Вычисление скорости ветра по U- и V- компонентам
реклама

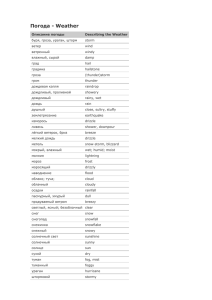
Разработка распределенных алгоритмов и высокопроизводительной программной системы для облачного хранения, потоковой обработки и сбора в реальном времени сверхбольших наборов научных данных М.Н.Жижин, А.Н.Поляков, А.А.Пойда, Д.П.Медведев НИЦ «Курчатовский институт» Государственный контракт № 07.514.11.4045 Выполняется в рамках федеральной целевой программы «Исследования и разработки по приоритетным направлениям развития научно-технологического комплекса России на 2007-2013 годы» Сверхбольшие наборы данных в научных областях • • • • • Физика высоких энергий (LHC) Астрофизика (SDSS, численные модели Вселенной) Геофизика и глобальные изменения климата (Архив метеонаблюдений WMO, климатологические и прогноз NCEP/NCAR и ECMWF, сейсмика, космическая погода SPIDR) Дистанционное зондирование (архивы изображений MODIS, DMSP, GOES) Биоинформатика и нанотехнологии (геном, архивы изображений с микроскопов, томографов) Необходимость исследований • • Нарастание объемов собираемых экспериментальных данных и увеличение их сложности, связанное с ростом числа и разрешающей способности научных сенсоров Экспоненциальный рост вычислительных возможностей и объемов результатов вычислений, требующих хранения для повторного анализа Перспективные технологии хранения и управления данными • • • • Объектные облачные хранилища данных Amazon S3, MS DataMarket, OpenStack Swift, Cassandra, DropBox Специализированные системы хранения адаптированные для хранения научных данных, такие как RasDaMan и SciDB Гибридные системы хранения (специализированную модель данных поверх хранилища более общего назначения) ActiveStorage Распределенная потоковая обработка Twitter Storm, Yahoo S7, IBM Streams, Hadoop. Недостатки существующих систем • • • • Разнообразие форматов данных и типов их представления Отсутствие достаточно универсального и высокоуровнего языка запроса, учитывающего специфику хранения (например, в облаке) и модели данных (в первую очередь многомерные массивы) Отсутствие масштабируемой, распределенной, открытой платформы для облачного хранения научных данных Отсутствие фреймворка, обеспечивающего распределенную параллельную обработку потоков научных данных Цель проводимых исследований • • Разработка программных систем, объединяющих высокопроизводительные технологии и параллельные алгоритмы управления сверхбольшими наборами научных данных Адаптация существующих сервисов доступа и управления данными, работающими преимущественно с локальными файловыми системами и отчасти с удаленными наборами данных, для работы с облачными хранилищами данных Особенности предлагаемого решения • • • • Распределенные потоковые вычисления в облаке Распределенные облачные хранилища Общий язык запросов для распределенного выполнения и управления рабочим потоком Интеграция и проведение совместного анализа в различных областях Архитектура системы OpenStack Swift Высокоотказоустойчивое, распределенное хранилище объектов или блобов с длительной поддержкой целостности. • Хранение образов узлов • Работа в качестве самостоятельного контейнера данных • Обеспечение отказоустойчивости и резервирования данных • Создание резервный копий и архивирование данных • Масштабируемость • RESTful S3-like интерфейс • поддержка системы авторизации и аутентификации пользователей (swauth, keystone) Облачное хранилище многомерных массивов Active Storage ActiveStorage - универсальное хранилище численных данных, предназначенное для хранения временных рядов, спутниковых изображений, результатов численного моделирования, а также любой другой информации, которая может быть представлена в виде многомерных численных массивов. Особенностями хранилища являются: Универсальная архитектура, позволяющая держать разнородные данные в единой системе хранения. Эффективное индексирование больших объемов данных (десятки и сотни терабайт). Возможность базовой обработки данных непосредственно на узлах хранилища (арифметические операции, статистическая обработка, линейная свертка). Интегрированные метаданные; описания данных неотделимо от самих данных. Возможность автоматического распределения данных (а также распараллеливания обработки) по нескольким узлам. Возможность использования в инфраструктуре Грид через сервисы