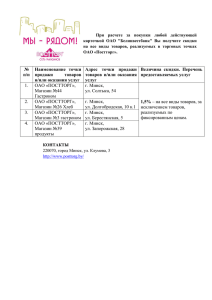
Основы баз данных
Содержание курса
Базы данных и системы управления
Организация доступа к данным
Реляционная алгебра
Основы SQL
Проектирование реляционных баз данных
Некоторые проблемы администрирования баз
данных
Взаимодействие с приложениями
Рекомендуемая литература
К.Дж. Дейт. Введение в системы баз
данных. Седьмое издание. – М.:
Вильямс, 2003. – 847 С.)
В. Иванюкович. Системы баз данных.
Вводный курс. Учебное пособие для
студентов специальности 1-40 01 02. –
Мн., МГЭУ им. А.Д. Сахарова, 2010. –
193 С.
Базы данных и системы управления
Файловые системы.
Сложность реализации информационных систем.
Информационная система представляет собой программноорганизационный комплекс, функции которого состоят в организации
сбора информации и в поддержке ее надежного хранения в памяти
компьютера, выполнении специфических для данного приложения
преобразований информации и/или вычислений, предоставлении
пользователям удобного и дружелюбного интерфейса, а также в
системе распространения данных.
Системы управления базами данных.
Данные – это представленная в формализованном виде конкретная
информация об объектах реального мира, их свойствах и
взаимосвязях. Данные могут быть представлены в виде скаляров,
векторов, матриц, тензоров, списков, файлов, иерархических и сетевых
структур и т.п.
Данные и их интерпретация.
Данные и их интерпретация
Номер
рейса
138
57
1234
242
86
137
241
577
78
578
Дни
Пункт Время
недели отправл. вылета
2_4_7 Минск
3_6
Ереван
2_6
Москва
1 по 7
Киев
2_3_5 Минск
1_3_5 Москва
1 по 7 Москва
1_3_5
Рига
3_6
Сочи
2_4_6 Таллинн
Пункт Время
Тип
Стоим.
назнач. прибыт. самолета билета
21.50 Москва 0.52
7.20
Киев
9.25
22.40 Минск 23.50
14.10 Москва 16.15
10.50
Сочи
13.06
17.15 Минск 18.44
9.05
Киев
11.05
21.53 Таллинн 22.57
18.25 Минск 20.12
6.30
Рига
7.37
ИЛ-86 115.00
ТУ-154 92.00
ТУ-134 73.50
ТУ-154 57.00
ИЛ-86 78.50
ИЛ-86 115.00
ТУ-154 57.00
АН-24 21.50
ТУ-134 44.00
АН-24 21.50
Концепция баз данных
Основная особенность СУБД – это наличие процедур
не только для ввода, хранения и обработки самих
данных, но и для описания их структуры. Файлы,
снабженные описанием хранимых в них данных и
находящиеся под управлением СУБД, стали
называть банками данных, а затем базами данных.
Создание структуры хранения
данных
СОЗДАТЬ ТАБЛИЦУ Расписание
(Номер_Рейса
Целое,
Дни_Недели
Текст (8),
Пункт_Отправления
Текст (24),
Время_Вылета
Время,
Пункт_Назначения
Текст (24),
Время_Прибытия
Время,
Тип_Самолета
Текст (8),
Стоимость_Билета
Денежный);
Поиск и обработка данных
ВЫБРАТЬ Номер_Рейса, Дни_Недели,
Время_Вылета
ИЗ ТАБЛИЦЫ Расписание
ГДЕ Пункт_Отправления = 'Москва'
И Пункт_Назначения = 'Минск'
И Время_Вылета > ‘17’;
ВЫБРАТЬ КОЛИЧЕСТВО (*)
ИЗ ТАБЛИЦЫ Расписание
ГДЕ Пункт_Отправления = 'Москва'
И Пункт_Назначения = 'Минск';
Реляционная модель
(relation – отношения)
данные на концептуальном уровне представляются в виде
двумерных таблиц, в которых хранится информация о
сущностях;
строки называются кортежами или записями и содержат
информацию об экземплярах сущности;
столбцы называются полями и содержат информацию об
атрибутах сущности.
реляционные системы представляют более простую среду для
разработки баз данных, чем иерархические или сетевые;
программное обеспечение, основанное на реляционной
алгебре, позволяет организовать практически любое
манипулирование данными.
Идея реляционной модели данных
Строки таблицы с n колонками, состоящими из элементов
множеств A1, A2, …, An, можно представить как подмножество в
прямом произведении A1A2… An. Строки образуют список из n
элементов, по одному из каждого множества Ai, а вся таблица
представляет собой n-арное отношение. Например, таблицу
КЛИЕНТЫ можно рассматривать как подмножество множества
A1A2A3A4, где A1 – множество кодов клиентов, A2 – множество
имен клиентов, A3 – множество их адресов, An – множество
названий организаций. Один из элементов этого отношения –
строка К1, Андрей, Минск, ИНКО.
Представленные таким образом таблицы можно обрабатывать,
используя алгебру отношений на множествах.
Основные термины
реляционного отношения
Домены
Первичный ключ
Табель
B1
Отношение
Фамилия
Код
отдела
Ильин
A1
Зарплата
100
B2
Петров
A1
140
B3
Котов
A3
185
B4
Волк
A3
115
Атрибуты
Степень
к
о
р
т
е
ж
и
к
а
р
д
и
н
а
л
ь
н
о
е
ч
и
с
л
о
Домены
Домены – это общая совокупность значений, из
которых берутся реальные значения
атрибутов. Домены ограничивают сравнения.
Пример создания и удаления доменов:
CREATE DOMAIN Фамилия
CHAR(20);
DESTROY DOMAIN Зарплата;
Отношения
Отношение определяется на множестве
доменов и состоит из заголовка
(интерпретация данных) и тела (набора
данных). Тело содержит множество кортежей
(кардинальное число) и атрибутов (степень).
Основные свойства отношений:
Нет одинаковых кортежей;
Кортежи не упорядочены сверху вниз;
Атрибуты не упорядочены слева направо;
Все значения атрибутов атомарны.
Отношения (2)
Именованное отношение называется
базовым, если оно является
непосредственной частью базы данных.
Производные отношения определяются
через базовые отношения посредством
реляционных выражений и, как правило, не
именованы. Именованное производное
отношение называется представлением.
Ключи
Потенциальные ключи в реляционной системе
обеспечивают основной механизм адресации на уровне
кортежей.
Потенциальный ключ – это минимальный набор атрибутов,
по значениям которых можно однозначно найти
требуемый кортеж отношения.
Из набора потенциальных ключей выбирается первичный
ключ – атрибут или сочетание атрибутов, который
выполняет особую роль в отношении.
Предикат
Для каждого отношения есть связанная с ним
интерпретация, или предикат, составляющий
критерий возможности обновления для этого
отношения. В любой момент времени отношение
содержит в точности те кортежи, при которых
предикат является истиной.
Реляционная алгебра
Замкнутость;
Правила наследования имен атрибутов;
Правила наследования потенциальных
ключей;
Совместимость по типу: Два отношения
совместимы по типу, если каждое из них
имеет одно и то же множество имен
атрибутов и соответствующие атрибуты
определены на одном и том же домене.
Традиционные реляционные операции (1)
Объединение
Объединением двух
совместимых по типу
отношений А и В (A
UNION B) называется
отношение с тем же
заголовком, как и в
отношениях А и В, и с
телом, состоящим из
множества всех
кортежей t,
принадлежащих А или В
или обоим отношениям.
При этом совпадающие
кортежи записываются
один раз.
Детали1
Д№
Имя_Д
Цв
Вес
Гор
Д1
Тестер
Черный
250
Минск
Д2
Дозиметр Серый
Радиомет
Черный
р
700
Борисов
1400
Гродно
Вес
Гор
1400
Гродно
140
Минск
Д3
Детали2
Д№
Имя_Д
Цв
Д4
Радиомет
Черный
р
Часы
Желтый
Д5
Рулетка
Красный
200
Брест
Д6
Лом
Черный
5000
Варшава
Вес
Гор
Д3
Детали1 UNION Детали2
Д№
Имя_Д
Цв
Д1
Тестер
Черный
250
Минск
Д2
700
Борисов
1400
Гродно
Д4
Дозиметр Серый
Радиомет
Черный
р
Часы
Желтый
140
Минск
Д5
Рулетка
Красный
200
Брест
Д6
Лом
Черный
5000
Варшава
Д3
Традиционные реляционные операции (2)
Пересечение
Пересечением дух
совместимых по типу
отношений А и В (A
INTERSECT B)
называется отношение с
тем же заголовком, как и в
отношениях А и В, и с
телом, состоящим из
множества всех кортежей Детали1 INTERSECT Детали2
t, которые принадлежат
одновременно обоим
отношениям А и В.
Детали1
Д№
Имя_Д
Цв
Вес
Гор
Д1
Тестер
Черный
250
Минск
Д2
Дозиметр
Серый
700
Борисов
Д3
Радиометр Черный
1400
Гродно
Вес
Гор
Детали2
Д№
Имя_Д
Цв
Д3
Радиометр Черный
1400
Гродно
Д4
Часы
Желтый
140
Минск
Д5
Рулетка
Красный
200
Брест
Д6
Лом
Черный
5000
Варшава
Д№
Д3
Имя_Д
Цв
Радиометр Черный
Вес
Гор
1400
Гродно
Традиционные реляционные операции (3)
Вычитание
Вычитанием двух совместимых по
типу отношений А и В (A MINUS B)
называется отношение с тем же
заголовком, как и в отношениях А и
В, и с телом, состоящим из
множества всех кортежей t,
принадлежащих отношению А и не
принадлежащих отношению В.
Детали1
Д№
Имя_Д
Д1
Тестер
Д2
Д3
Детали2
Д№
Цв
Вес
Гор
250
Минск
Дозиметр Серый
700
Борисов
Радиометр Черный
1400
Гродно
Вес
Гор
Имя_Д
Черный
Цв
Д3
Радиометр Черный
1400
Гродно
Д4
Часы
Желтый
140
Минск
Д5
Рулетка
Красный
200
Брест
Д6
Лом
Черный
5000
Варшава
Детали1 MINUS Детали2
Д№
Имя_Д
Цв
Д1
Тестер
Черный
Д2
Дозиметр Серый
Вес
Гор
250
Минск
700
Борисов
Традиционные реляционные операции (4)
Произведение
Декартово произведение двух отношений А и В (A TIMES B), где А и В не имеют общих
имен атрибутов, определяется как отношение с заголовком, который представляет
собой сцепление (конкатенацию) двух заголовков исходных отношений А и В, и телом,
состоящим из множества всех кортежей t таких, что t представляет собой сцепление
кортежа a, принадлежащего отношению А, и кортежа b, принадлежащего отношению
В. Кардинальное число результата равняется произведению кардинальных чисел
исходных отношений, а степень равняется сумме их степеней.
