ИНСТРУМЕНТАРИЙ БОЛЬШИХ ДАННЫХ
advertisement

ISSN 1028-7493
ИТ для бизнеса —
архитекторам
информационных систем
www.osmag.ru
ИНСТРУМЕНТАРИЙ
БОЛЬШИХ ДАННЫХ
ISSN 1028-7493
Открытые системы. СУБД №01 2014 Инструментарий Больших Данных • Автоматическое управление ИТ
СУ
БД
Открытые
системы
№01
2014
Боб Меткалф: Ethernet сорок лет спустя
Большие Данные против индустрии ИТ
Секреты интеграции в Airbus
Новые гибридные микропроцессоры
Уязвимости и защита стратегических инфраструктур
•
•
•
•
Toyota демонстрирует
трехколесный гибрид
мотоцикла, автомобиля
и Segway
AltOS
Источник: Electrolux
Компания Toyota представила концептуальную модель трехколесного «персонального средства передвижения» под
названием iRoad. Мини-автомобиль обтекаемой формы имеет два колеса спереди и одно сзади. Заднее поворачивается, тогда как передние на поворотах
автоматически наклоняются.
iRoad обладает необычайной маневренностью: можно повернуть руль прямо
перед препятствием, и автомобиль выполнит поворот не потеряв устойчивости. Максимальная скорость iRoad —
около 50 км/ч, средства управления
очень простые: руль, газ, тормоз и кнопка запуска. В салоне предусмотрены
места для двоих.
Источник: Toyota
Летающие роботы-уборщики и дышащие стены
Компания Electrolux объявила проекты, победившие на организованном ею конкурсе Electrolux Design Lab 2013. Первое место заняла концепция системы уборки дома, представляющей собой рой миниатюрных летающих роботов, которые
чистят поверхности каплями воды. Благодаря им хозяин квартиры может, удобно
устроившись в кресле после трудного дня, наблюдать, как «автоматические феи,
словно по волшебству, преображают дом перед его глазами».
Второй приз достался дышащим стенам. Стены двигаются, имитируя «дыхание»,
и при этом очищают воздух микрофильтрами, работающими по принципу рыбьих
жабр. С помощью приложения для смартфона можно переключать режимы работы
стен — «снятие стресса», «навевание воспоминаний», «поднятие настроения» и т. д.
Третье место занял детский 3D-принтер здоровой еды Atomium. По замыслу, ребенок сможет сперва нарисовать на листке бумаги, как должно выглядеть блюдо,
а принтер из смеси загруженных в него родителями порошкообразных ингредиентов и воды с помощью системы шприцев приготовит заказ.
Hershey собирается печатать
шоколад на 3D-принтере
Источник: NASA
Инженеры НАСА проектируют роботов совершенно нового вида — сферических,
которых можно будет просто сбросить на другую планету без повреждений от
удара и которые будут перемещаться, катаясь по ее поверхности.
Корпус таких роботов будет строиться по принципу «тенсегрити», то есть представлять собой сферическую каркасную структуру натяжения-сжатия, сетку из
тросов и стержней, объясняют проектировщики. Не имея жестких соединений, колес или гусениц, эти аппараты будут обладать уникальным уровнем надежности,
представляя собой легкие конструкции, полностью амортизирующие удар
о поверхность планеты при сбросе с орбиты.
Сегодня ученые исследуют Марс с помощью роботизированных вездеходов
Curiosity и Opportunity — колесных машин, оснащенных научными приборами
и механизированными манипуляторами.
Перекатывающийся шарообразный робот с гораздо меньшей вероятностью застрянет в песке — именно такой инцидент привел к потере марсохода Spirit: после
безуспешных попыток ученых вытащить робота, застрявшего в песчаной дюне,
его миссию пришлось прекратить.
Роботы-сферы смогут
найти применение и
на Земле. Например,
их можно было бы
сбрасывать с самолетов для изучения
труднодоступных
территорий. Кроме
того, такие роботы
помогли бы при обследовании трубопроводов, пещер
и туннелей.
Источник: 3D Systems
НАСА готовится исследовать планеты,
сбрасывая на них роботы-колобки
Hershey и 3D Systems приступают к разработке 3D-принтеров для «печати» пищевых продуктов — шоколадных и других
изделий. На выставке потребительской
электроники CES компания 3D Systems
уже продемонстрировала два подобных
принтера для создания кондитерских изделий, в том числе шоколадных. Первый
из них, под названием ChefJet, предполагается продавать по цене около 5 тыс.
долл., а второй, более мощный ChefJet Pro,
будет стоить около 10 тыс. долл. ChefJet
способен изготавливать объекты с максимальным размером 8х8х6 дюймов, а
ChefJet Pro — 10х14х8 дюймов. Оба принтера могут печатать съедобными материалами со вкусом шоколада, ванили,
мяты, яблока, вишни и арбуза.
колонка редактора
В поисках сокровищ
Б
ольшие Данные меняют жизнь общества — все больше государств,
компаний и отдельных людей устремляются на поиски сокровищ в виде
плодотворных идей, фактов или тенденций,
ранее скрытых в ворохе больших массивов разнообразных данных. Однако данные раскрывают свои секреты лишь тем,
кто готов «слушать» и вооружен необходимыми инструментами, позволяющими
обнаружить неочевидные корреляции и
охватить все имеющиеся массивы. Вместе
с тем облака и Большие Данные выявили
неподготовленность современной индустрии ИТ к работе с невиданными прежде
объемами информации, львиная доля которой хранится в реляционных СУБД, что,
по сути, оставляет, например, за бортом
анализа неструктурированные данные. За
пределами хорошо поддающихся изучению структурированных хранилищ оказываются целые «залежи» данных из малоинтересных, на первый взгляд, или вовсе
необработанных сведений, без вскрытия
которых сокровищ не найти.
Господствовавшая до сих пор идея сведения всего разнообразия данных только
к таблицам морально устарела, однако это
лишь часть проблемы — Большие Данные,
как пишет Леонид Черняк в этом номере
журнала, посвященном инструментам обработки больших массивов информации в
реальном времени, придали цивилизации
новое качество на культурном, научном
и технологическом уровнях. Так, например, родилось понятие электронной науки, основная задача которой — поставить
вопрос «что искать», а не «как», позволив
данным самим говорить за себя: скажем,
по накоплению признаков или по отклонениям буквально «на лету» обнаружить
новую тенденцию, неисправность узла
или зарождение очага социальной напряженности. Сегодня уже недостаточно
довольствоваться выборками из массива
данных, на чем построены многие разделы
традиционной науки, а требуется анализировать все в комплексе — нюансы, как
известно, часто скрываются в деталях,
которые при изучении только выборок
можно упустить.
Технологический уровень предполагает
переориентацию ИТ от поддержки счетных задач на обеспечение процедур сбора,
хранения и обработки больших наборов
данных с одновременным выполнением
аналитических преобразований. Однако
существующие инфраструктуры и инструментальные средства, которые сегодня пытаются применять для обработки Больших
Данных, оказались перед необходимостью
удовлетворения противоречивым требованиям: узкой специализации при решении
конкретных задач, тесной интеграции в
системном стеке, максимальной энергоэффективности и масштабируемости, высокой производительности и надежности,
безопасности и доступности.
Как отмечают авторы этого номера, у
индустрии пока нет целостной программы создания инструментария, адекватного проблеме Больших Данных, хотя
отдельные производители и предлагают
свои концепции, осознав, что MapReduce/
Hadoop — это далеко не единственная технология. Имеющиеся сегодня продукты
от различных стартапов носят фрагментарный характер — на рынке все еще нет
полноценных решений для обработки
огромных массивов неструктурированных данных различной природы, поступающих в режиме реального времени из
многочисленных источников. В перечень
ключевых технологий Больших Данных, по
мнению аналитиков, входят: поколоночные
СУБД и СУБД класса NoSQL; MapReduce/
Hadoop; Hive — средства выполнения традиционных приложений бизнес-аналитики на кластерах Hadoop; PIG — средства,
приближающие Hadoop к разработчикам
и бизнес-пользователям; WibiData — вебаналитика и Hadoop; PLATFORA — платформа автоматического формирования
заданий к Hadoop; системы хранения;
высокопроизводительные аналитические
обучающиеся платформы типа SkyTree.
Однако, по мнению Дмитрия Семынина,
эти и другие технологии хотя уже и вышли
из юношества, но еще не повзрослели, а
стек решений для Больших Данных, что
бы ни заявляли ведущие игроки рынка ИТ,
представляет собой аморфное — правда,
динамичное — образование. Современный
стек технологий Больших Данных — это
некий инкубатор, из которого впоследствии выйдут специализированные приложения, ориентированные на работу с
большими базами данных, аналитику реального времени, обработку разнородной
информации, обеспечение непротиворечивости используемых данных.
На новый ракурс Больших Данных указывает в своей статье Наталья Дубова, которая отмечает, что аналитика огромных
массивов разнообразных сведений и телеметрии нужна сегодня не только финансистам, биоинформатикам и маркетологам,
но и ИТ-специалистам. Существующие
инструменты управления не позволяют
оценить эффективность применения ИТ,
предсказать динамику изменения производительности, а главное — современный
уровень сложности ИТ-сред уже не оставляет места ручному управлению. Конечно,
сотрудники ИТ-служб и ИТ-менеджеры и
раньше решали аналитические задачи для
оптимизации управления инфраструктурой и сервисами, однако теперь требуется
новое поколение средств, позволяющих
справиться с обработкой постоянно растущих объемов разнородных и изменчивых данных, поступающих из всех доменов
инфраструктуры для построения точной
картины ее состояния.
Процесс качественного изменения запускается только после достижения требуемого потенциала — вода закипает лишь
при определенных условиях, и нельзя нагреть ее чуть-чуть, чтобы получить каплю
пара. Нельзя обработать часть Больших
Данных и ожидать, что откроются ворота к информационным сокровищам.
Неспособность существующих ИТ-систем
быстро обрабатывать большие объемы
разнообразных данных из различных источников подтолкнула индустрию к тому,
чтобы всерьез озаботиться созданием необходимого инструментария — аналитики
предсказывают ежегодный 30-процентный
рост рынка таких технологий, что в семь
раз опережает развитие всего рынка ИКТ.
Эпоха малых данных закончилась — будущее за Большими Данными и соответствующими им технологиями.
Дмитрий Волков
www.osmag.ru • 01/2014 • Открытые системы • 1
ОТКРЫТЫЕ СИСТЕМЫ. СУБД
Главный редактор
Дмитрий Волков, с.н.с., ИПМ РАН
Научные редакторы
Наталья Дубова, Леонид Черняк
Редакционный совет:
Валерий Аджиев, к.т.н., с.н.с., Университет Борнмута
(Великобритания);
Михаил Горбунов-Посадов, д.физ.-мат.н.,
доцент ВМК МГУ;
Сергей Кузнецов, д.физ.-мат.н., профессор МГУ;
Михаил Кузьминский, к.хим.н., с.н.с., ИОХ РАН;
Павел Храмцов, к.т.н., доцент, Национальный
исследовательский ядерный университет «МИФИ»;
Игорь Федоров, к.т.н., профессор МЭСИ;
Виктор Шнитман, д.т.н., профессор МФТИ;
Леонид Эйсымонт, к.физ.-мат.н.,
научный консультант, НИИ «Квант».
Корректор Ирина Карпушина
Верстка и графика Мария Рыжкова
Фотографии и дизайн обложки Игорь Лапшин
Адрес редакции:
Россия, 127254, Москва, ул. Руставели, д. 12а, стр. 2
Адрес для корреспонденции:
127254, Москва, а/я 42
Телефоны:
(495) 725-4780 (издательство),
(495) 619-1372 (редакция),
(495) 725-4785 (распространение, подписка)
Факс: (495) 725-4788
E-mail: osmag@osp.ru
Подписной индекс:
99482 — Каталог российской прессы «Почта России» МАП
72773 — Объединенный каталог «Пресса России» АПР
59869 — «Каталог. Издания органов научно-технической
информации»
Реклама
ООО «Рекламное агентство «Чемпионс» (499) 750-0467
Распространение
ООО «ОСП-Курьер» xpress@osp.ru
Содержание № 1 (197) 2014
Новости. факты. тенденции.
HP развивает решения DCIM
Watson коммерциализируется
AMD выпускает первый процессор ARM
IBM Connections: все в одном
Транзисторы на органике
Oracle вошла в число спонсоров OpenStack
EMC продвигается к «третьей вычислительной
платформе»
Шифрование оказалось ненадежным
VoltDB ускоряется в 50 раз
В Microsoft устроили конкурс по поиску простых
чисел
В Facebook открывают лабораторию искусственного
интеллекта
Флэш-хранилище для Больших Данных
Суперкомпьютеры ускорят квантовыми
вычислителями
платформы
10Все в одном: микропроцессор Kaveri
Леонид Черняк
Для получения преимуществ на современном
рынке микропроцессоров производители значительное внимание уделяют универсальности своих изделий, наделяя их возможностями
самоопределения.
инструменты больших данных
12Серьезно о технологиях
для Больших Данных
Леонид Черняк
Большие Данные и облака выявили неподготовленность индустрии ИТ к работе с невиданными прежде объемами информации,
львиная доля которой хранится в реляционных
СУБД. Вместе с тем на рынке нет полноценных
решений для обработки огромных массивов
неструктурированных данных различной природы, поступающих в режиме реального времени из многочисленных источников.
16Большие Данные для управления ИТ
Наталья Дубова
Аналитика Больших Данных становится необходима ИТ-менеджерам — существующие
инструменты управления ИТ не позволяют
оценить эффективность своего применения,
предсказать динамику изменения производительности, а главное — современный уровень
сложности ИТ-сред уже не оставляет места
ручному управлению.
20Большие Данные в руках брокера
©
2014 Издательство «Открытые системы»
Журнал зарегистрирован
в Министерстве РФ по делам печати,
телерадиовещания и средств массовых коммуникаций
04.11.1999
Свидетельство ПИ №77-1051
Журнал выходит 10 раз в год
Цена свободная
Учредитель и издатель:
Олег Болгарчук
Системы алгоритмической торговли широко
используются финансовыми организациями
для автоматизированного выставления биржевых заявок — анализ больших объемов
разнообразных данных позволяет получать
устойчивую прибыль путем выявления незначительных колебаний курсов.
программная инженерия
23Тестирование эластичных
компьютерных систем
ЗАО «Издательство «Открытые системы»
123056, Москва, Электрический пер., д. 8, стр. 3.
Алессио Гамби, Валдемар Хуммер, Хон
Линь Чыонг, Шахрам Дустдар
Президент Михаил Борисов
Генеральный директор Галина Герасина
Директор ИТ-направления Павел Христов
Коммерческий директор Татьяна Филина
Появившись вместе с облаками, эластичные
компьютерные системы привлекают сегодня
все больше внимания — они могут «сжиматься» и «растягиваться» в зависимости от рабочей нагрузки. Однако до сих пор неясно, как
тестировать эластичные системы и каковы
дальнейшие направления их развития.
Все права защищены.
При ис­поль­зо­ва­нии ма­те­ри­а­лов
не­об­хо­ди­мо раз­ре­ше­ние ре­дак­ции и ав­то­ров.
В номере использованы иллюстрации
и фотографии: ЗАО «Издательство «Открытые
системы» и IEEE Computer Society.
12+
Отпечатано в ООО «Богородский
полиграфический комбинат»
142400, Московская область,
г. Ногинск,
ул. Индустриальная, д. 40б
(495) 783-9366, (49651) 73179
Тираж 10 000 экз.
приложения
28Мониторинг рекламных роликов
Константин Селезнев, Максим Ефремов,
Вадим Мельников
Создание средств обработки видеоинформации традиционно считается сложной проблемой, которая под силу лишь крупным
производителям ПО, однако в ряде случаев
решение может быть достаточно простым —
например, при мониторинге показов рекламных видеороликов.
безопасность
30Защита критически важных
систем управления
Кристина Алкарас, Шерали Зидалли
Бесперебойная работа таких критически важных инфраструктур, как системы энергоснабжения, обеспечения водой или продуктами
питания, — задача государственной важности. Какие сегодня имеются архитектуры автоматизированных систем управления, в чем
состоят угрозы, где уязвимые места и как защищать такие инфраструктуры?
Интеграция
36Интеграция для Airbus
Никита Калуцкий
Авиастроительная отрасль — одна из наиболее
конкурентных, особенно в нише пассажирских
узкофюзеляжных лайнеров, однако развитие здесь
в ряде случаев сдерживается необходимостью
работы с унаследованными информационными
системами поддержки моделей самолетов, появившимися десятилетия назад.
стандарты
39Первоклассные объекты
Всемирной паутины
Паоло Чиккарезе, Стиэн Сойленд-Рейес,
Тим Кларк
До недавнего времени в WWW не было единой
модели аннотаций, независимой от контента, что затрудняло возможность их переноса
между системами и предметными областями.
Но сегодня спецификация Open Annotation
Data Model консорциума W3C кардинально
меняет принципы подготовки и распространения аннотаций.
мнение
42Стек для Больших Данных
Дмитрий Семынин
Все сегодня говорят о Больших Данных, но
мало кто знает, как с ними работать. Похоже,
что соответствующие технологии уже вышли
из юношества, но еще не повзрослели.
музей ос
44Закон Меткалфа сорок лет спустя
после рождения Ethernet
Боб Меткалф
Согласно закону Меткалфа, полезность сети пропорциональна квадрату числа ее пользователей.
Правда, критики уверены, что это преувеличение,
однако на реальных данных закон раньше никто не
проверял. Изобретатель Ethernet и автор закона
сам предпринял попытку сделать это.
экстремальные технологии
48Инструменты для «ковбоев»
Леонид Черняк
«Выпас данных» — так можно перевести название новой специальности data wrangling, в
задачу представителей которой входит подготовка больших массивов данных для их последующего анализа.
академия ОС. семинар
51Системы автоматической
обработки текстов
Дмитрий Ильвовский, Екатерина Черняк
Многообразие систем автоматической обработки неструктурированных текстов сегодня
вызывает необходимость их систематизации
и классификации с целью упрощения выбора решения, наиболее адекватного для конкретной задачи.
академия ОС. Библиотека
54Сила в простоте
Сергей Кузнецов
Тема ноябрьского номера журнала Computer
(IEEE Computer Society, V. 46, No 11, 2013) —
простота в информационных технологиях.
новости. факты. тенденции.
Открытые системы
сегодня
Компания Hewlett-Packard представила набор сервисов, призванных помочь организациям повысить эффективность управления своими ЦОД на основе принципов DCIM (Data Center
Infrastructure Management). Появление решений DCIM обусловлено ростом стоимости энергии и упрощением перемещения рабочей нагрузки за счет технологий виртуализации.
Исторически сложилось так, что управление вспомогательным оборудованием ЦОД осуществлялось без привязки к ИТоборудованию. Объединение данных, относящихся к этим независимым друг от друга операциям, позволит получить более
целостную картину затрат на функционирование ЦОД и поможет находить пути экономии за счет консолидации и перераспределения ресурсов.
В новых сервисах HP обобщен опыт управления инфраструктурой ЦОД c помощью системы Converged Management Framework.
Сервис HP Converged Management Workshop должен разъяснять сотрудникам ИТ-подразделения, обслуживающему и
операционному персоналу порядок использования технологий, сценариев и решений DCIM. Второе решение, Converged
Management Roadmap Service, будет анализировать операции
ИТ-департамента и обслуживающих подразделений и выявлять
области, которые можно подвергнуть перестройке в целях повышения эффективности. Если организация принимает решение о
переходе к концепции DCIM, то продукт Converged Management
Design Service предоставит ей подробный план построения архитектуры ЦОД. И наконец, компонент Converged Management
Implementation Services поможет организации внедрить у себя
модель DCIM. Компания HP готова интегрировать все элементы и предоставлять программное обеспечение (например, HP
OneView) для управления операциями.
Как прогнозируют аналитики IDC, в 2014 году модель DCIM
получит достаточно широкое распространение среди операторов ЦОД.
4 • Открытые системы • 01/2014 • www.osmag.ru
Oracle представляет
новую версию Exadata
Компания Oracle представила пятую версию своего аппаратнопрограммного комплекса управления базами данных Exadata.
Утверждается, что во многих областях новые машины позволяют добиться двукратного увеличения производительности
по сравнению с системами предыдущего поколения. В сравнении с версией X-3, Exadata X-4 выполняет в единицу времени
на 77–100% больше операций
ввода-вывода; пропускная способность Infiniband выросла
почти в два раза; в два раза
увеличилась и емкость флэшпамяти. Размер логического
буфера при заполнении всей
стойки увеличился с 44 до
88 Тбайт. Заметно возросли
производительность и емкость
дискового хранения. Теперь в
стойке X-4 при использовании
технологии сжатия Oracle можно хранить петабайты данных.
Благодаря увеличению буфера
флэш-памяти клиенты могут
держать большинство баз данных с оперативной обработкой
транзакций во флэш-памяти.
Таким образом, в одной стойке Exadata X-4 размещаются
сотни баз данных.
Обновленное программное
обеспечение Exadata сравнимо по своим возможностям
с СУБД Oracle 12c и 11gR2.
Источник: Oracle
HP развивает решения DCIM
новости. факты. тенденции.
четырех модулей памяти SODIMM, UDIMM или RDIMM. Что касается программного обеспечения, то в комплект войдет дистрибутив Fedora ARM Linux с драйверами устройств, веб-сервер
Apache, СУБД MySQL, языки PHP и Java 7 и 8, а также стандартный набор инструментов GNU для разработки приложений
Linux. Загрузка системы происходит в защищенном режиме с
помощью интерфейса UEFI.
В AMD уверены, что серверы на основе ее новых процессоров
подойдут для исполнения веб-приложений и управления системами хранения данных в дата-центрах.
Watson коммерциализируется
Новое подразделение корпорации IBM под названием Watson
Business Group займется разработкой облачных когнитивных
приложений и сервисов, ориентированных на корпоративных
пользователей. Первоначальные вложения в этот бизнес составят 1 млрд долл., 100 млн из которых пойдут на финансирование компаний-стартапов, разрабатывающих приложения для
облачной платформы Watson. В штат подразделения переводится около 2 тыс. сотрудников IBM.
Система Watson способна формулировать ответы на вопросы,
поставленные на естественном языке, используя обширную базу
знаний и обучаясь в процессе работы. В 2011 году суперкомпьютер с системой Watson победил в телевикторине Jeopardy, и с тех
пор IBM с переменным успехом пытается коммерциализировать
эту технологию. Компания запустила облачные сервисы на базе
Watson для решения различных проблем в бизнесе и в медицине, а в прошлом году открыла платформу Watson Ecosystem
для создания когнитивных приложений независимыми разработчиками. В подразделении Watson Business Group будут организованы лаборатории для изучения и испытания клиентами
когнитивных систем. Кроме того, будут проводиться различные
семинары и обучающие курсы.
AMD выпускает первый процессор ARM
Компания AMD объявила о планах начать в ближайшие месяцы
поставлять партнерам 64-разрядные процессоры архитектуры
ARM и соответствующие комплекты разработчика. Серия процессоров ARM компании будет носить название Opteron A1100,
а выпускаться они будут по технологии 28 нм. Образцы этих
чипов, под кодовым именем Seattle, партнеры AMD получат в
марте или апреле. Вместе с ними будут поставляться комплекты разработки, состоящие из системной платы и набора инструментов программирования.
Чипы серии Opteron A1100 будут базироваться на ядре ARM
Cortex A57. Процессоры будут иметь 4 Мбайт совместно используемого кэша второго уровня, а также 8 Мбайт кэша третьего
уровня и два канала памяти с поддержкой DDR3 и DDR4 и кодом
коррекции ошибок, обеспечивающие до 1855 млн пересылок в
секунду. Чипы будут выполнены в виде системы на кристалле,
поддерживающей сопроцессоры для шифрования и компрессии данных, а также восемь каналов PCI-Express Generation 3,
столько же портов Serial ATA 3, два порта Gigabit Ethernet и до
Компания «Аскон» представила мобильное приложение
«Компас:24», позволяющее просматривать созданные в системе «Компас-3D» модели на мобильных устройствах на платформе Android. С помощью приложения пользователь сможет
продемонстрировать свои разработки партнерам или коллегам, просмотреть 3D-модели, присланные по почте, обучать
сотрудников на наглядных примерах — и все это без привязки
к рабочему месту. А используя функцию динамического сечения, которая появится в новой версии «Компас-3D V15», прямо
в мобильном приложении можно будет посмотреть, что находится внутри разработанного узла или детали. Доступны следующие функции: вращение, масштабирование и панорамирование изображения; отображение информации о файле (автор,
комментарий); динамическое сечение плоскостью. В компании
надеются, что «Компас:24» станет полезным инструментом и для
инженера, который сможет без компьютера продемонстрировать свою модель на совещании и показать варианты решений,
проработанных в «Компас-3D», и для руководителя, который,
пользуясь планшетом с установленным приложением, будет
оперативно принимать решения вне зависимости от того, где
он находится в данный момент.
«Компас:24» станет первым мобильным приложением, созданным компанией специально для решения профессиональных задач конструктора, и дополнит линейку мобильных разработок
«Аскон». В 2012 году «Аскон» впервые вышел на рынок мобильных приложений с клиентом «Лоцман:24», который позволяет
специалистам сферы строительного проектирования удаленно и
в режиме онлайн вести мониторинг дел по проектам и согласовывать документы. Следующим шагом стал выпуск приложения
для проектирования внешнего облика изделия SubDivFormer,
которое может использоваться как для инженерных разработок,
так и для детских игр. А осенью 2013 года в App Store и Google
Play появилось первое игровое приложение компании — мобильный 3D-конструктор Machinator.
Google Play
Источник: IBM
3D-модели на мобильном
www.osmag.ru • 01/2014 • Открытые системы • 5
новости. факты. тенденции.
IBM Connections: все в одном
IBM перенесет в пакет Connections, состав которого до этого ограничивался средствами организации корпоративных социальных сетей, платформу электронной почты Notes/Domino, систему
аудио/видеосвязи, мгновенного обмена сообщениями и организации веб-конференций Sametime, а также набор офисных онлайн-приложений Docs. Все эти продукты будут в нынешнем году
обновлены и выпущены под брендом Connections. Платформа
корпоративных социальных сетей IBM позволяет создавать профили, блоги, вики, форумы и т. д. Как уточняют в IBM, продукты,
переносимые в пакет, уже интегрированы и взаимодействуют
с ней и друг с другом, а цель ребрендинга — подчеркнуть это.
Кроме того, корпорация сможет демонстрировать потенциальным заказчикам свою альтернативу сервисам Microsoft Office
365 и Google Apps. Приобрести пакет можно будет целиком или
частично. За отдельную плату будут предлагаться дополнения
для руководства (governance), аналитики и помощи в соблюдении нормативных требований.
Вначале будут обновлены облачные версии приложений, позднее — и локальные. Сильнее всего будет переработан почтовый клиент Notes/iNotes — появятся, например, возможности
автоматической сортировки сообщений по приоритетности и
распознавания писем, содержащих еще не выполненные задания. Чтобы подчеркнуть масштаб обновления, клиент получит
название Mail Next.
Транзисторы на органике
Группа исследователей сообщила в Nature Communications о
разработке самых быстрых в мире органических тонкопленочных транзисторов. По оценкам ученых, по сравнению с кремниевыми такие транзисторы будут обходиться гораздо дешевле в производстве. Есть еще одно преимущество: органические
транзисторы могут быть почти прозрачными. До сих пор такие
элементы не могли сравниться с кремниевыми по быстродействию, но авторы публикации, ученые Стэнфорда и Университета
Небраска-Линкольн, заявляют, что добились серьезных успехов
в этой области: их органические транзисторы сопоставимы по
скорости переключения с кремниевыми.
Органические транзисторы изготавливаются путем капания углеродно-пластиковым раствором на быстро вращающуюся стеклянную пластину. Исследователи доработали этот процесс, ускорив вращение и ограничившись частичным покрытием пластины.
Благодаря этому, по их словам, удалось добиться более равномерного и плотного распределения молекул раствора, за счет чего в
полученных транзисторах выросла мобильность носителей тока.
Со временем данная технология позволит выпускать недорогую
прозрачную электронику, считают разработчики.
Директору по данным — быть!
Пост директора по данным (Chief Data Officer, CDO) к концу этого года будет существовать примерно в четверти крупных международных компаний, считает вице-президент аналитической
фирмы Gartner Дебра Логан. Директор по данным занимается
управлением данными в масштабах всей компании. По подсчетам Gartner, сейчас это звание носит около сотни менеджеров
крупных компаний — в два раза больше, чем в 2012 году. 65% из
них работают в американских компаниях, а 20% — в британских.
При этом доля женщин среди директоров по данным составляет
25%, что почти вдвое выше, чем среди директоров информационных служб (13%).
Как правило, пост директора по данным вводят компании, работающие в отраслях со строгим регулированием, прежде всего в
финансах и страховании, а также государственные учреждения.
Однако в 2013 году этот пост начал появляться и в компаниях
других отраслей. Аналитик отмечает назначение директоров по
данным в некоторых рекламных компаниях. Директорам информационных служб не следует рассматривать директоров по данным как конкурентов, подчеркивает аналитик. Они занимаются
управлением данными, что позволяет директору информационной службы сосредоточиться на своих основных задачах.
Oracle вошла в число спонсоров OpenStack
Компания Oracle приобрела статус корпоративного спонсора
организации OpenStack Foundation, занимающейся разработкой программной платформы с открытым исходным кодом для
создания инфраструктурных облачных сервисов. В Oracle рассчитывают использовать компоненты OpenStack в собственных
разработках — в том числе в операционных системах Solaris и
Oracle Linux, виртуализационных платформах Oracle VM и Oracle
Virtual Compute Appliance, инфраструктурных сервисах (IaaS) и
системах семейств S3 Series, Axiom и StorageTek. Кроме того,
Oracle планирует добиться совместимости OpenStack с сервером
приложений Exalogic Elastic Cloud и сервисами Oracle Compute
Cloud и Storage Cloud.
Несмотря на масштабные планы интеграции OpenStack, финансовый вклад компании Oracle в работу OpenStack Foundation невелик и составляет лишь 25 тыс. долл. в год. Компании HP, IBM,
Red Hat и другие, имеющие статус платиновых спонсоров, платят 500 тыс. долл. в год и выделяют для работы над OpenStack
на постоянной основе как минимум двух сотрудников. Тем не
менее участие Oracle в OpenStack весьма важно, отмечают аналитики, и прежде всего — для все еще значительной аудитории
пользователей системы Solaris.
Дожить до 2015-го
Источник: Jinsong Huang, Yongbo Yuan
Аналитик Gartner Вильям Маурер предсказывает начало масштабных процессов консолидации на рынке облачных сервисов. В ближайшие два года около четверти компаний из числа ста крупнейших
облачных провайдеров мира разорятся или будут куплены, заявил
он на конференции Gartner Data Center Conference. Клиентам облачных сервисов придется учитывать высокий риск исчезновения
их провайдера. Некоторые клиенты из-за этого могут предпочесть
работать с крупными компаниями, но мелкие провайдеры, возможно, предложат более выгодные условия и дополнительные гарантии. Впрочем, аналитик не советует клиентам оказывать слишком
6 • Открытые системы • 01/2014 • www.osmag.ru
новости. факты. тенденции.
большое давление на провайдеров. Клиенты сейчас заинтересованы в выживании их провайдера, указывает он.
Участники конференции разделили мнение аналитика о риске
облачных решений. Почти 50% из них в ответах на проведенный
опрос указали, что откажутся от перехода к облачным технологиями при высоком уровне риска, 33% — при среднем, а 12% —
даже при малом. Несмотря на это, в Gartner прогнозировали, что
к концу 2013 года 80% организаций будут в той или иной мере
использовать облачные сервисы.
Графеновые флэш-стикеры dataStickies
вместят до 32 Гбайт
В компании dataStickies объявили о разработке потребительских
флэш-накопителей нового типа: по толщине они такие же, как бумажные стикеры. Устанавливать такой накопитель в разъем USB
не понадобится: как и бумажные аналоги, графеновые «стикеры»
можно приклеить на монитор, и обмен данными будет происходить без проводов через проприетарный интерфейс под названием Optical Data Transfer Surface.
Комплект накопителей будет похож на упаковку обычных стикеров,
обещают в компании, а емкость флэшек dataStickies составит от
4 до 32 Гбайт. Сама флэш-память будет выполнена на одиночном
слое графена. В компании объясняют, что собираются предложить
флэш-стикеры в различных расцветках, чтобы каждый цвет можно
было использовать для своего типа данных. А еще на dataStickies
можно будет писать маркером, как на обычных стикерах.
EMC продвигается
к «третьей вычислительной платформе»
Новую версию программного обеспечения управления ресурсами хранения данных EMC Storage Resource Management Suite
в корпорации EMC рассматривают как очередной шаг в реализации концепции «третьей платформы», объединяющей облачные и мобильные технологии, социальные сети и обработку
Больших Данных. Существующая сейчас на многих предприятиях инфраструктура была спроектирована для «второй платформы», клиент-серверной. Такие предприятия не располагают
ресурсами, необходимыми для перехода к «третьей платформе», считают в EMC.
В пакете SRM 3.0 реализован новый, более простой интерфейс
и новые средства анализа и визуализации для мультивендорных
сред хранения. Интеграция с программно-конфигурируемой
системой хранения данных ViPR дает возможность управления
с помощью одного пакета и традиционными, и программно-определяемыми средами. SRM 3.0 поддерживает также работу со
средствами анализа и оповещения для инфраструктуры резервного копирования и репликации EMC Data Protection Advisor в
масштабах всей инфраструктуры предприятия.
Стандарт или нестандарт?
Поискам ответов на этот вопрос была посвящена конференция
«Стандарт SAP: мифы и реальность», проведенная по инициативе ОАО «Сургутнефтегаз» при поддержке, в частности, компаний
SAP, HP, VMware, Inline Group, а также издательства «Открытые
системы». Безусловно, без стандартов не было бы вообще индустрии ПО, основанной на повторной применимости программ, помогающих различным пользователям вести бизнес, однако вряд
ли стоит считать нормальной ситуацию, когда только 4% исходного функционала системы ERP оказывается стандартным и может быть использовано как есть, а остальное приходится дорабатывать. «По мнению ряда крупнейших заказчиков SAP, включая и
“Сургутнефтегаз”, основная проблема — это необходимость в большом объеме дополнительного программирования», — считает Ринат
Гимранов, начальник управления ИТ компании «Сургутнефтегаз»,
уже 20 лет использующей системы от SAP.
Данная ситуация случайна или закономерна? Где водораздел между стандартом и нестандартом? В идеале все ПО должно применяться стандартно, а если возникает необходимость
в доработках, то как измерить их объем? Многолетний опыт
«Сургутнефтегаза» свидетельствует о том, что нестандарт идет
от версии к версии, причем в постоянной пропорции — лишь
30% кода можно использовать без доработок.
Без сложной системы управления бизнес «Сургутнефтегаза»
невозможен — сегодня в компании работают 29 продуктивных
систем от SAP, обрабатывающих 8 Тбайт данных, доступ к которым имеют 28 тыс. пользователей, однако, как было показано на конференции, во всех бизнес-процессах требовалась
модификация стандартных решений. В аналитических задачах
доля стандартных решений составила только 4%, а остальное —
собственные разработки специалистов «Сургутнефтегаза», выполненные, в частности, на инструментарии SAP. Аналогичная
ситуация, судя по докладам, складывается и у других крупных
заказчиков — в частности, в компании «Башнефть», представитель которой отметил, что доработки от поставщика ПО обычно
приходят с опозданием и не в полном объеме, поэтому предприятия вынуждены держать собственный штат программистов, соизмеримый с численностью сотрудников средней компании, занимающейся разработкой ПО.
Комментируя замечания, представители SAP отметили,
что бизнес компании все-таки состоит в поставке стандартного ПО, однако в ближайшее время планируется сделать акцент на развитии инструментария, упрощающего заказчикам
локализацию решений, и основной платформой разработки
будет HANA. Парируя критику заказчиков, Андрей Трегубов,
представитель SAP Labs, отметил, что в России 150 человек
занимаются локализацией продуктов, однако, по наблюдениям SAP, средний отечественный клиент не знает о функциональности, за которую он уже заплатил. В этой ситуации
требуется найти баланс между стандартом и собственными
разработками заказчиков, учитывающими, в частности, особенности динамичного российского законодательства. Кроме
этого, Трегубов обратил внимание на то, что не всегда ясно,
кто должен раскрывать функционал продуктов: сам заказчик,
интегратор или поставщик. Тем не менее он отметил, что в
компании ведется работа по гармонизации взаимодействия
партнеров и поставщика, особенно в вопросах включения в
стандарт новой функциональности — требуется встречное
движение производителя и заказчика.
www.osmag.ru • 01/2014 • Открытые системы • 7
новости. факты. тенденции.
ходом новой версии VoltDB сможет конкурировать с SAP HANA
и другими СУБД, работающими в памяти, которые рассчитаны
как на транзакционные, так и на аналитические задачи.
Источник: Bryce Vickmark
Бизнес-аналитика
остается в центре внимания
Шифрование оказалось ненадежным
Мариэль Медар и ее коллеги из Массачусетского технологического
института и Национального университета Ирландии опубликовали
доклад, показывающий, что при анализе надежности алгоритмов
шифрования опираться на определение информационной энтропии по Клоду Шеннону, как это принято, неверно. При таком
анализе принимается, что в исходных файлах информационная
энтропия максимально возможная, что, по мнению исследователей из МТИ, допустимо для коммуникационного трафика, при
большом объеме которого распределение битов действительно
приближается к равномерному. Но в криптографии важнее всего
не средний случай, а крайние, подчеркивают ученые: взломщику достаточно лишь одной надежной корреляции между исходным текстом и шифром, чтобы начать обнаруживать остальные
корреляции. Следствие — если заставить компьютер искать корреляции простым перебором, он добьется успеха гораздо быстрее, чем ранее считалось. Взлом шифра все еще будет задачей
колоссальной сложности, подчеркивают исследователи, но, например, в ходе атаки, которая полагается на встречаемость букв
в английских словах, выбранный пользователем пароль можно
угадать существенно скорее, чем предполагалось.
