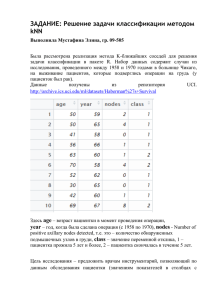
Реализация метода k ближайших соседей в пакете R Файл
реклама

Метод K-ближайших соседей для решения задачи классификации. Реализация в пакете R
Метод K-ближайших соседей для решения задачи классификации.
Реализация в пакете R
Рассмотрим реализацию метода K-ближайших соседей для решения задачи классификации в пакете R на примере, приведённом в [1, стр. 75 – 87]. В этом примере
использованы реальные данные. Они получены из медицинской базы данных штата
Висконсин, США и содержат результаты обследования 569 пациенток на предмет
обнаружения рака груди. Данные получены из репозитория GitHub
https://github.com/stedy/Machine-Learning-with-R-datasets – см. Рис.1.
Рис.1. Список файлов с данными для скачивания в репозитории GitHub
Выберем из списка файл wisc_bc_data.csv. Для начала откроем его – см. Рис.2.
…
Рис.2. Фрагменты таблицы с данными wisc_bc_data (https://github.com/stedy/Machine-Learning-with-Rdatasets/blob/master/wisc_bc_data.csv)
Здесь id – уникальный идентификатор пациентки; diagnosis – диагноз (значение переменной отклика): M (англ.: malignant) – злокачественный, B (англ.: benign)
– доброкачественный; остальные 30 столбцов содержат показатели, полученные с
1
Метод K-ближайших соседей для решения задачи классификации. Реализация в пакете R
помощью медицинских методов обследования. Все они представляют собой вещественные величины.
Цель исследования – предложить врачам инструментарий, позволяющий по
данным обследования пациентки (значениям показателей в столбцах с номерами
3 – 32) поставить диагноз (M или B).
Таким образом, мы имеем задачу бинарной классификации, поскольку классов всего 2 («M» и «B»).
Нажав на кнопку «Raw» (англ.: сырой, т.е. «сырые», исходные данные), откроем данные в виде, показанном на Рис.3.
Рис.3. Фрагменты текстового файла с данными wisc_bc_data.csv
Сохраним файл wbcd_data.txt на своём компьютере. Прочтём его в переменную wbcd1:
wbcd <- read.csv("wbcd_data.txt", stringsAsFactors = FALSE)
и выведем её значение. Получим результат, показанный на Рис. 4.
Рис.4. Фрагмент консоли с выведенным значением переменной wbcd.
1
Wbcd – от англ. Wisconsin breast cancer data
2
Метод K-ближайших соседей для решения задачи классификации. Реализация в пакете R
Мы назначили параметру stringsAsFactors (буквально: «строки как факторы»)
значение «FALSE», т.к. факторы соответствуют столбцам (а строки соответствуют
пациенткам).
Теперь мы можем обращаться к значениям столбцов по их именам. Например,
wbcd$id – вектор из уникальных идентификаторов пациенток;
wbcd$diagnosis – вектор из диагнозов и т.д.
Подсчитаем количество обоих значений диагноза:
table(wbcd$diagnosis)
Получим результат:
Реализованная в пакете R функция, выполняющая классификацию методом
kNN, предполагает, что переменная отклика (англ.: target feature) имеет тот же вид,
что и факторы. Поэтому перекодируем значения переменной отклика
(diagnosis), выделив 2 уровня («M» и «B») и заменив эти буквы на
«Malignant» и «Benign», соответственно:
wbcd$diagnosis <- factor(wbcd$diagnosis, levels = c("B", "M"),
labels = c("Benign", "Malignant"))
Подсчитаем проценты каждого из исходов, округлив результаты до десятых:
round(prop.table(table(wbcd$diagnosis))*100, digits = 1)
Получим:
Поскольку идентификатор нам для исследования не нужен, удалим этот столбец и сохраним данные в той же переменной:
wbcd <- wbcd[-1]
Посмотрим на сводные характеристики некоторых показателей (напомним,
что их всего 30), например, radius_mean, area_mean и smoothness_mean,
т.е. «средний радиус», «средняя площадь» и «средняя гладкость»2:
Здесь усреднение имеет следующий смысл: каждое из указанных измерений для каждой пациентки делается несколько раз и указывается среднее значение по числу измерений.
