Министерство образования и науки, молодежи и спорта Украины
ОДЕССКАЯ НАЦИОНАЛЬНАЯ АКАДЕМИЯ СВЯЗИ им. А.С. ПОПОВА
А. Г. Ложковский
ТЕОРИЯ МАССОВОГО ОБСЛУЖИВАНИЯ
В ТЕЛЕКОММУНИКАЦИЯХ
Учебник
Утвержден Министерством транспорта и связи Украины как учебник
для студентов высших учебных заведений, обучаемых по направлениею
„Телекоммуникации”
Одесса – 2012
План УМИ 2012 г.
УДК 621.39
ББК 32.81
Л71
Утверждено Министерством транспорта и связи Украины
(Письмо № 6778/23/14-08 от 22.09.2008 г.)
Рецензент – Захарченко Н. В.
Ложковский А.Г.
Л71 Теория массового обслуживания в телекоммуникациях: учебник
/ А.Г. Ложковский. – Одесса: ОНАС им. А. С. Попова, 2012. – 112 с.: ил.
ISBN 978-966-7595-43-3
Изложены основные положения и методы анализа теории массового
обслуживания в телекоммуникациях (теории телетрафика), на которых
базируются процедуры проектирования телекоммуникационных систем и
сетей. Рассмотрены математические модели систем распределения информации
с потерями, с очередью и с приоритетами. Приведены исследовательские
приемы этих систем в условиях идеализированной модели пуассоновского
потока и реальных потоков требований мультисервисных сетей связи.
Учебник предназначен для студентов и аспирантов, обучаемых по
направлению „Телекоммуникации”, а также для специалистов, занимающихся
практическим применением теории телетрафика.
РЕКОМЕНДОВАН
к изданию ученым советом
ОНАС им. А. С. Попова.
Протокол №10 от 30 мая 2008 г.
ISBN 978-966-7595-43-3
© Ложковский А.Г., 2010 (укр)
© Ложковский А.Г., 2012 (рус)
2
СОДЕРЖАНИЕ
ПРЕДИСЛОВИЕ..........................................................................................................4
3
ПРЕДИСЛОВИЕ
С возникновением телефонной связи появилась необходимость в
специальных математических методах оценки качества функционирования
телефонных систем, вследствие чего научными работами датского ученого
Агнера Крарупа Эрланга (1878-1929) в начале ХХ века заложены основы
теории телетрафика. Шведский ученый К. Пальм обобщил исследования
А. К. Эрланга и в своей докторской диссертации привел важные результаты по
изучению изменяемости телефонной нагрузки. Дальнейшее развитие этой
работы позволило в середине ХХ века русскому математику А.Я. Хинчину
начать новое научное направление прикладной математики, которая кроме
телекоммуникаций охватывает еще и процессы в системах производства,
обслуживания, управления и т.п. Данное направление названо теорией
массового обслуживания (ТМО). Эта теория, «выросшая» из теории
телетрафика, рассматривает более широкий круг вопросов количественной
оценки процессов массового обслуживания. Таким образом, теория
телетрафика является отдельным разделом ТМО, а теория массового
обслуживания в телекоммуникациях – и есть теория телетрафика.
Содержание теории телетрафика состоит в исследовании пропускной
способности телекоммуникационных систем (ТКС). Методами этой теории
разрабатываются новые научно обоснованные методы оценки характеристик
качества обслуживания. Теория телетрафика обеспечивает оценку всех
параметров ТКС и, прежде всего, учитывается стохастический (случайный)
характер потоков требований, поступающих в систему на обслуживание.
Оценка прогнозируемой пропускной способности и качества обслуживания очень важный этап проектирования ТКС и сетей. Здесь аналитические
расчеты строятся на математическом описании реакции системы на внешние
воздействия. Под реакцией системы понимается ее состояние (количество
занятых серверов или мест ожидания, время задержки и др.), а под внешними
воздействиями – потоки требований, сбои, отказы из-за ненадежности и т.п.
Внешний фактор влияния в мультисервисных сетях связи – это разнородность
информации, передаваемой в рамках единой сети: данные, речь, видео. Потоки
этой информации существенно отличаются между собой по приоритетам,
механизмам обслуживания, особенностями протоколов и т.д., и адекватной
здесь будет многомерная модель. Поэтому, для сложных систем аналитические
расчеты, выполняются с ограничением внешних факторов, раздельно для
каждого типа (группы) влияний или с применением многопоточных моделей.
Описание реакции системы на совокупность всех внешних воздействий –
чрезвычайно трудная задача, которая в общем виде не всегда решаема.
Количество внешних влияний может быть велико и каждое влияние не всегда
однозначно описывается простыми формулами, дающими конечный результат
с понятным физическим содержанием, а также описание внешних влияний не
всегда адекватно реальным процессам, происходящим в системе.
В математических моделях теории телетрафика учтены вид входного
потока, схема системы и дисциплина обслуживания.
4
Научно обоснованное планирование и оптимизация телекоммуникационных систем и сетей, обеспечивающих предоставление запрашиваемых
услуг с заданными показателями качества обслуживания, является очень
сложной научно-технической и экономической проблемой, без решения
которой невозможно создание информационной инфраструктуры, отвечающей
потребностям развитого общества. В развитии бизнеса отдельных
телекоммуникационных компаний этот фактор является важнейшим при
обосновании действий администрации, направленных на повышение
эффективности работы сети и качества обслуживания пользователей.
Решение данной проблемы базируется на решении задач анализа и
синтеза ТКС. Комплексное решение этих задач позволяет оптимизировать
структуру сети на продолжительную перспективу. В условиях развития
телекоммуникаций в соответствии с основными положениями концепции сетей
следующего
поколения
NGN,
обеспечивающих
предоставление
неограниченного набора услуг с заданными характеристиками качества
обслуживания QoS, указанные вопросы становятся еще более актуальными.
Избранная технология распределения информации в NGN определяет степень
сложности узлов коммутации, которая, безусловно, влияет на качество
обслуживания обмена информацией между терминалами пользователей. Кроме
того, качество обслуживания потоков информации влияет и на сами
характеристики передачи информации (например, задержки пакетов IPтелефонии приводят к снижению качества телефонной связи). Таким образом,
расширение спектра предоставляемых услуг и возрастающая сложность ТКС и
сетей требует решения проблемы разработки адекватных методов анализа и
синтеза этих систем с целью получения достоверных оценок их характеристик,
реализации задач их оптимизации относительно избранного критерия качества
обслуживания и разработки соответствующих алгоритмов управления ними.
Процессы функционирования сетей и систем связи можно представить
некоторой совокупностью систем массового обслуживания (СМО), для которых
определяются характеристики QoS. Одним из классов СМО в телекоммуникациях есть системы распределения информации (СРИ), к которым принадлежат сети связи в целом или отдельные коммутационные узлы, например,
пакетные коммутаторы, обслуживающие по определенным алгоритмам
сообщения телекоммуникационных служб. Количественная сторона процессов
обслуживания потоков сообщений (трафика) в СРИ является предметом теории
телетрафика. Эта теория, как самостоятельная научная дисциплина, содержит
набор вероятностных методов решения проблем проектирования новых и
эксплуатации действующих систем телекоммуникаций.
Создание теории телетрафика начато научными работами Эрланга А.К.
(выдающиеся B- и C-формула Эрланга). Ее развивали такие ученые, как Burce
P.J, Crommelin C. D., Kleinrock L., О'Dеll G.F., Palm C., Pollaczek F., Wilkinson
R.I. Существенный вклад в развитие теории телетрафика внесли представители
русской научной школы: Хинчин А. Я., Башарин Г.П., Лившиц Б.С., Харкевич
А.Д., Севастьянов Б.А., Нейман В.И, Степанов С.Н. и академики АН Украины
5
Гниденко Б.В., Коваленко И.Н., Королюк В.В. Достижением теории являются
учебники и научные работы Шнепса М.А., Корнышева Ю.Н. и других.
Пропускная способность СМО тесно связана с оценкой показателей
качества обслуживания трафика, что требует учета многих факторов для
построения адекватных, научно обоснованных методов их расчета. Методы
оценки характеристик качества обслуживания базируются на математических
моделях СРИ. Многообразие видов и топологий сетей, структур систем и
способов выделения сетевого ресурса для обслуживания трафика требует
разработки моделей, которые учитывают еще и реальный характер потоков
сообщений и детали обслуживания мультисервисного трафика разных
коммуникационных приложений (речь, видео, данные). Поэтому невозможно
построить единую модель, которая бы давала ответы на все вопросы
относительно функционирования новых сетей связи. Именно на основе
применяемых моделей СРИ разрабатываются методы оценки характеристик
QoS, достоверность которых зависит от адекватности модели реальной
ситуации, которая может возникнуть при проектировании и эксплуатации.
Оценка качества обслуживания трафика является одним из важнейших
научных направлений в исследованиях телекоммуникационных сетей. На этом
базируется продуманная и целенаправленная стратегия модернизации
современных сетей на этапе их конвергенции и замены технологии коммутации
каналов на коммутацию пакетов. Принципы функционирования сети
обусловлены режимами переноса информации, а качество обслуживания –
реальным характером трафика. При этих обстоятельствах необходима
разработка новых методов анализа и синтеза СРИ, которые адекватно
отображают реальные процессы обмена информацией в сети. Это даст
дальнейшее развитие теории телетрафика и обогатит практический
инструментарий среды проектирования инфокоммуникационных сетей, что, в
свою очередь, позволит обеспечить ощутимую экономию затрат на
строительство и эксплуатацию сетей связи. Благодаря более точным расчетам
повысится качество обслуживания и пропускная способность СРИ. Новые
методы оценки характеристик QoS необходимы в системах динамического
управления сетями для перераспределения их ресурсов и оптимизации трафика
и сети в целом на основе заданного (нормированного) качества обслуживания.
Таким образом, при системном подходе к проблеме планирования и
оптимизации ТКС и сетей невозможно обойтись без математических методов
анализа, синтеза и оценки качества предоставления информационных услуг в
условиях реальных потоков сообщений. Отсутствие таких методов приводит к
принятию неоптимальных решений в процессе разработки, проектирования и
эксплуатации ТКС и сетей, поскольку возникает резкое несоответствие между
ожидаемыми (проектными) показателями и реальным качеством обслуживания.
Телетрафик – это не только классические телефонные сообщения, но и
потоки сообщений в новых инфокоммуникационных сетях. Специфические
особенности разных СРИ увеличивают проблемы разработки универсальных
методов их анализа и синтеза. Особенно сложна эта проблема для таких
моделей трафика, которые адекватны реальным процессам формирования его
6
потоков в сети. Природа поступления потоков и их обслуживания зависит от
конкретного вида системы и сети, структурного состава абонентов, спектра
предоставляемых услуг и других факторов.
В теории телетрафика разработан ряд математических моделей и методов
решения задач анализа и синтеза СРИ для условий идеализированной
пуассоновской модели трафика. Однако, набор этих методов пока недостаточно
полон с точки зрения структурных особенностей реальных СРИ, дисциплин
обслуживания и в особенности характера трафика. Реальному трафику
современных мультисервисных сетей связи присущий значительно больший
уровень неравномерности интенсивности нагрузки, чем это предусмотрено
классической моделью пуассоновского потока. Для таких моделей трафика
теория телетрафика не имеет соответствующих методов расчета и на практике
оценка характеристик качества обслуживания мультисервисных сетей связи
ведется
приближенными
методами
и
средствами
имитационного
моделирования. „Нерезультативность” существующих методов определяется
тем, что они ориентированы на использование лишь первых моментов
распределений случайных величин, определяющих интенсивность трафика и
функционирование СРИ. При обслуживании реального трафика на характеристики QoS оказывают влияние и высшие моменты распределений названных
величин, которые определяют характер и степень неравномерности трафика.
Анализ научных публикаций показывает, что много теоретических
разработок нельзя использовать практически. Это связано с такими
недостатками теоретических исследований, как: применение математического
аппарата, не адекватно отображающего процессы в телекоммуникационных
сетях; неудачный выбор показателей и критериев оценки предлагаемых
решений; попытка получения аналитических зависимостей характеристик
телекоммуникационных сетей в границах, где аналитический аппарат не
работает; разработка методов, которые, улучшая один из параметров
телекоммуникационной системы, в конце концов, снижают эффективность
функционирования всей системы в целом; определение закономерностей, в
составе которых есть начальные данные, получить которые невозможно.
С учетом значимости данной научной проблемы можно констатировать,
что проблема развития теории телетрафика путем ее обогащения новыми
методами анализа и синтеза систем распределения информации, которые
функционируют в условиях обслуживания реальных потоков трафика, является
в особенности актуальной в современных условиях конвергенции сетей и
построения на этой основе сетей нового поколения NGN. Такая постановка
задачи отвечает общему подходу, принятому в международной практике и
сформулированному в рекомендациях ITU.
7
1 ЭЛЕМЕНТЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ
1.1 Случайные величины и вероятностные распределения
Теория вероятностей – это математическая наука, изучающая законномерности массовых случайных явлений. Исследуемые явления рассматриваются в абстрактной форме, независимо от их конкретной природы. Т.е. теория
вероятностей рассматривает не сами реальные явления, а их упрощенные
схемы – математические модели. Предметом теории вероятностей есть математические модели случайных явлений. При этом, под случайным явлением
понимают явление, предсказать результат которого невозможно (при неоднократном воспроизведении одного и того же опыта оно протекает каждый раз
по-иному). Примеры случайных явлений: выпадения герба при подбрасывании
монеты, выигрыш по лотерейному билету, результат измерения какой-нибудь
величины, продолжительность исправной работы телевизора и т.п.
Цель теории вероятностей – осуществление прогноза в области
случайных явлений, влияние на ход этих явлений, контроль их, ограничение
сферы действия случайности. Сейчас нет практически ни одной области науки,
в которой в той или иной степени не применялись бы вероятностные методы.
Задачи, результат которых нельзя предугадать с уверенностью, требуют
изучения не только основных закономерностей, определяющих явление в
целом, но и случайных, второстепенных факторов. Выявленные в таких задачах
(опытах) закономерности называют статистическими (или вероятностными).
Статистические закономерности исследуются методами специальных математических дисциплин – теории вероятностей и математической статистики.
Вероятность P является мерой возможности осуществления результата
или события A. Формально мера вероятности является функцией Р(A), ставящей
в соответствие результатам некоторые числа и удовлетворяющей требованиям:
− 0 ≤ Р(A) ≤ 1 для любого результата A;
− Р(A) = 1
в случае достоверного результата;
−
n
∑
i= 1
P( Ai ) = 1 ,
n – все пространство выборки возможных результатов.
Функция, ставящая в соответствие каждому результату из пространства
выборки некоторое действительное число, называется случайной величиной.
Дискретными называются случайные величины, принадлежащие конечному
или счетному множеству значений. Непрерывные случайные величины могут
принадлежать континууму значений. Например, интервал времени между
поступающими на обслуживание требованиями непрерывная случайная
величина, а количество требований, поступающих за интервал времени –
дискретной.
Вероятностный закон распределения представляет собой некоторое
правило задания вероятности для каждого из всех возможных значений
случайной переменной. Правило задания вероятности имеет две разных формы
в зависимости от того, случайная величина дискретна или непрерывна.
Для дискретной случайной величины K функция вероятности (закон
8
распределения) задается вероятностями каждого ее значения ki:
P( K = ki ) = p(ki ) ,
где ∑ p (k i ) = 1 .
i
Для каждого возможного значения ki закон распределения устанавливает
конкретную вероятность того, что дискретная случайная величина K принимает
значения ki.
Кумулятивная функция распределения F(k) описывается таким образом:
F ( k ) = P( K ≤ k )
Функция F(k) определяет вероятность того, что случайная величина K
примет значения не больше, чем k. Кумулятивная функция распределения
связана с функцией вероятности так:
F (k ) = ∑ p (ki )
ki ≤ k
Для непрерывных случайных величин необходима иная форма представления вероятностного распределения. Поскольку случайная величина может
принимать любое из бесконечного множества значений, то вероятность
конкретного значения равна нулю. Данное значение не невозможно, а оно
крайне невероятно вследствие бесконечного количества альтернативных
значений. При этом вероятность того, что случайная величина примет значения
в интервале между точками a и b, в большинстве случаев не будет равна нулю.
Функция вероятности для дискретного случая заменяется на непрерывную
функцию плотности вероятности f(x), обусловленную следующим выражением:
P ( a ≤ X ≤ b) =
∞
b
∫
f ( x)dx ,
где
∫
f ( x)dx = 1
−∞
a
Функция плотности вероятности при интегрировании на интервале от a
до b дает вероятность того, что непрерывная случайная величина X примет
значение из этого интервала.
Функция распределения F(x) для непрерывных случайных величин
определяется таким образом:
P( X ≤ x) = F ( x) =
x
∫
f ( x)dx
−∞
Функция F(x) определяет вероятность того, что непрерывная случайная
величина X примет значения, не больше чем x.
Плотность вероятности f(x) непрерывной случайной величины X
определяется как производная от ее функции F(x):
f ( x) = F ' ( x) .
Наиболее
распространенными
вероятностными
распределениями
дискретной случайной величины являются распределения Пуассона, Бернулли,
биномиальное, геометрическое и логарифмическое распределения.
Наиболее распространенными распределениями непрерывной случайной
величины являются распределения Гаусса (нормальный закон), Парето,
Пирсона, Вуйбулла, Релея, гамма-распределение, логарифмически нормальное,
экспоненциальное распределения.
9
1.2 Математическое ожидание и моменты распределения
Часто необходимо охарактеризовать случайную величину одним или
несколькими значениями, которые подытоживают информацию, имеющуюся в
функции распределения вероятности. Математическим ожиданием случайной
величины X, записываемым как M(X), есть значение, рассчитанное так:
M (X ) =
M (X ) =
n
∑
i= 0
∞
xi pi , если величина X дискретная;
∫ xf ( x)dx , если величина X
непрерывная.
(1.1)
(1.2)
0
Математическим ожиданием является взвешенная по вероятности
средняя величина всех возможных значений X, что определяет меру
центральности распределения. Поэтому эта величина часто называется средним
значением x .
Полным комплектом числовых характеристик случайной величины X
являются моменты распределения или математическое ожидание функций этих
случайных величин. В частности, математическое ожидание функции Xk
называется k-м начальным моментом или начальным моментом k-го порядка
случайной величины X и определяется так:
mk = M ( X k ) =
mk = M ( X k ) =
∞
n
∑
i= 0
∫x
k
x ki pi , где X дискретная;
f ( x)dx , где X непрерывная.
0
Из этого видно, что при k = 1 первый начальный момент m1 случайной
величины X является ее математическим ожиданием или средним значением x .
Вариацией k-го начального момента есть k-й центральный момент μk, что
определяется выражением
M [( X − m1 ) k ]
Итак, для вычисления k-го центрального момента случайной величины X
от ее значения отнимается первый начальный момент m1 или среднее значение
x . Центральные моменты k-го порядка для дискретной и непрерывной
случайной величины X соответственно определяются так:
n
1 n
µ k = ∑ ( xi − x ) k pi = ∑ ( xi − x ) k ;
n i= 0
i= 0
µ
∞
k
= ∫ ( x − x ) k f ( x)dx .
0
Особое значение имеет второй центральный момент μ2, называемый
дисперсией X и записываемый как D(X) или σ2. Дисперсия случайной величины
X есть мерой разброса ее вероятностного распределения. Если дисперсия
случайной величины мала, то вся выборка лежит около математического
ожидания. Квадратный корень из дисперсии σ2 называется стандартным
отклонением случайной величины или среднеквадратичным отклонением σ.
10
Центральный момент третьего порядка μ3, нормированный такой же
степенью среднеквадратичного отклонения, т.е. σ3, называется асимметрией
случайной величины Sk и для дискретной величины
1 n
( xi − x ) 3 .
µ 3 = Sk =
3 ∑
nσ i = 0
Центральный момент четвертого порядка μ4, нормированный такой же
степенью среднеквадратичного отклонения, т.е. σ4, называется эксцессом
случайной величины Ex и для дискретной величины
1 n
( xi − x ) 3 − 3
µ 4 = Ex =
4 ∑
nσ i = 0
Моменты более высоких порядков используются редко. Если по
заданным законам распределения случайной величины моменты распределения
можно определить однозначно, то обратная задача решаема не всегда.
Коэффициенты асимметрии (показатель сдвига вправо-влево вершины
функции распределения или скошенности) и эксцесса (показатель остроты пика
этой функции) используются для сравнения закона распределения любой
случайной величины с нормальным (Гаусса) законом, для которого Sk = Ex = 0.
Их можно определить через центральные моменты соответствующего порядка:
µ
µ
Sk = 33 ;
Ex = 42 − 3 .
µ2
µ 22
На диапазон разброса отдельных значений случайной величины от ее
среднего значения указывает дисперсия, но в случае сравнения этих диапазонов
для двух случайных величин разной размерности лучше использовать
нормированное значение дисперсии случайной величины ее средним
значением, которое называется коэффициентом вариации случайной величины:
σ
vx = .
x
Статистическая обработка массива значений случайной величины
позволяет компактно описать ее, понять структуру данных, провести
классификацию, увидеть закономерности в потоке случайных событий. Вместо
рассмотрения всех значений исследуемой величины составляются
описательные статистики, которые дают общее представление о значениях,
которые принимает эта величина. Среди них основными являются следующие:
максимум, минимум и среднее значение, дисперсия и стандартное отклонение,
медиана, квартили и квантили, мода, асимметрия и эксцесс.
Для исследования связи между двумя случайными величинами
вычисляется ковариация и коэффициент корреляции между ними. При этом
могут использоваться ранговые корреляции, статистика Спирмена R,
статистика Кендалла, Гамма-статистика, корреляция Пирсона. Для
определения, является ли результат исследования действительно значимым,
оценивается мера уверенности в его правильности по уровню значимости, для
чего используется метод наименьших квадратов.
11
2 ОБЩИЕ ПОЛОЖЕНИЯ ТЕОРИИ ТЕЛЕТРАФИКА
Возрастающая сложность ТКС и сетей требует разработки адекватных
методов расчета с целью получения достоверных оценок их характеристик,
реализации задач их оптимизации относительно выбранного критерия качества
обслуживания и разработки соответствующих алгоритмов управления ними.
Математические модели ТКС и сетей строятся на основе теории систем
массового обслуживания (СМО). СМО обслуживают требования, поступающие
в систему через случайные интервалы времени и продолжительность обслуживания также может быть случайной. Методами теории СМО исследуется
влияние случайных факторов на процессы функционирования системы.
Одним из классов СМО есть системы распределения информации (СРИ),
характеризующиеся наличием распределительной сети, подобно транспортным
системам или системам энергоснабжения. При передаче информации аналогом
распределительной сети есть телекоммуникационная сеть, состоящая из
каналов передачи информации и узлов коммутации. Совокупность этих средств
связывает источники информации с их потребителями. По каналам связи
передается основная информация, являющаяся непосредственно предметом
передачи и распределения, и вспомогательная, необходимая в процессе
управления работой всей системы. Узлы коммутации обеспечивают соединение
каналов передачи информации и в них по определенным алгоритмам
обслуживаются сообщения телекоммуникационных служб сети. При этом
обслуживание сообщения отождествляется с требованием на его передачу или
обработку и примерами их могут быть вызовы телефонной станции или пакеты
пакетного коммутатора. В качестве СРИ может рассматриваться не только сеть
связи в целом, но и пучок каналов или линий, отдельный коммутатор или весь
коммутационный узел.
Количественная сторона процессов обслуживания потоков требований
(трафика) в СРИ исследуется теорией телетрафика (другое название – теория
распределения информации).
Предметом теории телетрафика есть установление зависимостей между
характером потока требований, количеством каналов обслуживания,
производительностью отдельного канала и эффективным обслуживанием с
целью определения наилучших путей управления этими процессами.
Задача теории телетрафика состоит в установлении зависимости
результирующих показателей работы СРИ (например, среднего количества
требований, которые обслуживаются; среднего количества требований, которые
ожидают обслуживания в очереди и т.д.) от входных показателей (количества
каналов в системе, параметров входного потока требований и т.д.).
Результирующими показателями или исследуемыми характеристиками СРИ
являются показатели эффективности, которые описывают, способная ли данная
система справиться с потоком требований.
Методами теории телетрафика решаются задачи оптимизации,
направленные на определение такого варианта системы, при котором будет
12
обеспечен минимум суммарных затрат от ожидания обслуживания, потерь
времени и ресурсов на обслуживание, и простоев каналов обслуживания.
Теория телетрафика – это набор вероятностных методов анализа, синтеза
и оптимизации СРИ, т.е. проектирования новых и эксплуатации действующих
сетей связи. Без решения задач анализа, синтеза и на этой основе оптимизации
ТКС и сетей невозможно их дальнейшее развитие.
Задача анализа – это установление зависимостей и значений величин,
которые характеризуют качество обслуживания, от характеристик и параметров
входного потока требований, схемы и дисциплины обслуживания. Задача
анализа возникает в тех случаях, когда телекоммуникационная сеть или
система уже построена и функционирует. Целью анализа является получение
реальных характеристик СРИ, сравнение их с проектными характеристиками,
предоставление объективных оценок качества работы системы. Анализ
позволяет определить причины снижения качества обслуживания и выдать
рекомендации относительно устранения этих причин. Иногда анализ делается
после внесения изменений в систему или после подключения новых источников
нагрузки
(реконструкции).
Разработка
методов
оценки
качества
функционирования ТКС и сетей является основной целью теории телетрафика.
Задача синтеза – это определение структурных параметров сети или,
например, схемы коммутационного узла этой сети при заданных потоках,
дисциплине и качестве обслуживания. Задача синтеза в определенной мере
является
обратной
к
задаче
анализа.
Синтез
(проектирование)
телекоммуникационных сетей может состоять из нескольких этапов. С позиций
системной методологии, основными этапами решения задачи синтеза сетей и
систем связи есть: анализ проблемы; определение системы; определение целей,
критериев, ресурсов; определение альтернативных вариантов; оценка,
сравнение и выбор вариантов; реализация решения. Задачи проектирования и
планирования ТКС и сетей возникают из необходимости заблаговременного
выбора технических средств, которые обеспечивают удовлетворение
потребностей в передаче информационных сообщений. Целью проектирования
есть оптимальная структура сети на продолжительную перспективу с учетом
текущего состояния развития телекоммуникационной техники и технологий.
Задачи оптимизации близки к задачам анализа и синтеза. При
проектировании ТКС и сетей они формулируются так: определить структурные
параметры или алгоритмы функционирования сети (системы), для которых:
− при заданных потоках, качестве и дисциплине обслуживания
стоимость или объем сети (системы) минимальные;
− при заданных потоках, дисциплине обслуживания и стоимости
качественные показатели функционирования сети (системы)
оптимальные.
При эксплуатации ТКС и систем задача оптимизации формулируется как
задача управления потоками требований или структурой сети для достижения
наилучших показателей качества функционирования. Из-за больших вычислительных трудностей задачи оптимизации ТКС и сетей решаются на ЭВМ.
13
Анализ, синтез и оптимизация СРИ выполняются с применением теории
вероятностей, математической статистики, комбинаторных и алгебраических
методов, теории множеств, теории графов, принципов системного подхода
(системотехники) и др.
Основными методами решения задач в теории телетрафика являются
аналитический, числовой и метод статистического моделирования.
Аналитические методы позволяют решать задачи теории телетрафика
при относительно простых структуре системы, характеристиках потока и
дисциплинах обслуживания. Рассматриваются все возможные состояния
системы, обусловленные, например, положением каждой точки коммутации
или количеством занятых каналов. Такие состояния называются
микросостояниями системы. Когда поступает новое требование, заканчивается
любая из фаз работы управляющего устройства по установлению соединения
или заканчивается соединение, система изменяет свое микросостояние. Для
каждого микросостояния записывается уравнение статистического равновесия.
Решая систему этих уравнений, находят точное решение задачи в границах
принятой модели.
Числовые методы используют специальные алгоритмы для нахождения
приближенных решений итерационными или другими методами. Они
применяются для сложных систем, где количество микросостояний настолько
велико, что решить систему уравнений статистического равновесия
невозможно даже с помощью быстродействующих ЭВМ. Поэтому применяется
так называемый макроподход. В сложной системе с большим количеством
микросостояний по некоторому признаку микросостояния объединяются в
классы – макросостояния. Путем усреднения определяются интенсивности
переходов из одних макросостояний в другие. Для каждого макросостояния
записывается уравнение статистического равновесия. Решением системы уравнений выводятся приближенные формулы для вероятностей макросостояний.
Методы статистического моделирования наиболее универсальные и
пригодны для решения задач практически любой сложности. Метод состоит в
построении математической модели системы, реализация которой осуществляется в виде программы для ЭВМ. Моделирование позволяет получить
числовые результаты, характеризующие качество обслуживания при заданных
параметрах потока, схеме и дисциплине обслуживания. Однако, из-за
специфики метода он менее удобный по сравнению с аналитическим и
числовым методами при определении неявных закономерностей функционирования или зависимостей между отдельными характеристиками системы.
Для детального анализа исследуемых СРИ возможно объединение
аналитических и числовых методов с методом статистического моделирования.
Например, если для малых значений параметров системы удается получить
решение точными аналитическими методами и проанализировать предельные
случаи при асимптотическом поведении характеристик исследуемой системы,
то потом полученные сведения дополняются результатами статистического
моделирования в области реальных значений параметров системы.
14
3 МОДЕЛИ СИСТЕМ РАСПРЕДЕЛЕНИЯ ИНФОРМАЦИИ
Теория телетрафика оперирует не с самими системами распределения
информации, а с их математическими моделями. Для полного описания СРИ
необходимо указать вероятностные процессы, описывающие входной поток
требований, структуру системы и дисциплину обслуживания. Следовательно,
математическая модель СРИ содержит такие основные элементы:
1. Входной поток требований на обслуживание (трафик) – классифицируется по признакам стационарности, ординарности и последействия.
Основными характеристиками потока есть его параметр и интенсивность λ.
2. Структура системы распределения информации – это информация о
количестве обслуживающих устройств или серверов (дающих услуги), их
взаимное соединение (схема) и доступность для входных требований.
3. Дисциплина
обслуживания потока требований – характеризует
взаимодействие потока требований с системой распределения информации. В
теории телетрафика дисциплина обслуживания описывается:
− способом обслуживания требований;
− порядком обслуживания требований;
− режимами поиска выходов схемы (произвольный или групповой);
− законами распределения продолжительности обслуживания;
− наличием преимуществ (приоритетов) в обслуживании требований;
− наличием ограничений при обслуживании (по продолжительности
ожидания или обслуживания, количеству ожидающих требований);
− законами распределения вероятностей поломки элементов схемы.
Входной поток требований описывается функцией распределения
вероятностей длины интервалов времени между соседними требованиями A(z):
A(z) = P(≤ z),
(3.1)
где P(≤ z) – вероятность того, что время между соседними требованиями ≤ z.
Если интервалы времени между соседними требованиями независимые и
одинаково распределенные случайные величины, то входной поток образует
стационарный процесс восстановления. При этом неизменны во времени
вероятностные характеристики случайных процессов, что соответствует
реальным процессам в СМО на небольших отрезках времени. Значит, функция
распределения интервалов A(z) достаточна для описания потока требований.
Время, в течении которого требование находится в сервере, описывается
функцией распределения вероятностей продолжительности обслуживания В(x):
В(x) = P(≤ x),
(3.2)
где P(≤ x) – вероятность того, что время обслуживания ≤ x.
