Extended set system - LMS
реклама

ПРАВИТЕЛЬСТВО РОССИЙСКОЙ ФЕДЕРАЦИИ
ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ АВТОНОМНОЕ
ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
«Национальный исследовательский университет
«Высшая школа экономики».
Факультет бизнеса и менеджмента
Кафедра инноваций и бизнеса в сфере информационных технологий
ВЫПУСКНАЯ КВАЛИФИКАЦИОННАЯ РАБОТА
На тему: «Анализ сообщений пользователей Twitter для принятия
решений в биржевой торговле»
Студент группы № 241-м
Ли А.С.
Научный руководитель
ст. преподаватель, к.н.,
Проценко Д.С.
Москва 2015
2
ОГЛАВЛЕНИЕ
Введение
3
Глава 1. Основные понятия и термины
1.1.
Фондовая биржа, методы анализа и прогнозирования цен.
Понятие торговой системы.
1.2.
6
Социальная сеть Twitter, ее особенности. Twitter Streaming API
и его возможности. Сбор данных с помощью Twitter Streaming API. 10
1.3.
Анализ сообщений Twitter. Сентиментный анализ.
15
Глава 2. Анализ сообщений Twitter, формальное описание данных
для анализа. Понятие нейронной сети.
2.1.
Создание словаря классификаций эмоций (DCE).
Алгоритм сентиментного анализа твиттов.
2.2.
Нейронная сеть. Принципы работы нейронной сети.
2.3.
Описание данных для анализа.
22
27
Глава 3. Построение торговой системы
3.1.
Схема работы торговой системы.
3.2.
Построение и обучение торговых систем на основе нейронной
28
сети (Simple set system и Extended set system).
Оценка и сравнение результатов работы систем.
30
Заключение
39
Список использованной литературы
40
Приложение 1
41
Приложение 2
43
3
Введение
Вопрос прогнозирования движения цен инструментов фондового рынка
(акций, облигаций, опционов, фьючерсов), а также производных финансовых
инструментов (индексов) является темой многих научных исследований. Как
правило, для прогнозирования используются инструменты технического и
фундаментального анализа. Технический (графический) анализ опирается на
конкретные исторические данные цен за предыдущий период времени.
Фундаментальный анализ учитывает внешние факторы: экономические,
политические, которые отражаются на психологическом настроении людей.
Ключевым является построение такой торговой системы (торгового робота),
который бы учитывал не только формальные исторические данные (данные
технического анализа), но и психологические аспекты. Множество научных
исследований посвящено именно техническому анализу, но как показала
практика, опираясь только на него в некоторых случаях прогноз может быть
ошибочным, т.к. не учитываются аспекты фундаментального анализа
(психологическая составляющая).
В данной работе исследуется возможность применения анализа
настроения пользователей Twitter для повышения точности прогноза движения
цен инструментов фондового рынка. Предметом анализа являются сообщения
в Twitter, которыми делятся его пользователи. Сообщения в Twitter - так
называемые "твитты" предсталяют собой короткие сообщения (не более 140
символов). Обычно в твиттах люди в очень краткой форме делятся между
собой важной и интересной с их точки зрения информацией. Преимущества
Twitter - сообщения о каких-либо событиях появляются намного быстрее, чем
в каких-либо других новостных источниках, что является важным моментом,
т.к. в торговле очень важна скорость принятия решения. Поэтому Twitter стали
рассматривать как полезный источник информации для прогнозирования.
4
Основной целью выполнения работы является проверка гипотезы о том,
что сообщения пользователей Twitter могут использоваться в качестве
источника информации для повышения точности прогноза цен финансовых
инструментов на бирже.
Основные задачи, поставленные в работе:
1) Сбор всех необходимых данных и их формальное описание для
дальнейшего анализа;
2) Построение системы, анализирующей сообщения пользователей Twitter
на основе сентиментного анализа;
3) Построение 2-х торговых систем: системы, использующей лишь
биржевую
информацию;
системы,
которая,
помимо
биржевой
информации использует в работе информацию о сообщениях Twitter;
4) Оценка и сравнение результатов качества работы 2-х систем.
Получены следующие результаты:
1) Были собраны все необходимые данные для анализа - сообщения
пользователей Twitter (с помощью Twitter API), а также информация о
ценах за исторически период времени;
2) Разработан «словарь эмоций», на основе которого была создана система,
анализирующая твитты;
3) Построено и формально описано 2 множества: базовое множество,
которое
содержит
лишь
информацию
по
ценам
финансовых
инструментов и объемам торгов; расширенное - полученное путем
добавления к базовому множеству проанализированной с помощью
сентиментного анализа информации о сообщениях пользователей
Twitter;
4) Построены и обучены на основе нейронных сетей с помощью программы
STATISTICA две торговые системы на 2-х множествах;
5
5) Произведена оценка и сравнение качества работы построенных систем.
Было выявлено, что точность прогнозирования системы, использующей
информацию о сообщениях Twitter выше, чем у системы, работающей лишь на
данных биржи, что подтвердило гипотезу о том, что сообщения Twitter могут
повысить точность прогноза. Однако, для каждого отдельного финансового
инструмента необходимо производить обучение и настройку торговой
системы отдельно.
В дальнейшем можно попытаться оптимизировать работу торговой
системы разными способами, например, путем улучшения «словаря эмоций»
для более точной оценки эмоционального состояния людей или путем
предварительной фильтрации сообщений Twitter по определенным ключевым
словам и.т.д.
6
Глава 1. Основные понятия и термины
1.1.
Фондовая биржа, методы анализа и прогнозирования цен, понятие
«торговой системы»
Для исследования необходимо овладеть знаниями, связанными с
основными понятиями фондового рынка, методами анализа исторических
данных биржи.
Биржа
–
юридическое
лицо,
обеспечивающее
регулярное
функционирование организованного рынка товаров, валют, ценных бумаг и
производных финансовых инструментов. В зависимости от торгуемых активов
биржи подразделяются на: фондовые, товарные, валютные, фьючерсные.
Фондовая биржа – организация, предметом деятельности которой
являются обеспечение необходимых условий нормального обращения ценных
бумаг, определение их рыночных цен и распространение информации о них,
поддержание высокого уровня профессионализма участников рынка ценных
бумаг.
Ценная бумага – документ, удостоверяющий имущественные права с
соблюдением установленной формы обязательных реквизитов, осуществление
и передача которых возможны только при его предъявлении. Ценные бумаги
классифицируются по эмитентам, времени обращения, способа выплаты
дохода, уровню риска, территориям.
Трейдинг – это кратковременная игра на повышение или понижение курса
(котировки) акций. Время трейдинга исчисляется месяцами, неделями, днями
или даже часами.
При выборе инвестиционной стратегии и тактики используются
разнообразные методы оценки будущей стоимости инвестиции, а также
фундаментальный анализ, позволяющий исследовать все сферы фондового
7
рынка, и различные приемы технического анализа в целях прогнозирования
изменения рыночной конъюнктуры.
Фундаментальный анализ раскрывает основные факторы, влияющие на
прибыль и дивиденды компании и фондовый рынок в целом. Эти факторы
можно
разделить
на
две
группы:
1)
фундаментальные
условия
предпринимательства, или экономические факторы; 2) политические условия.
Для проведения фундаментального анализа используется подход сверху вниз.
Анализ начинается не с компании, а со среды, в которой протекает ее
деятельность.
Технический анализ – это общепринятый подход к изучению рынка,
имеющий целью прогнозирование движения курса акции и предполагающий,
что рынок обладает памятью, а поэтому на будущее движение курса оказывают
большое влияние наблюдаемы закономерности его прошлого поведения[1].
Технический
анализ
называют
графическим,
поскольку
графическое
представление анализируемой информации — основной метод изучения
состояния фондового рынка[4].
Торговая система – это набор правил, согласно которым принимается
решение об открытии или закрытии позиции. Обычно торговая система
включает в себя набор условий или правил для выполнения следующих
действий:
- открытие длинной позиции (покупка акций при игре на повышение);
- закрытие длинной позиции (продажа акций при игре на повышение);
- открытие короткой позиции (продажа акций при игре на понижение);
- закрытие короткой позиции (покупка акций при игре на понижение).
Эти правила должны быть четко сформулированы, чтобы их можно было
записать в виде алгоритма для автоматической работы на рынке[3].
Как правило, для построения торговой системы трейдеры используют
инструменты технического анализа. Технический анализ опирается на анализе
8
исторических данных, которые имеются в открытом доступе в интернете
(специализированные сайты), а также могут поставляться посредством
электронных торговых платформ.