Опираясь на свои выводы, авторы подготовили второй доклад,
в котором они показывают, как можно «вычислить» пароль, перехваченный путем прослушки беспроводного канала связи
между смарт-картой и карт-ридером, когда из-за помех часть
символов перехватить не удалось.
VoltDB ускоряется в 50 раз
Выпуская новую версию своей СУБД, в компании VoltDB надеются добиться более широкого признания на быстрорастущем рынке баз данных, работающих в оперативной памяти. Как
подчеркивают в компании, в VoltDB 4.0 радикально увеличена
скорость обработки аналитических запросов: некоторые из них
выполняются в 50 раз быстрее, чем раньше. Кроме того, теперь
стало проще добавлять новые узлы к работающим кластерам,
причем процесс расширения в большинстве случаев не оказывает влияния на производительность выполнения рабочей задачи, утверждают в компании.
Компания VoltDB была основана профессором Майклом
Стоунбрейкером, создателем Ingres и Postgres. Его новая СУБД
предлагается также в бесплатной версии без некоторых функций, имеющихся в коммерческой. Среди особенностей VoltDB —
автоматическое создание мгновенных снимков базы на диске
на случай необходимости восстановления системы и механизм
дублирования разделов баз K-safety, благодаря которому СУБД
продолжает работу после отказа одного из узлов кластера. С вы-
8 • Открытые системы • 01/2014 • www.osmag.ru
Вплоть до 2017 года руководители информационных служб сохранят высокий интерес к средствам анализа и бизнес-аналитики. В Gartner выделяют несколько основных тенденций развития рынка в ближайшие годы.
Уже к 2015 году для большинства разработчиков средств бизнес-аналитики основным направлением станет не составление
отчетов, а анализ данных с целью получения новой информации.
Сейчас непосредственным доступом к средствам аналитики обладают менее трети сотрудников, но эта доля будет расти. К 2017
году больше половины аналитических средств будут использовать потоки данных, генерируемые оснащенными датчиками
машинами, приложениями или сотрудниками. Аналитические
приложения, предлагаемые разработчиками программного
обеспечения, перестанут отличаться от приложений, предлагаемых сервис-провайдерами. Почти для любого «коробочного»
приложения можно будет найти аналог на базе SaaS.
Несмотря на большой интерес к средствам аналитики, вложения в эту область вплоть до 2016 года будут ограничиваться из-за неясности ситуации с обработкой Больших Данных.
Коммерческие компании пока не уверены, приносят ли эти технологии ощутимую выгоду.
В Microsoft устроили конкурс
по поиску простых чисел
Подразделение Microsoft
Windows Azure выступило в
роли устроителя конкурса
Prime Challenge по поиску
новых простых чисел, принять участие в котором могут как частные лица, так и
организации.
Самое большое из известных
на сегодня простых чисел состоит из 17 млн цифр. Задача
поиска новых простых чисел
становится все сложнее, но решение ее под силу любому, полагают в Microsoft. В первом десятке сразу четыре простых числа,
но чем дальше, тем их становится меньше, отмечают в корпорации. И пока никто не пытался найти их все. Участникам конкурса предоставляется возможность для поиска простых чисел
воспользоваться вычислительными мощностями дата-центров
Microsoft. Конкурс будет проходить до 29 марта 2014 года.
Количество
программистов-любителей растет
Из 18,5 млн разработчиков программного обеспечения в мире
примерно для 7,5 млн программирование не является основной
работой, утверждают аналитики IDC. Количество программистов-любителей растет гораздо быстрее, чем профессиональных
программистов, и, вероятно, темпы роста еще ускорятся.
Любителями программирования считают людей, занимающихся разработкой программ как минимум по 10 часов в месяц, несмотря на то что основной доход они получают от другой работы.
Некоторые из них занимаются программированием в качестве
новости. факты. тенденции.
хобби, другие же пытаются или заработать на продаже приложений, или участвуют в проектах с открытым кодом, или, наконец, пишут программы для автоматизации собственной основной работы. ИТ-компаниям и другим организациям, ведущим
бизнес через Интернет, не следует упускать из виду этих людей,
подчеркивают аналитики. Программисты-любители часто лучше разбираются в новых технологиях, и среди них можно найти подходящих кандидатов на постоянную работу. В странах с
развитым технологическим сектором доля любителей среди
разработчиков меньше как раз из-за того, что многие из них со
временем пополняют ряды профессиональных разработчиков,
отмечают аналитики IDC.
изобретение прокладывает путь к повышению защищенности
облачных сервисов, позволяя работать с зашифрованными данными без раскрытия оригинала. Методика, как поясняют в IBM,
«позволяет создавать зашифрованные большие двоичные объекты, которые можно комбинировать и обрабатывать, получая
результаты, идентичные тем, которые были бы без шифрования». В корпорации добавляют, что испытания практического
применения методики еще не окончены.
На протяжении уже двадцати лет подряд IBM становится лидером по числу американских патентов, полученных за год.
В Facebook открывают лабораторию
искусственного интеллекта
Руководителем лаборатории искусственного интеллекта, организуемой в компании Facebook, назначен специалист по машинному обучению из Нью-Йоркского университета Ян ЛеКун.
Он широко известен работами в области глубокого обучения и
машинного распознавания образов. О назначении ЛеКуна рассказал на конференции по глубокому обучению NIPS Deep Learning
Workshop генеральный директор Facebook Марк Цукерберг. Один
из учеников ЛеКуна, бывший сотрудник Google Марк-Аврелио
Ранзато, тоже приглашен на работу в лабораторию.
Подразделения новой лаборатории будут располагаться в НьюЙорке, Лондоне и в штаб-квартире Facebook в Менло-Парке в
Калифорнии. Основной темой исследований будет машинное
обучение — поиски методов, позволяющих обучить компьютеры извлекать полезную информацию из Больших Данных.
Искусственный интеллект поможет выявить оптимальные способы представления рекламы, взаимодействия с пользователями, определить факторы, привлекающие их к определенным
областям сайта и заставляющие их переходить из одной области в другую.
Флэш-хранилище для Больших Данных
Группа исследователей из Массачусетского технологического
института готовит к демонстрации сетевую систему хранения
Больших Данных на флэш-памяти, обещающую более высокую
скорость произвольного доступа, чем традиционные системы
на основе жестких дисков, соединенных сетью Ethernet.
Система получила название Blue Database Machine. По словам
разработчиков, она состоит из флэш-накопителей, которые управляются объединенными в сеть контроллерами на программируемых логических матрицах. Эти контроллеры также можно
использовать в качестве ускорителей, помогающих приложениям решать вычислительные задачи. Время случайного доступа к
данным на BlueDBM, исчисляемое десятками микросекунд, в отдельных случаях вдвое с лишним короче, чем у сред на жестких
дисках. По словам ученых, их система фактически обещает возможность создания интерактивных баз данных: при достаточном
количестве узлов в сети BlueDBM можно будет анализировать огромные объемы научных данных на такой высокой скорости, что
создастся впечатление мгновенной реакции на запросы.
Запатентован метод полностью
гомоморфного шифрования
В IBM сообщили о получении корпорацией патента на изобретение метода шифрования данных, являющегося полностью гомоморфным, то есть позволяющим свободно выполнять обработку информации без расшифровки. Как полагают в IBM, данное
Суперкомпьютеры ускорят квантовыми
вычислителями
Разработчик квантовых вычислительных систем компания
D-Wave рассчитывает, что ее передовая технология — какие бы
сомнения она ни вызывала в отрасли — найдет применение на
рынке высокопроизводительных вычислений (High Performance
Computing, HPC). По мнению специалистов D-Wave, квантовый
процессор — своего рода гигантский процессор для крупных
высокопроизводительных систем, выделяемый для решения
определенных задач, на обработку которых традиционными
вычислительными средствами может уйти много времени. В
компании назвали такой подход «квантовое ускорение высокопроизводительных вычислений».
Несмотря на то что теоретическая база квантовых вычислений
разрабатывается уже несколько десятилетий, эта технология
еще очень далека от коммерческого использования. D-Wave,
возможно, единственная компания, предлагающая завершенные решения, которые опираются на базовые принципы квантовой механики, изучающей законы поведения материи на микроскопическом уровне. D-Wave пока не предлагает квантовые
компьютеры общего назначения, вместо этого она располагает
системой, которую в компании называют квантовой нормализацией. Эта система рассчитана на обработку одного набора
задач, сложных для решения на классических компьютерах, известных как NP-сложные задачи (класс комбинаторных задач с
нелинейной полиномиальной оценкой числа итераций). Их суть
заключается в поиске наилучшего решения из значительного
числа переменных и, следовательно, возможных решений.
Компания D-Wave основана в 1999 году, в 2011 году она выпустила свое первое вычислительное устройство мощностью 128
кубитов. Кубит, или квантовый бит, — эквивалент бита в квантовых вычислениях. Сейчас компания предлагает устройство
D-Wave 2, его мощность составляет 512 кубитов. D-Wave 2 приобрели компания Google, которая тестирует возможность применения этой системы для распознавания образов, и НАСА.
www.osmag.ru • 01/2014 • Открытые системы • 9
платформы
Все в одном:
микропроцессор Kaveri
Для получения преимуществ на современном рынке микропроцессоров производители значительное внимание уделяют универсальности своих изделий,
наделяя их возможностями самоопределения. Не стала исключением и компания AMD, гибридные микропроцессоры которой можно с равным успехом
использовать в игровых, мобильных и серверных приложениях.
Ключевые слова: гетерогенные архитектуры, общая память, многопоточные вычисления
Keywords: heterogeneous architectures, shared memory, multi-threaded computing, HSA, HSAIL
Леонид Черняк
Н
едавняя премьера микропроцессоров AMD Kaveri A10-7850K и A8-7600
была представлена как сенсация, хотя
их основные параметры были известны давно. Мало того, история их создания растянулась на семь с половиной лет, если вести
отсчет от момента покупки компании ATI,
второго на тот момент производителя GPU
и графических плат. Согласно объявленному тогда плану «Fusion» предполагалось к
2008 году создать первый кристалл от объединенной компании, однако потом срок
был перенесен на 2011 год, и вот, наконец,
в начале 2014 года микропроцессор вышел
на рынок под именем Kaveri. Впрочем, подобная задержка закономерна и лишь подтверждает профессионалам правило — на
создание подлинной новации требуется не
менее семи лет. А в том, что это именно так
и сегодня вместе с Kaveri компания AMD
делает шаг не меньший, чем в 2003 году,
когда был выпущен процессор Opteron [1]
с архитектурой amd64, более известной
под именем x86-64, сомнений нет. Именно
Kaveri вполне можно признать первым полноценным гибридным APU — ускоренным
(Accelerated) или настроенным на приложения (Application). Kaveri — пример синергии
нескольких современных технологических,
архитектурных и программных новаций, и
важно, что микропроцессор появился как
раз в тот момент, когда появляются приложения, способные полноценно использовать
все его преимущества.
Термин APU был предложен в 2006 году
для обозначения устройств, служащих для
специализированных применений, но вскоре его распространили на кристаллы, сочетающие в себе CPU и GPU. Появление этих
гибридов в некоторой степени напоминает историю с процессорами 8086 и 8067.
Сначала был классический центральный
процессор CPU, затем в дополнение к нему
появился FPU — отдельный сопроцессор,
ускоряющий выполнение математических
операций над числами в формате с плавающей точкой. В последующем они объединились путем создания общей системы команд, а FPU как отдельный класс устройств
исчезли, и на протяжении последующих
лет развернулась гонка, в которой Intel и
AMD попеременно предлагали свои усовершенствования в систему команд. Однако
история с объединением CPU и GPU в один
кристалл APU имеет свою специфику —
GPU не передает свои полномочия CPU,
и полного слияния двух систем команд
нет. В APU оба типа устройств упакованы
на одной подложке, но живут раздельно,
хотя и делят между собой одну площадь,
работают в паре, а качество APU определяется тем, насколько эффективно налажено взаимодействие. За несколько лет
APU прочно вошли в жизнь — девять из
десяти современных ноутбуков содержат
такие процессоры. Однако вопрос о том,
какой должна быть пропорция между CPU
и GPU, чтобы процессор можно было назвать «настоящим APU» (True APU), остается
открытым. Некоторые эксперты считают,
что это 50:50 от площади подложки, что
близко к параметрам Kaveri (47% площади занимают ядра GPU), а в процессорах с
микроархитектурой Sandy Bridge — 17%, в
Ivy Bridge — 27%, в Haswell — 31%.
Среди множества особенностей, отличающих Kaveri, можно назвать следующие:
гетерогенная системная архитектура HSA
(Heterogeneous System Architecture) [2];
архитектура ядра x86-64 CPU Steamroller,
Mantle — графический API низкого уровня
и архитектура TrueAudio. Таким образом,
Kaveri с равным успехом может быть использован и для работы с данными, и для
10 • Открытые системы • 01/2014 • www.osmag.ru
выполнения игровых и мультимедийных
приложений, требующих поддержки GPU.
Микропроцессор выпускается в разных
модификациях с минимальным потреблением 35 ватт для серверов и до 95 ватт
для игровых компьютеров. Архитектуры
HSA и Steamroller важны для всех приложений, а Mantle и TrueAudio — для игровых. Универсальность процессора Kaveri
является его несомненным достоинством,
особенно потому, что некоторые возможности, в частности HSA, не могут быть немедленно востребованы, а еще должны
дойти до уровня массового использования
сообществом разработчиков.
Основной функционал HSA обеспечивает гетерогенный единообразный доступ
к памяти hUMA (heterogeneous Uniform
Memory Access) и является главным инструментом для полноценной интеграции
CPU и GPU. Теоретически возможны несколько уровней интеграции: самый примитивный — обмен пакетами данных между процессами; посложнее — управляемое
операционной системой использование
общего пространства памяти; высший
уровень — физическое объединение пространства данных в единой памяти. Эту
последовательность развития интеграции
CPU и GPU компания AMD прошла на экспериментальных чипах APU первых поколений, самыми заметными среди которых были Llano и Trinity, а все начиналось
с простого физического совмещения CPU
и GPU на кристалле при сохранении тех же
самых способов обмена данными, которые
использовались в случае раздельного исполнения на разных «камнях». Затем были
применены более действенные приемы,
но и они оказались малоэффективными,
а компания понесла ощутимые убытки,
вызванные «провалом» в дорожной карте, когда из-за неправильной организации
платформы
работ образовалась задержка с выпуском
очередного изделия. Архитектурные решения были инкрементальными и более-менее
в пределах разумного. В архитектуре HSA
упор сделан на разделяемую на страницы
память, имеются общие указатели и когерентная двунаправленная модель памяти,
что облегчает обмен данными между CPU
и GPU при выполнении общих задач. При
такой организации CPU и GPU могут читать
и модифицировать одни и те же области
памяти без ожидания какого-либо воздействия, а значит — исключаются бутылочные
горла и минимизируются задержки.
Архитектура hUMA сравнима с более
ранними — еще в первых GPU для доступа к памяти применялся метод NUMA (Non
Uniform Memory Access), предполагающий
фрагментацию на независимые разделы,
когда у CPU и GPU имеются собственные
автономные области памяти. Такой упрощенный подход приводит к необходимости копирования больших объемов данных
из одной области в другую, дополнительным сложностям в программировании
через графический драйвер и менеджер
видеопамяти, трудностям при синхронизации и трансляции адресов. Переход
на UMA, в данном случае в реализации
hUMA, позволяет CPU и GPU обращаться
в одну общую память. Для этого в новые
процессоры заложен механизм, поддерживающий когерентность кэшей CPU и GPU
на аппаратном уровне. До появления этого механизма схема взаимодействия CPU
и GPU предполагала, что в случае необходимости CPU записывает нужные для
обработки данные в область памяти GPU,
где выполняется необходимая обработка,
и данные возвращаются обратно в память
CPU. Наличие hUMA позволяет CPU передавать в GPU только указатель на данные,
а не сами данные, а затем после обработки использовать эти данные.
Для поддержки взаимодействия двух
типов процессоров разработан механизм
гетерогенных очередей hQ (Heterogeneous
Queuing), минимизирующий задержки и
позволяющий в полной мере использовать
потенциал APU. В традиционной архитектуре master-slave, где CPU — «хозяин», а
GPU — «раб», все задачи, предназначенные
для выполнения в GPU, сначала направляются в CPU, а затем в GPU. В таком случае
CPU должен взаимодействовать с операционной системой, управляющей очередями. Получив задание, ОС передает его
драйверу, преобразующему это задание в
команды конкретной графической системы. Гетерогенное управление очередями
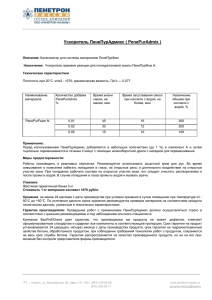
уравнивает положение CPU и GPU, заменяет
Архитектура master/slave
Архитектура с равенством CPU и GPU
Приложения
Приложения
Очередь
задач-приложений
Очередь
задач-приложений
Очередь
задач-приложений
Сервисы ОС
Драйвер
Очередь, управляемая ОС
CPU
GPU
CPU
GPU
От архитектуры master-slave к равенству процессоров
отношение master-slave — все процессоры
становятся равны (см. рисунок).
В новое ядро Steamroller x86-64 внесены усовершенствования, повышающие
эффективность CPU. Задействование при
проектировании библиотек высокой плотности — прием, заимствованный из проектирования GPU, — позволило на 30% повысить использование площади кристалла и
на столько же снизить энергопотребление.
Согласованность с GPU открывает возможность для сокращения потребления в тех
случаях, когда нагрузка преимущественно
графическая или вычислительная.
Графический интерфейс прикладного
программирования Mantle рассматривается
AMD в качестве более быстрой и приближенной к архитектуре GPU альтернативы
DirectX и OpenGL. К его преимуществам
относят эффективное управление аппаратурой, прямой доступ к памяти GPU и,
как следствие, повышенную по сравнению с DirectX и OpenGL скорость работы. Относительно TrueAudio предполагается, что эта технология окажет такое же
влияние на технологии воспроизведения
звука в игровых приложениях, как ранее
программы построения теней изменили
компьютерную графику.
Графическая архитектура Graphics Core
Next (GCN) Kaveri удовлетворяет не только
специфические игровые запросы, но и в наибольшей степени соответствует требованиям со стороны универсальных вычислений.
Устройство GCN GPU способно выполнять
вычислительные задачи, которые раньше
были доступны только CPU. Архитектура
GCN поддерживает такие языки, как C++
AMP (Accelerated Massive Parallelism) и
OpenCL, поддерживает разрешение UltraHD
(4K) и новые возможности постобработки
видео, улучшая качество изображения с
разрешением 1080 на мониторах, работающих в формате UltraHD.
Процессоры Kaveri производятся по
28-нанометровой технологии компанией
GlobalFoundries, частью акций которой вла-
деет AMD, передавшая GF свои производственные мощности. Теперь GF — один из
крупнейших контрактных производителей
микросхем, а сама AMD c 2012 года перешла в разряд компаний категории fabless,
ограничивающих свою деятельность проектированием и продажами микросхем.
Микропроцессор Kaveri содержит двухъядерные модули CPU Steamroller и GPU GCN
1.1, состоящие из восьми вычислительных
блоков по 512 графических ядер в каждом.
Процессор Kaveri A10-7850K работает на
частоте 3,7 ГГц в обычном режиме и на
3,8 ГГц — в режиме турбо, а GPU функционирует на частоте 720 МГц, что заметно
меньше, чем в предыдущих моделях от
AMD, хотя и может работать быстрее, но
общий лимит на энергопотребление этого
пока не позволяет.
Процессоры Kaveri уже получили доброжелательный отклик у сообщества разработчиков, ориентированных на OpenCL,
поскольку HSA обеспечивает поддержку и
ускорение выполнения всех существующих OpenCL-совместимых приложений.
Разработчики, отдающие предпочтение
Java, Fortran, OpenMP, C++ AMP и другим
средствам, могут воспользоваться непосредственно системой поддержки HSA и языком HSAIL — ассемблером для HSA.
Литература
1. Михаил Кузьминский. Многоядерные
процессоры AMD // Открытые системы.
СУБД. — 2005. — № 10. — С. 16–23.
URL: http://www.osp.ru/os/2005/10/380433
(дата обращения: 11.02.2014).
2. Тимур Палташев, Илья Перминов.
Гетерогенная архитектура для CPU, GPU
и DSP // Открытые системы.СУБД. —
2013. — № 08. — С. 12–15. URL:
http://www.osp.ru/os/2013/08/13037850
(дата обращения: 11.02.2014).
Леонид Черняк (osmag@osp.ru) — научный редактор, «Открытые системы.
СУБД» (Москва).
www.osmag.ru • 01/2014 • Открытые системы • 11
инструменты больших данных
Серьезно о технологиях
для Больших Данных
Большие Данные и облака выявили неподготовленность индустрии ИТ к
работе с невиданными прежде объемами информации, львиная доля которой хранится в реляционных СУБД, — господствовавшая до сих пор
идея сведения всего разнообразия данных к таблицам морально устарела.
Вместе с тем на рынке нет полноценных решений для обработки огромных массивов неструктурированных данных различной природы, поступающих в режиме реального времени из многочисленных источников.
Ключевые слова/keywords: ISTC-BD, CSAIL, MonetDB, ACID, SciDB
Леонид Черняк
С
ама по себе «проблема Больших
Данных» сопровождается рядом
собственных проблем, одна из которых заключается в том, что о Больших
Данных много говорят, но мало что реально делают. Спору нет, на глобальном
уровне проблема обработки больших
массивов данных объективно существует — человечество порождает все больше
контента, требующего переработки, однако действительно осязаемых достижений
на этом поприще пока немного. Отсюда
неоправданно большие ожидания и предвосхищения у одних наряду со скепсисом
у других и, как следствие, распространение недоверия к этой теме. В результате
термин «Большие Данные» оказался замылен раньше, чем понят.
Первые признаки обеспокоенности возможными негативными последствиями
неуправляемого роста объемов данных,
порождаемых мировой цивилизацией, и,
соответственно, проблемой извлечения заключенной в них информации стали проявляться еще с середины 40-х годов XX века.
Сегодня те объемы кажутся незначительными
на фоне непрерывного экспоненциального
роста на протяжении последних десятилетий, придавшего цивилизации совершенно
новое качество на культурном, научном и
технологическом уровнях.
Больше всего говорят о культурном уровне, который сводится к осознанию возможностей, открывающихся при извлечении новых знаний из накопленных данных, и, как
следствие, увеличению когнитивной способности человечества. Научный уровень
образован математическими методами
12 • Открытые системы • 01/2014 • www.osmag.ru
анализа данных, позволяющими совершать
открытия в астрономии, физике, химии и
других дисциплинах, образующие электронную науку (e-Science). Технологический
уровень предполагает переориентацию ИТ
со счетных задач как основного приложения
на сбор, хранение, обработку больших массивов данных с поддержкой тех или иных
аналитических методов.
До конца 90-х годов, когда средства работы с Большими Данными стали превращаться в инструмент для e-science, внимание общественности было сосредоточено
на осознании культурного феномена. Затем
внимание переключилось на переосмысление парадигмы e-science, после чего произошло знаменательное событие — объединение e-science и Big Data. Активное
развитие технологий, специально предназначенных для поддержки Больших Данных,
началось позже [1].
Такая последовательность развития трех
уровней, или феноменов Больших Данных,
по направлению от общих философских
воззрений к конкретным практическим
решениям стала причиной снисходительного отношения профессионалов от ИТ к
Большим Данным, акцентирующих свое
внимание лишь на технологиях и не учитывающих особенностей двух предшествующих феноменов. Успехи в сфере технологий
пока еще достаточно скромны, и интересные
решения имеются у небольших компаний,
а крупные, по законам рынка, поголовно
заявляют о готовности решать проблемы
Больших Данных уже давно имеющимися
в их распоряжении средствами.
От слов к делу
Сегодня все, что говорится на тему Больших
Данных, носит лишь фрагментарный ха-
инструменты больших данных
рактер — целостной программы решения
проблемы пока нет, причем даже на уровне
концепции, однако на этом фоне весьма ярко
обозначилась инициатива Intel. Программа
комплексного подхода предполагает создание крупного исследовательского центра
Intel Science and Technology Center for Big
Data (ISTC-BD), специализирующегося на
Больших Данных и базирующегося в лаборатории CSAIL (Computer Science and Artificial
Intelligence Laboratory). Лаборатория входит
в состав Массачусетского технологического
института, но при этом сохраняет автономность. К моменту создания центра ISTC-BD
в стенах CSAIL уже существовало более десяти коллективов, так или иначе связанных
с Большими Данными, их объединение одной программой позволит преодолеть раздробленность и логически связать вместе
отдельные технологические подходы.
Как же оказалось, что именно Intel поддерживает подобного рода широкомасштабные исследования? И почему в МТИ? К
моменту образования ISTC-BD по инициативе Intel были созданы Intel Science and
Technology Center for Pervasive Computing
(ISTC-PC), Intel Science and Technology Center
for Embedded Computing (ISTC-EC), Intel Science
and Technology Center for Visual Computing
(ISTC-VC) и Intel Science and Technology Center
for Cloud Computing (ISTC-CC). Хотя в явном
виде слова Big Data фигурируют только в
названии ISTC-BD, все остальные центры
каждый по-своему также нацелены на решение проблемы Больших Данных, но со
своими индивидуальными особенностями.
Каждый из центров ориентирован на определенное направление: Pervasive Computing
(повсеместные компьютерные системы) — это
прежде всего интеллектуальные устройства,
Embedded Computing — встроенные системы, Visual Computing — визуализация и Cloud
Computing — облака.
Программа работы на ближайшие несколько лет, принятая в ISTC-BD, охватывает все пять основных направлений современной компьютерной науки, связанной
с Большими Данными: базы, математические основы аналитики, визуализация, архитектура и обработка потоков. Однако какой
бы научной и финансовой базой ни обладал центр ISTC-BD, он сможет справиться
только с отдельными составляющими этих
направлений, и перечисленные пять пунктов можно рассматривать лишь как руководство к действию.
• Базы Больших Данных и аналитика.
Разработка программных платформ для
хранения и обработки больших массивов
данных, способных поддерживать аналитические системы, существенно превосходя-
щие современные. Аналитика переживает на научного руководителя bigdata@CSAIL
сегодня период глубокой трансформации, Майкла Стоунбрейкера, директора ISTC-BD
которая предполагает выход за пределы, Сэма Маддена и директора лаборатории
присущие реляционным системам, уже не параллельных вычислений Intel Прадипа
отвечающим требованиям разнообразных Даби. Тот факт, что именно Стоунбрейкер
методов анализа данных. Базы на основе ре- был призван на роль научного руководиляционных моделей не поддерживают много- теля, обнадеживает: пожалуй, сегодня это
главный авторитет
мерные объекты (масв области работы с
сивы), для которых
Большие Данные —
данными, признаннужна совсем иная,
новая теория и практика
Big Data относится к числу немногих
ный патриарх, создав«массивно-ориенназваний, имеющих вполне достоверший сорок лет назад
тированная» модель.
ную дату своего рождения — 3 сентября
компанию Relational
Кроме того, базы
2008 года, когда вышел специальный
Technology и одну из
общего назначения
номер британского журнала Nature,
первых реляционных
показывают низкую
подытоживающий дискуссии о роли
СУБД Ingres. В своем
производительность
данных в науке вообще и в электронной
почтенном возрасте
на больших объемах,
науке (e-science) в частности.
Леонид Черняк
Стоунбрейкер сохраа многие современ«Открытые системы», № 10, 2011
нил бунтарский дух
ные данные, такие как
Беркли 60-х и до сих
разного рода изображения, результаты наблюдений и экспе- пор проявляет удивительную открытость к
риментов, вообще не могут быть каким-то новшествам.
Основную часть исследований по прообразом индексированы.
• Математика и алгоритмы для Больших грамме ISTC-BD можно отнести к школе
Данных. Предполагается создать новые Стоунбрейкера, что и определяет специалгоритмы и ПО для обработки сигналов, фику программы — практически все ее
поиска и машинного обучения, способные компоненты так или иначе связаны с бамасштабироваться на сотни машин и на пе- зами данных. Например, планируется разтабайты данных. В отличие от большинства вивать СУБД, созданные в последние годы:
современных аналогов они должны быть StreamBase для потоковых данных, Vertica
адаптированы к работе в параллельном для хранилищ данных, VoltDB для операрежиме с данными, которые хранятся вне тивной обработки транзакций, Goby.com
для данных из World Wide Web и SciDB для
оперативной памяти.
• Визуа лизация Больших Данных. научных данных и аналитики. Описывая перНеобходимо создавать средства визуали- спективы развития СУБД, Стоунбрейкер, в
зации, позволяющие пользователям вза- частности, отмечает: «Сейчас у каждого из
имодействовать с большими массивами вертикальных рынков имеются свои проданных через различные устройства от ми- блемы, для решения которых требуются
ниатюрных смартфонов до панелей разме- наиболее удобные средства, и нет нужды
ром со стену, а для этого придется обеспе- ограничиваться унаследованными из прочить масштабирование визуализации при шлого реляционными системами». По его
мнению, для аналитики следует испольизменении объемов данных.
• Архитектура систем для Больших Данных. зовать поколоночные архитектуры, для
Архитектура современных компьютеров из- транзакционной работы — базы данных в
начально создавалась для расчетных опе- памяти, NoSQL-архитектуры — для операций, и необходимо переосмыслить гря- раций с данными, имеющими значениядущие инновации и подготовиться к ним, ключи, при этом с коммерческой точки
в том числе к процессорам с большим чис- зрения сегодня становятся привлекательлом ядер, к энергонезависимой оператив- ны и другие типы данных, включая графоной памяти и к оборудованию, способному вые. Подчеркивая значение новых данных,
Стоунбрейкер отмечает, что вся реформа
к реконфигурации.
• Потоковая обработка Больших Данных. здравоохранения США, получившая назваУвеличение потоков входных данных тре- ние Obamacare, построена именно на базах
бует от систем возможностей по их обра- данных типа NoSQL.
В течение ближайшего десятилетия, по
ботке и выполнения комплекса подготовительных операций, таких как фильтрация мнению Стоунбрейкера, сложится от трех
до шести заметно различающихся межи агрегирование.
ду собой основных категорий СУБД и для
И снова Стоунбрейкер
каждой из них определятся несколько усДетализация пунктов программы ISTC-BD пешных производителей, причем одноврев контексте деятельности Intel возложена менно будет сокращаться влияние реляци-
www.osmag.ru • 01/2014 • Открытые системы • 13
инструменты больших данных
CSAIL
Лаборатория компьютерной науки и искусственного интеллекта — самая крупная в
МТИ — была сформирована в 2003 году путем слияния знаменитых лабораторий:
Laboratory for Computer Science и Artificial Intelligence Laboratory. Образованию этих
двух лабораторий в МТИ предшествовали исследования в области компьютерной
науки с 30-х годов XX века, наибольшую известность получили дифференциальный анализатор Ванневара Буша и работы в области булевой алгебры, выполненные
Клодом Шенноном. Область искусственного интеллекта ярче всего представлена в
трудах Марвина Минского, датируемых 60-ми годами. Кроме этого, лаборатории известны своими достижениями, даже краткое перечисление которых, а также имен
ученых, связанных с ними, — отдельная тема. В итоге сегодня CSAIL признана одной
из самых влиятельных университетских лабораторий мира.
За право участия в инициативе, получившей название bigdata@CSAIL, боролись
более 50 университетов. Победа МТИ закономерна и одновременно символична еще
и потому, что сейчас администрация штата Массачусетс стремится возвратить утраченную позицию технологического лидера страны и стать концентратором исследований в области Больших Данных. К работе в рамках bigdata@CSAIL будут привлечены исследователи из нескольких ведущих университетов, например Стэнфорда,
а ее деятельность поддерживают несколько крупных корпораций, причем не только
компьютерные, такие как EMC, но и страховые, медийные и ряд других.
онных баз. Дать точный прогноз на будущее
Стоунбрейкер не берется, отмечая лишь
некоторые тенденции:
• усовершенствование баз NoSQL до достижения ими соответствия требованиям ACID
(атомарность, согласованность, изолированность, надежность) и создания языков высокого уровня для доступа к данным; например, в Google уже создана система Spanner,
полностью соответствующая ACID;
• обострение борьбы между Oracle и SAP, в
которой последняя имеет преимущество в
виде технологии поколоночной обработки
данных в памяти (СУБД HANA);
• обновление системной платформы Facebook,
которая уже несколько лет пытается освободиться от MySQL, создающей компании
изрядные проблемы.
Большие Данные и ISTC-BD
В своем представлении о сущности Больших
Данных в ISTC-BD опираются на классическое определение «четыре V»: «объем»
(Volume), «скорость обработки» (Velocity),
«достоверность» (Veracity) и «разнообразие»
(Variety) [2]. Но для начала в лаборатории
считают необходимым работать только с
двумя первыми свойствами.
Категорию Большой Объем в лаборатории разделяют на две части, исходя из
природы данных и способов работы с ними.
Для работы с традиционными таблицами
могут быть использованы методы классической аналитики, основанные на SQL
и весьма совершенные, поддерживаемые
серьезной теорией и огромной практикой.
По этой причине в ISTC-BD работ, связанных с обычными табличными данными, не
предполагается. Но есть объемные массивы данных, к которым традиционные методы не применимы, поэтому для работы
с ними приходится использовать разнообразные средства анализа, основанные
на машинном обучении, кластеризации,
предсказательном моделировании, категоризации и т. п.
В случае Большой Скорости данные тоже
могут быть более или менее традиционными,
но в другом контексте — независимо от типа
данных под большой скоростью обработки
понимается способность извлекать полезную
информацию из потока данных («льющихся
из трубы»). Традиционными можно считать
данные, для работы с которыми достаточно
ограничиться многочисленными методами
фильтрации с целью извлечения сложных
образов из потоков — это так называемая
потоковая обработка данных (Data Stream
Processing), где чаще всего используют
технологии обработки сложных событий
(Complex Event Processing, CEP) и системы
управления потоками данных (Data Stream
Management System, DSMS), включающие
первичную обработку, фильтрацию и агрегирование. Наибольших успехов в этом
направлении добились компании Apama
(входит в состав Software AG) с ее решением
Complex Event Processing Platform, TIBCO —
с решением StreamBase Systems, Sybase — с
системой ESP и IBM — с InfoSphere Streams.
Несмотря на то что Стоунбрейкер имел непосредственное отношение к созданию системы StreamBase в ISTC-BD, развитие в этом
направлении не предполагается.
Для другой категории потоковых данных
недостаточно методов фильтрации — они
предполагают оперативную обработку транзакций (OLTP), однако количество данных
в подобного рода системах во много раз
превышает объемы данных в традиционных системах OLTP. На данный момент в
качестве примера можно привести массо-
14 • Открытые системы • 01/2014 • www.osmag.ru
вые многопользовательские онлайн-игры
(Massively multiplayer Online Game, MMOG),
в которые одновременно играют несколько тысяч взаимодействующих друг с другом людей.
Базы для
научных данных
Потребность в хранении научных данных,
полученных в результате наблюдений или
экспериментов, а также обеспечении доступа к ним существует с момента появления
компьютеров, однако попытки удовлетворить ее стали возможны только недавно, а
до этого приходилось ограничиваться архивами файлов. Отсутствие соответствующих баз приводило к тому, что с большим
трудом собранные и обработанные ценные
данные со временем терялись, а любые
попытки каким-то образом архивировать
массивы вручную оказываются слишком
трудоемкими и непродуктивными.
Объем и ценность данных возрастают —
нынешняя сенсорная революция настоятельно
требует обеспечить их сохранность, причем
для этого сегодня имеются все технические
возможности. Нужны базы, способные хранить произвольные научные данные, поэтому
в рамках ISTC-BD развивается инициатива
по объединению нескольких проектов подобных баз. В первую очередь это относительно новая база SciDB, создаваемая под
руководством Стоунбрейкера и Дэвида
ДеВитта, а также два проекта: MonetDB
(Нидерланды) и Rasdaman (Германия). Для
доступа к массивам данных разрабатывается язык AQL (ArrayQL).
Предпосылки к созданию проекта SciDB
содержатся в «Четвертой парадигме науки»
Джима Грея; он считал, что сегодня, когда
открылась возможность обработки огромных объемов экспериментальных данных,
складываются новые научные методы, основанные на их анализе (e-Science), в которых доминируют синтезирующие теории,
а статистические методы применяются к
колоссальным объемам данных [3]. Проект
SciDB посвящен Грею, а непосредственным
импульсом к его инициации стало решение
о строительстве Большого обзорного телескопа в Чили. Телескоп должен быть введен
в строй только после 2020 года, и очевидно,
что база SciDB будет использована раньше
в других научных приложениях. В одной из
статей, посвященных SciDB, эту базу назвали
«реляционным ответом дедушки» на вызовы
со стороны Google, Hadoop и NoSQL.
SciDB представляет собой постреляционную аналитическую базу с открытыми
кодами, соответствующую ACID и адаптированную для работы на серверах стан-
инструменты больших данных
дартной архитектуры, собранных в гриды
или размещенных в облаках. Для аналитической работы с научными данными
SciDB удобнее, чем реляционные СУБД и
системы, основанные на подходах Hadoop.
SciDB ориентирована на серьезную аналитику и интегрирована с языками R и Python.
