Лабораторная работа №1 Исследование кэш-памяти и обхода памяти
реклама

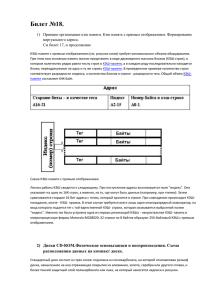
Лабораторная работа №1 Исследование кэш-памяти и обхода памяти Цель Определение размеров кэш-памяти 1. сравнить различные способы обхода данных 2. научиться определять размер кэш-памяти Задание Написать программу, многократно выполняющую чтение элементов массива заданного размера. Элементы массива представляют собой связный список, в котором значение очередного элемента представляет собой номер следующего. Таким образом, способ заполнения элементов массива определяет способ его обхода. Сам обход данных может быть выполнен циклом следующего вида: for (k=0, i=0; i<N; i++) k = x[k]; Определение размеров кэш-памяти Обходы Требуется реализовать три способа обхода массива 1. Прямой 1 2 3 4 5 6 7 0 7 0 1 2 3 4 5 6 2. Обратный 3. Случайный 7 3 4 2 5 0 1 6 Определение размеров кэш-памяти Заполнение массива для случайного обхода Определение размеров кэш-памяти Время чтения элемента, такты Построить графики зависимости среднего времени обращения к элементу массива (в тактах) от размера обрабатываемого массива для трех видов обхода. На графиках должны быть видны размеры всех уровней кэш-памяти. По результатам измерений сделать вывод о скорости различных способов обхода массива, а также о размерах различных уровней кэш-памяти. Сравнить полученные размеры уровней кэш-памяти с реальными значениями. Пример графиков, полученных на процессоре Intel Xeon E5420 (L1: 32 KB, L2: 6 MB): 250 200 150 прямой обратный случайный 100 50 0 1 2 4 8 16 32 64 128 256 512 1 2 4 8 16 32 KB KB KB KB KB KB KB KB KB KB MB MB MB MB MB MB Размер массива Контрольные вопросы 1. Что такое кэш-память? Какую проблему она решает? 2. Какой способ обхода данных в памяти является самым быстрым? Почему? 3. Какой способ обхода данных в памяти является самым медленным? Почему? 4. Приведите пример оптимального и неоптимального алгоритмов умножения двух матриц с точки зрения порядка обхода данных в памяти. Определение степени ассоциативности кэш-памяти множественно-ассоциативная организация кэш-памяти Большинство современных процессоров имеют множественноассоциативную организацию кэш-памяти. При множественноассоциативной организации кэш-память разделена на несколько множеств и на несколько банков ассоциативности. Каждый блок данных из оперативной памяти может быть помещен в одну из некоторого множества строк кэш-памяти. Число строк во множестве определяется числом банков ассоциативности. Например, кэш данных L1 в процессоре Pentium III имеет объем 16 KB, число банков ассоциативности - 4, число множеств - 128, размер строки - 32 Byte. Размер кэш-памяти: 16 KB = 4 × 128 × 32 B. Определение степени ассоциативности кэш-памяти множественно-ассоциативная организация кэш-памяти ОП Кэш 32 B 32 B 128 × 32 В = 4 КВ 32 B … 32 B 32 B 0 0 1 2 3 … 126 127 1 2 3 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B … … … … 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B Номер множества, в которое будет помещен элемент данных из памяти, определяется адресом этого элемента. Какой конкретный элемент множества будет выбран, определяется алгоритмом замещения (циклический, случайный, LRU, псевдо-LRU, …). Число элементов в каждом множестве (равное числу банков кэш-памяти) называется степенью ассоциативности кэш-памяти. Если вычислительная система имеет несколько уровней кэш-памяти, то у каждого уровня может быть своя степень ассоциативности. Определение степени ассоциативности кэш-памяти множественно-ассоциативная организация кэш-памяти 4 КВ 4 КВ 4 КВ 4 КВ ОП Кэш 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B … … … … 32 B 32 B 32 B 32 B 32 B 32 B 32 B 32 B Элементы данных, имеющих одинаковые номера множеств, т.е. отстоящие на определенное расстояние в памяти (4 KB), помещаются в одно и то же множество кэш-строк. На все эти данные приходится всего 4 кэш-строки, т.е. 4 × 32 B = 128 B. Если выполнять обход данных с шагом 4 KB (или кратным 4 KB), то из всех 16 KB кэша L1 будет использоваться всего 128 B, которые будут постоянно перезаписываться (эффект «буксования» кэш-памяти). Производительность подсистемы памяти при этом будет такая же, как при отсутствии кэшпамяти. Определение степени ассоциативности кэш-памяти Цель работы Научиться определять степень ассоциативности кэшпамяти. Определить степени ассоциативности кэш-памяти можно следующим способом. Выполняется обход N фрагментов данных суммарным объемом BlockSize, отстоящих друг от друга на величину Offset: Определение степени ассоциативности кэш-памяти Параметры обхода: BlockSize – суммарный объем данных, к которым происходит обращение. Offset – расстояние между началами соседних блоков. N – число фрагментов (на картинке N = 4). BlockSize должен быть не больше объема исследуемого уровня кэш-памяти. Offset должен быть кратен размеру банка ассоциативности. Как правило, эти размеры являются степенями двоек, так что в качестве Offset можно взять большое заведомо кратное значение (например, 8 MB). Изменяя число частей N, мы увидим, как меняется время обращения к одному элементу. Когда N превысит число банков ассоциативности, время сильно возрастет. Определение степени ассоциативности кэш-памяти Определение степени ассоциативности кэш-памяти Время чтения элмента, такты Написать программу, определяющую степень ассоциативности кэш-памяти. Программа должна многократно выполнять чтение элементов массива в порядке, указанном выше. Элементы массива представляют собой связный список, в котором значение очередного элемента представляет собой номер следующего. Параметры: BlockSize = 1 KB, Offset = 8 MB, N = 1…20. Построить график зависимости среднего времени обращения к элементу массива (в тактах) от N – числа фрагментов. По полученному графику определить степень ассоциативности кэш-памяти. Пример графика, полученного на процессоре Intel Xeon E5420 (L1: 4-way, L2: 8-way): 60 50 40 30 20 10 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Число фрагментов На графике видно замедление после 4 и после 8 фрагментов, что соответствует степеням ассоциативности кэшей L1 и L2 процессора Intel Xeon E5420. Контрольные вопросы 1. Что такое степень ассоциативности кэшпамяти? 2. Что такое эффект буксования кэш-памяти? Как его вызвать? Как его избежать? 3. Какой график получится в результате исследования кэша данных L1, описанного в теоретической части? Как изменится график, если расстояние между фрагментами взять 1 KB?