На бирже доступна следующая информация за определенный период
(минута, час, день, неделя, месяц):
1) Цена открытия
2) Цена закрытия
3) Максимальная цена
4) Минимальная цена
5) Объем торгов
Для анализа исторических данных существуют различные инструменты
технического
анализа
(всевозможные
индикаторы),
которые
дополнительно отображаются на ценовом графике и
обычно
являются так
называемыми «сигналами» для принятия решений. Однако использование
только одних индикаторов, которые встроены в торговые платформы,
подходит больше для «ручной торговли», когда анализ производится
непосредственно
человеком
и
заявки
выставляются
вручную.
Для
автоматической торговли необходимо разработать торговую систему (робота),
который бы анализируя исторические данные по ценам, делал прогноз.
Торговая
система
(робот)
представляет
собой
набор
формализованных правил, который принимая «на входе»
математически
исторические
данные, анализируя их, прогнозирует дальнейшее изменение цены, т.е.
выступает неким советником какую позицию на данный моменнт лучше занять
- «покупать», «продавать» или «ждать».
При построении торгового робота возникает ряд вопросов:
1) Какие данные необходимо использовать и как формально они должны
быть описаны для дальнейшего анализа?
9
2) Каким образом анализировать данные? Какой использовать метод анализа
(алгоритм)?
3) Каком образом должна функционировать торговая система в целом?
4) Как оценить точность работы торговой системы?
Рассмотрим каждый из этих вопросов более подробно далее в следующих
главах.
10
1.2.
Социальная сеть Twitter, ее особенности. Twitter Streaming API и его
возможности. Сбор данных с помощью Twitter Streaming API.
Twitter (Тви́ттер) — социальная сеть для публичного обмена короткими
(до 140 символов) сообщениями при помощи веб-интерфейса, SMS, средств
мгновенного обмена сообщениями или сторонних программ-клиентов для
пользователей интернета любого возраста.
Твитты – сообщения, которыми делятся пользователи Twitter.
Преимущества Twitter - сообщения о каких-либо событиях появляются
намного быстрее, чем в каких-либо других новостных источниках. Поэтому
Twitter стали рассматривать как полезный источник информации, которую
можно использовать для прогнозирования каких-либо показателей, в том числе
и финансовых. Его можно рассматривать в качестве источника информации о
настроении пользователей т.е. психологической составляющей, которой
зачастую не хватает в торговых системах, которые основываются лишь на
исторических
данных
цен.
Таким
образом,
можно
использовать
фундаментальный анализ при построении торговой системы.
Предметом анализа являются сообщения пользователей Twitter.
Возникает вопрос о том, каким образом можно получить достаточное
количество сообщений других пользователей необходимое для анализа? Для
этого для разработчиков предусмотрен инструмент API. В работе использовала
Twitter Streaming API (https://dev.twitter.com/streaming/overview) и метод GET
statuses/sample
(https://dev.twitter.com/streaming/reference/get
/statuses/sample),
который в режиме онлайн предоставляет до 1% от всего текущего потока
сообщений Твиттера.
Также
в
рамках
Twitter
API
существуют
инструмент
statuses/filter https://dev.twitter.com/streaming/reference/post/statuses/filter ,
POST
где
можно отфильтровать твитты по ключевым словам. Для поиска по
11
историческим
API
данным
есть
(https://dev.twitter.com/rest/public), но
он
Twitter REST
выдает
только
весьма
ограниченный объем сообщений по сравнению с Streaming API. Поэтому в
работе был использован именно Twitter Streaming API.
Для
упрощения
работы
с
Twitter
API
для
разных
языков
программирования существует специальные библиотеки.
Я, к примеру, использовала https://github.com/tweetstream/tweetstream для
Python. Был написан код на Python, который позволил скачивать в реальном
времени твитты в БД.
Для скачивания твиттов необходимо быть зарегистрированным в Twitter
как пользователь сети, создать приложение (https://apps.twitter.com) и получить
секретные ключи для доступа к Twitter API (ckey, csecret, atoken, asecret).
12
Рис.1 Получение секретных ключей для доступа к Twitter API
Ниже представлен разработанный алгоритм на Python, который
позволяет скачивать в режиме онлай до 1% сообщений пользователей Twitter,
фильтрует только необходимую информацию (т.к. по умолчанию без
фильтрации информация избыточна), создает файл в формате .csv и записывает
в файл полученные данные. Таким образом, мы получаем довольно
структурированную информацию по сообщениям Twitter, с которой довольно
удобно работать.
from tweepy import Stream
from tweepy import OAuthHandler
from tweepy.streaming import StreamListener
import time
13
ckey = 'rwn8w66ca3zygh8QByZrGKNwl'
csecret = 'bVMYFypFDR0oEGkqHrRQQ654hjJjdCkISoDeXiQU83s7wzzulB'
atoken = '2319285780-murJh6zedPjhREm0IS9rsoCvWV56LAzVgPjBkLd'
asecret = 'SoGICrzE86dHsFPMTre0MEthEwrfpWqEW1RgbCbNPRqOT'
class listener(StreamListener):
def on_data(self, data):
try:
#print(data)
tweet1 = data.split('"created_at":')[1].split(',"id":')[0]
tweet2 = data.split(',"text":')[1].split(',"source":')[0]
tweet = tweet1 + tweet2
print (tweet)
saveThis = tweet
saveFile = open('twitDB_18_05_3_1_final.csv','a')
saveFile.write(saveThis)
saveFile.write('\n')
saveFile.close()
return True
except BaseException as e:
print('failed ondata,')
print(str(e))
time.sleep(5)
def on_error(self, status):
print (status)
auth = OAuthHandler(ckey, csecret)
auth.set_access_token(atoken, asecret)
twitterStream = Stream(auth, listener())
twitterStream.sample(languages=['en'])
14
Рис.2 Отображение загружаемых в режиме онлайн сообщений в консоли
Рис.3 Сообщения, загруженные в базу данных .csv
Примеры загруженных сообщений пользователей Twitter приведены в
Приложении 1 к работе.
15
2.3. Анализ сообщений Twitter. Сентиментный анализ.
Основную информацию, которую хотим извлечь из сообщений Twitter –
настроение пользователей, их психологическое состояние. Поэтому для
анализа используется так называемый "сентиментный анализ" - область
компьютерной лингвистики, которая занимается изучением мнений и эмоций
в текстовых документах. Например, в самом простом случае можно посчитать
сколько за день было твиттов со словами "worry" - "волнение", "hope" "надежда", "fear" - "страх" и исходя из этого понять как эмоционально
настроены люди. Если они взволнованы или бояться, то скорее всего они
навряд ли будут активно что-то покупать и возможно это сигнал, что цены
будут падать. Можно использовать и другие эмоциональные шкалы (8 эмоций
- “happy”, “loving”, “calm”, “energetic”, “fearful”, “angry”, “tired” and “sad”) [2].
В самом простом случае алгоритм выглядит следующим образом:
Simple Sentiment Calculation.
Data: Preprocessed Twitter Data Result: Output: Sum[happy, loving, calm,
energetic, fearful, angry, tired, sad]
Find the Dictionaries
foreach Category=[happy, loving, calm, energetic, fearful, angry, tired, sad]
foreach word in AllTweetsInADay
If word In Dictionaries[Category] then
Sum[Category] + =1
end
end
return Sum
16
Глава 2. Анализ сообщений Twitter, формальное описание данных для
анализа. Понятие нейронной сети.
2.1. Создание словаря классификаций эмоций (DCE). Алгоритм
сентиментного анализа твиттов.
Для нашего исследования была использована эмоциональная шкала из 8
эмоций – BMIS (Brief Mood Introspection Scale), характеризующаяся 16
прилагательными (2 прилагательных на каждую из 8 эмоций): happy (happy,
lovely), loving (loving, caring), calm (calm, content), energetic (active, peppy),
fearful/anxious (jittery, nervous), angry (grouchy, fed up), tired (tired, drowsy), sad
(gloomy, sad).
