Применение методов регрессионного анализа для оценки
реклама

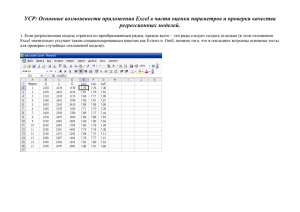
ПРИМЕНЕНИЕ МЕТОДОВ РЕГРЕССИОННОГО АНАЛИЗА ДЛЯ ОЦЕНКИ РЫНОЧНОЙ СТОИМОСТИ В СРЕДЕ MS EXCEL Анисимова Ирина Николаевна доцент Санкт-Петербургского Инженерно-экономического университета Наиболее распространенной на практике оценкой рыночной стоимости объекта является среднее арифметическое известных на рынке цен его аналогов. С теоретической точки зрения набор цен аналогов рассматривается как выборка из генеральной совокупности, а их среднее выступает в роли выборочной оценки математического ожидания. Последнее понимается как наиболее вероятное значение цены объектов такого типа в предположении о нормальности ее распределения. Генеральную совокупность при этом составляют цены всех объектов на определенном сегменте локального (регионального) рынка. Такой подход оправдан в случае, если основные характеристики аналогов совпадают с характеристиками объекта оценки, или их отличие незначительно. В противном случае перед расчетом среднего производят корректировки цен аналогов, причем доверие к полученным результатам корректировки определяется, в основном, авторитетом проводящего оценку эксперта. Альтернативой подобному подходу служит применение математически обоснованных методов регрессионного анализа, позволяющих определить усредненное изменение значения стоимости в зависимости от изменений влияющих факторов. Для задач оценки рыночной стоимости рассмотрено применение классической линейной регрессии, основанной на методе наименьших квадратов (МНК) [1]. Пусть имеется выборка из n известных значений цен объектов-аналогов y1, y2,…, yn. И пусть экспертом выделено k характеристик объекта недвижимости, влияющих на результирующее значение стоимости. Обозначим численные значения этих характеристик как xi1, xi2,…, xik, i=1,…,n для объектов-аналогов и x01, x02,…, xok – для объекта оценки. В собственно линейной модели регрессионная связь ищется в виде: ~ yi a0 a1 xi1 a2 x i 2 ... ak xik , i=1,…,n. К этому же виду могут быть приведены степенная ~ i=1,…,n yi a0 xi1a1 xi 2 a2 ... xik ak , (1) (2) и показательная ~ yi a0 a1 xi1 a2 xi 2 ...ak xik , i=1,…,n (3) зависимости. После логарифмирования правых и левых частей получим: i=1,…,n ln ~ yi ln a0 a1 ln xi1 a2 ln x i 2 ... ak ln xik , (4) ~ i=1,…,n. ln yi ln a0 xi1 ln a1 x i 2 ln a2 ... xik ln ak , (5) и После замены переменных ~yi ln ~yi , xij ln xij для i=1,…,n и j=1,…,k, a0 ln a0 в первом случае и ~yi ln ~yi , ai ln ai для i=1,…,n, a0 ln a0 – во втором, зависимости (2) и (3) примут вид (1). Значение ~yi , вычисленные с помощью регрессионной зависимости (1) для i-того аналога, могут отличаться от значения стоимости yi, известного на рынке: yi ~yi i . МНК ищет коэффициенты системы уравнений (1), исходя из условия минимизации суммы квадратов n отклонений: i 2 min . i 1 a В результате коэффициенты могут быть найдены из уравнения A=(XTX)-1XTY, где: n a0 n xi1 a1 i 1 A a2 , X T X n xi 2 i 1 n ak x ik i 1 n xi1 i 1 n xi1 i 1 n 2 xi1 xi 2 i 1 n xi 2 i 1 n xi1 xi 2 i 1 n xi 2 2 i 1 n n i 1 i 1 xi1 xik xi 2 xik n ... xik ... xi1 xik i 1 n , ... xi 2 xik i 1 n ... xik 2 i 1 i 1 n n yi i 1 n yi xi1 i 1 . X TY n y i xi 2 i 1 n yi xik i 1 (6) Получив коэффициенты регрессионной зависимости, можно вычислить значение стоимости ~y0 для объекта оценки, подставив в (1) значения x01, x02,…, xok его характеристик. Нельзя, однако, ограничиться этой точечной оценкой. Необходимо оценить точность и надежность полученного результата. Для этих целей может быть использован ряд статистических критериев. Приведенные ниже статистические оценки получены и справедливы в предположении нормальности распределения случайной величины y, а также независимости и нормальности распределения погрешностей i. 1) Стандартное отклонение (СКО) результата ŝ (или остаточное СКО): sˆ n n Qост , где Qост i 2 yi ~yi 2 , n k 1 i 1 i 1 (7) используется для построения доверительного интервала полученного результата. Вместо ŝ часто говорят о несмещенной оценке остаточной дисперсии ŝ 2 , sˆ sˆ 2 . Согласно [2] рыночная стоимость оцениваемого объекта со статистической надежностью 1 x01 , X0 x 0k попадет в доверительный интервал [ ~y0 t sˆ X 0T ( X T X ) 1 X 0 ] , где X0 – столбец : t – значение t-распределения Стьюдента для уровня значимости =1- и числа степеней свободы (n-k-1),. 