Что делает такой Sybase IQ уникальной ?
реклама

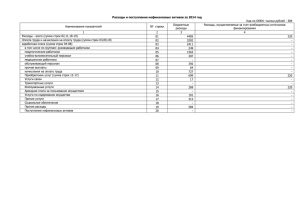
Что делает Sybase IQ такой уникальной ? Андрей Хромов ведущий технический консультант, Sybase CIS Что такое Sybase IQ • Sybase IQ – это специализированная аналитическая СУБД, оптимизированная по производительности для задач бизнес-аналитики, отчетности, хранилищ данных, используя для этого обычное H/W оборудование • Исключительная скорость выполнения запросов • Высокая скорость загрузки данных в режиме 24х7 • Компрессия данных, экономия затрат на диски • Простота настройки и администрирования • Практически линейная масштабируемость Почему Sybase IQ другая? • В отличии от других крупных игроков рынка СУБД, Sybase с самого начала выбрал подход, при котором для задач аналитики и ХД была разработана отдельная, специальная СУБД • Это позволило при проектировании IQ пойти на ряд решений-компромиссов, которые ни одна из OLTP систем не могла бы себе позволить Почему Sybase IQ другая? • С самого первого дня философией IQ было: “Главное – это скорость запросов” • С другой стороны, философия OLTP это: “Главное – это скорость транзакций” Почему Sybase IQ другая? • Первостепенной задачей при разработке было максимизировать производительность работы большого количества пользователей, выполняющих ad-hoc запросы по большим массивам данных • Базы данных, в которых сделан упор на оптимизацию скорости выполнения запросов, иногда называют “Оптимизированные на чтение” Почему Sybase IQ другая? • Приоритеты, стоявшие при создании IQ: • Производительность запросов в многопользовательской среде - очень высокий • Скорость массовой загрузки данных - высокий • Скорость одиночных Insert - низкий • Скорость одиночных Update - низкий Почему Sybase IQ другая? • Тенденция эволюции компьютерных компонент за последние 20 лет: • Объем жестких дисков вырос - в 10,000 раз • Скорость процессоров возросла - в 1,000 раз • Размер ОЗУ вырос - в 500 раз • Показатель дисков «Скорость передачи данных» (throughput) вырос - в 50 раз • Показатель дисков «Время поиска» (seek times) снизился - в 5 раз В чем отличие Sybase IQ? Наблюдение #1: • Большинству аналитических запросов при выборке данных с сервера СУБД требуется лишь небольшой процент колонок из числа всех колонок таблицы В чем отличие Sybase IQ? -1 Архитектурное решение IQ #1: • Хранить табличные данные по колонкам, а не по строкам, и таким образом дать возможность читать лишь те страницы, которые содержат только колонки, требуемые в запросе • Базы данных с такой архитектурой обычно называют: • СУБД с поколоночной организацией • или Колонко-ориентированные СУБД В чем отличие Sybase IQ? • Чтобы проиллюстрировать эффект различных архитектурных решений, принятых в условиях выбора той или иной альтернативы, мы будем рассматривать их на примере некой «обычной» БД • Ее характеристики достаточно типичны для большей части баз данных, используемых в приложениях аналитики (исходя из нашего опыта) • Поскольку это всего лишь «пример», ваши собственные реальные результаты могут несколько отличаться В чем отличие Sybase IQ? • Наша «обычная» база : • Самая большая таблица: • Количество строк: • Количество колонок: • Средняя ширина колонки: • Размер строки: • Общий размер таблицы: “T” 10 млрд. 50, “C1”, “C2”, … “C50” 8 байт 400 байт 3.6 Терабайт В чем отличие Sybase IQ? Таблица “T” в в колонкоориентированной базе -1 Таблица “T” в обычной построчной базе Page 1 of C1 Page 1 of C2 Page 1 of C3 C1 C2 C3 C1 C2 C3 C1 C1 ... C1 C2 ... C2 C3 ... C3 Page 1 C1 C2 C3 . . . C50 C2 C3 . . . C50 C1 C2 ... C1 C2 C3 . . . C50 C3 . . . C50 C3 . . . C50 