OGSA-DAI. • • • • • • • Схема базы данных Разбиение массивов на чанки Массив не разбитый на чанки 1 поисковый запрос 8 поисковых запросов Массив разбитый на чанки 4 поисковых запроса 4 поисковых запроса • Чанки хранятся в таблице базы данных как объекты chunk_key chunk 0 <Chunk0> • Чанки могут быть различных размеров 1 <Chunk1> 2 <Chunk2> 3 <Chunk3> Реанализ погоды NCEP/NCAR • Постоянно обновляемый набор данных • Включает вывод наблюдений и глобальной климатической модели • 74 погодных параметра • 5000 netCDF файлов, 30 – 500 MB каждый Временной интервал: • 1948 – 2008 гг. • 4-х часовые значения Покрытие: • Регулярная сетка, 2.5 x 2.5 градуса • T62 Гауссовская сетка, 192 x 94 точек. Сервис доступа к распределенным системам хранения VOSpace Особенности VOSpace • VOSpace не накладывает ограничений на способы хранения и передачи данных. Может работать с локальной файловой системой и OpenStack Swift. • Контролирует доступ и управление данными, метаданными и задачами синхронизации. • Позволяет подключать различные схемы авторизации (openID, oAuth и другие системы) • RESTfull интерфейс Интерфейс доступа к данным • подключаться к точкам входа нескольких распределённых хранилищ. • добавлять и удалять объекты данных и контейнеры хранения • управлять метаданными объектов • получать уникальные ссылки (URI) на объекты данных для доступа к ним • создавать серверные задачи для перемещения данных между различными хранилищами или точками входа. Сервис OPeNDAP для доступа к многомерным массивам • • Для реализации OPeNDAP сервиса был использован сервер данных THREDDS (Thematic Real-time Environmental Distributed Data Services), цель которого – обслуживать запросы пользователя, учитывая содержимое наборов данных наряду с их метаописанием. Сервер данных THREDDS использует модель данных Common Data Model для представления данных из различных источников, которые потом могут быть переданы пользователю несколькими путями: по протоколу OPeNDAP, через сервис OGC Web Coverage Service, как NetCDF подвыборку, по HTTP-протоколу THREDDS работает только с локально хранящимися данными. В ходе проекта, THREDDS был дооснащен возможностью сервировать данные, находящиеся в хранилище SWIFT. Страница формирования OPeNDAP запроса из файла, находящегося в объектном хранилище SWIFT Потоковая обработка данных Twitter STORM Storm – распределенная система реального времени для обработки данных. Аналогично тому, как Hadoop, поддерживает ряд примитивов для организации пакетной обработки, Storm поддерживает примитивы для организации обработки данных в реальном времени. • Простая модель программирования (Clojure, Java, Ruby, Python ). • Отказоустойчивость • Горизонтально расширяемая система (вычисления идут параллельно с использованием многопоточности многопроцессности и на нескольких серверах). • Storm гарантирует, что каждое сообщение в потоках будет полностью обработано как минимум один раз. Storm самостоятельно инициирует повторную отправку сообщений в случае ошибок при их обработке. • В качестве базового слоя для организации очереди сообщений используется ØMQ. • Запуск рабочих потоков как на кластере, так и в локальном режиме на одной машине. Архитектура STORM Развертывание Twitter Storm в системе облачных вычислений Виртуальная машина Виртуальная машина Виртуальная машина Виртуальная машина Zookeeper Кластер (на него устанавливается 0MQ И STORM) Виртуальная машина (головной узел кластера) Виртуальная машина На ряде виртуальных машин системы облачных вычислений разворачивается Zookeeper-кластер. Одна из машин назначается головным узлом кластера. На машины кластера устанавливаются приложения 0MQ (используемый Twitter Storm как базовый слой для организации очереди сообщений) и пакеты Twitter Storm. Неудобства работы с системой STORM и методы их решения Неудобства запуска рабочего потока в STORM: Запуск скрипта производится локально на головной машине кластера либо через скрипты (Leiningen или Maven), при этом каждый раз на удаленную машину надо закачивать библиотеки для выполнения программы. При запуске на кластере, состоящим из нескольких машин, сложен процесс сбора результирующих данных. Для преодоления этих неудобств была разработана инфраструктура развертывания и запуска рабочего потока в системе облачных вычислений: На головном узле разворачивается HTTP-сервлет, реализующий