ПреДСтавление знаний в информаЦионных СиСтемах Учебник
реклама

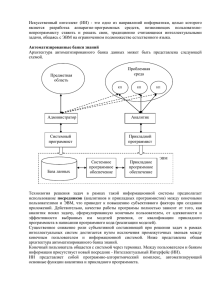
Высшее профессиональное образование Б А К А Л А В Р И АТ Б. Я. Советов, В. В. Цехановский, В. Д. Чертовской Представление знаний в информационных системах Учебник Допущено Учебно-методическим объединением вузов по университетскому политехническому образованию в качестве учебника для студентов высших учебных заведений, обучающихся по направлению подготовки «Информационные системы и технологии» 2-е издание, стереотипное УДК 681.518(075.8) ББК 32.81я73 С56 Рецензент: зав. кафедрой информационно-сетевых технологий Санкт-Петербургского государственного университета авиационного приборостроения, д-р техн. наук, проф. Л. А. Осипов С56 Советов Б. Я. Представление знаний в информационных системах : учебник для студ. учреждений высш. проф. образования / Б. Я. Советов, В. В. Цехановский, В. Д. Чертовской. — 2-е изд., стер. — М. : Издательский центр «Академия», 2012. — 144 с. — (Сер. Бакалавриат). ISBN 978-5-7685-9281-2 Учебник создан в соответствии с Федеральным государственным образовательным стандартом по направлению бакалавриата «Информационные системы и технологии». Рассмотрены современное состояние теоретических и прикладных вопросов представления знаний в информационных системах, идеология построения интеллектуальных систем, математический аппарат представления знаний, возможности и пути использования искусственного интеллекта при проектировании информационных систем. Изложены новые аспекты представления знаний на основе искусственных нейронных сетей, расчетно-логических систем, генетических алгоритмов, мультиагентных систем. Приведены примеры практической реализации представления знаний на базе декларативного языка Пролог. Для студентов учреждений высшего профессионального образования. Может быть полезен разработчикам и пользователям информационных систем; преподавателям и научным сотрудникам, сферой интересов которых является интеллектуализация различных предметных областей; менеджерам и руководителям различного ранга, желающим самостоятельно ознакомиться с современным состоянием информационных технологий. УДК 681.518(075.8) ББК 32.81я73 Оригинал-макет данного издания является собственностью Издательского центра «Академия», и его воспроизведение любым способом без согласия правообладателя запрещается © Советов Б. Я., Цехановский В. В., Чертовской В. Д., 2011 © Образовательно-издательский центр «Академия», 2011 ISBN 978-5-7685-9281-2 © Оформление. Издательский центр «Академия», 2011 Введение Понятия «интеллектуальная система», «знания» появились в 70-х годах XX века вследствие успеха научного направления, получившего название «искусственный интеллект» (ИИ). Основные направления исследований в области ИИ: • представление знаний и разработка систем, основанных на знаниях. Это основное направление ИИ. Оно связано с разработкой методов, способов, подходов к хранению знаний, созданием баз знаний, образующих ядро экспертных систем (ЭС). Включает в себя модели и методы извлечения и структурирования знаний и объединяется с инженерией знаний; • игры и творчество. Традиционно ИИ включает в себя игровые интеллектуальные задачи (например, шахматы). В их основе лежит один из разных подходов — лабиринтная модель и эвристика. В настоящее время это скорее коммерческое направление, так как в научном плане такие идеи считаются тупиковыми; • разработка естественных языковых (ЕЯ) интерфейсов и машинный перевод. В 1950-х годах она была одной из популярных. Первая программа в этой области — переводчик с английского на русский язык. Идея этих исследований оказалась неплодотворной. В настоящее время используется более сложная модель, использующая анализ и синтез естественного языка общения, и состоит из нескольких блоков: морфологический анализ, синтаксический анализ (приложения, грамматики и связей), семантический анализ (анализ смысла), прагматический анализ (анализ смысла в окружающем контексте); • распознавание образов. Традиционное направление ИИ, берущее начало у его истоков. Каждому объекту ставится в соответствие матрица признаков, по которой происходит его распознавание. Это направление близко к машинному обучению, тесно связано с нейрокибернетикой; • новые архитектуры компьютеров. Разработка новых аппаратных и программных решений, архитектур, направленных на распознавание символьных и логических данных, например, компьютеры баз данных и параллельные и конвейерные вычисления; • интеллектуальные роботы. В создании устройств, имитирующих деятельность