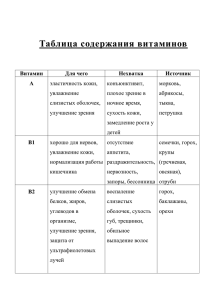
если (кокосы) то (вода, орехи)
advertisement
 то (вода, орехи)")
Поиск
ассоциативных
правил
Симашев Артем
Симашева Зарина
2012
Представление результатов
Решение задачи поиска ассоциативных правил, как и любой задачи,
сводится к обработке исходных данных и получению результатов.
Обработка над исходными данными выполняется по не которому
алrоритму Data Мining.
Результаты, получаемые при решении этой задачи, принято представлять
в виде ассоциативных правил. В связи с этим при их поиске
выделяют два
основных этапа:
нахождение всех частых наборов объектов;
rенерация ассоциативных правил из найденных частых наборов
объектов.
Ассоциативные правила имеют следующий вид:
если (условие) то (результат),
rде условие - обычно не лоrическое выражение (как в
классификационных
правилах), а набор объектов из множества 1, с которыми связаны
(ассоциированы) объекты, включенные в результат данноrо правила.
Например, ассоциативное правило:
если (кокосы, вода) то (орехи)
Основным достоинством ассоциативных правил является их леrкое
восприятие человеком и простая интерпретация языками проrраммирования.
Oднaко они не всеrда полезны. Выделяют три вида правил:
полезные правила - содержат действительную информацию, которая paнее
была неизвестна, но имеет лоrичное объяснение. Такие правила могут
быть использованы для принятия решений, приносящих выrоду;
тривиальные правила - содержат действительную и леrко объяснимую
информацию, которая уже известна. Такие правила, хотя и объяснимы, но
не могут принести какой-либо пользы, т. к. отражают или известные законы в
исследуемой области, или результаты прошлой деятельности. Иноrда
такие правила могут использоваться для проверки выполнения решений,
принятых на основании предыдущеrо анализа:
непонятные правила - содержат информацию, которая не может быть
объяснена. Такие правила могут быть получены или на основе аномальных
значений, или rлубоко скрытых знаний. Напрямую такие правила
нельзя использовать для принятия решений, т. к. их необъяснимость может
привести к непредсказуемым результатам. Для лучшеrо понимания
требуется дополнительный анализ.
Так, правила, построенные на основании набора
являются всеми возможными комбинациями объектов, входящих в него.
Например, для набора {кокосы, вода, орехи} могут быть построены
следующие правила:
если ( кокосы) то (вода) ; если (вода) то (кокосы, орехи) ;
если (кокосы) то (орехи) ; если (кокосы, орехи) то (вода);
если (кокосы) то (вода, орехи) ; если (орехи) то (вода) ;
если (вода, орехи) то (кокосы) ; если (орехи) то (кокосы)
если (вода) то (кокосы) ; если (орехи) то (вода, кокосы) ;
если (вода) то (орехи) ; если (вода, кокосы) то (орехи) .
Таким образом, количество ассоциативных правил может быть очень
большим и трудно воспринимаемым для человека. К тому же, не все из
построенных правил несут в себе полезную информацию.
Для оценки их полезности
используются следующие величины
Поддержка (support) - показывает, какой процент транзакций
поддерживает
данное правило. Так как правило строится на основании набора,
то, значит,
правило
имеет поддержку, равную поддержке набора F,
который
составляют Х и У:
Очевидно, что правила, построенные на основании одного и того
же набора,
имеют одинаковую поддержку, например, поддержка
Достоверность (confidence) - показывает вероятность того, что из наличия
в транзакции набора Х следует наличие в ней набора У.
Достоверностью правила
является отношение числа транзакций,
содержащих наборы Х и У, к числу транзакций, содержащих набор Х:
Очевидно, что чем больше достоверность, тем правило лучше, причем у правил,
построенных на основании одноrо и Toro же набора, достоверность будет
разная, например:
Улучшение (improvement) - показывает, полезнее ли правило случайноrо
уrадывания. Улучшение правила является отношением числа транзакций,
coдержащих наборы Х и У к произведению количества транзакций, содержащих набор Х, и количества транзакций, содержащих набор У:
Например:
Если улучшение больше единицы, то это значит, что с помощью правила
предсказать наличие набора У вероятнее, чем случайное уrадывание, если
меньше единицы, то наоборот.
