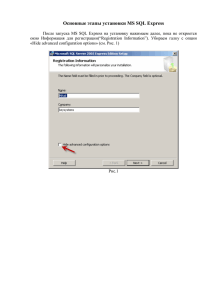
хранилища FILESTREAM
реклама

Техническая статья по SQL Server Автор: Пол С. Рэндел (Paul S. Randal) (SQLskills.com) Технические рецензенты: Александру Чирика (Alexandru Chirica), Аркадий Бржазовски (Arkadi Brjazovski), Прем Мехра (Prem Mehra), Джоанна Омел (Joanna Omel), Майк Рутрафф (Mike Ruthruff), Робин Дхаманкар (Robin Dhamankar) Опубликовано: октябрь 2008 г. Область применения: SQL Server 2008 Сводка. В настоящем техническом документе описывается версия SQL Server 2008 компонента FILESTREAM, который обеспечивает хранение и эффективный доступ к данным больших двоичных объектов с использованием SQL Server 2008 и файловой системы NTFS. Здесь рассматриваются варианты хранения больших двоичных объектов, настройки Windows и SQL Server для работы с данными файлового потока, рекомендации по использованию FILESTREAM совместно с другими компонентами и детали реализации, в частности секционирование и производительность. Технический документ предназначен для архитекторов, ИТ-специалистов и администраторов базы данных, занимающихся анализом или внедрением FILESTREAM. Предполагается, что читатель знаком с Windows и SQL Server и владеет как минимум базовыми знаниями о принципах работы баз данных, в частности транзакциях. Введение В современном обществе данные создаются с невероятной быстротой, а для их хранения и управления ими часто требуются эффективные методы. Для этого существуют различные технологии, и выбор технологии часто зависит от характера данных — структурированных, частично структурированных или неструктурированных. Структурированными данными называются данные, которые удобно хранить в реляционной схеме, например это могут быть данные по продажам компании. Их можно хранить в базе данных вместе с таблицами, содержащими сведения о продаваемых компанией товарах, о клиентах и о продажах товаров клиентам. Такие данные можно получать и обрабатывать с помощью полнофункционального языка запросов, например Transact-SQL. Частично структурированные данные, которые соответствуют нестрогой схеме, но не подходят для хранения в наборе таблиц базы данных, например это данные, каждая точка которых может иметь совершенно различные атрибуты. Частично структурированные данные часто хранятся с типом данных XML в программных продуктах базы данных Microsoft® SQL Server®, а для доступа к ним служит поэлементный язык запросов, например XQuery. Неструктурированные данные могут не иметь схемы (например, содержать данные в зашифрованном виде) или представлять собой большой массив двоичных данных (много мегабайтов или даже гигабайтов) на первый взгляд без схемы, но в действительности с очень простой, изначально присущей им схемой. Это могут быть файлы изображений, потоковое видео или аудиоклипы. В этом случае подразумевается, что двоичные данные могут содержать любые значения, а не только те, которые можно ввести с клавиатуры. Такие значения данных называются большими двоичными объектами, или BLOB. В настоящем техническом документе описывается версия SQL Server 2008 компонента FILESTREAM, который обеспечивает хранение и эффективный доступ к данным больших двоичных объектов с использованием SQL Server 2008 и файловой системы NTFS. Здесь рассмотрен сам компонент FILESTREAM, варианты хранения больших двоичных объектов, настройка операционной системы Windows® и SQL Server для работы с данными файловых потоков, рекомендации для объединения FILESTREAM с другими компонентами, детали реализации, например секционирование и производительность. Варианты для хранилища больших двоичных объектов Если структурированные и частично структурированные данные легко хранить в реляционной базе данных, то найти место хранения для неструктурированных данных или данных больших двоичных объектов несколько сложнее. При этом следует принимать во внимание следующие требования. 2 Производительность. Важнейший фактор — предполагаемый способ использования данных. Если требуется потоковый доступ, то хранение данных в базе данных SQL Server может привести к снижению быстродействия по сравнению с хранением во внешнем хранилище, например в файловой системе NTFS. При использования хранилища файловой системы данные считываются из файла и передаются клиентскому приложению (напрямую или с дополнительной буферизацией). Если большой двоичный объект хранится в базе данных SQL Server, то данные необходимо считать в память SQL Server (буферный пул), а затем через клиентское соединение передать клиентскому приложению. Это означает не только то, что данные будут проходить дополнительный шаг обработки, но также и то, что объем памяти SQL Server без необходимости «загрязняется» данными больших двоичных объектов, что может привести к дальнейшему снижению производительности SQL Server. Безопасность. Конфиденциальные данные, доступ к которым необходимо строго ограничивать, могут храниться в базе данных, а безопасность может обеспечиваться с помощью обычного управления доступом SQL Server. Если те же данные хранятся в файловой системе, то необходимо применять иные методы безопасности, например списки управления доступом (ACL). Размер данных. По результатам исследования, представленного ниже в этом техническом документе, большие двоичные объекты размером менее 256 КБ (например, значки миниприложений) лучше хранить в базе данных, а большие двоичные объекты размером больше 1 МБ — вне базы данных. Для объектов размером 256 КБ между 1 МБ выбор оптимального способа хранения зависит от соотношения операций считывания и записи данных и скорости «перезаписи». Хранение данных больших двоичных объектов исключительно в базе данных (например, с использованием типа данных varbinary (max)) ограничивается 2 ГБ на большой двоичный объект. Клиентский доступ. Протокол, используемый клиентом для доступа к данным SQL Server, например ODBC, может оказаться неподходящим для таких приложений, как потоковая передача больших видеофайлов. Это может потребовать хранения данных в файловой системе. Семантика транзакций. Если с данными больших двоичных объектов связаны структурированные данные, которые будут храниться в базе данных, то изменения в данных больших двоичных объектов должны соответствовать семантике транзакций, чтобы два набора данных оставались синхронизированными. Например, если в транзакции формируются данные больших двоичных объектов и создается строка в таблице базы данных, но затем выполняется откат, то создание данных больших двоичных объектов также нужно откатить. Процесс может оказаться очень сложным, если данные больших двоичных объектов хранятся в файловой системе без ссылки на базу данных. Фрагментация данных. Частые обновления и перезапись данных приводят к перемещению больших двоичных объектов в файлах базы данных SQL Server или в файловой системе в зависимости от места хранения данных. В этом случае, если большие двоичные объекты имеют большой объем, они могут сильно фрагментироваться (т. е. не будут храниться в одной непрерывной области диска). Фрагментацию проще устранять в файловой системе, нежели при использовании SQL Server. Управляемость. Решение, в котором используется несколько неинтегрированных технологий, будет более сложным и дорогостоящим в управлении, чем комплексное решение. Стоимость. Стоимость решения хранения зависит от используемой технологии. Приведенные выше объяснения, связанные с размерами и фрагментацией, основаны на известном исследовательском отчете Майкрософт: «To BLOB or Not to BLOB: Large Object Storage in a Database or a Filesystem? (Gray, Van Ingen, and Sears)». В документе, который вы найдете на странице, содержатся дополнительные сведения о достоинствах и недостатках подхода. http://research.microsoft.com/research/pubs/view.aspx?msr_tr_id=MSR-TR-2006-45 Существуют различные решения для хранения больших двоичных объектов, каждое из которых имеет свои достоинства и недостатки, зависящие от перечисленных выше требований. В следующей таблице сравниваются три типичных варианта хранения данных больших двоичных объектов, в том числе FILESTREAM, в SQL Server 2008. Критерий сравнения Максимальный размер большого двоичного объекта Производительность потоковой передачи крупных больших двоичных объектов Безопасность Затраты на ГБ Управляемость 3 Файловый сервер или файловая система Размер тома NTFS Решение хранения данных SQL Server FILESTREAM (с использованием varbinary (max)) 2 ГБ — 1 байт Размер тома NTFS Высокая Низкая Высокая Ручное управление списками управления доступом Встроенная Низкие Сложная Высокие Встроенная Интегрированная + автоматические списки управления доступом Низкие Встроенная Критерий сравнения Файловый сервер или файловая система Сложная Решение хранения данных SQL Server FILESTREAM (с использованием varbinary (max)) Согласованность Согласованность на уровне данных на уровне данных Интеграция со структурированными данными Разработка Более сложная Более простая Более простая и развертывание приложений Восстановление Отличное Слабое Отличное после фрагментации данных Производительность Высокая Средняя Низкая при частых небольших обновлениях Таблица 1. Сравнение технологий хранения больших двоичных объектов до SQL Server 2008 FILESTREAM — единственное решение, которое обеспечивает согласованность транзакций со структурированными и неструктурированными данными, а также интегрированное управление, безопасность, низкие затраты и превосходную производительность при потоковой передаче. Это достигается путем хранения структурированных данных в файлах базы данных, а неструктурированных данных больших двоичных объектов в файловой системе при сохранении согласованности транзакций между двумя хранилищами. Дополнительные данные об архитектуре FILESTREAM приведены в разделе «Общие сведения о FILESTREAM» ниже в этом техническом документе. Общие сведения о FILESTREAM Функция FILESTREAM впервые появилась в SQL Server 2008. Она позволяет хранить структурированные данные в базе данных, а связанные неструктурированные данные (т. е. большие двоичные объекты) — непосредственно в файловой системе NTFS. Это дает возможность обращаться к данным больших двоичных объектов через высокопроизводительные API потоковой передачи Win32®, не расплачиваясь снижением производительности при доступе к данным через SQL Server. FILESTREAM постоянно поддерживает согласованность транзакций между структурированными и неструктурированными данными, обеспечивая даже восстановление данных FILESTREAM на момент времени с использованием резервных копий журналов. Согласованность обеспечивается автоматически программой SQL Server и не требует пользовательской логики в приложении. В механизме FILESTREAM это достигается путем ведения эквивалента журнала транзакций базы данных, требования которого к управлению во многом такие же (более подробно это описано далее в разделе «Настройка сборки мусора FILESTREAM»). Сочетание журнала транзакций базы данных с журналом транзакций FILESTREAM позволяет правильно восстановить данные FILESTREAM и структурированные данные с точки зрения транзакций. FILESTREAM является не принципиально новым типом данных, а атрибутом хранилища существующего типа varbinary (max). FILESTREAM в основном работает так же, как и тип данных varbinary (max). Он изменяет способ хранения данных больших двоичных объектов, которые хранятся в файловой системе, а не в файлах данных SQL Server. Поскольку FILESTREAM реализуется в виде столбца типа varbinary (max) и интегрируется непосредственно в ядро СУБД, то большинство функций и средств управления без изменений работают с данными FILESTREAM. 