Коммерциализацией SciDB занимается компания Paradigm4.
СУБД MonetDB была создана 35 лет назад в голландском Национальном исследовательском институте математики и компьютерных наук (CWI), где в свое время работал
Эдсгер Дейкстра. Столь длительная история
сама по себе удивительна, но еще больше
поражает то, что крошечному коллективу, совсем недавно разросшемуся до двух
десятков сотрудников, удалось на многие
годы опередить весь остальной мир. В середине восьмидесятых по проекту Prisma
разрабатывалась распределенная СУБД с
поколоночным хранением данных в оперативной памяти, уже тогда работающая на
100 процессорах с общей памятью 1 Гбайт.
Затем было еще несколько проектов, и только в 2005 году началось распространение
MonetDB как продукта с открытым кодом.
От кодов, написанных десятилетия назад, сегодня ничего не осталось, но сохранился основополагающий принцип — алгоритмы этой
СУБД относятся к классу hardware-conscious
(учитывающие особенности процессоров и
допускающие тонкие настройки), в отличие
от других, не обладающих такими способностями (hardware-oblivious).
Наибольшей удачей для MonetDB оказалось использование СУБД в проекте
широкомасштабного исследования изображений и спектров звезд и галактик с помощью 2,5-метрового широкоугольного
телескопа в обсерватории Апачи-Пойнт в
Нью-Мексико. Исследования начались в
2000 году, и тогда выяснилось, что кроме
MonetDB ни одна база не может справиться с задачей накопления данных. Как следствие, в CWI был открыт специальный проект
по работе с научными данными SciBORQ
(Scientific data management with Bounds On
Runtime and Quality).
Появление СУБД Rasdaman (Raster data
manager) стало возможным благодаря исследованиям, которые с 1989 года ведет Петер
Бауманн в Институте компьютерной графики,
входящем в Общество Фраунгофера — объединение институтов прикладных исследований в Германии. Он разработал собственную
«алгебру массивов» и добавил к обычной реляционной базе еще один атрибут — массив.
Для хранения массивов в базе используется
известная технология больших двоичных
объектов (Binary Large OBject, BLOB).
Графовые СУБД
К графовым относят базы NoSQL, которые
предназначены для сохранения объектов
и отображения связей между ними средствами, заимствованными из теории графов.
Такая база представляет собой набор узлов (объектов) и ребер (отношений между
объектами). Для адресации каждому объекту присваивается уникальный идентификатор, содержащий сведения о входящих
и выходящих ребрах узла. Аналогичным
образом каждое ребро тоже имеет свой
собственный идентификатор и сведения
об узлах, между которыми оно находится. Такие базы чрезвычайно удобны для
работы с данными из социальных сетей, а
также в случаях, когда имеются сложные
отношения между объектами, — например,
цепочки поставок, логистика. По сравнению с реляционными графовые базы работают на порядки быстрее с графовыми
данными, поскольку напрямую отражают
структуры данных в объектно-ориентированных приложениях.
Сегодня имеется несколько десятков экспериментальных графовых баз, и самой продвинутой считается Neo4j, однако в ISTC-BD
намереваются разработать свою СУБД на основе движка GraphLab и параллельно ведутся работы по использованию разреженных
матриц. На первый взгляд представляется
рациональным в данном случае использовать
что-то в духе MapReduce/Hadoop, однако пакетная природа ограничивает возможности
использования этой группы технологий для
оперирования графовыми структурами.
Поэтому в ISTC-BD рассматриваются такие
альтернативные по отношению к MapReduce
решения, как Percolator, Dremel и Pregel, разрабатываемые в Google. Особое внимание
уделено системе Pregel, которая специально
предназначена для обработки больших графов и для задач графовой аналитики, обеспечивая не только высокую эффективность,
но и простоту кодов.
Большие транзакции
в реальном времени
Еще семь-восемь лет назад, когда о Больших
Данных не было речи, Стоунбрейкер рассуждал об архаичности таких универсальных
СУБД, как IBM DB2, Microsoft SQL Server и
Oracle, которые в той или иной форме наследуют System R, созданную еще в 70-е
годы. Изначально эти базы были рассчитаны на аппаратное обеспечение, существенно отличающееся от современного, что
проявляется в специфике их работы с дисками и использовании простых терминалов
в качестве рабочих мест, ограничивающих
самодеятельность пользователя. В ответ на
это Стоунбрейкер с коллегами предложил
специализированную базу H-Store для работы в грид-средах, уже в первой реализации показавшую производительность на два
порядка выше, чем традиционные СУБД.
Дальнейшая судьба H-Store и развиваемой
параллельно с ней базы C-store категории
shared nothing лежит в плоскости академических исследований, однако на их основе
создаются коммерческие версии, в случае
H-Store — это VoltDB, а в случае C-store —
Vertica. Коммерческие версии представляют
замороженные на какой-то момент времени
срезы своих академических прототипов, которые могут периодически, но не слишком
часто обновляться, а прототипы находятся
в процессе перманентного развития.
***
Большие Данные и облака выявили неподготовленность индустрии ИТ к работе с невиданными прежде объемами информации [4], львиная доля которой хранится в
реляционных СУБД, — господствовавшая
до сих пор идея сведения всего разнообразия данных к таблицам морально устарела.
Вместе с тем имеющиеся сегодня продукты, предлагаемые различными стартапами, носят фрагментарный характер и на
рынке все еще нет полноценных решений для обработки огромных массивов
неструктурированных данных различной
природы, поступающих в режиме реального времени из многочисленных источников. С другой стороны, любая новация
занимает серьезное место на рынке сразу после того, как инициатива переходит
к крупным производителям, — сегодня
подобающее место в сегменте Больших
Данных решила занять корпорация Intel,
поддерживающая лабораторию ISTC-BD
в составе МТИ и одной из первых осознавшая, что MapReduce/Hadoop — далеко не
единственная технология.
Литература
1. Леонид Черняк. Свежий взгляд на
Большие Данные // Открытые системы.
СУБД. — 2013. — № 7. — С. 48–51.
2. Леонид Черняк. Что делать с хаосом
данных? // Открытые системы.СУБД. —
2013. — № 9. — С. 16–20.
3. Леонид Черняк. Вычисления с акцентом на данные // Открытые системы.
СУБД. — 2008. — № 8. — С. 36–39.
4. Леонид Черняк. Смутное время СУБД //
Открытые системы.СУБД. — 2012. —
№ 2. — С. 16–21.
Леонид Черняк (osmag@osp.ru) — научный редактор, «Открытые системы.
СУБД» (Москва).
www.osmag.ru • 01/2014 • Открытые системы • 15
инструменты больших данных
Большие Данные
для управления ИТ
Аналитика Больших Данных нужна сегодня не только финансистам,
биоинформатикам и маркетологам. Она становится необходима
и ИТ-менеджерам. Существующие инструменты управления ИТ не позволяют оценить эффективность своего применения, предсказать динамику изменения производительности, а главное — современный уровень
сложности ИТ-сред уже не оставляет места ручному управлению.
Ключевые слова: метрики, мониторинг, неструктурированные данные, корреляция событий, предиктивная аналитика
Keywords: metrics, monitoring, unstructured data, event correlation, predictive analytics, Big Operational Data, ITOA
Наталья Дубова
И
нструментарий управления ИТинфраструктурой развивается
уже более 20 лет, и сегодня соответствующим системам отводится
важная роль в упорядочении сложности,
которую неминуемо порождают разнообразные технологические компоненты,
лежащие в основе практически любого
крупного бизнеса. Контролировать работоспособность распределенной сетевой
инфраструктуры, следить за состоянием
серверов и систем хранения и автоматизировать рутинные операции управления
ЦОД, обеспечивать доступность и надлежащую производительность бизнес-приложений, которые общаются с облаками
и используют мобильные интерфейсы, —
все эти и многие другие задачи реализуются системами управления ИТ. Однако
насколько эффективно?
Ответ определяется многими факторами, но очевидно, что в крупных ИТинфраструктурах средства мониторинга
и автоматизации управления генерируют и накапливают огромные массивы
данных, потенциал которых по большей
части остается нераскрыт. Разнообразные
метрики состояния компонентов инфраструктуры, данные лог-файлов, информация о событиях и другая телеметрия
от средств мониторинга и управления
серверами, системами хранения, сетевой и мобильной инфраструктурами и
приложениями поступают практически
непрерывно и в очень больших количествах. В среднем инфраструктура из 5 тыс.
16 • Открытые системы • 01/2014 • www.osmag.ru
серверов генерирует ежедневно около
1,3 Тбайт данных, из них 33 Гбайт — метрики и 1 Тбайт — неструктурированные
данные, например записи лог-файлов. При
этом корпоративная ИТ-инфраструктура
становится все более динамичной и очень
высока скорость изменений в среде, где
приложения развертываются на базе виртуализованных серверных инфраструктур, изменяя свою топологию в реальном
времени, а данные постоянно мигрируют
между хостами, где по требованию подключаются облачные ресурсы, а доступ к
приложениям пользователи получают с
различных мобильных устройств в нужный им момент времени.
Основные признаки Больших Данных
налицо. Системы ИТ-управления порождают огромные объемы и непрерывные
потоки данных различной природы, что
побудило даже ввести новый термин —
Большие Операционные Данные (Big
Operational Data), вместе с которым появилась и новая задача аналитики. Как и в
случае Больших Данных из других областей, Большие Операционные Данные —
это, преимущественно, «сырые» данные,
для извлечения пользы из которых нужны
развитые средства аналитики. Необходим
аналитический инструментарий, который
позволит агрегировать данные систем
управления инфраструктурой в разных
доменах, выявлять зависимости и корреляции, предсказывать сбои и падение
производительности, давать информацию
для оперативного и наиболее эффективного разрешения проблем, прогнозировать потребности информационных сервисов в различных ресурсах.
Руководителям разного уровня сегодня уже не обойтись без бизнес-аналитики
инструменты больших данных
как ключевого инструмента поддержки
принятия решений, но оказывается, что
и ИТ-менеджерам в не меньшей степени необходимы аналитические инструменты для поддержки оптимальных решений по восстановлению, обеспечению
производительности и развитию инфраструктуры, а в конечном итоге — для
лучшего понимания того, как ИТ-среда
влияет на процессы предоставления сервисов бизнесу.
Ответом на эту потребность стал новый класс программных средств — IT
Operations Analytics (ITOA). Рынок ITOA
только зарождается, но, по оценкам аналитиков, будет развиваться очень активно. В конце 2013 года его объем превысил
800 млн долл., что вдвое больше прошлогоднего показателя, и такие темпы роста
сохранятся и в 2014 году.
Алгоритмы
Аналитики Forrester определяют операционную ИТ-аналитику как «использование математических алгоритмов и
других методов для извлечения осмысленной информации из больших объемов
сырых данных, собираемых с помощью
технологий управления и мониторинга», отмечая, что эта формирующаяся
область аналитических средств берет
наработки и инструменты из бизнесаналитики и других областей (геофизика, экономика, генетика), где давно
существует развитый инструментарий
анализа. Это связано с тем, что многие
проблемы, порождаемые современными ИТ-системами, схожи с проблемами
других областей, и потому для их решения можно использовать аналогичные математические подходы. Но есть и
особенности, а главное — разнообразие
аналитических потребностей в управлении ИТ-инфраструктурой настолько
велико, что не может быть покрыто одним решением или универсальным алгоритмом. В конце 2012 года аналитики
отмечали активизацию исследований
и разработок в сфере ITOA, предсказывая, что в ближайшие годы это направление ИТ будет одним из самых
интересных с точки зрения появления
новых решений.
Можно выделить шесть типов аналитических алгоритмов, актуальных для
оперативной ИТ-аналитики: корреляция
событий; выявление топологических зависимостей; построение статистических
шаблонов; построение текстовых шаблонов; анализ конфигураций; экономическое моделирование.
Рынок на старте
В конце 2012 года аналитики Forrester отмечали, что ландшафт рынка ИТ-аналитики
типичен для активно формирующегося сегмента. Наиболее активны на нем небольшие компании, предлагающие инновационные решения в новой области:
BlueStripe Software, Netuitive, Splunk, Boundary, Prelert и VMTurbo. Например,
компания Netuitive реализует систему машинного обучения и прогнозной аналитики для задач управления производительностью приложений. В основе системы
лежит собственная разработка компании, Behavior Learning Engine, реализованная на базе запатентованных аналитических технологий.
Поскольку оперативная ИТ-аналитика работает с метриками производительности инфраструктуры, в группу потенциальных игроков рынка ITOA аналитики
Forrester включили известных разработчиков средств управления производительностью, таких как как NetScout, OPNET и SolarWinds. Все они уже имеют базовые аналитические инструменты, и от них можно ожидать реализации более
сложных алгоритмов.
Новый рынок не может не привлекать ключевых игроков в области ИТуправления. В результате приобретения других компаний на него уже вышли
BMC Software, CA, EMC, VMware и Compuware. Компании IBM и HP сочетают
внутренние разработки с покупками внешних технологий обработки и анализа
Больших Данных. Обе в 2013 году сделали анонсы в области ITOA. Компания HP
представила платформу HAVEn, объединившую продукты HP Autonomy, Vertica,
ArcSight и Operations Management с технологиями Hadoop. Первым решением на
базе HAVEn стала система HP Operations Analytics, реализующая средства аналитики данных ИТ-управления и безопасности и входящая в семейство решений
HP BSM для управления бизнес-сервисами.
Корпорация IBM в ноябре 2013 года анонсировала инструментарий Predictive
Insights для анализа данных лог-файлов, конфигураций, метрик производительности, данных различных систем мониторинга и управления производительностью
приложений. В системе используются инструментарий аналитической платформы Cognos, средства предсказательной аналитики и машинного обучения SPSS,
а также платформа обработки потоковых Больших Данных InfoSphere Streams.
Инструментарий корреляции событий — наиболее зрелый вид операционной ИТ-аналитики. В том или ином виде
эти алгоритмы изначально присутствовали в решениях для управления ИТ —
уже первые системы мониторинга генерировали большие потоки данных о
событиях в компонентах инфраструктуры, которые требовали фильтрации,
поскольку значительная часть событий
оказывалась несущественной. Средства
корреляции событий обрабатывают потоки из множества источников, анализируют зависимости между данными и
пытаются отделить ложные и незначительные события от тех, которые могут
вызвать реальные проблемы инфраструктуры и потому требуют корректирующих
воздействий.
Пережив бум в конце 90-х — начале
2000-х, средства корреляции событий
во второй половине нулевых стали вызывать скептицизм у пользователей: по
ряду причин завышенные ожидания не
оправдались. Как правило, наиболее функциональными в предлагаемых решениях
были средства корреляции событий сетевого мониторинга, а для других инфраструктурных доменов корреляция не
демонстрировала достаточной эффективности. Не оправдались надежды на
поддержку кросс-доменной корреляции
путем фильтрации на базе зависимостей
между событиями в разных областях
инфраструктуры — здесь требовалась
поддержка очень сложных моделей. Не
появилась возможность корреляции событий и на уровне приложений. Кроме
того, росла потребность в корреляции не
только бинарных событий — «работает/
не работает», но и более тонких градаций работоспособности компонентов.
Фатальные сбои оборудования сегодня
достаточно редки, но для эффективного
управления ИТ-сервисами важна своевременная информация даже о небольшом
падении производительности сервера
или сетевой инфраструктуры. Однако
традиционные алгоритмы корреляции
продолжают анализировать доступность,
а не производительность.
Все это является предпосылкой для
развития аналитических инструментов
корреляции событий нового поколения —
анализ взаимосвязей происходящего в
инфраструктуре является основой ITOA,
тесно связанной с другими ее компонентами. Инструменты операционной ИТаналитики могут упорядочивать входные
данные для корреляции, обрабатывая потоки сырых данных и создавая итоговое
событие, или формировать определенный
www.osmag.ru • 01/2014 • Открытые системы • 17
инструменты больших данных
Если это ключевая метрика сервиса,
... а это аномалия...
... какая из этих метрик соответствует аналогичному статистическому шаблону?
Данная
Статистический анализ определяет шаблоны производительности компонентов
ИТ-инфраструктуры
контекст, влияющий на модели корреляции, как это делают, например, программные средства отображения зависимостей между приложениями (Application
Dependency Mapping, ADM).
Средства выявления топологических
зависимостей строят визуальную карту
взаимосвязей между компонентами инфраструктуры. Этот инструментарий, в
частности, используется наиболее развитыми решениями по корреляции событий для более эффективной обработки
поступающих данных. Анализ связей позволяет определить с той или иной долей
вероятности узел инфраструктуры, ставший причиной проблемы. Системы могут
предлагать различные уровни сложности
топологического анализа, ограничиваясь
построением карты физических межсетевых соединений или обеспечивая более
полную картину логических взаимосвязей — между приложениями, между виртуальными и физическими серверами и
т. д. Чем сложнее поддерживаемая топологическая модель, тем более изощренные понадобятся средства визуализации,
способные отображать многомерные топологические карты.
Инструментарий топологического
анализа уже получил распространение
в средствах сетевого управления — например, в EMC IT Operations Intelligence и
IBM Tivoli Network Manager. Появляются
и поставщики, распространяющие возможности выявления топологических
зависимостей на другие домены ИТинфраструктуры, — например, компания
BlueStripe Software реализует такой инструментарий для анализа зависимостей
между приложениями.
Если топологические зависимости не
могут быть обнаружены явным образом
или неоднозначны, на помощь приходят
средства построения статистических шаблонов, определяющих корреляции метрик
компонентов ИТ-инфраструктуры путем
сравнения колебаний метрик и выявления схожих отклонений. Для компонентов с близкими шаблонами поведения
предполагается наличие неявной зависимости. Базовые средства статистического
анализа выявляют аномалии, сравнивая
текущее состояние метрик с шаблонами
«нормального» поведения, которые строятся на основе исторического анализа
поведения компонента инфраструктуры
(см. рисунок). Процессы построения статистических шаблонов могут потребовать
сложной математической обработки и
часто связаны с большой вычислительной нагрузкой. Пионерами статистического анализа в ИТ-управлении являются
компании Netuitive, ProactiveNet (куплена BMC Software в 2007 году) и Integrien
(куплена VMware в 2010 году).
Еще одним аналитическим инструментом, применимым в задачах управления ИТ, является текстовая аналитика. Текстовые лог-файлы или журналы,
протоколирующие все действия, происходящие с системой, могут стать ценным
источником информации для средств управления, но для этого надо иметь возможность в непрерывном потоке записей
выделять полезное и важное для понимания состояния инфраструктуры. Средства
текстовой аналитики сканируют и анализируют текстовые файлы и строят шаблоны, которые могут использоваться для
идентификации определенных условий и
18 • Открытые системы • 01/2014 • www.osmag.ru
поведения систем. Наиболее известным
примером подобных решений на рынке
являются продукты компаний Splunk,
SumoLogic, LogLogic (куплена Tibco) и
Pattern Insight (куплена VMware).
Чем сложнее ИТ-среда, тем важнее
для предоставления работоспособного,
надежного ИТ-сервиса становится анализ конфигураций. Конфигурационные
единицы — базовые блоки сервиса: серверы, сетевые компоненты, базы данных
и приложения. В ходе анализа конфигураций проверяются конфигурационные данные на соответствие заданным
политикам в отношении ИТ-сервисов и
составляющих их компонентов инфраструктуры, выявляются системы и сервисы, не соответствующие стандартным
конфигурациям.
Новая для ИТ-управления область
аналитики — экономические модели —
предлагает инструменты оценки факторов
«спроса и предложения» для построения
оптимальных моделей использования
ресурсов ИТ-инфраструктуры, задействованных в реализации определенных
сервисов. По оценке Forrester, первой с
такой функциональностью на рынок вышла
компания VMTurbo в 2009 году. Сейчас
экономические модели используются
преимущественно для виртуализованной
инфраструктуры, но аналитики рассчитывают на то, что в скором времени эти
модели станут востребованы в задачах
планирования ресурсов облачных сервисов, сетевой маршрутизации и высокопроизводительных вычислений.
Интеллект для
управления сервисами
Задачи оперативной ИТ-аналитики охватывают три основных направления.
Во-первых, это получение детального
представления о текущем состоянии ИТинфраструктуры, выявление шаблонов
использования и поведения ее различных
компонентов. Этот круг вопросов иногда
обозначают как аналитику доступности (availability analytics). Следующим по
уровню сложности является проактивный
анализ, который позволяет заблаговременно выявить возможные проблемы, например за час до возможного сбоя. Для
этого типа аналитических задач можно встретить обозначение — аналитика производительности (performance
analytics) ИТ-среды. Третий уровень ИТаналитики — предсказательный — обеспечивает прогноз событий и потребностей в ресурсах инфраструктуры на срок
от дней и недель до года. Аналитические
инструменты больших данных
задачи этого типа иногда обобщают термином аналитика мощностей (capacity
analytics).
Наибольший эффект от применения
ITOA можно получить, если поставить
анализ в контекст ИТ-сервисов, а не отдельных компонентов инфраструктуры.
Такие решения могут обеспечить серьезную интеллектуальную поддержку
эффективной реализации процессов
управления ИТ-сервисами, в особенности, если будут интегрированы с системами автоматизации ITSM. Средства
ИТ-аналитики помогают получить общую картину использования сервиса,
обрабатывая данные о поведении конечных пользователей, включая их доступ
с различных типов устройств и выполнение бизнес-транзакций. С помощью
аналитического инструментария можно повысить оперативность реакции
ИТ-службы на проблемы и инциденты
— анализ всех событий и изменений
конфигураций, произошедших в инфраструктуре с момента, когда все работало
нормально, позволяет быстро выявлять
корневые причины сбоев и значительно
сокращать среднее время восстановления. Имея модели зависимости сервисов от компонентов инфраструктуры,
построенные на основе базы данных
управления конфигурациями и данных
мониторинга в реальном времени, ITOA
может идентифицировать, какие сервисы оказываются затронуты тем или
иным сбоем, предоставляя ИТ-службе
возможность расставлять приоритеты
в своей работе.
Следующим шагом становится предупреждение проблем с помощью аналитики изучения поведения (behavior
learning analytics), которая собирает метрики производительности со всех компонентов «экосистемы» сервиса, «обучается» нормальному поведению сервиса и
дает сигнал о возникновении возможных
отклонений от нормы.
Большое значение аналитика приобретает в процессах управления изменениями, предоставляя возможность на основе метрик производительности, анализа
конфигураций и модели сервиса быстро
и исчерпывающе оценить последствия
внесения изменения в компоненты инфраструктуры для сервиса в целом.
Переходя к более сложной предсказательной аналитике, ИТ-менеджеры получают возможность оптимизировать
использование ресурсов инфраструктуры в рамках реализации определенных
сервисов. Недостаточность мощностей
Советы администратору
Администраторы корпоративных сетей имеют дело с огромным объемом данных
о трафике, каналах связи и сетевых устройствах, собираемых стандартными системами управления с различных датчиков, а также получаемых от программного
обеспечения сетевого уровня на клиентском и серверном оборудовании. Извлечь
из этого гигантского пула данных осмысленную информацию, полезную для решения текущих задач управления доступностью, конфигурациями, производительностью и безопасностью сетевой инфраструктуры, помогают инструменты
анализа Больших Данных.
Прежде всего необходимо выстроить четкую временную шкалу сетевых событий, с которой должны быть соотнесены все элементы пула данных сетевого
мониторинга. Только при условии такой синхронизации удастся получить правильный контекст анализа происходящего в сети, где непрерывно происходит
изменение условий и взаиморасположения событий. На полученную ось времени можно отображать проблемы, возникающие в сети, и выполнять корреляцию
между проблемными точками и метриками, собранными за определенный период, предшествующий появлению инцидента. Эта оценка имеет колоссальное значение для определения корневых причин сетевых сбоев — инструменты анализа
Больших Данных позволяют находить корреляции миллионов элементов данных
с проблемными точками и затем анализировать их на предмет выявления причины нарушений в работе.
Ключевое направление использования Больших Данных в сетевом мониторинге — определение базовых нормальных условий работы сети. Точное сопоставление проблемных точек со всеми сетевыми данными на временной шкале позволяет выявить промежутки, когда проблем нет вообще. Анализ данных, собранных
в такие благоприятные периоды, позволит администратору квалифицировать в
терминах собранных данных условия штатного поведения сети. Эти базовые нормальные условия могут использоваться при анализе периодов работы сети, когда
явных проблем нет, но сеть работает нестабильно.
Пристального внимания может потребовать ситуация, когда аналитика выявляет поведение сети, явно близкое к проблемному, но при этом сигналов о сбоях
от оборудования не поступает. Аналитические инструменты в этом случае помогут понять, что мешает проблеме реально проявить себя, и предложить способы
восстановления полностью нормальных условий.
Важно исследовать влияние событий, происходящих с сетевым оборудованием, приложениями, серверами и пользовательским трафиком — на любое существенное изменение в состоянии этих ресурсов сеть должна реагировать предсказуемо. Например, значительный рост трафика от приложения должен привести
к заметному увеличению времени отклика, более частой потере передаваемых
пакетов и другим проблемам. Если подобное происходит, но не связано с увеличением трафика, то можно сделать вывод о перегрузке сети. И наоборот, если
существенный рост трафика не имеет выраженных последствий, это может свидетельствовать об избыточности сетевых мощностей. И в том и в другом случае
анализ может стать базой для принятия решений об оптимизации расходов на
инфраструктуру.
приводит к перегрузке используемых
платформ, снижению производительности приложений и проблемам в обеспечении заданного уровня сервисов. С
другой стороны, непродуманное приобретение избыточных ресурсов выливается в лишние расходы. Предсказательная
аналитика помогает избежать таких
проблем — соответствующий инструментарий позволяет строить сценарии
«что-если» на основе анализа текущих
и исторических трендов использования
компонентов инфраструктуры и дает
возможность загодя планировать потребности инфраструктуры и сервисов
в ресурсах, оценивая вероятность успеха внесения различных изменений в
ИТ-среду.
***
Сотрудники ИТ-служб и ИТ-менеджеры
всегда в той или иной форме пытались решать аналитические задачи для оптимизации управления инфраструктурой и сервисами. Современный уровень сложности
ИТ-сред уже не оставляет места ручному
управлению — новое поколение средств
ITOA обещает справиться с проблемами
обработки постоянно растущих объемов
разнородных и изменчивых данных, поступающих из всех доменов инфраструктуры,
и позволит построить точную картину состояния и развития ИТ-сервисов.
Наталья Дубова (osmag@osp.ru) —
научный редактор, «Открытые системы.СУБД» (Москва).
www.osmag.ru • 01/2014 • Открытые системы • 19
инструменты больших данных
Большие Данные
в руках брокера
Системы алгоритмической торговли широко используются финансовыми организациями для автоматизированного выставления биржевых заявок — анализ больших объемов разнообразных данных в таких системах
позволяет, например с помощью стека решений от IBM, получать устойчивую прибыль путем выявления незначительных колебаний курсов.
Ключевые слова: Большие Данные, алгоритмическая торговля, прогнозирование, биржевые торги
Keywords: Big Data, algorithmic trading, forecasting, stock trading, NYSE, NASDAQ
горитмической торговли Getco (с 2013 года
KCG Holdings). Сегодня это один из ведущих торговых операторов в мире — сделки
Getco составляют от 10 до 20% дневного
объема торгов высоколиквидных акций таких компаний, как General Electric, Oracle и
Google. Эффективность алгоритмических
систем значительно выше работы трейдеров, и по некоторым оценкам [1,2] на долю
HFT приходится около 80% от общего объема торгов акциями в США.
Большие Данные
на бирже и не только
Олег Болгарчук
Н
ачиная с 80-х годов широкое распространение в финансовой сфере получила алгоритмическая,
или автоматическая, торговля (black-box
trading), позволяющая выставлять торговые заявки без непосредственного участия человека. Алгоритмическая торговля
помогает не только извлекать прибыль из
собственно процесса торгов, но и проводить большие сделки, не нарушая баланса
рынка, принимая решения в автоматизированном режиме.
Высокочастотной торговлей (HighFrequency Trading, HFT), часто являющейся наиболее прибыльной, называют работу
алгоритмических систем, автоматически
принимающих решение на основе информации, получаемой в электронном виде,
до того как она может быть обработана
человеком. Начало активного развития
HFT связывают с черным понедельником
19 октября 1987 года, когда промышлен-
ный индекс Доу — Джонса в течение дня
упал на 22,6%. Быстрое обрушение рынка
подтолкнуло Давида Уиткома, профессора
Ратгерского университета, задуматься об
автоматизации работы маркетмейкеров,
совершавших сделки в интересах клиентов. Он выступил инициатором создания
компании Automated Trading Desk, решения которой позволяют быстро рассчитывать направление движения рынка и
торговать намного эффективнее человека-брокера. В 2007 году ATD вошла в состав Citigroup.
В июне 1997 года Нью-Йоркская фондовая биржа сделала очередной шаг к переходу на десятичную систему счисления
при выставлении заявок — шаг изменения
цены составил 6,25 цента, что сделало более удобным использование различных
алгоритмов расчета средней цены для
выставления заявок. Вероятно, это подтолкнуло Дэна Тирни и Стивена Шулера,
торговавших фьючерсами и опционами на
Чикагской бирже, на создание компании ал-
20 • Открытые системы • 01/2014 • www.osmag.ru
При анализе рынков используется множество разнообразных источников данных: официальные документы, средства
массовой информации, социальные сети,
а также биржевые сводки — что все вместе
представляет значительный объем сырых
данных. Биржевые площадки распространяют данные по подписке в зависимости
от выбранного уровня глубины, однако нет
общего стандарта их предоставления, поэтому детализация данных может отличаться
от поставщика к поставщику. Крупнейшие
биржи, такие как NYSE и NASDAQ, предоставляют возможность получать обезличенные котировки каждого отдельного участника рынка в реальном времени. Заявки
на покупку и продажу распределяются в
широком интервале, требуя применения
различных методов для оценки стоимости
активов в произвольный момент времени.
Как следствие, объем информации только от одной биржи (например, NYSE или
NASDAQ) в среднем составляет 100 Гбайт
в сутки, не считая других данных и не учитывая ежегодного прироста, а в периоды
высокой активности данные поступают
со скоростью в несколько сот мегабит в
секунду. Нужно учесть, что в этом потоке
многие заявки не отражают цену и имеются внутренние колебания, затрудняющие
инструменты больших данных
определение общего тренда. Кроме того,
данные очень разнообразны: много участников, много площадок — что усложняет определение влияния одного актива на
цену другого.
Цена акций на разных площадках хорошо синхронизирована, и невозможно
получить прибыль из простой разницы
в цене активов на разных рынках, однако
торги проходят независимо и отличаются
составом участников, а значит, обработка
данных каждой дополнительной торговой площадки, такой как BATS или ARCA,
позволяет извлечь новую информацию и
улучшить точность предсказания цены.
Анализ большого количества данных может
дать незначительное улучшение точности (0,5–3%), что в ряде случаев считается
оправданным. В частности, использование данных ARCA и BATS в дополнение к
NYSE и NASDAQ дает улучшение именно
такого порядка, которое с учетом объема
заявок может сделать прибыльной работу автоматической торговой системы в
целом. Иначе говоря, выставление заявок
по случайному алгоритму приводит к торговле с нулевой прибылью, а в случае комиссии — и к убыткам. Даже небольшое
дополнительное увеличение количества
заявок, выставленных с учетом правильно предсказанного направления преимущественного движения показателей, может позволить приподняться над уровнем
рентабельности. Анализ исторических данных позволяет выявлять скрытые зависимости, фильтровать недостаточно точную
информацию и строить математическую
модель, учитывающую степень влияния
различных факторов и прогнозирующую
изменение цен на рынках. Найденные закономерности используются в процессе
торгов для определения трендов и увеличения прибыли инвестора, торгующего
активами на бирже.
Вместе с тем даже очень глубокий анализ различных данных еще не гарантирует
достижения желаемых целей. Например, в
рамках проекта SETI (Search for Extraterrestrial
Intelligence), инициированного в 1959 году
для поиска внеземных цивилизаций, миллионы компьютеров пользователей Сети
анализируют сигналы, собираемые все новыми и новыми радиотелескопами, однако
за все это время была зафиксирована всего
пара событий, отдаленно напоминающих
сигнал искусственного происхождения.
Нельзя обнаружить послание там, где его
нет, нельзя сделать биржевой прогноз на
основе «грязных» данных, генерируемых в
результате различных случайных и нерегулярных явлений. Перед началом проекта
Большие Данные для бизнес-аналитики
и прогнозирования
Индустрия
Примеры использования
Автострахование
Анализ поведения водителя, управление рисками
Анализ сети и оптимизация предложения услуг по данным мобильных устройств, датчиков и местоположению объекта
Профайлинг, объединение уголовных дел в одно производство, упреждающее управление безопасностью
Анализ показаний датчиков для повышения безопасности, управление рисками и затратами, оптимизация производства
Анализ данных измерительных устройств, сокращение затрат, улучшение обслуживания, повышение доходов, управление ресурсами
Улучшение обслуживания, повышение доходов, управление
ресурсами
Телекоммуникации
Безопасность
Топливно-энергетическая
ЖКХ
Транспорт
целесообразно провести предварительное
исследование имеющихся данных, а также
учесть особенности решения задач бизнес-аналитики в других областях, не обязательно связанных с финансовой сферой.
Например, в здравоохранении можно выявить причины повторных госпитализаций,
анализируя медицинские карты и изучая
процессы адаптации патогенных микроорганизмов к лекарственным препаратам и
вакцинам, одновременно сопоставляя полученные сведения с характерными для
данного региона запросами к поисковым
системам. В таблице приведены примеры
областей, анализируя состояние дел в которых можно достигнуть того или иного
целевого показателя.
Архитектура системы
алгоритмической
торговли
Прежде всего алгоритмической торговой
системе, как и любой другой системе, решающей задачи прогнозирования на основе Больших Данных, необходимо обеспечить сбор и накопление информации для
анализа. Изучение данных ведется специалистами в области статистического и
математического моделирования, которые
определяют структуру данных, проводят
их анализ и визуализацию, а также выдвигают и проверяют гипотезы для построения на их основе математической модели.
Данные, которые накапливались годами,
необходимо многократно пересчитывать
в процессе построения прогнозирующей
модели. Сокращение времени проверки
одной гипотезы за счет повышения производительности системы управления данными часто является критически важным,
и особенно для алгоритмической биржевой системы, где положительный результат
может быть достигнут путем непрерывной
подстройки модели под быстроменяющуюся микроструктуру рынка, а также за счет
постоянного увеличения количества и состава анализируемых данных.
Построение математической модели ведется на исторических данных, доступных
в любой момент времени и в любом порядке, однако при работе торговой системы в
реальных условиях данные поступают пос-
Обмен финансовой информацией
(FIX Protocol)
Брокерский надзор
в реальном времени
Аналитик
Рабочая
станция
Управление портфелем
и рисками
Биржевые щлюзы
(Dirеct Market Access)
ИТ-система брокера
Прогнозирование
изменения цены
Хранилище
Трейдер
Сбор и унификация данных
IBM PureData Systems
for Analytics
Построение модели
для прогноза
Аналитическая система
реального времени
IBM Statistical Package for the Social
Sciences (SPSS)
IBM InfoSphere Streams
Браузер
Построение отчетов
ERP
Синхронизация времени
Пример архитектуры алгоритмической торговой системы
www.osmag.ru • 01/2014 • Открытые системы • 21
инструменты больших данных
Стек для Больших Данных
IBM PureData System for Analytics. Специализированное решение для управления хранилищами данных, обеспечивающее интеграцию различных баз, серверов, систем хранения и средств расширенной аналитики. Высокая производительность достигается за счет
асимметричной обработки данных с массовым параллелизмом (Asymmetric Massively
Parallel Processing, AMPP), в которой серверы-лезвия и дисковые накопители интегрированы с фирменными инструментами фильтрации данных на основе программируемых
логических матриц. Такое сочетание обеспечивает высокое быстродействие при выполнении запросов в условиях разнотипных рабочих нагрузок при поддержке тысяч пользователей. Разработчики моделей и специалисты по анализу могут работать с данными
непосредственно в системе, не выгружая их в отдельную инфраструктуру.
IBM SPSS Modeler. Универсальная графическая среда для интеллектуального анализа
данных, ориентированная как на бизнес-пользователей, не обладающих серьезными математическими знаниями, так и на экспертов в этой области. В рамках одного продукта
решаются задачи подготовки данных, построения прогнозных моделей, оценки качества
моделей и их развертывания. Пользователю доступен набор автоматических средств по
подготовке данных, выбора моделей или их ансамблей для решения конкретной бизнесзадачи. В состав IBM SPSS Modeler входит набор зарекомендовавших себя алгоритмов:
различные виды регрессий, деревья решений, нейронные сети, машина опорных векторов,
сеть Байеса и т. д. Кроме того, представлен ряд методов для уменьшения размерности
и выявления наиболее важных для построения модели переменных. Предусмотрен импорт/экспорт разнообразных форматов данных: ODBC, плоские файлы, Excel, IBM SPSS
Statistics, IBM Cognos BI/TM, SAS.
IBM InfoSphere Streams. Платформа поддержки процессов принятия решений, анализа и сопоставления информации, поступающей в реальном времени из множества
источников. Благодаря распределению программы по узлам кластера имеется возможность обрабатывать данные с высокой пропускной способностью (несколько миллионов
событий или сообщений в секунду). InfoSphere Streams помогает анализировать данные
«в движении», что позволяет: просматривать данные и события по мере их возникновения; упростить разработку потоковых приложений за счет средств разработки на основе Eclipse; интегрировать уже используемые системы обработки структурированных
и неструктурированных данных. Платформа поддерживает повторное использование
кода на языках Java и C++, а также моделей Predictive Model Markup Language (PMML).
