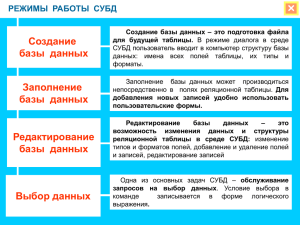
КРАТКОЕ СОДЕРЖАНИЕ КУРСА РЭИС Какие основные три класса АИС существуют? Основные средства АИС. Автоматизированная информационная система – это функционирующий на основе ЭВМ и других технических средств комплекс, обеспечивающий сбор, хранений, актуализацию и обработку информации в целях поддержки какого-либо вида деятельности. К числу основных компонентов такой системы относятся средства ПО, технические средства ПК, сети ПК, лингвистические средства интерфейсов пользователей и системного персонала, информационные ресурсы, которые хранятся, обрабатываются системой и выдаются пользователю. В зависимости от характера информационных ресурсов, с которыми имеют дело такие системы, различают три крупных их класса: - документальные системы; - фактографические системы; - интеллектуальные системы. К документальным системам относятся: ИПС, Гипертекстовые системы, Гипермедиа системы, Системы машинного перевода текста. Фактографические системы составляют другой класс автоматизированных информационных систем. Характерная особенность этих систем состоит в том, что они оперируют фактическими сведениями, представленными в виде специальным образом организованных совокупностей формализованных записей данных. В то время как документальные системы позаимствовали из технологии БД главным образом лишь некоторые идеи и элементы терминологии БД, в современных фактографических системах в полной мере используются как методология, так и инструментальные свойства БД. Фактографические информационные системы, созданные средствами СУБД принято называть банками данных (БнД). Фактографические системы используются не только для реализации различных справочных функций, но и для решения задач обработки данных. Под задачами обработки данных понимается специальный класс задач, решаемых на ПК, связанных с вводом, хранением, сортировкой, отбором по заданному условию и группировкой записей данных однородной структуры. Фактографические системы для обработки данных используют различные математические методы. При этом предусматривается создание и вывод различных отчетов с промежуточными и плановыми итогами по всему отчету. К Интеллектуальным информационным системам относятся Базы знаний и Экспертные системы. Эти системы после выполнения одного этапа умеют выбрать самостоятельно по результатам предыдущего этапа следующий этап обработки данных и так далее пока не будет выполнен весь цикл обработки данных. Три формы существования мира. Какие процессы называются информационными? Автоматизированная информационная система. Средства, относящиеся к компонентам АИС. Мир существует в трех основных формах: вещество, энергия, информация. Всё многообразие материальных объектов состоит из вещества. Объекты бывают разного вида: 1. Макромир – объекты: - неживые объекты: здания, транспорт, мебель, одежда и т.д.; - живые: растения, животные, люди и др. 2. Микромир – объекты: молекулы, атомы, элементарные частицы, нанообъекты. 3. Мегамир – объекты: планеты, звезды, галактики, млечный путь, Вселенная. Процессы, связанные с получением, хранением, обработкой и передачей информации, называются информационными процессами. История человеческого общества – это история накопления и преобразования информации. Человек воспринимает окружающий мир (получает информацию ) с помощью органов чувств (зрение, слух, осязание, обоняние, вкус). Чтобы правильно ориентироваться в мире, он запоминает полученные сведения ( х р а н и т инф о р м а ц и ю ) . В процессе достижения каких-либо целей человек для принятия решения ( о б р а б а т ы в а е т и н ф о р м а ц и ю ). В процессе общения с другими людьми человек п е р е д а е т и принимает и н ф о р м а ц и ю . Таким образом, человек живет в мире информации. Обмен информацией осуществляется с помощью языков как искусственных, так и естественных. Автоматизированная информационная система – это функционирующий на основе ЭВМ и других технических средств комплекс, обеспечивающий сбор, хранений, актуализацию и обработку информации в целях поддержки какого-либо вида деятельности. К числу основных компонентов такой системы относятся средства ПО, технические средства ПК, сети ПК, лингвистические средства интерфейсов пользователей и системного персонала, информационные ресурсы, которые хранятся и обрабатываются системой. ИНФОРМАЦИОННО-ПОИСКОВЫЕ СИСТЕМЫ (ИПС). Поисковый массив ИПС и что в него входит? Поисковый тезаурус и его роль в ИПС. Наиболее распространенными видами документальных систем являются ИПС, предназначенные для накопления и поиска по различным критериям документов, записанных на естественном языке, т.е. семантический поиск документов (смысловой поиск). Основные компоненты ИПС – ее программные средства, поисковый массив документов, средства формирования и поддержки информационного языка системы, информационно-поисковый тезаурус (ИПТ). Поисковый массив документов ИПС обычно называется банком данных (БнД). Он чаще всего не содержит непосредственно полных текстов документов, а, как правило, только рефераты или аннотации документов. При выполнении операций поиска документов система использует их поисковые образы – формализованные объекты, представленные на информационном языке системы и отражающие содержание соответствующих документов. Наиболее распространенными видами документальных систем являются информационно-поисковые системы (ИПС), предназначенные для поиска документов по смыслу (семантический поиск), записанных на естественном языке. Информационно-поисковый тезаурус (ИПТ), представляющий собой словарь дескрипторов с семантическими связями между ними. При выполнении операций поиска документов система использует их поисковые образы – формализованные объекты, представленные на информационном языке системы и отражающие содержание соответствующих документов. Формирование поисковых образов документов (ПОД) производится при вводе документов в систему автоматически с последующим контролем специалистами в их предметной области. Создание ПОД требует проведения процедуры индексирования документов (рефератов документов) – снабжения их ключевыми словами, (дескрипторами, ЛЕ), рубриками и т.п. Информационный запрос пользователя также автоматически преобразуется в поисковый образ запроса (ПОЗ) с последующим контролем специалистами в их предметной области. ПОЗ далее сопоставляется с ПОДами документов, хранимых в системе. В ответ на запрос выдаются рефераты всех документов, поисковые образы которых удовлетворяют ПОЗ’у. Такие документы называются релевантными запросу. Гипертекст. Что такое гипертекстовая информационная система? Гипертекст – это форма организации текстового материала, при которой его смысловые единицы (фразы, абзацы, разделы) представлены не в линейной последовательности, а как система явно указанных возможных переходов, связей между ними. Следуя этим связям, можно читать материал в любом порядке. Если речь идет о достаточно обширном материале с большим количеством связей, то возникает весьма сложное гипертекстовое пространство (сеть). Формирование и просмотр такой сети возможны только при помощи ПК. Компьютерная гипертекстовая технология в самой общей форме понимается как «поддержка связей», т.е. обеспечение максимальной комфортности для пользователя при формировании и обработке сети связей. Имеется в виду, прежде всего, предоставление пользователю возможности легко добавить в базу данных новые текстовые единицы, указывая их связи с уже имеющимися. Не менее важна для пользователя простота перемещения по образованной сети, т.е. возможность «читать» гипертекст в любом задуманном порядке. Гипертекст всегда представляет собой некоторую сеть или граф, отображающие систему связей между смысловыми единицами текста. Свойства гипертекста, его функциональные возможности в значительной степени зависят от структурных характеристик гипертекстовой сети. Она может иметь разную степень сложности, быть иерархической или циклической, члениться на обособленные части, быть «стройной» или «хаотической». Почти все авторы отмечают, что в гипертексте можно «заблудиться», потерять ориентацию, не найти удобных путей чтения. При формировании смысловых графов автор должен пользоваться определенными критериями и процедурами, чтобы отличать прямую смысловую связь от косвенной связи. Смежными по смыслу считаются лишь те понятия, которые можно объединить при помощи связок (типа «есть», «является причиной», «поэтому», «в этих целях» и др.). Такие графы стали называть «логико-смысловыми графами», а логико-смысловые графы вплотную приблизились к гипертекстам. Появилась возможность представления предметной области с разной степенью детализации путем построения укрупненных графов, включающих лишь те смысловые единицы, у которых число связей превышает определенный порог. Но для самого гипертекста здесь таятся интересные возможности: ведь таким способом в его смысловой сети можно автоматически отыскивать предпочтительные пути. Так могут интерпретироваться социальные позиции, системы взглядов, научные концепции, новые идеи, которые должны обладать