лабораторная работа 3 - Новгородский государственный
реклама

МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ
НОВГОРОДСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
ИМЕНИ ЯРОСЛАВА МУДРОГО
СТАТИСТИКА
Учебно-методическое пособие
по выполнению лабораторных работ
ВЕЛИКИЙ НОВГОРОД
2013
ББК 60.6я73
О28
Печатается по решению
РИС НовГУ
Рецензент
доктор экономических наук, профессор Омарова Н.Ю.
кандидат экономических наук, доцент Кормановская И.Р.
Статистика. Учебно-методическое пособие по выполнению лабораторных работ. / Сост.: Г.В.
Фетисова, Н.И. Гришакина, А.С. Зарецкая – НовГУ им. Ярослава Мудрого – Великий Новгород, 2013. – 76 с.
В пособии изложены основные требования, предъявляемые кафедрой при выполнении
лабораторных работ по дисциплинам «Статистика», «Статистика (теория статистики)», «Общая теория
статистики» для экономических специальностей и направлений.
В настоящем издании рассматривается содержание семи лабораторных занятий, представлены
задания для самостоятельной работы студентов. Приведены типовые примеры расчета статистических
показателей по каждой теме с помощью MS Excel 2007 и ППП Statistica 10.0.
Учебно-методическое издание предназначено для студентов очной и заочной форм обучения,
магистрантов, аспирантов.
ББК 60.6я73
® Новгородский государственный
университет, 2013
® Фетисова Г.В., Гришакина Н.И.,
Зарецкая А.С.,
составление, 2013
2
СОДЕРЖАНИЕ
ВВЕДЕНИЕ............................................................................................................................. .....................4
ЛАБОРАТОРНАЯ РАБОТА 1. ПОСТРОЕНИЕ АНАЛИТИЧЕСКОЙ ГРУППИРОВКИ В MS
EXCEL 2007..................................................................................................................................................5
ЛАБОРАТОРНАЯ РАБОТА 2. РАСЧЕТ СРЕДНИХ ВЕЛИЧИН С ИСПОЛЬЗОВАНИЕМ MS
EXCEL 2007..................................................................................................................................................9
ЛАБОРАТОРНАЯ РАБОТА 3. РАСЧЕТ ПОКАЗАТЕЛЕЙ ВАРИАЦИИ В MS EXCEL 2007..........16
ЛАБОРАТОРНАЯ РАБОТА 4. РАСЧЕТ ПОКАЗАТЕЛЕЙ В ППП STATISTICA 10.0.....................26
ЛАБОРАТОРНАЯ РАБОТА 5 АНАЛИЗ РЯДОВ ДИНАМИКИ С ПОМОЩЬЮ MS EXCEL 2007.32
ЛАБОРАТОРНАЯ РАБОТА 6. КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ В MS EXCEL
2007.................................................................................................................... .........................................41
ЛАБОРАТОРНАЯ РАБОТА 7. КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ В ППП
STATISTICA 10.0......................................................................................................................... ..............50
СПИСОК ЛИТЕРАТУРЫ.........................................................................................................................62
ПРИЛОЖЕНИЯ..........................................................................................................................................63
3
ВВЕДЕНИЕ
В связи с широким использованием современных компьютерных технологий и стандартных
пакетов программ при проведении анализа показателей, характеризующих разнообразные экономические
явления, к специалистам высокой квалификации, предъявляются новые требования, которые предполагают
знание этих технологий и программ и, как следствие, необходимость обучения студентов применению этих
технологий в решении разных экономических и социальных задач.
Статистика как отрасль знаний, описывающая массовые социально-экономические явления и
использующая для изучения этих явлений различные статистические методы и приёмы (сводка и
группировка, расчёт средних, относительных показателей, применение индексного метода и т.д.), должна
быть в прикладной своей части разработана в лабораторном практикуме.
Выполнение данного лабораторного практикума базируется на знании и умении применять
приложения Microsoft Excel 2007, а также ППП Statistica 10.0. Приёмы и методы обработки исходных
данных используют различные инструментарии таблиц Excel (установка фильтров при группировке,
применение формул при расчётах средних величин признаков, суммарных значений признака, различных
относительных величин, в том числе и индексов, построение графических изображений исходных и
расчётных данных).
Целью выполнения лабораторных работ по статистике является получение студентами навыков
практического применения полученных теоретических знаний. На лабораторных занятиях студенты
производят расчеты по данным заданий для самостоятельной работы с использованием MS Excel 2007, ППП
Statistica 10.0. Учебными планами и рабочими программами по статистике предусмотрено проведение
лабораторных занятий по следующим темам:
– построение статистической группировки;
– расчет средних величин;
– расчет показателей вариации;
– анализ динамических рядов;
– корреляционно – регрессионный анализ.
В каждой работе представлены поэтапная характеристика и примеры выполнения лабораторных
заданий, а так же упражнения для самостоятельной работы студентов.
По каждой теме лабораторной работы студент представляет на кафедру отчет, содержащий
результаты обработки данных на компьютере, анализ результатов. Оформление отчетов по лабораторным
занятиям выполняются в соответствии с Методическими указаниями по оформлению текстовых учебных
документов в институте экономики и управления НовГУ [14].
Образец оформления титульного листа приведен в приложении А.
3
ЛАБОРАТОРНАЯ РАБОТА 1
1.1 ПОСТРОЕНИЕ АНАЛИТИЧЕСКОЙ ГРУППИРОВКИ В MS EXCEL 2007
Основные термины: группировка, факторный признак, результативный признак, аналитическая
группировка, ранжирование, размах вариации, ряд распределения, вариант, частота, полигон, гистограмма.
Ход работы: Для построения аналитической группировки в MS Excel воспользуйтесь знаниями по
курсу «Информатика» и выполните последовательно следующие этапы:
1. Создать файл с исходными данными (таблица 1).
№ п/п
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Таблица 1
Данные о работе 25 предприятий одной из отраслей промышленности
Среднегодовая стоимость основных
Объем продукции, млн. руб.
производственных средств, млн. руб.
42
44
82
107
52
60
50
54
65
86
74
96
65
113
32
33
68
72
32
28
32
32
41
56
40
49
57
69
40
68
55
50
37
43
34
42
58
90
23
22
47
50
47
52
58
88
71
87
28
30
2. Произвести сортировку введенной информации по группировочному признаку. В данном
случае группировочным (факторным) признаком выступает «среднегодовая стоимость основных
производственных средств» (см. рисунок 1)
3. Определить размах вариации (R=Xmax–Xmin =82-23=59) путем ввода соответствующей
формулы (например, =B26 – B2).
4. Определить количество групп путем ввода формулы в свободную ячейку: =1+3,322*LOG(25). В
нашем случае n=1+3,322*LOG(25)=5,64, оставим 5 [12].
5. Определите величину интервала (h = R / n). В нашем случае h =59 / 5 = 11,8, возьмем шаг
интервала, равный целому числу 12 [20].
6. Построить и заполнить групповую сводную таблицу, в которой отразить распределение
факторного признака на группы, частоту (число предприятий, входящих в соответствующий интервал), а
также суммарные и средние значения факторного и результативного признаков (см. рисунок 2).
7. На основе полученных данных с помощью мастера диаграмм построить гистограмму и
полигон. При построении гистограммы по оси абсцисс отложить границы интервалов, по оси ординат –
частоту. При построении полигона по оси абсцисс отложить середины интервалов, по оси ординат –
частоту.
8. Сделать выводы относительно влияния факторного признака на результативный.
4
Рис. 1. Сортировка данных по показателю «Среднегодовая стоимость основных производственных
средств»
Рис. 2. Результаты заполнения сводной таблицы
5
1.2 ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
Вариант 1. Имеются данные о производительности труда и стаже работы рабочих по
производству пластиковых окон ООО «Стекло»
№ п/п Выработка, штук
Стаж работы в
№ п/п
Выработка, штук
Стаж работы в фирме,
фирме, лет
лет
1
28
0
17
42
2
2
35
0
18
70
26
3
68
20
19
70
25
4
65
20
20
60
17
5
55
9
21
55
18
6
65
20
22
71
18
7
45
6
23
60
25
8
68
25
24
70
25
9
55
14
25
62
23
10
40
0
26
40
1
11
56
13
27
65
10
12
48
5
28
54
16
13
50
12
29
65
26
14
65
20
30
68
22
15
42
1
31
32
3
16
40
1
32
57
14
Вариант 2. Имеются данные о производительности труда и месячной заработной плате рабочих
по производству пластиковых окон ООО «Стекло»
№ п/п
Выработка, штук
Заработная плата,
№ п/п
Выработка, штук
Заработная плата,
тыс. руб.
тыс. руб.
1
31
31,5
16
44
46,1
2
35
42,8
17
70
54,2
3
67
51,2
18
70
58,2
4
65
52,7
19
60
50,4
5
51
48,3
20
55
46,8
6
65
53,9
21
71
57,1
7
45
45,8
22
60
49,2
8
68
52,7
23
70
53,9
9
55
46,1
24
62
53,1
10
40
46,1
25
40
42,8
11
56
50,4
26
65
50,7
12
48
46,1
27
54
43,9
13
50
44,3
28
65
54,7
14
65
52,9
29
68
57,1
15
42
43,6
30
36
38,1
Вариант 3. Имеются данные о величине собственных оборотных средств (СОС) и заемных
средствах предприятий региона
№ п/п
Величина
Сумма кредита,
№ п/п
Величина
Сумма кредита,
собственных
млн. руб.
собственных
млн. руб.
оборотных средств,
оборотных
млн. руб.
средств, млн. руб.
1
39,5
4,5
11
36,8
3,5
2
35,1
4,5
12
39,5
5,5
3
69,7
2,1
13
71,2
3,5
4
65,4
3,1
14
63,8
3,9
5
21,8
5,9
15
55,9
4,1
6
85,1
1,5
16
71,2
3,5
7
56,7
2,5
17
34,9
5,8
8
49,1
2,5
18
49,2
2,9
9
81,3
1,5
19
62,8
2,4
10
29,9
3,5
20
49,1
5,4
6
Вариант 4. Имеются данные о производительности труда рабочих и прибыли от продаж
предприятий региона
№ п/п Производительность
Прибыль от
№ п/п
Производительность
Прибыль от
труда, млн. руб. на
продаж, млн. руб.
труда, млн. руб. на
продаж, млн.
чел.
чел.
руб.
1
2,7
32,7
16
3,9
46,1
2
1,9
25,8
17
4,7
54,2
3
2,6
51,2
18
1,8
28,4
4
3,8
54,2
19
3,6
50,4
5
2,6
32,5
20
2,5
32,7
6
2,9
41,3
21
2,4
39,1
7
1,7
29,1
22
3,5
49,2
8
3,8
52,7
23
4,1
53,9
9
5,4
46,1
24
3,6
44,1
10
4,6
46,1
25
4,8
42,8
11
2,8
38,2
26
6,4
50,7
12
3,9
46,1
27
2,8
25,8
13
1,9
19,3
28
3,9
54,7
14
2,8
32,9
29
6,1
57,1
15
3,2
43,6
30
3,4
34,8
Вариант 5. Имеются данные о производительности труда рабочих и степени износа оборудования
на предприятиях региона
№ п/п Производительность
Коэффициент
№ п/п
Производительность
Коэффициент
труда, млн. руб. на
износа, %
труда, млн. руб. на
износа, %
чел.
чел.
1
2,5
41,2
12
3,9
24,8
2
2,7
45,1
13
4,7
51,2
3
2,8
55,8
14
3,8
35,2
4
3,8
31,8
15
3,6
39,2
5
3,5
35,6
16
2,5
58,3
6
2,9
58,6
17
2,8
40,8
7
3,7
41,2
18
3,5
27,3
8
3,8
36,8
19
4,1
32,9
9
4,3
29,5
20
3,6
27,2
10
4,6
35,1
21
4,8
34,5
11
5,8
27,9
22
4,8
31,2
Вариант 6. Имеются данные агентства недвижимости «Звезда» о размерах кухни и ценах на
квартиры
№ п/п Цена 1 м2, тыс. руб.
Размер кухни, м2
№ п/п
Цена 1 м2, тыс. руб. Размер кухни, м2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
61,2
75,4
55,8
71,8
65,8
58,6
82,3
58,3
67,3
95,3
57,3
49,8
69,8
75,3
63,8
7,5
8,6
7,6
9,1
7,5
7,5
9,5
7,3
6,2
12,3
7,3
6,1
8,1
8,7
7,6
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
7
6,5
5,5
7,2
7,5
6,4
6,5
9,2
6,5
11,4
8,3
10,8
12,3
8,6
10,8
11,2
54,3
51,2
65,1
79,6
58,3
59,3
87,3
62,4
87,2
64,5
91,3
85,3
76,3
81,3
79,3
ЛАБОРАТОРНАЯ РАБОТА 2
2.1 РАСЧЕТ СРЕДНИХ ВЕЛИЧИН С ИСПОЛЬЗОВАНИЕМ MS EXCEL 2007
Основные термины: средняя величина, степенные средние, вариант, частота, мода, медиана.
Следует отметить, что расчет средних величин по сгруппированным данным, то есть средней
арифметической взвешенной, средней гармонической взвешенной, средней геометрической взвешенной и
т.д., а также моды и медианы в интервальных рядах распределения в MS Excel 2007 с помощью “Мастера
функций” не производится.
Ход работы:
1. Создать файл с исходными данными, по которым необходимо определить среднее значение
признака.
2. Определить среднюю величину признака, сделать вывод.
3. Отразить графически исходные данные и среднее значение.
Расчет средней арифметической простой.
Для определения средней арифметической необходимо поставить курсор в ячейку, в которую вы
хотите поместить среднее значение, затем войти в “Мастер функций”, выбрать категорию “Статистические”,
выбрать функцию “СРЗНАЧ”.
Рис. 3. Выбор необходимой функции
После того как выбор будет закончен, нажмите ОК.
Следующий шаг – это ввод области значений, по которой будет определяться средняя
арифметическая величина (рис. 4).
Рис. 4. Ввод области исходных значений
8
Выделив область значений В2:В11 и нажав ОК, получите среднее значение в клетке В13.
Для построения графика выделите область исходных данных и среднего значения B1:C11 (рис. 5),
меню «Вставка», «График».
Рис. 5. Построение графика
Расчет средней гармонической простой
Для определения средней гармонической простой необходимо поставить курсор в ячейку, в
которой вы хотите поместить среднее значение, затем войти в “Мастер функций”, выбрать категорию
“Статистические”, выбрать функцию “СРГАРМ”, как это показано на рисунке 6.
Затем пометить блок исходных данных, то есть информации, по которой будет производиться
расчет средней гармонической простой – рисунок 7.
Рис. 6. Выбор функции для расчета средней гармонической простой
Рис. 7. Ввод области исходных значений
Пометив блок значений с В2 по В7 и нажав ОК, получите среднее значение в клетке В9.
Построение графика осуществляется аналогично описанному ранее.
9
Расчет средней геометрической простой.
Перед определением средней геометрической простой необходимо рассчитать цепные
коэффициенты роста, затем поставить курсор в ячейку, в которой вы хотите поместить среднее значение,
войти в “Мастер функций”, выбрать категорию “Статистические”, выбрать функцию “СРГЕОМ”, как это
показано на рисунке 8.
Рис. 8. Выбор необходимой функции
Далее пометить блок исходных данных, то есть информации, по которой будет производиться
расчет средней геометрической простой – рисунок 9.
Пометив блок значений с С3 по С7 и нажав ОК, получите среднее значение в клетке В9.
Рис. 9. Выбор области исходных данных
Для построения графика выделите область исходных данных и среднего значения С3:D7 (рис. 10),
меню «Вставка», «График».