4 Необходимо отметить, что работа стандартного типа данных varbinary (max) совершенно не изменится в SQL Server 2008, включая установленный предельный размер 2 ГБ. Добавление атрибута FILESTREAM практически снимает со столбца varbinary (max) ограничение по размеру (в действительности размер ограничен базовым томом NTFS). Данные FILESTREAM хранятся в файловой системе в наборе каталогов NTFS, которые называются контейнерами данных и соответствуют специальным файловым группам в базе данных. Транзакционным доступом к данным FILESTREAM управляют SQL Server и драйвер фильтра файловой системы, который устанавливается в процессе активации FILESTREAM на уровне Windows. Использование драйвера фильтра файловой системы также обеспечивает удаленный доступ к данным FILESTREAM в формате UNC. SQL Server поддерживает в своем роде ссылки из строк таблицы на файлы FILESTREAM, связанные с ними. Это означает, что удаление или переименование файлов FILESTREAM непосредственно в файловой системе приведет к повреждению базы данных. Для использования FILESTREAM требуется несколько изменений схемы для таблиц данных (в первую очередь это потребует, чтобы каждая строка имела уникальный идентификатор). Кроме того, налагается ряд ограничений при объединении с другими компонентами (например, нет возможности шифровать данные FILESTREAM). Все это подробно описано ниже в разделе «Настройка SQL Server для работы с FILESTREAM». Данные FILESTREAM можно получать и обрабатывать двумя способами: через стандартную программную модель Transact-SQL либо через потоковые API Win32. Оба механизма полностью совместимы с транзакциями и поддерживают большинство операций DML, в том числе операции вставки, обновления, удаления и выборки. Данные FILESTREAM также поддерживаются при выполнении таких операций обслуживания, как резервное копирование, восстановление и проверка целостности. Важное исключение — невозможность частичного обновления данных FILESTREAM. Любое обновление значения данных FILESTREAM приводит к созданию новой копии файла данных FILESTREAM. Старый файл будет асинхронно удален, как описано ниже в разделе «Настройка сборки мусора FILESTREAM». Доступ к данным больших двоичных объектов с использованием двойственной модели программирования После сохранения данных в столбце FILESTREAM доступ к ним возможен через транзакции Transact-SQL или через Win32 API. В этом разделе содержатся некоторые общие сведения о моделях программирования и их использовании. Доступ через Transact-SQL С помощью Transact-SQL данные FILESTREAM можно вставлять, обновлять и удалять следующим образом. 5 Поля FILESTREAM можно заранее заполнить с помощью операции вставки (с пустым значением или малым значением, отличным от NULL). Однако интерфейсы Win32 более эффективны для потоковой передачи больших объемов данных. При обновлении данных FILESTREAM происходит изменение базовых данных больших двоичных объектов в файловой системе. Если в поле FILESTREAM содержится значение NULL, то данные больших двоичных объектов, связанные с этим полем, удаляются. Пофрагментное обновление данных на Transact-SQL, реализованное как метод UPDATE.Write(), нельзя использовать для частичного обновления данных FILESTREAM. При удалении строки, содержащей данные FILESTREAM, а также при удалении или усечении таблицы, содержащей данные FILESTREAM, базовые данные больших двоичных объектов в файловой системе также будут удалены. Физическое удаление файлов FILESTREAM выполняется как асинхронный фоновый процесс, как описано далее в техническом документе «Настройка сборки мусора FILESTREAM». Дополнительные сведения и примеры использования Transact-SQL для доступа к данным FILESTREAM см. в разделе электронной документации по SQL Server 2008 «Управление данными FILESTREAM на языке Transact-SQL» (http://msdn.microsoft.com/ru-ru/library/cc645962.aspx). Потоковый доступ Win32 Чтобы разрешить доступ к данным FILESTREAM из транзакции через файловую систему, новая встроенная функция GET_FILESTREAM_TRANSACTION_CONTEXT () возвращает токен текущей транзакции, с которой связан сеанс. Эта транзакция должна быть начата, но еще не зафиксирована и не откачена. Получение токена позволяет приложению связать потоковые операции файловой системы FILESTREAM с запущенной транзакцией. Эта функция возвращает значение NULL, если явно начатая транзакция отсутствует. Токен нужно получить до обращения к файлам FILESTREAM. В FILESTREAM ядро СУБД управляет пространством имен физической файловой системы больших двоичных объектов. Новая встроенная функция PathName предоставляет логический UNC-путь объекта больших двоичных объектов, соответствующего каждому из полей FILESTREAM в таблице. В приложении этот логический путь используется для получения дескриптора Win32 и работы с данными больших двоичных объектов через обычные интерфейсы файловой системы Win32. Эта функция возвращает значение NULL, если значением столбца FILESTREAM является NULL. Это подчеркивает тот факт, что файл FILESTREAM необходимо заранее создать, прежде чем к нему можно получить доступ на уровне Win32. Как это сделать, было описано выше. Поддержка потоков в Win32 работает в контексте транзакции SQL Server. После того как получен токен транзакции и путь, интерфейс OpenSqlFilestream Win32 API используется для получения дескриптора файла Win32. Кроме того, можно использовать управляемый интерфейс SqlFileStream API. Затем этот дескриптор можно передавать при вызове методов интерфейсов потоков Win32, например ReadFile() и WriteFile(), для доступа и обновления файла средствами файловой системы. Учтите, что файлы FILESTREAM нельзя удалять напрямую. Их также нельзя переименовывать в файловой системе. В противном случае будет потеряна согласованность на уровне ссылок между файловой системой и базой данных (т. е. база данных по сути дела будет повреждена). Доступ к файловой системе FILESTREAM моделирует инструкцию Transact-SQL, вызывая операции открытия и закрытия файлов. Эта инструкция запускается при открытии дескриптора файла и завершается при закрытии этого дескриптора. Например, при закрытии обработчика записи срабатывают все возможные триггеры AFTER, зарегистрированные в таблице, как если бы была выполнена инструкция UPDATE. Дополнительные сведения и примеры использования API-интерфейсов Win32 для доступа к данным FILESTREAM см. в разделе электронной документации по SQL Server 2008 «Управление данными FILESTREAM с помощью Win32» (http://msdn.microsoft.com/ru-ru/library/cc645940.aspx). 6 Семантика транзакций Прежде чем транзакция будет зафиксирована или откачена, все дескрипторы файлов должны быть закрыты. Если дескриптор остался открытым при фиксации транзакции, то фиксация завершится ошибкой, а все дальнейшие операции чтения и записи с этим дескриптором, как и следует ожидать, приведут к сбою. Затем необходимо откатить эту транзакцию. Аналогичным образом при завершении работы базы данных или экземпляра ядра СУБД все открытые дескрипторы станут недействительными. Если файл FILESTREAM открыт для выполнения записи, то создается новый файл нулевой длины и все измененное значение данных FILESTREAM записывается в него. Старый файл будет асинхронно удален, как описано в разделе «Настройка сборки мусора FILESTREAM» далее в техническом документе. При работе с FILESTREAM ядро СУБД обеспечивает надежность транзакций при фиксации для данных FILESTREAM больших двоичных объектов, измененных на основе потокового доступа к файловой системе. Это выполняется с помощью упомянутого выше журнала FILESTREAM и явного сброса содержимого файла FILESTREAM на диск. Семантика изоляции Управление семантикой изоляции осуществляется уровнями изоляции транзакций ядра СУБД. Если доступ к данным FILESTREAM осуществляется через Win32 API, то поддерживается только уровень изоляции READ COMMITTED. Доступ через Transact-SQL также обеспечивает уровень изоляции REPEATABLE READ и сериализуемые уровни изоляции. Кроме того, при доступе через Transact-SQL «грязное» считывание разрешено через уровень изоляции READ UNCOMMITTED или указание запроса NOLOCK, но такой доступ не отображает обновления откатом незавершенных данных FILESTREAM. Открытые операции доступа к файловой системе не ожидают никаких блокировок. Вместо этого открытые операции моментально завершаются ошибкой, если вследствие изоляции транзакции не удается получить доступ к данным. Потоковые вызовы API завершаются ошибкой ERROR_SHARING_VIOLATION, если вследствие нарушения изоляции продолжение открытой операции невозможно. Частичные обновления Чтобы разрешить частичные обновления, приложение может выполнить команду FSCTL_SQL_FILESTREAM_FETCH_OLD_CONTENT для выборки старого содержимого в файл, открытый с помощью ссылки на дескриптор. Это можно также сделать через управляемый интерфейс SqlFileStream API с помощью флажка ReadWrite. Это приведет к копированию старого содержимого на стороне сервера, как было описано выше. Чтобы обеспечить повышение производительности приложения и избежать потенциальных сбоев из-за истечения времени ожидания при работе с очень большими файлами, следует использовать асинхронные операции ввода-вывода. Если выполнение команды FSCTL произошло после записи в дескриптор, то сохраняется последняя операция записи, а результаты предыдущих операций записи в дескриптор теряются. Дополнительные сведения о частичных обновлениях см. в разделе «FSCTL_SQL_FILESTREAM_ FETCH_OLD_CONTENT» электронной документации по SQL Server 2008 (http://technet.microsoft.com/ ru-ru/library/cc627407.aspx). 