Детали
Д№
Имя_Д
Детали TIMES
Проекты
Д№
Имя_Д
Пр№
Имя_П
Д1
Тестер
Д1
Тестер
Пр1
Спутник
Д2
Дозиметр
Д1
Тестер
Пр2
Корунд
Д3
Радиометр
Д1
Тестер
Пр3
Лес
Д4
Часы
Д2
Дозиметр
Пр1
Спутник
Д2
Дозиметр
Пр2
Корунд
Д2
Дозиметр
Пр3
Лес
Д3
Радиометр
Пр1
Спутник
Проекты
Пр№ Имя_П
Пр1
Спутник
Д3
Радиометр
Пр2
Корунд
Пр2
Корунд
Д3
Радиометр
Пр3
Лес
Пр3
Лес
Д3
Радиометр
Пр1
Спутник
Д3
Радиометр
Пр2
Корунд
Д3
Радиометр
Пр3
Лес
Специальные реляционные операции (1)
Выборка
Выборка (RESTRICT или SELECT)
– это сокращенное название выборки, где обозначает любой
скалярный оператор сравнения (=,
, , > и т.д.). -выборкой из
отношения А по атрибутам X и Y
(A WHERE X Y) (порядок
учитывается!) называется
отношение, имеющее тот же
заголовок, что и отношение А, и
тело, содержащее множество всех
кортежей t отношения А, для
которых проверка условия «X Y»
дает значение истина. Атрибуты X
и Y должны быть определены на
одном и том же домене, а
оператор сравнения должен
иметь смысл для данного домена.
Детали
Д№
Имя_Д
Цв
Вес
Гор
Д1
Тестер
Черный
250
Минск
Д2
700
Борисов
1400
Гродно
Д4
Дозиметр Серый
Радиомет
Черный
р
Часы
Желтый
140
Минск
Д5
Рулетка
Красный
200
Брест
Д6
Лом
Черный
5000
Варшава
Вес
Гор
Д3
Детали WHERE Гор='Минск'
Д№
Имя_Д
Цв
Д1
Тестер
Черный
250
Минск
Д4
Часы
Желтый
140
Минск
Специальные реляционные операции (2)
Проекции
Проекцией (PROJECT) отношения А
по атрибутам X, Y, …, Z, где
каждый из атрибутов
принадлежит отношению А,
называется отношение с
заголовком {X,Y,…,Z} и телом,
содержащим множество кортежей
с атрибутами, совпадающими с
соответствующими атрибутами
отношения А.
Т.е., с помощью операции проекции
получается вертикальное
подмножество исходного
отношения
ДеталиХ
Д№
Имя_Д
Цв
Вес
Гор
Д1
Тестер
Черный
250
Минск
Д2
Дозиметр
Серый
700
Борисов
Д3
Радиометр Черный
1400
Гродно
Д4
Часы
Желтый
140
Минск
Д5
Рулетка
Красный
200
Брест
Д6
Тестер
Черный
5000
Варшава
ДеталиХ [Имя_Д, Цв]
Имя_Д
Тестер
Цв
Черный
Дозиметр Серый
Радиомет
Черный
р
Часы
Желтый
Рулетка
Красный
Специальные реляционные операции (3)
Соединение (JOIN) – это разновидность операции
произведения, в которой сцепление кортежей основывается на
задаваемом атрибуте или наборе атрибутов каждого из двух
отношений. Значения указанных атрибутов сравниваются с
целью наложения определенных ограничений на результат.
Наиболее часто используется естественное или внутреннее
соединение, когда отношения имеют общий атрибут и
результат содержит только строки, в которых значения общего
атрибута совпадают.
Естественное (или внутреннее) соединение (4)
Естественным (или внутренним) соединением отношений А и В (A
JOIN B) с заголовками X,Y и Y,Z соответственно и с атрибутами Y,
определенными на одном и том же домене, называется отношение с
заголовком {X,Y,Z} и телом, содержащим множество кортежей с
атрибутами, совпадающими с соответствующими атрибутами
отношений А и В.
ПоставщикиХ
П№
Имя_П
ПоставкиХ
П№
Д№
Статус Гор
Пр№
Кол
П1
Волк
20
Брест
П1
Д1
Пр1
200
П2
Заяц
10
Минск
П1
Д1
Пр4
700
П3
Лев
30
Гродно
П2
Д3
Пр1
400
П4
Лиса
20
Минск
П2
Д3
Пр2
200
П5
Бык
30
Брест
П2
Д3
ПР3
200
Д№
Пр№
Кол
ПоставщикиХ JOIN ПоставкиХ
П№
Имя_П
Статус Гор
П1
Волк
20
Брест
Д1
Пр1
200
П1
Волк
20
Брест
Д1
Пр4
700
П2
Заяц
10
Минск
Д3
Пр1
400
П2
Заяц
10
Минск
Д3
Пр2
200
П2
Заяц
10
Минск
Д3
ПР3
200
Специальные реляционные операции (5)
Внешнее соединение
При внешнем соединении кортеж, который невозможно
соединить с кортежем соответствующей таблицы из-за
отсутствия совпадающих значений, будет помещен в
результирующую таблицу, а для присоединенных атрибутов
значения определены не будут, т.е., им присвоят Null-значения.
ПоставщикиХ
П№
Имя_П
ПоставкиХ
П№
Д№
Статус Гор
Пр№
Кол
П1
Волк
20
Брест
П1
Д1
Пр1
200
П2
Заяц
10
Минск
П1
Д1
Пр4
700
П3
Лев
30
Гродно
П2
Д3
Пр1
400
П4
Лиса
20
Минск
П2
Д3
Пр2
200
П5
Бык
30
Брест
П2
Д3
ПР3
200
ПоставщикиХ LEFT JOIN ПоставкиХ
П№
Д№
Пр№
Кол
П1
Волк
Имя_П
Статус Гор
20
Брест
Д1
Пр1
200
П1
Волк
20
Брест
Д1
Пр4
700
П2
Заяц
10
Минск
Д3
Пр1
400
П2
Заяц
10
Минск
Д3
Пр2
200
П2
Заяц
10
Минск
Д3
ПР3
200
П3
Лев
30
Гродно
П4
Лиса
20
Минск
П5
Бык
30
Брест
Специальные реляционные операции (6)
Соединения
Отношения можно соединять по атрибутам,
имеющим либо общие домены, либо сопоставимые
домены, когда значения данных из одного домена
можно сопоставить со значениями данных из другого
домена.
Соединение обладает свойствами ассоциативности и
коммутативности.
Если отношения А и В не имеют общих имен
атрибутов, то естественное соединение
превращается в декартово произведение.
Специальные реляционные операции (7)
Делением (DIVIDED BY)
двух отношений,
бинарного и унарного,
является отношение,
содержащее все
значения одного
атрибута бинарного
отношения, которые
соответствуют (в
другом атрибуте)
всем значениям в
унарном отношении.
П№
Д№
Д№
П1
Д1
П1
Д2
П1
Д4
П2
Д1
П2
Д2
Второй пример:
П3
Д2
Д№
П4
Д1
П4
Д2
П2
П4
Д4
П4
DIVIDED BY
Д2
П№
=
Д4
DIVIDED BY
Д1
П1
П4
П№
=
П1
Дополнительные реляционные операции
Операция расширения
EXTEND A ADD expr AS Z;
Результат: Отношение с заголовком, эквивалентным заголовку отношения А,
расширенному новым атрибутом Z, который рассчитывается скалярным
выражением expr для кортежа отношения А.
Операция расширения обеспечивает возможность горизонтального или
построчного вычисления.
EXTEND Детали ADD Bec/1000 AS Вес(кг)
Д№
Имя_Д
Цв
Вес
Гор
Д1
Тестер
Черный
250
Минск
Д2
Дозиметр
Серый
700
Борисов
Д3
Радиометр Черный
1400
Гродно
Д4
Часы
Желтый
140
Минск
Д5
Рулетка
Красный
200
Брест
Д6
Лом
Черный
5000
Варшава
Вес(кг)
0,25
0,7
1,4
0,14
0,2
5
Пример: Подсчитать количество поставок, сделанных каждым
поставщиком.
EXTEND Поставщики ADD COUNT ((Поставки RENAME П№ AS X)
WHERE X= №) AS Кол_П;
П№
Имя_П
Статус
Гор
Кол_П
П1
Волк
20
Брест
6
П2
Заяц
10
Минск
2
П3
Лев
30
Гродно
1
П4
Лиса
20
Минск
3
П5
Бык
30
Брест
0
Операция расширения обеспечивает возможность
горизонтального или построчного вычисления.
Дополнительные реляционные операции.
Операция подведения итогов
SUMMARIZE A BY (A1,A2,…,An) ADD expr AS Z;
Результат: Отношение с заголовком {A1,A2,…,An,Z} и с телом,
содержащим все такие кортежи t, которые являются кортежами
проекции отношения А по атрибутам A1,A2,…,An, расширенного
значением для нового атрибута Z. Значение Z подсчитывается
вычислением итогового значения expr по всем кортежам отношения А.
Пример:
SUMMARIZE Поставки BY(Д№) ADD SUM(Кол) AS Общ_кол
Д№
Д1
Д2
Д3
Д4
Д5
Д6
Общ_кол
900
300
3500
1300
1100
1300
Пример: Подсчитать количество поставок, сделанных
каждым поставщиком.
SUMMARIZE Поставки BY (П№) ADD COUNT AS Кол_П;
П№
Кол_П
П1
6
П2
2
П3
1
П4
3
Дополнительные реляционные операции.
Возможные операции:
Переименование имени поля:
Детали RENAME Гор AS Гор_Д
Присвоение:
Поставки := Поставки MINUS (Поставки WHERE Кол = 0);
Обновление:
INSERT (Поставщики WHERE Гор_П=Минск ) INTO Temp;
UPDATE (Поставщики WHERE Гор_П=Брест) СТАТУС<40;
DELETE Поставщики WHERE Статус < 20;
Пример: Подсчитать количество поставок, сделанных
каждым поставщиком.
SUMMARIZE Поставки BY (П№) ADD COUNT AS Кол_П;
П№
Кол_П
П1
6
П2
2
П3
1
П4
3
Дополнительные реляционные операции.
Возможные операции:
Присвоение:
Поставки := Поставки MINUS (Поставки WHERE Кол = 0);
Обновление:
INSERT (Поставщики WHERE Гор_П=Минск ) INTO Temp;
UPDATE (Поставщики WHERE Гор_П=Брест) СТАТУС<40;
DELETE Поставщики WHERE Статус < 20;
Примеры использования реляционной алгебры
для выражения словесных запросов в виде
формул (1)
Получить имена поставщиков, которые поставляют
деталь Д2.
((Поставки JOIN Поставщики) WHERE Д№=’Д2’)
[Имя_П];
Примеры использования реляционной алгебры
для выражения словесных запросов в виде
формул (2)
Получить имена поставщиков, которые поставляют по
крайней мере одну черную деталь.
(((Детали WHERE Цв = ‘Черный’) JOIN Поставки)
[П№] JOIN Поставщики) [Имя_П];
или
(((Детали WHERE Цв = ‘Черный’) [Д№] JOIN
Поставки) JOIN Поставщики) [Имя_П];
Примеры использования реляционной алгебры
для выражения словесных запросов в виде
формул (3)
Получить имена поставщиков, которые поставляют
все детали.
((Поставки [П№,Д№] DIVIDED BY Детали [Д№]
JOIN Поставщики) [Имя_П];
Примеры использования реляционной алгебры
для выражения словесных запросов в виде
формул (4)
Получить номера поставщиков, которые поставляют
по крайней мере все те детали, которые поставляет
поставщик П2.
Поставки [П№,Д№] DIVIDED BY (Поставки WHERE
Имя_П=’П2’) [Д№]
Примеры использования реляционной алгебры
и SQL для выражения словесных запросов в
виде формул (5)
Получить имена поставщиков, которые не поставляют деталь Д2.