В словарь, помимо этих 16 прилагательных, также были добавлены все
их прилагательные-синонимы. Синонимы брались из WordNet словаря
(Принстонский университет). В результате, словарь состоит из следующих
слов:
Название
Прилагательные
эмоции
по шкале BMIS
happy
happy
Прилагательные-синонимы
felicitous, glad, well-chosen, blessed,
blissful,
bright,
golden,
halcyon,
prosperous, laughing, riant, fortunate,
willing
adorable, endearing, beautiful, lovable,
loving
lovely
loveable
loving
adoring, doting, fond, affectionate, fond,
lovesome, tender, amative, amorous,
amatory, romantic, attached, captivated,
17
charmed, enamored, infatuated, in love,
potty, smitten, soft on, taken with,
idolatrous, loverlike, loverly, overfond,
tenderhearted, touchy-feely, uxorious
calm
caring
compassionate
calm
unagitated, serene, tranquil, composed,
placid, quiet, still, smooth, unruffled,
settled, windless
content
contented, complacent, self-satisfied,
self-complacent, satisfied, smug
energetic
active
combat-ready, fighting, participating,
alive, dynamic, progressive, operational,
activist, activistic, hands-on, proactive,
involved, about, astir, acrobatic, athletic,
gymnastic, agile, nimble, quick, spry,
hot, hyperactive, overactive, on the go,
sporty, activated, counteractive, surfaceactive, brisk, bustling, busy, going, open,
springy, existent, existing, alive, live,
eruptive, activated
fearful/anxious
peppy
bouncing, bouncy, spirited, zippy
jittery
edgy, high-strung, highly strung, jumpy,
nervy, overstrung, restive, uptight, tense,
nervous
anxious, queasy, uneasy, unquiet, neural,
aflutter,
skittish,
flighty,
troubled, excited, excitable
spooky,
18
angry
grouchy
crabbed, crabby, cross, fussy, grumpy,
bad-tempered, ill-tempered, ill-natured
tired
fed up
disgusted, sick, tired of, displeased
tired
banal, commonplace, hackneyed, oldhat,
shopworn,
stock,
threadbare,
timeworn, trite, well-worn, all in, beat,
bushed, dead, aweary, weary, bleary,
blear, bleary-eyed, blear-eyed, bored,
world-weary,
burned-out,
burnt-out,
careworn, drawn, haggard, raddled,
worn, drooping, flagging, exhausted,
dog-tired, fagged, fatigued, played out,
spent, washed-out, worn-out, worn out,
gone,
footsore,
jaded,
wearied,
knackered, drained, ragged, travel-worn,
drowsy
unrefreshed,
unrested,
whacked,
unoriginal
drowsing, dozy, oscitant, yawning,
asleep, inattentive
sad
gloomy
glooming, gloomful, sulky, grim, blue,
depressed, dispirited, down, downcast,
downhearted, low, low-spirited, blue,
dark, dingy, disconsolate, dismal, grim,
sorry, drab, drear, dreary, dejected,
depressing, cheerless, uncheerful
deplorable,
sad
pitiful,
distressing,
sorry,
lamentable,
bittersweet,
doleful,
19
mournful,
heavyhearted,
pensive,
wistful, tragic, tragical, tragicomic,
tragicomical, sorrowful, bad
Для удобства назовем разработанный словарь – “Dictionary of
classification of emotions” (DCE).
В конечном итоге, в состав словаря вошли свыше 260 слов.
Классификация по эмоциям будет происходить описанным выше способом –
подсчетом
количества
слов
в
твиттах,
соответствующих
каждой
эмоциональной категории путем сравнения слов из словаря DCE.
Алгоритм сентиментного анализа твиттов
Алгоритм сентиментного анализа на основе составленного словаря DCE
был написан на языке С. Из текстового входного файла программой
считываются данные по твиттам, которые ранее были загружены с помощью
Twitter API.
Напомним, что данные входного файла выглядят следующим образом:
Mon May 18 00:34:23 +0000 2015"I need you so bad, my love you drive me mad\ud83c\udfb6
Mon May 18 00:34:23 +0000 2015"RT @VibeMagazine: .@MeekMill drops visuals for 'Energy
(Freestyle)' feat. cameos from @DeJLoaf & @NICKIMINAJ: http:\/\/t.co\/3CcEdunxRX
http:\/\u2026
Mon May 18 00:34:23 +0000 2015"@D1Kid_ thank you\u263a\ufe0f
Mon May 18 00:34:23 +0000 2015"RT @WW_1Dupdates: Harry on the red carpet
\ud83d\ude0d\u2764\ufe0f http:\/\/t.co\/l9yjgaxCA7
Mon May 18 00:34:23 +0000 2015"RT @HisAndHers: The struggle is real for Clippers fans...
#PlaylistForClippers http:\/\/t.co\/FEd33QZa9M
Mon May 18 00:34:23 +0000 2015"DOES ANYONE HAVE LIVESTREAM LINKS???!!?!? #BBMA2015 #BBMAs
Mon May 18 00:34:23 +0000 2015"RT @harrykilos: THEIR FSCES WHEN LIAM WAS THANKING Z THOUGH
\ud83d\udc40\ud83d\ude29\ud83d\udd2b\ud83d\udc80 http:\/\/t.co\/bKBPvgNGnC
Mon May 18 00:34:23 +0000 2015"I've already been drinking so who wants to bring me Chinese
& beer? I'll buy
Mon May 18 00:34:23 +0000 2015"RT @Iirryisreal: but seriously liam is very mature and he
always handles things like an adult and I'm glad I stan him
Mon May 18 00:34:23 +0000 2015"RT @clairemaree64: you're welcome for those legs @Zendaya
\ud83d\ude1d\ud83d\udc4f\ud83d\udc4f\ud83d\udc4f\ud83d\udc4f http:\/\/t.co\/YFFTRqUN64
20
Mon May 18 00:34:23 +0000 2015"@maryxcr she's probably gonna lip synch poorly or something
like there's no point of her being there unless 5h comes& sings like mariah lmao
Mon May 18 00:34:23 +0000 2015"RT @Jaureguable: This fandom trying to figure out what's
going on with Fifth Harmony at the BBMAs. http:\/\/t.co\/RN9eVUp7C5
Таким образом, каждая строка в файле соответствует одному твитту и
содержит информацию по дате и времени публикации, а также само
сообщение. Такое представление информации позволяет анализировать
данные за любой желаемый промежуток времени.
Подробный код программы описан в Приложении 2.
Касательно алгоритма работы, программа поочередно считывает по
одной строке из входного файла и производит анализ сообщения. Происходит
поиск в сообщении слов из DCE, если слово найдено, то частота,
соответствующая определенной эмоции увеличивается на 1.
В связи с тем, что данные по частотам могут быть сколь угодно большие
числа и в каждый момент времени их количество может сильно отличатся,
после подсчета частот, происходи их нормализация по формуле:
𝐹𝑟𝑒𝑞𝑢𝑒𝑛𝑐𝑦𝑖
𝑁𝑜𝑟𝑚𝑎𝑙𝑖𝑧𝑒𝑑 𝑓𝑟𝑒𝑞𝑢𝑒𝑛𝑐𝑦𝑖 = ∑8
𝑖=1 𝐹𝑟𝑒𝑞𝑢𝑒𝑛𝑐𝑦𝑖
,
где 𝑁𝑜𝑟𝑚𝑎𝑙𝑖𝑧𝑒𝑑 𝑓𝑟𝑒𝑞𝑢𝑒𝑛𝑐𝑦𝑖 − нормализованная частота 𝑖 −
ой эмоции, 𝐹𝑟𝑒𝑞𝑢𝑒𝑛𝑐𝑦𝑖 − частота эмоции.
Таким образом, результатом работы программы является вектор частот
по каждой из эмоций для каждого заданного интервала времени. В нашем
случае данные анализировались за каждый час, поэтому для каждого часа в
выходном текстовом файле программа записывала частоты и относительные
частоты для каждого часа.
Результаты работы программы записывались в файл в следующем виде:
Fri May 29
time:
04
21
frequencies: 1014 204 672 3403 145 179
normalized_frequencies: 0.101603 0.020441
0.078357 0.358818
time: 05
frequencies: 953 189 695 3455 113 192
normalized_frequencies: 0.095357 0.018911
0.083350 0.356614
time: 06
frequencies: 253 43 177 916 36 52 229
normalized_frequencies: 0.093773 0.015938
0.084878 0.367680
time: 13
frequencies: 1 1 0 20 1 0 2 28
normalized_frequencies: 0.018868 0.018868
0.037736 0.528302
time: 15
frequencies: 7 1 5 32 5 0 11 43
782 3581
0.067335 0.340982
0.014529
0.017936
833 3564
0.069542 0.345707
0.011307
0.019212
992
0.065604
0.339511
0.013343
0.019274
0.000000
0.377358
0.018868
0.000000
Инструменты анализа
В
качестве
инструментов
анализа
и
прогнозирования
будем
использовать нейронную сеть, который является одним из наиболее
эффективных методов в этой области. Преимущество нейронной сети
заключается в том, что возможно обучение на исторических данных на
конкретном рынке под конкретный финансовый инструмент с целью
дальнейшего построения точного прогноза.
В этом смысле можно сказать, что нейронная сеть позволяет смоделировать
«универсального робота», которого можно обучить под любой рынок вне
зависимости от выбора инструмента торговли.
Рассмотрим более подробно работу нейронной сети.
22
2.2. Нейронная сеть. Принципы работы нейронной сети.
Нервная система человека построена из элементов, которые называются
нейронами. Каждый нейрон обладает многими свойствами, общими с другими
органами тела, но ему присущи абсолютно уникальные способности:
принимать, обрабатывать и передавать электрохимические сигналы по
нервным путям, которые образуют коммуникационную систему мозга.