человека, можно выделить четыре этапа: донаучный, андроидный, период «кибернетических игрушек», современный 3 этап. Роботы могут имитировать человека, но не могут осмысленно говорить. Учебник посвящен основному направлению ИИ — представлению знаний и разработке систем, основанных на знаниях. Целью этого направления [12, 13, 14, 20, 27] явилось получение новых компьютерных алгоритмов в дополнение к традиционным алгоритмам, практически исчерпавшим свои возможности. Быстрому развитию указанного направления способствовали две основные причины: 1) потребность в компьютерном решении не формализуемых и трудно формализуемых задач, широко встречающихся в различных предметных областях и прежде всего — в процессах управления; 2) увеличение круга компьютерных пользователей-непрограммистов, среди которых все более представлены руководители различного ранга (лица, принимающие решения — ЛПР). В построении знаний как научного направления объединились когнитивный и логический подходы. Когнитивный (неформальный, нелогичный) подход рассматривал сложные проблемы, соответствующие реальности, но порой без должного теоретического обоснования. В логическом подходе изучались более простые задачи для более узкой области, однако теоретически и формально строго обоснованные. Сочетание этих подходов позволило получить серьезные теоретические результаты в различных сферах человеческой деятельности. Первоначальные результаты были получены в системах диагностики и проектирования, имеющих сравнительно простую разомкнутую структуру. В последнее время интеллектуальные системы (ИС) получили распространение в системах управления, имеющих более сложную структуру с обратной связью, что привело к интересным результатам. Стало возможным не только учесть и «переложить» на компьютер богатейшие знания ЛПР и экспертов, но и использовать полученные знания для обучения и повышения квалификации специалистов. Одновременно был осуществлен прорыв в системе программирования путем создания новых декларативных языков, программных продуктов и приложений. Это относится прежде всего к ЭС [8 — 11, 28, 30, 34]. В настоящее время представление знаний и моделирование концептуальных процессов является одним из важных вопросов инженерии знаний. По системам искусственного интеллекта (СИИ) насчитывается огромное число публикаций. Большинство из них представлены в виде статей в различных, часто трудно доступных для студентов журналах. К тому же систематизация работ в многогранной предметной области ИС для студентов представляет фактически неразрешимую задачу. Это относится и к публикациям, посвященным отдельным вопросам искусственного интеллекта [1, 2, 10, 11, 19, 28, 29, 32 — 34]. 4 Таким образом, существует настоятельная необходимость систематизации материалов по СИИ, это и явилось одной из причин написания авторами данного учебника системного характера. Наиболее развитыми в теоретическом плане являются ИС, поэтому им посвящена значительная часть книги. Теория остальных классов только начинает складываться и потому они рассмотрены не столь подробно. Гл а в а 1 Модели и методы представления знаний 1.1. Основные понятия и определения Дисциплина «Представление знаний в информационных системах» отличается специфической терминологией. Предметная область — область деятельности, описываемая знаниями и данными. Проблемная область — совокупность предметной области и задач, в ней решаемых. Данные — исходные, промежуточные или окончательные (выходные) конкретные сведения или факты о решаемой задаче в текущий момент времени. Знания — любая информация об общих свойствах и закономерностях предметной области, которая хранится в системе вне зависимости от того, решается или нет в данный момент задача и выраженная в терминах некоторой модели представления знаний. Знания имеют двоякую природу — фактуальную и операционную Фактуальное знание — известные сведения от объектах отражаемой реальности и накапливается в обычных базах данных (БД). Операционное знание — зависимости и отношения между объектами, которые позволяют интерпретировать данные или извлекать из них информацию. В инженерии знаний принято выделять два основных типа знаний: процедурные и декларативные [7]. Процедурные знания соответствуют понятию алгоритма, т. е. задаются упорядоченной последовательностью действий. Им соответствует традиционный процедурный стиль программирования. Декларативные знания не предписывают явно каких-либо действий, а лишь констатируют наличие у объектов некоторых свойств или отношений между объектами. Интеллект — мыслительная способность человека. Мышление — способность человека с помощью размышлений и последовательных мыслительных действий получать результаты. Искусственный интеллект (ИИ) — имеет две трактовки: 1) создание персонального компьютера, который перерабатывает информацию на уровне и по законам человеческого мозга (планмаксимум); 2) создание вычислительной системы, имитирующей человеческие навыки. 