И.А. КУЗНЕЦОВ Научный руководитель – А.И. ГУСЕВА, д.т.н, профессор
реклама

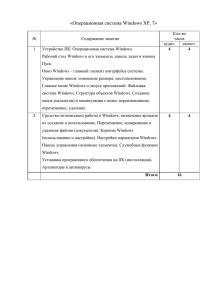
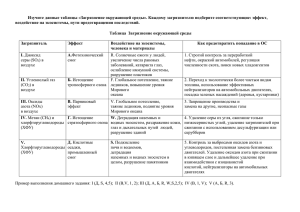
И.А. КУЗНЕЦОВ Научный руководитель – А.И. ГУСЕВА, д.т.н, профессор Национальный исследовательский ядерный университет «МИФИ» ПРЕДОБРАБОТКА ДАННЫХ, ВЫБОР И ФОРМИРОВАНИЕ ПРИЗНАКОВ ПРИ АНАЛИЗЕ ДАННЫХ При интеллектуальном анализе данных этап предобработки, порой, занимает до 80% времени исследователя. Если отнестись к этому этапу недостаточно серьезно, то придется столкнуться со следующим принципом: низкокачественная информация на входе – бесполезный результат на выходе. Работа выполнена при поддержке гранта РФФИ № 15-07-08742. При работе с каким-то набором данных никогда нельзя быть уверенным в том, что содержащиеся в нем данные представлены без пропусков, ошибок и противоречий. Очень часто такие наборы называют «сырыми», т.е. без какой-либо предварительной обработки. Основная задача этапа предобработки – это приведение данных из низкокачественных к высококачественным, т.е. полным и точным. Среди проблемных зон в «сырых» наборах выделяют следующие уровни [1]: уровень ячейки таблиц: o орфографические ошибки; o отсутствие данных; o фиктивные значения; o логически неверные значения; o составные значения; уровень записи в БД: o противоречивость значений в разных полях записи; уровень таблицы в БД: o нарушение уникальности; o отсутствие стандартов. Сам процесс очистки данных состоит из следующих этапов (см. Рис.1): Рисунок 1. Этапы предобработки данных Дополнительной задачей, от решения которой во многом зависит качество результатов – это процесс выделения и формирования новых признаков из набора данных. В одном наборе данных количество признаков может быть огромным и достигать 100 000 и более. В этом случае необходимо выбрать наиболее оптимальные признаки, так как их огромное количество может создать только лишний шум, привести к переобучению алгоритма, увеличить количество вычислений и снизить итоговую точность алгоритма. Существует ряд методов для выделения ключевых признаков из существующего набора [2]: Метод фильтров; Метод «обертки»; Встроенные методы. Иногда дополнительно выделяют гибридный метод, основанный на методе фильтров и методе «обертки». Существует также ряд подходов, которые позволяют снизить количество первоначальных признаков одним из следующих образов: удаление столбцов, где слишком много пропусков; удаление сильно коррелирующих между собой столбцов; метод главных компонент – удаление лишних столбцы с минимальной потерей информации; метод независимых компонент – расширение метода главных компонент и факторного анализа; и другие. Несмотря на обилие автоматических алгоритмов отбора и сокращения размерности набора данных, одним из ключевых факторов высокого качества итогового результата будет являться аналитическая работа исследователя при формировании производных признаков на основе существующих. Список литературы 1. 2. Барсегян А.А., Куприянов М.С., Холод И. И., Тесс М. Д., Елизаров С. И. – Анализ данных и процессов: учебное пособие, 3-е издание. СПб.: БХВПетербург, 2009 – 512 с. Priti Gupta, Omdutt Sharma. – Feature selection: an overview. International Journal of Information Engineering and Technology (IMPACT: IJIET) ISSN(E): Applied; ISSN(P): Applied Vol. 1, Issue 1, Jul 2015, 1-12