2. кубические сплайны - Высшая школа экономики
реклама

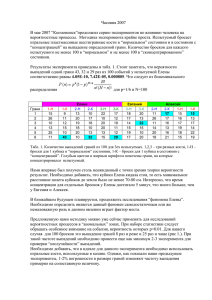
Правительство Российской Федерации Федеральное государственное автономное образовательное учреждение высшего профессионального образования «Национальный исследовательский университет «Высшая школа экономики» Московский институт электроники и математики Национального исследовательского университета «Высшая школа экономики» Кафедра информационных технологий и автоматизированных систем «ГЕОМЕТРИЧЕСКОЕ МОДЕЛИРОВАНИЕ В САПР» Учебно-методическое пособие по проведению курсового проектирования по дисциплине «Геометрическое моделирование в САПР» Москва 2012 Составители: к.т.н., проф. Ульянов Н.Г., к.т.н. доц. Попов С.Н., к.т.н. доц. Зародов А.Ф. Широкое внедрение средств автоматизации проектирования тесно связано с развитием средств компьютерной графики. В настоящее время наряду с развитием математического аппарата, все большее значение приобретает развитие технических и аппаратных средств. В учебном пособии рассматриваются как математические основы, используемые в современных системах компьютерной графики, так и аппаратно-программные средства современных компьютеров. Учебное пособие предназначено для студентов обучающихся по специальности 230104 «Системы автоматизации проектирования» при выполнении домашних заданий и курсового проекта по дисциплине «Геометрическое моделирование в САПР» УДК Учебно-метод. пособие по проведению по дисциплине «Геометрическое моделирование в САПР» / Моск. институт электроники и математики Национального исследовательского университета «Высшая школа экономики»; Сост. Н.Г.Ульянов, С.Н. Попов, А.Ф. Зародов М., 2012. 24с. Ил. 13 Библиогр.: Приложение: ISBN 2 Оглавление ВВЕДЕНИЕ ....................................................................................................................... 4 1.ФОРМИРОВАНИЕ МОДЕЛЕЙ ................................................................................ 4 1.1 Полигональные сетки .............................................................................................. 5 1.2. "Крылатое" представление сетки .......................................................................... 7 2. КУБИЧЕСКИЕ СПЛАЙНЫ ..................................................................................... 9 2.1. Интерполяция формой Эрмита ............................................................................ 10 2.2. Интерполяция формой Безье ............................................................................... 11 2.3. Интерполяция B-сплайнами ................................................................................ 12 2.4. Кривые и поверхности NURBS .......................................................................... 14 3. СТРУКТУРА ТВЕРДОТЕЛЬНОЙ МОДЕЛИ ..................................................... 15 3.1. Синтез твердого тела ............................................................................................ 17 3.2. Тело выдавливания ............................................................................................... 17 3.3. Тело вращения ....................................................................................................... 18 4. ГРАФИЧЕСКИЙ УСКОРИТЕЛЬ .......................................................................... 19 4.1. Трехмерная сцена.................................................................................................. 19 4.2. Программные интерфейсы ................................................................................... 20 4.3. Основные этапы работы 3D-конвейера .............................................................. 21 5. ТЕХНОЛОГИЯ CUDA ............................................................................................. 23 5.1. Графический процессор NVIDIA GeForce 8800 ................................................ 25 5.2. Унифицированный потоковый процессор ......................................................... 26 5.3. Архитектура ядра GPU NVIDIA GeForce 8800 .................................................. 28 3 ВВЕДЕНИЕ Развитие средств автоматизации проектирования тесно связано с развитием средств геометрического моделирования и машинной графики в соответствии с ГОСТ 2301.108-85 система автоматизированного проектирования (САПР) программный пакет, предназначенный для автоматизированного проектирования, разработки и производства конечного продукта, оформления конструкторской и технологической документации. Свойства графической системы САПР определяются математическим ядром. Математическое ядро- это библиотека функций, выполнение которых обеспечивает построение, хранение и обработку 3D моделей. Ядро не самоценно, оно создается для использования в прикладных программах. Доступ к функциям ядра конечному пользователю Математическое открывает ядро графический определяет предел пользовательский функциональных интерфейс.. возможностей использующей его САПР. Для разработки ядра используются основные положения дифференциальной геометрии, топологии, вариационного исчисления, численных методов, теория сплайнов для моделирования различных кривых, поверхностей и тел, а также алгоритмы выполнения операций над ними и вычисления их геометрических характеристик. В настоящее время известно несколько десятков сравнительно известных математических ядер. Помимо известных (Parasolid от EDS, ACIS от Spatial Corp и Open CASCADE от Matra Datavision) успешно развиваются и менее известные или более молодые геометрические ядра, например такие, как Thinkdesign kernel (think3, Inc.), VX Overdrive (Varimetrix Corp), КОМПАС-3D kernel (АО АСКОН). В предлагаемом пособии рассмотрены принципы и модели построения графических объектов. 