Практикум 2.1. Классические методы анализа. Структурный анализ на основе DFD - диаграмм
реклама

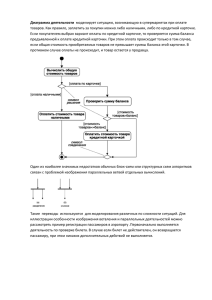
Практикум 2.1. Классические методы анализа. Структурный анализ на основе DFD - диаграмм Цель: Ознакомиться с технологией построения DFD - диаграмм с помощью CASE – средства BPWIN Задачи: получить общие сведения о моделировании потоков данных, о компонентах диаграммы потоков данных DFD; ознакомиться со средствами моделирования потоков данных в среде BPwin; научиться создавать контекстную диаграмму DFD и проводить ее декомпозицию; закрепить полученные знания в ходе самостоятельной работы. Задание 1. Общие сведения Задание 2. Знакомство с компонентами диаграммы потоков данных ( DFD ) в BPwin Задание 3. Знакомство со средствами создания DFD в среде BPWIN Задание 4 . Создание компонентов контекстной диаграммы Задание 5 . Декомпозиция контекстной диаграммы Задание 6. Самостоятельная работа Задание 7. Оформление отчета Задание 8. Анализ информационных процессов при снятии со счета в банке денег Задание 9. Декомпозиция контекстной диаграммы Задание 10. Альтернативные процессы Контрольные вопросы Задание 1. Общие сведения Ознакомьтесь с изложенными ниже общими сведениями. Общие сведения Диаграммы потоков данных (DFD) являются основным средством моделирования функциональных требований к проектируемой системе. С их помощью эти требования представляются в виде иерархии функциональных компонентов (процессов), связанных потоками данных. Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те, в свою очередь, преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям - потребителям информации. Состав диаграмм потоков данных Основными компонентами диаграмм потоков данных являются: внешние сущности; системы и подсистемы; процессы; накопители данных; потоки данных. Внешняя сущность - это материальный объект или физическое лицо, представляющие собой источник или приемник информации, например, заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что они находятся за пределами границ анализируемой системы. Построение иерархии диаграмм потоков данных Главная цель построения иерархии DFD – сделать требования к системе ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для этого целесообразно: размещать на каждой диаграмме от 3 до 7 процессов. Верхняя граница соответствует человеческим возможностям одновременного восприятия и понимания структуры сложной системы с множеством внутренних связей, нижняя граница выбрана по соображениям здравого смысла: нет необходимости детализировать процесс диаграммой, содержащей всего один процесс или два; не загромождать диаграммы не существенными на данном уровне деталями; декомпозицию потоков данных осуществлять параллельно с декомпозицией процессов. Эти две работы должны выполняться одновременно, а не одна после завершения другой; выбирать понятные имена процессов и потоков, не использовать аббревиатуры. Построение контекстных диаграмм – первый шаг построения DFD. В центре контекстной диаграммы находится главный процесс, соединенный с приемниками и источниками информации, посредством которых с системой взаимодействуют пользователи и другие внешние системы. Перед построением контекстной DFD анализируют внешние события (внешние сущности), оказывающие влияние на функционирование системы. Количество потоков на контекстной диаграмме должно быть по возможности небольшим, поскольку каждый из них может быть в дальнейшем разбит на несколько потоков на следующих уровнях диаграммы. Для проверки контекстной диаграммы можно составить список событий. Список событий – это описания действий внешних сущностей (событий) и соответствующих реакций системы на события. Одному (или более) потоку данных соответствует одно событие: входные потоки интерпретируются как воздействия, а выходные потоки – как реакции системы на входные потоки. Главный процесс не раскрывает структуры сложной системы (которая имеет большое количество внешних сущностей, многофункциональна, которую можно разбить на подсистемы). Для сложных систем строится иерархия контекстных диаграмм. При этом контекстная диаграмма верхнего уровня содержит набор подсистем, соединенных потоками данных. Иерархия контекстных диаграмм определяет взаимодействие основных функциональных подсистем как между собой, так и с внешними входными и выходными потоками данных и внешними объектами (источниками и приемниками информации), с которыми взаимодействует система. После построения контекстных диаграмм полученную модель следует проверить на полноту исходных данных об объектах системы и изолированность объектов (отсутствие информационных связей с другими объектами). Для каждой подсистемы, присутствующей на контекстных диаграммах, выполняется ее детализация