Модуль морфологического анализа, проверки орфографии и
реклама

МОДУЛЬ МОРФОЛОГИЧЕСКОГО АНАЛИЗА, ПРОВЕРКИ ОРФОГРАФИИ И ЛЕММАТИЗАЦИИ
РУССКОГО ЯЗЫКА
1. Модель описания словоизменения.
Для описания словоизменения слово, точнее, его нормальная форма, представленная в
словнике, разбивается на 4 формальных фрагмента:
•
•
•
•
псевдооснова - неизменяемая графическая последовательность;
псевдосуффикс;
чередующаяся часть основы;
окончание.
Окончание при генерации словаря отщепляется автоматически в соответствии с
грамматической информацией, содержащейся в таблице окончаний, приписанной данному
слову.
В случае, если в основе слова есть чередования, то определяется, какой фрагмент чередуется с
каким (подбирается таблица чередований в основе), а от основы отщепляется фрагмент,
соответствующий нормальной форме слова.
Псевдосуффиксы генерируются автоматически и используются лишь для уменьшения
физического размера словаря, поэтому на них подробнее останавливаться не имеет смысла.
В перечисленных ниже примерах чередующийся фрагмент основы выделен жирным шрифтом, а
окончание - косым:
•
•
•
•
•
кош-к-а - кош-ек
кноп-к-а - кноп-ок
ос-ел - ос-л-а
л-ед - л-ьд-а
в-обр-ать - в-бер-у
Для каждого слова после отщепления всех изменяемых частей в словарь заносится часть речи,
ссылка на таблицу чередований в основе (если есть) и ссылка на таблицу окончаний.
При работе анализатора нужная ступень чередования выбирается по жестким формальным
правилам, которые в этом документе не приводятся.
2. Физическое устройство словаря
Словарь разбит на страницы средним объемом 0xF000 байт. Такой размер обусловлен, с одной
стороны, тем, что ссылки между таблицами в этом случае можно делать шестнадцатибитными, с
другой строны - стремлением увеличить до минимума размер одной страницы словаря, что
положительно сказывается на производительности программы в целом. Существует индекс по
этим страницам, но на нем подробнее останавливаться смысла нет, так как и интересного там
ничего нет.
3. Физическое устройство страницы словаря
Каждая страница словаря представляет собою дерево, в каждом узле которого, можно считать,
находится таблица, ставящая в соответствие каждому символу смещение аналогичной таблицы
следующего уровня.
Пусть словарь содержит лишь слова "стол", "столешница", "стоять", "стоить", "стрелять",
"судить" и "ты". Тогда, после отщепления всех изменчивых фрагментов, мы получим (в порядке
следования) графические псевдоосновы "стол", "столешниц", "сто", "сто", "стрел", "су" и "т".
Дерево, строящееся из них, можно представить следующим образом:
Под "грамматической информацией" следует понимать в данном случае часть речи, ссылку на
таблицу чередований в основе, ссылку на таблицу окончаний и список чередующихся
приставок.
4. Сканирование словаря
При сканировании устроенного таким образом словаря фактически идет перебор элементов
таблицы очередного уровня (0 - для первой буквы слова, 1 - для второй и т. д).
Рассмотрим этот процесс на примере изображенного выше словаря. Пусть на обработку
поступило слово "суд". Тогда, находясь в корне дерева, мы можем утверждать, что если такое
слово в словаре есть, то оно находится на ветви, начинающейся от буквы "с".
Переходим на второй уровень. Теперь текущая буква слова - "у". Допустимые буквы после "с" в
нашем словаре - "т" и "у". Если искомое слово в словаре есть, оно лежит на ветви дерева, на
которую ссылается буква "у".
На третьем уровне таблица пуста, что означает, что возможно лишь отождествление по
окончаниям. Понятно, что на таблице чередований "д/ж/ж" (судить - сужу - суженный) и
таблице окончаний глагола "су-д-ить" слово "суд" отождествиться не может.
