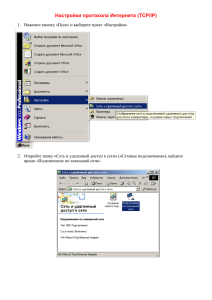
Администрирование информационных систем, В. П. Калюжный, Л. А. Осипов, СПБГУАП, Учебное пособие
реклама

Федеральное агенТство по образованию Государственное образовательное учреждение высшего профессионального образования Санкт-Петербургский государственный университет аэрокосмического приборостроения В. П. Калюжный, Л. А. Осипов Администрирование информационных сетей Учебное пособие Допущено Учебно-методическим объединением вузов по университетскому политехническому образованию в качестве учебного пособия для студентов высших учебных заведений, обучающихся по направлению подготовки 230200-Информационные системы Санкт-Петербург 2010 УДК 004 ББК 32.81 К17 Рецензенты: заведующий кафедрой «Информационные управляющие системы» Санкт-Петербургского государственного университета телекоммуникаций им. профессора Бонч-Бруевича, доктор технических наук, профессор М. О. Колбанев; профессор кафедры «Автоматизированные системы обработки информации и управления» Санкт-Петербургского государственного электротехнического университета «ЛЭТИ» доктор технических наук, заслуженный работник высшей школы РФ С. А. Яковлев Утверждено редакционно-издательским советом университета в качестве учебного пособия Калюжный В. П., Осипов Л. А. К17 Администрирование информационных сетей: учебное пособие / В. П. Калюжный Л. А. Осипов. – СПб.: ГУАП, 2010. – 96 с. ISBN 978-5-8088-0499-9 В пособии рассматриваются логические и технические основы построения объединенных компьютерных сетей и их администрирования, особое внимание уделено рассмотрению методов, функций и служб информационных систем администрирования. Предназначено для студентов, изучающих дисциплины «Администрирование в информационных системах», «Информационные системы и сети», «Вычислительные системы, сети и телекоммуникации», «Сетевое управление и протоколы» и «Интернет технологии». УДК 004 ББК 32.81 Учебное издание Калюжный Виталий Павлович Осипов Леонид Андроникович Администрирование информационных сетей Учебное пособие Редактор В. П. Зуева Верстальщик С. Б. Мацапура Сдано в набор 23.10.09. Подписано к печати 16.12.09. Формат 60×84 1/16. Бумага офсетная. Печать офсетная. Печ. л. 6,0. Уч.-изд. л. 5,9. Тираж 100 экз. Заказ № 828. Редакционно-издательский центр ГУАП 190000, Санкт-Петербург, Б. Морская ул., 67 ISBN 978-5-8088-0499-9 © ГУАП, 2010 © В. П. Калюжный Л. А. Осипов, 2010 Основные сокращения OC – операционная система. ISO – International Organization of Standardization – Международная организация по стандартизации. TCP/IP – Transmission Control Protocol / Internet Protocol – Набор используемых в Интернете сетевых протоколов, поддерживающий связь между объединенными сетями и разными операционными системами. ARP (Address Resolution Protocol – протокол разрешения адресов) – сетевой протокол, предназначенный для преобразования IPадресов (адресов сетевого уровня) в MAC-адреса (адреса канального уровня) в сетях TCP/IP. Определён в RFC 826. RARP (Reverse Address Resolution Protocol) – Обратный протокол преобразования адресов – выполняет обратное отображение адресов, т. е. преобразует аппаратный адрес в IP-адрес. IP – Internet Protocol – межсетевой протокол, основа стека протоколов TCP/IP. MAC-адрес (Media Access Control – управление доступом к носителю) – это уникальный идентификатор, сопоставляемый с различными типами оборудования для компьютерных сетей. RIP (Routing Information Protocol) – один из наиболее распространенных протоколов маршрутизации в небольших компьютерных сетях, дистанционно-векторный протокол. EIGRP (Enhanced Interior Gateway Routing Protocol) – протокол маршрутизации, разработанный фирмой Cisco на основе протокола IGRP, исправлены недостатки дистанционно-векторных протоколов. IGRP (Interior Gateway Routing Protocol) – протокол маршрутизации, разработан фирмой CISCO для своих многопротокольных маршрутизаторов в середине 80-х гг. для маршрутизации в пределах автономной системы (AS), дистанционно-векторный протокол. OSPF (Open Shortest Path First) – протокол динамической маршрутизации, основанный на технологии отслеживания состояния канала (link-state technology). ICMP – межсетевой протокол управления сообщениями (Internet Control Message Protocol). UDP – протокол пользовательских дейтаграмм (User Datag-ram Protocol). TCP – протокол управления передачей (Transmission Control Protocol). 3 NME – Network Management Entity. NMA – приложение (Network Management Application), которое собственно и осуществляет управление. MIB – база управляющей информации (Management Infor-mation Base). NM – сбор и анализ информации из сети (Network Moni-toring). NC – управление сетью (Network Control ). SNMP – простой протокол управления сетью. DES – (Data Encryption Standard), стандарт шифрования информации. SHA-1 (Secure Hash Algorithm), алгоритм шифрования, принятый Национальным Институтом стандартов США. ASCII – американский стандартный код обмена информации. DTE – терминальное оборудование. DCE – оборудование передачи данных. LAN – локальная сеть. UTP – неэкранированная витая пара. STP – экранированная витая пара. NIC – адаптер сетевого интерфейса. FTP – протокол передачи файлов. NFS – сетевая файловая система. PDU – пакет протокола SNMP. ПО – программное обеспечение. VLAN – виртуальная локальная сеть. Telnet – протокол эмуляции терминала. Internet – глобальная сеть. internet – технология Интернет. Ethernet – сетевая технолоия (ENET). InterNIC – Информационный центр Internet (Internet Net-work Information Center). TTL – Время жизни пакета (Time to Live). MTU – Максимальная единица передачи ( Maximum Transfare Unit). TELNET – программа удаленной эмуляции терминала. 4 Предисловие Целью пособия является систематическое изложение вопросов объединения информационных сетей и их обслуживания. В сравнительно небольшом объеме материала успех может быть достигнут, с одной стороны, путем последовательного изложения ключевых вопросов данной предметной области, а с другой – использованием везде, где это возможно, примеров. Эти примеры можно найти в пяти приложениях к пособию. В первом разделе излагаются основы стека протоколов TCP/IP, причем неосновные его части, такие как ICMP и ARP, изложены по возможности в деталях. Подробно рассмотрены вопросы организации IP-адресации и использования маски подсети. Во втором разделе рассмотрены вопросы маршрутизации в IPсетях в их развитии. Ключевым здесь является понимание основ IP-маршрутизации, на котором возможно дальнейшее освоение этой темы. Здесь же рассмотрены основные протоколы маршрутизации – RIP, OSPF и BGP. В третьем разделе изложены основы информационных систем администрирования и их программных платформ, организации баз данных администрирования, а также соответствующие процедуры, службы, объекты и методы. Все эти вопросы изложены в контексте применения основных инструментов администрирования – протокола SNMP и информационной базы данных MIB. Здесь же изложены вопросы, касающиеся обеспечения безопасности не в самих сетях, а в области сетевого управления. Четвертый раздел посвящен сетевой интеграции – важнейшему вопросу, без освоения которого решать практические задачи сетевого администрирования невозможно. Неустоявшаяся терминология дает о себе знать в практике и теории информационных сетей. Например, схожие по смыслу английские термины router и gateway достаточно точно можно перевести как маршрутизатор и шлюз соответственно. Не во всех случаях, однако, перевод оказывается удовлетворительным, в том числе и в источниках. У современного сетевого администратора есть возможность выбора инструментов в очень широком диапазоне – можно выбрать подходящую сетевую операционную систему и ограничиться ее библиотеками и утилитами, например, работать в командной строке UNIX – подобной ОС. Можно пользоваться протоколами управления сетью и мониторинга, а также приложениями, построенными на их основе. Можно использовать возможности современных ин5 теллектуальных сетевых устройств; можно использовать трафиканализаторы различного назначения и возможностей. Независимо от того, что предпочитает тот или иной специалист, непременным условием его успешной работы являются знания и навыки, полученные в результате практической работы и теоретической подготовки в заданной предметной области. Можно сказать иначе – тот, кто может построить сеть, тот сможет ею управлять. В приложениях к пособию изложен пример расчета объединенной сети. Авторы надеются, что учащиеся в полной мере воспользуются предоставляемой им возможностью для освоения предмета. 6 1. Основы TCP/IP 1.1. Введение Комплект протоколов TCP/IP – это сетевое программное обеспечение низкого уровня, в состав которого входит несколько компонентов: − межсетевой протокол (Internet Protocol, IP), который обеспечивает транспортировку без дополнительной обработки данных с одной машины на другую; − межсетевой протокол управляющих сообщений (Internet Control Message Protocol, ICMP), который отвечает за различные виды низкоуровневой поддержки протокола IP, включая сообщения об ошибках, содействие в маршрутизации, подтверждение получения сообщения; − протокол преобразования адресов (Address Resolution Protocol, ARP), выполняющий трансляцию логических сетевых адресов в аппаратные; − протокол пользовательских дейтаграмм (User Datagram Protocol, UDP) и протокол управления передачей (Transmission Control Protocol, TCP), которые обеспечивают пересылку данных из одной программы в другую с помощью протокола IP. Протокол UDP обеспечивает транспортировку отдельных сообщений без проверки, тогда как TCP более надежен и предполагает проверку установления соединения. Со стеком TCP/IP тесно связаны другие сетевые протоколы, например, SNMP, Telnet, FTP и другие. TCP/IP предоставляет пользователям однородный интерфейс, обеспечивающий взаимодействие с сетевыми аппаратными средствами различных типов. Этот протокол гарантирует возможность обмена данными (взаимодействия) между системами, невзирая на многочисленные различия, существующие между ними. TCP/IP, кроме того, позволяет соединять на программном уровне отдельные физические сети в более крупную и более гибкую логическую сеть. Стек протоколов TCP/IP базируется на простой четырехуровневой схеме. Канальный Сетевой Транспортный Прикладной Сетевые аппаратные средства и драйверы устройств Базовые коммуникации, адресация и маршрутизация Связь между программами в сети Прикладные программы конечных пользователей 7 ¨ÉÁÃĹ½ÆÇ BSQ ÌÉÇ»¾ÆÕ «É¹ÆÊÈÇÉËÆÔ ÌÉÇ»¾ÆÕ ª¾Ë¾»Ç ÌÉÇ»¾ÆÕ £¹Æ¹ÄÕÆÔ ÌÉÇ»¾ÆÕ SMPHJO UBML GUQ 5$1 *1 4/.1 %/4 O/TONQ4/.1 ´«µ 6%1 USBDFSPVUF *$.1 "31 ½É¹Â»¾ÉÔÌÊËÉÇÂÊË» Рис. 1 На рис. 1 показано, как различные компоненты и клиенты TCP/ IP вписываются в общую архитектуру. Протоколы каждого уровня строятся на основе тех, которые соответствуют более низкому уровню. Данные проходят вниз по стеку протоколов на машине-отправителе, затем движутся по физической сети и поднимаются вверх по стеку протоколов на машине-адресате. Например, прикладная программа, «думающая», что использует только протокол UDP, на самом деле вызывает протоколы UDP, IP и физические сети. Каждое соединение машины с сетью называется сетевым интерфейсом. Машина, имеющая более одного интерфейса, может принимать данные по одному интерфейсу и передавать их по другому, осуществляя таким образом пересылку данных между сетями. Эта функция называется маршрутизацией, а машина, выполняющая ее, маршрутизатором, или шлюзом. Данные передаются по сети в форме пакетов, каждый из которых состоит из заголовка и полезной нагрузки. Заголовок содержит сведения о том, откуда прибыл пакет и куда он направляется. Заголовок, кроме того, может включать контрольную сумму, информацию, характерную для конкретного протокола, и другие инструкции по обработке. Полезная нагрузка – это данные, подлежащие пересылке. Когда пакет путешествует вниз по стеку протоколов, готовясь к отправке, каждый протокол вводит в него свою собственную информацию заголовка. Законченный пакет одного протокола становится полезной нагрузкой пакета, генерируемого следующим протоколом. Эта операция известна как инкапсуляция, или оформление. На принимающей машине инкапсулированные кадры разворачиваются в обратном порядке. Например, UDP-пакет, передаваемый по сети Ethernet, содержит три различных «обертки». В среде Ethernet он «заворачива8 6%1È¹Ã¾Ë º¹ÂË *1È¹Ã¾Ë º¹ÂË ¹¼ÇÄÇ»Çà ¹¼ÇÄÇ»Çà ¹¼ÇÄÇ»Çà ¨ÉÁÃĹ½ÆÔ¾ &UIFSOFU *1 6%1 ½¹ÆÆÔ¾ º¹ÂË º¹ÂË º¹ÂË º¹ÂË ¹»¾ÉÑÁ˾ÄÕ &UIFSOFU º¹ÂË &UIFSOFUù½É º¹ÂË Рис. 2 ется» в простой заголовок, содержащий сведения об аппаратных адресах источника и получателя, длине кадра и его контрольной сумме. Полезной нагрузкой Ethernet-кадра является IP-пакет. Полезная нагрузка IP-пакета – UDP-пакет, и, наконец, полезная нагрузка UDP-пакета состоит собственно из передаваемых данных. На рис. 2 изображен типичный сетевой кадр. Размер пакетов может ограничиваться как характеристиками аппаратных средств, так и требованиями протоколов. Например, объем полезной нагрузки Ethernet-кадра не может превышать 1500 байт. В некоторых современных сетях используются пакеты размером менее 100 байт. Предельный размер пакета для конкретной сети или протокола называется максимальной единицей передачи (Maximum Transfer Unit, MTU). В стеке протоколов TCP/IP за разбивку пакетов в соответствии с MTU конкретной сети отвечает уровень IP. Если пакет направляется через несколько сетей, то у одной из промежуточных сетей MTU может оказаться меньшим, чем у сети-отправителя. В этом случае шлюз, ведущий к сети с меньшим MTU, выполнит дальнейшее деление пакета. Функцию сегментации могут выполнять и протоколы других уровней. Например, современные версии TCP сами настраивают размеры своих пакетов с целью повышения пропускной способности конкретной среды передачи данных. 1.2. Логическая структура сетевого программного взаимодействия в IP сетях Логическая структура сетевого программного взаимодействия, реализующего протоколы семейства TCP/IP в каждом узле сети internet, изображена на рис. 3. Прямоугольниками обозначены модули, а линии, соединяющие прямоугольники, – пути передачи 9 данных. Горизонтальная линия внизу рисунка обозначает кабель сети Ethernet, которая используется в качестве примера физической среды; «о» – это трансивер. Знак «*» – обозначает IP ¨©¡£¤¦´¨©§¯ªª´ адрес, а «@» – адрес узла в сети c c c Ethernet (Ethernet-адрес или 6%1 5$1 MAC). Введем ряд базовых терминов, которые мы будем исполь *1 зовать в дальнейшем. "31 Драйвер – это программа, непосредственно взаимодей&/&5 ствующая с сетевым адапте! ром. Модуль – это программа, взаимодействующая с драйвером, сетевыми прикладными программами или другими £¹º¾ÄÕ&UIFSOFU модулями. Драйвер сетевого Рис. 3 адаптера и, возможно, другие модули, специфичные для физической сети передачи данных, предоставляют сетевой интерфейс для протокольных модулей семейства TCP/IP. Название блока данных, передаваемого по сети, зависит от того, на каком уровне стека протоколов он находится. Блок данных, с которым имеет дело сетевой интерфейс, называется кадром; если блок данных находится между сетевым интерфейсом и модулем IP, то он называется IP-пакетом; если он – между модулем IP и модулем UDP, то – UDP-датаграммой; если между модулем IP и модулем TCP, то – ТСР-сегментом (или транспортным сообщением); наконец, если блок данных находится на уровне сетевых прикладных процессов, то он называется прикладным сообщением. Рассмотрим потоки данных, проходящие через стек протоколов (рис. 3). В случае использования протокола TCP (Transmission Control Protocol – протокол управления передачей), данные передаются между прикладным процессом и модулем TCP. Типичным прикладным процессом, использующим протокол TCP, является модуль FTP (File Transfer Protocol протокол передачи файлов). Стек протоколов в этом случае будет FTP/TCP/IP/ENET. При использовании протокола UDP (User Datagram Protocol – протокол пользовательских датаграмм), данные передаются между приклад10 ным про­цессом и модулем UDP. Например, SNMP (Simple Network Management Protocol – простой протокол управления сетью) пользуется транспортными услугами UDP. Его стек протоколов выглядит так: SNMP/UDP/IP/ENET. Модули TCP, UDP и драйвер Ethernet являются мультиплексорами n×1. Действуя как мультиплексоры, они переключают несколько входов на один выход. Они также являются демультиплексорами 1×n. Как демультиплексоры они переключают один вход на один из многих выходов в соответствии с полем типа в заголовке протокольного блока данных (рис. 4). Когда Ethernet-кадр попадает в драйвер сетевого интерфейса Ethernet, он может быть направлен либо в модуль ARP (Address Resolution Protocol адресный протокол), либо в модуль IP (Internet Protocol – межсетевой протокол). На то, куда должен быть направлен Ethernet-кадр, указывает значение поля типа в заголовке кадра. Если IP-пакет попадает в модуль IP, то содержащиеся в нем данные могут быть переданы либо модулю TCP, либо UDP, что определяется полем «протокол» в заголовке IP-пакета. Если UDP-датаграмма попадает в модуль UDP, то на основании значения поля «порт» в заголовке датаграммы определяется прикладная программа, которой должно быть передано прикладное сообщение. Если TCP-сообщение попадает в модуль TCP, то выбор прикладной программы, которой должно быть передано сообщение, осуществляется на основе значения поля «порт» в заголовке TCP-сообщения. Мультиплексирование данных в обратную сторону осуществляется довольно просто, так как из каждого модуля существует только один путь вниз. Каждый протокольный модуль добавляет к пакету свой заголовок, на основании которого машина, принявшая пакет, выполняет демультиплексирование. c O ¥ÌÄÕËÁÈľÃÊÇÉ ¨ÇËÇà ¦¦´® c O ¾ÅÌÄÕËÁÈľÃÊÇÉ ¨ÇËÇà ¦¦´® Рис. 4 11 c O ¥ÌÄÕËÁÈľÃÊÇÉ c ¨ÇËÇà ¦¦´® N c O ¾ÅÌÄÕËÁÈľÃÊÇÉ c ¨ÇËÇà ¦¦´® N Рис. 5 Данные от прикладного процесса проходят через модули TCP или UDP, после чего попадают в модуль IP и оттуда – на уровень сетевого интерфейса. Хотя технология internet поддерживает много различных сред передачи данных, здесь мы будем предполагать использование Ethernet, так как именно эта среда чаще всего служит физической основой для IP-сети. Узел на рис. 3 имеет одну точку соединения с Ethernet. Шестибайтный Ethernet-адрес является уникальным для каждого сетевого адаптера и распознается драйвером. Машина имеет также четырехбайтный IP-адрес. Этот адрес обозначает точку доступа к сети на интерфейсе модуля IP с драйвером. IP-адрес должен быть уникальным в пределах всей сети Internet. Узел может быть подключен одновременно к нескольким средам передачи данных. На рис. 6 показан узел с двумя сетевыми интерфейсами Ethernet. Заметим, что он имеет 2 Ethernet-адреса и 2 IP-адреса. Из представленной ¨©¡£¤¦´ ¨©§¯ªª´ схемы видно, что для машин с несколькими 5$1 6%1 сетевыми интерфейса ми модуль IP выполняет функции мультиплексо*1 ра n×m и демультиплек сора m×n (рис. 5). "31 "31 Таким образом, он осуществляет мульти&/&5 &/&5 плексирование входных ! ! и выходных данных в обоих направлениях. Модуль IP в данном слу&UIFSOFU чае сложнее, чем в пер&UIFSOFU вом примере, так как может передавать данРис. 6 12 ные между сетями. Данные могут поступать через любой сетевой интерфейс и быть ретранслированы через любой другой сетевой интерфейс. Процесс передачи пакета в другую сеть называ- 5$1 6%1 ется ретрансляцией IP-пакета. Машина, выполняющая ретрансляцию, называется шлюзом или маршрутизатором. Как показано на рис. 7 ретранслируемый пакет не пере*1 дается модулям TCP или UDP. Некоторые шлюзы вообще могут не иметь модулей TCP и UDP. Кадр Ethernet содержит адрес назначения, адрес источника, поле ¹ÆÆÔ¾ ¹ÆÆÔ¾ типа и данные. Размер адреса в ÈÇÊËÌȹ×Ë ÈÇÊËÌȹ×Ë Ethernet – 6 байт. Каждый сетеÇËÊ×½¹ Ê×½¹ вой адаптер имеет свой EthernetРис. 7 адрес. Адаптер контролирует обмен информацией, происходящий в сети, и принимает адресованные ему Ethernet-кадры, а также Ethernet-кадры с адресом «FF:FF:FF:FF:FF:FF» (в 16-ричной системе), который обозначает «всем» и используется при широко­ вещательной передаче. 1.3. Протокол IP Протокол IP представляет собой протокол сетевого уровня, который содержит информацию об адресации и управляющую информацию для маршрутизации пакетов. Протокол IP описан в RFC 791 и является основным протоколом сетевого уровня в наборе протоколов Internet. Вместе с протоколом управления передачей (TCP) протокол IP образует основу протоколов Internet. Протокол IP имеет две основные функции: обеспечение передачи дейтаграмм по объединенной сети методом негарантированной доставки без подтверждения соединения и обеспечение фрагментации и повторной сборки дейтаграмм для поддержки каналов передачи данных с различными размерами максимального передаваемого модуля данных (MTU). IP-пакет содержит несколько видов информации. Поля IPпакета, показанные на рис. 8, описаны далее: 13 ºÁ˹ ¾ÉÊÁØ *)- «ÁÈÊÄÌ¿ºÔ ¡½¾ÆËÁÍÁùÏÁØ É¾ÅØÊÌÒ¾Ê˻ǻ¹ÆÁØ §ºÒ¹Ø½ÄÁƹ ­Ä¹¼Á ¨ÉÇËÇÃÇÄ ½É¾ÊÁÊËÇÐÆÁù ªÅ¾Ò¾ÆÁ¾ Íɹ¼Å¾Æ˹ £ÇÆËÉÇÄÕƹØÊÌÅŹ À¹¼ÇÄǻù ½É¾ÊÈÇÄÌй˾ÄØ ª»ÇÂÊË»¹ À¹ÈÇÄƾÆÁ¾ ¹ÆÆÔ¾ ȾɾžÆÆǽÄÁÆÔ Рис. 8 − Версия. Версия используемого протокола IP. − Длина IP-заголовка (IP header length – IHL). Длина заголовка дейтаграммы в 32-разрядных словах. − Тип службы. Задает требуемый протоколом верхнего уровня способ обработки текущей дейтаграммы и присваивает дейтаграммам различные степени важности. − Общая длина. Длина всего IP-пакета в байтах, включая данные и заголовок. − Идентификация. Целое число, которое идентифицирует данную дейтаграмму. Это поле используется для облегчения соединения фрагментов дейтаграмм. − Флаги. Трехразрядное поле, в котором 2 младших бита управляют фрагментацией. Младший бит определяет, может ли пакет быть фрагментирован, а средний – является ли пакет последним в серии фрагментированных пакетов. Третий (старший) бит не используется. − Смещение фрагмента. Позиция данных фрагмента относительно начала данных в исходной дейтаграмме, что позволяет IPпроцессу правильно восстановить исходную дейтаграмму. − Время существования. Счетчик, который постепенно уменьшается до нуля, после чего дейтаграмма отбрасывается во избежание бесконечного цикла передачи пакетов. − Протокол. Протокол верхнего уровня, принимающий входящие пакеты после окончания обработки их протоколом IP. 14 − Контрольная сумма заголовка. Используется для проверки целостности IP-заголовка. − Адрес источника. Определяет узел-отправитель. − Адрес получателя. Определяет принимающий узел. − Свойства. Позволяет протоколу IP задавать дополнительные опции, такие как обеспечение безопасности. − Данные. Информация верхнего уровня. 