2) Коэффициент определенности R 2 QR QR Qост (8) позволяет судить о том, какой процент дисперсии известных рыночных данных объясняется с помощью регрессионной зависимости. Коэффициент определенности наряду с остаточным СКО служит показателем качества регрессионной модели [3, 4]. Из двух регрессионных моделей предпочтение отдают той, которая характеризуется меньшим остаточным СКО или большим коэффициентом определенности. Как видно, величина (8) обратно пропорциональна (7), поэтому применение этих двух критериев равнозначно. 3) Проверка значимости уравнения регрессии с помощью F-критерия Фишера основана на вычислении статистики F n (n k 1)QR , где QR ( ~yi y ) 2 . kQост i 1 (9) Остаточная сумма квадратов Qост представляет собой показатель ошибки предсказания с помощью регрессии известных рыночных значений стоимости. Ее сравнение с регрессионной суммой квадратов QR показывает, во сколько раз регрессионная зависимость предсказывает результат лучше, чем среднее y . Значение коэффициента Фишера (8) сравнивают с критическим значением Fкр, представляющее собой значение F-распределения (распределение Фишера-Снедекора) со степенями свободы (n-k-1), k и уровнем значимости =1-. Если неравенство F > Fкр выполнено, то регрессионная зависимость (1) статистически значимо (с надежностью ) описывает известные рыночные данные. Если регрессионная зависимость незначима, то принимается гипотеза о равенстве нулю всех коэффициентов регрессионной связи в генеральной совокупности. В таком случае 2 применение методов регрессионного анализа применительно к выбранным влияющим факторам не имеет смысла, и следует либо анализировать иные влияющие факторы, либо прибегнуть к оценкам с помощью среднего. Если же значимость регрессионной связи установлена, представляет интерес проверка значимости ее отдельных коэффициентов. Уравнение (6) позволяет найти выборочные оценки a0, a1,…, ak коэффициентов регрессионной зависимости. Проверка значимости коэффициентов регрессии основана на статистике t aj | aj | sˆ [( X T X ) 1 ] j 1 j 1 Здесь , имеющей распределение Стьюдента c n-k-1 степенями свободы. sˆ [( X TX ) 1 ] j 1 j 1 saj – СКО коэффициентов регрессии, (10) [( X TX ) 1 ] j 1 j 1 – диагональный элемент матрицы (XTX)-1, лежащий на пересечении j+1строки и j+1 столбца. Элемент, лежащий на пересечении 1 строки и 1 столбца, соответствует a0. Гипотеза о равенстве нулю (незначимости) данного коэффициента отвергается с вероятностью , если taj>t, . Факторы, имеющие незначимые коэффициенты уравнения регрессии, следует исключить и заново построить регрессионную модель, исходя из меньшего числа влияющих факторов. Рассмотренная регрессионная модель может быть реализована с помощью табличного процессора Excel, имеющего в своем распоряжении необходимые функции и механизмы. Собственно линейная многомерная регрессионная модель (1) опирается на использование функций ЛИНЕЙН и ТЕНДЕНЦИЯ, а также инструмента РЕГРЕССИЯ надстройки «Анализ данных» MS Excel. Функция ТЕНДЕНЦИЯ выдает значение ~y0 , полученное в результате интерполяции или экстраполяции для объекта оценки. При этом конкретный вид линейной зависимости, построенной по данным выборки, и ее оценки могут быть получены с помощью функции ЛИНЕЙН. Для получения оценок функция ЛИНЕЙН должна быть введена как функция массива размерностью 5(k+1), а ее последний аргумент должен быть указан в явном виде и иметь значение «истина». Приводимая