.
Style
Date
Time
none
“”
“”
short
“11/16/37”
“3:30 PM”
medium
“Nov 16, 1937”
“3:30:32 PM”
long
“November 16, 1937”
“3:30:32 PM”
full
“Tuesday, November 16, 1937 AD
“3:30:42 PM EST”
let date = Date()
let formatter = DateFormatter()
formatter.dateStyle = .long
formatter.timeStyle = .long
formatter.string(from: date)
// July 15, 2019 at 9:41:00 AM PST
formatter.dateStyle = .short
formatter.timeStyle = .short
formatter.string(from: date)
// "7/16/19, 9:41:00 AM"
NSDateFormatter *formatter = [[NSDateFormatter alloc] init];
[formatter setDateStyle:NSDateFormatterLongStyle];
[formatter setTimeStyle:NSDateFormatterLongStyle];
NSLog(@"%@", [formatter stringFromDate:[NSDate date]]);
// July 15, 2019 at 9:41:00 AM PST
[formatter setDateStyle:NSDateFormatterShortStyle];
[formatter setTimeStyle:NSDateFormatterShortStyle];
NSLog(@"%@", [formatter stringFromDate:[NSDate date]]);
// 7/16/19, 9:41:00 AM
dateStyle
and timeStyle are set independently. So, to display just the time for a particular date, for
example, you set dateStyle to none:
let formatter = DateFormatter()
formatter.dateStyle = .none
formatter.timeStyle = .medium
let string = formatter.string(from: Date())
// 9:41:00 AM
NSDateFormatter *formatter = [[NSDateFormatter alloc] init];
[formatter setDateStyle:NSDateFormatterNoStyle];
[formatter setTimeStyle:NSDateFormatterMediumStyle];
NSLog(@"%@", [formatter stringFromDate:[NSDate date]]);
// 9:41:00 AM
As you might expect, each aspect of the date format can alternatively be configured individually, a la
carte. For any aspiring time wizards NSDateFormatter has a bevy of different knobs and switches to
play with.
DateFormatter also has a dateFormat property that takes a familiar STRFTIME(3)-style format
string. We’ve already called this out for NumberFormatter, but it’s a point that bears repeating:
use presets wherever possible and only use custom format strings if absolutely necessary.
ISO8601DateFormatter
When we wrote our first article about NSFormatter back in 2013, we made a point to include discussion
of Peter Hosey’s ISO8601DateFormatter’s as the essential open-source library for parsing timestamps
from external data sources.
Fortunately, we no longer need to proffer a third-party solution, because, as of iOS 10.0 and macOS
10.12, ISO8601DateFormatter is now built-in to Foundation.
let formatter = ISO8601DateFormatter()
formatter.date(from: "2019-07-15T09:41:00-07:00")
// Jul 15, 2019 at 9:41 AM
JSONDecoder provides built-in support for decoding ISO8601-formatted timestamps by way of
the .iso8601 date decoding strategy.
import Foundation
let json = #"""
[{
"body": "Hello, world!",
"timestamp": "2019-07-15T09:41:00-07:00"
}]
"""#.data(using: .utf8)!
struct Comment: Decodable {
let body: String
let timestamp: Date
}
let decoder = JSONDecoder()
decoder.dateDecodingStrategy = .iso8601
let comments = try decoder.decode([Comment].self, from: json)
comments.first?.timestamp
// Jul 15, 2019 at 9:41 AM
DateIntervalFormatter
DateIntervalFormatter
is like DateFormatter, but can handle two dates at once — specifically, a
start and end date.
let formatter = DateIntervalFormatter()
formatter.dateStyle = .short
formatter.timeStyle = .none
let fromDate = Date()
let toDate = Calendar.current.date(byAdding: .day, value: 7, to: fromDate)!
formatter.string(from: fromDate, to: toDate)
// "7/15/19 – 7/22/19"
NSDateIntervalFormatter *formatter = [[NSDateIntervalFormatter alloc] init];
formatter.dateStyle = NSDateIntervalFormatterShortStyle;
formatter.timeStyle = NSDateIntervalFormatterNoStyle;
NSDate *fromDate = [NSDate date];
NSDate *toDate = [fromDate dateByAddingTimeInterval:86400 * 7];
NSLog(@"%@", [formatter stringFromDate:fromDate toDate:toDate]);
// "7/15/19 – 7/22/19"
Date Interval Styles
Style
Date
Time
none
“”
“”
short
“6/30/14 - 7/11/14”
“5:51 AM - 7:37 PM”
medium
“Jun 30, 2014 - Jul 11, 2014”
“5:51:49 AM - 7:38:29 PM”
long
“June 30, 2014 - July 11, 2014”
“6:02:54 AM GMT-8 - 7:49:34 PM GMT-8”
full
“Monday, June 30, 2014 - Friday, July 11,
2014
“6:03:28 PM Pacific Standard Time - 7:50:08 PM Pacific Standard
Time”
When displaying business hours, such as “Mon – Fri: 8:00 AM – 10:00 PM”, use the shortWeekday
Symbols of the current Calendar to get localized names for the days of the week.
import Foundation
var calendar = Calendar.current
calendar.locale = Locale(identifier: "en_US")
calendar.shortWeekdaySymbols
// ["Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"]
calendar.locale = Locale(identifier: "ja_JP")
calendar.shortWeekdaySymbols
// ["日", "月", "火", "水", "木", "金", "土"]
DateComponentsFormatter
As the name implies, DateComponentsFormatter works with DateComponents values (previously),
which contain a combination of discrete calendar quantities, such as “1 day and 2 hours”.
DateComponentsFormatter
provides localized representations of date components in several different,
pre-set formats:
let formatter = DateComponentsFormatter()
formatter.unitsStyle = .full
let components = DateComponents(day: 1, hour: 2)
let string = formatter.string(from: components)
// 1 day, 2 hours
NSDateComponentsFormatter *formatter = [[NSDateComponentsFormatter alloc] init];
formatter.unitsStyle = NSDateComponentsFormatterUnitsStyleFull;
NSDateComponents *components = [[NSDateComponents alloc] init];
components.day = 1;
components.hour = 2;
NSLog(@"%@", [formatter stringFromDateComponents:components]);
// 1 day, 2 hours
Date Components Unit Styles
Style
Example
positional
“1:10”
abbreviated
“1h 10m”
short
“1hr 10min”
full
“1 hour, 10 minutes”
spellOut
“One hour, ten minutes”
Formatting Context
Some years ago, formatters introduced the concept of formatting context, to handle situations where the
capitalization and punctuation of a localized string may depend on whether it appears at the beginning
or middle of a sentence. A context property is available for DateComponentsFormatter, as well as
DateFormatter, NumberFormatter, and others.
*
Formatting Context
Output
standalone
“About 2 hours”
listItem
“About 2 hours”
beginningOfSentence
“About 2 hours”
middleOfSentence
“about 2 hours”
dynamic
Depends*
A Dynamic context changes capitalization automatically depending on where it appears in the text for
locales that may position strings differently depending on the content.
RelativeDateTimeFormatter
RelativeDateTimeFormatter is a newcomer in iOS 13 — and at the time of writing, still undocumented,
so consider this an NSHipster exclusive scoop!
