Отношение
реклама

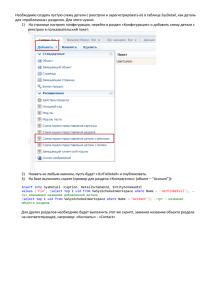
Желенкова О.П. Желенкова Ольга Петровна [email protected], http://www.sao.ru/hq/zhe/miscRU.html презентации к лекциям Пушников А.Ю. Введение в системы управления базами данных. Учебное пособие. http://citforum.ru/database/dblearn/index.shtml Зеленков Ю.А. Введение в базы данных. http://www.mstu.edu.ru/study/materials/zelenkov/toc .html Карпова И.П. Введение в базы данных. Учебное пособие. http://rema44.ru/resurs/study/dblectio/dblectio.html Реляционная модель данных Основы реляционной модели данных (РМД) изложены в статье Е.Ф. Кодда (1970г.), которая послужила стимулом для дальнейшего ее развития и внедрения в БД. В статье утверждается, что "реляционная модель предоставляет средства описания данных на основе только их естественной структуры, т.е. без потребности введения какой-либо дополнительной структуры для целей машинного представления". Другими словами, представление данных не зависит от способа их физической организации. Это обеспечивается за счет использования математической теории отношений (само название "реляционная" происходит от английского relation - "отношение"). Реляционная модель данных Наиболее распространенная трактовка РМД принадлежит К.Дейту, где реляционная модель состоит из следующих частей: структурная часть описывает, какие объекты рассматриваются реляционной моделью. Единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения; целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в реляционных базах данных. Это целостность сущностей и целостность внешних ключей; манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными реляционную алгебру и реляционное исчисление. Множество - неопределяемое понятие, представляющее некоторую совокупность данных. Элементы множества можно отличать друг от друга, а также определять, принадлежит ли данный элемент данному множеству. Над множествами можно выполнять операции объединения, пересечения, разности и дополнения. Новые множества можно строить при помощи понятия декартового произведения. Декартово произведение нескольких множеств - это множество кортежей, построенный из элементов этих множеств. Должность ФИО Должность Оклад директор Белов С.Ю. директор 40000 инженер Белов С.Ю. директор 75000 экономист Белов С.Ю. инженер 40000 Белов С.Ю. инженер 75000 ФИО Белов С.Ю. экономист 40000 Белов С.Ю. Белов С.Ю. экономист 75000 Рогов А.И. Рогов А.И. директор 40000 Панина А.А. Рогов А.И. директор 75000 Волкова Н.М. Рогов А.И. инженер 40000 Рогов А.И. инженер 75000 Рогов А.И. экономист 40000 Оклад 40000 … 75000 Волкова Н.М. … экономист … 40000 Полужирным шрифтом выделены записи, имеющие соответствие в предметной области. Отношение- это подмножество декартового произведения множеств. Отношения состоят из однотипных кортежей. Каждое отношение имеет предикат отношения и каждый nместный предикат задает n-арное отношение. Отношение является математическим аналогом понятия "таблица". Отношение состоит из заголовка отношения и тела отношения. Заголовок отношения - это аналог заголовка таблицы. Заголовок отношения состоит из атрибутов. Количество атрибутов называется степенью отношения. Тело отношения - это аналог тела таблицы. Тело отношения состоит из кортежей. Кортеж отношения является аналогом строки таблицы. Количество кортежей отношения называется мощностью отношения. Домен можно рассматривать как подмножество значений некоторого типа данных, имеющих определенный смысл, со следующими свойствами: • имеет уникальное имя (в пределах базы данных); • определен на некотором простом типе данных или на другом домене; • домен может иметь некоторое логическое условие, позволяющее описать подмножество данных, допустимых для данного домена; • несет определенную смысловую нагрузку. Домены ограничивают сравнения - некорректно, хотя и возможно, сравнивать значения из различных доменов. Кортеж - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута. "Значение" является допустимым значением домена данного атрибута. Кортеж - это набор именованных значений заданного типа. В классической реляционной модели используются только простые (атомарные) типы данных. Простые типы данных не обладают внутренней структурой. Отношение обладает следующими свойствами: • в отношении нет одинаковых кортежей; • кортежи не упорядочены (сверху вниз); • атрибуты не упорядочены (слева направо); • все значения атрибутов атомарны. Отношения совместимы по типу, если они имеют идентичные заголовки, а именно, • отношения имеют одно и то же множество имен атрибутов, т.