в этом случае статистика имеет вид: ak sak R2 F QR ak-1 sak-1 … … a1 sa1 a0 sa0 ŝ n-k-1 Qост Если требуется получить лишь отдельные характеристики из указанного в таблице набора, ЛИНЕЙН можно и не выводить на лист как функцию массива, а использовать в комбинации с функцией ИНДЕКС, указав местоположение в таблице (номер строки и номер столбца) интересующей характеристики. Так, например, значение коэффициента определенности R2 можно получить с помощью формулы =ИНДЕКС(ЛИНЕЙН(…); 3; 1). Как видно, проверка значимости уравнения регрессии в целом и его отдельных коэффициентов требуют дополнительно вычисления статистик taj и привлечения критических значений для F и taj. Fкр может быть получено с помощью функции FРАСПОБР, причем первым аргументом этой функции является уровень значимости , вторым – число степеней свободы регрессионного уравнения (числителя выражения (9)) n-k-1, третьим – количество факторов (число степеней свободы знаменателя (9)) k. Критические значения t могут быть найдены с помощью функции СТЬЮДРАСПОБР, возвращающей значения t-распределения Стьюдента для заданного уровня значимости (первый аргумент функции) и числа степеней свободы n-k1 (второй аргумент). Рассмотрим пример. Пусть требуется оценить рыночную стоимость производственного здания. Из рыночных данных известны цены и характеристики 10 аналогов - объектов недвижимости того же типа. Экспертами были отобраны четыре основных характеристики: общая площадь, состояние здания, наличие автономного теплоэнергоснабжения и местоположение, оказывающие наибольшее влияние на результирующую цену объекта. Всем характеристикам были присвоены количественные оценки, занесенные в таблицу Excel. 3 1 2 3 4 5 6 7 A Факторы площадь состояние автон.снабжение местоположение цена за 1 кв.м. B C D E 1 2 4,9 1 2 7 72,3 3 6,79 2 1 7 69,9 4 23,3 1 2 6 70,8 19 2 2 5 70,8 F G Аналоги 5 6 9,6 5,4 2 2 2 1 3 4 85 89,2 H I J K 7 8 7,3 3 3 2 107 9 4,8 2 2 2 92,1 10 8 2 2 4 92,1 6 1 1 4 71 L Объект оценки 20,78 2 2 3 Функция ЛИНЕЙН(B7:K7;B3:K6;ИСТИНА;ИСТИНА), введенная как функция массива размерностью 55 (k=4), возвращает следующую статистику. -2,86 6,18 6,88 -0,56 76,32 1,50 4,15 4,38 0,38 13,68 0,87 6,3 #Н/Д #Н/Д #Н/Д 8,15 5 #Н/Д #Н/Д #Н/Д 1293,41 198,35 #Н/Д #Н/Д #Н/Д Коэффициент определенности R2=0,87, то есть построенная модель объясняет 87% дисперсии цен аналогов, что является допустимым для экономической задачи результатом, учитывая малый объем (n=10) исходной выборки рыночных данных. Значение коэффициента Фишера F=8,15 требуется сравнить с критическим значением F-распределения. Последнее для уровня значимости 0,05 может быть получено функцией FРАСПОБР(0,05;5;4) и равно 6,256. Как видно, построенная регрессионная зависимость значима со статистической надежностью (доверительной вероятностью) 95% (=0,95). Проверим теперь значимость отдельных регрессионных коэффициентов. Первая строка результатов функции ЛИНЕЙН содержит регрессионные коэффициенты aj, начиная с k-того, а вторая строка – их СКО saj. Значения статистики (10) получаются как модули частных aj/saj: ta4=1,8997; ta3=1,4894; ta2=1,5697; ta1=1,4763; ta0=5,5801. Критическое значение для уровня значимости 0,05 возвращается функцией СТЬЮДРАСПОБР(0,05;5) и равно 2,5706. Таким образом, значимость большинства регрессионных коэффициентов со статистической надежностью 95% не подтверждается. Вместе с тем она подтверждается на менее жестком уровне значимости 0,2 (доверительная вероятность 80%), что можно считать допустимым результатом – значение функции СТЬЮДРАСПОБР(0,2;5)=1,4759 меньше всех taj. Тогда можно вычислить значение рыночной стоимости объекта оценки. Функция ТЕНДЕНЦИЯ(B7:K7;B3:K6;L3:L6;ИСТИНА) возвращает значение 82,32. Самую грубую оценку точности результата можно получить, воспользовавшись правилом «двух сигм»: 82,322*6,3. Построение более точного доверительного интервала требует формирования матрицы XTX и вектора X0 (см.