Рис. 10. Построение графика
10
Определение моды по несгруппированным данным.
Создать файл с исходными данными, по которым необходимо определить модальное значение
признака. Причем: аргументы должны быть числами, именами, массивами или ссылками, которые содержат
числа; если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или
пустые ячейки, то такие значения игнорируются; однако, ячейки, которые содержат нулевые значения
учитываются; если множество данных не содержит одинаковых данных, то функция МОДА возвращает
значение ошибки #Н/Д. (Пример: МОДА({5;6; 4; 4; 3; 2; 4}))
Итак, для определения моды необходимо поставить курсор в то место, где вы хотите поместить ее
значение, войти в “Мастер функций”, выбрать категорию “Статистические”, выбрать функцию “МОДА”.
Рис. 11. Выбор функции «МОДА»
Далее необходимо пометить блок исходных данных, то есть информации, по которой будет
производиться расчет – рисунок 12.
Рис. 12. Определение блока входящей информации
Пометив блок значений с В2 по В10 и нажав ОК, получим модальное значение товарооборота,
равное 398,5 млн. руб.
Определение медианы по несгруппированным данным.
Создайте файл с исходными значениями, причем: аргументы должны быть числами или именами,
массивами или ссылками, содержащими числа; Microsoft Excel проверяет все числа, содержащиеся в
аргументах, которые являются массивами или ссылками; если аргумент, который является массивом или
ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются;
однако, ячейки, которые содержат нулевые значения учитываются.
Итак, для определения медианы необходимо поставить курсор в то место, где вы хотите поместить
ее значение, затем войти в “Мастер функций”, выбрать категорию “Статистические”, выбрать функцию
“МЕДИАНА”.
11
Рис. 13. Выбор функции для определения медианного значения
Затем необходимо пометить блок исходных данных, то есть информации, по которой будет
производиться расчет – рисунок 14.
Пометив блок значений с В2 по В10 и нажав ОК, получим медианное значение товарооборота
магазинов, равное 417,1 млн. руб.
Рис. 14. Выделение блока входящей информации для определения медианы ряда
2.2 ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
Вариант 1.
Задача 1. Имеются данные о производстве станков на предприятиях машиностроительной отрасли:
№ предприятия
Произведено станков, тыс. ед.
Цена реализации 1 станка, тыс. руб.
1
45,3
96,2
2
32,8
104,8
3
67,2
97,9
4
36,9
115,3
5
48,1
101,8
6
56,2
95,8
7
47,9
104,8
8
47,2
101,8
9
59,4
103,8
Определить:
1. Среднее производство станков по отрасли на 1 предприятие;
2. Среднюю цену реализации станка;
12
3. Модальное и медианное значения цены реализации.
Задача 2. Имеются данные о производстве станков на предприятии машиностроительной отрасли:
Месяц
Произведено станков, ед.
Январь
5639
Февраль
4985
Март
5238
Апрель
5567
Май
6125
Июнь
6235
Июль
6189
Определить: среднемесячное производство станков и средний темп роста производства.
Вариант 2.
Задача 1. Имеются данные о производстве овощей в сельскохозяйственных предприятиях региона:
№ предприятия
Произведено картофеля, тыс. т.
Себестоимость производства 1 тонны,
тыс. руб.
1
25,3
17,2
2
32,8
14,8
3
27,2
17,9
4
26,9
15,3
5
25,3
18,8
6
26,2
15,8
7
25,3
14,8
8
26,3
13,8
Определить:
1. Среднее производство картофеля по региону на 1 предприятие;
2. Среднюю себестоимость производства 1 тонны картофеля;
3. Модальное и медианное значения производства картофеля.
Задача 2. Имеются данные о выручке от реализации картофеля в магазинах города:
Месяц
Выручка от реализации, млн. руб.
Январь
2,9
Февраль
2,7
Март
3,1
Апрель
3,0
Май
3,4
Июнь
3,7
Июль
3,5
Август
3,5
Сентябрь
3,7
Определить: среднемесячную выручку от реализации картофеля и средний темп роста выручки.
Вариант 3.
Задача 1. Имеются данные о производстве деталей рабочими на машиностроительном заводе
№ работника
Изготовлено деталей, тыс. ед.
Трудоемкость производства 1 детали,
мин.
1
2,3
7,2
2
3,1
6,8
3
2,7
6,8
4
2,9
6,9
5
2,3
7,4
6
2,5
7,6
7
2,8
7,1
8
3,3
6,6
Определить:
1. Среднее производство деталей на 1 работника;
2. Среднюю трудоемкость производства 1 детали;
3. Модальное и медианное значения производства деталей.
13
Задача 2. Имеются данные о производстве деталей на машиностроительном заводе:
Год
Произведено деталей, млн. ед.
2007
31,9
2008
32,5
2009
31,8
2010
30,1
2011
28,6
2012
29,4
2013
27,2
Определить: среднегодовое производство деталей и средний темп роста производства.
Вариант 4.
Задача 1. Имеются данные по регионам
№ региона
Потребительские расходы
Среднедушевой денежный доход,
населения, млрд. руб.
тыс. руб.
1
236,1
27,2
2
456,1
26,8
3
322,7
26,8
4
562,9
26,9
5
368,3
27,4
6
482,5
31,6
7
296,8
27,1
Определить:
1. Средние потребительские расходы на 1 регион;
2. Среднедушевой денежный доход по регионам;
3. Модальное и медианное значения среднедушевого денежного дохода.
Задача 2. Имеются данные о среднедушевом денежном доходе в регионе:
Год
Тыс. руб.
2010
20,1
2011
23,6
2012
25,4
2013
29,2
Определить: средний темп роста среднедушевого денежного дохода.
Вариант 5.
Задача 1. Имеются данные о производстве колбас на перерабатывающих предприятиях региона:
№ предприятия
Произведено колбас, тыс. т.
Себестоимость производства 1 тонны,
тыс. руб.
1
125,3
217,2
2
134,8
214,8
3
227,2
217,9
4
226,9
215,3
5
125,3
218,8
6
226,2
215,8
Определить:
1. Среднее производство колбас по региону на 1 предприятие;
2. Среднюю себестоимость производства 1 тонны колбас;
3. Модальное и медианное значения производства колбас.
Задача 2. Имеются данные о выручке от реализации колбас в магазинах города:
Месяц
Выручка от реализации, млн. руб.
Январь
12,9
Февраль
11,7
Март
10,1
Апрель
11,0
Май
10,4
Июнь
10,7
Июль
10,5
14
Определить: среднемесячную выручку от реализации колбас и ее средний темп роста.
Вариант 6.
Задача 1. Имеются данные о производстве удобрений на предприятиях химической отрасли:
№ предприятия
Произведено удобрений, тыс. т.
Цена реализации 1 т, тыс. руб.
1
245,3
26,2
2
332,8
24,8
3
267,2
27,9
4
236,9
25,3
5
248,1
21,8
6
256,2
25,8
7
257,9
24,8
8
247,2
21,8
9
359,4
23,8
Определить:
1. Среднее производство удобрений по отрасли на 1 предприятие;
2. Среднюю цену реализации 1 т удобрений;
3. Модальное и медианное значения цены реализации.
Задача 2. Имеются данные о производстве удобрений на предприятии химической отрасли:
Месяц
Произведено удобрений, тыс. т.
Январь
61,3
Февраль
58,4
Март
62,3
Апрель
59,7
Май
57,4
Июнь
52,1
Июль
48,3
Определить: среднемесячное производство удобрений и средний темп роста их производства.
ЛАБОРАТОРНАЯ РАБОТА 3
3.1 РАСЧЕТ ПОКАЗАТЕЛЕЙ ВАРИАЦИИ В MS EXCEL 2007
Основные термины: вариация, средняя величина, центр распределения, интенсивность вариации,
форма распределения, дисперсия, среднее квадратическое отклонение, квартиль, асимметрия, эксцесс.
Ход работы:
1. Создать файл с исходными данными, по которым необходимо рассчитать показатели
вариации, реализованные в MS Excel. Все возможные показатели вариации рассмотрены в “Мастере
функций”, категории “Статистические”.
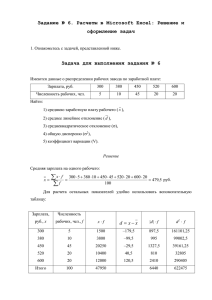
2. Определить дисперсию.
В MS Excel расчет дисперсии возможен
ДИСПА, ДИСПР, ДИСПРА.
с использованием статистических функций ДИСП,
ДИСП – оценивает дисперсию по выборке.
ДИСП(число1;число2; ...).
Число1, число2, ... - это от 1 до 30 числовых аргументов, соответствующих выборке из
генеральной совокупности.
ДИСП предполагает, что аргументы являются только выборкой из генеральной совокупности.
Если данные представляют всю генеральную совокупность, вычисляйте дисперсию, используя функцию
ДИСПР.
Логические значения, такие как ИСТИНА или ЛОЖЬ, а также текст игнорируются. Если они не
должны игнорироваться, пользуйтесь функцией рабочего листа ДИСПА.
ДИСП использует следующую формулу:
15
ÄÈÑÏ
n x 2 ( x ) 2
(1)
n (n 1)
ДИСПА – оценивает дисперсию по выборке. В расчете помимо численных значений
учитываются также текстовые и логические значения, такие, как ИСТИНА или ЛОЖЬ.
ДИСПА(значение1,значение2,...)
Значение1, значение2,... - это от 1 до 30 числовых аргументов, соответствующих выборке из
генеральной совокупности.
ДИСПА предполагает, что аргументы являются только выборкой из генеральной совокупности.
Если данные представляют всю генеральную совокупность, вычисляйте дисперсию, используя функцию
ДИСПРА.
Аргументы, содержащие значение ИСТИНА интерпретируются как 1, аргументы, содержащие
текст или значение ЛОЖЬ интерпретируются как 0 (ноль). Если текст и логические значения должны
игнорироваться, следует использовать функцию рабочего листа ДИСП.
ДИСПА использует следующую формулу:
ДИСПА
n x 2 ( x ) 2
n (n 1)
(2)
ДИСПР - вычисляет дисперсию для генеральной совокупности.
ДИСПР(число1;число2; ...)
Число1, число2, ... - это от 1 до 30 числовых аргументов, соответствующих генеральной
совокупности.
Логические значения, например ИСТИНА и ЛОЖЬ, а также текст игнорируются. Если они не
должны игнорироваться, используйте функцию листа Excel ДИСПРА.
ДИСПР предполагает, что аргументы представляют всю генеральную совокупность. Если
данные представляют только выборку из генеральной совокупности, то дисперсию следует вычислять,
используя функцию ДИСП.
Уравнение для ДИСПР имеет следующий вид:
ДИСПР
n x 2 ( x) 2
n2
(3)
ДИСПРА – вычисляет дисперсию для генеральной совокупности. В расчете помимо
численных значений учитываются также текстовые и логические значения, такие как ИСТИНА или ЛОЖЬ.
ДИСПРА(значение1,значение2,...)
Значение1,значение2,... - это от 1 до 30 числовых аргументов, соответствующих генеральной
совокупности.
ДИСПРА предполагает, что аргументы представляют всю генеральную совокупность. Если
данные представляют только выборку из генеральной совокупности, то дисперсию следует вычислять,
используя функцию ДИСПА.
Аргументы, содержащие значение ИСТИНА интерпретируются как 1, аргументы, содержащие
текст или значение ЛОЖЬ интерпретируются как 0 (ноль). Если текст и логические значения должны
игнорироваться, следует использовать функцию рабочего листа ДИСПР.
ДИСПРА использует следующую формулу:
ДИСПРА
n x 2 ( x ) 2
n2
(4)
Учитывая специфику исходной информации, необходимо выбрать соответствующую функцию
для расчета дисперсии и осуществить его в следующем порядке:
а) активизируйте ячейку, в которую вы хотите поместить значение дисперсии;
б) войдите в “Мастер функций”;
в) выберите категорию “Статистические”;
г) выберите необходимую функцию дисперсии;
16
Рис. 15. Выбор необходимой функции
д) после того, как выбор будет закончен, нажмите ОК;
е) укажите блок значений исходных данных, по которым производится расчет (рис. 16).
ж) нажмите ОК.
Рис. 16. Определение диапазона исходных данных
3.
Определить среднее линейное отклонение.
В MS Excel среднее линейное отклонение определяется с использованием функции СРОТКЛ.
СРОТКЛ - возвращает среднее абсолютных значений отклонений точек данных от среднего.
СРОТКЛ является мерой разброса множества данных.
СРОТКЛ(число1; число2; ...)
Число1, число2, ... - это от 1 до 30 аргументов, для которых определяется среднее абсолютных
отклонений. Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с
запятой.
Аргументы должны быть числами или именами, массивами или ссылками, содержащими числа.
Если аргумент, который является массивом или ссылкой, содержит тексты, логические
значения или пустые ячейки, то такие значения игнорируются; однако, ячейки, которые содержат нулевые
значения учитываются.
Уравнение для среднего отклонения следующее:
СРОТКЛ
1
xx
n
На результат СРОТКЛ влияют единицы измерения входных данных.
Порядок расчетов:
17
а) активизируйте ячейку для размещения значения СРОТКЛ;
б) войдите в “Мастер функций”;
в) выберите категорию “Статистические”;
г) выберите функцию СРОТКЛ (рис. 17);
д) нажмите ОК;
е) укажите блок значений исходных данных, по которым будет производиться расчет (рис. 18);
ж) нажмите ОК.
Рис. 17. Выбор функции СРОТКЛ
Рис. 18. Определение диапазона исходных данных
4.
Определить среднее квадратическое отклонение.
В MS Excel среднее квадратическое отклонение реализовано с помощью функций
СТАНДОТКЛОН, СТАНДОТКЛОНА, СТАНДОТКЛОНП, СТАНДОТКЛОНПА.
СТАНДОТКЛОН – оценивает стандартное отклонение по выборке. Стандартное отклонение это мера того, насколько широко разбросаны точки данных относительно их среднего.
СТАНДОТКЛОН(число1; число2; ...)
Число1, число2, ... - это от 1 до 30 числовых аргументов, соответствующих выборке из
генеральной совокупности. Можно использовать массив или ссылку на массив вместо аргументов,
разделяемых точкой с запятой.
Логические значения, такие как ИСТИНА или ЛОЖЬ, а также текст игнорируются. Если текст
и логические значения игнорироваться не должны, следует использовать функцию рабочего листа
СТАНДОТКЛОНА.
СТАНДОТКЛОН предполагает, что аргументы являются только выборкой из генеральной
совокупности. Если данные представляют всю генеральную совокупность, то стандартное отклонение
следует вычислять с помощью функции СТАНДОТКЛОНП.
Стандартное отклонение вычисляется с использованием "несмещенного" или "n - 1" метода.
СТАНДОТКЛОН использует следующую формулу:
СТАНДОТКЛОН
n x 2 ( x ) 2
n (n 1)
(5)
СТАНДОТКЛОНА – оценивает стандартное отклонение по выборке. Стандартное отклонение
18
- это мера того, насколько широко разбросаны точки данных относительно их среднего. В расчете также
учитываются текстовые и логические значения, такие как ИСТИНА или ЛОЖЬ.
СТАНДОТКЛОНА(значение1,значение2,...)
Значение1, значение2,... - это от 1 до 30 значений, соответствующих выборке из генеральной
совокупности. Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с
запятой.
СТАНДОТКЛОНА предполагает, что аргументы являются только выборкой из генеральной
совокупности. Если данные представляют всю генеральную совокупность, то стандартное отклонение
следует вычислять с помощью функции СТАНДОТКЛОНПА.