7 Сквозная запись с удаленных клиентов Удаленный доступ файловой системы к данным FILESTREAM осуществляется по протоколу Server Message Block (SMB). Если клиент является удаленным, то кэширование операций записи зависит от заданных параметров и используемого API. Например, по умолчанию машинный код API выполняет сквозную запись, а управляемые API по умолчанию используют буферизацию. Это различие появилось в результате отзывов пользователей о разных API и опыта их использования в предварительных CTP-версиях SQL Server 2008. В приложениях, работающих на удаленных клиентах, рекомендуется объединять небольшие операции записи (выполнять сквозную буферизацию), чтобы сократить число операций записи за счет укрупнения данных. Кроме того, если используется буферизация, то клиент должен выполнить явную очистку до фиксации транзакции. Создание представлений, отображаемых в памяти (в памяти операций ввода-вывода), с дескриптором FILESTREAM не поддерживается. Если для данных FILESTREAM используется отображение в памяти, то ядро СУБД не может гарантировать целостность, согласованность и надежность данных. Условия использования FILESTREAM Несмотря на многочисленные преимущества технологии FILESTREAM, в некоторых случаях она не будет оптимальным выбором. Как отмечалось ранее, размер данных больших двоичных объектов и шаблоны доступа — наиболее важные факторы, определяющие способ хранения данных больших двоичных объектов целиком внутри базы данных или в виде FILESTREAM. Размер влияет на следующие факторы: Эффективность доступа к данным больших двоичных объектов при использовании каждого механизма хранения. Как отмечалось ранее, потоковый доступ к крупным массивам данных больших двоичных объектов более эффективен с использованием FILESTREAM, однако частичные обновления выполняются медленнее (иногда значительно). Эффективность резервного копирования комбинированных структурированных данных и данных больших двоичных объектов с использованием каждого из механизмов хранения. Резервное копирование файлов базы данных SQL Server совместно с большим количеством файлов FILESTREAM выполняется медленнее, чем резервное копирование только файлов баз данных SQL Server такого же общего размера. Это связано с дополнительными затратами на резервное копирование каждого файла в файловой системе NTFS (одно на каждое значение данных FILESTREAM). Издержки будут тем заметнее, чем меньше размер файлов FILESTREAM (возрастает доля затрат времени в общем времени резервного копирования 1 МБ данных). В качестве примера на следующей диаграмме приведена относительная пропускная способность при локальном считывании данных больших двоичных объектов разного размера с помощью varbinary (max), FILESTREAM с помощью Transact-SQL и FILESTREAM через файловую систему NTFS. По синей линии можно видеть, что доступ в системе Win32 к данным FILESTREAM стал в несколько раз быстрее, чем доступ с использованием Transact-SQL к данным varbinary (max) по мере увеличения размера данных. Обратите внимание, что показатели пропускной способности даны в мегабитах в секунду (Мбит/с). 8 Рис. 1. Производительность при считывании больших двоичных объектов различных размеров Показатели NTFS включают время, необходимое для начала транзакции, получения пути и контекста транзакции из SQL Server, а также открытия дескриптора Win32 для данных FILESTREAM. Каждый тест был выполнен с использованием одного и того же компьютера с 4 процессорными ядрами и горячим буферным пулом SQL Server. Другой фактор, который следует учитывать, — можно ли переписать клиент или приложение промежуточного уровня на использование Win32 API наряду с обычным доступом к SQL Server. Если нет, то FILESTREAM будет неподходящим вариантом, поскольку оптимальная производительность достигается именно при использовании API потоковой передачи Win32. Настройка Windows для FILESTREAM Как и при любом развертывании, перед началом развертывания приложения, использующего FILESTREAM, важно подготовить сервер Windows, на котором будет размещаться база данных SQL Server и соответствующие контейнеры данных FILESTREAM. В этом разделе описано, как настроить оборудование хранилища и файловую систему NTFS при подготовке к использованию FILESTREAM. Затем будет показано, как включить FILESTREAM на уровне Windows. Выбор и настройка оборудования Одна из наиболее типичных причин низкой производительности при выполнении рабочей нагрузки — неудачная конфигурация оборудования. Иногда причина заключается в нехватке памяти, приводящей к «пробуксовке» в буферном пуле SQL Server, а иногда причина просто в том, что пропускная способность ввода-вывода оборудования хранилища недостаточна для данной рабочей нагрузки. Для приложений, которые будут использовать FILESTREAM для высокопроизводительной потоковой передачи данных больших двоичных объектов с использованием Win32 API, чрезвычайно важен выбор и настройка оборудования хранилища. 9 В следующих разделах приведены некоторые рекомендации по выбору и организации хранилища. Более глубокое рассмотрение этой темы можно найти в техническом документе «Physical Database Storage Design» на сайте TechNet (http://www.microsoft.com/technet/prodtechnol/sql/2005/ physdbstor.mspx). После проектирования и оптимизации структуры приложения рекомендуется провести нагрузочное тестирование, чтобы проверить производительность подсистемы вводавывода. Подробное описание см. в статье «Predeployment I/O Best Practices» на сайте TechNet SQL Server Best Practices (http://www.microsoft.com/technet/prodtechnol/sql/bestpractice/pdpliobp.mspx). Схема физического хранения Принимая решение о местоположении контейнера данных FILESTREAM, обязательно учитывайте предполагаемую рабочую нагрузку на него, а также рабочие нагрузки на все совместно размещенные контейнеры и файлы данных SQL Server. Возможно, потребуется разместить каждый контейнер данных FILESTREAM на отдельном томе, так как наличие нескольких контейнеров данных с интенсивными рабочими нагрузками на одном томе может привести к повышению конкуренции за ресурсы. Отсюда следует, что, если просто разместить их все на одном томе, не принимая в расчет рабочих нагрузок, то это чревато снижением производительности. Необходимая степень разделения, различная для разных клиентов. Можно также создать схему таблицы внутри SQL Server, которая обеспечит грубую балансировку нагрузки данных FILESTREAM между несколькими томами. Это описано в разделе «Балансировка загрузки данных FILESTREAM». Выбор уровня RAID Преимущества применения технологии RAID известны, и, кроме того, много написано о выборе уровня RAID, соответствующего требованиям приложения, поэтому в данном техническом документе эти вопросы не обсуждаются. В упомянутом выше техническом документе «Physical Database Storage Design» имеется отличный раздел об уровнях RAID и выборе уровней RAID. Ниже всего лишь кратко описаны факторы, которые необходимо принимать во внимание. Уровни RAID имеют ряд отличий, прежде всего по производительности чтения и записи, по стоимости и устойчивости к сбоям. Например, массив RAID 5 имеет относительно низкую цену, устойчив к сбою одного диска в массиве и не всегда пригоден для интенсивных рабочих нагрузок. С другой стороны, RAID 10 обеспечивает отличную производительность чтения и записи и устойчив к ошибкам нескольких дисков (в зависимости от уровня зеркального отображения), однако цена их выше при условии, что как минимум 50 % дисков в массиве RAID избыточные. Ниже перечислены три основных фактора, которые нужно учитывать при выборе уровня RAID. Выбор уровня RAID может быть другим для тома, где хранятся все пользовательские базы данных, и даже для томов, где хранятся файлы данных и файлы журнала одной базы данных. Если рабочая нагрузка связана с высокопроизводительной потоковой передачей данных FILESTREAM, то том контейнера данных FILESTREAM однозначно остановит свой выбор на использовании уровня RAID, поскольку он обеспечивает самую высокую производительность при считывании. Однако это может не дать высокой устойчивости при возникновении ошибок. С другой стороны, первым выбором может быть использование того же уровня RAID, что и у других томов, содержащих данные базы данных, но это может не обеспечить необходимого уровня производительности, требуемого для рабочей нагрузки. 