1.4. IР-адресация Схема IP-адресации неразрывно связана с процессом маршрутизации IP-дейтаграмм по объединенной сети. Каждый IP-адрес имеет специфические компоненты и соответствует основному формату. Как будет описано далее, IP-адреса делятся на категории и используются для создания адресов подсетей. Каждому узлу в сети TCP/IP присваивается уникальный 32-разрядный логический адрес, который делится на две главные части; номер сети и номер узла. Номер сети определяет сеть и если сеть является частью Internet, должен присваиваться Информационным центром Internet (Internet Network Information Center– InterNIC). Поставщик услуг Internet может получить у InterNIC блоки сетевых адресов и самостоятельно выделять адресное пространство по мере необходимости. Номер узла определяет узел в сети и присваивается администратором сети. ºÁ˹ ª¾ËÕ ¾ÊØËÁÐÆ¹Ø À¹ÈÁÊÕ ÊËÇÐùÅÁ ºÁËÇ» ¬À¾Ä ºÁËÇ» ºÁËÇ» ºÁËÇ» Рис. 9 32-разрядный IP-адрес представляет собой 4 группы по 8 битов, разделенные точками и обычно записываемые в десятеричном формате (так называемая десятичная запись с точками – dotted decimal notation). Каждый бит октета имеет двоичный вес (128, 64, 32, 16, 8, 4, 2, 1). Минимальное значение октета равно 0, максимальное – 255. Основной формат IP-адреса показан на рис. 9. 15 1.5. Классы IP-адресов IP-адреса делятся на пять классов: А, В, С, D и Е. Класс сети определяется первыми слева (старшими) битами. Справочная информация о пяти классах IP-адресов представлена в табл. 1. На рис. 10 показан формат классов IP-адресов. Следует обратить внимание на старшие биты в каждом классе. Таблица 1 Справочная информация о пяти классах IP-адресов Класс Формат IPадреса Назначение Старший бит (биты) Диапазон адресов Количе- Максимальство битов, ное количесеть/узел ство узлов A Несколько N.H.H.H* крупных организаций 0 1.0.0.0 – 126.0.0.0 7/24 16777214** (224–2) B орN.N.H.H Средние ганизации 1, 0 128.1 – 191.254.0.0 14/16 65534 (216–2) C N.N.N.H 1, 1, 0 192.0.1.0 – 223.255.254.0 22/8 254 (28–2) Сравнительно мелкие организации D – Не для Многоадрескоммер224.0.0.0 – ные группы 1, 1, 1, 0 239.255.255.255 ческого (RFC 1112) использования E – Экспери240.0.0 – ментальные 1, 1, 1, 1 254.255.255.255 – – – * N – номер сети; H – номер узла. ** Один адрес зарезервирован как широковещательный и еще один – для сети. ÁËÔ £Ä¹ÊÊ ª¾ËÕ £Ä¹ÊÊ# ª¾ËÕª¾ËÕ ¬À¾Ä ¬À¾Ä ª¾ËÕ ¬À¾Ä £Ä¹Êʪ ª¾ËÕ ª¾ËÕ Рис. 10 16 ¬À¾Ä ¬À¾Ä ª¾ËÕ ¬À¾Ä Для коммерческого использования доступны IP-адреса классов A, В и С. Класс адреса легко определить по его первому октету, сравнив это значение с диапазоном классов, представленных на рис. 11. Например, в IP-адресе 172.31.I.2 первый октет 172. Поскольку 172 лежит в пределах от 128 до 191, 172.31.1.2 является адресом класса В. 1.6. IP-адресация подсети IP-сети часто делятся на сети меньшего размера, называемые подсетями. Использование подсетей дает много преимуществ, главные из которых это повышенная гибкость, более эффективное использование сетевых адресов и возможность ограничить трафик, в том числе и широковещательный. Класс адреса Первый октет, десятичная запись Старшие биты Класс A 1–126 0 Класс B 128–191 10 Класс C 192–223 110 Класс D 224–239 1110 Класс E 240-254 1111 Рис. 11 Подсети администрируются локально. При этом внешне вся сеть выглядит единой и информация о внутренней структуре извне недоступна. Номер сети может разбиваться на несколько подсетей. Например, в состав сети с номером 172.16.0.0 могут входить подсети 172.16.1.0, 172.16.2.0, 172.16.3.0 и т. п. Наличие всех нулей в адресной части узла указывает на то, что это не адрес узла, а номер сети. Если создается локальная сеть, которую не планируется подключать к Internet, то можно выбрать любые IP-адреса. Однако из соображений безопасности и единообразия определенные IP-адреса были специально зарезервированы для подобных целей. Эти адреса представлены далее. 17 АДРЕСА, ЗАРЕЗЕРВИРОВАННЫЕ ДЛЯ ВНУТРЕННИХ СЕТЕЙ | Класс | Маска | Сетевые адреса | A | 255.0.0.0 | 10.0.0.0 – 10.255.255.255 | | B | 255.255.0.0 | 172.16.0.0 – 172.31.255.255 | | C | 255.255.255.0 | 192.168.0.0 – 192.168.255.255 | Следует упомянуть также об адресе 127.0.0.1, который нельзя нигде использовать. Этот адрес обозначает закольцованный интерфейс, который есть на любом PC, если даже он не подключен к сети. Пакеты, посланные на этот интерфейс, возвращаются, так нигде и не побывав. Используется при отладке сетевых программ. 1.7. Маска IP-подсети Адрес подсети создается «заимствованием» битов из поля узла и использованием их для поля подсети. Количество заимствованных битов из поля узла не является постоянным и определяется маской подсети. На рис. 12 показано, как заимствуются биты из поля адреса узла для создания поля адреса подсети. Маски подсети имеют тот же ½É¾ÊÃĹÊʹ½Ç½¾Ä¾ÆÁØƹÈǽʾËÁ ª¾ËÕ ¨Ç½Ê¾ËÕ ¬À¾Ä ¬À¾Ä ½É¾ÊÃĹÊʹÈÇÊľ½¾Ä¾ÆÁØƹÈǽʾËÁ Рис. 12 ª¾ËÕ »ÇÁÐÆǾ Èɾ½Ê˹»Ä¾ÆÁ¾ ¾ÊØËÁÐÆǾ Èɾ½Ê˹»Ä¾ÆÁ¾ ÊɹÀ½¾ÄÁ˾ÄØÅÁ ª¾ËÕ ¨Ç½Ê¾ËÕ ¬À¾Ä Рис. 13 18 Рис. 14 формат и представление, что и IP-адреса. Однако в маске подсети во всех разрядах, определяющих зоны сети и подсети, стоит двоичная единица, а во всех разрядах, определяющих поле узла, – двоичный ноль. Пример маски подсети показан на рис. 13. Подробнее маски подсети класса В и С будут описаны далее. Адреса класса А здесь не обсуждаются, поскольку они обычно делятся на подсети на границе 8 битов. Для подсетей класса В и С существуют различные типы масок подсети. Стандартная маска подсети для адреса класса В без подсетей – 255.255.0.0, а маска подсети для номера 171.16.0.0 класса В, где для подсети отводится 8 битов,– 255.255.0.0. Значение этих 8 битов – 28–2 (1 – для сетевого и 1 – для широковещательного адреса) = 254 возможных подсетей по 28–2 = 254 узла в каждой. Маска подсети для номера 192.168.2.0 класса С, где для подсети отводится 5 битов, имеет вид 255.255.255.248 (рис. 14). Если для подсети отводится 5 битов, то количество возможных подсетей равно 25–2 = 30, при этом в каждой из них будет 23–2 = 6 узлов. При проектировании сетей классов В и С для определения необходимого количества подсетей и узлов, а также выбора соответствующей маски сети можно воспользоваться справочными данными, приведенными в табл. 1,2,3 и на рис. 10, 11 и 14. 19 Таблица 2 Параметры подсетей класса В Количество битов Маска подсети Количество подсетей Количество узлов 2 3 4 5 6 7 8 9 10 11 12 13 14 255.255.192.0 255.255.224.0 255.255.240.0 255.255.248.0 255.255.252.0 255.255.254.0 255.255.255.0 255.255.255.128 255.255.255.192 255.255.255.224 255.255.255.240 255.255.255.248 255.255.255.252 2 6 14 30 62 126 254 510 1022 2046 4094 8190 16382 16382 8190 4094 2046 1022 510 254 126 62 30 14 6 2 Таблица 3 Параметры подсетей класса С Количество битов Маска подсети Количество подсетей Количество узлов 2 3 4 5 6 255.255.255.192 255.255.255.224 255.255.255.240 255.255.255.248 255.255.255.252 2 6 14 30 62 62 30 14 6 2 Обработка входящего пакета с использованием маски происходит следующим образом. Вначале из входящего пакета извлекается IP-адрес получателя и восстанавливается маска внутренней подсети. Затем путем логического умножения получается номер сети, причем IP-адрес узла получателя удаляется, а номер сети получателя остается. После этого находится номер сети получателя, и затем он сравнивается с исходящим интерфейсом. Наконец, кадр передается в сеть. 1.8. Протокол IСМР Очевидно, что элементы более или менее сложных сетей должны как-то реагировать на изменение их состояния – исчезновение и появление новых узлов, колебание нагрузки, и так далее. Для этой 20 цели служат служебные протоколы. Некоторые из них используются непосредственно для формирования таблицы маршрутизации (они называются протоколами маршрутизации), другие же служат для управления сетью в целом. Сообщения ICMP переносятся в IP-пакетах, и поэтому протокол ICMP в стеке протоколов должен быть на ступеньку выше IP. Однако поскольку сервис, предоставляемый этим протоколом, имеет смысл только в контексте IP-протокола, в большинстве операционных систем реализация ICMP входит в состав IP-модуля. ICMP предназначен для уведомления об ошибках при маршрутизации пакета и для выявления проблем в сети. ICMP-сообщения передаются в IP-пакетах с протоколом, равным 1. ICMP не нуждается в гарантированной доставке, однако, его сообщения защищены контрольной суммой. Каждое сообщение содержит тип, дополнительный код, уточняющий этот тип, и некоторую дополнительную информацию (в зависимости от типа и кода), позволяющую получателю более надежно обработать полученное сообщение. ICMP версии 4 поддерживает следующие типы сообщений: 1. Destination Unreachable Это сообщение посылается получателем или промежуточным маршрутизатором в случае, когда IP пакет невозможно доставить по назначению. При этом используются дополнительные коды: − net unreachable – недоступна вся подсеть получателя; − host unreachable – недоступна станция-получатель; − protocol unreachable – станция-получатель не поддерживает указанный в заголовке пакета протокол четвертого уровня; − port unreachable – протокол поддерживается, но в данный момент не существует приложения, получающего пакеты по указанному адресу четвертого уровня (этот адрес часто называют портом и он содержится не в заголовке IP-пакета, а в заголовке дейтаграммы или прикладного сообщения, который содержится в этом IPпакете); − fragmentation needed and DF set – необходима фрагментация для доставки пакета получателю, но в заголовке пакета поднят флаг «Don’t Fragment»; − source route failed – маршрут, предписанный отправителем в опции IP-пакета, не годится для доставки пакета получателю. В качестве дополнительной информации ICMP-пакет содержит заголовок и первые 64 бита исходного IP-пакета. Кроме того, 21 большинство шлюзов возвращают также в сообщение с кодом fragmentation needed and DF set, MTU, поддерживаемое на интерфейсе, через который пакет должен был быть послан. На этом механизме основан алгоритм определения MTU для пути, который станция может использовать, если по какой-то причине не хочет допускать фрагментации своих пакетов. 2. Time Exceeded Посылается в двух случаях: − с кодом 0, если TTL поле в заголовке IP-пакета стало равным нулю; − или с кодом 1, если получатель не может собрать дейтаграмму из-за слишком долгого отсутствия одного из фрагментов. В качестве дополнительной информации ICMP-пакет содержит заголовок и первые 64 бита исходного IP-пакета. 3. Parameter Problem Посылается, когда какой-то из параметров заголовка IP-пакета содержит ошибку. В качестве дополнительной информации ICMPпакет содержит номер байта, с которого начинается параметр, содержащий ошибку, заголовок и первые 64 бита исходного IPпакета. 4. Source Quench Посылается в случае, когда отправитель слишком быстро посылает пакеты, или в сети перегрузка, и промежуточный шлюз или получатель не справляется с их обработкой. Лучшее, что может сделать отправитель в этом случае – снизить темп. В идеале IPмодуль должен уведомить о сложившейся ситуации транспортный уровень. В качестве дополнительной информации ICMP-пакет содержит заголовок и первые 64 бита исходного IP-пакета. 5. Redirect Иногда возникает ситуация, когда промежуточный маршрутизатор посылает IP-пакет в тот же сетевой интерфейс, откуда он его принял (другому маршрутизатору). В этом случае станции, ответственной за этот крюк, посылается сообщение Redirect, говорящее о том, что ее таблица маршрутизации некорректна. Получив это сообщение, станция анализирует дополнительную информацию (заголовок и первые 64 бита исходного IP-пакета и адрес маршрутизатора) и обновляет таблицу маршрутизации. 6. Echo и Echo Reply Эти сообщения используются для определения, присутствует ли станция в сети и какое качество связи между двумя станциями. 22 Сообщение Echo содержит идентификатор, порядковый номер и (иногда) дополнительные данные. Станция, получив ICMPсообщение Echo, должна отправить полученный пакет назад, не изменяя его данных, а изменив только тип с Echo на Echo Reply и IP-заголовок. Таким образом, можно выяснить, есть ли в сети станция с указанным адресом и включена ли она. Послав серию пакетов и оценив процент потерявшихся (его можно определить, проанализировав идентификаторы и порядковые номера вернувшихся пакетов), можно судить, насколько хороша связь между станциями. С помощью ICMP-сообщений Echo и Echo Reply реализована хорошо известная программа ping. 7. Timestamp и Timestamp Reply Являются аналогами Echo и Echo Reply, но получатель Timestamp в возвращаемом пакете проставляет время (в миллисекундах от полуночи), соответствующее моментам, когда пакет был принят и когда он был отправлен назад. 1.9. Протокол ARP Для отображения IP-адресов в Ethernet-адреса используется протокол ARP (Address Resolution Protocol – протокол разрешения адресов). Разрешение (сопоставление) выполняется только для отправляемых IP-пакетов, так как только в момент отправки создаются заголовки IP и Ethernet. Преобразование адресов выполняется путем поиска в таблице. Эта таблица, называемая ARPтаблицей, хранится в памяти и содержит строки для каждого узла сети. В двух столбцах содержатся IP- и Ethernet-адреса. Если требуется преобразовать IP-адрес в Ethernet-адрес, то ищется запись с соответствующим IP-адресом. ARP-таблица необходима потому, что IP-адреса и Ethernetадреса выбираются независимо, и нет какого-либо алгоритма для преобразования одного в другой. IP-адрес выбирает менеджер сети с учетом положения машины в сети Internet. Если машину перемещают в другую часть сети Internet, то ее IP-адрес должен быть изменен. Ethernet-адрес выбирает производитель сетевого интерфейсного оборудования из выделенного для него по лицензии адресного пространства. Когда у машины заменяется плата сетевого адаптера, то меняется и ее Ethernet-адрес. В ходе обычной работы сетевая программа, такая как telnet, отправляет прикладное сообщение, пользуясь транспортными услу23 гами TCP. Модуль TCP посылает соответствующее транспортное сообщение через модуль IP. В результате составляется IP-пакет, который должен быть передан драйверу Ethernet. IP-адрес места назначения известен прикладной программе, модулю TCP и модулю IP. Необходимо на его основе найти Ethernet-адрес места назначения. Для определения искомого Ethernet-адреса используется ARP-таблица. Таблица заполняется автоматически модулем ARP по мере необходимости. Когда с помощью существующей ARP-таблицы не удается преобразовать IP-адрес, то происходит следующее: − по сети передается широковещательный ARP-запрос; − исходящий IP-пакет ставится в очередь. Каждый сетевой адаптер принимает широковещательные передачи. Все драйверы Ethernet проверяют поле типа в принятом Ethernet-кадре и передают ARP-пакеты модулю ARP. ARP-запрос можно интерпретировать так: «Если ваш IP-адрес совпадает с указанным, то сообщите мне ваш Ethernet-адрес». Каждый модуль ARP проверяет поле искомого IP-адреса в полученном ARP-пакете и, если адрес совпадает с его собственным IP-адресом, то посылает ответ прямо по Ethernet-адресу отправителя запроса. ARP-ответ можно интерпретировать так: «Да, это мой IP-адрес, ему соответствует такой-то Ethernet-адрес»... Этот ответ получает машина, сделавшая ARP-запрос. Драйвер этой машины проверяет поле типа в Ethernet-кадре и передает ARP-пакет модулю ARP. Модуль ARP анализирует ARP-пакет и добавляет запись в свою АRР-таблицу. Новая запись в ARP-таблице появляется автоматически, спустя несколько миллисекунд после того, как она потребовалась. Ранее на шаге 2 исходящий IP-пакет был поставлен в очередь. Теперь с использованием обновленной ARP-таблицы выполняется преобразование IP-адреса в Ethernet-адрес, после чего Ethernet-кадр передается по сети. Полностью порядок преобразования адресов выглядит так: − по сети передается широковещательный ARP-запрос; − исходящий IP-пакет ставится в очередь; − возвращается ARP-ответ, содержащий информацию о соответствии IP- и Ethernet-адресов; эта информация заносится в ARPтаблицу; − для преобразования IP-адреса в Ethernet-адрес у IP-пакета, поставленного в очередь, используется ARP-таблица; − Ethernet-кадр передается по сети Ethernet. 24 Если в сети нет машины с искомым IP-адресом, то ARP-ответа не будет и не будет записи в ARP-таблице. Протокол IP будет уничтожать IP-пакеты, направляемые по этому адресу. Протоколы верхнего уровня не могут отличить случай повреждения сети Ethernet от случая отсутствия машины с искомым IP-адресом. Некоторые реализации IP и ARP не ставят в очередь IP-пакеты на то время, пока они ждут ARP-ответов. Вместо этого IP-пакет просто уничтожается, а его восстановление возлагается на модуль TCP или прикладной процесс, работающий через UDP. Такое восстановление выполняется с помощью таймаутов и повторных передач. Повторная передача сообщения проходит успешно, так как первая попытка уже вызвала заполнение ARP-таблицы. Следует отметить, что каждый узел имеет отдельную ARP-таблицу для каждого своего сетевого интерфейса. 1.10. Протокол TCP Протокол управления передачей (Transmission Control Protocol – TCP) обеспечивает надежную передачу данных в среде IP. TCP относится к транспортному уровню. TCP предоставляет такие службы, как потоковая передача данных, надежность, эффективное управление потоком, дуплексный режим и мультиплексирование. При потоковой передаче данных TCP передает неструктурированный поток байтов, идентифицируемых по порядковым номерам. Эта служба полезна для приложений, поскольку им не приходится разбивать данные на блоки перед их передачей по протоколу TCP. TCP группирует байты в сегменты и передает их на уровень протокола IP для пересылки. Надежность TCP обеспечивается сквозной, ориентированной на соединение передачей пакетов по объединенной сети. Она достигается упорядочением байтов при помощи номеров подтверждения передачи, по которым получатель определяет, какой байт должен поступить следующим. Байты, не получившие подтверждения в течение определенного времени, передаются заново. Надежный механизм протокола TCP позволяет устройствам обрабатывать потерянные, задержанные, дублированные и неверно прочитанные пакеты. Механизм лимита времени позволяет устройствам распознавать потерянные пакеты и запрашивать их повторную передачу. 25 TCP обеспечивает эффективное управление потоком. При отправке подтверждений источнику данных принимающий TCPпроцесс указывает наибольший порядковый номер, который он может принять без переполнения внутренних буферов. В дуплексном режиме TCP-процесс может одновременно пересылать и принимать пакеты. Мультиплексирование TCP означает одновременную передачу по одному соединению нескольких диалогов верхнего уровня. Для использования надежных транспортных служб TCP-узлы должны устанавливать друг с другом сеансы, ориентированные на соединение. Установка соединения выполняется по механизму, называемому трехэтапной синхронизацией (three-way handshake). Этот механизм синхронизирует обе стороны соединения, позволяя им согласовать начальные порядковые номера. Он также обеспечивает готовность обеих сторон к передаче данных и информированность каждой из сторон о готовности другой. Это необходимо во избежание повторной передачи пакетов в процессе установки сеанса или после его разрыва. Каждый узел выбирает случайным образом порядковый номер, чтобы следить за приемом и передачей байтов потока. Затем механизм трехэтапной синхронизации работает следующим образом. Первый узел (узел А) инициирует соединение, отправляя пакет с начальным порядковым номером и битом синхронизации SYN для индикации запроса соединения. Второй узел (узел В) получает SYN, записывает порядковый номер X и отвечает подтверждением SYN (вместе с АСК = X + 1), узел В указывает собственный порядковый номер (SEQ = Y). Тогда, если АСК равен 20, то это означает, что узел принял байты с 0 по 19 и ожидает следующий байт 20. Эта технология называется подтверждением передачи. Затем узел А подтверждает прием всех байтов, посланных узлом В с подтверждением передачи, указывая следующий байт, который узел А ожидает получить (АСК = Y + 1). После этого может начаться передача данных. Простые транспортные протоколы могут обеспечивать надежность и такую технологию управления потоком, при которой исходный узел посылает пакет, запускает таймер и ждет подтверждения приема перед отправкой нового пакета. Если подтверждение не получено по истечении времени, узел передает пакет еще раз. Эта технология называется подтверждением приема и повторной передачей (Positive Acknowledgment and Retransmission – PAR). 