Аргументы, содержащие значение ИСТИНА, интерпретируются как 1. Аргументы, содержащие
значение ЛОЖЬ, интерпретируются как 0 (ноль). Если текст и логические значения должны игнорироваться,
следует использовать функцию рабочего листа СТАНДОТКЛОН.
Стандартное отклонение вычисляется с использованием "не Байесовского" или "n - 1" метода.
СТАНДОТКЛОНА использует следующую формулу:
n x 2 ( x ) 2
СТАНДОТКЛОНА
n (n 1)
(6)
СТАНДОТКЛОНП - вычисляет стандартное отклонение по генеральной совокупности.
Стандартное отклонение - это мера того, насколько широко разбросаны точки данных относительно их
среднего.
СТАНДОТКЛОНП(число1; число2; ...)
Число1, число2, ... - это от 1 до 30 числовых аргументов, соответствующих генеральной
совокупности. Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с
запятой.
Логические значения, такие как ИСТИНА или ЛОЖЬ, а также текст игнорируются. Если текст
и логические значения игнорироваться не должны, следует использовать функцию рабочего листа
СТАНДОТКЛОНА.
СТАНДОТКЛОНП предполагает, что аргументы образуют всю генеральную совокупность.
Если данные являются только выборкой из генеральной совокупности, то стандартное отклонение следует
вычислять с использованием функции СТАНДОТКЛОН.
Для больших выборок СТАНДОТКЛОН и СТАНДОТКЛОНП возвращают примерно равные
значения.
Стандартное отклонение вычисляется с использованием "смещенного" или "n" метода.
СТАНДОТКЛОНП использует следующую формулу:
СТАНДОТКЛОНП
n x 2 ( x ) 2
n2
(7)
СТАНДОТКЛОНПА – вычисляет стандартное отклонение по генеральной совокупности,
заданной аргументами, которые могут включать текст и логические значения. Стандартное
отклонение - это мера того, насколько широко разбросаны точки данных относительно их среднего.
СТАНДОТКЛОНПА(значение1,значение2,...)
Значение1,значение2,... это от 1 до 30 значений, соответствующих генеральной совокупности.
Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой.
СТАНДОТКЛОНПА предполагает, что аргументы образуют всю генеральную совокупность.
Если данные являются только выборкой из генеральной совокупности, то стандартное отклонение следует
вычислять с использованием функции СТАНДОТКЛОНА.
Аргументы, содержащие значение ИСТИНА, интерпретируются как 1, аргументы, содержащие
значение ЛОЖЬ, интерпретируются как 0 (ноль). Если текст и логические значения должны игнорироваться,
следует использовать функцию рабочего листа СТАНДОТКЛОНП.
Для больших выборок СТАНДОТКЛОНА и СТАНДОТКЛОНПА возвращают примерно равные
значения.
19
Стандартное отклонение вычисляется с использование "Байесовского" или "n" метода.
СТАНДОТКЛОНПА использует следующую формулу:
СТАНДОТКЛОНПА
n x 2 ( x ) 2
n2
(8)
В зависимости от специфики исходной информации выберите соответствующую функцию для
расчета среднего квадратического отклонения и осуществите его в порядке, аналогичном пункту 2.
5. Определить эксцесс и коэффициент асимметрии.
В MS Excel расчет эксцесса и коэффициента асимметрии реализован с помощью функций
ЭКСЦЕСС И СКОС.
СКОС - возвращает асимметрию распределения. Асимметрия характеризует степень
несимметричности распределения относительно его среднего. Положительная асимметрия указывает на
отклонение распределения в сторону положительных значений. Отрицательная асимметрия указывает на
отклонение распределения в сторону отрицательных значений.
СКОС(число1;число2; ...)
Число1, число2, ... - это от 1 до 30 аргументов, для которых вычисляется асимметричность.
Можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой.
Аргументы должны быть числами или именами, массивами или ссылками, содержащими числа.
Если аргумент, который является массивом или ссылкой, содержит тексты, логические
значения или пустые ячейки, то такие значения игнорируются; однако, ячейки, которые содержат нулевые
значения учитываются.
Если имеется менее трех точек данных, или стандартное отклонение равно нулю, то функция
СКОС возвращает значение ошибки #ДЕЛ/0!.
Уравнение для асимметрии определяется следующим образом:
3
x x
n
(9),
СКОС
i
(n 1) (n 2)
где - стандартное отклонение выборки.
ЭКСЦЕСС - возвращает эксцесс множества данных. Эксцесс характеризует относительную
остроконечность или сглаженность распределения по сравнению с нормальным распределением.
Положительный эксцесс обозначает относительно остроконечное распределение. Отрицательный эксцесс
обозначает относительно сглаженное распределение.
ЭКСЦЕСС(число1;число2; ...)
Число1, число2, ... - это от 1 до 30 аргументов, для которых вычисляется эксцесс. Можно
использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой.
Аргументы должны быть числами или именами, массивами или ссылками, содержащими числа.
Если аргумент, который является массивом или ссылкой, содержит тексты, логические
значения или пустые ячейки, то такие значения игнорируются; однако, ячейки, которые содержат нулевые
значения учитываются.
Если задано менее четырех точек данных или если стандартное отклонение выборки равняется
нулю, то функция ЭКСЦЕСС возвращает значение ошибки #ДЕЛ/0!.
Эксцесс определяется следующим образом:
4
2
xi x
n (n 1)
3 (n 1)
ЭКСЦЕСС
(n 2) (n 3) (10)
(n 1) (n 2) (n 3)
где
- стандартное отклонение выборки.
Порядок определения показателей аналогичен расчету дисперсии, предложенному выше.
6. Определить квартили и квартильное отклонение.
20
В MS Excel расчет квартилей реализован с помощью функции КВАРТИЛЬ.
КВАРТИЛЬ – возвращает квартиль множества данных. Квартиль часто используются при
анализе продаж, чтобы разбить генеральную совокупность на группы. Например, можно использовать
функцию КВАРТИЛЬ, чтобы найти 25 процентов наиболее доходных предприятий среди всех.
КВАРТИЛЬ (массив; часть)
Массив – это блок значений или интервал ячеек с числовыми значениями, для которых
определяется значения квартилей.
Таблица 2
Значения квартиля, которые необходимо рассчитать
Если значение равно
то КВАРТИЛЬ возвращает
0
минимальное значение
1
первую квартиль (25-ую персентиль)
2
значение медианы (50-ую персентиль)
3
третью квартиль (75-ую персентиль)
4
максимальное значение
Если массив пуст или содержит более 8191 точек данных, то функция КВАРТИЛЬ возвращает
значение ошибки #ЧИСЛО!.
Если значение не целое, то оно усекается.
Если значение < 0 или значение > 4, то функция КВАРТИЛЬ возвращает значение ошибки
#ЧИСЛО!.
МИН, МЕДИАНА и МАКС возвращают то же значение, что и функция КВАРТИЛЬ, если
аргумент значение равен 0 (нулю), 2 или 4 соответственно.
Порядок расчетов первого квартиля:
а) активизируйте ячейку для размещения расчетного значения;
б) войдите в “Мастер функций”;
в) выберите категорию “Статистические”;
г) выберите функцию КВАРТИЛЬ;
д) нажмите ОК;
е) укажите массив данных и значение (номер квартиля), в нашем случае 1 (рис. 19);
ж) нажмите ОК.
Рис. 19. Определение диапазона исходных данных для расчета квартиля
Расчет второго и третьего квартилей произведите аналогично.
7. Сформулируйте выводы по рассчитанным показателям.
8. Расчет показателей вариации можно осуществить также с помощью «Пакета анализа».
Создать файл с исходными данными.
Запустить «Пакет анализа»
В меню Сервис выберете команда Анализ данных. (Если такая команда отсутствует, в
«Настройках панели быстрого доступа» выбираем «Надстройки», далее «Пакет анализа», «Перейти», еще
раз устанавливаем флажок «Пакет анализа»).
21
Рис. 20. Запуск «Пакета анализа»
В списке инструментов статистического анализа выбираем Описательная статистика. Это
средство анализа служит для создания одномерного статистического отчета, содержащего информацию о
центральной тенденции и изменчивости входных данных.
Рис. 21. Выбор инструмента «Описательная статистика»
В диалоговом окне указываем входной интервал (интервал, где расположены исходные
данные). Выходной интервал (интервал, где будут указаны результаты расчетов). Некоторые сведения в
этом разделе могут быть неприменимы к отдельным языкам.
Входной диапазон
Ссылка на диапазон, содержащий анализируемые данные. Ссылка должна состоять не менее чем
из двух смежных диапазонов данных, данные в которых расположены по строкам или столбцам.
Группирование
Установите переключатель в положение «По столбцам» или «По строкам» в зависимости от
расположения данных во входном диапазоне.
Метки в первой строке/Метки в первом столбце
Если первая строка исходного диапазона содержит названия столбцов, установите переключатель
в положение Метки в первой строке. Если названия строк находятся в первом столбце входного диапазона,
установите переключатель в положение Метки в первом столбце. Если входной диапазон не содержит
меток, то необходимые заголовки в выходном диапазоне будут созданы автоматически.
Уровень надежности
Установите флажок, если в выходную таблицу необходимо включить строку для уровня
надежности. В поле введите требуемое значение. Например, значение 95% вычисляет уровень надежности
среднего со значимостью 0.05.
К-ый наибольший
Установите флажок, если в выходную таблицу необходимо включить строку для k-го наибольшего
значения для каждого диапазона данных. В соответствующем окне введите число k. Если k равно 1, эта
строка будет содержать максимум из набора данных.
К-ый наименьший
22
Установите флажок, если в выходную таблицу необходимо включить строку для k-го
наименьшего значения для каждого диапазона данных. В соответствующем окне введите число k. Если k
равно 1, эта строка будет содержать минимум из набора данных.
Выходной диапазон
Введите ссылку на левую верхнюю ячейку выходного диапазона. Этот инструмент анализа
выводит два столбца сведений для каждого набора данных. Левый столбец содержит метки статистических
данных; правый столбец содержит статистические данные. Состоящий их двух столбцов диапазон
статистических данных будет выведен для каждого столбца или для каждой строки входного диапазона в
зависимости от положения переключателя Группирование.
Новый лист
Установите переключатель, чтобы открыть новый лист в книге и вставить результаты анализа,
начиная с ячейки A1. Если в этом есть необходимость, введите имя нового листа в поле, расположенном
напротив соответствующего положения переключателя.
Новая книга
Установите переключатель, чтобы открыть новую книгу и вставить результаты анализа в ячейку
A1 на первом листе в этой книге.
Итоговая статистика
Установите флажок, если в выходном диапазоне необходимо получить по одному полю для
каждого из следующих видов статистических данных: Среднее, Стандартная ошибка (среднего), Медиана,
Мода, Стандартное отклонение, Дисперсия выборки, Эксцесс, Асимметричность, Интервал, Минимум,
Максимум, Сумма, Счет, Наибольшее (#), Наименьшее (#), Уровень надежности.
Рис. 22. Работа в диалоговом окне «Описательная статистика»
В результате получим следующие показатели
Рис. 23. Результаты расчетов показателей вариации
9.По всем рассчитанным показателям сделать выводы.
23
3.2 ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
Вариант 1. Имеются данные о производстве колбас на перерабатывающих предприятиях региона:
№ предприятия
Произведено колбас, тыс. т.
№ предприятия
Произведено колбас, тыс. т.
1
325,3
6
226,2
2
334,8
7
312,7
3
267,2
8
305,8
4
246,9
9
226,2
5
325,3
10
356,2
Вариант 2. Имеются данные о производстве удобрений на предприятиях химической отрасли:
№ предприятия
Произведено удобрений,
№ предприятия
Произведено удобрений,
тыс. т.
тыс. т.
1
245,3
6
256,2
2
332,8
7
267,2
3
267,2
8
247,2
4
236,9
9
359,4
5
248,1
Вариант 3. Имеются данные о производстве станков на предприятиях машиностроительной
отрасли:
№ предприятия
Произведено станков, тыс.
№ предприятия
Произведено станков,
ед.
тыс. ед.
1
85,3
7
77,9
2
72,8
8
47,2
3
67,2
9
59,4
4
66,9
10
77,9
5
48,1
11
77,9
6
56,2
Вариант 4. Имеются данные о производстве овощей в сельскохозяйственных предприятиях
региона:
№ предприятия
Произведено картофеля,
№ предприятия
Произведено картофеля,
тыс. т.
тыс. т.
1
125,3
5
125,3
2
112,8
6
166,2
3
147,2
7
125,3
4
136,9
8
176,3
Вариант 5. Имеются данные о производстве деталей рабочими на машиностроительном заводе
№ работника
Изготовлено деталей, тыс.
№ работника
Изготовлено деталей,
ед.
тыс. ед.
1
2,3
5
2,3
2
3,1
6
2,5
3
2,7
7
2,8
4
2,9
8
3,3
Вариант 6. Имеются данные по регионам
№ региона
Среднедушевой денежный
доход, тыс. руб.
1
26,2
2
26,8
3
26,8
4
26,9
№ региона
5
6
7
8
24
Среднедушевой денежный
доход, тыс. руб.
28,4
30,6
27,1
29,3
ЛАБОРАТОРНАЯ РАБОТА 4
4.1 РАСЧЕТ ПОКАЗАТЕЛЕЙ ВАРИАЦИИ В ППП STATISTICA 10.0
ЗАПУСК STATISTICA
Для запуска системы вначале нажмите кнопку Пуск в Windows (левый нижний угол края),
подведите курсор к кнопке Пуск и нажмите левую кнопку мыши, затем укажите в меню на команду
Программы.
После запуска программы вы увидите главное окно, а также окно Welcome to STATISTICA, в
котором будет предложено выбрать первое действие в начале работы с программой. Например, выберем
первое действие Open a STATISTICA Data File, которое означает открытие любого из файлов данных,
поставляемых в дополнение к непосредственно программе Statistica 10.0.
В появившемся меню выберите STATISTICA и далее подведите курсор к Basic Statistics and
Tables (Основные статистики и таблицы) (команда Statistics – Basic Statistics) и щелкните еще раз левой
кнопкой мыши.
После этих щелчков на экране вашего компьютера появится Рабочее Окно системы STATISTICA.
РАБОЧЕЕ ОКНО СИСТЕМЫ STATISTICA
Уже при беглом взгляде на окно системы (рис. 24) вы видите, что оно реализовано согласно
стандартам программ, работающих в среде Windows. Окно очень похоже на окно других прикладных
программ Windows, таких как MS Word, MS Excel и др.
Стоит отметить, что в версии программы 10.0 на рис. 24 вы видите новый вариант меню, при этом
пользователь может сменить его на привычный вид более ранних версий с помощью команды View –
Interface.
Рис 24. Окно системы 'STATISTICA'
Посмотрите внимательно на окно системы, оно имеет такую же структуру: верхний заголовок
STATISTICA 64–2 (4-0), запущен модуль Basic Statistics and Tables. Далее: строка меню, панель
инструментов и рабочая область, занимающая большую часть окна. В рабочую область выводятся все
документы системы, которые получаются в процессе анализа.
Меню занимает вторую строку основного окна модуля и содержит в себе систему выпадающих
меню. Ряд пунктов меню, таких как Home (Главная), View (Вид), Edit (Редактирование), Help (Справка),
стандартная для Windows, пункт Statistics (Статистика) специфичен для STATISTICA.
Выбор команды из выпадающего меню можно осуществить несколькими различными способами
(при помощи мыши или клавиатуры).