при помощи DFD. Это можно сделать путем построения диаграммы для каждого события. Каждое событие представляется в виде процесса с соответствующими входными и выходными потоками, накопителями данных, внешними сущностями и ссылки на другие процессы для описания связей между этим процессом и его окружением. Затем все построенные диаграммы сводятся в одну диаграмму нулевого уровня. При детализации процессов нужно выполнять следующие правила: • правило балансировки – детализирующая диаграмма в качестве внешних источников или приемников данных может иметь только те компоненты (подсистемы, процессы, внешние сущности, накопители данных), с которыми имеют информационную связь детализируемые подсистема или процесс на родительской диаграмме; • правило нумерации – при детализации процессов должна поддерживаться их иерархическая нумерация. Например, процессы, детализирующие процесс с номером 12, получают номера 12.1, 12.2, 12.3 и т. д. Спецификация процесса должна формулировать его основные функции таким образом, чтобы в дальнейшем специалист, выполняющий реализацию проекта, смог выполнить их или разработать соответствующую программу. Спецификация является конечной вершиной иерархии DFD. Решение о завершении детализации процесса и использовании спецификации принимается аналитиком исходя из следующих критериев: 1. наличия у процесса относительно небольшого количества входных и выходных потоков данных (2-3 потока); 2. возможности описания преобразования данных процессом в виде последовательного алгоритма; 3. выполнения процессом единственной логической функции преобразования входной информации в выходную; 4. возможности описания логики процесса при помощи спецификации небольшого объема (не более 20 – 30 строк). Спецификации должны удовлетворять следующим требованиям: для каждого процесса нижнего уровня должна существовать одна и только одна спецификация; спецификация должна определять способ преобразования входных потоков в выходные; нет необходимости (по крайней мере на стадии формирования требований) определять метод реализации этого преобразования; спецификация должна стремиться к ограничению избыточности -не следует переопределять то, что уже было определено на диаграмме; набор конструкций для построения спецификации должен быть простым и понятным. Фактически спецификации представляют собой описания алгоритмов задач, выполняемых процессами. Спецификации содержат номер и/или имя процесса, списки входных и выходных данных и тело (описание) процесса, являющееся спецификацией алгоритма или операции, трансформирующей входные потоки данных в выходные. Известно большое количество разнообразных методов, позволяющих описать тело процесса. Соответствующие этим методам языки могут варьироваться от структурированного естественного языка или псевдокода до визуальных языков проектирования. Задание 2. Знакомство с компонентами диаграммы потоков данных (DFD) в BPwin Ознакомьтесь с результатом использования DFD для описания процесса отгрузки горючего (рис.1). На диаграмме продемонстрированы процессы, преобразующие входные данные в выходные. Рис. 1. Диаграмма потоков данных процесса отгрузки горючего Основными компонентами диаграммы потоков данных являются: процессы (изображаются в виде прямоугольников). Если прямоугольник имеет в левом верхнем углу треугольную отметку – он не имеет декомпозиции. Если отметки нет, то имеется диаграмма его декомпозиции. Названия прямоугольников отображают работу процесса (рис. 2): Рис.2. Изображение процесса потоки данных. Изображаются в виде стрелок (рис.3), входящих и исходящих в блоки процессов и других компонентов диаграммы. Стрелки имеют название, описывающее вид информации на входе или выходе какого-то из процессов. Поток данных определяет информацию, передаваемую через некоторое соединение от источника к приемнику: Рис. 3. Потоки данных внешние сущности – это материальный объект или физическое лицо, представляющие собой источник или приемник информации, например, заказчики, персонал, поставщики, клиенты, склад. Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что они находятся за пределами границ анализируемой системы. В процессе анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы анализируемой системы, если это необходимо, или, наоборот, часть процессов может быть вынесена за пределы диаграммы и представлена как внешняя сущность. Внешняя сущность обозначает объекты или процессы внешней среды, от которых поступают запросы или данные, для которых формируются документы и выводится информация. Изображается квадратом или прямоугольником с тенью (рис. 4). Название отображает объект: Рис. 4. Внешняя сущность накопитель данных — это абстрактное устройство для хранения информации, которую можно в любой момент