5. Особенности реализации
Морфологический анализатор реализован в виде динамической библиотеки с экспортируемыми
функциями в стиле "C". Размер библиотеки со словарем - немногим более двух Mb. Двоичный
словарь включен в виде данных, что позволяет операционным системам оптимальным образом
подгружать и выгружать его страницы по мере надобности. Последнее (вкупе со способом
организации словаря - см. выше) обеспечивает высокую производительность анализатора более двадцати тысяч слов в секунду в режиме лемматизации с построением текстов
нормальных форм слов и грамматических описаний отождествлений.
Генерация словаря происходит полностью автоматически, процесс этот занимает не более трех
минут.
Процесс отождествления последовательности символов идет слева направо - то есть сначала
сканируется словарь основ, затем происходит отождествление остатка слова по
отсортированным лексикографически таблицам окончаний, что позволяет обрывать
сканирование, не проходя по всей таблице.
Основы в пределах страницы словаря разложены в таблицу переходов конечного автомата.
6. "Классический" программный интерфейс
6.1.
Структуры данных и терминология
Морфологический анализатор использует метафору аддитивности грамматической информации
о форме слова. Полное грамматическое описание формы слова занимает 16 бит и разбито на
следующие области:
•
•
•
•
•
•
•
•
•
временнáя характеристика глагольной формы - 3 бита;
лицо глагольной формы - 2 бита (1-е, 2-е и 3-е);
признак и тип причастия - 2 бита (действительное, страдательное, деепричастие и "не
причастие");
признак сравнительной степени - 1 бит;
признак краткой формы - 1 бит;
род - 2 бита (нет, м., ж., с.);
признак множественного числа - 1 бит;
падеж - 3 бита (8 значений);
признак возвратности - 1 бит.
Формально введены 2 дополнительных "времени" (помимо настоящего, прошедшего и
будущего) - инфинитив и императив.
Константы, позволяющие конструировать грамматические описания простым сложением,
приведены в заголовочном файле mlma1049.h.
Для полного грамматического описания формы слова используется структура
struct SGramInfo
{
unsigned char wInfo;
unsigned char iForm;
unsigned short gInfo;
unsigned char other;
},
где wInfo - информация о лексеме - часть речи и признаки флективности, iForm идентификатор формы слова, однозначно соответствующий грамматическому описанию для
данной части речи, gInfo - собственно грамматическое описание, other - некоторые
дополнительные признаки, из следует обратить внимание лишь на 2 - одушевленность (0x01) и
неодушевленность (0x02).
Также в заголовочном файле mlma1049.h декларированы коды ошибок, возвращаемые
функциями морфологического анализатора, и флаги его настройки.
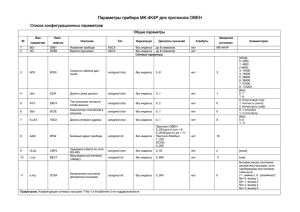
Коды ошибок морфологического анализатора
Код ошибки
Значение
Толкование
LEMMBUFF_FAILED
-1
Недостаточно места в массиве нормальных форм
LIDSBUFF_FAILED
-2
Недостаточно места в массиве лексем
GRAMBUFF_FAILED
-3
Недостаточно места для грамматических описаний
WORDBUFF_FAILED
-4
Слишком длинное слово или плохой указатель
PAGELOAD_FAILED
-5
Не удалось найти страницу словаря
PAGELOCK_FAILED
-6
Не удалось загрузить страницу словаря
Настройки анализатора
Флаг настройки
Значение
Толкование
sfStopAfterFirst
0x0001
Сканировать словарь до первого отождествления
sfIgnoreCapitals
0x0002
Игнорировать неправильные схемы капитализации
sfHardForms
0x0004
Разрешать затрудненные формы слов
nfAdjVerbs
0x0100
Нормализовать причастия, как прилагательные
Части речи
Часть речи
Внимание! Часть
Значение
речи есть
(SGramInfo.wInfo
& 0x3f)
1
Глагол несовершенного вида
2
Непереходный глагол несовершенного вида
3
Глагол совершенного вида
4
Непереходный глагол совершенного вида
5
Двувидовой глагол
6
Непереходный двувидовой глагол
7
Неодуш. существительное мужского рода
8