RESTful интерфейс управления рабочим потоком. Пользователю не надо взаимодействовать с локальной машиной. Используется дополнительное звено в цепочке запуска программы - развертывание (deploy): процесс передачи всех необходимых библиотек в систему STORM. После этого пользователь может повторно запускать этот же рабочий поток без необходимости повторной загрузки кода. Для сбора результатов реализован специальный обработчик, который передает данные на HTTP-сервлет, который в свою очередь возвращает их в потоке пользователю в ответ на его запрос запуска рабочего потока. • • • • • Инфраструктура создания и запуска рабочего потока я ан и HTTP Сервлет коды Jar + нужные Пар а пользователь мет р пр о сд ан ны х POST (deploy) POST (put results) ы за рез таты ул ь ад ие з ) н е RM тран рос ает STO п с Ра (дел За пус ка GET (run) Запрос данных таты р е з ул ь ный ал ь , к о Л D уск зап ется I а в и св а при рез у льта ты ActiveStorage Рас про ст (де ранен л ае и т ST е зада н OR M) ия З ро ап сд н ан ых Пример схемы рабочего потока TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout1", new GetData(), 10); builder.setSpout("spout2", new GetData(), 10); Fields tsr = new Fields("lat", "lon"); builder.setBolt("proc", new Processing(), 4).fieldsGrouping("spout1", tsr).fieldsGrouping("spout2", tsr); builder.setBolt("output", new OutputBolt(backUrl, taskId)).shuffleGrouping("proc"); Вычисление скорости ветра по U- и V- компонентам: Spout 1 (10 экземпляров) (Класс GetData) Все элементы потока с одинаковыми Lat и Lon попадают на один и тот же обработчик Spout 2 (10 экземпляров) (Класс GetData) Proc (4 экземпляра) (Класс Processing) Output (1 экземпляр) (Класс OutputBolt) Научные приложения • • • • • Анализ трендов и распознование объектов, например газовых факелов в базе данных ночных огней Поиск событий и анализ эффективности энергетических систем с учетом климатических факторов Экологический мониторинг с помощью сенсорных сетей Совместная интерпретация многопараметрических геофизических рядов, мультиспектральных изображений каменного материала (керна) Комплексный анализ естественных и искусственных полей и геодинамических моделей в задачах зондирования литосферы и верхней мантии Экспериментальные наборы данных • • • • Космическая физика (временные ряды SPIDR, включая геомагнитные, ионосферные, солнечные вариации) 100 Гб Климат (кубы данных реанализа и прогноза погоды) 200 Тб Дистанционное зондирование (продукты спутников DMSP в первую очередь ежегодные карты стабильных ночных огней) 400 Тб Геофизика (кубы данных сейсмической томографии, геомагнитного поля в коре и мантии Земли, временные ряды сейсмических и GPS наблюдений) 1 Тб Тайл сервер для визуализации и сравнения многоспектральных гигапиксельных изображений геологического керна Тайл сервер для визуализации и межгодового сравнения изображений ночных огней Земли Визуализация и сравнения геофизических полей Земли Виртуальная Обсерватория Программное обеспечение для управления метаданными с функциями преобразования и отображения на многообразии схем (стандартов) метаданных из различных предметных областей — метеорологии, солнечно-земной физики, сейсмологии. Принципиальная схема работы с метаданными и данными в ВО • Получение метаданных от источника • Создание записи метаданных • Сопровождение записи об источнике сопутствующей документацией и информацией • Заказ данных из источника с помощью OE-формы • Получение объекта данных • Работа с данными Information Search & Support Update News & Presentation MetaRecord Documents & WIKI User forum Transform to common format Metadata Ordering Extention Guide Data Resource Object Description Order form Visualisation Data Object Convertion Data Access & Processing Data Query Пример работы с метаданными Выводы В результате работы над проектом были получены следующие результаты: Разработана масштабируемая, распределенная, открытая платформа для облачного хранения научных данных. Создан фреймворк, обеспечивающий распределенную параллельную обработку потоков научных данных. На базе платформы развернуты сервисы визуализации данных. Создана система управления метаданными. Разработано прикладное программное обеспечение Active Storage для облачного хранения, обработки и доступа к сверхбольшим многомерным научным массивам научных данных. • • • • •