Page 2 of C1 Page 2 of C2 Page 2 of C3 C1 C2 C3 C1 C2 C3 C1 C2 C3 . . . C50 C1 ... C1 C2 ... C2 C3 ... C3 C1 C2 ... C1 C2 C3 . . . C50 C3 . . . C50 Page 2 C1 C2 В чем отличие Sybase IQ? -1 Чего мы в результате достигли: • Запрос №1: Агрегация по всем строкам в таблице: • Общее количество строк: 10 млрд • Количество колонок: 10 из 50 • Средняя ширина колонки: 8 байт • Полезный объем данных в строке: 80 байт из 400 • Объем данных, который нужно прочитать: • Построчная структура: 3.6 Тб • Поколоночная структура : 0.7 Тб В чем отличие Sybase IQ? -1 Еще пример выигрыша: • UPDATE двух колонок во всех строках таблицы “T”: • Общее количество строк : 10 млрд • Количество колонок : 2 из 50 • Средняя ширина колонки : 8 байт • Полезный объем данных в строке : 16 байт из 400 • Объем данных, который нужно прочитать/записать: • Построчная структура : 3.6 Тб • Поколоночная структура : 0.1 Тб В чем отличие Sybase IQ? -1 Чем пожертвовали в замен: • Одиночный INSERT в большую таблицу “T”: • Количество колонок : 50 • Количество страниц, которые нужно прочитать/записать: • Построчная структура : 1 страница • Поколоночная структура : 50 страниц Вот почему OLTP базы данных не могут себе позволить использовать поколоночная структуру! В чем отличие Sybase IQ? -1 Чем пожертвовали в замен: • Запрос №2: “SELECT * FROM T WHERE PKEY = 107” • Количество строк в результате : 1 из 10 млрд • Количество колонок : 50 из всех 50 • Объем данных, который нужно прочесть: • Построчная структура : 1 страница • Поколоночная структура : 50 страниц Этот эффект может быть уменьшен с помощью хорошо настроенного “prefetch read” В чем отличие Sybase IQ? -1 Чем НЕ СТАЛИ жертвовать: • INSERT или LOAD большого количества строк в T: • Количество колонок : 50 • Общее количество строк для вставки : 20,000 • Общий объем вставляемых данных: 7.6 Mb • Объем данных, который нужно записать: • Построчная структура : 7.6 Mb • Поколоночная структура : 7.6 Mb В чем отличие Sybase IQ? Наблюдение #2-A: • Стоимость «мегагерцев» процессоров снижается гораздо быстрее чем стоимость операций ввода/вывода. Наблюдение #2-B: • Алгоритмы сжатия работают более эффективно, когда данные содержат больше избыточности. Это гораздо в большей степени характерно для поколоночной структуры хранения, когда все значения колонки имеют один тип данных, чем для построчной структуры, когда строка содержит значения с множеством различных типов данных В чем отличие Sybase IQ? -2 Архитектурное решение IQ #2: • Все страницы, записываемые на диск, предварительно сжимаются. Для этого используется ассиметричный алгоритм, позволяющий снизить затраты времени на этапе распаковки (при чтении), за счет больших затрат на этапе сжатия. Как выглядит сжатие IQ? • Компрессия в IQ имеет двойственную природу • Каждая страница, когда пишется на диск, сжимается • Для сжатия IQ использует усовершенствованный алгоритм ассиметричного LZH • Некоторые индексы также обеспечивают «сжатие» за счет своей структуры • Индексы на основе битовых карт (LF, ассиметричный-HG, CMP, все Date, HNG) обладают «самокомпрессией» • “Токенизированные” индексы (FP(1), FP(2), FP(3)) обладают очень высоким уровнем «самокомпрессии» • Данные могут сжиматься до 95% Как происходит запись на диск Одна страница в памяти IQ =128 Кб или 16 блоков до сжатия: занято 10 блоков Компрессор Шифратор(?) после сжатия: занято 4 блока Перед записью на диск страница сжимается Если в IQ активировано шифрование, тогда страница потом еще и шифруется Запись на диск 1 участок на диске размером 4 блока или 32Кб В чем отличие Sybase IQ? -2 • Чтобы показать эффект от сжатия, предположим