единством, целостностью. Известны гипертекстовые системы, такие как учебные и справочные системы, в которых пользователь сам выбирает, как ему двигаться при освоении материала в сети связанных по смыслу текстовых фрагментов, причем система подсказывает ему возможные варианты такого движения. Гипермедиа системы. Принципиальной особенностью гипермедиа является распространение идеи гипертекста, т. е. ассоциативно связанной текстовой информации на изобразительную и звуковую информацию, хранящуюся в цифровой форме. Системы гипермедиа относятся к типу систем, базирующихся на использовании наиболее передовых технологий и технических средств и предназначенных для повышения эффективности и интенсивности процессов взаимодействия и всей среды, относящейся к знаниям. С другой стороны системы гипермедиа являются интеллектуальными информационными системами. Системы гипермедиа, как и гипертекстовые, могут рассматриваться в разных аспектах. Один из подходов, близкий программистам, заключается в том, чтобы сравнить методы доступа к информации в гипертексте с соответствующими методами в СУБД. Эти методы различны: в гипертексте они опираются на ассоциативные связи между понятиями, а в СУБД на структурные свойства данных. Между системами гипертекста и гипермедиа нет четкой границы. Эти системы представляют собой развитые информационные технологии, ориентированные в первую очередь на обработку знаний. Многие специалисты высоко оценивают перспективы технологий гипермедиа и гипертекста, считая, что они вышли на уровень стратегических ресурсов компьютерных корпораций. Три основные направления в гипертекстовых системах и возможности предоставляемые гипертекстовой системой пользователю при вводе фрагментов текста в БД? В применении гипертекстовых систем сложилось несколько основных направлений. Одно из них – электронная книга – обеспечивает более быстрое освоение материала с большим количеством ссылок и смысловых пересечений. В качестве объектов могут выступать справочные и учебные материалы, проектная и программная документация. Каждый фрагмент (текста) снабжается указанием всех его ссылок и возможных смысловых переходов к другим фрагментам документа. Другое направление применения гипертекстовых систем – компоновка крупных текстовых материалов из фрагментов, которые первоначально представлены в форме сети с указанием их взаимных смысловых связей. Третье направление – представление в форме единого гипертекста идей, аргументов и предложений, вносимых участниками коллективной работы, рассмотрение и анализ взаимосвязи этих идей и аргументов. Системы предоставляют пользователю возможность при вводе фрагментов текста в БД устанавливать между ними связи (ссылочные, смысловые, логические, ассоциативные и др.), обеспечивают компьютерную поддержку этих связей и перемещение по ним. Таким образом, гипертекст формируется как совокупность взаимосвязанных фрагментов текста. Эти фрагменты могут представлять собой, как целые документы, так и отдельные высказывания, формулировки идей, проблем, предложений, мероприятий, фактов. Система обеспечивает максимальную открытость гипертекста, возможность его пополнения, изменения структуры и содержания на любом этапе работы. Система не навязывает пользователю готовые схемы и ограничения на структуру представления информации. Гипертекстовые системы предназначены для использования в таких областях деятельности, как анализ проблем, изучение прецедентов, прогнозирование социальных явлений, обоснование управленческих решений, подготовка различных документов: обзоров, аналитических материалов, пояснительных записок, докладов и т.п. Гипертекст всегда представляет собой некоторую сеть или граф, отображающие систему связей между смысловыми единицами текста. Свойства гипертекста, его функциональные возможности в значительной степени зависят от структурных характеристик гипертекстовой сети. Она может иметь разную степень сложности, быть иерархической или циклической, члениться на обособленные части, быть «стройной» или «хаотической». Почти все авторы отмечают, что в гипертексте можно «заблудиться», потерять ориентацию, не найти удобных путей чтения. При формировании смысловых графов автор должен пользоваться определенными критериями и процедурами, чтобы отличать прямую смысловую связь от косвенной связи. Смежными по смыслу считаются лишь те понятия, которые можно объединить при помощи связок (типа «есть», «является причиной», «поэтому», «в этих целях» и др.). Такие графы стали называть «логико-смысловыми графами», а логико-смысловые графы вплотную приблизились к гипертекстам. Логико-смысловые графы, действительно, рассматривают как одну из версий гипертекста. Например, WWW – глобальная гипермедийная распределенная ИС, функционирующая в среде Интернет. В логико-смысловых графах стал применяться принцип полноты связей, т.е. связь стала фиксироваться для всех пар высказываний, которые могли быть соединены связкой. Для каждого нового высказывания, вводимого в логико-смысловой граф, нужно было указать все его связи с высказываниями, уже имеющимися в этом графе. Появилась возможность представления предметной области с разной степенью детализации путем построения укрупненных графов, включающих лишь те смысловые единицы, у которых число связей превышает определенный порог. Но для самого гипертекста здесь таятся интересные возможности: ведь таким способом в его смысловой сети можно автоматически отыскивать предпочтительные пути. Так могут интерпретироваться социальные позиции, системы взглядов, научные концепции, новые идеи, которые должны обладать единством, целостностью. Известны гипертекстовые системы, такие как учебные и справочные системы, в которых пользователь сам выбирает, как ему двигаться при освоении материала в сети связанных по смыслу текстовых фрагментов, причем система подсказывает ему возможные варианты такого движения. В соответствии с этим в применении гипертекстовых систем сложилось несколько основных направлений. Одно из них – электронная книга – обеспечивает более быстрое освоение материала с большим количеством ссылок и смысловых пересечений. В качестве объектов могут выступать справочные и учебные материалы, проектная и программная документация. Каждый фрагмент (текста) снабжается указанием всех его ссылок и возможных смысловых переходов к другим фрагментам документа. Другое направление применения гипертекстовых систем – компоновка крупных текстовых материалов из фрагментов, которые первоначально представлены в форме сети с указанием их взаимных смысловых связей. Третье направление – представление в форме единого гипертекста идей, аргументов и предложений, вносимых участниками коллективной работы, рассмотрение и анализ взаимосвязи этих идей и аргументов. Коммерческие гипертекстовые системы выпускаются с 1987 года. Системы предоставляют пользователю возможность при вводе фрагментов текста в БД устанавливать между ними связи (ссылочные, смысловые, логические, ассоциативные и др.), обеспечивают компьютерную поддержку этих связей и перемещение по ним. Таким образом, гипертекст формируется как совокупность взаимосвязанных фрагментов текста. Эти фрагменты могут представлять собой, как целые документы, так и отдельные высказывания, формулировки идей, проблем, предложений, мероприятий, фактов. Система обеспечивает максимальную открытость гипертекста, возможность его пополнения, изменения структуры и содержания на любом этапе работы. Система не навязывает пользователю готовые схемы и ограничения на структуру представления информации. Данные гипертекстовые системы предназначены для использования в таких областях деятельности, как анализ проблем, изучение прецедентов, прогнозирование социальных явлений, обоснование управленческих решений, подготовка различных документов: обзоров, аналитических материалов, пояснительных записок, докладов и т.п. Информационные системы машинного перевода. С развитием общества возникает потребность общения между народами и странами. Но этот процесс тормозится языковыми барьерами. Обучение иностранным языкам и переводческая деятельность в какой-то мере облегчают эту проблему, но не решают ее. Более радикальным решением является создание систем автоматического перевода с одних естественных языков на другие. Такие системы создаются во многих развитых странах мира, однако качество автоматического перевода оставляет желать лучшего. Говоря о машинном переводе, мы подразумеваем лишь частично автоматизированную деятельность, в которой на разных ее этапах участвует человек. Поскольку перевод специальных текстов при помощи компьютера может быть значительно проще и быстрее, системы машинного перевода стали полезным инструментов переводчика и важным фактором снижения затрат в этой области. Человеческий перевод текстов с одних естественных языков на другие – это сложный мыслительный процесс. Он осуществляется на основе восприятия исходного текста и передачи его смысла средствами другого языка. При этом переводятся не слова и их последовательность, а понятие и мыслительные образы, порождаемые сознанием переводчика под их воздействием. Системы машинного перевода текстов предназначены для моделирования работы человека переводчика. Но моделировать эту работу в полном объеме пока не удается. И нужно оперировать теми единицами языка и речи, которые позволяют наиболее точно передавать содержание текста, написано на одном языке, средствами другого языка. Такими единицами являются фразеологические обороты и терминологические словосочетания и, во вторую очередь, отдельные слова. Поэтому перспективные системы машинного перевода должны опираться на фразеологическое богатство естественных языков. Они должны быть системами фразеологического перевода. С точки зрения пользователя системы машинного перевода делятся на три типа: 1) информативные, предназначены для доступа к информации на иностранном языке и для тех, кто готов пользоваться «грубым» переводом, но понятным. Такие системы имеют словари большого объема и не опираются на новейшие достижения в лингвистике и программировании. 