Longtime readers may recall that DateFormatter actually gave this a try circa iOS 4 by way of the
doesRelativeDateFormatting property. But that hardly ever worked, and most of us forgot about it,
probably. Fortunately, RelativeDateTimeFormatter succeeds where doesRelativeDateFormatting
fell short, and offers some great new functionality to make your app more personable and accessible.
(As far as we can tell,) RelativeDatetimeFormatter takes the most significant date component and
displays it in terms of past or future tense (“1 day ago” / “in 1 day”).
let formatter = RelativeDateTimeFormatter()
formatter.localizedString(from:
formatter.localizedString(from:
formatter.localizedString(from:
formatter.localizedString(from:
DateComponents(day: 1, hour: 1)) // "in 1 day"
DateComponents(day: -1)) // "1 day ago"
DateComponents(hour: 3)) // "in 3 hours"
DateComponents(minute: 60)) // "in 60 minutes"
For the most part, this seems to work really well. However, its handling of nil, zero, and net-zero values
leaves something to be desired…
formatter.localizedString(from: DateComponents(hour: 0)) // "in 0 hours"
formatter.localizedString(from: DateComponents(day: 1, hour: -24)) // "in 1 day"
formatter.localizedString(from: DateComponents()) // ""
Styles
Style
Example
abbreviated
“1 mo. ago” *
short
“1 mo. ago”
full
“1 month ago”
spellOut
“one month ago”
*May
produce output distinct from short for non-English locales.
Using Named Relative Date Times
By default, RelativeDateTimeFormatter adopts the formulaic convention we’ve seen so far. But you
can set the dateTimeStyle property to .named to prefer localized deictic expressions — “tomorrow”,
“yesterday”, “next week” — whenever one exists.
import Foundation
let formatter = RelativeDateTimeFormatter()
formatter.localizedString(from: DateComponents(day: -1)) // "1 day ago"
formatter.dateTimeStyle = .named
formatter.localizedString(from: DateComponents(day: -1)) // "yesterday"
This just goes to show that beyond calendrical and temporal relativity, RelativeDateTimeFormatter
is a real whiz at linguistic relativity, too! For example, English doesn’t have a word to describe the day
before yesterday, whereas other languages, like German, do.
formatter.localizedString(from: DateComponents(day: -2)) // "2 days ago"
formatter.locale = Locale(identifier: "de_DE")
formatter.localizedString(from: DateComponents(day: -2)) // "vorgestern"
Hervorragend!
Formatting People and Places
Class
Example Output
Availability
PersonNameComponentsFormatter
“J. Appleseed”
iOS 9.0+
macOS 10.11+
CNContactFormatter
“Appleseed, Johnny”
iOS 9.0+
macOS 10.11+
CNPostalAddressFormatter
“1 Infinite Loop\n
Cupertino CA 95014”
iOS 9.0+
macOS 10.11+
CNContactFormatter is superseded by PersonNameComponentsFormatter.
Unless you’re working with existing CNContact objects, prefer the use of PersonNameComponents
Formatter to format personal names.
PersonNameComponentsFormatter
PersonNameComponentsFormatter
is a sort of high water mark for Foundation. It encapsulates one of
the hardest, most personal problems in computer in such a way to make it accessible to anyone without
requiring a degree in Ethnography.
The documentation does a wonderful job illustrating the complexities of personal names (if I might say
so myself), but if you had any doubt of the utility of such an API, consider the following example:
let formatter = PersonNameComponentsFormatter()
var nameComponents = PersonNameComponents()
nameComponents.givenName = "Johnny"
nameComponents.familyName = "Appleseed"
formatter.string(from: nameComponents) // "Johnny Appleseed"
Simple enough, right? We all know names are space delimited, first-last… right?
nameComponents.givenName = "约翰尼"
nameComponents.familyName = "苹果籽"
formatter.string(from: nameComponents) // "苹果籽约翰尼"
‘nuf said.
CNPostalAddressFormatter
CNPostalAddressFormatter provides a convenient Formatter-based API to functionality dating back
to the original AddressBook framework.
The following example formats a constructed CNMutablePostalAddress, but you’ll most likely use
existing CNPostalAddress values retrieved from the user’s address book.
let address = CNMutablePostalAddress()
address.street = "One Apple Park Way"
address.city = "Cupertino"
address.state = "CA"
address.postalCode = "95014"
let addressFormatter = CNPostalAddressFormatter()
addressFormatter.string(from: address)
/* "One Apple Park Way
Cupertino CA 95014" */
Styling Formatted Attributed Strings
When formatting compound values, it can be hard to figure out where each component went in the
final, resulting string. This can be a problem when you want to, for example, call out certain parts
in the UI.
Rather than hacking together an ad-hoc, regex-based solution, CNPostalAddressFormatter provides
a method that vends an NSAttributedString that lets you identify the ranges of each component
(PersonNameComponentsFormatter does this too).
The NSAttributedString API is… to put it politely, bad. It feels bad to use.
So for the sake of anyone hoping to take advantage of this functionality, please copy-paste and
appropriate the following code sample to your heart’s content:
var attributedString = addressFormatter.attributedString(
from: address,
withDefaultAttributes: [:]
).mutableCopy() as! NSMutableAttributedString
let stringRange = NSRange(location: 0, length: attributedString.length)
attributedString.enumerateAttributes(in: stringRange, options: []) {
(attributes, attributesRange, _) in
let color: UIColor
switch attributes[NSAttributedString.Key(CNPostalAddressPropertyAttribute)]
as? String {
case CNPostalAddressStreetKey:
color = .red
case CNPostalAddressCityKey:
color = .orange
case CNPostalAddressStateKey:
color = .green
case CNPostalAddressPostalCodeKey:
color = .purple
default:
return
}
}
attributedString.addAttribute(.foregroundColor,
value: color,
range: attributesRange)
One Apple Park Way
Cupertino
CA
95014
Formatting Lists and Items
Class
Example Output
Availability
ListFormatter
“macOS, iOS, iPadOS, watchOS, and tvOS”
iOS 13.0+
macOS 10.15+
ListFormatter
Rounding out our survey of formatters in the Apple SDK, it’s another new addition in iOS 13: List
Formatter. To be completely honest, we didn’t know where to put this in the article, so we just kind of
stuck it on the end here. (Though in hindsight, this is perhaps appropriate given the subject matter).
Once again, we don’t have any official documentation to work from at the moment, but the comments
in the header file give us enough to go on.
NSListFormatter provides locale-correct formatting of a list of items using the appropriate separator
and conjunction. Note that the list formatter is unaware of the context where the joined string will
be used, e.g., in the beginning of the sentence or used as a standalone string in the UI, so it will not
provide any sort of capitalization customization on the given items, but merely join them as-is.
The string joined this way may not be grammatically correct when placed in a sentence, and it
should only be used in a standalone manner.
tl;dr: This is joined(by:) with locale-aware serial and penultimate delimiters.
For simple lists of strings, you don’t even need to bother with instantiating ListFormatter — just call
the localizedString(byJoining:) class method.
import Foundation
let operatingSystems = ["macOS", "iOS", "iPadOS", "watchOS", "tvOS"]
ListFormatter.localizedString(byJoining: operatingSystems)
// "macOS, iOS, iPadOS, watchOS, and tvOS"
ListFormatter works as you’d expect for lists comprising zero, one, or two items.