10 Цель настоящего технического документа — подчеркнуть, что выбор уровня RAID для томов контейнера данных FILESTREAM должен быть обоснованным, решение должно приниматься после всесторонней оценки его достоинств и недостатков, а не после оценки единственного фактора. Выбор интерфейса диска Для типичных баз данных, содержащих данные больших двоичных объектов, общий размер данных часто многократно превосходит общий размер структурированных данных. В решении, связанном с хранением данных FILESTREAM на разных томах, предпочтительно использовать для тома более дешевое хранилище, например интегрированную среду разработки или SATA (далее просто «SATA»), а не дорогостоящее хранилище с интерфейсом SCSI. Прежде чем сделать этот выбор, необходимо понять и оценить связанные с ним компромиссы. В этом разделе приведен сравнительный обзор различных характеристик SCSI и IDE/SATA, которые помогут сделать обоснованный выбор исходя из требований к производительности, надежности и затратам. Емкость и производительность Диски SATA обычно имеют большую емкость, чем диски SCSI, но им присуща более низкая частота вращения. Частота вращения некоторых дисков SATA составляет 10 000 об/мин, но у большинства устройств она составляет от 5400 до 7200 об/мин. В продаже имеются высокопроизводительные диски SCSI с частотой вращения от 10 000 до 15 000 об/мин. Хотя показатель частоты вращения может оказаться полезным, при сравнении дисков необходимо учитывать задержку (время, за которое головка диска перемещается в нужное место на поверхности) и среднюю скорость передачи (объем данных, передаваемых или получаемых с поверхности диска за одну секунду). Также важно, чтобы диски могли эффективно выполнять сложные последовательности ввода-вывода. При выборе дисков убедитесь, что диски SATA поддерживают технологию Native Command Queue (NCQ), а диски SCSI — драйвер дисковой подсистемы Command Tag Queue (CTQ), это позволит им обрабатывать множественные и чередующиеся операции ввода-вывода для повышения производительности. В целом диски SCSI обычно имеют лучшие показатели задержки и скорости передачи и потому обеспечивают более высокую производительность при потоковой передаче, но их стоимость, как правило, выше. Надежность Для SQL Server требуется гарантированное упорядочение операций записи и устойчивость, чтобы обеспечить надежность и возможность восстановления через механизм упреждающего ведения журнала. Дополнительные сведения о требованиях к вводу-выводу см. в техническом документе TechNet «SQL Server I/O Basics» (http://www.microsoft.com/technet/prodtechnol/sql/2005/iobasics.mspx). По показателям надежности SCSI обычно превосходит SATA благодаря исчерпывающей поддержке принудительной записи данных на диск, чего нет в SATA. Это достигается за счет сквозной записи (записываемые данные вообще не кэшируются) либо принудительной передачи содержимого кэша на диск. Отсутствие любой из этих возможностей может повлиять на восстановление после сбоев питания, программного или аппаратного отказа. Все типы интерфейсов обеспечивают горячую замену, что позволяет вносить исправления при сохранении доступности. 11 Для работы FILESTREAM необходимо гарантировать упорядоченность записи и устойчивость. Устойчивость данных во время фиксации транзакции Упреждающее ведение журнала для создания и удаления файла FILESTREAM Устойчивость данных достигается за счет явной записи драйвером файловой системы FILESTREAM на диск тех файлов, которые были изменены до фиксации транзакции (подробное описание этого механизма выходит за рамки настоящего технического документа). Это гарантирует, что в случае отказа электропитания диски, не имеющие кэша с достаточным питанием от аккумулятора, не зафиксируются, но не записанные на диск данные FILESTREAM будут потеряны. Если диски SATA не поддерживают операцию принудительной записи на диск, то возможность восстановления снижается, что может привести к потере данных. Упреждающее ведение журнала зависит от целостности метаданных NTFS. А это в свою очередь зависит от надежности используемых дисков. Для SCSI такой проблемы не существует, но если диски SATA не обеспечивают принудительную запись на диск, то некоторые изменения метаданных NTFS могут быть потеряны в случае отказа питания. Результатом могут быть несколько вариантов. Не удалось восстановить NTFS и подключить том (т. е. контейнер данных FILESTREAM, в сущности, находится в режиме «вне сети»). Происходит восстановление NTFS, но изменения метаданных NTFS теряются, и SQL Server не располагает сведениями для отката незафиксированной транзакции, которая выполняет вставку данных FILESTREAM (т. е. происходит «утечка» данных FILESTREAM). Происходит восстановление NTFS, но изменения метаданных NTFS теряются, и SQL Server не имеет данных для отката незафиксированной транзакции, которая выполняет удаление данных FILESTREAM (т. е. данные FILESTREAM будут потеряны). Следует отметить, что все три сценария не хуже, чем в том случае, когда данные больших двоичных объектов хранятся вне базы данных на томе NTFS с дисками SATA, которые не поддерживают принудительную запись данных на диск. Использование FILESTREAM на томе с дисками SATA в этом случае фактически предпочтительнее, чем хранение данных больших двоичных объектов в необработанных файлах NTFS на том же томе, так как согласованность на уровне ссылок FILESTREAM обеспечивает механизм для обнаружения таких «повреждений» (с выполнением инструкции DBCC CHECKDB для базы данных). Таким образом, данные FILESTREAM надежно хранятся на дисковых томах SATA при условии, что диски SATA поддерживают принудительную запись данных через перенос содержимого кэша на диск. Настройка NTFS Даже самые продуманные подсистемы ввода-вывода на высокопроизводительном оборудовании могут функционировать не так, как требуется, если файловая система (в данном случае NTFS) настроена неправильно. В этом разделе описаны некоторые параметры настройки, которые могут повлиять на рабочую нагрузку, связанную с данными FILESTREAM. Более полный обзор NTFS см. статьях «NTFS Technical Reference» (http://technet.microsoft.com/ ru-ru/library/cc758691.aspx) и «Working with File Systems» (http://technet.microsoft.com/ru-ru/library/ bb457112.aspx) в библиотеке TechNet. 12 Оптимизация производительности NTFS По умолчанию настройка файловой системы NTFS не рассчитана на высокопроизводительное обслуживание рабочей нагрузки с десятками тысяч файлов в отдельном каталоге файловой системы (т. е. сценарий FILESTREAM). Необходимо настроить два параметра NTFS, обеспечивающие высокую производительность FILESTREAM. Особенно важно правильно задать параметры, прежде чем выполнять любые проверки производительности, в противном случае результаты не будут отражать истинную производительность FILESTREAM. Первый параметр конфигурации — отключение создания имен в формате 8.3 при создании файлов (или переименовании существующих). Этот процесс создает для каждого файла дополнительное имя, которое предназначено только для обратной совместимости с 16разрядными приложениями. Алгоритм создает новое имя в формате 8.3, а затем должен просмотреть через все существующие имена файлов в формате 8.3 имени в каталоге, чтобы убедиться в уникальности нового имени. По мере увеличения числа файлов в каталоге (обычно свыше 300 000) этот процесс будет занимать все больше времени. В свою очередь время создания файла увеличивается, а производительность снижается, поэтому, отключив этот процесс, можно значительно повысить производительность. Чтобы отключить этот процесс, введите следующую команду в командной строке, а затем перезагрузите компьютер. fsutil behavior set disable8dot3 1 Примечание. Этот параметр отключает создание имен в формате 8.3 на всех томах NTFS на сервере. Если какой-либо из томов используется 16-разрядными приложениями, то на нем после такого изменения могут возникнуть проблемы. Второй параметр, который можно отключить, — обновление сведений о времени последнего доступа к файлу. Если рабочая нагрузка выполняет краткие обращения к множеству файлов, то слишком много времени расходуется просто на запись времени последнего доступа к каждому из файлов. Отключение этого параметра может также существенно повысить производительность. Чтобы отключить этот процесс, введите следующую команду в командной строке, а затем перезагрузите компьютер. fsutil behavior set disablelastaccess 1 Размер кластера Во всех файловых системах Windows существует понятие кластера, который представляет собой единицу выделения места на диске. Поскольку кластер является наименьшей порцией дисковой памяти, которая может быть выделена, то для маленьких файлов часть кластера остается неиспользованной (в сущности, потерянной). Поэтому размер кластера обычно весьма мал, чтобы мелкие файлы не занимали на диске слишком много места. Большие файлы могут занимать множество кластеров. По мере увеличения размера файла в него добавляются новые кластеры. Если размер файла значительно увеличивается, но малыми фрагментами данных, то выделенные кластеры, скорее всего, будут располагаться на диске не последовательно (т. е. фрагментарно). Так что чем меньше кластеры и больше растет файл, тем более фрагментированным он становится. 13 Поэтому при определении размера кластера приходится идти на компромисс между потерями места на диске и фрагментацией. Более подробные сведения о различных размерах кластеров в файловых системах Windows приведены в статье базы знаний «Default Cluster Size for FAT and NTFS» (NTFS, FAT и http://support.microsoft.com/kb/140365). При использовании FILESTREAM рекомендуется делать так, чтобы отдельные блоки данных больших двоичных объектов составляли не менее 1 МБ. Если это так, то для снижения фрагментации рекомендуемый размер кластера NTFS для тома контейнера данных FILESTREAM должен составлять 64 КБ. Это необходимо сделать вручную, так как значение по умолчанию для томов NTFS до 2 терабайт (TБ) равно 4 КБ. Это можно сделать с помощью параметра /A в команде форматирования. Например, введите в командной строке: format F: /FS:NTFS /V:MyFILESTREAMContainer /A:64K Этот параметр должен сочетаться с большим размером буфера, как описано в разделе «Настройка производительности и рекомендации по проведению тестов производительности» далее в этом техническом документе. Управление фрагментацией Как отмечалось выше, при увеличении файлов на томе они будут фрагментироваться. Это означает, что выделенные кластеры для файла будут расположены не непрерывно. Если файл считывается последовательно, то головкам диска для считывания всех кластеров может потребоваться читать данные с разных участков диска. Даже если файлы не увеличиваются после их создания, но созданы на томе, где отсутствует единое непрерывное доступное пространство, может произойти их немедленная фрагментация, поскольку кластеры, необходимые для их размещения, расположены не непрерывно. Из-за фрагментации производительность операций последовательного чтения будет ниже, чем при отсутствии (или