е. для любого атрибута в одном отношении найдется атрибут с таким же наименованием в другом отношении, • атрибуты с одинаковыми именами определены на одних и тех же доменах. В математике чаще всего используют бинарные отношения (отношения степени 2). И, как правило, отношения заданы на бесконечных множествах и имеют бесконечную мощность В теории баз данных основными являются отношения степени n, и мощности отношений конечны (число хранимых строк в таблицах всегда конечно). Реляционной базой данных называется набор отношений. Схемой реляционной базы данных называется набор заголовков отношений, входящих в базу данных. Отношение находится в Первой Нормальной Форме (1НФ), если оно содержит только скалярные (атомарные) значения. Реляционная алгебра (РА) - формализованный набор операций с объектами РМД (n-арными отношениями). Операции РА применяются к отношениям и результатом операций являются отношения (замкнутость РА). Различают унарные и бинарные операции РА: унарные применяются к одному отношению (таблице), бинарные – к двум. Существует пять основных операций РА: селекция, проекция, декартово произведение, объединение, разность и три вспомогательных операции РА, которые могут быть выражены через основные: пересечение, соединение, деление. Язык SQL основан на операциях реляционной алгебры. Проекция (project) - унарная операция (выполняемая над одним отношением), служащая для выбора подмножества атрибутов из отношения R. Она уменьшает n-арность отношения и может уменьшить мощность отношения за счёт исключения одинаковых кортежей. Отношение R Проекция A,C(R) A B C A C a b c a c c a d c d c b d Селекция (select) - унарная операция, результатом которой является подмножество кортежей исходного отношения, соответствующих условиям, которые накладываются на значения определённых атрибутов. Отношение R Селекция C=d(R) A B C A B C a b c c a d c a d c b d c b d Бинарные операции РА: • разносхемные – применяются к любым двум отношениям. • односхемные – применяются к односхемным отношениям. Исходные отношения должны иметь одинаковое количество столбцов одинаковых (или сравнимых) типов. Сравнимыми считаются типы, относящиеся к одному и тому же семейству данных (в таблице полужирным шрифтом выделены базовые типы). Семейства типов данных Oracle: Числовые: DEC, DECIMAL, DOUBLE PRECISION, FLOAT, INT, INTEGER, NUMBER, NUMERIC, REAL, SMALLINT Символьные: CHAR, CHARACTER, LONG, LONG RAW RAW, ROWID, STRING, VARCHAR, VARCHAR2 Календарные: DATE Декартово произведение (cartesian product) - бинарная операция над разносхемными отношениями, соответствующая определению декартова произведения для РМД: в результате получается отношение, схема которого включает все атрибуты исходных отношений. Результирующее отношение содержит все возможные комбинации кортежей исходных отношений. Отношение R Отношение S Декартово произведение RS A B C D E A B C D E 1 4 g h a 1 4 g h a 2 5 a b c 1 4 a b c 3 6 2 5 g h a 2 5 a b c 3 6 g h a 3 6 a b c Объединение (union) - объединением двух односхемных отношений R и S называется отношение T = R U S, которое включает в себя все кортежи исходных отношений без повторов. Отношение R Отношение S Объединение R U S A B C A B C A B C a b c g h a a b c c a d a b c c a d c h c h d d c h c g h a h d d Разность (except) - разностью односхемных отношений R и S называется множество кортежей R, не входящих в S. Отношение R Отношение S Разность R–S A B C A B C A B C a