Искусственный нейрон имитирует свойства биологического нейрона. На
вход искусственного нейрона поступает некоторое множество сигналов,
каждый из которых является выходом другого нейрона. Каждый вход
умножается на соответствующий вес, и все произведения суммируются,
определяя уровень активации нейрона.
Рис. 3 Схема работы персептрона
Множество входных сигналов, обозначенных 𝑥1 , 𝑥2 , …, 𝑥𝑖 , … , 𝑥𝑛 ,
поступают на искусственный нейрон. Эти входные сигналы, в совокупности
обозначаемые вектором Х, соответствуют сигналам, приходящим в синапсы
биологического нейрона. Каждый сигнал умножается на соответствующий вес
𝑤1 , 𝑤, … , 𝑤𝑛 (множество всех весов обозначается вектором W), и поступает
на
суммирующий
блок,
обозначенный
∑.
Суммирующий
блок,
соответствующий телу биологического элемент, складывает взвешенные
входы алгебраически, создавая выход, который мы будем обозначать NET. В
векторных обозначениях это можно записать компактно NET = XW.
23
Сигнал, как правило, далее преобразуется активационной функцией F и
дает выходной нейронный сигнал OUT. Активационная функция может быть
обычной линейной функцией
OUT = F(NET),
где NET – константа, пороговой функцией
1, если 𝑁𝐸𝑇 > 𝑇;
OUT = {
0, если 𝑁𝐸𝑇 < 𝑇
где Т – некоторая постоянная пороговая величина, или же функцией, более
точно
моделирующей
нелинейную
передаточную
характеристику
биологического нейрона и представляющей нейронной сети больший
возможности.
Хотя один нейрон и способен выполнять простейшие процедуры
распознавания, но для серьезных нейронных вычислений необходимо
соединять нейроны в сети. Простейшая сеть (также называется персептроном)
состоит из группы нейронов, образующих слой. Каждый элемент из множество
входов Х отдельным весом соединен с каждым искусственным нейроном. А
каждый нейрон выдает взвешенную сумму входов в сеть.
Удобно считать веса элементами матрицы W. Матрица имеет m строк и
n столбцов, где n – число входов, а m – число нейронов. Например, - это вес,
связывающий третий вход со вторым нейроном. Таким образом, вычисление
выходного вектора N, компонентами которого являются выходы OUT
нейронов, сводится к матричному умножению N = XW, где N и X – векторыстроки.
24
Рис.4 Схема работы нейронной сети
Обучение искусственных нейронных сетей
Важнейшее свойство искусственных нейронных сетей – способность
обучаться. Сеть обучается, чтобы для некоторого множества входов давать
желаемое (или, по крайней мере, сообразное с ним) множество выходов.
Каждое такое входное (или выходное) множество рассматривается как вектор.
Обучение осуществляется путем последовательного предъявления входных
векторов с одновременной подстройкой весов в соответствии с определенной
процедурой. В процессе обучения веса сети постепенно становятся такими,
чтобы каждый входной вектор вырабатывал желаемый выходной вектор.
Различают алгоритмы обучения с учителем и без учителя.
Обучение с учителем предполагает, что для каждого входного вектора
существует целевой вектор, представляющий собой требуемый выход. Вместе
они называются обучающей парой. Обычно сеть обучается на некотором числе
таких обучающих пар. Предъявляется входной вектор, вычисляется выход сети
и сравнивается с соответствующим целевым вектором, разность (ошибка) с
помощью обратной связи подается в сеть, и веса изменяются в соответствии с
алгоритмом, стремящимся минимизировать ошибку. Векторы обучающего
множества предъявляются последовательно, ошибки вычисляются и веса
подстраиваются для каждого вектора до тех пор, пока ошибка по всему
обучающему массиву не достигнет приемлемо низкого уровня.
25
В обучении без учителя не используется целевой вектор. Обучающее
множество состоит лишь из входных векторов. Обучающий алгоритм
подстраивает веса сети так, чтобы получались согласованные выходные
векторы, т.е. чтобы предъявление достаточно близких входных векторов
давало одинаковые выходы.
Процесс обучения, следовательно, выделяет
статистические свойства обучающего множества и группирует сходные
векторы в классы. Предъявление на вход вектора из данного класса даст
определенный выходной вектор, но до обучения невозможно предсказать,
какой выход будет производиться данным классом входных векторов.
Алгоритм обучения однослойного персептрона
Персептрон должен решать задачу классификации по бинарным
входным сигналам. Набор входных сигналов будем обозначать n-мерным
вектором x. Все элементы вектора являются булевыми переменными
(переменными, принимающими значения «истина» и «ложь»). Будем считать,
что значению «ложь» соответствует числовое значение 0, значению «истина»
соответствует 1.
Персептроном будем называть устройство, вычисляющее следующую
систему функций:
𝑚
𝜓 = [∑ 𝑤𝑖𝑗 𝑥𝐼 > 𝜃] ,
𝑗 = 1, … , 𝑛,
𝑖=1
где 𝑤𝑖𝑗 - веса персептрона, 𝜃 - порог, 𝑥𝐼 - значения входных сигналов.
Обучение персептрона состоит в подстройке весовых коэффициентов.
Пусть имеется на набор пар векторов (𝑥 𝛼 , 𝑦 𝛼 ), 𝛼 = 1, … , 𝑝, называемый
обучающей выборкой. Будем называть нейронную сеть обученной на данной
обучающей выборке, если при подаче на входы сети каждого вектора 𝑥 𝛼 на
выходах всякий раз получается соответствующий вектор 𝑦 𝛼 .
26
Предложенный
Ф.
Розенблаттом
метод
обучения
состоит
в
итерационной подстройке матрицы весов, последовательно уменьшающей
ошибку в выходных векторах. Алгоритм включает несколько шагов:
Шаг 0. Начальные значения весов всех нейронов 𝑊(𝑡 = 0) полагаются
случайными.
Шаг 1. Сети предъявляется входной образ 𝑥 𝛼 , в результате формируется
выходной образ 𝑦̃ 𝛼 ≠ 𝑦 𝛼 .
Шаг 2. Вычисляется вектор ошибки 𝛿 𝛼 = (𝑦 𝛼 − 𝑦̃ 𝛼 ), делаемый сетью на
выходе. Дальнейшая идея состоит в том, что изменение вектора весовых
коэффициентов в области малых ошибок должно быть пропорционально
ошибке на выходе и равно нулю, если ошибка равна нулю.
Шаг 3. Вектор весов модифицируется по следующей формуле: 𝑊(𝑡 + ∆𝑡) =
𝑊(𝑡) + 𝜂𝑥 𝛼 ∙ (𝛿 𝛼 )𝑇 . Здесь 0 < 𝜂 < 1 - темп обучения.
Шаг 4. Шаги 1-3 повторяются для всех обучающих векторов. Один цикл
последовательного предъявления всей выборки называется эпохой. Обучение
завершается по истечении нескольких эпох: а) когда итерации сойдутся, т.е.
вектор весов перестает изменяться, или б) когда полная, просуммированная по
всем векторам абсолютная ошибка станет меньше некоторого малого значения
[5].
Теперь возникает вопрос способ описания данных для того, чтобы
можно было воспользоваться нейронной сетью.
27
2.4.
Описание данных для анализа.
Для проверки гипотезы о том, что данные Twitter действительно могут
повысить точность прогнозирования, рассмотрим 2 множества данных. Первое
множество содержит только данные по ценам (Simple set) за предыдущие 3 дня.
Второе
множество
получается
добавлением
к
базовому
множеству
нормализованных частот твиттов со словами, характеризующих 8 базовых
эмоций “happy”, “loving”, “calm”, “energetic”, “fearful”, “angry”, “tired” and
“sad” за определенный день (Extended set).
Simple set представим в виде векторов, состоящих из следующих
элементов (𝑂𝑝𝑒𝑛, 𝐻𝑖𝑔ℎ, 𝐿𝑜𝑤, 𝑉𝑜𝑙𝑢𝑚𝑒), где 𝑂𝑝𝑒𝑛 − цена открытия периода,
𝐻𝑖𝑔ℎ − максимальная цена за данный период, 𝐿𝑜𝑤 − минимальная цена,
𝑉𝑜𝑙𝑢𝑚𝑒 − объем торгов.
Прогнозироваться
будет
𝐶𝑙𝑜𝑠𝑒 −
цена закрытия периода.
В зависимости от того, какой по размеру исторический период будем брать для
прогнозирования, будет зависеть количество элементов на входе.
В нашем случае для обучения сети брался интервал в 8 часов, т.е. для
прогнозирования цены следующего (9-го) часа бралась информация за
предыдущие
8
часов.
Итого,
количество
входных
элементов
для
прогнозирования каждого последующего часа равно 32 (8*4).
Таким образом, Simple set состоит из 32 столбцов.