6 Первоначально работы велись в рамках первой трактовки. Однако вскоре выяснилось, что задача оказалась сложной и быстро решить ее невозможно. Ее приняли как план-максимум. Для продолжения работ по ИИ приняли вторую трактовку как средство достижения первой цели. Все работы по ИИ относятся фактически ко второму направлению. Информация, представляемая в ЭВМ, существует в двух формах: процедурной (программы) и декларативной (данные для программ). Одинаковое представление этих составляющих позволяет обрабатывать их одинаково. Программы совместно с данными образуют внутримашинную информационную базу. Развитие средств представления данных прошло несколько этапов: от матричного описания к абстрактным типам, списочным структурам и моделям данных в БД, в становлении которых также имел место переход от иерархических и сетевых к реляционным моделям и объектным структурам. При этом в наиболее развитых моделях выделяют интенсиональную и экстенсиональную компоненты. Экстенсиональная компонента — различные сведения о предметной области (данные). Интенсиональная компонента — схемы связей между атрибутами, отражающие основные закономерности системы в предметной области решаемых функциональных задач. Для разработчиков моделей данные — это схема БД, для представителей ИИ — это знания о проблемной области. При представлении знаний вводится протоструктура (первичная структура) информационных единиц в ЭВМ. При этом имена, свойства и отношения указываются информационными единицами — понятиями. Конкретные данные, соответствующие понятиям, представляют экземпляры протоструктуры. Отличия знаний от данных: 1) внутренняя интерпретируемость — знания могут быть доступны извне (вследствие именованности), а данные — только внутри программы, которая их обрабатывает; 2) структурированность знаний, их вложенность по принципу матрешки. На множестве информационных единиц устанавливаются: родовидовые отношения, обеспечивающие наследование свойств; отношения агрегации (часть- целое), отражающие физическое вложение компонентов; 3) связность. Между различными информационными единицами формируются связи различного типа: причинно-следственные, временны е, контекстные, статистические, модельные, функциональные, семантические, отражающие фактически существующие в предметной области отношения. Указанные свойства позволяют построить общую модель представления знаний; 7 4) семантическая метрика — позволяет отразить существующую на множестве информационных единиц ситуационную близость единиц и вывести знания, аналогичные известным; 5) активность знаний. Данные пассивны, знания порождают действия. Сформулированные свойства определяют ту грань, за которой данные переходят в знания. Состав знаний интеллектуальных информационных систем (ИИС) зависит от: • проблемной областью; • требований и целей пользователей; • назначения и структуры; • языка общения. При этом при разработке практически любой интеллектуальной системы необходимы как минимум знания: • о процессе решения задач; • языке общения и способах организации диалога ЭВМ-пользователь; • проблемной области; • способах представления и модификации знаний, используемые компонентой извлечения знаний, а также знания, используемые объяснительной компонентой (структурные и поддерживающие знания). В ИИ разработаны и нашли применение в ИИС следующие модели представления знаний: 1) сетевые модели (семантические и функциональные семантические сети); 2) фреймовые модели; 3) логические модели представления знаний; 4) продукционные модели; 5) нечеткие модели; 6) нейросетевые модели (технологии); 7) байесовские (вероятностные) модели (сети доверия); 8) эволюционные и генетические алгоритмы. Сравнительные характеристики наиболее распространенных методов описания знаний представлены в табл. 1.1. В качестве синонима понятия «система искусственного интеллекта» используют термин «интеллектуальная система». Интеллектуальная система (ИС) — техническая и программная система, которая способна решать задачи, традиционно считающиеся творческими. Схема ИС представлена на рис. 1.1. Блок «Интерфейс пользователя» предназначен для связи компьютера с пользователем, для которого предпочтительным