26 Присваивая каждому пакету порядковый номер, PAR позволяет узлам отслеживать пакеты, потерянные или дублированные вследствие сетевых задержек и преждевременной повторной передачи. Номера последовательностей посылаются обратно как уведомления в возможности отслеживания подтверждений приема. Однако PAR неэффективно использует пропускную способность, потому что перед отправкой нового пакета узел должен ждать подтверждения и, следовательно, пакет можно передавать только один за другим. Скользящее окно TCP позволяет использовать пропускную способность сети более эффективно, чем PAR, поскольку с его помощью узлы могут отправлять несколько байтов или пакетов, не дожидаясь подтверждения. В TCP принимающий узел определяет текущий размер окна каждого пакета. Поскольку по TCP-соединению данные передаются в виде потока байтов, размеры окон тоже выражаются в байтах. Таким образом, окно представляет собой количество байт данных, которые отправитель может послать до ожидания подтверждения приема. Начальные размеры окон определяются при настройке соединения, но могут изменяться при передаче данных для управления потоком. Например, нулевой размер окна означает запрет на передачу данных. Предположим, что TCP-отправителю надо послать с помощью скользящего окна последовательность байт (пронумерованных от 1 до 10) получателю с размером окна 5. Отправитель помещает в окно первые 5 байт, передает их все сразу и ждет подтверждения приема. Получатель отвечает АСК, равным 6, показывая, что получил байты с 1 по 5 и ждет байта 6. В том же пакете получатель показывает, что размер его окна равен 5. Отправитель сдвигает скользящее окно на 5 байт вправо и передаст байты с 6 по 10. Получатель отвечает АСК, равным 11, показывая, что он ожидает байта 11. В этом пакете получатель может указать, что его размер окна равен 0 (поскольку, например, его внутренние буферы заполнены). Тогда отправитель больше не сможет посылать байты, пока получатель не пошлет другой пакет с ненулевым размером окна. Поля и полный формат TCP-пакета показаны на рис. 15. Далее описаны поля TCP-пакета (рис. 15). − Порт источника и порт получателя. Точки, в которых процессы верхнего уровня источника и получателя принимают услуги TCP. 27 ºÁ˹ ¨ÇÉËÁÊËÇÐÆÁù ¨ÇÉËÈÇÄÌй˾ÄØ ¨ÇÉؽÃÇ»ÔÂÆÇÅ¾É ¦ÇžÉÈǽ˻¾É¿½¾ÆÁØ ª½»Á¼½¹ÆÆÔÎ ©¾À¾É»ÆÔ¾ ­Ä¹¼Á £ÇÆËÉÇÄÕƹØÊÌÅŹ §ÃÆÇ ¬Ã¹À¹Ë¾ÄÕÊÉÇÐÆÇÊËÁ ¨¹É¹Å¾ËÉÔ ÁÀ¹ÈÇÄƾÆÁ¾ ¹ÆÆÔ¾ ȾɾžÆÆǽÄÁÆÔ Рис. 15 − Порядковый номер. Обычно это номер, присвоенный первому байту данных в текущем сообщении. При установке соединения может также использоваться для обозначения исходного порядкового номера в предстоящей передаче. − Номер подтверждения. Порядковый номер следующего байта данных, который ожидает получить получатель. − Сдвиг данных. Число 32-разрядных слов в заголовке TCP. − Резервные. Область, зарезервированная для использования в будущем. − Флаги. Различная управляющая информация, в том числе биты SYN и АСК, используемые для установки соединения, и бит FIN для разрыва соединения. − Окно. Размер приемного окна получателя (объем буфера для входящих данных). − Контрольная сумма. Показывает, не был ли заголовок поврежден при передаче. − Указатель срочности. Указывает на первый байт срочных данных в пакете. − Параметры. Различные дополнительные параметры TCP. − Данные. Информация верхнего уровня. 1.11. Протокол UDP Протокол передачи дейтаграмм пользователя UDP (User Datagram Protocol – UDP) представляет собой протокол транспорт28 ºÁ˹ ¨ÇÉËÁÊËÇÐÆÁù ¨ÇÉËÈÇÄÌй˾ÄØ ÄÁƹ £ÇÆËÉÇÄÕƹØÊÌÅŹ Рис. 16 ного уровня, не требующий подтверждения соединения, и принадлежащий семейству протоколов Internet. В сущности, UDP является интерфейсом между IP и протоколами верхнего уровня. Порты протокола UDP различают приложения, запущенные на одном устройстве. В отличие от TCP, UDP не добавляет IP надежности, управления потоком, или функций исправления ошибок. Из-за простоты UDP его заголовки короче и требуют меньше сетевых ресурсов, чем TCP. UDP полезен в ситуациях, когда мощные механизмы обеспечения надежности протокола TCP не обязательны, например, когда управление потоком и коррекцию ошибок можно возложить на протокол верхнего уровня. UDP является транспортным протоколом для нескольких известных протоколов уровня приложений, в том числе NFS, SNMP, DNS и TFTP. Как показано на рис. 16, формат пакета UDP содержит четыре поля: порт источника, порт получателя, длина и контрольная сумма. Поля портов источника и получателя содержат 16-разрядные номера портов протокола UDP для демультиплексирования дейтаграмм при приеме процессов уровня приложений. Поле длины определяет размер UDP-заголовка и данных. Поле контрольной суммы может служить для проверки целостности UDP-заголовка и данных. 1.12. Путь вниз. Сокеты Рассмотрим способ, с помощью которого приложения могут получить сервис от TCP/IP. Чтобы иметь возможность посылать и получать данные, приложение должно получить сначала от операционной системы сокет. 29 Сокет – это уникальное число, дающее приложению возможность получить сервис от операционной системы. В то же время внутри операционной системы сокету соответствует структура, содержащая все параметры сервиса, ассоциированные с этим числом. Такая структура часто тоже носит название сокет. Приложению, чтобы получить сокет, нужно вызвать функцию с тем же именем. Параметры, передаваемые функции socket, зависят от сервиса, который приложение желает получить: − Первый параметр – это семейство протоколов, обслуживаемое сокетом. Чтобы посылать и получать TCP, UDP и IP-пакеты используется константа. Семейств протоколов довольно много (около десятка), но чаще всего приходится сталкиваться с константами PF_INET и PF_UNIX. Сокет, открытый для PF_UNIX, служит для межпроцессорного взаимодействия. Приложения на одном компьютере могут использовать для взаимодействия TCP и UDP, но сервис PF_UNIX создает меньше накладных расходов, и потому значительно эффективней. С другой стороны, некоторые операционные системы (не UNIX) поддерживают PF_INET, но не поддерживают PF_UNIX. Поэтому, если есть хоть какой-то шанс, что ваша программа будет перенесена куда-либо, кроме UNIX, PF_UNIX лучше не использовать, или, по крайней мере, написать два варианта под условной компиляцией и предоставить скрипт, способный определить, поддерживается ли в операционной системе PF_UNIX. − Второй параметр – тип сокета. Наиболее распространенными типами являются SOCK_DGRAM (сокет для протоколов, ориентированных на датаграммы, например UDP); SOCK_STREAM (сокет для протоколов, ориентированных на поток данных, таких как TCP); SOCK_RAW (для сокетов, обеспечивающих доступ к сервисам нижних уровней, например посылки и или получения IPпакетов). − Третий параметр – протокол. Его значение зависит от типа сокета и семейства протоколов. Для UDP и TCP-сокетов этот параметр не используется (равен нулю); для SOCK_RAW можно указать номер протокола, который должен фигурировать в IPзаголовке. Что дальше делать с сокетом, зависит от параметров, использованных при его создании. Во всех операциях с сокетами используется структура, содержащая адрес. 30 Существует большое количество адресов для различных семейств; они даже могут быть длиннее 16 байт, но все они должны приводиться к struct sockaddr (т. е. их первые два байта должны иметь тот же смысл, что и первые два байта в struct sockaddr). Для семейства DF_INET используется структура struct sockaddr_in, где, кроме полей sin_len и sin_family, содержатся номер TCP или UDP порта (2 байта) и IP-адрес (4 байта). И порт, и адрес должны лежать в сетевом порядке, т. е. наиболее значимые байты – первыми. Если IP-адрес или порт не имеют значения для данной операции, они заполняются нулями. Чтобы послать сообщение в UDP-сокет, обычно используется вызов sendto, в который передается сокет, указатель на буфер с данными, длина данных, указатель на структуру struct sockaddr, содержащую IP-адрес и порт получателя, ее размер (обычно пишут sizeof(struct sockaddr_in)) и дополнительные флаги (обычно 0). Если после посылки пакета пришло сообщение ICMP Destination Unreachable, при попытке послать следующий пакет, sendto вернет ошибку. Чтобы получать сообщения из UDP-сокета нужно сначала уведомить операционную систему, пакеты с каким IP-адресом получателя и каким портом вас интересуют. Чтобы сделать это, необходимо сформировать нужный адрес и передать его в вызов bind. Когда конкретный IP-адрес не играет роли, а нужен только порт, вместо него используется константа INADDR_ANY. Затем уже можно вызвать процедуру recvfrom, которая не только скопирует в ваш буфер полученный пакет, но и вернет адрес отправителя этого пакета (и IP-адрес, и порт). Чтобы воспользоваться сервисом TCP необходимо сначала установить соединение. Если приложение устанавливает соединение пассивно, оно должно: 1. Уведомить операционную систему о том, на каком порту и локальном IP-адресе оно собирается ожидать установления соединения с помощью вызова bind (точно так же, как для UDP). 2. Использовать вызов listen, чтобы операционная система реально начала обслуживать запросы о соединении от возможных партнеров. В эту процедуру передается параметр, обозначающий число запросов соединений, которые могут находиться в очереди и ожидать обработки – остальные попытки установления соединения будут отвергаться. 31 3. И, наконец, использовать вызов accept, чтобы принять одно соединение из тех, что находятся в очереди. Если в очереди соединений нет, процесс, вызвавший accept, зависнет до тех пор, пока кто-нибудь не попытается установить с ним соединение; accept возвращает новый сокет, который служит для передачи и чтения данных из соединения. Старый по-прежнему служит для обслуживания попыток установления соединения и может быть использован как параметр в следующем вызове accept. Активная сторона для установления соединения делает только один шаг – вызывает connect, передавая ему IP-адрес и порт партнера (в структуре struct sockaddr). После установления соединения обе стороны могут читать и посылать данные с помощью вызовов read и write соответственно (как из файла). После использования сокета, его надо закрыть с помощью вызова close, иначе порт, с которым он ассоциирован долгое время, будет недоступен для использования. 1.13. Технология Ethernet Технология Ethernet основана на методе множественного доступа к среде передачи данных с прослушиванием несущей и обнаружением коллизий – CSMA/CD. Каждый узел сети имеет сетевой адаптер – схему, реализующую метод CSMA/CD на аппаратном уровне. Адаптер имеет приемопередатчик-трансивер, подключенный к общей (разделяемой) среде передачи. Адаптер узла, нуждающийся в передаче информации, прослушивает линию и дожидается « тишины» – отсутствия сигнала (несущей). Далее он формирует кадр, начинающийся с синхронизирующей преамбулы, за которой следует поток двоичных данных в самосинхронизирующемся коде. Все остальные узлы принимают этот сигнал, синхронизируются по преамбуле и декодируют его в последовательность бит, помещаемую в свой приемный буфер. Окончание кадра определяется по пропаданию несущей, и по этому событию приемники анализируют принятый кадр. Этот кадр контролируется на отсутствие ошибок, после чего в «хорошем» кадре проверяется адресная информация. Возможно столкновение двух сигналов – коллизия, приводящая к их искажению, которое обнаруживается передатчиком. Передающие узлы, обнаружив коллизию, прекращают передачу кадра, после чего повторную попытку передачи сделают через случайный интервал вре32 мени после освобождения линии. При большой загрузке коллизии приводят к прогрессирующей деградации производительности, что является слабым местом технологии Ethernet. Сеть Ethernet относится к категории широковещательных. В таких случаях все станции видят все кадры вне зависимости от того, являются ли они их получателями. Каждая станция должна проверять, не ей ли предназначаются передаваемые данные. Полученные данные передаются на следующий уровень. В технологии Ethernet данные могут передаваться по коаксиальному или оптическому кабелю, а также через витую пару. Чаще всего при построении локальных сетей на основе этой технологии оптический кабель используется для формирования магистрали сети, в то время как витая пара применяется для подключения станций и серверов. В настоящее время определены три скорости передачи данных: − 10 Мбит / -10Base-T Ethernet; − 100 Мбит / -Fast Ethernet; − 1000 Мбит /-Gigabit Ethernet. Одним из главных достоинств сетей Ethernet является их экономичность. Также в Ethernet реализованы достаточно простые алгоритмы доступа к среде, адресации и передачи данных. Eще одним замечательным свойством сетей Ethernet является их хорошая расширяемость, т. е. легкость подключения новых узлов. Вопросы к первому разделу 1. Почему программа пользователя не может напрямую обратиться к протоколу IP? 2. Укажите достоинства и недостатки промежуточного восстановления фрагментированных дейтаграмм по сравнению со сборкой конечным получателем? 3. Чему равны накладные расходы на заголовок протокола IP? 4. Требуется фрагментировать IP-дейтаграмму. Какие параметры в поле параметров следует скопировать в заголовок каждого фрагмента, а какие должны быть помещены только в первый фрагмент? Обоснуйте свой ответ для каждого параметра. 5. Какой уровень определяет выбор маршрута в объединенной сети? 6. Что определяют спецификации физического уровня? 7. Что определяют спецификации транспортного уровня? 8. Что определяют спецификации канального уровня? 33 9. Что определяют спецификации сетевого уровня? 10. Какие существуют методы преобразования сетевых адресов в адреса MAC? 11. Опишите способы доступа к среде передачи, используемые в сетях Ethernet. 12. Чем управляет канальный уровень? 13. Какой метод доступа к среде передачи данных используется в сетях Ethernet? 14. Какой протокол сетевой службы OSI не требует подтверждения соединения. 15. Каковы две основные задачи IP? 16. В каком виде обычно представляется IP-адрес? 17. Как определяется класс IP-адреса? 18. Каково назначение маски подсети? 19. Каково назначение протокола ARP? 20. Каково назначение протокола ICMP? 21. Каково назначение таймера ожидания? 22. Какой адрес изменяется при передачи пакета от источника к получателю? 23. Перечислите достоинства и недостатки технологии Ethernet. 34 2. Маршрутизация в IP-сетях 2.1. Cтатическая маршрутизация Протокол IP является маршрутизирующим протоколом, иными словами, он выполняет саму маршрутизацию пакетов, а не определяет хорошие маршруты, как это делают протоколы маршрутизации. Возможности этого протокола для организации объединенных сетей ограничены лишь количественно – трудно вести большое количество объемных таблиц IP маршрутов, особенно если их содержимое постоянно меняется из-за изменений в сети. Кроме того, статическая маршрутизация не в состоянии реагировать на нежелательные изменения в сети, такие как выход из строя канала связи. Случай, когда сеть организована только на основе IP относится к статической маршрутизации. Здесь может быть два варианта. В первом случае имеется одна изолированная сеть без подсетей. Доставка кадров до места назначения происходит без участия IP протокола по аппаратным адресам, которые разрешает ARP протокол относительно IP адресов. Это вырожденный случай, он относится к прямой статической маршрутизации, которая не может быть использована для объединения ( интеграции сетей ). Более интересен случай косвенной статической маршрутизации, где можно организовать объединенную сеть только на основе возможностей протокола IP и его таблицы маршрутов. Для отправляемых IP-пакетов, поступающих от модулей верхнего уровня, модуль IP должен определить способ доставки – прямой или косвенный – и выбрать сетевой интерфейс. Этот выбор делается на основании результатов поиска в таблице маршрутов. Для принимаемых IP-пакетов, поступающих от сетевых драйверов, модуль IP должен решить, нужно ли ретранслировать IP-пакет по другой сети или передать его на верхний уровень. Если модуль IP решит, что IP-пакет должен быть ретранслирован, то дальнейшая работа с ним осуществляется так же, как с отправляемыми IP-пакетами. Входящий IP-пакет никогда не ретранслируется через тот же сетевой интерфейс, через который он был принят. Решение о маршрутизации принимается до того, как IP-пакет передается сетевому драйверу, и до того, как происходит обращение к ARP-таблице. Модуль IP осуществляет поиск в таблице маршрутов. Ключом поиска служит номер IP-сети, выделенный из IP-адреса места назначения IP-пакета. 35 Таблица маршрутов содержит по одной строке для каждого маршрута. Основными столбцами таблицы маршрутов являются номер сети, флаг прямой или косвенной маршрутизации, IP-адрес шлюза и номер сетевого интерфейса. Эта таблица используется модулем IP при обработке каждого отправляемого IP-пакета. В большинстве UNIX систем таблица маршрутов может быть изменена с помощью команды «route». Содержание таблицы маршрутов определяется менеджером сети, поскольку менеджер сети присваивает машинам IP-адреса. Рассмотрим пример объединения трех сетей в единую IP-сеть (рис. 17). Таблица 4 Таблица маршрутов в узле alpha Сеть Флаг вида маршрутизации 223.1.2.0 223.1.3.0 223.1.4.0 Прямая Косвенная Косвенная Адрес шлюза Номер интерфейса 223.1.2.1 223.1.2.1 Eth0 Eth0 Eth0 В столбце адрес шлюза таблицы маршрутов узла alpha указывается IP-адрес точки соединения узла delta с сетью 223.1.2.0. Пусть узел alpha посылает IP-пакет узлу epsilon. Этот пакет находится в модуле IP узла alpha, и IP-адрес места назначения равен IP-адресу узла epsilon (223.1.3.2). Модуль IP выделяет сетевой но- BMQIB &UI &UIFSOFU EFMUB &UI &UI &UI &UIFSOFU JPUB &UI &UIFSOFU Рис. 17 36 FQTJMPO &UI мер из IP-адреса (223.1.3.0) и ищет соответствующую ему строку в таблице маршрутов. Соответствие находится во второй строке. Запись в этой строке указывает на то, что машины требуемой сети доступны через шлюз 223.1.2.1. Модуль IP в узле alpha осуществляет поиск в ARP-таблице, с помощью которого определяет Ethernet-адрес, соответствующий IP-адресу шлюза. Затем IPпакет, содержащий IP-адрес места назначения epsilon, посылается через интерфейс Eth0 шлюзу 223.1.2.1. IP-пакет принимается сетевым интерфейсом шлюза delta и передается модулю IP. Проверяется IP-адрес места назначения, и, поскольку он не соответствует ни одному из собственных IP-адресов delta, шлюз решает ретранслировать IP-пакет. Модуль IP в узле delta выделяет сетевой номер из IP-адреса места назначения IP-пакета (223.1.3.0) и ищет соответствующую запись в таблице маршрутов. Таблица маршрутов шлюза delta выглядит так: Таблица 5 Таблица маршрутов шлюза delta Сеть Флаг вида маршрутизации 223.1.2.0 223.1.4.0 223.1.3.0 Прямая Прямая Прямая Адрес шлюза Номер интерфейса Eth0 Eth1 Eth2 Соответствие находится в третьей строке. Теперь модуль IP шлюза напрямую посылает IP-пакет узлу epsilon через интерфейс Eth2. Пакет содержит IP и Ethernet-адрес места назначения, равные epsilon. Узел epsilon принимает IP-пакет, и его модуль IP проверяет IP адрес места назначения. Он соответствует IP-адресу epsilon, поэтому содержащееся в IP-пакете сообщение передается протокольному модулю верхнего уровня. 2.2. Основы маршрутизации в IP-сетях Рассмотрим маршрутизацию в IP-сетях и связанные с ней проблемы. Отправители и промежуточные маршрутизаторы при выборе следующей промежуточной станции («next hop») руководствуются базой данных маршрутов, которая называется таблицей маршрутизации. 37 Таблица маршрутизации обычно содержит следующую информацию о каждом маршруте: адрес получателя; маска маршрута; адрес следующего пункта(next hop address) в маршруте; сетевой интерфейс, через который следует посылать пакет; длина маршрута; способ, с помощью которого он был получен, дополнительные флаги. Осуществляя маршрутизацию, станция может следовать приведенному далее алгоритму. 1. Из всех маршрутов в таблице маршрутизации выбираются актуальные (пригодные к использованию, не устаревшие) маршруты, для которых верно условие: если A – адрес получателя в таблице маршрутов; M – маска маршрута; N – длина маски; а D – адрес получателя из IP-заголовка пакета, то A & M = D & M; и N – маскимально. Если ни один маршрут не удовлетворяет этому условию, пакет уничтожается. 2. Для каждого маршрута в таблице хранится его длина – число шагов до подсети-получателя. Иногда, когда пересылка осуществляется через сеть с очень низкой производительностью, этой пересылке сопоставляется не один шаг, а несколько, чтобы длины двух маршрутов можно было сравнивать более корректно. Итак, из множества маршрутов, полученных в первом пункте,выбираются все маршруты с наименьшей длиной. 3. Маршруты могут быть добавлены в таблицу маршрутизации различными способами. Во-первых, они могут быть добавлены человеком (статические маршруты) с определенным приоритетом. Кроме того, маршруты могут добавляться в таблицу маршрутизации динамически, с помощью протоколов маршрутизации (о которых будет рассказано позднее). Таким маршрутам также приписываются приоритеты, которые зависят как того, с помощью какого протокола этот маршрут был получен, так и от того, какой приоритет этот маршрут имеет по внутренней шкале приоритетов протокола. Среди всех маршрутов, оставшихся после шага 2, отбираются маршруты с наивысшим приоритетом. 4. Если после третьего шага осталось больше одного маршрута, можно либо выбрать нужный маршрут случайным образом, либо использовать маршруты по очереди циклически (это подход предпочтительней, так как более равномерно расходует ресурсы сети). 5. Для использования выбранного маршрута нужно проанализировать флаги, выходной интерфейс и, возможно, next hop address. Маршруты могут иметь множество различных флагов, в зависимо38 сти от реализации сетевой поддержки в операционной системе, но общепринятый и действительно необходимый для осуществления маршрутизации по уже выбранному маршруту всего один: direct/ indirect. Этот флаг показывает, является ли маршрут прямым (т. е. конечный получатель находится в подсети, к которой у маршрутизатора есть интерфейс), или пакет должен пройти еще один или несколько маршрутизаторов на пути к конечному получателю. В первом случае next hop address не анализируется, в выходной интерфейс передается адрес получателя из заголовка пакета. Во втором случае в выходной интерфейс передается next hop address, соответствующий выбранному маршруту. Выходной интерфейс разрешает переданный ему IP адрес в адрес канального уровня и посылает кадр в сеть. На самом деле, только пп. 1 и 5 изложенного алгоритма можно считать более или менее общепринятыми. Способы выбора маршрута среди нескольких подходящих сильно зависят от сетевого программного обеспечения станции и политики маршрутизации в сети. В частности, станция может выбирать из нескольких маршрутов самый дешевый, если в сети принята тарификация, или для привилегированного трафика использовать одни маршруты, а для обычного другие. Критериев выбора маршрутов очень много и здесь приведены только некоторые из них. Описанная процедура маршрутизации достаточно сложна и обычно выполняется только на маршрутизаторах. Если хост находится в локальной сети, где имеется только один шлюз, ему не имеет смысла держать огромную таблицу, ведь вариантов всего два – либо получатель находится в той же подсети, и можно послать пакет ему напрямую, либо пакет придется отправлять маршрутизатору. Поэтому на узлах редко используют протоколы маршрутизации, а их таблица содержит всего два маршрута – прямой (в свою подсеть) и маршрут по умолчанию(default). Рутер, на который этот маршрут указывает, называется default gateway. Маршрут по умолчанию может быть и на маршрутизаторе. Если в таблице маршрутизации узла отсутствует маршрут по умолчанию, часть пакетов (те, для кого не нашлось обычных маршрутов) будет незбежно теряться. 