В последнем случае можно использовать отрицающее правило, т. е. правило,
которое предсказывает отсутствие набора У:
Таким образом, можно получить правило, которое предсказывает результат
лучше, чем случайным образом. Правда, на практике такие правила мало
применимы. Например, правило:
если (вода, орехи) то не пиво
мало полезно, т. к. слабо выражает поведение покупателя.
Данные оценки используются при rенерации правил. Аналитик при поиске
ассоциативных правил задает минимальные значения перечисленных величин.
В результате те правила, которые не удовлетворяют этим условиям,
отбрасываются и не включаются в решение задачи. С этой точки зрения
нельзя объединять разные правила, хотя и имеющие общую смысловую
наrрузку.
Например, следующие правила:
нельзя объединить в одно:
Т. к. достоверности их будут разные, следовательно, некоторые из них могут
быть исключены, а некоторые нет.
Алrоритм Apriori
Алrоритм Apriori определяет часто встречающиеся наборы за несколько этапов.
На i-м этапе определяются все часто встречающиеся i-элементные наборы.
Каждый этап состоит из двух шаrов:
формирования кандидатов
подсчета поддержки кандидатов
Рассмотрим i-й этап. На шаrе формирования кандидатов алrоритм создает
множество кандидатов из i-элементных наборов, чья поддержка пока
не вычисляется. На шаrе подсчета кандидатов алrоритм сканирует множество
транзакций, вычисляя поддержку наборов-кандидатов. После сканирования
отбрасываются кандидаты, поддержка которых меньше
определенноrо пользователем минимума, и сохраняются только часто
встречающиеся i-элементные наборы.
Во время 1-ro этапа выбранное множество наборов-кандидатов
содержит все 1-элементные частые наборы. Алrоритм вычисляет их
поддержку во время шаrа подсчета кандидатов.
Описанный алrоритм можно записать в виде следующеrо псевдокода:
множество k-элементных частых наборов, чья поддержка не меньше
заданной пользователем.
множество кандидатов k-элементных наборов потенциально частых.
Опишем данный алrоритм по шагам.
Шаг 1. Присвоить k = 1 и выполнить отбор всех 1-элементных наборов,
у которых поддержка больше минимально заданной пользователем
Шаг 2. k = k +1.
Шаг 3. Если не удается создавать k-элементные наборы, то
завершить алгоритм, иначе выполнить следующий шаг.
Шаг 4. Создать множество k-элементных наборов кандидатов в
частые наборы. Для этоrо необходимо объединить в k-элементные кандидаты
(к-1) - элементные частые наборы. Каждый кандидат
будет
формироваться путем добавления к (к-1) - элементному частому набору - р
элемента из другого (k - 1 ) - элементного частого набора - q. Причем
добавляется последний элемент набора q, который по порядку выше, чем
последний элемент набора
При этом первые все k – 2 элемента обоих наборов одинаковы.
Это может быть записано в виде следующеrо SQL подобноrо запроса.
Шаг5. Для каждой транзакции Т из множества D выбрать кандидатов из
множества присутствующих в транзакции Т. Для каждоrо набора из
построеннного множества
удалить набор, если хотя бы одно из ero (k - 1)
подмножеств не является часто встречающимся, т. е. отсутствует во множестве
. Это можно записать в виде следующеrо псевдокода:
Шаг 6. Для каждого кандидата из множества увеличить значение поддержки
на единицу.
Шаг 7. Выбрать только кандидатов из множества у которых значение
поддержки больше заданной пользователем
. Вернуться к шагу 2.
Результатом работы алгоритма является объединение всех множеств для
всех k.
Рассмотрим работy алгоритма на примере, приведенном в табл., при
. На первом шаге имеем следующее множество кандидатов
идентификаторы товаров)
(указываются
Заданной минимальной поддержке удовлетворяют только кандидаты 2, З,
5 и 6, следовательно:
На втором шаге увеличиваем значение k до двух. Так как можно построить 2элементные наборы, то получаем множество
Из построенных кандидатов заданной минимальной поддержке удовлетворяют
только кандидаты 2, 4, 5 и 6, следовательно:
На третьем шаге перейдем к созданию 3-элементных кандидатов и подсчету
их поддержки. В результате получим следующее множество .
Данный набор удовлетворяет минимальной поддержке, следовательно:
Так как 4-элементные наборы создать не удастся, то результатом работы
алгоритма является множество:
Вопросы:
1) Какие основные характеристики ассоциативных правил вы
узнали?
2) Какое свойство использует алгоритм Apriori?
Спасибо за внимание!
И за понимание =)