поместить в накопитель и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми. Накопитель данных может быть реализован физически в виде микрофиши, ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т. д. Накопитель данных на диаграмме потоков данных идентифицируется буквой D (рис. 5) и произвольным числом. Имя накопителя выбирается из соображения наибольшей информативности для проектировщика. Накопитель данных является прообразом будущей базы данных, и описание, хранящихся в нем данных должно быть увязано с информационной моделью (ERD). Накопители данных - хранилища информации, к которым можно обратиться за данными, или куда можно поместить преобразованные данные. Изображаются в виде прямоугольника с двойной чертой: Рис. 5. Изображение хранилища данных (накопителя) Процессы, хранилища имеют номера. Подчиненные блоки отображают уровни иерархии в номерах (рис. 6). Задание 3. Знакомство со средствами создания DFD в среде BPwin Запустите BPwin. Создайте новый файл командой File / New. Рис. 6. Выбор типа диаграммы В появившемся диалоговом окне (рис. 6) поставьте переключатель в положение DFD. Задайте имя модели в поле Name. В появившемся окне на вкладке General задайте имя автора Author. Внимательно рассмотрите панель инструментов и рис. 7. Ознакомьтесь с инструментами создания диаграммы потоков данных. Рис. 7. Панель инструментов среды BPwin для создания диаграмм. Задание 4 . Создание компонентов контекстной диаграммы. Ознакомьтесь с описанием задачи. Администрация больницы заказала разработку информационной системы для отдела приема пациентов и медицинского секретариата. Новая система предназначена для обработки данных о врачах, пациентах, приеме пациентов и лечении. Система должна выдавать отчеты по запросу врачей или администрации. В результате предпроектного обследования составлено следующее описание деятельности подразделений. Перед приемом в больницу проводится встреча пациента и врача. Врач сообщает в отдел приема пациентов об ожидаемом приеме больного и передает данные о нем. Если пациент принят в больницу впервые, то до его приема в больницу его регистрируют - присваивают регистрационный номер и записывают его данные (фамилия, имя и отчество, адрес и дата рождения). Спустя некоторое время врач оформляет в отделе приема пациентов прием больного. При этом определяется порядковый номер приема и запоминаются данные приема пациента. После этого отдел приема посылает сообщение врачу для подтверждения приема больного. В это сообщение включаются регистрационный номер пациента и его фамилия, порядковый номер приема, дата начала лечения и номер палаты. В день приема пациент сообщает в отдел приема о своем прибытии и передает данные о себе (или изменения в данных). Отдел приема проверяет и при необходимости корректирует данные о пациенте. Если пациент не помнит свой регистрационный номер, то выполняется соответствующий запрос. После регистрации пациент получает регистрационную карту, содержащую ФИО пациента, адрес, дату рождения, номер телефона, группу крови, название страховой компании и номер страховки. Во время пребывания в больнице пациент может лечиться у нескольких врачей; каждый врач назначает один или более курсов лечения, но каждый курс лечения назначается только одним врачом. Данные о курсах лечения передаются в медицинский секретариат, который занимается координацией лечения пациентов, регистрируются и хранятся там. Данные включают номер врача, номер пациента, порядковый номер приема, название курса лечения, дату назначения, время и примечания. При необходимости врач запрашивает в медицинском секретариате историю болезни пациента, содержащую данные о курсах лечения, полученных пациентом. Используя панель инструментов (рис.7), создайте контекстную DFD диаграмму, моделирующую потоки данных поликлиники, следуя (рис. 8). Главная цель контекстной диаграммы потоков данных - продемонстрировать, как каждый процесс преобразует входные данные в выходные, а также выявить отношения между этими процессами. Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы или подсистемы с внешними входами и выходами. Как видно из рис. 8, происходит обмен данными с внешними сущностями и хранилищами данных. Отметьте, что стрелки имеют разный цвет. Это для того, чтобы после декомпозиции диаграммы на диаграмме нижнего уровня было понятно, с какой внешней сущностью происходит обмен потоками данных. Создайте на контекстной диаграмме процесс, выбрав на панели инструментов инструмент Процесс, представленный прямоугольником с закругленными углами. Рис. 8. Контекстная диаграмма Задайте в контекстном меню свойства процесса: Name (Имя) – Система приема пациентов (рис. 9); Color (цвет) – выберите фиолетовый цвет, шрифт. Введите имя – Система приема