2) Профессиональные, которые дают лишь черновые наброски переводов для профессиональных переводчиков и тем освобождают их от черновой работы. Такие системы используются все реже, - как правило, при большом объеме текущей переводческой работы. 3) Персональные – для авторов, желающих перевести свои статьи на иностранный язык, которым они не вполне владеют. Такие системы обычно работают в диалоге с пользователем и могут давать удовлетворительный перевод. По применяемым лингвистическим методам системы машинного перевода можно разделить также на три типа: 1. Системы прямого перевода – наиболее многочисленные, поскольку начали создаваться еще в 50-60 годы для фиксированных пар языков. Эти системы выдавали пословные и лишь позднее переводы, основанные на анализе предложений входного языка. 2. Системы перевода с использованием языка-посредника, служащего для отображения «смысла» входного текста, который преобразуется в семантические и синтаксические представления. Этот метод применяется обычно при необходимости перевода исходного текста на несколько языков (в переводческих центрах Европейского сообщества, например). 3. Системы перевода с трансфертом являются более сложными, поскольку языки-посредники применяются дважды – 1 раз при переводе с входного языка, второй раз – при переводе на входной язык. За этот счет достигается более глубокий лингвистический анализ и синтез. В последние годы все большее применение в машинном переводе находят методы искусственного интеллекта, которые при переводе учитывают семантику текста. Это означает, что они опираются не столько на грамматические, сколько на семантико-синтаксические категории. Однако и методы искусственного интеллекта пока не дают всей информации, необходимой для полноценного машинного перевода. В частности, проблемы возникают при переводе с английского языка на японский. «Понимание» английского текста не дает достаточной информации о состоянии пишущего и читающего, необходимой для адекватного перевода на японский язык. Несмотря на все оговорки, связанные с несовершенством систем машинного перевода, существуют уже сотни достаточно широко используемых систем такого рода. Информационная система и управление. Современные методы управления предприятием требуют более совершенных технологических решений. Управление предприятием и информационные технологии тесно связаны с информационной системой. Часть информации находится под контролем управленческого персонала и используется им для принятия решений. Это контролируемая информация, но есть и бесконтрольная информация. Это область невостребованной информации. Чем больше область неконтролируемой информации, тем сложнее работать предприятию. Создание компьютерной ИС обеспечивает устранение неконтролируемой информации и необходимо решить, каким путем этого можно достичь. Таким образом, первоначально нужно определить круг задач, которые нужно решить и определить пути их решения. Недостаточный контроль информации оказывает серьезное влияние на результаты деятельности предприятия. Однако часто у управленцев складывается впечатление, что программные продукты ИС способны самостоятельно, без их активного участия полностью решить все проблемы компании. Как правило, такие проекты обречены на неудачу. Деятельность предприятия состоит не только из технологического процесса. Технологическому процессу сопутствует множество факторов и условий, придающих своеобразие управлению предприятием, а не его технологической деятельностью. И поэтому для каждого предприятия необходима своя система методов управления, которая позволила бы ему решать существующие проблемы. Управленческая информация – это не только информация производственного характера, но и информация «вокруг предприятия», информация экономической среды, в условиях которой действует предприятие. Использование ПО способно улучшить качество предоставления доступной информации, но не увеличить ее область. Область, на которой делается акцент – это способы расширения контролируемой внешней и внутренней управленческой информации, которая в последующем может стать частью компьютерной информационной системы организации. Под управлением предприятием понимается организация деятельности предприятия с учетом изменений в окружающей экономической и социальной среде. Управленческий персонал распределяет финансовые, трудовые и материальные ресурсы таким образом, чтобы реализовать намеченные планы. Задача управления состоит в том, чтобы отслеживать внутренние и внешние процессы и реагировать на них, чтобы изменения экономических условий способствовали развитию предприятия, а не наносили ему ущерб. Управленческие задачи на предприятии различаются по уровням. Высший управленческий персонал принимает долгосрочные стратегические решения и отслеживает выполнение решений принципиальных с точки зрения деятельности всей организации. Средний уровень реализует принятые на высшем уровне решения. Операционный уровень управления отвечает за текущее состояние дел на предприятии. Для работы управленцев на каждом из этих уровней требуются разные виды информации. Интегрированность данных. Минимизация избыточности данных. Репликаторы. Интегральная эффективность системы. БД рассматриваются как интегрированные совокупности данных. Это свойство БД означает, что каждый факт представлен в ней только один раз. Основополагающим принципом создания БД является наличие избыточных данных нарушает непротиворечивость БД и создает много сложностей по поддержанию БД в актуальном состоянии. Принцип минимизации избыточности данных на практике иногда сознательно нарушается ради улучшения некоторых других характеристик ИС. Так, в распределенных БД часто используется поддержка копий фрагментов базы данных (репликаторов) на разных узлах сети ради сокращения сетевого трафика и повышения производительности системы. Но за это приходиться платить необходимостью синхронизации репликаторов при обновлении одного из них. Обычно БД создается для удовлетворения информационных потребностей многих пользователей и для поддержки решения ряда задач (приложений). Это означает, прежде всего, что критерии оценки возможных вариантов построения БД направлены на обеспечение интегральной эффективности системы, а не эффективности удовлетворения информационных потребностей отдельных ее пользователей. Указанные категории могут учитывать приоритеты различных пользователей, особенно при работе в интерактивном режиме, приоритеты и частоту решения различных задач, что на практике оказывается весьма сложной задачей. Однако в ответственных случаях для решения этой трудной проблемы используют оптимизационные математические модели, проводят эксперименты с имитационными моделями исследуемой системы для получения нужных оценок. Три основных элемента для создания модели структуры данных. Необходимый начальный этап разработки любой ИС. Основная предпосылка модели структуры данных состоит в том, что структура данных предприятия может быть смоделирована с помощью трех элементов: сущностей, атрибутов сущностей и связей. Сущность – это такой тип объектов, который существует независимо и содержит данные, относящиеся к предметной области (например, сотрудник, счетфактура и др.) Атрибуты – это характеристики сущностей, с помощью которых может быть описан любой из объектов сущностей (Например, СОТРУДНИК: дата рождения, дата приема на работу, должность и т.д.) Связь – все сущности предприятия взаимосвязаны между собой и образуют систему (Например СОТРУДНИК связан с сущностью ПОДРАЗДЕЛЕНИЕ). Существует несколько типов связей: «один к одному», «один к многим», «многие к многим». Каждая ИС в зависимости от ее назначения имеет дело с той или иной частью реального мира, которую принято называть предметной областью системы. Анализ предметной области является необходимым начальным этапом разработки любой информационной системы. На этом этапе определяются информационные потребности всей совокупности пользователей будущей системы, которые, в свою очередь, предопределяют содержание ее БД. Рассмотрение реальных объектов в конкретной информационной системе требует абстрагироваться от их несущественных в данном случае свойств. Каждый объект обладает определенным набором свойств (атрибутов). Так, например, компьютер характеризуется названием фирмы-производителя, идентификатором модели, типом микропроцессора, объемом оперативной и внешней памяти, типом графической карты и т.