Тема: Кодирование текстовой информации. Цель: Познакомить
реклама

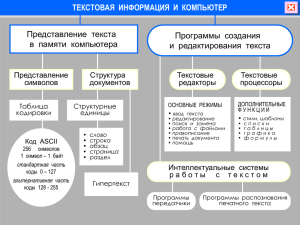
Тема: Кодирование текстовой информации. Цель: Познакомить с методами кодирования текстов в памяти компьютера. В компьютерной области текстом называют последовательность любых символов. На сегодня, машины пользуются набором таких символов, содержащих до 256 знаков. Причем, каждому соответствует свой восьмиразрядный двоичный код. Таким образом, в памяти компьютера любой символ текста занимает 8 бит или 1 байт. Имея это ввиду, представляется возможным измерять объем памяти, необходимый для хранения любого текстового документа. 1 бит (двоичная цифра) имеет два значения, добавление каждого разряда в код удваивает количество получаемых комбинаций: 2 бита - четыре варианта, 3 бита - восемь, 4 бита шестнадцать и т. д. К примеру, машинописная страница формата А4 содержит приблизительно 55 строк. На каждой из них помещается где-то 60 символов. Имея такую информацию, мы можем подсчитать количество текстовой информации на данной странице. Каждый символ - 1 байт информации, а всего символов - 3300 (60 умножаем на 55). Выходит, что на странице объем информации в районе 3 Кбайт. Таблица кодировки. Двоичные коды и соответствующие им символы связаны таблицей кодировки. Все используемые наПК таблицы основаны на американском стандарте ASCII4. Он определяет первые 128 кодов (латинские буквы, цифры, знаки). Остальные же 128 используются для спецсимволов и букв национальных алфавитов (русский, китайский, арабский). А, поскольку, общих стандартов для этого не было, возникло много кодировок, в том числе и для кириллицы. Именно поэтому, иногда можно увидеть чей-то текст в виде набора «закорючек». Для того, чтобы такие тексты можно было прочитать существуют программы-конверторы. Они заменяют двоичный код каждого символа на код другой кодировки. И, зачастую, пользователь должен указать, из какой в какую кодировки идет преобразование. Однако уже существуют программы, умеющие автоматически определять кодировку исходного текста. Итак, таблица, в которой всем символам машинного алфавита поставлены соответственные порядковые номера называется таблица кодировки. Таблица кодов ASCII. Как уже было сказано, международным стандартом для ПК стала таблица ASCII (Американский стандартный код для информационного обмена). Также можно встретить и другую таблицу - КОИ-8 (Код обмена информацией), использующаяся в компьютерных сетях. Таблица кодов ASCII делится на две части. В международной практике стандартом является лишь первая часть таблицы, то есть, символы с номерами от 0 (00000000), до 127 (01111111). Это строчные и прописные буквы латинского алфавита, цифры, знаки препинания, разного вида скобки, коммерческие и другие символы. Нумерацию символов от 0 до 31 принято называть управляющими. Они управляют процессом вывода текста на экран или печать, подачей звукового сигнала на акустические колонки, разметкой текста. Символ 32 – это пробел или пустая позиция в тексте. Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита. Вторая половина таблицы ASCII называемая кодовой страницей. Это остальные 128 кодов от 10000000 и до 11111111, имеющие различные варианты, и каждый (!) вариант имеет свой номер. В первую очередь, кодовая страница используется для размещения национальных алфавитов, отличительных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. Итак для каждого языка отдельно. Кодировка Unicode. Это 16-разрядная кодировка - в ней на каждый символ отводится по 2 байта памяти. Соответственно, увеличивается объем занимаемой памяти в 2 раза. Но зато такая кодовая таблица вмещает до 65536 символов. Полная версия Unicode включает в себя все существующие и вымершие алфавиты мира и множество математических, музыкальных, химических символов. Программы для работы с текстом. Стремление упростить работу с текстом привело к созданию множества программ, специально созданных для этого - текстовых редакторов. Текстовый процессор не просто заменитель пишущей машинки, а универсальное средство для работы с текстами. Они предоставляет очень широкие возможности манипулирования текстовыми документами. В таких программах можно работать не только с отдельными символами, но и со словами, строками, абзацами, графическими фрагментами. Кроме таких операций как набор текста, копирование, сохранение, перемещение и удаление фрагментов, изменение шрифта, цвета и размера, отправление текста на диск и печать. Обрабатываемый текст представляется как бы в виде листков бумаги заданного формата, прокручивающихся на экране. Преимущества файлового хранения текстов: 1) экономия бумаги 2) компактное размещение 3) возможность мгновенного копирования на другие носители 4) возможность передачи текста по линиям сети или Интернета Вопросы: 1. Что такое таблица кодировки? 2. Какая кодировка стала международным стандартом? 3. Что называется текстовым редактором?