следующее: • “T” в построчной структуре можно ужать на 25%. • “T” в поколоночной структуре можно ужать на 75%. • Если данные в таблице с течением времени будут меняться, для компрессора IQ это не проблема • Построчная СУБД далеко не всегда умеет легко переносить такие изменения • Эти уровни сжатия не являются чем-то необычным, но каждый раз цифры могут отличаться. В чем отличие Sybase IQ? -2 • Наша «обычная» БД (со сжатием): • Самая большая таблица: • Количество строк: • Данных в строке: • Общий объем исходных данных (в файле txt) : • Объем данных в базе данных: • Построчная структура: • Поколоночная структура: “T” 10 млрд. 400 байт 3.6 Тб 2.7 Тб, сжатые 0.9 Тб, сжатые В чем отличие Sybase IQ? -2 Чего в результате достигли (c учетом сжатия): • Запрос №1: Агрегация по всем строкам в таблице: • Общее количество строк: 10 млрд • Количество колонок: 10 из 50 • Средняя ширина колонки: 8 байт • Полезный объем данных в строке: 80 байт из 400 • Объем данных, который нужно прочитать: • Построчная структура: 2.7 Тб, сжатых • Поколоночная структура : 0.2 Тб, сжатых В чем отличие Sybase IQ? Наблюдение #3: • Показатель «скорость передачи данных» дисков улучшается заметно быстрее, чем показатель дисков «среднее время поиска». В чем отличие Sybase IQ? -3 Архитектурное решение IQ #3: • Уменьшить количество необходимых «поисков» путем увеличения размера страницы БД (например, 128K вместо 4K), что позволяет лучше использовать возможности современных дисковых подсистем. • Больший размер страницы позволяет также несколько улучшить средний коэффициент сжатия. В чем отличие Sybase IQ? -3 Чего в результате достигли: • Запрос №1: Агрегация по всем строкам в таблице: • Общее количество строк: 10 млрд • Количество колонок: 10 из 50 • Средняя ширина колонки: 8 байт • Полезный объем данных в строке: 80 байт из 400 • Общее число требуемых «поисков» на диске: • Построчная структура: 966 миллионов • Поколоночная структура : 6 миллионов В чем отличие Sybase IQ? Наблюдение #4-A: • Многие аналитические запросы в содержат в предложении WHERE несколько условий выборки по одной и той же таблице. Наблюдение #4-B: • Обычно, OLTP СУБД могут использовать в одном запросе только один индекс для каждой таблицы В чем отличие Sybase IQ? -4 Архитектурное решение IQ #4: • Присвоить каждой строке уникальный номер (rowid), который служил бы уникальным идентификатором этой строки • Представить набор строк, которые должны попасть в выборку, в виде битового массива – bitmap (т.е. логический массив битов, в котором если N-ый бит равен “1”, значит строка с rowid=N, является частью выборки) • Создать индексы, в которых каждое значение данных ассоциируется с уникальным битовым массивом (bitmap), представляющему набор строк, содержащих это значение В чем отличие Sybase IQ? Page 1 of C7 -4 Index on C7 MI CA 0 FL 0 NY 0 NY 0 0 1 FL CA 0 1 1 0 0 0 NY 0 0 1 FL 0 1 0 NY 0 0 1 FL 0 1 0 NY 0 0 1 ... ... ... ... ... Индекс на основе bitmap • Каждое уникальное значение колонки ассоциировано со своим битовым массивом (см.по вертикали) В чем отличие Sybase IQ? Index on C7 Index on C9 NY 0 DIV 0 ... 1 ... ... 1 Result 0 ... 1 0 0 0 1 0 0 1 0 0 0 1 0 1 1 1 0 0 0 1 1 ... ... 