д. Признание какого-либо атрибута существенным носит относительный характер. Атрибуты, существенные в рамках одной системы, могут, естественно, оказаться несущественными в другой ИС. Осмысление предметной области в терминах конкретных объектов оказывается чаще всего громоздким, не позволяет четко выкристаллизовать ее структуру. Поэтому в большинстве случаев прибегают к разбиению всего множества объектов предметной области на группы объектов, однородных по их структуре, называемых типами объектов. При этом считается, что все объекты одного типа обладают одинаковыми наборами атрибутов и, таким образом, считают их свойства свойствами типа. СУБД: назначение, состав, АБД. В соответствии с концепцией БД предполагается, что она представляет собой самостоятельный обобществленный централизованно управляемый ресурс некоторого сообщества пользователей, предназначенный для удовлетворения их информационных потребностей. Создание БД, поддержка ее в актуальном состоянии и обеспечение доступа пользователей к ней осуществляется с помощью специального программного инструментария, называемого СУБД. Одна установка СУБД на ПК может управлять несколькими БД. Пользователей БД называют конечными пользователями. Кроме того, в качестве пользователей могут рассматриваться различные прикладные программы или программные комплексы (ППП), оперирующие данными из БД. Такие программные средства называют приложениями СУБД, которые взаимодействуют с СУБД через ее интерфейсы прикладного программирования. Централизованный характер управления БД обусловлен необходимостью существования некоторого лица или группы лиц, на которых возлагаются функции администратора БД (АБД), действующего в интересах всех пользователей. АБД ответственен за поддержку системы в работоспособном состоянии, своевременную актуализацию данных, эффективное использование информационных ресурсов системы и ресурсов памяти, предоставление полномочий пользователям на доступ к данным. Создание БД, настройка СУБД на работу, схема БД, логическое представление данных, физическое представление данных. управление физическим размещением данных. СУБД общего назначения – сложный программный комплекс, предназначенный для выполнения всей совокупности функций, связанных с созданием и эксплуатацией систем БД, которые используются самостоятельно или в составе какой-либо крупной ИС. Разработчики систем БД имеют возможность настраивать СУБД общего назначения с создаваемой БД с учетом конкретных условий применения, инициировать БД, производить начальную загрузку и актуализацию данных. Системные механизмы таких СУБД выполняют функции управления ресурсами среды хранения, обеспечение логической и физической независимости данных, предоставление доступа к пользователям БД, защиту логической целостности БД, обеспечение физической целостности. Другая важная группа функций – управление полномочиями пользователей, организация параллельного доступа к БД, поддержка деятельности персонала администратора, ответственность за эксплуатацию БД. Для создания БД и настройки СУБД на работу, разработчик описывает логическую структуру полной БД, организацию хранимых данных в тех рамках, которые допускает, используемая СУБД, а также способы ведения БД пользователями. При этом используются предоставляемые СУБД языковые средства определения данных. Такие описания БД называются схемой БД (логической схемой), схемой хранения (внутренней схемой) и подсхемами (внешними схемами). В соответствии с заданной схемой БД СУБД структурирует данные, вводимые в БД, корректно интерпретирует хранимые данные при осуществлении доступа к ним. Принципиально важное свойство СУБД заключается в том, что она позволяет различать и поддерживать два независимых взгляда на БД – взгляд пользователя, часто называемый логическим представление данных, и взгляд системы, называемый физическим представлением данных, который характеризует организацию хранимых данных на МД. Пользователей не интересуют при работе с БД байты и биты, представляющие данные в среде хранения, их размещение в ВЗУ, указатели, поддерживающие связи между различными структурными компонентами хранимых данных, выбранные метода доступа. В тоже время все эти факторы важны для выполнения функций управления данными самой СУБД. Поддержка двух независимых представлений БД фактически сводится к тому, что на СУБД возлагается задача формирования из хранимой информации такого представления данных, которое отражает взгляд пользователя. Важно отметить, что логические средства представления БД могут по своей структуре существенно отличаться от структуры хранимых данных и синтезироваться не только непосредственно из фактических хранимых объектов БД и их связей, но и с помощью различного рода операций агрегирования данных и различных программных встроенных процедур обработки данных. Такие механизмы трансформации данных, развитые в различной степени в разных СУБД, помогают в значительной мере сократить объем работ по программированию прикладных систем, функционирующих в среде системы БД. Концепция независимости данных, имеющая важнейшее значение в технологиях БД. С информационной архитектурой системы БД тесно связана концепция независимости данных, имеющая важнейшее значение в технологии БД. Различают логическую и физическую независимость данных. Обеспечение логической независимости данных означает способность СУБД предоставлять администратору систем БД определенную степень свободы вариации логического представления БД без необходимости соответствующей модификации приложений и пользовательских запросов. В терминах архитектурных моделей ANSI/X3/SPARK это свойство можно рассматривать как возможность вариации концептуальной схемы БД без необходимости изменения внешних схем. Под физической независимостью данных понимается способность СУБД предоставлять администратору систем БД некоторую свободу модификации способов организации БД в среде хранения, не вызывая необходимости внесения соответствующих изменений в логическое её представление. Благодаря этому можно вносить изменения в организацию хранимых данных, производить настройку систем с целью повышения ее производительности и эффективности использования ресурсов памяти для хранения БД, не затрагивая созданных прикладных программ, использующих БД Что общего между предметной областью ИС и концептуальной схемой БД? Что общего между концептуальной и логической схемой БД? Что общего между логической и физической схемами БД? Информационная архитектура системы БД характеризует поддерживаемые в системе представления информационных ресурсов, их свойства и взаимосвязи. Концепции многоуровневой архитектуры стали основой современной технологии БД. Была предложена обобщенная трехуровневая модель информационной архитектуры системы БД, включающая концептуальный, внутренний и внешний уровни. Такая модель описывает архитектуру любой системы с той лишь оговоркой, что кое-какие ее компоненты или функции в конкретной СУБД могут иметь вырожденный характер. Концептуальный уровень архитектуры служит для. далее Именно в среду концептуального уровня при проектировании БД отображается модель предметной области системы. Правильно созданный концептуальный уровень превращается в логическую схему с помощью языка описания данных, т.е. это концептуальный уровень представленный средствами языка описания данных выбранной СУБД. Логическая схема используется программами СУБД для размещения данных в среде хранения на внутреннем уровне, для поддержки единого взгляда на базу данных, общего для всех ее приложений и запросов к БД конечных пользователей. Физическая схема БД создаётся на основе логической схемы. Механизмы СУБД, поддерживающие внутренний уровень архитектуры, служат для поддержки представления БД в среде хранения. Это единственный уровень информационной архитектуры, где БД в действительности представлена полностью в «материализованном» виде. Описание представления БД на внутреннем уровне архитектуры называется внутренней схемой или схемой хранения. Что такое мобильные базы данных? Сверхбольшие БД. Какие новые достижения находят применение при создании БД? Развитие беспроводной телекоммуникации открыло возможности для разработки распределённых систем с мобильной архитектурой, называемой системами мобильных баз данных. Однако с ними связан ряд проблем, которые ещё требуют своего разрешения: создание методов управления транзакциями, учитывающих специфику мобильных систем в мобильных и стационарных фрагментах БД и др. Еще одно актуальное направление – это создание техники управления сверхбольшими БД. В последние годы такие БД начали создаваться в ряде областей научных исследований, в частности в космических исследованиях, в молекулярной биологии, в физике частиц, в области аэрофотосъемки земной поверхности. В