1.ФОРМИРОВАНИЕ МОДЕЛЕЙ 4 Основным средством компьютерной графики в настоящее время является использование 3D моделей. При формировании 3D модели используются: двумерные элементы (точки, прямые, отрезки прямых, окружности и их дуги, различные плоские кривые и контуры); поверхности (плоскости, поверхности, представленные семейством образующих, поверхности вращения, криволинейные поверхности); объемные элементы: параллелепипеды, призмы, пирамиды, конусы, произвольные многогранники и т.п. Из этих элементов с помощью различных операций формируется внутреннее. На рис.1 показаны способы и формы представление модели. Основные формы представления 3D моделей Каркасные Сплошные тела Набор базовых геометрических элементов Поверхностные Набор ограничивающих поверхностей Набор ребер Рис.1 Формы представления моделей Форма представления модели существенно зависит от области приложения, поэтому в современных системах используют разнообразие моделей, применяя при этом средства перехода. 1.1 Полигональные сетки Полигональная сетка или неструктурированная сетка это совокупность вершин, ребер и граней которые определяют форму многогранного объекта в трехмерной компьютерной графике и объемном моделировании. Гранями обычно являются треугольники, четырехугольники или другие простые выпуклые многоугольники (полигоны), так как это упрощает рендеринг, но также может состоять из наиболее общих вогнутых многоугольников, или многоугольников с дырками. Разные представления полигональных сеток используются для разных целей и приложений. При описании различают объемные и простые полигональные сетки. Отличие заключается в том, что одни явно представляют и 5 поверхность и объем структуры, а другие только лишь поверхность (объем неявный). Рис.2 Представление каркасных моделей Основой является набор вершин (Vj,), ребер (Ek) и плоских многоугольников.(Pi). Существует несколько способов внутреннего представления полигональных сеток. Некоторые из них описаны в первой части данного пособия. Ниже представлены методы, используемые в современных пакетах САПР. Объекты, созданные с помощью полигональных сеток должны хранить разные типы элементов, таких как вершины, ребра, грани, полигоны и поверхности. Во многих случаях хранятся лишь вершины, ребра и либо грани, либо полигоны. Рендерер может поддерживать лишь трехсторонние грани, так что полигоны должны быть построены из их множества. Однако многие рендереры поддерживают полигоны с четырьмя и более сторонами, или умеют триангулировать полигоны в треугольники на лету, делая необязательным хранение сетки в триангулированной форме. Также в некоторых случаях, таких как моделирование сложных объектов, желательно уметь создавать и трех и четырех сторонние полигоны. Список граней Сетка с использованием списка граней представляет объект как множество граней и множество вершин. Это самое широко используемое представление, которое поддерживается современным графическим оборудованием. Список граней является предпочтительней, чем вершинное представление тем, что он позволяет явный поиск вершин грани, и граней окружающих вершину. На рис.3 вершина v5 выделена, чтобы показать грани, которые ее окружают. 6 Заметим, что в этом примере у каждой грани обязательно 3 вершины. Однако это не означает что у каждой вершины одно и то же количество окружающих граней. Рис.3 Список граней Для рендеринга грань посылается в графический процессор как множество индексов вершин и вершины посылаются как позиция/цвет/структуры нормалей (на рисунке дана лишь позиция). Поэтому изменения формы, но не геометрии, могут быть динамически обновлены, просто переслав данные вершины без обновления связанности граней. Моделирование требует быстрого обхода всех структур. С сеткой использующей список граней очень просто найти вершины грани. Также, список вершин содержит список всех граней связанных с каждой вершиной. В отличии от вершинного представления, и грани и вершины явно представлены, так что нахождение соседних граней и вершин постоянен по времени. Однако, ребра не заданы явно, так что требуется поиск нужен чтобы все грани, окружающие заданную. Другие динамические операции, такие как разрыв или объединение грани, также более сложны при использовании списка граней. 