b c g h a c a d c a d a b c c h c c h c h d d Пересечение (intersect) - пересечение двух односхемных отношений R и S есть подмножество кортежей, принадлежащих обоим отношениям. Это можно выразить через разность: R ∩ S = R – (R – S). Отношение R Отношение S Пересечение R–S A B C A B C A B C a b c g h a a b c c a d a b c c a d c h c c a d d r t g u v Соединение (join) - операция определяет подмножество декартова произведения двух разносхемных отношений. Кортеж декартова произведения входит в результирующее отношение, если для атрибутов разных исходных отношений выполняется некоторое условие F. Соединение может быть выражено так: R S = F (R S) F Если условием является равенство значений двух атрибутов исходных отношений, такая операция называется эквисоединением. Естественным называется эквисоединение по одинаковым атрибутам исходных отношений. Отношение R Соединение RS Отношение S A B C A D E A B C D E a b c g h a c a d b c c a d c b c c h c b c c h c h d d g b d h a g b d Деление (division). Пусть отношение R содержит атрибуты {r1,r2,...,rk, rk+1,...,rn}, а отношение S – атрибуты {rk+1,...,rn}. Тогда результирующее отношение содержит атрибуты {r1,r2,...,rk}. Кортеж отношения R включается в результирующее отношение, если его декартово произведение с отношением S входит в R. Деление может быть выражено так: R / S = r1,…,rk (R) – r1,…,rk ((r1,…,rk (R) S) – R). Отношение R Отношение S Частное R/S A B C D C D A B a b c b c b a b a b g h g h c f c f g h c f c b a v c b c v g h SQL – структурированный язык запросов к реляционным базам данных (БД), декларативный язык, основанный на операциях реляционной алгебры. Стандарты SQL, определённые Американским национальным институтом стандартов (ANSI): SQL-1 (SQL/89) – первый вариант стандарта. SQL-2 (SQL/92) – основной расширенный стандарт. SQL-3 (SQL/1999, SQL/2003) – относится к объектно-реляционной модели данных. Подмножества языка SQL: DDL (Data Definition Language) – команды создания/изменения/удаления объектов базы данных (create/alter/drop); DML (Data Manipulation Language) – команды добавления/модификации/удаления данных (insert/update/delete), а также команда извлечения данных select; DCL (Data Control Language) – команды управления данными (установка/снятие ограничений целостности). Входит в подмножество DDL. Особенности синтаксиса: В командах SQL не различаются прописные и строчные буквы (кроме содержимого символьных строк). Каждая команда может занимать несколько строк и заканчивается символом ';'. Символ и символьная строка заключается в одинарные кавычки: 'А', '2' , 'строка', 'другая строка' Однострочный комментарий начинается с символов '--'. Многострочный комментарий заключается в символы /* ... */. CREATE – создание объекта. ALTER – изменения структуры объекта. DROP – удаление объекта. Общий вид синтаксиса команд DDL: create alter drop } тип_объекта имя_объекта [параметры]; CREATE TABLE [имя_схемы.]имя_таблицы ( имя_поля тип_данных [(размер)] [NOT NULL] [DEFAULT выражение] [ограничения_целостности_поля…] .,.. [, ограничения_целостности_таблицы .,..] ) [ параметры ]; ограничения_целостности (ОЦ): [CONSTRAINT имя_ОЦ ] название_ОЦ [параметры] Символьные типы: CHAR [(длина)] – строка фиксированной длины. Длина по умолчанию – 1, максимальная длина 2000 б. Строка дописывается до указанной длины пробелами. VARCHAR2 (длина) – строка переменной длины. Максимальная длина 4000б. Хранятся только значащие символы. Числовой тип:NUMBER [(точность[, масштаб])] – используется для представления чисел с заданной точностью. Точность по умолчанию 38, масштаб по умолчанию – 0. number(4) – числа от -999 до 9999 number(8,2) – числа от -99999.99 до 999999.99 DATE – дата и время с точностью до секунды. Занимает 7 байт. sysdate – функция получения текущих даты и времени. Тип date поддерживает арифметику дат: sysdate+1 – завтра (дата1 – дата2) – количество дней, прошедших между двумя датами (sysdate – 0.5) – 12 часов назад В СУБД Oracle поддерживаются следующие ограничения