ListFormatter.localizedString(byJoining: [])
// ""
ListFormatter.localizedString(byJoining: ["Apple"])
// "Apple"
ListFormatter.localizedString(byJoining: ["Jobs", "Woz"])
// "Jobs and Woz"
Lists of Formatted Values
ListFormatter
exposes an underlying itemFormatter property, which effectively adds a map(_:)
before calling joined(by:). You use itemFormatter whenever you’d formatting a list of non-String
elements. For example, you can set a NumberFormatter as the itemFormatter for a ListFormatter to
turn an array of cardinals (Int values) into a localized list of ordinals.
let numberFormatter = NumberFormatter()
numberFormatter.numberStyle = .ordinal
let listFormatter = ListFormatter()
listFormatter.itemFormatter = numberFormatter
listFormatter.string(from: [1, 2, 3])
// "1st, 2nd, and 3rd"
If you set a custom locale on your list formatter, be sure to set that locale for the underlying
formatter. And be mindful of value semantics, too — without the re-assignment to itemFormatter
in the example below, you’d get a French list of English ordinals instead.
let
= Locale(identifier: "fr_FR")
listFormatter.locale =
numberFormatter.locale =
listFormatter.itemFormatter = numberFormatter
listFormatter.string(from: [1, 2, 3])
// "1er, 2e et 3e"
As some of the oldest members of the Foundation framework, NSNumberFormatter and NSDate
Formatter are astonishingly well-suited to their respective domains, in that way only decade-old
software can. This tradition of excellence is carried by the most recent incarnations as well.
If your app deals in numbers or dates (or time intervals or names or lists measurements of any kind),
then NSFormatter is indispensable.
And if your app doesn’t… then the question is, what does it do, exactly?
Invest in learning all of the secrets of Foundation formatters to get everything exactly how you want
them. And if you find yourself with formatting logic scattered across your app, consider creating your
own Formatter subclass to consolidate all of that business logic in one place.
FileManager
One of the most rewarding experiences you can have as a developer is to teach young people how
to program. If you ever grow jaded by how fundamentally broken all software is, there’s nothing like
watching a concept like recursion click for the first time to offset your world-weariness.
My favorite way to introduce the concept of programming is to set out all the ingredients for a peanut
butter and jelly sandwich and ask the class give me instructions for assembly as if I were a robot .
The punchline is that the computer takes every instruction as literally as possible, often with unexpected
results. Ask the robot to “put peanut butter on the bread”, and you may end up with an unopened jar
of Jif flattening a sleeve of Wonder Bread. Forget to specify which part of the bread to put the jelly on?
Don’t be surprised if it ends up on the outer crust. And so on. Kids love it.
The lesson of breaking down a complex process into discrete steps is a great encapsulation
of programming. And the malicious compliance from lack of specificity echoes the analogy of
“programming as wish making” from our article about numericCast(_:).
But let’s take the metaphor a step further, and imagine that instead of commanding a single robot to
(sudo) make a sandwich, you’re writing instructions for a thousand different robots. Big and small, fast
and slow; some have 4 arms instead of 2, others hover in the air, maybe a few read everything in reverse.
Consider what would happen if multiple robots tried to make a sandwich at the same time. Or imagine
that your instructions might be read by robots that won’t be built for another 40 years, by which time
peanut butter is packaged in capsules and jelly comes exclusively as a gas.
That’s kind of what it’s like to interact with a file system.
The only chance we have at making something that works is to leverage the power of abstraction. On
Apple platforms, this functionality is provided by the Foundation framework by way of FileManager.
We can’t possibly cover everything there is to know about working with file systems in a single article,
so this week, let’s take a look at the operations you’re most likely to perform when building an app.
FileManager
offers a convenient way to create, read, move, copy, and delete both files and directories,
whether they’re on local or networked drives or iCloud ubiquitous containers.
The common currency for all of these operations are paths and file URLs.
Paths and File URLs
Objects on the file system can be identified in a few different ways. For example, each of the following
represents the location of the same text document:
• Path: /Users/NSHipster/Documents/article.md
• File URL: file:///Users/NSHipster/Documents/article.md
• File Reference URL: file:///.file/id=1234567.7654321/
Paths are slash-delimited (/) strings that designate a location in the directory hierarchy. File URLs are
URLs with a file:// scheme in addition to a file path. File Reference URLs identify the location of a file
using a unique identifier separate from any directory structure.
Of those, you’ll mostly deal with the first two, which identify files and directories using a relational
path. That path may be absolute and provide the full location of a resource from the root directory, or
it may be relative and show how to get to a resource from a given starting point. Absolute URLs begin
with /, whereas relative URLs begin with ./ (the current directory), ../ (the parent directory), or ~
(the current user’s home directory).
FileManager
has methods that accept both paths and URLs — often with variations of the same
method for both. In general, the use of URLs is preferred to paths, as they’re more flexible to work with.
(it’s also easier to convert from a URL to a path than vice versa).
Locating Files and Directories
The first step to working with a file or directory is locating it on the file system. Standard locations vary
across different platforms, so rather than manually constructing paths like /System or ~/Documents,
you use the FileManager method url(for:in:appropriateFor:create:) to locate the appropriate
location for what you want.
The first parameter takes one of the values specified by FileManager.SearchPathDirectory. These
determine what kind of standard directory you’re looking for, like “Documents” or “Caches”.
The second parameter passes a FileManager.SearchPathDomainMask value, which determines the
scope of where you’re looking for. For example, .applicationDirectory might refer to /Applications
in the local domain and ~/Applications in the user domain.
let documentsDirectoryURL =
try FileManager.default.url(for: .documentDirectory,
in: .userDomainMask,
appropriateFor: nil,
create: false)
NSFileManager *fileManager = [NSFileManager defaultManager];
NSString *documentsPath =
[NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask,
YES) firstObject];
NSString *filePath = [documentsPath stringByAppendingPathComponent:@"file.txt"];
Files and directories can have alternate names from what’s encoded by the path.
For example, most macOS system directories are localized; although a user’s photos located at
~/Photos, the ~/Photos/.localized file can change how the folder is named in Finder and
Open / Save panels. An app can also provide locale-specific names for itself and directories it
creates.
Another example of this is when files are configured to hide their file extension. (You’ve probably
encountered this at some point, with some degree of bewilderment).