1.2. "Крылатое" представление сетки "Крылатое" представление явно описывает вершины, грани и ребра сетки. Это представление широко используется в программах для моделирования, что позволяет достичь гибкости в динамическом изменении геометрии сетки, так как могут быть быстро выполнены операции разрыва и объединения. Основной 7 недостаток - высокие требования к памяти и увеличенная сложность вычислений из-за содержания множества индексов. Рис.4 «Крылатое» представление сетки "Крылатое" представление решает проблему обхода от ребра к ребру и обеспечивает упорядоченное множество граней вокруг ребра. Для любого заданного ребра число исходящих ребер может быть произвольным. Чтобы упростить это, "крылатое" описание предоставляет лишь четыре ближайшие ребра по часовой и против часовой стрелки на каждом конце ребра. Другие ребра можно обойти постепенно. Рисунок 4 показывает пример параллелепипеда в "крылатом" представлении. 8 Полные данные по грани состоят двух вершин (конечные точки), двух граней (по каждую сторону), и четыре ребра ("крылатое" ребро). Рендеринг "крылатого" представления графическим оборудованием требует генерирования списка индексов граней. Обычно это делается тогда когда изменяется геометрия. "Крылатое" представление идеально подходит для динамической геометрии, такой как подразделение поверхностей и интерактивное моделирование, так как изменения сетки могут происходить локально. Обход вокруг сетки может быть эффективно выполнен для обнаружения столкновений. 2. КУБИЧЕСКИЕ СПЛАЙНЫ Сплайны - это гладкие (имеющие несколько непрерывных производных) кусочно-полиномиальные функции, которые могут быть использованы для представления функций, заданных большим количеством значений и для которых неприменима аппроксимация одним полиномом. Так как сплайны гладки, экономичны и легки в работе, они используются при построении произвольных функций для: моделирования кривых; аппроксимации данных с помощью кривых; выполнения функциональных аппроксимаций; решения функциональных уравнений. Здесь кратко излагаются некоторые основные положения и использования сплайнов в 3D графики. Важным их свойством является простота вычислений. На практике часто используют сплайны вида полиномов третьей степени. С их помощью довольно удобно проводить кривые, которые интуитивно соответствуют человеческому субъективному понятию гладкости. Определим искомую функцию y S x , причем поставим два условия: Функция должна проходить через все точки: S xi yi , i 0, m ; Функция должна быть дважды непрерывно дифференцируема, то есть иметь непрерывную вторую производную на всем отрезке x0 , xm . На каждом из отрезков xi , xi 1 , i 0, m 1 , ищется функция в виде полинома третьей степени: 3 S i x aij x xi . j j 0 9 Рис. 5 Сплайновая функция Поскольку для каждого из отрезков xi , xi 1 необходимо найти S Задача построения полинома сводится к нахождению коэффициентов a ij , при этом общее количество искомых коэффициентов будет 4m . Перейдем к более сложному случаю – заданию кривых в трехмерном пространстве. многозначности Для в функционального случае задания самопересечений кривой и y f x z f x неудобства при возможны значениях производных равных . Ввиду этого ищется функция в параметрическом виде. Пусть t независимый параметр, такой что - 0 t 1 . Кубическим параметрическим сплайном уравнений: xtназовем a x t 3 следующую b x t 2 c x t d xсистему ; 3 2 y t a y t b y t c y t d y ; z t a t 3 b t 2 c t d . Координаты точек описываются вектором z z zна кривой z xt , yt , zt , а три производные задают координаты соответствующего касательного вектора в точке. Например, для координаты x : dx 3a x t 2 2b x t c x . dt 2.1. Интерполяция формой Эрмита Одним из способов задания параметрического кубического сплайна является указание координат начальной и конечной точек, а также векторов касательных в них. Такой способ задания называется формой Эрмита. xt TM h Ghx P1x 2t 3 3t 2 1 P4 x 2t 3 3t 2 R1x t 3 2t 2 t R4 x t 3 t 2 . где Gb - геометрический вектор Безье. Четыре функции в скобках называются функциями сопряжения. Форму кривой, заданной в форме Эрмита, легко изменять, если учитывать, что направление вектора касательной задает начальное направление, а модуль 10 вектора касательной задает степень вытянутости кривой в направлении этого вектора, как показано на рисунке 6. Рис.6 Параметрический сплайн в форме Эрмита Вытянутость кривой вправо обеспечивается тем, что R1 R4 . 2.2. Интерполяция формой Безье Рассмотрим форму Безье, которая отличается от формы Эрмита способом задания граничных условий, а именно вместо векторов R1 и R4 вводятся точки (и соответствующие им радиус- векторы) P2 и P3 , как показано на рисунке 7, такие, что выполняются условия: P ' 0 R1 3P2 P1 и P ' 1 R4 3P4 P3 . Рис.7 Параметрический сплайн в форме Безье Переход от формы Эрмита к форме Безье осуществляется преобразованием: P1 1 P 0 Gh 4 R1 3 R4 0 0 P1 0 0 1 P2 M hbGb 3 0 0 P3 0 3 3 P4 0 0 (*) где Gb - геометрический вектор Безье. Подставляя это в выражение для xt , получаем 11 xt TM h Ghx TM h M hb Gbx 1 t 3 P1 3t t 1 P2 3t 2 1 t P3 t 3 P4 2 Полезным свойством сплайнов в форме Безье является то, что кривая всегда лежит внутри выпуклой оболочки, образованной четырехугольником P1 P2 P3 P4 . Это свойство можно доказать, пользуясь тем, что в выражении (*) коэффициенты принимают значения от 0 до 1 и их сумма равна единице. Матрица вида M h M hb 1 3 3 3 6 3 Mb 3 3 0 0 0 1 1 0 - называется матрицей Безье. 