2.3. Протоколы маршрутизации Эти протоколы определяют топологию сети и сохраняют информацию о ней в таблицах. 39 Протоколы маршрутизации выполняют две важнейшие функции. Во-первых, с их помощью определяется наилучший путь передачи пакета по сети. Обычно избирается путь, обеспечивающий минимальное количество ретрансляций при максимальной надежности. Как правило, это путь с минимальным числом транзитных узлов; передача данных в обход загруженных участков (с целью избежания заторов) − исключение из этого правила. Протокол маршрутизации предполагает постоянный сбор информации о состоянии маршрутов и обновление таблиц маршрутизации при изменении топологии сети вследствие отказов или перегрузок. Таким образом, таблицы маршрутизации должны содержать точную информацию о топологии сети. Во-вторых, функцией протоколов маршрутизации является передача пакетов по сети. Получая очередной пакет, маршрутизатор считывает адрес назначения из заголовка пакета и определяет, в каком направлении (через какой узел) следует осуществить дальнейшую передачу пакета. Для принятия такого решения используется информация из таблицы маршрутизации. Протокол маршрутизации может работать только тогда, когда формат пакетов соответствует одному из маршрутизирующих протоколов (routable protocol).Примеры маршрутизируемых протоколов − IP, IPX, Xerox Network System и т. д. Маршрутизирующие протоколы задают формат пакетов, в которые данные упаковываются для передачи по сети и передачу этих пакетов, а протоколы маршрутизации обеспечивают путь их следования по адресам назначения, приведенным в полях заголовка. Протоколы, используемые при создании таблицы маршрутизации, можно разделить на три категории: − протоколы длины вектора расстояния; − протоколы состояния канала; − протоколы политики маршрутизации. Классификация протоколов маршрутизации показана на рис. 18. Протоколы длины вектора − простейший и наиболее распространенный тип протоколов маршрутизации. Большинство используемых сегодня протоколов этого типа ведет свое начало от протокола Routing Information Protocol компании Xerox (иногда они так и называются). Протоколы данного класса включают IP RIP, IPX RIP, протокол управления таблицей маршрутизации RTMP и IGRP. 40 ¨ÉÇËÇÃÇÄÔŹÉÑÉÌËÁÀ¹ÏÁÁ ÆÌËɾÆÆÁ¾ÈÉÇËÇÃÇÄÔ Å¹ÉÑÉÌËÁÀ¹ÏÁÁ ¨ÉÇËÇÃÇÄÔ ½ÄÁÆÔ»¾ÃËÇɹ ƾÑÆÁ¾ÈÉÇËÇÃÇÄÔŹÉÑÉÌËÁÀ¹ÏÁÁ ÈÉÇËÇÃÇÄÔÈɹ»ÁÄŹÉÑÉÌËÁÀ¹ÏÁÁ ¨ÉÇËÇÃÇÄÔ ÊÇÊËÇØÆÁØùƹĹ ¨ÉÇËÇÃÇÄ *13*1 ¨ÉÇËÇÃÇÄ 041' ¨ÉÇËÇÃÇÄ *193*1 ¨ÉÇËÇÃÇÄ *4*4 ¨ÉÇËÇÃÇÄ 35.1 ¨ÉÇËÇÃÇÄ )FMMP ¨ÉÇËÇÃÇÄ *(31 ¨ÉÇËÇÃÇÄ /-41 ¨ÉÇËÇÃÇÄ &(1 ¨ÉÇËÇÃÇÄ #(1 ¨ÉÇËÇÃÇÄ &*(31 Рис. 18 Свое название этот тип протоколов получил от способа обмена информацией. Периодически каждый маршрутизатор копирует адреса получателей и метрику из своей таблицы маршрутизации и помещает эту информацию в рассылаемые соседям сообщения об обновлении. Соседние маршрутизаторы сверяют полученные данные со своими собственными таблицами маршрутизации и вносят необходимые изменения. Этот алгоритм прост и, как кажется на первый взгляд, надежен. К сожалению, он работает наилучшим образом в небольших сетях при отсутствии избыточности. Крупные сети не могут обойтись без периодического обмена сообщениями для описания сети, однако большинство из них избыточны. По этой причине в сложных сетях возникают проблемы при выходе линий связи из строя, так как несуществующие маршруты могут остаться в таблице маршрутизации в течение длительного периода времени. Вторую категорию протоколов обслуживания среды составляют протоколы состояния канала. Эти протоколы сложнее, чем протоколы длины вектора. В них используется детерминистское решение типичных для их предшественников проблем. Вместо рассылки соседям содержимого своих таблиц маршрутизации каждый маршрутизатор осуществляет широковещательную рассылку списка маршрутизаторов, с которыми он имеет непосредственную связь, 41 и напрямую подключенных к нему локальных сетей. Эта информация о состоянии канала рассылается в специальных объявлениях. За исключением широковещательных периодических сообщений о своем присутствии в сети, маршрутизатор рассылает объявления о состоянии каналов только в случае изменения информации о них или по истечении заданного периода времени. Недостатком таких протоколов состояния каналов, как OSPF, IS-IS и NLSP, являются их сложность и высокие требования к памяти. Они трудны в реализации и нуждаются в значительном объеме памяти для хранения объявлений о состоянии каналов. К третьей категории протоколов по обслуживанию среды относятся протоколы правил маршрутизации. Если протоколы маршрутизации на базе алгоритмов длины вектора и состояния канала решают задачу наиболее эффективной доставки сообщения получателю, то задача маршрутизации − наиболее эффективная доставка сообщения получателю по разрешенным путям. Такие протоколы, как BGP (Border Gateway Protocol) или EGP (Exterior Gateway Protocol), позволяют операторам Internet получать информацию о маршрутизации от соседних операторов на основе контрактов или других нетехнических критериев. Алгоритмы, используемые для политики маршрутизации, опираются на алгоритмы длины вектора, но информация о метрике и пути базируется на списке операторов магистрали. Глобальные сети часто подразделяются на автономные системы. Автономная система – это множество подсетей, ведущих согласованную политику маршрутизации (например, использующих единый протокол маршрутизации и метрики для маршрутов внутри автономной системы). Автономные системы зачастую принадлежат одному владельцу. Каждая автономная система имеет номер, выделяемый централизованно, и IP-адрес. Состав автономной системы обычно определяется как множество пар: IP/mask (например, 1.2.3.0/24). Каждая такая пара определяет подсеть. Значимая часть IP-адреса при этом называется префиксом, а число после ‘/’ – длиной префикса. Итак, все сетевые протоколы разделяются на протоколы, работающие внутри автономных систем (interior), и протоколы, используемые для обмена информацией между автономными системами (exterior). Внутри автономной системы может работать несколько interior-протоколов, если с точки зрения сетевого администратора так эффективнее или безопаснее. Маршруты, предоставляемые 42 interior-протоколами, как правило, более специфичны (имеют более длинную маску), чем маршруты, полученные от exteriorпротоколов. Но даже если маски двух маршрутов одинаковы, маршрут от interior-протокола всегда предпочтительнее. Примерами interior-протоколов могут служить RIP, OSPF, IS-IS и IGRP (устарел); exterior-протоколов – BGP и EGP (устарел). 2.4. Протокол маршрутной информации RIP Протокол маршрутной информации RIP причисляется к семейству протоколов, использующих дистанционно – векторный алгоритм. Это означает, что станции обмениваются не информацией, с помощью которой можно вычислять маршруты (как в случае OSPF), а самими маршрутами, с указанием их длины (distance). RIP не годится для использования в сетях, в которых расстояние между самыми удаленными станциями превышает 15 hop-ов (т. е., для пересылки пакета между ними требуется больше 14 промежуточных маршрутизаторов). При этом еще необходимо учитывать, что некоторым пересылкам может быть присвоена длина больше 1, если среда передачи имеет слишком низкую скорость. Про каждый маршрут шлюз, поддерживающий RIP, должен иметь следующую информацию: − адрес получателя; − маска маршрута (в первой версии RIP маски маршрутов не поддерживались, но во второй этот недочет был исправлен); − next hop (IP-адрес ближайшего рутера на пути к получателю); − выходной интерфейс; − метрика (длина) маршрута; − timer – время, прошедшее с момента, когда маршрут последний раз обновлялся. Каждый RIP – маршрутизатор время от времени (обычно раз в 30 секунд) посылает update-сообщения, описывающие информацию, хранящуюся в его базе маршрутов (т. е., фактически посылает всю свою таблицу маршрутизации соседям по сети). Кроме регулярных сообщений могут также посылаться нерегулярные (описывающие только часть базы маршрутов), если таблица маршрутизации изменилась. Такие сообщения называют «triggered updates». Рассмотрим алгоритм выявления наилучшего маршрута. Предположим, что D(i,j) – наилучший маршрут от i до j, а d(i,j) – стои43 мость прямой пересылки пакета из i в j (если i и j не находятся в одной сети, это число будем считать бесконечно большим). Тогда Если i = j, то D(i, j) = 0, иначе D(i, j) = min (d(i, k) + D(k, j)) k Таким образом, получив информацию от всех своих соседей, станция может правильно сформировать свою таблицу маршрутизации. При этом, когда приходит update-сообщение, маршрутизатор пересчитывает метрики для всех маршрутов и заменяет их на новые маршруты, если выясняется, что они эффективней. Есть только одно исключение: если шлюз X получил маршрут от шлюза R к получателю A с метрикой M1 (т. е. на X этот маршрут имел метрику M1 + 1), а потом пришло сообщение от R, в котором был маршрут к A с метрикой M2>M1, то X должен изменить метрику маршрута на большую. Для передачи своих сообщений RIP использует UDP (порт 520). Его сообщения могут посылаться на broadcast (если среда поддерживает broadcast), или на мультикастовый адрес 224.0.0.9, или нескольким определенным партнерам, заданным при конфигурировании шлюза. RIP-пакет выглядит так: «ÁÈȹþ˹ ¾ÉÊÁØ3*1 ¡½¾ÆËÁÍÁùËÇÉʾžÂÊË»¹ ¹½É¾ÊÇ» ¦ÌÄÁ ÁÄÁËּŹÉÑÉÌ˹ *1¹½É¾ÊÈÇÄÌй˾ÄØ È¾É»ÔÂȹɹžËÉŹÉÑÉÌ˹ ÁÄÁŹÊùŹÉÑÉÌ˹ ÁÄÁ/FYU)PQ ¥¾ËÉÁùŹÉÑÉÌ˹ Часть пакета, начиная с идентификатора, может повторяться (с разными маршрутами) до 25 раз. Типов пакетов бывает два – запрос и ответ. Запрос станция использует обычно при инициализации, когда хочет получить таблицу маршрутизации от соседей, не дожидаясь регулярного update-а. Ответ содержит всю таблицу маршрутизации станции, либо ее часть. Идентификатор семейства адресов для IP равен 2. Тэг маршрута в первой версии не присутствовал (это поле заполнялось нулями). Эта информация обычно используется при обмене маршрутами между протоколами (экспортировании и импортировании маршрутов). 44 Если в запросе указано, какие конкретно маршруты интересуют станцию, то станции присылается информация об этих маршрутах. Если в запросе присутствует только один элемент с идентификатором семейства адресов, равным нулю, и метрикой, равной 16, запрашивающему присылается вся таблица маршрутизации (возможно, в нескольких пакетах). Полей «маска» и «Next Hop» в первой версии не было. Поле «Next Hop» заполняется отправителем в том случае, если не он является промежуточным маршрутизатором для этого маршрута в данной подсети. В противном случае, при инсталлировании маршрута в таблицу маршрутизации шлюз-получатель проставляет для маршрута поле «next hop address», равное IP-адресу маршрутизатора, от которого он этот маршрут получил. Метрики маршрутов могут меняться от 1 до 15. Метрика, равная 16, означает «бесконечность». В «distance-vector»-алгоритме есть несколько неоднозначных мест. Во-первых, если шлюз, приславший лучший маршрут, скажем, выйдет из строя, то согласно алгоритму, этот, уже негодный маршрут, так и останется в таблице. Чтобы избежать этой ситуации, для каждого маршрута хранится его «возраст». Когда маршрут устаревает, он удаляется из таблицы. Обычно это происходит, когда от источника этого маршрута больше трех минут не поступало update-ов. Рутер-источник маршрута также может уведомить партнеров о том, что маршрут больше не актуален, прислав его с метрикой 16. Предположим, маршрутизаторы A, B, " # C, D подключены к сети X так, как это представлено на рис. 19. А стоимости пересылок равны: d(A,B) = 1 d(A,C) = 1 d(B,C) = 1 $ d(B,D) = 1 d(C,D) = 10 При такой конфигурации маршруты до сети X у разных маршрутизаторов будут выглядеть так: % ª¾ËÕ9 D: включен напрямую, metric 1 %ƹÈÉØÅÌ× ÈǽÃÄ×оÆÃ9 B: next hop D, metric 2 C: next hop B, metric 3 Рис. 19 A: next hop B, metric 3 45 Предположим, что связь между B и D прервалась. Тогда таблица маршрутизации на этих маршрутизаторах будет меняться так: D B C A dir,1 unreach B, 3 B, 3 dir,1 C, 4 A, 4 C, 4 dir,1 C, 5 A, 5 C, 5 dir,1 C, 6 A, 6 C, 6 … … … … dir,1 C, 11 A, 10 C, 11 dir,1 D, 12 D, 11 D, 12 dir = подключен напрямую (directly) unreach = недоступен (unreachable). A и C начинают считать, что они могут достигнуть сети X друг через друга, хотя это не так. Причина в том, что A и C транслировали маршрут, полученный ранее от B. Более того, они ввели в заблуждение и B. И только когда этот псевдо-маршрут сравнялся по стоимости с другим, плохим, но, по крайней мере работоспособным, он исчез из таблиц маршрутизации шлюзов. Если бы другого маршрута к X не было, стоимость псевдо-маршрута постепенно бы сравнялась с 16 и он бы тоже исчез. Отсюда можно сделать два вывода. Во-первых, шлюз не должен транслировать маршруты в ту сеть, из которой он их получил. Это правило называется «split horison». Во-вторых, для предупреждения аналогичных случаев, но когда конфигурация сети не так проста и эта мера не помогает, для удаления негодных маршрутов действительно нужна некоторая максимальная метрика (16), причем не очень большая, иначе этот процесс (его называют увеличение до бесконечности) сильно затянется. 2.5. Протокол открытия кратчайшего пути OSPF Протокол OSPF (Open Shortest Path First) основан на алгоритме поиска кратчайшего пути в графе Дейкстры. Если задан некоторый неориентированный граф, каждому его ребру можно сопоставить определенную метрику. Необходимо найти кратчайшие пути от некоторой вершины S до остальных вершин графа. Пусть E – множество вершин, кратчайший путь к которым уже найден, вначале содержит только S; R – множество оставшихся вершин графа, вначале – все вершины, кроме S; P – список кратчайших путей, вначале пустой. На каждом шаге алгоритма: 46 − поместить в множество О все вершины, соседствующие с вершинами из E; − если O – пусто, отметить все вершины из R, как недоступные, и завершить работу; − подсчитать метрики путей до всех вершин из O: для каждой вершины x это будет min D(s, k) + d(k, x), где k принимает значения всех вершин из E, граничащих с x; − все вершины, пути до которых минимальны, убрать из R, поместить в E, а пути до них поместить в P. В OSPF роли вершин графа играют сети и маршрутизаторы, имеющие к ним интерфейсы. Таким образом, все вершины, смежные с вершиной-маршрутизатором, являются сетями, а все вершины, смежные с вершиной-сетью, являются шлюзами. Метрики вершин характеризуют свойства среды передачи в подсети. Автономная система, в которой функционирует OSPF, делится на области (areas). Каждой области назначается уникальный номер (идентификатор). Таким образом, существует несколько видов маршрутизаторов: 1. Маршрутизаторы, граничащие с другой автономной системой, (AS boundary routers) отвечают за импортирование маршрутов, полученных от внешних (exterior) протоколов маршрутизации. Эти маршруты используются в SPF-алгоритме как уже заданные пути и не пересчитываются. При их распространении шлюз также может указать станции из автономной системы, через которые эти маршруты доступны. 2. Маршрутизаторы, ответственные за сбор информации из одной области и передачу ее другим областям. В автономной системе выделяется специальная область backbone. Она состоит из всех сетей, не принадлежащих ни одной из областей (например, сети на их границе), маршрутизаторов, имеющих с ними интерфейсы, и маршрутизаторов, принадлежащих сразу нескольким областям. Область backbone в противоположность обычным областям, не всегда бывает связной. Для передачи информации между рутерами, принадлежащими backbone, могут устанавливаться сквозные, прозрачные для промежуточных шлюзов, виртуальные соединения. Области, через которые прокладываются эти соединения, называются транзитными. Шлюзы, между которыми установлены виртуальные соединения, рассматриваются, как станции, подключенные к point-to-point сети (т. е. так же, как если бы они, к примеру, были соединены через модем). Виртуальные соединения 47 устанавливаются вручную сетевым администратором. Маршрутизаторы, входящие в несколько областей (если станция принадлежит backbone, она вовсе не обязательно принадлежит нескольким областям – она может иметь интерфейсы только в backbone-сети), называются Area border routers и отвечают за обмен информацией между областями. Они имеют несколько копий базы данных (по одной для каждой области, которой принадлежат) и, соответственно, для каждой из них выполняют SPF-алгоритм. В другие области они (как и AS boundary routers) распространяют не информацию о состоянии маршрутизаторов и сетей, к которым эти маршрутизаторы имеют интерфейс, а уже готовые маршруты с метриками. 3. Внутренние маршрутизаторы – это маршрутизаторы, принадлежащие только одной области. При этом для каждой сети не все маршрутизаторы присылают друг другу информацию, а из маршрутизаторов сети выбирается один – главный (designated router), который собирает информацию от всех и пересылает ее каждому. Причем шлюз, являющийся главным в одной сети, может не быть главным в другой. Каждому шлюзу в автономной системе присваивается идентификатор – RouterId (32 бита), который он должен включать во все отправляемые им пакеты (отправляемые им лично, а не те, что он ретранслирует). Шлюзы могут принадлежать к одной подсети (быть соседями), но не обмениваться информацией. Отношения шлюзов, когда они поддерживают обмен, называется «Adjacency». В таком отношении находятся все шлюзы с главным маршрутизатором подсети. Для определения соседей и выбора главного шлюза в подсети используется протокол HELLO, который здесь не рассматривается. Некоторые из областей автономных систем могут быть также сконфигурированы как «stub areas» (тупиковые). Такие области обычно доступны другим областям и автономным системам через один маршрутизатор, поэтому не имеет смысла распространять в них все маршруты, полученные из других областей, а нужно только разослать один маршрут 0.0.0.0 с адресом этого единственного шлюза в качестве адреса next hop. Тот же шлюз будет распространять информацию о маршрутах к подсетям, содержащимся в тупиковой области. Тупиковая область никогда не бывает транзитной. OSPF не использует ни UDP, ни TCP для передачи своих сообщений. Он передает их непосредственно в IP-пакетах с номером протокола, равным 89. Внутри одной подсети пакеты могут передаваться либо конкретной станции лично, либо по мультикастовому адресу 48 224.0.0.5 («всем OSPF-рутерам»). Если в подсети не поддерживается мультикастинг, шлюз нужно снабдить IP-адресами всех его соседей. При обмене информацией используется алгоритм подтверждений и переповторов. Пакеты, несущие в себе информацию, связанную с маршрутизацией (бывают еще HELLO-пакеты, запросы и подтверждения), могут содержать: 1. Router links advertisement Эта информация исходит от рутеров и описывает их интерфейсы. 2. Network links advertisement Генерируется главным шлюзом подсети и содержит информацию о всех маршрутизаторах подсети. Таким образом, первые два пункта предназначены для описания вершин графа, соответствующего области. 3, 4. Summary link advertisement Генерируется шлюзом, принадлежащим (нескольким областям (area border routers) и содержит маршрут к какой-нибудь подсети из другой области (3) или маршрут к какому-нибудь шлюзу на границе автономной системы (4) (AS boundary router). Эти маршруты генерируются после исполнения SPF-алгоритма на основе базы данных соответствующей области. При вычислении метрики маршрута на основе Summary link advertisement сначала вычисляется метрика пути до маршрутизатора из своей области, через который доступен этот маршрут, а затем к ней прибавляется метрика, содержащаяся в Summary link advertisement. 5. AS external link advertisement Генерируется шлюзами на границе автономных систем и содержит информацию о маршруте к какой-нибудь подсети из другой автономной системы. Как правило, метрики этих маршрутов несравнимы с метриками маршрутов в пределах автономной системы, т. е. если к подсети ведут только external-маршруты, берут маршрут с минимальной метрикой, не взирая на то, сколько добираться до шлюза внутри автономной системы, через который доступен этот маршрут. Если же метрики external-маршрутов равны, то выбирается ближайший маршрут с точки пути внутри автономной системы. Если же до подсети существует внутренний маршрут, внешние вообще не рассматриваются. Существуют, однако, метрики внешних маршрутов, сопоставимые с метриками внутренних маршрутов (например, если в соседней автономной системе в качестве внутреннего протокола также используется OSPF). В этом случае 49 метрика внешнего маршрута просто складывается с метрикой пути до промежуточного маршрутизатора, как в пп. 3 и 4. Пакеты типов 3–5 не передаются в тупиковую область. За этим исключением, все маршруты, полученные по backbone, должны передаваться area border шлюзами в области, к которым они принадлежат. Шлюз, получивший пакет из одной подсети, должен передать его для распространения главному шлюзу другой подсети. Процедура распространения link state advertisement внутри автономной системы называется flooding. Для каждого элемента информации из базы данных, полученного с помощью link state advertisement, хранится ее возраст. Если запись долго не обновляется, она удаляется из базы данных. При любом изменении базы данных (кроме изменения возраста записи после очередного link state advertisement) таблица маршрутизации или ее часть должна быть пересчитана. В случае добавления и или удаления записи о состоянии шлюза или сети в области, пересчитывается вся таблица маршрутизации. Для записей, соответствующих Summary link advertisement, пересчитываются только элементы таблицы, ведущие к объектам из других областей. 