небольшой) фрагментации. Проблема очень похожа на фрагментацию индексов в базе данных, из-за которой снижается производительность при просмотре диапазона запроса. Поэтому очень важно периодически устранять фрагментацию с помощью средства дефрагментации диска, чтобы поддерживать высокую производительность при последовательном чтении. Кроме того, если том, на котором размещается контейнер данных FILESTREAM, раньше использовался или по-прежнему содержит другие данные, то следует проверить уровень фрагментации и при необходимости выполнить дефрагментацию. Сжатие Данные, которые хранятся в файловой системе NTFS, могут быть сжаты. Это экономит место на диске, но создает дополнительную нагрузку на ЦП, который будет выполнять сжатие и распаковку данных при их считывании и записи соответственно. Сжатие также не принесет пользы, если данные плохо сжимаемы. Например, произвольные, зашифрованные данные или уже сжатые данные сжимаются плохо, но их все же придется обработать алгоритмом сжатия NTFS, что приведет к дополнительной нагрузке на ЦП. По этим причинам сжатие полезно только в случае, когда данные удается сильно сжать, а дополнительная нагрузка на ЦП не приведет к снижению производительности при выполнении рабочей нагрузки. Также необходимо отметить, что сжатие может быть включено только в случае, если размер кластера NTFS не превышает 4096 байт. 14 Можно включить сжатие при форматировании тома контейнера данных FILESTREAM, если команда форматирования выполняется с параметром /C. Например: format F: /FS:NTFS /V:MyFILESTREAMContainer /A:4096 /C Сжатие можно включить на существующем томе, выполнив следующие шаги. 1. В разделе «Мой компьютер» или в проводнике щелкните том правой кнопкой мыши, чтобы сжать или распаковать его. 2. Выберите Свойства, чтобы открыть диалоговое окно Свойства. 3. На вкладке Общие установите или снимите флажок Сжимать диск для экономии места, а затем нажмите кнопку ОК. 4. В диалоговом окне Подтверждение изменения атрибутов выберите, должно сжатие применяться ко всему тому или только к корневой папке. Это показано на следующем рисунке. Рис. 2. Сжатие существующего тома с помощью проводника Windows 15 Управление местом на диске Различные контейнеры FILESTREAM можно разместить на одном томе NTFS, но есть аргументы в пользу распределения места между контейнерами данных и томами NTFS в пропорции 1:1. Помимо потенциальных конфликтов с рабочей нагрузкой, отсутствует способ управлять использованием пространства на диске контейнером данных FILESTREAM в SQL Server, для этого требуются дисковые квоты NTFS. Дисковые квоты отслеживаются для каждого пользователя и тома, поэтому при наличии нескольких контейнеров данных FILESTREAM на одном томе сложно определить, какой контейнер данных использует больше места на диске. Обратите внимание, что все файлы FILESTREAM будут созданы в контексте учетной записи службы SQL Server. В случае ее смены место на диске передается новой учетной записи службы. Существует единственный драйвер фильтра файловой системы FILESTREAM для каждого тома NTFS, имеющего контейнер данных FILESTREAM, а также один драйвер фильтра для каждой версии SQL Server, имеющей контейнер данных FILESTREAM на томе. Каждый драйвер фильтра обеспечивает управление всеми контейнерами данных FILESTREAM для этого тома, для всех экземпляров, использующих конкретную версию SQL Server. Например, том NTFS, на котором размещено три контейнера данных FILESTREAM, по одному для каждого из трех экземпляров SQL Server 2008, будет иметь только один драйвер фильтра файловой системы FILESTREAM для SQL Server 2008. Безопасность Существует два требования безопасности при использовании компонента FILESTREAM. Во-первых, SQL Server должен быть настроен для использования встроенных средств безопасности. Во-вторых, если будет использоваться удаленный доступ, то порт SMB (445) должен быть разрешен на всех системах брандмауэров. Те же требования действуют и для обычного удаленного доступа к общему ресурсу. Дополнительные сведения см. в статье базы знаний «Service Overview and Network Port Requirements for the Windows Server System» (http://support.microsoft.com/kb/832017). Вопросы применения антивирусных программ В настоящее время антивирусные программы применяются повсюду. FILESTREAM не может помешать антивирусной программе проверять файлы в контейнере данных FILESTREAM (это привело бы к снижению безопасности). Программное обеспечение обычно имеет настраиваемую политику для мер, применяемых к файлу, заподозренному в вирусном заражении. Можно удалить файл или ограничить доступ к нему («поместить в карантин»). В обоих случаях доступ к данным больших двоичных объектов из зараженного файла будет запрещен, а для SQL Server этот файл будет восприниматься как удаленный. Рекомендуется настроить антивирусную программу не на удаление файлов, а на помещение их в карантин. В SQL Server можно использовать инструкцию DBCC CHECKDB для обнаружения файлов, которые кажутся отсутствующими, а затем администратор Windows может сопоставить имена этих файлов с данными журнала антивирусной программы и предпринять меры для устранения угрозы. Включение FILESTREAM в Windows FILESTREAM является гибридным компонентом, поэтому администратор Windows и администратор SQL Server должны выполнить определенные действия перед его включением. Это необходимо для того, чтобы сохранить разделение обязанностей между двумя администраторами, особенно если администратор SQL Server не является администратором Windows. При включении FILESTREAM на уровне Windows устанавливается драйвер фильтра файловой системы. Только администратор Windows имеет право сделать это. 16 На уровне Windows FILESTREAM включается во время установки SQL Server 2008 или с помощью диспетчера конфигурации SQL Server. Необходимо выполнить следующие шаги. 1. 2. 3. 4. 5. 6. 7. 8. 9. В меню Пуск выберите пункт Все программы, затем Microsoft SQL Server 2008, Средства настройки и нажмите Диспетчер конфигурации SQL Server. В списке служб щелкните правой кнопкой мыши Службы SQL Server, а затем выберите пункт Открыть. В оснастке Диспетчер конфигурации SQL Server выберите экземпляр SQL Server, на котором нужно включить FILESTREAM. Щелкните правой кнопкой мыши экземпляр и выберите пункт Свойства. В диалоговом окне Свойства SQL Server перейдите на вкладку FILESTREAM. Установите флажок Разрешить FILESTREAM при доступе через Transact-SQL. Если нужно считывать и записывать данные FILESTREAM из Windows, установите флажок Разрешить FILESTREAM при потоковом доступе файлового вводавывода. Введите имя общего ресурса Windows в поле Имя общего ресурса Windows. Имя общего ресурса, где расположены данные FILESTREAM Разрешить удаленным клиентам потоковый доступ к данным FILESTREAM. Нажмите кнопку Применить. На следующем рисунке показана вкладка FILESTREAM, как описано в процедуре. Рис. 3. Настройка FILESTREAM с помощью диспетчера конфигурации SQL Server 17 Эту процедуру необходимо выполнить для каждого экземпляра SQL Server, где будет использоваться компонент FILESTREAM. Обратите внимание, что на данном этапе контейнер данных FILESTREAM не задается — файловая группа FILESTREAM в базе данных создается после того, как FILESTREAM был включен в SQL Server. Обратите внимание, что можно запретить доступ FILESTREAM на уровне Windows, даже когда он включен сервером SQL Server. В этом случае экземпляр SQL Server перезапускается и все данные FILESTREAM будут недоступны. Отображается следующее предупреждение. Рис. 4. Отображается предупреждение при отключении FILESTREAM с помощью диспетчера конфигурации SQL Server Настройка SQL Server для FILESTREAM Каждый экземпляр SQL Server, где будет использоваться компонент FILESTREAM, необходимо настроить отдельно как на уровне Windows, так и на уровне SQL Server. После включения FILESTREAM необходимо настроить базу данных для хранения данных FILESTREAM, только после этого можно определять таблицы, содержащие столбцы FILESTREAM. В этом разделе описывается настройка FILESTREAM на уровне SQL Server и метод создания баз данных и таблиц с поддержкой FILESTREAM, а также объясняется, как FILESTREAM взаимодействует с другими функциями в SQL Server 2008. Вопросы безопасности Для FILESTREAM требуется использование встроенной системы безопасности (т. е. проверки подлинности Windows). Когда приложение Win32 пытается обратиться к данным FILESTREAM, пользователь Windows проходит проверку в SQL Server. Если пользователь имеет доступ через Transact-SQL к данным FILESTREAM, то предоставляется также доступ на уровне Win32 при условии, что токен транзакции был получен в контексте безопасности пользователя Windows, который открывает файл. Требования к проверке подлинности Windows определяются особенностями API файлового ввода-вывода Windows. Единственный способ передать идентификатор клиента из клиентского приложения в SQL Server во время операций файлового ввода-вывода — использовать токен Windows, связанный с потоком клиента. Созданный контейнер данных FILESTREAM будет автоматически защищен, поэтому только учетная запись службы SQL Server и члены группы BUILTIN\Administrators имеют доступ к дереву каталогов контейнера данных. Следует соблюдать осторожность, чтобы содержимое контейнера данных изменялось только с помощью поддерживаемых транзакционных методов, так как изменение с помощью других методов приведет к повреждению контейнера. 18 Включение FILESTREAM в SQL Server Второй шаг (включение FILESTREAM) выполняется на экземпляре SQL Server 2008. Этого не следует делать до тех пор, пока не будет включен FILESTREAM на уровне Windows и не подготовлен том NTFS, на котором будут храниться данные FILESTREAM (как описано выше в разделе «Настройка Windows для FILESTREAM»). На экземпляре SQL Server доступ к FILESTREAM управляется с помощью процедуры sp_configure, которая позволяет установить параметр конфигурации filestream_access_level в одно из трех значений. Допустимые параметры: 0 — отключить поддержку FILESTREAM для данного экземпляра. 