0 0 2.3. Интерполяция B-сплайнами Чуть более сложный тип интерполяции – так называемая полиномиальная сплайн-интерполяция, или интерполяция B-сплайнами. В отличие от обычной сплайн-интерполяции, сшивка элементарных B-сплайнов производится не в точках (ti, хi), а в других точках, координаты которых обычно предлагается определить пользователю. Таким образом, отсутствует требование равномерного следования узлов при интерполяции B-сплайнами. Сплайны могут быть полиномами первой, второй или третьей степени (линейные, квадратичные или кубические). Применяется интерполяция Bсплайнами точно так же, как и обычная сплайн-интерполяция, различие состоит только в определении вспомогательной функции коэффициентов сплайна. Рис.8 Интерполяция B-сплайнами Наиболее приемлем способ, при котором кривая описывается многочленом 3-й степени: 12 A11 t3 + A12 t2 + A13 t + A14; y(t) = A21t3 + A22t2 + A23t + A24; z(t) = A31 t3 + A32t2 + A33t + A34, x(t) = 0<t<1 (переход от точки i к i+1 точке) Кубические уравнения выбраны потому, что для сегментов произвольной кривой: -не существует представление более низкого порядка, которая обеспечивает сопряжение на границах связи -при более высоком порядке, появляются осцилляции и волнистость. Из ряда способов описания бикубических кривых (метод Эрмита, метод Безье и т.п.) наиболее применяем метод В-сплайнов, для которого характерно несовпадение кривой с аппроксимируемыми точками что, однако гарантирует равенство 1-й и 2-й производных при стыковке сегментов. В-сплайн описывается следующей формулой: x(t)=TMsGsx – обобщенная форма описания кривой для всех методов где: T=[t3,t2,t,1] – параметр, определяющий переход от точки Pi к Pi +1 М – матрица обобщения для В – сплайна. Для трехмерных поверхностей определяется два параметра S и T, изменение которых дают координату любой точки на поверхности. Фиксация одной переменной позволяет перейти к построению кривой на поверхности. Общая форма записи (для направления x): x(S,t)=SCxTT где: Cx – коэффициенты кубического многочлена (для определения коэффициентов y,z соответственно Cy,Cz) Для В-сплайна: 13 X(S,t)=SMsPxMsTTT Y(S,t)=SMsPyMsTTT Z(S,t)=SMsPzMsTTT P – управляющие точки (16 точек) (4 по S и 4 по T). 2.4. Кривые и поверхности NURBS Рассмотрим NURBS-кривые, поскольку это дает базовое понимание Всплайнов, а затем обобщим их на поверхности. Неоднородный рациональный B-сплайн, NURBS ( Non-uniform rational Bspline) - математическая форма, применяемая в компьютерной графике для генерации и представления кривых и поверхностей. В общем случае В-сплайн состоит из нескольких сплайновых сегментов, каждый из которых определен как набор управляющих точек. Поэтому коэффициенты многочлена будут зависеть только от управляющих точек на рассматриваемом сегменте кривой. Этот эффект называется локальным управлением, поскольку перемещение управляющей точки будет влиять не на все сегменты кривой. На рисунке 9 показано, как управляющие точки влияют на форму кривой. Рис. 9 В-сплайн с управляющей точкой Р4 в нескольких положениях В-сплайн интерполирует набор из р+1 управляющей точки , и состоит из р-(n-1) сегментов кривой . Кроме того, мы можем определить общий параметр t, нежели отдельный для каждого сегмента в интервале от 0 до 1. Таким образом, для каждого сегмента кривой t будет принадлежать интервалу каждый сегмент будет влиять ровно n управляющих точек от . Более того, на до . 14 Для каждого i >= n существует узел между и для значения ti параметра t. Для В-сплайна существует p-n-2 узлов. Отсюда исходит понятие однородности: если узлы равномерно распределены на интервале от 0 до 1, т.е. , то говорят, что В-сплайн равномерный. В противном случае – неравномерный. Стоит также обратить внимание на факт, что эти определения касаются узлов, возрастающих по значению, т.е. . Теперь предположим, что координаты (x, y, z) точки кривой представлены в виде рациональной дроби. В этом случае говорят, что В-сплайн рациональный, иначе – нерациональный: Подводя итог, можно указать на существование 4 типов В-сплайнов: - равномерные нерациональные; - неравномерные нерациональные; - равномерные рациональные; - неравномерные рациональные. Последний тип и представляет собой NURBS как наиболее общий случай Всплайнов. 3. СТРУКТУРА ТВЕРДОТЕЛЬНОЙ МОДЕЛИ Выбор структуры, или топологии, твердотельной модели определяется способом дальнейшего использования синтезируемой модели. Для внешнего использования топология определяется форматом файла, но, как правило, это одна из реберных поверхностных модели. Для внутреннего использования наиболее удобна топология "крылатого" представления (winged-edge representation). Структурными элементами гранично-заданных моделей являются вершины V, ребра E и грани F. Ниже приведен пример описания твердотельной модели цилиндра. Патчи боковой его грани являются полными (без усечения), а верхняя и нижняя грани усеченны цепочками е8-е7-е6-c5 и е1-е2-е3-е4 соответственно. Твердотельная модель цилиндра в вершинном представлении показана на рисунке 10. В таблицах 1и 2 для данной модели цилиндра приведены примеры вершинного и «крылатого» представления. 