2.6 . Протокол граничного шлюза BGP BGP предназначен для обмена информацией между автономными системами. BGP-партнеры использует TCP (порт 179) для обмена информацией. После установления соединения они обмениваются сообщениями для согласования соединения. Затем каждый из партнеров посылает другому свою таблицу маршрутизации. После этого сообщения посылаются по мере изменения таблицы маршрутизации, но посылается не вся таблица, а только информация, касающаяся изменения. Когда соединение закрывается, все маршруты, полученные из этого соединения становятся недействительными. Чтобы поддерживать BGP, станции не должны быть шлюзами. Хост из одной автономной системы может обмениваться информацией с хостом из другой автономной системы и распространять ее дальше в свою автономную систему, и наоборот – получать от внутренних протоколов, вроде OSPF информацию о своей автономной системе и передавать ее партнеру. Внутри автономной системы может быть несколько станций, поддерживающих BGP. Партнеры из своей автономной системы и соединения с ними на50 зываются внутренними, а все остальные – внешними. Все внешние партнеры шлюза должны разделять с ним локальную подсеть. Сообщения в BGP бывают четырех типов: 1. OPEN – посылается после установления TCP-соединения. В нем содержатся идентификатор автономной системы, BGPидентификатор пославшего, hold time (интервал времени в секундах, через который партнер должен посылать сообщение KEEPALIVE, чтобы убедиться, что соединение еще не закрылось), и некоторые необязательные параметры. 2. KEEPALIVE – используется для проверки связи. Пакет в TCPсоединении потеряться или исказиться не может, но само соединение может закрыться, например, если где-то вышел из строя канал связи. 3. С помощью сообщения UPDATE партнер может передать об одном хорошем маршруте и о нескольких ранее переданных, но ставших непригодными. При этом про новый маршрут может сообщаться: − как он был получен (через внутренний или внешний протокол маршрутизации); − через какие автономные системы шла информация об этом маршруте (это необходимо для выявления циклов); − next hop – адрес шлюза на границе автономных систем, которому партнер может отправлять пакеты, посылаемые по этому маршруту; если этот параметр не указан, в качестве next hop используется партнер, передавший информацию об этом маршруте; − приоритет маршрута (для сравнения нескольких маршрутов); − информация о том, была ли применена агрегация. Агрегация – это обобщение маршрута, или укорачивание префикса, принадлежащего маршруту. Предположим, что несколько подсетей с префиксами X1/N,... Xk/N составляют одну большую подсеть с префиксом Y/M, где начала X1,... Xk совпадают с Y до M-го бита, а M < N. Предположим также, что все эти подсети с точки зрения некоторого отправителя доступны через один шлюз. Тогда маршруты к этим сетям можно обобщить в один с префиксом Y/M. Маршрут в BGP-update сообщении может содержать целый список префиксов (т. е. получается «гипер-маршрут», несущий информацию о достижимости целого «куста» сетей. Про маршруты, ставшие непригодными, параметры не передаются, а только списки префиксов. 51 4. Сообщение NOTIFICATION посылается для уведомления об ошибке. Обычно это ошибка в формате пакета, но бывают и другие сообщения, например, когда выявлен цикл в маршрутизации. Получив информацию о достижимости различных сетей в различных автономных системах, станция, поддерживающая BGP, может построить граф, выявить все циклы, вычислить кратчайшие пути и передать в свою автономную систему с помощью какогонибудь внутреннего протокола маршрутизации. 2.7. Организация динамических маршрутов Шлюзы используют протоколы маршрутизации для поддержания своих таблиц в актуальном состоянии, и благодаря этому они способны выбирать хорошие маршруты в зоне ответственности. Это верный, но несколько упрощенный взгляд на положение дел. Если, например, локальная сеть A подключена к другой сети B с помощью шлюза и для этого использован статический маршрут, как это часто и бывает на практике, то в случае выхода из строя канала связи между этим шлюзом и сетью B, взаимодействие между сетями станет невозможным. Рассмотрим схему, в которой три сети A, B, и C взаимодействуют между собой с помощью трех маршрутизаторов, как это показано на рис. 20. Каждый из шлюзов обслуживает по одному ethernet-сегменту с IP-сетью класса C (маска 255.255.255.0). Кроме того, каждый из них имеет PPP-соединения с двумя другими. &UI " QQQ 1QQ QQQ QQQ QQQ $ &UI Рис. 20 52 # QQQ &UI Таблица маршрутов на шлюзе A может быть задана командами: root# route add -net 192.168.1.0 netmask 255.255.255.0 eth0 root# route add -net 192.168.2.0 netmask 255.255.255.0 ppp0 root# route add -net 192.168.3.0 netmask 255.255.255.0 ppp1 Если канал связи A и В в этой схеме выйдет из строя, то взаимодействие между сетями 192.168.1.0 и 192.168.2.0 станет невозможным, поскольку шлюз A будет пытаться передать пакеты через интерфейс ppp0. В то же время существует потенциальная возможность использовать исправные каналы связи между А и В через шлюз С. Это можно сделать, если на каждом из шлюзов будет запущен демон динамической маршрутизации. Такие демоны контролируют состояния своих интерфейсов и трафика через них. Это дает им возможность изменять свои таблицы маршрутов, чтобы подстроиться под изменения, произошедшие в структуре сети при сбое одного из соединений. Для настройки динамической маршрутизации в рассмотренном примере достаточно выполнить на каждом из маршрутизаторов по две команды. Например, на маршрутизаторе A: root# route add -net 192.168.1.0 netmask 255.255.255.0 eth0 root# /usr/sbin/routed Демон `routed’ при запуске автоматически находит все активные сетевые интерфейсы, а также передает и принимает специальные пакеты. С их помощью воссоздается текущая структура сети, и в соответствии с ней настраивается таблица маршрутов. Вопросы ко второму разделу 1. Какой уровень определяет выбор маршрута в объединенной сети? 2. Какие службы сильнее нагружают сеть: ориентированные на соединение или не требующие подтверждения соединения? 3. Опишите способы доступа к среде передачи, используемые в сетях Ethernet. 4. Опишите одноадресатную, многоадресатную и широковещательную рассылку данных. 5. Какой метод доступа к среде передачи данных используется в сетях Ethernet? 6. Что такое коммутатор? 7. Что такое маршрутизация пакетов? 8. Назовите несколько типов алгоритмов маршрутизации. 53 9. Чем отличается коммутатор от концентратора? 10. Чем отличается статическая маршрутизация от динамической? 11. В чём заключаются отличия маршрутизатора от коммутатора? 12. Назовите несколько метрик, используемых протоколами маршрутизации. 13. Согласно иерархической терминологии ISO какие устройства называются промежуточными (IS)? 14. Каковы средства обеспечения устойчивости протокола RIP? 15. Каково назначение таймера ожидания? 16. Каков максимальный диаметр сети RIP? 17. При использовании какого типа алгоритмов маршрутизации шлюз имеет информацию лишь о своих соседях? 18. На какие два типа делятся оконечные системы? 19. Какие протоколы маршрутизации относятся к дистанционновекторным? 20. Для чего маршрутизаторам необходимы метрики? 21. Какой адрес изменяется при передачи пакета от источника к получателю? 22. В чём заключаются преимущества алгоритмов маршрутизации по состоянию канала по сравнению с дистанционно-векторными алгоритмами? 23. Согласно иерархической терминологии ISO какие устройства называются оконечными (ES)? 24. В чём заключается основной недостаток статической маршрутизации? 25. В чём заключаются различия домена маршрутизации и автономной системы? 26. Чем отличаются алгоритмы маршрутизации по состоянию канала от дистанционно-векторных алгоритмов? 27. При каком алгоритме маршрутизации в таблице маршрутизации каждого маршрутизатора составляется картина всей сети? 28. От чего зависит величина задержки при маршрутизации? 29. Какие обычно ставятся цели при разработке алгоритмов маршрутизации? 30. Дайте определение автономной системы. 31. От чего зависит величина задержки при маршрутизации? 32. Что такое маршрутизация пакетов? 54 3. Информационные системы администрирования На практике администратору приходится не только вести сеть, т. е. поддерживать ее в работоспособном состоянии, но и по существу строить ее. В сравнительно небольшой сети администратор еще может себе позволить конфигурировать каждый узел вручную. Однако в крупной сети, включающей в себя несколько подсетей, физически расположенных достаточно далеко друг от друга, с множеством протоколов и потребностью в обеспечении качества обслуживания и тарификации, это практически невозможно сделать. Для этого необходим стандартный ( поддерживаемый большинством устройств) удаленный способ управления, чтобы можно было автоматизировать этот процесс. Было разработано несколько служебных сетевых протоколов, служащих исключительно целям управления сетью (network management). Словосочетание «network management» можно перевести как «управление сетью» такой перевод корректен, но не совсем полно отражает сущность этого понятия. Дело в том, что с помощью служебных протоколов можно не только управлять ее активными компонентами-маршрутизаторами, коммутаторами и т. д., но и другими объектами, которые не обеспечивают работу сети, а лишь используют ее. 3.1. Методы, функции и службы администрирования Ключевыми функциями администрирования являются: 1. Fault Management (выявление сбоев) В задачи этой области сетевого управления входит: − выявить наличие сбоя в сети – сбой (fault); отличается от ошибки (error) тем, что ошибку (например потерю пакета) не нужно исправлять, а сбой требует постороннего вмешательства; − изолировать оставшуюся часть сети таким образом, чтобы она продолжала функционировать нормально; − сконфигурировать сеть так, чтобы минимизировать вред, причиненный сбоем (например, временно поставить менее мощный маршрутизатор взамен вышедшего из строя или установить обходные виртуальные соединения); − заменить или починить вышедшие из строя компоненты сети и привести сеть в ее исходное состояние. 2. Accounting management (сбор статистики и тарификация) 55 В коммерческих сетях как правило сетевые ресурсы предоставляются не бесплатно, особенно если трафику пользователя гарантируется некоторое качество обслуживания. Для точного определения количества ресурсов, использованных клиентом (чтобы можно было выставить счет) должен вестись учет. Даже если в сети нет тарификации, все равно стоит вести учет потребляемых пользователем ресурсов, чтобы справедливо их распределять, выявлять узкие места сети и наилучшим образом планировать расширение сети. 3. Configuration and name management (конфигурирование) Название этой области говорит само за себя – это изменение различных параметров устройств, установление и разрыв соединений и многие другие вещи, необходимые для нормального взаимодействия компонент сети. 4. Performance management (управление сетью с целью измерения и повышения ее производительности) Эта область в чем-то напоминает accounting management, однако она ориентирована именно на измерение и повышение производительности сети. Менеджеру (человеку) следует знать об: − утилизации сети (все ли ресурсы используются достаточно эффективно или в какой-то части сети слишком большие «излишки» неиспользуемых ресурсов); − появлении лишнего трафика (чреватого задержками и потерями); − падении пропускной способности сети до неприемлемого уровня; − возникновении узких мест; − увеличении времени реакции (среднего времени ответа на запросы при осуществлении схемы клиент-сервер). Собирая и анализируя эту информацию, можно сделать вывод об увеличении или уменьшении производительности сети в целом. 5. Security management (защита сети от несанкционированного доступа) Как правило, в задачи security management входит создание, распространение и хранение ключей, паролей и другой аналогичной информации, необходимой для контроля доступа к сетевым ресурсам. Кроме того, в задачи этой части сетевого управление входит отслеживание и фиксирование попыток несанкционированного доступа. 56 Кроме деления на перечисленные пять областей, в сетевом управлении также различают Network Monitoring и Network Control. Network Monitoring занимается исключительно сбором и анализом информации, никак не влияя на конфигурацию сети. Network Control, наоборот, является средством для изменения состояния сети. Назовем системой управления сетью множество устройств и приложений, в совокупности обеспечивающих удобный и мощный интерфейс для управления отдельными компонентами сети и сетью в целом и, по возможности, встроенных в существующие элементы сети. Последнее означает, что развертывание системы управления сетью не должно требовать нового оборудования, и программного обеспечения, и если это возможно, должно работать на уже существующих в сети узлах в имеющихся на них операционных средах. На каждом узле, входящем в систему сетевого управления, должно работать соответствующее программное обеспечение, обеспечивающее работу этой системы. Его называют Network Management Entity (NME). В задачи NME входит: − сбор и хранение статистики; − реакция на команды, исходящие из центра управления сетью (например, передача собранной статистики и информации о текущем состоянии узла, изменение параметров узла, запуск тестов); − уведомление центра управления о серьезных изменениях состояния узла. По крайней мере один из узлов сети должен исполнять роль центра управления. Такой узел называется менеджером. В сети может быть несколько менеджеров, но эта ситуация нежелательна, так как команды, присылаемые с различных менеджеров, могут взаимодействовать друг с другом. На менеджере помимо NME должно работать приложение NMA (Network Management Application), которое собственно и осуществляет управление сетью, предоставляя администратору удобный интерфейс. Узлы сети, управляемые менеджером, обычно называются агентами. Бывает так, что устройства от некоторых производителей не поддерживают принятый в сети протокол управления, а имеют свой собственный. Чтобы управлять такими устройствами используются агенты, которые отвечают не только за себя, но и за одно или несколько таких устройств, переводя запросы менеджера на понятный им «язык», и пересылая менеджеру полученные от них ответы. Такие агенты называются «proxy». 57 Совокупность информации агента, доступная менеджеру, называется Management Information Base (MIB). Она делится на три типа: − статическая (информация о конфигурации узла, которая изменяется редко, например, число его сетевых интерфейсов); − динамическая (информация, связанная с работой сети и изменяющаяся достаточно часто, например, ARP-таблица); − статистическая (информация, которая может быть выведена из динамической информации агентом или менеджером и представляет обобщенные данные, годные для дальнейшего анализа, например среднее число ошибок, возникающих на некотором сетевом интерфейсе, в течение одной минуты). Как было отмечено, Network Monitoring – это сбор и анализ информации из сети. Существует два подхода для его реализации в системе управления сетью: Polling (посылка запросов) и Event Reporting (уведомление о событиях). В первом случае агент играет пассивную роль: менеджер собирает нужную ему информацию, время от времени запрашивая значения различных параметров агента. Во втором случае менеджер посылает запросы редко (например, после команды администратора или после перезагрузки), а агент должен сам сообщать о серьезных изменениях своего состояния или периодически докладывать менеджеру о своем состоянии, даже если ничего серьезного не произошло. Оба подхода имеют недостатки: в первом случае (когда агент пассивен) происходит серьезная нагрузка на сеть, так как для эффективного управления менеджеру нужна актуальная информация, и он соответственно должен ее достаточно часто обновлять. Во втором случае нагрузка меньше, но если агент окончательно выйдет из строя, менеджер может так и не получить сообщения об аварии, и будет ошибочно считать, что агент в порядке. Наиболее разумно в той или иной степени использовать оба метода, регулируя частоту обмена данными в зависимости от размеров и пропускной способности сети и серьезности последствий различных сбоев. Различают три вида Network Monitoring: 1. Performance Monitoring Часть программного обеспечения, осуществляющего Performance Monitoring, служит для оценки производительности сети в целом и ее отдельных компонент по следующим параметрам: 58 A. Availability (доступность) – часть времени (в процентах), в течение которого компонента сети или некоторое приложение доступно для пользователя. Этот параметр характеризует надежность оцениваемого объекта. Например, сервер, к которому ведут несколько физических каналов, более доступен, нежели сервер, подключенный к сети только через один физический канал. Также на доступность влияет время, необходимое для восстановления этих физических каналов после аварии. B. Response Time (время реакции) – абсолютное время, которое проходит между посылкой запроса с терминала пользователя до получения ответа. Оценка времени реакции зависит от приложения. C. Accuracy (точность) – часть времени (в процентах), в течение которого не было зафиксировано ошибок при передаче информации. D. Throughput (пропускная способность) – частота возникновения событий, специфичных для приложения, например: − число байт, переданных по FTP между компьютерами A и B через сеть N за 5 минут; − число виртуальных соединений, проходящих через ATMкоммутатор S; − количество транзакций с базой данных, осуществленное сотрудником за один час. E. Utilization (степень использования) – доля (в процентах) реально используемых ресурсов сети по сравнению с ее теоретическими возможностями. Для вычисления всех этих параметров Performance Monitoring может осуществлять сбор информации (performance measurement), ее анализ (performance analisis) и искусственное генерирование трафика (synthetic traffic generation) для изучения свойств сети при определенном уровне загруженности. 2. Fault Monitoring Задачей этой области является скорейшее выявление сбоев. Для этой цели менеджер может использовать сообщения агентов об авариях, анализировать статистические данные (например, резкое увеличение ошибок при посылке пакетов на некотором сетевом интерфейсе шлюза может указывать на неисправность сетевого адаптера) и запускать тесты (например, посылать пробные пакеты, скажем ICMP Echo). 3. Accounting Monitoring 59 Эта область отвечает за учет использования ресурсов клиентами. Примерами подобных ресурсов могут быть: − коммуникационные ресурсы (например, физические каналы); − аппаратные ресурсы (например, серверы); − программное обеспечение (различные приложения, базы данных); − различные виды сервисов, доступных через сеть. Для каждого типа ресурсов фиксируется, кто именно их использует и в какой степени. Часто эта информация собирается на агенте и по запросу передается менеджеру, однако, иногда используются специальные устройства, служащие исключительно для сбора данных такого рода. Network Control подразделяется на два вида: 1. Configuration Control, отвечающий за инициализацию, поддержку и завершение работы компонент и подсистем сети. Он включает в себя: − определение конфигурационной информации (т. е. объектов, отражающих состояние логических или физических ресурсов агента; для каждого объекта должны быть определены его свойства и атрибуты); − установление и изменение значений атрибутов объектов; − установление и изменение связей и соотношений между объектами; − получение информации о текущем состоянии объектов; − распространение программного обеспечения. 2. Security Control, обеспечивающий защиту сети от различного рода атак. Основными типами атак являются: − нарушение связи; − перехват информации; − изменение данных; − подделка (фабрикация) данных. Они соответственно затрагивают секретность системы, целостность данных в системе и доступность системы для клиента. В задачи Security Control входит: − отслеживание, регистрация и пресечение всех попыток несанкционированного доступа; − создание резервных копий; − хранение и распространение информации о правах пользователей и групп пользователей ключей и паролей; − шифрование. 