языком «разговора» является естественный язык или близкий к нему. Необходимо отметить специфическое понятие «естественный язык», под которым понимается фактически искусственный язык, 8 Т а б л и ц а 1.1 Сравнительные характеристики метода описания знаний Метод Достоинства Недостатки Семантические сети Возможность представления смысла фраз и ограничений. Наличие внутренней структуры. Определение операций над объектами (естественный язык) Отсутствие средств описания временной зависимости. Произвольность структуры. Сложность сочетания с методами логики Фреймы Наличие внутренней структуры и связности Жесткость структуры. Трудности построения модулей и модификации. Сложность сочетания с методами логики Продукции Модульность. Простота модификации правил. Отделение предметных правил от управления. Простота сочетания с методами логики Отсутствие внутренней структуры. Зависимость шагов вывода от принятой стратегии вывода полученный из естественного человеческого языка (русского, английского или любого другого) путем удаления неоднозначностей (синонимов, омонимов, идиоматических выражений). Этот язык Рис. 1.1. Схема ИC: МЛВ — машина логического вывода; БД — база данных 9 в теории автоматизированных систем называется «искусственный язык» или «информационный язык». Основу ИС составляют блоки БД, База правил, МЛВ. Исходные данные хранятся в БД. В базе правил фиксируются знания и опыт эксперта. МЛВ выводит результат, взаимодействуя с БД и базой правил. Все три блока должны быть описаны математически. Правила записываются через интерфейс эксперта (см. рис. 1.1) в виде сложных правильно построенных формул (ППФ) при посредничестве специалиста по знаниям. Форма, в которой записываются ППФ, определяется синтаксисом, а истинностное значение алгоритмов логического вывода семантикой или смыслом. По запросу пользователя компьютер с помощью блока «Объяснения» может дать ответ на вопрос КАК (с помощью набора каких правил) получен результат и ПОЧЕМУ компьютер задает пользователю уточняющие вопросы, связанные, как правило, с данными. Для стыковки интерфейса пользователя (работающего на естественном языке) с перечисленными блоками используют лингвистический и лексический процессоры. Лингвистический процессор непосредственно работает с естественным языком, преобразуя результат в «машинный вид». Лексический процессор — словарный состав языка. Иногда добавляют и синтаксический процессор, при этом под синтаксисом понимают правила сочетания слов внутри предложения и построения предложений. В блоке «Получение знаний» выделяют два процесса: • если информация поступает из книг (документов), то говорят о выявлении знаний; • если она получается на основе работы эксперта, то говорят об извлечении знаний. Преобразование полученной информации специалистом по знаниям называется получением знаний. Сложность здесь заключается в том, что эксперт может не владеть языками программирования, в то время как инженер по знаниям может недостаточно ориентироваться в данной предметной области. Для описания правил (база правил) используется математическое формальное описание знаний. Для математического описания блока МЛВ применяется специальный математический аппарат — аппарат логического вывода. Выделяют следующие методы логики вывода: 1) традиционная логика; 2) булева алгебра (алгебра логики); 3) исчисление предикатов. Необходимо, чтобы виды математического описания знаний и вывода «понимали» друг друга. Существует множество классификаций ИС. Воспользуемся классификацией, изображенной на рис. 1.2. 10 Рис. 1.2. Классификация ИC: СЕЯ — системы на естественном языке; РЛС — расчетно-логические системы; ИНС — искусственные нейронные сети; СГА — системы с генетическими алгоритмами; МАС — многоагентные системы; ЭС — экспертные системы; ОПИМ — обобщенная прикладная интеллектуальная модель Системы на естественном языке специфичны и предназначены преимущественно для таких целей, как машинный перевод, генерация документов, автоматическое аннотирование и реферирование. Экспертные системы (ЭС) предполагают высокую степень формализации процессов. Разновидностью ЭС можно считать расчетно-логические системы, оперирующие с функциями вместо правил. Интеллектуальные пакеты в настоящее время стали оболочками экспертных систем (ЭС без базы правил). Наиболее известными оболочками являются GURU и G2. Искусственные нейронные сети (ИНС) представляют собой фактически разновидность систем автоматического управления, использующие свойства нейрона. Генетические алгоритмы относятся к разновидности эволюционных эвристических