15 Рис.10 Граничное представление твердотельной модели цилиндра Таблица1. Вершинное представление цилиндра vertex coordinates edge vertices face edges v1 x1, y1, z1 e1 v1, v2 f1 e4, e9, e8, e10 v2 x2, y2, z2 e2 v2, v3 f2 e3, e12, e7, e9 v3 x3, y3, z3 e3 v3, v4 f3 e2, e11, e6, e12 v4 x4, y4, z4 e4 v1, v4 f4 e1, e10, e5, e11 v5 x5, y5, z5 e5 v6, v5 f5 e1, e2, e3, e4 v6 x6, y6, z6 e6 v7, v6 f6 e8, e7, e6, e5 v7 x7, y7, z7 e7 v8, v7 v8 x8, y8, z8 e8 v5, v8 e9 v4, v8 e10 v1, v5 e11 v2, v6 e12 v3, v7 Таблица 2 «Крылатое представление цилиндра edge vstart vend ncw nccw vertex coordinates face first edge sign v1 v1 v2 e2 e10 v1 x1, y1, z1 f1 e8 v2 v2 v3 e3 e11 v2 x2, y2, z2 f2 e3 v3 v3 v4 e4 e12 v3 x3, y3, z3 f3 e2 v4 v1 v4 e1 e9 v4 x4, y4, z4 f4 e1 v5 v6 v5 e8 e11 v5 x5, y5, z5 f5 e1 + v6 v7 v6 e5 e12 v6 x6, y6, z6 f6 e5 + v7 v8 v7 e6 e9 v7 x7, y7, z7 v8 v5 v8 e7 e10 v8 x8, y8, z8 v9 v4 v8 e8 e3 v10 v1 v5 e5 e4 v11 v2 v6 e6 e1 v12 v3 v7 e7 e2 16 3.1. Синтез твердого тела В современных системах геометрического моделирования сформировались следующие способы синтеза твердотельных моделей: за основу берется конкретный примитив (параллелепипед, цилиндр, шар); из других твердотельных моделей (операции булевых сочетаний, модификация граней, фаски) и их частей (выдавливание, вращение грани); из кривых с помощью процедурных методов. Целесообразно использовать только последний способ. Наиболее распространенными процедурными методами синтеза являются: выдавливание плоской кривой по направлению; вращение плоской кривой вокруг оси; лофтинг интерполяция поверхности между плоскими замкнутыми кривыми (профили, сечения, образующие); протягивание плоской кривой (профиль, или образующая) вдоль плоской или пространственной кривой (путь, или направляющая). Рассмотрим принципы синтеза твердотельных моделей на примере двух первых, наиболее простых методах. В каждом случае на кривые, участвующие в синтезе, налагаются определенные ограничения во избежание получения топологически некорректных многосложных моделей. 3.2. Тело выдавливания Как видно из рисунка 13, тело выдавливания образуется из двух усеченных плоских патчей (f1 и f2) и неусеченных патчей, составляющих боковую поверхность тела. Отсюда очевидны два необходимых условия: образующий контур c (цепочка кривых) не должен иметь самопересечений; образующий контур должен быть замкнут; направление выдавливания d не должно быть параллельно плоскости образующего контура c. 17 Рис.13 Тело выдавливания 3.3. Тело вращения Тело вращения можно построить двумя способами: путем полного обращения образующей вокруг оси и неполного обращения. В первом случае боковая поверхность может быть представлена с помощью одного полного (неусеченного) патча и двух (верхний и нижний) усеченных патчей. Во втором случае добавляется еще два усеченных патча f3 и f4. Рис.14 Тела вращения: а – полный оборот, б – неполный оборот Поскольку при построении будут получены конические кривые (с1) и поверхности (f2), то в целях точности целесообразно их построения осуществлять по специальным алгоритмам с использованием весов NURBS. Для соблюдения правильности топологии должны выполняться следующие условия: - образующая не должна пересекать ось вращения; 18 - образующая не должна пересекать саму себя. Пример: использование произвольной параметрической поверхности для построения твердотельной модели проиллюстрирован на рисунке. Рис.15 Твердое тело как параллелепипед, ограниченный параметрической поверхностью Здесь твердотельная модель состоит из: - неусеченной поверхности f1 как NURBS-аппроксимация графика функции двух переменных; - плоской прямоугольной неусеченной грани f2; - четырех боковых неусеченных граней f3-f6. 4. ГРАФИЧЕСКИЙ УСКОРИТЕЛЬ 4.1. Трехмерная сцена Трехмерная сцена представляет собой набор отдельных групп элементов: группы трехмерных объектов, группы источников освещения, группы применяемых текстурных карт, группы камер. Трехмерный объект обладает свойствами координат вершин треугольников в пространстве сцены и локальных координат в пространстве текстурной карты. Источник освещения может обладать следующим набором свойств: координатами в пространстве сцены, ориентацией (направленностью), типом излучения (фоновым, точечным), цветом и алгоритмом изменения светового излучения. Камера представляет собой точку, откуда наблюдатель обозревает трехмерную сцену. 19 Текстурой (или текстурной картой) называют двух- или трехмерное изображение, имитирующее зрительное восприятие человеком свойств различных поверхностей. На полигон можно накладывать несколько текстур, смешивая их различными способами, с тем, чтобы моделировать зрительный образ нужного материала. Специализированные текстуры (например, карты окружающей среды) сами не отображаются, а используются для модификации других текстур накладываемых на полигон. Аппаратные средства В самом общем виде современный ускоритель ЗD-графики должен иметь: блок геометрических преобразований (геометрический процессор), блок расчета освещения блок механизма установки примитивов блок обработки текстур блок обработки буфера кадра. Геометрический процессор обрабатывает примитивы и строит проекцию трехмерной сцены. Блок расчета освещения формирует данные о параметрах освещения для вершин примитивов. Блок установки примитивов с помощью данных, полученных из буфера глубины, определяет видимость отображаемой точки (пиксела). Видимые пикселы обрабатываются в блоке текстур различными методами с применением одной из технологий фильтрации и наложения текстурных карт. Обработанный таким образом пиксел,вновь помещается в буфер кадра, либо заменяя находящееся там значение, либо смешиваясь с ним по выбранному правилу. 