60 3.2. Организация баз данных администрирования (протокол SNMP) Simple Network Manager Protocol является развитием протокола Simple Gateway Management Protocol (SGMP), разработанного еще в 1987 г. и служившего для управления маршрутизаторами. SNMP появился в начале 90-х гг. и является одним из самых распространенных протоколов сетевого управления, в основном, за счет своей простоты. SNMP имеет дело с абстрактными переменными и таблицами из MIB. Разные агенты поддерживают различные MIB. Часть из них стандартизирована, другая часть называется private MIB и специфична для конкретного устройства конкретного производителя. Стандартные MIB описываются на формальном языке, являющемся частью спецификации SNMP. Имея формальное описание MIB, можно заставить менеджера работать с агентом, поддерживающим этот MIB. Кроме MIB, SNMP специфицирует возможные PDU (пакеты), которые менеджер может посылать агенту (например, чтобы получить или изменить значение переменной) или агент менеджеру (например, чтобы уведомить его о каком-то чрезвычайном событии). Как уже было сказано, сами MIBы определены в отдельных стандартах, а SNMP определяет только их структуру и способ описания. Все объекты (managed objects) SNMP MIBа составляют в иерархию – дерево. В этом дереве только листья соответствуют реальным (физическим или логическим объектам), а остальные служат для объединения объектов в группы. Каждый узел дерева имеет номер. Таким образом, любой узел дерева уникально идентифицируется последовательностью, составленной из его номера и номеров всех его предков (номера старших узлов идут первыми). Эта последовательность называется объектным идентификатором. Обычно объектный идентификатор записывается как последовательность номеров и/или имен узлов, разделенных точками. Корнем дерева является узел iso с номером 1. К нему прикрепляются все остальные деревья стандартных, экспериментальных и частных MIBов (рис. 21). В MIB могут присутствовать как обычные переменные, уникальные для агента (например переменная, значение которой показывает, может ли станция маршрутизировать пакеты, т. е. является ли она шлюзом), так и целые таблицы (например, таблица сетевых 61 JTP PSH EPE JOUFSOFU EJSFDUPSZ NHNU NJC TZTUFN JOUFSGDFT BU JQ JDNQ UDQ VEQ FHQ USBOTNJTTJPO TONQ FYQFSJNFOUBM QSJWBUF FOUFSQSJTFT Рис. 21 интерфейсов или маршрутизации), размеры которых различны у разных агентов и могут меняться в процессе работы агента. Таблицы содержат фиксированное количество столбцов и переменное число строк. В некоторых таблицах строки можно динамически добавлять и удалять. Все «клетки» таблицы, соответствующие одному столбцу, представляют собой разные экземпляры одного и того же объекта. Для их идентификации к идентификатору этого объекта приписывается индекс – один или несколько подидентификаторов. Длина индекса и его семантика зависят от конкретной таблицы. Для общности доступа к объектам, не являющимся полями таблицы, к их объектным идентификаторам так же приписывается подидентификатор – 0. Он показывает, что речь идет об экземпляре объекта на данном агенте, а не об абстрактной 62 сущности, описанной в MIBе. Для каждого объекта в MIBе указывается следующая информация: 1. Имя объекта 2. SYNTAX (тип объекта) Наиболее распространенными типами объектов являются: − базовые типы: integer (целый), octetstring (строка), null (пустое значение), object identifier (объектный идентификатор) и opague (произвольная последовательность байт); − производные от базовых, но используемые в большинстве MIBов: − counter (счетчик; принимает неотрицательные целые значения; каждое новое значение, должно быть больше старого, за исключением переполнения, когда оно обращается в ноль); − gauge (принимает неотрицательные целые значения в любой последовательности; при переполнении принимает максимальное допустимое значение), − ipaddress (строчка с фиксированной длиной 4), − timeticks (принимает неотрицательные значения в сотых долях секунды). Для определения объектов в SNMP используется подмножество ASN.1 (Abstract Syntax Notation One). ASN.1 позволяет определять любое количество типов на базе перечисленных или других уже определенных типов. Обычно это делается с помощью перечисления возможных значений, создания диапазона, ограничения длины строк или их алфавита или определения структированных типов: массивов (SEQUENCE OF), множеств (SET) и структур (SEQUENCE). Имена типов, определенных таким образом, также можно указывать в поле SYNTAX при определении объекта. Определения типов либо находятся в том же MIB-модуле, что и определения объектов, либо импортируются из других MIBов (объекты также можно импортировать). Имена типов начинаются с большой буквы, а объектов – с маленькой. Объект-таблица обычно имеет имя <prefix>Table и представляется как массив элементов структурного типа, носящего имя <Prefix>Entry. У этого объекта, как правило, есть только один потомок с именем <prefix>. Дети этого объекта – поля (столбцы) таблицы. Они не могут быть структурированного типа и обычно носят имена, начинающиеся с того же префикса, что и имя таблицы. 63 3. ACCESS В этом пункте указывается, что менеджер может делать с объектом: − создавать (только для полей таблицы); − изменять его значение; − запрашивать его значение; − получать его значение от агента в трэпе (трэп-уведомление – это сообщение от агента менеджеру по инициативе агента с целью уведомить менеджера о каком-то важном событии); − или объект вообще недоступен (недоступными могут, например, быть объекты, не являющиеся листьями дерева MIB, но не только они). Таким образом, объекты могут быть: − not-accessible (недоступен); − accessible-for-notify (доступен только для передачи в трэпе); − read-only (доступен только для чтения); − read-write (доступен для чтения и для записи); − read-create (доступен для создания, чтения и записи). 4. STATUS (статус объекта) Степень обязательности реализации этого объекта на агенте (при условии, конечно, что на агенте вообще реализуется это поддерево MIB). Возможные значения: − mandatory (обязан присутствовать); − optional (необязателен); − deprecated (существует другой, лучший объект, выполняющий те же функции, но данный объект должен быть реализован в целях совместимости со старыми − менеджерами); − obsolete (устарел и не должен быть поддержан). 5. Описание объекта Описание семантики объекта на английском языке, необходимое для его корректной реализации на агенте. 6. DEFAULT Значение объекта по умолчанию (необязательно). 7. INDEX (только для таблиц) Имена одного или нескольких объектов, которыми индексируется таблица. Эти объекты должны быть простых типов (не структурированных). Все перечисленные простые типы (кроме null) могут быть типами индексных объектов со следующими оговорками: 64 − при индексации IP-адресом индекс состоит из четырех 4 подидентификаторов (соответствующих значениям четырех байт IPадреса в сетевом порядке); − при индексировании строчкой первым подидентификатором является ее длина, а затем идут числа, соответствующие значениям байт, содержащих символы строки (т. е. равные ASCII-кодам этих символов); − при индексировании объектом типа «объектный идентификатор» сначала идет длина этого идентификатора, а потом все его подидентификаторы. 8. Личный подидентификатор объекта (уникальный среди его братьев) и имя его отца. Все управление по SNMP заключается в изменении значений переменных и добавлении и или удалении строк таблиц. Таким образом, какие-то действия, реальное воздействие на аппаратуру, запуск тестов и т. д. рассматриваются как побочные эффекты изменения MIB. SNMP-пакеты обычно передаются в UDP-датаграммах, однако, возможна передача SNMP и посредством другого ориентированного на датаграммы протокола транспортного уровня. Пакет содержит версию протокола, тип PDU, идентификатор запроса (который копируется без изменений в ответ), номер ошибки, если таковая произошла, и некоторую другую информацию, в том числе список объектных идентификаторов переменных и их значений, который интерпретируется менеджером или агентом в зависимости от типа PDU. Первая версия SNMP специфицирует следующие типы PDU: 1. GetRequest PDU служит для получения значений всех переменных, содержащихся в запросе. Если при попытке получить значение очередной переменной на агенте происходит ошибка (например объект не реализован или нет запрошенного экземпляра), обработка запроса прерывается и менеджеру возвращается пакет с ошибкой и номером объектного идентификатора, при обработке которого она произошла. Значений уже обработанных переменных менеджер в этом случае не получает. Если значения всех переменных получены успешно, агент генерирует GetResponse PDU, в который копируется идентификатор запроса и помещаются значения, соответствующие всем объектным идентификаторам из запроса. (Для возвращения ошибки также используется GetResponse). 2. GetNextRequest PDU служит для обхода листьев дерева MIB в лексико-графическом порядке. 65 Для каждого объектного идентификатора, содержащегося в запросе, агент должен вернуть значение переменной из MIB, реализованного на агенте, с объектным идентификатором непосредственно следующим в лексико-графическом порядке за указанным. Если переменная недоступна для чтения, рассматривается следующая за ней. В ответ на GetNextRequest агент генерирует GetResponse (как и на Get). Таким образом, менеджеру необязательно знать, например, строки с какими индексами присутствуют в данный момент в таблице, а достаточно в первом запросе послать объектный идентификатор без индекса вообще, а в последующих – объектные идентификаторы, полученные в результате предыдущих запросов. 3. SetRequest PDU в списке переменных содержит уже не только объектные идентификаторы, но и значения, которые агент должен присвоить указанным переменным. Если какой-либо переменной, содержащейся в запросе, присвоить значения невозможно, значения остальных переменных должны оставаться прежними, а менеджеру возвращается ошибка (в GetResponse). Если все присваивания прошли удачно, то агент генерирует GetResponse, содержащий новые значения всех переменных из запроса. Чтобы добавить строчку в таблицу, в первой версии SNMP достаточно послать один или несколько SetRequest на поля с несуществующим индексом. Как только для всех полей таблицы станут известны значения, строка таблицы становится полноправной. До этого ее поля (даже уже назначенные) не могут быть получены с помощью GetRequest. Для удаления строчки таблицы, в ней обычно присутствует некоторое поле, которому можно присвоить значение «invalid» или «destroy», в результате чего строчка из таблицы исчезает. 4. Trap PDU служит для сообщения менеджеру о каком-то чрезвычайном событии. Как и остальные PDU, оно может содержать объектные идентификаторы и значения переменных для сообщения менеджеру дополнительной информации. Стандартными трэпами являются: − coldStart – перезагрузка с возможным изменением конфигурации агента; − warmStart – реинициализация без изменений конфигурации агента; − linkDown – падение сетевого интерфейса; 66 − linkUp – поднятие сетевого интерфейса; − authenticationFailure – ошибка при верификации протокольного сообщения. Вторая версия SNMP лучше специфицирована, чем первая, однако, многие агенты и менеджеры по-прежнему поддерживают обе версии. Перечислим наиболее серьезные дополнения, введенные во вторую версию. 1. В SNMPv2 специфицировано значительно большее число ошибок, которые агент может возвращать менеджеру на его запросы. Это позволяет менеджеру более точно диагностировать причину, по которой запрос был отвергнут. 2. Изменился алгоритм обработки Get и GetNext: теперь при отсутствии в MIB запрошенной переменной, значения остальных возвращаются менеджеру. 3. Появилась новое PDU: GetBulk. Это PDU позволяет получить от агента гараздо больше информации, чем с GetNext. Для части объектных идентификаторов, переданных в GetBulk, выполняется обычный GetNext, а для остальных GetNext выполняется N раз (где N – некоторое число, параметр GetBulk) и все объектные значения соответствующих им переменных записываются в Response PDU, генерируемый агентом. 4. Более корректно специфицирован алгоритм для обработки SetRequest. При обработке этого запроса агент должен сначала «протестировать» возможность присваивания всех переменных, содержащихся в запросе, затем, если все в порядке, выполнить «Set Commit» – реальные присваивания. Если одно из реальных присваиваний выполнить не удается, все уже сделанные присваивания должны быть аннулированы (этот процесс называется Set Undo). Если Set Undo прошел успешно, менеджеру возвращается ошибка CommitFailed; иначе – UndoFailed. Такой алгоритм позволяет наиболее корректно реализовать требование «все или ничего» к SetRequest. 5. Более корректно определена технология добавления строк в таблицы. Таблица, в которую менеджеру разрешается добавлять строки, должна иметь поле типа RowStatus. Это тип-перечисление со следующими значениями: − active; − notReady; 67 − notInService; − createAndGo; − createAndWait; − destroy. Есть два способа добавлять строку в таблицу: 1. Посылается один SetRequest, содержащий значения всех полей новой строки (кроме, возможно, полей, имеющих значение по умолчанию) и значение createAndGo для RowStatus-а. Если все значения корректны, их столько, сколько нужно, и ресурсов у агента достаточно, то строка сразу становится активной. В противном случае менеджеру возвращается ошибка. 2. Посылается серия запросов, в первом из которых содержится значение для RowStatus, равное createAndWait. После этого на GetRequest на RowStatus агент возвращает либо notInService (если значение всех полей новой строки известны), либо notReady (если чего-то не хватает). Когда строка находится в состоянии notInService, ее можно активировать, присвоив RowStatus-у значение «active». Первый способ более быстр и прост, а второй – дает больше возможностей для диагностики, если что-то пойдет не так. Активную запись можно перевести в состояние «notInService» (присвоив это значение RowStatus-у). Обычно это делается, если семантика таблицы такова, что какие-то ее поля нельзя изменять у активной записи. Для удаления строки таблицы нужно присвоить RowStatus-у значение «destroy». 3.3. Безопасность в сетевом управлении Атаки могут производиться на аппаратное и программное обеспечение, данные и линии связи (коммуникации). Выделяют четыре вида атак: 1. Interruption (прерывание нормальной работы) Атакам этого рода могут подвергаться все перечисленные объекты. Примерами могут служить кража компьютера, уничтожение файлов, нарушение работы программ, нарушение коммуникаций. Такие атаки легко обнаруживаются, и, при известных мерах предосторожности, их последствия быстро восстанавливаются. 2. Interception (перехват, несанкционирование использование) Этим атакам подвержено все, кроме аппаратного обеспечения. Примеры: незаконное копирование файлов, использование программ, подслушивание телефонных разговоров. Этот вид атак за68 частую очень сложно выявить, так как они не заметны пользователю. 3. Modification (модификация) – искажение существующих файлов, внесение изменений в программное обеспечение таким образом, что оно начинает выполнять несвойственные ему задачи, замена содержимого сообщений, передаваемых по сети. 4. Fabrication (подделка) – генерация фальшивых объектов, не существовавших ранее (подтасовка данных, передача сообщений от чужого имени). В первых версиях SNMP практикуется community-based security model – система безопасности, основанная на паролях. Агент поддерживает одну или несколько community. Community – это с одной стороны слово-пароль, передаваемое в SNMP-пакете, а с другой – права, которые этот пароль дает. Для каждого объекта, реализованного в MIB агента определено, для каких community он доступен и с какими правами (чтение, запись, добавление и т. д.). По умолчанию агент поддерживает community «public», дающую минимальные права, которая может использоваться любым менеджером. Обычно для этой community не разрешается запись. Очевидно, что модель небезупречна – требуется гарантия неприкосновенности линий связи, иначе пароль легко перехватить и безнаказанно использовать. При разработке SNMPv3 к проблемам безопасности подошли серьезнее. Рассмотрим некоторые способы защиты информации от искажения, подделки и перехвата при передаче по линиям связи. Обычно при шифровании оперируют следующими понятиями: − исходный (незашифрованный текст); − алгоритм шифрования; − секретный ключ, используемый в алгоритме шифрования; − зашифрованный текст; − алгоритм дешифрации. При этом алгоритмы должны быть таковы, чтобы злоумышленник, даже зная их, и имея доступ к образцам зашифрованного текста, не смог бы его расшифровать или узнать ключ. Помимо этого, отправитель и получатель должны позаботиться о безопасной передаче и хранении ключей. Наиболее распространенный способ шифрования основан на стандарте DES (Data Encryption Standard), принятом в 1977 г. Национальным Бюро Стандартов США. Текст разбивается на куски по 64 бита и шифруется с помощью 56-битового ключа. В простейшем случае все кусочки шифруются независимо, с помощью кодовой книжки, которая для каждого ключа и каждо69 го образца содержит соответствующую зашифрованную последовательность. Однако такой алгоритм шифрования ненадежен – собрав достаточно много зашифрованных текстов, можно подобрать ключ. Гораздо более надежными являются алгоритмы, в результате работы которых каждый последующий фрагмент зашифрованного текста зависит от предыдущих. Шифрование текста защищает его от перехвата, модификации и фабрикации, однако требует достаточно больших затрат. Поэтому часто применяется другой способ защиты от модификации и фабрикации (но не от перехвата) – дайджест сообщения. Дайджест сообщения – это некоторая последовательность фиксированной длины (много меньшей, чем длина сообщения), полученная в результате выполнения некоторой функции, входными данными для которой являются сообщение и секретный ключ. Дайджест должен зависеть от всего сообщения, а не от одной его части. Для вычисления дайджеста часто применяется алгоритм MD5. Текст, подаваемый на вход алгоритму, разбивается на блоки по 512 бит, а на выходе получается 128-битовый дайджест. Кроме MD-5 для тех же целей применяется SHA-1 (Secure Hash Algorithm), принятый Национальным Институтом стандартов и технологий США в 1993 г. (в результате его работы генерируется 160-битовый дайджест) и HMAC (Hash Message Authentication Code). SNMPv3 не ориентируется на один определенный алгоритм шифрования или генерации дайджеста, а позволяет применять несколько алгоритмов и легко добавлять новые. В SNMPv3-пакетах передаются SNMPv1 и SNMPv2 PDU. Кроме того, SNMPv3 более аккуратно описывает архитектуру программного обеспечения SNMP-станции и предоставляет обширный MIB для конфигурирования SNMP-параметров агента. Чтобы быть надежным, легко сопровождаемым и расширяемым, программный продукт должен состоять из отдельных модулей (подсистем) со строго специфицированными обязанностями. Интерфейс одного модуля с остальными также должен быть тщательно прописан. В этом случае замена одной реализации модуля на другую не затронет остальное программное обеспечение системы. В первых версиях SNMP структура SNMP-системы никак не описывалась. В третьей версии этот недочет был устранен. SNMPсистема (агент или менеджер) включает в себя SNMP Engine – набор низкоуровневых подсистем, отвечающих за обработку пакетов и обеспечивающих работу SNMP-приложений, которые и определяют роль станции в системе сетевого управления. SNMP Engine имеет идентификатор (его еще называют contextEngineId) и может включать в себя следующие подсистемы: 70 1. Dispatcher Этот модуль осуществляет: − интерфейс с транспортным уровнем (посылку и прием пакетов); − передачу пакетов подсистеме Message Processing System для извлечения SNMP PDU; − передачу PDU в Message Processing System для построения пакета; − интерфейс с приложением (посылку и прием SNMP PDU). 2. Message Processing Subsystem осуществляет преобразование пакетов в PDU и наоборот, пользуясь при необходимости услугами Security Subsystem для верификации сообщений и их шифрования и дешифрации. Message Processing Subsystem может поддерживать обработку пакетов в форматах SNMPv1, SNMPv2 и SNMPv3 (но необязательно во всех сразу). 3. Security Subsystem отвечает за безопасность. В ее функции входят две задачи: − проверка, что сообщение не искажено или сфабриковано (для этого может использоваться дайджест); − обеспечение секретности сообщения (для этого необходимо шифрование). При генерации пакета подсистема безопасности вставляет свои поля (например, дайджест) в заголовок. В случае, когда применяется шифрование, эти поля остаются незашифрованными. Формат этих полей в SNMPv3 не фиксируется – для каждой модели он свой. Номер модели находится в части пакета, не подлежащей шифрованию, так что Security Subsystem получателя всегда может определить, какой алгоритм применять для дешифрации и верификации сообщения. В SNMPv3 принята User-Based Security Model, определяющая для каждого пользователя информацию о его ключах и алгоритме шифрования, которая используется подсистемой для дешифрации и верификации сообщений. 4. Access Control Subsystem Эта подсистема тоже имеет отношение к безопасности. Присутствует она только на агенте и осуществляет контроль за доступом к MIB. В SNMPv3 принята модельVACM для реализации подсистемы контроля доступа. Для принятия решения о запрете или разрешении доступа к MIB используются следующие параметры: A. Имя контекста. SNMP-агент может поддерживать несколько контекстов. Со стороны это выглядит, как если бы он поддерживал несколько MIBов. Однако эти MIBы могут пересекаться. 71 B. Тип доступа (чтение, запись, уведомление (трэп)). C. Имя пользователя (менеджера), для которого запрашивается доступ. D. Уровень секретности (как посылается или как было принято сообщение). Для некоторых MIBов вполне вероятна ситуация, когда, скажем, разрешение на чтение предоставляется, только если сообщение будет зашифровано. Возможно также, что читать MIB разрешается всегда, а изменять его – только если сообщение гарантированно пришло от достойного доверия менеджера (т. е., содержит правильный дайджест). E. Security Model. Какая именно модель безопасности в ходу тоже играет роль – алгоритмы шифрования, например, могут быть разной надежности. F. Объектный идентификатор переменной. В результате работы подсистемы могут быть приняты следующие решения: − successAllowed – доступ разрешен; − notInView – объект существует в MIB, однако тип доступа неподходящий (например, попытка записи для read-only переменной); − noSuchView – указанный тип доступа вообще не поддерживается на агенте; − noSuchContext – агент не поддерживает контекст с указанным именем; − noGroupName – для данного пользователя не поддерживается указанная securityModel; − noAccessEntry – для данной комбинации модели, уровня секретности, контекста и пользователя не нашлось ни одного доступного объекта. Для каждой из перечисленных подсистем SNMPv3-спецификация описывает примитивы, для взаимодействия с другими подсистемами и приложениями. Рассмотрим SNMP-приложения, которые могут совместно пользоваться услугами перечисленных подсистем. 1. Генератор команд. Это приложение запускается на менеджере и служит для формирования запросов к агенту и обработки полученных ответов. 2. Обработчик команд – приложение на агенте, отвечающее на запросы менеджера. 72 3. Генератор уведомлений (трэпов) может присутствовать как на агенте, так и на менеджере. Он служит для формирования уведомлений менеджера о каких-либо чрезвычайных событиях. 4. Обработчик уведомлений имеется только на менеджере. Он занимается анализом уведомлений, поступивших от агента или от другого менеджера. 