методов. Многоагентные системы преследуют цель согласования теорий БД и баз знаний (БЗ). Информационные системы чаще всего оперируют с дискретными величинами, но все чаще необходима связь дискретных и непрерывных величин. В настоящее время появились дополнительные классы (обобщенная прикладная интеллектуальная модель (ОПИМ), гибридные модели). Существует множество вариантов реализации гибридных систем. В работе [33] рассмотрена гибридная система, базирующаяся на исчислении нечетких величин. Решается задача учета характеристик лица, принимающего решение (ЛПР), и эксперта, при этом знания, носящие нечеткий характер, обусловливают следующие проблемы: 1) выбор способа представления нечетких величин; 11 2) формализация предпочтений ЛПР в условиях неопределенности путем построения модели для анализа и настройки характеристик пользователя; 3) выбор критерия оптимальности предпочтения. На роль гибридных систем претендуют ИНС, системы с генетическими алгоритмами (СГА) и экспертные системы реального времени (ЭСРВ). Далее будут приведены почти все классы систем, за исключением специфических систем на естественном языке и гибридных систем. Теория наиболее развита для широко распространенных ЭС, в связи с чем в книге проблематика представления знаний в ЭС рассмотрена подробнее. 1.2. Сетевые и фреймовые модели Семантическая сеть (СС) — диаграмма, описывающая связи (отношения) между понятиями (концептами) и конкретными объектами некоторой области знаний. Формально СС задается помеченным ориентированным графом, вершинам которого ставятся в соответствие сущности рассматриваемой предметной области (объекты, свойства, события, процессы, явления), а дугам — отношения между сущностями, которые они связывают. СС, в которых вершины не имеют внутренней структуры, называются простыми. Если вершины обладают внутренней структурой, СС называется иерархической. В основе процедур вывода на СС лежит использование транзитивности (наследования) свойств, а также обслуживание запросов путем сопоставления фрагментов сети (подграфов). При этом строится соответствующая запросу подсеть, которая сопоставляется с хранящейся в БЗ сетью. Обработка сложных запросов требует реализации более сложных переборных процедур. При этом в общем случае может существовать несколько вариантов обработки запроса, отличающихся вычислительной сложностью. Очевидно, что эффективность поиска будет определяться особенностями конкретной СС. К достоинствам СС принято относить гибкость, экономичность представления и функциональную подобность памяти человека. Недостатками СС являются: проблемы с исключениями при наследовании и представлением процедурных знаний, сложность поисковых процедур. Проиллюстрируем СС на примере выражения Студент пришел в аудиторию и слушал лекцию, которую читал преподаватель. Лекция была посвящена ЭС. Введем обозначения: xi — элементы (существительные); rj — связки (глаголы). 12 Студент — x1; аудитория — x2; лекция — x3; преподаватель — x4; ЭС — x5; пришел — r1; слушал — r2; читал — r3; была посвящена — r4. На основе принятых обозначений можно дать графическую трактовку предложения (рис. 1.3). Данный способ удобен при оперировании с естественным языком (ЕЯ), однако плохо сочетается с теоретическим аппаратом описания машины логического вывода (МЛВ). Концепция фреймов как модели представления знаний была предложена М. Минским в 1975 г. [23]. Он определил фрейм как «структуру данных для представления стереотипных ситуаций». Эта структура может быть наполнена самой разнообразной информацией об объектах и событиях, которые можно ожидать в этой ситуации, а также о том, как использовать содержащуюся во фрейме информацию. Фрейм содержит множество характеристик ситуации, называемых слотами, и их значений. В самом общем виде фрейм состоит из имени фрейма и последовательности слотов. Концепция фрейма определяет общий подход к представлению знаний, в рамках которого предложено множество различных конкретных конструкций фреймов. В качестве примера рассмотрим фреймовую модель представления знаний в системе FRL (Frame Representation Language). В этой системе фрейм определен как конструкция следующего вида: <ИФ, <ИС, УН, УТД, ЗС, Д, < X >∗, где ИФ — имя фрейма; ИС — имя слота; УН — указатель наследования; УТД — указатель типа данных; ЗС — значение слота; Д — демон; < X >∗ — последовательность произвольной длины из элементов < X >. Имя фрейма является его уникальным идентификатором в рамках рассматриваемой фреймовой системы и используется для обращений к нему. Имя слота выполняет роль