Extended set представим путем добавления к элементам вектора Simple
set частоты слов по 8 эмоциям (“happy”, “loving”, “calm”, “energetic”, “fearful”,
“angry”, “tired” and “sad”) за предыдущие 8 дней. В результате получаем 96 (32
+ 8х8) столбцов.
Общий вид вектора расширенного множества:
(𝑂𝑝𝑒𝑛, 𝐻𝑖𝑔ℎ, 𝐿𝑜𝑤, 𝑉𝑜𝑙𝑢𝑚𝑒, 𝐻𝑎𝑝𝑝𝑦, 𝐿𝑜𝑣𝑖𝑛𝑔, 𝐶𝑎𝑙𝑚, 𝐸𝑛𝑒𝑟𝑔𝑒𝑡𝑖𝑐, 𝐹𝑒𝑎𝑟𝑓𝑢𝑙, 𝐴𝑛𝑔𝑟𝑦, 𝑇𝑖𝑟𝑒𝑑, 𝑆𝑎𝑑)
28
Глава 3. Построение торговой системы
3.1. Схема работы торговой системы.
Обобщим результаты и рассмотрим схему работы нашей торговой
системы в целом для ее дальнейшей реализации.
1 Этап
База
сообщений
пользователе
й Twitter за N
– дней
Анализатор
сообщений на
основе
сентиментного
анализа
→ 𝑆1 = (𝑒1 , 𝑒2 , … , 𝑒8 )
→ 𝑆2 = (𝑒1 , 𝑒2 , … , 𝑒8 )
………………………….
→ 𝑆𝑁−1 = (𝑒1 , 𝑒2 , … , 𝑒8 )
→ 𝑆𝑁 = (𝑒1 , 𝑒2 , … , 𝑒8 )
Рис.5 Анализ сообщений
На первом этапе анализируются загруженные сообщения из Twitter с
помощью сентиментного анализа за N-дней. На выходе получается N векторов
(за N-дней). Каждый из векторов 𝑆𝑖 = (𝑒1 , 𝑒2 , … , 𝑒8 ) (𝑖 = ̅̅̅̅̅
1, 𝑁) состоит из
нормализованных частот по 8-ми эмоциям (“happy”, “loving”, “calm”,
“energetic”, “fearful”, “angry”, “tired” and “sad”).
Далее на основе исторических цен и полученных N-векторов
формируется расширенное множество Extended set.
2 Этап (построение и обучение нейронной сети)
Обучение нейронной сети происходит последовательно на 2-х
множествах: на множестве Simple set, состоящим из N-векторов типа
(𝑂𝑝𝑒𝑛, 𝐻𝑖𝑔ℎ, 𝐿𝑜𝑤, 𝑉𝑜𝑙𝑢𝑚𝑒),
а затем на расширенном множестве Extended set, полученном на 1 Этапе.
29
Таким образом, получаем 2 торговые системы:
Simple set system, обученная на базовом множестве
Extended set system, обученная на расширенном множестве
Simple
set
Нейронная
сеть
Рис. 6 Обучение Simple set system
Extended
set
Нейронная
сеть
Рис. 7 Обучение Extended set system
После того, как получим 2 обученные на исторических данных торговые
системы, необходимо проверить результаты их работы и вычислить какая из
систем наиболее точно осуществляет прогнозирование.
Реализация первого этапа уже описана выше. Остается 2 этап,
реализация которого описана далее.
30
3.2. Построение и обучение торговых систем на основе нейронной сети
(Simple set system и Extended set system). Оценка и сравнение результатов
работы систем.
Теперь переходим ко второму этапу построения торговой системы –
построение и обучение нейросетей на 2-х множествах: простом (Simple set) и
расширенном (Extended set). Далее, на практике сравним результаты их
работы.
2 этап – построение и обучение нейронной сети
Simple set system
Для построения и обучения нейронной сети был использована пробная
версия программного продукта «STATISTICA Automated Neural Networks»
компании StatSoft. Программа позволяет в автоматическом режиме строить,
обучать, а также проводить анализ работы различных нейронных сетей на
различных данных. При желании, также можно вручную настраивать
требуемые параметры сети.
В нашем случае, для обучения нейронной сети использовались данные
по курсу валютной пары eur/usd за май месяц в почасовой разбивке. Данные по
котировкам брались из сайта finam.ru, где можно в удобном формате загрузить
исторические данные по различным финансовым инструментам за выбранный
период времени. Загруженные данные сохранялись в файле формата .csv, а
затем копировались на лист данных программы STATISTICA для дальнейшего
анализа. Всего для обучения и построения были загружены данные по ценам
за 513 часов.
31
Рис 8. Загруженные данные для анализа
Для
анализа
была
построена
модель
Time
series
(regression)
(нейросетевая модель на основе регрессии временного ряда), т.к. в нашем
случае мы хотим, чтобы наша сеть осуществляла прогнозирование будущих
цен, исходя из исторических данных за прошлый период.
Рис. 9 Построение нейросети и выбор переменных для анализа в программе
STATISTICA
В качестве входных переменных (Continuous inputs) для нейронной сети
были выбраны переменные по цене открытия, закрытия, максимальной,
минимальной ценам и объеме (Open, High, Low, Volume). Целевой переменной
32
(Continuous targets) выбрана цена закрытия периода Close, она и будет далее
прогнозироваться.
Рис. 10 Выбор числа временных шагов и размера выборок для прогнозирования
Далее был выбрано число 8 в качестве Number of time steps used as inputs
– число временных шагов, подаваемых на вход сети. Это означает, что на вход
будут подаваться данные по предыдущим 8-ми периодам (8-ми часам), по ним
и строится прогноз на 1 шаг – 1 час (прогноз следующего часа).
В качестве параметров построения были выбраны соотношения для выборки
Train – 70% (обучение), Test – 15% (тестирование), Validation (контрольная
выборка) – 15%.
Рис. 11 Настройка параметров нейронной сети
Был использован автоматический поиск наилучшей нейронной сети с
числом скрытых слоев от 3 до 10. Обучалось 20 различных сетей и сохранялись
5, которые давали наилучший результат работы. В качестве функций
33
активаций для скрытых и выходных нейронов были выбраны для обучения все
виды. Далее мы выберем наилучшую по результатам. После выбора
необходимых параметров, была запущена программа обучения сетей.
Рис. 12 Процесс обучения нейронных сетей
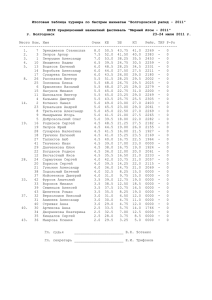
Рис. 13 Результаты процесса обучения
После завершения процесса обучения, программа выдала 5 сетей с
наилучшим результатом работы. Как видно из таблицы, все сети имеют
приблизительно одинаково высокий уровень производительности (>0.99)
близкий к 1 и достаточно маленькой ошибкой.
Рис. 14 Графическое представление результатов прогноза сетей на обучающей выборке
34
На представленном выше графике видно, что каждая из сетей дает
прогнозы, которые близкие к реальным.
Рис. 15 Гистограмма остатков
Если также обратить внимание гистограмму остатков, то все сети имеют
распределение близкое к нормальному. Поэтому для прогнозирования можем
выбрать любую из сетей. Выберем ту, у которой производительность на всех
трех выборках (обучающей, тестовой и контрольной) наибольшая – первая
сеть – MLP-32-8-1. Это сеть с 8-ю скрытыми нейронами, имеющую
логистическую функция активации для скрытого слоя и тождественную
функцию для выходного.
Далее рассчитаем среднюю ошибку прогноза нашей сети на контрольной
и тестовой выборках. Сначала рассчитывалась относительная ошибка каждого
из прогнозов по формуле: 𝐸𝑟𝑟𝑖 =
|𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑖 −𝐹𝑎𝑐𝑡𝑖 |
𝐹𝑎𝑐𝑡𝑖
, где 𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑖 -предсказанное
нейронной сетью значение, 𝐹𝑎𝑐𝑡𝑖 -фактическое значение. Далее бралось
среднее значение всех ошибок.
35
Рис. 16 Результаты прогнозирования сетей на тестовой и контрольной выборках
Были получены следующие результаты:
Средняя относительная
ошибка на контрольной
выборке
0,00116574
Средняя относительная
ошибка на тестовой
выборке
0,001096382
Итого, средняя ошибка на Simple set: 0,001131061, т.е. 0,1131061%.
Extended set system
Следующим этапом будет построение и обучение нейронной сети на
расширенном множестве, т.е. на множестве, содержащем помимо биржевой
информации по ценам и объемам, также данные, полученные путем
сентиментного анализа – относительные частоты слов, соответствующие
различным эмоциональным состояниям.
Для этого, необходимо рассчитать с помощью построенного ранее
анализатора относительные частоты слов в твиттах с разбивкой за каждый 1
час и использовать полученные данные для обучения сети. Как и ранее, для
обучения сети использовали программный продукт STATISTICA.