Для открытия какого-либо пункта меню произведите одно из следующих действий:
– подведите курсор и щелкните левой кнопкой мыши на пункте меню;
– нажмите комбинацию клавиш ALT+<подчеркнутая буква в названии меню>. Например, для
открытия пункта меню Edit (Редактирование), нажмите ALT+E;
– нажмите клавишу F10. После этого вы перейдете в строку с выпадающим меню. При помощи
стрелок клавиатуры, выберите необходимый пункт меню.
Отметим, что многие команды из выпадающего меню вызываются при помощи определенной
комбинации “горячих” клавиш. Например, для выбора команды Open Data (Открыть данные) из меню
Home (Главная) используйте комбинацию CTRL + O.
25
Панель инструментов занимает третью и четвертую строчки рабочего окна и располагается ниже
строки меню.
Панель инструментов содержит кнопки для быстрого доступа к наиболее часто используемым
командам меню. При помощи щелчка мышью на какой-либо кнопке можно получить быстрый доступ к
соответствующей команде.
Каждому типу документа STATISTICA соответствует своя панель инструментов. Внешний вид
панели инструментов и ее расположение в окне системы можно настроить при помощи команды Windows
(Окна) из меню View (Вид). Эти установки действуют только для текущего сеанса работы. Панель
инструментов может быть введена в одну и две строчки и может быть расположена в разных частях
основного окна системы. Постоянный вид панели инструментов может быть установлен в меню Display
Options (Опции) командой Display (Экран). Мы будем работать с панелью, состоящей из двух строк.
При первом запуске STATISTICA автоматически открывается файл без каких-либо числовых
данных. При следующих запусках автоматически открывается последний файл, с которым вы работали в
системе.
Отметим, что в рабочей области может находиться только один файл с исходными данными
(однако может быть неограниченное число файлов с промежуточными результатами и графиками).
Сделаем небольшое замечание об организации исходных данных в STATISTICA.
Исходные данные в системе STATISTICA организованы в виде электронной таблицы. Если вы
имеете опыт работы с электронными таблицами (например, с MS Excel), то вам будет несложно освоиться с
электронными таблицами в STATISTICA. Таблицы с исходными данными в STATISTICA носят особое
название, чтобы не путать их с другими таблицами системы.
Электронная таблица системы SPREADSHEETS состоит из строк и столбцов. В отличие от обычных
электронных таблиц, где строки и столбцы равноправны, в STATISTICA они имеют разные смысловые значения.
Столбцы электронной таблицы с исходными данными называются Variables (Переменные), а строки Cases
(Наблюдения). В качестве переменных обычно выступают исследуемые величины, а наблюдения — это значения,
которые принимают переменные в отдельных измерениях.
Система может работать как с численными, так и с текстовыми данными, что, конечно, важно в практических
статистических исследованиях. В частности, электронные таблицы могут, содержать и численную, и текстовую
информацию. Аналогично MS Excel они поддерживают различные типы операций с данными, такие как операции с
использованием буфера обмена Windows; операции с выделенными блоками значений, в том числе и с использованием
метода drag-and-drop, автозаполнение блоков и т. д.
ОТКРЫТИЕ ФАЙЛА ДАННЫХ
Подведите курсор мыши к пункту меню Home (Главная) и щелкните левой кнопкой. Во вкладке File (Файл)
нажмите команду Open Document (Открыть документ).
Команды из выпадающего меню можно вызвать также с помощью определенной комбинации “горячих”
клавиш. Например, для выбора команды Open Document (Открыть документ) из меню Home (Главная) используйте
комбинацию CTRL + O.
После нажатия этих клавиш или щелчка мышью на команде Open Document (Открыть документ) на экране
появится диалоговое окно, в котором выбирается файл данных (рис. 25).
С системой STATISTICA поставляется большое число файлов, содержащих интересные данные. Эти файлы
находятся можно открыть и посмотреть, зайдя в папку Datasets (путь: StatSoft – STATISTICA 10 – Examples – Datasets).
Файлы STATISTICA с исходными данными имеют расширение *. sta.
Рис. 25. Каталог файлов системы STATISTICA
26
СОЗДАНИЕ ФАЙЛА ДАННЫХ
Создадим файл с исходными данными для расчета показателей вариации (см. таблицу 2).
Таблица 2
1
2
3
4
5
6
7
Данные об объеме продаж
№ предприятия
Объем продаж, млн. руб.
635,5
583,7
269,8
398,5
568,1
417,1
398,5
Исходное положение: вы находитесь в основном рабочем окне системы STATISTICA.
Начальные действия: подведите курсор мыши к строке меню к пункту Home (Главная) и щелкните левой
кнопкой.
В верхней части окна расположена строка меню. Создание нового файла данных начинается с
выбора в этой строке пункта Home (Главная). Подведите курсор мыши к этому слову и щелкните левой кнопкой. Во
вкладке File (Файл) выберите команду New Spreadsheet (Новая электронная таблица).
Шаг 1. Создание электронной таблицы.
Выберите команду New Spreadsheet (Новая электронная таблица) из меню Home (Главная). В рабочей
области появится пустая электронная таблицы. Чтобы сохранить таблицу, во вкладке File (Файл) нажмите Save As
(Сохранить как), выберите папку, в которую вы сохраните файл, задайте имя – STUD.sta – и нажмите кнопку Сохранить.
Рис. 26 Задание имени файла
Вы можете пользоваться этой таблицей как страницей в записной книжке и внести в нее
необходимые данные.
Рис. 27. Пустая электронная таблица для ввода данных
В заголовке окна электронной таблицы автоматически отображается имя файла и его размер
(STUD (10vby10c)).
Размер таблицы по умолчанию принят 10 на 10 (10 переменных с именами VAR1, VAR2, VAR3…,
27
VAR10 и 10 пронумерованных наблюдений).
Сделаем в таблице столько строк и столбцов, сколько нужно. Нам нужно, чтобы в таблице
имелись 1 переменная и 7 наблюдений.
Шаг 2. Настройка таблицы.
Произведем настройку размеров таблицы. Создадим столько переменных и наблюдений, сколько
необходимо.
Нажмите пункт меню Data (Данные) и выберите команду Delete Variables (Удаление
переменных) (вкладка Variables (Переменные)). Укажите диапазон удаляемых переменных (рис. 28).
Нажмите кнопку ОК.
Рис. 28. Окно удаления ненужных переменных
Необходимое число наблюдений – 7; в созданной таблице число наблюдений равно 10.
Три лишних наблюдения из таблицы следует удалить. Для этого воспользуйтесь кнопкой “Cases”
Cases (Наблюдения) и командой Delete (Удалить). В появившемся окне сделайте установки (рис. 29).
Рис. 29. Окно удаления ненужных наблюдений
Задайте диапазон удаляемых наблюдений в диалоговом окне Delete Cases (Удаление
наблюдения). Нажмите кнопку ОК. Если вам требуется добавить число переменных, необходимо нажать
кнопку Variables и выбрать команду Add, далее указать диапазон добавляемых переменных. Аналогично
можно добавить число наблюдений (Cases).
Шаг 3. Подготовка таблицы к вводу данных, заголовок таблицы и имена переменных.
Дважды щелкните мышью на белом поле в таблице под словами: Data: STUD*(1v by 7c).
Введем заголовок таблицы: “Данные об объеме продаж продукции, млн. руб.”, как показано на
рисунке 30.
Рис. 30. Введение заголовка таблицы
Таблица почти готова к вводу данных, однако, придадим ей еще несколько более удобный вид:
введем имена переменных, которые отражают смысл записей, и специфицируем их.
Дважды щелкните на имени переменной VAR1 в электронной таблице. На экране появится окно
спецификации переменной VAR1. В поле Name (Имя) напишите: Объем пр. Длина имени не должна
превышать 8 символов.
28
Рис. 31. Окно спецификации переменной VAR1
Шаг 4. Ввод данных в электронную таблицу.
Так как данных немного, будем вводить их с клавиатуры. Введите данные, как показано на
рисунке 32.
Рис. 32. Таблица с введенными данными с клавиатуры
ВЫЧИСЛЕНИЕ ОПИСАТЕЛЬНЫХ СТАТИСТИК В СИСТЕМЕ
В STATISTICA описательные статистики вычисляются чрезвычайно легко. Покажем, как
вычисляются описательные статистики на примере данных таблицы 2.
Шаг 1.
Выполните следующую команду: Statistics(Статистики) – BasicStatistics (Основные статистики).
Данная команда позволяет быстро рассчитать основные статистики для одной или целого списка
переменных (например, корреляционные матрицы для всех переменных в файле данных). Затем в
появившемся окне Basic Statistics and Tables: STUD выберите пункт Descriptive Statistics (Описательные
статистики) и нажмите OK.
После нажатия кнопки OK на экране появится выпадающее меню.
Шаг 2.
В выпадающем меню выбираем необходимую переменную (Variables) и отмечаем галочками
необходимые характеристики ряда распределения (вкладка Advanced) (рис.33), затем нажимаем кнопку
Summary, и электронная таблица с основными описательными статистиками для выбранной переменной
появится на экране (см. таблицу 3).
29
Рис. 33. Окно выбора характеристик ряда распределения
Таблица 3
Электронная таблица с описательными статистиками показателя объема продаж продукции
предприятиями
Descriptive Statistics (STUD)
Variable
ОБЪЕМ
ПР
Valid N
7
Mean
Confidence
-95,000%
Confidence
95,000%
346,1430
588,4856
467,3143
Median
Mode
417,1000
398,5000
Standard
Error
Skewness
49,52008
0,116832
Frequency
of Mode
2
Sum
Minimum
3271,200
269,80000
Kurtosis
Std.Err.
Kurtosis
-1,18736
1,587451
Descriptive Statistics (STUD)
Variable
ОБЪЕМ
ПР
Maximum
Range
635,50000
365,7000
Variance
17165,67
Std.Dev.
4,201360
Std.Err.
Skewness
0,793725
Отметим, что таблица результатов отличается от таблицы с исходными данными. Этот
специальный тип таблиц в STATISTICA носит название scrollsheets.
Прокручивая электронную таблицу результатов, вы увидите слева направо следующие
описательные статистики переменной: Объем продаж, млн. руб.
Valid N – истинное число наблюдений переменной ОБЪЕМ ПРОДАЖ (число наблюдений без
пропусков);
Mean – выборочное Среднее;
Confid – 95% – нижняя граница 95% доверительного интервала для среднего;
Confid + 95% – верхняя граница 95% доверительного интервала для среднего;
Median – медиана (значение переменной ОБЪЕМ ПРОДАЖ, делящее ранжированный ряд на две
равные части);
Mode – мода (значение переменной ОБЪЕМ ПРОДАЖ, чаще всего встречающееся в
наблюдениях);
Frequency of Mode – частота моды (или модального значения) (количество встретившихся в
наблюдениях модальных значений переменной ОБЪЕМ ПРОДАЖ);
Sum – сумма (сумма значений переменной ОБЪЕМ ПРОДАЖ);
Minimum – минимум (минимальное значение переменной ОБЪЕМ ПРОДАЖ);
Maximum – максимум (максимальное значение переменной ОБЪЕМ ПРОДАЖ);
Range – размах (то есть разность между максимумом и минимумом);
Variance – выборочная дисперсия;
Std. Dev. – стандартное отклонение;
Standard Error– стандартная ошибка;
Skewness – выборочный коэффициент асимметрии;
Std. Err. Skewness – стандартная ошибка коэффициента асимметрии;
Kurtosis – выборочный коэффициент эксцесса;
Std. Err. Kurtosis – стандартная ошибка эксцесса.
4.2 ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
Использовать те же варианты, что и в лабораторной работе № 3
30
ЛАБОРАТОРНАЯ РАБОТА 5
5.1 АНАЛИЗ РЯДОВ ДИНАМИКИ С ПОМОЩЬЮ MS EXCEL 2007
Основные термины: ряд динамики, уровень ряда, скользящая средняя, экспоненциальное
сглаживание, тренд, линейная диаграмма.
Ход работы:
1.СКОЛЬЗЯЩЕЕ СРЕДНЕЕ И ЭКСПОНЕНЦИАЛЬНОЕ СГЛАЖИВАНИЕ
1.Сформировать файл с исходными данными о среднедневной реализации продуктов
сельскохозяйственного производства магазинами потребительской кооперации города (рисунок 34). В
указанном периоде (2010 – 2013 гг.) требуется выявить основную тенденцию развития данного
экономического процесса и характер его сезонных колебаний.
Рис. 34. Исходные данные (Размер реализации)
2.Выберите в меню Сервис пункт Анализ данных, появится окно с одноименным названием,
главным элементом которого является область Инструменты анализа. В данной области представлен список
реализованных в Microsoft Excel методов статистической обработки данных. Каждый из перечисленных
методов реализован в виде отдельного режима работы, для активизации которого необходимо выделить
соответствующий метод указателем мыши и щелкнуть по кнопке ОК. После появления диалогового окна
вызванного режима можно приступать к работе.
Режим работы «Скользящее среднее» служит для сглаживания уровней эмпирического
динамического ряда на основе метода простой скользящей средней.
Режим работы «Экспоненциальное сглаживание» служит для сглаживания уровней эмпирического
динамического ряда на основе метода простого экспоненциального сглаживания.
В диалоговых окнах данных режимов (рисунок 35 и 36) задаются следующие параметры:
1. Входной интервал – вводится ссылка на ячейки, содержащие исходные данные.
2. Флажок Метки – устанавливается активное состояние, если первая строка (столбец) во входном
диапазоне содержит заголовки. Если заголовки отсутствуют, флажок следует деактивизировать. В этом
случае будут автоматически созданы стандартные названия для данных выходного диапазона.
3. Интервал (только в диалоговом окне Скользящее среднее) – вводится размер окна сглаживания
р. По умолчанию р=3.
Рис. 35. Диалоговое окно скользящего среднего
31
4. Фактор затухания (только в диалоговом окне Экспоненциальное сглаживание) – вводится
значение коэффициента экспоненциального сглаживания p. По умолчанию, p=0,3.
5. Выходной интервал / Новый рабочий лист / Новая рабочая книга – в положении Выходной
интервал активизируется поле, в которое необходимо ввести ссылку на левую верхнюю ячейку выходного
диапазона. Размер выходного диапазона будет определен автоматически, и на экране появится сообщение в
случае возможного наложения выходного диапазона на исходные данные. В положении Новый рабочий
лист открывается новый лист, в который начиная с ячейки А1 вставляются результаты анализа. Если
необходимо задать имя в поле, расположенное напротив соответствующего положения переключателя. В
положении Новая рабочая книга открывается новая книга, на первом листе которой начиная с ячейки А1
вставляются результаты анализа.
6. Вывод графика – устанавливается в активное состояние для автоматической генерации на
рабочем листе графиков фактических и теоретических уровней динамического ряда.
7. Стандартные погрешности – устанавливаются в активное состояние, если требуется включить
в выходной диапазон столбец, содержащий стандартные погрешности.
Рис. 36. Диалоговое окно экспоненциального сглаживания
3. Для решения задачи используем режим работы «Скользящее среднее».
Значения параметров, установленных в одноименном диалоговом окне, представлены на рисунке
37, рассчитанные в данном режиме показатели – на рисунке 38, а построенные графики – на рисунке 39.
Рис. 37. Заполнение диалогового окна
32
Рис. 38. Результаты анализа
Рис. 39. Скользящее среднее
В столбце D (рисунок 38) вычисляются значения сглаженных уровней. Например, значение
первого сглаженного уровня рассчитывается в ячейке D5 по формуле =СРЗНАЧ(С2:С5), значение второго
сглаженного уровня – в ячейке D6 по формуле =СРЗНАЧ(С5:С8) и т.д.
В столбце E вычисляются значения стандартных погрешностей с помощью формулы =КОРЕНЬ
(СУММАКВРАЗН (блок фактических значений; блок прогнозных значений) / размер окна сглаживания).