Имеются средства интеграции с СУБД DB2, Informix, Netezza, IBM solidDB, IBM InfoSphere
Warehouse, IBM WebSphere Operational Decision Management, IBM InfoSphere DataStage,
IBM Smart Analytics System, Oracle, Microsoft SQLServer и MySQL.
ледовательно и обработка поступившего
блока должна происходить независимо
от времени получения следующего блока
данных (см. рисунок). Необходимо, чтобы
математическая модель, построенная на
исторических данных, была инвариантной
к модулю прогнозирования, работающему с непрерывным потоком информации.
Модуль сбора данных также должен обеспечивать не только запись данных в хранилище, но и их одновременную передачу
в модуль прогнозирования, загружающий
текущие данные в математическую модель
для расчета вероятной цены активов через
заданный промежуток времени.
Одним из возможных наборов компонентов, позволяющих организовать взаимный обмен информацией для такого рода
задач, являются продукты из стека решений компании IBM для работы с Большими
Данными (см. врезку).
Понимание динамики изменения цены
критически важно для извлечения прибыли инвестором из процесса торгов, однако этого еще недостаточно — необходима
разработка специализированного модуля
управления портфелем и рисками, обеспечивающего выставление заявок с учетом
требований законодательства, текущего
состояния портфеля, доступности кредитных средств, транзакционных издержек и
статистики работы на различных торговых
площадках, времени суток и т. д.
С определенным упрощением можно
сказать, что обработка всех доступных
данных в алгоритмической торговле дает
возможность заранее покупать активы, которые будут дорожать, и продавать активы,
которые будут дешеветь. Многие брокеры
и некоторые биржи используют действия
своих клиентов в качестве индикаторов в
работе их собственных систем алгоритмической торговли. Имея возможность
исполнять свои заявки в первую очередь,
они используют наиболее выгодные предложения на рынке и не позволяют клиентам
получать устойчивую прибыль. Такие манипуляции брокера могут быть выявлены
инвестором, например, при статистическом
анализе задержек в ходе обработки заявок.
Точность определения временных интервалов в многосерверной системе обеспе-
22 • Открытые системы • 01/2014 • www.osmag.ru
чивает модуль синхронизации времени.
Необходимо использовать по-настоящему
прямой доступ к рынку, когда заявки отправляются непосредственно в информационную систему биржи (биржевой шлюз),
и крупные брокеры предоставляют такую
возможность. Чтобы снизить финансовые
риски, они требуют немалый гарантийный
депозит и наличие интерфейса, позволяющего остановить систему клиента в случае
необходимости. Также многие компании
заботятся об уменьшении расстояния между их системой и биржевым шлюзом, так
как иногда задержки в телекоммуникационных системах оказывают существенное
влияние на результаты торговли.
***
Алгоритмическая торговля — лишь один
пример прикладной области, где анализ
Больших Данных позволяет заработать.
Доход 300 компаний, специализирующихся в сфере алгоритмической торговли,
превысил в прошлом году 20 млрд долл.
Преимущества использования глубокого
анализа всей имеющейся информации уже
оценили крупные торговые сети, которые
хотят прогнозировать спрос на товары для
сокращения своих издержек или формируют адресные программы продвижения
товаров для конкретных групп покупателей, обобщая данные из социальных сетей.
В таких далеких от финансов областях, как,
например, служба исполнения наказания,
разнообразные данные используются для
оценки вероятности повторного совершения
преступления осужденным при решении
вопроса о его досрочном освобождении.
В общем случае анализ Больших Данных
позволяет вносить существенный вклад
в достижение целевых показателей, определенных в стратегии организации и
направленных на получение реального
результата.
Литература
1. Das R., Hanson J.E., Kephart J.O.,
Tesauro G. Agent-Human Interactions in
the Continuous Double Auction. Institute
for Advanced Commerce, IBM T.J. Watson
Research Center, 2001. URL: http://
spider.sci.brooklyn.cuny.edu/~parsons/
courses/840-spring-2005/notes/das.pdf
(дата обращения: 05.11.2013).
2. Algorithmic Trading: Hype or
Reality? // Aite Group. URL: http://www.
aitegroup.com/Reports/ReportDetail.
aspx?recordItemID=206 (дата обращения:
05.11.2013).
Олег Болгарчук (oleg.bolgarchuk@ru.ibm.com) —
ИТ-архитектор, IBM (Москва).
программная инженерия
Тестирование
эластичных
компьютерных систем
Появившись вместе с облаками, эластичные компьютерные системы
привлекают сегодня все больше внимания — они могут «сжиматься»
и «растягиваться» в зависимости от рабочей нагрузки, обеспечивая
баланс между потреблением ресурсов, затратами и качеством обслуживания. Однако до сих пор неясно, как тестировать эластичные системы
и каковы дальнейшие направления их развития.
Ключевые слова: динамические системы, нагрузочное тестирование, облака, уровень обслуживания, растяжение, деформация
Keywords: dynamical systems, stress testing, cloud, service level, stretching, deformation
Алессио Гамби,
Валдемар Хуммер,
Хон Линь Чыонг,
Шахрам Дустдар
О
блака проложили путь к появлению
нового класса компьютерных систем,
в основе архитектуры которых лежит
принцип эластичности [1].
Ресурсная эластичность позволяет компьютерным системам динамически получать
и отдавать ресурсы (например, виртуальные
машины). Системы, поддерживающие такую эластичность, задействуют дополнительные ресурсы, когда требуется повысить
вычислительную мощность. Эластичность
может достигаться за счет инфраструктурных возможностей, процессов и кадровых
ресурсов. Обладающие этим свойством
системы способны динамически менять
качество обслуживания, в частности, поддерживая приложения с интенсивной обработкой данных, динамически меняющие
уровень их согласованности, за счет сведения к минимуму задержек или зарезервированного объема ресурсов [2]. Системы,
предлагающие эластичность бюджета, динамически адаптируют уровень денежных
затрат на эксплуатацию, допуская вариативность уровня обслуживания, что бывает полезно в научно-исследовательских
приложениях [3].
Обратной стороной эластичных компьютерных систем является необходимость в спе-
циальных методах тестирования. Динамизм
таких систем определяется большим набором факторов, куда входят: бизнес-логика
приложения; рабочая нагрузка; управляющая логика, регулирующая процесс резервирования ресурсов (адаптацию системы);
инфраструктура предоставления ресурсов
и т. п. Все это затрудняет проектирование
эластичных систем и прогнозирование их
эволюции, причем сегодня исследовательское сообщество не уделяет достаточного
внимания их тестированию. Следует наметить новые методологии, дополняющие
традиционное тестирование ПО концепциями эластичности и ориентированные
на выявление проблем, характерных для
систем повышенной гибкости.
Метафоры
Интуитивно понятно, что, например, ресурсно-эластичные компьютерные системы напоминают эластичные материалы,
меняющие форму в ответ на внешние воздействия, — они так же «растягиваются»
под влиянием внешних стимулов и сжимаются до первоначального состояния, когда
эти стимулы исчезают. Рассмотрим в связи
с этим две метафоры. Первая — «эластичный материал» — поможет определить основные понятия, свойства и терминологию
для описания эластичности компьютерной
системы. Вторая — «механические испытания» — позволит определиться с методиками тестирования.
Если воспользоваться метафорой эластичных материалов, то аналогами эластичной
компьютерной системы, ее рабочей нагрузки
и изменения масштаба станут соответственно образец (материал), стресс-фактор (например, усилие растяжения) и деформация
(например, удлинение). Кривая зависимости
деформации от напряжения — это стандартный и наглядный способ продемонстрировать, как меняется эластичность образца
(рис. 1). На ней обычно отмечают точки, в
которых материал меняет свое состояние в
зависимости от силы напряжения.
Об эластичности говорят, когда образец
после деформации возвращается в исходную форму — деформация пропорциональна напряжению. При линейной зависимости
эластичность можно выразить через модуль
упругости — то есть через деформацию на
единицу напряжения. О пластичности говорят, когда образец уже не может вернуться в исходную форму после исчезновения
напряжения. В контексте ПО пластичными
можно назвать системы, способные масштабироваться только вверх (и имеющие
риск сбоя при достижении определенного
масштаба), в то время как эластичные системы могут динамически масштабироваться вверх и вниз.
Образец, не допускающий деформации, — неэластичный. Если компьютерная
система или ее часть неэластична, она не
адаптируется к изменениям рабочей нагрузки, а значит, ей либо не хватает ресурсов,
Alessio Gambi, Waldemar Hummer, Hong-Linh Truong, Schahram Dustdar, Testing Elastic Computing Systems, IEEE Internet Computing, November/December 2013,
IEEE Computer Society. All rights reserved. Reprinted with permission.
www.osmag.ru • 01/2014 • Открытые системы • 23
программная инженерия
Тестирование эластичных
компьютерных систем
Сегодня еще нет готовых концептуальных схем тестирования эластичных систем
и соответствующих направлений исследований. Проведенные работы в основном
касались нагрузочного тестирования, тестирования масштабируемости и создания
технического фундамента для эффективного выполнения тестов в облаке. Например,
имеются исследования по проведению тестирования согласно сервисной модели
(Testing as a Service, TaaS) в облаке, в том числе изучены проблемы распараллеливания тестов, обеспечения отказоустойчивости, а также бюджетирования. Но акцент
делается на эластичности самой платформы TaaS, а не тестируемых с ее помощью
приложений.
Эластичные системы — близкие родственники адаптивных систем, поэтому принципы их разработки частично применимы к первым, но не охватывают всех аспектов.
Нередко при проектировании инженеры идеализируют среду, условия применения и
рабочие задачи. Например, принимается, что приводные механизмы идеальны, адаптация оказывает мгновенное влияние на поведение системы, ее работоспособность
стабильна, а рабочие нагрузки предсказуемы. Но на практике это не так, и особенно
в облаках, для которых характерны шум, временные явления, непредвиденные события и резко меняющаяся нагрузка. Так что если полагаться на подобные предположения, то эластичные системы будут слишком неустойчивы, а обеспечиваемые
ими качество обслуживания и экономия затрат будут далеки от оптимальных или
вообще противоположны им. Такое положение дел несовместимо с требованиями
высокого качества и надежности бизнес-критичных приложений, которые заманчиво
реализовать именно с помощью эластичных компьютерных систем.
Необходимы новые методологии и инструменты, затрагивающие не только проектирование и реализацию эластичных систем, но также их моделирование, сравнительное тестирование и аттестацию. Эластичность и ее особенности должны стать
объектом исследований — в частности, сегодня ведутся исследования, направленные на улучшение качества эластичных программных систем и посвященные методам систематического и сравнительного тестирования, а также формализации и
имитации.
В ходе испытаний на растяжение эластичная система подвергается постоянной
нагрузке, увеличиваемой перед каждым
запуском теста до тех пор, пока не начнутся сбои. При каждом повышении нагрузки
тестировщики проверяют, восстанавливается ли система до первоначальной конфигурации, и собирают данные о ее поведении
для построения кривой напряжения-деформации. В контексте ПО испытание на рас-
Эл а с т и
ч но с т ь
Предел вынужденной эластичности
Разрушение
Напряжение
Предел напряжения
Предел пропорциональности
Напряжение
либо их выделено слишком много. В свою
очередь, «утончение» (сужение до точки,
necking) происходит, когда образец начинает разрушаться.
Особый интерес представляют точки
перехода — граница между эластичным и
пластичным состоянием: предел прочности — точка перед тем, как начинают появляться разрывы; критическая точка — образец разрушается.
Для описания поведения эластичных компьютерных систем нужно идентифицировать их различные состояния, переходные
точки и разработать модели, соответствующие кривым напряжения-деформации.
Такие модели позволят разработчикам
прогнозировать поведение систем в различных условиях эксплуатации и сравнивать реализации — по аналогии с тем, как
инженеры сравнивают между собой материалы (вязкие, хрупкие, как на рис. 1, б ).
Подобные возможности критически важны для оценки соответствия эластичных
систем пользовательским требованиям и
спецификациям сложных систем, а также
для повышения качества ПО. Пользуясь
метафорой «эластичные материалы», для
оценки эластичного и неэластичного поведения вычислительных систем можно подобрать аналогии в виде различных типов
механических испытаний.
тяжение проводится по тем же основным
принципам, что и нагрузочное тестирование, но при этом регистрируются свойства,
касающиеся эластичности, а не только быстродействие программы.
Кривые напряжения-деформации не
учитывают время, представляя лишь статичный срез состояния эластичности системы, и, когда нужно проанализировать
динамические аспекты эластичности, требуются другие методологии моделирования
и тестирования. Сведения о способности к
расширению и сжатию при эксплуатации
системы полезны, только если эти процессы происходят без сбоев и своевременно.
Если ресурсно-эластичная система тратит
слишком много времени на получение дополнительных ресурсов при флуктуации
нагрузки, это означает, что программа не
обеспечивает нужного быстродействия.
Аналогично, если высвобождение ресурсов происходит слишком медленно, значит, система обходится дороже расчетного
бюджета. С другой стороны, если времени
на высвобождение уходит слишком мало,
то система может оказаться слишком агрессивной, начинается «пробуксовка» изза чересчур большой частоты операций с
ресурсами, вследствие чего система обходится дороже, чем ожидалось.
Испытание на удар — один из способов
анализа системы в динамике. При таких
испытаниях образцы подвергаются пиковым нагрузкам, чтобы выяснить, сколько
энергии они могут поглотить, как быстро
и разрушатся ли они. В контексте ПО ударное тестирование позволяет исследовать
адаптацию системы и выяснять, при каких
условиях возникают отказы. В целом метод похож на традиционное тестирование
Разрушение
Хрупкость
Разрушение
Вязкость
Утончение
Пластичность
Деформация
а)
Деформация
б)
Рис. 1. Кривые напряжения-деформации для эластичных материалов. Отмечены
точки изменения состояний: а — переходные точки и б — поведение на различных
уровнях напряжения
24 • Открытые системы • 01/2014 • www.osmag.ru
программная инженерия
ПО под нагрузкой. Например, при ударном
тестировании можно выяснить точку, на
которой система начинает отклонять недопустимо много запросов.
Интерес также представляет такая характеристика эластичной системы, как
деградация системы, обусловленная циклическими адаптациями. При неудачной архитектуре эластичной системы деградация
качества у нее может проявиться раньше,
чем у традиционных систем, под влиянием
«изнуряющей» серии циклов масштабирования и сжатия. По аналогичным причинам
сбои в эластичной системе могут распространяться быстрее и приводить к крупномасштабным авариям.
При испытаниях на усталость физические образцы материалов подвергаются циклическому напряжению, которое вызывает
локальные адаптации и в конечном счете
может привести к структурным повреждениям. Задача таких испытаний — определить период наработки системы на отказ
и выяснить, насколько ухудшаются ее эластичные свойства со временем. Циклическое
напряжение может иметь фиксированную
или случайно меняющуюся амплитуду и
частоту. Цели и процедуры такого тестирования подобны испытаниям ПО на выносливость. Отличие в том, что задача этих
испытаний — выявить ошибки, касающиеся
управления памятью, утечек и переполнений буфера, которые труднее обнаружить
при «мгновенных» тестах. А задача тестирования на усталость — найти проблемы,
возникающие при непрерывной и циклической адаптации программной системы,
например при подключении и отключении
вычислительных узлов кластера.
Тестирование на усталость также помогает в изучении процесса распространения
сбоев в эластичных материалах при циклической адаптации. Подвергая образец
циклическому напряжению, испытатели
выясняют, увеличиваются ли трещины и
приводят ли в конечном счете к разрушению образца. Что касается ПО, то здесь
можно выяснить, как локальные сбои распространяются по системе, может ли эластичная система автоматически их устранить
(самовосстановиться) и приведут ли такие
сбои со временем к системной аварии. Когда
тестирование на утомляемость проводится в форме резонансного испытания, это
позволяет выяснить, какие циклические
нагрузки приводят к неконтролируемому
росту частоты операций резервирования
ресурсов. Возможность выяснить, есть ли
у систем такие «резонансные частоты», поможет проектировщикам предусмотреть
средства их блокирования.
Аналогии между испытаниями механических
и компьютерных систем
Механические испытания Аналогия для эластичной компьютерной системы
Увеличение или уменьшение масштаба системы при
Деформация образца
резервировании или высвобождении ресурсов
Восстановление первонаВысвобождение вычислительных ресурсов
чальной формы
Пластичность
Неспособность системы к уменьшению масштаба
Утончение
Необратимый системный сбой
Идентификация эластичных состояний и переходов
между системными конфигурациями — например,
выдача конечного числа запросов с постоянной скороИспытание на растяжение
стью, чтобы вызвать увеличение масштаба системы и
проверить, сможет ли она восстановить первоначальную конфигурацию
Методы тестирования, изучающие, насколько быстро ресурсы могут быть зарезервированы эластичной
системой, — например, выдача запросов по ступенчатой функции с целью вызвать увеличение масштаба
Испытание на удар
системы без достижения состояния «утончения» (без
сбоев) и измерение времени, уходящего на достижение
максимально возможной конфигурации
Методы тестирования, изучающие, способна ли система
выйти за рамки бюджета за период наблюдения, — например, волнообразная выдача запросов, вызывающих
Испытание на усталость
чередующееся увеличение и уменьшение масштаба с
последующим измерением затрат на задействованные
ресурсы согласно заданной модели тарификации
Методики тестирования, изучающие изменения в эластичном поведении системы, которые вызываются помехами и конфликтами физических ресурсов базовой
платформы, — например, развертывание ресурсоемких
Испытание на сдвиг
виртуальных машин рядом на тех же физических серверах, на которых работает система, и последующее
сравнение ее эластичного поведения с эталонами
Имеется ряд неочевидных факторов, влияющих на уровень эластичности программной
системы в период исполнения, — например,
если такая система делит инфраструктурные ресурсы с другими пользователями
облака, создающими большую нагрузку
(иногда их называют «шумные соседи»), то
качество такой системы может ухудшиться
из-за борьбы за ресурсы. Данная ситуация
также может вызвать переход эластичной
системы в неоптимальные и рискованные
состояния. Знание побочных эффектов,
возникающих из-за других пользователей
инфраструктуры, помогает разработчикам
оценить устойчивость эластичной системы. В подобных случаях полезным может
быть испытание на сдвиг. Если говорить о
механике, то в процессе таких испытаний
образцы подвергаются действию поперечных сил, способных вызвать деформацию
материала, — под их действием материал
может адаптироваться до тех пор, пока не
разрушится. Для ПО тоже можно подгото-
вить тесты, вызывающие неверное поведение системы вследствие «поперечных сил»,
таких как борьба за ресурсы.
Приведенные метафоры помогают понять
основные концепции схемы тестирования и
рекомендации по его проведению. В таблице перечислен ряд аналогий между миром
механических испытаний и тестированием
эластичных систем.
Концептуальная схема
Схема тестирования эластичности состоит
из четырех этапов: разработка сценария,
исполнение, анализ данных и совершенствование теста (рис. 2). Для этапа подготовки сценария входными данными являются
цели тестирования, а результатом — набор
спецификаций теста (тестовый комплект).
В рамках тестового сценария указываются
характеристики и конфигурации эластичной
системы, генераторы входной рабочей нагрузки и ее тип. В частности, нужно задать
интенсивность и состав запросов, а также
www.osmag.ru • 01/2014 • Открытые системы • 25
программная инженерия
Усталость Резонанс Растяжение
Удар
Сдвиг
Разработка
тестового
сценария
Спецификация
тестового сценария
Обновленный сценарий
80%
Совершенствование
теста
Обновление
и сопровождение
теста
Тестировщик
Мониторинг
прогресса и затрачиваемых
усилий
Эластичная компьютерная система
Исполнение теста
Эластичный
контроллер
Интерпретация
и контроль
точности
80%
Результаты теста
Время
Системные
показатели
Анализ данных
Сымитированные
клиенты
Облачная инфраструктура в виде
сервиса
Ресурсы
Время
Свойства
Время
Модели
Рабочая
нагрузка
Вердикт
Качество
Время
Х%
Охват
Рис. 2. Концептуальная схема тестирования эластичных компьютерных систем
входные данные и их вариации в процессе
исполнения теста, моделирующие флуктуации уровня нагрузки. Например, в тестовом
сценарии в зависимости от времени может
волнообразно варьироваться число активных
пользователей. Рабочая нагрузка, созданная таким образом, вызывает срабатывание
эластичных механизмов системы. Тестовые
сценарии могут содержать указания о настройках среды и их вариациях. К примеру,
в сценарии теста на усталость может быть
указано, что в определенный момент обрывается соединение с сетью или в облаке
развертываются дополнительные ресурсоемкие виртуальные машины, что приводит
к обострению борьбы за ресурсы.
В процессе тестирования исполняется
один или несколько экземпляров эластичной
системы с различными нагрузками и в разных условиях. Реальное число одновременно работающих экземпляров варьируется в
зависимости от ограничений по бюджету и
доступным ресурсам. При исполнении теста регистрируются системные показатели,
указанные в спецификациях тестового сценария. Одновременно тестировщики могут
следить за прогрессом тестирования, а также объемом затраченных усилий (времени,
денег и ресурсов).
На этапе анализа данных готовятся окончательные результаты теста. В зависимости
от выбранных целей тестирования результаты могут представлять собой отчеты о
прохождении/провале теста, анализ охвата, сведения о локализации сбоев и т. д.
Тестировщики анализируют результаты, интерпретируют их и проверяют точность, что
позволяет выявлять проблемы, требующие
исправлений кода, а также недоработки в
самих тестовых сценариях.
На стадии совершенствования теста
учитываются изменения кода системы и
принимаются меры по улучшению качества тестового сценария.
Чтобы данную концептуальную схему
можно было начать применять на практике,
предстоит решить несколько задач.
Методологический подход
Тестировщикам необходимы языки описания уровня эластичности, который должна
демонстрировать система, а также способ
26 • Открытые системы • 01/2014 • www.osmag.ru
измерить реально достигнутую эластичность. Такие языки должны давать возможность описывать как статичные (не
меняющиеся со временем) свойства эластичности, так и динамичные (зависящие от
времени), а также связи между резервированием ресурсов, затратами и качеством.
У тестировщиков должны быть средства,
позволяющие формализовать требования
заказчиков к эластичной системе, а также
выяснять и контролировать характеристики эластичности.
Кроме того, тестировщикам нужны мерки и критерии охвата, для чего могут потребоваться новые абстракции, касающиеся кода и поведения системы. К примеру,
тестировщикам может понадобиться охватить все возможные системные конфигурации и переходы между ними, а также
конкретные последовательности смены
конфигураций.
Тестировщики должны определиться, на
каком уровне будут оцениваться свойства
эластичности: системы, блока или компонента. Когда программная система имеет
отдельные эластичные компоненты, для
программная инженерия
выяснения их взаимного влияния критически важны интеграционные тесты.
Дополнительные тесты потребуют соответствующих инструментов — например,
средств создания макетов системы, позволяющих проводить тестирование на уровне
блоков и компонентов.
Независимо от масштаба тестирования нужны точные руководства по применимости тестов для эластичных систем.
Некоторые методы, например испытания
на удар и усталость, можно применять для
достижения сходных целей тестирования,
тогда как другие, например испытания на
сдвиг и резонансное, имеют более узкие
цели и, соответственно, более ограниченный круг применений. Применимость теста также может ограничиваться контекстом. Когда некоторую цель тестирования
можно достичь несколькими способами,
в руководстве должны быть четко указаны условия, при которых предпочтителен
каждый метод.
Подготовка сценария
тестирования
Тестировщики могут создавать тестовые сценарии вручную или воспользоваться автоматизированными генераторами. Последние
должны быть оптимизированы для достижения целей тестирования, в том числе для
выявления пределов эластичности и пластичности системы, неоптимальной адаптации
системы с точки зрения затрат и качества,
а также резонансных колебаний.
Если речь идет о ресурсно-эластичных системах, тестовые сценарии нужно
составлять в терминах вариаций рабочей
нагрузки, вызывающих то или иное состояние эластичности или определенные
адаптации. Создавать такие нагрузки непросто: тестировщикам или генераторам
тестовых сценариев придется иметь дело
с многомерным, зависящим от времени
пространством входных тестовых данных. Различным функциям системы может требоваться разный объем ресурсов,
а интенсивность и состав запросов могут
со временем меняться.
Дополнительно осложняет ситуацию то,
что эластичность нельзя непосредственно
наблюдать — о ней можно лишь судить по
набору косвенных системных показателей,
от уровня сложности взаимодействий которых сильно зависит процесс подготовки
тестового сценария. Кроме того, поскольку эластичность — это нефункциональное
свойство, а облака — это обычно «шумные»
среды, то тестовые сценарии должны предусматривать контроль точности, а тестировщикам придется выполнить тест мно-
гократно для сбора достаточного объема
показателей.
Тестовые сценарии должны быть переносимыми и пригодными для многократного использования. Их необходимо
генерировать, следуя общим принципам
и процессам, не зависящим от конкретных облачных приложений и платформ.
Общую задачу подготовки тестовых сценариев можно было бы решить, составляя
их в виде расписаний выдачи запросов или
в форме статистических распределений запросов. Если говорить о сценариях, учитывающих характеристики среды, как в случае
с испытаниями на сдвиг, то тестировщикам
придется указывать дополнительные параметры: имитируемые сбои, размещение
виртуальных машин, а также другие параметры платформы, которые трудно выразить абстрактно, не имея соответствующих
моделей. Сегодня существуют модели и
таксономии сбоев для определенных видов
эластичных систем, например событийнозависимых платформ обработки данных,
однако общие исследования, посвященные
сбоям эластичных компьютерных систем,
еще не проводились.
Исполнение теста
и анализ результатов
Тестировщики должны инсталлировать
и настроить эластичную компьютерную
систему и генераторы нагрузки в целевом
облаке, запустить все компоненты, собрать
данные мониторинга, проанализировать
их после выполнения теста и высвободить
вычислительные ресурсы. На данном этапе понадобятся средства автоматического
управления выполнением тестов на различных платформах. Разработка автоматизированных инструментов, упрощающих и ускоряющих работу тестировщиков, — одна
из приоритетных задач.
Тестировщики могут развернуть несколько экземпляров эластичных систем
бок о бок для параллельного тестирования либо в разных облаках для сопоставления результатов. Следует иметь в виду,
что при отсутствии оптимизации рост
объема ресурсов при распараллеливании
теста может сделать этот процесс слишком затратным. Вспомогательные инструменты должны оптимально распределять
ресурсы между очередными прогонами
теста, чтобы уложиться в ограничения по
времени и бюджету.
Инструменты выполнения тестов должны позволять оценивать точность получаемых при тестировании данных. В частности,
если рабочие условия слишком «шумные»,
вспомогательный инструментарий может
автоматически запланировать повторные
запуски, а кроме того, ему следует реагировать на перемежающиеся отказы или недопустимые состояния платформ.
При исполнении тестов могут генерироваться большие объемы данных, которые
нужно проанализировать для подсчета окончательных результатов. Нужны предельно
эффективные методы анализа, применяемые
для оценки эластичного поведения, охвата
и соответствия системы спецификациям.
Тесты призваны помочь разработчикам выявлять проблемы и находить решения, так
что результаты должны быть максимально
точными. Тестировщикам предстоит перерабатывать тесты, когда они не обеспечивают
точность, а также для отражения изменений
в самой эластичной системе.
У тестировщиков должна быть возможность задать адекватные показатели качества и определить, когда платформа, на которой работает система, эволюционирует,
вследствие чего сценарий тестирования
становится невыполнимым. В частности,
изменения в схемах тарификации и пакетах
облачных сервисов могут привести к выходу
тестирования за рамки бюджета. С учетом
подобной возможности, вероятно, следует
пересмотреть принципы регрессионного
тестирования и обеспечения многократной используемости тестов.
***
Эластичность становится сегодня одним из
ключевых свойств, присущих облачным системам, поэтому необходимы новые исследования на эту тему в сфере программной
инженерии, затрагивающие множество дисциплин, от разработки требований до совершенствования языков программирования
и методов сопровождения ПО.
Литература
1. S. Dustdar et al., Principles of Elastic
Processes. IEEE Internet Computing, vol. 15,
no. 5, 2011, P. 66–71.
2. D. Agrawal et al., Database Scalability,
Elasticity, and Autonomy in the Cloud.
Proc. Int’l Conf. Database Systems for
Advanced Applications, Springer, 2011, P.
2–15.
3. E.-K. Byun et al., Cost-Optimized
Provisioning of Elastic Resources for
Application Workflows. Future Generation
Computer Systems, vol. 27, no. 8, 2011, P.
1011–1026.
Алессио Гамби, Валдемар Хуммер,
Хон Линь Чыонг, Шахрам Дустдар
({gambi, hummer, truong, dustdar}@usi.ch) —
сотрудники Венского технического
университета (Австрия).
www.osmag.ru • 01/2014 • Открытые системы • 27
приложения
Мониторинг
рекламных роликов
Создание средств обработки видеоинформации традиционно считается
сложной проблемой, которая под силу лишь крупным производителям
ПО, однако в ряде случаев решение может быть достаточно простым —
например, при мониторинге показов рекламных видеороликов.
Ключевые слова: мультимедийные СМИ, рейтинг показа, архив трансляций, сканирование видеопотока
Keywords: multimedia media rating display, archive broadcasts, videoscan
Константин Селезнев,
Максим Ефремов,
Вадим Мельников
О
тслеживание показа видеороликов в
мультимедийных СМИ (телевидение,
Интернет) актуально для заказчиков
из разных отраслей: для рекламодателей,
которым важно подтверждение фактов
реальной демонстрации их роликов аудитории потенциальных покупателей; для
агентств, которым требуется собирать статистику и составлять рейтинги показа; для
производителей видеоконтента, которым
надо обнаруживать факты несанкционированного показа и т. д. Пока число роликов и телеканалов невелико, эти задачи
можно решать вручную, но по мере их
увеличения ручной просмотр всей сетки
вещания становится невозможен. Входной
информацией для автоматического мониторинга являются поток телеканалов
и база данных видеороликов, а выходной
— время показа, дифференцированное по
роликам и каналам.
Система автоматического мониторинга
должна обрабатывать трансляции десятков
телеканалов в цифровом качестве в режиме 24/7 без прерывания работы при добавлении новых каналов и дополнительной
настройки системы. В ходе мониторинга
необходимо вести базу данных видеороликов, а также предоставлять средства ее
пополнения. Суммарное количество отслеживаемых роликов может достигать
десятков тысяч, при этом один и тот же
ролик может быть показан как в полной,
так и в сокращенных версиях. Работая в
режиме реального времени, система мониторинга должна также уметь накапливать архив трансляций за некоторый период времени с указанием, когда, где и
какой ролик был показан с точностью его
позиционирования до нескольких кадров.
Вполне естественным требованием может
быть отсутствие какого-либо специализи-
рованного аппаратного и программного
обеспечения, а также чрезмерных требований к ресурсам.
На рынке имеется несколько систем выполнения автоматического мониторинга —
например Actus AdWatch компании Actus
Digits, позволяющая отслеживать рекламные ролики в телетрансляциях. Ключевыми
характеристиками данного продукта является высокая достоверность обнаружения,
наличие двух независимых систем обнаружения (по видео- и аудиоматериалу),
формирование подробных отчетов о результатах мониторинга. Система работает
в режиме 24/7 и поддерживает широкий
круг форматов кодирования входного потока. Однако цена и высокие требования к
оборудованию затрудняют использование
такого продукта отечественными заказчиками, которым нужно недорогое, но достаточно эффективное решение.
В общем случае для проведения видеомониторинга необходим анализ входных
данных и формальное описание ключевых
требований к системе, но для упрощения
видеоинформацию можно представить в
виде последовательности кадров с растровым изображением и свести задачу
отслеживания видеоролика к поиску в
телетрансляции определенного множества кадров. Решение такой задачи «в лоб»
вряд ли возможно. Действительно, если
считать, что в базе данных 10 тыс. роликов, то каждый новый кадр трансляции потенциально может быть началом любого
ролика из базы, и этот кадр нужно искать
среди 10 тыс. образцов. Далее, при телевещании используется частота 25 кадров
в секунду — это значит, что операцию поиска нужно выполнять 25 раз на каждую
секунду трансляции, то есть для обработки
часового фрагмента требуется выполнить
поиск 60*60*25 = 90 000 раз. Эти проблемы, конечно, решаемы путем распараллеливания и использования специализированных аппаратных систем, однако есть еще
28 • Открытые системы • 01/2014 • www.osmag.ru
ряд более серьезных проблем сравнения
кадров, которые невозможно решить методом «грубой силы».
Во-первых, в телетрансляции могут присутствовать различные визуальные элементы (логотипы, бегущие строки, экстренные
вставки и т. д.), искажающие изначальный
видеоряд, поэтому поиск кадров должен
быть нечетким, учитывающим возможные искажения. Во-вторых, хотя система и ориентирована на прием цифрового
сигнала, в котором отсутствуют помехи,
нет гарантии, что транслируемые ролики
будут передаваться без искажений и в их
исходном разрешении. Ролик может изменяться даже при смене формата и метода
сжатия данных, особенно в случае использования сжатия с потерями. В-третьих, изза проблем на уровне передачи данных
возможны ситуации, когда система будет
получать только часть кадров трансляции.
Таким образом, поиск должен быть устойчив к смене разрешения, частоты кадров
и метода сжатия видеопотока. Анализ перечисленных требований по «нечеткости»
сравнения позволяет сделать вывод, что
краеугольным камнем системы мониторинга должна быть процедура сравнения
двух кадров, от точности которой и будет
зависеть эффективность.
Сравнение кадров происходит на основе их сигнатур, представляющих собой
битовую матрицу размером 32x32 элемента. Такой размер выбран для того, чтобы
одна строка матрицы представляла собой
двойное слово (32 бит) — это позволяет эффективно использовать особенности оборудования, оперируя двойными словами,
а не массивами байтов. Кадр разбивается на 1024 (32x32) ячейки, и, таким образом, каждый бит сигнатуры соответствует строго одной ячейке. В каждой ячейке
вычисляется средняя яркость пиксела, и
если она выше заданного порогового значения, то соответствующий бит сигнатуры устанавливается в единицу, иначе — в
приложения
ноль. Величина порогового значения выбирается с помощью метода Оцу [1], применяемого ко всему кадру.
Очевидно, что если два кадра идентичны или отличаются только разрешением,
то их сигнатуры в большинстве случаев
будут совпадать. При плавном изменении
изображения соседние кадры будут иметь
одинаковую сигнатуру, следовательно,
система становится менее чувствительна
к пропуску кадров. Если же в телетрансляции присутствует логотип, бегущая строка или подобные изменения, то сигнатуры
будут незначительно отличаться и для их
нечеткого сравнения можно использовать
расстояние Хэмминга [2], равное количеству различающихся битов. Сигнатуры
можно считать одинаковыми, если это
расстояние не больше заданной пороговой
величины. Расстояние Хэмминга может
использоваться в различных алгоритмах
многомерной индексации и поиска данных
(R-деревья, M-деревья и т. д.). В результате экспериментов было установлено, что
для работы с сигнатурами кадров наиболее эффективны BK-деревья (метрические
деревья Баркхарда — Келлера), позволяющие достаточно быстро построить дерево
поиска, а затем по заданной сигнатуре осуществлять поиск похожих, просматривая
всего 5–8% узлов дерева.
У каждого ролика выбирается несколько опорных кадров, для которых строятся
сигнатуры и заносятся в поисковое дерево. Имеется два способа выбора опорных
кадров. Для первого кадры берутся через
равные промежутки времени, начиная с
первого, для второго предполагается разбиение ролика на несколько сцен, у каждой из которых берется начальный кадр.
Критерием начала новой сцены является
резкое изменение изображения — различие между кадрами превышает некоторый порог.
Алгоритм сканирования видеопотока
(см. рисунок) выглядит следующим образом. Для каждого кадра вычисляется
его сигнатура, которая затем ищется в
дереве поиска. В результате формируется последовательность найденных кадров,
для каждого из которых известно, в какой
момент времени он был получен и в какой рекламный ролик входит. При этом
возможна ситуация, когда один и тот же
опорный кадр входит в несколько роликов
или, наоборот, для реально переданного
ролика была определена только часть его
опорных кадров.
Далее информация о найденных кадрах
передается в модуль голосования, где учитываются следующие факторы: сколько
Выбранные кадры
Отдельные кадры
опорных кадров рорекламных
трансляции
роликов
лика было найдено,
какова степень совпадения найденных
Сигнатуры
Сигнатуры
сигнатур, есть ли отклонение по времеBK-дерево для
поиска сигнатур
ни (задержка или ускорение ролика при
трансляции). Если в
Последовательность
Голосование
найденных кадров
один и тот же момент
трансляции определенным критериям
Показанные ролики
удовлетворяют сразу
несколько роликов,
то выбирается ро- Сканирование видеопотока
лик с максимальной
продолжительностью. На выходе модуля оно хорошо распараллеливается, поэтому
голосования формируется информация для работы системы можно использовать
о найденных роликах. При этом если рас- масштабируемый кластер с балансировсматривать частную задачу мониторинга, кой нагрузки. В таком кластере имеются
то появляется возможность обнаруживать вычислительные узлы и один центральный
неизвестные ролики, отсутствующие в базе узел, выполняющий роль хранилища видеданных. Так, если невелико время между офайлов. На нем же располагается операпоказом двух обнаруженных известных тивная база данных, содержащая сведения
роликов, то с большой вероятностью мож- о всех поступивших в систему видеофайно утверждать, что это время было занято лах и статусах их обработки (скопирован
еще неизвестным роликом.