ближайшие годы объемы таких БД будут достигать 10 Пб. Ежедневный прирост объема некоторых из них уже сейчас достигает нескольких терабайтов. Для систем такого рода требуются новые методы эффективного доступа и хранения данных, обеспечения целостности данных. Развитие средств вычислительной и коммуникационной техники, новые достижения в смежных областях информационных технологий, развитие новых сфер применения будут предъявлять новые требования к технологиям БД и стимулировать дальнейшее развитие этого важного направления технологий современных информационных систем. Хотя технологии БД имеют уже более чем 40-летнюю историю, они не только не исчерпали своего потенциала, но и до сих пор активно используются в разработках информационных систем различного назначения и продолжают развиваться. Существенное влияние оказывают высокие темпы развития ПК и сетевого оборудования, достижения в смежных областях информационных технологий. Широко известна активная деятельность международного консорциума W3C, направленная на преодоление тех ограничений, которые свойственны действующей версии Web. Консорциум W3C является организацией, ответственной за техническую политику развития Web. Главные его усилия в настоящее время направлены на создание технологической платформы Web нового поколения, основанной на расширяемом языке разметки XML, принятом W3C в качестве стандарта консорциума. Эти разработки стимулировали исследования подходов к созданию систем БД XML, интеграции технологий Web и технологий БД, методов интеграции информационных ресурсов XML и систем БД. В результате сформировалось новое направление в технологиях БД, разработан ряд коммерческих и свободно распространяемых СУБД нового типа, называемых XML-ориентированными СУБД Языковые средства СУБД. Функциональные возможности данных становятся доступными пользователю благодаря комплексу языковых средств. Для квалифицированных пользователей языковые средства представляются в явной синтаксической форме. К ним относятся язык описания данных, язык манипулирования данными, язык запросов. В других случаях функции языков могут быть доступны неявным образом, например, в форме языка запросов 4-го поколения (4GL) – включающего различного рода меню, диалоговые сценарии или заполняемые пользователем экранные формы, различные диаграммы и другие средства визуального представления данных. Для того, чтобы иметь развитые средства разработки приложений, в СУБД обеспечиваются интерфейсы прикладного программирования. Приложения для таких систем могут разрабатываться с помощью расширения традиционного языка программирования операторами (командами, макрокомандами, функциями, процедурами и т.д.) указанного интерфейса. Стали разрабатываться языки, представляющие собой расширения известных языков программирования Паскаль, Ада, Модула, либо являлись оригинальными языками, например, Атлант, Тексис, Галилео и др. Тем не менее они не нашли широкого практического распространения. Причиной этого является интенсивное внедрение в практическое программирование объектного языка С++, основанного на привычном большому кругу программистов языке С. А в середине 1990-х годов к нему добавился также язык Java. Сочетание объектного языка программирования и объектной БД снимает проблему – главную причину рождения языков программирования баз данных. Функции службы АБД. Обязанности администратора предметной области и приложений. Обязанности администратора БД. На ранней стадии развития технологии баз данных появилась необходимость персонала АБД для централизованного характера управления данными в системах БД, постоянно требующего поиска компромиссов между противоречивыми требованиями различных пользователей или приложений в этой социальной пользовательской среде. Весь комплекс функций АБД ассоциировался с ролью системного персонала, для обозначения которой использовался термин «Администратор Базы Данных». Это сложилось только вместе с признанием концепции многоуровневой архитектуры СУБД. Персонал АБД выполняет несколько функций, каждая из них возлагается на одно или несколько лиц в зависимости от масштаба системы, количества ее пользователей, поддерживаемого набора приложений и других факторов. В небольших системах каждая из этих функций или даже все они могут выполняться одним лицом. Более того, в простейших случаях, особенно часто встречающихся при работе с БД на ПК, одно лицо может совмещать в себе функции разработчика, пользователя, персонала АБД. В соответствии со структуризацией различаются функции администратора предметной области, администратора приложений, администратора БД, администратора безопасности. Администратор предметной области должен обеспечить адекватность концептуальной схемы БД информационным потребностям пользователей и приложений. Он несет ответственность и за адекватное отображение в концептуальной схеме БД тех изменений, которые происходят в предметной области системы. Он должен обеспечивать в необходимых случаях реструктуризацию БД – изменение концептуальной схемы БД – и приведение содержимого БД в соответствие с новой схемой. Администратор приложений несет ответственность за обеспечение адекватности внешних схем БД информационным потребностям соответствующих приложений, а также за описания отображения внешних схем БД в концептуальную. Задача администратора БД заключается в обеспечении необходимого уровня производительности системы. Эта задача решается путем использования эффективных методов доступа, рациональной стратегии размещения данных на носителях и оптимальной степени избыточности данных. В обязанности администратора БД также включают: - сбор и обработку статистики функционирования системы; - обеспечение эффективного использования ресурсов пространства памяти на МД; - обеспечение надежности функционирования системы; - оценку необходимости перенастройки среды хранения БД; - изменение при необходимости внутренней схемы базы данных; - переопределение отображения концептуальной схемы в новую внутреннюю; - приведение хранимой БД в соответствие новой внутренней схеме; восстановление состояния БД при нарушениях ее логической и\или физической целостности. В обязанности администратора безопасности входит управление полномочиями пользователей, определение ограничений управления доступом к данным в БД, поддержка технологии обеспечения безопасности данных. В системах БД часто предусматривается также функция администратора данных. Эта функция заключается в обеспечении достоверности и полноты данных, содержащихся в БД, их согласованности, а также соблюдения регламента работ по актуализации БД. В коммерческих СУБД предусматривается, как правило, специальный инструментарий, обычно организованный в виде различного рода программутилит АБД. Для чего служат механизмы СУБД, поддерживающие внутренний уровень архитектуры? Что такое внешние БД и что обозначают внешние схемы? Механизмы СУБД, поддерживающие внутренний уровень архитектуры, служат для поддержки представления БД в среде хранения. Это единственный уровень информационной архитектуры, где БД в действительности представлена полностью в «материализованном» виде. Описание представления БД на внутреннем уровне архитектуры называется внутренней схемой или схемой хранения. Поскольку все уровни модели информационной архитектуры должны отражать разные точки зрения на одну и туже единственную БД, материализованную в среде хранения на МД, необходимо в составе функциональной архитектуры СУБД иметь такие механизмы, которые обеспечивали бы соответствие между представлениями БД на разных уровнях информационной архитектуры системы. В архитектурной модели для этих целей служат механизмы междууровневого отображения данных «внешний концептуальный» и «концептуальный - внутренний». Именно функциональные возможности этих механизмов обеспечивают абстракцию данных в системе, определяют ту степень свободы, которая предоставляется на связанных ими уровнях для выбора представления БД, и, тем самым, достижимую в системе степень независимости данных. Пользователи имеют дело с представлениями БД на внешнем уровне, с так называемыми внешними базами данных. Описания таких представлений называются внешними схемами. В системе БД может одновременно поддерживаться несколько внешних схем для различных групп пользователей или приложений. Такая архитектурная модель является универсальной в том смысле, что в ее рамки укладывается информационная архитектура любой системы БД. Различия архитектуры конкретных систем определяются лишь тем, какие модели данных поддерживаются на архитектурных уровнях используемых в них СУБД, какими возможностями обладают их механизмы междууровневого отображения данных, являются ли управляемыми механизмы их уровней и механизмы междууровневого отображения данных. Архитектура систем БД. Три уровня информационной архитектуры систем БД. Концептуальный уровень БД. Для понимания принципов функционирования систем баз данных необходимо рассмотреть архитектурные особенности такой системы. Следует принимать во внимание, что архитектура систем БД, их пространственную и информационную