Long story short, when displaying the name of a file or directory to the user, don’t simply take the
last path component. Instead, call the method displayName(atPath:):
let directoryURL: URL = /path/to/directory
// Bad
let filename = directoryURL.pathComponents.last
// Good
let filename = FileManager.default.displayName(atPath: url.path)
Determining Whether a File Exists
You might check to see if a file exists at a location before trying to read it, or want to avoid overwriting
an existing one. To do this, call the fileExists(atPath:) method:
let fileURL: URL = /path/to/file
let fileExists = FileManager.default.fileExists(atPath: fileURL.path)
NSURL *fileURL = <#/path/to/file#>;
NSFileManager *fileManager = [NSFileManager defaultManager];
BOOL fileExists = [fileManager fileExistsAtPath:[fileURL path]];
Getting Information About a File
The file system stores various pieces of metadata about each file and directory in the system. You can
access them using the FileManager method attributesOfItem(atPath:). The resulting dictionary
contains attributes keyed by FileAttributeKey values, including .creationDate:
let fileURL: URL = /path/to/file
let attributes =
FileManager.default.attributesOfItem(atPath: fileURL.path)
let creationDate = attributes[.creationDate]
NSURL *fileURL = <#/path/to/file#>;
NSFileManager *fileManager = [NSFileManager defaultManager];
NSError *error = nil;
NSDictionary *attributes = [fileManager attributesOfItemAtPath:[fileURL path]
error:&error];
NSDate *creationDate = attributes[NSFileCreationDate];
File attributes used to be keyed by string constants, which made them hard to discover through
autocompletion or documentation. Fortunately, it’s now easy to see everything that’s available.
Listing Files in a Directory
To list the contents of a directory, call the FileManager method contentsOfDirectory(at:including
PropertiesForKeys:options:). If you intend to access any metadata properties, as described in the
previous section (for example, get the modification date of each file in a directory), specify those here
to ensure that those attributes are cached. The options parameter of this method allows you to skip
hidden files and/or descendants.
let directoryURL: URL = /path/to/directory
let contents =
try FileManager.default.contentsOfDirectory(at: directoryURL,
includingPropertiesForKeys: nil,
options: [.skipsHiddenFiles])
for file in contents {
…
}
NSFileManager *fileManager = [NSFileManager defaultManager];
NSURL *bundleURL = [[NSBundle mainBundle] bundleURL];
NSArray *contents = [fileManager contentsOfDirectoryAtURL:bundleURL
includingPropertiesForKeys:@[]
options:NSDirectoryEnumerationSkipsHiddenFiles
error:nil];
NSPredicate *predicate = [NSPredicate predicateWithFormat:@"pathExtension ==
'png'"];
for (NSURL *fileURL in [contents filteredArrayUsingPredicate:predicate]) {
// Enumerate each .png file in directory
}
Recursively Enumerating Files In A Directory
If you want to go through each subdirectory at a particular location recursively, you can do so by
creating a FileManager.DirectoryEnumerator object with the enumerator(atPath:) method:
let directoryURL: URL = /path/to/directory
if let enumerator =
FileManager.default.enumerator(atPath: directoryURL.path)
{
for case let path as String in enumerator {
// Skip entries with '_' prefix, for example
if path.hasPrefix("_") {
enumerator.skipDescendants()
}
}
}
NSFileManager *fileManager = [NSFileManager defaultManager];
NSURL *bundleURL = [[NSBundle mainBundle] bundleURL];
NSDirectoryEnumerator *enumerator = [fileManager enumeratorAtURL:bundleURL
includingPropertiesForKeys:@[NSURLNameKey, NSURLIsDirectoryKey]
options:NSDirectoryEnumerationSkipsHiddenFiles
*url, NSError *error)
{
if (error) {
NSLog(@"[Error] %@ (%@)", error, url);
return NO;
}
}];
errorHandler:^BOOL(NSURL
return YES;
NSMutableArray *mutableFileURLs = [NSMutableArray array];
for (NSURL *fileURL in enumerator) {
NSString *filename;
[fileURL getResourceValue:&filename forKey:NSURLNameKey error:nil];
NSNumber *isDirectory;
[fileURL getResourceValue:&isDirectory forKey:NSURLIsDirectoryKey
error:nil];
// Skip directories with '_' prefix, for example
if ([filename hasPrefix:@"_"] && [isDirectory boolValue]) {
}
}
[enumerator skipDescendants];
continue;
if (![isDirectory boolValue]) {
[mutableFileURLs addObject:fileURL];
}
Creating a Directory
To create a directory, call the method createDirectory(at:withIntermediateDirectories
:attributes:). In Unix parlance, setting the withIntermediateDirectories parameter to true is
equivalent to passing the -p option to mkdir.
try FileManager.default.createDirectory(at: directoryURL,
withIntermediateDirectories: true,
attributes: nil)
NSFileManager *fileManager = [NSFileManager defaultManager];
NSString *documentsPath =
[NSSearchPathForDirectoriesInDomains(NSDocumentDirectory,
NSUserDomainMask,
YES) firstObject];
NSString *imagesPath = [documentsPath stringByAppendingPathComponent:@"images"];
if (![fileManager fileExistsAtPath:imagesPath]) {
NSError *error = nil;
[fileManager createDirectoryAtPath:imagesPath
withIntermediateDirectories:NO
attributes:nil
error:&error];
}
Deleting a File or Directory
If you want to delete a file or directory, call removeItem(at:):
let fileURL: URL = /path/to/file
try FileManager.default.removeItem(at: fileURL)
NSFileManager *fileManager = [NSFileManager defaultManager];
NSString *documentsPath =
[NSSearchPathForDirectoriesInDomains(NSDocumentDirectory,
NSUserDomainMask,
YES) firstObject];
NSString *filePath = [documentsPath
stringByAppendingPathComponent:@"image.png"];
NSError *error = nil;
if (![fileManager removeItemAtPath:filePath error:&error]) {
NSLog(@"[Error] %@ (%@)", error, filePath);
}
FileManagerDelegate
FileManager
may optionally set a delegate to verify that it should perform a particular file operation.
This is a convenient way to audit all file operations in your app, and a good place to factor out and
centralize business logic, such as which files to protect from deletion.
There are four operations covered by the FileManagerDelegate protocol: moving, copying, removing,
and linking items — each with variations for working with paths and URLs, as well as how to proceed
after an error occurs:
If you were wondering when you might create your own FileManager rather than using this shared
instance, this is it.
From the documentation:
You should associate your delegate with a unique instance of the FileManager class, as opposed to
the shared instance.
class CustomFileManagerDelegate: NSObject, FileManagerDelegate {
func fileManager(_ fileManager: FileManager,
shouldRemoveItemAt URL: URL) -> Bool
{
// Don't delete PDF files
return URL.pathExtension != "pdf"
}
}
// Maintain strong references to fileManager and delegate
let fileManager = FileManager()
let delegate = CustomFileManagerDelegate()
fileManager.delegate = delegate
NSFileManager *fileManager = [[NSFileManager alloc] init];
fileManager.delegate = delegate;
NSURL *bundleURL = [[NSBundle mainBundle] bundleURL];
NSArray *contents = [fileManager contentsOfDirectoryAtURL:bundleURL
includingPropertiesForKeys:@[]
options:NSDirectoryEnumerationSkipsHiddenFiles
error:nil];
for (NSString *filePath in contents) {
[fileManager removeItemAtPath:filePath error:nil];
}
// CustomFileManagerDelegate.m
#pragma mark - NSFileManagerDelegate
- (BOOL)fileManager:(NSFileManager *)fileManager
shouldRemoveItemAtURL:(NSURL *)URL
{
return ![[[URL lastPathComponent] pathExtension] isEqualToString:@"pdf"];
}
When you write an app that interacts with a file system, you don’t know if it’s an HDD or SSD or if
it’s formatted with APFS or HFS+ or something else entirely. You don’t even know where the disk is: it
could be internal or in a mounted peripheral, it could be network-attached, or maybe floating around
somewhere in the cloud.