((Поставщики [П№] MINUS (Поставки WHERE Д№=’Д2’) [П№])
JOIN (Поставщики) [Имя_П];
SQL:
SELECT DISTINCT Поставщики.[Имя_П] FROM Поставщики
WHERE Поставщики.[П.№] NOT IN
(SELECT Поставки.[П№] FROM Поставки
WHERE Поставки.[Д№]=’Д2’);
Основы SQL
(Structured Query Language)
SELECT Имя поставщика
FROM Поставщик
Команда SQL
предложения
'
'
WHERE Город Минск
ORDER BY Статус;
Ключевые слова
Имена
Завершающая" ; ".
Синтаксис SQL
запятые используются для разделения компонентов
списка параметров;
точки используются для отделения имен таблиц от
имен полей;
точка с запятой ставится в конце инструкции Jet SQL;
квадратные скобки используются для выделения
имен полей только тогда, когда в именах
используются пробелы или другие знаки пунктуации,
не разрешенные в SQL;
одинарная кавычка применяется для описания
строчных переменных;
символы * и ? используются для маскирования
окончания или одного символа соответственно;
символ # применяется для представления одной
цифры в операторе LIKE.
Классификация операторов SQL
Операторы определения данных – определяют
содержимое реляционной базы данных в виде таблиц и
представлений;
Операторы манипулирования данных – используются для
извлечения, вставки, обновления и удаления данных,
содержащихся в таблицах и представлениях;
Операторы управления данными – ограничивают доступ к
данным.
Создание и обслуживание таблиц
CREATE TABLE Проекты
(Пр№ CHAR(3)
ИмяПр CHAR(15)
Гор
CHAR(20));
NOT NULL PRIMARY KEY,
UNUQUE,
Ограничения на атрибуты:
NOT NULL – не разрешает присваивать значения NULL;
DEFAULT – задает значения по умолчанию;
PRIMARY KEY – задает первичный ключ для таблицы;
FOREIGN KEY (или REFERENCES) – задает внешний
ключ;
UNIQUE – не позволяет вводить в столбец
повторяющиеся значения;
CHECK – ограничивает с помощью логических
выражений значения, которые могут добавляться в
столбец.
Создание внешних ключей
CREATE TABLE Поставки
(П№ CHAR(3)
NOT NULL REFERENCES Поставщики,
Пр№ CHAR(5)
NOT NULL REFERENCES Проекты,
Д№
CHAR(3)
NOT NULL REFERENCES Детали,
Кол
INTEGER
DEFAULT ′???′
CONSTRAINT ключ PRIMARY KEY (П№ , Пр№, Д№));
Обеспечение целостности данных по ссылкам
CREATE TABLE Поставки
(П№
CHAR(3)
REFERENCE Поставщики
ON UPDATE CASCADE
ON DELETE SET NULL,
Пр№
CHAR(5)
NOT NULL REFERENCE Проекты
RESTRICT,
Д№
CHAR(3)
NOT NULL REFERENCE Детали,
Кол
INTEGER
DEFAULT ′???′
CONSTRAINT ключ PRIMARY KEY (П№ , Пр№, Д№));
Обеспечение целостности атрибута
CREATE TABLE Детали
(Д№
CHAR(3)
NOT NULL PRIMARY KEY,
Имя_Д
CHAR(15)
UNUQUE,
Цвет
CHAR(10)
CHECK (Цвет='Черный' OR Цвет
='Красный' OR Цвет ='Желтый' OR Цвет ='???'),
Вес
INTEGER,
Гор
CHAR(20));
Редактирование таблицы
ALTER TABLE Детали ADD [Дата изготовления] DATE;
Характер изменения:
ADD, MODIFY, DELETE
Удаление таблицы:
DROP TABLE Детали;
Управление данными
Доступ к данным
Виды полномочий: SELECT, UPDATE, ALL
GRANT UPDATE ON Поставки TO USER1;
Полномочия для всех пользователей:
GRANT UPDATE ON Поставки TO PUBLIC;
Удаление полномочий:
REVOKE UPDATE ON Поставки FROM USER1;
Запрос на выборку
SELECT [ALL/DISTINCT] [TOP n [PERCENT]] список полей
FROM имена таблиц
[WHERE условие отбора]
[ORDER BY столбцы сортировки [ASC/DESC]];
ALL – включает все строки, соответствующие указанным
далее условиям отбора;
DISTINCT (ключевое слово из ANSI SQL-92) – исключает
строки с повторяющимися данными на основе только
данных результирующего набора записей;
TOP n [PERCENT] ограничивает количество записей в
результирующей таблице первыми n или n% набора.
Запрос на выборку
Пример
SELECT Имя_Д, Вес
FROM Детали
WHERE Вес>500
ORDER BY [Вес] DESC;
Статистические функции
SELECT статистическая функция (имя поля) AS
заголовок поля [, список полей]
FROM имена таблиц
[WHERE условие отбора]
GROUP BY условие группировки
[HAVING условие для результата]
[ORDER BY столбцы сортировки];
Статистические функции.
Пример 1
Подсчитать общее количество деталей:
SELECT SUM(Поставки.Кол)
FROM Поставки;
Можно рассчитать несколько статистических выражений:
SELECT MIN(Кол), MAX(Кол), SUM(Кол), AVG(Кол)
FROM Поставки;
Статистические функции.
Пример 2
Количество кортежей в отношении:
SELECT COUNT (*) AS Кол_кортежей
FROM Поставки;
Статистические функции.
Пример 3
Применение статистических функций к отдельным группам
кортежей:
SELECT Пк.ПN, SUM(Пк.Кол)
FROM Поставки AS Пк
GROUP BY Пк.ПN;
В предложении SELECT необходимо указывать
атрибут, по которому производится группировка и
нельзя указывать имена атрибутов, не входящих в
предложение GROUP BY.
!
Статистические функции.
Пример 3
Ограничения на результат:
SELECT Пк.ПN, SUM (Пк.Кол)
FROM Поставки AS Пк
GROUP BY Пк.ПN
HAVING COUNT(*)>2;
Создание соединений (1)
Произведение двух отношений:
SELECT *
FROM Проекты, Поставки;
Соединение:
SELECT *
FROM Проекты, Поставки
WHERE Проекты.ПрN=Поставки.ПрN;
Создание соединений (2)
Можно соединить произвольное число отношений:
SELECT DISTINCT П.Имя_П, Д.Имя_Д,
Пр.Имя_Пр, Пк.Кол
FROM Поставщики AS П, Детали AS Д,
Проекты AS Пр, Поставки AS Пк
WHERE Д.ДN=Пк.ДN
AND П.ПN=Пк.ПN
AND Пр.ПрN=Пк.ПрN
AND Пк.Кол>500;
Создание соединений (3)
SELECT список полей
FROM имя таблицы {INNER/LEFT/RIGHT} JOIN связанная
таблица
ON условие связи
[WHERE условие отбора]
[ORDER BY столбцы сортировки];
Тип соединения:
INNER – соединяет записи из двух таблиц, если связующие поля этих
таблиц содержат одинаковые значения;
LEFT (RIGHT) –левое внешнее соединение включает все записи из первой
(левой) таблицы и присоединяет к ним записи из второй таблицы, если
связующие поля содержат одинаковые значения. Правое внешнее
соединение включает все записи из второй (правой) таблицы и
присоединяет к ним записи из первой таблицы, если связующие поля
содержат одинаковые значения.
Конструкция ON условие связи описывает связь между полями соединений.
Создание соединений
Пример 1
Соединение отношений Проекты и Поставки базы данных
Проекты-Поставщики-Детали
SELECT DISTINCT Пр.Имя_Пр, Пр.Гор, Пк.ДN, Пк.Кол
FROM (Проекты Пр INNER JOIN Поставки Пк)
ON Пр.ПрN=Пк.ПрN;
Создание соединений
Пример 2
Какие детали поставляются несколькими поставщиками?
SELECT F.ПN, S.ПN, F.ДN
FROM Поставки AS F,
Поставки AS S
WHERE F.ДN=S.ДN;
Добавим:
AND F.ПN<>S.ПN
и
DISTINCT
F.ПN
S.ПN
F.ДN
П1
П1
Д1
П1
П1
Д1
П1
П5
Д1
П1
П1
Д1
П1
П1
Д1
П1
П5
Д1
П5
П1
Д1
П5
П1
Д1
П5
П5
Д1
…
…
…
Вложенные запросы
SELECT список полей
FROM список таблиц
WHERE [имя таблицы.] имя поля
IN (SELECT оператор выборки
[GROUP BY условие группировки]
[HAVING условие отбора])
[ORDER BY столбцы сортировки];
Вложенные запросы
Пример 1
Найти номера поставщиков, поставляющих хотя бы
одну черную деталь.
SELECT Пк.ПN FROM Поставки Пк
WHERE Пк.ДN IN
(SELECT Д.ДN FROM Детали Д
WHERE Д.Цвет='Черный');
Вложенные запросы
Пример 2
Можно добавить имена поставщиков:
SELECT П.Имя_П FROM Поставщики П
WHERE П.ПN IN
(SELECT Пк.ПN FROM Поставки Пк
WHERE Пк.ДN IN
(SELECT Д.ДN FROM Детали Д
WHERE Д.Цв='Черный'));
Вложенные запросы
Пример 3
Такой же результат можно получить соединением:
SELECT DISTINCT П.Имя_П
FROM Поставщики П, Поставки Пк, Детали Д
WHERE П.ПN=Пк.ПN
AND Пк.ДN=Д.ДN
AND Д.Цв='Черный';
Как лучше?
Вложенные запросы
Пример 4
Проверка на существование :
SELECT * FROM Поставщики П
WHERE П.ПN NOT IN
(SELECT Пк.ПN FROM Поставки Пк);
Запрос на объединение
SELECT оператор выборки
UNION
SELECT оператор выборки
[GROUP BY условие группировки]
[HAVING итоговое условие]
[UNION
SELECT оператор выборки
[GROUP BY условие группировки]
[HAVING итоговое условие]]
[UNION
…]
[ORDER BY столбцы сортировки];
Запрос на объединение
Пример
SELECT Имя_П AS Наименование
FROM Поставщики
WHERE Гор=’Минск’
UNION SELECT Имя_Пр AS Наименование
FROM Проекты
WHERE Гор=’Минск’
ORDER BY Наименование;
Оператор EXISTS
Оператор EXISTS в предложении WHERE выполняет
проверку на существование данных, которые
удовлетворяют критериям соответствующего
вложенного запроса, и возвращает булево значение
«истина» или «ложь».