Например,
значение
в
ячейке
Е10
рассчитывается
по
формуле
=КОРЕНЬ(СУММКВРАЗН(С7:С10;О7:В10)/4).
Вместе с тем, как отмечалось выше, если размер окна сглаживания является четным числом
(р=2m), то рассчитанное усредненное значение нельзя сопоставить какому-либо определенному моменту
времени t, поэтому необходимо применять процедуру центрирования.
Для рассматриваемого примера р=4, поэтому процедура центрирования необходима. Так, первый
сглаженный уровень (265,25) записывается между II и III кв. 2006 г. и т.д. Применяя процедуру
центрирования (для этого используем функцию СРЗНАЧ), получаем сглаженные уровни с центрированием.
Для III кВ. 2006 г. определяется серединное значение между первым и вторым сглаженными уровнями:
(265,25 + 283,25)/2 = 274,25; для IV кв. 2006 г. центрируются второй и третий сглаженные уровни: (283,25 +
292,00)/2 = 287,6 и т.д. Рассчитанные значения представлены в таблице 4. Скорректированный график
скользящей средней представлен на рисунке 40.
33
Год
2010
2011
2012
2013
Таблица 4
Динамика сглаженных уровней реализации продукции
Сглаженные уровни
Квартал
Размер реализации, тыс. руб.
с центрированием, тыс. руб.
1
175
2
263
3
326
274,3
4
297
287,6
5
247
297,0
6
298
307,5
7
366
334,6
8
341
374,1
9
420
402,9
10
441
421,0
11
453
429,0
12
399
430,8
13
426
435,4
14
449
446,6
15
482
16
460
Рис. 40. Скорректированный график скользящего среднего
4. Рассмотренная задача может быть решена и с помощью метода простого экспоненциального
сглаживания. Для этого необходимо использовать режим работы «Экспоненциальное сглаживание».
Значения параметров, установленных в одноименном диалоговом окне, представлены на рисунке 41,
рассчитанные в данном режиме показатели – рисунок 42, а построенные графики – на рисунке 43.
Рис. 41. Заполнение диалогового окна «Экспоненциальное сглаживание»
34
Рис. 42. Результаты анализа
Рис. 43. Экспоненциальное сглаживание
В столбце D (см. рисунок 42) вычисляются значения сглаженных уровней на основе рекуррентных
соотношений.
В столбце E рассчитываются значения стандартных погрешностей с помощью формулы
=КОРЕНЬ(СУММКВРАЗН (блок фактических значений; блок прогнозных значений) / 3). Как легко
заметить (сравните рисунок 40 и 43), при использовании метода простого экспоненциального сглаживания,
в отличие от метода простой скользящей средней, сохраняются мелкие волны.
2. ПОСТРОЕНИЕ ТРЕНДОВЫХ МОДЕЛЕЙ
1.В Microsoft Excel трендовые модели строятся на основе диаграмм, представляющих уровни
динамики. Для эмпирического ряда динамики может быть построена диаграмма одного из следующих
типов: гистограмма, линейчатая диаграмма, график, точечная диаграмма, диаграмма с областями.
Для построения линии тренда необходимо в построенной по исходным данным диаграмме
выделить ряд динамики и выбрать в контекстном меню (вызывается щелчком правой клавиши мыши)
команду Добавить линию тренда. Будет вызвано диалоговое окно Линия тренда, содержащее вкладку
Тип (рисунок 44), на которой задается тип тренда:
1. Линейный;
2. Логарифмический;
3. Полиноминальный(от 2-ой до 6-ой степени включительно);
4. Степенной;
5. Экспоненциальный;
6. Скользящее среднее (с указанием периода сглаживания от 2 до 15).
35
Рис. 44. Меню «Линия тренда»
Вкладка Параметры (см. рисунок 44) предназначена для задания параметров тренда:
1. Имя тренда – имя линии тренда, располагается в легенде диаграммы; возможны следующие
варианты задания имени тренда:
автоматическое – Microsoft Excel именует линию тренда, основываясь на выбранном типе
тренда и ряде динамики, с которым она ассоциирована, например, Линейный (ряд I);
другое – вводится уникальноеимя тренда, максимальная длина составляет 256 символов.
2. Прогноз вперед на – количество периодов, на которое линия тренда проектируется в будущее,
то есть в направлении от оси Y (поле не доступно в режиме скользящего среднего).
3. Прогноз назад на – количество периодов, на которое линия тренда проектируется в прошлое,
т.е. в направление к оси Y (поле не доступно в режиме скользящего среднего).
4. Пересечение кривой с осью Y в точке – точка, в которой линия тренда пересекает ось Y (поле не
доступно в режиме скользящего среднего).
5. Показывать уравнение на диаграмме – на диаграмме будет показано уравнение линии тренда.
6. Поместить на диаграмму величину достоверности аппроксимации (R2) – на диаграмме будет
показано значение коэффициента детерминации.
2.Требуется по данным о динамике производства продукции на ОАО «Ривьера» (табл. 5)
построить трендовую модель товарооборота.
Таблица 5
Динамика производства продукции ОАО «Ривьера»
Год
Производство продукции, тыс. тонн
2003
25,9
2004
26,5
2005
25,3
2006
25,8
2007
26,3
2008
26,1
2009
27
2010
27,4
2011
27,1
2012
28,2
2013
28,4
Для решения поставленной задачи, прежде всего в порядке первого приближения, намечаются
типы функций, которые могут отобразить имеющиеся в динамическом ряду изменения. В помощь этому
исходные данные, приведенные в таблице 5, изображаются графически с помощью мастера диаграмм (см.
36
рисунок 45).
Рис. 45. Динамика производства продукции ОАО «Ривьера», тыс. тонн
По характеру размещения уровней анализируемого ряда динамики можно сделать предположение
о возможном аналитическом выравнивании изучаемого ряда типовой математической функцией. Это может
быть и линейная функция, и показательная, и полином 2-го порядка, и ряд других функций.
Для нахождения наиболее адекватного уравнения тренда используем инструмент «Подбор линии
тренда» из мастера диаграмм Microsoft Excel (отметки Показать уравнение на графике и Поместить на
диаграмму величину достоверности аппроксимации). Представим отдельные виды трендов на рисунках 46,
47, 48.
Рис. 46 Динамика эмпирических и теоретических уровней производства продукции ОАО «Ривьера»
(линейный тренд), тыс. тонн
Рис. 47. Динамика эмпирических и теоретических уровней производства продукции
ОАО «Ривьера» (логарифмический тренд), тыс. тонн
37
Рис. 48 Динамика эмпирических и теоретических уровней производства
продукции ОАО «Ривьера» (степенной тренд), тыс. тонн
Результаты подбора уравнения приведены
рассматривались полиномы выше 3-го порядка).
в таблице
6
(при подборе
уравнения не
Таблица 6
Уравнения тренда
Вид уравнения
Линейное
Логарифмическое
Полином 2-го порядка
Полином 3-го порядка
Степенное
Экспоненциальное
Уравнение
Коэффициент
детерминации R
y = 0,26x + 25,167
y = 0,9597Ln(x) + 25,2
y = 0,0354x2 - 0,1652x + 26,088
y = -0,0042x3 + 0,1103x2 - 0,5401x + 26,542
y = 25,236x0,0357
y = 25,207e0,0097x
0,7556
0,5195
0,8650
0,8758
0,5195
0,7534
Принимая во внимание физическую сущность изучаемого процесса и результаты проведенного
аналитического выравнивания, в качестве аппроксимирующей модели тренда выбираем полином 3-го
порядка – рисунок 49.
Рис. 49. Динамика эмпирических и теоретических уровней производства
продукции ОАО «Ривьера» (полином третьего порядка), тыс. тонн
Используя данный тренд, можно выполнить краткосрочный прогноз (в примере на рисунке 49 на
три года вперед).
5.2 ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
38
Вариант 1. Представив уровни в виде единого ряда, состоящего из 36 уровней, выявить основную
тенденцию развития за 2011 – 2013 годы методами скользящей средней, экспоненциального сглаживания и
аналитического выравнивания, выполнить прогноз на 1 квартал 2014 года.
Таблица 7
Динамика прибыли ОАО «Веста», млн. руб.
Месяц
2011 г.
2012 г.
2013 г.
Январь
31,9
39,3
43,2
Февраль
33,7
37,2
43,1
Март
35,1
40,2
44,8
Апрель
38,4
37,2
47,3
Май
41,2
35,8
46,2
Июнь
38,6
34,9
45,2
Июль
34,2
38,2
47,2
Август
38,2
36,1
49,4
Сентябрь
34,5
42,8
52,8
Октябрь
34,1
35,7
53,2
Ноябрь
39,5
34,1
50,1
Декабрь
35,8
35,9
53,1
Вариант 2. Представив уровни в виде единого ряда, состоящего из 24 уровней, выявить основную
тенденцию развития за 2008 – 2013 годы методами скользящей средней, экспоненциального сглаживания и
аналитического выравнивания, выполнить прогноз на 2014 год.
Таблица 8
Динамика среднеквартальной стоимости основных средств ЗАО «Пилигрим», млн. руб.
Квартал
2008 г.
2009 г.
2010 г.
2011 г.
2012 г.
2013 г.
1
131,5
158,2
154,1
152,8
159,3
145,2
2
137,0
151,2
152,4
155,1
142,3
158,2
3
135,4
152,1
155,7
161,2
147,2
162,1
4
145,8
152,1
158,2
157,9
151,3
165,3
Вариант 3. Представив уровни в виде единого ряда, состоящего из 36 уровней, выявить основную
тенденцию развития за 2011 – 2013 годы методами скользящей средней, экспоненциального сглаживания и
аналитического выравнивания, выполнить прогноз на 1 квартал 2014 года.
Таблица 9
Динамика производства удобрений ЗАО «Химик», тыс .тонн
Месяц
2009 г.
2010 г.
2011 г.
Январь
21,9
24,3
25,6
Февраль
23,7
25,3
27,9
Март
25,1
24,1
29,4
Апрель
27,1
27,2
29,6
Май
26,0
28,4
30,2
Июнь
25,1
27,3
30,4
Июль
24,2
26,3
30,1
Август
23,1
25,1
27,5
Сентябрь
24,5
25,8
26,1
Октябрь
24,1
24,7
26,8
Ноябрь
23,4
24,1
26,5
Декабрь
23,1
24,9
26,1
Вариант 4. Представив уровни в виде единого ряда, состоящего из 24 уровней, выявить основную
тенденцию развития за 2008 – 2013 годы методами скользящей средней, экспоненциального сглаживания и
аналитического выравнивания, выполнить прогноз на 2014 год.
Таблица 10
Динамика средних остатков оборотных активов АО «Альянс», млн. руб.
Квартал
2008 г.
2009 г.
2010 г.
2011 г.
2012 г.
2013 г.
1
65,8
62,1
54,1
40,2
43,8
35,7
2
63,2
52,1
39,2
37,2
40,2
32,5
3
55,1
47,2
32,1
38,2
45,8
30,8
4
57,4
52,8
38,1
37,8
40,1
31,9
Вариант 5. Представив уровни в виде единого ряда, состоящего из 20 уровней, выявить основную
39
тенденцию развития за 2010 – 2013 годы методами скользящей средней, экспоненциального сглаживания и
аналитического выравнивания, выполнить прогноз на 2014 год.
Таблица 11
Динамика инвестиций в основной капитал АО «Факел», млн. руб.
Квартал
2010 г.
2011 г.
2012 г.
I
12,4
13,5
18,9
II
15,1
18,5
21,3
III
18,5
21,3
25,8
IV
14,8
17,2
16,9
2013 г.
21,3
25,3
27,1
21,8
Вариант 6. Представив уровни в виде единого ряда, состоящего из 36 уровней, выявить основную
тенденцию развития за 2011 – 2013 годы методами скользящей средней, экспоненциального сглаживания и
аналитического выравнивания, выполнить прогноз на 1 квартал 2014 года.
Таблица 12
Динамика среднемесячной заработной плате работников ЗАО «Кураж», тыс . руб.
Месяц
2011 г.
2012 г.
2013 г.
Январь
26,3
28,5
34,3
Февраль
26,9
27,9
36,7
Март
27,3
31,4
34,3
Апрель
25,8
33,3
34,1
Май
27,5
34,1
35,2
Июнь
29,1
32,5
35,4
Июль
30,5
33,7
35,9
Август
28,2
33,4
37,5
Сентябрь
28,7
34,6
39,9
Октябрь
29,1
33,1
41,8
Ноябрь
29,0
35,1
43,1
Декабрь
30,1
37,3
41,0
ЛАБОРАТОРНАЯ РАБОТА 6
6.1 КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ В MS EXCEL 2007
Основные термины: причинно-следственные отношения, результативный признак, факторный
признак, стохастическая связь, прямая связь, обратная связь, парная регрессия, множественная регрессия,
коэффициент регрессии, мультиколлинеарность, коэффициент детерминации, линейный коэффициент
корреляции, множественный коэффициент корреляции, экономическая интерпретация модели.
Ход работы:
1. На примере таблицы 1создайте файл исходных данных в MS Excel (рис. 50)
Рис. 50. Данные о работе 25 предприятий одной из отраслей промышленности
40
2. Построение корреляционного поля
Для построения корреляционного поля выделяем блок исходной информации, в командной строке
выбираем меню Вставка/ Диаграмма. В появившемся диалоговом окне выберите тип диаграммы:
Точечная; вид: Точечная диаграмма, позволяющая сравнить пары значений (рис. 51).
Рис. 51. Выбор типа диаграммы
Таким образом, получаем корреляционное поле зависимости y от x. Далее добавим на графике
линию тренда, для чего выполним следующие действия:
1. В области диаграммы щелкнуть правой кнопкой мыши по любой точке графика. Появляется
контекстное меню (см. рисунок 52), в котором выбираем команду Добавить линию тренда.
Рис. 52. Вид окна для выбора тренда
2. В появившемся диалоговом окне выбираем тип графика (в нашем примере линейная) и
параметры уравнения, как показано на рисунке 53.
41
Рис. 53. Установка параметров линии тренда
Нажимаем Закрыть. Результат представлен на рисунке 54.
Рис. 54. Корреляционное поле зависимости объема продукции от среднегодовой стоимости основных
производственных средств
Аналогично определяются параметры других функций.
3.
Построение корреляционной матрицы.
В блок исходных данных добавим еще один факторный признак. Для построения корреляционной
матрицы в меню Данные выбираем Анализ данных.
В диалоговом окне Анализ данных выбираем Корреляция (рисунок 55).
Рис. 55. Диалоговое окно Анализ данных
42
После нажатия ОК в появившемся диалоговом окне указываем входной интервал (в нашем
примере В2:D26), группирование (в нашем случае по столбцам) и параметры вывода, как показано на
рисунке 56.
Рис. 56. Диалоговое окно Корреляция
Результат расчетов представлен в таблице 13.
Таблица 13
Столбец 1
Столбец 2
Столбец 3
Корреляционная матрица
Столбец 1 Столбец 2 Столбец 3
1
0,907705863 1
0,888413524 0,3251463
1
ОДНОФАКТОРНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
С ПРИМЕНЕНИЕМ ИНСТРУМЕНТА РЕГРЕССИИ
Для проведения регрессионного анализа зависимости объемов продукции от среднегодовой
стоимости ОПС в меню Сервис выбираем Анализ данных и указываем инструмент анализа Регрессия
(Рисунок 57). С помощью инструмента анализа данных Регрессия, помимо результатов регрессионной
статистики, дисперсионного анализа и доверительных интервалов, можно получить остатки и графики
подбора линии регрессии, остатков и нормальной вероятности.