2
3
Метод K-ближайших соседей для решения задачи классификации. Реализация в пакете R
summary(wbcd[c("radius_mean", "area_mean", "smoothness_mean")])
Для каждого из названных 3-х показателей мы тем самым получим минимальное и максимальное значения, выборочное среднее и выборочную оценку медианы, а также выборочные оценки 25%-го и 75%-го квантилей (см. Рис.5).
Рис.5. Сводные характеристики 3-х выбранных показателей
Нетрудно видеть, что диапазоны значений выбранных нами показателей сильно
различаются. Применим нормализацию данных. Для этого напишем функцию:
normalize <- function(x) {return ((x - min(x)) / (max(x) - min(x)))}
Теперь, чтобы применить эту функцию к списку, будем использовать функцию lapply (здесь буква «l» – от английского «list», т.е. список, «apply» - англ.:
«применить»). Кроме того, преобразуем результат в объект data.frame (это, как
мы уже знаем, позволит обращаться непосредственно к строкам или столбцам матрицы) и сохраним результат в переменной: wbcd_n:
wbcd_n <- as.data.frame(lapply(wbcd[2:31], normalize))
Здесь мы указываем, что применяем нормализацию к столбцам с номерами 2 - 31.
(Напомним, что мы уже удалили первый столбец – id, теперь первый столбец содержит значения переменной отклика, а столбцы с номерами 2 — 31 содержат значения факторов (предикторов). После нормализации все переменные будут иметь
диапазон [0, 1]. В этом нетрудно убедиться, вновь вызвав функцию summary (но
уже для новой переменной, т.е. wbcd_n).
К сожалению, у нас нет данных, «непомеченных» буквами «M» и «B» (а есть только
данные, диагноз для которых уже поставлен). Поэтому для тестирования метода
kNN, разобьём выборку на 2 части – одну из них будем использовать как обучающую, а другую (несмотря на то, что мы знаем значения переменной отклика для
каждой записи в ней) будем использовать для прогноза значения переменной отклика. Потом мы сможем сравнить полученные результаты с истинным значением
переменной отклика (диагнозом).
Пусть в обучающую выборку (назовём её wbcd_train) войдут первые 469 записей:
4
Метод K-ближайших соседей для решения задачи классификации. Реализация в пакете R
wbcd_train <- wbcd_n[1:469, ]
В «подопытную» группу войдут остальные записи, т.е. те, что имеют номера от 470
до 569:
wbcd_test <- wbcd_n[470:569, ]
Замечание. Когда мы делим данные на «обучающие» и «тестовые», важно, чтобы обучающая
выборка была репрезентативной, т.е. содержала записи с разными значениями переменной отклика.
Нам нужно убрать значения переменной отклика из наборов данных (т.е.
оставить только значения факторов). Сохраним значения диагнозов в отдельных
векторах:
wbcd_train_labels <- wbcd[1:469, 1]
Это будут диагнозы из обучающей выборки («1» означает, что мы берём их из первого столбца).
wbcd_test_labels <- wbcd[470:569, 1]
Это – диагнозы для тестовой выборки (напомним, что мы их уже знаем, но хотим
использовать для проверки точности работы метода kNN).
Итак, данные для анализа готовы. Теперь нам нужна функция knn(). Она
находится в пакете class, который необходимо подключить.
Подключение пакетов в среде R
Выбор пакета в среде R осуществляется при помощи опции «Включить пакеты» меню «Пакеты» среды R. При выборе этой опции пользователю предлагается список установленных пакетов – см. Рис. 6.
Рис.6. Выбор пакета (из установленных)
5
Метод K-ближайших соседей для решения задачи классификации. Реализация в пакете R
Если нужный пакет ещё не установлен, его необходимо установить. Для
этого нужно выбрать из меню «Пакеты» опцию «Установить пакет(ы)». Откроется окно «Packages» со списком пакетов, доступных для установки.