Пример. Найти имена поставщиков, которые
поставляют деталь Д1:
SELECT DISTINCT П.Имя_П FROM Поставщики AS П
WHERE EXISTS
(SELECT * FROM Поставки AS Пк
WHERE Пк.ПN=П.ПN
AND Пк.ДN='Д1');
Два решения задачи:
Найти номера деталей, поставляемых поставщиком из
города, название которого начинается с буквы М
SELECT DISTINCT Пк.ДN FROM Поставки AS Пк
WHERE Пк.ПN IN
(SELECT П.ПN FROM Поставщики AS П
WHERE П.Гор LIKE 'М*');
SELECT DISTINCT Пк.Д№ FROM Поставки Пк
WHERE EXISTS
(SELECT * FROM Поставщики П
WHERE П.П№ = Пк.П№
AND Гор LIKE ′М*′);
Можно добавить сведения из третьей таблицы:
SELECT DISTINCT Д.Имя_Д
FROM Детали AS Д
WHERE EXISTS
(SELECT DISTINCT Пк.ДN
FROM Поставки AS Пк
WHERE EXISTS
(SELECT *
FROM Поставщики AS П
WHERE П.ПN=Пк.ПN
AND Гор LIKE 'М*')
AND Д.ДN=П.ДN);
Реализация операции пересечения
Пересечение таблиц Детали и Поставщики по полю Гор
SELECT DISTINCT Д.Гор
FROM Детали AS Д
WHERE EXISTS
(SELECT *
FROM Поставщики П
WHERE Д.Гор=П.Гор);
Реализация операции пересечения (2)
Разность таблиц Детали и Поставщики по полю Гор
SELECT DISTINCT Д.Гор
FROM Детали Д
WHERE
(SELECT COUNT (*)
FROM Поставщики П
WHERE Д.Гор = П.Гор) >0;
Реализация операции вычитания (1)
Разность таблиц Детали и Поставщики по полю Гор
SELECT DISTINCT Д.Гор
FROM Детали Д
WHERE NOT EXISTS
(SELECT *
FROM Поставщики П
WHERE Д.Гор=П.Гор);
Реализация операции вычитания (2)
Разность таблиц Детали и Поставщики по полю Гор
SELECT DISTINCT Д.Гор
FROM Детали Д
WHERE
(SELECT COUNT (*)
FROM Поставщики П
WHERE Д.Гор = П.Гор) =0;
Реализация операции деления
Получить номера поставщиков, поставляющих все детали
SELECT DISTINCT Пк.ПN
FROM Поставки AS Пк
WHERE NOT EXISTS
(SELECT Д.ДN FROM Детали AS Д
WHERE NOT EXISTS
(SELECT Пк1.ДN
FROM Поставки AS Пк1
WHERE Пк1.ПN=Пк.ПN
AND Пк1.ДN=Д.ДN));
Запросы на изменение записей
Добавление записей:
INSERT INTO таблица-получатель
SELECT список полей FROM таблица-источник;
[WHERE условие удаления];
Удаление записей:
DELETE FROM имя таблицы
[WHERE условие удаления];
Создание таблицы:
SELECT список полей
INTO новая таблица
FROM исходная таблица
[WHERE условие выбора];
Обновление:
UPDATE имя таблицы
SET имя_поля_1=значение [,имя_поля_2=значение[,…]]
[WHERE условие обновления];
Перекрестные запросы
TRANSFORM статистическая функция (имя поля) [AS наименование]
SELECT список полей
FROM имя таблицы
PIVOT поле [IN (значение_1[, значение_2[, ...]])];
Перекрестные запросы
Пример
Представить данные о количествах деталей, поставленных
каждым поставщиком.
TRANSFORM Sum(Пк.Кол)
SELECT Пк.ПN, Sum(Пк.Кол) AS [ВСЕГО:]
FROM Поставки AS Пк
GROUP BY Пк.ПN
PIVOT Пк.ДN;
ПN ВСЕГО:
Д1
Д2
Д3
П1
900
900
П2
3200
3100
П3
700
200
П4
600
П5
3110
Д4
Д5
Д6
100
500
600
110
300
200
800
1000
700
Типы данных
Категории
Character string – Строки символов;
Bit string – Строки битов;
Exact numeric – Рациональные (целые и
действительные) числа с плавающей
десятичной точкой;
Approximate numeric – Вещественные числа
(с плавающей точкой);
Date time – значения даты и времени;
Interval – интервалы даты и времени.
Строковые типы данных
Character (n) – строка фиксированной длины n. Если
символов меньше чем n, то добавляются пробелы.
Синонимы – Char(n) (в SQL Server – до 8000 символов).
Character varying (n) – строка переменной длины, длинной
менее n. Синонимы: Char varying, Charvar.
National Character (National Char, NChar) – совпадает с
типом Char, только хранит лишь стандартизованные
многобайтовые или двухбайтовые знаки (Unicode).
Записывается: N'a*b'. National Character Varying – то же
для строк переменной длины.
Unicode – единое множество 16-разрядных чисел, которое
представляет знаки почти всех мировых языков.
Содержит 65536 = 216 знаков.
В СУБД Access к строковым типам данных относятся: text
(до 256 символов) и memo.
Битовые типы данных
BIT (n) – строка фиксированной длины (фиксированные числа
битов). Max длина определяется СУБД. Если длина строки
меньше n, то получите сообщение об ошибке. В стоке BIT
перед первой кавычкой должна стоять латинская В, например,
В'01001' – это строка типа BIT(5). Bit varying – аналогично, как
Charvar.
Тип данных BIT используется для хранения так называемых
больших бинарных объектов (Binary Large Object – BLOB) –
например, звук, изображение (в SQL Server – до 2Е31 байт).
В СУБД Access к BIT типу данных относятся: YES, NO, BINARY,
OLE OBJECT.
Точные числовые типы данных
Точность – число значащих цифр в записи числа;
Масштаб – число цифр справа от десятичной точки (масштаб ≤
точности).
Типы:
Numeric (точность [,масштаб]) – представляет произвольное
рациональное число (точность меньше 38) – 5-17 байт.
Decimal – аналогичен NUMERIC, но только задает нижнюю
границу точности, т.е. СУБД может выбрать большую точность,
чем заказано пользователем.
Integer (или INT) – представляет произвольное целое число
(–2E31…(2E31–1) – 4 байта
SMALLINT – повторяет INT, только интервал допустимых
значений уже (-32768…32768) – 2 байта.
В СУБД Access: DECIMAL, INTEGER, BYTE, LONG INTEGER.
Пример:
Хранение числа 123,55
Спецификация столбца Хранится значение
Numeric (5)
124
Numeric (5.0)
124
Numeric (5.1)
123,6
Numeric (5.2)
123,55
Numeric (4.0)
124
Numeric (4.1)
123,6
Numeric (4.2)
Выходит за пределы точности
Вещественные числовые типы данных
Числа с плавающей точкой применяются для хранения
приближенных числовых значений.
FLOAT (точность) – представляет произвольное рациональное
приближение действительного числа с плавающей точкой.
Значение точности представляется не в количестве значащих
десятичных цифр, а в количестве битов. Точность не должна
быть меньше 1.
Для преобразования десятеричной точности в бинарную надо
умножить десятеричную точность на 3.32193.
Например, 7 знаков точности дают 24 бита.
REAL – совпадает с FLOAT, но точность вводить не надо, ее
автоматически определяет СУБД. Числа типа REAL называют
числами одинарной точности с плавающей точкой.
DOUBLE PRECISION –числа двойной точности с плавающей
точкой.
В СУБД Access – SINGLE, DOUBLE.
Календарные типы данных
DATE – имеет формат YYYY-MM-DD.
TIME – имеет формат HH:MM:SS. Можно добавить аргумент
“точность” для долей секунд.
TIMESTAMP – имеет формат YYYY-MM-DD_ HH:MM:SS.
Интервальные типы данных.
B СУБД ACCESS: date/time.
Значения NULL
Это не 0, не пустая строка (′ ′) и не строка пробелов. NULL не
принадлежит ни к какому типу данных и его можно записать в
любой столбец, кроме тех, для которых задано ограничение
NOT NULL.
Значения NULL можно найти и идентифицировать
предложением IS NULL.
Значения NULL не равны друг другу. Поэтому нельзя
определить, соответствует ли какое-нибудь значение NULL
другому значению в базе данных. Тем не менее, предложение
DISTINCT воспринимает все NULL одинаково для удаления
повторяющихся строк.
При сортировке значения NULL будут либо больше, либо
меньше любых значений, в зависимости от СУБД.
Значения NULL размножаются в процессе вычислений.
Итоговые функции игнорируют NULL в процессе вычислений.
При группировке предложением GROUP BY все значения NULL
будут помещены в одну группу.
Взаимодействие пользователя
с базой данных
Сервер
Клиенты
База данных
СУБД
Приложения
Конечные пользователи
(приложения)
Основные компоненты информационной
технологии обработки данных
Классификаторы
и справочники
База данных
Создание отчетов
(выходных форм)
Обработка данных
Сбор
данных
Группировка
Сортировка
Временные
файлы
Банк данных
Агрегирование
Вычисление
периодических
по запросу
Данные
из внешней среды
Информация для
внутреннего и внешнего
использования
Трехуровневая модель
архитектуры систем баз данных
Внешний уровень
(индивидуальное представление пользователей)
Концептуальный уровень
(обобщенное представление пользователей)
Внутренний уровень
(представление в памяти)
Модели данных
Информационно-логическая или инфологическая
(infological) модель данных – это описание,
выполненное с использованием естественного
языка, математических формул, таблиц, графиков и
других средств, понятных всем людям, работающим
над проектированием базы данных.
Модель "сущность-связь" (Entity-Relationship или ERдиаграмма) – предложена Питером Ченом (Peter
Chen) в 1975 году.
Модели данных.
Основные термины
Сущность – любой различимый объект, информацию о
котором необходимо хранить в базе данных.
Атрибут – поименованная характеристика сущности.
Идентификаторы или ключи –минимальный набор
атрибутов, по значениям которых можно однозначно
найти требуемый экземпляр сущности.
Связь – это ассоциирование двух или более сущностей.
Степень связи указывает на количество
ассоциированных сущностей. Связи, соединяющие две
сущности, наиболее часто встречаются на практике и
называются бинарными.
Связь «один-к-одному» (1:1): В каждый момент времени
каждому представителю сущности А соответствует
1 или 0 представителей сущности В, а каждому
представителю сущности В соответствует 1 или 0
представителей сущности А.
Код студента (номер
зачетной книжки)
0125
0134
Фамилия
Ильин
Петров
Код студента
0134
0125
Личное дело
№1
№2
Связь «один-ко-многим» (1:М): одному представителю
сущности А соответствуют 0, 1 или несколько
представителей сущности В, а любому представителю
сущности В соответствует 1 или 0 представителей
сущности А.
Код студента
0125
0134
0086
Номер
группы
1
2
Фамилия
Ильин
Петров
Комаров
Номер группы
1
1
2
Кафедра
Экологических информационных систем
Ядерной и радиационной безопасности
Связь «многие-ко-многим» (N:М): каждому
представителю сущности А может соответствовать
множество представителей сущности В, а каждому
представителю сущности В может соответствовать
множество представителей сущности А.
Фамилия
Ильин
Петров
Комаров
Изучаемые
дисциплины
Топография
Молекулярная биология
Этика
Иерархическая модель данных
Клиент 1
Имя 1
Адрес 1
Заказ 1
Т1
120 р.
50 шт.
Т2
40 р.
120 шт.
Клиент 2
Имя 2
Адрес 2
Заказ 2
Т3
60 р.
75 шт.
Клиент 3
Имя 3
Адрес 3
Заказ 3
Т1
120 р.
30 шт.
Т3
60 р.
75 шт.
Заказ 4
Т2
40 р.
100 шт.
Т3
60 р.
200 шт.
Заказ 5
Т1
120 р.
40 шт.
Т3
60 р.
130 шт.
Недостатки:
1. невозможно избежать дублирования информации о товарах;
2. нельзя ввести информацию о товарах, на которые нет заказов;
3. нельзя вести учет запаса товаров на складе.