The best strategy for ensuring that things work across each of the various permutations is to work
through FileManager and its related Foundation APIs.
Temporary Files
Volumes have been written about persisting data, but when it comes to short-lived, temporary files,
there is very little to go on for Cocoa. (Or if there has, perhaps it was poetically ephemeral itself).
Temporary files are used to write data to disk before either moving it to a permanent location or
discarding it. For example, when a movie editor app exports a project, it may write each frame to a
temporary file until it reaches the end and moves the completed file to the ~/Movies directory. Using
a temporary file for these kinds of situations ensures that tasks are completed atomically (either you get
a finished product or nothing at all; nothing half-way), and without creating excessive memory pressure
on the system (on most computers, disk space is plentiful whereas memory is limited).
There are four distinct steps to working with a temporary file:
1. Creating a temporary directory in the filesystem
2. Creating a temporary file in that directory with a unique filename
3. Writing data to the temporary file
4. Moving or deleting the temporary file once you’re finished with it
Creating a Temporary Directory
The first step to creating a temporary file is to find a reasonable, out-of-the-way location to which you
can write — somewhere inconspicuous that doesn’t get in the way of the user or get picked up by a
system process like Spotlight indexing, Time Machine backups, or iCloud sync.
On Unix systems, the /tmp directory is the de facto scratch space. However, today’s macOS and iOS
apps run in a container and don’t have access to system directories; a hard-coded path like that isn’t
going to cut it.
If you don’t intend to keep the temporary file around, you can use the NSTemporaryDirectory()
function to get a path to a temporary directory for the current user.
let temporaryDirectoryURL = URL(fileURLWithPath: NSTemporaryDirectory(),
isDirectory: true)
NSURL *temporaryDirectoryURL = [NSURL fileURLWithPath: NSTemporaryDirectory()
isDirectory: YES];
Alternatively, if you intend to move your temporary file to a destination URL, the preferred (albeit more
complicated) approach is to call the FileManager method uri(for:in:appropriateFor:create:).
let destinationURL: URL = /path/to/destination
let temporaryDirectoryURL =
try FileManager.default.url(for: .itemReplacementDirectory,
in: .userDomainMask,
appropriateFor: destinationURL,
create: true)
NSURL *destinationURL = <#/path/to/destination#>;
NSFileManager *fileManager = [NSFileManager defaultManager];
NSError *error = nil;
NSURL *temporaryDirectoryURL =
[fileManager URLForDirectory:NSItemReplacementDirectory
inDomain:NSUserDomainMask
appropriateForURL:destinationURL
create:YES
error:&error];
The parameters of this method are frequently misunderstood, so let’s go through each to understand
what this method actually does:
• We pass the item replacement search path (.itemReplacementDirectory) to say that we’re
interested in a temporary directory.
• We pass the user domain mask (.userDomainMask) to get a directory that’s accessible to
the user.
• For the appropriateForURL parameter, we specify our destinationURL, so that the
system returns a temporary directory from which a file can be quickly moved to the destination
(and not, say across different volumes).
• Finally, we pass true to the create parameter to save us the additional step of creating it
ourselves.
The
resulting
directory
will
have
a
path
that
looks
something
like
this:
file:///var/folders/l3/kyksr35977d8nfl1mhw6l_c00000gn/T/
TemporaryItems/(A%20Document%20Being%20Saved%20By%20NSHipster%208)/
Creating a Temporary File
With a place to call home (at least temporarily), the next step is to figure out what to call our temporary
file. We’re not picky about what to it’s named — just so long as it’s unique, and doesn’t interfere with
any other temporary files in the directory.
The best way to generate a unique identifier is the ProcessInfo property globallyUniqueString:
ProcessInfo().globallyUniqueString
[[NSProcessInfo processInfo] globallyUniqueString];
The
resulting
filename
will
look
B72B049E9254-25121-000144AB9F08C9C1
something
like
this:
42BC63F7-E79E-4E41-8E0D-
Alternatively, UUID also produces workably unique identifiers:
UUID().uuidString
[[NSUUID UUID] UUIDString]
A generated UUID string has the following format: B49C292E-573D-4F5B-A362-3F2291A786E7
Now that we have an appropriate directory and a unique filename, let’s put them together to create our
temporary file:
let destinationURL: URL = /path/to/destination
let temporaryDirectoryURL =
try FileManager.default.url(for: .itemReplacementDirectory,
in: .userDomainMask,
appropriateFor: destinationURL,
create: true)
let temporaryFilename = ProcessInfo().globallyUniqueString
let temporaryFileURL =
temporaryDirectoryURL.appendingPathComponent(temporaryFilename)
NSURL *destinationURL = <#/path/to/destination#>;
NSFileManager *fileManager = [NSFileManager defaultManager];
NSError *error = nil;
NSURL *temporaryDirectoryURL =
[fileManager URLForDirectory:NSItemReplacementDirectory
inDomain:NSUserDomainMask
appropriateForURL:destinationURL
create:YES
error:&error];
NSString *temporaryFilename =
[[NSProcessInfo processInfo] globallyUniqueString];
NSURL *temporaryFileURL =
[temporaryDirectoryURL
URLByAppendingPathComponent:temporaryFilename];
Writing to a Temporary File
The sole act of creating a file URL is of no consequence to the file system; a file is created only when the
file path is written to. So let’s talk about our options for doing that:
Writing Data to a URL
The simplest way to write data to a file is to call the Data method write(to:options):
let data: Data = some data
try data.write(to: temporaryFileURL,
options: .atomic)
NSData *data = <#some data#>;
NSError *error = nil;
[data writeToURL:temporaryFileURL
options:NSDataWritingAtomic
error:&error];
By passing the atomic option, we ensure that either all of the data is written or the method returns
an error.
Writing Data to a File Handle
If you’re doing anything more complicated than writing a single Data object to a file, consider creating
a FileHandle instead, like so:
let fileHandle = try FileHandle(forWritingTo: temporaryFileURL)
defer { fileHandle.closeFile() }
fileHandle.write(data)
NSError *error = nil;
NSFileHandle *fileHandle =
[NSFileHandle fileHandleForWritingToURL:temporaryFileURL
error:&error];
[fileHandle writeData:data];
[fileHandle closeFile];
Writing Data to an Output Stream
For more advanced APIs, it’s not uncommon to use OutputStream to direct the flow of data. Creating
an output stream to a temporary file is no different than any other kind of file:
let outputStream =
OutputStream(url: temporaryFileURL, append: true)!
defer { outputStream.close() }
data.withUnsafeBytes { bytes in
outputStream.write(bytes, maxLength: bytes.count)
}
NSOutputStream *outputStream =
[NSOutputStream outputStreamWithURL:temporaryFileURL
append:YES];
[outputStream write:data.bytes
maxLength:data.length];
[outputStream close];
In Swift, calling fileHandle.closeFile() or outputStream.close() within a defer
statement is a convenient way to fulfill the API contract of closing a file when we’re done with it. (Of
course, don’t do this if you want to keep the file handle open longer than the enclosing scope).
Moving or Deleting the Temporary File
Files in system-designated temporary directories are periodically deleted by the operating system. So if
you intend to hold onto the file that you’ve been writing to, you need to move it somewhere outside the
line of fire.