1 — включить FILESTREAM только для доступа через Transact-SQL. 2 — включить FILESTREAM для Transact-SQL и потокового доступа через Win32. В следующем примере показано, как включить FILESTREAM для Transact-SQL и потокового доступа через Win32. EXEC sp_configure filestream_access_level, 2; GO RECONFIGURE; GO Инструкция RECONFIGURE необходима для того, чтобы вновь заданное значение вступило в силу. Обратите внимание, что если FILESTREAM не включен на уровне Windows, то он не будет включен на уровне SQL Server при выполнении приведенного выше кода. Текущее заданное значение можно найти с помощью приведенного ниже кода. EXEC sp_configure filestream_access_level; GO Если FILESTREAM не настроен на уровне Windows, то значение «config_value» на выходе sp_configure будет отличаться (т. е. 0) от «run_value» после выполнения инструкции RECONFIGURE. Создание базы данных с поддержкой FILESTREAM После того как компонент FILESTREAM будет включен на уровнях Windows и SQL Server, станет возможно определить контейнер данных FILESTREAM. Это делается путем определения файловой группы FILESTREAM в базе данных. Существует соответствие 1:1 между файловыми группами FILESTREAM и контейнерами данных FILESTREAM. 19 Файловую группу FILESTREAM можно определить как во время создания базы данных, так и отдельно с помощью инструкции ALTER DATABASE. В следующем примере создается файловая группа FILESTREAM в существующей базе данных. ALTER DATABASE Production ADD FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM; GO Предложение CONTAINS FILESTREAM необходимо для того, чтобы отличить новую файловую группу от стандартных файловых групп базы данных. Если компонент FILESTREAM отключен, то выполнение данной инструкции завершится следующей ошибкой. Сообщение 5591, уровень 16, состояние 3, строка 1 Компонент FILESTREAM отключен. При условии, что FILESTREAM включен на уровнях Windows и SQL Server, файловая группа будет создана. На этом этапе контейнер данных FILESTREAM определен путем добавления одного файла в файловую группу. Указанный путь представляет собой путь к каталогу, который будет создан в качестве корневого для контейнера данных. Должен быть указан весь путь, за исключением окончательного имени каталога. В следующем примере определяется контейнер данных для созданной ранее файловой группы FileStreamGroup1. ALTER DATABASE Production ADD FILE ( NAME = FSGroup1File, FILENAME = 'F:\Production\FSDATA') TO FILEGROUP FileStreamGroup1; GO На этом этапе будет создан каталог FSDATA. Он не будет содержать ничего, кроме двух объектов. 20 Файл filestream.hdr. Это метаданные FILESTREAM для контейнера данных. Каталог $FSLOG. Аналог FILESTREAM для журнала транзакций базы данных. Следует отметить, что база данных может иметь несколько файловых групп FILESTREAM. Это может оказаться полезным для того, чтобы разделить хранилище больших двоичных объектов для нескольких таблиц в базе данных. Создание таблицы для хранения данных FILESTREAM Если база данных содержит файловую группу FILESTREAM, то можно создавать таблицы, содержащие столбцы FILESTREAM. Как упоминалось ранее, столбец FILESTREAM определяется как столбец varbinary (max) с атрибутом FILESTREAM. Следующий код создает таблицу с одним столбцом FILESTREAM. USE Production; GO CREATE TABLE DocumentStore ( DocumentID INT IDENTITY PRIMARY KEY, Document VARBINARY (MAX) FILESTREAM NULL, DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL UNIQUE DEFAULT NEWID ()) FILESTREAM_ON FileStreamGroup1; GO В таблице может содержаться несколько столбцов FILESTREAM, но данные из этих столбцов должны храниться в одной файловой группе FILESTREAM. Если предложение FILESTREAM_ON не указано, то будет использоваться файловая группа FILESTREAM, выбираемая по умолчанию. Такая конфигурация может оказаться неоптимальной и привести к проблемам с производительностью. После создания таблицы контейнер данных FILESTREAM будет содержать другой каталог, соответствующий таблице с вложенным каталогом, соответствующим столбцу FILESTREAM в таблице. Этот вложенный каталог будет содержать файлы данных после введения данных в таблицу. Структура каталогов будет зависеть от числа столбцов FILESTREAM в таблице и от того, является ли таблица секционированной. Обратите внимание, что таблица, имеющая один или несколько столбцов FILESTREAM, должна также иметь столбец типа uniqueidentifier с атрибутом ROWGUIDCOL. Этот столбец не должен допускать значений NULL и должен иметь относящееся к одному столбцу ограничение UNIQUE или PRIMARY KEY. Значение идентификатора GUID для столбца должно быть предоставлено либо приложением во время вставки данных, либо ограничением DEFAULT, которое использует функцию NEWID () (или NEWSEQUENTIALID (), если задана репликация слиянием, как описано в разделе «Сочетания функций и ограничения» ниже). 21 Дополнительные сведения о подробностях и ограничениях схемы и параметров таблицы см. в разделе «CREATE TABLE (Transact-SQL)» электронной документации по SQL Server 2008 на странице http://msdn.microsoft.com/ru-ru/library/ms174979.aspx. Настройка сборки мусора FILESTREAM Файлы данных FILESTREAM в контейнере данных FILESTREAM нельзя обновить частично. Это означает, что при любом изменении данных больших двоичных объектов в столбце FILESTREAM будет создаваться новый файл данных FILESTREAM. «Старый» файл необходимо хранить до тех пор, пока он нужен для целей восстановления. Файлы, представляющие удаленные данные FILESTREAM, или подвергшиеся откату операции вставки данных FILESTREAM аналогичным образом сохраняются. Файлы, которые больше не нужны, удаляются процессом сборки мусора. Это автоматический процесс, в отличие от Windows SharePoint® Services, где сборщик мусора необходимо реализовать вручную для внешнего хранилища больших двоичных объектов. Все файловые операции FILESTREAM сопоставляются с регистрационным номером транзакции (LSN) в журнале транзакций базы данных. После усечения журнала транзакций с удалением номера LSN операции FILESTREAM файл больше не нужен и может быть обработан сборщиком мусора. Поэтому все, что может помешать усечению журнала транзакций, также может помешать и физическому удалению файла FILESTREAM. Некоторые примеры. В модели восстановления FULL или BULK_LOGGED не было выполнено резервное копирование журналов. Существует длительно выполняющаяся активная транзакция. Не запущено задание чтения журнала репликации. Сборка мусора FILESTREAM — фоновая задача, которая активируется процессом контрольной точки базы данных. Контрольная точка автоматически выполняется при создании достаточного журнала транзакций. Дополнительные сведения см. в разделе «CHECKPOINT и активная часть журнала» электронной документации по SQL Server 2008 (http://msdn.microsoft.com/ ru-ru/library/ms189573.aspx). С учетом того, что файловые операции FILESTREAM минимально протоколируются в журнале транзакций базы данных, может пройти много времени, прежде чем число записей в журнале транзакций достигнет величины, которая запустит процесс контрольных точек, и начнется сборка мусора. При возникновении проблем можно начать сборку мусора с помощью инструкции CHECKPOINT. Вопросы секционирования Если таблица, содержащая данные FILESTREAM, секционирована, то предложение FILESTREAM_ON должно задавать схему секционирования, в том числе файловые группы FILESTREAM, на основе функции секционирования таблицы. Это является обязательным, так как в обычной схеме секционирования задействованы обычные файловые группы, которые не могут использоваться для хранения данных FILESTREAM. Определение таблицы (в инструкции CREATE TABLE или CREATE CLUSTERED INDEX … WITH DROP_EXISTING) указывает обе схемы секционирования. Схема секционирования FILESTREAM может указывать, что все секции сопоставляются с одной файловой группой, но так делать не рекомендуется, так как это может привести к снижению производительности. 22 Этот синтаксис показан в следующем (искусственном) примере. CREATE PARTITION FUNCTION DocPartFunction (INT) AS RANGE RIGHT FOR VALUES (100000, 200000); GO CREATE PARTITION SCHEME DocPartScheme AS PARTITION DocPartFunction TO (Data_FG1, Data_FG2, Data_FG3); GO CREATE PARTITION SCHEME DocFSPartScheme AS PARTITION DocPartFunction TO (FS_FG1, FS_FG2, FS_FG3); GO CREATE TABLE DocumentStore ( DocumentID INT IDENTITY PRIMARY KEY, Document VARBINARY (MAX) FILESTREAM NULL, DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL UNIQUE DEFAULT NEWID () ON Data_FG1) ON DocPartScheme (DocumentID) FILESTREAM_ON DocFSPartScheme; GO Обратите внимание, что для использования столбца DocumentID в качестве столбца секционирования базовый некластеризованный индекс, применяющий ограничение UNIQUE к DocGUID, должен быть явным образом размещен в файловой группе, так как столбец DocumentID может быть столбцом секционирования. Это означает, что переключение секций возможно только в том случае, если ограничения UNIQUE отключены перед выполнением переключения секций, так как они представляют собой невыровненные индексы, а затем повторно включены. 