в архив, скопирован во временный архив,
Для создания промышленной системы отсканирован и т. д). Вычислительный узел
необходим ее опытный образец и оценка обращается к оперативной базе и получапараметров его работы, в том числе точ- ет из нее информацию о том, какой файл
ности и скорости распознавания. Для этого и как обрабатывать дальше. Затем копируиспользовались записи видеотрансляций ет к себе необходимые файлы, выполняет
общей продолжительностью 107 часов. требующееся преобразование, пересылает
База данных включала 500 роликов, кото- результаты работы обратно в хранилище
рые в указанных записях видеотрансляций и делает необходимые отметки в операвстречаются 1600 раз. Система обработа- тивной базе.
ла данный поток за 58 минут при точности
***
распознавания 98%.
Применяя простые алгоритмы и методы,
Информация поступает в систему в виде можно построить систему мониторинга
файлов, каждый из которых соответству- рекламных роликов, демонстрирующую
ет одному часу вещания одного канала высокую точность поиска и быстродейси содержит высококачественное видео с твие, достаточное для решений масштаба
большим разрешением и частотой кадров. реального времени. При этом не обязаКаждый такой файл сохраняется в архиве, тельно использовать специализированное
где для экономии дисковой памяти преоб- оборудование, что и подтверждает опытразуется в формат с меньшим разрешени- ная эксплуатация системы, реализованная
ем и частотой кадров. Аналогично, каждый для одного из заказчиков из сферы медифайл преобразуется в формат, необходи- абизнеса.
мый системе сканирования видеороликов,
и, наконец, в формат временного архива. Литература
Если система обнаруживает неизвестный 1. Гонсалес Р. Цифровая обработролик, то из временного архива берется ка изображений / Р. Гонсалес, Р. Вудс.
необходимый фрагмент трансляции и до- Техносфера. 2006. 1072 с.
бавляется в базу данных роликов. Формат 2. Блейхут Р. Теория и практика кодов, контхранения временного архива совпадает с ролирующих ошибки. М.: Мир, 1986. 576 с.
форматом хранения видеороликов.
Таким образом, каждый входной файл Константин Селезнев (skostik@relex.ru),
преобразуется в три различных видеофайла, Максим Ефремов (mefremov@relex.ru),
один из которых поступает на вход системы Вадим Мельников (vadim@relex.ru) —
сканирования. Преобразование видеофайлов сотрудники компании «РЕЛЭКС»
является ресурсоемкой операцией, однако (Воронеж).
www.osmag.ru • 01/2014 • Открытые системы • 29
безопасность
Защита критически
важных систем
управления
Бесперебойная работа таких критически важных инфраструктур, как
системы энергоснабжения, обеспечения водой или продуктами питания, — задача государственной важности. Какие сегодня имеются архитектуры автоматизированных систем управления, в чем состоят угрозы,
где уязвимые места и как защищать такие инфраструктуры?
Ключевые слова: SCADA, АНБ, кибератаки, угрозы, уязвимости, управление безопасностью, промышленные системы
Keywords: NSA, cyber attacks, threats, vulnerabilities, security management, industrial systems
Кристина Алкарас,
Шерали Зидалли
П
овсеместное применение информационных и коммуникационных технологий
способствует повышению продуктивности, снижению производственных затрат и
улучшению качества жизни. ИТ играют ключевую роль в развертывании, эксплуатации
и техническом обслуживании критически
важных инфраструктур, осуществляющих
снабжение людей водой, энергоносителями,
газом, электричеством и продуктами питания [1]. Важнейшим элементом таких инфраструктур являются управляющие системы
диспетчерского контроля и сбора данных
(Supervisory Control And Data Acquisition,
SCADA), нарушение работы которых может
привести к серьезным социальным и экономическим последствиям государственного
масштаба, что обусловлено сильными взаимосвязями между различными элементами комплекса жизнеобеспечения [2]. Чтобы
гарантировать высокую работоспособность,
надежность и безопасность критически важной инфраструктуры, необходимо спланировать и принять защитные меры.
По данным АНБ и Кибернетического командования США, за период с 2009 по 2011
год количество кибератак на критически важную инфраструктуру этой страны выросло в
17 раз (см. Таблицу) [3], причем тенденция
к росту сохраняется с учетом того, что все
больше систем SCADA подключаются к глобальным сетям. А по данным компьютерной
группы реагирования на чрезвычайные ситуации Министерства внутренней безопаснос-
ти США, если в 2009 году было всего девять
инцидентов, потребовавших помощи этой
организации, то в 2011-м — уже 198.
Большинство атак были направлены
против госструктур и энергетической отрасли, а главными целями были подрыв
обслуживания, а также раскрытие, искажение или уничтожение информации.
Устроителей кибератак можно разделить
на несколько групп:
• технически грамотные индивидуумы,
которые, полагаясь на собственный опыт
и инструментальные средства, обнаруживают уязвимости систем;
• киберпреступники, пытающиеся в целях
обогащения подорвать нормальную работу
критически важных объектов с помощью
различных вредоносных программ (вирусов, червей, троянцев) и DoS-атак;
• устроители атак, действующие при финансовой поддержке враждебных государств и занимающиеся в основном кибершпионажем;
• атакующие, следующие религиозным или
политическим убеждениям, — например,
так называемые хактивисты, взломавшие
системы финансовых корпораций и поставщиков коммунальных услуг.
Угрозы и уязвимости
Системы SCADA включают в себя средства
приема и обработки критически важной информации (сигналов тревоги, измерений и
команд), которая поступает с удаленных
подстанций, представляющих собой автоматизированные системы, напичканные
различным оборудованием: периферийные
терминалы, программируемые контроллеры
и датчики. Связь с подстанциями двухсторонняя — они могут получать управляющие
команды, которые исполняются с помощью
сервомеханизмов [2]. В этой структуре ИКТ
играют важнейшую роль: в частности, дистанционное получение данных и наблюдение
в реальном времени часто осуществляется
с помощью Интернета и веб-интерфейсов.
Как следствие, появились новые стандарты
на коммуникационные протоколы SCADA,
такие как Modbus-TCP, Distributed Network
Protocol (DNP3), IEC-60870-5-104 и InterControl
Center Protocol (ICCP, IEC60870-6), регулирующие автоматизацию и управление, а
также порядок соединения систем SCADA
друг с другом.
На рисунке показана типичная архитектура SCADA: диспетчерская, корпоративная
сеть и удаленная подстанция. Диспетчерская
следит за работой системы, анализируя
информацию от подстанций на серверах
SCADA и сохраняя показатели, сведения о
процессах и сигналы тревоги, связанные с
различными событиями. Внешний доступ
к этим ресурсам необходимо защищать
и тщательно контролировать с помощью
механизмов безопасности — межсетевых
экранов, демилитаризованных зон, антивирусов, систем распознавания и предотвращения вторжений.
Угрозы компонентам SCADA
Внешние угрозы сетям SCADA и их компонентам, отвечающим за управление и безопасность работы, — это преднамеренные
атаки и аварии.
Cristina Alcaraz, Sherali Zeadally, Critical Control System Protection in the 21st Century. IEEE Computer, October 2013, IEEE Computer Society. All rights reserved.
Reprinted with permission.
30 • Открытые системы • 01/2014 • www.osmag.ru
безопасность
Интерфейсы человек-машина, серверы и базы архивных данных. Большинство
сетевых доменов SCADA, управляющих устройств и информационных систем, таких
как серверы и терминалы, лишены адекватных средств контроля доступа, а процесс аутентификации часто либо отсутствует, либо неэффективен — обычно это
просто традиционная пара «имя-пароль».
Атакующий нередко может выяснить такие
верительные данные с помощью методов
«грубой силы» — словарной атаки или социальной инженерии. Еще проще ему будет, если пользователи SCADA вообще не
придают значения важности защиты верительных данных.
Уязвимости и усложнения архитектуры
могут быть вызваны взаимозависимостью
сервисов и приложений и их функциональной неизолированностью. Если управляющее приложение зависит от других, нарушение (вызванное, например, DoS-атакой)
может привести к эффекту каскада, подрывающего работу других важных сервисов.
Атакующие также могут воспользоваться
сервисами операционной системы, которые
ассоциированы с несанкционированными,
но активными портами.
Генерируемые в процессе работы SCADA
данные вместе с верительными данными
обычно сохраняются в архивных базах, и
при отсутствии шифрования или демилитаризованных зон атакующие могут получить к ним доступ, скомпрометировав
мобильные или веб-приложения, широко
применяемые сегодня для управления и
технического обслуживания критически
важной инфраструктуры. Если сервис, обращающийся к базам для проверки верительных данных, недостаточно защищен (например, использует HTTP без шифрования
или туннелирования), атакующий может
с помощью SQL-инъекции дистанционно
считывать контент, манипулировать с ним,
тиражировать информацию или выполнять
произвольный код [1].
Защитные компоненты. Большинство
компонентов, отвечающих за защиту сетевого периметра (межсетевые экраны,
системы обнаружения и предотвращения
вторжений, демилитаризованные зоны), не
приспособлены для полноценного анализа
и аутентификации входящего и исходящего
сетевого трафика SCADA. Их главный недостаток — невозможность задания правил, позволяющих защитить всю систему
SCADA, чьи коммуникационные пакеты
могут быть проприетарными и иметь определенные уязвимости. Неверная или
неполная конфигурация может привести
к появлению брешей [2].
Кибератаки на управляющие системы предприятий
энергетического сектора
Атака или ее
объект
Год
Метод совершения
Цель
Извлечение конУстановка програмфиденциальной
мных средств
информации
Кража кода и срыв Перехват контроработы программи- ля над промышЧервь Stuxnet 2010
руемого логического ленными процессами
контроллера
SQL-инъекция с целью Перехват конфикомпрометации акка- денциальной инунтов VPN, проведен- формации (сведеNight Dragon
2011
ная с использованием ния о тендерах и
средств удаленного ад- будущих проектах
бурения)
министрирования
Американские
Адресная рассылка фи- Хищение пользогазовые магис- 2012 шинговых писем элек- вательских верительных данных
трали
тронной почты
Электросеть
2009
Архитектурные сложности сетей SCADA
и проприетарные коммуникационные протоколы могут затруднить анализ трафика
системами распознавания и предотвращения вторжений, а неудачное или противоречивое сочетание конфигураций защитных
механизмов способно создать конфликты
при контроле легитимности и аутентификации трафика. Вредоносный код может
проникнуть в сеть SCADA, даже не прибегая
к обходу механизмов защиты периметра.
Например, сотрудник может открыть сообщение электронной почты с вредоносным
вложением или воспользоваться инфицированным USB-накопителем. Согласно отчету,
опубликованному US-CERT, подавляющее
большинство зарегистрированных инцидентов безопасности было спровоцировано
сообщениями адресного фишинга, имеющими вредоносные вложения.
Полевые устройства и встроенные
системы. Полевые устройства, например
устройства связи с объектом и программируемые контроллеры, не требуют аутентификации или защищены лишь паролем.
Доступ к таким устройствам осуществляется локально по беспроводным сетям или
дистанционно по кабельным, однако если
такие сети соединены с Интернетом, то могут возникнуть проблемы с безопасностью.
Атакующие могут получить верительные
данные, а затем считывать или менять конфигурации и критически важную информацию (сигналы тревоги, показатели, команды).
В результате изменения злоумышленником
конфигурации сфальсифицированные показатели могут поступать как в систему
сигнализации, так и операторам, маскируя
атаку вполне штатной телеметрией.
Мотив
Кибершпионаж
Кибершпионаж
Кибершпионаж
Нет точных сведений; вероятно, кибершпионаж
Недавно инженеры SCADA стали внедрять
беспроводные сенсорные сети, для которых
характерны малые затраты на установку и
сопровождение, — сенсорные узлы непрерывно следят за физическими событиями,
обрабатывают информацию и отправляют
ее на промежуточные устройства (шлюзы
или устройства связи с объектом), функционирующие между сенсорной сетью и
диспетчерской. Такие устройства обычно уязвимы для DoS-атак (например, осуществляемых путем массированной бомбардировки управляющими запросами),
способных вывести подстанцию из строя.
Помимо этого, многие сенсорные узлы не
защищены от вмешательства, а их срок
службы зависит от энергоснабжения или
механизмов периодического включениявыключения, рекомендованных отраслевыми коммуникационными стандартами,
такими как WirelessHART, ISA100.11a или
ZigBee [2]. Атакующий может использовать
эти ограничения для разрушения узла или
захвата контроля над ним, подрыва функциональности или истощения ресурсов с
помощью DoS-атак.
Управляющие и защитные компоненты от сторонних поставщиков. В рамках
модернизации систем SCADA с ними интегрируют компоненты от сторонних поставщиков, реализующие функции управления
и защиты. Но, не пройдя тщательного предварительного тестирования, такие компоненты могут оказаться несовместимыми с
уже имеющимися. Ошибки в реализации
сторонних инструментов могут приводить к
непредвиденным сбоям или фрагментации
памяти, чем может воспользоваться атакующий для инициирования ошибок перепол-
www.osmag.ru • 01/2014 • Открытые системы • 31
безопасность
Корпоративная сеть
Диспетчерская
DMZ
VPN
Основной Вспомогасервер тельный
сервер
Серверы
SCADA
IDS
HMI
Modbus-TCP/
IEC-104/DNP3
Гидроэлектроподстанция
Шлюз
IDS
RTU
Электрогенератор
DMZ: демилитаризованная зона
HMI: и нтерфейс человекмашина
IDS: с истема распознавания
вторжений
RTU: у стройство связи
с объектом
VPN: в иртуальная частная сеть
WSN: б
еспроводная
сенсорная сеть
Показатели
WSN
Команда
Привод
Сетевая архитектура SCADA
нения буфера. Кроме того, большинство полевых устройств и защитных компонентов
обычно устанавливаются, конфигурируются
и сопровождаются внешними специалистами, которые получают полный доступ к
уязвимым местам системы, иногда также
располагая механизмами удаленного доступа и возможностью обратной инженерии обслуживаемой системы [1].
Угрозы коммуникационным
системам
Коммуникационные системы SCADA подвержены различным угрозам и уязвимы
для атак.
Коммутируемая связь и TCP/IP. В некоторых сетях SCADA для удаленного доступа используются модемы, работающие
по коммутируемым соединениям, и здесь
злоумышленники могут устраивать атаки,
основанные на последовательном переборе
всех телефонных номеров в поисках модема, или применять средства взлома паролей.
Через Интернет также может быть устроена традиционная атака на весь стек TCP/
IP. Попав внутрь системы, взломщик может
дистанционно проводить атаки других типов
— например, считывать и менять файлы или
протоколы, сбрасывать дампы памяти, вызывать управляющие команды, отправлять
поддельные сообщения типа ARP (Address
Resolution Protocol) со сфальсифицированными MAC-адресами. Сообщения SCADA,
в свою очередь, могут переадресовываться
для организации атаки.
Возможна также организация таких
действий, как: атаки путем многократной
отправки одного и того же сообщения, что,
вызывая автоматический ответ системы,
может привести к ее неправильной работе
или запуску кризисных сценариев; атаки
подмены, когда внедряются сфальсифици-
рованные данные, чтобы заставить систему
выполнять нештатные операции или выдавать подставные данные мониторинга; атаки
подделки DNS, когда для выполнения вредоносных акций в сеть передаются фальшивые отклики системы доменных имен еще
до ответа реальных серверов DNS.
Кроме этого, могут устраиваться DoSатаки путем: отправки потока команд на
определенный адрес; передачи запросов на
соединения TCP с более высокой частотой,
чем машина могла бы обработать («SYNфлуд»); бомбардировки запросами на доступ
к носителю информации, мешающей другим
узлам отправлять на него данные.
Если для контроля и получения данных
используются уязвимые протоколы на базе
TCP/IP, такие как Telnet или HTTP без туннелирования, то защищенность пересылаемой информации или верительных данных оказывается под угрозой — отсутствие
шифрования и аутентификации позволяет
атакующим перехватывать или менять сообщения, содержащие сигналы тревоги, команды или показатели.
Уязвимости также могут возникнуть по
вине большинства коммуникационных протоколов SCADA. Например, связь по Modbus/
TCP осуществляется открытым текстом без
шифрования — у протокола также отсутствует аутентификация, и в ходе сеансов
проверяется только действительность некоторых элементов сообщения, например
адреса и кода функции.
Протокол DNP3 тоже страдает от похожих недостатков, и хотя он предусматривает частую проверку контрольной суммы
и синхронизацию, а также допускает использование нескольких форматов данных,
механизмы безопасности в нем отсутствуют. Аналогично — в ICCP не используются
шифрование и аутентификация, и к тому же
32 • Открытые системы • 01/2014 • www.osmag.ru
серверы ICCP уязвимы для атак на переполнение буфера [1]. Пользуясь перечисленными уязвимостями, злоумышленники могут
манипулировать с фреймами протокола
и их управляющими функциями, вмешиваться в сетевой протокол синхронизации
времени или создавать скрытые каналы
передачи критически важной информации,
например верительных данных, в обход механизмов контроля доступа операционной
системы. Также возможна организация атак,
направленных на внедрение сфальсифицированных данных, когда атакующие могут
испортить реальные показатели, подменив
их фальшивыми.
Беспроводная связь. Беспроводные
сети среднего и малого масштаба позволяют операторам соединяться с системой локально — в частности, децентрализованные
беспроводные сети могут использоваться
для получения санкционированного доступа к полевому оборудованию или шлюзам
для настройки, обслуживания или управления системами SCADA. Для беспроводных
сетей малого радиуса действия, таких как
ZigBee, ISA100.11a и WirelessHART, свойственны малые зоны охвата, ограниченные
вычислительные возможности и низкие
скорости передачи данных [2].
Для беспроводных технологий характерны проблемы с безопасностью и ненадежностью связи — перенасыщение сети
репитерами и маршрутизаторами для усиления сигнала может привести к росту задержки передачи и ухудшить способность
сети к сосуществованию с другими сетями
(например, с Bluetooth) из-за взаимных помех. В результате передача данных будет
проходить с искажениями и замедлениями; возможно также снижение доступности активных узлов, изменение сетевой
топологии и разрыв каналов связи. Все это
снижает качество обслуживания, замедляя
обработку информации и ухудшая выполнение функций SCADA. Например, один из
методов организации атаки состоит в намеренном создании шума по всем доступным
каналам, помехи от которого нарушат связь
(атака глушения). В качестве меры противодействия могут применяться скачкообразная перестройка рабочей частоты или
черные списки частот. Атакующие, в свою
очередь, могут отыскать недостаточно защищенную беспроводную сеть и перехватывать информацию с ее помощью [2].
Существуют три категории угроз, возникающих при использовании беспроводных
сенсорных сетей [2]. В первую категорию
входят угрозы конфиденциальности: снятие
защиты изнутри, сниффинг, анализ трафика
и физические атаки. Атака снятия защиты
безопасность
изнутри состоит в том, что имеющий соответствующие полномочия настраивает
средства безопасности на определенном
узле SCADA так, чтобы с него извне можно было получать критически важную информацию. Атака сниффинга — это прослушивание каналов связи. Технология
Zigbee-PRO, в частности, уязвима для атак
сниффинга, так как в ней используется
протокол симметричного обмена ключами
Symmetric-Key-Key-Exchange — достаточно
неэффективный, частично полагающийся
на передачу данных открытым текстом. В
ходе атаки анализа трафика рассчитываются таблицы маршрутизации путем наблюдения за информационным потоком и
выявления закономерностей. Атакующий
также может определить местонахождение шлюза, чтобы впоследствии устроить
на него DoS-атаку. Физическая атака — кража узлов для извлечения информации из
их памяти либо нарушения функциональности или связи.
Ко второй категории относятся угрозы
целостности: атаки фальсификации маршрутов и «атаки Сибиллы». В ходе атак первого
типа фальсифицируются запросы на поиск
оптимальных маршрутов либо ответы на
такие запросы, что позволяет организовать
«атаку-воронку» (переадресация трафика
на определенный узел) или «атаку-червоточину» (переадресация трафика на определенный узел с использованием группы
скомпрометированных узлов внутри сети).
При «атаке Сибиллы» устроитель маскируется под группу одновременно работающих
пользователей с применением информации
о легитимных узлах сети — их идентификаторов и верительных данных.
Третья группа — это угрозы готовности:
флуд-атаки, избирательная переадресация,
«черная дыра» и «червоточина», а также атаки глушения. При флуде путем трансляции
огромного количества широковещательных
пакетов вызывается перегрузка коммуникационных каналов. При избирательной
переадресации на очередной транзитный
участок проходят только отдельные пересылаемые пакеты, а в ходе организации
«черной дыры» часть пакетов «исчезает» на
скомпрометированных узлах. Большинство
атак такого рода требуют присутствия вредоносных узлов внутри сети или предварительного проведения других атак для кражи
верительных данных.
Облака. Облака могут применяться в
защите критически важной инфраструктуры, так как позволяют недорого и с высокой готовностью хранить резервные копии данных. Мониторинг диспетчерских
SCADA, утративших контроль над своими
рабочими сетями, можно осуществлять
из других диспетчерских по протоколу
ICCP. Облако представляет собой совместно используемую среду, в которой из-за
неверной конфигурации систем безопасности или программных ошибок информация о SCADA может стать доступной
другим абонентам. Атакующий, пользуясь
уязвимостями облака, может выдать себя
за легитимного пользователя и получить
несанкционированный доступ к системе.
Защита данных в облаке и обеспечение их
конфиденциальности являются важными
аспектами безопасности — например, получив информацию о прежних инцидентах
в критически важной инфраструктуре, атакующие могут выяснить дополнительные
сведения о ее уязвимостях.
Защита для SCADA
В сетях SCADA безопасность необходима
на всех уровнях, от физического до сервисов, сетей, сред хранения и систем обработки данных. Задача обеспечения безопасности — создать гарантии готовности,
целостности, конфиденциальности, аутентификации, авторизации, неподдельности
и учитываемости.
Управление безопасностью
Любая критически важная управляющая
система должна предоставлять все необходимые средства управления безопасностью, регулируемые политиками и отвечающие стандартам и официальным
рекомендациям.
Управление безопасностью. Управление
системными ресурсами и их использование должны осуществляться под контролем средств безопасности. Выбор таких
средств зависит от уровня сложности системы, которая должна быть охвачена ими
целиком. В отчете Министерства внутренней безопасности США средства контроля
безопасности поделены на две категории: на
организационные и операционные. Первые
отвечают за организационное управление
(физическое и кибернетическое) — к этой
категории относятся политики безопасности и средства безопасности предприятия и
персонала. Вторые позволяют защищенно
выполнять определенные последовательности действий, такие как приобретение
систем и сервисов или конфигурационное
управление. Существующие на сегодня
стандарты и рекомендации по средствам
управления безопасностью (например,
NIST 800-82 и NIST-800-53) охватывают
не только вопросы безопасности, интероперабельности, масштабируемости и расширяемости информационных систем, но
и такие аспекты, как физическая безопасность и безопасность окружающей среды.
В частности, упомянутые стандарты предписывают следить за посетителями и контролировать местонахождение физических
активов в чрезвычайных ситуациях [2].
Еще одна задача управления безопасностью — обеспечение возможности ее поддержки — решается путем тестирования
систем и проверки соответствия требованиям. К числу таких процессов относится
своевременное выявление сбоев и их устранение для снижения рисков и расходов
на техобслуживание. Многие администраторы выполняют процедуры аттестации
на протяжении всего жизненного цикла
системы, чтобы поддерживать желаемый
уровень ее работоспособности. Помимо
этого, следует обучать персонал и проводить аудиты и сертификации всех сетевых
доменов SCADA. Для прохождения проверки система должна отвечать некоторым условиям — например, стандартному набору
Common Criteria Evaluation Assurance Level
(ISO-15408), регламентирующему уровни
гарантии выполнения определенных функциональных, структурных и методических
требований, соответствие которым определяется путем оценки процессов, документации, уязвимостей и т. д. Опираясь на
подобные стандарты, пользователи могут
указывать свои требования к безопасности,
разработчики — обозначать защищенность
своих продуктов, а тестировщики — оценивать такие продукты на предмет наличия слабых мест.
Аутентификация и авторизация.
Политики контроля доступа призваны ограничивать санкционированный доступ и
действия внутри системы SCADA, однако
применяемые сегодня политики безопасности и средства контроля доступа недостаточно строги: все внешние соединения
с диспетчерской SCADA должны надлежащим образом контролироваться; должен
проводиться мониторинг любой активности внутри системы с протоколированием
времени, имени пользователя, действия и
его объекта. Для этого нужны механизмы
контроля доступа с четко обозначенными
ролями и привилегиями, а также средства
слежения за активностью, которые позволили бы блокировать любые злоупотребления ресурсами или подозрительные акты
доступа к системе.
Для систем SCADA также нужны средства управления идентификацией. Политики
контроля доступа должны регулировать
использование механизмов безопасности
и ПО, отвечающего за авторизацию с терминалов. После аутентификации пользова-
www.osmag.ru • 01/2014 • Открытые системы • 33
безопасность
телей система должна аутентифицировать
и их последующие действия. Для этого понадобятся средства назначения и контроля
пользовательских ролей, прав и обязанностей. К сожалению, в большинстве систем
SCADA до сих пор используются простые
механизмы аутентификации на основе имени и пароля — в таких случаях назначение
ролей опирается на уже имеющиеся права.
Необходимо также ограничить количество
сеансов в расчете на пользователя и ввести
блокировку сеанса при превышении определенного количества неудачных попыток
входа. Для сохранения последовательности
в проведении политик безопасности любые
изменения в пользовательских аккаунтах
и действия, выполненные во время сеанса,
должны регистрироваться, что упростит
аудиты или криминалистическую экспертизу. Все, что касается контроля доступа и
назначения ролей, нужно задавать, пересматривать и обновлять согласно имеющимся политикам и рекомендациям (см.,
например, NIST-800-82). В таких политиках должны быть четко указаны правила
составления и сроки действия верительных данных.
Механизмы безопасности для
компонентов SCADA
Аппаратные и программные компоненты
SCADA необходимо постоянно защищать с
помощью грамотно сконфигурированных
механизмов безопасности.
Человеко-машинные интерфейсы, серверы и архивы. В целях предотвращения
неаутентифицированного и несанкционированного доступа для каждого аккаунта
должны быть указаны действия, разрешенные в рамках сеанса. Во время самих сеансов
должны работать средства автоматического
предотвращения выполнения запрещенных
действий, например установки неутвержденного ПО или посторонних сервисов. В
частности, не должно быть возможности
простого изменения настроек интерфейса — любые изменения в его конфигурации
должны требовать санкции ответственного персонала, а вносить их должны только
администраторы с соответствующими привилегиями, ведущие мониторинг активных,
неактивных и скомпрометированных аккаунтов, исходя из информации о сроках действия верительных данных и распознанных
вторжениях [2].
Для ограничения доступа к ресурсам
критически важной инфраструктуры можно
пользоваться соответствующими механизмами ОС, например средствами управления ролевым доступом или контейнерами.
Системы SCADA требуют наличия: межсете-
вого экрана с правилами, четко разграничивающими сферы влияния функциональных
сервисов; демилитаризованных зон и механизмов аутентификации, автоматической
блокировки и автоотключения; аппаратно
контролируемых «диодов данных» (data
diodes, однонаправленные шлюзы безопасности, защищающие серверы или базы данных от атак, исходящих из внешних сетей).
При использовании диодов данных извне
можно выполнять запросы к определенным
серверам защищенной сети, но изменить
данные на них невозможно [1].
Для SCADA также требуется система
оперативного управления инцидентами и
реагирования на них, предупреждающая
операторов об аномалиях, вызванных неисправностями или посторонними вмешательствами. Такая система должна быть
способна предвидеть нарушения и выдавать соответствующие предупреждения.
Вся генерируемая ею информация должна
храниться в резервных системах, сконфигурированных с расчетом на мгновенную
доступность, например в облаке.
Защитные компоненты. Согласно рекомендациям NIST по безопасности АСУ ТП
[2], сеть SCADA следует разделить на три
основные зоны: межсетевые экраны, системы предотвращения вторжений и демилитаризованная зона. Состав этих трех зон
представляет собой первую линию обороны АСУ ТП, тогда как контроль операций
доступа к критически важным серверам
можно назвать средствами глубокой обороны. Эксперты полагают, что для организации удаленного доступа к сетям SCADA
также необходимы виртуальные частные
сети, серверы RADIUS и виртуальные локальные сети, позволяющие уменьшить
трафик и разграничить группы операционных сервисов и ресурсов, отвечающих
за операции управления. Проприетарность
протоколов SCADA может затруднить проектирование сетевых зон, но в этом могут
помочь специализированные решения —
например, межсетевой экран Tofino для
Modbus TCP.
Защитные компоненты следует своевременно обновлять, чтобы они могли противостоять новым векторам атак. Существуют
диагностические решения, помогающие защитным компонентам распознавать и отслеживать посторонние сервисы, например
сканеры портов, а также выявлять важные
изменения в конфигурациях средств безопасности. Следует запретить использование
персональных медиаустройств и уж точно не
делать их частью SCADA. Если операторам
разрешено подключать личные носители к
системе, то требуются ограничительно-ау-
34 • Открытые системы • 01/2014 • www.osmag.ru
тентифицирующие механизмы и тщательные проверки.
Полевые устройства и встроенные системы. Полевые устройства и встроенные
системы следует непрерывно защищать
с помощью систем наблюдения (датчиков
или видеокамер). Малозатратные методы
маскировки местонахождения помогут
предохранить оборудование от внешних
угроз. Локальный или удаленный доступ к
устройствам должен аутентифицироваться, а все действия должны авторизоваться и
протоколироваться. Для контроля доступа
и авторизации рекомендуется применять
встроенные межсетевые экраны [2], однако
системы такого рода требуют определенных вычислительных ресурсов, не всегда
доступных на полевых устройствах.
Для предотвращения перегрузки критически важных подстанций требуется дублирование шлюзов или устройств связи с
объектом, чтобы резервные могли вступить в действие в любой момент. Обычно
при этом для тиражирования информации
и мониторинга реального времени применяют протоколы обмена данными с промежуточным накоплением. Кроме того, помогает развертывание малоресурсоемких
высокоэффективных систем обнаружения
вторжений на различных стратегических
точках управляющей подсети — например,
на шлюзах или коммуникационных серверах, отвечающих за связь в режиме «ведущий-ведомый», требуемом для большинства протоколов SCADA (например, Modbus,
DNP3 и IEC-104).
Сопровождение программных и аппаратных компонентов. Процедуры сопровождения заключаются в аттестации и
верификации с целью проверки целостности и работоспособности технического оснащения, а также распознавания и предотвращения сбоев или ошибок реализации
согласно заранее составленной политике.
В такой политике необходимо указать, как
и в какое время проверять компонент для
обнаружения и устранения угроз или уязвимостей, когда выполнять обновление и кто
отвечает за эти процедуры. Если сопровождение проводят третьи стороны, их права
должны быть жестко ограничены с точки
зрения возможности внесения системных
изменений. Все подобные действия также
должны контролироваться и протоколироваться для дальнейшего анализа.
Защита коммуникаций
Коммуникационные каналы SCADA нуждаются в постоянной защите.
Коммутируемые линии и связь по
TCP/IP. Здесь следует применять механизмы
безопасность
аутентификации, автоматически разрывающие неавторизованные вызовы и пресекающие попытки установить связь после определенного количества неудачных попыток.
Возможны применение систем обратного
вызова с идентификацией звонящих, периодическое обновление верительных данных,
частый аудит активных модемов с отключением неиспользуемых и регистрация всех
попыток удаленного доступа.
Для защиты сообщений SCADA, передаваемых по TCP/IP, можно использовать
виртуальные частные сети с режимом IPsecтуннеля и протоколом SSL, а VPN на основе
SSL полезны для передачи трафика HTTPS
и удаленной отправки запросов через вебсервисы. Запросы от таких сервисов к базам данных нужно аутентифицировать и
контролировать, а для защиты содержимого самих баз применять шифрование.
Криптографические сервисы наподобие
AGA-12 можно также использовать для защиты коммуникационных каналов. Еще один
способ обеспечения конфиденциальности —
применение внешних по отношению к защищаемой системе устройств, которые, не
требуя ее модификации, кодируют информацию между портом RS/EIA-232 устройства связи с объектом и модемом.
Недавно утвержден стандарт безопасности SCADA IEC-62351, рекомендующий
пользоваться протоколами TLS/SSL, цифровыми сертификатами, кодом подлинности сообщений, парами ключей длиной не
меньше 1024 разрядов и криптографическими сервисами, такими как RSA и цифровая подпись. Появились и новые защищенные коммуникационные протоколы SCADA,
такие как Secure DNP3 и DNPSec. Первый
добавляет процедуру аутентификации по
методу запрос-ответ к верификации узла
источника по уникальному ключу сеанса, а
DNPSec снабжает протокол DNP3 средствами аутентификации и контроля целостности данных. Отличие между Secure DNP3 и
DNPSec в том, что Secure DNP3 модифицирует уровень приложений протокола DNP3,
тогда как DNPSec меняет структуру сообщения на канальном уровне [1].
Беспроводные коммуникационные
системы. Чтобы свести к минимуму доступность беспроводной сети для атакующих, перед ее развертыванием следует
провести анализ возможных препятствий
распространению сигнала, а также определиться с мощностью и территорией охвата
антенн. В самой сети необходимо пользоваться списками контроля доступа и защищенными протоколами аутентификации, такими как Extensible Authentication Protocol с
TLS или серверами RADIUS. Стоит сменить
верительные данные, установленные производителем по умолчанию, прежде чем
развертывать сеть. Точкам доступа следует назначить уникальный идентификатор
набора сервисов SSID, отключить широковещательный режим и задействовать
фильтрацию по MAC-адресам, а также по
возможности исключить использование
протокола DHCP.
Беспроводные каналы связи стоит защитить шифрованием с часто обновляемыми
ключами. Например, в сетях IEEE 802.11i
следует применять Wi-Fi Protected Access
(WPA/WPA2) с AES и Cipher Block Chaining
Message Authentication Code (CBC-MAC) для
аутентификации и контроля целостности. В
сетях IEEE 802.15.4 с ограниченным числом
узлов в основном используется симметричная криптография, поскольку применение
шифрования с открытым ключом может
быть слишком затратным [2]. В промышленных коммуникационных протоколах,
таких как ISA100.11a и ZigBee Smart Energy
2.0 Profile, имеются упрощенные схемы
шифрования на эллиптических кривых с
заранее сконфигурированными цифровыми сертификатами.
Когда есть потребность во взаимодействии беспроводных сетей разных типов
через шлюзы, необходимо, чтобы это делалось через VPN-туннель IPSec. Кроме
того, следует рассмотреть возможность
использования малоресурсоемких систем
предотвращения вторжений, дублирования,
незатратных методов определения надежности информации от узлов, схем маскировки местонахождения и систем оперативного управления инцидентами. Следует также
спланировать процедуры сопровождения и
аудиторских проверок.
Облака. Операции резервного копирования ресурсов SCADA в облако и восстановления следует контролировать строгими
политиками безопасности, указывающими,
кто и как может управлять резервными копиями. Частная облачная инфраструктура
позволяет организации — владельцу ресурсов SCADA эксклюзивно пользоваться облаком. При этом оно может принадлежать
и быть подконтрольным как самой организации, так и авторизованным третьим сторонам. Учитывая, что облачные узлы могут
непредвиденно выходить из строя, вызывая
сбой всей системы, стоит держать несколько
копий данных в различных местах в самом
облаке, а также предусмотреть резервные
конфигурации, способные в полуавтоматическом режиме возвращаться к предыдущим корректным состояниям.
В сетях SCADA стоит использовать
криптографические сервисы при опера-
циях загрузки или выгрузки из облака, а
также шифровать данные, размещаемые
в облаке. Необходимо также обеспечить
защищенную виртуализацию ресурсов,
разграничить функциональные сервисы
для защиты операционных процессов,
следить за активностью в облаке и относящимися к SCADA действиями третьих
сторон, а также защищать информацию
о местонахождении ресурсов в облачной среде.
***
В области защиты критически важной инфраструктуры сегодня остаются нерешенными ряд вопросов, в частности, связанных с
созданием решений, позволяющих организовать безопасное взаимодействие между
частными и государственными структурами, а также между странами. Потребуются,
например, методики для анализа источника нежелательного события, масштабов
его распространения, силы и последствий.
Необходимы также территориально распределенные, работающие на опережение
системы обеспечения ситуационной осведомленности и защиты сложных сред. Для
защиты критически важной информации и
маскировки местонахождения узлов могут
применяться средства самостабилизации,
управления доверием и обеспечения конфиденциальности. В конечном счете при
защите SCADA необходимо добиться требуемого качества обслуживания и должного уровня безопасности без принесения
в жертву быстродействия системы. Кроме
того, нужно оценить применяемые технологии с точки зрения уровней защищенности и сложности с применением стандартизованных методологий и процедур
тестирования.
Литература
1. E. Knapp. Industrial Network Security.
Securing Critical Infrastructure Networks
for Smart Grid SCADA, and Other Industrial
Control Systems, Syngress, 2011.
2. C. Alcaraz. Interconnected Sensor
Networks for Critical Information
Infrastructure Protection. Doctoral
Dissertation, Computer Science Dept.,
University of Malaga, 2011.
3. D. Sanger, E. Schmitt. Rise Is Seen in
Cyberattacks Targeting US Infrastructure.
The New York Times, 26 July 2012.
Кристина Алкарас (alcaraz@lcc.uma.es) —
научный сотрудник лаборатории
сетей, информации и безопасности Университета Малаги. Шерали
Зидалли (szeadally@uky.edu) — доцент
Университета Кентукки.
www.osmag.ru • 01/2014 • Открытые системы • 35
интеграция
Интеграция для Airbus
Авиастроительная отрасль — одна из наиболее конкурентных, особенно
в нише пассажирских узкофюзеляжных лайнеров, однако развитие здесь
в ряде случаев сдерживается необходимостью работы с унаследованными
информационными системами поддержки моделей самолетов, появившимися десятилетия назад. В ряде случаев можно из имеющейся разрозненной информации воссоздать модель технической системы и обеспечить
доступ к ней современных систем управления жизненным циклом.