Для описания интервала времени между соседними требованиями или
продолжительности обслуживания применяются разные законы. Чаще всего
используются распределения, данные ниже и обозначенные буквами:
– M – экспоненциальный (M – марковская модель) – коэф. вар. vx = 1;
– H – гиперэкспоненциальный (Hyper-exponential) – вар.vx = 1 … ∞;
– D – детерминированный (Determined) – коэф. вар.vx = 0;
– U – равномерный (Uniform) – коэф. вар. vx = 0,58;
15
– E – распределение Эрланга – коэф. вар.vx = 0 … 1;
– G – произвольный или обобщенный (General).
Дисциплина обслуживания потока требований определяет правила
обслуживания и судьбу требований при их поступлении в систему. Различают
такие типы СМО, которые определяются способом обслуживания требований:
1. Системы с потерями – требования, которые при поступлении в
систему не находят в ней ни одного свободного сервера, получают отказ в
обслуживании и теряются.
2. Системы с очередями – требования, которые не могут быть обслужены
сразу из-за занятости всех серверов системы, становятся в очередь, и с
помощью некоторой дисциплины обслуживания очереди определяется, в каком
порядке ожидающие требования выбираются из очереди для обслуживания.
Наиболее распространенными дисциплинами обслуживания очереди есть:
– FF (FIFO – first in first out) – требования из очереди обслуживаются в
порядке их поступления (упорядоченная очередь);
– LF (LIFO – last in first out) – каждый раз преимущество для
обслуживания имеет требование, поступившее в очередь последним;
– SR (SIRO – service in random order) – следующее требование для
обслуживания из очереди выбирается случайно (случайная очередь).
3. Комбинированные системы с очередями и потерями (системы с
очередью при ограничениях). Например, ожидать может только конечное
количество требований, обусловленное количеством мест ожидания, меньше
бесконечности. Возможно и так – требование теряется тогда, когда время
ожидания в очереди или пребывание в системе превышает заданные границы.
4. Приоритетные системы – для требований предусмотрены разные
приоритеты в обслуживании. Если требование, которое поступило, имеет
высокий приоритет, а все серверы заняты, то оно или занимает одно из первых
мест в очереди, или временно прекращает обслуживание требования низкого
приоритета и занимает его место в сервере. При этом могут быть применены
такие приоритетные правила:
– абсолютный приоритет с прерыванием (pre-emptive discipline) –
требование высокого приоритета перерывает обслуживание
требования низкого приоритета. Может быть: абсолютный приоритет с
потерями (pre-emptive loss discipline), абсолютный приоритет с
дообслуживанием (pre-emptive resume discipline) и абсолютный с
обслуживанием сначала (pre-emptive repeat different discipline);
– относительный приоритет (head of the line priority discipline) – требование высшего приоритета станет в начало в очереди без прерывания.
Смешанные приоритеты предопределяют выбор абсолютного или
относительного приоритетного правила в зависимости от уже реализованной
части продолжительности обслуживания, а динамические – в зависимости от
типа текущих требований и соотношения количества требований разных
приоритетов, который есть в серверах и в очереди.
Основные характеристики, представляющие структуру СРИ такие:
− кол-во обслуживающих устройств (серверов, линий, каналов, портов);
16
− количество мест ожидания или максимальная длина очереди (емкость
памяти, в которой накапливаются ожидающие требования);
− доступность – способ включения серверов, где каждому требованию
доступны все или не все (всем требованиям в совокупности доступны
все) серверы. Схема бывает полнодоступной или неполнодоступной;
− взаимное соединение (схема) – способ включения серверов, где
каждое требование обслуживается одним сервером или не одним, но
поэтапно. Схема бывает однокаскадной или многокаскадной (цепной).
Структурные характеристики системы частично предопределяют
дисциплину обслуживания потока требований. Например, при количестве мест
ожидания r = 0 будет система с потерями, при 0 < r < ∞ – комбинированная
система с очередью и с потерями, a при r = ∞ – чистая система с очередью.
Для сокращения записи Д. Кендаллом предложено специальное условное
обозначение базовой модели, где из всех параметров математической модели
СРИ представлены четыре элемента и записывается это так: A/B/m/r.
Элемент А характеризует поток требований и определенной буквой из
приведенных выше видов распределений помечается функция распределения
вероятностей интервалов времени между соседними требованиями.
Элемент В характеризует случайные последовательности длительности
обслуживания на отдельных серверах системы и аналогично предыдущему
может использовать такие же распределения.
Элементы m и r характеризуют количество обслуживающих устройств и
мест ожидания в системе соответственно.
Сокращенная запись базовой модели кроме основных обозначений может
содержать еще и дополнительные символы, которые указываются после знака
„:” и могут уточнять особенности системы. Например. Запись M/D/120/r = ∞
означает, что СМО с m = 120 обслуживающими устройствами обслуживает
простейший поток требований (M), где каждое требование имеет постоянную
длительность обслуживания (D). Есть бесконечное количество мест ожидания
(r = ∞), что и определяет дисциплину обслуживания с очередями. Запись
G/M/120:Loss означает, что СРИ обслуживает произвольный поток требований
с экспонентным распределением их длительности. Емкость накопительной
памяти, где требования ожидают в случае занятия всех 120 серверов системы,
равна нулю (не записывается), и поэтому данная система с потерями (Loss).
Итак, базовая математическая модель СМО описывается рядом символов:
первый – функция распределения интервалов времени между требованиями,
второй – функция распределения продолжительности обслуживания, третий и
следующий (необязательный) символы – схема и дисциплина обслуживания.
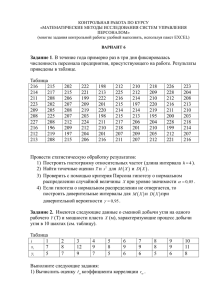
Построение математической модели (рис. 3.1), адекватно отображающей
реальную систему распределения информации, во многих случаях является
непростой задачей. От правильного выбора модели зависит точность решения
задач анализа, синтеза и оптимизации.
17
Рис
уно
к
3.1
–
Кла
сси
фик
аци
я
сис
тем
мас
сов
ого
обс
луж
ива
ния
На длину
очереди
На время
пребывания
в очереди
«Первым
пришел –
первым
обслужен»
«Последним
пришел –
первым
обслужен»
Вид
огр
ани
чен
ия
С
неогр
анич.
очере
дью
Огр
ани
чен
ия
на
оче
ред
ь
С
огран
ич.
очере
дью
Вы
бор
тре
бов
ани
й из
оче
ред
и
Случайный
выбор
Абсолютный
приоритет
Относительный
приоритет
18
Без
прио
ритет
а
Дис
цип
лин
а
оче
ред
и
С
прио
ритето
м
Хара
ктер
исти
ка
канал
ов
Одно
родн
ые
Хар
ак
те
рис
ти
ка
при
ори
те
та
Специальные
правила
приоритета
Раз
омк
нутые
Зам
кну
тые
С
оче
ред
ями
С
пот
еря
ми
Мн
ого
кан
аль
ные
Не
однородн
ые
Пара
ллель
но
Вкл
юче
ние
кан
ало
в
Посл
едовател
ьнно
Сп
осо
б
вы
бор
а
тр
ебо
ван
ий
Сп
осо
б
обс
лу
жи
ван
ия
олво
кан
ало
в
СИС
ТЕМ
Ы
МА
СС
ОВ
ОГО
ОБС
ЛУ
ЖИ
ВАН
ИЯ
К
Одн
ока
нал
ьны
е
4 МАТЕМАТИЧЕСКАЯ МОДЕЛЬ ПОТОКА ТРЕБОВАНИЙ
В теории массового обслуживания одним из основных понятий есть
случайная последовательность требований, поступающих в систему на
обслуживание. Совокупность (последовательность) событий поступления в
систему в моменты t1…tn требований образуют поток требований (рис. 4.1).
0 t1
t2
t3
t4
t5
t6
t
Рисунок 4.1 – Поток требований на обслуживание
Поток определяется моментами поступлений tx и количеством требований kn, поступивших в момент tn. При этом kn и tn в общем случае случайны. У
рекуррентного потока требований kn = 1 для всех n = 1, 2, … , а интервалы
времени между событиями поступления требований zn = tn – tn-1 есть
стохастично независимые и одинаково распределенные случайные величины.
При постоянном интервале времени между требованиями zn поток есть
детерминированным, однако, в телекоммуникациях потоки чаще случайные.
Случайный поток требований может быть описанным двумя способами.
1. Случайный поток требований описывается функцией распределения
вероятностей интервалов времени между соседними требованиями F(t):
F(t) = P(zn ≤ t),
(4.1)
где P(zn ≤ t) – вероятность того, что время между соседними требованиями
zn ≤ t.
Основная характеристика потока – это среднее значение длительности
интервалов z, что для случайной величины есть математическое ожидание z .
Параметр, обратный к математическому ожиданию z , есть интенсивность
потока поступления требований λ за единицу времени, коими измеряется z :
1
λ = .
(4.2)
z
Например, при z = 0,1 с интенсивность потока λ = 10 требований в секунду, а
при z = 100 мс – интенсивность потока λ = 0,01 требования в миллисекунду.
Наиболее распространенной математической моделью потока требований
в телефонных сетях связи является модель экспонентного распределения
интервалов времени между требованиями (вызовами АТС) с параметром λ:
(4.3)
P( z n ≤ t ) = 1 − e − λ t .
Плотность этого распределения позволяет рассчитать вероятность любой
продолжительности zx = t случайной величины z (интервалов между
требованиями) по заданной интенсивности поступления требований λ:
(4.4)
p (t ) = λ e − λ t .
Среднее значение случайной величины t, распределенной по экспонентному закону (4.4), равно λ-1 и потому из (4.2) следует, что параметр данного
распределения λ – это среднее количество требований за единицу времени, в
19
которых измеряется z . Поток, где все zn имеют одинаковое экспонентное
распределение с параметром λ, очень важный пример рекуррентного потока.
На рис. 4.2 представлены два графика экспонентного распределения (4.4),
обозначеные p(z) и p1(z) с параметрами λ = 0,5 и λ1 = 0,25 соответственно.
Рисунок 4.2 – Экспонентное распределение интервала z
Из графиков видно, что в потоке, заданного функцией p(z), значительно
больше доля вероятностей коротких интервалов между требованиями, чем в
потоке, заданного функцией p1(z). Это говорит о большей интенсивности
потока требований, которая в первом случае составляет λ = 0,5, а во втором –
λ1 = 0,25 требований в единицу времени. Среднее значение интервала времени
между требованиями такое: z = 2 и z1 = 4 единицы времени соответственно.
2. Случайный поток требований описывается функцией Pi(t) – распределением вероятностей количества требований i за условную единицу времени t.
Например, если диаграмму процесса поступления требований, представленную
на рис. 4.1, условно поделить на одинаковые промежутки времени
длительностью t, что в разы или десятки раз превышает среднее значение
интервалов z , то на каждый из таких условных интервалов припадет случайное
количество требований i. Функция распределения случайной величины i будет
описывать поток требований, поступающих в систему на обслуживание.
Известно, если интервал времени между событиями (требованиями) z
распределен по экспонентному закону, то количество таких событий i за
условную единицу времени t будет распределено по закону Пуассона:
(λ t ) i − λ t
(4.5)
Pi (t ) =
e .
i!
Величина λt это параметр распределения Пуассона. По нему можно
рассчитать вероятность поступления в систему точно i требований за условную
единицу времени длительностью t, зная интенсивность потока требований λ.
Для приведенного выше примера экспонентного потока с
интенсивностью λ = 0,5 построено распределение Пуассона случайного
количества требований, которое приходится на условные интервалы времени,
например, продолжительностью t = 20 c (рис. 4.3).
20
Рисунок 4.3 – Распределение Пуассона при λ = 0,5 и t = 20 c
Среднее значение случайной величины i, распределенной по закону (4.5),
определяется как i = λ t , и в этом случае λt = 10. Из рис. 4.3 видно, что
вероятность такого значения количества требований i за условную единицу
времени t есть наибольшей, и это есть вероятность среднего значения i . При
возрастании i от нуля к i вероятность Pi(t) постепенно возрастает, а потом –
уменьшается. Данный график почти симметричный, а форма аппроксимирующей кривой приближается к форме нормального закона распределения.
Таким образом, математическую модель потока требований,
поступающего в СРИ на обслуживание, можно отобразить двумя способами с
помощью вероятностных функций распределения:
− интервалов времени между соседними требованиями z, (4.4);
− количества требований i за условную единицу времени t, (4.5).
В первом случае, применяются непрерывные законы, а во втором –
дискретные.
Каждый из потоков называется по виду вероятностного закона
распределения интервалов времени между требованиями или их количества за
условную единицу времени. Модель потока, определяемая распределением
(4.5) называется пуассоновским потоком (используется в телефонных сетях).
Пуассоновские потоки делятся на потоки первого и второго рода. Для
потоков первого рода вероятность поступления требований в систему не
зависит от того, сколько требований уже есть в ней. СМО с такими потоками
называются системами с бесконечным числом источников или открытыми
системами. Потоки первого рода возникают из-за наложения многих потоков
отдельных источников, причем поведение каждого источника независимо.
Потоки требований второго рода получаются в СМО с конечным числом
источников или в так называемых замкнутых системах. Поскольку в момент,
когда требование обслуживается или ожидает, ее источник уже не может
порождать новых требований, то вероятность того, что поступит требование из
совокупности требований всех источников, зависит от того, сколько
требований в системе и от каких они источников. Такие потоки называются
примитивными.
21
Оценка качества обслуживания или пропускной способности СРИ требует
учета всех элементов ее модели. Наиболее сложно учесть математическую
модель входного потока требований. Именно по этой причине весь пакет задач
анализа и синтеза СРИ для любых из ее схем и дисциплин обслуживания решен
только для случая простейшей модели трафика – пуассоновского потока. Для
неё известны все аналитические формулы расчета основных характеристик
качества обслуживания в системах распределения информации [1-3].
Стремительное развитие телекоммуникационных технологий, новые
принципы построения сетей связи, изменение структурного состава абонентов
и спектра предоставляемых услуг влияет на изменение характера трафика. Эти
факторы увеличивают неравномерность интенсивности потоков требований,
измеряемую дисперсией интенсивности. Результаты статистических измерений,
выполняемых на разных сетях связи, дают возможность выделить 3 типа
трафика, к которым следует употреблять следующие математические модели:
I тип – в моносервисных сетях с однородным трафиком. Это телефонные
сети с единственной услугой телефонной связи, а поэтому трафик однородный.
Простейшая модель пуассоновского потока соответствует таким условиям, а
значения интенсивности трафика и ее дисперсии достаточно близки.
ІІ тип – в мультисервисных сетях с разнородным трафиком.
Интегральный характер мультисервисной сети с расширенным спектром
предоставляемых услуг предопределяет разнородность трафика, которая сильно
изменяет его параметры и математическую модель. Реальным потокам присуща
повышенная неравномерность трафика, при которой дисперсия интенсивности
трафика превышает ее математическое ожидание от 2 до 15 раз. Иногда данное
превышение бывает и большим, но это происходит или за пределами ЧНН, или
на небольших пучках каналов [4].
ІІІ тип – в пакетных сетях с мультисервисным трафиком. Трафик имеет
долгосрочные зависимости в интенсивности и еще более существенно
отличается от пуассоновского потока. Адекватной моделью потоков в таких
сетях есть самоподобные процессы. В мультисервисных пакетных сетях трафик
есть разнородным и с определенными требованиями к QoS. Здесь передачу
потоков разных служб обеспечивает одна и та же сеть с едиными протоколами
и законами управления. Поскольку источники каждой службы могут иметь
разные скорости передачи информации или изменять ее в процессе сеанса
связи, то объединенному потоку пакетов присуща так называемая «пачечность»
трафика (burstness), измеряемая коэффициентом пачечности [1]. Эта пачечность
обуславливает еще большую неравномерность трафика, при которой дисперсия
интенсивности трафика превышает ее математическое ожидание от 20 до 60 раз
и большее.
Независимо от способа задания математической модели потока
требований выбранная модель обязательно должна быть адекватной реальным
потокам трафика телекоммуникационных сетей, поскольку от этого
существенно зависит точность расчета характеристик качества обслуживания и
пропускной способности СРИ при их анализе, синтезе и оптимизации.
22
5 НАГРУЗКА И ЕЁ ВИДЫ
Суммарное время обслуживания всех входных требований является
нагрузкой для серверов (приборов, линий, каналов) СМО. Чем большее это
время – тем больше нагрузки „обслуживают” серверы системы. В теории
телетрафика различают входную (traffic offered), обслуженную (traffic carried) и
избыточную (overflow traffic) нагрузку. Избыточная нагрузка – это разность
между входной и обслуженной нагрузками, которая для систем с потерями
будет потерянной нагрузкой.
5.1 Определение и интенсивность нагрузки
Нагрузка измеряется в часо-занятиях. Например, нагрузка в одно часозанятие (1 ч.-зан.) получается непрерывным обслуживанием требований одним
сервером на протяжении одного часа или двумя серверами сроком по полчаса
каждый и т.д. Поэтому параметр „нагрузка” не дает четких сведений
относительно напряженности работы системы, поскольку неизвестно, за какое
время она выполнена. Суммарное время обслуживания всех требований равное,
например, 20 ч.-зан. может свидетельствовать о работе в системе 1 сервера на
протяжении 20 часов или 20 серверов на протяжении 1 часа каждый. Поэтому
введено понятия интенсивности обслуженной нагрузки Y, определяемая как
приведенное время нагрузки. Она рассчитывается как суммарное время
обслуживания всех требований xi на интервале времени t2 – t1, разделенное на
величину этого интервала (t2 – t1 может равняться, например, одному часу):
Y=
∑
xi
.
t 2 − t1
(5.1)
Количество занятых серверов системы, используемых при обслуживании
требований входного потока, тоже есть нагрузкой системы. При поступлении
требования в систему один из серверов занимается, а в конце его обслуживания
– этот сервер освобождается и требование „выходит из системы”. Из-за
случайности данных событий в моменты поступления требований или моменты
их выхода в системе будет занято разное количество серверов. Таким образом,
в каждое мгновенье количество занятых серверов системы или количество
одновременно обслуживаемых требований определяет мгновенное значение
обслуженной нагрузки. Поскольку это количество случайно, то основной
характеристикой обслуженной нагрузки есть её среднее значение, которое так
же, как и (5.1), называется интенсивностью обслуженной нагрузки Y. Если в
многосерверной системе за время его работы от t1 до t2 с любой
периодичностью, например τ = 1 с, n = (t2 – t1) / τ раз вычислить (сканировать)
количество занятых серверов Ci и в итоге рассчитать их среднее значение
1 n
Y = ∑ Ci ,
(5.2)
n i= 1
то оно однозначно совпадет со значением, рассчитанным для этой же системы
по формуле (5.1).
23
На диаграмме рис. 5.1. наглядно показано функционирование 4-серверной
системы при обслуживании входной нагрузки. На оси ординат отображены
точки, символизирующие номера определенных серверов системы, а на оси
абсцисс – время, на которое каждый из этих серверов занимается требованием
для его обслуживания. Здесь отображена только обслуженная нагрузка и не
видно того, поступали в систему еще требования или нет.
4
3
2
1
0
1
2
3
4
5
6
7
8
9
10
t, c
Рисунок 5.1 – Диаграмма функционирования 4-серверной системы
Суммарное время занятия всех серверов системы определится так
(индексами обозначенные номера серверов, отображенных на оси ординат):
∑ xi = (3c + 3c)1 + (5c) 2 + (4c)3 + (2c + 2c + 2c) 4 = 21 c .
Интенсивность обслуженной нагрузки за 10 с в соответствии с формулой
(5.1) составит Y = 21/10 = 2,1 у.е. (условных единиц).
Среднее количество занятых серверов по интервалам сканирования 1 с
(i – это номер отсчета сканирования на оси абсцисс) составит:
1 9
2 + 3 + 2 + 1+ 3 + 3 + 1+ 2 + 2 + 2
Y=
Ci =
= 2,1 ó.î.
∑
10 i = 0
10
Таким образом, интенсивность обслуженной нагрузки – это приведенное
время суммарного обслуживания всех требований (5.1) или среднее значение
количества занятых серверов (5.2). Оба способа определения интенсивности
обслуженной нагрузки могут использоваться в средствах измерения параметров
нагрузка на действующих сетях связи. Среднее количество занятых серверов
еще называют загруженностью системы.
За единицу измерения интенсивности нагрузки принят 1 Эрланг (1 Эрл),
которую названо в честь основателя теории телетрафика А.К. Эрланга.
Нагрузка на серверы системы есть результат общего процесса
поступления и обслуживания требований. Поскольку требования поступают в
систему через случайные интервалы времени (или количество требований за
условную единицу времени случайно) и продолжительность обслуживания
также может быть случайной, то и нагрузка является случайной величиной. В
связи с этим интенсивность входной нагрузки Λ нормируется средним
временем обслуживания требований x (не путать с интенсивностью потока
поступления требований λ). Эта интенсивность определяется в соответствии со
24
вторым способом представления математической модели входного потока
требований, например (4.5), но при этом за условную единицу времени t
берется средняя продолжительность обслуживания требований x . Таким
образом, интенсивность входной нагрузки
Λ = λx.
(5.3)
Для случая, приведенного на рис. 4.3, величина λt = 10 есть
интенсивностью входной нагрузки в 10 Эрл только при условии, если средняя
продолжительность обслуживания x = t = 20 с. Итак, интенсивность входной
нагрузки Λ, измеренная в Эрлангах, это среднее количество требований,
поступающее в систему за среднее время обслуживания одного требования.
Иначе, это есть интенсивность потока поступления требований λ, отнесенная к
средней продолжительности обслуживания x .
Интенсивность входной нагрузки можно определять как интенсивность
обслуженной нагрузки в предположении того, что потери требований входного
потока отсутствуют, то есть каждому поступившему требованию
предоставляется свободный сервер при любых условиях (например, в системе
бесконечное количество серверов).
В основном при исследованиях рассматриваются стационарные потоки
требований. В этом случае как входная, так и обслуженная нагрузки
описываются стационарными случайными процессами и их статистические
параметры в вероятностном смысле не зависят от времени.
Интенсивность входной нагрузки Λ – это среднее количество требований,
поступающих в систему за среднее время обслуживания одного требования.
Интенсивность обслуженной нагрузки Y – это среднее количество занятых
серверов. В обоих случаях данные интенсивности являются оценками нагрузок,
которые являются случайными величинами.
В соответствии с (1.1) математическое ожидание, а поэтому и среднее
количество требований, поступающее в систему за среднее время
обслуживания одного требования, можно рассчитать так:
Λ =
∞
∑
i= 0
iPi ,
(5.4)
где Pi – вероятность того, что за интервал времени t = x в систему поступит
точно i требований, где i = 0, …, ∞.
В соответствии с (1.1) математическое ожидание, а поэтому и среднее
количество занятых серверов системы, можно рассчитать так
Y=
m
∑
j= 0
jp j ,
(5.5)
где Pj – вероятность того, что в произвольный момент времени в системе из m
серверов занято точно j серверов, где j = 0, …, m.
Математическое ожидание интенсивности нагрузки иногда называют
просто нагрузкой, что есть неточным определением.
25
5.2 Дисперсия и скученность нагрузки
Кроме интенсивности нагрузки (математическое ожидание) важной
характеристикой случайной величины нагрузки есть дисперсия, которая для
входной и обслуженной нагрузки соответственно определится так:
DΛ =
∞
2
∑ ( i − Λ ) Pi ;
DY =
i= 0
m
2
∑ ( j − Y ) Pj .
i= 0
(5.6)
Если поток входных требований будет экспонентным (4.4), то
создаваемая им нагрузка, как случайная величина, имеет распределение
Пуассона (4.5). Для случайной величины, описываемой этим распределением,
характерна одинаковость первых двух моментов, то есть дисперсия нагрузки DΛ
совпадает с ее математическим ожиданием Λ. Такая нагрузка называется
пуассоновской нагрузкой первого рода и она считается условно равномерной.
Если дисперсия нагрузки меньше ее математического ожидания, то
нагрузку называют сглаженной, поскольку ее отклонения от среднего значения
будут меньше, чем для пуассоновской нагрузки.
Нагрузка, где дисперсия больше математического ожидания называется
скученной. В этом случае требования поступают не равномерно: для некоторых
интервалов времени количество входных требований мало, а на других
интервалах их количество велико, т.е. требования группируются на коротких
интервалах времени. Например, скученная нагрузка создается так называемым
избыточным потоком требований, которые потеряны (не обслужены) в системе
А і поступают для обслуживания на другую систему В. Этот поток есть
прерывистым, так как на систему B требования могут поступать только при
условии, что в системе А отсутствуют свободные серверы.
Скученность нагрузки S определяется как отношение дисперсии нагрузки
DΛ к ее математическому ожиданию Λ:
D
S= Λ .
(5.7)
Λ
Величина S, называемая коэффициентом скученности нагрузкии, равна
единице для пуассоновского потока, меньше единицы для выровненного
(сглаженного) потока и больше единицы для скученного (избыточного) потока
нагрузки.
Если на серверы системы поступают сразу n потоков требований, то
интенсивность объединенного потока будет равна сумме математических
ожиданий Λі. Для статистически независимых потоков дисперсия
объединенного потока будет равна сумме дисперсий Di соответствующих
нагрузок. Таким образом, математическое ожидание Λ и дисперсия DΛ
суммарной нагрузки рассчитываются по следующим формулам:
Λ
∑
=
n
∑
i= 0
D∑ =
Λi;
n
∑
i= 0
Di .
(5.8)
Следует различать скученность входной и обслуженной нагрузок.
Безусловно, SΛ > SY, поскольку в системе обслуживается только часть входной
нагрузки, да и обслуженная нагрузка сглаживается системой.
26
6 ХАРАКТЕРИСТИКИ КАЧЕСТВА ОБСЛУЖИВАНИЯ
Для любой телекоммуникационной системы важна оценка степени
удовлетворения потребности в обслуживании, или качество обслуживания
(QoS – Quality of Service). В теории телетрафика качество обслуживания
потока требований характеризуется возможностью немедленного
обслуживания требования или продолжительностью ожидания начала
обслуживания. Из математической модели СРИ следует, что эти
возможности определяются избранной дисциплиной обслуживания
требований. Поэтому для каждой дисциплины обслуживания требований
присущий определенный набор основных и вспомогательных характеристик
качества обслуживания.
6.1 Системы с потерями
Из экономических соображений СРИ проектируются с дисциплиной
обслуживания с потерями, где требованию, поступившему в систему в
момент отсутствия свободных обслуживающих устройств, отказывается в
обслуживании и оно сразу же теряется. Основной количественной оценкой
качества обслуживания при этом есть вероятность потери требования
PВ (B – blocking). Вероятность PВ на отрезке времени (t 1 , t 2 ) определяется как
отношение количества потерянных за это время требований СВ(t 1 , t 2 ) к общему
количеству требований, поступившим за одно и то же время в систему С(t 1 , t 2 ):
C (t , t )
PÂ = Â 1 2 .
(6.1)
C (t1 , t 2 )
Вспомогательными характеристиками QoS есть вероятность потери
нагрузки (количество требований за условную единицу времени) и вероятность
потерь по времени, которые используются редко. Вероятность потери нагрузки
определяется как отношение интенсивности утраченной нагрузки ко входной, а
вероятность потерь по времени – это суммарная доля времени из промежутка
времени (t 1 , t 2 ), в котором были заняты все серверы системы.
Среднее количество требований в системе N характеризует степень
загруженности системы и совпадает со средним количеством занятых серверов,
а это есть интенсивность обслуженной нагрузки Y. Все другие требования,
поступившие при занятости всех серверов, теряются и в систему не попадают.
Среднее время пребывания требования в системе T совпадает со средним
временем обслуживания требования x .
Для систем с потерями интенсивность обслуженной нагрузки меньше
входной нагрузки на величину ΛPB, то есть
Y = Λ (1 − PB ) .
Величина ΛPB является интенсивностью избыточной нагрузки, и ее поток
по своей структуре существенно отличается от поступающего в систему потока
нагрузки более неравномерным характером.
27
6.2 Системы с очередями
Для количественной оценки качества обслуживания систем с очередью
рассчитывают такие основные характеристики:
− вероятность ожидания Pw>0 (среднюю долю задержанных требований);
− среднюю длину очереди Q;
− среднюю продолжительность ожидания задержанных требований tq;
− среднюю продолжительность ожидания любого требования W.
Вероятность Pw>0 за время (t 1 , t 2 ) определяется как отношение количества
требований, попавших за этот отрезок времени в очередь СQ(t 1 , t 2 ) к общему
количеству требований, поступившими за то же время в систему С(t 1 , t 2 ):
CQ (t1 , t 2 )
Pw > 0 =
.
(6.2)
C (t1 , t 2 )
Длина очереди – ключевой параметр качества обслуживания (и показатель
эффективности функционирования СРИ). Определяется количеством ожидающих обслуживания требований. Длина очереди зависит от того, когда и сколько
требований поступило в систему, сколько времени истрачено на обслуживание
требований. Поскольку длина очереди есть случайная величина, в качестве
показателя длины очереди используется ее математическое ожидание Q.
Среднее время ожидания в очереди tq образуется за счет задержки
требований в очереди. Оно зависит от количества требований, находящихся в
данный момент в очереди, времени окончания обслуживания всех предыдущих
требований и т.д.
Среднее время ожидания в системе W представляет собой среднее
значение времени ожидания, отнесенное ко всем требованиям – задержанным и
не задержанным. Этот параметр вводится из-за того, что не все требования
попадают в очередь, а часть из них при наличии свободных серверов системы
обслуживается немедленно.
Вспомогательными характеристиками QoS есть среднее количество
требований в системе N и среднее время пребывания требования в системе T.
Они являются вспомогательными, поскольку их можно рассчитать из основных
характеристик.
Среднее количество требований в системе N определяет степень
загруженности системы и при неограниченной очереди состоит из среднего
количества поступающих в систему требований Λ, и тех, что ожидают в
очереди Q:
N = Λ + Q.
(6.3)
Среднее время пребывания требования в системе T – время, проведенное
одним требованием в системе и усредненное по всем требованиям
(задержанным и не задержанным). Оно состоит из среднего времени
обслуживания x и среднего времени ожидания требований в системе W:
T= x+W.
(6.4)
Для каждой модели потока все характеристики качества обслуживания
находятся в определенной функциональной зависимости.
28
6.3 Комбинированные системы (с очередями и потерями)
Система с очередью при ограничениях на максимальное количество
требований, находящихся в очереди, или на максимальное время ожидания
начала обслуживания является системой с комбинированной дисциплиной
обслуживания. При ограниченном количестве мест ожидания (максимальная
длина очереди) в случае поступления требования в момент, когда все серверы и
места ожидания заняты предыдущими требованиями, данное требование
теряется. При ограниченном времени ожидания если требование находится в
очереди свыше допустимого времени, то ему отказывается в обслуживании, и
оно тоже теряется. Поэтому, кроме характеристик QoS чистой системы с
очередями, рассчитываются и такие:
– вероятность потери требования PB (при ограниченной длине очереди);
– вероятность ожидания свыше допустимого времени PW > t.
Вероятность PW>t зависит от дисциплины обслуживания очереди и самым
простым для расчета есть случай упорядоченной очереди FIFO. Эту вероятность еще называют условными потерями, поскольку требование, ожидающее
свыше допустимого времени t, может утратить актуальность для пользователя.
6.4 Приоритетные системы
В современных ТКС и сетях используется приоритетное обслуживание
передаваемых и обрабатываемых данных. Аналитические методы исследования
приоритетных дисциплин обслуживания требований разработаны, в основном,
для дисциплин с одним классом приоритетов, и большинство результатов
получено при разных допущениях и предположениях, ограничивающих их
применение на практике. Поэтому, для исследования влияние приоритетов на
характеристики QoS системы целесообразно применять моделирование.