23 Продолжая предыдущий пример, приведенный ниже код создает таблицу, а затем пытается переключить секции. CREATE TABLE NonPartitionedDocumentStore ( DocumentID INT IDENTITY PRIMARY KEY, Document VARBINARY (MAX) FILESTREAM NULL, DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL UNIQUE DEFAULT NEWID ()); GO ALTER TABLE DocumentStore SWITCH PARTITION 2 TO NonPartitionedDocumentStore; GO Переключение секции завершается следующим сообщением об ошибке. Сообщение 7733, уровень 16, состояние 4, строка 1 «ALTER TABLE SWITCH» — ошибка при выполнении инструкции. Таблица «FileStreamTestDB.dbo.DocumentStore» секционирована, а индекс «UQ_Document_8CC1617F60ED59» не секционирован. Отключить уникальный индекс в исходной таблице и повторить попытку можно с использованием следующего кода. ALTER INDEX [UQ__Document__8CC331617F60ED59] ON DocumentStore DISABLE; GO ALTER TABLE FileStreamTest3 SWITCH PARTITION 2 TO NonPartitionedFileStreamTest3; GO 24 Эта попытка также завершится следующим сообщением об ошибке. Сообщение 4947, уровень 16, состояние 1, строка 1 ALTER TABLE SWITCH — ошибка при выполнении инструкции. Отсутствует идентичный индекс в исходной таблице «FileStreamTestDB.dbo.DocumentStore» для индекса «UQ_NonParti_8CC3316103317E3D» в целевой таблице «FileStreamTestDB.dbo.NonPartitionedDocumentStore». Прежде чем выполнить переключение, убедитесь в том, что отключены уникальные индексы как в секционированных, так и несекционированных таблицах. ALTER INDEX [UQ__NonParti__8CC3316103317E3D] ON NonPartitionedDocumentStore DISABLE; GO ALTER TABLE DocumentStore SWITCH PARTITION 2 TO NonPartitionedDocumentStore; GO ALTER INDEX [UQ__NonParti__8CC3316103317E3D] ON NonPartitionedDocumentStore REBUILD WITH (ONLINE = ON); ALTER INDEX [UQ__Document__8CC331617F60ED59] ON NonPartitionedDocumentStore REBUILD WITH (ONLINE = ON); GO Дополнительные сведения о секционировании данных FILESTREAM будут приведены в будущем техническом документе о секционировании в SQL Server 2008. Балансировка нагрузки данных FILESTREAM Секционирование можно также применять для создания схемы таблицы, которая допускает грубую балансировку нагрузки данных FILESTREAM между несколькими томами. Это может оказаться желательным по многим причинам, в частности из-за аппаратных ограничений или чтобы разрешить хранение гиперобъектов в таблице на разных томах. 25 Следующий код демонстрирует функцию и схему секционирования по столбцу uniqueidentifier, который, в сущности, распределяет данные FILESTREAM по 16 томам при чередовании структурированных данных между двумя файловыми группами. USE master; GO -- Создание базы данных CREATE DATABASE Production ON PRIMARY (NAME = 'Production', FILENAME = 'E:\Production\Production.mdf'), FILEGROUP DataFilegroup1 (NAME = 'Data_FG1', FILENAME = 'F:\Production\Data_FG1.ndf'), FILEGROUP DataFilegroup2 (NAME = 'Data_FG2', FILENAME = 'G:\Production\Data_FG2.ndf'), FILEGROUP FSFilegroup0 CONTAINS FILESTREAM (NAME = 'FS_FG0', FILENAME = 'H:\Production\FS_FG0'), FILEGROUP FSFilegroup1 CONTAINS FILESTREAM (NAME = 'FS_FG1', FILENAME = 'I:\Production\FS_FG1'), FILEGROUP FSFilegroup2 CONTAINS FILESTREAM (NAME = 'FS_FG2', FILENAME = 'J:\Production\FS_FG2'), FILEGROUP FSFilegroup3 CONTAINS FILESTREAM (NAME = 'FS_FG3', FILENAME = 'K:\Production\FS_FG3'), FILEGROUP FSFilegroup4 CONTAINS FILESTREAM (NAME = 'FS_FG4', FILENAME = 'L:\Production\FS_FG4'), FILEGROUP FSFilegroup5 CONTAINS FILESTREAM (NAME = 'FS_FG5', FILENAME = 'M:\Production\FS_FG5'), FILEGROUP FSFilegroup6 CONTAINS FILESTREAM (NAME = 'FS_FG6', FILENAME = 'N:\Production\FS_FG6'), 26 FILEGROUP FSFilegroup7 CONTAINS FILESTREAM (NAME = 'FS_FG7', FILENAME = 'O:\Production\FS_FG7'), FILEGROUP FSFilegroup8 CONTAINS FILESTREAM (NAME = 'FS_FG8', FILENAME = 'P:\Production\FS_FG8'), FILEGROUP FSFilegroup9 CONTAINS FILESTREAM (NAME = 'FS_FG9', FILENAME = 'Q:\Production\FS_FG9'), FILEGROUP FSFilegroupA CONTAINS FILESTREAM (NAME = 'FS_FGA', FILENAME = 'R:\Production\FS_FGA'), FILEGROUP FSFilegroupB CONTAINS FILESTREAM (NAME = 'FS_FGB', FILENAME = 'S:\Production\FS_FGB'), FILEGROUP FSFilegroupC CONTAINS FILESTREAM (NAME = 'FS_FGC', FILENAME = 'T:\Production\FS_FGC'), FILEGROUP FSFilegroupD CONTAINS FILESTREAM (NAME = 'FS_FGD', FILENAME = 'U:\Production\FS_FGD'), FILEGROUP FSFilegroupE CONTAINS FILESTREAM (NAME = 'FS_FGE', FILENAME = 'V:\Production\FS_FGE'), FILEGROUP FSFilegroupF CONTAINS FILESTREAM (NAME = 'FS_FGF', FILENAME = 'W:\Production\FS_FGF'); GO USE Production; GO -- Создание функции секционирования на основе последних 6 байт GUID CREATE PARTITION FUNCTION LoadBalance_PF (UNIQUEIDENTIFIER) AS RANGE LEFT FOR VALUES ( CONVERT (uniqueidentifier, '00000000-0000-0000-0000-100000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-200000000000'), 27 CONVERT (uniqueidentifier, '00000000-0000-0000-0000-300000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-400000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-500000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-600000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-700000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-800000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-900000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-a00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-b00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-c00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-d00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-e00000000000'), CONVERT (uniqueidentifier, '00000000-0000-0000-0000-f00000000000')); GO -- Создание схемы секционирования FILESTREAM, которая обеспечивает сопоставление до 16 файловых групп FILESTREAM CREATE PARTITION SCHEME LoadBalance_FS_PS AS PARTITION LoadBalance_PF TO ( FSFileGroup0, FSFileGroup1, FSFileGroup2, FSFileGroup3, FSFileGroup4, FSFileGroup5, FSFileGroup6, FSFileGroup7, FSFileGroup8, FSFileGroup9, FSFileGroupA, FSFileGroupB, FSFileGroupC, FSFileGroupD, FSFileGroupE, FSFileGroupF); GO -- Создание схемы секционирования данных для циклического перебора между двумя файловыми группами CREATE PARTITION SCHEME LoadBalance_Data_PS 28 AS PARTITION LoadBalance_PF TO ( DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2, DataFileGroup1, DataFileGroup2); GO -- Создание секционированной таблицы CREATE TABLE DocumentStore ( DocumentID INT IDENTITY, Document VARBINARY (MAX) FILESTREAM NULL, DocGUID UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL DEFAULT NEWID (), CONSTRAINT DocStorePK PRIMARY KEY CLUSTERED (DocGUID), CONSTRAINT DocStoreU UNIQUE (DocGUID)) ON LoadBalance_Data_PS (DocGUID) FILESTREAM_ON LoadBalance_FS_PS; GO Балансировку нагрузки можно протестировать с помощью следующего кода. SET NOCOUNT ON; GO -- Вставка 10 000 строк для тестирования балансировки нагрузки DECLARE @count INT = 0; WHILE (@count < 10000) BEGIN 29 INSERT INTO DocumentStore DEFAULT VALUES; SET @count = @count + 1; END; GO -- Проверка распределения SELECT COUNT ($PARTITION.LoadBalance_PF (DocGUID)) FROM DocumentStore GROUP BY $PARTITION.LoadBalance_PF (DocGUID); GO Результатами образцового выполнения этого теста были 631, 641, 661, 640, 649, 637, 618, 618, 576, 608, 595, 645, 640, 616, 602 и 623 строк в каждой из файловых групп от FILESTREAM FS_FG0 до FS_FGF. Сочетания функций и ограничения Поскольку компонент FILESTREAM хранит данные в файловой системе, существуют некоторые ограничения и особенности при взаимодействии FILESTREAM с другими компонентами SQL Server. В этом разделе приведены общие сведения о сочетаниях компонентов, которые необходимо учитывать. Дополнительные сведения см. в разделе «Использование FILESTREAM с другими компонентами SQL Server» электронной документации по SQL Server 2008 (http://msdn.microsoft.com/ru-ru/library/bb895334.aspx). Репликация Как репликация транзакций, так и репликация слиянием поддерживают данные FILESTREAM, однако необходимо учитывать множество факторов, например: 30 Если топология репликации включает экземпляры с использованием различных версий SQL Server, существуют ограничения на размер данных, которые можно передавать в экземпляры более низкого уровня. Параметры фильтра репликации определяют, реплицирован ли атрибут FILESTREAM, или не используют репликацию транзакций. Размер максимального значения данных varbinary (max), которые могут быть реплицированы в репликации транзакций без репликации атрибута FILESTREAM, — 2 ГБ. Если используется репликация слиянием, то для нее и FILESTREAM требуется столбец типа uniqueidentifier. Следует соблюдать осторожность в отношении схемы таблицы при использовании репликации слиянием, чтобы идентификаторы GUID были последовательными (т. е. использовать NEWSEQUENTIALID() вместо NEWID()). Зеркальное отображение базы данных Зеркальное отображение базы данных не поддерживает FILESTREAM. Создание файловой группы FILESTREAM на основном сервере невозможно. Настройка зеркального отображения базы данных, содержащей файловые группы FILESTREAM, невозможна. Шифрование Данные FILESTREAM нельзя шифровать с помощью методов шифрования SQL Server. Если включено прозрачное шифрование данных, то данные FILESTREAM не шифруются. Отказоустойчивая кластеризация FILESTREAM полностью совместим с отказоустойчивыми кластерами. На всех узлах кластера необходимо включить поддержку FILESTREAM на уровне Windows, а контейнеры FILESTREAM разместить в хранилище общего доступа, чтобы эти данные были доступны для всех узлов. Дополнительные сведения см. в разделе электронной документации по SQL Server 2008: «Как установить FILESTREAM в кластере отработки отказа» (http://msdn.microsoft.com/ ru-ru/library/cc645886.aspx). Полнотекстовый Полнотекстовое индексирование обрабатывает столбцы FILESTREAM таким же образом, как и столбцы типа varbinary (max). Таблица должна иметь дополнительный столбец, в котором содержится расширение имени файла для данных больших двоичных объектов, сохраненных в столбце FILESTREAM. Моментальные снимки базы данных SQL Server не поддерживает моментальные снимки базы данных для контейнеров данных FILESTREAM. Если файл данных FILESTREAM задействован в предложении CREATE DATABASE ON, то эта инструкция завершится ошибкой. Если база данных содержит данные FILESTREAM, то по-прежнему можно создать моментальный снимок базы данных обычных файловых групп. В этом случае выдается предупреждающее сообщение и файловые группы FILESTREAM будут отмечены в моментальном снимке базы данных как «вне сети». Запросы будут работать правильно с моментальным снимком базы данных, если не предпринимается попытки доступа к данным FILESTREAM. В противном случае возникнет ошибка. Невозможно восстановить базу данных до моментального снимка, если база данных содержит данные FILESTREAM, поскольку не существует способа определить состояние данных FILESTREAM в момент времени, представленный моментальным снимком базы данных. Представления, индексы, статистика, триггеры и ограничения Столбцы FILESTREAM не могут быть частью ключа индекса или указаны как столбец INCLUDE в некластеризованном индексе. Можно определить вычисляемый столбец, который ссылается на столбец FILESTREAM, но вычисляемый столбец не может быть индексирован. Невозможно создать статистику для столбца FILESTREAM. 