Рис. 57. Диалоговое окно Анализ данных
После нажатия ОК в диалоговом окне Регрессия указываем входной интервал Y (в нашем
примере А2:А26) и входной интервал X (в нашем примере B2:B26), а также параметры вывода, остатки,
нормальную вероятность как указано на рисунке 58.
43
Рис. 58. Диалоговое окно Регрессия
Результат расчетов представлен в приложении В. Аналогично проводится парный регрессионный
анализ по второй переменной (Приложение Г).
ОДНОФАКТОРНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
С ПРИМЕНЕНИЕМ “МАСТЕРА ФУНКЦИЙ”
Однофакторный регрессионный анализ можно осуществлять с помощью “Мастера функций” ППП
Excel. Встроенная статистическая функция ЛИНЕЙН определяет параметры линейной регрессии y=a+bx.
Порядок вычисления следующий:
1) введите исходные данные или откройте существующий файл, содержащий анализируемые
данные;
2) выделите область пустых ячеек 5х2 (5 строк, 2 столбца) для вывода результатов
регрессионной статистики или область 1х2 – для получения только оценок коэффициентов регрессии;
3) активизируйте Мастер функций;
4) в окне Категория (см. рисунок 59) выберите Статистические, в окне Функция – ЛИНЕЙН.
Щелкните по кнопке ОК;
5) заполните аргументы функции (см. рисунок 60):
Известные_значения_y – диапазон, содержащий данные результативного признака;
Известные_значения_x – диапазон, содержащий данные факторов независимого признака;
Константа – логическое значение, которое указывает на наличие или отсутствие свободного
члена в уравнении; если Константа = 1, то свободные член рассчитывается обычным образом, если
Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию
по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если
Статистика = 0, то выводятся только оценки параметров уравнения.
Щелкните по кнопке ОК;
6) в левой верхней ячейке выделенной области появится первый элемент итоговой таблицы.
Чтобы раскрыть всю таблицу, нажмите клавишу <F2>, а затем – на комбинацию клавиш
<CTRL>+<SHIFT>+<ENTER>.
Рис. 59. Диалоговое окно Мастер функций
44
Рис. 60. Диалоговое окно ввода аргументов функции ЛИНЕЙН
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей
схеме:
Таблица 14
Результаты регрессии
Значение коэффициента b
Значение коэффициента a
Среднеквадратическое отклонение b
Среднеквадратическое отклонение a
Коэффициент детерминации R2
Среднеквадратическое отклонение y
F- статистика
Регрессионная сумма квадратов
Число степеней свободы
Остаточная сумма квадратов
Для вычисления параметров экспоненциальной кривой y x в MS Excel применяется
встроенная статистическая функция ЛГРФПРИБЛ. Порядок вычисления аналогичен применению функции
ЛИНЕЙН.
Для данных из нашего примера результат вычисления функции ЛИНЕЙН представлен на рисунке
61, функции ЛГРФПРИБЛ – на рисунке 62.
Рис. 61. Результат вычисления функции ЛИНЕЙН
Рис. 62. Результат вычисления функции ЛГРФПРИБЛ
МНОГОФАКТОРНЫЙ РЕГРЕССИОННЫЙ АНАЛИЗ
Эта операция производится с помощью инструмента анализа данных Регрессия. Она аналогична
расчету параметров парной линейной регрессии, описанной выше, только в отличие от парной регрессии в
45
диалоговом окне при заполнении параметра входной интервал X следует указать не один столбец, а все
столбцы, содержащие значения факторных признаков. Результаты анализа представлены в приложении Д.
На основе результатов регрессионного анализа сделаем следующие выводы.
Параметризованное уравнение
у = -6,815 + 0,891 х1 + 4,975 х2
Параметр а = -6,815 - начальная точка отсчета, обусловленная влиянием других факторов, не
учтенных в данной модели (если а – отрицателен, то он не интерпретируется), параметр b1 = 0,891
показывает, что если фактор х1 увеличить на единицу, то у увеличится на 0,891, знак плюс при параметре
свидетельствует о наличии прямой связи. Параметр b2 = 4,975 показывает, что если фактор х2 увеличить на
единицу, то у увеличится на 4,975.
Расчетные значения t-критерия Стьюдента, необходимые для оценки параметров модели,
составили tb1 =4,27 , tb2 =3,41. Табличное значение t-критерия, для 22 степеней свободы и 5% уровня
значимости составило tтабл =2,07. Так как расчетные значения превышают табличное, оба параметра
признаются значимыми (существенными). Выявление недостаточной существенности факторов х1 и х2,
сделанный на основе t-критерия приводит к необходимости ввода дополнительных факторов в
аппроксимирующую модель.
Еще одним показателем качества подобранной модели традиционно считается коэффициент
множественной корреляции. В нашем случае он равен 0,941, что характеризует тесную связь между y и
двумя факторными признаками. Чтобы оценить степень совокупного влияния факторов х1 и х2 на у
воспользуемся коэффициентом детерминации (R2), он равен 0,885, что означает что 88,5% вариации у
обусловлено факторами, отобранными в модель. Чем ближе R2 к 100%, тем лучше подобранная модель
описывает данные эксперимента.
Назначение таблицы дисперсионного анализа - дать ответ о наличии значимого влияния уровней
факторов на исследуемый отклик (результативный признак).
SS - сумма квадратов;
d.f. - степени свободы;
MS - средние квадраты;
F - отношение, рассматривается как частное от деления средних квадратов, обусловленных
факторами на средние квадраты остатков;
Значимость F - в данном случае минимальный уровень значимости соответствующего Fотношения.
Таким образом, факторный и остаточный анализ дисперсий показал, что при уровне значимости
= 0,05, числе степеней свободы числителя V = 2 и знаменателя V =22 F = 84,5 Fтабл = 4,3,
следовательно, гипотеза об отсутствии влияния факторов на результативный признак должна быть
отвергнута, т. е. связь имеется, что и подтверждается значением 4,72347E-11, т. к. обычно, если эта величина
близка к нулю, есть основание отвергнуть нулевую гипотезу и делаем окончательный вывод от
адекватности полученной модели экспериментальным данным.
Предсказанное Y – теоретические значения результативного признака, полученные по модели.
Остатки – отклонение фактических значений результативного признака от теоретических.
46
6.2 ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
Вариант 1
№
п/п
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
индекс
снижения
себестоимости,
%, y
71,2
90,8
99,8
76,8
119,15
21,9
48,4
173,5
74,1
68,6
60,8
355,6
264,8
251,3
118,6
31,1
57,7
51,6
64,7
48,3
15
87,5
108,4
267,3
34,2
трудоемкость
единицы
изделия, час,
x1
0,29
0,41
0,41
0,22
0,29
0,51
0,36
0,23
0,26
0,27
0,29
0,01
0,01
0,18
0,25
0,31
0,38
0,24
0,31
0,42
0,51
0,31
0,37
0,16
0,18
коэффициент
сменности
оборудования,
x2
1,21
1,28
1,33
1,22
1,28
1,47
1,35
1,51
1,26
1,27
1,15
1,46
1,27
1,43
1,5
1,11
1,15
1,21
1,35
1,1
1,2
1,15
1,25
1,26
1,36
производитель
ность труда,
млн. руб. на
чел., y
10,02
8,16
3,78
6,48
10,44
7,65
8,77
7
11,06
9,02
13,28
9,27
6,7
6,69
9,42
7,24
5,39
5,61
5,59
6,57
6,54
4,23
5,22
18
11,03
Вариант 2
фондовоору
женность
труда, млн.
руб. на чел.,
x1
4,02
3,23
2,74
3,1
5,21
3,65
3,67
3,28
5,12
3,58
5,63
3,94
3,82
4,8
5,01
4,12
3,11
2,49
2,87
2,05
3,11
2,11
4,66
5,93
6,62
Вариант 3
коэффициент
сменности
оборудования
, x2
1,51
1,36
1,27
1,43
1,5
1,22
1,41
1,47
1,35
1,4
1,55
1,15
1,09
1,26
1,36
1,15
1,12
1,17
1,16
1,15
1,22
1,18
1,17
1,38
1,51
производитель
ность труда,
млн.. руб. на
чел., y
10,02
8,16
3,78
6,48
10,44
7,65
8,77
7
11,06
9,02
13,28
9,27
6,7
6,69
9,42
7,24
5,39
5,61
5,59
6,57
6,54
4,23
5,22
14,1
11,03
среднегодовая
стоимость
ОПФ, млн.
руб., x1
153,81
107,34
80,83
89,2
91,43
87,16
97,29
84,33
158,42
59,4
99,63
91,32
101,32
75,66
123,68
37,21
83,37
32,87
45,63
104,55
84,36
25,76
29,52
141,99
178,11
среднегодовой
фонд заработной
платы, тыс. руб.,
x2
20719
26813
33956
17016
54873
19074
18432
17556
63854
18947
65985
29626
11688
21955
19854
20193
20122
7612
27404
19648
43799
6235
11524
17309
22225
№
п/п
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
индекс
снижения
себестоимости,
%, y
71,2
90,8
99,8
76,8
119,15
21,9
48,4
173,5
74,1
68,6
60,8
355,6
264,8
325,1
118,6
31,1
57,7
51,6
64,7
48,3
15
87,5
108,4
267,3
34,2
Вариант 4
трудоемкость
единицы
изделия, час,
x1
0,29
0,41
0,41
0,22
0,29
0,51
0,36
0,23
0,26
0,27
0,29
0,01
0,01
0,18
0,25
0,31
0,38
0,24
0,31
0,42
0,51
0,31
0,37
0,16
0,18
коэффициент
сменности
оборудования,
x2
1,4
1,28
1,25
1,22
1,5
1,12
1,27
1,63
1,46
1,27
1,35
1,46
1,64
1,42
1,5
1,14
1,41
1,47
1,35
1,4
1,2
1,15
1,35
1,26
1,36
рентабельность,
%, y
5,23
7,99
17,5
17,16
14,54
6,24
12,08
9,49
9,28
11,42
10,31
8,65
10,94
9,87
6,14
12,93
9,78
13,22
17,29
7,11
22,49
12,14
15,25
20,3
11,56
Вариант 5
коэффициент
сменности
оборудования,
x1
1,16
1,58
1,22
1,22
1,35
1,08
1,27
1,14
1,14
1,27
1,43
1,12
1,35
1,41
1,08
1,35
1,2
1,2
1,39
1,3
1,37
1,58
1,37
1,87
1,28
удельный вес
потерь от брака,
%, x2
0,81
0,66
0,15
0,21
0,35
0,95
0,32
0,54
0,75
0,16
0,24
0,59
0,56
0,63
1,1
0,39
0,73
0,28
0,1
0,68
0,87
0,49
0,16
0,85
0,13
фондоотдача,
у
1,45
1,3
1,37
1,65
1,91
1,68
1,94
1,89
1,94
2,06
1,96
1,02
1,85
0,88
0,62
1,09
1,6
1,59
1,4
2,22
1,32
1,48
0,68
2,3
1,37
Вариант 6
производитель
ность труда,
млн. руб. на
чел., х1
9,26
9,38
12,11
15,4
11,7
9,87
10,12
9,12
6,88
12,8
10,9
5,49
6,5
6,61
4,32
7,37
7,07
8,25
8,15
8,72
6,64
8,1
5,52
9,37
8,25
удельный вес
рабочих в
составе ППП,
x2
0,78
0,75
0,68
0,85
0,87
0,76
0,88
0,81
0,85
0,91
0,86
0,74
0,66
0,72
0,68
0,77
0,83
0,81
0,79
0,93
0,78
0,89
0,79
0,93
0,84
ЛАБОРАТОРНАЯ РАБОТА 7
7.1 КОРРЕЛЯЦИОННО-РЕГРЕССИОННЫЙ АНАЛИЗ В ППП STATISTICA 10.0
Ход работы:
1.
Построение корреляционной матрицы и диаграммы рассеяния
1. Создать файл исходных данных (таблица 1).
2. В меню модуля “Основные статистики” выбираем “Correlation matrices”.
Рис. 63. Меню модуля “Основные статистики и таблицы”
После выбора этой процедуры откроется диалоговое окно Корреляции Пирсона.
Рис. 64. Корреляции Пирсона
Вы можете выбрать переменные как из одного списка (то есть матрица будет квадратной), так и из
двух списков (прямоугольная матрица).
В данном примере для простоты выберем все переменные для анализа. Однако следует помнить,
что корреляции Пирсона больше подходят для переменных, измеренных в количественных шкалах.
Рис. 65. Выбор переменных
Нажмите ОК, чтобы вернуться в диалоговое окно Корреляции Пирсона, где также нажимаем ОК
и получаем результат.
Рис. 66. Корреляционная матрица
Две остальные опции из диалогового окна Корреляции Пирсона позволяют получить таблицу
данных с коэффициентами корреляции, а также более подробными статистиками (например, р - значение,
число пар N, r2 – коэффициент детерминации, t – значения и т. д.).
После того как получена оценка корреляций, посмотрим зависимости на графиках.
Чтобы визуализировать значения корреляций между переменными, можно построить график
корреляций. Если щелкнуть по соответствующему коэффициенту корреляции правой кнопкой мыши, то
появится меню:
Рис. 67. Меню “Быстрые статистические графики”
Теперь перейдите в подменю
рассеяния/довер. (QuickStatsGraphs).
Быстрые
статистические
графикии
выберите
Диаг.
Будет построен график с параметрами, заданными по умолчанию (диаграмма рассеяния для
выбранного коэффициента корреляции с прямой регрессии, 95% - я доверительная полоса и уравнение
регрессии в заголовке).
Рис. 68. Меню Построение диаграммы рассеяния для коэффициента корреляции
Рис. 69. Диаграмма рассеяния коэффициента корреляции
Опишем некоторые возможности для настройки построенного графика зависимости.
Если вы щелкните где-нибудь на свободном месте снаружи осей графика, появится меню
глобальных опций.
Рис. 70. Меню глобальных опций
Большинство основных настроек формата графика доступно в диалоговом окне Общая разметка
(см. выше первую опцию контекстного меню).
Рис. 71. Меню “Общая разметка”
Ниже показаны основные соглашения по использованию мыши для настройки графиков.
Дважды щелкните мышью по элементу графика,
например, по линиям сетки, для открытия диалогового
окна настройки для этого объекта
Щелчок правой клавишей мыши по
объекту (например, масштабу) откроет
контекстное меню всех возможных
видов операций, которые доступны для
выделенного элемента графика
Рис. 72. Настройки графиков
2 Множественная регрессия
Шаг 1. Из Переключателя модулей STATISTICA откройте модуль Множественная регрессия –
Multiple Regression. Для этого откройте пункт меню Statistics и нажмите кнопку Multiple Regression
(Множественная регрессия).
Шаг 2. На экране появится стартовая панель модуля (рис.73):
Рис. 73. Стартовая панель модуля Множественная регрессия
Нажмите кнопку Открыть данные (Open Data) и откройте созданный файл данных ***. Далее
выберите переменные для анализа. Выбор переменных осуществляется с помощью кнопки Переменные
(Variables), находящейся в левом верхнем углу панели.
После того как кнопка будет нажата, диалоговое окно Выбрать списки зависимых и
независимых переменных – Select dependent and independent variable list – появится на вашем экране
(рис. 74).
Рис. 74. Окно выбора переменных для анализа
Высветив имя переменной в левой части окна, выберите зависимую переменную. Высветив имя
переменной в правой части окна, выберите независимую переменную. То же можно сделать, просто набрав
номера переменных в строках: Список зависимых переменных – Dependent variable list и Список
независимых переменных – Independent variable list.
Высветив имена переменных, как показано на рисунке, нажмите кнопку ОК в правом верхнем
углу окна Select dependent and independent variable list. Вы вновь окажитесь в стартовой панели модуля.