целостности: уникальность: UNIQUE (имя_атрибута1 [, имя_атрибута2,...]) обязательность / необязательность: NOT NULL / NULL первичный ключ: PRIMARY KEY(имя_атрибута1 [, имя_атрибута2,...]) внешний ключ: FOREIGN KEY(имя_атрибута1 [, имя_атрибута2,...]) REFERENCES имя_таблицы [(имя_атрибута1 [, имя_атрибута2,...])] условие на значение поля: CHECK (условие) Например: check (salary>=4500), check (date2 > date1) Добавление одной или нескольких строк в таблицу: INSERT INTO имя_таблицы [(список_полей_таблицы)] { VALUES (список_выражений) | запрос }; insert into depart values(7, 'Договорной отдел'); Изменение данных: UPDATE имя_таблицы SET имя_поля1 = выражение1 [, имя_поля2 = выражение2,…] [WHERE условие]; update job set rel = 'консультант‘ where tabno = 74 and pro = 30; Если условие не указано, обновляются все строки таблицы. Если ни одна строка не удовлетворяет условию, ни одна строка не будет обновлена. Удаление строк из таблицы. DELETE FROM имя_таблицы [ WHERE условие ]; delete from job where tabno=147; Удаляет одну или несколько строк из таблицы. Если условие не указано, удаляются все строки таблицы. Если ни одна строка не удовлетворяет условию, ни одна строка не будет удалена. Замечание: отменить удаление данных можно командой ROLLBACK; SELECT [{ ALL | DISTINCT }] { список_вывода | * } FROM имя_таблицы1 [ алиас1 ] [, имя_таблицы2 [ алиас2 ].,..] [ WHERE условие_отбора_записей ] [ GROUP BY { имя_поля | выражение }.,.. ] [ HAVING условие_отбора_групп ] [ UNION [ALL] SELECT …] [ ORDER BY имя_поля1 | целое [ ASC | DESC ] [, имя_поля2 | целое [ ASC | DESC ].,..]]; Формирование списка вывода (проекция) Список ввода находится между ключевыми словами SELECT и FROM. select * from project; select name 'ФИО', post 'Должность', salary*0.87 'Зарплата‘ from emp; Упорядочение результата: order by select * from Project order by dbegin; Выбор данных из таблицы (селекция): WHERE – содержит условия выбора отдельных записей. Условие является логическим выражением и может принимать одно из 3-х значений: • TRUE – истина, • FALSE – ложь, • NULL – неизвестное, неопределённое значение (интерпретируется как ложь). Условие формируется путём применения различных операторов и предикатов. Операторы сравнения: = равно, <>, != не равно, > больше, >= больше или равно, <= меньше или равно, < меньше. Логические операторы: AND – логическое произведение (И), OR – логическая сумма (ИЛИ), NOT – отрицание (НЕ). select * from emp where depno = 2 AND salary > 30000 ; Предикат вхождения в список значений: имя_поля IN ( значение1 [, значение2,... ] ) select * from emp where post IN ( 'инженер', 'ведущий инженер' ); Предикат вхождения в диапазон: имя_поля BETWEEN мин_значение AND макс_значение Минимальное значение должно быть меньше либо равно максимальному. select * from emp where salary*0.87 BETWEEN 20000 AND 30000; Предикат поиска подстроки: имя_поля LIKE 'шаблон' Этот предикат применяется только к полям типа CHAR и VARCHAR. Возможно использование шаблонов: '_' – один любой символ, '%' – произвольное количество любых символов (в т.ч., ни одного). select * from emp where post LIKE '%экономист%' ; COUNT – подсчёт количества строк (значений). Применяется к записям и полям любого типа. Имеет 3 формата вызова: count (*) – количество строк результата; count (имя_поля) – количество значений указанного поля, не являющихся NULLзначениями. count (distinct имя_поля) – количество разных не-NULL значений указанного поля. MAX, MIN – определяет максимальное (минимальное) значение указанного поля результирующем множестве. Применяется к полям любого типа. SUM – определяет арифметическую сумму значений указанного числового поля в результирующем множестве записей. AVG – определяет среднее арифметическое значений указанного числового поля в результирующем множестве записей. Не учитывает NULL-значения, и сумма значений поля делится на количество определённых значений. select count(*) from emp; Агрегирующие функции обычно используются совместно с