Сетевая модель данных
Клиент 1
Имя 1
Адрес 1
Фирма 3
Заказ 1
Дата
Приемщик
Скидка
50
100
Т1
Цена 120 р.
Запас 150 шт.
Клиент 2
Имя 1
Адрес 1
Фирма 3
Заказ 2
Дата
Приемщик
Скидка
75
Т2
Цена 40 р.
Запас 300 шт.
Клиент 3
Имя 1
Адрес 1
Фирма 3
Заказ 3
Дата
Приемщик
Скидка
Заказ 4
Дата
Приемщик
Скидка
Заказ 5
Дата
Приемщик
Скидка
30
100
40
150
Т3
Цена 60 р.
Запас 240 шт.
200
60
Т4
Цена 110 р.
Запас 150 шт.
Недостатки:
1. базы данных сложны и их сложность возрастает при увеличении
количества сущностей или атрибутов;
2. новые манипуляции с данными потребуют создания новых связей.
Реляционная модель
(relation – отношения)
данные на концептуальном уровне представляются в виде
двумерных таблиц, в которых хранится информация о
сущностях;
строки называются кортежами или записями и содержат
информацию об экземплярах сущности;
столбцы называются полями и содержат информацию об
атрибутах сущности.
реляционные системы представляют более простую среду для
разработки баз данных, чем иерархические или сетевые;
программное обеспечение, основанное на реляционной
алгебре, позволяет организовать практически любое
манипулирование данными.
Идея реляционной модели данных
Строки таблицы с n колонками, состоящими из элементов
множеств A1, A2, …, An, можно представить как подмножество в
прямом произведении A1A2… An. Строки образуют список из n
элементов, по одному из каждого множества Ai, а вся таблица
представляет собой n-арное отношение. Например, таблицу
КЛИЕНТЫ можно рассматривать как подмножество множества
A1A2A3A4, где A1 – множество кодов клиентов, A2 – множество
имен клиентов, A3 – множество их адресов, An – множество
названий организаций. Один из элементов этого отношения –
строка К1, Андрей, Минск, ИНКО.
Представленные таким образом таблицы можно обрабатывать,
используя алгебру отношений на множествах.
Реляционная модель
Клиенты
ID
Имя
Андрей
Анна
Дмитрий
Петр
К1
К2
К3
К4
…
Адрес
Минск
Гродно
Брест
Пинск
Фирма
ИНКО
Тролль
Нейрон
Антей
Товары
Код
Т1
Т2
Т3
Т4
…
Наименование Цена Запас Производитель
Шнур
Розетка
Пила
Щепцы
120
40
60
110
150
300
240
150
…
продолжение
Заказы
№
1
2
3
4
5
…
ID клиента Приемщик Скидка
К1
К1
К2
К3
К3
Маша
Илья
Надежда
Анна
Виктор
5%
0
7%
10%
5%
Дата
…
21.01.2007 …
22.01.2007
22.01.2007
25.01.2007
26.01.2007
Спецификация заказа
№ заказа
1
1
2
3
3
4
4
5
5
Код товара
Т1
Т2
Т3
Т1
Т3
Т2
Т3
Т1
Т3
Количество Дата исполн.
50
100
75
30
150
100
200
40
130
…
Реляционная модель
Клиенты
Заказы
ID
Имя
Спецификация
№
Код
№ заказа
Код товара
Адрес
ID
клиента
Фирма
Приемщик
К4
Скидка
Дата
исполнения
…
Дата
…
…
Товары
Количество
Наименование
цена
Запас
Производитель
…
Схема учебной базы данных
Детали
Д№
Имя_Д
Цв
Вес
Гор
Поставки
1
М
Д№
П№
Пр№
Кол
Проекты
Пр№
Имя_Пр
Имя_Рук
1
М
Поставщики
М 1
П№
Имя_П
Статус
Гор
Учебная база
Поставки
П№
Д№
П1
Д1
П1
Д1
П2
Д3
П2
Д3
П2
Д3
П2
Д3
П2
Д3
П2
Д3
П2
Д3
П2
Д5
П3
Д3
П3
Д4
П4
Д6
П4
Д6
П5
Д2
П5
Д2
П5
Д5
П5
Д5
П5
Д6
П5
Д1
П5
Д3
П5
Д4
П5
Д5
П5
Д6
Пр№
Пр1
Пр4
Пр1
Пр2
ПР3
ПР4
ПР5
ПР6
ПР7
ПР2
ПР1
ПР2
ПР3
ПР7
ПР2
ПР4
ПР5
ПР7
ПР2
ПР4
ПР4
ПР4
ПР4
ПР4
Кол
200
700
400
200
200
500
600
400
800
100
200
500
300
300
200
100
500
100
200
100
200
800
400
500
Детали
Д№
Имя_Д
Д1
Тестер
Д2
Дозиметр
Д3
Радиометр
Д4
Часы
Д5
Рулетка
Д6
Лом
Цв
Черный
Серый
Черный
Желтый
Красный
Черный
Вес
250
700
1400
140
200
5000
Гор
Минск
Борисов
Гродно
Минск
Брест
Варшава
Поставщики
П№
П1
П2
П3
П4
П5
Имя_П
Волк
Заяц
Лев
Лиса
Бык
Статус
20
10
30
20
30
Гор
Брест
Минск
Гродно
Минск
Брест
Проекты
Пр№
Пр1
Пр2
Пр3
Пр4
Пр5
Пр6
Пр7
Имя_П
Спутник
Корунд
Лес
Шина
Азот
Электро
Кристалл
Гор
Минск
Минск
Брест
Бобруйск
Гродно
Молодечно
Пинск
Основные функции СУБД (1)
создание
самой базы данных, ее объектов и структур –
таблиц, индексов, связей…;
модификация объектов и структур базы данных;
ввод, чтение и изменение данных;
обеспечение целостности данных;
обеспечение безопасности данных;
управление параллельной обработкой данных;
создание резервных копий.
Основные функции СУБД (2)
Непосредственное
управление данными во
внешней памяти;
Управление
буферами оперативной памяти;
Основные функции СУБД (3)
Транзакции
Транзакция – это последовательность операций над базой
данных, рассматриваемых СУБД как единое целое.
Если во время выполнения неких обновлений произошла
ошибка, то все эти обновления будут аннулированы.
Операторы COMMIT и ROLLBACK.
Свойства транзакций:
Атомарность;
Согласованность;
Изоляция;
Устойчивость (долговечность).
Основные функции СУБД (4)
Журнализация
Журнал – это особая часть базы данных, недоступная
пользователям СУБД и поддерживаемая с особой
тщательностью, в которую поступают записи обо всех
изменениях основной части базы данных.
Стратегия "упреждающей" записи (протокол Write Ahead
Log – WAL).
Восстановление базы данных после мягкого и жесткого
сбоев.
Основные функции СУБД (5)
Поддержка языков баз данных
SQL, Structured Query Language:
Язык определения схемы базы данных
(SDL – Schema Definition Language
или DDL – Data Definition Language);
Язык манипулирования данными
(DML – Data Manipulation Language).
Язык управления доступом к данным (полномочиями)
(DCL – Data Control Language),
Язык управления транзакциями (TCL – Transaction Control
Language,)
Развитие стандарта
Год
1986
Название
SQL-86
1989
1992
1999
SQL-89
SQL-92
SQL:1999
2003
SQL:2003
2006
SQL:2006
2008
SQL:2008
Изменения
Первый вариант стандарта, принятый институтом ANSI и
одобренный ISO
Доработанный вариант предыдущего стандарта
Значительные изменения.
Добавлена поддержка регулярных выражений, рекурсивных
запросов, поддержка триггеров, базовые процедурные
расширения, нескалярные типы данных и некоторые объектноориентированные возможности.
Введены расширения для работы с XML-данными, оконные
функции (применяемые для работы с OLAP-базами данных
(online analytical processing), генераторы последовательностей и
основанные на них типы данных.
Функциональность работы с XML-данными значительно
расширена. Появилась возможность совместно использовать в
запросах SQL и XQuery.
Улучшены возможности оконных функций, устранены некоторые
неоднозначности стандарта SQL:2003
Ключи и целостность реляционных
данных (1)
Целостность (integrity – неприкосновенность,
сохранность, целостность) – правильность
данных в любой момент времени.
Поддержание целостности базы данных – защита
данных от неверных изменений или разрушений.
Основные механизмы обеспечения целостности
данных связаны с понятием первичных и
внешних ключей.
Ключи и целостность данных (2)
Потенциальные ключи
Потенциальный ключ K для некоторого отношения
R – это подмножество множества атрибутов R,
обладающее следующими свойствами:
1. Свойством уникальности (нет двух различных
кортежей в отношении R с одинаковым
значением K).
2. Свойством неизбыточности (никакое из
подмножеств K не обладает свойством
уникальности).
Ключи и целостность данных (3)
Потенциальные ключи
Первичный и альтернативные ключи являются частным
случаем потенциального ключа.
Надмножество потенциального ключа называется
суперключом (например, суперключом для отношения
Проекты является множество атрибутов
{Пр№, Имя_проекта}).
Суперключ обладает свойством уникальности, но не
обязательно обладает свойством несократимости.
Потенциальный ключ – это частный случай суперключа .
Ключи и целостность данных (4)
Потенциальные ключи
Правило целостности объектов:
Ни один элемент первичного ключа базового
отношения не может быть Null-значением.
Если кортеж имеет Null-значение некоторого
атрибута, то это означает, что в таком кортеже
значение атрибута по какой-то причине
отсутствует.
Ключи и целостность данных (5)
Потенциальные ключи
Потенциальные ключи в реляционной системе
обеспечивают основной механизм адресации на уровне
кортежей.
Потенциальный ключ – это минимальный набор атрибутов,
по значениям которых можно однозначно найти
требуемый кортеж отношения.
При выборе первичного ключа следует отдавать
предпочтение несоставным ключам или ключам,
составленным из минимального числа атрибутов.
Не допускается, чтобы любой атрибут первичного ключа
отношения принимал неопределенное Null-значение.
Ключи и целостность данных (6)
Внешние ключи
Основное назначение внешних ключей – организация связей
между отношениями. Связь создается по данным,
хранящимся в поле первичного ключа одной таблицы и в
поле внешнего ключа другой таблицы с данными, такими
же по смыслу и типу.
Условия необходимости выбора внешних ключей:
1. Если сущность С связывает сущности А и В, то она
должна включать внешние ключи, соответствующие
первичным ключам сущностей А и В или одной из них.
2. Если сущность В обозначает сущность А, то она должна
включать внешний ключ, соответствующий первичному
ключу сущности А.
Ключи и целостность данных (7)
Внешние ключи
Целостность по ссылкам:
База данных не должна содержать
несогласованных значений внешних ключей.
Т.е., если В ссылается на А, то А должно
существовать.
Правило целостности по ссылкам позволяет
поддерживать базу данных в корректном
состоянии.
Ключи и целостность данных (8)
Внешние ключи
Правило внешних ключей предполагает принятие
решения:
1. Что должно случиться при попытке удалить объект
ссылки внешнего ключа?
2. Что должно случиться при попытке обновить
потенциальный ключ, на который ссылается
внешний ключ?
Существует две возможности:
ограничение – «ограничить» операции до момента
появления первой ссылки;
каскадирование – «каскадировать» операции,
удаляя или обновляя все соответствующие
атрибуты.