В случае успешной установки в каталоге, где находится пакет R (например,
С:\\Program Files\\R – адрес будет указан в появившемся в этом случае сообщении)
появится папка, названная так же, как выбранный пакет.
Если указанным способом установить пакет не удаётся, нужно вызвать функцию install.packages(“имя библиотеки”). В этом случае нам будет предложено
выбрать «зеркало» CRAN (англ.: Comprehensive R Archive Network, т.е. «Полная
сеть архивов R») – см. Рис. 7.
Рис.7. Фрагмент окна для выбора «зеркала» CRAN
После установки пакета нужно вызвать функцию library:
library("class")
Вызовем теперь функцию knn():
wbcd_test_pred <- knn(train = wbcd_train, test = wbcd_test,cl =
wbcd_train_labels, k=21)
Здесь параметр train – имя обучающей выборки, test – имя тестовой выборки, cl
– имя файла со значениями переменной отклика для данных из обучающей выборки, k – число «опрошенных» соседей.
Распечатаем результат (мы сохранили его в переменной wbcd_test_pred) – см.
Рис.8.
6
Метод K-ближайших соседей для решения задачи классификации. Реализация в пакете R
Рис.8. Результаты работы метода kNN.
Распечатаем истинные значения переменной отклика для тестовой выборки (мы
ведь их, на самом деле, знаем – мы ранее сохранили их в файле) – см. Рис.9.
Рис.9. Истинные значения переменной отклика для тестовой выборки
На первый взгляд кажется, что эти списки совпадают, но при внимательном рассмотрении можно обнаружить отличия. Возникает вопрос:
насколько точен прогноз, сделанный методом kNN?
Ответить на этот вопрос нам поможет функция CrossTable из пакета
gmodels.
library("gmodels")
CrossTable(x = wbcd_test_labels, y = wbcd_test_pred, prop.chisq=FALSE)
Результат показан на Рис. 10.
7
Метод K-ближайших соседей для решения задачи классификации. Реализация в пакете R
Рис.10. Распределение результатов работы метода k-NN
Здесь
– левый верхний угол (Benign, Benign) содержит так называемые TN (англ.: True
Negative) прогнозы, т.е. те случаи, когда рака у пациентки на самом деле не было,
и метод kNN (правильно) решил, что его нет. Всего в тестовой выборке пациенток
с доброкачественными образованиями было 77 (см. столбец «Row Total»), и метод
kNN во всех 77 случаях правильно определил, что злокачественной опухоли нет.
Иными словами, ни у одной из здоровых пациенток метод kNN не определил онкологического заболевания.
– правый верхний угол (Benign, Malignant) – FP (англ.: False Positive) – содержит
количество ошибочно поставленных диагнозов «рак». Таких, как мы видим, не
оказалось.
– левый нижний угол (Malignant, Benign) – FN (англ.: False Negative) – содержит
количество «пропущенных» случаев заболевания. Иными словами, у 2-х пациенток (из 23) новообразование на самом деле было злокачественным, а метод kNN
этого не заметил.
– правый нижний угол (Malignant, Malignant) – TP (англ.: True Positive) – содержит количество правильно диагностированных случаев онкологического заболевания – 21 (из 23).
Мы описали верхний ряд чисел в каждой ячейке.
Второй ряд содержит относительные величины – частные от деления элементов
верхней строки на соответствующее число в строке «Row total».
8
Метод K-ближайших соседей для решения задачи классификации. Реализация в пакете R
Третий ряд содержит частные от деления элементов верхней строки на соответствующее число в столбце «Column total».
Четвёртый ряд содержит частоты – частные от деления элементов верхней строки
на объём тестовой выборки.
Таким образом, общее число ошибок метода kNN равно 2, что составляет 2% от
общего числа прогнозов.
Литература
1._Brett Lantz. Machine Learning with R. Pack Publishing. Birmongham-Mumbai, 2013.
9