Одуш. существительное мужского рода
9
Одуш.-неодуш. существительное мужского рода
Неодуш. существительное мужского рода, склоняющееся по схеме
среднего
Одуш. существительное мужского рода, склоняющееся по схеме женского
Одуш. существительное мужского рода, склоняющееся по схеме среднего
Неодуш. существительное женского рода
Одуш. существительное женского рода
Одуш.-неодуш. существительное женского рода
Неодуш. существительное среднего рода
Одуш. существительное среднего рода
Одуш.-неодуш. существительное среднего рода
Неодуш. существительное общего рода
Одуш. существительное общего рода
Неодуш. существительное мужского/среднего рода
Одуш. существительное мужского/среднего рода
Неодуш. существительное женского/среднего рода
Неодуш. существительное множественного числа
Прилагательное
Прилагательное, образованное от географического названия
Притяжательное местоимение
Местоименное прилагательное
Местоимение множественного числа
Местоимение мужского рода
Местоимение женского рода
Местоимение среднего рода
Числительное
Числительное "два"
Собирательное числительное
Порядковое числительное
Имя собственное
Имя мужского рода
Имя женского рода
Отчество мужского рода
Отчество женского рода
Фамилия
Неизменяемое географическое название
Географическое название мужского рожа
Географическое название женского рода
Географическое название среднего рода
Географическое название множественного числа
Вводное слово
Междометье
Предикатив
Предлог
Союз
Частица
Наречие
Аббревиатура, пишущаяся прописными буквами
Аббревиатура, пишущаяся строчными буквами
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
59
60
6.2.
Проверка правописания
short WINAPI mlmaruCheckWord( const char* lpWord, word16 options );
Функция выполняет проверку правописания слова по словарю и возвращает
•
1, если слово опознано;
•
•
0, если слово не опознано;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
6.3.
lpWord - указатель на строку в кодировке 1251 Windows Cyrillic;
options - настройки морфологического анализатора (см. выше).
Лемматизация
short WINAPI mlmaruLemmatize( const char* lpWord,
word16
dwSets,
char*
lpLemm,
word32*
lpLids,
char*
lpGram,
word16
ccLemm,
word16
cdwLid,
word16
cbGram );
Функция выполняет отождествление поданной строки по морфологическому словарю и
возвращает
•
•
•
количество лексем, с формами которых произошло отождествление;
0, если слово не опознано;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
•
•
•
•
•
•
lpWord - указатель на строку в кодировке 1251 Windows Cyrillic;
dwSets - настройки морфологического анализатора (см. выше);
lpLemm - указатель на массив, в который анализатор помещает разделенные нулевым
символом нормальные формы слов, с которыми произошло отождествление (если
передано нулевое значение, нормальные формы не строятся);
lpLids - указатель на массив, в который анализатор кладет идентификаторы лексем,
соответствующие нормальным формам слов (если передано нулевое значение,
идентификаторы лексем не выдаются);
lpGram - указатель на массив, в который анализатор выдает грамматические описания
(SGramInfo) тех форм, с которыми произошло отождествление (если передано нулевое
значение, грамматические описания не строятся);
ccLemm - размер массива lpLemm или 0, если lpLemm == NULL;
cdwLid - размерность массива lpLids или 0, если lpLids == NULL;
ccGram - размер массива lpGram или 0, если lpGram == NULL.
Формат формируемого массива грамматических описаний:
Первым байтом лежит количество грамматических описаний отождествившихся форм для
очередной лексемы. Следом за ним лежит указанное количество структур SGramInfo,
каждая из которых описывает отождествление с конкретной грамматической формой.
Всего же в lpGram восстанавливается столько блоков описанной структуры, с формами
скольких лексем произошло отождествление.