31 Ограничения PRIMARY KEY, FOREIGN KEY и UNIQUE не могут быть созданы на основе столбцов FILESTREAM. Индексированные представления не могут содержать столбцы FILESTREAM, однако это возможно для неиндексированных представлений. Триггеры INSTEAD OF не могут быть определены для таблиц, содержащих столбцы FILESTREAM. Уровни изоляции Если доступ к данным FILESTREAM осуществляется через Win32 API, то поддерживается только уровень изоляции READ COMMITTED. Доступ через Transact-SQL также обеспечивает уровень изоляции REPEATABLE READ и сериализуемые уровни изоляции. Кроме того, при доступе через Transact-SQL «грязное» считывание разрешено через уровень изоляции READ UNCOMMITTED или указание запроса NOLOCK, но такой доступ не отображает обновления откатом незавершенных данных FILESTREAM. Резервное копирование и восстановление FILESTREAM работает со всеми моделями восстановления и всеми формами резервного копирования и восстановления (журнал, полное и разностное резервное копирование). В случае сбоя, если указан параметр CONTINUE_AFTER_ERROR для параметра BACKUP или RESTORE, данные FILESTREAM невозможно восстановить без потери данных (аналогично восстановлению обычных данных, если задан параметр CONTINUE_AFTER_ERROR). Безопасность Если необходим доступ к данным FILESTREAM, то экземпляр SQL Server должен быть настроен для встроенной безопасности Win32. Доставка журналов Доставка журналов поддерживает FILESTREAM. Как на сервере-источнике, так и на сервереполучателе должна быть запущена версия SQL Server 2008 или более поздняя версия, а также должен быть включен компонент FILESTREAM на уровне Windows. SQL Server Express SQL Server Express поддерживает FILESTREAM. Ограничение размера базы данных в 4 ГБ не включает контейнер данных FILESTREAM. Но если данные FILESTREAM пересылаются между компонентом и экземпляром SQL Server Express с помощью компонента Service Broker, то необходимо проявлять осторожность, так как компонент Service Broker не поддерживает хранение данных в FILESTREAM в очередях передачи или назначения. Это означает, что при создании какой-либо очереди может быть достигнут предельный размер базы данных 4 ГБ. В этом случае можно использовать схему, в которой диалог компонента Service Broker передает уведомления о необходимости отправки или получения данных FILESTREAM. Затем выполняется собственно передача данных FILESTREAM через удаленный доступ к общему ресурсу FILESTREAM контейнера данных FILESTREAM экземпляра SQL Server Express. 32 Настройка и тестирование производительности При настройке рабочей нагрузки FILESTREAM необходимо учитывать ряд важных факторов. Убедитесь, что оборудование для работы FILESTREAM настроено правильно. Убедитесь, что отключено формирование имен в формате 8.3 в файловой системе NTFS. Убедитесь, что отключено отслеживание времени последнего доступа в файловой системе NTFS. Убедитесь, что контейнер данных FILESTREAM находится не на фрагментированном томе. Убедитесь, что размер больших двоичных данных подходит для хранения в FILESTREAM. Убедитесь, что контейнеры данных FILESTREAM имеют собственные, выделенные тома. Важно указать размер буфера, используемый протоколом SMB для буферизации операции считывания данных FILESTREAM. Во время тестирования с ОС Windows Server® 2003 больший размер буфера обычно обеспечивает более высокую пропускную способность; размеры буфера кратны величине примерно 60 КБ. В других операционных системах буферы более крупных размеров могут оказаться более эффективными. Существуют дополнительные факторы, которые следует учитывать при сравнении рабочей нагрузки FILESTREAM с другими вариантами хранения (после настройки рабочей нагрузки FILESTREAM). Убедитесь, что оборудование хранения и уровень RAID одинаковы для обоих. Убедитесь, что параметр сжатия тома одинаков для обоих. Учтите, выполняет ли FILESTREAM сквозную запись в зависимости от используемого API и указанных параметров. Вопросы миграции данных Распространенный сценарий применения SQL Server 2008 — перенос существующих данных больших двоичных объектов в хранилище FILESTREAM. Описание полного набора средств или кода для выполнения таких переносов выходит за рамки настоящего технического документа, однако ниже приводится простой рабочий процесс. 33 Обратите внимание на размеры данных при использовании FILESTREAM и убедитесь, что их средние значения приемлемы для хранилища FILESTREAM. Просмотрите доступные сведения о сочетаниях и ограничениях компонентов, чтобы убедиться в соответствии хранилища FILESTREAM всем другим требованиям приложения. Следуйте инструкциям в приведенном выше разделе «Настройка производительности и рекомендации по проведению тестов производительности». Убедитесь, что экземпляр SQL Server использует встроенную подсистему безопасности, а FILESTREAM включен на уровнях Windows и SQL Server. Убедитесь, что в расположении контейнера данных FILESTREAM достаточно места на диске для хранения перенесенных данных больших двоичных объектов. Создайте необходимые файловые группы FILESTREAM. Дублируйте соответствующие схемы таблиц, преобразуя необходимые столбцы больших двоичных объектов для FILESTREAM. Перенесите все данные, отличные от данных больших двоичных объектов, в новую схему. Перенесите все данные больших двоичных объектов в новые столбцы FILESTREAM. Рекомендации по использованию FILESTREAM В этом разделе собраны рекомендации, составленные по результатам использования FILESTREAM во время предварительного внутреннего и открытого тестирования компонента. Однако, как и прочие рекомендации, они являются обобщениями, которые не являются универсальными для любых ситуаций или сценариев. Рекомендации следующие (в произвольном порядке): Следует избегать многочисленных малых добавлений к файлу FILESTREAM, так как каждое добавление создает новый файл FILESTREAM. Это может оказаться весьма ресурсоемким для больших файлов FILESTREAM. Если возможно, добавления следует объединить в столбец varbinary (max), а затем при достижении порогового значения размера добавить к столбцу FILESTREAM. Для рабочей нагрузки записи, имеющей большое число потоков, попробуйте задать параметр AllocationSize для API OpenSqlFilestream или SqlFilestream. Чем крупнее размер начального выделения, тем ниже будет фрагментация на уровне файловой системы, особенно в сочетании с большим размером кластера NTFS, как описано выше. Если файлы FILESTREAM имеют большой размер, избегайте обновлений Transact-SQL, которые будут добавлять данные в начало или конец файла. Данные обычно буферизуются в базе данных tempdb, а затем возвращаются в новый физический файл, что может повлиять на производительность. При считывании значений FILESTREAM следует учитывать следующие моменты. o Если необходимо считать только первые несколько байтов, то попробуйте использовать подстроки. o Если нужно считывать весь файл, то рассмотрите возможность доступа Win32. o Если нужно считывать произвольные фрагменты файла, то можно открыть дескриптор файла с помощью SetFilePointer. o При считывании всего файла установите флажок FILE_SEQUENTIAL_ONLY. o Используйте размер буфера, кратный 60 КБ (как описано выше). Размер файла FILESTREAM можно получить без открытия дескриптора файла путем добавления материализованного вычисляемого столбца в таблицу, где будет храниться размер файла FILESTREAM. Вычисляемый столбец обновляется, в то время как файл уже открыт для записи. Заключение В этом техническом документе описывается компонент FILESTREAM SQL Server 2008, который обеспечивает хранение и эффективный доступ к данным больших двоичных объектов с использованием SQL Server 2008 и файловой системы NTFS. В заключение будет полезно повторить основные положения технического документа. Хранилище FILESTREAM не всегда является подходящим решением. На основе проведенных исследований и знаний о работе компонента FILESTREAM можно сделать вывод, что данные больших двоичных объектов размером не менее 1 МБ, доступ к которым осуществляется через Transact-SQL, лучше всего подходят для хранения в качестве данных FILESTREAM. 34 Необходимо уделить внимание обновлению рабочей нагрузки, так как при любом частичном обновлении файла FILESTREAM формируется полная копия файла. Если рабочая нагрузка по обновлению особенно велика, то ее влияние на производительность может оказаться таким, что использование FILESTREAM окажется невыгодным. Необходимо изучить взаимное влияние компонентов, чтобы развертывание прошло успешно. Например, в SQL Server 2008 RTM зеркальное отображение базы данных несовместимо с использованием данных FILESTREAM, как и любая форма изоляции моментального снимка. Большинство других сочетаний компонентов поддерживаются, однако некоторые из них могут иметь ограничения (например, репликация). В этом техническом документе не представлена исчерпывающая классификация компонентов и их взаимодействия, поэтому, прежде чем приступать к развертыванию, следует ознакомиться с разделами недавно вышедшей электронной документации по SQL Server, особенно учитывая, что некоторые ограничения, скорее всего, будут устранены в будущих выпусках. Наконец, если FILESTREAM развернут без правильно настроенных Windows и SQL Server, то, возможно, ожидаемых уровней производительности добиться не удастся. Рекомендации и сведения о конфигурации, приведенные выше, помогут избежать снижения производительности. Для получения дополнительных сведений см. http://www.microsoft.com/sqlserver/: веб-сайт SQL Server http://technet.microsoft.com/ru-ru/sqlserver/: технический центр SQL Server http://msdn.microsoft.com/ru-ru/sqlserver/: центр разработчиков SQL Server Помогла ли вам эта статья? Пожалуйста, оставьте свой отзыв. Оцените материал по шкале от 1 (плохо) до 5 (отлично) и обоснуйте свою оценку. Например: Вы высоко оценили этот документ из-за наличия подходящих примеров, четких снимков экрана, ясного изложения или по какой-либо другой причине? Вы низко оценили степень полезности этого документа из-за плохих примеров, нечетких снимков экрана и неясного изложения? Ваш отзыв поможет нам повысить качество выпускаемых нами технических документов. Отправить отзыв 35