Комбинированные системы с ограничениями на длину очереди и время
ожидания наиболее распространены в телекоммуникациях. В условиях
разнородного трафика (речь, видео, данные) такую систему дополняют
механизмом приоритетов, в котором все требования разделяют на категории и
требования более высокой категории при обслуживании имеют определенные
преимущества (приоритеты) перед требованиями более низкой категории. Для
количественной оценки качества обслуживания систем с приоритетами
рассчитываются такие же характеристики, как и для системы с очередями, но
для каждого из введенных приоритетов в отдельности. Например, среднее
время ожидания в очереди требования k-го приоритета, среднее количество
требований в системе k-го приоритета и т.п.
Примером системы с потерями может быть телефонная станция –
абонент, являющийся инициатором телефонного вызова, получает отказ в
обслуживании, если необходимый канал связи уже занят (технология
коммутации каналов). Модель системы с очередью, комбинированной системы
и с приоритетами применяема для сетей, базирующихся на технологии
коммутации пакетов.
29
6.5 Пропускная способность и производительность
В любой из СРИ качество обслуживания сильно влияет на такие
характеристики системы, как пропускная способность и производительность.
При этом, критерием качества обслуживания для систем с потерями есть
вероятность потери требования, а для систем с очередями – вероятность ожидания. Чем больше допустимая норма потерь, тем хуже качество обслуживания.
Пропускная способность – это максимальная интенсивность нагрузки,
обслуживаемая системой при обеспечении заданного качества обслуживания.
При малой вероятности потерь интенсивность обслуженной нагрузки
близка к интенсивности входной и пропускная способность близка к интенсивности входной нагрузки. Однако при больших потерях это отличие велико, и
ухудшение допустимого качества обслуживания позволяет увеличить
пропускную способность. Чем выше норма качества обслуживания, тем больше
серверов нужно для обеспечения заданной пропускной способности.
Пропускная способность системы не равна количеству серверов в ней,
поскольку интенсивность обслуженной нагрузки – это среднее количество
занятых серверов. Из-за случайности потоков нагрузки среднее количество
занятых серверов не достигает имеющегося количества серверов в системе.
Задача состоит лишь в приближении среднего количества занятых серверов к
количеству серверов системы.
Производительность – это предельное, статистически усредненное
количество требований, обслуживаемые системой за единицу времени при
заданном качестве обслуживания. Эта характеристика используется, как
правило, для оценки систем управления и управляющих устройств.
Пропускная способность и производительность СРИ зависят не только от
вероятности потерь, но и от структуры системы (количества серверов и схемы
их включения), дисциплины обслуживания и закона распределения продолжительности обслуживания. На пропускную способность и качество
обслуживания влияет и вид потока требований или его математическая модель.
При измерении пропускной способности СРИ важно понятие блокирования требования – это событие, состоящее в отсутствии свободных и доступных
путей соединения в нужном направлении в момент поступления требования (в
момент попытки установления соединения). В системе с потерями блокированные требования теряются и показателем пропускной способности есть доля
потерянных требований.
Для системы с очередью различают неограниченную и ограниченную
очереди (количество мест ожидания). Если накопитель очереди имеет
неограниченную емкость, то основными характеристиками есть среднее время
ожидания и вероятность ожидания (вероятность блокирования). В случае
накопителя с ограниченной емкостью добавляется еще одна характеристика –
вероятность потери требования, тогда вероятность блокирования равна сумме
двух вероятностей – ожидания и потери требования.
В системе с повторными попытками подсчитывается количество
повторных попыток на одно требование и прочие характеристики.
30
7 АНАЛИЗ СМО С ПУАССОНОВСКИМ ПОТОКОМ ТРЕБОВАНИЙ
Исследование работы СМО под влиянием случайных факторов возможно
только с помощью случайных процессов. Случайный процесс – это функция
X(t), значения которой случайные величины. Выбор случайных процессов,
используемых для описания и анализа систем, зависит от структуры и типа
системы, от предположения о независимости или зависимости случайных
величин в системе, от вида их функций распределений.
Если все функции распределения, характеризующие поведение элементов
системы, экспонентные, то систему можно описать с помощью однородных
непрерывных марковских цепей или их подвида однородных процессов
размножения и гибели, как модели СМО. При этом аналитическое определение
величин, характеризующих систему, относительно несложно.
В условиях случайных потоков требований расчеты степени загруженности или пропускной способности и характеристик качества обслуживания
ведутся на основе вероятностных функций распределения состояний системы,
определяющие эти характеристики. При пуассоновском потоке для определения стационарных вероятностей состояний системы используется математический аппарат марковского процесса с составлением и решением системы
линейных алгебраических уравнений равновесия. Состояние системы – это
текущее количество требований, которые обслуживаются в серверах или
ожидают в очереди. Изменение состояний системы – это случайный процесс,
являющийся результатом общего процесса поступления и обслуживания
требований. Закон распределения состояний системы, в отличие от среднего
количества требований в ней (загруженности), более полно характеризует
функционирования СМО под влиянием случайных факторов.
Самый эффективный математический аппарат анализа разработан для
систем, работа которых описывается однородными цепями или процессами
Маркова. Характеристики марковских моделей определяются путем решения
систем линейных уравнений (алгебраических, дифференциальных или
интегральных). Гипотезы о марковости работы системы сильно ограничивают,
поэтому в качестве математических моделей очень сложных реальных систем
применят более общие классы случайных процессов. Марковости модели
можно достичь усложнением фазового пространства моделирующего процесса.
Процесс есть марковский (без последействия), если для любого момента
времени поведение системы в будущем зависит только от текущего состояния
системы и не зависит от того, когда и как система в это состояние пришла.
Марковский процесс с дискретным пространством состояний – это цепь
Маркова. Множество {S} образует цепь Маркова, если вероятность того, что
следующее состояние будет Sk+1 зависит только от текущего состояния Sk, или
влияние всей предыстории процесса сосредоточено на текущем состоянии.
В цепи Маркова поток случайных величин определяется только вероятностью перехода от предыдущего значения случайной величины (состояния
системы) к следующему. Для однородной цепи Маркова вероятности этих
переходов не зависят от номера шага, на котором система достигает опреде31
ленного состояния. В соответствии с теоремой Маркова, если количество состояний системы S конечно, и из каждого состояния можно перейти за определенное количество шагов в любое другое состояние, то предельные вероятности состояний существуют и не зависят от начального состояния системы.
Условием применения цепей Маркова для нахождения вероятностей состояний системы есть экспонентное распределение интервалов времени между
требованиями потока. Экспонентное распределение единственное из всех
непрерывных законов, имеющее свойство отсутствия последействия. Оно
означает: если продолжительность интервала между требованиями экспоненциальная, то с любого момента от начала этого интервала остаток времени до
его конца не зависит от событий до этого момента, и будет иметь тоже
экспоненциальное распределение с тем же параметром, что и весь интервал.
Экспонентное распределение интервалов времени между требованиями
вызывает пуассоновское распределение количества требований за условную
единицу времени и поэтому свойство отсутствия последействия переносится и
на пуассоновский поток требований, который вместе с тем есть:
− стационарным, так как вероятность количества требований на отрезке
времени зависит только от продолжительности этого отрезка и не
зависит от того, где именно на оси времени он размещен;
− ординарным, так как вероятность поступления более одного требования за бесконечно малый отрезок времени есть бесконечно малой
сравнительно с вероятностью поступления ровно одного требования
(это означает, что требования поступают только по одному);
− без последействия, так как для любых отрезков времени, которые не
пересекаются, количество требований одного отрезка не зависит от
того, сколько требований поступило на другом.
Для такого потока интенсивность λ, то есть среднее количество
требований на единицу времени, есть величина постоянная (неизменная).
Если в модели не все распределения экспонентные, ищут такие
аналитические приемы, которые приводят исследуемые процессы к
марковским, или ищут такие моменты времени, в которых процесс становится
марковским. Далее простыми методами дискретных марковских цепей
вычисляются искомые величины или вероятности, характеризующие состояние
системы, после чего они превращаются в соответствующие величины
исходного процесса. Для решения задач такого типа применяются методы
полумарковских процессов или вложенных цепей Маркова. Однако, реальные
результаты с применением этих методов полученные для небольшого класса
систем (например, формула Поллачека-Хинчина для системы типа M/G/1/∞),
или получены только частичные и приближенные результаты (например, для
систем типа M/G/m/∞, GI/G/1/∞ и др.).
При максимальной точности описания работы реальных сложных систем
соответствующие математические модели становятся все более и более
сложными. При этом усложняется их математический анализ, аппарат анализа
становится громоздким и часто недоступным в инженерной практике.
32
7.1 Система с потерями M/M/m
Полнодоступная схема СРИ с m серверами обслуживает пуассоновский
поток требований по дисциплине с потерями. Интервал времени между
требованиями и длительность обслуживания распределены экспоненциально.
Параметр потока требований λ, а средняя продолжительность обслуживания –
x . Определить стационарное распределение вероятностей состояний системы
Pk (k = 0 … m) и характеристики качества обслуживания (QoS).
Для ординарного потока интенсивность поступления требований
совпадает с параметром потока λ. Совокупность моментов завершения
обслуживания требований образуют поток освобождения серверов системы с
параметром µ, называемый интенсивностью обслуживания требований и
рассчитываемый как обратная величина к продолжительности обслуживания:
1
µ = .
(7.1)
x
Дискретные состояния системы Sk изменяются при каждом поступлении
требования или окончании его обслуживания. Цепь Маркова с конечным
количеством состояний изображается в виде диаграммы переходов (рис. 7.1).
λ
λ
S0
S1
µ
λ
λ
S2
…
λ
S
Smm
S3
3µ
2µ
kµ
…
..
Рисунок 7.1 – Диаграмма переходов m-серверной системы с потерями
Для пуассоновского потока интенсивность поступления требований λ
постоянна. Если система находится в состоянии Sk и поступает требование, то
система переходит с одинаковой интенсивностью λ в состояние Sk+1 при любом
k. При окончании обслуживания требования интенсивность, с которой система
переходит из состояния Sk в состояние Sk-1, зависит от количества занятых
серверов или текущего состояния системы. Если, например, система находится
в состоянии S1, то по окончании обслуживания требования, занимающего один
сервер, система переходит в состояние S0 с интенсивностью µ. Если система в
состоянии S2, то она может перейти в состояние S1 с интенсивностью уже 2µ,
поскольку может закончиться обслуживание любого из двух требований,
занимающих два сервера системы, и т.д. Если обслуживанием заняты k
серверов, то поток освобождения серверов, переводящих систему из состояний
Sk в Sk-1, будет в k раз интенсивнее.
Стационарное распределение вероятностей состояний системы Pk для
однородной дискретной цепи Маркова определяется системой линейных
алгебраических уравнений:
Pk =
∑
i
33
Pi pi , k ,
(7.2)
где pi,k – вероятность перехода системы из состояния i в состояние k [5]. При
m
этом распределение (7.2) должно удовлетворять условию нормировки ∑ Pk = 1.
k= 0
Сумма в (7.2) вычисляется для всех возможных вариантов состояний i, из
которых можно перейти в состояние k. В случае ординарного потока в это
состояние можно перейти только из состояний k – 1, k и k + 1. Поэтому, за счет
уменьшения количества возможных вероятностей pi,k система уравнений (7.2)
сократится:
Pk = Pk − 1 pk − 1, k + Pk pk , k + Pk + 1 pk + 1, k .
(7.3)
Переход из состояния k – 1 в состояние k возможен в случае поступления
требования, вероятность чего пропорциональна параметру λ, а переход из k + 1
в состояние k возможен в случае окончания обслуживания требования,
вероятность чего при экспонентном распределении продолжительности
обслуживания х пропорциональна параметру µ. Поэтому, вероятность pk-1,k = λ,
а вероятность pk+1,k = µ(k + 1) (см. рис. 7.1).
Вероятность перехода системы из состояния k в состояние k очевидна –
система не может перейти из состояния k ни в состояние k – 1, ни в состояние
k + 1, так как её состояние неизменно:
p k ,k = 1 − p k , k − 1 − p k ,k + 1 = 1 − µ k − λ .
(7.4)
Итак, из (7.3) с учетом (7.4) в итоге имеем
Pk = λ Pk − 1 + Pk [1 − µ k − λ ] + µ (k + 1) Pk + 1 .
(7.5)
После раскрытия скобок и объединения последовательно получаем:
Pk = λ Pk − 1 + Pk − µ kPk − λ Pk + µ (k + 1) Pk + 1 ,
0 = λ Pk − 1 − (λ + µ k ) Pk + µ (k + 1) Pk + 1 ,
а после переноса:
(λ + µ k ) Pk = λ Pk − 1 + µ (k + 1) Pk + 1 .
(7.6)
Система уравнений (7.6) описывает стационарный режим в цепи Маркова
и является математической моделью процесса обслуживания требований
потока. В этом режиме выполняется закон сохранения интенсивности
вероятностей – интенсивность потока вероятностей в состояние k равна
интенсивности потока из этого состояния в состояния k – 1 или k + 1. Поэтому
(7.6) является уравнением равновесия или баланса.
Решение уравнения баланса начнем со значения k = 0, при котором из
(7.6) получаем
λ P0 = λ P− 1 + µ P1 .
Вероятность P–1 ≡ 0 как вероятность несуществующего состояния и
потому λ P0 = µ P1 , откуда следует, что:
λ
P1 = P0 .
µ
При k = 1 из (7.6) получаем (λ + µ ) P1 = λ P0 + 2µ P2 и потому
34
2
λ 1
λ
λ λ
P2 =
P1 =
P0 =
P0 .
2µ
2µ µ
µ
2
⋅
1
При k = 2 из (7.6) получаем (λ + 2µ ) P2 = λ P1 + 3µ P3 и потому
λ
λ
λ λ λ
P3 =
P2 =
P0 =
3µ
3µ 2µ µ
µ
3
1
P0 .
3⋅ 2 ⋅ 1
Без продолжения из приведенных расчетов (индукции) видно, что
λ
Pk =
Pk − 1 ,
µk
(7.7)
и
k
λ 1
(k = 1, 2, … m)...
(7.8)
Pk =
P0
µ k!
С учетом условия нормировки, внесенного в стационарное распределение
вероятностей состояний системы (7.2), вероятность P0 определится так:
−1
m λ i 1
(7.9)
P0 = ∑ .
µ
i
!
i = 0
Распределение (7.8) является искомым стационарным распределением
вероятностей состояний полнодоступной системы с потерями, обслуживающей
пуассоновский поток требований. Данная задача впервые решена
А.К. Эрлангом
в предположении об экспонентном распределении
продолжительности обслуживания, но со временем доказано, что (7.8) верно
для любого произвольного закона, то есть и для модели M/G/m.
Относительная простота решения данной задачи поясняется следующим.
Здесь исследуется стационарный режим системы, которая достигается системой
на бесконечном отрезке времени, когда система обслуживания работает в
состоянии статистического равновесия. Для того чтобы полученные
вероятности состояний системы (количества занятых серверов) не зависели от
того, в каком состоянии система была в начальный момент, данный процесс
должен быть эргодическим. В соответствии с теоремой Маркова любой
транзитивный (из любого состояния можно перейти в любое другое)
однородный (вероятности перехода из состояния в состояние не зависят от того,
в какой момент времени начало перехода) процесс с конечным количеством
состояний имеет эргодическое свойство [6, с. 149]. Для любого марковского
процесса, имеющего эргодическое свойство, после довольно продолжительного
времени функционирования системы обязательно наступит стационарный
режим, где вероятность того, что система будет в k-м состоянии, не зависит от
того, в каком состоянии она находилась в начальный момент времени.
Соответственно указанному в эргодической теореме [7] достаточному
критерию эргодичности марковского процесса, процесс будет эргодическим,
если выполняется условие:
35
λ
< m.
(7.10)
µ
Это означает, что в среднем должно поступать меньше требований, чем
их можно обслужить, или среднее количество требований за единицу времени
обслуживания не должно превышать количества серверов.
С учетом (5.3) и (7.1) выясняется, что параметром стационарного
распределения вероятностей состояний системы (7.8) и (7.9) есть
интенсивность входной нагрузки Λ, и, таким образом, можно записать:
Λk
Pk = mk! i
(k = 1, 2, … m)...
(7.11)
Λ
∑i= 0
i!
Распределение (7.11) называется первым распределением Эрланга, по
которому можно рассчитать вероятность занятости k серверов полнодоступной
m-серверной системы с потерями при обслуживании пуассоновского потока
требований.
Для состояния k = m из (7.11) получаем B-формулу Эрланга,
обозначаемую как Em(Λ), и по которой можно рассчитать основную
характеристику качества обслуживания потока требований – вероятность
потери требования PВ (6.1). Для упрощения вычислений значения Em(Λ)
приводятся в таблицах Эрланга.
Фактически при k = m из (7.11) получаем значение вероятности занятия
всех серверов системы или вероятности потерь по времени (см. гл. 6).
Очередное требование, поступающее в систему, будет утрачено
(заблокировано) в том случае, когда все серверы заняты. Но только при условии
пуассоновского потока значение вероятности занятия всех серверов системы
совпадает с вероятностью потери требования независимо от того, поступает в
этот момент требование или нет. Из-за свойства отсутствия последействия
интенсивность поступления требований не зависит от состояния системы.
Для односерверной системы M/G/1 из (7.11) при условии m = 1 можно
рассчитать:
– вероятность того, что сервер свободный P0:
1
P0 =
;
1+ Λ
– вероятность того, что сервер занятый P1:
Λ
P1 = 1 − P0 = PB = Em (Λ ) = Y = N =
;
1+ Λ
Как видим, вероятность P1 совпадает с вероятностью потери требования
PB и с интенсивностью обслуженной нагрузки Y, а также со средним
количеством требований в системе N .
36
7.2 Система с неограниченной очередью M/M/m/∞
Полнодоступная СРИ с m серверами и неограниченным количеством мест
ожидания в очереди обслуживает пуассоновский поток требований с
дисциплиной обслуживания очереди FIFO. Интервал времени между
требованиями и продолжительность их обслуживания имеют экспонентные
законы распределения. Параметр потока требований λ, а среднее значение
длительности обслуживания – x . Определить стационарное распределение
вероятностей состояний системы Pk (k = 0 … ∞) и характеристики QoS.
Дискретные состояния системы Sk изменяются при каждом событии
поступления требования или окончании его обслуживания. Цепь Маркова с
конечным количеством состояний дана в виде диаграммы переходов (рис. 7.2).
…
λ
λ
… λ
λ
S0
λ
S1
µ
S2
2µ
S
Sm m
3µ
…
mµ
λ
Sm+ 1
mµ
mµ
…
Рисунок 7.2 – Диаграмма переходов m-серверной системы с очередью
Параметр потока освобождения серверов системы µ рассчитывается по
формуле (7.1). Интенсивность потока освобождения для состояний системы
k = 0 … m зависит от k и определяется аналогично ее определению на
диаграмме переходов рис. 7.1 – она есть переменной и равна kµ. Для состояний
системы k = m … ∞ эта интенсивность неизменная и равна mµ, поскольку при
этом уже есть очередь и изменение её состояния зависит от освобождения
любого из всех m серверов.
Поэтому, определение стационарных вероятностей состояний системы Pk
состоит из двух частей:
− для состояний системы k = 0 … m – количество занятых серверов или
требований, которые обслуживаются;
− для состояний системы k = m … ∞ – количество занятых мест
ожидания очереди, или требований, которые ожидают.
Распределение количества занятых серверов определяется по алгоритму
формул (7.2) – (7.8) и для состояний k = 0 … m имеем:
k
λ 1
(k = 1, 2, … m)...
(7.12)
Pk =
P0
µ k!
Для состояний k = m … ∞ уравнения баланса системы подобно (7.6), но
при неизменной интенсивности потока освобождения серверов mµ имеем:
(λ + mµ ) Pk = λ Pk − 1 + mµ Pk + 1 .
(7.13)
Отсюда, если для состояний k = 0 … m аналогично формуле (7.7)
1λ
Pk =
Pk − 1 ,
(7.14)
kµ
то для состояний k = m … ∞
37
1 λ
Pk − 1 ...
(7.15)
mµ
Результат решения уравнения (7.15) очевидный. Путем последовательной
подстановки в (7.15) значений k = m + 1; k = m + 2; k = m + 3 и т.д. проверяем:
k− m
λ
λ
Pk = m+ 1 =
P =
Pm ;
mµ m mµ
Pk =
Pk = m+ 2
λ
λ λ
λ
=
Pm+ 1 =
Pm =
mµ
mµ mµ
mµ
k− m
Pm ;
k− m
λ
λ λ
λ λ λ
λ
Pk = m+ 3 =
Pm+ 2 =
Pm+ 1 =
Pm =
mµ
mµ mµ
mµ mµ mµ
mµ
а это (индукция) подтверждает, что для любого k = m … ∞ верно
λ
Pk =
mµ
Поскольку из (7.12) для Pm имеем:
k− m
Pm ,
Pm .
(7.16)
m
λ 1
Pm =
P0 ,
µ
m
!
то в итоге из (7.16) и (7.17) для состояний k = m … ∞ получается, что
(7.17)
m
k− m
λ 1
λ
(7.18)
Pk =
P0 , (k = m … ∞)...
µ
m
!
mµ
Формулы (7.12) и (7.18) определяют стационарное распределение вероятностей состояний системы Pk для всех возможных значений k или состояний
серверов и мест ожидания очереди. Вероятность P0 для этого случая находим из
∞
условия нормировки ∑ Pk = 1 , откуда подстановкой всех значений Pk из (7.12) и
k= 0
(7.18) получаем (слагаемые, не зависящие от k, вынесены за знак 2-й суммы):
m − 1 λ k 1 λ m 1 ∞ λ k − m
= 1.
P0 ∑
+
(7.19)
∑
µ
k
!
µ
m
!
m
µ
k = 0
k = m
Вторая сумма от k = m до ∞ существует только при условии (λ / mµ) < 1
(сходимость ряда по признакам Даламбера) и потому она рассчитывается по
формуле суммы членов бесконечно убывающей геометрической прогрессии:
∞
λ
∑ mµ
k= m
k− m
k
∞
λ
1
mµ
= ∑
=
=
λ
mµ − λ .
k = 0 mµ
1−
mµ
Подставив это выражение в (7.19) получаем:
m − 1 λ k 1
P0 = ∑
+
µ
k
!
k = 0
38
λ
µ
m
1 mµ
m! mµ − λ
(7.20)
−1
.
(7.21)
Использованное в (7.19) условие сходимости ряда (λ / mµ) < 1 совпадает с
(7.10), которое есть условием эргодичности процесса. Это в свою очередь не
позволяет бесконечно возрастать очереди, что есть залогом нормального
функционирования всей системы.
Поскольку Λ = λ / µ (и поэтому из (7.10) обязательно Λ < m), то уравнения
(7.12), (7.18) и (7.21), окончательно определяющие стационарное распределение
вероятностей состояний Pk, можно записать в одной системе уравнений так:
k
P = Λ P
ïðè k = 1 ... m
k k! 0
k− m m
Λ
Λ
P0
ïðè k = m ... ∞
Pk = m
m
!
−1
m− 1 k
m
Λ
Λ
m
P =
+
0 k∑= 0 k! m! m − Λ
(7.22)
(7.23)
(7.24)
Это есть второе распределение Эрланга, по которому можно рассчитать
вероятность состояний (занятости серверов и мест ожидания в очереди)
полнодоступной системы с неограниченной очередью при обслуживании
пуассоновского потока требований.
Основной характеристикой качества обслуживания этой системы есть
вероятность ожидания Pw>0 (W > 0 означает, что время ожидания есть),
которую можно определить из функции распределения состояний системы Pk. В
условиях пуассоновского потока Pw>0 равна вероятности занятости всех m
серверов системы с учетом всех возможных состояний очереди (m серверов
заняты и 0 требований в очереди, m серверов заняты и 1 требование в очереди,
2 требования в очереди и т.д., а потому не путать с состоянием Pm):
Pw > 0 =
∞
∑
Pk ,
(7.25)
k= m
где k – состояние системы (0 < k ≤ m – серверы, m < k ≤ ∞ – очередь).
Подстановкой (7.23) в (7.25) с учетом свойства (7.20) получим:
k− m
∞
Λm
Λm m
Λ
(7.26)
Pw > 0 = ∑ Pk =
P0 ∑
=
P0 .
m
!
m
m
!
m
−
Λ
k= m
k= m
Подстановка (7.24) в (7.26) дает
Λm m
! m− Λ
Pw > 0 = m − 1 m
.
(7.27)
k
Λ
Λm m
∑ k! + m! m − Λ
k= 0
Формула (7.27) называется C-формулой Эрланга и обозначается Сm(Λ).
Для системы M/M/m/∞ по ней можно рассчитать вероятность ожидания Pw>0
(6.2). Данную формулу можно переписать так:
∞
39
Pw > 0
Λm m
m! m − Λ
= Cm (Λ ) = m
=
k
m
m
Λ
Λ
Λ
m
∑ k! − m! + m! m − Λ
k= 0
m
Поделив числитель и знаменатель на
∑
k= 0
Λ
Λm m
m! m − Λ
.
m k
Λ
Λm m
∑ k! + m! m − Λ − 1
k= 0
k
k!
(см. 7.11) получаем:
m
E m (Λ ) m
m− Λ
C m (Λ ) =
=
.
m
m − Λ [1 − Em (Λ )]
1 + Em (Λ )
− 1
m− Λ
Em (Λ )
Данная формула устанавливает взаимосвязь между B– и C-формулами
Эрланга, а это позволяет рассчитывать значение вероятности Сm(Λ) по
значениям Em(Λ) формулы (7.11), приведенные в соответствующих таблицах.
Очевидно, что при одинаковых условиях всегда вероятность Сm(Λ) > Em(Λ).
Если обозначим
ρ =
Λ
,
m
(7.28)
где ρ – интенсивность удельной нагрузки (нагрузка на один сервер), то эту
формулу можно записать так:
C m (Λ ) =
1
1− ρ
+ ρ .
Em (Λ )
(7.29)
Средняя длина очереди Q (среднее количество требований в очереди)
может быть найдена из распределения вероятностей состояний системы Pk при
k = m+1, m+2, … , ∞ (в очереди 1, 2 и т.д. требований) по правилу вычисления
математического ожидания:
Q=
∞
∑
( k − m) Pk .
k = m+ 1
Подставив из (7.23) вероятности состояний очереди Pk имеем (слагаемые,
которые не зависят от k вынесен за знак суммы):
∞
Λm
Λ
Q=
P0 ∑ (k − m)
m! k = m + 1
m
40
k− m
.
∞
x
i= 0
(1− x ) 2
i
Известно, что ∑ ix =
, а потому
Λ
Λ
m
Q=
P0
(7.30)
2 .
m!
Λ
1−
m
Из (7.17) и (7.26) следует, что вероятность состояния Pm определится как
m
Λ
Pm = 1 − Pw > 0 .
m
(7.31)
−1
Λm
, которая получена
Подставив в (7.30) вместо вероятности P0 = Pm
m!
из формулы (7.17), а вместо Pm ее значения из (7.31), после сокращений имеем:
Q=
Λ
Pw > 0 .
m− Λ
(7.32)
Среднюю продолжительность ожидания для любого требования W
получим из формулы Литтла – за W единиц времени ожидания в очередь
поступит в среднем Q = ΛW требований, а поэтому с учетом (7.32)
W=
Q
1
=
Pw > 0 .
Λ m− Λ
(7.33)
Среднюю продолжительность ожидания для задержанных требований tq
получим из толкования величины Q, как интенсивности нагрузки, которая
создается требованиями, ожидающими в очереди. Величина ΛPw>0 – это
интенсивность потока требований из очереди, где каждое требование в среднем
ожидает время tq. Итак, Q = ΛPw>0 tq, откуда с учетом (7.32)
tq =
Q
1
=
.
Λ Pw > 0 m − Λ
(7.34)
Значения W и tq представлены в единицах средней продолжительности
обслуживания. Такой нормированный вид показывает, во сколько раз эти
значения возрастают или убывают по сравнению со средним временем
обслуживания x . Из (7.33) и (7.34) получается очевидное соотношение: W ≤ tq.
Таким образом, все основные характеристики QoS найдены. Среднее
количество требований в системе N (суммарно тех, что обслуживаются и тех,
что ожидают обслуживания) определяется по формуле (6.3), а среднее время
пребывания требования в системе T (состоит из среднего времени
обслуживания и среднего времени ожидания) – по формуле (6.4).
При проектировании систем распределения информации часто
необходимо знать отдельные значения функции распределения времени
ожидания требований в системе. Функция распределения времени ожидания в
41
системе Pw>t – это вероятность того, что требование, поступающее в систему в
любом из ее состояний, будет ожидать время свыше t. Для расчета этой
вероятности используем условную вероятность Pk(w>t), которая толкуется как и
предыдущая, но при условии поступления требования в состоянии системы
k = m…∞... Поскольку ожидание возможно только в случае, когда заняты все m
серверов системы, то по формуле полной вероятности получим:
∞
∑
Pw > t =
Pk Pk ( w > t ) .
k= m
(7.35)
Требование, что ждет в очереди последним, начнет обслуживаться только
при условии, если за время его ожидания t закончится обслуживание k – m + 1
требований (k – m есть длина очереди). Таким образом, время ожидания будет
больше t, если за это время из очереди выйдет не больше k – m предыдущих
требований. Итак, вероятность того, что требование, которое поступает в
систему в состоянии k, будет ожидать время свыше t равна вероятности того,
что за это же время освободится не больше i = k – m серверов.
При экспонентном распределении продолжительности обслуживания
поток освобождений серверов системы является пуассоновским с параметром
mμ (рис. 7.2). Вероятность того, что за время t освободится точно i серверов
рассчитывается по формуле Пуассона (4.5), а вероятность того, что освободится
не больше k – m серверов равна сумме:
Pk ( w > t ) =
k− m
∑
j= 0
(mµ t ) j − mµ t
e
.
j!
Подставив это выражение и (7.23) в формулу (7.35) и последовательно
сокращая [2, с. 110] получим:
Pw > t
∞
k− m
(mµ t ) j − mµ t
= ∑ Pk ∑
e
= Pw > 0 e − ( mµ − Λ )t .
j!
k= m
j= 0
Из этого по правилу определения математического ожидания рассчитаем
среднюю продолжительность ожидания в системе W:
W=
∞
∫ Pw > t dt =
0
∞
Pw > 0 ∫ e − ( mµ − Λ )t =
0
Pw > 0
,
mµ − Λ
что при условии μ = 1 (означает, что W измеряется в единицах средней
продолжительности обслуживания x = 1 / µ ) дает аналогичный (7.33) результат.
В системах распределения информации не всегда требования из очереди
поступают на обслуживание в порядке поступления. Есть немало случаев, когда
выбор из очереди случайный. Хотя дисциплина выбора из очереди не влияет на
среднее время ожидания W, но случайный выбор из очереди увеличивает
дисперсию времени ожидания сравнительно с выбором в порядке поступления.
42
7.3 Система с ограниченной очередью M/M/m/r
Полнодоступная СРИ с m серверами и ограниченным количеством мест
ожидания в очереди r обслуживает пуассоновский поток требований с дисциплиной обслуживания очереди FIFO. Интервал времени между требованиями и
длительность их обслуживания распределены экспонентно. Интенсивность
входной нагрузки Λ. Необходимо определить стационарное распределение
вероятностей состояний системы Pk (k = 0…m+r) и характеристики QoS.