Итого, входные данные выглядят следующим образом:
36
Рис. 17 Представление входных данных для обучения нейросети на расширенном
множестве
Таким образом, на вход сети подаются 12-мерные вектора вида
(𝑂𝑝𝑒𝑛, 𝐻𝑖𝑔ℎ, 𝐿𝑜𝑤, 𝑉𝑜𝑙𝑢𝑚𝑒, 𝐻𝑎𝑝𝑝𝑦, 𝐿𝑜𝑣𝑖𝑛𝑔, 𝐶𝑎𝑙𝑚, 𝐸𝑛𝑒𝑟𝑔𝑒𝑡𝑖𝑐, 𝐹𝑒𝑎𝑟𝑓𝑢𝑙, 𝐴𝑛𝑔𝑟𝑦, 𝑇𝑖𝑟𝑒𝑑, 𝑆𝑎𝑑)
за предыдущие 8 часов. Как и в прошлом случае, прогнозируется цена
закрытия каждого часа – Close. Итого, для прогнозирования следующей цены
закрытия часа подается 96(12*8) входов.
Воспользовавшись автоматическим обучением на уже расширенном
входном множестве в STATISTICA, получили следующие результаты по
сетям:
Рис. 18 Результаты обучения сетей на расширенном множестве
Все сети имеют практически одинаковую производительность, выберем
ту, у которой она выше – первая в списке сеть – MLP 96-6-1. Эта сеть содержит
6 скрытых нейрона, в качестве функции активации в скрытом слое выступает
Гиперболический тангенс, функция Синуса является выходной функцией.
Рассчитаем среднюю ошибку прогноза на контрольной и тестовой выборках.
37
Рис. 19 Расчет средней ошибки прогноза
Средняя
ошибка
рассчитывается
аналогично,
как
арифметическое всех относительных ошибок прогноза (𝐸𝑟𝑟𝑖 =
среднее
|𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑖 −𝐹𝑎𝑐𝑡𝑖 |
𝐹𝑎𝑐𝑡𝑖
,
где 𝑃𝑟𝑒𝑑𝑖𝑐𝑡𝑖 -предсказанное нейронной сетью значение, 𝐹𝑎𝑐𝑡𝑖 -фактическое
значение).
Итого, средняя ошибка на Extended set: 0,001007943, т.е. 0,1007943%.
По результатам, видно, что средняя ошибка нейронной сети,
построенной на расширенном множестве (данные по ценам, объемам и данные
по твиттам) меньше, чем на простом множестве (данные по ценам, объемам).
Это говорит о том, что на расширенном множестве мы смогли построить сеть,
которая более точно прогнозирует цены закрытия часа, по сравнению с сетью,
использующую лишь данные о котировках. Данное исследование подтвердило
гипотезу о том, что информация, полученная путем сентиментного анализа
твиттов, может использоваться для повышения точности прогноза.
Следует, также отметить, что подобный подход можно использовать для
построения торговых систем для прогнозирования движения цен других
финансовых инструментов: индексы, другие валютные пары, металлы и т.д.
38
Для того, чтобы понять действительно ли на других рынках и
инструментах системы такого рода будут прогнозировать более точно,
необходимо попробовать построить такие системы и проверить на практике
действительно ли точность прогнозов повышается.
Существует еще много вопросов, которые можно исследовать в данной
области. Например, возможность оптимизации путем создания словарей более
точно классифицирующих эмоциональное состояние людей.
Для исследования в работе твитты загружались в реальном времени –
Twitter API дает возможность загружать до 1% всех твиттов. Причем, брались
абсолютно все твитты. На мой взгляд, в дальнейшем, можно рассмотреть
возможность
фильтрации
твиттов
по
ключевым
словам,
тематикам,
георафическому расположению и т.д. и таким образом, попробовать
оптимизировать системы, повысив точность прогнозов.
39
Заключение
Основным практическим результатом работы стало построение двух
торговых систем: системы, использующей лишь биржевую информацию;
системы, которая, помимо биржевой информации использует в работе
информацию о сообщениях Twitter.
Было выявлено, что точность прогнозирования системы, использующей
информацию о сообщениях Twitter выше, чем у системы, работающей лишь на
данных биржи.
Таким образом, можно сделать вывод, что сообщения Twitter могут
повысить точность прогноза. Однако, для каждого отдельного финансового
инструмента необходимо производить обучение и настройку торговой
системы отдельно.
В дальнейшем можно попытаться оптимизировать работу торговой
системы разными способами, например, путем улучшения «словаря эмоций»
для более точной оценки эмоционального состояния людей или путем
предварительной фильтрации сообщений Twitter по определенным ключевым
словам и.т.д. Таким образом, направлений исследования и интересных задач в
области применения информации о твиттах для прогнозирования движения
цен финансовых инструментов довольно много.
40
Список использованной литературы
[1].
Bollen J., Mao H., Zeng X. “Twitter mood predicts the stock market”, 2010
[2].
Ding T, Fang V., Zuo D. “Stock Market Prediction based on Time Series Data and
Market Sentiment”, 2013
[3].
Gashke N., Mayer D. “The Experience and Meta-Experience of Mood”, State
University of New York at Purchase, 1988
[4].
Программный продукт Финам // Официальный сайт [Электронный ресурс]
URL: http://www.finam.ru/ (Дата обращения 29.05.2015)
[5].
Kumar S., Morstater F, Liu H. “Twitter Data Analytics”, 2013
[6].
Makise K. “Twitter API: Up and Running”, O’REILLY, 2009
[7].
Pak A., Paroubek P. “Twitter as a Corpus for Sentiment Analysis and Opinion
Mining”, France, 2010
[8].
Porshnev A., Redkin I., Shevchenko A. “Improving Prediction of Stock Market
Indices by Analyzing the Psychological States of Twitter Users”. Social Science
Research Network, Rochester, NY, 2013
[9].
Porshnev A., Redkin I., Karpov N. “Modelling movement of stock market indexes
with data from emoticons of Twitter users”, 2014
[10]. Программный продукт StatSoft® // Официальный сайт StatSoft Russia
[электронный
ресурс].
URL:
http://statsoft.ru/products/STATISTICA_
Neural_Networks/ (Дата обращения 26.05.2015)
[11]. Программный продукт Streaming API компании Twitter Inc. // Официальный
сайт Twitter Inc.: [электронный ресурс]. URL: http://www.twitter.com (Дата
обращения 20.02.2015)
[12]. Жуков Е.Ф. «Рынок ценных бумаг». Юнити, 2009 г.
[13]. Лиховидов В.Н., Сафин В.И. «Представление данных и основные фигуры на
рынке FOREX». FxClub, г.Москва, 2001 г.
[14]. Яхъяева Г.Э. «Нечеткие множества и нейронные сети». Бином, г.Москва,
2008г.
41
Приложение 1
Thu May 28 05:19:34 +0000 2015"Dollar rises to 13-year high against yen
http:\/\/t.co\/oeM4pIXazh
Thu May 28 05:19:34 +0000 2015"@AlexandraPresny Blessed!
Thu May 28 05:19:34 +0000 2015"Deals #5053: http:\/\/t.co\/Bk5tNcEn8f Bali Cotton
Creations Hi-Cut style 2191 http:\/\/t.co\/kHR4MrFset
Thu May 28 05:19:35 +0000 2015"No mom, I can't sleep when it feels like the SAHARA DESERT
IN MY ROOM
Thu May 28 05:19:35 +0000 2015"RT @misguider: i wanna be the person you have on your mind
all the time
Thu May 28 05:19:35 +0000 2015"RT @misguider: i wanna be the person you have on your mind
all the time
Thu May 28 05:19:35 +0000 2015"RT @FactSoup: Never be afraid to be yourself.
Thu May 28 05:19:35 +0000 2015"RT @Janessa_Mariee: @john @sammy I love this shots feature
where it shows the score of the game. \ud83d\ude0d brilliant!!!!!!!! @shots
http:\/\/t.co\/dmA\u2026
Thu May 28 05:19:35 +0000 2015"RT @watchs_: 9 Pictures That Show How Michael Jackson's
Face Changed\n\n http:\/\/t.co\/QR7rW7GCru http:\/\/t.co\/EEYFWEiJj6
Thu May 28 05:19:35 +0000 2015"@xCloka IM CHOKING ON MY DRINK HAHAHAHHDJAHAHAHAH
Thu May 28 05:19:35 +0000 2015"please watch &amp; share a video on the awareness of
Clinical Depression : http:\/\/t.co\/heOUlrfGyz \n#MentalHealthAwarenessMonth #Miami #Cali
Thu May 28 05:19:35 +0000 2015"I should stop drinkin right now but my bottle isn't empty.