Переменные для анализа выбраны.
Никаких дополнительных установок в стартовой панели в данном случае не нужно.
Нажмите кнопку ОК в правом углустартовой панели.
Шаг 3. В диалоговом окне Результаты Множественной регрессии – Multiple Regression Results
просмотрите результаты оценивания. Результаты можно просмотреть в численном и графическом виде.
Окно результатов анализа имеет следующую структуру: верх окна – информационный. Он состоит
из двух частей: в первой части содержится основная информация о результатах оценивания, во второй
высвечивается значимые регрессионные коэффициенты. Внизу окна Результаты множественной
регрессии находятся функциональные кнопки, позволяющие просмотреть результаты анализа (рис. 75).
Рис. 75. Окно оценивания параметров
Рассмотрим вначале информационную часть окна. В ней содержатся краткие сведения о
результатах анализа. А именно:
Dependent (Имя зависимой переменной). В данном случае – PROISVOD.
No. ofcases (Число наблюдений, по которым построена регрессия).
Multiple R (Коэффициент множественной корреляции).
R? (Квадрат коэффициента множественной корреляции), обычно называемый
коэффициент детерминации.
Adjusted R?: (Скорректированный коэффициент детерминации), определяемый как:
AdjustedR2 = 1-(1-R2)*(n/(n-p)),
где n – число наблюдений в модели, p – число параметров модели (число независимых
переменных плюс 1, так как в модель включен свободный член).
Standard error of estimate (Стандартнаяошибкаоценки). Эта статистика является мерой
рассеяния наблюдаемых значений относительно регрессионной прямой.
Intercept (Оценка свободного члена регрессии). Значение коэффициента А0 в уравнении
регрессии.
Std. Error (Стандартная ошибка оценки свободного члена). Стандартная ошибка
коэффициента А0 в уравнении регрессии.
t (df) andp-value (Значение t-критерия и уровень p).t-критерий используется для проверки
гипотезы о равенстве 0 свободного члена регрессии.
F – значения F-критерия.
df– число степеней свободы F-критерия.
р – уровень значимости.
Шаг 4. Перейдем в функциональную часть окна результатов.
Прежде всего, нажмите кнопку Итоговый результат регрессии – Summary: Regression Results.
На экране появится электронная таблица вывода – Workbook, в которой представлены итоговые результаты
оценивания регрессионной модели.
Рис. 76. Итоговая таблица регрессии
Это стандартная таблица вывода регрессионного анализа. В первом столбце таблицы даны
значения коэффициентов beta (b*) – стандартизированные коэффициенты регрессионного уравнения,
во втором – стандартные ошибки beta (b), в третьем точечные оценки параметров модели:
Далее, стандартные ошибки для A0, A1, значения статистик t-критерия и т.д.
Шаг 5. Оценка адекватности модели. Важным элементом анализа является оценка адекватности
модели.
После того как доказана адекватность модели, полученные результаты можно уверенно
использовать для дальнейших действий.
Анализ адекватности основывается на анализе остатков.
Остатки представляют собой разности между наблюдаемыми значениями и модельными, то есть
значениями, подсчитанными по модели с оцененными параметрами.
В STATISTICA в модуле Множественная регрессия имеется специальное диалоговое окно, в
котором проводится всесторонний анализ остатков.
Нажмите кнопку Анализ остатков – Residual Analysis.
Следующее диалоговое окно Анализ остатков – ResidualAnalysis появится на экране (рис. 77).
Рис. 77. Диалоговое окно Анализ остатков в модуле Множественная регрессия
Рис. 78. График НАБЛЮДАЕМЫЕ ПЕРЕМЕННЫЕ-ОСТАТКИ
Нажмите в этом окне, например, кнопку Residuals. На экране появится график (см. рисунок 78),
который говорит о достаточной адекватности модели.
7.2 ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
Использовать те же варианты, что и в лабораторной работе № 6
ТЕРМИНЫ ПАКЕТА “STATISTICA”
Add
Добавить
Convert
Преобразование
Add Cases
Add Variables
Advanced Intellegent
Problem Solver
Advise
Accept
Action
Activation
Activation Function
Add Cases
All Layers
Append Network
Apply
Area Under Curve
Assigned Cases
Automatic Network Design
Automatic Network
Designer
Automatic update on Exit
Добавить наблюдения
Добавить переменные
Расширенный мастер решения
задач
Совет
Принять
Действие
Активация
Функция активации
Добавить наблюдения
Все слои
Присоединить сеть
Применить
Площадь под кривой
Связанные наблюдения
Автоматическое построение сети
Автоматический конструктор
сети
Автоматически обновлять при
выходе
Дополнительно
Обратное распространение
Пошаговое исключение
Исходные ошибки
Основной
Основной мастер решения задач
Create Data Set
Create Network
Cross Verification
Создать набор данных
Создать сеть
Кросс-проверка
Crossover Rate
Current Layer
Data Management
Data Set
Data Set Datasheer
Data Set Editor
Data Set Shuffle
Default
Definition
Delimiter
Delta-Bar-Delta
Details
Detail Shown
Скорость скрещивания
Текущий слой
Управление данными
Набор данных
Таблица данных
Редактор данных
Перемешать данные
По умолчанию
Определение
Разделить
Дельта-дельта с чертой
Подробности
Степень подробности
Deviation
Отклонение
Dimenionality Reduction
Direct
Discard
Division
Division of Cases
Duration of Design Process
Понижение размерности
Прямой
Отвергнуть
Деление
Разбиение наблюдений
Длительность поиска
Лучшая
Dynamic Link Library
Сохранение лучшей сети
Edit Case Names
Динамически подключаемая
библиотека
Редактировать имена
наблюдений
Редактирование параметров
пре/постпроцессирования
Auxiliary
Back Propagation
Backwards Stepwise
Baseline Errors
Basic
Basic Intellegent Problem
Solver
Best
Best Network Retention
Типы сетей, среди которых
производится поиск (сетикандидаты)
Cases (Train, Verify, Test) Наблюдения (обучающие,
контрольные, тестовые)
Case Errors
Ошибки наблюдений
City-Block Error
Ошибка "городских кварталов"
Class Labeling
Разметка классов
Class Labeling of Radial
Присвоение меток классов
Units
радиальным элементам
Classes
Классы
Classification
Классификация
Classification Output Type Форма результата классификации
Classification Statistics
Статистика классификации
Candidate Network Types
Classification Confidence
Threshold
Classification Statistics
Datasheet
Cluster Diagram
Clustering Networks
Commit Network to
Network Set
Доверительный порог
классификации
Таблица статистик
классификации
Диаграмма кластеров
Сети для кластеризации
Поместить сеть в набор сетей
Editing Pre/Post Processing
Enlarge Set
Увеличить набор
Entropy
Epochs
Epsilon
Error
Энтропия
Эпохи
Эпсилон
Ошибка
Error function
Error Mean
Explicit Deviation Assignment
Exponential distribution
Feature Selection
Функция ошибки
Среднее ошибки
Явное задание отклонений
Экспоненциальное
распределение
Отбор признаков
Hidden
Скрытый
Hidden Units
Скрытые элементы
Generalized Regression
Обобщенная регрессия
Generalized Regression Training Обучение обобщенной
регрессии
Complexity
Confidence
Сложность
Доверие
Generation
Genetic Algorithm Input
Selection
Method
MicroScroll
Поколение
Генетический алгоритм
отбора входных данных
Метод
Микро-прокрутка
Confidence limits
Conjugate Gradient
Descent
GRNN
Group Sets
Ignore
Inform User First
Initialization Algorithms
Input Variable
Input Feature Selection
Input/Output Variable
Input Datasheet
Intelligent Problem Solver
Intelligent Problem Solver
Message
IO Settings
Isotropic
Isotropic Deviation
Assignment
Iterations
Jog Weights
Keep Diverse
K-Means
K-Means Center
Assignment
K-Nearest Neighbor
Deviation
Kohonen Network
Kohonen Training
Доверительные границы
Спуск по сопряженным
градиентам
Обобщенно-регрессионные сети
Сгруппировать множества
Не учитывать
Сначала сообщать пользователю
Алгоритм инициализации
Входная переменная
Отбор входных признаков
Входная/выходная переменная
Таблица входных значений
Мастер решения задач
Сообщения мастера решения
задач
Параметры ввода/вывода
Изотропный
Изотропный выбор отклонений
Min/Mean
Minimax
Minimum Improvement
Min Proportion
Missing Value
Momentum
Move Cases
Multilayer Perceptron (MLP)
Mutation Rate
Name
Name and Nominals
Минимум/среднее
Минимаксное
Минимальное улучшение
Минимальная доля
Пропущенное значение
Инерция
Переместить наблюдения
Многослойный персептрон
Скорость мутаций
Имя
Имя и номинальные
Nearest Neighbor
Neighborhood
Network Advisor
Ближайший сосед
Окрестность
Наставник
Число итераций
Встряхнуть веса
Сохранять разнообразие
К-средних
Выбор центров по К-средним
Network (Append)
Network Illustration
Network Set
Network Set Editor
Network Set Options
Сеть (добавить)
Схема сети
Набор сетей
Редактор набора сетей
Параметры набора сетей
Отклонение по К ближайшим
соседям
Сеть Кохонена
Обучение Кохонена
Network to Replace
Заменяемая сеть
Network Wizard
Network for Classification
Layer
Слой
Neuro-Genetic Input
Layers Datasheet
Layers Shown
Таблица слоев
Показываемые слои
Selection Algorithm
No Layers
Мастер создания сети
Сети для задач
классификации
Нейрогенетический
алгоритм
отбора входных данных
Число слоев
Learned Vector
Quantization Training
Learning rate
Квантование обучающего
вектора
Скорость обучения
Noise
Шум
Nominal Variables
Levenberg-Marquardt
Linear
Linear Network
Lock
Левенберга-Маркара
Линейный
Линейная сеть
Блокировать
Nonlinear
Normal Distribution
Normalization
One-off Input Datasheet
Logistic
Lookahead
Loss Coefficient
Loss Matrix
Main
Mask
Max/SD
Логистическая
Горизонт
Коэффициент потерь
Матрица потерь
Главное
Маска
Максимальное/(стандартное
отклонение)
Среднее/(стандартное
отклонение)
One-of-N
Open Data Set
Open Network
Optimum Threshold
Options
Output Type
Output Variable
Номинальное
(категориальные)
переменные
Нелинейный
Нормальное распределение
Нормировка
Таблица задания одного
входного вектора
Один-из-N
Открыть набор данных
Открыть сеть
Оптимальный порог
Опции
Тип выхода
Выходная переменная
Outputs Datasheet
Таблица выходных значений
Mean/SD
Median
Medium
Медиана
Средняя (длительность поиска)
Outputs Shown
Partially or unusually defined
text values
Merge
Performance
Объединить
Качество
Penalty
Retain Best Network
Показатель при выводе
Частично или нестандартно
заданные текстовые
значения
Штраф
Восстановить лучшую сеть
Plot
PNN
Population
Popup Class Selector
Predict
Prediction
График
Вероятная нейронная сеть
Популяция
Контекстный выбор класса
Прогнозировать, предсказывать
Прогноз
RMS (Root Mean Squared) error
Run
Run All Cases
Run Data Set
Среднеквадратичная ошибка
Запуск
Прогнать все наблюдения
Прогнать набор данных
Run One-off Case
Pre/Post Processing
Pre/Post Processing
Datasheet
Pre/Post Processing Editor
Пре/постпроцессирование
Таблица
пре/постпроцессирования
Редактор
пре/постпроцессирования
Таблица редактора
пре/постпроцессирования
Главные компоненты
Анализ главных компонент
Run Single Case
Run/Activations
Прогнать отдельное
наблюдение
Прогнать одно наблюдение
Запуск/активации
Subsample
Save as Type
Подвыборка
Тип сохраняемого файла
априорные вероятности
Вероятность
Вероятностное обучение
Тип задачи
Формирование уменьшенного
набора данных
Удалить
Псевдообратный
Постсинаптическая функция
Быстрое распространение
Радиальные базисные функции
Scale
Select
Sensitivity Analysis
Set Case Types
Set Variable Types
Масштаб
Выбрать
Анализ чувствительности
Задать типы наблюдений
Задать типы переменных
Set Weights
Shift
Shuffle
Shuffle Cases
Single Case
Задать веса
Сдвиг, смещение
Перемешать
Перемешать наблюдения
Одно наблюдение
Радиальная выборка
Ранг
Диапазон, размах
Выделение диапазона ячеек
Отношение
Поля для вещественных чисел
Сети и одним выходом
Сглаживание
Константа сглаживания
Сортировать по возрастанию
Сортировать по убыванию
Стандартная (наблюдения
независимы)
Статистики
Шаг
Условия остановки
Pre/Post Processing
Editor's Datasheet
Principal Components
Principal Components
Analysis
Prior probabilities
Probabilistic
Probabilistic Training
Problem Type
Producing a Reduced Data
Set
Prune
Pseudo-Inverse
PSP-function
Quick Propagation
Radial Basis Function
(RBF)
Radial Sampling
Rank
Range
Range selection
Ratio
Real number fields
S.D. (Standard Deviation) Ratio Отношение стандартных
отклонений
Sample
Выборка
Real-time update
Receiver Operating
Characteristic (ROC)
Redundancy of variables
Regression
Пересчитывать по ходу
Операционная характеристика
Избыточность переменных
Single output networks
Smoothing
Smoothing Constant
Sort Ascending
Sort Descending
Standart (each case is
independent)
Statistics
Step
Stopping Conditions
Регрессия, зависимость
Sum-squared error function
Regression Statistics
Regularization
Reinitialize
Target Error
Test
Text Import Wizard
Reject
Статистики регрессии
Регуляризация
Переустановить,
инициализировать
Отвергнуть
Функция ошибки как сумма
квадратов разностей между
выходами сети и целевыми
значениями
Целевая ошибка
Тестовое (множество)
Мастер импорта текста
Threshold
Порог
Replace
Заменить
Thorough
Полный (режим поиска)
Replace Oldest
Replace Worst
Response Graph
Заменить самую первую
Заменить худшую
График отклика
Time Series
Time Series Period
Time Series (predict later values
from earlier ones)
Response Surface
Restore
Topological Map
Total
Train
Train RMS (Root Mean
Squared) Error
Training Error
Поверхность отклика
Восстановить
Топологическая карта
Всего
Обучить, обучающее множество
Среднеквадратичная ошибка
обучения
Ошибка обучения
Time Series Projection
Topological Classes
Unlock
Update
Value
Variable Definition
Training Error Graph
Training Graph
Training Set
Train-Multilayer
Perceptrons
Two-State Conversion
Type
Type of Network
График ошибки обучения
График обучения
Обучающее множество
Обучение многослойного
персептрона
Преобразование в два значения
Тип
Тип сети
Unit Names
Unit Penalty
Unit Number
Unknown
Имена элементов
Штраф за элемент
Номер элемента
Неизвестно
Временный ряд
Период временного ряда
Временной ряд (прогноз
следующих значений по
предыдущим)
Проекция временного ряда
Топологические классы
Разблокировать
Пересчитать, обновить
Значение
Определение переменной
Тип переменных в файлах
данных
Variant
Вариант
Verbose
Подробно
Verification Error
Контрольная ошибка
Verification Standard Deviation Контрольное отношение
Ratio
стандартных отклонений
Verification Set
Контрольное множество
Verify
Контрольное (множество)
Weigend Weight Regularization Регуляризация весов по
Вигенду
Weights Distribution
Распределение весов
Win Frequencies Datasheet
Таблица частот выигрышей
Variable type in Data Files
СПИСОК ЛИТЕРАТУРЫ
1. Афанасьев, В.Н. Анализ временных рядов и прогнозирование [Текст]: учебник./ Афанасьев,
В.Н., Юзбашев, М.М. М.: Финансы и статистика, 2001. - 228с.