При ограниченной очереди, где количество мест ожидания r < ∞, имеем
комбинированную систему M/M/m/r – с очередью и потерями. Если в момент
поступления требования в системе есть хотя бы один свободный сервер, то оно
сразу начинает обслуживаться. Если все серверы системы заняты, то
требование становится в очередь при условии, что в ней ожидает меньше, чем r
требований (есть места для ожидания). Если же в очереди есть уже r ранее
поступивших требований, то текущее требование теряется. Итак, требованию
отказывается в обслуживании, если в системе уже есть l = m + r требований. Из
этих l требований m обслуживаются, а r ожидают в очереди.
Очевидно, если r = 0, то система описывается моделью M/M/m и задача
решается с помощью первого распределения Эрланга (7.11). Если r = ∞, то
система описывается моделью M/M/m/∞ и задача сводится к предыдущей.
Для комбинированной системы M/M/m/r, частично аналогичной системе
M/M/m/∞, уравнения (7.22) и (7.23) определяют стационарное распределение
вероятностей состояний системы Pk для k = 1 … m и k = m … l соответственно.
l
Поэтому вероятность P0 определяется из условия нормирования ∑ Pk = 1 ,
k= 0
откуда подстановкой всех значений Pk формул (7.22) и (7.23) получаем:
m− 1 Λ k Λ m l Λ k − m
P0 ∑
+
= 1.
(7.36)
∑
k
!
m
!
m
k= m
k = 0
Поскольку сумма от k = m до l может быть рассчитана по формуле суммы
r = l – m членов геометрической прогрессии со знаменателем Λ / m, то
−1
r+ 1
Λ
m− 1 k
m 1−
Λ
Λ
m
.
P0 = ∑
+
(7.37)
Λ
k = 0 k! m!
1−
m
Вероятность полной занятости системы PЗН (ожидания или потери требования) в этом случае определяется аналогично (7.26), но сумма будет не до ∞, а
только до l. Заменив эту сумму подобно, как в формулах (7.36) и (7.37), имеем:
r+ 1
l
Λm
Λ
Pçí = ∑ Pk =
P0 ∑
m! k = m m
k= m
l
k− m
Подстановка P0 из (7.37) в (7.38) дает
43
Λ
1−
m
Λ
m
=
P0
Λ
m!
1−
m
.
(7.38)
r+ 1
Λ
1−
m
Λ
m
m!
Λ
1−
m
Pçí =
r+ 1 .
Λ
m− 1 k
m 1−
Λ
Λ
m
∑ k! + m!
Λ
k= 0
1−
m
1
Учитывая, что
1−
Λ
m
Pçí =
=
m
m − Λ , данную формулу можно переписать так:
Λm m
m! m − Λ
m− 1 k
1 −
Λ
Λm m
+
∑
m! m − Λ
k = 0 k!
Λ
m
r + 1
1 −
Λ
m
r + 1
.
(7.39)
Очевидно, если r = ∞, то формула (7.37) совпадает с (7.24), а формула
(7.39) – с C-формулой Эрланга (7.27). Если r = 0, то (7.37) совпадает с (7.9), а
формула (7.39) – с B-формулой Эрланга (7.11). Из этого явствует, что при
изменении длины очереди от ∞ до 0 величина вероятности PЗН модели M/M/m/r
находится в диапазоне значений, полученных по формулам (7.27) и (7.11) для
моделей M/M/m/∞ и M/M/m/0 соответственно. Таким образом, (7.39) есть
обобщающее решение для полнодоступных систем с потерями, с
неограниченной и ограниченной очередями при условии обслуживания
пуассоновского потока требований и экспонентной продолжительности их
обслуживания.
Формулу (7.39) можно упростить таким же способом, как это получено в
(7.29) с учетом (7.28)
Pçí =
1− ρ r+ 1
1− ρ
.
+ ρ − ρ r+ 1
Em (Λ )
(7.40)
В системе с ограниченной до r очередью событие потери требования
состоится в том случае, когда при поступлении требования в очереди уже есть r
требований, которые поступили раньше. Ведь вероятность потери требования
PB равна вероятности того, что в системе уже есть l = m + r требований (потому
r = l – m ) или система в состоянии Pl. Для пуассоновского потока вероятность
PB = Pl при любом законе длительности обслуживания.
44
Поэтому, в соответствии с (7.23) и (7.37) получим:
r
m
Λ Λ
m m!
l− m m
Λ
Λ
PB = Pl =
P0 =
m!
m
Λ
+
∑ k!
k= 0
m− 1 k
r+ 1
Λ
m 1−
Λ
m
m! 1 − Λ
m
.
(7.41)
Вероятность ожидания при ограниченной до r очереди Pw>0(r) или долю
ожидающих требований рассчитаем так: Pw>0(r) = PЗН – PB. Подставив сюда
(7.39) и (7.41) соответственно имеем
r
Λm m Λ
1 −
m! m − Λ m
Pw > 0 ( r ) =
.
r + 1
m− 1 k
m
Λ
Λ
m
Λ
∑ k! + m! m − Λ 1 − m
k= 0
(7.42)
Эту вероятность можно рассчитать аналогично формуле (7.38), но с
верхней границей суммирования l – 1, что дает аналогичный результат:
k− m
l− 1
l− 1 Λ
Λm
Pw > 0 ( r ) = ∑ Pk =
P0 ∑
m! k = m m
k= m
Λm m
=
m! m − Λ
Λ r
1 − P0 .
m
Формулу (7.41) с учетом (7.38) можно записать так:
r
Λ
Λ
1−
l− m m
Λ
Λ
m
m
PB =
P0 = Pçí r + 1 .
m!
m
Λ
1−
m
Учитывая (7.28), данную формулу можно упростить:
PB = Pçí
ρ r (1 − ρ )
1− ρ r+ 1
.
(7.43)
Подставив в (7.43) формулу (7.40) имеем
PB =
ρr
1
ρ − ρ r+ 1 .
+
Em (Λ )
1− ρ
Формулу (7.42) можно переписать не как разность (7.39) и (7.41), а как
разность (7.40) и (7.43), что дает
45
1− ρ r
Pw > 0 (r ) =
1− ρ
.
+ ρ − ρ r+ 1
Em (Λ )
Из (7.43) и учетом (7.16), где k = l и r = l – m, следует, что
Pçí = Pl
1− ρ r+ 1
ρ r (1 − ρ )
= Pm
1− ρ r+ 1
.
1− ρ
Для односерверной системы M/M/1/r из (7.37), (7.39), (7.42) и (7.43)
можно рассчитать:
– вероятность P0 (сервер и места в очереди свободные) из (7.37) –
1− ρ r+ 1
P0 = 1 + ρ
1 − ρ
−1
=
1− ρ
1− ρ r+ 2
;
– вероятность Pзн из (7.39) или Pзн = 1 – P0, что дает
Pçí =
ρ (1 − ρ r + 1 )
;
1− ρ r+ 2
– вероятность Pw>0(r) из (7.42) и подстановкой (7.28) дает
Pw > 0 ( r ) =
ρ (1 − ρ r )
1− ρ r+ 2
;
– вероятность PB из (7.43) и подстановкой выше найденного Pзн дает
PB =
ρ
r+ 1
(1 − ρ )
1− ρ
r+ 2
.
Из (7.18) следует, что в системе M/M/1/r состояния системы имеют
распределение
k
Pk = ρ P0 =
В системе M/M/1/∞ из этой
распределение состояний системы
ρ k (1 − ρ )
1− ρ r + 2
.
формулы
имеем
геометрическое
Pk = ρ k (1 − ρ ) .
Таким образом, все характеристики качества обслуживания системы
M/M/m/r найдены.
46
7.4 Система с неограниченной очередью M/D/m/∞
В ТКС, основанных на технологии коммутации пакетов, применяется
дисциплина обслуживания с очередью. Есть системы, где время обслуживания
постоянно, например, процесс обслуживания требований управляющими
устройствами узлов коммутации или пакетов одинаковой длины. В модели
M/M/m/∞ с экспонентным временем обслуживания требований вероятность
ожидания рассчитана по C-формуле Эрланга (7.27). Для модели M/D/m/∞ с
дисциплиной очереди FІFO есть решение К.Д. Кроммелина [3], на базе уравнений состояний Фрая. Решение системы уравнений методом производных функций так сложно, что для инженерных расчетов вместо точных аналитических
формул применяются соответствующие диаграммы (кривые Кроммелина).
В [8] предложен более простой метод расчета модели M/D/m/∞, в котором
используется C-формула Эрланга.
Необходимо найти все характеристики качества обслуживания QoS:
– среднюю продолжительность ожидания требований в системе W;
– среднюю длину очереди Q;
– среднее количество требований в системе N;
– вероятность ожидания Pw>0 ;
– среднюю продолжительность ожидания требований в очереди tq.
Характеристики качества обслуживания модели M/M/m/∞ между собой
функционально зависимы. Средняя длительность ожидания для любого
требования W (которое ожидает и не ожидает) есть средним значением времени
ожидания, отнесенным ко всем требованиям. Если же известна средняя
длительность ожидания только задержанных требований tq, то для определения
W необходимо умножить эту длительность на вероятность Pw> 0, показывающую
среднюю долю задержанных требований. Поэтому, из (7.34) и (7.33) получаем
W = t q Pw > 0 .
(7.44)
По формуле Литтла за W единиц времени ожидания в очередь поступит
ΛW требований и поэтому
Q= ΛW .
(7.45)
Из этих соотношений характеристик QoS следует, что для анализа модели
M/M/m/∞ с экспонентным (М) распределением длительности обслуживания
надо рассчитать лишь среднюю длительность ожидания требований в очереди
tq (7.34) и вероятность ожидания Pw> 0 (7.27), так как среднюю длительность
ожидания требований W(M) найдем из (7.33).
Для расчета вероятности Pw> 0 в модели M/D/m/∞ с постоянной
длительностью обслуживания данный в п. 7.2 алгоритм определения состояний
статистического равновесия системы применять нельзя. Теперь вероятность
окончания обслуживания требования (при экспонентном распределении x
пропорциональна mμ) определяется не количеством занятых серверов m
(рис. 7.2), а моментами начала обслуживания, и потому будет зависеть от
размещения исследуемого интервала на оси времени – процесс не будет
эргодическим (см. п. 7.1).
47
Если теоретическое решение очень сложное, то нередко достаточно
получить приближенное выражение, на котором может строиться весь метод
расчета. Признанным методом аналитических приближений есть имитационное
моделирование, позволяющее эффективно проверять качество используемых
предположений. По результатам имитационного моделирования с применением
алгоритма [9] установлено, что время ожидания W при постоянной (D) и
экспонентной (M) длительности обслуживания в таком соотношении:
2
2
1
m
m
(7.46)
W( D ) = W( M ) 2
2
= Cm (Λ )
.
m
+
Λ
m
−
Λ
m
+
Λ
Формула (7.46) определяет, что для многоканальной системы при m = Λ
средняя длительность ожидания при постоянной и экспонентной длительности
обслуживания отличаются в 2 раза, что соответствует такому же соотношению,
установленному формулой Поллачека-Хинчина для односерверной системы. С
возрастанием емкости системы m это соотношение спадает и имитационное
моделирование свидетельствует, что в широком диапазоне изменения m и Λ
точность оценки средней длительности ожидания (7.46) не хуже ±10 %.
Вероятность ожидания Pw>0 находим из функции распределения
состояний системы Pk и здесь вероятность Pw>0 равна вероятности того, что при
поступления требования оно застает все m серверов занятыми (7.25). Это
можно записать так:
Pw > 0
∞
=
∑
Pk = 1 −
k= m
m− 1
∑
k= 0
Pk .
(7.47)
В условиях неограниченного количества серверов (m = ∞) требования
обслуживаются без потерь. При постоянной продолжительности обслуживания,
когда нет потерь, свойства потока освобождений совпадают со свойствами
потока поступления требований, так как происходит только сдвиг во времени
на величину x между моментом поступления требования и моментом
окончания его обслуживания. При этом состояние системы полностью
определяется свойствами потока требований, а функции распределения
количества требований в системе Pk и количества требований Pі, поступивших
за время x , полностью совпадают с распределением Пуассона
Λi − Λ .
(7.48)
Pk = Pi =
⋅e
i!
При конечном m и бесконечном количестве мест ожидания требования
также обслуживаются без явных потерь. Однако, сейчас требования, поступающие после занятия всех серверов системы, попадают в очередь на ожидание, и в
случае освобождения хотя бы одного из m занятых серверов подаются из
очереди на обслуживание. Теперь на серверы системы поступают требования
из основного потока с интенсивностью Λ и из очереди с интенсивностью ΛW.
Таким образом, с учетом (7.45) суммарная интенсивность нагрузки на
серверы системы увеличивается до величины
Λ∑ = Λ + Q.
(7.49)
48
Интенсивность нагрузки Λ∑ равна среднему количеству требований в
системе N (6.3).
Из приведенных доводов получаем простой метод расчета характеристик
качества обслуживания системы M/D/m/∞, состоящий из шести шагов:
1. По (7.29) при заданных Λ и m рассчитывается Сm(Λ) для модели
M/M/m/∞.
2. По (7.46) для заданных Λ и m определяется W(D) (аппроксимация).
3. По (7.45) для Λ и рассчитанного значения W(D) определяется Q.
4. По (7.49) рассчитывается суммарная интенсивность нагрузки Λ∑ .
5. По (7.47) и (7.48) для Λ∑ рассчитывается вероятность ожидания Pw>0.
6. По рассчитанными W(D) и Pw >0 из формулы (7.44) определяется tq.
Следует отметить, что при m близких к Λ, т.е. в диапазоне емкостей
системы Λ < m ≤ ( Λ + Λ / 2 ), дополнительный поток требований из очереди
сильно увеличивает не только суммарную интенсивность нагрузки Λ∑, но и ее
суммарную дисперсию σ Σ2 , которая для пуассоновского потока равна Λ .
Поэтому, в данном диапазоне емкостей системы для повышения точности
расчета Pw>0 и tq надо на шаге 5 вместо распределения Пуассона (7.48)
использовать распределение нормального закона (Гаусса) с подстановкой (7.49)
Λ∑ и σ Σ2 = Λ + Q / 2 . Для исключения бесконечной очереди обязательно m > Λ.
Оценка степени точности предложенного метода расчета характеристик
QoS модели M/D/m/∞ проверена имитационным моделированием, результаты
которого [9] подтвердили, что в широком диапазоне изменения m и Λ
относительная ошибка расчета всех характеристик QoS не превышает ±10 %.
Результатами имитационного моделирования с такой же точностью
оценки определено и соотношения вероятностей ожидания при экспонентной и
постоянной продолжительности обслуживания в моделях M/M/m/∞ и M/D/m/∞:
1
Pw > 0 ≈ Cm (Λ ) ⋅
1
(7.50)
m ,
0
2⋅ 2
m+ Λ
где Pw > 0 – вероятность ожидания при постоянной, а Сm(Λ) – при экспонентной
продолжительности обслуживания.
Из (7.44) следует, что вероятность ожидания при любых условиях – это
соотношение средних длительностей ожидания в системе W и очереди tq.
Поэтому из (7.46) и (7.50) имеем среднюю продолжительность ожидания
требований в очереди tq(D) при постоянной длительности обслуживания:
2
1
m
Cm (Λ ) ⋅
⋅ 21
3
W( D )
1
m
m− Λ
m+ Λ
2
tq( D) =
=
=
2
. (7.51)
−1
Pw > 0
m
−
Λ
m
+
Λ
m
Cm (Λ ) ⋅ 2 − 1
m+ Λ
Анализируя формулы (7.46), (7.50) и (7.51) замечаем, что одноименные
характеристики QoS в моделях M/M/m/∞ и M/D/m/∞ при экспонентной и
49
постоянной продолжительности обслуживания связаны между собой такой
аппроксимирующей функцией:
k
k − 1
m
(7.52)
F (k ) = 2
,
m
+
Λ
где k = 1, 2 и 3 для характеристик Pw > 0, W(D) и tq(D) соответственно.
Итак, путем применения аппроксимирующей функции (7.52) могут быть
рассчитаны основные характеристики качества обслуживания в модели
M/D/m/∞ через C-формулу Эрланга, справедливую для модели M/M/m/∞:
C (Λ )
Pw > 0 = m
,
2 ⋅ F (k )
W( D ) =
t q( D) =
Cm (Λ )
m− Λ
⋅ F (k + 1) ,
(7.53)
1
F ( k + 2)
m− Λ
где k = 1 для всех приведенных характеристик.
Имитационным моделированием установлено, что при замене в (7.53)
коэффициента k = 1 на k = 0,01Λ (может быть не целым) точность оценки
основных характеристик качества обслуживания повышается до ±5 %.
Кроммелином рассмотрена система с очередью, в которой обслуживание
ожидающих требований выполняется в порядке поступления (упорядоченная
очередь). Но есть примеры систем с очередью, в которых обслуживание
ожидающих требований выполняется при случайном выборе их из очереди.
Однолинейная система с постоянной продолжительностью обслуживания
и случайным выбором из очереди ожидающих требований исследована Берком
[3]. Анализ распределения времени ожидания W в однолинейной системе с
постоянной продолжительностью обслуживания при случайном выборе
требований из очереди и выборе требований в порядке поступления
показывает, что для небольших значений продолжительности ожидания (от 0,1
до 3 x ) качество обслуживания требований выше при случайном выборе из
очереди. Для больших значений продолжительности ожидания (> 3 x ) качество
обслуживания требований при случайном выборе из очереди существенно
хуже, чем при обслуживании требований в порядке очереди.
Следует напомнить вывод, сделанный в конце подраздела 7.2, что
дисциплина выбора из очереди (в порядке поступления, случайном порядке или
любой другой дисциплине) не влияет на среднее время ожидания требования
начала обслуживания W, но влияет на дисперсию времени ожидания.
50
7.5 Система с неограниченной очередью M/G/1/∞
Односерверная система (рис. 7.3) с неограниченным количеством мест
ожидания обслуживает пуассоновский поток требований. Длительность обслуживания имеет произвольный закон распределения B(x) с математическим
ожиданием x . Интенсивность потока требований λ. Найти характеристики QoS.
обслуженные требования
поток требований λ
сервер
∞
...
5 4
3 2 1
очередь
FIFO
Рисунок 7.3 – Модель односерверной системы с очередью
В модели распределение длительности обслуживания не экспонентное, а
интервал времени между требованиями имеет экспонентное распределение.
Поэтому данная задача решается методом вложенных цепей Маркова.
Понятие вложенной цепи Маркова сводится к следующему. Пусть (gt) –
случайный процесс с непрерывным временем, приобретающим только целые
числовые значения из некоторого множества G, и существует последовательность t1, t2, ... (тоже случайная) моментов времени такая, что процесс (ξn)
ξ n = gt ,
n = 1, 2, …
(7...54)
n
является однородной марковской цепью с дискретным временем, т.е. для
п = 2 , 3, ... имеет место:
Ψ (ξ n = j | ξ n − 1 = i, ξ n − 2 = in − 2 ,...ξ 1 = i1 ) =
= Ψ (ξ n = j | ξ n − 1 = i ) = Ψ (ξ 2 = j | ξ 1 = i ) ,
(7.55)
где j, и, и1 … G.
Процесс (ξn) есть марковской цепью, вложенной в (gt). Основное
содержание метода вложенных цепей Маркова состоит в том, что для данного
случайного процесса, описывающего поведение рассмотренной модели,
конструируется удобная марковская цепь, исследуемая аналитическими
методами, обычными для цепей Маркова, и полученные результаты (например,
стационарные вероятности состояний) пересчитываются для величин исходной
системы.
Исследуемая модель принимает состояния 0, 1, 2, ..., а gt – количество
требований, находящихся в системе в момент времени t или gt, есть состояние
системы в момент времени t; (gt) – не марковская цепь. Определим
характеристики QoS – средние значения количества требований и времени
ожидания в системе.
Метод вложенных цепей состоит из следующих четырех шагов:
Ш а г 1 . Определим последовательности моментов времени (tn),
0 < t1 < t2 < ... < ∞, что позволяет конструирование вложенной цепи Маркова.
Разумеется, если все распределения экспонентные, то (gt) – однородная
51
марковская цепь и в качестве (tn) можно выбрать любую возрастающую
последовательность моментов времени 0 ≤ tn < ∞. Если не все распределения,
характеризующие поведение элементов системы, экспонентные, то (gt) – не
марковская цепь, и если только одно распределение не экспоненциально, то
состояние системы в момент времени t можно описать с помощью величины ξ*t:
ξ*t = (gt, rt),
(7.56)
*
где ξ t – преобразование Лапласа-Стилтьеса непрерывной функции
распределения ξt, с помощью которого путем дифференцирования можно
определить соответствующие моменты этого распределения.
Для дополнительной переменной rt полагается следующее: rt равно
остаточному временные не экспонентно распределенной величины в момент
времени t, если такой существует (например, остаточное время обслуживания,
остаточное время паузы); rt = 0, если отсутствует такое остаточное время
(например, не обслуживается ни одно требование; нет паузы с неэкспонентным
распределением).
Значения t n находится таким способом. Остаточным временем r t есть
остаточная продолжительность обслуживания. Она будет равна нулю, если
некоторое требование оставляет систему. Поэтому полагается, чтобы t n
равнялось моменту времени, когда n-ое требование покидает систему (момент
выхода).
Сконструированный с помощью дополнительной переменной rt
двумерный стохастический процесс (ξ*t) рассматривается только в
определенных точках t n , то есть в моменты выхода требований из системы,
а потому он есть однородным марковским и распределение этого процесса
можно определить.
Ш а г 2 . Вычислим переходные вероятности для вложенной цепи
Маркова. Пусть ξn – количество требований, которые находятся в системе
непосредственно после момента t n , то есть ξ n = g t n + 0 . При этом (ξn) –
однородная марковская цепь. Пусть рi,j – независимая от п вероятность
перехода системы в момент выхода из нее требования:
pi, j = Ψ (ξ n + 1 = j | ξ n = i ) ,
и, j = 0, 1, 2, ...
Обозначим через k j вероятность того, что за время обслуживания
некоторого требования в систему поступает j новых требований; тогда
pi , j
kj
= k j− i+ 1
0
при j = 0, 1, 2,..., i = 0;
при j > i − 1,
i = 1, 2, ... :
(7.57)
в других случаях.
Поскольку требования поступают по пуассоновскому закону с
интенсивностью λ, то для них вероятность того, что на интервале времени
продолжительностью t поступит точно j требований, равна (4.5), и потому
∞
(λ t ) j − λ t
kj = ∫
e dB(t ), j = 0, 1, ...
j
!
0
Производящая функция K*(z) распределения (kj) по определению:
52
(7.58)
∞
∑
*
K (z) =
k jz j .
(7.59)
j= 0
где z – комплексная переменная. Из (7.59) с учетом (7.58) и в соответствии с
[5, с.205]
(7.60)
K * ( z ) = B * (λ − λ z ) .
Поскольку B(x) есть функцией распределения продолжительности
обслуживания, то полученное из (7.58) уравнение устанавливает взаимосвязь
между образующей функцией K* дискретного распределения случайной
величины kj (количества требований за время обслуживания) и
преобразованием
Лапласа-Стилтьеса
B*
плотности
непрерывного
распределения случайной величины x (продолжительности обслуживания) в
точке (λ – λz). Первая производная образующей функции в точке z = 1 и
преобразования Лапласа-Стилтьеса в точке z = 0 позволяет вычислить первые
моменты рассматриваемой случайной величины. Поэтому из этого для данного
уравнения следует, что
K *' (1) = − λ B*' (0) = λ x = ρ .
(7.61)
В (7.61) последнее уравнение следует из (5.3) и (7.28).
Ш а г 3 . Вычислим стационарное распределение для вложенной цепи
Маркова. Вложенная марковская цепь неприводима, апериодическая и в случае
ρ < 1 – эргодическая (доказано с помощью теоремы Фостера). Поэтому
существует точно одно стационарное начальное распределение (Pj) цепи, где Pj
– вероятность того, что в стационарном состоянии требование, покидающее
систему, после себя оставляет j требований. Поэтому вероятности Pj
удовлетворяют системе уравнений, аналогичной (7.2):
Pj = ∑ Pi pi, j ,
(7.62)
i
т. е.
P0 = k0 ( P0 + P1 ) ;
Pj = P0 k j +
j+ 1
∑
i= 0
j = 1, 2, ...
Pi k j − i + 1 ,
Аналогично (7.59) образующая функция Р*(z) распределения P = (Pj)
P* ( z ) =
∞
∑
j= 0
z j Pj ,
| z |< 1 ,
поэтому имеем:
∞
P* ( z ) = P0 ∑ k j z j +
j= 0
∞
∑
j= 0
z
j
j+ 1
∑
i= 1
*
Pi k j − i + 1 = P0 K ( z ) +
∞
∑
i= 1
Pi z i − 1K * ( z ) .
После сокращений получаем, что
P0 (1 − z ) K * ( z )
K * ( z) *
*
*
P ( z ) = P0 K ( z ) +
( P ( z ) − P0 ) =
.
z
K * ( z) − z
53
(7.63)
В (7.63) входит неизвестная пока что константа Р0. Ее можно определить
с помощью следующих вычислений, типичных при работе с образующими
функциями.
*
*
Поскольку lim P ( z ) = lim K ( z ) = 1 , а
z→ 1
z→ 1
K *(z) − 1 1 − z
K *( z) − z
= K *' (1) + 1 = 1 − ρ ,
= lim
+
z→ 1
z→ 1
1− z
1 − z
1− z
это из (7.63) при z → 1 следует уравнение: 1 = Р0 / (1 – ρ), из чего
P0 = 1 − ρ ,
lim
(7.64)
(1 − ρ )(1 − z ) K * ( z )
(1 − ρ )(1 − z )
*
P ( z) =
=
z
.
(7.65)
K * ( z) − z
1− *
B (λ − λ z )
Формулу (7.65) называют соотношением Поллачека-Хинчина, которое
задает образующую функцию стационарного распределения вложенной
марковской цепи в точках, когда требования оставляют систему М/G/l/∞, как
функцию от преобразования Лапласа-Стилтьса функции распределения
продолжительности обслуживания.
Ш а г 4 . Пересчитаем полученные на шаге 3 результаты в искомые
величины системы: 1. Среднее количество требований в системе 2. Среднее
время ожидания в системе (в том числе и для точек, отличных от tn).
1. Среднее количество требований в системе N.
В рассмотренной модели М/G/l/∞ вероятности того, что в стационарном
состоянии поступающее в систему требование застает в ней j других
требований, равны стационарным вероятностям Рj наличия в системе j
требований непосредственно после окончания обслуживания некоторого
требования, и потому они задаются формулой (7.65). Из-за свойства
пуассоновского потока требований эти вероятности равны стационарным
вероятностям Pj в любой момент времени.
Математическое ожидание (среднее значение) количества требований N,
которые находятся в системе, равно производной от (7.65):
λ 2 µ 2x
N = P *' (1) = ρ +
,
(7.66)
2(1 − ρ )
где
2
x
µ =
∞
∫x
2
0
dB ( x) = x 2 + σ 2x .
(7.67)
Параметры x 2 и σ 2x характеризуют математическое ожидание (среднее
значение) и дисперсию или второй центральный момент функции
распределения случайной длительности обслуживания требований x.
Формулу (7.66) называют формулой Поллачека-Хинчина.
54
2. Среднее время ожидания в системе W.
Пусть W(t) – стационарная функция распределения времени ожидания и
W*(s) – его преобразования Лапласа-Стилтьеса:
∞
*
∫e
W (s) =
− st
dW (t ) .
0
Пусть V – функция распределения времени пребывания в стационарном
состоянии; время пребывания равно времени ожидание плюс время
обслуживания. Поскольку время ожидания и следующая продолжительность
обслуживания стохастично независимые, то для преобразования ЛапласаСтилтьеса V*(s) времени пребывания в стационарном состоянии на основании
теоремы свертки (умножения) имеем:
V * ( s) = W * ( s) B* ( s) .
(7.68)
Количество требований, находящееся в системе, когда ее покидает
некоторое требование, равно количеству требований, поступающих в систему
за время пребывания в системе требования, которое покидает её. Поэтому,
между функцией распределения времени пребывание V(t) и распределением P j
существует такая связь:
∞
(λ t ) j − λ t
Pj = ∫
e dV (t ) .
(7.69)
j!
0
Для образующей функции P*(z) распределения (Р i ) из (7.69) с учетом
(7.68) и (7.60) получаем:
*
P ( z) =
∞
∑
j= 0
j
z Pj =
∞
∫e
− λ t (1− z )
dV (t ) = V * (λ − λ z ) = W * (λ − λ z ) B * (λ − λ z ) .
0
Из этого и из (7.65) следует, что
P* (1 − s / λ )
(1 − ρ ) s
W * (s) =
=
.
B* ( s)
s − λ + λ B* ( s)
Поскольку математическое ожидание W = –W*'(0), то, взяв производную
для стационарного состояния, получаем:
λ µ 2x
λ ( x 2 + σ 2x )
W=
=
.
(7.70)
2(1 − ρ )
2(1 − ρ )
Для характеристики второго центрального момента распределения
длительности обслуживания σ 2x часто используется коэффициент вариации νx:
ν
x
=
σx
.
x
(7.71)
Сумму x 2 + σ 2x с учетом (7.71), можно представить как x 2 (1 + ν 2x ) .
Подставив это в (7.66) и (7.70) получим окончательные формулы расчета N и W.
55
С учетом (6.3), (6.4), (7.44) и (7.45) получаем все другие характеристики QoS,
формулы которых занесенные в табл. 7.1. Значения W, tq и T нормируются по x .
Таблица 7.1 – Характеристики качества обслуживания модели М/G/l/∞
M/G/1/∞
Модель
M/D/1/∞
M/M/1/∞
Рw>0
ρ
ρ
ρ
Q
ρ 2 (1 + ν 2x )
2(1 − ρ )
W
ρ (1 + ν 2x )
2(1 − ρ )
ρ2
2(1 − ρ )
ρ
2(1 − ρ )
ρ2
1− ρ
ρ
1− ρ
tq
1 + ν 2x
2(1 − ρ )
1
2(1 − ρ )
1
1− ρ
ρ2
ρ +
2(1 − ρ )
ρ
1+
2(1 − ρ )
ρ2
ρ
ρ +
=
1− ρ 1− ρ
ρ
1
1+
=
1− ρ 1− ρ
Характеристика
QoS
ρ 2 (1 + ν 2x )
2(1 − ρ )
N
ρ +
T
ρ (1 + ν 2x )
1+
2(1 − ρ )
В табл. 7.1 записаны и формулы всех характеристик QoS моделей М/D/l/∞
и М/M/l/∞, для которых коэффициент вариации ν продолжительности
обслуживания регулярного и экспонентного распределений равен 0 и 1
соответственно. Из табл. 7.1 видно, что при постоянной продолжительности
обслуживания значения W, tq и Q в два раза меньшие, чем при экспонентной.
Приведенные в табл. 7.1 значения характеристик QoS для модели М/M/l/∞
соответственно совпадают с (7.27), (7.32), (7.33) и (7.34).
Для m-серверной системы M/G/m/∞ простого решения не существует,
однако есть приближенные оценки. В частности, среднее стационарное время
ожидания Wm удовлетворяет неравенству
x 2 + σ 2x
.
Wm ≤
2m − 2λ x
Доказательство данного соотношения приведено в [7].
56
7.6 Система с приоритетами M/G/1/∞
Установление приоритетов для ожидающих требований – один из
эффективных способов управления размерами очереди и временем пребывания
в ней. При поступлении в систему требования с высоким приоритетом
обслуживание требования с более низким приоритетом или перерывается
(абсолютный приоритет), или требование с высоким приоритетом становится в
начало очереди ожидающих требований (относительный приоритет).