уникального идентификатора слота в рамках фрейма. Некоторые слоты могут определяться для внутрисистемных целей или отражать информацию, общую для любых иерархий знаний. Например, в системе FRL слот DEFINEDON хра- Рис. 1.3. Семантическая сеть 13 нит дату определения фрейма, а слот IS-A указывает, какому классу принадлежит данный фрейм. Указатель наследования используется во фреймовых системах иерархического типа для указания способа наследования информации, содержащейся в слотах фреймов верхнего уровня, соответствующими слотами фреймов нижних уровней. В системе FRL используются следующие типы наследования: • U (unique) — значение слота фрейма нижнего уровня не связано со значением соответствующего слота родительского фрейма; • S (same) — значение слота дочернего фрейма должно совпадать со значением соответствующего слота родительского фрейма; • R (range) — значение слота дочернего фрейма должно лежать в диапазоне, заданном в соответствующем слоте родительского фрейма; • O (override) — значение слота дочернего фрейма по умолчанию определяется значением слота родительского фрейма (как в случае S ), но при явном задании определяется этим значением (как в случае U ). Наследование позволяет извлекать информацию из родительских фреймов и, таким образом, может рассматриваться как один из механизмов вывода во фреймовой системе. Указатель типа данных явно указывает тип информации, содержащейся в слоте. Значение слота хранит конкретное значение в соответствии с указателем типа данных. Особенностью фреймовых систем является возможность помещать в слоты не только данные, но и процедуры, которые в этом случае называют присоединенными процедурами. Таким образом, фреймы представляют собой комбинацию декларативных и процедурных знаний. Демоны являются специфическим видом присоединенных процедур, которые автоматически запускаются некоторым типовым событием, связанным с данным слотом. Основными видами демонов являются: • IF-NEEDED — запускается, если в момент обращения к слоту его значение не определено; • IF-ADDED — запускается при записи в слот нового значения; • IF-REMOVED — запускается при стирании значения слота. Таким образом, управление выводом во фреймовых системах выполняется с использованием механизма наследования, присоединенных процедур и демонов. Концепция фреймов явилась важнейшей теоретической предпосылкой создания и развития объектно-ориентированного программирования. Существуют различные градации фреймов [9, 32, 33]. Воспользуемся одной из них. Выделим фреймы-описания (элементы) и ролевые фреймы (связки). Фрейм F может иметь иерархическую структуру 14 F = [<N1,V1>, …, <Nn,Vn>], где N1, …, Nn — название слота; V1, …, Vn — значение слота. Каждая такая пара называется слот. Возможны ссылки на другие фреймы. Приведем примеры: фрейм-описание [<машины>, <станки токарные, 70>, <станки фрезерные, 20>]; ролевой фрейм [<отгрузка>, <станки токарные, 70>, <куда, Москва>, <откуда, СПб>, <вид транспорта, железная дорога>]. Существуют также понятия фрейм-образец (прототип, без введенных данных), называемый интенсиональное описание, фреймэкземпляр с соответствующими конкретными данными или экстенсиональное описание. В другой градации [32] выделяют следующие фреймы: фреймыструктуры (объекты, понятия), фреймы-роли (вариант поведения объекта), фреймы-сценарии (взаимодействие связанных процессов) и фреймы-ситуации (влияние внешней среды). Все процедуры фреймов подразделяются на две группы: демоны и присоединенные процедуры. Демоны действуют автоматически при удалении, запросе, изменении данных, а присоединенные процедуры действуют лишь после выполнения условий. В силу необычности описания и сложности языка программирования фреймы получили ограниченное применение. К тому же они не сочетается с методами МЛВ. 1.3. Логические модели представления знаний В основе логических моделей представления знаний лежит понятие формальной системы, задаваемой четверкой [13]: S = <B, F, A, R>, где B — множество базовых символов (алфавит) формальной системы S; F — синтаксические правила построения формул теории из символов алфавита; A — выделенное множество формул, называемых аксиомами теории S, которые полагаются априори истинными; R — конечное множество отношений между формулами, называемых правилами вывода. Формальная система называется разрешимой, если существует эффективная процедура (алгоритм), позволяющая для любой заданной формулы определить, выводима ли она в данной формальной системе. Наиболее распространенной формальной системой, используемой для представления знаний является