5. proxy Это приложение может быть запущено на агенте, отвечающем не только за себя, но и за одно или несколько других устройств в сети и служит для передачи им запросов от менеджера (в понятной для них форме) и передачи менеджеру полученной от них информации. Прежде всего, агенту необходимо знать, с какими менеджерами ему следует взаимодействовать и какие параметры для этой цели использовать (например, модель и уровень безопасности). Для этой цели существует две таблицы: snmpTargetAddrTable, содержит информацию о транспортном протоколе менеджера и его адрес и ссылается на вторую таблицу – snmpTargetParamsTable, в которой как раз и находятся все параметры, необходимые агенту для формирования пакетов. Несколько менеджеров могут иметь одни и те же параметры и ссылаться на одну строчку в snmpTargetParamsTable. Каждому менеджеру из таблицы snmpTargetAddrTable приписывается один или несколько тэгов. Один и тот же тэг может приписываться нескольким менеджерам. Эти тэги используются для того, чтобы на подмножество элементов snmpTargetAddrTable можно было ссылаться из других таблиц. В частности, Notification MIB содержит таблицу snmpNotifyTable, в которой описаны все уведомления, которые может посылать станция. Каждый элемент этой таблицы содержит тэг, с помощью которого можно узнать, каким именно станциям может быть послано данное уведомление. Каждому уведомлению может быть приписано несколько фильтров, описанных в snmpNotifyFilterTable. Каждый фильтр описывает семейство поддеревьев MIB. Делается это с помощью указания объектного идентификатора поддерева и маски. Маска показывает, какие именно (по номерам) под-идентификаторы объекта следует анализировать, чтобы определить, удовлетворяет ли он фильтру. Если для трэпа указаны фильтры и идентификаторы всех объектов, содержащиеся в трэпе, и идентификатор самого трэпа удовлетворяют этим фильтрам, то трэп посылается. Для конфигурирования USM (User-Based Security Model) используется группа usmUser, включающая в себя таблицу usmUserTable. Для каждого пользователя 73 указывается его имя, протокол верификации и шифрования и ключи к ним. MIB для VACM более обширный. Он включает: − таблицу контекстов vacmContextTable; − таблицу vacmSecurityToGroupTable, отображающую имя пользователя и модель безопасности на имя группы (для нескольких пользователей и моделей может иметь место одна и та же политика доступа к MIB, поэтому они объединяются − в группы); − vacmViewTreeFamilyTable – таблицу, каждый элемент которой описывает семейство поддеревьев MIBа, для которых разрешен тот или иной доступ (семейство описывается как в таблице фильтров – с помощью объектного идентификатора и маски); − таблицу для управления доступом vacmAccessTable, которая для комбинации имени группы, контекста, модели и уровня безопасности содержит ссылки на элементы таблицы vacmViewTreeFamilyTable (по одной для каждого типа доступа – чтения, записи и уведомления). Большинство таблиц для конфигурирования SNMP содержит поле, в котором указывается тип памяти для хранения данного элемента таблицы: динамическая или постоянная. Таким образом, менеджер может сконфигурировать агента временно, до ближайшей перезагрузки, или установить постоянные параметры конфигурации. Вопросы к третьему разделу 1. Назовите ключевые области сетевого управления и характеризуйте их. 2. В чем различие между Network Monitoring и Network Control? 3. Какие приложения должны быть запущены на менеджере сети и какие функции они выполняют? 4. Что такое MIB и на какие части ее можно разделить? 5. Перечислите виды Network Monitoring и охарактеризуйте их. 6. На какие виды подразделяется Network Control? 7. Перечислите области сетевого управления, определенные IOS. 8. Как строится структура MIB SNMP? 9. Какая информация содержится в MIB для каждого объекта? 10. Перечислите состояния, в которых может находиться объект. 74 11. Перечислите типы PDU и охарактеризуйте их. 12. Перечислите основные отличия второй версии SNMP от первой. 13. Перечислите виды атак, которым может быть подвержено аппаратное и программное обеспечение, а также данные и коммуникации. 14. Опишите систему безопасности протокола SNMP. 15. Какие преимущества у системы безопасности протокола SNMP версии 3 вы знаете? 75 4. Объединение сетей Сетевой интеграции присуще использование глобальных каналов и глобальных сетей. При их взаимодействии характерна несимметричность, когда для доступа используют глобальные сети (каналы) общего пользования или частные. Наиболее распространено использование коммутируемых и выделенных телефонных линий, а также абонентских окончаний ISDN. Коммутируемые или выделенные линии могут соединять конечные объединяемые системы непосредственно друг с другом или через их связи с поставщиками услуг глобальных сетей с коммутацией пакетов, кадров или ячеек. Физически связь в большинстве случаев устанавливается через соединение с оборудованием операторов связи, но для передачи данных коммутируемые цепи, а тем более выделенные линии прозрачны. Связь двух или более локальных сетей, территориально разнесенных друг от друга, в единую сеть часто организуют на основе протокола точка – точка PPP. Этот протокол состоит из трех частей: − Метод формирования дейтаграмм для передачи по последовательным каналам. РРР использует протокол High-level Data Link Control (HDLC) (Протокол управления каналом передачи данных высокого уровня) в качестве базиса для формирования дейтаграмм при прохождении через каналы с непосредственным соединением. − Расширяемый протокол LCP для организации, выбора конфигурации и проверки соединения канала передачи данных. − Семейство протоколов NCP (Network Control Protocols) для организации и выбора конфигурации различных протоколов сетевого уровня. РРР предназначен для обеспечения одновременного использования множеством протоколов сетевого уровня. PPP является развитым инструментом для работы на последовательных линиях и имеет следующие преимущества: − возможность одновременной работы по различным сетевым протоколам, а не только по IP; − проверка целостности данных путем подсчета контрольной суммы; − поддержка динамического обмена адресами IP; − возможность сжатия заголовков IP и TCР-пакетов. Для связи локальных сетей между собой и с внешним миром применяется маршрутизатор. Маршрутизатор расположен между коммуникационной аппаратурой и интерфейсом локальной сети. 76 Поскольку несколько локальных сетей могут объединяется в единую корпоративную сеть, то вместо множества двухточечных соединений удобно использовать публичные глобальные сети. Проблемы безопасности в этом случае решает технология виртуальных частных сетей VPN. Такая интеграция достигается путем организации в глобальной сети с коммутацией пакетов туннелей – виртуальных каналов, соединяющих пары точек подключения к сети и эмулирующих двухточечное соединение. Входы и выходы из туннелей располагаются в точках подключения абонентов к общей сети. Через одно подключение к сети возможна организация множества туннелей. По туннелям данные передаются как по двухточечному соединению с PPP. Шифрование потока, отправляемого в туннель, и дешифрование принимаемого потока обеспечивает конфиденциальность передачи по публичным сетям. Для организации сети используется туннелирование второго уровня – инкапсуляция в туннельный протокол кадров PPP, которые несут в себе данные протоколов третьего уровня. Поддержку туннелирования обеспечивают маршрутизаторы и коммутаторы. Объединение LAN с помощью PPP PPP – это двухточечная система, которая позволяет использовать PPP соединение как между двумя UNIX узлами, так и для связи двух или более сетей (или для связи локальной сети с Internet), создавая глобальную сеть (Wide Area Network -- -- WAN). Для того чтобы использовать PPP, необходимо обеспечить выполнение следующих условий: − ядро Linux компилируется с включенной поддержкой PPP; − в системе должна быть программа пользовательского уровня, позволяющая устанавливать и обслуживать PPP соединение; − на другом конце последовательного канала должна быть система, понимающая используемый протокол. Протокол PPP реализован в виде модуля ядра, который помещает сетевые пакеты в выходную очередь последовательного устройства и извлекает поступающие пакеты из входной очереди. Этим модулем легко манипулировать с помощью команды ifconfig. Модемы, связывающие локальную сеть с внешним миром по коммутируемым линиям, могут предоставлять два вида услуг: − Установление исходящего соединения (dial-out) по инициативе пользователя локальной сети. Этот сервис реализуется коммуникационным сервером (Communication server), который обеспечивает разделяемое использование физически подключенных к нему модемов клиентами локальной сети. Для клиента создается иллю77 зия подключения модема к локальному СОМ-порту его компьютера. Коммуникационные серверы позволяют экономить количество модемов и телефонных линий, исходя из того, что модем одновременно не нужен всем пользователям сразу. Если модемов у сервера несколько, они образуют модемный пул, из которого любой пользователь (имеющий доступ к серверу) может использовать любой свободный модем. − Ответ на входящие звонки (dial-in), реализуемый сервером удаленного доступа RAS (Remote Access Server). Эти соединения устанавливаются по инициативе удаленных пользователей (одиночных или пользователей локальной сети через их коммуникационный сервер) для предоставления им доступа к ресурсам сети. Для этого сервиса процедура авторизации пользователя может использовать обратный вызов (call back); после установления соединения пользователь вводит свое имя и пароль, после чего сервер «вешает трубку» и сам «звонит» абоненту по одному из номеров, связанных с этим клиентом в базе данных сервера. Таким образом, можно разрешать конкретным пользователям звонить только с определенных телефонов (в целях повышения безопасности). Для того, чтобы организовать связь через канал с непосредственным соединением, инициирующий РРР вначале отправляет пакеты LCР для задания конфигурации соединения, а также проверки канала передачи данных. После того, как канал установлен и пакетом LCР выполнено необходимое согласование факультативных средств, инициирующий РРР отправляет пакеты NCP, чтобы выбрать и определить конфигурацию одного или более протоколов сетевого уровня. Как только конфигурация каждого выбранного протокола определена, дейтаграммы из каждого протокола сетевого уровня могут быть отправлены через данный канал. Канал сохраняет свою конфигурацию до тех пор, пока пакеты LCP или NCP явно не закроют его или пока не произойдет какое-нибудь внешнее событие (например, истечет срок бездействия таймера или вмешается какой-нибудь пользователь). Точная последовательность событий, происходящих при установлении РРР-соединения, зависит от операционной системы и типа сервера, с которым осуществляется связь. Соединения можно устанавливать либо вручную, либо динамически. При ручном подключении пользователь запускает команду, которая вызывает модем, входит в удаленную систему и загружает в ней демон протокола РРР. Если эта процедура заканчивается успешно, последовательный порт конфигурируется как сетевой ин78 терфейс. В этом случае канал обычно остается активным длительное время, что лучше всего подходит для выделенных телефонных линий. В динамической конфигурации демон наблюдает за последовательными «сетевыми» интерфейсами, отслеживая запросы на передачу данных через них. Когда кто-то пытается послать пакет, демон автоматически вызывает модем для установления соединения, передает пакет и, если канал возвращается в режим ожидания, по истечении соответствующего периода времени разрывает соединение. Динамические каналы применяются, когда по телефонной линии передаются как голосовые, так и двоичные данные, а также когда осуществляются звонки на большие расстояния или соединение является платным. Программы, реализующие обе эти схемы, входят в состав большинства версий РРР. Шифрование потока, отправляемого в туннель, и дешифрование принимаемого потока обеспечивает конфиденциальность передачи по публичным сетям. В зависимости от того, какие данные вкладываются в туннельный протокол, различают два уровня туннелирования. Наиболее широко распространено (и стандартизовано) туннелирование 2-го уровня (Layer 2 tunneling) – инкапсуляция в туннельный протокол кадров РРР (2-й уровень), которые несут в себе данные протоколов 3-го уровня (IP, IPX...). Альтернативой ему является туннелирование 3-го уровня (Layer 3 tunneling) – инкапсуляция в туннельный протокол непосредственно пакетов сетевого уровня. Поддержка VPN (организация туннельных окончаний) может быть включена в оборудование удаленного доступа. В глобальных сетях поддержку туннелирования должны обеспечивать маршрутизаторы и/или коммутаторы. Маршрутизаторы являются пограничными сетевыми устройствами, т. е. устанавливаются на границе между двумя сетями или между локальной сетью и Internet, выполняя роль сетевого шлюза. Они имеют как минимум два порта. К одному из этих портов подключается локальная сеть, и этот порт называется внутренним LAN-портом. Ко второму порту подключается внешняя сеть (Интернет), и этот порт называется внешним WAN-портом. Иногда маршрутизаторы имеют один WAN-порт и несколько (от одного до четырех) внутренних LANпортов, которые объединяются в коммутатор. Программное обеспечение протокола PPP состоит из двух частей: демон протокола PPP и поддержка протокола PPP ядром ОС. Для организации канала связи между двумя удаленными узлами, производится инсталляция протокола PPP на обоих концах 79 соединения. Прежде всего устанавливается маршрут от машины, выполняющей PPP соединение с сетями на удаленном конце связи. Специальный сетевой маршрут добавляется для каждой сети, которая доступна через соединение. Это делается с использованием команды ‘route’ для каждой сети в скрипте /etc/ppp/ip-up. Далее сообщается всем хостам каждой LAN, что узел, выполняющий PPP соединение является фактически ‘шлюзом’ для сетей на удаленный конец ppp соединения. Как только связь PPP установлена, pppd ищет /etc/ppp/ip-up и выполняет скрипт. Он позволяет автоматизировать любые специальные команды маршрутизации и любые другие действия, которые требуется выполнить при активизации PPP соединения. Вопросы к четвертому разделу 1. Почему протокол PPP удобен для сетевой интеграции, в особенности, если используются коммутируемые соединения и выделенные линии связи? 2. Из каких частей состоит PPP и какие функции они выполняют? 3. Перечислите преимущества протокола PPP и объясните, как эти преимущества могут быть использованы? 4. В чем заключается туннелирование второго уровня? 5. Какие протоколы относятся к протоколам третьего уровня при туннелировании? 6. Использует ли протокол PPP маршрутизацию? 7. На чем основана высокая защищенность и конфиденциальность виртуальных частных сетей? 8. Каков алгоритм установления исходящего и входящего соединения по коммутируемым линиям? 9. Какие требования необходимо выполнить, чтобы узел использующий UNIX-подобную ОС, мог установить PPP соединение? 10. В чем отличие между туннелированием второго и третьего уровня; какое из них предпочтительней? 11. Из каких частей состоит программное обеспечение протокола PPP на узле и какие функции оно выполняет? 12. Необходим ли сервер для организации PPP соединения между узлами находящимися в разных сетях? 80 Приложение 1 Логический расчет объединенной сети Использование маски подсети дает возможность организовать в одной сети несколько подсетей. Это означает также, что можно решить противоположную задачу – создать объединенную IP-сеть, т. е. решить задачу сетевой интеграции. Предположим, что в нашем распоряжении имеется два адресных пространства IP-адресов класса С: 192.168.50.x и 192.168.51.x, которыми мы можем распоряжаться по своему усмотрению. Где x означает любое десятичное число в диапазоне от 0 до 255 – итого 256 чисел. Значения x равные 11111111 и 00000000, т. е.255 и 0 в десятичной системе, использовать нельзя, поскольку первое в Ethernet означает широковещательный запрос, а второе обозначает номер сети. Таким образом, если не стоит задача разбиения таких двух сетей с номерами 192.168.50.0 и 192.168.51.0 на подсети, с использованием стандартной маски 255.255.255.0, в каждой из них можно организовать по 256 – 2 = 254 узла. Существует возможность забрать из младшего октета IP-адреса несколько битов на нужды организации подсетей из каждой сети с номерами 192.168.50.0 и 192.168.51.0, как об этом упоминалось в подразд. 1.7. Пусть это будут три бита ( разумеется старшие ). Обозначим их на рис. 22 как a,b,c. Оставшиеся пять битов пойдут на IP-адреса в каждой из подсетей, которые должны образоваться после такого выбора. Сначала определим номера подсетей в сети с номером 192.168.50.0. Три бита, выделенные на подсети, могут образовать восемь двоичных чисел, как это показано на схеме, причем, из этого числа следует исключить числа 000 и 111, так как они не могут использоваться. Остается шесть чисел: 001; 010; 011; 100; 101; 110, которые и образуют шесть подсетей с номерами: 00100000; 01000000; 01100000; 10000000; 10100000; 11000000 (192.168.50.32; 192.168.50.64; 192.168.50.96; 192.168.50.128; 192.168.50.160; 192.168.50.192.). Где биты a, b, c имеют веса 128, 64, и 32, соответственно. Определим непересекающиеся пространства IP-адресов для первой и последней из этих шести подсетей. Пять битов, оставшихся от байта и предназначенные для адресации узлов обозначены как *. Эти пять битов могут образовать 32 двоичных комбинации, каждая из которых адресует узел подсети. На рис. 22 показаны первые и последние из этих 32 комбинаций. Числа 00000 и 11111, как и в 81 B C D ª¾ËÕ ®ÇÊË ¨Ç½Ê¾ËÕ ¬À¾Ä c c c c c c c c c c Рис. 22 предыдущем случае, использовать нельзя. Таким образом, под узлы в каждой из подсетей остается 32 – 2 = 30 комбинаций. Нетрудно заметить, что IP-адреса для первой подсети получаются путем присоединения к двоичному коду 001 всех допустимых тридцати комбинаций выделенных под узлы. Это тридцать чисел: 00100001; 00100010; 00100011;... 00111101; 00111110, или в десятичном представлении: 33; 34; 35;... 61; 62. В итоге получилось, что тридцать IP-адресов: 192.168.50.33; 192.168.50.34;... 192.168.50.61; 192.168.50.62 вошли в первую подсеть. Проделав аналогичные рассуждения, нетрудно получить адресное пространство для последней, шестой подсети. Это будут IP-адреса: 192.168.50.193; 192.168.50.194;... 192.168.50.221; 192.168.50.222. Следует иметь в виду, что разбиение сети 192.168.50.0 способной адресовать 254 узла на шесть подсетей формально уменьшает потенциальное адресное пространство на 254 – 180 = 74 адресов, поскольку произведение 6 на 30 дает число 180. Несложно заметить, что эти потери, в нашем случае, происходят в начале и в конце диапазона ( по 32 IPадреса ), а также в пяти промежутках ( по 2 IP-адреса ) между подсетями. На самом деле эти потери кажущиеся, поскольку подсети входят в сеть, и большую их часть 74 – 10 = 64 можно использовать для адресации сетевых устройств, относящихся не к подсетям, а к самой сети. 82 Здесь было рассмотрено, что произойдет, если забрать из младшего октета ( байта ) IP-адреса три бита на организацию подсетей в сети 192.168.50.0. Получилось, что таким образом в ней можно создать шесть подсетей по тридцать узлов в каждой. Проделав аналогичные рассуждения, несложно прийти к выводу, что выделяя 2, 4, 5 и 6 битов на нужды организации подсетей класса С, можно получить 2, 14, 30 и 62 сети, соответственно, как это показано в табл. 3 подразд. 1.7 пособия. Процедура изъятия битов IP-адреса на организацию подсетей заключается в логическом умножении маски подсети на соответствующие биты адреса. В нашем примере изымалось три старших бита из младшего октета, т. е. использовалась маска подсети 11111111.11111111.111 11111.11100000 или 255.255.255.224. Значения масок для другого количества требуемых подсетей можно найти в той же табл. 3. Вопрос о том, как следует выбирать маску из табл. 3, исходя из потребностей при проектировании сети, может оказаться не таким простым, как кажется на первый взгляд. Например, выбор маски 255.255.255.192 может оказаться негибким решением, не учитывающим возможность изменения сети, в том числе ее расширения. Маска 255.255.255.252 и вовсе кажется настоящей экзотикой. Чаще всего на практике используют маски 255.255.255.224 и 255.255.255.240, при этом всегда следует помнить, что выбор, при котором один или несколько диапазонов IP-адресов пока не используется, разумен. 83 Приложение 2 Инженерный расчет объединенной сети Расчет объединенной сети подразумевает выполнение нескольких последовательных шагов: − установление физической связанности (определение типов сетевых соединений и выбор сетевого оборудования); − определение количества подсетей, узлов и интерфейсов для каждого сегмента; − определение маски подсети, назначение IP-адресов сетевым интерфейсам, определение маршрутов и адресов для широковещательных запросов; − установление интерфейсам сетевых устройств IP-адресов, маски и широковещательного адреса; − установление направлений связи на маршрутизаторах, а также направлений связи на узлах и других сетевых устройствах. К логическому расчету можно отнести третий из перечисленных пунктов, хотя он тесно связан со вторым. Остальные пункты можно отнести к инженерному расчету, за исключением настройки сетевых устройств. Предположим, что необходимо создать объединенную сеть, в которую должны войти три подсети, в каждой из которых содержится 11, 14 и 20 узлов соответственно. Как это следует из рассуждений, приведенных в Прил. 1. и данных приведенных в табл. 3 из подразд. 