Рассмотрим два случая приоритетов и в случае абсолютного приоритета
возьмем прерывание с продолжением обслуживания (дообслуживание). Более
подробно с приоритетными системами можно ознакомиться в [1, 2].
7.6.1 Относительный приоритет
Требования с r приоритетами (чем меньше номер, тем выше приоритет)
поступают в однолинейную систему и образуют r пуассоновских потоков с
интенсивностью λk, где k = 1, …, r. Общий поток есть пуассоновским с интенсивностью λ С =
r
∑
λ k . В пределах каждого приоритета требования обслужи-
k= 1
ваются в порядке поступления. Функция распределения общего времени
1 r
обслуживания требований всех приоритетов имеет вид B ( x) = ∑ λ k Bk ( x) , где
λ k=1
B k ( x ) – функция распределения времени обслуживания требования с k-м
приоритетом с средним время обслуживания 1 / μk. Прерывание обслуживания
не допускается. После окончания обслуживания любого требования из очереди
выбирается требование с высшим приоритетом.
Обозначим интенсивность удельной нагрузки k-го приоритета:
λ
ρk = k ,
k = 1, …, r;
(7...72)
µk
и суммарная нагрузка всех потоков с 1 по k-й приоритет:
Rk =
k
∑
ρ i , де R0 = 0,
i= 1
k = 1, …, r.
(7.73)
Суммарная нагрузка потоков всех приоритетов Rr < l (условие
эргодичности процесса). С использованием обозначения (7.67), где
∞
∫x
2
dB( x) = x 2 + σ 2x , определим среднее время ожидания требования с k-м
0
приоритетом:
λ С ( x 2 + σ 2x )
.
(7.74)
2(1 − R k − 1 )(1 − R k )
Выявим уровень влияния относительных приоритетов на среднее время
ожидания Wk каждого из приоритетов на примере организации 5 приоритетов,
где потоки каждого из приоритетов одинаковой интенсивности λ k = λ, и
длительность обслуживания требований каждого из приоритетов одинаковая и
Wk =
57
постоянная. Соответственно интенсивность обслуживания μ k = μ, а σ 2x = 0 .
Поскольку Wk будем измерять в единицах средней длительности обслуживания
x , то в числителе (7.74) при x 2 = 1 / µ = 1 запишем λ С x 2 = ρ .
На рис. 7.4 показаны графики зависимости среднего времени ожидания
требований k-го приоритета от общей интенсивности нагрузки ρ потоков всех
приоритетов. Поскольку все интенсивности одинаковые, то в каждой точке
графика интенсивность нагрузки потока k-го приоритета будет 1/5 от общей
интенсивности ρ.
Рисунок 7.4 – Влияние относительных приоритетов
на среднее время ожидания
Здесь пунктирными линиями изображены графики среднего времени
ожидания Wk, выраженного в единицах средней длительности обслуживания x
при относительных приоритетах (1, …, 5) и постоянном времени обслуживания,
равному для всех пяти равных по интенсивности пуассоновских потоков.
Из рисунка видно, что при введении приоритетов среднее время
ожидания для отдельных потоков можно сделать меньше, чем это было бы в
случае без приоритетного обслуживания (показано непрерывной линией).
Если, например, r = 2, то требования первого приоритета являются
приоритетными, а второго – неприоритетными. Среднее время ожидания
приоритетных и неприоритетных требований из (7.74) определится:
λ С ( x 2 + σ 2x )
.
(7.75)
W1 =
2(1 − ρ 1 )
λ С ( x 2 + σ 2x )
W2 =
.
(7.76)
2(1 − ρ 1 )(1 − ρ 1 − ρ 2 )
Среднее время пребывания требования k-го приоритета в системе Tk
определяется как сумма Wk и среднего времени обслуживания 1 / μk.
7.6.2 Абсолютный приоритет с дообслуживанием
58
Возможны разные режимы прерывания обслуживания требования
низкого приоритета при поступлении в систему требования более высокого
приоритета. Рассмотрим случай с дообслуживанием (см. гл. 3).
Из (7.74) с учетом (7.73) и (7.72) следует среднее время ожидания
требований первого приоритета
λ 1 ( x 12 + σ 12 )
.
W1 =
2(1 − ρ 1 )
и по (7.66) среднее количество требований первого приоритета в системе
λ 21 ( x 12 + σ 12 )
.
N1 = ρ 1 +
2(1 − ρ 1 )
Общее выражение для среднего времени ожидания требований других
приоритетов 1 ≤ k ≤ r получается аналогично (7.74):
r
Wk =
∑
i= 1
λ i ( xi2 + σ i2 )
.
2(1 − Rk − 1 )(1 − Rk )
Если, например, r = 2, то есть приоритетные (приоритет 1) и
неприоритетные (приоритет 2) требования. Среднее время ожидания
неприоритетных требований (до начала обслуживания)
λ 1 ( x 12 + σ 12 ) + λ 2 ( x 22 + σ 22 )
.
(7.77)
W2 =
2(1 − ρ 1 )(1 − ρ 1 − ρ 2 )
Отсюда среднее время пребывания в системе неприоритетных требований
T2 (с учетом прерываний и дообслуживания) получается добавлением средней
продолжительности обслуживания, так что
1
T2 = W2 +
.
(7.78)
µ 2 (1 − ρ 1 )
2
2
2
2
Сравнение (7.76) и (7.77) показывает, что при x 1 + σ 1 = x2 + σ 2 среднее
время ожидания при абсолютном приоритете с дообслуживанием такое же, как
и при относительном приоритете, но разные времена пребывания в системе T.
При относительном приоритете время пребывания в системе равно (1 / μ2) + W2,
то есть меньше, чем T2 в формуле (7.78).
Сложнее найти характеристики очереди неприоритетных требований.
Среднее количество неприоритетных требований в системе
λ 1λ 2 ( x 12 + σ 12 ) + λ 2 ( x 22 + σ 22 )
1
.
N2 =
ρ2+
1− ρ 1
2(1 − ρ 1 − ρ 2 )
где
λ2
–
интенсивность
потока
неприоритетных
требований.
Продолжительность обслуживания определяется распределением B2(x) со
средним значением x2 = 1 / µ 2 и ρ 2 = λ 2 / µ 2 .
59
7.7 Система с потерями MB/M/m – мультисервисный узел доступа
При создании пакетных сетей связи возникает проблема расчета
пропускной способности сетей широкополосного мультисервисного доступа.
На практике при этом используют математическое моделирование, или, без
надлежащего обоснования, традиционные формулы теории телетрафика.
Общего аналитического или инженерного метода решения проблемы нет.
УД 1
УД 2
N1, α1, α2
N2, α1, α2
Транспортная
сеть
V, R
v2, R2
Рисунок 7.5 – Автономный сегмент сети доступа
ВД m
Типичная структура автономного кластера сети доступа (рис. 7.5) предуNm, α1,каскадное
α2
сматривает
подключение узлов доступа (УД) и, иногда, возможность
взаимной связи абонентов кластера. Она содержит транзитный узел доступа
УД1 и каскадно подключенные через него УД2…УДm. Узлами доступа, в
зависимости от конкретной
vm, Rmтехнологии, могут быть мультиплексоры линий
хDSL (DSLAM), базовые станции WiMAX и/или WiFi и прочее оборудование.
Потоки требований из-за конечного количества источников описываются
моделью примитивного потока (пуассоновского потока второго рода), где
распределение интервалов между требованиями экспонентное, а параметр λ не
постоянный, а пропорциональный количеству свободных источников нагрузки.
Состояния последовательно соединенных УД зависимы, так как каждое
требование занимает в них определенную пропускную способность, и из-за
потерь изменяется характер нагрузки, поступающей на транзитный УД. Для
получения точных результатов следует рассчитывать каждый автономный
сегмент сети доступа с каскадным включением УД (кластер) в целом, не
расчленяя его на отдельные УД, а это очень сложно. Обозначим:
N1, N2 … Nm – емкости соответствующих узлов доступа;
R1 … Rm – скорости передачи, необходимые обеспечить для УД1…УДm;
R – общая скорость передачи, которая необходима в направлении к
транспортной сети от всех узлов доступа рассмотренного кластера;
v1…vm – расчетное количество условных каналов для УД 1…УДm
соответственно;
V – расчетное общее количество условных каналов для направления к
транспортной сети;
α1, α2 – интенсивность одного источника нагрузки (абонента) в
свободном состоянии соответственно внутри кластера и к транспортной сети.
60
Надо определить количество условных каналов так, чтобы не превышались нормативные потери требований, а потом определить для каждого канала
скорость передачи так, чтобы не превышались нормы потерь пакетов, тогда
определим нужную полосу пропускания в Мбит/с каждого направления связи.
Требования обслуживаются с явными потерями, время обслуживания
требований экспонентное, а поток требований от каждой группы абонентов
примитивный, т.е. со свойствами ординарности, стационарности и простого
последействия. При этом состояния системы распределены по закону Энгсета,
называемом распределением Эрланга-Бернулли или усеченным распределением Бернулли. Модель потока обозначим MB – экспонентное распределение
интервала между требованиями с усеченным распределением Бернулли
состояний системы. Такая модель присущая малым группам абонентов (до 300).
Обозначим Р(k1, l1; … ; km, lm) – вероятность наличия на УД1…УДm
соответственно k1…km соединений внутри кластера и l1…lm соединений к
транспортной сети. Исходя из формулы Энгсета [2] для конкретного і-го УД
вероятность наличия kі + lі соединений равна:
С Nli α l2i C Nki − l α 1ki p0 ,
(7.79)
i
i
i
где р0 – вероятность отсутствия соединений. Тогда для стационарного режима
имеем:
1 m li li k i
P(k1, l1;...; km , lm ) = ∏ С N α 2 C N − l α 1ki ,
(7.80)
i
i
i
C i= 1
где константу С находим из условия нормировки ∑ P (k1, l1;...k m , lm ) = 1, а
сумма включает все состояния, где выполняется: 0 ≤ ki + li ≤ vi ,
m
∑
i= 1
li ≤ V .
Расчеты по формуле (7.80) громоздкие. Их можно упростить, если
предположить симметричность кластера сети доступа, т. е. задать Ni = N, vi = v
для всех значений и (0 ≤ и ≤ m). Упрощение достигается за счет появления
множества состояний кластера, в каждом из которых все состояния одинаково
вероятны [15].
Рассмотрим кластер доступа с учетом допущений относительно его
симметричности. Обозначим ikl – количество УД, имеющих по k соединений
внутри кластера и по l соединений к транспортной сети. Для отдельно взятого
УД вероятность наличия k + l соединений определяется формулой (7.79) с
учетом того, что Ni = N. Тогда вероятность того, что из всех УД i00 имеют по
k = 0 и l = 0 соединений, i01 – по k = 0 и l = 1 соединений и так далее:
P(i00 , i01 ,..., iv 0 ) = Ñmi00 (C N0 α 02C N0 − 0 α 10 ) i00 × Cmi01− i (C 1N α 12C N0 − 1α 10 )i01 × ...
00
× C iv 0 v − 1v − k (C N0 α 02C Nv − 0 α 1v )iv 0 × P(m,0,...,0).
m − ∑ ∑ i kl
(7.81)
k = 0l = 0
Здесь Р(m, 0...0...…0)=Р0 – вероятность того, что в кластере нет ни одного
соединения, т.е. i00 = m. Можно показать, что
61
С mi00 C mi01− i ...C iv 0 v− 1v− k
00
m−
m!
.
i00 !i01!...iv 0 !
=
∑ ∑ ikl
k = 0l = 0
Тогда уравнение (7.81) запишется так:
v v− l
m!
P (i00 , i01 ,..., iv 0 ) = v − l v
∏ ∏ (C Nl α l2C Nk − l α 1k )ikl × P0 .
∏ ∏ ikl ! l = 0 k = 0
(7.82)
k = 0l = 0
Таким образом, вероятности макросостояний кластера доступа
описываются
мультиномиальним распределением. Очевидны следующие
ограничения:
v v− l
∑ ∑
0 ≤ ikl ≤ m, 0 ≤ k + l ≤ v,
ikl = m, 0 ≤
l = 0k = 0
v v− l
∑ ∑
likl ≤ V .
l = 0k = 0
Вероятность наличия j соединений (0 ≤ j ≤ V) от всех т УД в общем
направлении
Pj = ∑ P(i00 , i01 ,..., iv 0 ) = B j (m) P0 ,
(7.83)
j
где суммирование выполняется по k и l, что удовлетворяет уравнению
v v− l
∑ ∑
likl = j.
l = 0k = 0
Преобразуем выражение для Вj(т) в вид, удобный для расчетов.
Поскольку вероятность наличия j соединений в общем направлении можно
представить произведением вероятности наличия l соединений от
определенного УД на вероятность наличия j – l соединений от других т – 1 УД,
то имеет место рекуррентное соотношение:
B j ( m) =
v v− l
∑ ∑
C Nl α l2 C Nk − l α 1k B j − l (m − 1).
l= 0 k= 0
j
С учетом уравнения
v v− s
m!
v− l v
∏ ∏
k = 0l = 0
ikl !
= m∑
∑
(7.84)
irs (m − 1)!
s
v v− l
s = 0r = 0
∏ ∏
ikl !
получим второе
l = 0k = 0
рекуррентное соотношение:
∑
jB j (m) =
j
v v− s
m∑
∑
s
s = 0r = 0
irs (m − 1)!
v− l v
∏∏
k = 0l = 0
v v− s
= m∑
∑
ikl !
v v− l
∏ ∏
l
k
k i kl
(C N
α l2 C N
=
− lα 1 )
l = 0k = 0
(7.85)
s
r
r
sC N
α 2s C N
− s α 1 B j − s ( m − 1).
s = 1r = 0
После нескольких преобразований получим:
jB j ( m) = mNα
v
2
∑
C Ns −−11α
s= 1
s− 1
2 B j − s (m
62
v− s
− 1) ∑ C Nr − s α 1r .
r= 0
(7.86)
С учетом уравнения C Nl = C Nl − 1 + C Nl − −11 из (7.86) надо
v
v− s
s= 0
r= 0
mNB j ( m) = mN ∑ C Ns − 1α 2s B j − s ( m − 1) ∑ C Nr − s α 1r +
+ mNα
v
C Ns −−11α 2s − 1 B j − s ( m
2
s= 0
∑
(7.87)
v− s
∑
1) C Nr − s α 1r .
r= 0
−
Из сравнения (7.86) и (7.87) следует, что:
v
v− s
s= 0
r= 0
(mN − j ) B j (m) = mN ∑ C Ns − 1α 2s B j − s (m − 1) ∑ C Nr − s α 1r .
Тогда
α
+
v
∑
C Ns − 1α 2s B j − 1− s (m −
2 [(mN − ( j − 1)]B j − 1 (m) = α 2 mN
s= 0
v
v− s
α 1α 2 mN C Ns − 1α 2s B j − 1− s (m − 1) C Nr −−1s − 1α 1r − 1.
s= 0
r= 0
∑
v− s
1) ∑ C Nr − s − 1α 1r +
r= 0
(7.88)
∑
Рассмотрим первое слагаемое правой части выражения (7.88):
v− s
v
α 2 mN ∑ C Ns − 1α 2s B j − 1− s (m − 1) ∑ C Nr − s − 1α 1r =
s= 0
v
r= 0
v− s− 1
= α 2 mN ∑ C Ns − 1α 2s B j − 1− s (m − 1)
∑
s= 0
v
r= 0
C Nr − s − 1α 1r +
(7.89)
+ α 2 mN ∑ C Ns − 1α 2s B j − 1− s (m − 1)C Nv −− ss − 1α 1v − s .
s= 0
Обозначим s + 1 = s’. Тогда в формуле (7.89)
v
α 2 mN ∑ C Ns − 1α 2s B j − 1− s (m − 1)
s= 0
v+ 1
= α 2 mN
∑
C Ns ′ −− 11α
s′ = 1
s′ − 1
2 B j − s ′ (m
v− s− 1
∑
C Nr − s − 1α 1r =
r= 0
v − s′
− 1) ∑ C Nr − s ′ α 1r =
(7.90)
r= 0
jB j ( m) + α 2 mNC Nv − 1α v2 B j − v − 1 (m − 1)C N− 1− v − 1α 1− 1 = jB j ( m).
Рассмотрим второе слагаемое правой части выражения (7.88) и при этом
обозначим r – 1 = r’. Тогда
v− s
v
α 1α 2 mN ∑ C Ns − 1α 2s B j − 1− s (m − 1) ∑ C Nr −−1s − 1α 1r − 1 =
α
s= 0
v+ 1
C Ns ′ −− 11α 2s ′ − 1 B j − s ′ ( m −
1α 2 mN
s′ = 1
∑
63
r= 0
v − s′
1) ∑
r′ = 0
C Nr ′ − s ′ α 1r ′
(7.91)
= α 1 jB j (m).
Подставив (7.89), (7.90) и (7.91) в (7.88), получим:
α 2 [(mN − ( j − 1)]B j − 1 (m) =
v
jB j ( m) + α 2 mN ∑ C Ns − 1α 2s B j − 1− s (m − 1)C Nv −− ss − 1α 1v − s + α 1 jB j (m).
s= 0
Учитывая то, что С Ns − 1C Nv −− ss − 1 = C Nv − 1C vs и заменив индекс суммирования
предыдущим обозначением, получим третье, наиболее удобное для расчетов
рекуррентное соотношение:
v
α2
jB j (m) =
[( mN + j + 1) B j − 1 ( m) − mNC Nv − 1 ∑ Cvl α l2 α 1v − l B j − 1− l (m − 1)],
1+ α 1
l= 0
(7.92)
B− j ≡ 0 .
v
k k
Для j = 0 из (7.87) нужно, чтобы B0 (m) = B0 ( m − 1) ∑ Ñ N α 1 . Очевидно
k= 0
также, что B0 (1) =
v
∑
Ñ Nk α 1k . Эту сумму можно выразить через формулу Энгсета,
k= 0
приведенную в таблицах [2]:
ε ( N , v, α 1 ) =
C Nv α 1v
.
v
∑
C Nk α 1k
k= 0
Тогда для 1 ≤ i ≤ т
получим:
C Nv α 1v
B0 (1) =
,
B0 (i ) = [ B0 (1)]i .
(7.93)
ε ( N , v, α 1 )
С учетом (7.93) из выражения (7.92) последовательно определяются все
значения Bj(m), по которым рассчитываются характеристики качества
обслуживания абонентов в схеме рис. 7.5. Обозначим:
− Pi – вероятность занятости i условных каналов для рассмотренного УД
при связи внутри кластера;
− Пj – вероятность занятости j условных каналов по направлению к
транспортной сети;
− Pij – вероятность одновременной занятости i условных каналов для
рассмотренного УД при связи внутри кластера и j условных каналов
по направлению к транспортной сети.
Можно показать, что имеют место соотношения:
i
Pi =
∑
l= 0
C Nl α l2C Ni − −l l α 1i − l
V
∑
x= 0
V−l
∑
j= 0
B j (m − 1)
,
B x ( m)
Ï
j
=
B j ( m)
V
∑
x= 0
64
B x ( m)
,
(7.94)
i
Pij =
∑
l= 0
C Nl α l2C Ni − −l l α 1i − l B j − l (m − 1)
V
∑
x= 0
.
B x ( m)
Отсюда определяются потери по времени Pt – вероятность занятости всех
доступных условных каналов. Для связи внутри кластера Pt =Pv. Для связи в
направлении транспортной сети величина потерь по времени определяется
суммой двух вероятностей – вероятности Pv и вероятности занятости V
условных каналов при условии, что для рассмотренного УД есть хотя бы один
свободный условный канал связи с транзитным УД, то есть
Pt = Pv +
v− 1
∑
i= 0
PiV = Pv + Ï
V
− PvV . Однако реально важны потери не по времени, а
по требованиями, обусловленные отношением интенсивностей потоков
потерянных и входных требований. Для конкретного УД интенсивность
потоков требований внутри кластера λк и внешнего λв соответственно равны:
λê=
v
∑
i= 0
α 1 ( N − i ) Pi ,
v
∑
λâ=
i= 0
α 2 ( N − i ) Pi .
(7.95)
Интенсивности потерянных требований составляют:
− для потока внутри кластера – α1(N – v)Рv;
− для внешнего потока на участке к транзитному узлу – α2(N – v)Рv;
− на участке к транспортной сети –
v− 1
∑
i= 0
α 2 ( N − i ) PiV .
Тогда потери требований РВ для связи внутри кластера и для внешней
связи составляют соответственно:
PBê
α ( N − v) Pv
= 1
,
λê
PBâ =
α 2 ( N − v) Pv +
v− 1
∑
i= 0
α 2 ( N − i ) PiV
.
(7.96)
λê
Для любой УД интенсивности обслуженной нагрузки при связи внутри
кластера и внешней связи соответственно равны:
Yê =
v
∑
i= 0
Yâ =
iPi ,
V
∑
j= 0
jPj.
(7.97)
Таким образом, используя рекуррентные соотношения (7.92) и (7.93),
можно рассчитать потери требований и соответствующую им пропускную
способность (Эрл) сети мультисервисного абонентского доступа. Рекуррентный
метод расчета количества условных каналов позволяет оценить погрешность
приближенных методов расчета, поскольку дает точные результаты в частном
случае симметричности сети доступа, то есть при одинаковых емкостях узлов
доступа и одинаковых параметрах абонентской нагрузки каждого узла.
65
7.8 Модель обслуживания мультисервисного трафика
В мультисервисных сетях связи, основанных на пакетных технологиях
передачи информации, по общим трактами связи передаются речевые потоки,
потоки данных, видео и др. При этом передача отдельных видов информации
требует разных скоростей передачи. Поэтому в зависимости от категории
требования на предоставление определенного сервиса (услуги) для каждого из
потоков информации необходимо занять определенный ресурс из общего
ресурса пропускной способности (Кбит/с). Например, передача речи требует
гарантированной скорости передачи 64 Кбит/с, связь видео-конференции с
кодеком H.263 – 320 Кбит/с, обмен файлами, например, 1024 Кбит/с [17]. Для
распределения общего ресурса скорости передачи между этими услугами весь
ресурс можно представить определенным количеством условных портов, где
скорость передачи каждого составляет минимальную скорость одной из услуг.
В данном случае скорость передачи одного условного порта составит 64 Кбит/с
и, в зависимости от категории требования, выполняется одновременное занятие
одного или нескольких портов, через которые передаются пакеты с заданной
битовой скоростью. Таким образом, при поступлении требования на
предоставление услуги передачи речи будет одновременно занят 1 порт, на
видео-конференцсвязь – 5, а на передачу файлов – 16 условных портов.
Примечание.
1. Без изменения сущности модели масштаб скорости передачи
условного порта может быть и другим. Например, она может быть
кратной скорости передачи одного или нескольких пакетов
переданной информации. Таким образом, изменяется только
количество занимаемых условных портов, каждый из которых
представляет собой ячейку памяти накопления и передачи пакетов.
2. При поступлении требования на предоставление определенного
сервиса устанавливается соединение между соответствующими
потребителями сервиса, а потом в границах этого соединения передаются информационные пакеты с заданной для сервиса скоростью.
Каждое требование требует установления одного соединения.
В такой модели обслуживания мультисервисного трафика надо отличать
поток требований на предоставление сервиса от потока занятия портов,
поскольку они сильно отличаются по своим свойствам. Очевидно, если поток
требований на предоставление сервиса ординарный, то поток занятия портов
будет неординарным, так как для обслуживания отдельных соединений порты
занимаются группами. С учетом указанного обстоятельства следует различать и
два понятия нагрузки: нагрузка по требованиям и нагрузка на порты.
Для СМО (системы серверов) мгновенная интенсивность обслуженной
нагрузки по требованиям в момент времени t имеет значения j(t), что равно
количеству одновременно обслуживаемых требований (соединений). В отличие
от этого, интенсивность обслуженной нагрузки на порты – это количество i(t)
одновременно занятых портов в момент t. В общем случае i(t) ≠ j(t), так как
одно требование (соединение) может занимать сразу несколько портов.
66
Аналогично надо различать соответствующие виды входной нагрузки: по
требованиям и на порты. Мгновенная интенсивность входной нагрузки по
требованиям в момент времени t есть случайная величина, равная количеству
требований, обслуживаемых в этот момент в СМО с бесконечным количеством
одновременных соединений (см. п. 5.1: один сервер – одно соединение).
Рассмотрим частный случай, когда для обслуживания каждого входного
требования необходимо одинаковое количество m свободных портов. Тогда в
любой момент времени обслуженная нагрузка на порты будет в m раз больше
нагрузки по требованиям: i(t) = mj(t). Если поток требований экспоненциальный
и характеризуется параметром λ, то входная нагрузка по требованиям будет
пуассоновской, а её математическое ожидание ΛВ и дисперсию DВ можно
вычислить с помощью следующего соотношения:
Λ В = DВ = λ x ,
где x – среднее время обслуживания одного требования (соединения).
В воображаемой системе с бесконечным количеством портов, как и в
реальной, количество занятых портов будет в m раз больше количества
обслуженных требований (соединений). Отсюда следуют формулы, по которым
можно определить интенсивность входной нагрузки на порты и ее дисперсию:
Λ П = mΛ В = mλ x ,
DП = m 2 DВ = m 2λ x .
(7.98)
Здесь применяется правило, известное из теории вероятностей: если
случайная величина увеличивается на постоянный коэффициент, то на этот же
коэффициент нужно умножить ее математическое ожидание, а дисперсия
должна увеличиваться на коэффициент в квадрате.
Из этих формул видно, что DП > ΛП, и нагрузка есть скученной из-за
неординарности потока занятий портов. Коэффициент скученности SП (5.4)
равен количеству портов, необходимых для обслуживания одного требования:
DП m 2λ x
SП =
=
= m.
(7.99)
ΛП
mλ x
При поступлении требований от источников разных категорий формулы
(7.98) справедливые для математического ожидания и дисперсии нагрузки на
порты, которая создается требованиями i-й категории, i = 1, …, n:
Λ i = mi λ i xi ,
Di = mi2 λ i xi ...
Подставляя эти соотношения в формулу (5.8) и (5.7), можем найти
коэффициент скученности объединенной нагрузки на порты:
n
SП =
∑
i= 0
n
∑
i= 0
Di
Λ
i
n
=
∑
i= 0
n
∑
mi2λ i xi
i= 0
.
(7.100)
mi λ i xi
Коэффициент скученности мультисервисной нагрузки равен средневзвешенному количеству портов m, необходимых для обслуживания требований
отдельных категорий, с весами mi λ i xi , которые равны интенсивности нагрузки
на порты, создаваемой требованиями этих категорий, i = 1, …, n.
67
7.8.1 Аппроксимация Хейворда
На полнодоступную систему из V портов поступает пуассоновский поток
требований с интенсивностью λ, причем каждое требование требует для своего
обслуживания одновременно т портов, т > 1. Порты занимаются на случайное
время обслуживания, средняя продолжительность которого равна x . В случае
завершения обслуживания все порты из группы одновременно освобождаются.
Если в момент поступления требования в системе отсутствует необходимое
количество свободных портов, то требование теряется.
При расчете вероятности потерь требований π для анализируемой системы, названной системой U, непосредственное применение B-формулы Эрланга
невозможно из-за неординарного потока занятий портов. Вместо этого
исследуем видоизмененную систему U’, состоящую из v = V / m комплектов,
каждый из которых содержит т портов. Теперь каждому входному требованию
для обслуживания будет необходим один комплект и потому поток занятия
комплектов ординарный. Нагрузка в системе U’ определяются количеством
занятых комплектов (а не портов), т.е. совпадает с нагрузкой по требованиям и
есть пуассоновской с интенсивностью ΛВ = λ x . Поэтому, для расчета
вероятности потерь требований в системе U’ применяем B-формулу Эрланга:
ΛВ
π ' = Ev ( Λ В ) = v v! .
Λ
∑ i!i
i= 0
С точки зрения статистических характеристик процесса обслуживания
требований, системы U и U’ целиком эквивалентны и, в частности, очевидно,
что π = π'. Отсюда с учетом соотношений (7.99) и (7.100) следует:
Λ
π = E V П
(7.101)
S П
Sп
Итак, когда мультисервисная нагрузка создается несколькими
категориями источников с разной кратностью требований mi, суперпозицию
входных потоков можно заменить одним потоком, который имеет такие же
значения математического ожидания ΛП и дисперсии DП нагрузки на порты.
Хотя в действительности непуассоновськие потоки имеют довольно сложные
статистические свойства, и для полного описания таких потоков нужно
использование большего количества характеристик, на практике обычно
предполагают, что вероятность потери требования слабо зависит от моментов
распределения нагрузки более высокого порядка и их можно не учитывать.
Если известна вероятность потерь требований π в некоторой системе из V
портов при мультисервисной нагрузке с интенсивностью Λ П и коэффициентом
скученности SП, то в любой системе с такими же параметрами V, ΛП и SП потери
требований будут приблизительно равны π.
Вычислив коэффициент скученности объединенного потока требований
по формуле (7.100), можем потом при помощи соотношения (7.101) определить
вероятность потери любого требования, что дает приближенную оценку
68
средних (или общих) потерь. Для разных категорий источников нагрузки
требования теряются при разных состояниях системы и, как следствие,
вероятностные характеристики качества обслуживания требований отличаются.
Для расчета индивидуальных потерь, то есть вероятности потерь требований i-й
категории, при i = 1, …, n, можно применить приближенное соотношение:
m
πi = i π .
Si
Таким образом, при обслуживании мультисервисной нагрузки, имеющей
непуассоновский характер, расчет потерь требований в исходной системе
заменяется аналогичной задачей для эквивалентной системы, где такая задача
может быть решена с использованием B-формулы Эрланга. Сравнительный
анализ такого подхода и имитационного моделирования свидетельствует, что
предлагаемые приближенные формулы имеют точность, целиком достаточную
для решения инженерных задач.
Формула (7.101) называется формулой или аппроксимацией Хейворда и
ее обоснование исследовано в некоторых научных работах [18].
7.8.2 Пример расчета вероятности потерь
На систему из V = 45 портов поступают требования п = 2 категорий.
Поток требований сервиса телефонии (1-я категория) с параметрами:
λ1 = 0,14 требования за 1 с, x1 = 100 с, m1 = 1.
Поток требований сервиса видео-телефонии (2-я кат.) с параметрами:
λ2 = 0,05 требования за 1 с, x 2 = 56 с, m2 = 5.
Определить общие (средние) и индивидуальные потери требований.
Решение задачи.
Общая интенсивность нагрузки на порты от источников всех категорий:
ΛП = m1λ 1 x1 + m2 λ 2 x2 = 1 ∙ 0,14 ∙ 100 + 5 ∙ 0,05 ∙ 56 = 28 (Эрл).
Дисперсия нагрузки на порты от источников всех категорий:
DП = m12 λ 1 x1 + m22 λ 2 x2 = 12 ∙ 0,14 ∙ 100 + 52 ∙ 0,05 ∙ 56 = 84.
Коэффициент скученности нагрузки:
SП = DП / ΛП = 84/28 = 3.
По формуле Хейворда и из таблиц B-формулы Эрланга определяем
среднюю вероятность потерь для общего входного потока требований:
Λ
28
π = E V Ï = E 45 = E15(9,33) = 0,027.
SÏ
3
3
S
Ï
Индивидуальные вероятности потерь для требований 1-й и 2-й категорий:
π1 = (m1 / SП) ∙ π = (1/3) ∙ 0,027 = 0,009,
π2 = (m2 / SП) ∙ π = (5/3) ∙ 0,027 = 0,045.