архитектуру. Свойства пространственной и информационной архитектуры поддерживаются средствами функциональной архитектуры системы. Информационная архитектура системы БД характеризует поддерживаемые в системе представления информационных ресурсов, их свойства и взаимосвязи. Концепции многоуровневой архитектуры стали основой современной технологии БД. Была предложена обобщенная трехуровневая модель информационной архитектуры системы БД, включающая концептуальный, внутренний и внешний уровни. Такая модель описывает архитектуру любой системы с той лишь оговоркой, что кое-какие ее компоненты или функции в конкретной СУБД могут иметь вырожденный характер. Концептуальный уровень архитектуры служит для поддержки единого взгляда на базу данных, общего для всех ее приложений. Именно в среду концептуального уровня при проектировании БД отображается модель предметной области системы. Какими ресурсами управляет внутренний уровень архитектуры БД? Важным функциональным компонентом СУБД являются механизмы внутреннего уровня информационной архитектуры системы, реализующие функции среды хранения БД. БД в действительности представлена полностью в «материализованном» виде только в среде хранения. На всех остальных уровнях архитектуры системы имеются «метаданные». Механизмы среды хранения БД в СУБД служат для управления двумя группами ресурсов системы – это ресурсами хранимых данных и ресурсами пространства памяти среды хранения. Механизмы среды хранения должны выполнять целый ряд операций: - определение места размещения новых данных в пространстве памяти на МД; - выделение необходимого ресурса памяти и запоминание адресов; - формирование и разрушение связей с другими данными; - удаление хранимых данных с освобождением занимаемой ими памяти; - поиск данных в пространстве памяти по заданным их атрибутам или по «адресу»; - выборка хранимых данных для обработки. Все указанные операции выполняются по запросам механизмов концептуального уровня данной СУБД. Многоуровневый подход к архитектуре СУБД предлагает независимость организации среды хранения данных от модели данных концептуального уровня – т.е. физическую независимость данных. Нужно учитывать, что ряд объектов среды хранения данных СУБД поддерживаются файловой системой (ОС), в обстановке которой работает данная СУБД. И хотя среда хранения БД должна располагать более тонкими механизмами, чем файловая система, специфика файловой системы также оказывает на ее организацию значительное влияние. Пример глубоко проработанной концепции управления средой хранения БД представляет собой язык определения хранимых данных разработанный CODASYL. Если запись концептуального уровня разбивается в среде хранения на несколько частей, то ее фрагмент представляется экземплярами хранимых записей каких-либо типов. Все они связываются указателями или размещаются по специальному закону так, чтобы механизмы междууровневого отображения данных могли опознать все компоненты и осуществить сборку полной записи по запросу механизмов концептуального уровня. Каждой хранимой записи в пространстве памяти ставится в соответствие ее адрес, определяющий место размещения записи. Существуют два вида адресации хранимых записей – прямая (непосредственная) и косвенная. Прямая адресация предусматривает указание непосредственного местоположения записи в пространстве памяти, т.е. адрес. Прямая адресация не позволяет, однако, перемещать записи внутри области хранения без изменения их непосредственного адреса. Такие изменения привели бы к необходимости коррекции различных указателей на записи в среде хранения, что было бы чрезвычайно трудоемкой процедурой, поэтому перемещать записи при прямой адресации нецелесообразно. Подобная ситуация особенно часто возникает при работе с записями переменной длины. Для преодоления указанных трудностей применяется другой вид адресации – косвенная адресация. Часть пространства каждой страницы отводится для индекса страницы. Число статей в нем одинаково для всех страниц. Адресом записи в пространстве памяти на МД служит номер этой записи в области. С помощью простых операций можно по номеру записи определить номер нужной страницы и номер в индексе этой страницы. Найденный индекс будет содержать указатель на соответствующую запись – непосредственный адрес ее местоположения. Если запись после ее модификации не вмещается на прежнее место, то она помещается на специально отведенные в данной области памяти страницы переполнения, и соответствующий индекс по-прежнему указывает новое место ее размещения. Номер записи сохраняется, а меняется в индексе только адрес нового места размещения. Какими важнейшими характеристиками должны обладать СУБД для разработки информационной системы? Основная цель логического проектирования БД. Главная задача физического проектирования БД. Выбор СУБД является важным этапом проектирования БД. Проблема выбора СУБД, а также оценки характеристик их функционирования злободневны на всех стадиях развития технологий БД, когда речь идет о требованиях к производительности, ресурсам памяти, надежности. В наиболее критических случаях производится сравнительный анализ характеристик различных СУБД. Оценка производительности СУБД для некоторых типов приложений может выполняться с помощью эталонных тестов, разработанных консорциумом TCP (Transaction Processing Performance Council). Проектировщики очень часто руководствуются лишь собственными интуитивными экспертными оценками требований к выбираемой системе по нескольким важнейшим количественным и качественным характеристикам. К числу таких характеристик относятся: - тип модели данных, которую поддерживает данная СУБД, ее адекватность потребностям рассматриваемой предметной области; - масштабы разрабатываемой системы – количество пользователей, объем данных, интенсивность потока запросов; - аппаратно-программная платформа; - характеристики производительности системы; - наличие в данной СУБД средств разработки приложений; - запас функциональных возможностей для дальнейшего развития системы; - степень оснащенности системы инструментарием для АБД; - удобство и надежность СУБД в эксплуатации. Этап логического проектирования БД состоит в отображении концептуальной модели предметной области в модель данных, поддерживаемую СУБД, выбранной для реализации системы. В результате выполнения этого этапа создаются схемы БД концептуального и внешнего уровней архитектуры, специфицированные на языках описания данных конкретной СУБД. Этап физического проектирования БД требует поиска проектных решений, обеспечивающих эффективную поддержку построенной «логической» структуры БД в среде хранения. В ряде современных реляционных БД организация хранения данных в значительной степени определяется по умолчанию на основе концептуальной схемы БД. Сколько и какие этапы включает процесс проектирования БД? Для понимания принципов функционирования систем баз данных необходимо рассмотреть архитектурные особенности такой системы. Следует принимать во внимание, что архитектура систем БД это её пространственная и информационная архитектура. Свойства пространственной и информационной архитектуры поддерживаются средствами функциональной архитектуры системы. Информационная архитектура системы БД характеризует поддерживаемые в системе представления информационных ресурсов, их свойства и взаимосвязи. Три этапа включает процесс проектирования БД. Концепции многоуровневой архитектуры стали основой современной технологии БД. Была предложена обобщенная трехуровневая модель информационной архитектуры системы БД, включающая концептуальный, внутренний и внешний уровни. Такая модель описывает архитектуру любой системы с той лишь оговоркой, что кое-какие ее компоненты или функции в конкретной СУБД могут иметь вырожденный характер. Концептуальный уровень архитектуры служит для поддержки единого взгляда на базу данных, общего для всех ее приложений. Именно в среду концептуального уровня при проектировании БД отображается модель предметной области системы. Механизмы СУБД, поддерживающие внутренний уровень архитектуры, служат для поддержки представления БД в среде хранения. Это единственный уровень информационной архитектуры, где БД в действительности представлена полностью в «материализованном» виде. Описание представления БД на внутреннем уровне архитектуры называется внутренней схемой или схемой хранения. Наконец, пользователи БД имеют дело с представлениями БД на внешнем уровне, с так называемыми внешними базами данных. Описания таких представлений называются внешними схемами. В системе БД может одновременно поддерживаться несколько внешних схем для различных групп пользователей или приложений. Поскольку все уровни модели информационной архитектуры должны отражать разные точки зрения на одну и туже единственную БД, материализованную в среде хранения на МД, необходимо в составе функциональной архитектуры СУБД иметь такие механизмы, которые обеспечивали бы соответствие между представлениями БД на разных уровнях информационной архитектуры системы. В архитектурной модели для этих целей служат механизмы междууровневого