1 ... -4 Для идентификации строк выборки по нескольким условиям по разным колонкам одной таблицы используются несколько bitmap-индексов: C7 = “NY” AND C9 = “DIV” Типы индексов в IQ • Индексы на основе bitmap-ов • • • • • LF Ассиметричный HG DATE, TIME, DTTM CMP HNG • На основе таблиц соответствий («токенизация») • FP(1), FP(2), FT(3) • Индексы, имеющие группы • HG, UHG, UMCHG (Foreign Key), MCHG (Primary Key) • WRD Слишком сложно? • • • • Индексы для IQ – это «его все» Но, индексы - это 90% требуемого для IQ тюнинга И вы строите индексы всего лишь один раз … И если вы ошиблись с выбором, INDEX_ADVISOR подскажет вам, где нужен дополнительный индекс • Nomura (бывший Lehman’s Brothers) утверждает, что его 20+ серверов IQ требуют от DBA работы по обслуживанию менее, чем полдня в неделю В чем отличие Sybase IQ? -4 Эффект от использования RowId и bitmap-ов: • Возможность использовать в одном запросе нескольких индексов для доступа к одной и той же таблицы. • Поощряется создание большого количества индексов, причем для одной колонки можно создавать несколько индексов разных типов. • Саму структуру хранения колонки можно также использовать в качестве индекса (если не найдется более подходящего специального индекса). В чем отличие Sybase IQ? -4 Еще эффект от использования RowId и bitmap-ов: • Номера строк таблицы, удовлетворяющих условию запроса, идентифицируются еще до начала считывания нужных колонок, тем самым экономя на затратах чтения. • Методы доступа, базирующиеся на индексах, позволяют повысить производительность операций Join, группировки, сортировки. • Наряду с высокой скоростью выборки данных, индексы также являются источником метаданных. • Поддержание статистики не требует никаких затрат В чем отличие Sybase IQ? -4 Чего добились: • Запрос №2: Агрегация выборочных строк большой таблицы Т : • Общее количество строк: 10 млрд • Условия выборки: 2 условия типа “C=VAL” селективность каждого - 20% данных • Ожидаемое количество строк в выборке: • Построчная: 2 млрд. (1 индекс использован). • Поколоночная: 0.4 млрд. (2 индекса использовано) В чем отличие Sybase IQ? -4 Чем пожертвовали: • Наличие большого числа индексов на таблице ускоряет запросы, но замедляет команды INSERT и LOAD. • Цена вставки одной строки становится выше. В чем отличие Sybase IQ? Наблюдение #5: • Когда “Главное – это запросы”, запрос никогда не должен ждать, пока страница модифицируется. В чем отличие Sybase IQ? -5 Архитектурное решение IQ #5: • Когда кому-то нужно изменить страницу, он должен скопировать её, создав новую версию, позволяя таким образом запросам продолжать чтение этой страницы не прерываясь. • Эта техника называется «Версионность на основе моментальных снимков страниц» (Page-Level Snapshot Versioning) или «Копирование страницы при записи» (PageCopy-On-Write). В чем отличие Sybase IQ? -5 Эффект от версионности на основе снимков: • ID транзакции уникально идентифицирует соответствующую версию каждой таблицы, а в свою очередь версия таблицы идентифицирует соответствующие страницы данных для данной версии таблицы • Две версии одной и той же таблицы используют одни и те же немодифицированные страницы в любой транзакции между этими двумя версиями • Запросы всегда работают на уровне изоляции 3 • Это немного увеличивает расход дискового места, так как нередко требуется наличие нескольких версий одних и тех же страниц В чем отличие Sybase IQ? Наблюдение #6: • Предполагается, что операции записи, такие как LOAD и INSERT, происходят относительно нечасто, с типичным интервалом в десятки секунд или еще реже. В чем отличие Sybase IQ? -6 Архитектурное решение IQ #6: • Снизить затраты, связанные с блокировками, используя для записи блокировки на уровне таблицы. • Вместе со версиями на основе снимков (решение #5), это позволяет сохранить число версий таблицы на небольшом (управляемом) уровне. В чем отличие Sybase IQ? Наблюдение #7: • Негативные эффект от выбора плохого плана запроса увеличивается во много раз, если таблица имеет размер в 10-и и 100-и