Например, при лемматизации слова "клавиатуры" функция mlmaruLemmatize
возвращает 1. Это означает, что отождествление произошло с формами одной лексемы,
в lpLemm будет восстановлено слово "клавиатура", в lpLids - идентификатор лексемы, а
в lpGram будет помещен один блок грамматических описаний (количество
отождествлений - 3, Р.ед., И.мн., В.мн.).
6.4.
Построение словоформы по ее идентификатору
short WINAPI mlmaruBuildForm( const char* lpWord,
word32
dwLxID,
word16
dwsets,
byte08
idForm,
char*
lpDest,
word16
ccDest );
Функция строит формы указанного слова, соответствующие идентификатору, и возвращает
•
•
•
количество построенных форм (значение больше нуля);
0, если такого слова нет в словаре или у слова нет такой формы;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
•
•
•
•
6.5
lpWord - указатель на строку в кодировке 1251 Windows Cyrillic (может быть 0, в этом
случае обязательно должен быть задан идентификатор лексемы);
dwLxID - идентификатор лексемы (если задана строка, то его можно не указывать,
однако желательно указать, чтобы не были построены шумовые формы, возникающие
при отождествлении переданной строки с формами нескольких лексем);
dwSets - настройки морфологического анализатора (см. выше);
idForm - идентификатор грамматической формы слова;
lpDest - указатель на массив, в который анализатор помещает разделенные нулевым
символом формы слова;
ccDest - размер массива lpDest
Построение словоформы по ее грамматическому описанию
short WINAPI mlmaruBuildFormGI( const char* lpWord,
word32
dwLxID,
word16
dwSets,
word16
grInfo,
byte08
bFlags,
char*
lpDest,
word16
ccDest );
Функция строит формы указанного слова, соответствующие переданному грамматическому
описанию, и возвращает
•
•
•
количество построенных форм (значение больше нуля);
0, если такого слова нет в словаре или у слова нет такой формы;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
•
•
•
•
•
6.6.
lpWord - указатель на строку в кодировке 1251 Windows Cyrillic (может быть 0, в этом
случае обязательно должен быть задан идентификатор лексемы);
dwLxID - идентификатор лексемы (если задана строка, то его можно не указывать,
однако желательно указать, чтобы не были построены шумовые формы, возникающие
при отождествлении lpWord с формами нескольких лексем);
dwSets - настройки морфологического анализатора (см. выше);
grInfo - аддитивное грамматическое описание формы слова (см. выше);
bFlags - флаги одушевленности/неодушевленности;
lpDest - указатель на массив, в который анализатор помещает разделенные нулевым
символом формы слова;
ccDest - размер массива lpDest.
Итератор по идентификаторам лексем
short WINAPI mlmaruEnumWords( TEnumWords enumproc, void *lpv );
Функция - итератор по всем лексемам словаря. Возвращает
•
1 в случае успешного завершения перебора;
•
•
0 в случае прерывания пользователем;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
enumproc - указатель на функцию - callback, вызываемую для каждой лексемы;
lpv - внешний параметр, передаваемый enumproc без изменений.
Функция enumproc должна соответствовать следующему прототипу:
typedef short (* TEnumWords)( unsigned long lid, void* lpv );
6.7.
Низкоуровневая подсказка
short WINAPI mlmaruCheckHelp( const char* lpWord, char* lpList );
Функция низкоуровневого обслуживания подсказки для проверки орфографии и подобных
нужд. В ответ на строку-шаблон, содержащую один символ ? или * строит список символов,
которые могли бы стоять на его месте. При этом * служит для усечения справа, а ? обозначает
один символ. Возвращает
•
•
•
количество построенных символов в случае успешного завершения перебора;
0 в случае, если данному шаблону не соответствует ни одна словоформа;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
6.8.
lpWord - указатель на строку-шаблон в кодировке 1251 Windows Cyrillic;
lpList - адрес массива размером не менее 35 символов, в который будут помещены
символы-заместители.