С таким качеством система с пропускной способностью 45 ∙ 64 Кбит/с =
2,88 Мбит/с обслуживает нагрузку сервисов телефонии и видео-телефонии.
69
8 АНАЛИЗ СМО В УСЛОВИЯХ РЕАЛЬНОГО ПОТОКА ТРЕБОВАНИЙ
Интегральный характер мультисервисных сетей с широким спектром
услуг предопределяет разнородность трафика, которая сильно изменяет его
параметры и математическую модель. Параметры трафика – это интенсивность
нагрузки Λ (среднее количество требований, поступивших в систему за
среднюю длительность обслуживания) и дисперсия интенсивности нагрузки σ 2.
Математической моделью трафика есть вероятностная функция распределения
случайного количества требований i за среднюю длительность обслуживания x.
В модели пуассоновского потока требований интервал времени между
требованиями z распределен по экспонентному закону. Степень отклонения
других потоков от пуассоновского можно оценить по коэффициенту вариации
νz функции распределения интервала z. Для экспонентного распределения νz ≡ 1.
Модель пуассоновского потока не всегда адекватно описывает реальные потоки
требований в телекоммуникациях и потому нужны иные распределения для их
описания, обеспечивающие лучшее согласие с данными измерений. Замена
экспонентного распределения другими функциями заметно усложняет модель,
а сложные модели не всегда поддаются аналитическому решению.
Реальные потоки требований в мультисервисных сетях формируются
множеством источников с разной удельной интенсивностью нагрузки (разнородные потоки). В процессе создания потока требований участвуют источники,
принадлежащие к разным группам потребителей сервисов с близкими
интенсивности нагрузки. Значения интенсивности результирующего потока
требований в каждый момент времени зависит от того, к какой группе по
интенсивности нагрузки принадлежит источник и каково соотношение
численности этих источников. Более адекватно описать поток или распределение интервалов времени между требованиями можно не экспонентным распределением (M), а их смесью – гиперэкспонентным распределением (HM):
P( z ) =
k
∑
i= 1
pi λ i e − λ i z
при
k
∑
i= 1
pi = 1 .
Этому распределению соответствует прерывистый пуассоновский поток
k-го порядка. Практические измерения показывают, что реальные потоки
достаточно аппроксимировать с k = 2. Так можно описать больший разброс
величины интервала времени между требованиями z и обеспечить значения
коэффициентов νz ≥ 1, а это позволяет описывать потоки с дисперсией интенсивности нагрузки σ2, превышающей ее математическое ожидание Λ от единиц
до десятков раз. Соотношение σ2 и Λ иногда называется пикфактором трафика.
Гиперэкспонентный интервал времени между требованиями приводит к
такому распределению количества требований на интервале в среднюю
длительность обслуживания, которое хорошо аппроксимируется нормальным
(Гаусса) законом. Для реальных потоков требований мультисервисных сетей
связи адекватна математическая модель с гиперэкспонентным распределением
интервала времени между требованиями, количество которых на интервале
времени аппроксимируется нормальным распределением.
70
8.1 Функция распределения состояний системы с потерями HM/D/m
Полнодоступная схема СМО с m серверами работает по дисциплине
обслуживания с потерями. Длительность обслуживания постоянная и равна x .
В систему поступает поток требований с интенсивностью Λ, а интервал между
требованиями с гиперэкспонентным распределением. Количество требований в
единицу времени x распределено по нормальному закону Определить
стационарное распределение вероятностей состояний системы Pk (k = 0, …, m)...
Состояние системы определяется количеством занятых серверов. Случайный процесс поступления требований модифицирует состояния системы со
скоростью, обусловленной интенсивностью нагрузки Λ. Здесь Λ – это суммарное количество требований j, поступивших за время средней длительности
обслуживания x . Интенсивность перехода системы из одного состояния в
другое зависит от свойств потока требований, описываемого соответствующим
распределением вероятностей Qj, где j в диапазоне от 0 до ∞ – количество
требований за время x . Все события поступления требований принадлежат
пространству состояний Q. События занятия серверов образуют новое дискретное подпространство P, описываемое распределением вероятностей Pi, где i –
количество занятых серверов (i = 0, …, m). Пространство P меньше пространства Q, ибо состояния i > m для системы невозможны, а j может быть огромно.
В системе с потерями независимо от ее текущего состояния для каждого
из случаев поступления j > m требований происходит событие „отказ в
обслуживании”. Это очевидно, ибо за время x (постоянная длительность
занятия серверов) поступит j > m требований и ни один из вновь занятых
серверов за это же время не освободится. Если система находится в начальном
состоянии i = 0 (все серверы свободные), то для каждого из вариантов
поступления за один и тот же отрезок времени j ≤ m требований событие „отказ
в обслуживании” не произойдет. События поступления за время x точно j
требований, образуют полную группу несовместных гипотез H0, H1, … , Hj с
∞
априорными вероятностями Q(H0), Q(H1), … , Q(Hj) и потому ∑ Q ( H j ) = 1 .
j= 0
Событие A, состоящее в „отсутствии отказа в обслуживании” может произойти
только вместе с одной из гипотез группы H0, H1, …, Hm. Условные вероятности
гипотез поступления j ≤ m требований (апостериорные), при условии осуществления события A (отсутствие потерь) вычисляются по формуле Байеса:
Q( H j )Q( A | H j )
Q( H j | A) = m
.
(8.1)
∑ Q( H k )Q( A | H k )
k= 0
Так как событие A (отсутствие отказа в обслуживании), появляющееся с
каждой из гипотез группы H0, H1, …, Hm есть достоверным, то условные
вероятности Q(A|Hj) = 1. Поэтому, если для осуществления события возможна
только часть гипотез, а другие невозможны, то для получения апостериорных
вероятностей надо каждую из априорных вероятностей этой части возможных
гипотез разделить на их сумму. Поэтому:
71
Q( H j )
Q( H j | A) =
m
∑
Q( H k )
.
k= 0
Для системы, будущей в начальном состоянии (все серверы свободны),
условные вероятности Q(Hj|A) соответствуют вероятностям занятия i = j
серверов, т.е. вероятностям Pi. Они также образуют полную группу несовместm
ных событий подпространства P и потому ∑ Pi = 1 . Итак, вероятности занятия
i= 0
серверов Pi представлены через вероятности поступления требований Q(Hj), т.е.
Q( H i )
Pi =
m
.
(8.2)
∑ Q( H k )
k= 0
Условием стационарности распределения есть эргодичность процесса
обслуживания требований. Это значит, что полученные вероятности состояний
системы (количества занятых серверов) не должны зависеть от того, в каком
состоянии система была в начальный момент времени (принято, что в
начальный момент все серверы свободны). Известно, что свойство
эргодичности имеют марковские процессы и для любого такого процесса после
довольно продолжительного времени работы системы обязательно настанет
стационарный режим, где вероятность того, что система будет в i-м состоянии,
не зависит от того, в каком состоянии она находилась в начальный момент
времени. Соответственно теореме Маркова условием эргодичности процесса
есть (7.10) и тогда система работает в состоянии статистического равновесия.
Подставив в (8.2) вместо вероятностей Q(Hi) вероятности из распределения Пуассона (7.48), получим первое распределение Эрланга (7.11), верное для
модели M/G/m, и по которому рассчитываем вероятности всех состояний
системы. Однако, в этом случае математическое ожидание случайного процесса
поступления требований с интенсивностью Λ равно его дисперсии σ 2. Но если в
(8.2) вместо вероятностей Q(Hi) и Q(Hk) подставить вероятности, найденные по
нормальному закону, то будет формула расчета состояний модели HM/D/m:
2
2
1
e − (i − Λ ) / 2σ
1
Pi = m 2π σ
= m
. (8.3)
− (k − 2Λ + i)(k − i )
1
− ( k − Λ ) 2 / 2σ 2
e
∑
∑ exp
k = 0 2π σ
k= 0
2σ 2
2
При σ = Λ нормальный случайный процесс есть марковским и при этом в
соответствии с (7.10) при Λ < m расчетные значения, получаемые по формулам
распределения Эрланга (7.11) и (8.3) довольно близки – расхождение не более
1 %. При σ2 > Λ распределение интервалов времени между требованиями уже
не экспоненциально и поток требований теряет свойство отсутствия
последействия. Процесс обслуживания становится сложнее и возникает
зависимость вероятностей состояний системы от ее начального состояния.
Возникает зависимость и от вида распределения продолжительности
72
обслуживания требований, в отличие от распределения Эрланга, верного при
любом законе распределения длительности обслуживания. Поэтому,
вероятность занятия всех серверов системы уже не совпадает с вероятностью
отказа в обслуживании, как это наблюдается при пуассоновском потоке.
Данную задачу для модели HM/D/m можно решить и другим способом.
В условиях неограниченного количества серверов (модель HM/D/∞)
требования обслуживаются без потерь. При постоянной длительности
обслуживания x, когда нет потерь, свойства потока освобождений совпадают со
свойствами потока поступления требований, так как происходит только сдвиг
во времени на величину x между моментом поступления требования и
моментом его выхода из системы (завершения обслуживания). При этом,
состояния системы полностью определяются свойствами потока требований, а
вероятностные функции распределения количества требований в системе i и
поступающего за время x количества требований j, полностью совпадают. При
нормальном распределении количества требований, поступающих в систему за
среднюю длительность их обслуживания, нормальная функция распределения
потока требований Pj определит функцию распределения состояний системы Pi:
−
(i− Λ ) 2
1
2
(8.4)
e 2σ .
2π σ
При ограниченном до m количестве серверов пространство состояний
системы также ограничено от 0 до m. Вероятностную функцию распределения
состояний системы HM/D/m можно аппроксимировать усеченным нормальным
законом, определяющим вероятности состояний системы Pi при 0 ≤ j ≤ m:
Pj = Pi =
Pi =
где
A=
A
e
2π σ
( j− Λ )2
−
2σ
2
,
(8.5)
1
0− Λ
m− Λ
u2
u2
σ
σ
−
−
1
2
2
e
du − ∫ e
du .
∫
2π 0
0
Если m = ∞, то A = 1 и потому (8.4) и (8.5) совпадают. При всех других m
значения формул (8.3) и (8.5) совпадают, что подтверждает правильность обеих
способов решения задачи. Для (8.3), (8.4) и (8.5) выполняется
m
∑
i= 0
Pi = 1 .
На рис. 8.1 даны графики аппроксимации функции распределения состояний системы, обслуживающей поток с параметрами: интенсивность Λ = 100
Эрл и дисперсия σ2 = 400 (пикфактор σ2/ Λ = 4). Пунктирная линия – система с
неограниченным количеством серверов, где m = ∞, непрерывная – система с
m = 125, штриховая – с m = 115 и штрихпунктирная – с m = 110 серверов.
73
Рисунок 8.1 – Аппроксимация состояний усеченным нормальным законом
В широком диапазоне изменения параметров трафика Λ и σ2 и количества
серверов m относительная погрешность предложенной аппроксимации
усеченным нормальным законом не превышает 1% для всех значений Pi, кроме
Pj=m. Процесс обслуживания требований в системе является эргодическим или
не зависит от начального состояния системы при условии m > Λ [2]. Если
количество серверов m существенно превышает значение интенсивности Λ, то
начальное состояние системы не оказывает большого влияния на функцию
распределения состояний системы. При уменьшении m начальное состояние
системы проявляет свое наибольшее влияние именно на вероятность Pi=m. Это
происходит из-за „скученности” потока требований реального трафика, которая
следует из его свойства σ2 > Λ. Именно в случае „перегрузки” системы, когда
заняты все серверы, при освобождении любого из серверов он тут же
занимается очередным требованием из-за скученности требований на данном
интервале времени, а это поддерживает систему более продолжительное время
в состоянии „насыщения”, то есть в состоянии Pi=m.
При σ2 ≡ Λ законы Гаусса и Пуассона почти совпадают уже при Λ > 20.
Здесь данное усеченное нормальное распределение дает значения вероятностей
состояний системы, очень близкие к значениям, получаемых по распределению
Эрланга (7.11), которым определяются состояния системы типа M/G/m с
экспонентным распределением интервала времени между требованиями потока
и где σ2 ≡ Λ. Гиперэкспонентное распределение при k = 1 обращается в
экспонентное и оно есть обобщающим. В отличие от распределения Эрланга,
верного при любом (G) законе распределения длительности обслуживания,
усеченное нормальное распределение состояний системы при σ 2 > Λ верно
только для модели HM/D/m, т.е. для постоянной длительности обслуживания.
Регулярным (постоянным) законом распределения длительности обслуживания описывается работа управляющих устройств узлов коммутации или
длительность обработки пакетов в пакетных сетях передачи данных, где потоки
не есть пуассоновскими. Здесь применение данной аппроксимации адекватно.
74
8.2 Вероятность потерь системы HM/D/m
Соотношение первых двух моментов случайного количества требований
за среднюю длительность обслуживания (интенсивность нагрузки) определяет
скученность интенсивности нагрузки или пикфактор трафика
σ2
.
S=
Λ
В наиболее часто применяемой математической модели пуассоновского
потока требований σ2 ≡ Λ, поскольку интервал времени между требованиями z
распределен по экспонентному закону, а количество требований за среднюю
длительность обслуживания распределено по закону Пуассона. Реальным
потокам присуща повышенная неравномерность трафика, где дисперсия
интенсивности нагрузки σ2 превышает ее математическое ожидание Λ от 2 до
15 раз. Иногда данное соотношение бывает еще больше, но это происходит или
за пределами ЧНН, или на небольших пучках каналов. Поэтому для реальных
потоков, как правило, S > 1.
Определение основной характеристики QoS – вероятности отказа в
обслуживании из-за занятости всех серверов системы – базируется на
определении вероятностной функции распределения состояний системы Pi.
В модели HM/D/m вероятность отказа в обслуживании зависит от
пикфактора интенсивности нагрузки S и при условии m > Λ равна вероятности
занятия всех m серверов системы (8.3), умноженной на S:
1
σ2
PB =
m
(8.6)
− (k − 2Λ + m)(k − m) Λ .
∑ exp
2σ 2
k= 0
В [10] показано, что регулярный закон распределения продолжительности
обслуживания с точки зрения качества обслуживания наихудший и потому
формула (8.6) есть не что иное, как верхняя оценка возможных значений
вероятности отказа в обслуживании. Для других законов распределения
продолжительности обслуживания требований к формуле (8.6) применяется
специальная аппроксимирующая функция, полученная по результатам
имитационного моделирования [9], и в которой коэффициентом h задается вид
закона распределения длительности обслуживания:
S
( S 2 − 1)(σ − Λ + m)
PB =
1 −
2
m
(8.7)
σ
(
S
h
−
h
+
5
)
,
− (k − 2Λ + m)(k − m)
∑ exp
2Λ S
k= 0
где h равно 4.25, 3.55 и 2.85 для равномерного, экспонентного и
логарифмически
нормального
законов
распределения
длительности
обслуживания соответственно. Видно, что при S = 1 (то есть σ2 = Λ) данная
формула превращается в формулу (8.3) для случая i = m – состояние системы m
(занятые все серверы).
75
На рис. 8.2 приведены зависимости вероятности потерь PB от количества
серверов в системе HM/G*/m и вида закона распределения продолжительности
обслуживания при Λ = 100 Эрл и S = 8 (G* – регулярный, равномерный,
экспоненциальный и логарифмически нормальный законы распределения
продолжительности обслуживания).
Рисунок 8.2 – Зависимость PB от m и закона распределения
длительности обслуживания
Пунктирная кривая Em(Λ) показывает зависимость потерь от m,
рассчитанную по B-формуле Эрланга. Штриховыми линиями 1, 2, 3 и 4
показаны зависимости вероятности потерь требований для регулярного,
равномерного, экспонентного и логарифмически нормального законов
распределения продолжительности занятия соответственно.
Графики демонстрируют, что, например, при емкости системы m = 125
серверов вероятность потери требования, рассчитанная по B-формуле Эрланга,
составит PB = 0,002. В то же время, если в систему поступает не пуассоновский
поток, а более неравномерный с пикфактором S = 8, то при постоянной
длительности обслуживания требований реальные потери составят PB = 0,07,
что в 35 раз больше. Для того чтобы удержать качество обслуживания на
заданном уровне PB = 0,002 необходимо в системе иметь реально m = 172
сервера, а не 125. Такова ошибка в расчетах СМО, когда используются
неадекватные методы, не учитывающие характер входного потока требований.
Видно, что при значительной (S = 8) дисперсии интенсивности нагрузки
лучшее качество обслуживания будет там, где в законе распределения длительности обслуживания больше доля (вероятность) коротких требований. Менее
короткие по длительности обслуживания требования скорее покидают систему,
освобождая серверы для использования их следующими требованиями.
В табл. 1 Приложения даны сведения об интенсивности нагрузки Y,
обслуженной m-серверным полнодоступным пучком при потерях 1, 3 и 5 ‰ и
коэффициенте скученности нагрузки S = 1, …, 5. При S = 1 представленные
значения совпадают со значениями, рассчитанными по B-формуле Эрланга.
76
8.3 Система с неограниченной очередью HM/D/m/∞
В полнодоступную m-серверную систему с неограниченной очередью
поступает гиперэкспонентный поток требований с интенсивностью Λ, пикфактором S > 1 и нормальным распределением количества требований за единицу
времени x, где x – постоянная длительность обслуживания требования. Выбор
из очереди – в порядке поступления. Определить характеристики QoS:
− вероятность ожидания Pw>0 ;
− среднюю длину очереди Q;
− среднюю продолжительность ожидания требований в системе W;
− среднюю продолжительность ожидания требований в очереди tq.
Распределение вероятностей Pi случайного количества требований i,
поступающих в систему за единицу времени x, описанного нормальным
законом распределения:
Pi =
1
⋅e
2π ⋅ σ
− ( i− Λ
2⋅ σ
2
)
2
.
(8.8)
Независимо от вида потока требований W и Q находятся по формулам
(7.44) и (7.45) на основании определения и формулы Литтла. Из формул видно,
что данные характеристики QoS зависят от Pw>0 и tq, которые определяются из
функций распределения состояний системы Pj и времени ожидания требований
в очереди P(tq). Однако, для непуассоновского потока не существует общего
метода получения таких функций, и формулы для них не являются простыми.
Для расчета tq применим такие, установленные раньше, результаты:
− из C-формулы Эрланга следует, что в системе M/M/m/∞ средняя
длительность ожидания требований в очереди tq(M) = 1 / (m – Λ);
− из формулы Поллачека-Хинчина следует, что в системе M/D/1/∞
средняя длительность ожидания требований в очереди tq(D) = tq(M) / 2.
Очевидно, что в искомом выражении для расчета tq системы HM/D/m/∞
должны учитываться данные выводы. Первый – потому, что пуассоновский
поток (M) есть частным случаем гиперэкспонентного (Н). Второй – поскольку
односерверная система (m = 1) есть частным случаем многосерверной.
В [11] для системы HM/D/m/∞ показано, что tq(D) > tq(M) в S / (k = 2) раз при
количестве серверов m = Λ. Это хорошо согласуется с приведенными выше
соотношениями – через пикфактор S учтено отличие гиперэкспонентного
потока от пуассоновского, и отличие в два раза средней продолжительности
ожидания при постоянной и экспонентной длительности обслуживания, но
отнесено это к характерной точке m = Λ.
С ростом емкости системы m коэффициент k = 2 убывает приблизительно
со скоростью k(m) ≈ (m + Λ) / m. По результатам имитационного моделирования
системы HM/D/m/∞ установлено, что точность расчета tq повышается при
замене данной зависимости на k(m) ≈ (m + Λ + 1 + Λ / m) / m. Окончательная
формула для расчета tq системы HM/D/m/∞ имеет вид:
77
tq ≈
1
m
S
⋅S⋅
=
.
m− Λ
m + Λ + 1 + Λ / m ( m + 1) ⋅ [1 − ( Λ / m ) 2 ]
(8.9)
Для расчета Pw>0 применим такие аргументы. Вероятность Pw>0 – это
вероятность занятости всех m серверов (7.47).
Аналогично модели M/D/m/∞, при конечном числе m и неограниченном
количестве мест ожидания требования обслуживаются без потерь. На серверы
системы поступают требования из первичного потока с интенсивностью Λ и из
очереди с интенсивностью Λ⋅P> 0⋅tw (см. 7.34). Поэтому общая интенсивность
нагрузки на систему увеличивается до величины Λ2 = Λ + Q (см. п. 7.4).
При гиперэкспонентном потоке функция распределения количества
требований в системе (обслуживаются и в очереди) или состояний системы Pj
отличается от функции распределения Pi количества поступающих требований.
На рис. 8.3 даны распределения состояний систем с m = 105, 110 и 120 серверов
(m > Λ) при гиперэкспонентном потоке требований с Λ = 100 Эрл и S = 4.
Рисунок 8.3 – Распределение состояний системы HM/D/m/∞
Из рис. 8.3 видно, что при уменьшении m разброс отдельных значений
функции распределения состояний системы от среднего значения
увеличивается. Из чего следует, что дополнительный поток требований из
очереди увеличивает общую интенсивность нагрузки Λ2 и ее дисперсию σ 22 .
Заметно, что уже при m = 120 (пунктирная линия) функция распределения
состояний системы достаточно симметричная, что позволяет ее целиком
аппроксимировать нормальным законом распределения. Аппроксимация этих
функций нормальным законом (8.8) с параметрами
Λ2 = Λ + Q ;
σ2≈ σ +
78
Q
.
2
(8.10)
(8.11)
дает хорошие результаты на левом отрезке функции распределения состояний
системы, обусловленном границами суммирования в (7.47), т.е. от 0 до m – 1:
Pw > 0 = 1 −
m− 1
∑
i= 0
Pi .
Из этого следует простой итерационный алгоритм расчета основных
характеристик качества обслуживания системы HM/D/m/∞:
– из (8.9) для заданных Λ, S и m рассчитывается tq;
– из (7.47) и (8.8) для заданных Λ и σ2 определяется первичная
вероятность Pw>0 (как для случая, когда требования из очереди не идут в
систему и не увеличивают нагрузки на нее);
– для рассчитанных tq и Pw>0 в соответствии с (7.44) и (7.45) определяются
первичные значения W и Q;
– для рассчитанных из (8.10) и (8.11) значений Λ2 и σ2 в соответствии с
(7.47) и (8.8) определяется уточненная вероятность Pw>0, т. е. с учетом влияния
дополнительной нагрузки на серверы системы из очереди. (При этом длина
очереди более реальная, поскольку требования, которые не идут из системы
немедленно, оказывают содействие возрастанию очереди);
– по уточненному Pw>0 из (7.44) и (7.45) уточняются значения W и Q.
Путем имитационного моделирования установлено, что реализация этого
алгоритма в большом диапазоне варьирования параметров Λ, S и m дает всегда
заниженную оценку вероятности Pw>0, однако, при этом относительная ошибка
никогда не превышает -10 %. Поэтому, поскольку на последнем шаге снова
уточняются значения W и Q, то можно еще раз пересчитать Pw>0 с более
точными значениями Λ3 и σ3. Проверка этого шага показала, что результаты
расчетов после третьей итерации всегда дают верхнюю оценку вероятности
Pw>0, которая не превышает +10 % [11].
79
8.4 Система с неограниченной очередью fBM/D/1/∞
Трафик мультисервисных сетей с коммутацией пакетов характеризуется
наличием долгосрочных зависимостей в интенсивности нагрузки и
существенным отличием статистических свойств потоков пакетов от
пуассоновского потока. Адекватной моделью потоков в таких сетях считаются
самоподобные (self-similarity) процессы, где входной поток описывается
фрактальним броуновским движением (модель fBM). Однако, исследование
характеристик качества обслуживания СРИ в этих условиях является очень
сложной
математической
задачей.
Причиной
тому
есть
слабая
формализованность модели самоподобных потоков, вследствие чего и
невозможно получить аналитически обоснованные результаты для оценки
параметров QoS в системах распределения информации.
Для односерверной системы с бесконечной очередью и постоянным
временем обслуживания (модель fBM/D/1/∞) приближенное решение приведено
в [1], где показано, что количество требований в рассмотренной системе в
любой момент времени t может быть представлено случайной величиной
где
N (t ) = sup s ≤ t ( A(t ) − A(t ) − µ (t − s )) ,
A(t ) = λ t +
a λ Z (t ) .
Случайный процесс Z(t) является нормализованным фрактальным
броуновским движением с параметром Херста Н (H = 0,5 ... 1), а
положительный коэффициент а является некоторым множителем масштаба.
λ
В состоянии статистического равновесия при ρ = < 1 вероятность того,
µ
что количество требований в системе N превысит заданную величина х,
представлена в виде функции:
µ − λ (1− H ) / H µ − λ
µ − λ
x
.
Pr( N > x) = Pr sup t > 0 Z (t ) −
t >
= f
aλ
aλ
aλ
aλ
Для случая, когда эта вероятность равна заведомо заданной величине
Рг(N > х) = ε из вышеприведенного следует, что
1− ρ
0 .5
ρ
0 .5
H − 0 .5 1 − H
µ
H
x
=
H
H
aH
= const ,
f (ε )
а это означает, что
N = x=
(1 − ρ
ρ
H
H
) −1
0.5
H−1
80
.
(8.12)
Величина х найдена из предыдущего в предположении, что const = 1.
Вероятность, равная единице – это достоверное событие и, поэтому, х – это
количество требований в системе, которое не может быть превышено, то есть
это может быть верхняя оценка среднего количества требований N в системе
fBM/D/1/∞.
Поскольку из формулы Литтла следует, что Т = N / λ, то среднее время
пребывания требования в системе при μ = 1, то есть в единицах времени
продолжительности обслуживания, определяется формулой:
H
H
T=
(1 − ρ ) H − 1 1 (1 − ρ ) H − 1
=
.
0.5
H − 0.5
ρ
ρ
ρ
H − 1
(8.13)
H − 1
Исходя из того, что для любой односерверной системы средняя длина
очереди Q = N – ρ, то с учетом (8.12) получим:
H
Q=
(1 − ρ ) H
0.5
ρ
− 1
− ρ.
(8.14)
H−1
Результат (8.12), (8.13) и (8.14) считается аналитическим решением для
системы fBM/D/1/∞. Однако, при анализе этого результата можно заметить, что
при задании коэффициента Херста H = 0,5 (несамоподобный процесс) имеем
известный результат для среднего количества требований, средней
продолжительности пребывания и средней длины очереди в системе типа
М/М/1/∞. Это достаточно нелогичный результат, поскольку исследовалась
система с детерминированным временем обслуживания fBM/D/1/∞. При
изменении коэффициента Херста от значения H = 1 (максимальное значение) до
H = 0,5 (минимальное значение),
несомненно, видоизменяется поток
требований и соответствующая функция распределения вероятности интервала
времени между требованиями, но не изменяется функция распределения
продолжительности обслуживания. Разумеется, при H = 0,5 поток теряет
свойства самоподобности, но в этом случае результаты (8.12–8.14) должны
коррелироваться с результатами для некоторой модели с постоянной
длительностью обслуживания, а не экспонентной [12].
Из приведенного на рис. 8.6 графика зависимости среднего времени
пребывание требований в системе T следует, что при нагрузке ρ > 0,3 система
fBM/D/1/∞ с входным потоком требований, имеющим характер самоподобного
процесса, будет затрачивать на обработку больше времени, чем при отсутствии
свойства самоподобия, то есть чем системы M/M/1/∞ и M/D/1/∞.
81
Рисунок 8.6 – Зависимость среднего времени пребывания требований
в системе Т для моделей M/M/1/∞, M/D/1/∞ и fBM/D/1/∞ при H = 0,7
Из приведенного на рис. 8.7 графика зависимости среднего количества
требований в системе N для систем M/M/1/∞, M/D/1/∞ и fBM/D/1/∞ следует
аналогичный вывод, что при нагрузке ρ > 0,3 в системе с входным потоком
требований, имеющим характер самоподобного процесса, будет больше
требований, чем при отсутствии самоподобности.
Рисунок 8.7 – Зависимость среднего количества требований в системе N
для моделей M/M/1/∞, M/D/1/∞ и fBM/D/1/∞ при H = 0,7
82
К подобному выводу можно прийти и после анализа графика зависимости
средней длины очереди Q от ρ в тех же системах, приведенному на рис. 8.8.
Рисунок 8.8 – Зависимость средней длины очереди Q для моделей M/M/1/∞,
M/D/1/∞ и fBM/D/1/∞ при H = 0,7
На всех графиках можно видеть, что с ростом интенсивности нагрузки ρ
ухудшаются характеристики качества обслуживания T, N и Q, но еще более
существенным образом они ухудшаются при наличии свойств самоподобия во
входном потоке требований. Результат в виде выражений (8.12), (8.13) и (8.14)
показывает степень этого влияния в зависимости от величины коэффициента H.
Однако, для данного результата (формулы Норроса), полученного в
предположении постоянной продолжительности обслуживания, при H = 0,5
выражения (8.12), (8.13) и (8.14) дают оценки параметров качества
обслуживания, характерные для пуассоновского потока с экспонентным
законом распределения продолжительности обслуживания, а не регулярного
(модель M/M/1/∞). Установить степень точности данного результата можно
при помощи имитационного моделирования.
При имитационном моделировании достаточно оценить только один из
параметров, например N, поскольку параметры Q и T связаны с N известными
функциональными зависимостями. Результаты имитационного моделирования
СМО типа fBM/D/1/∞ при H = 0,7 приведены на рис. 8.9 и показаны линией, в
виде знаков „+”.
83
Рисунок 8.9 – Моделирования среднего количества требований в системе N
для модели fBM/D/1/∞ при H = 0,7
Результаты моделирования показывают, что для входного потока со
свойствами самоподобия с ростом интенсивности нагрузки ρ ухудшаются
характеристики качества обслуживания, но не настолько, как это определяется
формулой Норроса. Расхождение результатов моделирования и оценок,
полученных по формулам (8.12), (8.13) и (8.14) может составлять сотни
процентов. Оценка Норроса сильно завышена и надо более точное решение.
Наиболее перспективным есть метод оценки параметров качества
обслуживания самоподобного трафика, в котором предложено использовать
методы расчета известных классических распределений, энтропия которых
наиболее близка к энтропии распределения состояний системы в условиях
обслуживания самоподобного трафика [13]. При этом возможен расчет
характеристик QoS в моделях с самоподобным трафиком при любом законе
распределения длительности обслуживания по формуле Полачека-Хинчина.
Случайный процесс (СП) поступления пакетов в СРИ, образует поток
пакетов (трафик) характеризуется определенным законом распределения. Он
устанавливает связь между значением случайной величины (количеством
пакетов) и вероятностью появления этого значения. В большинстве случаев для
расчета параметров QoS достаточно знать о законе распределения только
некоторые его числовые характеристики – моменты распределения разных
порядков. Для расчета пуассоновского распределения достаточно математического ожидания Λ, а для нормального – необходимы Λ и дисперсия D.
Основные характеристики случайного процесса Λ и D, хотя и важны, в то
же время не являются исчерпывающими, а иногда и недостаточными для
прогнозирования значения случайной величины. Иногда СП характеризуются
одинаковыми значениями Λ и D, но внутренняя структура этих процессов
84
разная. Одни могут иметь плавно меняющиеся реализации, а другие – ярко
выраженную колебательную структуру при скачкообразном изменении
отдельных значений случайной величины (например, резкое возрастание
количества пакетов в сети, приводящее к „пачечности” трафика). Для
„плавных” процессов характерна большая предсказуемость реализаций, а для
„пачечных” – очень малая вероятностная зависимость между двумя
случайными величинами СП. В таких случаях закон распределения, характеризующий СП, несет в себе некоторую неопределенность и позволяет с большей
или меньшей надежностью прогнозировать значение случайной величины.