If you already know where the file’s going to live, you can use FileManager to move it to its permanent
home:
let fileURL: URL = /path/to/file
try FileManager.default.moveItem(at: temporaryFileURL,
to: fileURL)
NSFileManager *fileManager = [NSFileManager defaultManager];
NSURL *fileURL = <#/path/to/file#>;
NSError *error = nil;
[fileManager moveItemAtURL:temporaryFileURL
toURL:fileURL
error:&error];
Or, if you’re not entirely settled on that, you can use the same approach to locate a cache directory
where the file can lie low for a while:
let cacheDirectoryURL =
try FileManager.default.url(for: .cachesDirectory,
in: .userDomainMask,
appropriateFor: nil,
create: false)
NSFileManager *fileManager = [NSFileManager defaultManager];
NSError *error = nil;
NSURL *cacheDirectoryURL =
[fileManager URLForDirectory:NSCachesDirectory
inDomain:NSUserDomainMask
appropriateForURL:nil
create:NO
error:&error];
Although the system eventually takes care of files in temporary directories, it’s not a bad idea to be a
responsible citizen and follow the guidance of “take only pictures; leave only footprints.”
FileManager can help us out here as well, with the removeItem(at:) method:
try FileManager.default.removeItem(at: temporaryFileURL)
NSFileManager *fileManager = [NSFileManager defaultManager];
NSError *error = nil;
[fileManager removeItemAtURL:temporaryFileURL
error:&error];
“This too shall pass” is a mantra that acknowledges that all things are indeed temporary.
Within the context of the application lifecycle, some things are more temporary than others, and it’s
with that knowledge that we choose to act appropriately: seeking to find the right place, make a unique
impact, and leave without a trace.
Perhaps we can learn something from this cycle in our own, brief and glorious lifecycle.
CoreGraphics Geometry
Primitives
Unless you were a Math Geek or an Ancient Greek, Geometry probably wasn’t your favorite subject in
school. More likely, you were that kid in class who dutifully programmed all of those necessary formulæ
into your TI-8X calculator to avoid rote memorization.
So for those of you who spent more time learning TI-BASIC than Euclid, here’s the cheat-sheet for how
geometry works in Quartz 2D, the drawing system used by Apple platforms:
1.0
(x: 1.0, y: 2.0)
CGFloat
CGPoint
(dx: 4.0, dy: 3.0)
CGVector
(width: 4.0, height: 3.0)
(origin: (x: 1.0, y: 2.0),
size: (width: 4.0, height: 3.0))
CGSize
CGRect
• A CGFloat represents a scalar quantity.
• A CGPoint represents a location in a two-dimensional coordinate system and is defined by x and
y scalar components.
• A CGVector represents a change in position in 2D space and is defined by dx and dy scalar
components.
• A CGSize represents the extent of a figure in 2D space and is defined by width and height
scalar components.
• A CGRect represents a rectangle and is defined by an origin point (CGPoint) and a size
(CGSize).
import CoreGraphics
let
let
let
let
var
float: CGFloat = 1.0
point = CGPoint(x: 1.0, y: 2.0)
vector = CGVector(dx: 4.0, dy: 3.0)
size = CGSize(width: 4.0, height: 3.0)
rectangle = CGRect(origin: point, size: size)
CGVector isn’t widely used in view programming; instead, CGSize values are typically used to
express positional vectors. Unfortunately, this can result in awkward semantics, because sizes may
have negative width and / or height components (in which case a rectangle is extended in the
opposite direction along that dimension).
(x, y)
macOS
(x, y)
iOS
On iOS, the origin is located at the top-left corner of a window, so x and y values increase as they move
down and to the right. macOS, by default, orients (0, 0) at the bottom left corner of a window, such
that y values increase as they move up.
You can configure views on macOS to use the same coordinate system as iOS by overriding the is
Flipped property on subclasses of NSView.
Every view in an iOS or macOS app has a frame represented by a CGRect value, so one would do well
to learn the fundamentals of these geometric primitives.
In this week’s article, we’ll do a quick run through the APIs with which every app developer should
be familiar.
Introspection
“First, know thyself.” So goes the philosophical aphorism. And it remains practical guidance as we begin
our survey of CoreGraphics API.
As structures, you can access the member values of geometric types directly through their stored
properties:
point.x // 1.0
point.y // 2.0
size.width // 4.0
size.height // 3.0
rectangle.origin // {x 1 y 2}
rectangle.size // {w 4 h 3}
You can mutate variables by reassignment or by using mutating operators like *= and +=:
var mutableRectangle = rectangle // {x 1 y 2 w 4 h 3}
mutableRectangle.origin.x = 7.0
mutableRectangle.size.width *= 2.0
mutableRectangle.size.height += 3.0
mutableRectangle // {x 7 y 2 w 8 h 6}
For convenience, rectangles also expose width and height as top-level, computed properties; (x and y
coordinates must be accessed through the intermediary origin):
rectangle.origin.x
rectangle.origin.y
rectangle.width
rectangle.height
However, you can’t use these convenience accessors to change the underlying rectangle like in the
preceding example:
mutableRectangle.width *= 2.0 // {x 1 y 2 w 8 h 3} //
️ Left side of
mutating operator isn't mutable: 'width' is a get-only property
Accessing Minimum, Median, and Maximum Values
Although a rectangle can be fully described by a location (CGPoint) and an extent (CGSize), that’s just
one side of the story.
For the other 3 sides, use the built-in convenience properties to get the minimum (min), median (mid),
and maximum (max) values in the x and y dimensions:
minX
midX
maxX
minY
midY
maxY
rectangle.minX // 1.0
rectangle.midX // 3.0
rectangle.maxX // 5.0
rectangle.minY // 2.0
rectangle.midY // 3.5
rectangle.maxY // 5.0
Computing the Center of a Rectangle
It’s often useful to compute the center point of a rectangle. Although this isn’t provided by the
framework SDK, you can easily extend CGRect to implement it using the midX and midY properties:
extension CGRect {
var center: CGPoint {
return CGPoint(x: midX, y: midY)
}
}
Normalization
Things can get a bit strange when you use non-integral or negative values in geometric calculations.
Fortunately, CoreGraphics has just the APIs you need to keep everything in order.
Standardizing Rectangles
We expect that a rectangle’s origin is situated at its top-left corner. However, if its size has a negative
width or height, the origin could become any of the other corners instead.
For example, consider the following bizarro rectangle that extends leftwards and upwards from its origin.
let ǝןƃuɐʇɔǝɹ = CGRect(origin: point,
size: CGSize(width: -4.0, height: -3.0))
ǝןƃuɐʇɔǝɹ // {x 1 y 2 w -4 h -3}
We can use the standardized property to get the equivalent rectangle with non-negative width and
height. In the case of the previous example, the standardized rectangle has a width of 4 and height of 3
and is situated at the point (-3, -1):
ǝןƃuɐʇɔǝɹ.standardized // {x -3 y -1 w 4 h 3}
Integrating Rectangles
It’s generally a good idea for all CGRect values to be rounded to the nearest whole point. Fractional
values can cause the frame to be drawn on a pixel boundary. Because pixels are atomic units, a fractional
value causes drawing to be averaged over the neighboring pixels. The result: blurry lines that don’t
look great.