отображения данных «внешний концептуальный» и «концептуальный - внутренний». Именно функциональные возможности этих механизмов обеспечивают абстракцию данных в системе, определяют ту степень свободы, которая предоставляется на связанных ими уровнях для выбора представления БД, и, тем самым, достижимую в системе степень независимости данных. Такая архитектурная модель является универсальной в том смысле, что в ее рамки укладывается информационная архитектура любой системы БД. Различия архитектуры конкретных систем определяются лишь тем, какие модели данных поддерживаются на архитектурных уровнях используемых в них СУБД, какими возможностями обладают их механизмы междууровневого отображения данных, являются ли управляемыми механизмы их уровней и механизмы междууровневого отображения данных. Выбор СУБД. Выбор СУБД является важным этапом проектирования БД. Проблема выбора СУБД, а также оценки характеристик их функционирования злободневны на всех стадиях развития технологий БД, когда речь идет о требованиях к производительности, ресурсам памяти, надежности. В наиболее критических случаях производится сравнительный анализ характеристик различных СУБД. Оценка производительности СУБД для некоторых типов приложений может выполняться с помощью эталонных тестов, разработанных консорциумом TCP (Transaction Processing Performance Council). Проектировщики очень часто руководствуются лишь собственными интуитивными экспертными оценками требований к выбираемой системе по нескольким важнейшим количественным и качественным характеристикам. К числу таких характеристик относятся: - тип модели данных, которую поддерживает данная СУБД, ее адекватность потребностям рассматриваемой предметной области; - масштабы разрабатываемой системы – количество пользователей, объем данных, интенсивность потока запросов; - аппаратно-программная платформа; - характеристики производительности системы; - наличие в данной СУБД средств разработки приложений; - запас функциональных возможностей для дальнейшего развития системы; - степень оснащенности системы инструментарием для АБД; Какие технологии существуют, которые поддерживают проектирование БД и разработку программного кода приложений ИС? Проектирование БД – это одна из наиболее ответственных и трудных задач, связанных с созданием системы базы данных. В результате ее решения должны быть определены и содержание БД, и эффективный, с точки зрения всего сообщества будущих пользователей, способ ее организации в среде СУБД, выбранной для ИС. В крупных системах проектирование БД требует особой тщательности, поскольку цена допущенных на этой стадии просчетов и ошибок особенно велика. Проектирование БД не может быть полностью автоматизированным. Значительное место в нем отводится интуиции и опыту специалистапроектировщика. Сформировался рынок коммерческих программных инструментальных средств, на котором представлен широкий спектр таких инструментов. Они предназначены для создания и поддержания разрабатываемых систем на протяжении всего их жизненного цикла, т.е. периоде от принятия решения о создании системы до снятия ее с эксплуатации, либо только для поддержки отдельных этапов. Эти инструменты CASE-технологий базируются на различных разновидностях структурных или объектно-ориентированных методов. Существуют программные продукты CASE-технологий, которые поддерживают проектирование баз данных и разработку программного кода приложений. Некоторые из этих программных продуктов ориентированы на довольно широкий набор СУБД. Другие предназначены для конкретных СУБД. Важное достоинство использования CASE-технологий в том, что в процессе разработки системы осуществляется автоматическое документирование проекта. - удобство и надежность СУБД в эксплуатации. Основы проектирования БД. Это одна из наиболее ответственных и трудных задач, связанных с созданием системы баз данных. В результате ее решения должны быть определены и содержание БД, и эффективный, с точки зрения всего сообщества будущих пользователей, способ ее организации в среде СУБД, выбранной для ИС. В крупных системах проектирование БД требует особой тщательности, поскольку цена допущенных на этой стадии просчетов и ошибок особенно велика в дальнейшем. Проектирование БД не может быть полностью автоматизированным. Значительное место в нем отводится интуиции и опыту специалистапроектировщика. Сформировался рынок коммерческих программных инструментальных средств, на котором представлен широкий спектр таких инструментов. Они предназначены для создания и поддержания разрабатываемых систем на протяжении всего их жизненного цикла, т.е. периоде от принятия решения о создании системы до снятия ее с эксплуатации, либо только для поддержки отдельных этапов. Эти инструменты CASE-технологий базируются на различных разновидностях структурных или объектно-ориентированных методов. Существуют программные продукты CASE-технологий, которые поддерживают проектирование баз данных и разработку программного кода приложений. Некоторые из этих программных продуктов ориентированы на довольно широкий набор СУБД. Другие предназначены для конкретных СУБД. Это позволяет использовать автоматизированные средства для реинжиниринга системы – ее модернизации в процессе разработки и эксплуатации с учетом изменившихся требований. Многомерные модели данных. Многомерные модели данных. Такие модели данных стали основой инструментальных средств поддержки принятия решений. Они оперируют многомерными представлениями данных (в виде гиперкуба). Различные разновидности многомерной модели стали широко использоваться в корпоративных системах баз данных. В середине 1990-х годов в связи с развитием технологий интерактивной аналитической обработки данных (OLAP). Основные понятия многомерной модели данных – измерение и ячейка. Каждое измерение представляет собой множество однородных значений данных, образующее грань гиперкуба. Обычно значениями измерений являются признаковые данные. Примерами измерений являются годы, месяцы, кварталы, регионы, города, районы, названия предприятий, виды продукции и т.п. Измерения играют роль индексов, совокупности значений которых идентифицируют в гиперкубе конкретные его ячейки, или осей координат в многомерной системе координат гиперкуба. Ячейки (называемые также показателями) представляют собой числовые величины – литералы, переменные или формулы. Операционные возможности многомерных моделей данных ориентированы на поддержку анализа данных. Предусматривается конструирование разнообразных агрегаций данных в рамках заданного гиперкуба, построение различных его проекций – подмножеств гиперкуба, полученных путем фиксации значений других измерений, детализация (дезагрегация) данных и вращение (изменение порядка измерений) гиперкуба, а также ряд других операций. Модель данных. Основу механизмов управления данными любой СУБД составляет некоторая модель данных. Так называется инструмент моделирования предметной области, позволяющий отображать ее состояние и динамику в среде БД, управляемой системой. Более точно, модель данных – это совокупность правил структурирования данных в БД, допустимых операций над ними и ограничений целостности, которым эти данные должны удовлетворять. Если некоторая модель данных реализуется механизмами управления данными определенной СУБД, то говорят, что эта СУБД поддерживает указанную модель данных. СУБД может поддерживать несколько моделей данных. Такую систему называют мультимедийной. Прежде всего, модель данных представляет собой средство выражения модели предметной области в среде системы БД. Поэтому можно рассматривать модель данных как метамодель для описания различных предметных областей в среде выбранной СУБД. Однако для разработчика и пользователей СУБД единственно конструктивной является «материализация» модели данных в форме полной спецификации воплощающей ее языковые средства – языка определения данных и языка манипулирования данными. Модель данных определяет не только структурные и операционные возможности моделирования данных, но и виды допустимых ограничений целостности данных (логические ограничения). Эти ограничения дают возможность СУБД следить за тем, чтобы в базе данных содержались только допустимые значения данных и между ними поддерживались только допустимые связи. В современном понимании модель данных – это не результат, а инструмент моделирования предметной области. В процессе эволюции технологий БД было создано значительное количество разнообразных моделей данных. Разрабатываются сейчас и будут разрабатываться в дальнейшем новые модели. Такая ситуация является следствием реальных потребностей практики обработки данных. В каждом случае разработки системы БД нужно иметь возможности выбора способа видения предметной области, адекватного потребностям пользователей. Какие известны ранние модели данных, как называются и чем они характерны? Сетевая модель данных. Иерархическая модель данных. Ранние модели данных называются графовыми моделями. Они представляют собой инструменты для создания и использования различных разновидностей БД сетевой и