Итак, используемые вероятностные законы распределения, описывающие
трафик в пакетных сетях, не дают такой количественной оценки
неопределенности состояния СМО, как энтропия распределения:
H ( m) = −
m
∑
Pj log Pj .
j= 1
Энтропия не зависит от значений, которые приобретает случайная
величина, а только от их вероятностей.
Оценка параметров качества обслуживания самоподобного трафика
возможна энтропийным методом, сводящимся к использованию методов
расчета известных распределений, энтропия которых совпадает или наиболее
близкая к энтропии состояний системы при обслуживании самоподобного
трафика [13].
Результатами моделирования установлено, что в тех точках, где
одинакова энтропия распределения состояний системы, одинаковы и
исследуемые параметры качества обслуживания, такие как средняя длина
очереди Q и средняя продолжительность ожидания требований W. Например,
для моделей M/M/1/∞ и fBM/D/1/∞ при коэффициенте Херста H = 0,8 и ρ = 0,6
энтропии распределений состояний системы довольно близки и равны 1,683 и
1,719 соответственно. При этом для модели fBM/D/1/∞ средняя длина очереди
Q = 0,982 и средняя продолжительность ожидания всех требований W = 1,611,
что превышает соответствующие значения для модели M/M/1/∞ всего на 3 %
(на столько же отличие и значений энтропии). Такое же совпадение основных
параметров качества обслуживания СМО с очередью наблюдается во всех
других точках, для которых одинаковые значения энтропии распределения
состояний системы, независимо от закона распределения продолжительности
обслуживания. Поэтому для этих расчетов можно применять формулы
Поллачека-Хинчина из табл. 7.1 модели M/G/1/∞.
Алгоритм применения энтропийного метода расчета QoS такой:
1. Для установленного закона распределения состояний системы
определяется энтропия распределения HfBM (по известными формулам).
2. Изменением коэффициента вариации νx для модели, например
M/HM/1/∞, достигается совпадение значений энтропии HM/HM/1 = HfBM.
3. С помощью данного коэффициента вариации νx определяется среднее
количество пакетов в системе N по формуле Поллачека-Хинчина (табл. 7.1).
4. Через известные соотношения находятся другие характеристики QoS.
85
Расчет характеристик QoS в модели с самоподобным трафиком при
любом законе распределения длительности обслуживания возможен. Необходимое условие такого – определение энтропии распределения состояний системы.
Доказательство свойства самоподобия реального трафика выполняется
методом абсолютных моментов. В качестве значений случайного процесса
рассматривается количество требований, поступающее в СМО за единицу
времени. Исходную последовательность количества требований длиной N
разделим на блоки длиной m (отдельные агрегированные процессы размером
m). На непересекающихся временных интервалах, то есть на границах каждого
блока k-я последовательность имеет среднее значение:
1 m
X k( m ) =
∑ X ( k − 1) m+ 1 , k = 1, 2, 3 …, [N / m]
m j= 1
После расчета среднего значения X для всей последовательности, потом
для каждого блока k рассчитаем дисперсию Dk:
2
1 m ( m)
Dk( m) =
Xk − X .
∑
N / m j= 1
Для самоподобного процесса дисперсия агрегированных процессов
должна убывать медленнее, чем величина, обратная размеру выборки m [1]. Для
выявления этого свойства построим дисперсионно-временной график
зависимости дисперсий агрегированных процессов от степени агрегирования m.
Поскольку Херстом было показано, что:
max D − min D
≈ H log N ,
log
2
Dk(m)
это график этой зависимости строим тоже в логарифмическом масштабе.
max D − min D
Выражение в левой части этого уравнения
называется R/S
Dk( m )
статистикой или нормированным размахом. Из полученного графика
определяем коэффициент β, как тангенс угла наклона аппроксимирующей
кривой к построенной зависимости. Данная аппроксимация выполняется
методом
минимального
среднеквадратичного
отклонения
от
экспериментальных данных. Коэффициент β (0 < β < 1), задающий
асимптотические свойства характеристик самоподобного случайного процесса
связан с параметром Херста следующим соотношением [1]:
β
H = 1− .
2
Для реальных процессов, не имеющих свойства самоподобия, H < 0,5, а
для самоподобных процессов с долгосрочной зависимостью этот параметр
изменяется в границах 0,65-0,8 (процесс имеет продолжительную память).
(
86
)
8.5 Система с неограниченной очередью G/M/1/∞
В мультисервисных пакетных сетях связи входные информационные
потоки могут иметь постоянную (CBR), переменную (VBR) и смешанную
битовую скорость, от чего математическая модель потока может быть от
простейшей пуассоновской до сложной модели фрактальних процессов
(самоподобный трафик). Закон распределения интервала времени между
требованиями в этих потоках может быть произвольный и потому в
обобщенной модели резонно исследовать обобщенный (G) вид распределения
случайной величины этого интервала. Длина пакетов каждой из служб общей
для них мультисервисной сети (остюда и продолжительность обслуживания)
может быть разной – для одних служб постоянной, а для других – переменной.
В таком случае также желательно исследовать общий вид распределения
случайной величины продолжительности обслуживания.
Системы с очередью типа G/G/m/∞ – очень важные модели,
рассматриваемые в теории телетрафика. При их исследовании применялись
разные методы и получено много приближенных результатов. Частный случай
– система с очередью и одним сервером (m = 1) рассматривался, например в [7],
где получены только приближенные результаты. Однако, до сих пор в общем
случае не существует простых и точных, непосредственно применяемых на
практике, формул для расчета характеристик QoS в стационарном режиме.
Во многих случаях односерверной системы хорошим приближением есть
экспонентная функция распределения продолжительности обслуживания
требований. Поэтому, определим характеристики QoS для модели G/M/1/∞ [14].
Коэффициент использования серверов системы ρ (utilization factor)
определяется как отношение интенсивности входного потока требований λ к
интенсивности обслуживания µ. В m-серверной системе все серверы обеспечат
1
λx
интенсивность обслуживания mµ = m . Итак, в m-серверной системе ρ =
.В
x
m
односерверной системе ρ в m раз больше и совпадает с интенсивностью
нагрузки Λ (5.3) или с интенсивностью входного потока требований λ, если x
является одной условной единицей времени обслуживания. При условии
0 ≤ ρ < 1 процесс в системе эргодичен и стационарное распределение
вероятностей состояний системы существует.
Для всех односерверных систем ρ = 1 – p0, где p0 – вероятность свободности системы (состояние p0 – занято 0 серверов). Итак, ρ – численно совпадает
с вероятностью занятости системы Pзн (состояние p1 – занят единственный
сервер, соответствует доле времени занятости сервера). С учетом требований
очереди в стационарном режиме существует стационарное распределение
количества требований в системе pk, где k – количество требований. Это
распределение не зависит от момента прибытия требования в систему.
При пуассоновском потоке вероятность ожидания Pw>0 совпадает с
вероятностью занятости системы Pзн (см. 7.47). Для односерверной модели
M/G/1/∞ с произвольным распределением длительности обслуживания данные
вероятности одинаковы и Pw>0 = ρ. Однако, для модели G/M/1/∞ такого
87
равенства нет, т.е. по этому параметру модели не инвариантны. В [5, с. 272]
показано, что система G/M/1∞ приводит к геометрическому распределению rk
количества требований в системе в моменты поступления новых требований,
где k – количество требований. Распределение pk отличается от распределения
rk тем, что p0 = 1 – Pзн (или p0 = 1 – ρ), в то время как r0 = 1– Pw>0. Для системы
M/G/1/∞ выполняется равенство pk = rk.
Требование должно ожидать обслуживания с вероятностью Pw>0 = 1 – r0.
Поэтому при экспонентном распределении длительности обслуживания
безусловное распределение длительности ожидания найдем так:
− μ (1− Pw> 0 )t
, при t ≥ 0.
(8.15)
W (t ) = 1 − Pw> 0 e
Из этого можно рассчитать среднее время ожидания в системе W и все
остальные параметры качества обслуживания:
ρ
Рзн = ρ ;
Рw > 0 = 1 −
;
N
ρ ⋅ Рw > 0
Рw> 0
W=
Q=
;
;
1 − Рw > 0
1 − Рw > 0
1
ρ
tq = T =
N=
;
.
1 − Pw > 0
1 − Pw > 0
Поскольку µ = 1, т.е. средняя длительность обслуживания x = 1 / µ
принимается за условную единицу времени, то W, tq и T оцениваются в
единицах средней длительности обслуживания.
В табл. 8.1 приведены зависимости между основными параметрами QoS
для модели G/M/1/∞.
Таблица 8.1 – Зависимости между параметрами QoS в системе G/M/1/∞
Характеристика
QoS
Q
Характеристика QoS
W
tq
N
Рзн
ρ
ρ
Pw>0
Q
ρ+Q
W
1+ W
Q
–
ρ ⋅W
ρ ⋅ (t q − 1)
–
tq − 1
1+ W
–
ρ ⋅ (1 + W )
tqρ
–
1+ W
tq
N
ρ
W
tq
Q
ρ
Q
1+
ρ
N
ρ+Q
T
1+
Q
ρ
ρ
88
1−
ρ
1
tq
ρ
N
1−
N−ρ
Q
N
N ⋅ Pw > 0
N
−1
ρ
N
ρ
Q
Ðw> 0
Из таблицы следует, что при наличии лишь одного известного параметра
(например, известен параметр Q, W, tq или N) все остальные параметры
рассчитываются через приведенные в таблице соотношения.
Для модели G/M/1/∞ выявлены и проверены с помощью имитационного
моделирования важные свойства односерверной системы, выполняемые только
при экспонентной длительности обслуживания (выделены рамкой в табл. 8.1).
Во-первых, среднее время ожидания в очереди tq численно совпадает со
средним временем пребывания требования в системе T. Это означает, что
среднее время ожидания в системе W меньше среднего времени ожидания в
очереди tq на величину средней длительности обслуживания (единица времени
x ):
W = tq − 1 .
(8.16)
Во-вторых, вероятность ожидания можно определить как
Q
Pw > 0 =
.
(8.17)
N
По определению (6.2) вероятность ожидания Pw>0 – это отношение
количества задержанных требований к общему количеству поступивших
требований, но как в данном случае, долю ожидающих требований можно
определить и как отношение среднего количества требований в очереди Q к
среднему количеству требований в системе N. Отсюда, с учетом формулы
Литтла, вытекают несколько важных соотношений между параметрами QoS,
справедливых уже для моделей G/G/1/∞ и G/G/m/∞ (в правой колонке табл. 8.1).
Для системы GI/G/1/∞ Маршаллом предложена приближенная верхняя
(High) оценка среднего стационарного времени ожидания WH [1]:
σ 2z + σ 2x
WH ≤
.
2( z − x )
Нижняя (Low) оценка среднего стационарного времени ожидания WL
предложена Штойяном в [7]:
WL ≥
σ 2x
x
− .
2( z − x ) 2
Анализ системы типа GI/G/1/∞, в которой учитывается вид функции
распределения интервала времени между требованиями входного потока и
продолжительности обслуживания требований, с помощью приведенных
приближенных верхней и нижней оценок иногда дает более точный результат
сравнительно с максимальными оценками, которые получаются при
использовании марковских моделей.
89
8.6 Система с неограниченной очередью G/D/1/∞
В мультисервисных сетях связи трафик имеет сложную структуру,
требующую для своего описания существенного усложнения математической
модели потока требований. Закон распределения интервала времени между
требованиями в этих потоках может быть произвольный и потому в модели,
обслуживающей мультисервисный трафик, резонно исследовать обобщенный
(G) вид распределения случайной величины этого интервала.
В мультисервисных пакетных сетях требованием на обслуживание можно
считать каждый отдельный пакет информации. Длина пакетов может быть
неизменной при постоянной продолжительности их обслуживания, например,
как в технологии ATM. В таком случае в исследованиях можно ограничиться
только детерминированным законом распределения продолжительности
обслуживания (D). Однако, и для переменной длины пакетов при анализе
пакетных коммутаторов следует учитывать наличие у каждого пакета заголовка
фиксированной длины, который требует учета в продолжительности
обслуживания некоторого постоянного слагаемого, даже если распределение
длин пакетов есть, например, экспонентным. Итак, разработка метода расчета
основных характеристик качества обслуживания требований в системах,
представленных моделью G/D/1/∞ также есть актуальной.
В п. 8.7 показано, что для модели G/M/1/∞ с геометрическим
распределением rk (распределение количества требований в системе в моменты
поступления новых требований) при экспонентном законе распределения
продолжительности обслуживания среднее время ожидания в системе W
определяется как
W=
Рw > 0
.
1 − Рw > 0
(8.18)
С учетом этого результата и формулы Литтла в табл. 8.2 приведены
формулы расчета характеристик качества обслуживания для модели G/M/1/∞ и
известный результат для модели M/D/1/∞, который следует из формулы
Поллачека-Хинчина (7.66).
В формулы расчета характеристик QoS модели G/G/1/∞ введем величину
tq – W (табл. 8.2). Правильность этого шага легко проверить подстановкой в
каждую из них справедливого по определению для любой модели уравнения:
Pw > 0 =
W
.
tq
Для расчета характеристик QoS модели G/D/1/∞ используем выявленное в
п. 8.7 свойство модели G/M/1/∞, а именно: tq = T. Поскольку из определения
среднего времени пребывания требования в любой системе (в том числе и в
модели G/G/1/∞) следует, что
T = W + 1,
90
(8.19)
то с учетом приведенного свойства модели G/M/1/∞
tq − W = 1 .
(8.20)
Видно, что при выполнении условия (8.20), каждая из формул расчета
характеристик QoS модели G/G/1/∞ совпадает с аналогичной формулой модели
G/M/1/∞. Также известно, что для модели M/D/1/∞:
t q − W = 0,5 .
(8.21)
Поэтому, при выполнении условия (8.21) вместе с условием Pw>0 = ρ,
присущему пуассоновскому потоку, каждая из формул модели G/G/1/∞
превратится в соответствующую формулу модели M/D/1/∞ (столбики 4 и 2
табл. 8.2).
Таблица 8.2 – Основные параметры качества обслуживания
Хар-ка
QoS
M/D/1/∞
G/M/1/∞
Рзн
ρ
ρ
Pw>0
ρ
Q
W
tq
N
T
1−
Модель
G/G/1/∞
точно
W
tq
приблизительно
Q
t q Pw > 0
ρ,
ρ
N
G*/D/1/∞
,
Q
tqρ
ρ2
2(1 − ρ )
ρ
2(1 − ρ )
1
2(1 − ρ )
ρ Pw > 0
1 − Pw > 0
ρ Pw > 0
(t q − W )
1 − Pw > 0
ρ Pw > 0
2(1 − Pw > 0 )
Pw > 0
1 − Pw > 0
1
1 − Pw > 0
Pw > 0
2(1 − Pw > 0 )
1
2(1 − Pw > 0 )
ρ2
ρ +
2(1 − ρ )
ρ
1+
2(1 − ρ )
ρ
1 − Pw > 0
Pw > 0
(t q − W )
1 − Pw > 0
1
(t q − W )
1 − Pw > 0
ρ Pw > 0
ρ+
(t q − W )
1 − Pw > 0
1
1 − Pw > 0
1+
Pw > 0
(t q − W )
1 − Pw > 0
ρ (2 − Pw > 0 )
2(1 − Pw > 0 )
2 − Pw > 0
2(1 − Pw > 0 )
Если предположить, что условие (8.21) осуществимо и при Pw>0 ≠ ρ, то с
тех же формул модели G/G/1/∞ можно получить соответствующие формулы
расчета характеристик QoS модели G/D/1/∞ (столбик 5 табл. 8.2). Но поскольку,
как показывает имитационное моделирование, полученные таким образом
формулы дают не совсем точные и разные результаты для разных входных
потоков, то лучше назвать такую модель с условно общим распределением
случайной величины интервала времени между требованиями и обозначить
G*/D/1/∞.
91
Для модели G*/D/1/∞ разность (8.21) не всегда равна 0,5. По результатам
имитационного моделирования, выполненного с помощью алгоритма [9],
установлено, что для потоков, в которых коэффициент вариации
продолжительности интервала времени между требованиями vz < 1 (более
выровненный поток по сравнению с пуассоновским) tq – W < 0,5. Например, при
равномерном распределении интервала времени между требованиями (модель
U/D/1/∞) vz = 0,58. Для пуассоновского потока с экспонентным распределением
указанного интервала при vz ≡ 1 или с распределением Вейбулла при
подобранном коэффициенте формы распределения так, чтобы vz = 1, условие
(8.20) выполняется. Для гиперэкспонентного, логарифмически нормального
или распределений Парето и Вейбулла при параметрах распределений, которые
обеспечивают значение vz от единиц до нескольких десятков (очень
неравномерные потоки), разность tq и W всегда немного больше 0,5.
В случае tq – W < 0,5 результаты расчетов немного выше результатов
моделирования, при tq – W = 0,5 – они целиком совпадают, а при tq – W > 0,5 –
результаты расчетов оказываются немного заниженными. При этом
наибольшая погрешность вычислений по формулам модели G*/D/1/∞
сравнительно с результатами моделирования наблюдается в случае
самоподобного потока требований, сгенерированному по распределениию
Парето. Например, при задании параметра формы распределения a = 1,3
(соответствует коэффициенту самоподобности трафика H = 0,85 [13] и vz ≥ 30)
погрешность вычислений не превышает 20 % для всех параметров QoS. При
увеличении a и связанным с этим уменьшением H, например, до значений 1,9 и
0,55 соответственно (еще самоподобный процесс), данная погрешность не
превышает уже 10 %.
Следует отметить, что точность расчетов несколько повышается при
уменьшении интенсивности нагрузка ρ и во многих случаях при ρ < 0,5
погрешность расчетов не превышает 5 %.
Важность данного метода мотивируется существенным усложнением
моделей трафика в современных сетях связи и отсутствием адекватных этому
усложнению методов расчета параметров качества обслуживания. В
особенности полезным данный метод может быть в случае обслуживания
самоподобного трафика, поскольку его точность несравненно выше точности
существующих методов расчета.
92
9 ИМИТАЦИОННОЕ МОДЕЛИРОВАНИЕ СМО
9.1 Метод статистических испытаний
Математические модели функционирования СМО, рассмотренные в гл. 7
и 8, ориентированы на возможность получения в той или иной форме
аналитических решений для обусловленных характеристик СМО. Возможность
получения таких решений существенным образом ограничивается видом
входных потоков, законом распределения длительности обслуживания и
структурой СМО. Использование методов моделирования позволяет заметно
ослабить ограничения, относящиеся к виду входных потоков требований.
Поэтому, основным инструментарием исследования задач, не поддающимся
аналитическим и численным методам, есть имитационное моделирование.
Метод статистических испытаний (метод Монте-Карло) основан на
моделировании исследуемого процесса. Основной его принцип – построение
такой искусственной вероятностной модели, параметры которой представляют
собой решение поставленной задачи. Если такая модель построена, то,
пользуясь методами математической статистики, можно оценить неизвестные
параметры, то есть найти приближенное решение задачи.
Для моделирования процесса на ЭВМ необходимо превратить его
математическую модель СМО в специальный моделирующий алгоритм. При
статистическом моделировании реализация моделирующего алгоритма есть
имитация элементарных явлений, составляющих исследуемый процесс, с
сохранением их логической структуры, последовательности протекания во
времени и в особенности характера и состава информации о состояниях
процесса. Можно указать на имеющуюся аналогию с исследованием процессов
в действительности. В том и другом случае есть возможность использовать для
решения поставленных задач любую информацию о состояниях процесса, если
только она доступна соответствующей регистрации.
Отсюда следует, что структура моделирующего алгоритма может слабо
зависеть от совокупности искомых величин, а определяется главным образом
построением математической модели. При исследовании СМО этот метод
позволяет учитывать: вид всех потоков событий; нестационарность потоков в
системе; разного рода ограничения (например, ограничения на время
пребывания в СМО); влияние состояния СМО на интенсивность потоков и т.п.
Вместе с тем, результаты моделирования, как и при любом численном
методе, всегда носят исключительный характер. Для получения качественных
выводов нужно исследовать большое количество СМО, причем и в этом случае
качественный результат может носить исключительный характер. В ряде
случаев может сказываться принципиально ограниченная точность получаемых
результатов, в особенности, если используется ЭВМ с небольшой длиной
разрядной сетки. Необходимость наличия довольно мощной универсальной
ЭВМ также может быть важным препятствием к использованию метода.
Поэтому, несмотря на несомненные достоинства, метод имитационного
моделирования не может заменить аналитических исследовательских приемов
СМО, а является их дополнением.
93
9.2 Синтез моделирующих алгоритмов
Основными принципами построения моделирующих алгоритмов есть:
– принцип, который позволяет определять последовательные состояния
системы через некоторые интервалы времени (принцип Δt);
– принцип последовательного проведения требований.
Первый принцип состоит в том, что состояния СМО определяются для
моментов времени, разделенных одинаковыми интервалами времени Δt. При
этом для большинства таких моментов состояние СМО не изменяется в
сравнении с предыдущим моментом, т.е. весь интервал времени Δt есть
неинтересным для исследования. Интерес представляют особые состояния,
отвечающие моментам поступления требований в систему и моментам выхода
требований из неё. При увеличении Δt растет вероятность попадания в интервал особого состояния и снижается точность и достоверность моделирования
(за счет возможного попадания в один интервал двух и больше особых
состояний). Уменьшение Δt приводит к резкому росту времени моделирования.
При моделировании процессов обработки требований в СМО удобнее
строить моделирующие алгоритмы по принципу последовательного проведения
требований. Его идея состоит в последовательном воспроизведении истории
отдельных требований в порядке поступления их в систему: алгоритм
обращается к сведениям о других требованиях лишь в том случае, если это
необходимо для решения вопроса о дальнейшем порядке обслуживания данной
заявки. Такого рода моделирующие алгоритмы экономные, не требуют
специальных мер по учету особых состояний системы, н они имеют довольно
сложную логическую структуру и не всегда доступные для построения.
При моделировании приходится решать следующие задачи:
1. Получение последовательности случайных чисел, равномерно
распределенных в интервале [0, 1].
2. Преобразование чисел полученной последовательности в величины,
имеющих некоторую определенную функцию распределения.
3. Построение логической схемы алгоритма, учитывающего особенности
работы СМО, что моделируется.
4. Построение алгоритмов фиксации состояний СМО и обработки
результатов моделирования.
5. Выбор количества реализаций в соответствии с заданной точностью
обусловленных характеристик СМО.
6. Моделирование на ЭВМ.
7. Окончательная обработка и анализ результатов.
Для моделирования потоков событий необходимы алгоритмы выработки
случайных величин, соответствующих длительностям интервалов времени
между соседними событиями необходимого вида потока. Возможную нестационарность потоков можно организовать введением в алгоритм формирования
случайных величин зависимости от текущего времени поступления (или начала
обслуживания) определенного требования. Эти случайные величины должны
быть распределены по определенному закону, т.е. имеет место задача создания
94
последовательности случайных величин с определенной функцией распределения. Сначала получают последовательность чисел, равномерно распределенных в интервале [0, 1], а потом эту последовательность превращают в
последовательность случайных величин с необходимой функцией распределения. Способы получения случайных чисел с равномерным распределением:
– алгоритмический – получение ряда псевдослучайных чисел;
– начальное занесение в память ЭВМ таблицы случайных чисел,
полученных из натурного эксперимента испытания СМО.
При первом способе последовательность псевдослучайных чисел
вырабатывается самой ЭВМ с помощью специальных алгоритмов. При этом
предъявляются следующие требования:
– получаемая последовательность чисел должна иметь статистическую
структуру, очень близкую к структуре равномерной совокупности;
– количество операций, необходимое для выработки каждого числа
последовательности, не должно быть слишком большим.
Последовательность псевдослучайных чисел характеризуется периодичностью повторения. Надо так подбирать „случайные” числа хi (i = 1, 2, ..., m),
чтобы длина периода повторения была наибольшей.
Для обоснования „случайности” последовательности псевдослучайных
чисел необходимо использовать систему следующих тестов:
– проверка частот повторения чисел из разных интервалов;
– проверка пар;
– проверка интервалов;
– проверка комбинаций.
Множество псевдослучайных чисел, удовлетворяющее всем этим тестам,
называется локально случайным. Все упомянутые выше тесты характеризуются
одним общим свойством: испытанные псевдослучайные числа (или разряды в
них) классифицируются по некоторыми признаками (разным для каждого
теста) и полученное эмпирическое распределение сравнивается с теоретическим. Для сравнения применяются обычные статистические критерии.
Имея случайные числа, равномерно распределенные на интервале [0, 1]
можно получить последовательность случайных величин ξ с заданной
плотностью распределения f (х), если решить уравнение
ξ
∫
f ( x)dx = U ,
a
где U – число из исходной равномерной последовательности; а – минимально
возможное число из последовательности случайных величин с плотностью
распределения f(х)
Наиболее распространенными есть три подхода к статистическому
моделированию систем массового обслуживания:
– моделирование марковского процесса;
– моделирование полумарковского процесса;
– моделирование реального процесса обслуживания.
95
9.3 Моделирование марковского процесса
В СМО поступает поток требований с функцией распределения интервала
времени между требованиями А(z). Длительность обслуживания случайная
величина с функцией распределения В(x). Определить характеристики QoS.
Моделирование марковского процесса возможно только для
экспонентных законов, где функция А(z) = 1 – e-λz и В(x) = 1 – e-μx. При этом
работа m-серверной системы с потерями описывается марковским процессом
х(t), где его состояния принимают значения 0, 1, 2, ..., m. Любая траектория
марковского процесса устроена таким образом, что время пребывания ξ и в і-м
состоянии имеет экспонентное распределение с параметром λ + i, т.е.
P{ ξ i > t} = e − (λ + i )t .
(9.1)
В момент выхода из этого состояния осуществляется переход в состояние
i + 1 с вероятностью
λ
pi =
(9.2)
λ + i
или в состоянии i – 1 с вероятностью
i
qi =
(9.3)
λ + i
При i = m возможен переход только в состояние m – 1 с вероятностью,
равной 1 (рис. 3.23, а). Поэтому, при воссоздании работы системы необходимо
моделировать два случайных механизма: время пребывания в і-м состоянии
согласно (9.1) и вероятности переходов по (9.2) и (9.3), что показано на рис. 9.1.
i+1
i
ξ≈e
− (λ + i )t
i -1
λ
λ+i
i
λ+i
i+1
i
1
ξ=
λ+i
i-1
t
а)
λ
λ+i
i
λ+i
t
б)
Рисунок 9.1 – Траектория марковского процесса со случайным (а) и
детерминированным (б) временами пребывания в состояниях
Итак, для моделирования необходимы: программа реализации случайных
величин, распределенных по экспонентному закону (9.1); программа генерирования равномерно распределенных случайных чисел для выбора направления
переходов по (9.2) и (9.3); ячейки памяти для фиксации текущего времени
системы, которое меняется прыжками в соответствии со случайными
периодами пребывания в последовательных состояниях, и n разрядов (а не m
ячеек) для записи номеров занятых серверов или одна ячейка для записи
количества занятых серверов. Такой подход дает большую экономию
машинной памяти, что особенно важно при моделировании сложных систем.
96
9.4 Моделирования вложенной цепи Маркова
Из анализа свойств траектории марковского процесса х(t) следует, что
при вычислении оценки среднего количества занятых серверов случайные
периоды пребывания в отдельных состояниях можно заменить их средними
значениями. Рассмотрим траекторию процесса х(t) к моменту ТN, то есть к
моменту N-го перехода. Необходимо вычислить
T
1 N
M j (TN ) =
(9.4)
∫ f [ x(t )]dt .
TN 0
В нашем случае f[х(t)] = i, если х(t) = i , i = 0, 1, ..., m. Функционал (9.4)
представляет собой случайную величину, зависящую от выборочной
траектории процесса х(t). При замене ξи случайного времени пребывания в
состоянии i-го средним значением 1 / (λ + i) (рис. 9.1, б) среднее значение
функционала (9.4) сохраняется неизменным, а его дисперсия существенным
образом уменьшается, так как устраняется один из двух случайных механизмов,
порождающих траекторию x(t), а именно случайные распределения (9.1).
Уменьшение дисперсии является первым преимуществом такого подхода к
статистическому моделированию, а отсутствие потребности в моделировании
случайных интервалов пребывания – второй.
Опишем этот алгоритм моделирования в общем случае. Пусть данный
однородный марковский процесс х(t) с дискретным множеством состояний S,
обусловленный матрицей интенсивностей перехода A = ||aху||, х, y∈ S.
Траектории процесса х(t) являются ступенчатыми функциями и имеют простое
вероятностное содержание. Если в момент t процесс х(t) находится в состоянии
х, то время, которое осталось находиться в этом состоянии tx есть случайной
величиной, распределенной по экспонентному закону
P{ t x > z} = e − axx z .
В момент выхода t + tх процесс переходит в состояние у с вероятностью
a xy
p xy =
, y ≠ x, y∈ S .
− a xx
Величины рху есть переходными вероятностями вложенной цепи Маркова.
На процесс х(t) можно смотреть как на марковскую цепь с присоеди-ненными
случайными величинами. В состоянии х присоединенной случайной величиной
считаем tх – случайное время пребывания в этом состоянии.
Результатом моделирования обычно есть среднее значение интеграла
некоторой функции f(х), определенной над процессом х(t) согласно (9.4). В этом
случае выгодно заменять tx на среднее значение 1 / (–aхх).
Этот алгоритм можно применить и в случае произвольных законов. Надо
только их предварительно аппроксимировать такими распределениями,
которые являются линейными комбинациями или свертками экспонентных
распределений. Это приводит к некоторому увеличению числа состояний, тем
не менее, как показывает практика моделирования, получается экономия
машинного времени и объемов памяти.
97
9.5 Моделирование реального процесса обслуживания
При имитационном моделировании алгоритм воссоздаёт процесс работы
системы во времени, имитируя шаги процесса или элементарные явления с
сохранением их временной и логической структуры. Алгоритм моделирования
таков, чтобы за минимальное время получить статистические оценки максимальной точности. Есть несколько подходов к имитационному моделированию
СМО. Один из них – это моделирование реального процесса обслуживания
входного потока требований. Здесь используются подпрограммы реализации
двух случайных величин: соответственно функции распределения интервалов
времени между требованиями A(z) и функции распределения длительности
обслуживания B(x) (см. гл. 3). Процесс прибытия требований в систему
моделируется как рекуррентный – момент прибытия очередного требования
получаем добавлением случайного интервала A(z) к предыдущему, а моменты
освобождения серверов – добавлением к текущему моменту времени случайной
длительности обслуживания B(x). Интервалы формируются датчиками
псевдослучайных чисел, настроенными на нужные законы распределения.
Случайные величины A(z) и B(t) с нужным законом распределения
получаются из последовательности случайных величин с равномерным распределением на отрезке [0, 1], а те – из последовательности случайных величин,
распределенных по закону Бернулли с параметром p = 0,5. Для получения
случайных величин с нужной функцией распределения F(t), случайная
величина t вычисляется как обратная функция F–1 от аргумента, которым есть
величина x, равномерно распределенная на отрезке [0, 1], то есть t = F–1(x) [2].
Поток требований можно задать рядом интервалов времени z между
требованиями. Для моделирования любого потока достаточно на i-м шаге
получить значение величины zi, с соответствующей моделированному потоку
функцией распределения F(z). В пуассоновском потоке с параметром λ экспонентная функция распределения z между i-м и (i - 1)-м требованиями такая:
z
− ∫ λ dt
,
(9.5)
Fi ( z ) = 1 − e 0
где λ – параметр потока на интервале [0, z].