Извлечение информации о лексеме
short WINAPI mlmaruGetWordInfo( word32 dwLxId, byte08* lpInfo );
Функция извлекает из словаря информацию о лексеме dwLxId - часть речи и некоторые
признаки словоизменения. Возвращает:
•
•
•
положительное значение в случае успеха;
0 в случае, если такая лексема в словаре отсутствует;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
dwLxId - идентификатор лексемы;
lpInfo - указатель на байт, куда следует поместить описание лексемы.
7. CXX-интерфейс
В настоящее время в рамках развития модуля реализован также расширенный интерфейс
доступа к модулю, более удобный в использовании и реализованный в духе стандарта COM. Он
НЕ является истинным COM-интерфейсом, к нему нет и не может быть type library, однако
доступ и обращения к нему выполняются практически так же.
Реально доступны два интерфейса взаимодействия - multibyte, использующий кодировку 1251
Windows Cyrillic, и widechar, опирающийся на unicode.
7.1.
Структуры данных и терминология
В дополнение к структуре SGramInfo, описанной выше, используются еще две структуры,
похожих одна на другую:
typedef struct
{
lexeme_t
const char*
SGramInfo*
unsigned
} SLemmInfoA;
nlexid;
plemma;
pgrams;
ngrams;
typedef struct
{
lexeme_t
nlexid;
const unsigned short* plemma;
SGramInfo*
pgrams;
unsigned
ngrams;
} SLemmInfoW;
Обе они описывают отождествления одной лексемы при лемматизации, однако первая из них
используется в multibyte-, а вторая - в unicode-интерфейсе при вызове функции лемматизации.
В этих структурах:
•
•
•
•
nlexid - идентификатор лексемы;
plemma - указатель на строку словарной формы слова или NULL, если построение
словарных форм не требуется;
pgrams - указатель на массив грамматических описаний отождествлений с формами
данной лексемы или NULL, если грамматические описания не требуются;
ngrams - количество грамматических описаний отождествлений для данной лексемы или
0, если грамматические описания не требуеются.
Сами интерфейсы декларированы в заголовочном файле mlma1049.h так, чтобы обращение к
ним было возможным не только из C++, но и из C-приложений с помощью приведенных там же
макроопределений. Для большей читаемости и наглядности здесь они приводятся так, как если
бы они были декларированы явно в программном коде C++.
struct IMlmaMb
{
virtual int CheckWord( const char*
pszstr, unsigned cchstr,
unsigned
dwsets );
virtual int Lemmatize( const char*
pszstr, unsigned cchstr,
SLemmInfoA*
plexid, unsigned clexid,
char*
plemma, unsigned clemma,
SGramInfo*
pgrams, unsigned ngrams,
unsigned
dwsets );
virtual int BuildForm( char*
output, unsigned
cchout,
lexeme_t
nlexid, unsigned char idform );
virtual int FindForms( char*
output, unsigned
cchout,
const char*
pszstr, unsigned
cchstr,
unsigned char
idform );
virtual int CheckHelp( char*
output, unsigned
cchout,
const char*
pszstr, unsigned
cchstr );
};
struct IMlmaWc
{
virtual int CheckWord( const unsigned short* pszstr, unsigned cchstr,
unsigned
dwsets );
virtual int Lemmatize( const unsigned short* pszstr, unsigned cchstr,
SLemmInfoW*
plexid, unsigned clexid,
unsigned short*
plemma, unsigned clemma,
SGramInfo*
pgrams, unsigned ngrams,
unsigned
dwsets );
virtual int BuildForm( unsigned short*
output, unsigned
cchout,
lexeme_t
nlexid, unsigned char idform );
virtual int FindForms( unsigned short*
output, unsigned
cchout,
const unsigned short* pszstr, unsigned
cchstr,
virtual int
unsigned char
idform );
CheckHelp( unsigned short*
output, unsigned
cchout,
const unsigned short* pwsstr, unsigned
cchstr );
};
7.2.
Доступ к интерфейсам
Для доступа к интерфейсам библиотека экспортирует два метода:
int MLMAPROC
mlmaruLoadMbAPI( IMlmaMb** );
int MLMAPROC
mlmaruLoadWcAPI( IMlmaWc** );
Оба метода ожидают указатель на указатель на интерфейс в качестве параметра и возвращают
либо 0, либо код ошибки в случае некорректного параметра. Никаких иных причин отказа в
инициализации не предусмотрено, так как резервирование памяти или иные операции, которые
могут быть неуспешными, при этом не производятся.