2. Боровиков, В. STATISTICA. Искусство анализа данных на компьютере: для профессионалов
[Текст]. 2е издание (+CD). –Спб.:Питер, 2003. – 688с.
3. Годин А. М. Статистика: учебник : для вузов / А. М. Годин. - 9-е изд., перераб. и испр. - М. :
Издательско-торговая корпорация "Дашков и К", 2011. – 457 с.
4. Гусаров, В.М. Статистика: [Текст]: учебное пособие для ВУЗов. 2-е изд.- М.: Юнити-Дана,
2008. - 479 с.
5. Дубров, А.М. Многомерные статистические методы; Учебник [Текст]./ Дубров, А.М.,
Мхитарян, В.С., Трошин Л.И. – М.: Финансы и статистика, 2003. – 352с.
6. Елисеева, И.И., Юзбашев, М.М. Общая теория статистики. [Текст]: учебное пособие / Елисеева,
И.И., Юзбашев, М.М. / Под ред. И.И. Елисеевой, 4 издание перераб. и доп.- М.: Финансы и статистика, 2003.
- 480с.
7. Ефимова, М.Р. Общая теория статистики [Текст]/ Ефимова, М.Р., Петрова, Е.В., Румянцев, В.Н.
- М.: ИНФРА-М, 2010. - 416 с.
8. Заварина, Е.С. Основы региональной статистики [Текст]: учебник/ Е.С. Заварина, К.Г. Чобану;
под ред. Е.С. Завариной. – М.: Финансы и статистика, 2006. – 416с.
9. Кулагина, Г.О. Экономическая статистика [Текст]: учебно-методическое пособие./ Кулагина,
Г.О., Башкатов, Б.И., Квасова, Н.А. М.: Издательство МНЭПУ, 1999. - 116с.
10. Курс социально – экономической статистики[Текст]: учебник для ВУЗов /Под ред. Проф.
М.Г. Назарова. – М.: Финстатинформ, ЮНИТИ-ДАНА, 2000. – 771 с.
11. Макарова, Н.В. Статистика в Excel [Текст]: учебное пособие / Макарова, Н.В., Трофимец,
В.Я. – М.: Финансы и статистика, 2003. – 386с.
12. Мармоза А.Т., Практикум по математической статистике: Учебное пособие. – К.: Высшая
школа., 1990. – 191 с.
13. Микроэкономическая статистика [Текст]: учебник /Под ред. С.Д. Ильенковой. – М.: Финансы
и статистика.2004. – 544с.
14. Оформление текстовых учебных документов в Институте экономики и управления:
методические указания / Сост.: Р. А. Тимофеева, Е. И. Морозова; НовГУ им. Ярослава Мудрого. – Великий
Новгород, 2012 – 52 с.
15. Салин В.Н. Курс теории статистики для подготовки специалистов финансово-экономического
профиля [Текст]: учебник / Салин В.Н. Чурилова Э.Ю.. – М.: Финансы и статистика, 2006. – 480с.
16. Социально – экономическая статистика [Текст]: учебник для ВУЗов /Под ред. Проф. Б.И.
Башкатова. – М.: ЮНИТА-ДАНА, 2002.-703с.
17. Справочник по прикладной статистике. В 2-х т., [Текст], под ред. Э. Ллойда, У. Ледермана,
Ю.Н. Тюрина - М.: Финансы и статистика, 1989, 1990. – 276 с., 293с.
18. Статистика : учебник / Елисеева И. И. [и др.] ; под ред. И. И. Елисеевой ; С.-Петерб. гос. ун-т
экономики и финансов. - М. : Юрайт, 2011. - 565 c.
19. Теория статистики. [Текст]/ Под ред. проф. Г.А. Громыко М.: ИНФРА-М, 2000. - 414 с. (Серия "Высшее образование).
20. Теория статистики : Учеб. для вузов / Под ред.Р.А. Шмойловой. - 5-е изд. - М. : Финансы и
статистика, 2009. - 654с.
21. Теория статистики с основами теории вероятности. [Текст]: учеб. пособие / Под ред.
Елисеевой И.И., М.: ЮНИТИ, 2001. - 446 с.
22. Тюрин, Ю.Н., Макаров, А.А. Анализ данных на компьютере. [Текст] / Тюрин, Ю.Н., Макаров,
А.А. / Под ред. В.Э. Фигурнова. - М.: ИНФРА, Финансы и статистика, 2005. - 384 с., ил.
23. Шмойлова, Р.А. и др. Практикум по теории статистики [Текст]: учебное пособие /Р.А.
Шмойлова, В.Г. Минашкин, Н.А. Садовникова/Под ред. Р.А. Шмойловой – 2е издание, перераб. и доп. – М.:
Финансы и статистика, 2005. - 576с.
24. Эконометрика [Текст]: учебник/ И.И. Елисеева, С.В. Курышева, Т.В. Костеева и др.; /Под ред.
И.И. Елисеевой. – 2е издание, перераб. и доп. – М.: Финансы и статистика, 2005. – 576с.
25. Яглом, А.М. Корреляционная теория стационарных случайных функций (с примерами из
метеорологии) [Текст] // Гидрометеоиздат. 1981. - 280с.
ПРИЛОЖЕНИЕ А
ПРИМЕР ОФОРМЛЕНИЯ ТИТУЛЬНОГО ЛИСТА
25мм
30 мм
Министерство образования и науки Российской Федерации
Федеральное государственное бюджетное образовательное учреждение
высшего профессионального образования
«Новгородский государственный университет имени Ярослава Мудрого»
Институт экономики и управления
Кафедра статистики и экономико-математических методов
ПОСТРОЕНИЕ АНАЛИТИЧЕСКОЙ ГРУППИРОВКИ В MS EXCEL
Вариант 3
Лабораторная работа по учебной дисциплине
«Статистика»
по направлению 080100.62 – Экономика
Отчет
Доцент,
к.э.н.
(подпись)
Г.В. Фетисова
«____» ___________ 20 г.
Студент гр.2631до
Архипова Е.В.
(подпись)
В.В. Иванов
«____» ___________ 20 г.
25 мм
15 мм
ПРИЛОЖЕНИЕ Б
Число
степеней
свободы
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Таблица значений t Стьюдента для P=0,05 и 0,01
Число
Р=0,05
Р=0,01
степеней
Р=0,05
свободы
12,706
63,655
22
2,074
4,303
9,925
23
2,069
3,182
5,841
24
2,064
2,776
4,604
25
2,060
2,571
4,032
26
2,056
2,447
3,707
27
2,052
2,365
3,499
28
2,048
2,306
3,355
29
2,045
2,262
3,250
30
2,042
2,228
3,169
32
2,037
2,201
3,106
34
2,032
2,179
3,055
36
2,027
2,160
3,12
38
2,025
2,145
2,977
40
2,021
2,131
2,947
42
2,017
2,120
2,921
44
2,015
2,110
2,898
46
2,012
2,101
2,878
48
2,010
2,093
2,861
50
2,007
2,086
2,845
55
2,005
2,080
2,831
60
2,000
1,960
Р=0,01
2,818
2,807
2,796
2,787
2,778
2,771
2,764
2,757
2,750
2,739
2,728
2,718
2,711
2,704
2,696
2,691
2,685
2,681
2,678
2,668
2,660
2,576
ПРИЛОЖЕНИЕ В
Результаты регрессионного анализа зависимости объемов продукции от среднегодовой стоимости основных производственных средств
ВЫВОД ИТОГОВ
Регрессионная статистика
Множественный R
0,907705863
R-квадрат
0,823929933
Нормированный R-квадрат
0,816274713
Стандартная ошибка
11,01917442
Наблюдения
25
Дисперсионный анализ
df
SS
Регрессия
MS
F
1
13068,64929
13068,64929
Остаток
23
2792,710713
121,4222049
Итого
24
15861,36
Коэффициенты
Стандартная ошибка
t-статистика
107,6298137
P-Значение
Значимость F
3,80323E-10
Нижние 95%
Верхние 95%
Y-пересечение
-11,90489127
7,350084421
-1,619694494
0,118929755
-27,10969926
3,29991672
Переменная X 1
1,478554701
0,142518454
10,37447896
3,80323E-10
1,183732818
1,773376583
Продолжение Приложения В
ВЫВОД ОСТАТКА
ВЫВОД ВЕРОЯТНОСТИ
Наблюдение
Предсказанное Y
Остатки
1
50,19440616
-6,194406156
2
109,3365942
-2,336594179
3
64,97995316
-4,979953162
4
62,02284376
-8,02284376
5
84,20116427
6
Стандартные остатки
-0,574238522
Персентиль
Y
2
22
-0,21660872
6
28
-0,461655383
10
30
-0,743739727
14
32
1,798835731
0,16675703
18
33
97,50815657
-1,508156574
-0,139810271
22
42
7
84,20116427
28,79883573
2,66973144
26
43
8
35,40885915
-2,40885915
-0,223307882
30
44
9
88,63682837
-16,63682837
-1,54227984
34
49
10
35,40885915
-7,40885915
-0,686821662
38
50
11
35,40885915
-3,40885915
-0,316010638
42
50
12
48,71585146
7,284148545
0,675260645
46
52
13
47,23729675
1,762703245
0,163407449
50
54
14
72,37272666
-3,372726664
-0,312661057
54
56
15
47,23729675
20,76270325
1,924759812
58
60
16
69,41561726
-19,41561726
-1,799881229
62
68
17
42,80163265
0,198367347
0,0183892
66
69
18
38,36596855
3,634031449
0,33688473
70
72
19
73,85128137
16,14871863
1,497030722
74
86
20
22,10186685
-0,101866845
-0,009443337
78
87
21
57,58717966
-7,587179659
-0,703352464
82
88
22
57,58717966
-5,587179659
-0,517946952
86
90
23
73,85128137
14,14871863
1,31162521
90
96
24
93,07249247
-6,072492472
-0,562936788
94
107
25
29,49464035
0,505359652
0,046848232
98
113
Продолжение приложения В
ПРИЛОЖЕНИЕ Г
Результаты регрессионного анализа зависимости объемов продукции от производительности труда рабочих
ВЫВОД ИТОГОВ
Регрессионная статистика
Множественный R
R-квадрат
Нормированный R-квадрат
Стандартная ошибка
0,888413524
0,78927859
0,780116789
12,0548171
Наблюдения
25
Дисперсионный анализ
df
SS
Регрессия
MS
1
12519,03185
12519,03185
Остаток
23
3342,32815
145,3186152
Итого
24
15861,36
Коэффициенты
Стандартная ошибка
t-статистика
F
86,14885183
P-Значение
Значимость F
3,06099E-09
Нижние 95%
Верхние 95%
Y-пересечение
12,44069016
5,74490853
2,165515795
0,040963905
0,556441477
24,32493884
Переменная X 1
10,11691259
1,089991851
9,281640579
3,06099E-09
7,862092667
12,37173252
Продолжение Приложения Г
ВЫВОД ОСТАТКА
ВЫВОД ВЕРОЯТНОСТИ
Наблюдение
Предсказанное Y
Остатки
Стандартные остатки
Персентиль
Y
1
35,70958912
8,290410878
0,702517476
2
22
2
97,42275593
9,577244068
0,811561867
6
28
3
66,0603269
-6,060326897
-0,513543372
10
30
4
36,72128038
17,27871962
1,464173812
14
32
5
88,3175346
-2,3175346
-0,196384544
18
33
6
86,29415208
9,705847919
0,822459572
22
42
7
95,39937341
17,60062659
1,491451745
26
43
8
37,73297164
-4,73297164
-0,401065199
30
44
9
71,11878319
0,881216807
0,074673043
34
49
10
38,7446629
-10,7446629
-0,910487257
38
50
11
38,7446629
-6,744662899
-0,571533019
42
50
12
39,75635416
16,24364584
1,376463151
46
52
13
43,8031192
5,196880805
0,440376194
50
54
14
74,15385697
-5,153856971
-0,436730416
54
56
15
88,3175346
-20,3175346
-1,721678617
58
60
16
82,24738704
-32,24738704
-2,732597129
62
68
17
50,88495801
-7,88495801
-0,668159984
66
69
18
36,72128038
5,278719619
0,447311097
70
72
19
84,27076956
5,729230437
0,485486735
74
86
20
35,70958912
-13,70958912
-1,161730835
78
87
21
47,84988423
2,150115768
0,182197713
82
88
22
51,89664927
0,103350731
0,008757792
86
90
23
84,27076956
3,729230437
0,316009616
90
96
24
75,16554823
11,83445177
1,002834397
94
107
25
33,6862066
-3,686206603
-0,312363838
98
113
Продолжение Приложения Г
ПРИЛОЖЕНИЕ Д
Результаты регрессионного анализа зависимости объемов продукции от среднегодовой стоимости основных производственных средств и
производительности труда рабочих
ВЫВОД ИТОГОВ
Регрессионная статистика
Множественный R
0,940660077
R-квадрат
0,884841381
Нормированный R-квадрат
0,874372416
Стандартная ошибка
9,111861171
Наблюдения
25
Дисперсионный анализ
df
Регрессия
SS
MS
2
14034,78769
7017,393846
Остаток
22
1826,572308
83,02601399
Итого
24
15861,36
Коэффициенты
Стандартная ошибка
t-статистика
F
84,52042328
P-Значение
Значимость F
4,72347E-11
Нижние 95%
Верхние 95%
Y-пересечение
-6,815190854
6,25831457
-1,08898183
0,287947575
-19,79414083
6,163759123
Переменная X 1
0,891354299
0,208613703
4,272750476
0,000309914
0,458715961
1,323992638
Переменная X 2
4,975033303
1,458422693
3,411242382
0,002503221
1,950449771
7,999616834
Продолжение Приложения Д
ВЫВОД ОСТАТКА
ВЫВОД ВЕРОЯТНОСТИ
Наблюдение
Предсказанное Y
Остатки
Стандартные остатки
Персентиль
Y
1
42,06426632
1,93573368
0,221887477
2
22
2
108,0661414
-1,066141445
-0,122208669
6
28
3
65,90290922
-5,902909223
-0,676633181
10
30
4
49,69260405
4,307395954
0,493744172
14
32
5
88,43558838
-2,435588382
-0,279184357
18
33
6
95,46277042
0,537229583
0,061581052
22
42
7
91,91811169
21,08188831
2,416555058
26
43
8
34,14572999
-1,145729986
-0,13133167
30
44
9
82,65209467
-10,65209467
-1,221018386
34
49
10
34,64323332
-6,643233316
-0,761494361
38
50
11
34,64323332
-2,643233316
-0,302986087
42
50
12
43,16292534
12,83707466
1,471476238
46
52
13
44,26158436
4,738415637
0,543150694
50
54
14
74,33970736
-5,339707362
-0,612075002
54
56
15
66,1517309
1,848269105
0,21186167
58
60
16
76,53702541
-26,53702541
-3,041861432
62
68
17
45,07004478
-2,070044777
-0,237283165
66
69
18
35,43093525
6,569064746
0,752992635
70
72
19
80,20609496
9,793905036
1,122646625
74
86
20
25,12853463
-3,12853463
-0,358614754
78
87
21
52,49107778
-2,49107778
-0,285544944
82
88
22
54,4810911
-2,481091102
-0,2844002
86
90
23
80,20609496
7,793905036
0,893392487
90
96
24
87,31617089
-0,316170885
-0,036241742
94
107
25
28,59029947
1,409700533
0,16158984
98
113