4.2. Программные интерфейсы Скорость и качество обработки трехмерной сцены во многом зависят от совершенства инструкций, передаваемых приложением графическому ускорителю. Такие инструкции объединены в специализированные прикладные программные библиотеки (Graphics API). С одной стороны, инструкции должны учитывать особенности построения аппаратной части графического адаптера. С другой стороны, конструкция графического адаптера должна соответствовать возможностям API. Точного соответствия между аппаратурой и API не бывает: иногда разработчики видеокарты опережают время и вводят функции, которые не поддерживаются действующими API. Часто в API появляются инструкции, 20 которые не могут быть выполнены конкретным графическим адаптером. Поддержка API реализуется через драйвер видеокарты. Бывает, что разработчики игр пытаются использовать функции видеокарты, недоступные через стандартную версию API. В этом они создают собственные мини-драйверы. Совокупность аппаратных и программных средств обработки трехмерных сцен образует графический конвейер, конечным итогом работы которого является кадр, размещенный на экране монитора. 4.3. Основные этапы работы 3D-конвейера Большинство приложений трехмерной графики, в том числе игр, при построении объемных сцен придерживаются определенной последовательности действий, в совокупности составляющей ЗD-конвейер. Итогом работы ЗDконвейера является визаулизация (рендеринг) результирующего изображения на дисплее компьютера. Группу операции, выполняющих обособленные промежуточные действия, принято называть этапом, или стадией ЗD-конвейера. Описываемая ниже последовательность операций отнюдь не является жестко заданной, а скорее общепринятой в современных графических подсистемах. При конкретной реализации на программном и аппаратном уровнях могут появляться существенные отличия, однако смысловое содержание блоков практически не меняется. Итак, на сегодняшний день процесс визуализации трехмерной сцены на экране компьютера выглядит в общих чертах следующим образом. Первый этап Здесь определяется состояние объектов, принимающих участие в сцене, которую необходимо отобразить. На первый взгляд к самой графике этот этап отношения не имеет. На самом деле он является определяющим, ибо состояние объектов и их взаимное положение формируют логику последующих действий программы. С каждым объектом в сцене связана соответствующая текущему моменту геометрическая модель Практически все операции на первом этапе выполняет центральный процессор. Результаты его работы пересылаются в графический чипсет посредством драйвера. Второй этап Происходит декомпозиция (разделение на примитивы) геометрических моделей. Внешний вид объекта формируется с помощью набора определенных примитивов. Чаще всего в роли примитива выступает треугольник как простейшая плоская фигура, однозначно располагаемая в трехмерном пространстве. Все прочие 21 элементы состоят из таких треугольников. Таким образом, можно утверждать, что по большей части термины «полигон» и «треугольник» применительно к игровой SD-графике суть синонимы. Современные графические процессоры умеют выполнять дополнительные операции, например тессялизацию (Tesselation), то есть разделение исходных треугольников на более мелкие. Некоторые графические чипсеты могут аппаратно обрабатывать геометрические модели, построенные на основе параметрических поверхностей (механизм RT-Patches). Часть графических процессоров умеет превращать плоские треугольники в трехмерные поверхности путем «выдавливания» в третье измерение (механизм N-Patches). Итоговый трансформаций результат и операций освещения второго этапа (Transform&Lighting, пересылается T&L) в блок геометрического процессора. Третий этап В блоке T&L на аппаратном уровне к вершинам треугольников применяют различные эффекты преобразований и освещенности. Содержание операций блоков T&L новейших графических чипсетов можно динамически изменять посредством вершинных шейдеров (Vertex Shaders) — специальных микропрограмм, включаемых в код игры. То есть сегодня персональный компьютер в дополнение к центральному процессору получил полноценный программируемый графический процессор. По завершении операций трансформации и расчета освещенности параметры вершин нормализуются и приводятся к целочисленному виду. Четвертый этап На данном этапе происходит так называемая установка примитивов (Triangle Setup). Графический процессор пока ничего не знает о свойствах треугольников, поскольку обрабатывал вершины по отдельности. Теперь необходимо «собрать» вершины в треугольники и преобразовать результаты в координаты и цвет каждого пиксела, а также отсечь невидимые области. В ходе «сборки» определяется видимость объектов с позиции камеры. Полигоны, находящиеся ближе к камере, могут загородить более удаленные полигоны. Для хранения информации о степени удаленности объекта от плоскости проецирования используют специальный буфер глубины (Z-буфера). Современные графические процессоры применяют различные механизмы отсечения невидимых полигонов на ранних этапах ЗD-конвейера с тем, чтобы избежать излишних операций. Данные буфера глубины обрабатываются специализированными блоками графического процессора. 