1.17, приемлемым решением будет выбор маски 255.255.255.224. В самом деле, эта маска обеспечивает разбиение сети192.168.50.0 на 6 подсетей по 30 узлов в каждой, что гарантирует хороший запас как по количеству подсетей, так и узлов. Для повышения производительности проектируемой сети следует использовать такую ее сегментацию, при которой подсети, cтроятся на основе предусмотренных для этого отдельных коммутаторов. Эти коммутаторы, в свою очередь, должны объединяться с помощью маршрутизатора, а вся сеть иметь древовидную структуру. Такие решения гарантируют локализацию широковещательного трафика, ограничивая его подсетью, и оправданы для сети cреднего размера. Главным преимуществом такого подхода является локализация трафика и, как следствие, уменьшение числа коллизий, и, следовательно, повышение пропускной способности и надежности. Использование коммутаторов 2-го уровня ( не маршрутизирующих ) не локализует широковещательный трафик 84 на всех уровнях, однако, такое решение экономично и оправдано, если предполагается, что они используются для объединения узлов в подсети. Объединяющим подсети устройством может быть либо маршрутизатор, либо коммутатор-маршрутизатор. Эти устройства относятся к 3-му уровню и способны работать также быстро, как и коммутаторы 2-го уровня. Выберем 6-портовый полнодуплексный маршрутизатор c портами 1Гб/c и дополнительным Combo портом для подключения модуля с применением оптоволокна в соответствии со стандартом (1000 BASE-SX/LX mini-GBIC). Этот порт может понадобиться для подключения к другой объединенной локальной сети, т. е. для сетевой интеграции на уровне сетей, а не подсетей. Опционально маршрутизатор может поддерживать мониторинг, защиту по МАС-адресам, загрузку ПО, VLAN, SNMP, Telnet и т. п. К коммутаторам, объединяющим узлы в подсети, может не предъявляться повышенных требований, однако, полнодуплексный режим и скорость 1Гб/с желательно обеспечить, поскольку в этом случае, вся сеть будет работать на этой скорости. Учитывая, что в подсетях должно быть 11, 14 и 20 узлов, выберем два 16-портовых и один 24-портовый коммутатор. Имея в виду предыдущий выбор, в качестве кабельной системы нашей локальной сети следует выбрать кабель – витую пару категории 5e и выше и разъемы RG-45. Коммутаторы второго уровня, как сетевые устройства, не обязаны иметь логические IP-адреса и маску, поскольку они работают по аппаратным ( MAC ) адресам и коммутируют кадры, анализируя их Ethernet заголовки. Для этого они используют MAC адреса источника и получателя кадра. Если, однако, выбран интеллектуальный коммутатор 2-го уровня, то ему, как и любому другому адресуемому сетевому устройству необходимо указать IP, широковещательный адрес и маску. Узлы, подключаемые к коммутаторам 2-го уровня, а также коммутатор-маршрутизатор, должны иметь IP-адрес, маску и адрес для широковещательных запросов для каждого из своих сетевых интерфейсов. Таким образом, все устройства, входящие в локальную сеть, должны настраиваться. Сначала определим, какие настройки следует сделать, а затем ( в Прил. 3 ), как они устанавливаются. Для этого следует определиться с тем, какие из устройств относятся к подсетям, а какие – образуют сеть. Начнем снизу вверх. Не вызывает сомнений, что узлы данной подсети, подключаемые к портам своего коммутатора относятся только к своей подсети. Ло85 гическим признаком этого является маска подсети, которая должна быть установлена в настройках сетевого интерфейса на каждом из узлов. Кроме того, каждому сетевому интерфейсу следует указать IP-адрес из того адресного пространства, к которому он относится, в соответствии с номером подсети. Как это делается, описано в Прил. 1. Назначим маску и IP-адреса для узлов первой подсети (192.168.50.32 ) в нашей сети 192.168.50.0. Поскольку в ней должно быть 11 узлов, нас устроит маска подсети 255.255.255.224. В самом деле, такая маска образует 6 подсетей с 30 узлами в каждой из них. Попутно заметим, что эта маска подходит и для организации остальных двух подсетей, где число узлов равно 14 и 20 соответственно. Не следует забывать, что разные маски в разных подсетях одной сети выбирать нельзя, поскольку, в этом случае, пространства IP-адресов будут перекрываться. Таким образом, интерфейсам узлов первой подсети назначаются следующие IP-адреса: 192.168.50.33; 192.168.50.34;... 192.168.50.42; 192.168.50.43, а маска подсети для всех подсетей данной сети одинакова и равна 255.255.255.224. Нечасто бывает так, что ресурсы, входящие в данную подсеть, такие как сетевые принтеры, файл-серверы и т. п., в полной мере удовлетворяют потребности пользователей. С другой стороны, все сетевые службы, необходимые для организации рабочих групп и тем более, домена, нуждаются в широковещательном трафике, выходящем за пределы данной подсети. Отсюда следует необходимость настройки интерфейсов узлов, входящих в подсети, на широковещательный трафик за пределами данной подсети. Это можно сделать, выбрав в качестве такого запроса 192.168.50.255, что означает: всем в данной сети. Перейдем к выбору настроек подчиненных коммутаторов 2-го уровня. Таких коммутаторов три, по числу подсетей, причем каждый из них формально относится как к своей подсети, так и к сети192.168.50.0. Интеллектуальный коммутатор настраивается как сетевое устройство, имеющее IP-адрес и маску, при этом не имеет значения, через какой из своих портов он подключен к управляющему устройству. Маршрутизатор следует настраивать как устройство, принадлежащее одновременно к данной сети 192.168.50.0, и к данной подсети по тому внутреннему интерфейсу, который к ней ведет. Следовательно, маска у внешних интерфейсов должна быть 255.255.255.0, а у внутренних – 192.168.50.224. IP-адресам для сетевых устройств, находящихся выше в иерархии, принято назначать меньшие числа. Cледуя этой традиции, назначим маршрутизатору IP-адреса 192.168.50.1 и192.168.50.2 для внешних интер86 фейсов и маску 255.555.555.0 для его трех внутренних интерфейсов назначим последние IP-адреса из каждого диапазона 1-й, 2-й и 3-й подсетей: 192.168.50.62, 192.168.50.94, 192.168.50.126. Разумеется, можно выбрать любой свободный адрес, главное, чтобы он входил в соответствующий диапазон и не был назначен какому-нибудь узлу в данной подсети. Трем подчиненным коммутаторам 2-го уровня (интеллектуальным) следует назначить адреса: 192.168.50.3; 192.168.50.4 и 192.168.50.5, соответственно, если предполагается, что они будут управляться извне. Если управляющий менеджер – один из узлов данной подсети, предпочтительней внутренний адрес из данной подсети. Для того чтобы подключить сеть 192.168.50.0 к другой сети или сетям, помимо Combo порта маршрутизатора, рассчитанного на стандарт 100 BASE – SX/LX, следует использовать его внешние интерфейсы 192.168.50.1 и 192.168.50.2. Настройки внешнего сетевого интерфейса маршрутизатора не относятся к расчету локальной сети, и поэтому эти воросы не будут здесь рассмотрены. Следует заметить, что маршрутизатор является не только средством сетевой интеграции, но и обеспечивает возможность подключения к глобальной сети Internet. Для того чтобы все узлы сети 192.168.50.0 имели возможность взаимодействовать с ним, нет необходимости принимать какие-либо дополнительные меры. В самом деле – шлюз 192.168.50.1 является участником, всех трех подсетей через интерфейсы eth0, eth1 и eth2, а его таблица маршрутов через интерфейс ppp0 обеспечит подключение к глобальной сети. 87 Приложение 3 Сетевые настройки В Прил. 2 на примере было показано, как выбирать параметры локальной сети исходя из ее структуры. Здесь же пойдет речь о том, как их реализовать. Рассмотрим, как настраиваются интерфейсы сетевых устройств. Исходными данными для такого рассмотрения послужат предположения, сделанные в Прил. 2. Речь пойдет о локальной сети с номером 192.168.50.0. Усвоение этого вопроса важно с практической точки зрения, поскольку оно дает инструмент для практической работы администратора. Ключевым пунктом здесь является то, на основе какой сетевой операционной системы следует осваивать это дело. За и против такого выбора найдется немало аргументов. Несомненным, однако, является то, что следует выбрать UNIX – подобную OC, в противном случае, трудно будет тем, кто захочет разобраться в этом деле детально. Команда ifconfig позволяет конфигурировать сетевые интерфейсы, а команда route обеспечивает необходимую маршрутизацию. Рассмотрим подробнее каждую из них. В качестве аргументов команда ifconfig использует номер интерфейса и IP-адрес. Кроме того, она имеет ряд опций. Команда ifconfig используется для того, чтобы присвоить заданному сетевому интерфейсу указанный IP-адрес. Таким образом, она дает знать операционной системе, что данный интерфейс существует и что она может обращается к нему по указанному IP-адресу. Команда ifconfig имеет следующий синтаксис: # ifconfig интерфейс-хост_сеть_флаг_адрес_опции Флаг-хост_сеть может принимать одно из двух значений – host или – net. Флаг-host свидетельствует о том, что данный IP-адрес является адресом хост-компьютера, a – net означает, что данный IP-адрес являетcя номером сети. По умолчанию принимается флагhost. У команды ifconfig есть несколько опций, которые задают различные характеристики интерфейса, например максимальное число байтов, которое он может передать за один раз (mtu), широковещательный адрес и т. д. Опция up активизирует интерфейс, а опция down деактивизирует его. В следующем примере команда ifconfig используется для конфигурирования интерфейса Ethernet. # ifconfig eth0 192.168.50.2 88 Для такой простой конфигурации, как эта, ifconfig автоматически создаёт стандартный широковещательный адрес и маску сети. Стандартный широковещателъный адрес – это сетевой адрес с машинной частью, указанной как 255. Стандартная маска сети – 255.255.255.0. Если пользователь подключен к сети с другой сетевой маской и конкретным широковещательным адресом, их необходимо указать в командной строке ifconfig. Широковещательный адрес указывается в опции broadcast, а маска сети – в опции netmask. В следующем примере ifconfig задает сетевую маску и широковещательный адрес. # ifconfig eth0 192.168.50.170 broadcast 192.168.50.255 netmask 255.255.255.0 В случае необходимости можно с помощью команды ifconfig конфигурировать закольцовывающий интерфейс. Этот интерфейс имеет имя lо и специальный IP-адрес, 127.0.0.1. Процедура конфигурирования закольцовывающего интерфейса показана в следующем примере. # ifconfig 1о 127.0.0.1 Команда ifconfig очень полезна для проверки статуса интерфейса. Если ввести ее только с именем интерфейса, то ifconfig выдаст информацию об этом интерфейсе. # ifconfig eth0 Чтобы посмотреть, конфигурирован ли закольцовывающий интерфейс, нужно дать команду ifconfig с именем этого интерфейса, lо: # ifconfig 1о lo Link encap:Local Loopback inet addr:127.O.O.1 Beast:127.255.255.255 Mask:255.О.О.О UP BROADCAST LOOPBACK RUNNING MTU:2000 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 TX packets:12 errors:0 dropped:0 overruns:0 Чтобы вывести содержимое таблицы маршрутов на дисплей, нужно дать команду route без аргументов. # route Kernel routing table Destination Gateway Genmask Flags MSS Window Use Iface loopback * 255.0.0. U 1936 0 12 lo guap.ru * 255.255.255.0 U 1936 0 0 eth0 Каждая запись таблицы маршрутов состоит из нескольких полей содержащих такую информацию, как, например, конечный 89 пункт маршрута и тип используемого интерфейса. Поля таблицы маршрутов перечислены в таблице. Таблица Поле Destination Gateway Genmask Flags MSS Metric Ref Window Use Iface Описание IP-адрес конечного пункта маршрута IP-адрес или хост-имя шлюза, используемого на данном маршруте; символ * говорит о том, что шлюз в сети не используется Маска сети маршрута Тип или состояние маршрута: U=активный, Н=хост, G=шлюз, D=динамический, М=модифицированный TCP MSS (Maximum segment size) для маршрута – максимально количество данных, которое может быть передано за один раз «Стоимость» маршрута (количество переходов до шлюза) Количество использований маршрута на текущий момент Размер окна приема. Наибольшее количество данных, которое принимающая сторона может принять Количество пакетов, пересланных по данному маршруту Тип интерфейса, используемого на данном маршруте В таблице маршрутов должна содержаться по крайней мере одна запись, предназначенная для закольцовывающего интерфейса, иначе это интерфейс придется конфигурировать командой route. IP-адрес интерфейса нужно ввести в таблицу до того, как этот интерфейс будет задействован. Адрес добавляется с помощью команды route с опцией add. route add адрес В следующем примере показано, как в таблицу маршрутов вводится IP-адрес закольцовывающего интерфейса. # route add 127.0.0.1 Опция add имеет несколько спецификаторов. Если вы добавляете конкретный статический маршрут, то эти спецификаторы понадобятся для ввода таких параметров, как маска сети, шлюз, интерфейс и адрес пункта назначения. Если же интерфейс уже конфигурирован командой ifconfig, то система может получить основную информацию из данных конфигурации интерфейса. Например, чтобы задать маршрут для Ethernet-соединения, которое уже конфигурировано командой ifconfig, нужно лишь ввести спецификатор-net и IP-адрес пункта назначения. С помощью этого адреса ifconfig находит соответствующий интерфейс и на основа90 нии этой информации организует маршрут. Задание маршрута для интерфейса Ethernet иллюстрируется следующим примером. # route add-net 192.168.50.0 Если узел подключен к глобальной сети, в таблице маршрутов должна быть сделана по крайней мере одна запись, задающая маршрут по умолчанию. По этому маршруту пакет посылается в том случае, если все остальные маршруты не могут привести его в пункт назначения. Пункт назначения для такого маршрута задается ключевым словом default. Если нужно удалить один из существующих маршрутов, следует вызвать команду ifconfig с опцией del и номером маршрута, например: # route del-net 192.168.53.0 Далее показан процесс удаленного конфигурирования сетевого интерфейса по протоколу telnet с помощью команд route и ifconfig. Вначале при помощи команды route добавляется сеть, а затем для интерфейса с номером eth0 задается IP-адрес, маска и широковещательный адрес. Таким образом, команда ifconfig позволяет сконфигурировать сетевые интерфейсы, а команда route обеспечивает необходимую маршрутизацию. 91 Приложение 4 Конфигурирование объединенной сети Предположим, что сеть Ethernet организована как сеть класса C с номером 192.168.50.0, а вашему узлу был выделен адрес 192.168.50.35 в подсети 192.168.50.32, и интерфейс маршрутизатора, через который подсеть может быть подключена к другой сети, имеет адрес 192.168.50.2, кроме того, необходимо обеспечить подключение сети 192.168.50.0 к внешнему миру. Предполагается, что в сети три подсети, следовательно, у шлюза должно быть пять интерфейсов, включая двухточечное соединение ppp0.Сначала необходимо настроить сетевой интерфейс узла. root# ifconfig eth0 192.168.50.35 netmask 255.255.255.224 broadcast 192.168.50.255 Эта команда присваивает интерфейсу eth0 IP-адрес 192.168.50.35 и определяет его в подсеть с номером 192.168.50.32, а также устанавливает адрес для широковещательного запроса, выходящий за пределы подсети. Такое решение оправдано, если там есть сетевые устройства, с которыми необходим обмен. Если такой необходимости нет, например, в случае, когда все, что вам нужно, находится в вашей подсети, то лучше закрыть подсеть для широковещательных запросов, поскольку щироковещательный трафик во всей сети уменьшится. Это можно сделать, введя адрес для широковещательного запроса 192.168.50.63, двоичное число в младшем октете запроса будет 00111111. После этого следует добавить в таблицу маршрутизации на вашем узле строку, согласно которой пакеты на узлы своей подсети ядро могло бы отправлять через интерфейс eth0. Это можно сделать с помощью команды route: root# route add -net 192.168.50.32 netmask 255.255.255.224 eth0. Опция – net указывает, что адрес назначения в таблице маршрутизации будет номером сети ( в нашем случае это подсеть с номером 192.168.50.32.) С помощью опции -host можно задать маршрут на конкретный IP-адрес. Эти команды позволяют устанавливать IPсоединения со всеми узлами в локальном ethernet-сегменте, т. е. в подсети 192.168.50.32. Для того чтобы узел 192.168.50.35 имел возможность посылать свои кадры шлюзу по простому правилу: если в таблице маршрутов нет соответствующей строки – посылаем шлюзу, т. е.используем маршрут по умолчанию, введем строку: root# route add default gw 192.168.31.168 eth0. 92 Опция `gw’ указывает программе route что следующий аргумент -- IP-адрес, на который надо отправлять все пакеты, соответствующие этой строке таблицы маршрутов. Итак, полностью настройка узла будет выглядеть так: root# ifconfig eth0 192.168.50.35 netmask 255.255.255.224 broadcast 192.168.50.255 root# route add -net 192.168.50.32 netmask 255.255.255.224 eth0 root# route add default gw 192.168.31.168 eth0. Перейдем к настройке шлюза. У него несколько интерфейсов: одно PPP-соединение с внешним миром через модем, второй внешний интерфейс 192.168.50.2 для соединения с другой сетью и три внутренних интерфейса, по числу подсетей. Соединение с первой подсетью осуществляется через внутренний интерфейс eth0 192.168.50.62. Число 62 в младшем октете этого адреса – последнее из диапазона 33 – 62, который определяет маска 255.255.255.224 для первой подсети. Настройка внешней маршрутизации будет выглядеть так: root# route add -net 192.168.51.0 netmask 255.255.255.0 eth3 root# route add default ppp0 Внутренний интерфейс шлюза в первую подсеть настраивается так же, как и для узлов с помощью команды ifconfig: root # ifconfig eth0 192.168.50.62 netmask 255.255.255.224 broadcast 192.168.50.255 Настройка других внутренних интерфейсов шлюза производится аналогично. Внешний IP-интерфейс шлюза, можно настроить, введя строку: root # ifconfig eth3 192.168.50.2 netmask 255.255.255.0 broadcast 192.168.50.255 Разница состоит в том, что шлюз, в отличии от узла 192.168.50.35, включен этим интерфейсом не в подсеть 192.168.50.32, а в сеть 192.168.50.0. Настройка маршрута через внешний интерфейс шлюза выглядит просто, и этому есть объяснение. Протокол PPP связывает две точки Point-to-Point, например, два модема через коммутируемое соединение. Маршрутизация не нужна, и, следовательно, не нужно указывать логические адреса. Для сетей других типов, таких как ethernet, arcnet или token ring требуется указывать адрес шлюза, так как в них может подключаться сразу несколько узлов к одному сегменту сети. 93 94 ©½» Á & U I *1 .B T L # S P BE DB TU ÄÂÂÉȶÈÄÆ ÄÂÂÉÈ ¶ÈÄÆ ©½» Á & UI& & UUI I *1 .B T L # S P BE DB TU QQQ QQQ $PNCP *OUFSOFU §Ë»Â¶Ä·Ð»º¾Ã»ÃÃĿǻȾ ÄÂÂÉȶÈÄÆ ©½» Á & U I *1 &UI .B T L # S P BE DB TU *1 .B T L &UI *1 # S P BE DB TU .B T L & *1 # SP BE DB TU .B T L # S P BE DB TU & U I & U I & U I ©½» Á & & U I *1 .B T L # S P BE DB TU ¢¶ÆÎÆÉȾ½¶ÈÄÆ Æ *1 .B T L # SP BE DB TU Схема объединенной сети 192.168.50.0 Приложение 5 Библиографический список 1. Кульгин М. В. Компьютерные сети. Практика построения. Для профессионалов. 2-е издание. – СПб.: Питер, 2003. 2. Олифер В. Г., Олифер Н. А. Компьютерные сети: Принципы, технологии, протоколы. – СПб.: Питер, 2000. 3. Калюжный В. П., Калюжный И. В. Технические основы удаленного доступа: учеб. пособие / СПбГУАП. СПб., 2005. 102с. 4. Крейг Закер. Компьютерные сети. Модернизация и поиск неисправностей. – СПб.: БХВ-Петербург, 2005. 5. Гук М. Аппаратные средства локальных сетей. Энциклопедия. – СПб.: Питер, 2005. 6. Калюжный В. П., Зайченко К. В. и др. Банковская и офисная электронная аппаратура: учеб. пособие / СПбГУАП. СПб., 1999. 126 с. 7. Востриков А. А., Калюжный В. П., Сергеев М. Б. Пластиковые карты с открытой памятью: учеб. пособие / СПбГУАП. СПб., 2002. 104 с. 8. RFC 2271 – 2275 ( Request for comments ) Безопасность в сетевом управлении. 9. RFC 1321; RFC 2104 ( Request for comments ) Алгоритмы шифрования. 95 Содержание Основные сокращения................................................................... Предисловие ................................................................................ 1. Основы TCP/IP.......................................................................... 1.1. Введение........................................................................... 1.2. Логическая структура сетевого программного взаимодействия в IP сетях................................................................................ 1.3. Протокол IP....................................................................... 1.4. IР-адресация..................................................................... 1.5. Классы IP-адресов.............................................................. 1.6. IP-адресация подсети.......................................................... 1.7. Маска IP-подсети............................................................... 1.8. Протокол IСМР.................................................................. 1.9. Протокол ARP ................................................................... 1.10. Протокол TCP.................................................................. 1.11. Протокол UDP.................................................................. 1.12. Путь вниз. Сокеты............................................................ 1.13. Технология Ethernet......................................................... Вопросы к первому разделу............................................................. 2. Маршрутизация в IP-сетях......................................................... 2.1. Cтатическая маршрутизация............................................... 2.2. Основы маршрутизации в IP-сетях........................................ 2.3. Протоколы маршрутизации................................................. 2.4. Протокол маршрутной информации RIP................................ 2.5. Протокол открытия кратчайшего пути OSPF.......................... 2.6 . Протокол граничного шлюза BGP........................................ 2.7. Организация динамических маршрутов................................ Вопросы ко второму разделу.......................................................... 3. Информационные системы администрирования............................. 3.1. Методы, функции и службы администрирования.................... 3.2. Организация баз данных администрирования (протокол SNMP)...................................................................... 3.3. Безопасность в сетевом управлении....................................... Вопросы к третьему разделу.......................................................... 4. Объединение сетей..................................................................... Вопросы к четвертому разделу........................................................ Приложение 1. Логический расчет объединенной сети....................... Приложение 2. Инженерный расчет объединенной сети..................... Приложение 3. Сетевые настройки.................................................. Приложение 4. Конфигурирование объединенной сети....................... Приложение 5. Схема объединенной сети 192.168.50.0...................... Библиографический список............................................................ 96 3 5 7 7 9 13 15 16 17 18 20 23 25 28 29 32 33 35 35 37 39 43 46 50 52 53 55 55 61 68 74 76 80 81 84 88 92 94 95