The integral property takes the floor each origin value and the ceil each size value. This ensures
that your drawing code aligns on pixel boundaries crisply.
let blurry = CGRect(x: 0.1, y: 0.5, width: 3.3, height: 2.7)
blurry // {x 0.1 y 0.5 w 3.3 h 2.7}
blurry.integral // {x 0 y 0 w 4 h 4}
Though keep in mind that CoreGraphics coordinates operate in terms of points not pixels. So, for
example, a Retina screen with pixel density of 2 represents each point with 4 pixels and can draw
± 0.5f point values on odd pixels without blurriness.
Transformations
While it’s possible to mutate a rectangle by performing member-wise operations on its origin and size,
the CoreGraphics framework offers better solutions by way of the APIs discussed below.
Translating Rectangles
Translation describes the geometric operation of moving a shape from one location to another.
Use the offsetBy method (or CGRectOffset function in Objective-C) to translate a rectangle’s origin
by a specified x and y distance.
rectangle.offsetBy(dx: 2.0, dy: 2.0) // {x 3 y 4 w 4 h 3}
Consider using this method whenever you shift a rectangle’s position. Not only does it save a line
of code, but it more semantically represents intended operation than manipulating the origin values
individually.
Contracting and Expanding Rectangles
Other common transformations for rectangles include contraction and expansion around a center
point. The insetBy(dx:dy:) method can accomplish both.
When passed a positive value for either component, this method returns a rectangle that shrinks by the
specified amount from each side as computed from the center point. For example, when inset by 1.0
horizontally (dy = 0.0), a rectangle originating at (1, 2) with a width of 4 and height equal to 3,
produces a new rectangle originating at (2, 2) with width equal to 2 and height equal to 3. Which is
to say: the result of insetting a rectangle by 1 point horizontally is a rectangle whose width is 2 points
smaller than the original.
rectangle // {x 1 y 2 w 4 h 3}
rectangle.insetBy(dx: 1.0, dy: 0.0) // {x 2 y 2 w 2 h 3}
When passed a negative value for either component, the rectangle grows by that amount from each
side. When passed a non-integral value, this method may produce a rectangle with non-integral
components.
rectangle.insetBy(dx: -1.0, dy: 0.0) // {x 0 y 2 w 6 h 3}
rectangle.insetBy(dx: 0.5, dy: 0.0) // {x 1.5 y 2 w 3 h 3}
For more complex transformations, another option is CGAffineTransform, which allows you to
translate, scale, and rotate geometries — all at the same time! (We’ll cover affine transforms in a
future article)
Identities and Special Values
Points, sizes, and rectangles each have a zero property, which defines the identity value for each
respective type:
CGPoint.zero // {x 0 y 0}
CGSize.zero // {w 0 h 0}
CGRect.zero // {x 0 y 0 w 0 h 0}
Swift shorthand syntax allows you to pass .zero directly as an argument for methods and initializers,
such as CGRect.init(origin:size:):
let square = CGRect(origin: .zero,
size: CGSize(width: 4.0, height: 4.0))
To determine whether a rectangle is empty (has zero size), use the isEmpty property rather than
comparing its size to CGSize.zero.
CGRect.zero.isEmpty // true
CGRect has two additional special values: infinite and null:
CGRect.infinite // {x -∞ y -∞ w +∞ h +∞}
CGRect.null // {x +∞ y +∞ w 0 h 0}
CGRect.null
is conceptually similar to NSNotFound, in that it represents the absence of an expected
value, and does so using the largest representable number to exclude all other values.
CGRect.infinite
has even more interesting properties, as it intersects with all points and rectangles,
contains all rectangles, and its union with any rectangle is itself.
CGRect.infinite.contains( any point ) // true
CGRect.infinite.intersects( any other rectangle ) // true
CGRect.infinite.union( any other rectangle ) // CGRect.infinite
Use isInfinite to determine whether a rectangle is, indeed, infinite.
CGRect.infinite.isInfinite // true
But to fully appreciate why these values exist and how they’re used, let’s talk about geometric
relationships:
Relationships
Up until this point, we’ve been dealing with geometries in isolation. To round out our discussion, let’s
consider what’s possible when evaluating two or more rectangles.
Intersection
Two rectangles intersect if they overlap. Their intersection is the smallest rectangle that encompasses all
points contained by both rectangles.
In Swift, you can use the intersects(_:) and intersection(_:) methods to efficiently compute the
intersection of two CGRect values:
let square = CGRect(origin: .zero,
size: CGSize(width: 4.0, height: 4.0))
square // {x 0 y 0 w 4 h 4}
rectangle.intersects(square) // true
rectangle.intersection(square) // {x 1 y 2 w 3 h 2}
If two rectangles don’t intersect, the intersection(_:) method produces CGRect.null:
rectangle.intersects(.zero) // false
rectangle.intersection(.zero) // CGRect.null
Union
The union of two rectangles is the smallest rectangle that encompasses all of the points contained by
either rectangle.
In Swift, the aptly-named union(_:) method does just this for two CGRect values:
rectangle.union(square) // {x 0 y 0 w 5 h 5}
So what if you didn’t pay attention in Geometry class — this is the real world. And in the real world,
you have CGGeometry.h and all of the types and functions it provides.
Know it well, and you’ll be on your way to discovering great new user interfaces in your apps. Do a
good enough job with that, and you may encounter the best arithmetic problem of all: adding up all the
money you’ve made with your awesome new app. Mathematical!
Bundles and Packages
In this season of giving, let’s stop to consider one of the greatest gifts given to us by modern computer
systems: the gift of abstraction.
Consider those billions of people around the world who use computers and mobile devices on a daily
basis. They do this without having to know anything about the millions of CPU transistors and SSD
sectors and LCD pixels that come together to make that happen. All of this is thanks to abstractions
like files and directories and apps and documents.
This week on NSHipster, we’ll be talking about two important abstractions on Apple platforms: bundles
and packages.
Despite being distinct concepts, the terms “bundle” and “package” are frequently used interchangeably.
Part of this is undoubtedly due to their similar names, but perhaps the main source of confusion is that
many bundles just so happen to be packages (and vice versa).
So before we go any further, let’s define our terminology:
• A bundle is a directory with a known structure that contains executable code and the resources
that code uses.
• A package is a directory that looks like a file when viewed in Finder.
The following diagram illustrates the relationship between bundles and packages, as well as things like
apps, frameworks, plugins, and documents that fall into either or both categories:
If you’re still fuzzy on these distinctions, here’s an analogy that might help you keep things straight:
Think of a package as a box ( ) whose contents are sealed away and are considered to exist as
a single entity. Contrast that with bundles, which are more like backpacks ( ) — each with special
pockets and compartments for carrying whatever you need, and coming in different configurations
depending on whether it’s for taking to school, work, or the gym. If something’s both a bundle and
a package, it’s like a piece of luggage ( ): sealed like a box and organized into compartments like
a backpack.
Bundles
Bundles are primarily for improving developer experience by providing structure for organizing code
and resources. This structure not only allows for predictable loading of code and resources but allows
for system-wide features like localization.