Ключевые слова: унаследованные системы, А320, регулярные выражения
Keywords: legacy systems, regular expressions
Никита Калуцкий
Р
ынок гражданских авиаперевозок растет сегодня невиданными темпами —
в ближайшие 20 лет ему понадобится более 35 тыс. новых лайнеров, причем
почти 25 тыс. из них придется на узкофюзеляжные самолеты вместимостью свыше
90 пассажиров. Именно в этой нише сейчас
разгорается борьба между Airbus и Boeing,
однако движение вперед в ряде случаев
сдерживается необходимостью поддержки
унаследованных систем.
Первый полет узкофюзеляжного А320
был совершен в 1987 году, положив начало серийному производству этих авиалайнеров, которых уже произведено свыше 5
тыс. штук, и спрос на них не уменьшается. Конечно, такое крупное и наукоемкое
производство не может обойтись без информационного обеспечения соответствующего уровня, однако со времени разработки и внедрения A320 прошло более
20 лет, за которые ИТ-оснастка самолета
существенно устарела. Цикл разработки
таких сложных изделий, как авиалайнер,
длится не менее десяти лет — например,
разработка новейшей модели Airbus A350
заняла более девяти лет и проводилась с
применением всех имеющихся современных компьютерных средств проектирования и производства, чего нельзя сказать о
рубеже 70-х и 80-х годов, когда А320 был
в стадии разработки.
На сегодняшний день в промышленности сформировался подход к проектированию на основе использования таких
систем, как CAD/CAE/CAM, PDM (Product
Data Management) и PLM (Product Lifecycle
Management), подразумевающий непрерывную информационную поддержку жизненного цикла изделия на всех его стадиях. Как
известно, вычислительная техника конца
80-х годов не имела той вычислительной
мощности, какая есть сегодня, а аппаратное большого спроса на А320 требуются пособеспечение стоило очень дорого и обладало тоянно. Попутно приходится искать спеограниченными возможностями по хране- циалистов, имеющих опыт работы с устанию и обработке информации. Кроме того, ревшей системой, а также развертывать
все перечисленные программные комплек- специальные системы связующего уровня
сы тогда еще только зарождались, и разра- (middleware) для интеграции унаследованботчики A320 использовали такие системы, ной системы с современными платформами.
как: CATIA CADAM Drafting — одна из пер- Однако очевидно, что введение дополнивых систем автоматизированного проекти- тельных уровней в любую информационрования Dassault Systemes, позволяющая ную систему неизбежно сказывается на ее
выполнять двухмерные чертежи и стро- общей надежности.
ить объемные примитивы (2.5D); GILDA/
Упрощенно фюзеляж А320 представляTAKSY — терминальное консольное при- ет собой цилиндр диаметром 4 м и длиной
ложение, относящееся к семейству систем почти 40 м, изготовленный из листов дюPDM компании Clustria.
ралюминия толщиной несколько миллиБурное развитие ИТ привело к тому, что метров. Изнутри эти листы подкреплены
многие программные продукты, бывшие продольными профилями («стрингерами»),
актуальными еще несколько лет назад, се- идущими он носа к хвосту самолета, а такгодня устарели, однако сами изделия, со- же через каждые полметра труба изнутри
зданные с их помощью, например А320, до усилена шпангоутами. На сегодня технолосих пор конкурентоспособны. Данная ситу- гически невозможно изготовить фюзеляж
ация получила название проблемы унас- целиком как одно целое, поэтому его делят
ледованных систем, возникающей, когда на секции и производят по отдельности и
время жизни технической системы намного даже в разных странах. К примеру, носовую
превосходит время
жизни программных
средств, с помощью
которых она создавалась [1]. Внедрив
мощную по меркам
80-х годов систему,
концерн Airbus не
может сегодня от нее
отказаться — это означало бы остановку
производства. Как
следствие, концерну
приходится тратить
серьезные средства
только на поддержку
работоспособности
устаревшей системы,
данные из которой,
однако, в условиях Рис. 1. Образец спецификации экспортированного документа
36 • Открытые системы • 01/2014 • www.osmag.ru
интеграция
секцию А320 изготавливают во Франции
(Сен-Назер), центральную — в Германии
(Гамбург), а хвостовую — в Испании. Затем
все они грузятся в транспортный самолет
Airbus «Белуга» и доставляются на линию
окончательной сборки в Тулузе.
Теперь допустим, что инженер получил
задание проанализировать прочность стыка
двух секций фюзеляжа, который представляет собой сложную в инженерном плане
конструкцию, состоящую из нескольких
сотен деталей и нескольких тысяч крепежных элементов. Для того чтобы сделать анализ прочности, требуется собрать массу
данных: достать чертежи и снять нужные
размеры; выяснить механические свойства деталей на основе сведений о составе
алюминиевого сплава, формы заготовки
или полуфабриката, параметрах термообработки. Все эти данные требуется найти
в документах, экспортированных из PDMсистемы 80-х (рис. 1).
Деньги сегодня экономят все, и Airbus
здесь не исключение — на каждую работу
выделяется строго определенное время, и
в случае его превышения исполнитель должен доделывать ее за счет своего личного
времени. А ведь, кроме сбора данных о деталях конструкции, инженеру нужно еще
провести собственно расчет и оформить его
результаты по строгому шаблону, принятому в Airbus. Механизация труда, предполагающая выполнение с помощью ПК тех же
действий, что и вручную (поиск документа
в архиве, выписывание искомых данных и
т. п.), реализованная в системе подготовки
А320 и вполне отвечающая уровню развития
вычислительной техники конца прошлого
века, уже не позволяет эффективно работать в современных условиях. Концерну требовалось иное решение поддержки задачи
сопровождения лайнера А320.
Решение
На базе массива имеющихся спецификаций
(текстовых документов) можно организовать поиск нужных для расчетов данных,
написав процедуру синтаксического разбора и отбора ценных данных с их последующим размещением в предварительно
развернутой базе. После чего можно пользоваться всеми преимуществами централизованного хранения, управления данными
и современных интерфейсов. В Airbus для
оформления инженерной документации
используется пакет Microsoft Office 2010
for Windows, поэтому для обеспечения наилучшей совместимости использовалась
платформа .NET Framework 4.0.
Данное решение можно охарактеризовать
как «PDM наоборот», и в отличие от «прямого»,
Множество доступных документов
Бумажные чертежи
CAD-модели
Электронные чертежи
Спецификации
Извещения об изменении
Прочие документы
Оцифровка документации
Поиск и сбор данных
Подготовка данных
к сохранению в базе
База данных
Универсальный интерфейс доступа
Пользователь 1
Пользователь 2
Пользователь 3
...
Пользователь N
Рис. 2. Схема комплекса восстановления информационной модели
когда имеется цифровая модель технической системы (самолета), из которой можно
получить нужную информацию, здесь идут
от обратного: из имеющейся разрозненной
информации воссоздается модель технической системы (пусть и не полная, поскольку
политика информационной безопасности
Airbus очень строгая и доступ ко всему изделию предоставляется только ограниченному
кругу специалистов). Далее воссозданная модель готова для получения из нее требуемой
инженерной информации, которую можно
разделить на два основных типа.
• Внутренняя иерархия изделия. Для этого выстраивается дерево технологического членения конструкции для вычисления
вхождения деталей в сборки разного уровня, вплоть до финальной сборки всего самолета. После чего можно получить граф,
состоящий из сотен узлов, по которому
прослеживается, в каких агрегатах самолета
используется конкретная деталь.
• Спецификация деталей. Для найденной
в дереве иерархии детали можно получить
всю информацию о ее физических свойствах, геометрических размерах, особенностях исполнения, поставщике и др.
Конечно, в результате была получена
модель из «отсоединенных» данных, не
позволяющая оперативно отслеживать
изменения оригинала, однако для проекта A320 скорость изменений невелика или
близка к нулю.
Поскольку разработчик сам выбирает
инструментальную платформу, то можно заранее позаботиться о многих полезных функциях, таких как: интеграция с расчетными
модулями и средствами их автоматизации;
автоматизация процесса создания отчета,
например средствами Microsoft Office; минимизация потерь времени на поиск вручную, что особенно актуально для работы в
команде, когда возможны потери времени
из-за дублирования; исключение ошибок,
сделанных по невнимательности.
Для практической реализации предложенного подхода (рис. 2) был разработан
программный комплекс на базе платформы .NET, имеющей встроенный обработчик
регулярных выражений, который выполняет поиск с возвратом для регулярных
выражений и реализует традиционный
недетерминированный конечный автомат (НКА), аналогичный используемым
в языках высокого уровня Perl и Python,
а также в приложениях Emacs и Tcl. При
использовании логики НКА поиск управляется регулярным выражением: производится проверка на совпадение с текстом
для каждой части регулярного выражения
и, в случае неудачи, происходит возврат
и проверка очередного подвыражения.
Недетерминированность автомата проявляется в том, что из одного состояния
по одному и тому же сигналу возможны
переходы в различные состояния.
www.osmag.ru • 01/2014 • Открытые системы • 37
интеграция
Для сохранения в
целевой базе данных
формируется SQLзапрос типа INSERT,
Рис. 3. Обнаружение даты выпуска в экспортированном докугде аргументом выменте
ступает подготовСуть работы синтаксического разборщи- ленный набор данных, поддерживаемый
ка состоит в переборе заданных регуляр- целевой базой данных.
ных выражений для выделения из слабоструктурированного текста ценных данных. Доступ к данным
Определение ценности производится по В качестве основы интерфейса взаимодейсметаданным, представленным в формате твия конечного пользователя и системы
шаблонов регулярных выражений, задан- служит библиотека Microsoft ActiveX Data
ных пользователем. На рис. 3 показана часть Objects 6.0 Library (ADO), предоставляющая
спецификации A320, с упоминанием даты прикладным системам набор функций для
прямой работы с используемой в настовыпуска в формате:
«DATE<пробел>:<пробел>День(ХХ) ящей разработке базой данных Microsoft
<пробел>Месяц(ХХ)<пробел>Год(ХХХХ)», SQL Server. Потенциальными пользоватетогда шаблон регулярного выражения бу- лями библиотеки являются системы инженерных расчетов, офисные приложения
дет иметь вид:
пакета Microsoft Office, системы электронDATEs:sd{2}sd{2}sd{4},
где: s — метасимвол, описывающий про- ного документооборота, системы CAD/
бел; d — цифровой символ; {n} — оператор CAM/CAE, PDM, PLM, ERP, САРР, MES и т. д.
квантификации, определяющий, сколько Именно у этих систем возникает необходираз может встречаться предшествующее мость прямого взаимодействия с данными
об изделии для получения первичной инвыражение.
После анализа текста, проводимого с ис- формации о конструкторском проекте и
пользованием необходимого набора шабло- ее обновления.
Основное назначение модуля ADO —
нов регулярных выражений, осуществляются
проверка на целостность и непротиворе- обеспечить программистам — разработчивость данных путем выполнения проце- чикам прикладных систем доступ к любодур поиска дублируемых данных, проверка му источнику данных, поддерживающему
доступности данных о деталях, на которые СОМ-интерфейс. Данные, хранящиеся в
есть ссылки в сборках, и т. д. В случае удов- восстановленной информационной моделетворительного результата выполняется ли, становятся, таким образом, доступными
многим популярным современным прилотрансформация данных.
Назначение этапа трансформации со- жениям, которые, в свою очередь, пополнястоит в приведении типов отобранных ются новым инструментарием. Например,
из текстового документа данных к типам Microsoft Excel позволяет проводить научданных, поддерживаемых СУБД Microsoft ные, инженерные, экономические и статистические расчеты, пользуясь встроенной
SQL Server.
библиотекой функций. Имеется возможность манипулировать
данными, используя,
в том числе, доступ
к удаленным базам.
Набор инструментов
Visual Studio позволяет
создавать приложения
для платформы .NET
Framework, расширяющие пакет Microsoft
Office, — например, в
проекте для A320 использовалась библиотека Microsoft.Office.
Interop.Excel, содержащая набор интерфейсов для обеспечеРис. 4. Результат работы с надстройкой Excel
ния взаимодействия
38 • Открытые системы • 01/2014 • www.osmag.ru
между объектной моделью COM приложения Excel и сторонними приложениями. На
рис. 4 показан результат работы надстройки
Excel. Входными данными здесь являются
набор номеров чертежей нескольких конструктивных элементов (выделено рамкой),
а выходными — наименование детали, материал, заготовка, термообработка, ссылка
на чертеж и др.
***
Опытная эксплуатация программного комплекса позволила ускорить поиск нужных
данных (геометрических размеров деталей,
материалов и т. д.), повысить удобство работы
по сравнению с «ручным» методом поиска в
слабоструктурированном массиве файлов и
папок, упростить процесс проверки корректности данных и исключить дублирование
при поиске нужного документа. Решение
оказалось достаточно универсальным, что
позволило применять его для решения таких
задач, как: автоматизация инженерных расчетов, основанная на мгновенном получении
физических свойств анализируемой детали,
ее геометрических параметров (2D-чертеж
или 3D-модель); автоматизированное построение иерархической схемы деталей и
сборок изделия; автоматизированное создание альбома чертежей в формате Word
по указанному списку чертежных номеров
с заданным форматированием.
Вместе с тем у подхода имеется ряд ограничений — например, работа возможна
с изолированными данными, а обновления,
хотя и нечастые, происходят с запозданием,
что повышает риск получения устаревшей
информации.
В целом предложенный подход может
быть использован при работе с унаследованными информационными системами, позволяющими получать текстовые
документы, предназначенные для печати
(спецификации). Если получен массив таких документов, то настройка на работу с
другой унаследованной информационной
системой будет заключаться в составлении нового набора шаблонов регулярных
выражений для отбора ценных данных и
их последующего сохранения.
Литература
1. Стефан Бургер, Оливер Хуммел, Мат-
тиас Хейниш. Программы для Airbus // Открытые системы. — 2013. — № 3. — С. 51–53.
URL: http://www.osp.ru/os/2013/03/13035120
(Дата обращения: 11.02.2014).
Никита Калуцкий
(nikita.kalutsky@progresstech.ru) — инженер, компания «Прогресстех-Дубна»
(Дубна).
стандарты
Первоклассные
объекты Всемирной
паутины
До недавнего времени в WWW не было единой модели аннотаций, независимой от контента, что затрудняло возможность их переноса между
системами и предметными областями. Но сегодня спецификация Open
Annotation Data Model консорциума W3C кардинально меняет принципы
подготовки и распространения аннотаций.
Ключевые слова: аннотации, облако связанных данных, автоматизированный анализ
Keywords: Open Annotaion Model, OWL, W3C, annotations, cloud-related data, automated analysis
Паоло Чиккарезе,
Стиэн Сойленд-Рейес,
Тим Кларк
У
ченые испокон веков делали пометки
от руки в книгах и рукописях, а сегодня пользователи блогов и сайтов
могут выражать мнения о контенте путем
размещения комментариев и аннотаций,
средства поддержки которых до недавнего времени предоставлялись только на
узкоспециальных сервисах и рассматривались как полезные, но все же элементы
World Wide Web второго класса. Сегодня
веб-аннотации становятся самостоятельным видом связанных данных и помимо
текстовых комментариев могут принимать различные формы — например, аннотацией в виде закладки можно снабдить
фрагмент кадра в видеопотоке. Появились
технологии и стандарты создания, публикации, синдикации, коллажирования и
отображения аннотаций практически для
любого контента. Это произошло отчасти
благодаря наличию потребности в средствах аннотирования веб-контента у аналитиков, издателей и владельцев образовательных баз данных.
Возможность снабжения контента аннотациями в той или иной форме — это базовый, определяющий элемент Web 2.0: Flickr
дает возможность размечать тегами и классифицировать снимки, а также выделять
участки изображения; Twitter и Facebook
поддерживают хэштеги; SoundCloud поз-
воляет отмечать понравившиеся фрагменты музыкальных треков; Youtube дает
возможность публиковать ролики в качестве ответов на другие. В социальных
сетях вроде Facebook и Google+ можно
поделиться ссылкой на новость, которую
затем комментируют друзья, а социальные
медиасайты наподобие Reddit ранжируют
новости по числу пользовательских голосов, позволяя снабжать их комментариями-дискуссиями.
Общее у всех этих сервисов — особенности поддерживаемых ими аннотаций.
Объект аннотации идентифицируется по
ссылке на веб-страницу, изображение или
видео, а сами аннотации существуют внутри
единой системы либо на сайте провайдера
ресурса, либо на стороннем сайте закладок.
Хотя многие из таких систем предлагают
REST-интерфейсы для доступа извне, сами
эти интерфейсы от сайта к сайту разнятся. До
недавнего времени не было единой модели
аннотаций, независимой от аннотируемого
контента, поэтому, например, на страницу SoundCloud трудно было бы перенести
комментарии, оставленные в Facebook или
Reddit. Для обычных пользователей социальных СМИ это, возможно, не проблема,
в отличие от аналитиков и исследователей,
работающих в Сети.
Семантика, а не только
комментарии
В июле 2013 года компания Google объявила о доступности 800 млн докумен-
тов, аннотированных с использованием
11 млрд понятий из базы Freebase, то есть
размеченных семантическими тегами [1].
Тексту каждого документа сопоставлена статичная URI-ссылка в стандартном
формате, указывающая на информацию о
понятиях, сущностях, людях, местах, процессах и т. п. При этом по ссылке в базе
может находиться информация из внешних ресурсов, например из «Википедии».
Пояснять термины можно не только пользуясь Freebase, но и включая сведения из
DBPedia или других источников. Кроме
того, можно пользоваться онтологиями:
формальными словарями с классами,
свойствами и связями.
Применяя формальные словари, описанные на языке Web Ontology Language
(OWL), можно создавать более подробные и удобные для машинной обработки
структуры, чем традиционные словари
или энциклопедии. Формальные онтологии соотносят элементы из одного домена
с элементами из другого и обеспечивают
возможность автоматизированной обработки таких структур с формулировкой
логических выводов. Формальные онтологии также могут дополнять, идентифицировать или размечать тегами вхождения
словаря или энциклопедии. Например,
если известно, что слову BACE1, упомянутому в тексте биомедицинской тематики,
соответствует ссылка на описание гена
бета-секретазы из некоторой онтологии,
то, пользуясь ею и связанными ресурсами,
Paolo Ciccarese, Stian Soiland-Reyes, Tim Clark, Web Annotation as a First-Class Object, IEEE Internet Computing, November/December 2013, IEEE Computer Society.
All rights reserved. Reprinted with permission.
www.osmag.ru • 01/2014 • Открытые системы • 39
стандарты
Open Annotation Model
Согласно Open Annotaion Model (см. рис. А) аннотации объявляются с помощью предиката hasTarget, обозначающего аннотируемый объект, и hasBody — ресурса, имеющего отношение
к объекту. Предусмотрены также свойства, указывающие источник аннотации и причину ее создания. Тело и объект могут
быть любого типа, но OA рекомендует указывать абстрактный
тип (например, изображение, звук или текст) согласно стандарту
Dublin Core Metadata Initiative. Наличие типа упрощает отображение аннотации. Тело может иметь тип Tag, применяемый для
простой разметки ключевыми словами, или SemanticTag, когда
в качестве тега используется URI-ссылка на ресурс, предоставляющий дополнительные сведения по аннотируемому объекту.
Обычные строки, например текстовый тег, можно внедрять напрямую согласно спецификации Content in RDF.
Объект или тело можно указать косвенно с помощью класса
SpecificResource, в котором предусмотрен параметр hasSource —
ссылка на ресурс. Есть также свойства Selector и State, позволяющие обозначить соответственно границы аннотируемого фрагмента (выделенный текст, область SVG-файла, фрагмент URI и
т. д.) и его состояние — характеристику (например, формат или
отметку времени), позволяющую выбрать верный вариант репрезентации. Таким образом, можно, к примеру, снабдить аннотацией круглый участок JPEG-изображения. Аннотации можно
присвоить стиль CSS с помощью свойства styledBy. Пользуясь
им в сочетании с селектором, можно, допустим, выделить цветом часть текста или воспроизвести некоторый фрагмент видео
можно выяснить, какой белок экспрессируется данным геном, его последовательность аминокислот и варианты, а кроме
того, узнать, что его связывают с болезнью
Альцгеймера. Можно также найти экспериментальные данные, аннотированные с
помощью данного термина либо связанного с ним. Помимо этого, можно составить
«коллаж» на основе связанной информации из нескольких баз данных и наложить
его поверх текста, в котором упоминается
ген. Учитывая, что объемы научных публикаций растут экспоненциально, подобные справочные системы, помогающие в
понимании написанного, становятся все
более необходимы.
Семантическая разметка уже давно активно используется, и, возможно, самая
важная область ее применения — это наука.
К примеру, в европейской базе научных
статей PubMed Central сегодня семантически размечаются все вхождения каждого названия белка, гена и химического
соединения, встречающиеся в тексте.
Однако применение тегов связано с рядом вопросов. Как отображать теги и другие
виды аннотаций? Внедрять их непосредственно в текст или хранить отдельно? Как
делиться ими между различными системами? Допустим, хранимая на локальном
сервере PDF-копия некоторого текста была
аннотирована комментариями, семантическими тегами и видеороликами и ими
нужно поделиться с издателем оригинальной HTML-версии текста. Как это сделать?
на замедленной скорости. Модель OA, в том числе селекторы,
состояния и стили, можно расширять в соответствии с требованиями конкретного приложения.
x:MyAnno
oa:hasBody
rdf:type
oa:
Annotation
oa:hasTarget
rdf:type
oa:Specific
Resource
urn:uuid
oa:hasSource
identifies
Рис. А. Аннотация может быть не только текстовой: изображение, полученное с телескопа Hubble Deep Field, аннотировано с использованием OA. Объект аннотации — снимок
группы галактик, а ее тело — видеоролик с пояснением к
изображению
Как заставить копию обновляться вместе
с оригиналом, подобно другим связанным
данным в WWW? Можно ли управлять
доступом, предоставив его автору или
определенной пользовательской группе?
Все эти возможности сегодня становятся
доступными веб-разработчикам благодаря инструментам и моделям аннотаций на
основе связанных данных.
Эволюция аннотаций
избежать модификации исходного текста документов, внедряемые в них в аннотации размещались на специальном
сервере, подконтрольном W3C. В состав
Annotea входили схема RDF и REST-API
для извлечения и публикации аннотаций. Аннотации хранились отдельно от
документов и состояли из тела (например, комментария или ответа); набора
свойств, относящихся к источнику аннотации (автор, дата создания и модификации); контекста (механизма указания на
конкретный фрагмент документа). Для
аннотации были определены несколько подклассов: вопрос, комментарий и
пример. Широкому распространению
Больше десяти лет тому назад были
предприняты первые попытки снабдить
Всемирную паутину аннотациями в рамках проектов Distributed Link Service [2]
и Conceptual Open Hypermedia [3], для
того чтобы помочь
взаимодействию
людей с помощью
основанных на
метаданных переносимых аннотаций и
закладок. Примерно
в то же время был
начат Annotea —
один из ранних
проектов W3C, в
рамках которого
разрабатывалась
система переносимых аннотаций и
метаданных, ассоциируемых со страницей в целом или Рис. 1. Создание цифровой аннотации — резюме для исследос ее частью. Чтобы вательского доклада — с помощью Domeo
40 • Открытые системы • 01/2014 • www.osmag.ru
стандарты
Annotea помешал ряд препятствий, и
главным было отсутствие широкого
сообщества пользователей (нетехнических специальностей), которым были
бы нужны функции Annotea. Но спецификация проложила путь, по которому
пошло развитие последующих систем
аналогичного назначения.
Open Annotation Model
В 2009 году были начаты два параллельных проекта, опирающихся на RDF и отчасти созданных по образцу Annotea: Open
Annotation Collaboration (OAC) и Annotation
Ontology (AO). Обе модели переняли базовую структуру Annotea: аннотация с указанием объекта (аннотируемого ресурса)
и тела — внешней информации о целевом
объекте. Проекты различались функциональностью согласно потребностям своих
пользовательских сообществ.
Спецификация OAC разрабатывалась
для гуманитарных наук, а AO была рассчитана на биомедицину, позволяя аннотировать и семантически связывать
вхождения баз данных, документов и понятий, перечисленных в онтологиях. Обе
достаточно похожи, чтобы их можно было
свести в один проект, что и произошло —
под эгидой группы W3C Open Annotation
Community Group была создана спецификация Open Annotation Model. Сохранив
ряд особенностей предыдущих моделей,
она стала более гибкой и функционально
богатой, чтобы удовлетворять потребности широкого сообщества пользователей:
спецификация развивается при участии
более 50 организаций и многочисленных индивидуальных разработчиков, а
группа OA — пятая сегодня по численности в W3C.
Спецификация OA позволяет объединять аннотации в облако открытых
связанных данных — Linked Open Data
Cloud. Для этого в качестве тела аннотации используется семантический тег,
загружаемый ресурс RDF или внедренный именованный граф. Последний подход получил развитие в рамках проекта
Wf4Ever Research Objects: аннотацияграф может служить высокоуровневым
словарно-независимым механизмом
выражения связей между ресурсами,
относящимися к объекту какого-либо
исследования.
Инструменты
аннотирования
Аннотации применяются для связывания
данных в целом ряде онлайн-сервисов,
для чего разработаны соответствую-
щие инструментарии.
Например, система
DBPe d ia Sp otl i g ht
позволяет автоматически аннотировать
упоминания ресурсов DBPedia в текстах,
объединяя тем самым
источники неструктурированной информации в облако связанных данных.
С помощью инструментария Domeo
можно вызывать внешние сервисы или алгоритмы анализа текста и преобразовывать
результаты их работы в аннотации, которые затем человек
может дополнительно отредактировать.
Domeo также позволяет вручную создавать семантически Рис. 2. Карта 1507 года с изображением Гибралтарского пролива,
аннотированная при помощи сервиса Maphub. Присутствуют сеструктурированные
мантические теги — ссылки на вхождение в DBPedia
аннотации и в полуавтоматическом режиме на базе готовых годня полноценными объектами в Web
словарей (рис.1).
наравне с традиционным контентом.
Utopia Doсuments — средство просмотра
PDF-документов, позволяющее создавать Литература
наглядные представления приведенных в 1. D. Orr et al., 11 Billion Clues in 800
нем данных и искать ссылки на внешние Million Documents: A Web Research
ресурсы. Данная функция реализована Corpus Annotated with Freebase
на базе механизма автоматизированно- Concepts , Research Blog: The Latest
го анализа аннотаций, которыми до этого News from Research at Google. 17
вручную были снабжены элементы статьи, July 2013. URL: http://googleresearch.
например цифры и таблицы. При этом blogspot.com/2013/07/11-billion-cluesUtopia Documents сверяется с многочис- in-800-million.html (дата обращения:
ленными источниками связанных данных, 05.01.2014).
в том числе с DBPedia и Open PHACTS. 2. L. Carr et al., The Distributed Link
Инструмент взяли на вооружение, в час- Service: A Tool for Publishers, Authors,
тности, в Biochemical Journal — редакция and Readers. Proc. 4th Int’l World Wide
пользуется Utopia для создания аннотаций Web Conf., W3C, 1995, P. 647–656.
3. L. Carr et al., Conceptual Linking:
в опубликованных статьях.
Maphub — онлайн-приложение для ис- Ontology-Based Open Hypermedia. Proc.
следования и аннотирования оцифрован- 10th Int’l Conf. World Wide Web, ACM,
ных исторических карт (рис. 2). Maphub 2001, P. 334–342.
позволяет сопровождать аннотации вхождениями «Википедии», посвященными Паоло Чиккарезе (ciccarese@gmail.com) —
местам и зданиям, и формирует семан- преподаватель Гарвардской медитические теги — ссылки на соответству- цинской школы, Стиэн Сойленд-Рейес
(soiland-reyes@cs.manchester.ac.uk) — нающие вхождения DBPedia.
учный сотрудник Школы компьютерных
***
До появления Open Annotation Model наук Манчестерского университета,
не существовало активно развиваемой Тим Кларк (tim_clark@harvard.edu) —
пользовательским сообществом всео- ИТ-директор Института нейродегебъемлющей модели аннотаций на основе неративных болезней Массачусетской
связанных данных. Благодаря активному больницы, один из основателей W3C
освоению OA аннотации становятся се- Open Annotation Community Group.
www.osmag.ru • 01/2014 • Открытые системы • 41
мнение
Стек для Больших Данных
Все сегодня говорят о Больших Данных, но мало кто знает, как с ними работать. Похоже, что соответствующие технологии уже вышли из юношества,
но еще не повзрослели, а стек решений, что бы ни заявляли ведущие игроки, представляет собой весьма аморфное, хотя и динамичное образование.
Ключевые слова: стек технологий, аналитика реального времени, неструктурированные данные, очистка данных
Keywords: Big Data landscape, real-time analytics, unstructured data, data cleaning
Дмитрий Семынин
П
роцесс обработки Больших Данных
поддерживается сегодня сложным
конгломератом решений, состоящих как минимум из трех технологических
уровней (рис. 1). На уровне приложений,
привязанном к конкретному языковому
стандарту, платформе и программной методологии, формируются комплексные запросы к данным непосредственно на языке
запросов или посредством инструментария
их генерации. Запросы строятся с учетом
специфики и возможностей приложения,
ограничений или особенностей применяемой программной модели и схем данных,
а также подчас с некоторыми элементами
обучения приложения типовым запросам.
Уровень аналитики или автоматической
обработки данных («движок» или ядро)
содержит основные алгоритмы работы с
данными. Системный уровень — это среда хранения данных.
Продукты, применяемые сегодня в контексте технологического стека Больших
Данных, были изначально предназначены
для вполне определенных задач — например, движки Flume и Dremel, используемые
соответственно прикладными уровнями
Apache и Google, выросли непосредственно
из технологий СУБД. Введя специальные
инструменты оценки уровней вложенности, для определения избыточности,
а также решив проблему оптимальной
работы с разреженными данными, эти
инструменты существенно увеличили
эффективность обработки. Технология
Teradata построена на принципах параллельной обработки данных, эффективность которой достигается только при
наличии соответствующей структуры
базы данных, позволяющей вывить малозависимые логические сущности внутри
базы. Фактически данный движок является технологически близким к Hadoop,
с использованием HDFS, но с некоторым
инструментальным обвесом, позволяющим
подкручивать приоритизацию пользовательских запросов и управлять доступом
к внешним источникам данных и их предварительной подготовкой.
Для эффективного решения бизнес-задач необходимы сбалансированная работа
и хорошо налаженное взаимодействие всех
уровней стека технологий, однако сегодня
эти уровни существуют самостоятельно.
Использование тех или иных инструментов
на каждом из уровней накладывает технологические ограничения на применение
инструментов следующего слоя. Например,
инструменты с открытым кодом требуют,
как правило, дополнительных разработок
либо оптимизации имеющихся. Однако
производители, занимаясь продвижением собственного инструментария и технологий (рис. 2), при построении цельного программно-аппаратного решения для
работы с Большими Данными выступают
исключительно в интересах собственных
разработок. Как следствие, очень трудно
получить какую-либо информацию по особенностям взаимодействия технологических инструментов разных уровней стека
либо по успешной практике их внедрения.
Складывается впечатление, что предлагаемые сегодня решения в области Больших
Данных носят фрагментарный характер и
не покрывают всего спектра бизнес-задач.
Многие коммерческие компании, обладая
достаточно эффективным продуктом для
одного лишь сегмента стека, выдают его за
панацею для решения всех задач, связанных
Flume BigQuery
SQL
Meteor
JAQL
PACT
Flume
Engine
S3
Dremel
Service
Tera
Data
Tree
Engine
GFS
Tera
Data
Store
Azure
Engine
Azure
Data
Store
Nephele
Hive
с Большими Данными, предполагая, что
возможный частный эффект, полученный
при модернизации общей инфраструктуры, позволит хотя бы в какой-то степени
достичь обещанной эффективности и оправдать инвестиции клиента. Тем не менее
ясно, что, например, пришло время новых
СУБД для работы с Большими Данными, а
круг бизнес-задач, решаемых традиционными монолитными приложениями, неуклонно сужается.
По мнению аналитиков KPMG, 75% руководителей испытывают трудности с принятием решений по выбору технологий работы
с Большими Данными, хотя 96% признают,
что анализ всех имеющихся в их компаниях
данных необходим, но сейчас проводится
недостаточно эффективно. Одним из препятствий является неспособность определить, какие именно данные необходимо
анализировать, — фактически речь идет о
смене традиционного представления об основных информационных потоках, использующихся для решения бизнес-задач, и очень
немногие менеджеры пока находят в себе
силы разорвать шаблоны традиционных
подходов. Да и опытные ИТ-специалисты
не всегда готовы принять новые алгоритмы,
интегрированные в структуру данных, которые основаны на выполнении агрегирования данных непосредственно в массиве
данных в памяти, а не посредством вычислительной обработки.
Pig
MapReduce Model
Haloop
HDFS
Hadoop/
YARN
Voldemort
Рис. 1. Пример экосистемы Больших Данных
42 • Открытые системы • 01/2014 • www.osmag.ru
Sawzall
Scope
Языки
высокого
уровня
Dataflow
Модель
программирования
MPI/
Erlang
Dryad
Среда исполнения
L
F
S
CosmosFS
Pregel
Giraph
DryadLINQ
Среда хранения
мнение
Трансформация традиционных архитектур СУБД от монолитных к многозвенным
заставила задуматься об эффективности
хранения данных в облаках, однако вскоре
оказалось, что наиболее значительные вычислительные ресурсы требуются уже на
уровне сбора и предварительной обработки
данных (рис. 1), где из многочисленных источников происходит формирование базы,
пригодной для анализа на уровне приложения. При этом ресурсоемкие задачи сбора
и предобработки не представляют собой
привычный непрерывный транзакционный
процесс, а могут быть распараллелены и
распределены.
Кроме того, с ростом объемов данных
увеличивается расстояние между точками
их хранения и анализа — ведь до сих пор
актуальна задача уменьшения стоимости
хранения. Кстати, именно поэтому уже который раз переносится дата кончины ленточных носителей, которые по-прежнему
остаются самой дешевой платформой для
долгосрочного хранения. Однако для эффективного анализа данные должны быть
максимально приближены к процессору.
И, как следствие, сегодня возник целый
парад архитектурных решений, соревнующихся в эффективности организации иерархии и доставки данных для анализа. В
основном это референсные архитектуры,
рекомендованные под SAP HANA, Vertica,
Greenplum и др. непосредственно производителями оборудования, либо ускорители работы с массивами данных, такие,
например, как решения от Violin Memory
для флэш-памяти.
Перечисленные факторы не позволяют
сегодня хотя бы приблизительно зафиксировать стек технологий для Больших
Данных, который находится в состоянии
постоянных изменений. Мало того, одной
из особенностей использования Больших
Данных является отсутствие уверенности
в качестве сырых данных — применяемые
сегодня специальные процедуры синхронизации и поддержания консистентности
образуют чрезвычайно сложный конгломерат, в зависимость от которого нельзя
ставить сроки и результаты анализа, но
тем не менее необходимо учитывать определенный процент несогласованной
информации.
Очень серьезно ситуацию со стеком
технологий Больших Данных подогревает направление Smart City, Smarter Plane,
которое будет предъявлять совсем иные
требования к работе с данными. Так, например, уже сейчас корпорация Coca-Cola
зарезервировала 16 млн MAC-адресов
для сетевых устройств, отслеживающих
Вертикальные
приложения
Мультимедийные
приложения
Бизнесаналитика
Аналитика
и визуализация
Infrastructure
As A Service
Структурированные
базы данных
Приложения анализа
журналов событий
Data As A Service
Инфраструктура
поддержки аналитики
Операционная
инфраструктура
Базовые технологии
Рис. 2. Один из вариантов стека технологий для Больших Данных
движение продукции компании, установив в качестве пилотного проекта более
3500 таких устройств в сети ресторанов
Burger King. Это означает, что следующим
шагом в развитии аналитических систем,
работающих с Большими Данными, будет
аналитика реального времени; то есть, не
успев стабилизироваться, стек опять будет пересматриваться — к слоям сбора и
индексации, предварительного агрегирования информации, а также к средствам
визуализации будут предъявляться уже
совсем другие требования.
В России одним из основных сдерживающих факторов для развития аналитических систем, базирующихся на технологиях
Больших Данных, является неготовность
топ-менеджеров привлекать средства
аналитики к процессу принятия решений.
Тем не менее, согласно опросу KPMG, 85%
руководителей задумываются об этом,
но испытывают сложности при выборе
средств анализа и интерпретации данных
и сомневаются в возможностях быстродействия инструментов анализа. Однако и
эффективного традиционного инструмента
аналитики, даже работающего в режиме
реального времени, недостаточно — краеугольным камнем эффективности аналитических систем для Больших Данных становятся методы анализа. Сегодня имеется
много специализированных наработок на
базе статистических и численных методов
анализа финансовой информации, применимых и для задач Больших Данных, но
для проблем, связанных с социальными,
маркетинговыми и исследовательскими
задачами, нужно учитывать еще множество факторов, например региональные
особенности экономики и социальных отношений. Для получения качественной и
достоверной информации необходимо организовать процедуры ее сбора с учетом
лингвистики, геораспределенности, индустриальной специфики и множества других
особенностей, ранее либо не попадавших
в поле зрения аналитиков, либо скрытых
толстым слоем накопленных, но никем не
обработанных наблюдений. В этих условиях значимым конкурентным преимуществом становится простота настройки
аналитики на предметную область, а также возможность адаптации инструментария к предметной области. Как следствие,
преднастроенные экспертами схемы сами
по себе будут пользоваться спросом — независимо от инструментария из стека технологий Больших Данных. Они сами будут
инструментом, позволяющим применить
экспертные знания к существенно большему количеству типовых задач.