выше). Использование стандартных функций Excel обладает тем преимуществом, что результат пересчитывается автоматически при изменении данных выборки (при условии неизменности k и n). Вместе с тем использование инструмента РЕГРЕССИЯ надстройки Excel «Анализ данных» позволяет избежать некоторых дополнительных расчетов, проводимых, в частности, для проверки значимости. Кроме того, этот инструмент позволяет получать и визуально анализировать значения погрешностей i. Ниже приведена статистика, выданная инструментом РЕГРЕССИЯ для рассмотренного примера. Для некоторых значений в скобках приведены обозначения соответствующих величин. Регрессионная статистика Множественный R 0,93 2 R-квадрат (R ) 0,87 Нормированный R0,76 квадрат Стандартная ошибка ( ŝ ) 6,3 Наблюдения (n) 10 4 Дисперсионный анализ df Регрессия Остаток (k) (n-k-1) Итого Y-пересечение Переменная X1 Переменная X2 Переменная X3 Переменная X4 4 5 (QR) (Qост) 9 SS 1293,41 198,35 (QR/k) (Qост/(n-k-1)) F Значимость F 8,15 () 0,02 1491,76 Коэффици Стандарт енты ная ошибка t-статистика (a0) (a1) (a2) (a3) (a4) (ta0) (ta1) (ta2) (ta3) (ta4) 76,32 -0,56 6,88 6,18 -2,86 MS 323,35 39,67 (sa0) (sa1) (sa2) (sa3) (sa4) 13,67 0,38 4,38 4,15 1,50 5,58 -1,48 1,57 1,49 -1,90 P-Значение Нижние Верхние Нижние Верхние 95% 95% 80,0% 80,0% (0) 0,003 (1) 0,2 (2) 0,18 (3) 0,2 (4) 0,12 41,16 111,48 -1,52 0,41 -4,38 18,14 -4,49 16,85 -6,72 1,01 56,14 -1,11 0,41 0,06 -5,08 96,51 -0,00 13,34 12,31 -0,64 Последние четыре столбца содержат границы доверительных интервалов для регрессионных коэффициентов, построенные для стандартного (95%) и выбранного пользователем уровней надежности. Для получения стоимости объекта оценки ~y0 попрежнему используется функция ТЕНДЕНЦИЯ. После каждого изменения данных выборки инструмент РЕГРЕССИЯ должен быть применен заново. Отметим, что пакет «Анализ данных» не входит в стандартную конфигурацию MS Excel, устанавливаемую по умолчанию. Поэтому он должен быть включен при установке приложения MS Excel или в дальнейшем установлен дополнительно. Для ряда экономических задач зависимости (2) или (3) лучше объясняют реальные связи, чем (1). MS Excel располагает функциями ЛГРФПРИБЛ и РОСТ, аналогичными ЛИНЕЙН и ТЕНДЕНЦИЯ, но для показательной зависимости (3). Следует отметить, что функция ЛГРФПРИБЛ выдает коэффициенты aj показательной зависимости (3), однако вся остальная статистика рассчитана для линеаризованной зависимости (5), что значительно снижает ее ценность. Параметры регрессионных зависимостей (2) и (3) рассчитываются с помощью (6) после преобразования для линейных моделей (4), (5). При этом оценки коэффициентов регрессии проводятся для моделей (4), (5), в то время как остальные оценки – для зависимостей вида (2), (3). В ходе реализации могут оказаться полезными следующие функции Excel: СУММКВ, СУММПРОИЗВ – для формирования матриц XTX, XTY, функции массивов МОБР и МУМНОЖ – для вычисления обратной матрицы и перемножения матриц, СУММКВРАЗН – для подсчета сумм квадратов разностей в оценках (7) и (9), ИНДЕКС – для выделения элементов матрицы в оценках (10), а также упомянутые выше функции FРАСПОБР и СТЬЮДРАСПОБР. Заметим, что в качестве аргументов функций СУММКВ, СУММПРОИЗВ, СУММКВРАЗН можно указывать массивы (диапазоны ячеек) Excel. Табличный процессор MS Excel является привычной и достаточно удобной средой проведения вычислений, а использование его стандартных функций и инструментов позволяет эффективно реализовать регрессионную модель. ЛИТЕРАТУРА 1. Грибовский С.В. Оценка доходной недвижимости. – СПб.: Питер, 2001. 2. Дубров А.М., Мхитарян В.С., Трошин Л.И. Многомерные статистические методы: Учебник. – М.: Финансы и статистика, 2000. 3. Теория статистики: Учебник/Под ред.проф. Р.А.Шмойловой. – М.: Финансы и статистика, 1999. 4. Демиденко Е.З. Линейная и нелинейная регрессия. – М.: ИМЭМО, 1973. 5