пациентов. На вкладке Fonts (рис. 10) задайте шрифт с набором кириллицы и отметьте флажки: All activities on this diagram All activities in this model Change all occurences of font in model На вкладке Color выбирается цвет диаграммы. Рис. 9. Окно свойств процесса Укажите на вкладке Fonts Рис. 10. Задание шрифта Полученное изображение процесса можно перемещать, изменять его размер Добавьте на контекстную диаграмму внешние сущности: Пациент, Врач, Администрация больницы, выбирая последовательно инструмент External ReferenceTool (Сущность рис. 7). Задайте имена сущностям, используя контекстное меню и соответствующую вкладку появившегося окна. Добавьте на контекстную диаграмму потоки данных. Стрелки создаются инструментом с изображением горизонтальной стрелки Precedence Arrow Tool. Если стрелка выходит из сущности или другого процесса, необходимо щелкнуть стрелкой в крайней области объекта так, чтобы появился затемненный треугольник. Обозначить щелчком левой кнопки мыши начало стрелки и, не отпуская нажатую клавишу мыши, протащить стрелку до нужной части другого объекта, пока не появится затемненный сектор. Отпустить клавишу. Правой кнопкой вызовите контекстное меню. Задайте имя процесса, цвет стрелки. Таким же образом добавьте стрелки, выходящие из Процесса. Сохраните файл с именем Поликлиника с лабораторными работами и отчетами. Задание 5 . Декомпозиция контекстной диаграммы Декомпозиция (процесс разбиения) продолжается до тех пор, пока не будет достигнут уровень, на котором процессы становятся элементарными и детализировать их далее невозможно. Перейдите на следующий уровень декомпозиции, щелкнув по кнопке "Переход к дочернему уровню" (рис. 7). Задайте количество подпроцессов на листе декомпозиции – 3. Назовите их, как указано на рис. 11. Продлите стрелки, перешедшие с контекстной диаграммы до нужного процесса (рис. 11). Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те, в свою очередь, преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам, накопителям данных или внешним сущностям – потребителям информации. Рис. 11. Диаграмма декомпозиции Задание 6. Самостоятельная работа Проделайте еще одну декомпозицию процесса "Администрирование врачей и пациентов". На диаграмме декомпозиции создайте процессы "Обслужить пациента" и "Подготовить отчет о пациенте", "Зарегистрировать пациента", "Зарегистрировать врача". Задание 7. Оформление отчета Оформить диаграммы: отчет, в котором сделать описание данных, составляющих Таблица 1. Накопители данных Названи Атрибу Откуда Куда е ты поступает передается накопителя информация Описать данные, которые могут быть представлены для отчетов: Данные о принятых за день пациентах; История болезни пациента. Задание 8. Анализ информационных процессов при снятии денег со счета в банке. Создать контекстную диаграмму (DFD). Придумать ей название. Постановка задачи: Создать диаграмму потоков данных процесса "Снятия денег клиентом со счета в банке". Процесс происходит следующим образом: клиент вставляет свою карточку в банкомат; банкомат выдает приветствие и предлагает клиенту персональный идентификационный номер; клиент вводит номер; банкомат выводит список доступных действий: o снять деньги со счета; o проверить счет; клиент выбирает пункт "Снять деньги"; банкомат запрашивает, сколько денег нужно снять; Клиент вводит требуемую сумму; банкомат определяет, достаточно ли на счету денег; банкомат вычитает требуемую сумму из счета клиента; банкомат выдает клиенту требуемую сумму наличными; банкомат возвращает клиенту его карточку. ввести свой Задание 9. Декомпозиция контекстной диаграммы. 1. Придумать, на какие процессы разбить контекстную диаграмму. 2. Определить накопители, участвующие в процессе и описать атрибуты данных, хранящихся в них. 3. Процессы на подчиненном уровне обозначить разным цветом. Задание 10. Альтернативные процессы. Измените созданную диаграмму с учетом следующих условий: банкомат подтверждает введенный клиентом номер. подтверждается, выполняется альтернативный поток событий. Если номер не Ввод неправильного идентификационного номера: o клиент получает информацию о том, что введен неправильный пин- код; o банкомат возвращает клиенту его карточку. Если денег на счету меньше суммы, затребованной клиентом, то выполняется следующий поток событий: Сумма на счету меньше требуемой: o банкомат информирует клиента, что денег на его счету недостаточно; o банкомат возвращает клиенту его карточку. Контрольные вопросы Какова цель создания диаграммы потоков данных DFD? Как можно использовать результат конечной декомпозиции? Что такое внешняя сущность? Привести примеры. Зачем используются цвета на диаграмме? Что такое накопитель данных? Опишите компоненты диаграммы потоков данных, их вид и назначение.