иерархической структуры данных. Классическими представителями таких моделей являются – сетевая модель данных CODASYL (СУБД IDMS компании CULINET) и иерархическая модель данных (СУБД IMS компании IBM). Хотя в настоящее время в большинстве коммерческих СУБД используются реляционные, объектные и объектно-реляционные модели данных, до сих пор эксплуатируется значительное количество установок СУБД, основанных на графовых моделях. Это модель данных, относящаяся к категории графовых моделей. Основные элементы структуры сетевой БД CODASYL – это тип записи и тип набора данных. Тип записи определяет множество записей (экземпляров записей) БД, обладающих структурой и другими свойствами, специфицированными в описании данного типа записей в схеме базы данных. Тип набора CODASYL представляет собой множество наборов, обладающих структурой и другими свойствами, определенными в схеме БД для этого типа набора. Все экземпляры записей одного набора соединяются указателями в цепной список. Указатели обеспечивают обход всех записей в прямом и обратном направлении. В сетевой модели данных CODASYL были разработаны языки манипулирования данными для языков программирования Кобол и Фортран. На основе модели данных CODASYL был создан ряд широко распространенных коммерческих СУБД. В 1968 году была создана международная Рабочая группа по БД CODASYL, где был представлен полный комплекс языковых средств описания данных и манипулирования данными. В документах CODASYL были впервые систематизированы и сформулированы некоторые фундаментальные концепции технологии БД. Была впервые предложена концепция многоуровневой архитектуры СУБД. Процедуры БД CODASYL стали средством создания активных БД задолго до того, как в языке SQL была предложена аналогичная концепция триггера. Представителем другой модели данных является СУБД IMS компании IBM Corp. Система IMS эксплуатируется до настоящего времени на платформах мейнфреймов, выпускаемых той же компанией IBM. Иерархическая модель данных является хрестоматийной разновидностью графовой модели данных. Вершинам деревьев соответствуют сегменты некоторых типов. Сегменты представляют собой записи, состоящие из простых элементов данных различных типов. Представителем этой модели данных является СУБД IMS. Система IMS эксплуатируется до настоящего времени на платформах мейнфреймов, выпускаемых той же компанией IBM. Иерархическая модель данных является хрестоматийной разновидностью графовой модели данных. Вершинам деревьев соответствуют сегменты некоторых типов. Сегменты представляют собой записи, состоящие из простых элементов данных различных типов. Экземпляр сегмента каждого типа идентифицируется уникальным значением ключа, определенного для сегментов этого типа. БД представляет собой совокупность таких деревьев. Наряду с навигационными операциями поддерживаются операции манипулирования данными – вставка, обновление и удаление сегментов с естественным каскадным распространением операции удаления. Реляционная модель данных. Объектная модель данных. Объектно–реляционная модель данных. Реляционная модель была предложена в 1969г. Э. Коддом, сотрудником исследовательского центра компании IBM в Сан-Хосе (Калифорния). Она получила название базовой реляционной модели и стала основой коммерческих реляционных СУБД. Эта модель основана на математическом понятии отношения (от англ. relation). Операционные возможности модели имеют две эквивалентные формы, одна из которых – реляционная алгебра (Булева алгебра), другая – реляционное исчисление. Это позволило сформировать развитую математическую теорию реляционных моделей данных. СУБД, поддерживающие реляционную модель заняли доминирующее положение среди инструментальных средств разработки систем БД. В соответствии с реляционной моделью данных база данных (БД) представляется в виде совокупности таблиц, над которыми могут выполняться операции, формулируемые в терминах реляционной алгебры или реляционного исчисления. В реляционной модели операции над объектами БД имеют теоретико-множественных характер. Каждая операция манипулирования данными в такой модели обрабатывает множество строк таблицы. Это дает возможность пользователям формулировать их запросы более компактно, в терминах более крупных конструкций данных. Однако такой подход порождает и сложные проблемы, связанные с обеспечением достаточно высокого уровня производительности СУБД этого класса, которые приходится решать разработчикам таких СУБД. Другая проблема возникает, когда нужно обеспечить интерфейс СУБД, поддерживающей реляционную модель данных, с программами на традиционных языках программирования. Она заключается в несоответствии структур данных модели и языков программирования, ориентированных на «позаписную» обработку. Для ее решения пришлось дополнить реляционную модель данных специальной согласующей конструкцией данных, называемой курсором. Курсор – это временная таблица, содержащая результаты обработки запроса. Прикладная программа может последовательно просматривать строки такой таблицы (курсора) и обрабатывать их индивидуально. Характерной чертой графовых и реляционных моделей данных является подход к данным как к самостоятельно существующим абстрактным объектам. Эта модель была предложена в 1969г. Э. Коддом, сотрудником исследовательского центра компании IBM в Сан-Хосе (Калифорния). Она получила название базовой реляционной модели и стала основой коммерческих реляционных СУБД. Еще в середине 1970-х годов начали проводиться исследования и разработки моделей данных нового типа, призванных решить задачу семантики предметной области. Такие модели данных стали называться семантическими. В их создании приняли участи многие крупные научные центры, как у нас, так и за рубежом. Тем не менее, семантические модели данных не стали основой создания коммерческих СУБД для широкого использования. В конце 1980-х годов успехи объектно-ориентированного программирования стимулировали разработки СУБД, основанных на объектной модели данных. В отличие от реляционных систем среди разработчиков объектных СУБД в течение значительного времени не существовало единодушия конкретного воплощения объектной модели данных. Многочисленные разновидности объектной модели данных получили широкое распространение в области программирования БД и информационных систем. Популярность объектного подхода в области баз данных в значительной мере объясняется предоставляемыми им более естественными возможностями моделирования предметной области, чем при использовании графовых моделей данных и реляционной модели данных. В объектных моделях предусматривается отношение наследования между типами объектов. Подтип наследует атрибуты состояния и операции своего типа. На основе объектных моделей в конце 1980-90 годов возникла новая категория СУБД, называемых объектными СУБД. Основным понятием объектных моделей данных является объект. При этом объект понимается как сущность, обладающая состоянием и поведением. Состояние объекта определяется совокупностью его атрибутов, которые могут принимать значения предписанных типов. Поведение объекта, в свою очередь, определяется совокупностью операций, специфицированных для этого объекта. Объекты в объектных моделях типизируются. Свойства типа объектов (атрибуты и операции) применяются ко всем его экземплярам. Поддерживаются связи между типами объектов. Были разработаны технологии неоднородных распределенных объектных систем, новые методологии объектного анализа и проектирования сложных программных и информационных систем. Для объектных СУБД актуальной стала проблема стандартизации. Эта проблема была решена в 1993 году рабочей группой ODMG, которая разработала стандарт объектных баз данных (ODMG-93). Действующий в настоящее время стандарт был одобрен международным консорциумом в 2000 г. Объектные СУБД стали широко применяться во многих крупных проектах информационных систем. Эта среда включает объектные технологии языка Java для создания неоднородных распределенных объектных сред и компонентную модель консорциума ODMG. Немаловажное значение имеет также возможность интегрировать объектные технологии в среду Веб. Объектно–реляционная модель данных. Это гибридная модель данных, сочетающая возможности реляционной модели с поддержкой объектных свойств данных. Такие модели стали использоваться как паллиатив, обеспечивающий преодоление ограниченных возможностей реляционной модели, которые препятствовали эффективной реализации многих приложений: -слабая система типов данных; -сложности интеграции в новые технологические среды, которые основаны, главным образом, на объектных моделях. В настоящее время в большинстве коммерческих СУБД используются реляционные, объектные и объектно-реляционные модели данных. Объектнореляционный подход в технологиях баз данных получил основательную поддержку благодаря принятой в 1999 году очередной версии международного стандарта языка SQL (SQL-1999). В этом стандарте воплощен некоторый вариант объектно-реляционной модели данных, обеспечивающий преемственность для реляционной модели, поддерживаемой ранними версиями языка SQL.