22 В конечном счете, на выходе блока геометрических преобразований получают проекцию трехмерной сцены на плоскость визуализации. Координаты и исходный цвет видимых пикселов передаются в текстурный конвейер (Texture Pipeline). Пятый этап Графический чипсет может иметь несколько параллельных текстурных конвейеров. В каждом из них происходит наложение текстур различного типа, в том числе и тех, которые сами не отображаются (например, карты высот), а служат для модификации других текстур. На этом этапе в современных чипсетах возможно исполнение пиксельных шейдеров (Pixel Shaders) — специальных микропрограмм, определяющих порядок смешивания текстур, полученных на выходе из каждого конвейера. Здесь также учитывается информация (полученная на этапе установки примитивов) о принадлежности пиксела к определенному треугольнику. В целом указанные операции составляют суть процесса визуализации (рендеринга). Шестой этап На заключительном этапе работы ЗD-конвейера к полученному в текстурном блоке плоскому изображению применяют операции устранения дефектов (например, часто используют билинейные, анизотропные и другие фильтры). Операции конечной обработки применяют какой-либо эффект (например, туман) к целиком сформированному изображению. Перед выводом в буфер кадра в последний раз проверяется видимость пикселов, и наконец изображение появляется на экране. Перечисленные этапы в конкретных графических чипсетах могут быть переставлены, разделены, объединены, выполняться неоднократно (в несколько проходов), однако их физический смысл остается неизменным. Технологически некоторые элементы этапов или этапы целиком могут быть выполнены различными способами. Вариант реализации зависит от особенностей приложения и видеокарты. В зависимости от типа видеоускорителя часть этапов просчитывается программно, а часть- аппаратно. Самые современные ускорители имеют на борту графический процессор, способный аппаратно просчитывать этапы трансформации (преобразований) и расчета освещения, наложения текстур. 5. ТЕХНОЛОГИЯ CUDA 23 CUDA (Compute Unified Device Architecture) - программно-аппаратная архитектура параллельных вычислений, которая позволяет существенно увеличить вычислительную производительность благодаря использованию графических процессоров фирмы NVIDIA. CUDA позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах NVIDIA, и включать специальные функции в программу. Архитектура CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью. Для трансляции кода в состав CUDA SDK входит собственный Сикомпилятор командной строки nvcc компании NVIDIA. Компилятор nvcc предназначен для трансляции host-кода (главного, управляющего кода) и deviceкода (аппаратного кода) (файлов с расширением .cu) в объектные файлы, пригодные в процессе сборки конечной программы или библиотеки в любой среде программирования. Архитектура CUDA применима для выполнения графических вычислений, различных научных вычислений, с использованием видеокарт NVIDIA (астрофизика, биология, химия, физика, компьютерная томография и многое другое). Основное преимущество данной технологии заключается в том, что графический чип изначально проектируется под выполнение множества потоков, а каждое ядро обычного CPU (центральный процессор) выполняет поток последовательных инструкций. Любой современный GPU(графический процессор) является мультипроцессором, состоящим из нескольких вычислительных кластеров, с множеством ALU (арифметико-логическое устройство) в каждом. В следующем разделе дано краткое описание видеокарты GeForce 8800 GT на базе чипа G92, из которого видны преимущества архитектура CUDA перед классической архитектурой. Ниже представлена сравнительная диаграмма роста производительности CPU и GPU. 24 Рис.8 Диаграмма динамики роста производительности CPU и GPU 5.1. Графический процессор NVIDIA GeForce 8800 Графические процессоры GeForce 8800 воплощают в себе следующие технологии: унифицированная шейдерная архитектура, состоящая из 128 параллельных потоковых процессоров, которые функционируют на частоте 1,35 ГГц; технология обработки физики NVIDIA Quantum Effects, реализующая визуальные эффекты графической реализм; одновременное 16x сглаживание и 128-битное освещение в широком динамическом диапазоне (HDR). Физический шейдер оперирует физическими свойствами объекта и позволяет рассчитывать в реальном времени изменения его геометрии под действием различных физических явлений (к примеру, развивающийся на ветру плащ героя, сминаемый лист бумаги, мнущийся при столкновении со стеной кузов автомобиля). Появление геометрических шейдеров полностью изменило архитектуру графических чипов: конвейеры из специализированных блоков уступили место шейдерным процессорам, которые могут выполнять самые различные функции 3Dрендеринга с одинаковой эффективностью. Такая архитектура позволяет крайне гибко распоряжаться вычислительными ресурсами графического процессора, выделяя больше шейдерных процессоров на те стадии, на которые приходится наибольшая нагрузка при рендеринге сцены. 