Ключи и целостность данных (9)
Внешние ключи
Реляционная модель допускает появление Null-значений
среди атрибутов внешних ключей!
Определение внешнего ключа:
Внешний ключ FK в отношении R2 – это подмножество
множества атрибутов R2 такое, что существует
базовое отношение R1 с потенциальным ключом CK, для
которого каждое значение FK в текущем значении R2
или является Null-значением, или совпадает со значением
CK некоторого кортежа в текущем значении R1.
Ключи и целостность данных (10)
Целостность атрибута
Значение каждого атрибута берется из
соответствующего домена.
Моделирование концептуальной схемы
базы данных (1)
Пример:
Банковская компания хранит информацию о своих
счетах (№счета, баланс), клиентах (№ клиента, имя,
адрес, статус) и филиалах банка (название, адрес,
директор).
Счета могут быть двух типов – депозитные и текущие.
Клиенты могут иметь произвольное число счетов.
Несколько клиентов могут совместно использовать
общий счет.
Каждый счет обрабатывается одним филиалом.
Моделирование схемы (2)
Сущности и атрибуты
Название
Филиалы
Директор
Адрес
Имя
ID
клиента
Клиенты
Адрес
Статус
Номер
счета
Счета
Баланс
Моделирование схемы (3)
Модель данных «сущность-связь»
Филиал
1
М
Счет
М
N
Клиент
Моделирование схемы (2)
Слабая сущность
Дата регистрации
Филиал 1
M
Счет
1
M Регистрация M
1
ID клиента
Счет
Депозиты
Текущие
Создание подтипов. Генерализация. Специализация.
Номер счета
1
Клиент
Схема учебной базы данных
Детали
Д№
Имя_Д
Цв
Вес
Гор
Поставки
1
М
Д№
П№
Пр№
Кол
Проекты
Пр№
Имя_Пр
Имя_Рук
1
М
Поставщики
М 1
П№
Имя_П
Статус
Гор
Организация доступа к данным (1)
СУБД
Запрос хранимой записи
Возвращение хранимой записи
Диспетчер файлов
Запрос хранимой страницы
Возвращение храним. страницы
Диспетчер дисков
Операция ввода/вывода
Чтение данных с диска
Чтение
данных с диска
База данных на внешних
носителях
Организация доступа к данным (2)
Кластеризация
Кластеризация данных – метод хранения данных, когда
их физическая организация отражает определенный
логический порядок.
Внутрифайловая кластеризация осуществляется в рамках
одного хранимого файла.
Межфайловая кластеризация учитывает несколько
файлов.
Организация доступа к данным (3)
Начальное расположение страниц
Организация доступа к данным (4)
Текущее расположение страниц
Организация доступа к данным (5)
Индексирование
Индексный
файл
Город
Индексированный файл
Ук
П№
Имя_П
Статус
Гор
Брест
П1
Волк
20
Брест
Брест
П2
Заяц
10
Минск
Гродно
П3
Лев
30
Гродно
Минск
П4
Лиса
20
Минск
Минск
П5
Бык
30
Брест
Организация доступа к данным (6)
Индексирование
Индексы обеспечивают прямой доступ к кортежу
отношения.
Индексный файл – это хранимый файл особого типа,
в котором каждая запись состоит из двух значений,
а именно данных и RID-указателя, необходимого для
связывания с соответствующей записью
индексированного файла.
Если индексирование организовано на основе ключевого
поля, то индекс называется первичным (или уникальным),
а если индекс организован на основе другого поля, то он
называется вторичным.
Организация доступа к данным (7)
Индексирование
Последовательный доступ к файлу.
Прямой доступ к файлу.
Несколько индексов.
Пример: "Найти поставщиков из Бреста со статусом 20".
Если согласно индексу ГОРОД для поставщиков из Бреста найдены записи с RIDуказателями r1 и r5, а согласно индексу СТАТУС – r1 и r4, то условиям запроса
удовлетворяет только запись с данными о поставщике c указателем r1.
Сложный индекс.
Плотные и неплотные индексы.
Организация доступа к данным (8)
Несколько индексов
Индекс
Город
Город
Индексированный файл
У
к
Брест
Брест
Гродно
Минск
Минск
Индекс
Статус
Ук
Статус
П№
Имя_П
Статус
Гор
П1
Волк
20
Брест
10
П2
Заяц
10
Минск
20
П3
Лев
30
Гродно
20
П4
Лиса
20
Минск
30
П5
Бык
30
Брест
30
Организация доступа к данным (9)
Сложный индекс
Индексный файл
Город
Индексированный файл
Ук
П№
Имя_П
Статус
Гор
Брест/20
П1
Волк
20
Брест
Брест/30
П2
Заяц
10
Минск
Гродно/30
П3
Лев
30
Гродно
Минск/10
П4
Лиса
20
Минск
Минск/20
П5
Бык
30
Брест
Организация доступа к данным (10)
Неплотный индекс
Индексированный файл
Индексный
файл
Поставщик
Ук
П1
П4
П№
Имя_
П
Статус
Гор
П1
Волк
20
Брест
П2
Заяц
10
Минск
П3
Лев
30
Гродно
П4
Лиса
20
Минск
П5
Бык
30
Брест
1-я страница
2-я страница
Организация доступа к данным (11)
Индексирование
Рекомендуется создавать индексы для следующих
типов атрибутов:
Первичные ключи (ускорение поиска записи);
Внешние ключи (ускорение выполнения соединений);
Атрибуты, часто фигурирующие в запросах,
ответами на которые являются небольшие
множества записей;
Атрибуты, по которым часто сортируются данные.
Организация доступа к данным (12)
Бинарные деревья
Индексы бинарного типа состоят из двух частей:
набора последовательностей и набора индексов.
Набор последовательностей представляет собой
индекс, содержащий указатели на все записи в
файле. Этот индекс физически упорядочен,
обычно по значению первичного ключа.
Набор индексов – это неплотный иерархический
индекс для последовательного набора.
Организация доступа к данным (13)
Бинарные деревья
45 78
7
1
4
7
26
48 66
90 96
11 13 26 30 33 45 46 47 48 52 54 66 69 71 78 85 87 90 91 92 96 97 98 99
Организация доступа к данным (14)
Сбалансированное дерево
18
8
6
8
10
9
21
10
17
18
19
33
21
33
37
Организация доступа к данным (15)
Несбалансированное дерево (добавили 12, 14, 17)
18
8
6
8
10
9
21
14
10
12
18
14
17
19
33
21
33
37
Организация доступа к данным (16)
Результат действия алгоритма балансировки
17
9
6
8
9
12
10
19
12
14
17
18
33
19
21
33
37
Организация доступа к данным (17)
Хеширование
Хеширование (хеш-адресация или хешиндексирование) –технология быстрого прямого
доступа к хранимой записи на основе заданного
значения некоторого поля.
Организация доступа к данным (18)
Хеширование
Каждая хранимая запись базы данных размещается по
адресу (RID-указателю или номеру страницы), который
вычисляется с помощью специальной хеш-функции на
основе значения некоторого поля данной записи,
называемого хеш-полем.
Для сохранения записи в СУБД сначала вычисляется хешадрес новой записи, а затем диспетчер файлов помещает
эту запись по вычисленному адресу.
Для извлечения нужной записи по заданному значению
хеш-поля в СУБД сначала вычисляется хеш-адрес, а затем
диспетчеру файлов посылается запрос для извлечения
записи по вычисленному адресу.
Организация доступа к данным (19)
Хеширование (пример)
Есть записи с данными о поставщиках с номерами
100, 200, 300, 400 и 500;
Для хранения каждой из них предназначается отдельная
страница;
Хеш-функция:
хеш-адрес = остаток от деления на 13 числа,
содержащегося в поле П№.
Записи будут сохранены на страницах
9, 5, 1, 10, 6
Организация доступа к данным (20)
Хеширование. Недостатки
Физическая последовательность записей внутри
хранимого файла почти всегда отличается от
последовательности ключевого поля, а также любой
другой логически заданной последовательности.
Страницы заполняются неравномерно.
Возникновение коллизий, т.е. ситуаций, когда две или
более записи имеют одинаковые адреса.
Возрастание числа коллизий с увеличением размера
хранимого файла.
Организация доступа к данным (21)
Хеширование.
Точка привязки – это начальный адрес цепочки
указателей (цепочки коллизий), связывающей вместе все
записи или все страницы с записями, которые имеют
одинаковый хеш-адрес.
реорганизовать файл, т.е. выгрузить данный файл и
загрузить его вновь, используя новую хеш-функцию
Организация доступа к данным (22)
Методы сжатия. Дифференциальное сжатие
Roberton
Robertson
Robertstone
Robinson
0
- Roberton++++
6 - son+++
7 - tone+
3 - inson++++
Организация доступа к данным (23)
Методы сжатия. Иерархическое сжатие
Брест
Гродно
Минск
П1
П3
П2
Волк 20
Лев 30
Заяц 10
П5
Бык 30
П2
Лиса 20
Страница р1
Страница р2
П1 Волк 20 Брест
П2 Заяц 10 Минск
Пр2 Д3 300 Пр2 Д4 100
Пр3 Д1 50
Пр1 Д3 200 Пр2 Д4 200
Пр5 Д1 150 Пр7 Д2 220
Организация доступа к данным (24)
Методы сжатия. Кодирование по методу Хаффмена
Символ
E
A
D
C
B
Частота
35%
30%
20%
10%
5%
Код
1
01
001
0001
0000
Какие английские слова
закодированы?
00110001010011
010001000110011
Средний размер символа:
0,35 * 1 + 0,30 * 2 + 0,20 * 3 + 0,10 * 4 + 0,05 * 4 = 2,15 битов
ПРОЕКТИРОВАНИЕ
РЕЛЯЦИОННЫХ БАЗ ДАННЫХ
Основная цель проектирования баз данных – это сокращение
избыточности хранимых данных, а следовательно,
экономия объема используемой памяти, уменьшение
затрат на многократные операции обновления
избыточных копий и, в первую очередь, устранение
возможности возникновения противоречий из-за хранения
в разных местах сведений об одном и том же объекте.
Проектирование баз данных.
Проблемы, которые необходимо избегать
Аномалии обновления – из-за избыточности данных при их
обновлении необходимо просматривать все данные, тем не
менее, может возникнуть ситуация, когда не все данные будут
обновлены (потенциальная противоречивость данных).
Аномалии включения – возможна ситуация, когда в базу нельзя
ввести данные, прежде чем не будут получены и введены
некоторые дополнительные сведения.
Аномалии удаления – обратная проблема может возникнуть
при удалении некоторых данных (возможна потеря полезной
информации).
Не минимизировано количество Null-значений. Так же как
избыточность, неопределенные значения являются
источниками потенциальных проблем в реляционных базах
данных, так как невозможно определить, что они означают.
Поэтому их использование желательно свести к минимуму.
Нормализация отношений
Нормализация – это разбиение (или
декомпозиция) таблицы на две или более,
обладающих лучшими свойствами при
добавлении, изменении и удалении данных;
Нормализованное отношение;
Нормальные формы.
Функциональные зависимости (1)
Пусть X и Y – произвольные
подмножества множества
атрибутов отношения R.
Y функционально зависит от X тогда
и только тогда, когда каждое
значение множества X связано в
точности с одним значением
множества Y.