Um not a quitter bruh
Thu May 28 05:19:35 +0000 2015"@VaughnPalmer @keithbaldrey If more than 300,000 ha burns
again this year, that will be 1st time 2 back to back 300,000+ years in BC history
Thu May 28 05:19:35 +0000 2015"RT @watchs_: 9 Pictures That Show How Michael Jackson's
Face Changed\n\n http:\/\/t.co\/QR7rW7GCru http:\/\/t.co\/EEYFWEiJj6
Thu May 28 05:19:35 +0000 2015"Craving for waffles\ud83c\udf6b
Thu May 28 05:19:35 +0000 2015"RT @HalseyItalia: 'Halsey's butt is better than you'
http:\/\/t.co\/mGBMd8olzL
Thu May 28 05:19:35 +0000 2015"RT @sensitivebaby: i was too good to you
Thu May 28 05:19:35 +0000 2015"Pier drunk with his drunk ass
Thu May 28 05:19:35 +0000 2015"RT @VIPGDJ: Youngbae and kwon twins liked GD's posts
http:\/\/t.co\/8vdp9WUQ88
Thu May 28 05:19:35 +0000 2015"RT @watchs_: 9 Pictures That Show How Michael Jackson's
Face Changed\n\n http:\/\/t.co\/QR7rW7GCru http:\/\/t.co\/EEYFWEiJj6
Thu May 28 05:19:35 +0000 2015"RT @Kayluh_luh: @ryanedgarjames come turn my light off
pleaseeee!! I'm too comfy in bed
Thu May 28 05:19:35 +0000 2015"@Dylans_Graphics that means give me pack
Thu May 28 05:19:35 +0000 2015"RT @Gurmeetramrahim: Congratulations n blessings to all for
adding up 4 new Asia n India records to the name of MSG The Messenger http:\/\/t.\u2026
Thu May 28 05:19:36 +0000 2015"when's it my turn to get fucked the fuck up
Thu May 28 05:19:36 +0000 2015"RT @ivanastrada1: SOLO 6 DIAS PARA THE WALKING DEAD\u2665
Thu May 28 05:19:36 +0000 2015"@pwhiteley41 @Buybeckford @themightyleeds don't agree with
a clean slate mate they should go not acceptable IMO taking piss out of club
Thu May 28 05:19:36 +0000 2015"RT @9GAG: Is your summer body ready?\n\nMe:
http:\/\/t.co\/QGSOlKtYPT
Thu May 28 05:19:36 +0000 2015"NORTH'S EYELASHES
Thu May 28 05:19:36 +0000 2015"Baby fix me
Thu May 28 05:19:36 +0000 2015"Can care less. Do you \u270c
Thu May 28 05:19:36 +0000 2015"RT @CountOnVic: Wayyyy up I feel blessed #SheWon
https:\/\/t.co\/QYordBB9fP
Thu May 28 05:19:36 +0000 2015"@MULLINGERECTION: My #TeenChoice nominee for
#ChoiceMusicGroupMale is One Direction http:\/\/t.co\/aueNMslJYu\n\n60
Thu May 28 05:19:36 +0000 2015"I've never done heroine
Thu May 28 05:19:36 +0000 2015"RT @GirlNotes: id rather be a nap queen than a \ntrap queen
tbh
42
Thu May 28 05:19:36 +0000 2015"7 Rules to Follow to Become a Better Conversationalist http:\/\/t.co\/RVUgwPRKu5 http:\/\/t.co\/Y217CrVBci
Thu May 28 05:19:37 +0000 2015"RT @WorIdStarVidz: mind = blown https:\/\/t.co\/KwmoZwexOj
Thu May 28 05:19:37 +0000 2015"RT @OnlyHipHopFacts: \Waaaaaaay up I feel blessed\"
https:\/\/t.co\/OSlYl4sq5I"
Thu May 28 05:19:37 +0000 2015"oh and red edgeworth vs blue wright
Thu May 28 05:19:37 +0000 2015"@RubaJJ i know i think HEB is the only district that lets
us get out so early..
Thu May 28 05:19:37 +0000 2015"RT @SLAMonline: Kanye is impressed.
http:\/\/t.co\/VaVWMPJJkl
Thu May 28 05:19:37 +0000 2015"RT @MyrandaMendozaa: i love you being around..did that
change for you?
Thu May 28 05:19:37 +0000 2015"Warriors oust Rockets in Game 5, off to Finals
http:\/\/t.co\/IKkf4jfyXr
Thu May 28 05:19:37 +0000 2015"It's always there. Sometimes in the front, sometimes in the
back, it's always there somewhere.
Thu May 28 05:19:37 +0000 2015"RT @AdamSpolane: Crap, I had McHale as the first first
person to rip a boxscore at the podium. He was -120, Harden +100, Riley Curry was +2\u2026
Thu May 28 05:19:37 +0000 2015"RT @gifsIrh: ok this is so cute !!
https:\/\/t.co\/wfhnd1XtYk
Thu May 28 05:19:37 +0000 2015"\@KNBeautiesPH: Oh my blue hearts! \ud83d\ude0d\ud83d\udc99
-\ud83c\udf80 http:\/\/t.co\/oeK65PrWGi\"\n#PSYAngGabingHindiMalilimutan"
Thu May 28 05:19:37 +0000 2015"RT @MedievalReacts: Barber: \what you after mate?\n\nMe:
\"just spruce me up a bit\"\n\nBarber: \"say no more fam\" http:\/\/t.co\/Af0kNfReQV"
Thu May 28 05:19:37 +0000 2015"\u201c@BestKathNiels: From A to Z all that really matters
is I and U. \ud83d\udc99\n\n#PSYAngGabingHindiMalilimutan - \ud83d\udc30
http:\/\/t.co\/crXINp1y4V\u201d
Thu May 28 05:19:37 +0000 2015"RT @SexualGif: a night like this would be chill
\ud83c\udf0c\ud83c\udf06\u26fa\ufe0f http:\/\/t.co\/K1wi3WxX8N
Thu May 28 05:19:38 +0000 2015"\u201c@KrisVinesGames: @IonnaMcKenzie Looking good
\ud83d\ude09\ud83d\udc4d\u201dthank you\u2764\ufe0f
Thu May 28 05:19:38 +0000 2015"RT @NBA_Skits: Lil B reminding the crowd who owns the
cooking dance. \nhttp:\/\/t.co\/uYCPMRmZI5
Thu May 28 05:19:38 +0000 2015"RT @NYTHealth: Strong evidence that treating more people
with H.I.V. earlier would save more lives http:\/\/t.co\/WWXqOKQcnh
Thu May 28 05:19:38 +0000 2015"Hi @Harry_Styles!\nI love you so much \ud83d\udc98\nMy
birthday is on \nJune 3rd, &amp; \nIt'll mean a lot for your,\nCongratulations! \nx22
Thu May 28 05:19:38 +0000 2015"Girls Who Squat Before And After. http:\/\/t.co\/K52O1EoSAm
#Workout #diet #healthy #girls #fitness #fispo http:\/\/t.co\/5ifwaALASD
Thu May 28 05:19:38 +0000 2015"#ChoiceTVChemistry Oliver &amp; Felicity
\n#ChoiceTVBreakOutStar Emily Bett Rickards &amp; Carlos Valdes #ChoiceSciFiTVShow Arrow
\n#TeenChoice 14
Thu May 28 05:19:38 +0000 2015"#NowPlaying \My Ghost\" Glass Pear da Streets Of Love
\u266b http:\/\/t.co\/g1QmoTHs6m"
Thu May 28 05:19:38 +0000 2015"Stalkistice Yo
Thu May 28 05:19:38 +0000 2015"RT @femaIes: this just kills me...
http:\/\/t.co\/9TznSdRRvH
Thu May 28 05:19:38 +0000 2015"@DMartinez_04 lol I passed all my classes though
\ud83d\ude02\ud83d\ude02\ud83d\ude02
Thu May 28 05:19:38 +0000 2015"Translates into 8 out of 10 days of pure profits!
http:\/\/t.co\/QCPqAe1qTm #binarytradingoptions
Thu May 28 05:19:38 +0000 2015"76 My #TeenChoice nominee for #ChoiceMusicNextBigThing is
Zayn Malik http:\/\/t.co\/e2iBEv1S90
Thu May 28 05:19:38 +0000 2015"RT @LOHANTHONY: bye dana :( keep the east coast warm and
fabulous for me. never not all smiles when i'm around this\u2026
https:\/\/t.co\/9m3fNWYL5u
Thu May 28 05:19:38 +0000 2015"Let's be honest, everyone was watching Riley Curry during
that press conference. #RileyCurry #toocute
Thu May 28 05:19:38 +0000 2015"I just wanna cuddle
43
Приложениие 2
В приложении подробно описана реализация программы сентиментного
анализа твиттов. Программа написана на языке С.