***
Современный стек технологий Больших
Данных — это пока еще некий инкубатор, из
которого впоследствии образуются универсальные или специализированные решения
по работе с данными на четырех основных
направлениях: работа с большими базами,
аналитика реального времени, обработка
разнородной информации (структурированной, слабо связанной, неструктурированной), обеспечение непротиворечивости
используемых данных.
Дмитрий Семынин (dsemynin@amt.ru) —
директор департамента инфраструктуры информационных систем, компания AMT Group (Москва).
www.osmag.ru • 01/2014 • Открытые системы • 43
музей ОС
Закон Меткалфа
сорок лет спустя
после рождения
Ethernet
Согласно закону Меткалфа, полезность сети пропорциональна квадрату числа ее пользователей. Правда, критики уверены, что это преувеличение, однако на реальных данных закон раньше никто не проверял.
Изобретатель Ethernet и автор закона сам предпринял попытку сделать это, сопоставив сведения о росте численности пользователей сети
Facebook за последнее десятилетие с доходами одноименной компании.
Ключевые слова: число Данбара, закон Мура
Keywords: Xerox PARC, 3Com, Dunbar number, Facebook, IEEE 802, Moore Law
Боб Меткалф
В
мае 2013 года ИТ-индустрия отметила сорокалетний юбилей Ethernet —
участники торжественных мероприятий вспомнили невоспетых героев,
которым эта технология обязана своим
прогрессом, и оглянулись на основные
вехи в истории развития отрасли, достигшей сегодня стомиллиардного оборота.
Упоминался также и «закон», носящий
мое имя. Согласно закону Меткалфа, полезность сети пропорциональна квадрату численности ее пользователей: V~N2.
Появился он как концептуальный инструмент продаж Ethernet в начале 1980-х, а
широкой публике стал известен в середине 90-х, когда Джордж Гилдер, до этого популяризировавший закон Мура [1],
рассказал и о моем законе [2].
Сегодня США тратят огромные средства на «гигафикацию» Интернета — модернизацию инфраструктуры Сети для
поддержки новых применений в широком
круге областей, включая образование,
энергетику и здравоохранение, причем
как оправдание этих колоссальных инвестиций нередко упоминается, в частности, закон Меткалфа. Вместе с тем
критики закона утверждают, что N2 —
это преувеличение сетевого эффекта,
а закон не только ошибочен, полагают
они, но и опасен, учитывая что оценка
сетевого эффекта играет центральную
роль в принятии важнейших решений об
инфраструктурных инвестициях. Такие
решения, в том числе «благодаря» закону Меткалфа, в 90-х годах привели к
печально знаменитому фиаско, известному как массовый крах доткомов. И
сегодня, заявляют противники, из-за
закона Меткалфа фондовый рынок необоснованно переоценивает стоимость
интернет-компаний, таких как Google,
LinkedIn, Facebook или Twitter. Однако
никто, включая меня самого, раньше
не предпринимал попыток собрать доказательную базу в пользу справедливости закона или против него. Так что в
сороковую годовщину Ethernet я решил
вернуться к своему закону и сопоставил
его с ростом численности пользователей
Facebook за последнее десятилетие и
доходами этой компании, приняв их как
меру полезности сети.
Как бы то ни было, независимо от точности, с которой закон Меткалфа прогнозирует рост полезности сети, он остается
важным инструментом постановки целей
в процессе разработки новшеств [3].
Рождение Ethernet
Появление на свет Ethernet произошло
22 мая 1973 года, когда я передал руководителям исследовательского центра
Xerox PARC докладную записку с описанием возможного принципа действия
локальной сети (рис. 1).
После основания корпорации 3Com, которая была создана в 1979 году в первую
очередь для коммерциализации Ethernet,
я с 1982 по 1984 год работал в ней вицепрезидентом по сбыту и маркетингу, а
после того как в августе 1981 года был
представлен IBM PC, мы наняли шесть
торговых агентов, раньше занимавшихся
мини-компьютерами, для продажи плат
адаптеров Ethernet владельцам первых
ПК. Поскольку мини-компьютеры стоили
что-то около 30 тыс. долл., а наши платы — примерно тысячу, продавцы начали предлагать первым покупателям ПК
сети Ethernet из 30 узлов, однако тогда
мало кто понимал, зачем вообще нужна
локальная сеть. Стоит ли говорить, что
период времени, проходивший от первой
встречи с потенциальным покупателем
до покупки адаптера «стремился к бесконечности». Представьте себе менталитет
начала 80-х — куда бы я ни сунулся со
своим коаксиальным кабелем, мне везде
Bob Metcalfe, Metcalfe’s Law after 40 Years of Ethernet. IEEE Computer, December 2013, IEEE Computer Society. All rights reserved. Reprinted with permission.
44 • Открытые системы • 01/2014 • www.osmag.ru
музей ОС
Рис. 1. Схема Ethernet из записки для руководства Xerox PARC, поданной Меткалфом
22 мая 1983 года. С разрешения Xerox PARC
Сетевой эффект
и закон Меткалфа
Примерно в то же время мне пришла в
голову идея, которую через 15 лет назвали законом Меткалфа.
В ходе презентации для торговых
агентов 3Com я поставил в проектор
35-миллиметровый слайд с графиком,
изображенным на рис. 2, с целью показать, что, когда сеть слишком маленькая, ее стоимость больше, чем ее
полезность, но когда сеть становится
достаточно большой, достигая некоторой критической массы, то полезность
растет без ограничений. Я утверждал,
что общая полезность V сети пропорциональна квадрату числа общающих-
ся по ней устройств: когда каждый из
N узлов соединяется с N-1 остальных
узлов, V будет пропорциональна числу
возможных соединений, N* (N — 1), то
есть приблизительно N2.
Вооружившись выкладками о преимуществах сетевого эффекта, торговые агенты 3Com отправились убеждать клиентов расширять сети Ethernet
за пределы критической массы, которая
по нашим оценкам составляла 30 узлов. Остальное, как говорится, история.
Многие клиенты 3Com поверили нам и
добавили к своим пробным сетям новые
адаптеры Ethernet, а наша компания в
конечном счете от сотен адаптеров за
месяц пришла к миллионным продажам. В марте 1984 года 3Com разместила
Полезность (долл.)
говорили, что не собираются прокладывать новую проводку для передачи пакетов Ethernet между компьютерами, а
если уж это так нужно, то пусть они передаются по электропроводке, которая
и так уже везде есть. Сегодня, напомню,
существует стандарт IEEE «наоборот» —
на передачу электропитания по кабелям
Ethernet.
На собрании, прошедшем в 1983 году
на озере Тахо, команда 3Com по сбыту и
маркетингу приняла решение снизить цену
на платы Ethernet и предложить заказчикам стартовый комплект за 3 тыс. долл.
на три узла со всеми кабелями, коннекторами и программным обеспечением на
дискете. Цена комплекта была меньше
установленной в большинстве компаний
планки на сумму, выше которой обычно
требовалось специальное разрешение руководства, — отважные ранние пользователи могли записать сетевые комплекты
в счет оплаты текущих расходов. Наши
торговые агенты сперва сомневались,
поскольку комиссия за продажу такого
комплекта для них была небольшой, но
скоро ранние обладатели ПК вдруг начали
закупать наши комплекты в неожиданно
больших количествах.
Преимущество комплектов было в
том, что они позволяли трем ПК делить
один принтер и жесткий диск, который
в те дни стоил немало — в 1983 году немногие компании могли позволить себе
купить десятимегабайтный винчестер
от IBM, предлагаемый с революционным на то время PC XT. Принтер Apple
LaserWriter, появившийся двумя годами
позже, стоил 7 тыс. долл. Таким образом,
покупатели нашего стартового комплекта видели возможность амортизировать
стоимость принтера и жесткого диска за
счет объединения в локальную сеть трех
ПК. А кроме того, по локальной сети можно было совершенно бесплатно обмениваться электронной почтой.
Итак, месяцы спустя торговые агенты 3Com вернулись к своим покупателям, чтобы продать им еще по 30 плат
Ethernet. Но заказчики хотя и признали,
что комплекты оправдали все обещания, жаловались, что пользы от столь
маленьких сетей не много — в сети из
трех человек переписываться по электронной почте особенно не о чем, хотя
лично я в полной мере ощутил пользу от
подключения настольных компьютеров к
локальной сети еще в 1972 году. Почему
же в 1983 году клиенты 3Com не ощутили того же, купив стартовые комплекты
локальных сетей для ПК?
Стоимость = N
Критическая масса
Общая полезность = N2
N
Количество устройств
Рис. 2. Полезность сети пропорциональна квадрату количества подключенных к ней
устройств
www.osmag.ru • 01/2014 • Открытые системы • 45
музей ОС
7
Млрд долл.
6
5
4
Метрика оценки среднемесячного
количества пользователей
Кривая роста полезности сети,
согласно закону Меткалфа
Среднемесячное количество пользователей
Доход в млрд долл.
нас до недавнего времени не попытался
проверить справедливость своего закона
на данных по реальным сетям.
Возвращение
к закону Меткалфа
Чтобы возразить критике закона, я предпринял попытку проверить его в контексте реальных данных, рассматривая N в
2
формуле V ~ N2 как функцию времени.
1
При этом период времени ограничен —
используются данные за десять лет работы
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
сети Facebook, разумеется, воплощающей
группообразующую сеть Рида. В компании постоянно сообщают об экспоненциРис. 3. Графики роста количества пользователей Facebook и доходов компании за
альном росте количества пользователей,
десять лет
которое уже составляет миллиарды, ну а
свои акции на NASDAQ, а пик оборота, Сарнофф, руководитель Radio Corporation что же насчет групп? Склонны ли группы
составивший 5,7 млрд долл., пришелся of America в 1930–1970 годы, которого друзей в Facebook расти неограниченно
на 1999 год.
называют отцом американского теле- или их численность приближается к неРазумеется, клиентов 3Com убедил видения, предположил, что полезность кому пределу?
массово покупать платы Ethernet не широковещательной сети растет пропорТут самое время вспомнить о числе
только закон Меткалфа — цена адапте- ционально числу зрителей: V ~ N. Но ве- Данбара. Антрополог Робин Данбар предров стремительно падала, и у них появ- щательные сети отличаются от Интернета положил, что существует некий предел
лялись все новые приложения помимо тем, что из последнего можно извлекать количества людей, с которыми человек
печати и разделения дисков. Сегодня пользу, общаясь как с источником веща- может поддерживать постоянные социальцена адаптеров Ethernet практически ния, так и друг с другом.
ные связи, — по его мнению, этот предел
нулевая и входит в стоимость любого
Дэвид Рид [4] постулировал, что «груп- равен 150 [6], по другим предположениПК, а Ethernet стал фактическим стан- пообразующая сеть» может породить 2n ям, он находится в диапазоне от 100 до
дартом для «трубопроводов», переда- сетей, то есть V ~ 2n. Учитывая, что 2n 230. В конце 2012 года у Facebook было
ющих пакеты Интернета и локальных растет не в пример
примерно 1,06 млрд
сетей, через которые большинство поль- быстрее, чем N2, на
пользователей и 150
Дедушка Internet
зователей осуществляют доступ к элек- фоне закона Рида
млрд связей между
Ключевой фигурой в процессе создания
тронной почте и WWW. Если Wi-Fi счи- жалобы на «сильное
друзьями, то есть в
ARPAnet был Ларри Робертс. Следующая
тать беспроводным вариантом Ethernet, преувеличение» в адсреднем по 141 другу
волна была связана с именами Винта
то сейчас ежегодно в общей сложнос- рес закона Меткалфа
на пользователя, что
Серфа, Роберта Кана, Боба Меткалфа
ти продается свыше миллиарда портов выглядят неумеспоразительно близи Тима Бернерса-Ли. Но это уже совершенно иной период, который проходил
Ethernet во всех типах кабельных и бес- тными. Основная
ко к числу Данбара.
под знаком коммерциализации.
проводных устройств, от настольных ПК претензия к посПонятно, что часть
Леонид Черняк
леднему была лучдо мобильных телефонов.
новых пользователей
«Открытые системы», № 12, 2002
На протяжении последних 30 лет, в то ше всего выражена в
Facebook еще не до
время как рост Интернета превосходил публикации журнала
конца сформировали
все ожидания, многие подвергают сом- IEEE Spectrum [5] Эндрю Одлизко, Бобом свои сети друзей, а инструменты, именению справедливость закона Меткалфа, Бриско и Бенджамином Тилли, которые ющиеся в социальной сети, позволяют
хотя роль сетевого эффекта в расшире- мой закон назвали «неверным» и «опас- завести сколько угодно «френдов». Так
нии Интернета и росте числа приложе- ным». Предположив, что не все сетевые что, скорее всего, предел числа друзей
ний не отрицается. Сомнения в том, что соединения одинаково полезны, и ссыла- Facebook больше числа Данбара.
полезность сети действительно растет ясь на закон Ципфа, Одлизко формулируНа рис. 3 приведены графики оценки
пропорционально квадрату числа поль- ет возражение, которое я буду называть роста числа пользователей и увеличезователей. Эти сомнения можно понять, законом его имени: рост полезности сети ния доходов компании Facebook за деособенно если учесть, что мой закон приблизительно равен N* ln(N). Однако сять лет1.
первоначально относился к сетям из 30 закон Одлизко страдает от тех же двух
узлов, тогда как сегодня в Интернете их проблем, что и мой собственный. Во- Обещание Ethernet:
первых, как и N2, график N*ln(N) с ростом эластичность
около 2,4 млрд.
N стремится к бесконечности. В законе пропускной способности
Закон Меткалфа и другие Одлизко сетевая полезность растет мед- На праздновании сорокалетней годовщиЗакон Меткалфа — не единственный и леннее, чем в законе Меткалфа, но также ны Ethernet многие спрашивали, что седаже не первый «сетевой» закон. Дэвид без ограничений. Во-вторых, ни один из годня означает слово Ethernet. Педанты
3
1
В русскоязычном переводе статья публикуется с небольшими сокращениями; в частности, опущены рассуждения автора относительно особенностей построения графиков. — Прим. ред.
46 • Открытые системы • 01/2014 • www.osmag.ru
музей ОС
объяснят, что Ethernet — это локальная вышалась в прошлые разы, многие подвер- пам, снижаются затраты на эксплуатасеть производительностью 2,94 Мбит/с с гали сомнению необходимость очередной цию сетей.
управлением доступом по методу CSMA/ слишком высокой ступени, которая еще не
Закон Мура, по прогнозам, будет дейсCD (множественный доступ с контролем нужна была существовавшим на то время твовать еще 15 лет. Подобные предсканесущей и обнаружением коллизий), с приложениям. Но всякий раз перспекти- зания делались и раньше, но, поскольку
восьмиразрядной адресацией, работа- вы Ethernet воплоэластичность проющая на коаксиальном кабеле и исполь- ща лись в ж изнь:
пускной способности
Порталы и жизненные циклы
зовавшаяся в Xerox PARC в 70-х. Другие после очередных
Ethernet зависит от
Закон Меткалфа часто используют для
уточнят, что Ethernet — это набор все- ускорений появляпродолжения дейсиллюстрации эффективности транвозможных стандартов семейства IEEE лись непредвидентвия закона Мура,
закционных сетей, которая пропор802. Некоторые также отождествляют ные ранее прилоциональна квадрату числа участников
будем надеяться,
сети. Очевидно, что факс-аппараты
Ethernet с IEEE 802.3, то есть с кабельной жения и возрастало
ч т о он в с кор ом
или телефоны становятся реальным
локальной сетью, в отличие от беспро- число пользоватевремени не натолинструментом бизнеса, только тогда,
водной Wi-Fi — 802.11. Кто-то еще ска- лей. Сегодня сети
кнется на одно из
когда они есть в достаточном колижет, что Ethernet — это просто синоним Ethernet прокладыестественных огчестве. Дэвид Рид пошел дальше, он
локальной сети для ПК.
вают путь от мегараничений, таких
утверждает, что сформулировал на
А я бы, как «главный», сказал, что битного Интернета к
как скорость света,
основе закона Меткалфа свой закон
Ethernet — это бренд, символ инновации. гигабитному. Между
оптические пределы
для таких сетей, которые позволяют
Однако бренды — это обещания, так что тем растет и молитографии, кванобразовывать группы.
Леонид Черняк
же обещает бренд Ethernet?
бильный Интернет,
товые эффекты при
«Открытые системы», № 02, 2002
Ethernet базируется на открытых стан- и несмотря на соуменьшении тополодартах де-юре — в частности, на IEEE 802. перничество между
гического размера
Если говорить об уровнях протоколов технологиями LTE и Wi-Fi, обе обменива- элемента или перегрев.
Интернета, то это «трубопровод» физи- ются пакетами с магистральными сетями
Разумеется, закон Мура — это не закон
ческого уровня для передачи пакетов. Gigabit Ethernet.
природы, а скорее пророчество, сбываться
Стандартизация обеспечивает максиИтак, сорок лет спустя Ethernet про- которое заставляют открытия ученых и
мальную интероперабельность и ускоряет должает демонстрировать эластичность инвестиции производителей микросхем.
снижение затрат за счет консолидирован- пропускной способности: чем больше она Так что и в развитие Ethernet стоит проных инвестиций и ценовой конкуренции. становится, тем больше нужно миру. Когда должать инвестировать — «постройте, и
В отличие от реализаций с открытым ко- это закончится? Есть ли число Данбара они придут».
дом, реализации Ethernet принадлежат для скорости Ethernet, быстрее которой
Литература
их разработчикам, поэтому конкурен- сети не понадобятся? Пока нет.
1. Gilder G. Microcosm: The Quantum
ция между поставщиками Ethernet весь***
ма ожесточенная, что заставляет их при- Закон Меткалфа подразумевает сущест- Revolution in Economics and Technology.
слушиваться к заказчикам, снижать цены вование «критической массы» — размера Touchstone, 1989.
и продолжать разрабатывать новшества, сети, после достижения которого доход 2. Gilder G. Telecosm: The World after
сохраняя при этом интероперабельность от нее начинает становиться больше, Bandwidth Abundance. Touchstone, 2000.
своих продуктов. Стандарты Ethernet стре- чем затраты. Точку критической массы 3. Metcalfe B. There Oughta Be a Law.
мительно развиваются, но эта эволюция можно задать как отношение стоимости The New York Times, 15 July 1996.
сдерживается обещанием обратной сов- сети к полезности для ее участников. В 4. Reed D. P. That Sneaky Exponential —
местимости. Закон
Интернете это со- Beyond Metcalfe’s Law to the Power of
Меткалфа опирается
отношение быстро Community Building. 1999. URL: www.
Программное обеспечение:
на использование сеначало стремиться к reed.com/dpr/locus/gfn/reedslaw.html
переворот грядет...
(дата обращения 11.02.2014).
тевого эффекта при
нулю. Почему?
В феврале 1995 года Боб Меткалф
предсказал, что сетевые программы
сохранении парка
Развитие сетей 5. Briscoe B., Odlyzko A., Tilly B.
просмотра превратятся, по сути дела,
установленного обозависит от закона Metcalfe’s Law Is Wrong. IEEE Spectrum,
в господствующую операционную сисрудования, не треМура, который го- 1 July 2006. URL: http://spectrum.ieee.
тему следующего поколения. Скорость
буя создания сети
ворит, что чис ло org/computing/networks/metcalfes-lawроста Сети определяется внутрензаново с каж дым
транзисторов в ин- is-wrong (дата обращения 11.02.2014).
ними законами ее развития. Это так
новым поколением
тегральной схеме уд- 6. Primates on Facebook. The
называемый эффект сети, или закон
технологий.
ваивается пример- Economist, 26 Feb. 2009.
Меткалфа. Сеть выходит из под чьего
Еще одно обено каждые два года.
угодно контроля.
Джордж Гилдер
щание бренда
Закон Меткалфа, в Боб Меткалф (bob.metcalfe@utexas.edu) —
«Открытые системы», № 03, 1996
Ethernet — «постсвою очередь, зави- профессор Техасского университета,
ройте, и они присит от закона Мура лауреат Национального зала славы
дут». Рассмотрим для примера скорость в двух отношениях. С появлением более изобретателей, премии The Internet
передачи данных. Вначале у Ethernet она быстрых и дешевых процессоров и памяти Hall of Fame, Почетной медали IEEE и
составляла 2,4 Мбит/с, а сегодня — 100 создаются более полезные приложения, Национальной технологической меГбит/с. IEEE стандартизует 400-гигабит- которым нужна все большая пропускная дали, присужденной за изобретение,
ный вариант, и не за горами появление способность. Одновременно, благодаря стандартизацию и коммерциализацию
терабитного. Когда скорость Ethernet по- более быстрым и дешевым сетевым чи- Ethernet.
www.osmag.ru • 01/2014 • Открытые системы • 47
экстремальные технологии
Инструменты для «ковбоев»
«Выпас данных» — так можно перевести название новой специальности data wrangling, в задачу представителей которой входит подготовка
больших массивов данных для их последующего анализа.
Ключевые слова: очистка данных, качество данных
Keywords: data quality, Data Science, data wrangling
Леонид Черняк
Г
оворят, что аналитики с квалификацией Data Science больше всего страдают от того, что 80% их рабочего
времени уходит на подготовку данных, а
оставшиеся 20% занимают сетования на
низкое качество исходных данных. Это,
конечно, преувеличение, однако значительная, если не большая часть рабочего
времени этих дорогостоящих специалистов уходит на рутинную работу, связанную с наведением порядка в данных, а не
на собственно аналитику и извлечение
содержательной информации из данных.
Этот не слишком творческий, но необходимый процесс первичной обработки данных с подачи ученых из Калифорнийского
университета в Беркли теперь называют
data wrangling («выпас данных»), а специалистов, использующих его, вполне можно назвать пастухами для данных — или
ковбоями.
Процесс data wrangling — это подготовка сырых данных для выполнения
последующей аналитики над ними, преобразование сырых данных, хранящихся
в любых произвольных форматах, в требуемые для аналитических приложений.
Несмотря на новизну технологий, стоя-
щих за data wrangling, их экономическое
значение уже сейчас высоко оценивается
и постоянно растет, поскольку цена хранения и обработки неуклонно снижается,
а стоимость труда аналитиков, напротив,
неуклонно растет — возникла острая необходимость оптимизировать труд специалистов data scientist. Однако на фоне
других широковещательных заявлений о
Больших Данных сообщение о «ковбоях»
выглядит достаточно скромно, воистину — мы чаще всего связываем прогресс
с межпланетными перелетами, хотя гораздо больше приходится сталкиваться
со стиральными машинами.
Существование разнообразных технологий очистки данных (data cleansing, data
cleaning или data scrubbing) не новость —
все они давно и успешно применяются для
поиска ошибок в базах данных и таблицах.
Обычно такие технологии используют при
загрузке хранилищ данных на этапе ETL
и в системы бизнес-аналитики. Суть этих
технологий в повышении качества данных,
улучшении их соответствия окружающему миру. Понятие data quality еще в 1972
году предложил швед с болгарским именем Христо Иванов, но спустя сорок лет
возникает иная потребность — теперь
нужно не просто обеспечить соответс-
48 • Открытые системы • 01/2014 • www.osmag.ru
твие данных внешней среде, а научиться
воплощать в данных все многообразие
внешнего мира, а потом еще каким-то образом использовать эти данные. Вот для
этого и нужны средства data wrangling,
которые не только улучшают качество
данных, но и обеспечивают единообразное согласование данных, поступающих
из многочисленных источников. Здесь еще
нет полной формализации, поэтому чаще
всего такую работу приходится выполнять
в полуавтоматическом режиме — приведением данных в порядок заняты специалисты в области «выпаса данных», а суть
их деятельности состоит в сборе и организации данных, получаемых из внешних
источников. По своему положению в спектре занятости в ИТ этот вид деятельности
можно сравнить с работой программистакодировщика, с тем различием, что одни
имеют дело с кодами, а другие — с данными. Подобное разделение обязанностей
можно обнаружить и в промышленности,
где также есть две специализации — материаловеды и технологи.
Из крупных поставщиков на этом поприще известна компания Informatica,
а также ряд компаний-стартапов.
• Компания Datameer предлагает интегрированное решение Datameer Analytics
Solution, с помощью которого можно
осуществлять консолидацию данных,
управление ими в динамике и визуализацию результатов. Это решение позволяет
пользователям, привыкшим к работе в
среде электронных таблиц, легко адаптироваться к Hadoop. В состав DAS входит более сотни стандартных табличных
функций и набор средств для обработки
текстов на естественных языках.
• Компания ClearStory развивает инструменты для Data Intelligence (DI) — совокупности технологий, упрощающих
бизнес-пользователям работу с интересующими их данными. Основное различие между DI и BI в их предназначении:
задача BI — делать выводы, а DI — в информационном обеспечении. По мнению специалистов из ClearStory, DI и
BI — части целого, более высококачест-
экстремальные технологии
венная подготовка данных служит гарантией для более эффективного анализа
и в итоге позволяет создать предприятие, извлекающее наибольшую пользу
из данных (Data Intelligencе Entertprise).
В работе такого предприятия сочетается
деятельность тех, кто готовит данные, с
деятельностью тех, кто извлекает из данных полезную информацию.
• Dataiku специализируется на Data
Science, в качестве вспомогательного инструмента предлагая Data Science Studio
с функциями data wrangling.
Впрочем, перечисленные компании не
только «пасут данные» — в 2012–13 годах
было образовано несколько компаний,
специализирующихся исключительно в
этой сфере: Paxata, Trifacta, DataWrangler
и Data Tamer. Все они основаны серьезными специалистами — выходцами из
крупных корпораций и из ведущих университетов Америки. Еще есть сообщество, разрабатывающее продукт с открытым кодом OpenRefine.
OpenRefine
Технология OpenRefine ведет свою родословную от средств очистки данных
Google Refine. Замена Google в названии
на Open произошла после того, как компания Google отказалась от поддержки
этого проекта, но образовалось сообщество, которое продолжает его развитие. В 2010 году Google купила компанию
Metaweb Technologies, имевшую на тот
момент два открытых проекта: основной
Freebase и вспомогательный Gridworks.
Первый весьма амбициозен и заключался
в создании силами сообщества некоторой
мировой коллаборативной базы знаний,
собираемой из Web. Второй проект скромнее — это инструмент подготовки данных
для Freebase, вот его-то и переименовали в Google Refine. В Google приобрели
Metaweb главным образом ради Freebase,
а сам инструмент, к тому же работающий
в автономном режиме на компьютере
пользователя, интереса не представляет,
поэтому в 2012 году компания отпустила его в свободное плавание под именем
OpenRefine. Этот шаг стал успешным — за
время своего существования под именем
Google Refine продукт вызвал заметный
интерес у различных специалистов, главным образом у data scientist.
Математическая основа OpenRefine
весьма оригинальна и построена на архитектуре фасетного просмотра (Faceted
Browsing Architecture). «Фасет» — это
грань или плоскость на граненом изделии, не случайно граненый кристалл стал
эмблемой OpenRefine. Фасетный поиск се их подготовки, как и уже имеющиеся
(faceted search, faceted navigation или средства [1]. Существующие аналоги типа
faceted browsing) — это метод доступа к ETL или MDM не столь оперативны и менее
данным, организованным по принципам приспособлены для самообслуживания,
фасетной классификации, предложен- поскольку требуют поддержки со стороной еще в 30-е годы XX века для целей ны персонала ИТ, к тому же Adaptive Data
библиографии. В этом контексте фасе- Preparation позволяет смешивать данные
том называют какой-то определенный из разных источников.
Как многие стартапы, Paxata не стрепризнак, пересечение которых образует фасетную структуру, или формулу, а мится раньше времени раскрывать свои
классификационные индексы образуются карты, и из открытых источников можно
путем сочетания фасетных признаков в сделать вывод о том, что в Adaptive Data
соответствии с фасетной формулой. Такой Preparation используется комбинация
же подход к индексации используется технологий из поисковых систем и платформ, поддерживающих социальные сети,
в СУБД Endeca, купленной Oracle.
Внешне OpenRefine напоминает элек- что дает возможность применительно к
тронную таблицу, но по устройству сис- сырым данным выполнять «интеллектуальную» индексатема скорее подобна
цию, распознавание
базе данных. Данные
Аналитика
текстовых образов
содержатся в таблинеструктурированных данных
и статистический
це со строками и коФасетный поиск был предложен инанализ графов.
лонками, аналогично
дийским библиотековедом Сиркали
Применяя свои
реляционной СУБД.
Ранганатаном как вариант библиоа
лгоритмы
как к
Каждому проекту
течно-библиографического подхода
структурированным,
соответствует одна
к многоаспектной классификации для
так и неструктуриротаблица. Работая с
обычных бумажных библиотек и позже
ванным данным [2],
ней, пользователь
распространен для компьютерных приложений. Фасетная формула не только
Paxata может строможет фильтровать
определяет порядок следования терить полноценные и
строки, используя
минов в поисковом образе докуменгибкие модели данфасеты, которыми
та (например, процесс — материал —
ных в форме графов,
заданы критерии
оборудование — свойство и т. д.), но
находить общности
фи льтрации. Все
и играет роль индекса.
и ассоциации между
действия пользоЛеонид Черняк
«Открытые системы», № 06, 2012
различными фрагвателя отражаются
ментами данных,
средствами пользоавтоматически обвательского интерфейса и сохраняются в протоколе проекта. наруживать и выделять в данных обраВсе трансформации данных могут быть зы и аномалии, создавать визуальное
описаны на собственном языке OpenRefine представление данных, позволяющее
Expression Language или же на Jython (ре- быстро и просто оценивать их состояние. Дальнейшая работа с визуализиализация Python на языке Java).
рованными текстами может осущестPaxata
вляться индивидуально или методами
Компания Paxata была создана ветерана- краудсорсинга.
ми отрасли с большим производственным
стажем работы, в том числе и в SAP, кото- Trifacta
рые поставили перед собой цель создать Компания Trifacta создана в 2012 году проПО нового поколения, позволяющее поль- фессорами Джозефом Хеллерстейном и
зователям собственными силами готовить Джефри Хиром из Стэнфорда и Беркли,
большие наборы данных для последующей которые коммерциализовали в этой комобработки и для анализа. Облачный про- пании опыт и знания двадцатилетних совдукт компании, Adaptive Data Preparation, местных исследований в области очистки
позиционируется между средствами визу- данных. Из всех компаний, работающих
альной аналитики и извлечения информа- в области data wrangling, Trifacta имеет
ции из данных, предлагаемыми Tableau и самую долгую предысторию и самый сеQlikTech, с одной стороны, и репозитори- рьезный научный задел. Хеллерстейн и
ями данных типа Hadoop или параллель- Хир, еще будучи аспирантами, начинали
ными базами данных класса in-memory, с свою научную работу в середине девядругой. Adaptive Data Preparation призван ностых в Беркли по программе с образобеспечить пользователям необходимую ным названием Potter's Wheel (гончарсвободу оперирования данными в процес- ный круг), отражающим идею создания
www.osmag.ru • 01/2014 • Открытые системы • 49
экстремальные технологии
Data munging
В некоторых источниках data munging и data wrangling представлены как синонимы, что не совсем корректно — термином data munging обычно называют ограниченное подмножество действий над данными, попадающее в категорию data
wrangling, причем последний термин является более общим. Чаще всего продукт
data munging представляет собой написанные пользователем программы для работы со строчными данными на языках Perl, R, Python или иных, приспособленных
к работе с текстовыми файлами. Сам термин data munging на десятки лет старше
data wrangling и происходит от необычного глагола mung или munge, которым на
компьютерном жаргоне обозначают необратимое преобразование данных. Слово
mung — абсолютный компьютерный неологизм: в обычном английском языке его
нет. Происхождение mung датируется 1960 годом, тогда он появился в МТИ для
обозначения некоторых операторов в популярном в то время текстовом редакторе TECO (Text Editor and COrrector). За неудобства операторов mung стали в шутку
расшифровывать как «Mash Until No Good» (мешай пока не испортишь). С тех пор
неудобство прошло, а слово осталось.
изделия из сырой массы с использованием рук и специального инструмента.
Свое отношение к идее очистки данных
они выразили следующим образом: «На
практике данные из реального мира
не соответствуют ограничениям схем,
форматов и способов записи, которые
накладывают на них СУБД. Причиной
тому являются многообразие источников данных и неизбежные ошибки. До
помещения их в базы и хранилища данные должны пройти процесс очистки».
Эти слова были актуальны уже давно, но
стали особо важны сейчас, когда объемы
данных и их разнообразие приобрели совершенно иные масштабы.
Создатели Trifacta подвергают критическому анализу существующие методы
очистки данных и предлагают свой собственный, который и был положен в основу современных продуктов компании. По
их мнению, все известные средства очистки очень похожи и состоят из двух типов
инструментов: одни служат для анализа,
а вторые — для преобразования данных.
Алгоритмическая основа могла быть разной (и data mining, и машинное обучение,
и еще что-то), но все их объединял общий
подход — оба инструмента использовались в пакетном режиме применительно
к некоторому набору данных. Со времен
первых мэйнфреймов хорошо известны
недостатки пакетного режима разработки,
и главный из них — результаты обработки
не видны вплоть до ее окончания. Сразу
получить нужный результат не удается —
для достижения приемлемого качества
требуется выполнить определенное число
итераций, и чтобы избавить программиста от пакетного режима, был разработан
интерактивный режим взаимодействия
человека с машиной, а Хеллерстейн и Хир
предложили аналогичный подход к очистке, заменив пакетный режим интерактивным. В этом их главная идея.
Название следующего проекта Trifacta —
Data Wrangler, что отлично отражает его
сущность. Но, в отличие от других близких по смыслу проектов, он более технологичен — здесь не только обеспечивается преобразование сырых данных в
более приемлемую для анализа форму,
но и создается описание выполненных
действий, чтобы в последующем можно
было это описание оценить и, если нужно, отредактировать и повторить преобразование. В этом проекте сочетаются
пользовательский интерфейс, поддерживающий диалоговый режим, и язык
декларативного типа для описания преобразований. Описание на языке, близком к естественному, создается методом
программирования путем демонстрации
(Programming by Demonstration, PbD),
используемым для обучения роботов.
Система не просто механически фиксирует введенные пользователем команды,
как, например, это делается в текстовых
редакторах при сохранении введенных
действий в одной макрокоманде, а еще
и связывает их с особенностями преобразуемых данных так, чтобы в последующем описание можно было адаптировать
для тех случаев, когда данные похожи на
преобразованные, но имеют некоторые
отличия. Отредактированное описание
можно использовать многократно.
Data Tamer
Ком па н и я Data Ta mer бы ла соз д ана в прошлом году группой ученых из
Массач усетского технологического
института под руководством Майкла
Стоунбрейкера, а ее название, переводимое как «укротитель данных», — явный
парафраз от «data wrangler». О компании
известно очень мало, но она привлекает
к себе внимание очень известными именами своих основателей. О ее будущей
деятельности можно косвенно судить
50 • Открытые системы • 01/2014 • www.osmag.ru
по отдельным тематическим статьям, в
которых применительно к данной компании упоминаются такие слова, как
«присмотр», «наблюдение» или «опека»;
скорее всего, речь идет о создании системы для масштабируемого наблюдения.
Наблюдение за данными предполагает
создание системы сбора сведений из десятков тысяч источников, объединенных
принадлежностью к общему домену знаний: это содержательно связанные между собой сайты, научные статьи, истории
болезней или иные формы представления результатов исследований. Каждый
из источников содержит в себе фрагмент
полезной информации, но его автор сам
не в состоянии совместить свой вклад с
информацией, скрытой в данных, находящихся в тысячах аналогичных источников. Задача состоит в том, чтобы агрегировать распределенную информацию
для извлечения нового знания. Она решается путем совмещения функционала
системы Data Tamer, обладающей способностью к обучению, и деятельности
нескольких категорий специалистов, управляющих работой системы и процессом ее обучения. За сбор данных из источников отвечает администратор Data
Tamer Administrator, он же организует
совместную работу прикладных специалистов Domain Experts, а в ряде случаев
целесообразно использовать приемы из
краудсорсинга.
***
Первой реакцией на проблему Больших
Данных стало появление специалистов в
области Data Science, однако со временем
выяснилось, что данные требуют предварительной обработки, и в ответ возникло
направление Data Wrangling, появились
«ковбои данных». Не исключено, что на
этом пути индустрию ждет еще немало
неожиданностей.
Литература
1. Леонид Черняк. Технологии анали-
тики действия // Открытые системы.
СУБД. — 2013. — № 6. — С. 43–47. URL:
http://www.osp.ru/os/2013/06/13036855
(дата обращения: 05.02.2014).
2. Леонид Черняк. Аналитика неструктурированных данных // Открытые
системы.СУБД. — 2012. — № 6. —
С.30-34. URL: http://www.osp.ru/
os/2012/06/13017038 (дата обращения:
05.02.2014).
Леонид Черняк (osmag@osp.ru) — научный редактор, «Открытые системы.
СУБД» (Москва).
академия ОС • семинар
Системы
автоматической
обработки текстов
Многообразие систем автоматической обработки
неструктурированных текстов сегодня вызывает необходимость
их систематизации и классификации с целью упрощения выбора
решения, наиболее адекватного для конкретной задачи.