Bundles fall into one of the following three categories, each with their own particular structure and
requirements:
• App Bundles, which contain an executable that can be launched, an Info.plist file describing
the executable, app icons, launch images, and other assets and resources used by the executable,
including interface files, strings files, and data files.
• Framework Bundles, which contain code and resources used by the dynamic shared library.
• Loadable Bundles like plug-ins, which contain executable code and resources that extend the
functionality of an app.
Accessing Bundle Contents
In apps, playgrounds, and most other contexts the bundle you’re interested in is accessible through the
type property Bundle.main. And most of the time, you’ll use url(forResource:withExtension:) (or
one of its variants) to get the location of a particular resource.
For example, if your app bundle includes a file named Photo.jpg, you can get a URL to access it like so:
Bundle.main.url(forResource: "Photo", withExtension: "jpg")
Or if you’re using the Asset Catalog, you can simply drag & drop from the Media Library ( ⇧
⌘
M
) to your editor to create an image literal.
For everything else, Bundle provides several instance methods and properties that give the location of
standard bundle items, with variants returning either a URL or a String paths:
URL
Path
Description
executableURL
executablePath
The executable
url(forAuxiliaryExecutable:)
path(forAuxiliaryExecutable:)
The auxiliary executables
resourceURL
resourcePath
The subdirectory containing resources
sharedFrameworksURL
sharedFrameworksPath
The subdirectory containing shared frameworks
privateFrameworksURL
privateFrameworksPath
The subdirectory containing private frameworks
builtInPlugInsURL
builtInPlugInsPath
The subdirectory containing plug-ins
sharedSupportURL
sharedSupportPath
The subdirectory containing shared support files
appStoreReceiptURL
The App Store receipt
Getting App Information
All app bundles are required to have an Info.plist file that contains information about the app.
Some metadata is accessible directly through instance properties on bundles, including bundleURL and
bundleIdentifier.
import Foundation
let bundle = Bundle.main
bundle.bundleURL
// "/path/to/Example.app"
bundle.bundleIdentifier // "com.nshipster.example"
You can get any other information by subscript access to the infoDictionary property. (Or if that
information is presented to the user, use the localizedInfoDictionary property instead).
bundle.infoDictionary["CFBundleName"] // "Example"
bundle.localizedInfoDictionary["CFBundleName"] // "Esempio" (`it_IT` locale)
Getting Localized Strings
One of the most important features that bundles facilitate is localization. By enforcing a convention for
where localized assets are located, the system can abstract the logic for determining which version of a
file to load away from the developer.
For example, bundles are responsible for loading the localized strings used by your app. You can access
them using the localizedString(forKey:value:table:) method.
import Foundation
let bundle = Bundle.main
bundle.localizedString(forKey: "Hello, %@",
value: "Hello, ${username}",
table: nil)
However, it’s almost always a better idea to use NSLocalizedString so that utilities like genstrings
can automatically extract keys and comments to .strings files for translation.
NSLocalizedString("Hello, %@", comment: "Hello, ${username}")
$ find . \( -name "*.swift" !
! -path "./Carthage/*"
! -path "./Pods/*"
\)
|
tr '\n' '\0' |
xargs -0 genstrings -o .
\
\
\
\
\
\
# find all Swift files
# ignoring dependencies
# from Carthage and CocoaPods
# change delimiter to NUL
# to handle paths with spaces
Packages
Packages are primarily for improving user experience by encapsulating and consolidating related
resources into a single unit.
A directory is considered to be a package by the Finder if any of the following criteria are met:
• The directory has a special extension like .app, .playground, or .plugin
• The directory has an extension that an app has registered as a document type
• The directory has an extended attribute designating it as a package *
Accessing the Contents of a Package
In Finder, you can control-click to show a contextual menu with actions to perform on a selected item.
If an item is a package, “Show Package Contents” will appear at the top, under “Open”.
Selecting this menu item will open a new Finder window from the package directory.
You can, of course, access the contents of a package programmatically, too. The best option depends on
the kind of package:
• If a package has bundle structure, it’s usually easiest to use Bundle as described in the previous
section.
• If a package is a document, you can use NSDocument on macOS and UIDocument on iOS.
• Otherwise, you can use FileWrapper to navigate directories, files, and symbolic links, and
FileHandler to read and write to file descriptors.
Determining if a Directory is a Package
Although it’s up to the Finder how it wants to represent files and directories, most of that is delegated
to the operating system and the services responsible for managing Uniform Type Identifiers (UTIs).
To determine whether a file extension is one of the built-in system package types or used by an installed
app as a registered document type, access the URL resource isPackageKey:
let url: URL = …
let directoryIsPackage = (try? url.resourceValues(forKeys:
[.isPackageKey]).isPackage) ?? false
Or, if you don’t have a URL handy and wanted to check a particular filename extension, you could
instead use the Core Services framework to make this determination:
import Foundation
import CoreServices
func filenameExtensionIsPackage(_ filenameExtension: String) -> Bool {
guard let uti = UTTypeCreatePreferredIdentifierForTag(
kUTTagClassFilenameExtension,
filenameExtension as NSString, nil
)?.takeRetainedValue()
else {
return false
}
}
return UTTypeConformsTo(uti, kUTTypePackage)
let xcode = URL(fileURLWithPath: "/Applications/Xcode.app")
directoryIsPackage(xcode) // true
If you want to set the so-called “package bit” for a file the hard way (rather than calling URL.set
ResourceValues(_:)), spelunking through CarbonCore/Finder.h indicates that you can do this
by setting the kHasBundle (0x2000) flag in the com.apple.FinderInfo extended attribute:
$ xattr -wx com.apple.FinderInfo /path/to/package \
00 00 00 00 00 00 00 00 20 00 00 00 00 00 00 00 \
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
As we’ve seen, it’s not just end-users that benefit from abstractions — whether it’s the safety and
expressiveness of a high-level programming language like Swift or the convenience of APIs like
Foundation, we as developers leverage abstraction to make great software.
For all that we may (rightfully) complain about abstractions that are leaky or inverted, it’s important to
take a step back and realize how many useful abstractions we deal with every day, and how much they
allow us to do.
Miscellaneous
Empathy
Great software is created to scratch one’s own itch. Being close to a problem provides not only insight
for how to solve it, but the motivation to actually follow through.
It’s the better angels of our nature that compel us to share these solutions with one other. And in the
open source world, we do so freely, with only a karmic expectation of paying the favor forward.
We naturally want to help one another, to explain ideas, to be generous and patient. However, on the
Internet, human nature seems to drop a few packets. Practicing empathy online becomes a feat of moral
athleticism. Lacking many of the faculties to humanize and understand one another (facial expressions,
voice tonality, non-verbal cues) we can lose sight of who we’re talking to, and become less human
ourselves.
Before engaging with someone, take a moment to visualize how that encounter would play out in real
life. Would you be proud of how you conducted yourself?
Rather than responding defensively to snark or aggression, stop to consider what could have motivated
that reaction. Is there something you could be doing better as a programmer or community member?
Or are they just having a bad day? (We’ve all had our bad days).
And let it never be that someone is marginalized for their ability to communicate in English. Be patient
and ask questions. Respond simply and clearly.
Everything you need to succeed as a software developer extends from a conscious practice of empathy.