#pragma warning(disable: 4996)
#include <string.h>
#include <stdio.h>
using namespace std;
//////////////////////////главная
функция//////////////////////////
int main()
{
int* semant_func(char*);
FILE *fin;
FILE *fout;
char arr[2000];
char date[10], tmp_date[10];
char time[2], tmp_time[2];
char *tweet;
int flag = 0;
int total_freq=0;
float temp;
int flag_time = 0;
int* result;
int result2[8] = { 0, 0, 0, 0, 0, 0, 0, 0 };
int n = 0;
fin = fopen("Sentiment_Input_29_05.txt", "r");
////входной файл
fout = fopen("Sentiment_Output_29_05.txt", "w");
////////////выходной файл
while (fgets(arr, 2000, fin) != NULL){
44
for (int i = 0; i < 10; i++) {
tmp_date[i] = arr[i];
}
for (int j = 0; j < 2; j++){
tmp_time[j] = arr[11 + j];
}
tweet = &arr[31];
if (flag == 0) {
for (int i = 0; i < 10; i++) { date[i] =
tmp_date[i]; fprintf(fout, "%c", date[i]); }
fprintf(fout, "\n");
fprintf(fout, "\ntime: ");
for (int j = 0; j < 2; j++){
time[j] = tmp_time[j];
fprintf(fout, "%c", time[j]);
}
//fprintf(fout, "\n");
flag = 10;
}
for (int i = 0; i < 10; i++){
if (date[i] != tmp_date[i]){
date[i] = tmp_date[i];
fprintf(fout, "%c", date[i]);
for (int i = 0; i < 8; i++){
result2[i] = 0;
}
}
}
result = semant_func(tweet);//////вызов функции
///сентиментного анализа
for (int i = 0; i < 8; i++){
45
}
result2[i] = result2[i] + result[i];
///-----
for (int j = 0; j < 2; j++){
if (time[j] != tmp_time[j]){
time[j] = tmp_time[j];
flag_time = 1;
}
}
if ((flag_time == 1)){
fprintf(fout, "\nfrequencies: ");/////////вывод
частот
for (int y = 0; y < 8; y++) {
fprintf(fout, " %d ", result2[y]);
total_freq = total_freq + result2[y];
}
fprintf(fout, "\nnormalized_frequencies: ");
//вывод нормализованных
частот
if (total_freq != 0){
for (int y = 0; y < 8; y++) {
temp = result2[y];
temp = (temp / total_freq);
fprintf(fout, " %f ", temp);
}
}
fprintf(fout, "\ntime: ");
for (int j = 0; j < 2; j++){
fprintf(fout, "%c", time[j]);
}
for (int y = 0; y < 8; y++) {
total_freq = result2[y] = 0;
}
46
flag_time = 0;
flag = 1;
}
}
fprintf(fout, "\nfrequencies: ");
for (int y = 0; y < 8; y++) {
fprintf(fout, " %d ", result2[y]);
total_freq = total_freq + result2[y];
}
fprintf(fout, "\nnormalized_frequencies: ");
if (total_freq != 0){
for (int y = 0; y < 8; y++) {
temp = result2[y];
temp = (temp / total_freq);
fprintf(fout, " %f ", temp);
}
}
fclose(fin);
fclose(fout);
return 0;
}
//////////////////функция сентиментного
анализа//////////////////
int* semant_func(char* message){
int freq_arr[8] = { 0,0,0,0,0,0,0,0 };
char* emotions8[8] = { "happy", "loving", "calm",
"energetic", "fearful/anxious", "angry", "tired", "sad"};
//freq_arr[0] = "happy"
char* happy[20] = {"happy", "lovely", "felicitous",
"glad", "well - chosen", "blessed", "blissful", "bright",
"golden", "halcyon", "prosperous", "laughing", "riant",
47
"fortunate", "willing","adorable", "endearing", "beautiful",
"lovable", "loveable"};
//freq_arr[1] = "loving"
char* loving [31] = { "loving", "caring", "adoring",
"doting", "fond", "affectionate", "fond", "lovesome",
"tender", "amative", "amorous", "amatory", "romantic",
"attached", "captivated", "charmed", "enamored",
"infatuated", "in love", "potty", "smitten", "soft on",
"taken with", "idolatrous", "loverlike", "loverly",
"overfond", "tenderhearted", "touchy - feely", "uxorious",
"compassionate"};
//freq_arr[2] = "calm"
char* calm [19]= { "calm", "content", "unagitated",
"serene", "tranquil", "composed", "placid", "quiet", "still",
"smooth", "unruffled", "settled", "windless",
"contented", "complacent", "self - satisfied",
"self - complacent", "satisfied", "smug"};
//freq_arr[3] = "energetic"
char* energetic [47]= { "active", "peppy", "combat ready", "fighting", "participating", "alive", "dynamic",
"progressive", "operational", "activist", "activistic",
"hands - on", "proactive", "involved", "about", "astir",
"acrobatic", "athletic", "gymnastic", "agile", "nimble",
"quick", "spry", "hot", "hyperactive", "overactive", "on the
go", "sporty", "activated", "counteractive", "surface active", "brisk", "bustling", "busy", "going", "open",
"springy", "existent", "existing", "alive", "live",
"eruptive", "activated",
"bouncing", "bouncy", "spirited", "zippy"};
//freq_arr[4] = "fearful/anxious"
char* fearful[23] = { "jittery", "nervous", "edgy",
"high - strung", "highly strung", "jumpy", "nervy",
"overstrung", "restive", "uptight", "tense",
"anxious", "queasy", "uneasy", "unquiet", "neural",
"aflutter", "skittish", "flighty", "spooky", "troubled",
"excited", "excitable"};
48
//freq_arr[5] = "angry"
char* angry[14] = { "grouchy", "fed up", "crabbed",
"crabby", "cross", "fussy", "grumpy", "bad - tempered", "ill
- tempered", "ill - natured",
"disgusted", "sick", "tired of", "displeased"};
//freq_arr[6] = "tired"
char* tired [60]= { "tired", "drowsy", "banal",
"commonplace", "hackneyed", "old - hat", "shopworn", "stock",
"threadbare", "timeworn", "trite", "well - worn", "all in",
"beat", "bushed", "dead", "aweary", "weary", "bleary",
"blear", "bleary - eyed", "blear - eyed", "bored", "world weary", "burned - out", "burnt - out", "careworn", "drawn",
"haggard", "raddled", "worn", "drooping", "flagging",
"exhausted", "dog - tired", "fagged", "fatigued", "played
out", "spent", "washed - out", "worn - out", "worn out",
"gone", "footsore", "jaded", "wearied", "knackered",
"drained", "ragged", "travel - worn", "unrefreshed",
"unrested", "whacked", "unoriginal",
"drowsing", "dozy", "oscitant", "yawning",
"asleep", "inattentive"};
//freq_arr[6] = "sad"
char* sad [45]= { "gloomy", "sad", "glooming",
"gloomful", "sulky", "grim", "blue", "depressed",
"dispirited", "down", "downcast", "downhearted", "low", "lowspirited", "blue", "dark", "dingy", "disconsolate", "dismal",
"grim", "sorry", "drab", "drear", "dreary", "dejected",
"depressing", "cheerless", "uncheerful",
"deplorable", "distressing", "lamentable",
"pitiful", "sorry", "bittersweet", "doleful", "mournful",
"heavyhearted", "pensive", "wistful", "tragic", "tragical",
"tragicomic", "tragicomical", "sorrowful", "bad"};
int length_arr[8] = {20,31,19,47,23,14,60,45};
for (int i = 0; i < length_arr[0]; i++){
49
if (strstr(message, happy[i]) != NULL){
freq_arr[0] = freq_arr[0] + 1;
}
}
for (int i = 0; i < length_arr[1]; i++){
if (strstr(message, loving[i]) != NULL){
freq_arr[1] = freq_arr[1] + 1;
}
}
for (int i = 0; i < length_arr[2]; i++){
if (strstr(message, calm[i]) != NULL){
freq_arr[2] = freq_arr[2] + 1;
}
}
for (int i = 0; i < length_arr[3]; i++){
if (strstr(message, energetic[i]) != NULL){
freq_arr[3] = freq_arr[3] + 1;
}
}
for (int i = 0; i < length_arr[4]; i++){
if (strstr(message, fearful[i]) != NULL){
freq_arr[4] = freq_arr[4] + 1;
}
}
for (int i = 0; i < length_arr[5]; i++){
if (strstr(message, angry[i]) != NULL){
freq_arr[5] = freq_arr[5] + 1;
}
}
for (int i = 0; i < length_arr[6]; i++){
if (strstr(message, tired[i]) != NULL){
freq_arr[6] = freq_arr[6] + 1;
}
}
50
for (int i = 0; i < length_arr[7]; i++){
if (strstr(message, sad[i]) != NULL){
freq_arr[7] = freq_arr[7] + 1;
}
}
return freq_arr;
}