7.3.
Проверка правописания
int CheckWord( pszstr, cchstr, dwsets );
Функция выполняет проверку правописания слова по словарю и возвращает
•
•
•
1, если слово опознано;
0, если слово не опознано;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
•
7.4.
pszstr - указатель на строку, которую требуется проанализировать;
cchstr - длина строки в символах или (unsigned)-1, если строка заканчивается нулевым
символом;
dwsets - настройки морфологического анализатора (см. выше).
Лемматизация
int
Lemmatize( pszstr, cchstr,
plexid, clexid,
plemma, clemma,
pgrams, ngrams,
dwsets );
Функция выполняет отождествление поданной строки по морфологическому словарю и
возвращает
•
•
•
количество лексем, с формами которых произошло отождествление;
0, если слово не опознано;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
•
•
•
•
pszstr - указатель на строку, которую требуется проанализировать;
cchstr - длина строки в символах или (unsigned)-1, если строка заканчивается нулевым
символом;
plexid - указатель на массив структур SLemmInfoA или SLemmInfoW, в зависимости от
используемого интерфейса, куда будут восстановлены описания отождествившихся
лексем;
clexid - размерность этого массива;
plemma - указатель на массив, куда анализатор восстановит словарные формы слов,
или NULL, если этого не требуется;
clemma - размерность этого массива;
•
•
•
7.5.
pgrams - указатель на массив, куда анализатор восстановит грамматические описания
(SGramInfo) отождествившихся форм, или NULL, если этого не требуется;
cgrams - размерность этого массива;
dwsets - настройки морфологического анализатора (см. выше).
Построение формы слова
int
BuildForm( output, cchout,
nlexid, idform );
Функция выполняет построение указанной формы слова для заданной лексемы,
восстанавливает графические варианты начертания этой формы в выходной массив, разделяя
их нулевым символом, и возвращает
•
•
•
количество построенных вариантов начертания формы слова;
0, если слово не опознано;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
•
•
7.7.
output - указатель на массив, куда анализатор восстановит построенные варианты
формы слова;
cchout - размерность этого массива;
nlexid - идентификатор лексемы;
idform - идентификатор формы слова.
Построение форм возможных лексем
int
FindForms( output, cchout,
pszstr, cchstr,
idform );
Функция выполняет построение указанной формы слова для всех лексем, с которыми
произойдет отождествление поданной словоформы. Данная функция полезна для
использования в системах, которые не сохраняют идентификаторы лексем. Восстанавливает
графические варианты начертания формы в выходной массив, разделяя их нулевым символом,
и возвращает
•
•
•
количество построенных вариантов начертания формы слова;
0, если слово не опознано;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
•
•
•
7.8.
int
output - указатель на массив, куда анализатор восстановит построенные варианты
формы слова;
cchout - размерность этого массива;
pszstr - указатель на строку ключевой словоформы;
cchstr - длина строки в символах или (unsigned)-1, если строка заканчивается нулевым
символом;
idform - идентификатор формы слова.
Орфографическая подсказка
CheckHelp( output, cchout,
pszstr, cchstr );
Функция низкоуровневого обслуживания подсказки для проверки орфографии и подобных
нужд. В ответ на строку-шаблон, содержащую один символ ? или * строит список символов,
которые могли бы стоять на его месте. При этом * служит для усечения справа, а ? обозначает
один символ. Функция возвращает
•
•
количество построенных символов;
значение меньше нуля в случае ошибки (коды ошибок см. выше).
Аргументы:
•
•
•
•
output - указатель на массив, куда анализатор восстановит построенный список
символов;
cchout - размерность этого массива;
pszstr - указатель на строку шаблона;
cchstr - длина строки в символах или (unsigned)-1, если строка заканчивается нулевым
символом.