миллиардов строк. В чем отличие Sybase IQ? -7 Архитектурное решение IQ #7-A: • Все простые условия выборки (типа SARG) оцениваются еще до того, когда принимаются основные решения оптимизатора, таким образом предоставляя оптимизатору более точную информацию для этих решений. Архитектурное решение IQ #7-B: • Насколько возможно, сделать выполнение запроса способным адаптироваться к ситуации, когда первоначальный план оказался не идеальным из-за неточной оценочной информации В чем отличие Sybase IQ? Наблюдение #8: • Масштабируемость в условиях смешанной нагрузки требует использования преимуществ как технологии SMP так и кластерной технологии. В чем отличие Sybase IQ? -8 Архитектурное решение IQ #8: • Реализация ассиметричного кластера с общим доступом к дискам, названного IQ Multiplex • Внутри кластера возможно лишь ограниченное количество узлов “Писателей” (до IQ 15 – лишь 1 ), что позволяет избежать необходимости использовать менеджер управления распределенными транзакциями и минимизировать синхронизационный трафик в кластере. • Пользователи на узлах «Читателях» кластера видят наиболее последние зафиксированные (commited) версии таблиц, как если бы они работали в односерверной (безкластерной) конфигурации В чем отличие Sybase IQ? -8 Эффект от Multiplex: • Возможность подключить к одному набору дисков множество серверов IQ (используя, например, SAN). • Единственное ограничение – число портов к дискам и суммарная пропускная способность дисковой системы. • Линейная масштабируемость в условиях роста числа пользователей достигается простым добавлением в кластер Multiplex нового узла- «Читателя». • Группируя пользователей на определенных узлах кластера, можно изолировать их от работы других пользователей или от процессов загрузки данных. В чем отличие Sybase IQ? Совокупный итог всех этих «отличий» IQ: • Непревзойденная производительность запросов в многопользовательской среде • Непревзойденная эффективность использования дисков • Требуются менее дорогие дисковые подсистемы • Способность легко масштабироваться в случае будущего роста нагрузок Итак, он другой … • Но, в нем используется стандартный ANSI 92 SQL • Все команды те же самые (лишь небольшое отличие в синтаксисе) • Используются все стандартные интерфейсы доступа • • • • Open Client (Sybase) ODBC JDBC OLE-DB • Все стандартные ETL инструменты поддерживают IQ • Все стандартные Front-End средства поддерживают IQ Итак, он другой … • Чтобы получить первый эффект от использования IQ, вам потребуется • Курс «IQ Administration» • Курс «IQ Developers» 4 дня 3 дня • Чтобы получить тоже самое от ASE или Oracle • ASE – наверное 7 курсов, примерно 30 дней • Oracle – наверное 10 курсов, примерно 55 дней • Чтобы стать экспертом – добавьте для IQ еще 3 дня • Чтобы стать экспертом в «других» СУБД – вам может потребоваться целая жизнь… Рекомендации по выбору -1 1. Если ваш OLTP сервер удовлетворяет Ваши требования к производительность запросов и отчетов, и не требует от вас слишком больших расходов, тогда продолжайте его использовать. 2. Если Вы не удовлетворены текущей производительностью запросов, тогда рассмотрите возможность переноса ваших аналитических запросов на Sybase IQ. Рекомендации по выбору -2 3. Если обслуживание растущего объема данных в OLTP БД требует от вас слишком больших затрат или мешает работе оперативных(транзакционных) систем, рассмотрите возможность переноса ваших исторических данных на Sybase IQ. 4. Чем больше ваши объемы данных, чем сложнее запросы, чем больше количество разнотипных запросов, тем больше преимуществ Вы получите от перехода на Sybase IQ. Вопросы ?