предложением GROUP BY. Например, следующая команда считает количество сотрудников по отделам: select depno, count(*) from emp group by depno; Правило использования GROUP BY : В списке вывода при использовании GROUP BY могут быть указаны только функции агрегирования, константы и поля, перечисленные в GROUP BY. Если включить в список выбора поля, не указанные в GROUP BY, то СУБД не будет выполнять такой запрос и выдаст ошибку "нарушение условия группирования" (not a GROUP BY expression). Например, нельзя получить сведения о том, у каких сотрудников самая высокая зарплата в своём отделе с помощью такого запроса: select depno, name, max(salary) as max_sal from emp group by depno; Этот запрос синтаксически неверен! Если необходимо вывести не все записи, полученные в результате группировки (GROUP BY), то условие на группы можно указать во фразе HAVING (но не во фразе WHERE). Пример. Список отделов, в которых работает больше пяти человек: select depno, count(*), 'человек(а)' from emp group by depno having count(*)>5; Правило: нельзя указывать агрегирующие функции в части WHERE – это синтаксическая ошибка! Унарные операции: селекция – выбор из таблицы подмножества строк по условию. select * from emp where depno = 5; проекция – выбор из таблицы подмножества столбцов. select distinct name, post, salary from emp; Бинарные операции РА: • разносхемные – применяются к любым двум отношениям. • односхемные – применяются к односхемным отношениям. Исходные отношения должны иметь одинаковое количество столбцов одинаковых (или сравнимых) типов. Сравнимыми считаются типы, относящиеся к одному и тому же семейству данных. Объединение двух односхемных отношений содержит все строки исходных отношений без повторов. Разность двух односхемных отношений содержит все строки первого отношения, не входящие во второе отношение (без повторов). Пересечение двух односхемных отношений содержит все строки, входящие и в первое, и во второе отношения (без повторов). Объединение реализуется с помощью специального ключевого слова UNION (или UNION ALL, если не нужно удалять повторы). Список сотрудников с телефонами или адресами (если нет телефона): select depno, name, PHONE from emp where phone is not null UNION ALL select depno, name, ADR from emp where phone is null; Разность в Oracle реализуется с помощью специального ключевого слова MINUS. Список сотрудников 5-го и 8-го отделов, которые не являются инженерами: select * from emp where depno IN (5, 8) MINUS select * from emp where post LIKE '%инженер%' order by depno; Переcечение реализуется с помощью специального ключевого слова INTERSECT. Список сотрудников 5-го и 8-го отделов, которые являются инженерами: select * from emp where depno IN (5, 8) INTERSECT select * from emp where post LIKE '%инженер%' order by depno; Декартово произведение (ДП): операция над двумя произвольными (возможно, разносхемными) отношениями. Результат ДП – все комбинации строк исходных отношений. Пример: Пример декартова произведения реальных таблиц: select * from depart, emp; Если в части FROM указываются 2 и более таблицы, то СУБД по умолчанию строит их декартово произведение. Другая разносхемная операция – соединение: селекция от декартова произведения. Примеры. 1. Список отделов и их сотрудников: select * from depart, emp where emp.depno = depart.did; 2. Список проектов и их участников: select * from project, emp, job where emp.tabno = job.tabno and job.pro = project.pro; 1. Выбор записей из указанной таблицы (from). 2. Проверка для каждой записи условия отбора (where). 3. Группировка полученных в результате отбора записей (group by) и вычисление для этих групп значений агрегирующих функций. 4. Выбор тех групп, которые удовлетворяют условию отбора групп (having). 5. Сортировка полученных записей в указанном порядке (order by). 