Для моделирования потока с параметром λ необходимо найти обратную
функцию к функции (9.5) и для экспонентного распределения получаем
− ln(1 − xi )
zi =
.
(9.6)
λ
Плотность гиперэкспонентного распределения определяется как
(9.7)
p( z ) = p1 λ 1e − λ1⋅ z + p 2 λ 2 e − λ 2 ⋅ z .
Это значит, что с вероятностью p1 интервал времени между требованиями
имеет экспонентное распределение с параметром λ1, а с вероятностью p2 – с
параметром λ2 (соответственно, p1 + p2 = 1). Для моделирования такого потока
требований используется вспомогательный датчик случайных равномерно
распределенных чисел на интервале [0, 1] y, задающий вероятности p1 и p2
98
(p2 = 1 – p1). Случайная величина zi определяется в зависимости от полученного
значения p1 и соответственно выражению (9.6), поэтому
− ln(1 − xi )
при yi ≤ p1
λ1
zi =
.
(9.8)
− ln(1 − xi )
при yi > p1
λ2
Итак, при получении от вспомогательного датчика случайной величины
yi, не превышающей заданной вероятности p1, интервал zi формируется исходя
из значения параметра λ1. В противоположном случае (yi > p1, „сгенерирована”
вероятность p2) – исходя из значения параметра λ2. Этот способ очень простой и
не требует нахождения обратной функции к плотности (9.7).
Самоподобный поток можно получить от суперпозиции нескольких
независимых с одинаковым распределением ON/OFF источников, интервалы
между ON и OFF периодами которого имеют эффект Ноа. Именно эффект Ноа
в распределении длительностей ON/OFF периодов есть базовым при
моделировании самоподобного трафика и он есть синонимом бесконечной
дисперсии. Математически для достижения этого эффекта можно использовать
распределение Парето, которое еще называют „распределением с длинным
хвостом”. Плотность распределения Парето задается функцией:
a+ 1
a b
f ( x) = ,
b x
где a – параметр формы, b – мода распределения (здесь это минимальное
значение случайной величины x). Причем, при a ≤ 2 дисперсия бесконечна (что
и нужно в качестве одного из условий самоподобия). Наличие в распределении
так называемого „длинного хвоста” обеспечивает свойство пачечности трафика,
поскольку в распределении сильно возрастает вероятность длинных интервалов
между требованиями (например, отсутствие пакетов на интервале) и для
„поддержки” заданного среднего значения количества требований необходима
их концентрация (увеличение) на других интервалах времени.
Параметр формы a и параметр Херста H находятся в такой зависимости:
3− a
H=
.
2
В практическом моделировании распределение Парето получается путем
перехода от равномерного распределения методом обратной функции:
b
zi =
aU ,
i
где zi – i-й интервал между требованиями, U – случайное число, равномерно
распределенное на интервале [0, 1].
Алгоритм моделирования на рис. 9.2 позволяет исследовать СМО типа
GI/G/m/r. При этом могут быть любыми тип входного потока, распределение
длительности обслуживания и дисциплина обслуживания – с потерями при
r = 0, с неограниченной очередью при r = ∞, и комбинированная при 0 < r < ∞.
99
Очистка счетчиков,
Т = 0, Т1 = 0,
Oj = ∞ , j = 1…m
Начало
Формир. zi
O = min[Oj]
T = T + zi
Нет
T+zi > O
Да
T=O
Pk = Pk + (T-T1)
Pk = Pk + (T-T1)
T1 = T
T1 = T
k = Kmax
Да
k=k-1
d=d+1
Да
Нет
k<m
k=k+1
Нет
Да
Сw = С w + 1
s=s+1
Wk = T
TCw=T-Wm+1
Формир. On
Формир. zi
Wi = Wi+1
i=m+1…Kmax
s=s+1
Зм. Yвх
k>m
Нет
Вибор n
Формир. Oj
Изм. Yвх
Формир. zi
Oj=∞
Нет
Изм. Yобсл
s > Smax
Да
Pk = Pk / T, k=0…Kmax
PB = d / (d+s)
Pw=Cw/s
Рисунок 9.2 – Алгоритм имитационной модели
100
Конец
Для основных переменных имитационной модели приняты следующие
обозначения (назначения других переменных указаны далее по тексту):
− s – текущее количество обслуженных требований;
− Smax – максимальное количество обслуженных требований;
− d – количество потерянных (не обслуженных) требований;
− k – текущее количество требований в системе (в серверах и очереди);
− r – количество комплектов ожидания;
− m – количество серверов в системе;
− n – номер занимаемого сервера (n ≤ m);
− Kmax – максимальное количество требований в системе (Kmax = m + r);
− Сw – количество требований, попавших в очередь на ожидание.
Работа модели начинается с установки в нуль таймера (счетчика)
текущего времени T, таймера момента предыдущего события T1 и всех других
накопительных счетчиков. Моментам выхода из системы требований
приписываются значения, которые превышают предельное значение таймера T
(все серверы свободные).
Момент выхода требования из системы соответствует моменту освобождения сервера и записывается в индивидуальную ячейку памяти, закрепленную
за каждым сервером. При занятии сервера в нее записывается момент его будущего освобождения, найденный как сумма значений таймера текущего времени
и длительности обслуживания B(t). При освобождении сервера в эту ячейку
записывается такое значение (например, 1099, „бесконечность”), которого
никогда не достигнет в результате всего времени моделирования таймер T.
После сброса схемы в исходное состояние формируется случайный
момент zi прибытия i-го требования. Из ячеек памяти, закрепленных за каждым
сервером, выбирается минимальный из моментов освобождения серверов
Oj (j – номер освобождающегося сервера). Вариант обработки текущего
события определяется соотношением между T + zi и Oj. Если T + zi ≤ min[Oj], то
текущим событием есть прибытие требования. Соответственно перемещается
таймер текущего времени T. К счетчику Pk времени нахождения системы в
состоянии с k требованиями (в серверах и в очереди) прибавляется разность
T – T1 и обновляется значение T1. Если новое требование застает в системе Kmax
требований (заняты все m серверов и все r комплектов ожидания, т.е. k = Kmax),
то к счетчику отказов d прибавляется 1. Далее формируется момент zi+ 1
прибытия нового требования. После подпрограммы измерения избыточной
нагрузки выполняется возвращение к оператору проверки условия T + zi > Oj
(поскольку z обновленное).
При наличии в системе свободных мест (серверы или комплекты
ожидания) k < Kmax. Поэтому текущее значение количества требований в
системе k увеличивается на единицу и проверяется наличие свободных
серверов. Если k > m, то их нет, соответственно данное требование
направляется в комплект ожидания. При этом счетчик задержанных требований
Cw увеличивается на единицу, а в закрепленной за комплектом ожидания ячейке
памяти Wk записывается момент занятия T. Потом формируется момент
101
прибытия очередного требования zi+1 и запускается подпрограмма измерения
входной нагрузки Yвх.
Если есть хотя бы один свободный сервер (k ≤ m), то определяется его
номер n по наличию признака „∞” в закрепленной за ним ячейке памяти. Далее
формируется момент будущего освобождения On = T + B(t) n-го сервера и
записывается в его ячейку памяти. Потом счетчик количества обслуженных
требований s увеличивается на 1. После подпрограммы измерения входной
нагрузки Yвх формируется следующий момент zi+1 прибытия нового требования.
После подпрограммы измерения обслуженной Yобсл нагрузки выполняется
проверка достижения заданного количества обслуженных требований Smax. Если
предел количества обработанных требований не достигнут, то выполняется
возвращение к оператору поиска минимального из моментов освобождения
серверов Oj. В противном случае ведется расчет стационарных вероятностей Pk,
которые определяются как доля общего времени T, в течение которого в
системе было занято ровно k мест (серверов и комплектов ожидания). Для этого
накопленные значения счетчиков Pk делятся на значение таймера общего
времени моделирования T. Вероятность потерь по времени Pt соответствует
доле времени, в течение которого в системе были занятые все m серверов, или
отношению суммарного времени занятия m серверов за интервал времени
наблюдения к длине этого интервала, то есть Pk / T при k = m. Вероятность
потерь по требованиям PB находится из отношения количества потерянных
требований d к общему количеству входных требований d + s (потерянных и
обслуженных). Вероятность ожидания Pw>0 находится из отношения количества
задержанных требований Cw к общему количеству обслуженных требований s.
Если T + zi > min[Oj], то очередным событием есть завершение начатого
обслуживания и освобождение места в системе (сервера или комплекта ожидания j). Здесь также перемещается таймер текущего времени T, к счетчику Pk
времени пребывания системы в состоянии с k занятыми местами прибавляется
разность T – T1 и обновляется значение T1. Потом количество занятых мест
(количество обслуженных системой требований) k уменьшается на единицу.
При k ≥ m есть очередь, а поэтому, после освобождения сервера из первого
(головного) комплекта ожидания ожидающее требование, передается сразу же в
этот сервер на обслуживание. При этом количество обслуженных требований s
увеличивается на 1. Длительность ожидания каждого требования из очереди,
которую рассчитывают как разность между текущим моментом времени T и
моментом времени постановки требования в очередь на ожидание (записано в
ячейку Wm+ 1), накапливается в специальном массиве TCw для определения
функции распределения длительности ожидания и других моментов. Вслед за
этим требования (записи в ячейках памяти о моментах постановки в очередь),
находящиеся в комплектах ожидания начиная из второго, последовательно
перемещаются в комплекты с номером на единицу меньшим (обслуживание
требований происходит по правилу FIFO). Потом для данного сервера, который
принял требование из очереди на обслуживание формируется момент будущего
освобождения On = T + B(t) и записывается в его ячейку памяти.
102
Если k < m, то очереди нет и освобождается сервер системы. В ячейку
памяти, закрепленную за освобожденным сервером j, записывается „бесконечность” – признак свободности сервера. После этого выполняется переход на
выбор следующего минимального из моментов освобождения серверов Oj.
Подпрограммы „измерения” обслуженной и входной (сумма обслуженной
и избыточной) нагрузок и их дисперсии содержат массивы для сохранения всех
интервалов времени между требованиями и всех длительностей обслуживания
требований. Обслуженная нагрузка определяется из отношения суммарного
времени занятия всех серверов к общему времени наблюдения. Входная
нагрузка определяется из отношения среднего времени занятия сервера к
среднему времени интервала между двумя требованиями (Mt / Mz). Она же
определяется и как среднее число требований за среднюю длительность занятия
сервера Mt. При этом дисперсия нагрузки находится как дисперсия количества
требований за Mt для всех интервалов Mt, содержащихся в периоде наблюдения.
Для исследования системы с дисциплиной обслуживания с потерями
необходимо выбрать количество комплектов ожидания r = 0, при этом
автоматически Kmax = m.
Для проверки корректности построения имитационной модели
необходимо выполнить следующие тесты:
– проверка „случайности” генератора равномерно распределенных чисел
на интервале [0, 1] по критерию χ2 Пирсона ;
– проверка произвольно распределенных случайных чисел по
центральным моментам распределения, коэффициентам асимметрии и эксцесса.
Можно испытать имитационную модель на получение заранее известных
результатов. Для этого генерируется пуассоновский поток (экспонентное
распределение интервалов времени между требованиями) и значения
вероятностей потерь сравниваются со значениями формулы Эрланга.
Моделирование функций A(z) и B(x) путем перехода от равномерного
распределения методом обратной функции выполняется по формулам табл. 9.1.
Таблица 9.1 – Метод моделирования случайной величины
Вид функции
Плотность
распределени
я
Параметр
распределения
Релея
xi = −
λ e− λ x
Экспонентная λ – интенсивность
x
e
b
b – мода распределения
−
x2
a− 1 − λ 0 xa
a – параметр формы
λ 0 ax
Парето
a – параметр формы
b – мода распределения
(b -минимальное значение)
a b
b x
103
1
ln U i
λ
xi = b − ln U i
2b 2
Вейбулла
Способ
моделирования
e
a+ 1
1
xi = − ln U i
λ
b
xi =
(U i ) 1 / a
1/ a
Контрольные вопросы и задачи
1. В чем сущность задач анализа телекоммуникационных систем?
2. Какая значимость задач синтеза телекоммуникационных систем?
3. В чем состоит цель задачи оптимизации телекоммуникационных
систем?
4. Назовите основные методы решения задач теории телетрафика.
5. Какие компоненты входят в математическую модель системы
распределения информации?
6. Как описывается дисциплина обслуживания требований в СРИ?
7. Как описывается входной поток требований на обслуживание в СРИ?
8. Какой вид распределения имеет интервал времени между
требованиями в пуассоновском потоке?
9. Какие виды вероятностных распределений применяются для
описания случайных процессов, происходящих в СРИ (входной
поток, продолжительность обслуживания, состояния системы)?
10. Назовите виды СРИ по способам обслуживания требований.
11. Назовите типы дисциплин обслуживания очереди в СРИ.
12. Назовите основные правила обслуживания требований в СМО с
приоритетами.
13. Назовите основные характеристики, представляющие структуру СРИ.
14. Объясните структуру условного обозначения базовой модели СРИ по
Кендаллу.
15. Что такое „интенсивность потока требований”?
16. Что такое „интенсивность обслуживания требований”?
17. Что такое „нагрузка” СРИ?
18. Что такое „интенсивность нагрузки” и какими способами ее можно
определить?
19. В чем различие между входной и обслуженной нагрузкам СРИ?
20. Какие свойства у пуассоновского потока требований?
21. Какие
типы
реального
трафика
определены
для
телекоммуникационных сетей и в чем различие между ними?
22. Назовите характеристики качества обслуживания для системы с
потерями.
23. Назовите характеристики качества обслуживания для системы с
очередями.
24. Что такое „пропускная способность” СРИ?
25. Какими методами исследуется функционирование СРИ при условии
обслуживания пуассоновского потока требований?
26. Какие признаки пуассоновского потока требований?
104
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
Что определяет понятие „состояние системы”?
Для расчета какой системы предназначена B-формула Эрланга?
Какой параметр QoS можно рассчитать по C-формуле Эрланга?
Что определяет формула Литтла?
Для расчета какой системы предназначена формула ПоллачекаХинчина?
Как отличаются характеристики качества обслуживания в моделях
M/M/1/∞ и M/D/1/∞?
Что такое „гиперэкспоненциальное распределение”?
Как отличаются между собой интенсивность нагрузки и ее дисперсия
для пуассоновского и реального (гиперэкспоненциального) потока
требований?
Что такое „коэффициент скученности” нагрузки или „пикфактор”
трафика СРИ?
Чем характерный трафик пакетных сетей связи и какой моделью он
может быть описан?
В каких пределах может быть коэффициент Херста для
самоподобных и несамоподобных потоков трафика.
Что определяет энтропия вероятностного распределения?
Определить долю потерянных требований для системы M/M/1, в
которую поступает поток требований с интенсивностью λ = 2, а
интенсивность обслуживания μ = 4.
Определить среднее количество требований в очереди в системе
M/M/1/∞, в которую поступает поток требований с интенсивностью
λ = 2, а интенсивность обслуживания μ = 2,5.
Определить вероятность ожидания и вероятность потери требования
для системы M/M/1/5, в которую поступает поток требований с
интенсивностью λ = 2, а интенсивность обслуживания μ = 4.
На сколько отличается среднее количество требований в системах
M/M/1/∞ и M/D/1/∞, в которую поступает поток требований с
интенсивностью 2 требования в секунду при средней
продолжительности обслуживания требований x = 0,35 с.
Сколько в среднем (в секундах) будут ожидать требования в очереди
системы M/M/80/∞ при интенсивности нагрузки Λ = 70 Эрл и средней
продолжительности обслуживания 35 с.
Определить вероятность ожидания в системе M/M/80/∞ при
интенсивности нагрузки Λ = 70 Эрл.
Доказать, что вероятность ожидания в системе M/M/m/r всегда
меньше такой же вероятности в системе M/M/m/∞.
105
Список литературы
1. Крылов В.В., Самохвалова С.С. Теория телетрафика и её приложения. –
СПб.: БХВ-Петербург. – 2005. – 288 с.: ил.
2. Шнепс М.А. Системы распределения информации. Методы расчета:
Справ. пособие. – М.: Связь, 1979. – 344 с., ил.
3. Корнышев Ю.Н., Фань Г.Л. Теория распределения информации: Учеб.
пособие для вузов. – М.: Радио и Связь. – 1985. – 184 с., ил.
4. Ложковский А.Г., Захарченко Н.В., Горохов С.М. Экспериментальная
оценка модели потока вызовов на современных телефонных сетях //
Наукові праці ОНАЗ ім. О.С. Попова. – 2001. – №2. – С. 40–43.
5. Клейнрок Л. Теория массового обслуживания. Пер. с англ. – М.:
Машиностроение. – 1979. – 432 с., ил.
6. Вентцель Е.С., Овчаров Л.А. Теория случайных процессов и её
инженерные приложения. – М.: Наука. Ред. физ.-мат. лит. – 1991.– 384с.
7. Кениг Д., Штойян Д. Методы теории массового обслуживания. Пер. с
нем. – М.: Радио и Связь. – 1981. – 128 с., ил.
8. Ложковський А.Г. Спрощений метод розрахунку багатоканальної системи
з чергою в моделі M/D/m/∞ (Задача Кроммеліна) // Наукові праці ОНАЗ
ім. О.С. Попова. – 2008. – № 2. – С. 69-76.
9. Ложковский А.Г., Салманов Н.С., Вербанов О.В. Моделирование
многоканальной системы обслуживания с организацией очереди //
Восточно-европейский журнал передовых технологий. –
2007. –
№3/6(27). – С.72-76.
10. Ложковський А.Г. Нова методика оцінювання імовірності втрат викликів,
наближена до реальних умов // К.: Зв’язок. – 2004. – №3. – С. 52–53.
11. Ложковский А.Г. Метод расчета систем обслуживания с ожиданием при
произвольном потоке вызовов // К.: Зв’язок. – 2006. – № 1. – С. 57–60.
12. Ложковский А.Г. Сравнительный анализ методов расчета характеристик
качества обслуживания при самоподобных потоках в сети // Моделювання
та інформаційні технології. Зб. наук. пр. ІПМЕ ім. Г. Є. Пухова НАН
України. – Вип. 47. – К.: 2008. – С. 187-193.
13. Ложковский А.Г., Ганифаев Р.А. Оценка параметров качества
обслуживания самоподобного трафика энтропийным методом // Наукові
праці ОНАЗ ім. О.С. Попова. – 2008. – № 1. – С. 57-62.
14. Ложковский А.Г. Расчет одноканальных систем с бесконечной очередью
при экспоненциальной длительности обслуживания // Наукові праці
ОНАЗ ім. О.С. Попова. – 2009. – № 2. – С. 10-13.
15. Ложковский А.Г. Рекуррентный метод расчета пропускной способности
пакетной сети доступа / А.Г. Ложковский, Н.С. Салманов, Н.А. Чумак //
Наукові праці ОНАЗ ім. О.С. Попова. – 2006. – № 2. – С. 44-48.
16. Лившиц Б.С. Теория телетрафика: Учебник для вузов / Б.С. Лившиц, А.П.
Пшеничников, А.Д. Харкевич // М.: Связь. – 1979. – 224 с., ил.
17. Степанов С.Н. Основы телетрафика мультисервисных сетей. – М.: ЭкоТрендз. – 2010. – 392 с.: ил.
106
Дополнительная литература
18. Величко В.В., Субботин Е.А., Шувалов В.П., Ярославцев А.Ф.
Телекоммуникационные системы и сети. Том 3. Мультисервисные сети. –
М.: Горячая линия – Телеком, 2005. – 592 с.: ил.
19. Штермер Х., Белендорф Э. и др. Теория телетрафика. Основы расчета
систем проводной связи. Перевод с нем. – М.: Связь, 1971. – 319 с.
20. Эллдин А., Линд Г. Основы теории телетрафика. – М.: Связь, 1972 г. –
200 с.
21. Бенеш В.Э. Математические основы теории телефонных сообщений.–
Перевод с нем. – М.: Связь, 1968. – 291 с.
22. Башарин Г.П., Харкевич А.Д., Шнепс М.А. Массовое обслуживание в
телефонии. – Изд-во «Наука», 1968.
23. Башарин Г.П., Кокотушкин В.А. О некоторых направлениях развития
математической теории телетрафика. Обзор. // Теория телетрафика. Х.
Штермер и др. – М.: Связь, 1971. – с. 292-304.
24. Башарин Г.П. О вычислении моментов обслуженной и избыточной
нагрузок сложной системы – Изв. АН СССР. Техн. Кибернетика № 1,
1972. – с. 42-51.
25. Вентцель Е.С. Теория вероятностей. – М.: Гос. Издательство физ.-мат.
литературы, 1962. – 564с.
26. Вентцель Е.С., Овчаров Л.А. Прикладные задачи теории вероятностей. –
М.: Радио и связь. – 1983. – 416 с., ил.
27. Ионин Г.Л., Седол Я.Я. Статистическое моделирование систем
телетрафика. - М.: Радио и связь. – 1982. – 184 с.
28. Кожанов Ю.Ф. Расчет и проектирование электронных АТС: Справочник.
– М.: Радио и связь. 1991. – 144 с., ил.
29. Корнышев Ю.Н. Оптимизация проектных решений для сельских
телефонных сетей. – М.: Связь, 1983. – 136 с.
30. Лившиц А.Л., Мальц Э.А. Статистическое моделирование систем
массового обслуживания. – М.: Сов. Радио, 1978.
31. Нейман В.И. Структуры систем распределения информации. – 2-е изд,
перераб. и доп. – М.: Радио и связь, 1983. – 216 с., ил.
32. Севастьянов Б.А. Эргодическая теорема для марковских процессов и ее
приложение к телефонным системам с отказами. Сб. «Теория
вероятностей и ее применения», 1957, т. 2, вып. 1. – с. 106-116.
33. Справочник по теории вероятностей и математической статистике / В.С.
Королюк и др. – М.: Наука. Главная редакция физико-математической
литературы, 1985. – 640 с.
34. Фигурин В.А., Оболонкин В.В. Теория вероятностей и математическая
статистика: Учеб. Пособие. – Мн.: ООО «Новое знание», 2000. – 208 с.
35. Хинчин А.Я. Математические методы теории массового обслуживания. //
Работы по математической теории массового обслуживания. Изд-во физ.мат. Лит-ры. – М.: 1963. – с. 7-148.
107
Список обозначений и сокращений
Cm(Λ)
Em(Λ)
k
m
N
Pk
Pw>0
PВ
Q
r
S
T
tq
W
x
Y
z
λ
Λ
μ
ρ
FIFO
LIFO
QoS
SIRO
ЧНН
ЭВМ
СМО
СРИ
ТМО
– C-формула Эрланга
– B-формула Эрланга
– состояние системы (количество занятых серверов)
– количество серверов системы
– среднее количество требований в системе
– вероятность состояния системы в случае занятости k
серверов
– вероятность ожидания
– вероятность потери (блокирования) требования
– средняя длина очереди
– количество мест ожидания в очереди
– коэффициент скученности нагрузка (пикфактор трафика)
– средняя продолжительность пребывания требований в
системе
– средняя продолжительность ожидания требований в
очереди
– средняя продолжительность ожидания требований в
системе
– продолжительность обслуживания требования
– интенсивность обслуженной нагрузки
– продолжительность интервала времени между
требованиями
– интенсивность потока требований
– интенсивность входной нагрузки
– интенсивность обслуживания требований
– интенсивность удельной нагрузки
– First in first out (первый обслуживается первым)
– Last in first out (последний обслуживается первым)
– Quality of Service (качество обслуживания)
– Service in random order (случайное обслуживание)
– час наибольшей нагрузки
– электронная вычислительная машина
– Система массового обслуживания
– Система распределения информации
– Теория массового обслуживания
108
Предметный указатель
B-формула Эрланга
C-формула Эрланга
Абсолютный приоритет
Относительный приоритет
Вложенная цепь Маркова
Геометрическое распределение
Гиперэкспонентное распределение
Дисперсия
Второе распределение Эрланга
Экспонентное распределение
Энтропия распределения
Закон Пуассона
Вероятность потери требования
Вероятность ожидания
Интенсивность входной нагрузки
Интенсивность обслуживания
Интенсивность обслуженной нагрузки
Интенсивность удельной нагрузки
Коэффициент асимметрии
Коэффициент вариации
Коэффициент эксцесса
Коэффициенте Херста
Марковская цепь
Математическое ожидание
Метод Кроммелина
Моменты распределения
Нагрузка
Нормальный закон
Преобразования Лапласа-Стилтьеса
Первое распределение Эрланга
Пикфактор трафика
Поток требований
Производительность
Пропускная способность
Пуассоновский поток
Распределение вероятностей состояний системы
Распределение Парето
Самоподобный процесс
Среднее время пребывания требования в системе
Средняя длина очереди
Среднее количество требований в системе
Средняя продолжительность ожидания в системе
Средняя продолжительность ожидания в очереди
Скученность интенсивности нагрузка
Усеченный нормальный закон
Формула Литтла
Формула Норроса
Формула Поллачека-Хинчина
109
Стр.
37
41
60
55
53
10, 91
71, 99
11
40
20, 99
86
21
28
29, 40
25
34
24
41
12
12
12
82
32
11
48
11
24
78
53
37
76
21
31
31
22
38
93, 100
81
28, 29
29
28, 29
29
29
76
74
48
85
55
ПРИЛОЖЕНИЕ
Таблица 1 – Интенсивность нагрузки Y, обслуженной m-серверным
полнодоступным пучком при потерях 1, 3 и 5 ‰ и коэффициенте
S скученности входной нагрузки
m
S=5
S=4
S=3
S=2
S=1
Y в Эрл
при потерях РB
Y в Эрл
при потерях РB
Y в Эрл
при потерях РB
Y в Эрл
при потерях РB
Y в Эрл
при потерях РB
0,001 0,003 0,005 0,001 0,003 0,005 0,001 0,003 0,005 0,001 0,003 0,005 0,001 0,003 0,005
5
0,61
0,66
0,69
0,69
0,75
0,80
0,72
0,87
0,93
0,74
0,93
1,00
0,76
1,00
1,13
10
2,10
2,28
2,42
2,33
2,57
2,74
2,59
2,91
3,11
2,94
3,35
3,59
3,09
3,63
3,94
15
4,14
4,53
4,80
4,54
5,01
5,33
5,00
5,59
5,96
5,59
6,29
6,67
6,07
6,89
7,34
20
6,54
7,17
7,59
7,13
7,87
8,34
7,80
8,66
9,18
8,62
9,58 10,08 9,40
25
9,24
10,10 10,68 10,00 10,99 11,61 10,86 11,99 12,67 11,88 13,09 13,71 12,96 14,23 14,92
30
12,14 13,25 13,98 13,07 14,32 15,08 14,11 15,49 16,31 15,32 16,76 17,50 16,67 18,15 18,94
35
15,20 16,57 17,44 16,29 17,79 18,71 17,50 19.13 20,09 18,90 20,55 21,40 20,50 22,16 23,05
40
18,40 20,01 21,03 19,65 21,39 22,45 21,02 22.89 23,98 22,59 24,44 25,40 24,42 26,26 27,25
45
21,72 23,56 24,73 23,12 25,07 26,28 24,64 26.74 27,95 26,36 28,40 29,48 28,42 30,43 31,50
50
25,13 27,21 28,51 26,66 28,85 30,19 28,33 30.66 32,00 30,22 32,44 33,62 32,48 34,65 35,80
55
28,62 30,93 32,36 30,29 32,71 34,16 32,10 34.64 36,08 34,14 36,54 37,81 36,59 38,91 40,22
60
32,19 34,72 36,28 33,98 36,62 38,20 35,93 38.88 40,21 38,11 40,69 42,05 40,75 43,23 44,53
65
35,81 38,56 40,25 37,73 40,59 42,29 39,82 42.77 44,38 42,13 44,87 46,33 44,95 47,57 48,95
70
39,50 42,46 44,27 41,54 44,61 46,42 43,75 46.91 48,59 46,19 49,10 50,65 49,19 51,94 53,39
75
43,23 46,41 48,34 45,39 48,66 50,60 47,73 51.08 52,83 50,30 53,36 54,99 53,46 56,34 57,86
80
47,01 50,40 52,45 49,29 52,75 54,80 51,75 55.29 57,11 54,45 57,66 59,36 57,75 60,77 62,35
85
50,83 54,43 56,60 53,22 56,89 59,04 55,79 59.53 61,41 58,61 61,97 63,76 62,07 65,21 66,87
90
54,70 58,48 60,76 57,19 61,06 63,31 59,88 63.80 65,75 62,82 66,31 68,19 66,41 69,68 71,39
95
58,59 62,58 64,97 61,19 65,24 67,62 64,00 68.12 70,10 67,04 70,68 72,63 70,78 74,17 75,94
100
62,5
66,7
69,2
65.2
69,5
71,9
68,1
72,4
74,5
71,3
75,1
77,1
75,2
78,7
80,5
110
70,5
75,0
77,8
73,4
78,0
80,6
76,5
81,1
83,3
79,9
83,9
86,1
84,0
87,7
89,7
120
78,5
83,5
86,4
81,6
86,6
89,3
84,9
89,9
92,2
88,5
92,8
95,1
92,9
96,8
98,9
130
86,7
92,0
95,1
89,9
95,3
98,1
93,4
98,7
101,1
97,2
101,7 104,2 101,8 106,0 108,2
140
94,9
100,5 103,9
98,3
104,0 106,9 102,0 107,5 110,1 105,9 110,7 113,3 110,8 115,2 117,4
150
103,2 109,2 112,6 106,8 112,8 115,8 110,7 116,5 119,2 114,7 119,8 122,5 119,8 124,4 126,8
160
111,5 117,9 121,4 115,3 121,6 124,8 119,4 125,4 128,2 123,6 128,9 131,7 128,9 133,6 136,1
170
120,0 126,6 130,3 123,9 130,5 133,8 128.1 134,4 137,4 132,5 138,0 141,0 138,0 142,9 145,5
180
128,5 135,4 139,2 132,6 139,5 142,8 136,9 143,4 146,5 141,4 147,2 150,2 147,2 152,2 154,9
190
137,0 144,3 148,2 141,2 148,4 151,9 145,8 152,5 155,7 150,4 156,4 159,5 156,2 161,6 164,4
200
145,5 153,2 157,1 150,0 157,5 161,0 154,6 161,6 164,9 159,4 165,6 168,9 165,4 170,9 173,7
210
154,2 162,1 166,2 158,7 166,5 170,1 163,5 170,7 174,2 168,4 174,8 178,2 174,6 180,3 183,3
240
180,2 189,1 193,4 185,2 193,8 197,6 190,4 198,2 202,0 195,6 202,7 206,4 202,4 208,6 211,8
110
10,46 11,04
Учебное издание
ЛОЖКОВСКИЙ Анатолий Григорьевич
ТЕОРИЯ МАССОВОГО
ОБСЛУЖИВАНИЯ В
ТЕЛЕКОММУНИКАЦИЯХ
Редактор
Компьютерная верстка
Гусак В. Т.
Корнейчук Е. С.
Издательство ОНАС им. А. С. Попова
(свидетельство ДК № 3633 от 27. 11. 2009 г.)
Сдано в набор 06.07.2012. Подписано к печати 1.10.2012
Формат 60х90/16. Тираж 300.
Усл. печ. л. 7,0. Усл. авт. печ. л. 7,3. Заказ № 4959
Отпечатано с готового оригинал-макета в типографии
Одесской национальной академии связи им. А. С. Попова
г. Одесса, ул. Ковалевского, 5
Тел. (048) 70-50-494
111