Ключевые слова: автоматический перевод, неструктурированные данные, компьютерная лингвистика, извлечение смысла
Keywords: machine translation, unstructured data, computational linguistics, semantic analysis
Дмитрий Ильвовский,
Екатерина Черняк
З
адачи обработки текстов — неструктурированной документации, историй болезни, патентов и диссертаций
и т. п. — можно разбить на две условные
категории. К первой относятся задачи, с
которыми ежедневно сталкивается любой пользователь: проверка орфографии,
фильтрация спама, автоматический перевод
небольших фрагментов текста (несколько
предложений) и др. С точки зрения исследователей в области автоматической обработки текстов (АОТ), все эти задачи почти
решены, и сегодня более актуальны задачи
из второй категории, требующие обработки
больших текстовых массивов: нахождение
релевантных ответов на вопросы (задачи
«вопрос-ответ»), полноценный машинный
перевод целостных текстов, анализ мнений
и отзывов, конструирование рекомендательных систем, работающих с большими
массивами неструктурированных данных.
Отличительная особенность таких задач —
их сложность и отсутствие формализации,
приводящие к тому, что для них пока еще нет
полноценного набора решений, а применяются вспомогательные методы выделения
ключевых слов и словосочетаний, суммаризации (автоматического реферирования)
текстов и классификации текстов.
Теоретическую основу автоматической
обработки текстов составляет компьютерная лингвистика, наиболее востребованы в
которой методы машинного обучения, статистического анализа, модели Маркова, логические модели и модификации этих методов с учетом специфики Больших Данных
[1]. Существует несколько подходов к такой
модификации: распараллеливание алгоритмов, применение методов снижения раз-
мерности, предобработка данных, в ходе
которой целостные тексты заменяются их
отдельными элементами. Несмотря на различие между национальными языками, лингвистические методы могут быть универсальными — некоторые морфологические
и синтаксические модели удается использовать для анализа текстов как на английском, так и на русском языке.
Появление компьютеров, на которых
можно было целиком хранить, обрабатывать
корпусы, содержащие наборы эталонных
текстов, и проводить сложные вычисления,
позволило активно использовать статистические методы и методы машинного обучения для работы с текстами [2]. В целом в
начале 90-х годов в области компьютерной
лингвистики произошел переход к статистическим методам и, затем, методам машинного обучения и анализа данных [3],
которые применяют к уже написанным и
существующим текстам.
В настоящее время в области автоматической обработки текстов в России значительная часть работ посвящена переносу
методов, разработанных для английского
языка, на русский, и, к сожалению, оригинальных разработок очень мало.
Cистемы АОТ можно классифицировать
по виду лицензирования (проприетарные —
как правило, принадлежащие известным
производителям, и академические разработки — распространяемые бесплатно);
открытости (системы могут быть либо доступны только узкому кругу людей, либо
находиться в открытом доступе); целевой
аудитории (исследователи в области компьютерной лингвистики, разработчики, рядовые пользователи и т. п., что определяет интерфейс системы); мультиязычности
(различие по числу поддерживаемых языков); характеру (готовые системы или биб-
лиотеки инструментов обработки текстов);
универсализму (решение конкретных задач,
обработка текстов в целом); используемым
данным (тип и объемы обрабатываемых данных); применяемым экспертным правилам
и математическим моделям; ориентации на
конкретную прикладную область.
Мультиязычные системы часто более
коммерчески привлекательны и просты
в использовании. В свою очередь, системы, ориентированные на конкретный язык
или подмножество языков, обеспечивают
пусть и небольшой, но очень важный во
многих задачах прирост качества за счет
учета специфики языка. Классический
пример мультиязычной системы — переводчик Google.
Системы, рассчитанные на достаточно
широкое (и, как правило, коммерческое)
использование, обладают хорошо развитым интерфейсом для конечного пользователя (например, Microsoft Bing Translator и
Google translator, «ОРФО», программа для
автоматического переключения между различными раскладками клавиатуры Punto
Switcher, различные утилиты «Яндекса» и
т. д.). Ряд этих систем обладает также своим
собственным программным интерфейсом
(«ОРФО», Microsoft Bing Translator). Но в
данном случае он является скорее приятным дополнением, чем основным способом использования систем. Напротив, для
систем, рассчитанных только на исследователей или являющихся составной частью
более объемных проектов, программный
интерфейс становится главным (а часто и
единственным) способом взаимодействия.
Интерфейсы для конечных пользователей
в этих системах рассчитаны скорее на работу в тестовом режиме и часто являются консольными. В качестве примеров такого рода систем можно назвать mystem,
www.osmag.ru • 01/2014 • Открытые системы • 51
академия ОС • семинар
Задачи компьютерной лингвистики
В сфере обработки текстов на сегодняшний день сформировалось два подхода: на основе моделей языка и правил, составленных экспертами; на базе машинного обучения.
Первый позволяет достичь лучших результатов, однако составление моделей и правил
настолько трудоемкий процесс, что уступающие по качеству методы машинного обучения практически его вытеснили. Повышение качества достигается не за счет совершенствования математических методов, а за счет увеличения и улучшения обучающей
выборки. Оба подхода направлены сегодня на решение следующих задач.
• Анализ и градация мнений. Соотнесение текста, написанного от первого лица, с дискретной шкалой оценок: плохо, хорошо, очень хорошо и т. д. Используется для анализа
отзывов в интернет-магазинах и высказываний в социальных сетях.
• Анализ тональности высказываний. Выявление позитивного или негативного отношения к обсуждаемому предмету. Используется для анализа отзывов, генерации диалога и т. д.
• Классификация текстов по темам. Отнесение текста к той или иной тематике.
Используется во многих приложениях — в частности, в рекомендательных системах, для
рубрикации текстов в онлайн-библиотеках и для организации новостных потоков.
• Генерация речи. Используется в робототехнике, смартфонах, навигаторах.
• Ведение диалога. Анализ реплик собеседника и формирование на их основе ответов.
Используется в робототехнике, экспертных системах — например, Королевский банк
Шотландии частично заменил контакт-центры роботами, поддерживающими диалог
с пользователем.
• Проверка правописания. Используется в текстовых редакторах, поисковых системах.
• Извлечение смысла из текста. Выделение ключевых слов и словосочетаний, трендов,
суммаризация. Применяется в новостных системах для агрегирования серии новостных
сообщений, базах знаний для организации хранения знаний и вывода новых фактов.
• Поиск ответов на вопросы. Подборка по вопросу и, возможно, контексту наиболее
релевантного ответа. Применяется в поисковых и экспертных системах.
• Машинный перевод.
AOT, pyMorphy 1 и 2, «Томита парсер» [4],
OpenXerox, Snowball. Почти все они предназначены для решения конкретных задач,
возникающих на различных этапах анализа
текстов: выделения слов из текста (токенизация), морфологического анализа (определения частей речи и других грамматических
характеристик), построения синтаксической структуры предложений и т. д.
Корпусы — неотъемлемая часть многих
систем обработки текстов. Каждое слово в
корпусах снабжено исчерпывающими грамматическими характеристиками: к какой части речи оно принадлежит, в какой форме оно
находится, какова его синтаксическая роль.
Корпусы служат входными данными для
обучения в задачах классификации текстов
по темам и жанрам, для обучения синтаксических парсеров и программ, используемых
для снятия омонимии и разрешения анафоры. Параллельные корпусы, состоящие
из одинаковых текстов на разных языках,
используют для обучения машинных переводчиков. Как правило, корпусы собираются
десятилетиями, и в их создании участвуют
большие исследовательские группы — например, проект «Национальный корпус русского
языка» существует уже 13 лет и поддерживается компанией «Яндекс».
Важный тип входных данных любой системы АОТ — морфологические словари.
Например, библиотека «АОТ», используемая
во многих исследовательских и коммерчес-
ких проектах, представляет собой словарь
Зализняка в цифровой форме. Тезаурусы (или
семантические сети) — другой тип широко
востребованных входных данных. Пожалуй,
самый известный тезаурус — это WordNet,
представляющий собой ресурс, в котором
слова связаны с помощью так называемых
семантических отношений: синонимии, гиперонимии (частное — обобщение), гипонимии (обобщение — частное), меронимии
(часть — целое) и др. WordNet полезен в задачах машинного перевода, генерации текстов, классификации текстов. К сожалению,
русского аналога WordNet пока нет.
Решение практически любой задачи АОТ
так или иначе включает в себя проведение анализа текста на нескольких уровнях
представления.
1. Графематический анализ. Выделение
из массива данных предложений и слов
(токенов).
2. Морфологический анализ. Выделение
грамматической основы слова, определение частей речи, приведение слова к словарной форме.
3. Синтаксический анализ. Выявление
синтаксических связей между словами в
предложении, построение синтаксической
структуры предложения.
4. Семантический анализ. Выявление семантических связей между словами и синтаксическими группами, извлечение семантических отношений.
52 • Открытые системы • 01/2014 • www.osmag.ru
Каждый такой анализ — самостоятельная
задача, не имеющая собственного практического применения, но активно используемая для решения более общих задач. Многие
исследовательские системы предназначены для решения именно вспомогательных
задач. Такие системы применяются либо
для апробации методов и проведения вычислительных экспериментов, либо в качестве составных частей (или библиотек) для
систем, решающих ту или иную прикладную задачу. Примером таких систем могут
служить средство NLTK для графематического анализа и токенизации, морфологический анализатор mystem и синтаксический
парсер «ЭТАП3».
Универсализм в АОТ подразумевает
наличие в системе набора взаимосвязанных методов и подходов. Существует два
класса таких систем. К первому относятся системы, разрабатываемые исследовательскими департаментами крупных компаний: IBM, Intel, SAS, ABBYY, Microsoft,
Xerox и т. д. В качестве примеров систем,
предназначенных для обработки текстов на английском языке, можно назвать
IBM Content Analytics, SAS Text Miner и
IBM Watson. Ко второму классу относятся открытые интегрированные программные пакеты, созданные в университетах
и представляющие собой множество методов и моделей, построенных на единой
программной и математической платформе. Для английского языка можно назвать
системы Apache OpenNLP, StanfordNLP,
NLTK, GATE. Систем для работы с русским
языком, претендующих на универсализм,
пока нет, более того, в случае русского
языка отсутствуют даже доступные для
конечного пользователя системы, решающие основные лингвистические задачи:
выделение ключевых слов, классификация текстов по темам, определение тональности текстов. В таблице перечислены программные системы, работающие с
русским языком.
Некоторые системы АОТ направлены
на анализ текстов определенных жанров
или тематики. Например, система Watson
применяется в медицине для диагностирования и облегчения процедуры принятия врачами решений. Рекомендательная
система новостных сообщений News360
представляет собой приложение для мобильных устройств, с помощью которого
пользователь может читать и выбирать наиболее интересную для него информацию.
На основе предпочтений пользователя система предлагает новые статьи, собранные с
разных новостных порталов и отвечающие
конкретной тематике. В некоторых случа-
академия ОС • семинар
Системы АОТ для русского языка
Название
Применение
Языки
Интерфейсы
NLTK
Разработка систем
анализа текстов
Английский + поддержка обучения класКомандная строка
сификаторов для ос- Python
тальных языков
PyMorphy2
Морфологический
словарь для исследовательских и коммерческих проектов
Русский
Командная строка
Python
«Томита Парсер»
(«Яндекс»)
Выделение именованных сущностей
Русский
API
«Яндекс.Спеллер»
Проверка орфографии
Русский
Онлайн-версия
и API
Извлечение знаний
из текстовых коллекций
и их структурирование
в виде онтологии
Синтаксический анализ
и визуализация деревьев разбора
Английский, русский,
немецкий, французПользовательский
ский
ОntosMiner
«ЭТАП3»
Русский
Пользовательский,
API
«Антиплагиат»
Проверка текстов на на- Русский
личие заимствований
Специальный ресурс в Интернете
«ОРФО»
Проверка орфографии
Русский
Пользовательский
и API
Microsoft Word
Текстовый процессор
с проверкой орфографии и синтаксиса
Почти все языки
Пользовательский
и API
«Наносемантика»
«Генон»
2long2read
Интернет-роботы, помогающие при регист- Русский
рации на ресурсах
(ведение диалога)
Поиск ответа на вопрос
на популярных викиРусский
и интернет-ресурсах
Выделение ключевых
предложений в связном Русский
тексте
ях эти системы умеют определять тональность новостного сообщения — например,
пользователь может просматривать только
хорошие новости и исключить из своей ленты все плохие. Рекомендательные системы,
работающие с текстовыми данными, особенно востребованы в интернет-магазинах.
С точки зрения АОТ отзыв пользователя
интернет-магазина — это текст, имеющий
явную тональную окраску и посвященный
конкретному предмету. По отзыву пользователя необходимо определить, остался ли
он доволен купленным товаром или нет, а
если ему что-то не понравилось, то понять,
что именно. Кроме того, перед интернетмагазинами встает задача выявления поддельных отзывов, написанных производителем товара.
***
Сегодня многие модели, разработанные в
недрах научных сообществ, взяты на вооружение крупными игроками рынка ИТ
Целевая аудитория
Доступность
Студенты, исследователи и разработчики
Бесплатно
в области NLP
Студенты, исследователи и разработчики
Бесплатно
в области NLP
Студенты, исследователи и разработчики
в области NLP
Широкий круг онлайнпользователей и разработчиков сервисов и
мобильных приложений
Бесплатно
Бесплатная онлайнверсия и платный
доступ к API
Студенты, исследовате- Бесплатная демоли и разработчики в об- версия
ласти NLP
Студенты, исследователи и разработчики в области NLP
Рядовые пользователи
и пользователи специальной версии для университетов
Пользователи персональных компьютеров
и разработчики онлайнсервисов и мобильных
приложений
Пользователи персональных компьютеров
и мобильных устройств,
разработчики
Бесплатно
Бесплатно
Платно
Платно
Пользовательский
Посетители соответствующих ресурсов
Бесплатно
Пользовательский
Пользователи
Интернета
Бесплатно
Пользовательский
и API
Пользователи
Интернета
Бесплатно
(Google, IBM, Microsoft), однако в секторе,
ориентированном на работу с русским языком, наблюдается ощутимое отставание
от английского, китайского, арабского и
от европейских языков. Существующие
системы решают либо совсем простые
(проверка орфографии, базовая корректировка поискового запроса), либо вспомогательные (выделение основы слов, приведение слова к начальной форме), либо
специальные задачи (автоматическое составление резюме, анализ компетенций,
анализ профиля среднестатистического
пользователя социальной сети). Сравнение
с рядом славянских и восточно-европейских языков также оказывается не в пользу русского.
Литература
1. Sergei O. Kuznetsov/ Fitting Pattern
Structures to Knowledge Discovery in Big
Data. ICFCA 2013. P. 254–266.
2. Christopher Manning, Hinrich
Schuetze. Foundations of Statistical Natural
Processing. MIT Press, 1999.
3. Boris Mirkin/ Core Concepts
in Data Analysis: Summarization,
Correlation and Visualisation, DOI
10.1007/978-0-85729-287-2. Springer, 2011.
4. Константин Селезнев, Александр Владимиров. Лингвистика и обработка текстов //
Открытые системы. — 2013. — № 04. — C. 46–49.
URL: http://www.osp.ru/os/2013/04/
13035562 (дата обращения: 05.02.2014).
Дмитрий Ильвовский (dilvovsky@hse.ru) —
сотрудник лаборатории интеллектуальных систем и структурного анализа,
Екатерина Черняк (echernyak@hse.ru) —
сотрудник международной лаборатории анализа и выбора решений, НИУВШЭ (Москва). Работа проведена в
рамках Программы фундаментальных
исследований НИУ ВШЭ.
www.osmag.ru • 01/2014 • Открытые системы • 53
академия ОС • библиотека
Сила в простоте
Тема ноябрьского номера журнала Computer (IEEE Computer Society,
Vol. 46, No. 11, 2013) — простота в информационных технологиях.
Ключевые слова: эффективность ПО, оптимизация программ, уcтранение избыточности
Keywords: Simplicity in IT, software efficiency, program optimization, dispel redundancy
Сергей Кузнецов
Л
юбому опытному разработчику
программного обеспечения известно, что самый сложный шаг
разработки — это поиск эффективного
и в то же время простого решения. Одно
из основных правил состоит в том, что
красивым и действительно работающим
может быть только простое решение. В
тематической подборке этого номера
простота в ИТ (Simplicity in IT) понимается в более широком смысле: простота
производственной инженерии программного обеспечения.
Вводную заметку приглашенные редакторы номера Тизиана Маргария (Tiziana
Margaria) и Майк Хинчи (Mike Hinchey)
озаглавили «Простота в ИТ: сила отказа
от лишнего» («Simplicity in IT: The Power
of Less»). Программные системы не являются материальными объектами, однако
многим аспектам правильно организованных систем свойственна красота простоты: эффективность замысла или концепции, правильность и ясность структуры,
строгость организации кода, надежность,
удобство использования и т. д. Однако
красоту простоты легко испортить путем
принятия неверных решений, включения в систему необоснованных функциональных возможностей, использования
устаревших предположений о критериях
эффективности и т. п. Можно заметить,
что модернизация и развитие часто связаны с отказом от ставших избыточными
компонентов. Так появились, например,
технологии безлошадных экипажей, беспроводных коммуникаций и т. д. Всем им
присуща характеристика «без» — без чего-то, что присутствовало в технологии
предыдущего поколения.
Во времена, когда большее число функциональных возможностей приносит
большую прибыль, строить стратегию
на простоте рискованно, однако имеются
разные формы упрощения — и одной из
наиболее очевидных является простота
использования программных продуктов
конечными пользователями. Упрощение
более глубоких слоев ПО индустрией
пока отвергается, хотя у этого подхода
имеется огромный потенциал для консолидации, унификации и оптимизации,
а также для упрощения эксплуатации
систем даже при наличии длинных цепочек проектирования, производства и
сопровождения. Однако упрощение как
отдельная цель исследований сегодня
недооценивается, и одним из наиболее
успешных направлений, в котором упрощение играет ключевую роль, является тестирование на основе моделей
(Model-Based Testing, MBT). Исходным
недостатком MBT являлась потребность
в наличии априорных тестовых моделей,
редко доступных на практике из-за высокой стоимости их построения и сопровождения. Однако исследования показали, что качественные тестовые модели
можно построить полностью автоматически с использованием методов обучения автоматов, что превращает MBT в
область моделирования на основе тестирования. Этот шаг может повлиять на
современную технологию тестирования,
но он далеко не очевиден — например,
нужно развить методы обучения автоматов для обеспечения их достаточной
54 • Открытые системы • 01/2014 • www.osmag.ru
масштабируемости. Потенциал упрощения, воздействующего на весь жизненный цикл программного обеспечения,
реализуется в этом примере за счет инвертирования представлений о моделях
и тестировании. Превращение глубоко
теоретического направления обучения
автоматов в практическую дисциплину
может способствовать применимости
MBT как общепринятой технологии, но
прежде необходимо ответить на два основных вопроса: какие функциональные
возможности являются обязательными
и как реализовать эти обязательные возможности при меньших инфраструктурных потребностях, с меньшими расходами и риском?
Для такого упрощения требуются
безболезненные приспосабливаемость
и изменчивость, на пути которых стоит
архитектурное проектирование — изменение архитектуры системы настолько
же болезненно, как и изменение схемы
базы данных. Даже если поиски упрощений происходят только во время изменений, сулящих наибольшую выгоду, эти
упрощения могут повлиять на гораздо
большее число аспектов, что приводит к
изменению приоритетов решений, возможно, вызывая потребность в изменении и архитектуры.
Первые две тематические статьи дают
общее представление о применении методов упрощения в ИТ. В статье «Исследование подходов к упрощению в информационно-коммуникационной технологии» («Simplicity Research in Information
and Communication Technology») Барри
Флойд (Barry Floyd) и Стив Боссельман
(Steve Bosselmann) приводят обзор состояния дел и исследовательских проблем в
области упрощения и ИТ. Обсуждаются
публикации, посвященные этому подходу
(см. рисунок), общие принципы и рекомендации, выработанные в ходе выполнения проекта IT Simply Works European
Support Action (ITSy).
Ян Босх (Jan Bosch) в статье «Достижение
простоты на основе трехуровневой модели
продуктов» («Achieving Simplicity with the
академия ОС • библиотека
Three-Layer Product Model») рассматривает проблему делегирования ответственности в ходе разработки и сопровождения
ИТ-продуктов. Из опыта работы с крупными компаниями выводится несколько
принципов и рекомендаций определения
внутрифирменных центров компетенции
и контроля развития циклов разработки
продуктов.
В следующих четырех статьях номера исследуется потенциал подхода упрощения для достижения успеха на всех
этапах жизненного цикла разработки
ПО. Обсуждаются различные аспекты
неоднородности и изменчивости. В статье «Компонентные модели рассуждений» («Component Models for Reasoning»)
Кристина Сецелеану (Cristina Seceleanu)
и Ивица Крнкович (Ivica Crnkovic) приводят обзор абстрактных характеристик
распространенных компонентных моделей. Сравнивается их пригодность для
использования в целях формальных рассуждений с точки зрения возможностей
композиции — основного преимущества,
связанного с повторным использованием
компонентов.
А нна-Лена Лампрех т (A nna-L ena
Lamprecht), Стефан Науйокат (Stefan
Naujokat) и Ина Шейфер (Ina Schaefer)
в своей статье «Управление изменениями за рамками характеристических моделей» («Variability Management beyond
Feature Models») представляют подход
к упрощению управления и реализации
вариантов, возникающих при развитии
продукта и в процессе его разработки.
Эта полностью автоматическая генерация вариантов процесса обеспечивает
возможность упрощения определения
процесса на основе знаний, в результате
чего становится возможным прямой синтез исполняемых процессов.
Статью «Оперативная интеграция высокоуровневых процессов» («Plug-andPlay Higher-Order Process Integration»)
Йоханнес Ньюбауер (Johannes Neubauer) и
Бернхард Стеффен (Bernhard Steffen) посвятили подходу, позволяющему избежать
непредвиденных трудностей, возникающих при интеграции бизнес-процессов,
управлении их изменениями и обеспечении интероперабельности. Привлечение
эксперта прикладной области в процесс
разработки программного обеспечения
позволяет сократить число коммуникационных осложнений на протяжении всего
жизненного цикла разработки.
Чандра Прасад (Chandra Prasad) и
Вольфрам Шульте (Wolfram Schulte) в статье «Расширение возможностей средств
Программная инженерия и
формальные методы
4%
Наукометрия и
образование
1%
Теория вычислений
2%
Научные вычисления
17%
Алгоритмы
и структуры данных
37%
Основы математики
1%
Управление
3%
Междисциплинарные
приложения
7%
Искусственный
интеллект
14%
Информатика
5%
Параллельные и распределенные системы
2%
Компьютерная безопасность
и криптография
1%
Архитектура компьютеров
5%
Компьютерная графика и
визуализация
1%
Распределение статей, посвященных упрощению, по разным категориям ИТ
разработки» («Taking Control of Your
Engineering Tools») описывают переход к
этапу исполнения крупных, распределенных и неоднородных программных систем.
В то время как традиционные средства
разработки программного обеспечения
не поддерживают его миграцию в облачную инфраструктуру, система сборки, созданная в Microsoft в 2012 году, эту возможность обеспечивает. На основе опыта,
полученного при создании этой системы
авторы формулируют шесть принципов,
упрощающих облачную разработку.
Две последние заметки тематической
подборки посвящены состоянию дел в двух
разных прикладных областях. В заметке
«Инфраструктура интеграции инструментальных средств разработки надежных
встраиваемых систем» («A Tool Integration
Framework for Sustainable Embedded Systems
Development» Тибериу Сецелеану (Tiberiu
Seceleanu) и Гаетана Сапиенца (Gaetana
Sapienza) описывают, как воплощаются в
практические подходы результаты исследований, ранее полученных в индустрии
встраиваемых систем.
Регина Херцлингер (Regina Herzlinger),
Марго Зельцер (Margo Seltzer) и Марк Гаино
(Mark Gayno) в заметке «Применение KISS
в информационной технологии здравоохранения» («Applying KISS to Healthcare
Information Technology») характеризуют
текущее состояние ИТ в области здравоохранения. Кратко описываются проблемы, возникающие из-за неоднородности и
плохой совместимости информационных
систем. Предлагается набор упрощающих
принципов, которые, будучи очевидными
для разработчиков программного обеспечения, часто в реальной жизни нарушаются.
Вне тематической подборки опубликована статья «Быстрое прототипирование многозвенных облачных сервисов и
систем» («Rapid Prototyping of Multitier
Cloud-Based Services and Systems»), в которой Аршдип Бахга (Arshdeep Bahga) и
Виджай Мадизетти (Vijay Madisetti) описывают созданную ими облачную компонентную модель (Cloud Component Model,
CCM), позволяющую разработчикам многозвенных облачных приложений использовать преимущества облачной инфраструктуры независимо от применяемых
языка или платформы. Также создано несколько методологий использования CCM,
включая подход, помогающий разработчикам выбирать экономически эффективные реализации и выявлять возникающие
узкие места.
Всего вам доброго, Сергей Кузнецов
(kuzloc@ispras.ru) — профессор, МГУ
(Москва).
www.osmag.ru • 01/2014 • Открытые системы • 55
Open Systems. DBMS
IT for Bussiness
Innovative Technology for Computer Professionals
Editor in Chief
Dmitry V. Volkov, Senior Research Fellow, Keldysh
Institute of Applied Mathematics
Associate Editor in Chief, Research Features
Leonid S. Chernyak
Associate Editor in Chief, Special Issues
Natalia A. Dubova
Editorial Board
Valery D. Adzhiev, PhD in Computer Sciences, Senior
Research Lecturer, Bournemouth University, UK
Mikhail M. Gorbunov-Possadov, Doctor of physics
and mathematics, Assistant Professor, Moscow State
University, Keldysh Institute of Apllied Mathematics
Sergey D. Kuznetsov, Doctor of physics and mathematics, Professor, Moscow State University
Mikhail B. Kuzminsky, PhD of chemistry, Senior
Research Fellow, Institute of Organic Chemistry
Pavel B. Khramtsov, PhD in Computer Sciences,
Assistant Professor, National Research Nuclear
University (MEPhI)
Viktor Z. Shnitman, Doctor of technics, Professor,
Moscow Institute of Physics and Technology
Igor G. Fiodorov, PhD, Professor, MESI
Leonid K. Eisymont, PhD of physics and mathematics,
Senior Research Lecturer, RSI «KVANT»
Editorial Staff
Design
Maria S. Ryshkova
Cover Design
Igor A. Lapshin
Administrative Staff
President
Mikhail E. Borisov
General Manager
Galina A. Gerasina
Director, IT Media Group
Pavel V. Khristov
Commercial Director
Tatiana N. Filina
Circulation: Open Systems Journal (ISSN 1028-7493) is published
monthly by the Open Systems Publishing. Open Systems
Headquarters, Rustaveli str., 12A build 2, Moscow, Russia, 127254;
voice +7 495 725-4780; fax +7 495 725-4783.
Editorial: Unless otherwise stated, bylined articles, as well
as product and service descriptions, reflect the author’s or
firm’s opinion. Inclusion in Open Systems Journal does not
necessarily constitute endorsement by the Open Systems
Publishing. All submissions are subject to editing for style,
clarity, and space.
Permission to reprint/republish this material for commercial,
advertising, or promotional purposes or for creating new
collective works for resale or redistribution must be obtained
from the OpenSystems Publishing.
Copyright © 2014 Open Systems Publishing. All rights
reserved.
2014, Volume 22, Number 1
COVER FEATURES
BIG DATA TOOLS
12 An Earnest Talk on Big Data Technology
Big data and clouds exposed the unpreparedness of IT
industry to handle previously unheard of data amounts,
the lion's share of which is stored in relational databases:
the formerly dominant idea of converging all the diverse
data into plain tables is out-of-date now. Meanwhile, the
market has no comprehensive solutions for processing
large unstructured data flows coming in real-time from
a multitude of sources.
Leonid Chernyak (osmag@osp.ru),
Associate Editor in Chief, Open Systems
16 Big Data for IT Management
Big data analysis brings value today not only to bankers, biomedical scientists and marketers, but also to IT
managers. Meanwhile, existing IT management tools
do not provide means to assess their efficiency or to
predict performance dynamics. Moreover, the modern complexity of IT environments leaves no place for
manual management approaches at all.
Natalya Dubova (osmag@osp.ru), Associate
Editor in Chief, Special Features, Open Systems
20 Big Data in Broker's Hands
Algorithmic trade systems are used extensively by financial institutions for automated stock market bargaining.
The analysis of large amounts of diverse data performed
using corresponding systems, such as the solutions stack
from IBM Corp., allows getting a stable income through
discovering minute stock quote fluctuations.
Oleg Bolgarchuk (oleg.bolgarchuk@ru.ibm.com),
IT Architect, IBM
PLATFORMS
10 K averi All-in-One: AMD Kaveri APU
To gain competitive advantage in the microprocessor market, vendors make significant effort to provide
versatility of their products giving them self-regulation
capabilities. AMD is no exception with its hybrid chips
that could be equally well used in gaming, mobile, and
server applications.
Leonid Chernyak (osmag@osp.ru),
Associate Editor in Chief, Open Systems
SOFTWARE ENGINEERING
23 Testing Elastic Computing Systems
Elastic computing systems are a new breed of software
system that arose with cloud computing and continue
to gain increasing attention and adoption. They stretch
and contract in response to external stimuli such as the
input workload, aiming to balance resource use, costs,
and quality of service. Here, the authors introduce novel
ideas on testing for elastic computing systems.
Alessio Gambi (gambi@usi.ch), Waldemar
Hummer (hummer@usi.ch), Hong-Linh Truong
(truong@usi.ch), Schahram Dustdar (dustdar@usi.ch),
Researchers, Vienna University of Technology
APPLICATIONS
28 Video Commercials Monitoring
The development of video data processing systems is
traditionally thought of as a arduous task that could be
accomplished only by large software vendors. In certain cases however, the solution can be quite simple,
e.g., when the need to monitor the number of views of
a video commercial is to be addressed.
Konstantin Seleznyov (skostik@relex.ru),
Maksim Efremov (mefremov@relex.ru),
Vadim Melnikov (vadim@relex.ru), Engineers, RELEX
SECURITY
30 Critical Control System Protection
in the 21st Century
Critical control systems manage many of today’s critical infrastructures, whose continuous operation, maintenance, and protection are high national priorities. The
authors present the fundamental architectural components of these systems, identify vulnerabilities and potential threats, and describe protection solutions that
can be deployed to mitigate attacks.
Cristina Alcaraz (alcaraz@lcc.uma.es),
Postdoctoral researcher, University of Malaga;
Sherali Zeadally (szeadally@uky.edu),
Associate professor, University of Kentucky
INTEGRATION
36 I ntegration for Airbus
Aircraft industry is among the most competitive ones,
especially the niche of passenger narrowbody jet airliners. A stumbling block for the development in this area
is the necessity to work with legacy computer systems
used in aircraft models created decades ago. In some
cases however, the existing information siloes may allow
to recreate the model of such a legacy system to connect
it to modern lifecycle management solutions.
Nikita Kalutsky (nikita.kalutsky@progresstech.ru),
Engineer, Progresstech-Dubna
STANDARDS
39 Web Annotation
as a First-Class Object
The W3C Open Annotation Data Model provides facilities for annotating content directly on the Web without
changing the original content. Third-party semantic
annotations of content are now emerging as first-class
objects on the Web.
Paolo Ciccarese (ciccarese@gmail.com), Instructor
in Neurology, Harvard Medical School; Stian SoilandReyes (soiland-reyes@cs.manchester.ac.uk), technical
software architect, University of Manchester; Tim Clark
(tim_clark@harvard.edu), Director of Informatics
at the MassGeneral Institute for Neurodegenerative
Disease
OPINION
42 B
ig Data Solutions Stack
Everyone seems to talk about big data these days, but few
know how to handle them. It looks like the necessary technologies have come of age, but still haven't matured yet while
the solutions stack, whatever the leading market players
say, is a rather amorphous even if dynamic entity.
Dmitry Semynin (dsemynin@amt.ru), Director, AMT Group
OS MUSEUM
44 M
etcalfe’s Law after 40 Years of Ethernet
Critics have declared Metcalfe’s law, which states that
the value of a network grows as the square of the number of its users, a gross overestimation of the network
effect, but nobody has tested the law with real data.
Using a generalization of the sigmoid function called
the netoid, Ethernet’s inventor and the law’s originator models Facebook user growth over the past decade
and fits his law to the associated revenue.
Bob Metcalfe (bob.metcalfe@utexas.edu), Professor
of Innovation and Murchison Fellow of Free Enterprise,
The University of Texas at Austin.
EXTREME TECHNOLOGY
48 Tools for Data «Cowboys»
The responsibility of experts in the new field of data wrangling
is to prepare large data sets for subsequent analysis.
Leonid Chernyak (osmag@osp.ru),
Associate Editor in Chief, Open Systems
OS ACADEMY. Workshop
51 Automated Text Processing Systems
The current diversity of automated unstructured text
processing systems creates a need for their systematization and categorization required to ease the choice of
a solution optimally fit for a task at hand.
Dmitriy Ilvovsky (dilvovsky@hse.ru), Fellow;
Yekaterina Chernyak (echernyak@hse.ru), Fellow,
Higher School of Economics
OS Academy. Library
54 Power in simplicity
The November issue of Computer Magazine
(IEEE Computer Society, Vol. 46, No. 11, 2013) deals
with the topic of simplicity in IT
Sergey Kuznetsov (kuzloc@ispras.ru),
Professor, Moscow State University
Toyota демонстрирует
трехколесный гибрид
мотоцикла, автомобиля
и Segway
AltOS
Источник: Electrolux
Компания Toyota представила концептуальную модель трехколесного «персонального средства передвижения» под
названием iRoad. Мини-автомобиль обтекаемой формы имеет два колеса спереди и одно сзади. Заднее поворачивается, тогда как передние на поворотах
автоматически наклоняются.
iRoad обладает необычайной маневренностью: можно повернуть руль прямо
перед препятствием, и автомобиль выполнит поворот не потеряв устойчивости. Максимальная скорость iRoad —
около 50 км/ч, средства управления
очень простые: руль, газ, тормоз и кнопка запуска. В салоне предусмотрены
места для двоих.
Источник: Toyota
Летающие роботы-уборщики и дышащие стены
Компания Electrolux объявила проекты, победившие на организованном ею конкурсе Electrolux Design Lab 2013. Первое место заняла концепция системы уборки дома, представляющей собой рой миниатюрных летающих роботов, которые
чистят поверхности каплями воды. Благодаря им хозяин квартиры может, удобно
устроившись в кресле после трудного дня, наблюдать, как «автоматические феи,
словно по волшебству, преображают дом перед его глазами».
Второй приз достался дышащим стенам. Стены двигаются, имитируя «дыхание»,
и при этом очищают воздух микрофильтрами, работающими по принципу рыбьих
жабр. С помощью приложения для смартфона можно переключать режимы работы
стен — «снятие стресса», «навевание воспоминаний», «поднятие настроения» и т. д.
Третье место занял детский 3D-принтер здоровой еды Atomium. По замыслу, ребенок сможет сперва нарисовать на листке бумаги, как должно выглядеть блюдо,
а принтер из смеси загруженных в него родителями порошкообразных ингредиентов и воды с помощью системы шприцев приготовит заказ.
Hershey собирается печатать
шоколад на 3D-принтере
Источник: NASA
Инженеры НАСА проектируют роботов совершенно нового вида — сферических,
которых можно будет просто сбросить на другую планету без повреждений от
удара и которые будут перемещаться, катаясь по ее поверхности.
Корпус таких роботов будет строиться по принципу «тенсегрити», то есть представлять собой сферическую каркасную структуру натяжения-сжатия, сетку из
тросов и стержней, объясняют проектировщики. Не имея жестких соединений, колес или гусениц, эти аппараты будут обладать уникальным уровнем надежности,
представляя собой легкие конструкции, полностью амортизирующие удар
о поверхность планеты при сбросе с орбиты.
Сегодня ученые исследуют Марс с помощью роботизированных вездеходов
Curiosity и Opportunity — колесных машин, оснащенных научными приборами
и механизированными манипуляторами.
Перекатывающийся шарообразный робот с гораздо меньшей вероятностью застрянет в песке — именно такой инцидент привел к потере марсохода Spirit: после
безуспешных попыток ученых вытащить робота, застрявшего в песчаной дюне,
его миссию пришлось прекратить.
Роботы-сферы смогут
найти применение и
на Земле. Например,
их можно было бы
сбрасывать с самолетов для изучения
труднодоступных
территорий. Кроме
того, такие роботы
помогли бы при обследовании трубопроводов, пещер
и туннелей.
Источник: 3D Systems
НАСА готовится исследовать планеты,
сбрасывая на них роботы-колобки
Hershey и 3D Systems приступают к разработке 3D-принтеров для «печати» пищевых продуктов — шоколадных и других
изделий. На выставке потребительской
электроники CES компания 3D Systems
уже продемонстрировала два подобных
принтера для создания кондитерских изделий, в том числе шоколадных. Первый
из них, под названием ChefJet, предполагается продавать по цене около 5 тыс.
долл., а второй, более мощный ChefJet Pro,
будет стоить около 10 тыс. долл. ChefJet
способен изготавливать объекты с максимальным размером 8х8х6 дюймов, а
ChefJet Pro — 10х14х8 дюймов. Оба принтера могут печатать съедобными материалами со вкусом шоколада, ванили,
мяты, яблока, вишни и арбуза.
ISSN 1028-7493
ИТ для бизнеса —
архитекторам
информационных систем
www.osmag.ru
ИНСТРУМЕНТАРИЙ
БОЛЬШИХ ДАННЫХ
ISSN 1028-7493
Открытые системы. СУБД №01 2014 Инструментарий Больших Данных • Автоматическое управление ИТ
СУ
БД
Открытые
системы
№01
2014
Боб Меткалф: Ethernet сорок лет спустя
Большие Данные против индустрии ИТ
Секреты интеграции в Airbus
Новые гибридные микропроцессоры
Уязвимости и защита стратегических инфраструктур
•
•
•
•