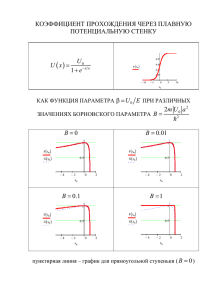
Адаптивная оптимизация сервера , обрабатывающего очередь
advertisement

АДАПТИВНАЯ ОПТИМИЗАЦИЯ
СЕРВЕРА , ОБРАБАТЫВАЮЩЕГО
ОЧЕРЕДЬ ЗАДАНИЙ
Дипломная работа студента 545 группы
Ле Чунг Хьеу
Научный руководитель : О. Н. Граничин
Рецедент : А. С. Лопатин
Санкт – Петербург
2007
ВВЕДЕНИЕ
Проблема эффективного обслуживания
сервером очереди заданий.
Рандомизированный алгоритм стохастической
аппроксимации.
Обучение с подкреплением.
ПОСТАНОВКА ЗАДАЧИ
Рассмотрим задачу повышения эффктивности
сервера:
L(x) – среднее время ожидания клиентами.
q(x) – стоимость исползования параметра x.
y(x) – время, которое задание ожидало в сервере до
момента своего завершения.
Требуется найти параметра θ :
f(x) → min по x ( Θ )
ПОСТАНОВКА ЗАДАЧИ
Эту задачу оптимизации не решить
традиционными средствами.
F(x,ω) – эмпирическая функция.
f(x) = E{F(x,ω)}.
Ft(x,ω) – случайная функция дескретного
времени t = 1 , 2 , . . .
ft(x) = Eω{Ft(x,ω)}.
θt = argminxft(x).
Требуется по наблюдениям Ft(x,ω) → {θn}
|θn - θt|→ min.
ОБУЧЕНИЕ С ПОДКРЕПЛЕНИЕМ
o
Обучение с подкреплением, представляет класс задач, в
которых агент, действуя в определенной среде, должен
найти оптимальную стратегию взаимодействия с ней.
Цель агента – максимизировать суммарную награду.
ОБУЧЕНИЕ С ПОДКРЕПЛЕНИЕМ
Оценочная Функция :
V π ( s ) E π {R t | s t s}
Q π (s, a) E π {R t | s t s, a t a}
RL алгоритмы основано на оценке оценочной
функцией.
Оценка Стратегии.
Усовершенствование Стратегии.
Повторение Стратегии.
РАНДОМИЗИРОВАННЫЕ АЛГОРИТМЫ
СТОХАСТИЧЕСКОЙ АППРОКСИМАЦИИ
p
r
Пусть F(ω(x) : R R R - дифференцируемая
по второму аргументу.
n
n
Наблюдении y n F(ω , x ) v n .
Требуется по наблюдениям : y1 , y2 , . . .
построить последовательность оценок {θn}
вектора θ :
f(x) p F(ω(x)Pω (dω) min
R
SPSA ДЛЯ РЕШЕНИЯ ЗАДАЧИ О СЕРВЕРЕ
1.
2.
Положим k = 0 и выберем некоторое начальное значение оценки
θ0.
В начале каждого k-го такта вычисляем
θ'k P[a,b] (θ k βΔ k ).
3.
4.
Запускаем сервер с значением параметра x = θk’.
После завершения k-го такта подсчитаем новую оценку по
правилу
α
θ k 1 P[a, b] (θ k Δ k y k ).
β
5.
6.
Увеличиваем номер такта k = k+1.
Переход к п.2 (повтор действий заново).
МОДЕЛИРОВАНИЕ
Интерфейс программы :
РЕЗУЛЬТАТЫ
Результаты программы с фиксированным
значением
РЕЗУЛЬТАТЫ
Минимум функции = 51 достигается при
значении θ = 0.84.
РЕЗУЛЬТАТЫ ПРОГРАММЫ С АЛГОРИТМОМ
SPSA
θ = 0.12.
θ = 1.
РЕЗУЛЬТАТЫ ПРОГРАММЫ С АЛГОРИТМОМ
МОНТЕ КАРЛО
ЗАКЛЮЧЕНИЕ
Работа с алгоритмом SPSA .
Работа с методом Монте Карло .