Обозначение: XY
П№ Гор
Д№
Кол
П1
Брест
Д1
100
П1
Брест
Д2
100
П2
Минск
Д1
200
П2
Минск
Д2
200
П3
Гродно Д2
300
П4
Минск
Д2
400
П4
Минск
Д4
400
П4
Минск
Д5
400
Функциональные зависимости (2)
Тривиальные зависимости – те, которые не могут
не выполняться:
{П№,Д№}П№
Неприводимые зависимости:
Атрибут В неприводимо зависим от составного атрибута
А, если он функционально зависит от А и не зависит
функционально от любого подмножества атрибута А.
Функциональные зависимости (3)
Диаграмма функциональных зависимостей для учебной
базы данных «Проекты, Поставщики, Детали»
Имя_Пр
Имя_Д
Пр№
Гор
Имя_П
Цвет
Д№
П№
П№
Статус
Вес
Пр№
Д№
Гор
Кол
Гор
Первая нормальная форма (1)
Таблица находится в первой нормальной форме (1НФ)
тогда и только тогда, когда ни одна из ее строк не
содержит в любом своем поле более одного
значения и ни одно из ее ключевых полей не пусто.
П№
Гор
Д№
Кол
П4
Минск
Д2,Д4,Д5
400
Первая нормальная форма (2)
Универсальное отношение
П№ Статус Гор_П Д№
Имя_Д
Цв
Вес
Гор_Д
Кол
П1
20
Брест
Д1
Тестер
Черный
250
Борисов 300
П1
20
Брест
Д2
Дозиметр
Серый
700
Минск
200
П1
20
Брест
Д3
Радиометр Черный
1400 Минск
400
П1
20
Брест
Д4
Часы
Желтый
140
Брест
200
П1
20
Брест
Д5
Рулетка
Красный 200
Пинск
100
П1
20
Брест
Д6
Лом
Черный
5000 Могилев 100
П2
10
Минск Д1
Тестер
Черный
250
Борисов 300
П2
10
Минск Д2
Дозиметр
Серый
700
Минск
400
П3
30
Гродно Д2
Дозиметр
Серый
700
Минск
200
П4
10
Минск Д2
Дозиметр
Серый
700
Минск
200
П4
10
Минск Д4
Часы
Желтый
140
Брест
300
Первая нормальная форма (3)
Диаграмма функциональных зависимостей
Кол
Гор_П
Статус
П№
Имя_Д
Цв
Гор_Д
Вес
Д№
Первая нормальная форма (4)
Аномалии
Вставка (Insert). Нельзя вставить данные о поставщике
(П5), не указав деталь (Null-значение в ключевом поле
недопустимо).
Удаление (Delete). При удалении некоторого кортежа
приходится удалять слишком много другой информации
(удаление информации о поставке удаляет информацию о
поставщике).
Обновление (Update). Избыточная информация может
привести к несовместимым результатам. Если поставщик
П1 переехал в другой город, а обновление сделано не во
всех кортежах, то база данных будет содержать
противоречивую информацию.
Вторая нормальная форма (1)
Таблица находится во второй нормальной форме
(2НФ), если она удовлетворяет определению 1НФ
и все ее поля, не входящие в первичный ключ,
связаны неприводимой зависимостью с
первичным ключом.
Вторая нормальная форма (2)
Диаграмма функциональных зависимостей отношения,
приведенного к 2НФ
Имя_Д
Гор_П
П№
Д№
Статус
Цв
Вес
Гор_Д
П№
Кол
Д№
Вторая нормальная форма (3)
Преобразованные отношения
П№ Д№
Кол
Брест
П1
Д1
300
10
Минск
П1
Д2
200
П3
30
Гродно
П1
Д3
400
П4
10
Минск
П1
Д4
200
П5
20
Брест
П1
Д5
100
П1
Д6
100
П2
Д1
300
П2
Д2
400
П3
Д2
200
П4
Д2
200
П4
Д4
300
П№
Статус
П1
20
П2
Д№
Имя_Д
Гор_П
Цв
Вес
Гор_Д
Д1
Тестер
Черный
250
Борисов
Д2
Дозиметр
Серый
700
Минск
Д3
Радиометр Черный
1400 Минск
Д4
Часы
Желтый
140
Брест
Д5
Рулетка
Красный 200
Пинск
Д6
Лом
Черный
5000 Могилев
Вторая нормальная форма (4)
Аномалии
Вставка – нельзя включить данные о некотором
городе и его статусе, пока в нем нет поставщика.
Удаление – при удалении поставщика теряется
информация о статусе города.
Обновление – статус городов повторяется
несколько раз. При изменении статуса города
приходится просматривать множество строк,
чтобы исключить получение противоречивого
результата, но вероятность ошибки остается.
Транзитивные зависимости
Если выполняются функциональные зависимости
АВ и ВС, то выполняется также и
функциональная зависимость АС.
Возможная декомпозиция:
П№
Гор_П
Гор_П
Статус
Третья нормальная форма (1)
Отношение находится в третьей нормальной
форме (3НФ) тогда и только тогда, когда оно
находится в 2НФ и каждый неключевой атрибут
нетранзитивно зависит от первичного ключа.
Другими словами:
Таблица находится в третьей нормальной форме
(3НФ), если она находится в 2НФ и ни одно из ее
неключевых полей не зависит функционально от
любого другого неключевого поля.
Третья нормальная форма (2)
Варианты декомпозиции
П№ Статус
Гор_П
П1
20
Брест
П2
10
Минск
П3
30
Гродно
П4
10
Минск
П5
20
Брест
Функциональные зависимости:
П№Город
П№ Статус
ГородСтатус
Варианты декомпозиции:
А:
(П№, Город) и (Город, Статус)
В:
(П№, Город) и (П№, Статус)
С:
(П№, Статус) и (Город, Статус)
Третья нормальная форма (3)
Декомпозиция с сохранением зависимости
(Риссанен (Rissanen)).
Проекции R1 и R2 отношения R независимы тогда и
только тогда, когда
каждая функциональная зависимость в отношении R
является логическим следствием функциональных
зависимостей в проекциях R1 и R2;
общие атрибуты проекций R1 и R2 образуют
потенциальный ключ, по крайней мере, для одной
из них.
Т.е., отношение R{A,B,C}, удовлетворяющее
функциональным зависимостям A→B и B→C,
следует разбивать на проекции {A,B} и {B,C}, а не
{A,B} и {A,C}
Нормальная форма Бойса-Кодда (1)
(Bouce-Codd)
Определение 3НФ не корректно, если
отношение имеет два или более потенциальных
ключа;
два потенциальных ключа являются сложными и
они перекрываются
Нормальная форма Бойса-Кодда (2)
Отношение находится в нормальной форме БойсаКодда (НФБК) тогда и только тогда, когда
детерминанты являются потенциальными
ключами.
Или
Таблица находится в нормальной форме БойсаКодда (НФБК), тогда и только тогда, когда
любая функциональная зависимость между ее
полями сводится к неприводимой функциональной
зависимости от потенциального ключа.
Нормальная форма Бойса-Кодда (3)
Пример отношения в НФБК
Отношение Поставщик (П№, Имя_П, Статус, Город)
с неперекрывающимися ключами
П№
Имя_П
Город
Статус
Нормальная форма Бойса-Кодда (4)
Пример
Отношение СДП с атрибутами
(С,Д,П).
Ограничения:
Каждый студент изучает данный
предмет у одного преподавателя
({С,Д}П);
Каждый преподаватель ведет только
один предмет (но каждый предмет
может преподаваться несколькими
преподавателями) (ПД).
С
Д
П
Олег Математ Ильин
Олег Физика
Петров
Петр Математ Ильин
Петр Физика
Иванов
С
Есть два перекрывающихся ключа –
{С,Д} и {С,П}
П
Д
Четвертая нормальная форма (1)
Пример. Отношение ДПУ
Д
Ненормализованное
отношение:
Физика
П
У
Петров Механика
Иванов Оптика
Математика Иванов Геометрия
Мат. анализ
Нормализованное
отношение:
Д
П
У
Физика
Петров
Механика
Физика
Петров
Оптика
Физика
Иванов Механика
Физика
Иванов Оптика
Математика Иванов Геометрия
Математика Иванов Мат. анализ
Четвертая нормальная форма (2)
Пример. Проекции {Д,П} и {Д,У} отношения ДПУ
Д
П
Д
У
Физика
Петров
Физика
Механика
Физика
Иванов
Физика
Оптика
Математика Иванов
Математика Геометрия
Математика Мат. анализ
Четвертая нормальная форма (3)
Многозначные зависимости
В отношении ДПУ есть две многозначные зависимости:
ДП и ДУ.
Первая означает, что хотя для каждой дисциплины не
существует одного соответствующего только этой
дисциплине преподавателя, т.е. не выполняется
функциональная зависимость ДП, тем не менее, каждая
дисциплина имеет определенное множество
преподавателей, независимо от наименования учебника.
Вторая зависимость имеет подобное толкование.
Четвертая нормальная форма (4)
Многозначные зависимости. Определение
Пусть А,В,С являются произвольными подмножествами
множества атрибутов отношения R.
В многозначно зависит от А (АВ) тогда и только тогда,
когда множество значений В, соответствующее заданной
паре значений (А,С) отношения R, зависит только от А, но
не зависит от С.
Многозначные зависимости всегда образуют связанные пары:
AB||C.
Многозначные зависимости – это обобщение функциональных
зависимостей в том смысле, что каждая функциональная
зависимость является многозначной, у которой зависимая
часть является одноэлементным множеством.
Четвертая нормальная форма (5)
Определение
Отношение R находится в 4НФ, если оно находится
в НФБК и все многозначные зависимости
отношения R фактически являются
функциональными зависимостями от
потенциальных ключей.
Четвертая нормальная форма (6)
Теорема Фейгина (R. Fagin)
Пусть А,В,С являются множествами атрибутов
отношения R{А,В,С}. Отношение R будет равно
соединению его проекций {А,В} и {А,С} тогда и
только тогда, когда для отношения R
выполняются многозначные зависимости АВ
и АС.
Четвертая нормальная форма (7)
Теорема Фейгина (R. Fagin)
Концепция независимых проекций Риссанена
применима и к выбору пути декомпозиции, если
вместо функциональных зависимостей
присутствуют многозначные зависимости A→→B
и A→→C. В этом случае следует провести
декомпозицию на отношения {A,B} и {A,C}.
Пятая нормальная форма (1)
Отношение Поставщики-Детали-Проекты
ПДПр
П
Д
ПД
Пр
П
ДПр
Д
Д
ПрП
Пр
Пр
П
П1 Д1 Пр2
П1 Д1
Д1 Пр2
Пр2
П1
П1 Д2 Пр1
П1 Д2
Д2 Пр1
Пр1
П1
П2 Д1 Пр1
П2 Д1
Д1 Пр1
Пр1
П2
П1 Д1 Пр1
ПДПр’
П
Д
Пр
ПДПр
(исходн)
П1
Д1 Пр2
П
Д
Пр
П1
Д2 Пр1
П1 Д1 Пр2
П2
Д1 Пр1
П1 Д2 Пр1
П2
Д1 Пр2
П2 Д1 Пр1
П1
Д1 Пр1
П1 Д1 Пр1
Пятая нормальная форма (2).
Необходимость ограничений
Декомпозируемость отношения может быть
фундаментальным и независящим от времени
свойством, если добавить дополнительное
ограничение.
Пятая нормальная форма (3).