исчисление предикатов первого порядка. Алфавит языка логики предикатов включает следующие группы символов: 15 • предметные константы: a, b, c, …; • предметные переменные: x, y, z, …; • функциональные символы: f, g, h, …; • предикатные символы: P, Q, R, …; • логические связки: ˥, & , ∨, →, ↔; • кванторы: ∀, ∃. Множество D объектов, о которых ведется рассуждение, называется областью интерпретации языка логики предикатов или фактуальными знаниями. Предметные константы соответствуют конкретным элементам множества D, а предметные переменные могут принимать значения в множестве D. Функциональные символы соответствуют функциям, заданным операционными знаниями на области интерпретации. Функциональный символ вместе со списком аргументов образует функциональную форму. Термом является всякая предметная константа, предметная переменная либо функциональная форма. Аргументами функциональной формы могут быть любые термы, например f (a, x, g(c, z)). Логическая модель, построенная на основе логики предикатов первого порядка, предполагает в общем случае пропозициональный взгляд на знание, когда в качестве элемента знания рассматривается некоторое утверждение и, соответственно, элементарное знание представляется атомарной формулой языка логики предикатов. Понятие формулы в логике предикатов определяется следующим образом: • всякий атом есть формула; • если A и B — формулы, то ˥A, A&B, A∨B, A→B и A↔B также формулы; • если A — формула и x — переменная, то ∀xA и ∃xA — формулы; • других формул нет. Для записи некоторого утверждения на языке логики предикатов необходимо: • зафиксировать множество объектов, о которых идет речь, как область интерпретации; • выделить функциональные связи и отношения (свойства), упоминаемые в данном утверждении, и сопоставить им функциональные и предикатные символы соответствующей местности; • определить логическую структуру утверждения, включая области действия кванторов, и записать утверждение в виде формулы. Процесс вывода строится как последовательность шагов получения целевой формулы с помощью правил вывода, к которым относятся следующие классические правила: Modus Ponens, цепное, подстановки, резолюций 1. Правило Modus Ponens: A, A B . B 16 Если A — выводима и A влечет B, то B — выводимая формула. 2. Цепное правило: A B, B C . A C Если формулы A B и B C выводимы, то выводима и формула A C . 3. Правило подстановки: если формула A(x) выводима, то выводима и формула A(B), в которой все вхождения литерала x заменены на формулу B. 4. Правило резолюций: если выводимы формулы двух дизьюнктов, имеющих контрарную пару A ∨ c и B ∨ ˥c, то выводима формула дизь­юнкта A ∨ B, полученного из данных двух удалением контрарной пары. Можно построить процесс вывода с использованием только правил подстановки и резолюции, так как правило Modus Ponens и цепное правило можно рассматривать как частные случаи правила резолюций, интерпретируя формулу A B как дизъюнкт ˥A ∨ B. Эффективной языковой реализацией логического подхода к представлению и обработке знаний является язык Пролог. Программы на языке Пролог носят декларативный характер — в них отсутствуют такие управляющие конструкции, как условные операторы, операторы цикла и операторы передачи управления. Программа на этом языке является, по существу, спецификацией решаемой задачи в терминах объектов предметной области, фактов и правил, описывающих отношения на множестве данных объектов. Встроенный механизм логического вывода, базирующийся на методе резолюций логики предикатов, на основе данной спецификации и инициирующего запроса-цели строит алгоритм процесса дедукции для доказательства данного целевого утверждения. К достоинствам языка Пролог можно отнести следующее : • уровень языка достаточно высок, что проявляется при сравнении возможностей, которые достигаются одинаковыми по размеру исходного текста программами на императивном языке и на языке Пролог; • на языке Пролог можно эффективно строить адекватные конструкции, предназначенные для обработки входной и выходной информации, представляемой на естественном языке; • программист, использующий язык Пролог, избавлен от необходимости тщательно продумывать последовательность операторов и его усилия целиком сосредоточены на описании закономерностей (правил и фактов) предметной области и на конструировании целевых запросов к данной БЗ; • программу на языке Пролог относительно легко модифицировать при необходимости внесения новой информации о предметной области, так как отдельные правила и факты не связаны между собой общими именами переменных. 17