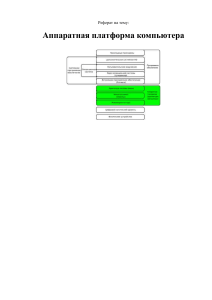
1.4. Структуры данных Структура данных – это совокупность
реклама

1.4. Структуры данных Структура данных – это совокупность элементов данных, между которыми существуют некоторые отношения, причем элементами данных могут быть простые данные и структуры данных. Структуру данных можно определить, как S=(D,R), где D- множество элементов данных, R-множество отношений (связей) между элементами данных. Каждую структуру данных можно характеризовать ее логическими и физическими представлениями, а также совокупностью операций над этими представлениями. Физическая структура данных - это реальное расположение данных на устройстве хранения информации. Логическая структура данных - это то, как информация представляется программе или пользователю. Например, файл данных - это совокупность информации, которая хранится как единое целое. Это её логическая структура. Физически файл может быть записан на жестком диске компьютера несколькими, разбросанными в разных местах, кусками. Чаще всего, говоря о той или иной структуре данных, имеют в виду ее логическое представление, так как физическое представление обычно скрыто от “внешнего наблюдателя”. Важным признаком структуры является ее изменчивость − изменение числа элементов структуры и (или) связей между элементами структуры. По этому признаку различают структуры статические и динамические. В зависимости от характера взаимного расположения элементов структуры делятся на линейные (списки), табличные, иерархические (дерево). Линейная структура данных (список) — это упорядоченная структура, в которой адрес данного однозначно определяется его номером. Примером линейной структуры может быть список учебной группы или дома, стоящие на одной улице. В списках, как правило, новый элемент начинается с новой строки. Если элементы располагаются в строчку, нужно внести разделительный знак между элементами. Поиск осуществляется по разделителям (чтобы найти, например, десятый элемент, надо отсчитать девять разделителей). Если элементы списка одной длины, структура называется вектором данных, разделители не требуются. При длине одного элемента − d, зная номер элемента − n , его начало определяется соотношением d (n − 1). Табличная структура данных - это упорядоченная структура, в которой адрес данного однозначно определяется двумя числами - номером строки и номером столбца, на пересечении которых находится ячейка с искомым элементом. Если элементы располагаются в строчку, нужно внести два разделительных знака - разделительный знак между элементами строки и разделительный знак между строками. Поиск, аналогично линейной структуре, осуществляется по разделителям. Если элементы таблицы одной длины, структура называется матрицей данных, разделители в ней не требуются. При длине одного элемента - d, зная номер строки − m и номер столбца n, a также строк и столбцов М, N, найдем адрес его начала: d [N(m - 1) + (n - 1)1. Таблица может быть и n-мерная. Например: Номер факультета 5 Номер курса (на факультете) 3 Номер специальности (на курсе) 2 Номер группы в потоке одной специальности 2 Номер студента в группе 14 Размерность такой таблицы равна пяти, и для однозначного отыскания данных о студенте в подобной структуре надо знать все пять параметров (координат). Нерегулярные данные, которые трудно представляются в виде списка или таблицы, могут быть представлены в иерархической структуре, в которой адрес каждого элемента определяется путем (маршрутом доступа), идущим от вершины структуры к данному элементу. Иерархическую структуру образуют, например, почтовые адреса (рис. 1.9.) Россия Московская область Якиманка Москва Лубянка Сретенка д.1 д.2 Приморский край Ильинка Петровка д.3 Рис.1.9. Пример иерархической структуры данных. Адрес одного из домов, расположенных, к примеру на улице Сретенка, может выглядеть следующим образом: Россия \ Москва \ ул. Сретенка \ д. 2. Основным недостатком иерархических структур данных является увеличенный размер пути доступа. Очень часто бывает так, что длина маршрута оказывается больше, чем длина самих данных, к которым он ведет. Поэтому в информатике применяют методы для регуляризации иерархических структур с тем, чтобы сделать путь доступа компактным. Один из методов получил название дихотомии. Его суть понятна из примера, представленного на рис. 1.10. Процессор Процессор Не процессор Не процессор Intel Процессор Intel Процессор Intel Pentium Не процессор Intel Pentium Не процессор Intel Pentium 4 Процессор Intel Pentium 4 Рис. 1.10. Метод дихотомии. В иерархической структуре, построенной методом дихотомии, путь доступа к любому элементу можно представить как путь через рациональный лабиринт с поворотами налево (0) или направо (1) и, таким образом, выразить путь доступа в виде компактной двоичной записи. В нашем примере путь доступа к процессору Intel Pentium 4 выразится следующим двоичным числом: 1010. Списочные и табличные структуры являются простыми. Ими легко пользоваться, поскольку адрес каждого элемента задается числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы. Они также легко упорядочиваются. Основным методом упорядочения является сортировка. Данные можно сортировать по любому избранному критерию, например по алфавиту, по возрастанию порядкового номера или по возрастанию какого-либо параметра. Несмотря на многочисленные удобства, у простых структур данных есть и недостаток — их трудно обновлять. Если, например, перевести студента из одной группы в другую, изменения надо вносить сразу в два журнала посещаемости; при этом в обоих журналах будет нарушена списочная структура. Если переведенного студента вписать в конец списка группы, нарушится упорядочение по алфавиту, а если его вписать в соответствии с алфавитом, то изменятся порядковые номера всех студентов, которые следуют за ним. Таким образом, при добавлении произвольного элемента в упорядоченную структуру списка может происходить изменение адресных данных у других элементов. В журналах успеваемости это пережить нетрудно, но в системах, выполняющих автоматическую обработку данных, нужны специальные методы для решения этой проблемы. Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней. Даже если в учебном заведении будет создан новый факультет, это никак не отразится на пути доступа к сведениям об учащихся прочих факультетов. Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочения. Часто методы упорядочения в таких структурах основывают на предварительной индексации, которая заключается в том, что каждому элементу данных присваивается свой уникальный индекс, который можно использовать при поиске, сортировке и т. п. Ранее рассмотренный принцип дихотомии на самом деле является одним из методов индексации данных в иерархических структурах. После такой индексации данные легко разыскиваются по двоичному коду связанного с ними индекса.