Свойства некоторых отношений
Утверждение, что ПДПр равно соединению трех
проекций ПД, ДПр, ПрП эквивалентно следующему
утверждению:
ЕСЛИ пара (П1,Д1) принадлежит отношению ПД
И пара (Д1,Пр1)
принадлежит отношению ДПр
И пара (Пр1,П1)
принадлежит отношению ПрП,
ТО тройка (П1,Д1,Пр1)
принадлежит отношению
ПДПр.
Обратное утверждение также верно!
Пятая нормальная форма (4).
Свойства некоторых отношений
С другой стороны, справедливо утверждение, что
пара (П1,Д1) присутствует в отношении ПД, если
тройка (П1,Д1,Пр2) присутствует в отношении
ПДПр,
пара (П1,Пр1) – в отношении ППр, если (П1,Д2,Пр1)
есть в ПДПр,
пара (Д1,Пр1) – в отношении ДПр, если (П2,Д1,Пр1)
есть в ПДПр.
Тогда, если учесть первое утверждение, то в таком
отношении должен присутствовать и кортеж
(П1,Д1,Пр1).
Пятая нормальная форма (5).
Ограничение
Если кортежи (П1,Д1,Пр2), (П2,Д1,Пр1) и (П1,Д2,Пр1)
принадлежат отношению ПДПр, то и кортеж
(П1,Д1,Пр1) также принадлежит этому отношению.
Пятая нормальная форма (6).
Примеры аномалий
П1,Д1,Пр1
Смитт поставляет гаечные ключи для
Манхеттенского проекта
П1,Д1
Смитт поставляет гаечные ключи,
П1,Пр1
Смитт является поставщиком для
Манхеттенского проекта
Д1,Пр1
Гаечные ключи используются в
Манхеттенском проекте.
Пятая нормальная форма (7)
Зависимость соединения
Отношение R(X,Y,...,Z) удовлетворяет зависимости
соединения *(X,Y,...,Z) в том и только в том случае,
когда R восстанавливается без потерь путем
соединения своих проекций на X, Y, ..., Z.
Пятая нормальная форма (8)
Новая формулировка теоремы Фейгина
Отношение R(А,В,С) удовлетворяет зависимости
соединения *(АВ, АС) тогда и только тогда, когда
оно удовлетворяет многозначным зависимостям
АВ и АС, т.е.,
А В || С ≡ *{АВ, АС}
Зависимость соединения является обобщением
понятия многозначной зависимости. Более того,
это наиболее общая форма зависимости.
Пятая нормальная форма (9)
Примеры аномалий
П
Д
Пр
П1 Д1 Пр2
П1 Д2 Пр1
Если в отношение вставить кортеж
(П2,Д1,Пр1), то необходимо
вставить и кортеж (П1,Д1,Пр1).
Но если вставить кортеж
(П1,Д1,Пр1), то добавлять кортеж
(П2,Д1,Пр1) не обязательно.
Пятая нормальная форма (10)
Примеры аномалий
П
Д
Пр
П1 Д1 Пр2
П1 Д2 Пр1
П2 Д1 Пр1
П1 Д1 Пр1
В отношении кортеж (П2,Д1,Пр1)
можно удалить без проблем.
Но если удалять (П1,Д1,Пр1), то
необходимо удалить один из
оставшихся, чтобы не было
некоторой цикличности в данных.
Пятая нормальная форма (11)
Определение
Отношение R находится в пятой нормальной форме
в том и только в том случае, когда любая
зависимость соединения в R следует из
существования некоторого возможного ключа в R.
Процедура нормализации и проектирования
Цели нормализации
исключение
некоторых типов избыточности;
устранение некоторых аномалий обновления,
включения и удаления;
проектирование макета базы данных, который
являлся бы "хорошим" представлением реального
мира, был интуитивно понятен и служил хорошей
основой для дальнейшего развития;
упрощение процесса наложения ограничений
целостности.
Процедура нормализации и проектирования
Основные шаги
Унифицированное отношение должно быть
приведено к 1НФ.
2. Отношения в 1НФ следует разбить на проекции
для исключения всех функциональных
зависимостей, которые не являются
неприводимыми:
K1, K2, F (K2F)
K1, K2
K2, F (K2F)
1.
Процедура нормализации и проектирования
Основные шаги
Отношения в 2НФ следует разбить на проекции для
исключения любых транзитивных функциональных
зависимостей.
K, F1, F2
K, F1
F1, F2
4. Отношения в 3НФ рекомендуется разбить на проекции для
исключения любых оставшихся функциональных
зависимостей, в которых детерминанты не являются
потенциальными ключами. В результате будет получен
набор отношений в НФБК.
3.
Процедура нормализации и проектирования
Основные шаги
5.Отношения в НФБК следует разбить на проекции для
исключения всех многозначных зависимостей, которые не
являются функциональными зависимостями. В результате
будет получен набор отношений в 4НФ.
6.Отношения следует разбить на проекции для исключения
любых зависимостей соединения, которые не
подразумеваются потенциальными ключами, если их можно
выявить. Таким образом будет получен набор отношений в
5НФ (полная декомпозиция отношений).
Процедура нормализации и проектирования
Разбиение на проекции должно
выполняться без потерь данных и с
сохранением функциональных и
многозначных зависимостей!
Пример проектирования базы данных (1)
Семантическое описание
Для каждого отдела: уникальный номер отдела, бюджет и
уникальный номер руководителя отдела;
для каждого сотрудника: уникальный номер сотрудника,
номер текущего проекта, номер кабинета, номер телефона,
а также название выполняемой работы вместе с датами и
размерами всех оплат, полученных за выполнение данной
работы;
для каждого проекта: уникальный номер проекта и бюджет;
для каждого кабинета: уникальный номер кабинета,
площадь, номера всех телефонов.
Пример проектирования базы данных (2)
Семантические ограничения
Ни один сотрудник не является одновременно руководителем
нескольких отделов;
ни один сотрудник не работает одновременно более чем в одном
отделе;
ни один сотрудник не работает одновременно более чем с одним
проектом;
ни один сотрудник не имеет одновременно более одного кабинета;
ни один сотрудник не имеет одновременно более одного телефона;
ни один сотрудник не имеет одновременно более одного задания;
ни один проект не дается одновременно более чем одному отделу;
ни один кабинет не относится одновременно более чем к одному
отделу.
Пример проектирования базы данных (3)
Иерархическое представление структуры информации о
персонале компании, которая должна храниться в базе
данных
Отделы
Сотрудники
Задания
Ведомость
Проекты
Кабинеты
Телефоны
Пример проектирования базы данных (4)
Исходная иерархическая структура
ОТДЕЛЫ
(ОТД№, БЮДЖЕТ_О, РУК№,
СОТРУДНИКИ, ПРОЕКТЫ, КАБИНЕТЫ)
CANDIDATE KEY
?
Здесь атрибуты СОТРУДНИКИ, ПРОЕКТЫ, КАБИНЕТЫ
состоят из значений-отношений.
Пример проектирования базы данных (5)
Распишем их вложенные атрибуты:
ОТДЕЛЫ (ОТД№, БЮДЖЕТ, РУК№,
СОТРУДНИКИ (СОТР№, ПРОЕКТ№, КАБ№,ТЕЛ№,
РАБОТА(ТЕМА, ОПЛАТА(ДАТА, СУММА))),
ПРОЕКТЫ (ПРОЕКТ№, БЮДЖЕТ_П),
КАБИНЕТЫ (КАБ№, ПЛОЩАДЬ,
ТЕЛЕФОН(ТЕЛ№)))
CANDIDATE KEY (ОТД№)
CANDIDATE KEY (РУК№)
Пример проектирования базы данных (6)
Набор отношений в 1НФ
ОТДЕЛЫ1
(ОТД№, БЮДЖЕТ_О, РУК№)
PRIMARY KEY (ОТД№)
ALTERNATE KEY (РУК№);
СОТРУДН1
(СОТР№, ОТД№, ПРОЕКТ№, КАБ№, ТЕЛ№)
PRIMARY KEY (СОТР№);
РАБОТА1
(ТЕМА, СОТР№)
PRIMARY KEY (ТЕМА, СОТР№);
ОПЛАТА1
(СОТР№, ТЕМА, ДАТА, СУММА)
PRIMARY KEY (СОТР№, ТЕМА, ДАТА);
ПРОЕКТЫ1
(ПРОЕКТ№, БЮДЖЕТ_П, ОТД№)
PRIMARY KEY (ПРОЕКТ№);
КАБИНЕТЫ1 (КАБ№, ПЛОЩАДЬ, ОТД№)
PRIMARY KEY (КАБ№);
ТЕЛЕФОНЫ1 (ТЕЛ№, КАБ№)
PRIMARY KEY (ТЕЛ№);
Пример проектирования базы данных (7)
Набор отношений в 2НФ
ОТДЕЛ2
СОТРУДН2
ОПЛАТА2
ОТД№
СОТР№
СОТР№
БЮДЖЕТ_О
ОТД№
РУК№
КАБИНЕТ2
ТЕЛЕФОН2
ПРОЕКТ№
КАБ№
ТЕЛ№
ДАТА
ОТД№
ПЛОЩАДЬ
КАБ№
ПРОЕКТ№
ТЕМА
БЮДЖЕТ_П
ОТД№
КАБ№
СУММА
ТЕЛ№
ПРОЕКТ2
Пример проектирования базы данных (8)
Приведение отношения СОТРУДНИКИ к 3НФ
СОТРУДН3 (СОТР№, ПРОЕКТ№, ТЕЛ№)
PRIMARY KEY (СОТР№);
X (ТЕЛ№, КАБ№)
PRIMARY KEY (ТЕЛ№);
Y (ПРОЕКТ№, ОТД№)
PRIMARY KEY (ПРОЕКТ№);
Z (КАБ№, ОТД№)
PRIMARY KEY (КАБ№).
Пример проектирования базы данных (9)
Отношения базы данных, приведенные к 3НФ
ОТДЕЛЫ3 (ОТД№, БЮДЖЕТ_О, РУК№)
PRIMARY KEY (ОТД№)
ALTERNATE KEY (РУК№);
СОТРУДН3 (СОТР№, ПРОЕКТ№, ТЕЛ№)
PRIMARY KEY (СОТР№);
ОПЛАТА3 (СОТР№, ТЕМА, ДАТА, СУММА)
PRIMARY KEY (СОТР№, ТЕМА, ДАТА);
ПРОЕКТЫ3 (ПРОЕКТ№, БЮДЖЕТ_П, ОТД№)
PRIMARY KEY (ПРОЕКТ№)
КАБИНЕТЫ3
(КАБ№, ПЛОЩАДЬ, ОТД№)
PRIMARY KEY (КАБ№);
ТЕЛЕФОНЫ3
(ТЕЛ№, КАБ№)
PRIMARY KEY (ТЕЛ№);
Пример проектирования базы данных (10)
Набор отношений в 3НФ
ОТДЕЛ
СОТРУДН
ОПЛАТА
ПРОЕКТЫ
КАБИНЕТ
ТЕЛЕФОН
ОТД№
СОТР№
СОТР№
ПРОЕКТ№
КАБ№
ТЕЛ№
БЮДЖЕТ_О
ПРОЕКТ№
ДАТА
ОТД№
ПЛОЩАДЬ
КАБ№
РУК№
ТЕЛ№
ТЕМА
БЮДЖЕТ_П
ОТД№
СУММА