6. Извлечение из полученных записей тех полей, которые заданы в списке вывода, и формирование результирующего отношения. Если в части FROM указывается 2 и более таблицы, то приведенный алгоритм выполняется для декартова произведения этих таблиц. Подзапрос – это запрос SELECT, расположенный внутри другой команды. Подзапросы можно разделить на следующие группы в зависимости от возвращаемых результатов: скалярные – запросы, возвращающие единственное значение (начинаются с немодифицированного оператора сравнения); векторные – запросы, возвращающие от 0 до нескольких элементов (начинаются с оператора IN или модифицированного оператора сравнения); табличные – запросы, возвращающие таблицу. Подзапросы бывают: некоррелированные – не содержат ссылки на запрос верхнего уровня; вычисляются один раз для запроса верхнего уровня; коррелированные – содержат условия, зависящие от значений полей в основном запросе; вычисляются для каждой строки запроса верхнего уровня. В команде INSERT: Вместо VALUES, например, добавление данных из одной таблицы в другую: insert into emp select * from new_emp; В команде UPDATE: в части WHERE для вычисления условий, например, повышение зарплаты на 10% всем участникам проектов: update emp set salary = salary*1.1 where tabNo IN (select tabNo from job); в части SET для вычисления значений полей, например, повышение зарплаты на 10% за каждое участие сотрудника в проекте: update emp e set salary = salary*(1+(select count(*)/10 from job j where j.tabNo = e.tabNo) ); В команде DELETE: в части WHERE для вычисления условий, например, удаление сведений об участии в закончившихся проектах: delete from job where pro IN (select pro from project where dend < sysdate); Чаще всего подзапрос располагается в части WHERE. список сотрудников, у которых зарплата выше, чем средняя по предприятию: select * from emp where salary > (select avg(salary) from emp); DEPNO NAME POST SALARY 2 Малова Л.А. гл. бухгалтер 59240 5 Павлов А.А. директор 80000 5 Кроль А.П. зам. директора 70000 список сотрудников, у которых зарплата выше, чем средняя по каждому отделу предприятия: select * from emp where salary > ALL (select avg(salary) from emp group by depno); Подзапрос в части FROM. список сотрудников, у которых зарплата выше, чем средняя в отделе, в котором работает данный сотрудник, через коррелированный подзапрос: select * from emp e where salary > (select avg(salary) from emp m where m.depno = e.depno); Это работает долго, т.к. коррелированный подзапрос вычисляется для каждой строки основного запроса. Можно ускорить выполнение данного запроса: select * from emp e, (select depno, avg(salary) sal from emp group by depno) m -- подзапрос вычисляется 1 раз where m.depno = e.depno and salary > sal; Подзапрос в части HAVING. список отделов, в которых средняя зарплата ниже, чем средняя по предприятию: select depno, avg(salary) sal from emp group by depno having avg(salary) < (select avg(salary) from emp); Подзапрос в части SELECT. список сотрудников с указанием количества проектов, в которых они участвуют: select depno, name, (select count(*) from job j where j.tabno = e.tabno) cnt from emp e; Этот запрос выведет даже тех сотрудников, которые не участвуют в проектах (для них cnt будет равен 0). Представление (view, обзор) – это хранимый запрос, создаваемый на основе команды SELECT. Представление реально не содержит данных. Запрос, определяющий представление, выполняется тогда, когда к представлению происходит обращение с другим запросом, например, SELECT, UPDATE и т.д. Назначение представлений: • Хранение сложных запросов. • Представление данных в виде, удобном пользователю. • Сокрытие конфиденциальной информации. • Предоставление дифференцированного доступа к данным. Создание представления выполняется командой CREATE VIEW: CREATE [ OR REPLACE ] VIEW <имя представления> [ (<список имён столбцов>) ] AS <запрос> [ WITH CHECK OPTION ]; Запрос (команда SELECT), на основании которого создаётся представление, называется определяющим запросом, а таблицы, к которым происходит обращение в определяющем запросе – базовыми таблицами. Определяющий запрос по стандарту SQL не может включать предложение ORDER BY.