25 Процессоры GeForce 8800 открыли новую ступень в развитии графических процессоров - переход к унифицированным потоковым шейдерным процессорам. 5.2. Унифицированный потоковый процессор Компания NVIDIA обосновывает необходимость перехода к унифицированным процессорам следующим образом. Предположим, что в воображаемом графическом процессоре с классической архитектурой присутствуют четыре вершинных и восемь пиксельных процессоров. Если используются преимущественно вершинные шейдеры (трехмерные модели с насыщенной геометрией), то может возникнуть ситуация, что будут заняты все четыре вершинных процессора и только один пиксельный процессор, а оставшиеся семь пиксельных производительность процессоров всего будут бездействовать. графического В процессора этом случае определяется производительностью и количеством вершинных процессоров. В случае если используются преимущественно пиксельные шейдеры (трехмерные модели с насыщенными пиксельными эффектами), то может возникнуть обратная ситуация, когда будут заняты только один вершинный процессор и все семь пиксельных процессоров. В этом случае производительность всего графического процессора определяется производительностью и количеством пиксельных процессоров. Рис. 9 Проблема сбалансированной нагрузки при использовании вершинных и пиксельных конвейеров Данной проблемы можно избежать, если вместо четырех вершинных и восьми пиксельных процессоров (в сумме 12) использовать 12 унифицированных процессоров, которые могли бы выполнять как вершинные, так и пиксельные шейдеры. 26 Рис.10 Решение проблемы сбалансированной нагрузки при использовании унифицированных процессоров Унифицированные процессоры (Unified Streaming Processors, USP) представляют собой скалярные процессоры общего назначения для обработки данных с плавающей запятой. Кроме этого они способны выполнять геометрические (Geometry) и физические (Physics) расчеты, чего вообще не было предусмотрено в графических процессорах предыдущих поколений. Рис.11 Задачи, решаемые унифицированными процессорами В процессорах существует два типа математики: векторная и скалярная. В случае векторной математики данные (операнды) представляются в виде n-мерных векторов, при этом над большим массивом данных проводится всего одна операция. В скалярной математике операции осуществляются над парой чисел. Понятно, что векторная обработка увеличивает скорость и эффективность обработки за счет того, что обработка целого набора (вектора) данных выполняется одной командой. В скалярном режиме потребуется сгенерировать целую последовательность команд: прочитать элемент B(i), прочитать элемент C(i), выполнить операцию сложения, записать результат в A(i), увеличить параметр 27 цикла, проверить условие цикла и т.д. В векторном режиме массивы элементов B(i) и С(i) можно рассматривать как n-мерные векторы. В таком случае этот фрагмент кода преобразуется в следующую последовательность: загрузить массив B, загрузить массив C, реализовать операцию векторного сложения и запись результата в массив A. В последнее время наблюдается переход от векторных к скалярным вычислениям. Поэтому в унифицированных процессорах NVIDIA применяются скалярные исполнительные блоки. При этом векторный шейдерный программный код преобразуется в скалярные операции непосредственно графическим процессором GeForce 8800. 5.3. Архитектура ядра GPU NVIDIA GeForce 8800 В графическом процессоре NVIDIA GeForce 8800 применяются 128 потоковых унифицированных процессоров. Рис.12 Структурная схема графического процессора NVIDIA GeForce 8800 Потоковые процессоры сгруппированы в восемь блоков по 16 штук, каждый из которых оснащен четырьмя текстурными модулями и общим L1-кэшем. Каждый блок представляет собой два шейдерных процессора (состоящих из восьми потоковых процессоров каждый), при этом все восемь блоков имеют доступ к любому из шести L2-кэшей и к любому из шести массивов регистров общего назначения. Таким образом, обработанные одним шейдерным процессором данные могут быть использованы другим шейдерным процессором. 28 На каждые четыре потоковых процессора приходится один текстурный блок, включающий один блок адресации текстур (Texture Address Unit, TA) и блока фильтрации текстур (Texture Filtering Unit, TF). Графический процессор GeForce 8800 GTX обладает шестью разделами растровых операций (ROP). Рис.13 Организация потоковой циклической обработки данных В архитектуре GeForce 8800 входящие данные (input stream) поступают на вход одного унифицированного процессора, обрабатываются им, по выходе (output stream) записываются в регистры, а затем вновь подаются на вход другого процессора для исполнения следующей операции обработки. 29